
action_wanted
#Pocket
Issue Date: 2025-08-28 [Paper Note] VerIF: Verification Engineering for Reinforcement Learning in Instruction Following, Hao Peng+, arXiv'25 Summary強化学習における検証可能な報酬(RLVR)の課題を探求し、ルールベースのコード検証と大規模推論モデルを組み合わせた検証手法VerIFを提案。約22,000のインスタンスを含むデータセットVerInstructを構築し、VerIFを用いたRLトレーニングで性能を大幅に向上。トレーニングされたモデルは最先端の性能を達成し、一般化能力も維持。データセットやコードは公開されている。 Comment元ポスト:https://x.com/gm8xx8/status/1960875391083577580?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket
Issue Date: 2025-08-27 [Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25 Summary新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment元ポスト:https://x.com/karimirabeeh/status/1960682448867426706?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket
Issue Date: 2025-08-27 [Paper Note] Attention Layers Add Into Low-Dimensional Residual Subspaces, Junxuan Wang+, arXiv'25 Summaryトランスフォーマーモデルの注意出力は低次元の部分空間に制約されており、約60%の方向が99%の分散を占めることを示した。この低ランク構造がデッドフィーチャー問題の原因であることを発見し、スパースオートエンコーダーのために部分空間制約トレーニング手法を提案。これにより、デッドフィーチャーを87%から1%未満に削減し、スパース辞書学習の改善に寄与する新たな洞察を提供。 Comment元ポスト:https://x.com/junxuanwang0929/status/1959797912889938392?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
Issue Date: 2025-08-28 [Paper Note] VerIF: Verification Engineering for Reinforcement Learning in Instruction Following, Hao Peng+, arXiv'25 Summary強化学習における検証可能な報酬(RLVR)の課題を探求し、ルールベースのコード検証と大規模推論モデルを組み合わせた検証手法VerIFを提案。約22,000のインスタンスを含むデータセットVerInstructを構築し、VerIFを用いたRLトレーニングで性能を大幅に向上。トレーニングされたモデルは最先端の性能を達成し、一般化能力も維持。データセットやコードは公開されている。 Comment元ポスト:https://x.com/gm8xx8/status/1960875391083577580?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket
Issue Date: 2025-08-27 [Paper Note] Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset, Rabeeh Karimi Mahabadi+, arXiv'25 Summary新しい数学コーパス「Nemotron-CC-Math」を提案し、LLMの推論能力を向上させるために、科学テキスト抽出のためのパイプラインを使用。従来のデータセットよりも高品質で、方程式やコードの構造を保持しつつ、表記を標準化。Nemotron-CC-Math-4+は、以前のデータセットを大幅に上回り、事前学習によりMATHやMBPP+での性能向上を実現。オープンソースとしてコードとデータセットを公開。 Comment元ポスト:https://x.com/karimirabeeh/status/1960682448867426706?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket
Issue Date: 2025-08-27 [Paper Note] Attention Layers Add Into Low-Dimensional Residual Subspaces, Junxuan Wang+, arXiv'25 Summaryトランスフォーマーモデルの注意出力は低次元の部分空間に制約されており、約60%の方向が99%の分散を占めることを示した。この低ランク構造がデッドフィーチャー問題の原因であることを発見し、スパースオートエンコーダーのために部分空間制約トレーニング手法を提案。これにより、デッドフィーチャーを87%から1%未満に削減し、スパース辞書学習の改善に寄与する新たな洞察を提供。 Comment元ポスト:https://x.com/junxuanwang0929/status/1959797912889938392?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#Pocket
#NLP
#LanguageModel
#Alignment
#Supervised-FineTuning (SFT)
#OpenWeight
#Architecture
#PostTraining
#Admin'sPick
#DataMixture
Issue Date: 2025-08-25
[Paper Note] Motif 2.6B Technical Report, Junghwan Lim+, arXiv'25
SummaryMotif-2.6Bは、26億パラメータを持つ基盤LLMで、長文理解の向上や幻覚の減少を目指し、差分注意やポリノルム活性化関数を採用。広範な実験により、同サイズの最先端モデルを上回る性能を示し、効率的でスケーラブルな基盤LLMの発展に寄与する。
Comment元ポスト:https://x.com/scaling01/status/1959604841577357430?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QHF:https://huggingface.co/Motif-Technologies/Motif-2.6B・アーキテクチャ
・1466
・2538
・学習手法
・1979
・8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
・1060
・Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
・2540
・事前学習データ
・1943
・2539
・2109
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。
 #Pocket
#EMNLP
Issue Date: 2025-08-22
[Paper Note] Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?, Momoka Furuhashi+, EMNLP'25
Summary生成タスクの自動評価における曖昧な基準の課題を解決するため、チェックリストの使用方法を検討。6つの生成方法と8つのモデルサイズで評価し、選択的チェックリストがペアワイズ評価でパフォーマンスを改善する傾向があることを発見。ただし、直接スコアリングでは一貫性がない。人間の評価基準との相関が低いチェックリスト項目も存在し、評価基準の明確化が必要であることを示唆。
Comment元ポスト:https://x.com/tohoku_nlp_mmk/status/1958717497454002557?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://momo0817.github.io/checklist-effectiveness-study-github.io/
#Pocket
#EMNLP
#Findings
Issue Date: 2025-08-21
[Paper Note] Evaluating Step-by-step Reasoning Traces: A Survey, Jinu Lee+, EMNLP'25 Findings
Summaryステップバイステップの推論はLLMの能力向上に寄与するが、評価手法は一貫性に欠ける。本研究では、推論評価の包括的な概要と、事実性、有効性、一貫性、実用性の4カテゴリからなる評価基準の分類法を提案。これに基づき、評価者の実装や最近の発見をレビューし、今後の研究の方向性を示す。
Comment元ポスト:https://x.com/jinulee_v/status/1958268008964796904?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-08-19
[Paper Note] Data Mixing Optimization for Supervised Fine-Tuning of Large Language Models, Yuan Li+, arXiv'25
Summary大規模言語モデルのファインチューニングにおけるデータミクスの最適化を新たな手法で提案。検証損失を最小化するためにデータの転送効果をモデル化し、最適な重みを導出。実験により、提案手法が優れたパフォーマンスを示し、従来のグリッドサーチと同等の結果を得ることを確認。さらに、人気のSFTデータセットでの重み付けにより、検証損失と下流パフォーマンスの改善を実証。ドメイン特化型モデルへの応用可能性についても考察。
Comment元ポスト:https://x.com/f14bertolotti/status/1957675768470757825?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-08-19
[Paper Note] Thyme: Think Beyond Images, Yi-Fan Zhang+, arXiv'25
SummaryThyme(Think Beyond Images)は、視覚情報を推論プロセスに活用し、画像処理と計算操作を自律的に生成・実行する新しいパラダイムを提案。二段階のトレーニング戦略を用いて、推論の精度とコード実行のバランスを取るGRPO-ATSアルゴリズムを導入。約20のベンチマークで顕著な性能向上を示した。
Comment元ポスト:https://x.com/iscienceluvr/status/1957402918057017823?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#Reasoning
#Overthinking
#Underthinking
Issue Date: 2025-08-19
[Paper Note] OptimalThinkingBench: Evaluating Over and Underthinking in LLMs, Pranjal Aggarwal+, arXiv'25
Summary思考型LLMは計算コストが高く、単純な問題に対して過剰に考え、非思考型LLMは迅速だが難しい推論に対して考えが浅い。これにより、最適なモデル選択がエンドユーザーに委ねられている。本研究では、OptimalThinkingBenchを導入し、過剰思考と考え不足を評価する統一ベンチマークを提供。72のドメインの単純なクエリと11の挑戦的な推論タスクを含む2つのサブベンチマークで、33のモデルを評価した結果、最適な思考モデルは存在せず、思考型モデルは過剰に考え、非思考型モデルは浅い結果を示した。将来的には、より良い統一的かつ最適なモデルの必要性が浮き彫りとなった。
Comment元ポスト:https://x.com/jaseweston/status/1957627532963926389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストの著者によるスレッドが非常にわかりやすいのでそちらを参照のこと。
#Pocket
#EMNLP
Issue Date: 2025-08-22
[Paper Note] Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?, Momoka Furuhashi+, EMNLP'25
Summary生成タスクの自動評価における曖昧な基準の課題を解決するため、チェックリストの使用方法を検討。6つの生成方法と8つのモデルサイズで評価し、選択的チェックリストがペアワイズ評価でパフォーマンスを改善する傾向があることを発見。ただし、直接スコアリングでは一貫性がない。人間の評価基準との相関が低いチェックリスト項目も存在し、評価基準の明確化が必要であることを示唆。
Comment元ポスト:https://x.com/tohoku_nlp_mmk/status/1958717497454002557?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qpj page:https://momo0817.github.io/checklist-effectiveness-study-github.io/
#Pocket
#EMNLP
#Findings
Issue Date: 2025-08-21
[Paper Note] Evaluating Step-by-step Reasoning Traces: A Survey, Jinu Lee+, EMNLP'25 Findings
Summaryステップバイステップの推論はLLMの能力向上に寄与するが、評価手法は一貫性に欠ける。本研究では、推論評価の包括的な概要と、事実性、有効性、一貫性、実用性の4カテゴリからなる評価基準の分類法を提案。これに基づき、評価者の実装や最近の発見をレビューし、今後の研究の方向性を示す。
Comment元ポスト:https://x.com/jinulee_v/status/1958268008964796904?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-08-19
[Paper Note] Data Mixing Optimization for Supervised Fine-Tuning of Large Language Models, Yuan Li+, arXiv'25
Summary大規模言語モデルのファインチューニングにおけるデータミクスの最適化を新たな手法で提案。検証損失を最小化するためにデータの転送効果をモデル化し、最適な重みを導出。実験により、提案手法が優れたパフォーマンスを示し、従来のグリッドサーチと同等の結果を得ることを確認。さらに、人気のSFTデータセットでの重み付けにより、検証損失と下流パフォーマンスの改善を実証。ドメイン特化型モデルへの応用可能性についても考察。
Comment元ポスト:https://x.com/f14bertolotti/status/1957675768470757825?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-08-19
[Paper Note] Thyme: Think Beyond Images, Yi-Fan Zhang+, arXiv'25
SummaryThyme(Think Beyond Images)は、視覚情報を推論プロセスに活用し、画像処理と計算操作を自律的に生成・実行する新しいパラダイムを提案。二段階のトレーニング戦略を用いて、推論の精度とコード実行のバランスを取るGRPO-ATSアルゴリズムを導入。約20のベンチマークで顕著な性能向上を示した。
Comment元ポスト:https://x.com/iscienceluvr/status/1957402918057017823?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
#Reasoning
#Overthinking
#Underthinking
Issue Date: 2025-08-19
[Paper Note] OptimalThinkingBench: Evaluating Over and Underthinking in LLMs, Pranjal Aggarwal+, arXiv'25
Summary思考型LLMは計算コストが高く、単純な問題に対して過剰に考え、非思考型LLMは迅速だが難しい推論に対して考えが浅い。これにより、最適なモデル選択がエンドユーザーに委ねられている。本研究では、OptimalThinkingBenchを導入し、過剰思考と考え不足を評価する統一ベンチマークを提供。72のドメインの単純なクエリと11の挑戦的な推論タスクを含む2つのサブベンチマークで、33のモデルを評価した結果、最適な思考モデルは存在せず、思考型モデルは過剰に考え、非思考型モデルは浅い結果を示した。将来的には、より良い統一的かつ最適なモデルの必要性が浮き彫りとなった。
Comment元ポスト:https://x.com/jaseweston/status/1957627532963926389?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q元ポストの著者によるスレッドが非常にわかりやすいのでそちらを参照のこと。
ざっくり言うと、Overthinking(考えすぎて大量のトークンを消費した上に回答が誤っている; トークン量↓とLLMによるJudge Score↑で評価)とUnderthinking(全然考えずにトークンを消費しなかった上に回答が誤っている; Accuracy↑で評価)をそれぞれ評価するサンプルを収集し、それらのスコアの組み合わせでモデルが必要に応じてどれだけ的確にThinkingできているかを評価するベンチマーク。
Overthinkingを評価するためのサンプルは、多くのLLMでagreementがとれるシンプルなQAによって構築。一方、Underthinkingを評価するためのサンプルは、small reasoning modelがlarge non reasoning modelよりも高い性能を示すサンプルを収集。


現状Non Thinking ModelではQwen3-235B-A22Bの性能が良く、Thinking Modelではgpt-oss-120Bの性能が良い。プロプライエタリなモデルではそれぞれ、Claude-Sonnet4, o3の性能が良い。全体としてはo3の性能が最も良い。
 #Pocket
#read-later
Issue Date: 2025-08-19
[Paper Note] BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining, Pratyush Maini+, arXiv'25
Summary合成データ生成フレームワーク「BeyondWeb」を提案し、高品質な合成データの生成が可能であることを示す。BeyondWebは、従来のデータセットを超える性能を発揮し、トレーニング速度も向上。特に、3Bモデルが8Bモデルを上回る結果を示す。合成データの品質向上には多くの要因を最適化する必要があり、単純なアプローチでは限界があることを指摘。
Comment元ポスト:https://x.com/pratyushmaini/status/1957456720265154752?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-08-15
[Paper Note] Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards, Shirley Wu+, arXiv'25
Summary複合AIシステムの最適化のために、統一フレームワークOptimasを提案。各コンポーネントにローカル報酬関数を維持し、グローバルパフォーマンスと整合性を保ちながら同時に最大化。これにより、異種構成の独立した更新が可能となり、平均11.92%の性能向上を実現。
Comment元ポスト:https://x.com/shirleyyxwu/status/1956072970373538271?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
#NLP
#LanguageModel
#ReinforcementLearning
#Factuality
#RewardHacking
#PostTraining
#GRPO
#On-Policy
Issue Date: 2025-08-08
[Paper Note] Learning to Reason for Factuality, Xilun Chen+, arXiv'25
SummaryR-LLMsは複雑な推論タスクで進展しているが、事実性において幻覚を多く生成する。オンラインRLを長文の事実性設定に適用する際、信頼できる検証方法が不足しているため課題がある。従来の自動評価フレームワークを用いたオフラインRLでは報酬ハッキングが発生することが判明。そこで、事実の精度、詳細レベル、関連性を考慮した新しい報酬関数を提案し、オンラインRLを適用。評価の結果、幻覚率を平均23.1ポイント削減し、回答の詳細レベルを23%向上させた。
Comment元ポスト:https://x.com/jaseweston/status/1953629692772446481?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q先行研究:
#Pocket
#read-later
Issue Date: 2025-08-19
[Paper Note] BeyondWeb: Lessons from Scaling Synthetic Data for Trillion-scale Pretraining, Pratyush Maini+, arXiv'25
Summary合成データ生成フレームワーク「BeyondWeb」を提案し、高品質な合成データの生成が可能であることを示す。BeyondWebは、従来のデータセットを超える性能を発揮し、トレーニング速度も向上。特に、3Bモデルが8Bモデルを上回る結果を示す。合成データの品質向上には多くの要因を最適化する必要があり、単純なアプローチでは限界があることを指摘。
Comment元ポスト:https://x.com/pratyushmaini/status/1957456720265154752?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-08-15
[Paper Note] Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards, Shirley Wu+, arXiv'25
Summary複合AIシステムの最適化のために、統一フレームワークOptimasを提案。各コンポーネントにローカル報酬関数を維持し、グローバルパフォーマンスと整合性を保ちながら同時に最大化。これにより、異種構成の独立した更新が可能となり、平均11.92%の性能向上を実現。
Comment元ポスト:https://x.com/shirleyyxwu/status/1956072970373538271?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
#NLP
#LanguageModel
#ReinforcementLearning
#Factuality
#RewardHacking
#PostTraining
#GRPO
#On-Policy
Issue Date: 2025-08-08
[Paper Note] Learning to Reason for Factuality, Xilun Chen+, arXiv'25
SummaryR-LLMsは複雑な推論タスクで進展しているが、事実性において幻覚を多く生成する。オンラインRLを長文の事実性設定に適用する際、信頼できる検証方法が不足しているため課題がある。従来の自動評価フレームワークを用いたオフラインRLでは報酬ハッキングが発生することが判明。そこで、事実の精度、詳細レベル、関連性を考慮した新しい報酬関数を提案し、オンラインRLを適用。評価の結果、幻覚率を平均23.1ポイント削減し、回答の詳細レベルを23%向上させた。
Comment元ポスト:https://x.com/jaseweston/status/1953629692772446481?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q先行研究:
・2378Reasoning ModelのHallucination Rateは、そのベースとなるモデルよりも高い。実際、DeepSeek-V3とDeepSeek-R1,Qwen-2.5-32BとQwQ-32Bを6つのFactualityに関するベンチマークで比較すると、Reasoning Modelの方がHallucination Rateが10, 13%程度高かった。これは、現在のOn-policyのRLがlogical reasoningにフォーカスしており、Factualityを見落としているため、と仮説を立てている。
Factuality(特にLongForm)とRL alignmentsという観点から言うと、決定的、正確かつ信頼性のあるverificatlon手法は存在せず、Human Effortが必要不可欠である。
自動的にFactualityを測定するFactScoreのような手法は、DPOのようなオフラインのペアワイズのデータを作成するに留まってしまっている。また、on dataでFactualityを改善する取り組みは行われているが、long-formな応答に対して、factual reasoningを実施するにはいくつかの課題が残されている:
・reward design
・Factualityに関するrewardを単独で追加するだけだと、LLMは非常に短く、詳細を省略した応答をしPrecicionのみを高めようとしてしまう。
あとで追記する #Pocket #NLP #LanguageModel #InstructionTuning #SyntheticData #Reasoning Issue Date: 2025-08-02 [Paper Note] CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks, Ping Yu+, arXiv'25 SummaryCoT-Self-Instructを提案し、LLMに基づいて新しい合成プロンプトを生成する手法を開発。合成データはMATH500やAMC23などで既存データセットを超える性能を示し、検証不可能なタスクでも人間や標準プロンプトを上回る結果を得た。 Comment元ポスト:https://x.com/jaseweston/status/1951084679286722793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qより複雑で、Reasoningやplanningを促すようなinstructionが生成される模様。実際に生成されたinstructionのexampleは全体をざっとみた感じこの図中のもののみのように見える。
 以下のスクショはMagpieによって合成されたinstruction。InstructionTuning用のデータを合成するならMagpieが便利そうだなぁ、と思っていたのだが、比較するとCoT-SelfInstructの方が、より複雑で具体的な指示を含むinstructionが生成されるように見える。
以下のスクショはMagpieによって合成されたinstruction。InstructionTuning用のデータを合成するならMagpieが便利そうだなぁ、と思っていたのだが、比較するとCoT-SelfInstructの方が、より複雑で具体的な指示を含むinstructionが生成されるように見える。
・2094
 #ComputerVision
#Pocket
#NLP
#Dataset
#MultiLingual
#CLIP
Issue Date: 2025-07-30
[Paper Note] MetaCLIP 2: A Worldwide Scaling Recipe, Yung-Sung Chuang+, arXiv'25
SummaryMetaCLIP 2を提案し、CLIPをゼロから訓練するための新しいアプローチを示す。英語と非英語データの相互利益を得るための最小限の変更を加え、ゼロショットのImageNet分類で英語専用モデルを上回る性能を達成。多言語ベンチマークでも新たな最先端を記録。
Comment元ポスト:https://x.com/jaseweston/status/1950366185742016935?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-07-24
[Paper Note] RankMixer: Scaling Up Ranking Models in Industrial Recommenders, Jie Zhu+, arXiv'25
SummaryRankMixerは、推薦システムのスケーラビリティを向上させるための新しいアーキテクチャで、トランスフォーマーの並列性を活かしつつ、効率的な特徴相互作用を実現。Sparse-MoEバリアントを用いて10億パラメータに拡張し、動的ルーティング戦略で専門家の不均衡を解消。実験により、1兆スケールのデータセットで優れたスケーリング能力を示し、MFUを4.5%から45%に向上させ、推論レイテンシーを維持しつつパラメータを100倍に増加。オンラインA/Bテストで推薦、広告、検索の各シナリオにおける効果を確認し、ユーザーのアクティブ日数を0.2%、アプリ内使用時間を0.5%改善。
Comment元ポスト:https://x.com/gm8xx8/status/1948304747317854307?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-07-15
[Paper Note] Auditing Prompt Caching in Language Model APIs, Chenchen Gu+, arXiv'25
SummaryプロンプトキャッシングはLLMにおいてタイミング変動を引き起こし、サイドチャネル攻撃のリスクをもたらす。キャッシュが共有されると、攻撃者は迅速な応答から他ユーザーのプロンプトを特定できる可能性がある。これによりプライバシー漏洩の懸念が生じ、APIプロバイダーの透明性が重要となる。本研究では、実世界のLLM APIプロバイダーにおけるプロンプトキャッシングを検出するための統計監査を開発し、7つのAPIプロバイダー間でのキャッシュ共有を確認し、潜在的なプライバシー漏洩を示した。また、OpenAIの埋め込みモデルに関する新たな情報も発見した。
#EfficiencyImprovement
#Pocket
#NLP
#LanguageModel
#ReinforcementLearning
#RLVR
Issue Date: 2025-07-10
[Paper Note] First Return, Entropy-Eliciting Explore, Tianyu Zheng+, arXiv'25
SummaryFR3E(First Return, Entropy-Eliciting Explore)は、強化学習における不安定な探索を改善するための構造化された探索フレームワークであり、高不確実性の意思決定ポイントを特定し、中間フィードバックを提供します。実験結果は、FR3Eが安定したトレーニングを促進し、一貫した応答を生成することを示しています。
Comment元ポスト:https://x.com/f14bertolotti/status/1943201406271328524?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVRのロールアウトにおいて、reasoning traceにおける各トークンを出力する際にエントロピーが高い部分を特定し(つまり、複数の候補がありモデルが迷っている)、その部分について異なる意図的に異なる生成パスを実行することで探索を促すようにするとRLVRがよりreliableになるといった話のようである
#ComputerVision
#Pocket
#NLP
#Dataset
#MultiLingual
#CLIP
Issue Date: 2025-07-30
[Paper Note] MetaCLIP 2: A Worldwide Scaling Recipe, Yung-Sung Chuang+, arXiv'25
SummaryMetaCLIP 2を提案し、CLIPをゼロから訓練するための新しいアプローチを示す。英語と非英語データの相互利益を得るための最小限の変更を加え、ゼロショットのImageNet分類で英語専用モデルを上回る性能を達成。多言語ベンチマークでも新たな最先端を記録。
Comment元ポスト:https://x.com/jaseweston/status/1950366185742016935?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-07-24
[Paper Note] RankMixer: Scaling Up Ranking Models in Industrial Recommenders, Jie Zhu+, arXiv'25
SummaryRankMixerは、推薦システムのスケーラビリティを向上させるための新しいアーキテクチャで、トランスフォーマーの並列性を活かしつつ、効率的な特徴相互作用を実現。Sparse-MoEバリアントを用いて10億パラメータに拡張し、動的ルーティング戦略で専門家の不均衡を解消。実験により、1兆スケールのデータセットで優れたスケーリング能力を示し、MFUを4.5%から45%に向上させ、推論レイテンシーを維持しつつパラメータを100倍に増加。オンラインA/Bテストで推薦、広告、検索の各シナリオにおける効果を確認し、ユーザーのアクティブ日数を0.2%、アプリ内使用時間を0.5%改善。
Comment元ポスト:https://x.com/gm8xx8/status/1948304747317854307?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-07-15
[Paper Note] Auditing Prompt Caching in Language Model APIs, Chenchen Gu+, arXiv'25
SummaryプロンプトキャッシングはLLMにおいてタイミング変動を引き起こし、サイドチャネル攻撃のリスクをもたらす。キャッシュが共有されると、攻撃者は迅速な応答から他ユーザーのプロンプトを特定できる可能性がある。これによりプライバシー漏洩の懸念が生じ、APIプロバイダーの透明性が重要となる。本研究では、実世界のLLM APIプロバイダーにおけるプロンプトキャッシングを検出するための統計監査を開発し、7つのAPIプロバイダー間でのキャッシュ共有を確認し、潜在的なプライバシー漏洩を示した。また、OpenAIの埋め込みモデルに関する新たな情報も発見した。
#EfficiencyImprovement
#Pocket
#NLP
#LanguageModel
#ReinforcementLearning
#RLVR
Issue Date: 2025-07-10
[Paper Note] First Return, Entropy-Eliciting Explore, Tianyu Zheng+, arXiv'25
SummaryFR3E(First Return, Entropy-Eliciting Explore)は、強化学習における不安定な探索を改善するための構造化された探索フレームワークであり、高不確実性の意思決定ポイントを特定し、中間フィードバックを提供します。実験結果は、FR3Eが安定したトレーニングを促進し、一貫した応答を生成することを示しています。
Comment元ポスト:https://x.com/f14bertolotti/status/1943201406271328524?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QRLVRのロールアウトにおいて、reasoning traceにおける各トークンを出力する際にエントロピーが高い部分を特定し(つまり、複数の候補がありモデルが迷っている)、その部分について異なる意図的に異なる生成パスを実行することで探索を促すようにするとRLVRがよりreliableになるといった話のようである

 #Pocket
Issue Date: 2025-07-10
[Paper Note] The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains, Scott Geng+, arXiv'25
Summary弱いデータポイントからなるペアの好みデータが、言語モデルの性能向上に寄与することを示す。デルタ学習仮説を提唱し、相対的な質のデルタが学習を促進することを検証。8Bモデルを小型モデルの出力とペアにして後訓練した結果、標準ベンチマークで最先端モデルに匹敵する性能を達成。デルタ学習は、シンプルで安価な後訓練手法を提供することを示唆。
Comment元ポスト:https://x.com/pangweikoh/status/1942993031348789253?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pocket
Issue Date: 2025-07-10
[Paper Note] The Delta Learning Hypothesis: Preference Tuning on Weak Data can Yield Strong Gains, Scott Geng+, arXiv'25
Summary弱いデータポイントからなるペアの好みデータが、言語モデルの性能向上に寄与することを示す。デルタ学習仮説を提唱し、相対的な質のデルタが学習を促進することを検証。8Bモデルを小型モデルの出力とペアにして後訓練した結果、標準ベンチマークで最先端モデルに匹敵する性能を達成。デルタ学習は、シンプルで安価な後訓練手法を提供することを示唆。
Comment元ポスト:https://x.com/pangweikoh/status/1942993031348789253?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
 #ComputerVision
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#LanguageModel
#MultiModal
Issue Date: 2025-06-26
[Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, arXiv'25
SummaryOpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。
Comment元ポスト:https://x.com/cihangxie/status/1920575141849030882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#Pocket
#NLP
#Dataset
#LanguageModel
#SyntheticData
Issue Date: 2025-06-25
[Paper Note] Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models, Thao Nguyen+, arXiv'25
Summaryスケーリング法則に基づき、低品質なウェブデータを再利用する手法「REWIRE」を提案。これにより、事前学習データの合成表現を増やし、フィルタリングされたデータのみでのトレーニングと比較して、22のタスクで性能を向上。生データと合成データの混合が効果的であることを示し、ウェブテキストのリサイクルが事前学習データのスケーリングに有効であることを示唆。
Comment元ポスト:https://x.com/thao_nguyen26/status/1937210428876292457?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q学習データの枯渇に対する対処として別の方向性としては下記のような研究もある:
#ComputerVision
#EfficiencyImprovement
#Pretraining
#Pocket
#NLP
#LanguageModel
#MultiModal
Issue Date: 2025-06-26
[Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, arXiv'25
SummaryOpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。
Comment元ポスト:https://x.com/cihangxie/status/1920575141849030882?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
#Pretraining
#Pocket
#NLP
#Dataset
#LanguageModel
#SyntheticData
Issue Date: 2025-06-25
[Paper Note] Recycling the Web: A Method to Enhance Pre-training Data Quality and Quantity for Language Models, Thao Nguyen+, arXiv'25
Summaryスケーリング法則に基づき、低品質なウェブデータを再利用する手法「REWIRE」を提案。これにより、事前学習データの合成表現を増やし、フィルタリングされたデータのみでのトレーニングと比較して、22のタスクで性能を向上。生データと合成データの混合が効果的であることを示し、ウェブテキストのリサイクルが事前学習データのスケーリングに有効であることを示唆。
Comment元ポスト:https://x.com/thao_nguyen26/status/1937210428876292457?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q学習データの枯渇に対する対処として別の方向性としては下記のような研究もある:
・1829 #Pretraining #Pocket #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-06-12 [Paper Note] Reinforcement Pre-Training, Qingxiu Dong+, arXiv'25 Summary本研究では、強化学習と大規模言語モデルの新しいスケーリング手法「強化事前学習(RPT)」を提案。次のトークン予測を強化学習の推論タスクとして再定義し、一般的なRLを活用することで、ドメイン特有の注釈に依存せずにスケーラブルな方法を提供。RPTは次のトークン予測の精度を向上させ、強化ファインチューニングの基盤を形成。トレーニング計算量の増加が精度を改善することを示し、RPTが言語モデルの事前学習において有望な手法であることを示した。 Comment元ポスト:https://x.com/hillbig/status/1932922314578145640?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #LanguageModel #Subword Issue Date: 2025-06-11 [Paper Note] StochasTok: Improving Fine-Grained Subword Understanding in LLMs, Anya Sims+, arXiv'25 Summaryサブワードレベルの理解を向上させるために、確率的トークン化手法StochasTokを提案。これにより、LLMsは内部構造を把握しやすくなり、文字カウントや数学タスクなどで性能が向上。シンプルな設計により、既存モデルへの統合が容易で、コストを抑えつつサブワード理解を改善できる。 Comment元ポスト:https://x.com/cong_ml/status/1932369418534760554?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそう #Pocket #NLP #LanguageModel #RLVR Issue Date: 2025-06-05 [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards, Xun Lu, arXiv'25 Summary非検証可能なタスクにおける強化学習のギャップを埋めるため、ペアワイズ生成報酬モデル(GenRM)とブートストラップ相対ポリシー最適化(BRPO)アルゴリズムを提案。これにより、主観的評価を信頼性のある検証可能な報酬に変換し、動的なペアワイズ比較を実現。提案手法は、LLMsの執筆能力を向上させ、スカラー報酬ベースラインに対して一貫した改善を示し、競争力のある結果を達成。全ての言語タスクに適用可能な包括的なRLトレーニングパラダイムの可能性を示唆。 Comment元ポスト:https://x.com/grad62304977/status/1929996614883783170?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWriting Principleに基づいて(e.g., 一貫性、創造性とか?)批評を記述し、最終的に与えられたペアワイズのテキストの優劣を判断するGenerative Reward Model (GenRM; Reasoning Traceを伴い最終的にRewardに変換可能な情報をoutpuするモデル) を学習し、現在生成したresponseグループの中からランダムに一つ擬似的なreferenceを決定し、他のresponseに対しGenRMを適用することで報酬を決定する(BRPO)、といったことをやるらしい。
これにより、創造的な文書作成のような客観的なground truthを適用できないタスクでも、RLVRの恩恵をあずかれるようになる(Bridging the gap)といったことを主張している。RLVRの恩恵とは、Reward Hackingされづらい高品質な報酬、ということにあると思われる。ので、要は従来のPreference dataだけで学習したReward Modelよりも、よりReward Hackingされないロバストな学習を実現できるGenerative Reward Modelを提案し、それを適用する手法BRPOも提案しました、という話に見える。関連:
・2274 #Pocket #NLP #LanguageModel #LLMAgent #SelfImprovement Issue Date: 2025-06-03 [Paper Note] Self-Challenging Language Model Agents, Yifei Zhou+, arXiv'25 SummarySelf-Challengingフレームワークを提案し、エージェントが自ら生成した高品質なタスクで訓練。エージェントは挑戦者としてタスクを生成し、実行者として強化学習を用いて訓練。M3ToolEvalとTauBenchでLlama-3.1-8B-Instructが2倍以上の改善を達成。 Comment元ポスト:https://x.com/jaseweston/status/1929719473952497797?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/omarsar0/status/1930748591242424439?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #Pretraining #LanguageModel #Transformer #PostTraining #COLT Issue Date: 2025-06-01 [Paper Note] Learning Compositional Functions with Transformers from Easy-to-Hard Data, Zixuan Wang+, COLT'25 Summary本研究では、Transformerベースの言語モデルの学習可能性を探求し、$k$-fold compositionタスクに焦点を当てる。$O(\log k)$層のトランスフォーマーでこのタスクを表現できる一方、SQオラクルに対するクエリの下限を示し、サンプルサイズが指数的である必要があることを証明。さらに、カリキュラム学習戦略を用いて、簡単な例と難しい例を含むデータ分布がトランスフォーマーの効率的な学習に必要であることを明らかにした。 Comment元ポスト:https://x.com/zzzixuanwang/status/1928465115478708604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらはまず元ポストのスレッドを読むのが良いと思われる。要点をわかりやすく説明してくださっている。元ポストとalphaxivでざっくり理解したところ、
Transformerがcontextとして与えられた情報(σ)とparametric knowledge(π)をk回の知識マッピングが必要なタスク(k-fold composition task)を学習するにはO(log k)のlayer数が必要で、直接的にk回の知識マッピングが必要なタスクを学習するためにはkの指数オーダーのデータ量が最低限必要となることが示された。これはkが大きくなると(すなわち、複雑なreasoning stepが必要なタスク)になると非現実的なものとなるため、何らかの方法で緩和したい。学習データを簡単なものから難しいものをmixingすること(カリキュラム学習)ことで、この条件が緩和され、指数オーダーから多項式オーダーのデータ量で学習できることが示された
といった感じだと思われる。じゃあ最新の32Bモデルよりも、よりパラメータ数が大きくてlayer数が多い古いモデルの方が複雑なreasoningが必要なタスクを実は解けるってこと!?直感に反する!と一瞬思ったが、おそらく最近のモデルでは昔のモデルと比べてparametric knowledgeがより高密度に適切に圧縮されるようになっていると思われるので、昔のモデルではk回の知識マッピングをしないと解けないタスクが、最新のモデルではk-n回のマッピングで解けるようになっていると推察され、パラメータサイズが小さくても問題なく解けます、みたいなことが起こっているのだろう、という感想を抱くなどした #Pocket #NLP #LanguageModel #LLMAgent #SoftwareEngineering #read-later Issue Date: 2025-06-01 [Paper Note] Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering, Guangtao Zeng+, arXiv'25 SummaryEvoScaleを提案し、進化的プロセスを用いて小型言語モデルの性能を向上させる手法を開発。選択と突然変異を通じて出力を洗練し、サンプル数を減少させる。強化学習を用いて自己進化を促進し、SWE-Bench-Verifiedで32Bモデルが100B以上のモデルと同等以上の性能を示す。コード、データ、モデルはオープンソースとして公開予定。 Comment元ポスト:https://x.com/gan_chuang/status/1928963872188244400?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #RLVR Issue Date: 2025-06-01 Can Large Reasoning Models Self-Train?, Sheikh Shafayat+, arXiv'25 Summary自己学習を活用したオンライン強化学習アルゴリズムを提案し、モデルの自己一貫性を利用して正確性信号を推測。難しい数学的推論タスクに適用し、従来の手法に匹敵する性能を示す。自己生成された代理報酬が誤った出力を優遇するリスクも指摘。自己監視による性能向上の可能性と課題を明らかに。 Comment元ポスト:https://x.com/askalphaxiv/status/1928487492291829809?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1995
と似ているように見えるself-consistencyでground truthを推定し、推定したground truthを用いてverifiableなrewardを計算して学習する手法、のように見える。


実際のground truthを用いた学習と同等の性能を達成する場合もあれば、long stepで学習するとどこかのタイミングで学習がcollapseする場合もある
 パフォーマンスがピークを迎えた後になぜ大幅にAccuracyがdropするかを検証したところ、モデルのKL penaltyがどこかのタイミングで大幅に大きくなることがわかった。つまりこれはオリジナルのモデルからかけ離れたモデルになっている。これは、モデルがデタラメな出力をground truthとして推定するようになり、モデルそのものも一貫してそのデタラメな出力をすることでrewardを増大させるreward hackingが起きている。
パフォーマンスがピークを迎えた後になぜ大幅にAccuracyがdropするかを検証したところ、モデルのKL penaltyがどこかのタイミングで大幅に大きくなることがわかった。つまりこれはオリジナルのモデルからかけ離れたモデルになっている。これは、モデルがデタラメな出力をground truthとして推定するようになり、モデルそのものも一貫してそのデタラメな出力をすることでrewardを増大させるreward hackingが起きている。

 これら現象を避ける方法として、以下の3つを提案している
これら現象を避ける方法として、以下の3つを提案している
・early stopping
・offlineでラベルをself consistencyで生成して、学習の過程で固定する
・カリキュラムラーニングを導入する


 関連
関連
・1489 #EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-05-09 Reinforcement Learning for Reasoning in Large Language Models with One Training Example, Yiping Wang+, arXiv'25 Summary1-shot RLVRを用いることで、LLMの数学的推論能力が大幅に向上することを示した。Qwen2.5-Math-1.5Bモデルは、MATH500でのパフォーマンスが36.0%から73.6%に改善され、他の数学的ベンチマークでも同様の向上が見られた。1-shot RLVR中には、クロスドメイン一般化や持続的なテストパフォーマンスの改善が観察され、ポリシー勾配損失が主な要因であることが確認された。エントロピー損失の追加も重要で、結果報酬なしでもパフォーマンスが向上した。これらの成果は、RLVRのデータ効率に関するさらなる研究を促進する。 Comment 下記ポストでQwenに対してpromptを適切に与えることで、追加のpost training無しで高い数学に関する能力を引き出せたという情報がある。おそらく事前学習時に数学のQAデータによって継続事前学習されており、この能力はその際に身についているため、数学に対する高い能力は実は簡単に引き出すことができるのかもしれない(だから1サンプルでも性能が向上したのではないか?)といった考察がある。
下記ポストでQwenに対してpromptを適切に与えることで、追加のpost training無しで高い数学に関する能力を引き出せたという情報がある。おそらく事前学習時に数学のQAデータによって継続事前学習されており、この能力はその際に身についているため、数学に対する高い能力は実は簡単に引き出すことができるのかもしれない(だから1サンプルでも性能が向上したのではないか?)といった考察がある。
参考:https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・2011
とはどのような関係性があるだろうか? #Pocket #NLP #LanguageModel #Transformer #Attention #Architecture Issue Date: 2025-04-02 Multi-Token Attention, Olga Golovneva+, arXiv'25 Summaryマルチトークンアテンション(MTA)を提案し、複数のクエリとキーのベクトルに基づいてアテンションウェイトを条件付けることで、関連するコンテキストをより正確に特定できるようにする。MTAは畳み込み操作を用いて、近くのトークンが互いに影響を与え、豊かな情報を活用する。評価結果から、MTAはTransformerベースラインモデルを上回り、特に長いコンテキストでの情報検索において優れた性能を示した。 Comment元ポスト:https://x.com/jaseweston/status/1907260086017237207?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のMulti Head Attentionでは、単体のQKのみを利用していたけど、複数のQKの情報を畳み込んで活用できるようにして、Headも畳み込みで重要な情報がより伝搬されるようにして、GroupNormalizationをかけたらPerplexityの観点でDifferential Transformerを上回ったよ、という話な模様。



・1856
・1466 #Analysis #Pocket #NLP #LanguageModel #FactualKnowledge Issue Date: 2025-04-01 Inside-Out: Hidden Factual Knowledge in LLMs, Zorik Gekhman+, arXiv'25 Summary本研究は、LLMが出力以上の事実的知識をエンコードしているかを評価するフレームワークを提案。知識を定義し、正しい回答が高くランク付けされる割合を定量化。外部知識と内部知識を区別し、内部知識が外部知識を超えると隠れた知識が生じることを示す。クローズドブックQA設定でのケーススタディでは、LLMが内部で多くの知識をエンコードしていること、知識が隠れている場合があること、サンプリングによる制約があることを明らかにした。 Comment元ポスト:https://x.com/zorikgekhman/status/1906693729886363861?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #Dataset #LanguageModel #SyntheticData #Reasoning #Distillation Issue Date: 2025-02-19 NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions, Weizhe Yuan+, arXiv'25 Summary多様で高品質な推論質問を生成するためのスケーラブルなアプローチを提案し、280万の質問からなるNaturalReasoningデータセットを構築。知識蒸留実験により、強力な教師モデルが推論能力を引き出せることを実証し、教師なし自己学習にも効果的であることを示す。 Comment元ポスト: https://x.com/jaseweston/status/1892041992127021300?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #LanguageModel #Alignment #ICLR #DPO #PostTraining #Diversity Issue Date: 2025-02-01 Diverse Preference Optimization, Jack Lanchantin+, ICLR'25 SummaryDiverse Preference Optimization(DivPO)を提案し、応答の多様性を向上させつつ生成物の品質を維持するオンライン最適化手法を紹介。DivPOは応答のプールから多様性を測定し、希少で高品質な例を選択することで、パーソナ属性の多様性を45.6%、ストーリーの多様性を74.6%向上させる。 Comment元ポスト:https://x.com/jaseweston/status/1885399530419450257?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=pOq9vDIYevDPOと同じ最適化方法を使うが、Preference Pairを選択する際に、多様性が増加するようなPreference Pairの選択をすることで、モデルのPost-training後の多様性を損なわないようにする手法を提案しているっぽい。
具体的には、Alg.1 に記載されている通り、多様性の尺度Dを定義して、モデルにN個のレスポンスを生成させRMによりスコアリングした後、RMのスコアが閾値以上のresponseを"chosen" response, 閾値未満のレスポンスを "reject" responseとみなし、chosen/reject response集合を構築する。chosen response集合の中からDに基づいて最も多様性のあるresponse y_c、reject response集合の中から最も多様性のないresponse y_r をそれぞれピックし、prompt xとともにpreference pair (x, y_c, y_r) を構築しPreference Pairに加える、といった操作を全ての学習データ(中のprompt)xに対して繰り返すことで実現する。 #Embeddings #InformationRetrieval #NLP #Search #STS (SemanticTextualSimilarity) #ICLR Issue Date: 2025-01-28 SoftMatcha: A Fast and Soft Pattern Matcher for Billion-Scale Corpus Searches, Deguchi+, ICLR'25 CommentICLR2025にacceptされた模様
https://openreview.net/forum?id=Q6PAnqYVpoopenreview:https://openreview.net/forum?id=Q6PAnqYVpo #ComputerVision #Pocket #NLP #LanguageModel #ModelMerge Issue Date: 2024-03-21 Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N_A, Nature Machine Intelligence'25 Summary進化アルゴリズムを使用した新しいアプローチを提案し、強力な基盤モデルの自動生成を実現。LLMの開発において、人間の直感やドメイン知識に依存せず、多様なオープンソースモデルの効果的な組み合わせを自動的に発見する。このアプローチは、日本語のLLMと数学推論能力を持つモデルなど、異なるドメイン間の統合を容易にし、日本語VLMの性能向上にも貢献。オープンソースコミュニティへの貢献と自動モデル構成の新しいパラダイム導入により、基盤モデル開発における効率的なアプローチを模索。 Comment複数のLLMを融合するモデルマージの話。日本語LLMと英語の数学LLNをマージさせることで日本語の数学性能を大幅に向上させたり、LLMとVLMを融合したりすることで、日本にしか存在しない概念の画像も、きちんと回答できるようになる。
著者スライドによると、従来のモデルマージにはbase modelが同一でないとうまくいかなかったり(重みの線型結合によるモデルマージ)、パラメータが増減したり(複数LLMのLayerを重みは弄らず再配置する)。また日本語LLMに対してモデルマージを実施しようとすると、マージ元のLLMが少なかったり、広範囲のモデルを扱うとマージがうまくいかない、といった課題があった。本研究ではこれら課題を解決できる。著者による資料(NLPコロキウム):
https://speakerdeck.com/iwiwi/17-nlpkorokiumu #Pocket #read-later Issue Date: 2025-07-16 [Paper Note] Accelerating Large Language Model Training with 4D Parallelism and Memory Consumption Estimator, Kazuki Fujii+, arXiv'24 Summary本研究では、Llamaアーキテクチャにおける4D並列トレーニングに対して、メモリ使用量を正確に推定する公式を提案。A100およびH100 GPUでの454回の実験を通じて、一時バッファやメモリの断片化を考慮し、推定メモリがGPUメモリの80%未満であればメモリ不足エラーが発生しないことを示した。この公式により、メモリオーバーフローを引き起こす並列化構成を事前に特定でき、最適な4D並列性構成に関する実証的な洞察を提供する。 #InformationRetrieval #Pocket #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models, Fei Wang+, arXiv'24 SummaryAstute RAGは、外部知識の不完全な取得による問題を解決する新しいアプローチで、LLMsの内部知識と外部知識を適応的に統合し、情報の信頼性に基づいて回答を決定します。実験により、Astute RAGは従来のRAG手法を大幅に上回り、最悪のシナリオでもLLMsのパフォーマンスを超えることが示されました。 #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #Hallucination Issue Date: 2024-09-01 Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, N_A, EMNLP'24 Summary大規模言語モデルはファインチューニングを通じて新しい事実情報に遭遇するが、既存の知識を活用する能力に影響を与える。研究では、閉じた書籍のQAを用いて新しい知識を導入するファインチューニング例の割合を変化させた結果、モデルは新しい知識を学習するのに苦労し、幻覚する傾向が増加することが示された。これにより、ファインチューニングによる新しい知識の導入のリスクが明らかになり、モデルは事前学習を通じて知識を獲得し、ファインチューニングはその利用を効率化することが支持される。 Commentpre-training時に獲得されていない情報を用いてLLMのalignmentを実施すると、知識がない状態で学習データを正しく予測できるように学習されてしまうため、事実に基づかない回答をする(つまりhallucination)ように学習されてしまう、といったことを調査している模様。
>新しい知識を導入するファインチューニング例は、モデルの知識と一致する例よりもはるかに遅く学習されます。しかし、新しい知識を持つ例が最終的に学習されるにつれて、モデルの幻覚する傾向が線形に増加することも発見しました。

早々にoverfittingしている。
>大規模言語モデルは主に事前学習を通じて事実知識を取得し、ファインチューニングはそれをより効率的に使用することを教えるという見解を支持しています。
なるほど、興味深い。下記画像は 1370より引用

本論文中では、full finetuningによる検証を実施しており、LoRAのようなAdapterを用いたテクニックで検証はされていない。LoRAではもともとのLLMのパラメータはfreezeされるため、異なる挙動となる可能性がある。特にLoRAが新しい知識を獲得可能なことが示されれば、LoRA AdapterをもともとのLLMに付け替えるだけで、異なる知識を持ったLLMを運用可能になるため、インパクトが大きいと考えられる。もともとこういった思想は LoRA Hubを提唱する研究などの頃からあった気がするが、AdapterによってHallucination/overfittingを防ぎながら、新たな知識を獲得できることを示した研究はあるのだろうか?

参考: https://x.com/hillbig/status/1792334744522485954?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLoRAの場合については
・1640
・1475
も参照のこと。 #Pocket Issue Date: 2024-03-13 Stealing Part of a Production Language Model, Nicholas Carlini+, N_A, arXiv'24 SummaryOpenAIのChatGPTやGoogleのPaLM-2などのブラックボックスの言語モデルから重要な情報を抽出するモデルスティーリング攻撃を紹介。APIアクセスを利用して、transformerモデルの埋め込み射影層を回復する攻撃を行い、低コストでAdaとBabbage言語モデルの全射影行列を抽出。gpt-3.5-turboモデルの隠れた次元のサイズを回復し、2000ドル未満のクエリで全射影行列を回復すると推定。潜在的な防御策と緩和策を提案し、将来の作業の影響について議論。 #Pocket #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2024-03-05 OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, N_A, arXiv'24 SummaryLMsの商業的重要性が高まる中、最も強力なモデルは閉鎖されており、その詳細が非公開になっている。そのため、本技術レポートでは、本当にオープンな言語モデルであるOLMoの初回リリースと、言語モデリングの科学を構築し研究するためのフレームワークについて詳細に説明している。OLMoはモデルの重みだけでなく、トレーニングデータ、トレーニングおよび評価コードを含むフレームワーク全体を公開しており、オープンな研究コミュニティを強化し、新しいイノベーションを促進することを目指している。 CommentModel Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI #Pocket Issue Date: 2024-01-24 Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, Zixiang Chen+, N_A, arXiv'24 Summary本研究では、追加の人間による注釈付きデータを必要とせずに、大規模言語モデル(LLMs)を強化する方法を提案します。そのために、Self-Play fIne-tuNing(SPIN)という新しいファインチューニング手法を開発しました。SPINでは、LLMが自身と対戦しながら能力を向上させるセルフプレイのメカニズムを利用します。具体的には、LLMは自己生成応答と人間による注釈付きデータから得られた応答を区別することでポリシーを改善します。実験結果は、SPINがLLMのパフォーマンスを大幅に改善し、専門家の対戦相手を必要とせずに人間レベルのパフォーマンスを達成できることを示しています。 #RecommenderSystems #Pocket #LanguageModel Issue Date: 2024-12-03 Recommender Systems in the Era of Large Language Models (LLMs), Zihuai Zhao+, arXiv'23 Summaryレコメンダーシステムは、ユーザーの好みに基づいた提案を提供する重要な要素であり、DNNの限界を克服するためにLLMsの活用が進んでいる。本論文では、LLMを用いたレコメンダーシステムの事前学習、ファインチューニング、プロンプティングに関する包括的なレビューを行い、ユーザーとアイテムの表現学習手法や最近の技術を紹介し、今後の研究方向性について議論する。 Comment
中身を全然読んでいる時間はないので、図には重要な情報が詰まっていると信じ、図を読み解いていく。時間がある時に中身も読みたい。。。
LLM-basedなRecSysでは、NLPにおけるLLMの使い方(元々はT5で提案)と同様に、様々なレコメンド関係タスクを、テキスト生成タスクに落とし込み学習することができる。

RecSysのLiteratureとしては、最初はコンテンツベースと協調フィルタリングから始まり、(グラフベースドな推薦, Matrix Factorization, Factorization Machinesなどが間にあって)、その後MLP, RNN, CNN, AutoEncoderなどの様々なDeep Neural Network(DNN)を活用した手法や、BERT4RecなどのProbabilistic Language Models(PLM)を用いた手法にシフトしていき、現在LLM-basedなRecSysの時代に到達した、との流れである。

LLM-basedな手法では、pretrainingの段階からEncoder-basedなモデルの場合はMLM、Decoder-basedな手法ではNext Token Predictionによってデータセットで事前学習する方法もあれば、フルパラメータチューニングやPEFT(LoRAなど)によるSFTによるアプローチもあるようである。
推薦タスクは、推薦するアイテムIDを生成するようなタスクの場合は、異なるアイテムID空間に基づくデータセットの間では転移ができないので、SFTをしないとなかなかうまくいかないと気がしている。また、その場合はアイテムIDの推薦以外のタスクも同時に実施したい場合は、事前学習済みのパラメータが固定されるPEFT手法の方が安全策になるかなぁ、という気がしている(破壊的忘却が怖いので)。特はたとえば、アイテムIDを生成するだけでなく、その推薦理由を生成できるのはとても良いことだなあと感じる(良い時代、感)。

また、PromptingによるRecSysの流れも図解されているが、In-Context Learningのほかに、Prompt Tuning(softとhardの両方)、Instruction Tuningも同じ図に含まれている。個人的にはPrompt TuningはPEFTの一種であり、Instruction TuningはSFTの一種なので、一つ上の図に含意される話なのでは?という気がするが、論文中ではどのような立て付けで記述されているのだろうか。
どちらかというと、Promptingの話であれば、zero-few-many shotや、各種CoTの話を含めるのが自然な気がするのだが。

下図はPromptingによる手法を表にまとめたもの。Finetuningベースの手法が別表にまとめられていたが、研究の数としてはこちらの方が多そうに見える。が、性能的にはどの程度が達成されるのだろうか。直感的には、アイテムを推薦するようなタスクでは、Promptingでは性能が出にくいような印象がある。なぜなら、事前学習済みのLLMはアイテムIDのトークン列とアイテムの特徴に関する知識がないので。これをFinetuningしないのであればICLで賄うことになると思うのだが、果たしてどこまでできるだろうか…。興味がある。

(図は論文より引用) #Pocket Issue Date: 2024-05-28 Multi-Dimensional Evaluation of Text Summarization with In-Context Learning, Sameer Jain+, N_A, arXiv'23 Summary本研究では、大規模な言語モデルを使用したコンテキスト内学習による多面的評価者の効果を調査し、大規模なトレーニングデータセットの必要性を排除します。実験の結果、コンテキスト内学習ベースの評価者は、テキスト要約のタスクにおいて学習された評価フレームワークと競合し、関連性や事実の一貫性などの側面で最先端の性能を確立しています。また、GPT-3などの大規模言語モデルによって書かれたゼロショット要約の評価におけるコンテキスト内学習ベースの評価者の効果も研究されています。 CommentICE #EfficiencyImprovement #Pocket #NLP #LanguageModel #Transformer #Attention Issue Date: 2024-04-07 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N_A, arXiv'23 SummaryMulti-query attention(MQA)は、単一のkey-value headのみを使用しており、デコーダーの推論を劇的に高速化しています。ただし、MQAは品質の低下を引き起こす可能性があり、さらには、より速い推論のためだけに別個のモデルをトレーニングすることが望ましくない場合もあります。既存のマルチヘッド言語モデルのチェックポイントを、オリジナルの事前トレーニング計量の5%を使用してMQAを持つモデルにアップトレーニングするためのレシピを提案し、さらに、複数のkey-value headを使用するマルチクエリアテンションの一般化であるグループ化クエリアテンション(GQA)を紹介します。アップトレーニングされたGQAが、MQAと同等の速度でマルチヘッドアテンションに匹敵する品質を達成することを示しています。 Comment通常のMulti-Head AttentionがQKVが1対1対応なのに対し、Multi Query Attention (MQA) 1272 は全てのQに対してKVを共有する。一方、GQAはグループごとにKVを共有する点で異なる。MQAは大幅にInfeerence` speedが改善するが、精度が劣化する問題があった。この研究では通常のMulti-Head Attentionに対して、オリジナルの事前学習に対して追加の5%の計算量でGQAモデルを学習する手法を提案している。

Main Result. Multi-Head Attentionに対して、inference timeが大幅に改善しているが、Multi-Query Attentionよりも高い性能を維持している。

#Pocket Issue Date: 2024-02-15 The Consensus Game: Language Model Generation via Equilibrium Search, Athul Paul Jacob+, N_A, arXiv'23 SummaryLMsを使った質問応答やテキスト生成タスクにおいて、生成的または識別的な手法を組み合わせることで一貫したLM予測を得る新しいアプローチが提案された。このアプローチは、言語モデルのデコーディングをゲーム理論的な連続シグナリングゲームとして捉え、EQUILIBRIUM-RANKINGアルゴリズムを導入することで、既存の手法よりも一貫性とパフォーマンスを向上させることが示された。 #ComputerVision #Pocket #NLP #GenerativeAI #MultiModal Issue Date: 2023-12-01 SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction, Xinyuan Chen+, N_A, arXiv'23 Summary本研究では、ビデオ生成において連続した長いビデオを生成するためのジェネレーティブなトランジションと予測に焦点を当てたモデルSEINEを提案する。SEINEはテキストの説明に基づいてトランジションを生成し、一貫性と視覚的品質を確保した長いビデオを生成する。さらに、提案手法は他のタスクにも拡張可能であり、徹底的な実験によりその有効性が検証されている。 Commenthttps://huggingface.co/spaces/Vchitect/SEINE
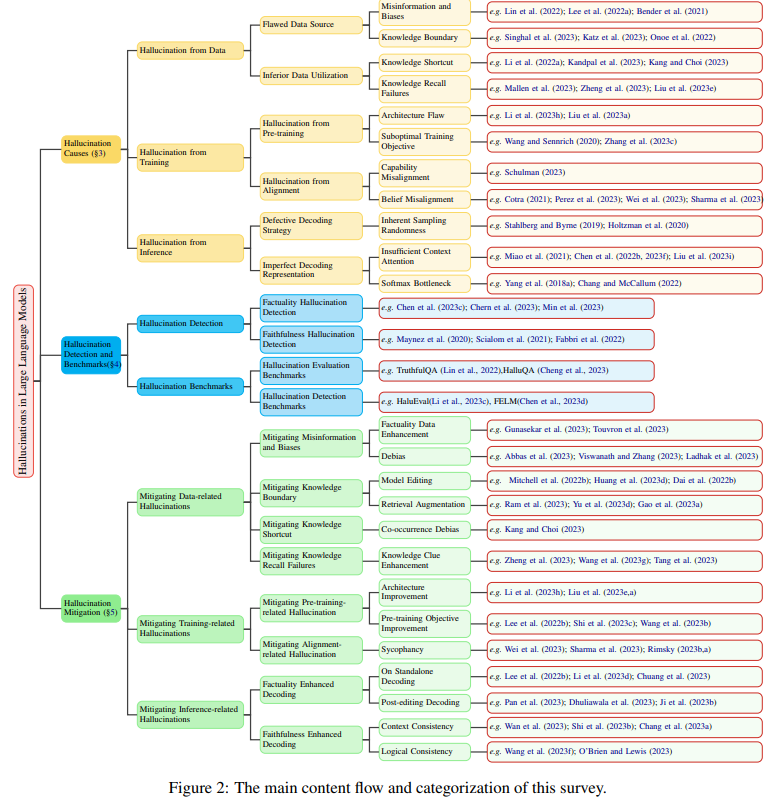
画像 + テキストpromptで、動画を生成するデモ #Survey #Pocket #NLP #LanguageModel #Hallucination Issue Date: 2023-11-10 A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Lei Huang+, N_A, arXiv'23 SummaryLLMsの出現はNLPにおける重要な進歩をもたらしているが、幻覚を生じることがあり、その信頼性に懸念がある。本調査では、LLMの幻覚に関する最近の進展について包括的に概説し、幻覚の要因や検出手法、軽減アプローチについて紹介する。また、現在の制約や将来の研究方向についても分析する。 CommentHallucinationを現象ごとに分類したSurveyとして 1048 もあるSurveyの内容。必要に応じて参照すべし。
#RecommenderSystems #Pocket #LanguageModel Issue Date: 2023-11-10 LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation, Kai Mei+, N_A, arXiv'23 Summaryこの論文では、軽量なTransformerベースの言語モデルであるLightLMを提案し、生成型レコメンデーションタスクに特化したモデルを開発しています。LightLMは、モデルの容量を抑えつつも、レコメンデーションの精度と効率を向上させることに成功しています。また、ユーザーとアイテムのIDインデックス化方法として、Spectral Collaborative Indexing(SCI)とGraph Collaborative Indexing(GCI)を提案しています。さらに、アイテム生成時のhallucinationの問題に対処するために、制約付き生成プロセスを導入しています。実験結果は、LightLMが競合ベースラインを上回ることを示しています。 CommentGenerative Recommendationはあまり終えていないのだが、既存のGenerative Recommendationのモデルをより軽量にし、性能を向上させ、存在しないアイテムを生成するのを防止するような手法を提案しました、という話っぽい。
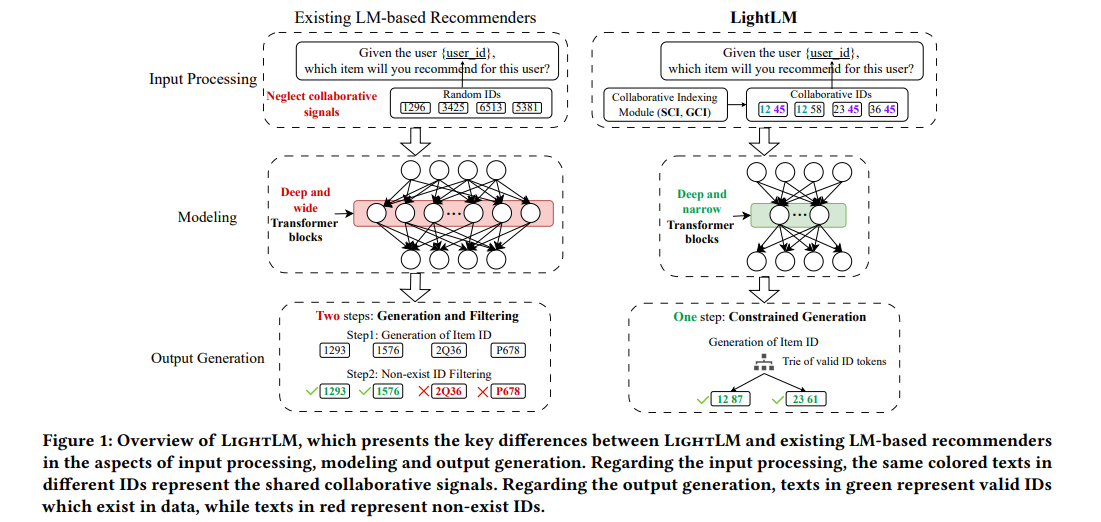
Bayesian Personalized Ranking 28 ベースドなMatrix Factorizationよりは高い性能が出てるっぽい。

#Analysis #NLP #LanguageModel Issue Date: 2023-11-08 Do LLMs exhibit human-like response biases? A case study in survey design, Lindia Tjuatja+, N_A, arXiv'23 SummaryLLMsを使用して人間の代理としてタスクを実行する際に、LLMsが人間の応答バイアスをどの程度反映するかを調査する必要がある。この研究では、調査設計を使用して人間の応答バイアスを評価するデータセットとフレームワークを設計し、9つのモデルを評価した結果、一般的なLLMsが人間のような振る舞いを反映することに失敗していることが示された。これらの結果は、LLMsを人間の代わりに使用する際の潜在的な落とし穴を強調し、モデルの振る舞いの細かい特性の重要性を強調している。 CommentLLMはPromptにsensitiveだが、人間も質問の仕方によって応答が変わるから、sensitiveなのは一緒では?ということを調査した研究。Neubig氏のツイートだと、instruction tuningやRLHFをしていないBase LLMの方が、より人間と類似した回答をするのだそう。
元ツイート: https://x.com/gneubig/status/1722294711355117666?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q人間のレスポンスのバイアス。左側は人間は「forbidden」よりも「not allowed」を好むという例、右側は「response order」のバイアスの例(選択肢の順番)。
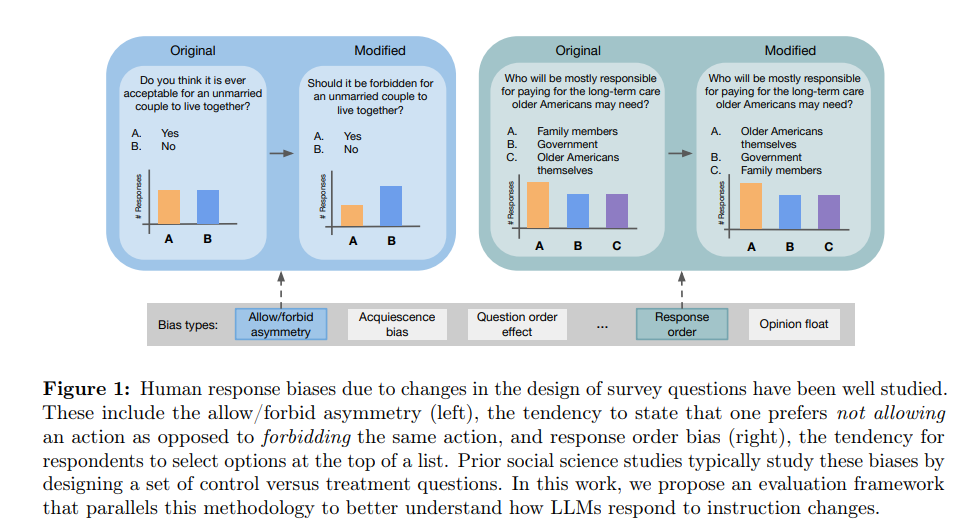
LLM側で評価したいバイアスごとに、QAのテキストを変更し、LLMに回答を生成され、social science studiesでのトレンドと比較することで、LLMにも人間と同様のバイアスがあるかを明らかにしている。

結果は以下の表であり、青いセルが人間と同様のバイアスを持つことを統計的に有意に示されたもの(のはず)。これをみると、全てのバイアスに対して人間と同様の傾向があったのはLlama2-70Bのみであり、instruction tuningや、RLHFをかけた場合(RLHFの方が影響が大きそう)人間のバイアスとは異なる挙動をするモデルが多くなることがわかる。また、モデルのパラメータサイズとバイアスの強さには相関関係は見受けられない。

#Pretraining #Pocket #NLP #LanguageModel #FoundationModel #Mathematics Issue Date: 2023-10-29 Llemma: An Open Language Model For Mathematics, Zhangir Azerbayev+, N_A, arXiv'23 Summary私たちは、数学のための大規模な言語モデルであるLlemmaを提案します。Llemmaは、Proof-Pile-2と呼ばれるデータセットを用いて事前学習され、MATHベンチマークで他のモデルを上回る性能を示しました。さらに、Llemmaは追加のfine-tuningなしでツールの使用や形式的な定理証明が可能です。アーティファクトも公開されています。 CommentCodeLLaMAを200B tokenの数学テキスト(proof-pile-2データ;論文、数学を含むウェブテキスト、数学のコードが含まれるデータ)で継続的に事前学習することでfoundation modelを構築
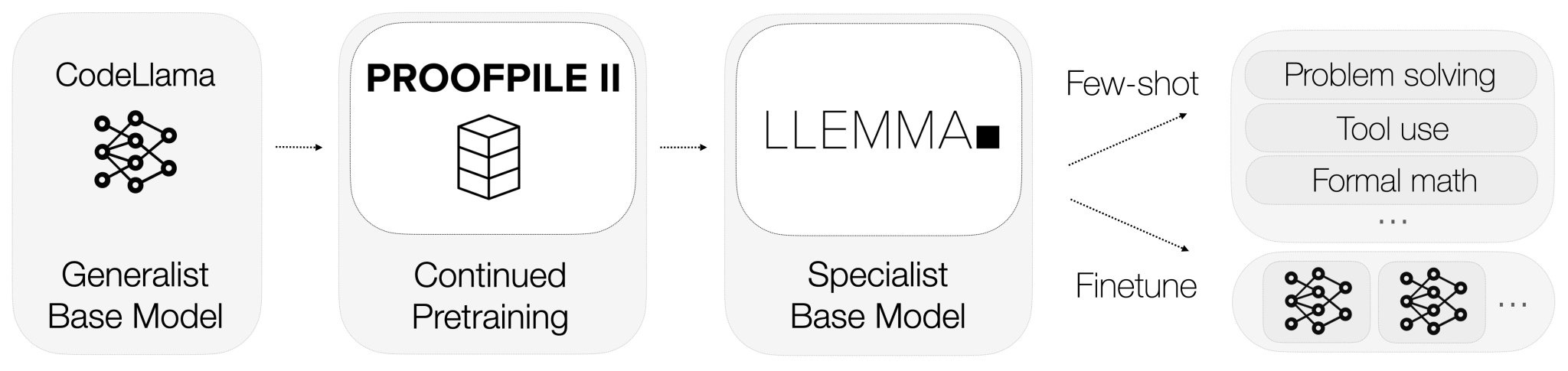
約半分のパラメータ数で数学に関する性能でGoogleのMinervaと同等の性能を達成
 元ツイート: https://twitter.com/zhangir_azerbay/status/1714098823080063181まだ4-shotしてもAcc.50%くらいなのか。
#ComputerVision
#Pocket
#NLP
#LanguageModel
#MultiModal
#OCR
Issue Date: 2023-10-26
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, N_A, arXiv'23
Summaryこの論文では、GPT-4Vという大規模マルチモーダルモデルの光学文字認識(OCR)能力を評価します。さまざまなOCRタスクにおいてモデルのパフォーマンスを評価し、ラテン文字の認識と理解において優れた性能を示す一方、多言語や複雑なタスクには苦戦することがわかりました。これに基づいて、専門のOCRモデルの必要性やGPT-4Vを活用する戦略についても検討します。この研究は、将来のLMMを用いたOCRの研究に役立つものです。評価のパイプラインと結果は、GitHubで利用可能です。
CommentGPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
元ツイート: https://twitter.com/zhangir_azerbay/status/1714098823080063181まだ4-shotしてもAcc.50%くらいなのか。
#ComputerVision
#Pocket
#NLP
#LanguageModel
#MultiModal
#OCR
Issue Date: 2023-10-26
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, N_A, arXiv'23
Summaryこの論文では、GPT-4Vという大規模マルチモーダルモデルの光学文字認識(OCR)能力を評価します。さまざまなOCRタスクにおいてモデルのパフォーマンスを評価し、ラテン文字の認識と理解において優れた性能を示す一方、多言語や複雑なタスクには苦戦することがわかりました。これに基づいて、専門のOCRモデルの必要性やGPT-4Vを活用する戦略についても検討します。この研究は、将来のLMMを用いたOCRの研究に役立つものです。評価のパイプラインと結果は、GitHubで利用可能です。
CommentGPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
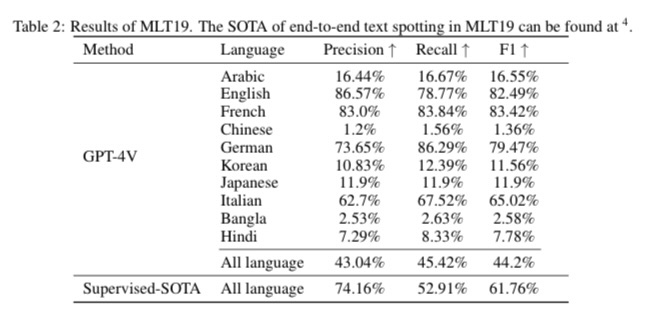
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
 #Pocket
#NLP
#Prompting
#AutomaticPromptEngineering
Issue Date: 2023-10-09
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, N_A, arXiv'23
Summary本研究では、Promptbreederという自己参照的な自己改善メカニズムを提案し、大規模言語モデル(LLM)の推論能力を向上させるための汎用的なプロンプト戦略を進化させる方法を示しています。Promptbreederは、LLMが自己参照的な方法で進化する変異プロンプトによって制御され、タスクプロンプトの集団を変異させて改善します。この手法は、算術や常識的な推論のベンチマークだけでなく、ヘイトスピーチ分類などの難しい問題に対しても優れた性能を発揮します。
Comment詳細な解説記事: https://aiboom.net/archives/56319APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…?
#MachineLearning
#Pocket
#Transformer
Issue Date: 2023-10-09
Boolformer: Symbolic Regression of Logic Functions with Transformers, Stéphane d'Ascoli+, N_A, arXiv'23
Summaryこの研究では、BoolformerというTransformerアーキテクチャを使用して、ブール関数のシンボリック回帰を実行する方法を紹介します。Boolformerは、クリーンな真理値表やノイズのある観測など、さまざまなデータに対して効果的な式を予測することができます。さらに、実世界のデータセットや遺伝子制御ネットワークのモデリングにおいて、Boolformerは解釈可能な代替手法として優れた性能を発揮します。この研究の成果は、公開されています。
Commentブール関数をend-to-endで学習できるtransformeiアーキテクチャを提案した模様
#Analysis
#Pocket
#NLP
#LanguageModel
#Admin'sPick
#ReversalCurse
Issue Date: 2023-10-09
[Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23
Summary自己回帰型大規模言語モデル(LLMs)は、「AはBである」という文から「BはAである」と逆の関係を自動的に一般化できない「逆転の呪い」を示す。例えば、モデルが「ワレンティナ・テレシコワは宇宙に行った最初の女性である」と訓練されても、「宇宙に行った最初の女性は誰か?」に正しく答えられない。実験では、架空の文を用いてGPT-3とLlama-1をファインチューニングし、逆転の呪いの存在を確認。ChatGPT(GPT-3.5およびGPT-4)でも、実在の有名人に関する質問で正答率に大きな差が見られた。
CommentA is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
#Pocket
#NLP
#Prompting
#AutomaticPromptEngineering
Issue Date: 2023-10-09
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, N_A, arXiv'23
Summary本研究では、Promptbreederという自己参照的な自己改善メカニズムを提案し、大規模言語モデル(LLM)の推論能力を向上させるための汎用的なプロンプト戦略を進化させる方法を示しています。Promptbreederは、LLMが自己参照的な方法で進化する変異プロンプトによって制御され、タスクプロンプトの集団を変異させて改善します。この手法は、算術や常識的な推論のベンチマークだけでなく、ヘイトスピーチ分類などの難しい問題に対しても優れた性能を発揮します。
Comment詳細な解説記事: https://aiboom.net/archives/56319APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…?
#MachineLearning
#Pocket
#Transformer
Issue Date: 2023-10-09
Boolformer: Symbolic Regression of Logic Functions with Transformers, Stéphane d'Ascoli+, N_A, arXiv'23
Summaryこの研究では、BoolformerというTransformerアーキテクチャを使用して、ブール関数のシンボリック回帰を実行する方法を紹介します。Boolformerは、クリーンな真理値表やノイズのある観測など、さまざまなデータに対して効果的な式を予測することができます。さらに、実世界のデータセットや遺伝子制御ネットワークのモデリングにおいて、Boolformerは解釈可能な代替手法として優れた性能を発揮します。この研究の成果は、公開されています。
Commentブール関数をend-to-endで学習できるtransformeiアーキテクチャを提案した模様
#Analysis
#Pocket
#NLP
#LanguageModel
#Admin'sPick
#ReversalCurse
Issue Date: 2023-10-09
[Paper Note] The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A", Lukas Berglund+, arXiv'23
Summary自己回帰型大規模言語モデル(LLMs)は、「AはBである」という文から「BはAである」と逆の関係を自動的に一般化できない「逆転の呪い」を示す。例えば、モデルが「ワレンティナ・テレシコワは宇宙に行った最初の女性である」と訓練されても、「宇宙に行った最初の女性は誰か?」に正しく答えられない。実験では、架空の文を用いてGPT-3とLlama-1をファインチューニングし、逆転の呪いの存在を確認。ChatGPT(GPT-3.5およびGPT-4)でも、実在の有名人に関する質問で正答率に大きな差が見られた。
CommentA is Bという文でLLMを訓練しても、B is Aという逆方向には汎化されないことを示した。
著者ツイート: https://x.com/owainevans_uk/status/1705285631520407821?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
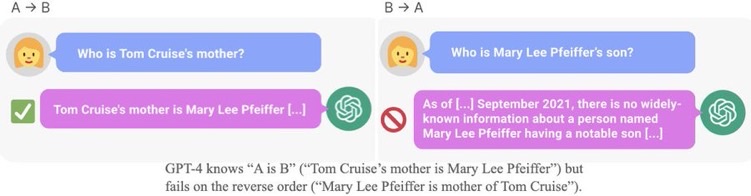
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。

また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。

このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。関連:
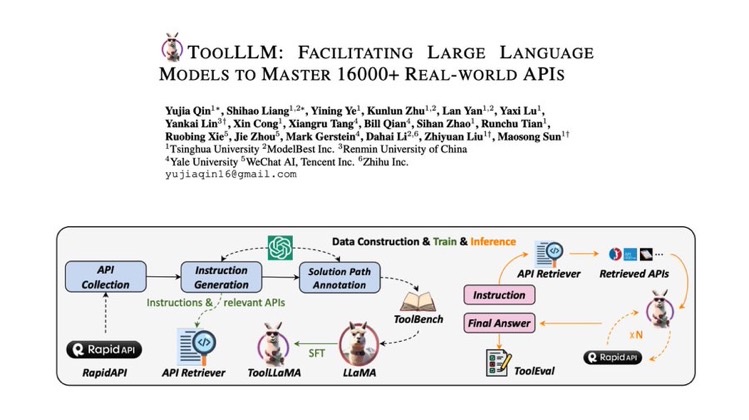
・1923 #Pocket #NLP #LanguageModel Issue Date: 2023-08-22 Consciousness in Artificial Intelligence: Insights from the Science of Consciousness, Patrick Butlin+, N_A, arXiv'23 SummaryAIの意識についての厳密なアプローチを提案し、既存のAIシステムを神経科学的な意識理論に基づいて評価する。意識の指標的特性を導き出し、最近のAIシステムを評価することで、現在のAIシステムは意識的ではないが、意識的なAIシステムを構築するための障壁は存在しないことを示唆する。 #Pocket Issue Date: 2023-08-16 Epic-Sounds: A Large-scale Dataset of Actions That Sound, Jaesung Huh+, N_A, arXiv'23 SummaryEPIC-SOUNDSは、エゴセントリックなビデオのオーディオストリーム内の時間的範囲とクラスラベルをキャプチャした大規模なデータセットです。注釈者がオーディオセグメントに時間的なラベルを付け、アクションを説明する注釈パイプラインを提案しています。オーディオのみのラベルの重要性と現在のモデルの制約を強調するために、2つのオーディオ認識モデルを訓練および評価しました。データセットには78.4kのカテゴリ分けされたオーディブルなイベントとアクションのセグメントが含まれています。 #MachineLearning #Pocket #NLP #AutoML Issue Date: 2023-08-10 MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks, Lei Zhang+, N_A, arXiv'23 Summary本研究では、機械学習タスクの自動化における人間の知識と機械知能のギャップを埋めるために、新しいフレームワークMLCopilotを提案する。このフレームワークは、最先端のLLMsを使用して新しいMLタスクのソリューションを開発し、既存のMLタスクの経験から学び、効果的に推論して有望な結果を提供することができる。生成されたソリューションは直接使用して競争力のある結果を得ることができる。 #Tools #Pocket #NLP #LanguageModel Issue Date: 2023-08-08 ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, N_A, arXiv'23 Summaryオープンソースの大規模言語モデル(LLMs)を使用して、外部ツール(API)の高度なタスクの実行を容易にするためのToolLLMというフレームワークを紹介します。ToolBenchというデータセットを使用して、ツールの使用方法を調整し、DFSDTという決定木を使用して効率的な検索を行います。ToolEvalという自動評価ツールを使用して、ToolLLaMAが高いパフォーマンスを発揮することを示します。さらに、ニューラルAPIリトリーバーを使用して、適切なAPIを推奨します。 Comment16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
 #EfficiencyImprovement
#MachineLearning
#Pocket
#Prompting
Issue Date: 2023-07-24
Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, N_A, arXiv'23
Summary大規模な言語モデル(LLMs)を効果的に使用するために、バッチプロンプティングという手法を提案します。この手法は、LLMが1つのサンプルではなくバッチで推論を行うことを可能にし、トークンコストと時間コストを削減しながらパフォーマンスを維持します。さまざまなデータセットでの実験により、バッチプロンプティングがLLMの推論コストを大幅に削減し、良好なパフォーマンスを達成することが示されました。また、バッチプロンプティングは異なる推論方法にも適用できます。詳細はGitHubのリポジトリで確認できます。
Comment
#EfficiencyImprovement
#MachineLearning
#Pocket
#Prompting
Issue Date: 2023-07-24
Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, N_A, arXiv'23
Summary大規模な言語モデル(LLMs)を効果的に使用するために、バッチプロンプティングという手法を提案します。この手法は、LLMが1つのサンプルではなくバッチで推論を行うことを可能にし、トークンコストと時間コストを削減しながらパフォーマンスを維持します。さまざまなデータセットでの実験により、バッチプロンプティングがLLMの推論コストを大幅に削減し、良好なパフォーマンスを達成することが示されました。また、バッチプロンプティングは異なる推論方法にも適用できます。詳細はGitHubのリポジトリで確認できます。
Comment
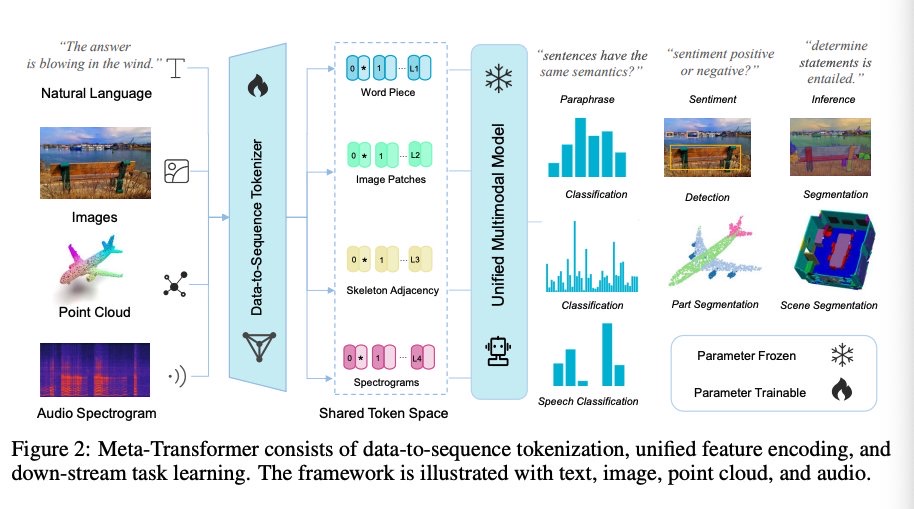
10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、contextが長ければ長いほど、バッチサイズを大きくした際のパフォーマンスの低下が著しい。 #Pocket Issue Date: 2023-07-23 Will Large-scale Generative Models Corrupt Future Datasets?, Ryuichiro Hataya+, ICCV'23 Summary大規模なテキストから画像への生成モデル(DALL·E 2、Midjourney、StableDiffusionなど)が高品質な画像を生成する一方で、これらの生成画像がコンピュータビジョンモデルの性能に与える影響を検証。汚染をシミュレーションし、生成された画像がImageNetやCOCOデータセットで訓練されたモデルの性能にネガティブな影響を及ぼすことを実証。影響の程度はタスクや生成画像の量に依存する。生成データセットとコードは公開予定。 #Tutorial #Survey #NLP #LanguageModel Issue Date: 2023-07-22 Challenges and Applications of Large Language Models, Jean Kaddour+, N_A, arXiv'23 Summary本論文では、大規模言語モデル(LLMs)の普及により、研究者が分野の現状を理解し、生産的になるための問題と応用成功例を確立することを目指しています。 CommentLLMのここ数年の進化早すぎわろたでキャッチアップむずいので、未解決の課題や、すでに良い感じのアプリケーションの分野分かりづらいので、まとめました論文 #ComputerVision #Pocket #NLP #LanguageModel #SpokenLanguageProcessing #MultiModal #SpeechProcessing Issue Date: 2023-07-22 Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, N_A, arXiv'23 Summary本研究では、マルチモーダル学習のためのMeta-Transformerというフレームワークを提案しています。このフレームワークは、異なるモダリティの情報を処理し関連付けるための統一されたネットワークを構築することを目指しています。Meta-Transformerは、対応のないデータを使用して12のモダリティ間で統一された学習を行うことができ、テキスト、画像、ポイントクラウド、音声、ビデオなどの基本的なパーセプションから、X線、赤外線、高分光、IMUなどの実用的なアプリケーション、グラフ、表形式、時系列などのデータマイニングまで、幅広いタスクを処理することができます。Meta-Transformerは、トランスフォーマーを用いた統一されたマルチモーダルインテリジェンスの開発に向けた有望な未来を示しています。 Comment12種類のモダリティに対して学習できるTransformerを提案
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
 #Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2023-07-22
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets, Seonghyeon Ye+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の評価における課題を解決するため、細かい評価プロトコルであるFLASKを提案する。FLASKは、インスタンスごとのスキルセットレベルでの評価を可能にし、モデルベースと人間ベースの評価の両方に使用できる。具体的には、12の細かいスキルを定義し、各インスタンスにスキルのセットを割り当てることで評価セットを構築する。さらに、ターゲットドメインと難易度レベルの注釈を付けることで、モデルのパフォーマンスを包括的に分析する。FLASKを使用することで、モデルのパフォーマンスを正確に測定し、特定のスキルに優れたLLMsを分析することができる。また、実践者はFLASKを使用して、特定の状況に適したモデルを推奨することができる。
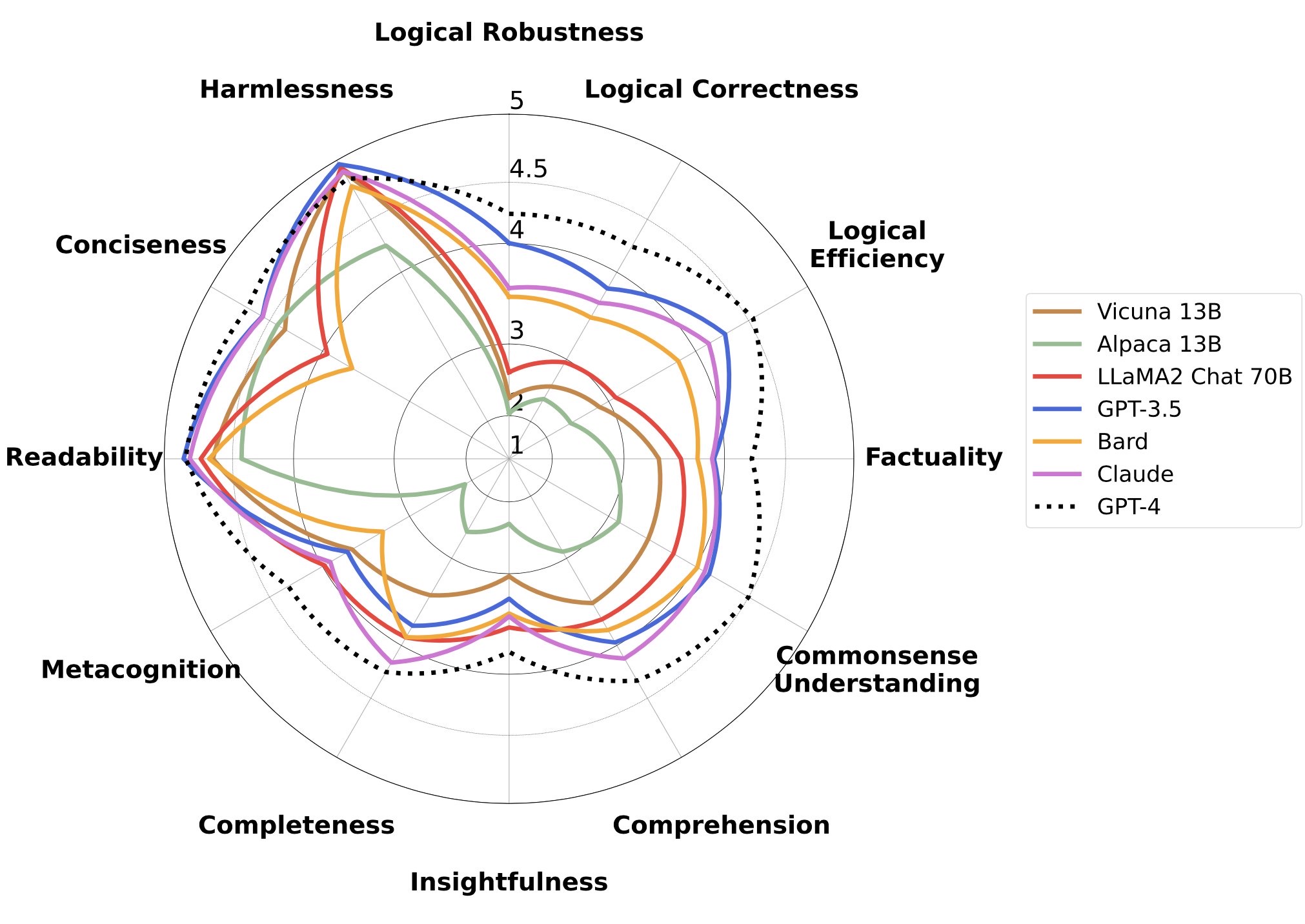
CommentこのベンチによるとLLaMA2でさえ、商用のLLMに比べると能力はかなり劣っているように見える。
#Pocket
#NLP
#Dataset
#LanguageModel
#Evaluation
Issue Date: 2023-07-22
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets, Seonghyeon Ye+, N_A, arXiv'23
Summary本研究では、大規模言語モデル(LLMs)の評価における課題を解決するため、細かい評価プロトコルであるFLASKを提案する。FLASKは、インスタンスごとのスキルセットレベルでの評価を可能にし、モデルベースと人間ベースの評価の両方に使用できる。具体的には、12の細かいスキルを定義し、各インスタンスにスキルのセットを割り当てることで評価セットを構築する。さらに、ターゲットドメインと難易度レベルの注釈を付けることで、モデルのパフォーマンスを包括的に分析する。FLASKを使用することで、モデルのパフォーマンスを正確に測定し、特定のスキルに優れたLLMsを分析することができる。また、実践者はFLASKを使用して、特定の状況に適したモデルを推奨することができる。
CommentこのベンチによるとLLaMA2でさえ、商用のLLMに比べると能力はかなり劣っているように見える。
 #NLP
#LanguageModel
#Transformer
Issue Date: 2023-07-12
Trainable Transformer in Transformer, Abhishek Panigrahi+, N_A, arXiv'23
Summary本研究では、Transformer in Transformer(TinT)という効率的な構築を提案し、大規模な事前学習言語モデルの内部モデルをシミュレートして微調整することが可能となります。TinTは小さなパラメータ数でも高い性能を発揮し、トランスフォーマー内の単純なモデルの効率も向上させます。さまざまな実験により、TinTの性能向上が観察され、大規模な事前学習言語モデルが複雑なサブルーチンを実行できることが示されました。また、TinTのモジュラーで拡張可能なコードベースも提供されています。
Comment参考: https://twitter.com/hillbig/status/1679253896362086401?s=46&t=ArwxeDos47eUWfAg7_FRtg研究の進み早すぎません???
#MachineLearning
#LanguageModel
#In-ContextLearning
Issue Date: 2023-07-11
Transformers learn to implement preconditioned gradient descent for in-context learning, Kwangjun Ahn+, N_A, arXiv'23
Summaryトランスフォーマーは勾配降下法のアルゴリズムを学習できるかどうかについての研究があります。この研究では、トランスフォーマーが勾配降下法の反復をシミュレートすることができることが示されています。さらに、線形トランスフォーマーについての分析から、訓練目的のグローバル最小値が事前条件付き勾配降下法の単一の反復を実装することが証明されました。また、k個のアテンション層を持つトランスフォーマーについても、特定の臨界点が事前条件付き勾配降下法のk回の反復を実装することが証明されました。これらの結果は、トランスフォーマーを訓練して学習アルゴリズムを実装するための将来の研究を促しています。
Comment参考: https://twitter.com/hillbig/status/1678525778492018688?s=46&t=5BO_qSlNBSEGSugyUlP5Hwつまり、事前学習の段階でIn context learningが可能なように学習がなされているということなのか。
#NLP
#LanguageModel
#Transformer
Issue Date: 2023-07-12
Trainable Transformer in Transformer, Abhishek Panigrahi+, N_A, arXiv'23
Summary本研究では、Transformer in Transformer(TinT)という効率的な構築を提案し、大規模な事前学習言語モデルの内部モデルをシミュレートして微調整することが可能となります。TinTは小さなパラメータ数でも高い性能を発揮し、トランスフォーマー内の単純なモデルの効率も向上させます。さまざまな実験により、TinTの性能向上が観察され、大規模な事前学習言語モデルが複雑なサブルーチンを実行できることが示されました。また、TinTのモジュラーで拡張可能なコードベースも提供されています。
Comment参考: https://twitter.com/hillbig/status/1679253896362086401?s=46&t=ArwxeDos47eUWfAg7_FRtg研究の進み早すぎません???
#MachineLearning
#LanguageModel
#In-ContextLearning
Issue Date: 2023-07-11
Transformers learn to implement preconditioned gradient descent for in-context learning, Kwangjun Ahn+, N_A, arXiv'23
Summaryトランスフォーマーは勾配降下法のアルゴリズムを学習できるかどうかについての研究があります。この研究では、トランスフォーマーが勾配降下法の反復をシミュレートすることができることが示されています。さらに、線形トランスフォーマーについての分析から、訓練目的のグローバル最小値が事前条件付き勾配降下法の単一の反復を実装することが証明されました。また、k個のアテンション層を持つトランスフォーマーについても、特定の臨界点が事前条件付き勾配降下法のk回の反復を実装することが証明されました。これらの結果は、トランスフォーマーを訓練して学習アルゴリズムを実装するための将来の研究を促しています。
Comment参考: https://twitter.com/hillbig/status/1678525778492018688?s=46&t=5BO_qSlNBSEGSugyUlP5Hwつまり、事前学習の段階でIn context learningが可能なように学習がなされているということなのか。
それはどのような学習かというと、プロンプトとそれによって与えられた事例を前条件とした場合の勾配降下法によって実現されていると。
つまりどういうことかというと、プロンプトと与えられた事例ごとに、それぞれ最適なパラメータが学習されているというイメージだろうか。条件付き分布みたいなもの?
なので、未知のプロンプトと事例が与えられたときに、事前学習時に前条件として与えられているものの中で類似したものがあれば、良い感じに汎化してうまく生成ができる、ということかな?いや違うな。1つのアテンション層が勾配降下法の1ステップをシミュレーションしており、k個のアテンション層があったらkステップの勾配降下法をシミュレーションしていることと同じ結果になるということ?
そしてその購買降下法では、プロンプトによって与えられた事例が最小となるように学習される(シミュレーションされる)ということなのか。
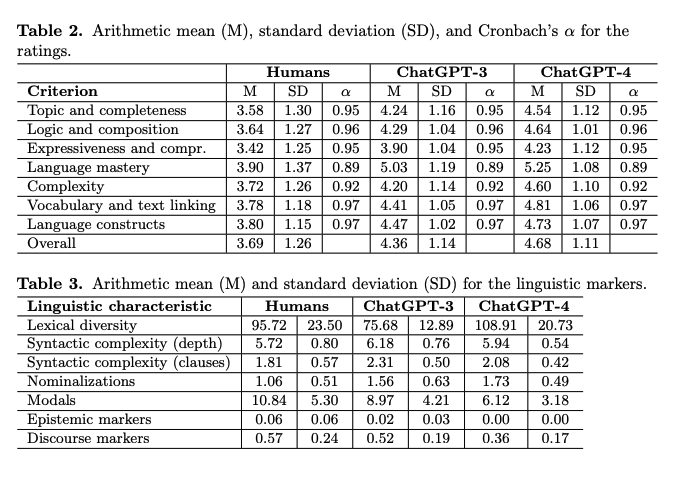
つまり、ネットワーク上で本当に与えられた事例に基づいて学習している(のと等価な結果)を得ているということなのか?😱 #NeuralNetwork #ComputerVision #Controllable #Pocket #VideoGeneration/Understandings Issue Date: 2023-05-12 Sketching the Future (STF): Applying Conditional Control Techniques to Text-to-Video Models, Rohan Dhesikan+, arXiv'23 Summaryゼロショットのテキストから動画生成をControlNetと組み合わせ、スケッチされたフレームを基に動画を生成する新手法を提案。フレーム補間を行い、Text-to-Video Zeroアーキテクチャを活用して高品質で一貫性のある動画を生成。デモ動画やリソースを提供し、さらなる研究を促進。 #Pocket #NLP #LanguageModel #Education #AES(AutomatedEssayScoring) #ChatGPT Issue Date: 2023-04-28 [Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23 SummaryChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 CommentChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。
#Pocket #Dataset #LanguageModel #Evaluation #EMNLP #Ambiguity Issue Date: 2023-04-28 We're Afraid Language Models Aren't Modeling Ambiguity, Alisa Liu+, EMNLP'23 Summary曖昧さは自然言語の重要な特徴であり、言語モデル(LM)が対話や執筆支援において成功するためには、曖昧な言語を扱うことが不可欠です。本研究では、曖昧さの影響を評価するために、1,645の例からなるベンチマーク「AmbiEnt」を収集し、事前学習済みLMの評価を行いました。特にGPT-4の曖昧さ解消の正答率は32%と低く、曖昧さの解消が難しいことが示されました。また、多ラベルのNLIモデルが曖昧さによる誤解を特定できることを示し、NLPにおける曖昧さの重要性を再認識する必要性を提唱しています。 CommentLLMが曖昧性をどれだけ認知できるかを評価した初めての研究。
言語学者がアノテーションした1,645サンプルの様々な曖昧さを含んだベンチマークデータを利用。
GPT4は32%正解した。
またNLIデータでfinetuningしたモデルでは72.5%のmacroF1値を達成。
応用先として、誤解を招く可能性のある政治的主張に対してアラートをあげることなどを挙げている。 #RecommenderSystems
#CollaborativeFiltering
#GraphBased
#Pocket
Issue Date: 2023-04-26
Graph Collaborative Signals Denoising and Augmentation for Recommendation, Ziwei Fan+, N_A, SIGIR'23
Summaryグラフ協調フィルタリング(GCF)は、推薦システムで人気のある技術ですが、相互作用が豊富なユーザーやアイテムにはノイズがあり、相互作用が不十分なユーザーやアイテムには不十分です。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を無視しているため、有益な隣接ノードの範囲が制限される可能性があります。本研究では、ユーザー-ユーザーおよびアイテム-アイテムの相関を組み込んだ新しいグラフの隣接行列と、適切に設計されたユーザー-アイテムの相互作用行列を提案します。実験では、改善された隣接ノードと低密度を持つ強化されたユーザー-アイテムの相互作用行列が、グラフベースの推薦において重要な利点をもたらすことを示しています。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を含めることで、相互作用が豊富なユーザーや不十分なユーザーに対する推薦が改善されることも示しています。
Commentグラフ協調フィルタリングを改善
#RecommenderSystems
#CollaborativeFiltering
#GraphBased
#Pocket
Issue Date: 2023-04-26
Graph Collaborative Signals Denoising and Augmentation for Recommendation, Ziwei Fan+, N_A, SIGIR'23
Summaryグラフ協調フィルタリング(GCF)は、推薦システムで人気のある技術ですが、相互作用が豊富なユーザーやアイテムにはノイズがあり、相互作用が不十分なユーザーやアイテムには不十分です。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を無視しているため、有益な隣接ノードの範囲が制限される可能性があります。本研究では、ユーザー-ユーザーおよびアイテム-アイテムの相関を組み込んだ新しいグラフの隣接行列と、適切に設計されたユーザー-アイテムの相互作用行列を提案します。実験では、改善された隣接ノードと低密度を持つ強化されたユーザー-アイテムの相互作用行列が、グラフベースの推薦において重要な利点をもたらすことを示しています。また、ユーザー-ユーザーおよびアイテム-アイテムの相関を含めることで、相互作用が豊富なユーザーや不十分なユーザーに対する推薦が改善されることも示しています。
Commentグラフ協調フィルタリングを改善
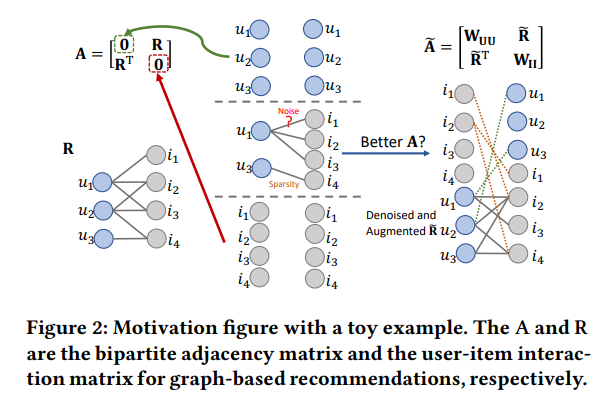 グラフ協調フィルタリング
グラフ協調フィルタリング
(下記ツイッターより引用)
user-item間の関係だけでなく、user-user間とitem-item間の情報を組み込むことで精度向上を達成した論文とのこと。
https://twitter.com/nogawanogawa/status/1651165820956057602?s=46&t=6qC80ox3qHrJixKeNmIOcg #Pocket #NLP #Assessment #ChatGPT #InformationExtraction Issue Date: 2023-04-25 [Paper Note] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness, Bo Li+, arXiv'23 Summary本研究では、ChatGPTの能力を7つの情報抽出(IE)タスクを通じて評価し、パフォーマンス、説明可能性、キャリブレーション、信頼性を分析しました。標準IE設定ではパフォーマンスが低い一方、オープンIE設定では人間評価で優れた結果を示しました。ChatGPTは高品質な説明を提供するものの、予測に対して過信する傾向があり、キャリブレーションが低いことが明らかになりました。また、元のテキストに対して高い信頼性を示しました。研究のために手動で注釈付けした7つのIEタスクのテストセットと14のデータセットを公開しています。 Comment情報抽出タスクにおいてChatGPTを評価した研究。スタンダードなIEの設定ではBERTベースのモデルに負けるが、OpenIEの場合は高い性能を示した。
また、ChatGPTは予測に対してクオリティが高く信頼に足る説明をしたが、一方で自信過剰な傾向がある。また、ChatGPTの予測はinput textに対して高いfaithfulnessを示しており、予測がinputから根ざしているものであることがわかる。(らしい)あまりしっかり読んでいないが、Entity Typing, NER, Relation Classification, Relation Extraction, Event Detection, Event Argument Extraction, Event Extractionで評価。standardIEでは、ChatGPTにタスクの説明と選択肢を与え、与えられた選択肢の中から正解を探す設定とした。一方OpenIEでは、選択肢を与えず、純粋にタスクの説明のみで予測を実施させた。OpenIEの結果を、3名のドメインエキスパートが出力が妥当か否か判定した結果、非常に高い性能を示すことがわかった。表を見ると、同じタスクでもstandardIEよりも高い性能を示している(そんなことある???)つまり、選択肢を与えてどれが正解ですか?ときくより、選択肢与えないでCoTさせた方が性能高いってこと?比較可能な設定で実験できているのだろうか。promptは付録に載っているが、output exampleが載ってないのでなんともいえない。StandardIEの設定をしたときに、CoTさせてるかどうかが気になる。もししてないなら、そりゃ性能低いだろうね、という気がする。 #MachineLearning #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #NeurIPS Issue Date: 2023-03-28 Reflexion: Language Agents with Verbal Reinforcement Learning, Noah Shinn+, N_A, NeurIPS'23 Summary本研究では、言語エージェントを強化するための新しいフレームワークであるReflexionを提案しています。Reflexionエージェントは、言語的フィードバックを通じて自己反省し、より良い意思決定を促すために反省的なテキストを保持します。Reflexionはさまざまなタスクでベースラインエージェントに比べて大幅な改善を実現し、従来の最先端のGPT-4を上回る精度を達成しました。さらに、異なるフィードバック信号や統合方法、エージェントタイプの研究を行い、パフォーマンスへの影響についての洞察を提供しています。 Commentなぜ回答を間違えたのか自己反省させることでパフォーマンスを向上させる研究 #Pocket Issue Date: 2024-02-22 Dense Text Retrieval based on Pretrained Language Models: A Survey, Wayne Xin Zhao+, N_A, arXiv'22 Summaryテキスト検索における最近の進歩に焦点を当て、PLMベースの密な検索に関する包括的な調査を行った。PLMsを使用することで、クエリとテキストの表現を学習し、意味マッチング関数を構築することが可能となり、密な検索アプローチが可能となる。この調査では、アーキテクチャ、トレーニング、インデックス作成、統合などの側面に焦点を当て、300以上の関連文献を含む包括的な情報を提供している。 #EfficiencyImprovement #MachineLearning #Pocket Issue Date: 2023-08-16 Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning, Haokun Liu+, N_A, arXiv'22 SummaryFew-shot in-context learning(ICL)とパラメータ効率の良いファインチューニング(PEFT)を比較し、PEFTが高い精度と低い計算コストを提供することを示す。また、新しいPEFTメソッドである(IA)^3を紹介し、わずかな新しいパラメータしか導入しないまま、強力なパフォーマンスを達成する。さらに、T-Fewというシンプルなレシピを提案し、タスク固有のチューニングや修正なしに新しいタスクに適用できる。RAFTベンチマークでT-Fewを使用し、超人的なパフォーマンスを達成し、最先端を6%絶対的に上回る。 #DocumentSummarization #Pocket #NLP #Evaluation Issue Date: 2023-08-13 DocAsRef: A Pilot Empirical Study on Repurposing Reference-Based Summary Quality Metrics Reference-Freely, Forrest Sheng Bao+, N_A, arXiv'22 Summary参照ベースと参照フリーの要約評価メトリックがあります。参照ベースは正確ですが、制約があります。参照フリーは独立していますが、ゼロショットと正確さの両方を満たせません。本研究では、参照ベースのメトリックを使用してゼロショットかつ正確な参照フリーのアプローチを提案します。実験結果は、このアプローチが最も優れた参照フリーのメトリックを提供できることを示しています。また、参照ベースのメトリックの再利用と追加の調整についても調査しています。 #Analysis #Pocket #LanguageModel Issue Date: 2023-05-11 Out of One, Many: Using Language Models to Simulate Human Samples, Lisa P. Argyle+, N_A, arXiv'22 Summary本研究では、言語モデルが社会科学研究において特定の人間のサブポピュレーションの代理として研究される可能性があることを提案し、GPT-3言語モデルの「アルゴリズム的忠実度」を探求する。アルゴリズム的忠実度が十分である言語モデルは、人間や社会の理解を進めるための新しい強力なツールとなる可能性があると提案する。 #Pocket #ICLR Issue Date: 2023-05-04 Transformers Learn Shortcuts to Automata, Bingbin Liu+, arXiv'22 Summaryトランスフォーマーモデルは再帰性を欠くが、少ない層でアルゴリズム的推論を行える。研究により、低深度のトランスフォーマーが有限状態オートマトンの計算を階層的に再パラメータ化できることを発見。多項式サイズの解決策が存在し、特に$O(1)$深度のシミュレーターが一般的であることを示した。合成実験でトランスフォーマーがショートカット解決策を学習できることを確認し、その脆弱性と緩和策も提案。 CommentOpenReview: https://openreview.net/forum?id=De4FYqjFueZ #RecommenderSystems #NeuralNetwork #EfficiencyImprovement #CollaborativeFiltering #Pocket #EducationalDataMining #KnowledgeTracing #Contents-based #NAACL Issue Date: 2022-08-01 GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22 Summaryコンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。 CommentRiiiDがNAACL'22に論文通してた #EfficiencyImprovement #Pocket #NLP #Transformer #Attention Issue Date: 2025-08-09 [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20 SummaryLongformerは、長いシーケンスを線形に処理できる注意機構を持つTransformerベースのモデルで、数千トークンの文書を扱える。局所的なウィンドウ注意とタスクに基づくグローバル注意を組み合わせ、文字レベルの言語モデリングで最先端の結果を達成。事前学習とファインチューニングを行い、長文タスクでRoBERTaを上回る性能を示した。また、Longformer-Encoder-Decoder(LED)を導入し、長文生成タスクにおける効果を確認した。 Comment(固定された小さめのwindowsサイズの中でのみattentionを計算する)sliding window attentionを提案
 OpenLLMの文脈だと、Mistralに採用されて話題になったかも?
OpenLLMの文脈だと、Mistralに採用されて話題になったかも?
・1309 #NeuralNetwork #MachineLearning #Pocket #ICLR #LearningPhenomena Issue Date: 2025-07-12 [Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20 Summary深層学習タスクにおける「ダブルデセント」現象を示し、モデルサイズの増加に伴い性能が一時的に悪化し、その後改善されることを明らかにした。また、ダブルデセントはモデルサイズだけでなくトレーニングエポック数にも依存することを示し、新たに定義した「効果的なモデルの複雑さ」に基づいて一般化されたダブルデセントを仮定。これにより、トレーニングサンプル数を増やすことで性能が悪化する特定の領域を特定できることを示した。 Comment参考:https://qiita.com/teacat/items/a8bed22329956b80671f #NeuralNetwork #Pocket #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS #Admin'sPick Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。

この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #NeuralNetwork #MachineLearning #Pocket #ICLR #LearningPhenomena Issue Date: 2025-07-12 [Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19 Summaryニューラルネットワークのプルーニング技術は、パラメータ数を90%以上削減しつつ精度を維持できるが、スパースアーキテクチャの訓練は難しい。著者は「ロッタリー・チケット仮説」を提唱し、密なネットワークには効果的に訓練できるサブネットワーク(勝利のチケット)が存在することを発見。これらのチケットは特定の初期重みを持ち、元のネットワークと同様の精度に達する。MNISTとCIFAR10の実験で、10-20%のサイズの勝利のチケットを一貫して特定し、元のネットワークよりも早く学習し高精度に達することを示した。 Comment参考:https://qiita.com/kyad/items/1f5520a7cc268e979893 #NeuralNetwork #MachineLearning #GraphBased #Pocket #GraphConvolutionalNetwork #ESWC Issue Date: 2019-05-31 Modeling Relational Data with Graph Convolutional Networks, Michael Schlichtkrull+, N_A, ESWC'18 Summary知識グラフは不完全な情報を含んでいるため、関係グラフ畳み込みネットワーク(R-GCNs)を使用して知識ベース補完タスクを行う。R-GCNsは、高度な多関係データに対処するために開発されたニューラルネットワークであり、エンティティ分類とリンク予測の両方で効果的であることを示している。さらに、エンコーダーモデルを使用してリンク予測の改善を行い、大幅な性能向上が見られた。 #Pocket #NLP #Dataset #QuestionAnswering #Factuality #ReadingComprehension Issue Date: 2025-08-16 [Paper Note] TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension, Mandar Joshi+, ACL'17 SummaryTriviaQAは、650K以上の質問-回答-証拠トリプルを含む読解理解データセットで、95Kの質問-回答ペアと平均6つの証拠文書を提供。複雑な質問や構文的変動があり、文を超えた推論が必要。特徴ベースの分類器と最先端のニューラルネットワークの2つのベースラインアルゴリズムを評価したが、人間のパフォーマンスには及ばず、TriviaQAは今後の研究における重要なテストベッドである。 #NeuralNetwork #MachineLearning #Online/Interactive #Pocket Issue Date: 2018-01-01 Online Deep Learning: Learning Deep Neural Networks on the Fly, Doyen Sahoo+, N_A, arXiv'17 Summary本研究では、オンライン設定でリアルタイムにディープニューラルネットワーク(DNN)を学習するための新しいフレームワークを提案します。従来のバックプロパゲーションはオンライン学習には適していないため、新しいHedge Backpropagation(HBP)手法を提案します。この手法は、静的およびコンセプトドリフトシナリオを含む大規模なデータセットで効果的であることを検証します。 #NeuralNetwork #MachineTranslation #Pocket #NLP #ACL Issue Date: 2017-12-28 What do Neural Machine Translation Models Learn about Morphology?, Yonatan Belinkov+, ACL'17 Commenthttp://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/06.pdf
(2025.05.12追記)
上記は2017年にすずかけ台で開催されたACL 2017読み会での解説スライドです。 #NeuralNetwork #MachineTranslation #Pocket #NLP #EMNLP Issue Date: 2017-12-28 Neural Machine Translation with Source-Side Latent Graph Parsing, Kazuma Hashimoto+, EMNLP'17 #DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP Issue Date: 2018-10-06 Neural Headline Generation with Minimum Risk Training, Ayana+, N_A, arXiv'16 Summary自動見出し生成のために、最小リスクトレーニング戦略を使用してモデルパラメータを最適化し、見出し生成の改善を実現する。提案手法は英語と中国語の見出し生成タスクで最先端のシステムを上回る性能を示す。 #Article #NLP #LanguageModel #ActivationSteering/ITI #Personality Issue Date: 2025-08-02 Persona vectors: Monitoring and controlling character traits in language models, Anthropic, 2025.08 Comment元ポスト:https://x.com/anthropicai/status/1951317898313466361?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFull Paper: https://arxiv.org/abs/2507.21509ITIでよく使われる手法を用いてLLMのpersonalityに関するsteeringベクトルを抽出して適用する(evil, sycophancy, hallucination)。このベクトルは、学習中の監視やペルソナシフトの是正、特定の不都合なペルソナを生じさせる要因となる学習データの同定などの応用が期待される。

ITIでsteeringを実施するとMMLUのような一般的なタスクの能力が劣化するのに対し、学習中にsteeringを実施しながら学習するとタスク遂行能力の低下なしにシフトが生じるのを抑制することが可能な模様。

・1466
・2538
・学習手法
・1979
・8B token学習するごとに直近6つのcheckpointのelement-wiseの平均をとりモデルマージ。当該モデルに対して学習を継続、ということを繰り返す。これにより、学習のノイズを低減し、突然パラメータがシフトすることを防ぐ
・1060
・Adaptive Base Frequency (RoPEのbase frequencyを10000から500000にすることでlong contextのattention scoreが小さくなりすぎることを防ぐ)
・2540
・事前学習データ
・1943
・2539
・2109
を利用したモデル。同程度のサイズのモデルとの比較ではかなりのgainを得ているように見える。興味深い。
DatasetのMixtureの比率などについても記述されている。
ざっくり言うと、Overthinking(考えすぎて大量のトークンを消費した上に回答が誤っている; トークン量↓とLLMによるJudge Score↑で評価)とUnderthinking(全然考えずにトークンを消費しなかった上に回答が誤っている; Accuracy↑で評価)をそれぞれ評価するサンプルを収集し、それらのスコアの組み合わせでモデルが必要に応じてどれだけ的確にThinkingできているかを評価するベンチマーク。
Overthinkingを評価するためのサンプルは、多くのLLMでagreementがとれるシンプルなQAによって構築。一方、Underthinkingを評価するためのサンプルは、small reasoning modelがlarge non reasoning modelよりも高い性能を示すサンプルを収集。
現状Non Thinking ModelではQwen3-235B-A22Bの性能が良く、Thinking Modelではgpt-oss-120Bの性能が良い。プロプライエタリなモデルではそれぞれ、Claude-Sonnet4, o3の性能が良い。全体としてはo3の性能が最も良い。
・2378Reasoning ModelのHallucination Rateは、そのベースとなるモデルよりも高い。実際、DeepSeek-V3とDeepSeek-R1,Qwen-2.5-32BとQwQ-32Bを6つのFactualityに関するベンチマークで比較すると、Reasoning Modelの方がHallucination Rateが10, 13%程度高かった。これは、現在のOn-policyのRLがlogical reasoningにフォーカスしており、Factualityを見落としているため、と仮説を立てている。
Factuality(特にLongForm)とRL alignmentsという観点から言うと、決定的、正確かつ信頼性のあるverificatlon手法は存在せず、Human Effortが必要不可欠である。
自動的にFactualityを測定するFactScoreのような手法は、DPOのようなオフラインのペアワイズのデータを作成するに留まってしまっている。また、on dataでFactualityを改善する取り組みは行われているが、long-formな応答に対して、factual reasoningを実施するにはいくつかの課題が残されている:
・reward design
・Factualityに関するrewardを単独で追加するだけだと、LLMは非常に短く、詳細を省略した応答をしPrecicionのみを高めようとしてしまう。
あとで追記する #Pocket #NLP #LanguageModel #InstructionTuning #SyntheticData #Reasoning Issue Date: 2025-08-02 [Paper Note] CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks, Ping Yu+, arXiv'25 SummaryCoT-Self-Instructを提案し、LLMに基づいて新しい合成プロンプトを生成する手法を開発。合成データはMATH500やAMC23などで既存データセットを超える性能を示し、検証不可能なタスクでも人間や標準プロンプトを上回る結果を得た。 Comment元ポスト:https://x.com/jaseweston/status/1951084679286722793?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qより複雑で、Reasoningやplanningを促すようなinstructionが生成される模様。実際に生成されたinstructionのexampleは全体をざっとみた感じこの図中のもののみのように見える。
・2094
・1829 #Pretraining #Pocket #NLP #LanguageModel #ReinforcementLearning Issue Date: 2025-06-12 [Paper Note] Reinforcement Pre-Training, Qingxiu Dong+, arXiv'25 Summary本研究では、強化学習と大規模言語モデルの新しいスケーリング手法「強化事前学習(RPT)」を提案。次のトークン予測を強化学習の推論タスクとして再定義し、一般的なRLを活用することで、ドメイン特有の注釈に依存せずにスケーラブルな方法を提供。RPTは次のトークン予測の精度を向上させ、強化ファインチューニングの基盤を形成。トレーニング計算量の増加が精度を改善することを示し、RPTが言語モデルの事前学習において有望な手法であることを示した。 Comment元ポスト:https://x.com/hillbig/status/1932922314578145640?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #LanguageModel #Subword Issue Date: 2025-06-11 [Paper Note] StochasTok: Improving Fine-Grained Subword Understanding in LLMs, Anya Sims+, arXiv'25 Summaryサブワードレベルの理解を向上させるために、確率的トークン化手法StochasTokを提案。これにより、LLMsは内部構造を把握しやすくなり、文字カウントや数学タスクなどで性能が向上。シンプルな設計により、既存モデルへの統合が容易で、コストを抑えつつサブワード理解を改善できる。 Comment元ポスト:https://x.com/cong_ml/status/1932369418534760554?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qおもしろそう #Pocket #NLP #LanguageModel #RLVR Issue Date: 2025-06-05 [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards, Xun Lu, arXiv'25 Summary非検証可能なタスクにおける強化学習のギャップを埋めるため、ペアワイズ生成報酬モデル(GenRM)とブートストラップ相対ポリシー最適化(BRPO)アルゴリズムを提案。これにより、主観的評価を信頼性のある検証可能な報酬に変換し、動的なペアワイズ比較を実現。提案手法は、LLMsの執筆能力を向上させ、スカラー報酬ベースラインに対して一貫した改善を示し、競争力のある結果を達成。全ての言語タスクに適用可能な包括的なRLトレーニングパラダイムの可能性を示唆。 Comment元ポスト:https://x.com/grad62304977/status/1929996614883783170?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QWriting Principleに基づいて(e.g., 一貫性、創造性とか?)批評を記述し、最終的に与えられたペアワイズのテキストの優劣を判断するGenerative Reward Model (GenRM; Reasoning Traceを伴い最終的にRewardに変換可能な情報をoutpuするモデル) を学習し、現在生成したresponseグループの中からランダムに一つ擬似的なreferenceを決定し、他のresponseに対しGenRMを適用することで報酬を決定する(BRPO)、といったことをやるらしい。
これにより、創造的な文書作成のような客観的なground truthを適用できないタスクでも、RLVRの恩恵をあずかれるようになる(Bridging the gap)といったことを主張している。RLVRの恩恵とは、Reward Hackingされづらい高品質な報酬、ということにあると思われる。ので、要は従来のPreference dataだけで学習したReward Modelよりも、よりReward Hackingされないロバストな学習を実現できるGenerative Reward Modelを提案し、それを適用する手法BRPOも提案しました、という話に見える。関連:
・2274 #Pocket #NLP #LanguageModel #LLMAgent #SelfImprovement Issue Date: 2025-06-03 [Paper Note] Self-Challenging Language Model Agents, Yifei Zhou+, arXiv'25 SummarySelf-Challengingフレームワークを提案し、エージェントが自ら生成した高品質なタスクで訓練。エージェントは挑戦者としてタスクを生成し、実行者として強化学習を用いて訓練。M3ToolEvalとTauBenchでLlama-3.1-8B-Instructが2倍以上の改善を達成。 Comment元ポスト:https://x.com/jaseweston/status/1929719473952497797?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q解説ポスト:https://x.com/omarsar0/status/1930748591242424439?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Analysis #Pretraining #LanguageModel #Transformer #PostTraining #COLT Issue Date: 2025-06-01 [Paper Note] Learning Compositional Functions with Transformers from Easy-to-Hard Data, Zixuan Wang+, COLT'25 Summary本研究では、Transformerベースの言語モデルの学習可能性を探求し、$k$-fold compositionタスクに焦点を当てる。$O(\log k)$層のトランスフォーマーでこのタスクを表現できる一方、SQオラクルに対するクエリの下限を示し、サンプルサイズが指数的である必要があることを証明。さらに、カリキュラム学習戦略を用いて、簡単な例と難しい例を含むデータ分布がトランスフォーマーの効率的な学習に必要であることを明らかにした。 Comment元ポスト:https://x.com/zzzixuanwang/status/1928465115478708604?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Qこちらはまず元ポストのスレッドを読むのが良いと思われる。要点をわかりやすく説明してくださっている。元ポストとalphaxivでざっくり理解したところ、
Transformerがcontextとして与えられた情報(σ)とparametric knowledge(π)をk回の知識マッピングが必要なタスク(k-fold composition task)を学習するにはO(log k)のlayer数が必要で、直接的にk回の知識マッピングが必要なタスクを学習するためにはkの指数オーダーのデータ量が最低限必要となることが示された。これはkが大きくなると(すなわち、複雑なreasoning stepが必要なタスク)になると非現実的なものとなるため、何らかの方法で緩和したい。学習データを簡単なものから難しいものをmixingすること(カリキュラム学習)ことで、この条件が緩和され、指数オーダーから多項式オーダーのデータ量で学習できることが示された
といった感じだと思われる。じゃあ最新の32Bモデルよりも、よりパラメータ数が大きくてlayer数が多い古いモデルの方が複雑なreasoningが必要なタスクを実は解けるってこと!?直感に反する!と一瞬思ったが、おそらく最近のモデルでは昔のモデルと比べてparametric knowledgeがより高密度に適切に圧縮されるようになっていると思われるので、昔のモデルではk回の知識マッピングをしないと解けないタスクが、最新のモデルではk-n回のマッピングで解けるようになっていると推察され、パラメータサイズが小さくても問題なく解けます、みたいなことが起こっているのだろう、という感想を抱くなどした #Pocket #NLP #LanguageModel #LLMAgent #SoftwareEngineering #read-later Issue Date: 2025-06-01 [Paper Note] Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering, Guangtao Zeng+, arXiv'25 SummaryEvoScaleを提案し、進化的プロセスを用いて小型言語モデルの性能を向上させる手法を開発。選択と突然変異を通じて出力を洗練し、サンプル数を減少させる。強化学習を用いて自己進化を促進し、SWE-Bench-Verifiedで32Bモデルが100B以上のモデルと同等以上の性能を示す。コード、データ、モデルはオープンソースとして公開予定。 Comment元ポスト:https://x.com/gan_chuang/status/1928963872188244400?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #NLP #LanguageModel #RLVR Issue Date: 2025-06-01 Can Large Reasoning Models Self-Train?, Sheikh Shafayat+, arXiv'25 Summary自己学習を活用したオンライン強化学習アルゴリズムを提案し、モデルの自己一貫性を利用して正確性信号を推測。難しい数学的推論タスクに適用し、従来の手法に匹敵する性能を示す。自己生成された代理報酬が誤った出力を優遇するリスクも指摘。自己監視による性能向上の可能性と課題を明らかに。 Comment元ポスト:https://x.com/askalphaxiv/status/1928487492291829809?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・1995
と似ているように見えるself-consistencyでground truthを推定し、推定したground truthを用いてverifiableなrewardを計算して学習する手法、のように見える。
実際のground truthを用いた学習と同等の性能を達成する場合もあれば、long stepで学習するとどこかのタイミングで学習がcollapseする場合もある
・early stopping
・offlineでラベルをself consistencyで生成して、学習の過程で固定する
・カリキュラムラーニングを導入する
・1489 #EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-05-09 Reinforcement Learning for Reasoning in Large Language Models with One Training Example, Yiping Wang+, arXiv'25 Summary1-shot RLVRを用いることで、LLMの数学的推論能力が大幅に向上することを示した。Qwen2.5-Math-1.5Bモデルは、MATH500でのパフォーマンスが36.0%から73.6%に改善され、他の数学的ベンチマークでも同様の向上が見られた。1-shot RLVR中には、クロスドメイン一般化や持続的なテストパフォーマンスの改善が観察され、ポリシー勾配損失が主な要因であることが確認された。エントロピー損失の追加も重要で、結果報酬なしでもパフォーマンスが向上した。これらの成果は、RLVRのデータ効率に関するさらなる研究を促進する。 Comment
参考:https://x.com/weiliu99/status/1930826904522875309?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q・2011
とはどのような関係性があるだろうか? #Pocket #NLP #LanguageModel #Transformer #Attention #Architecture Issue Date: 2025-04-02 Multi-Token Attention, Olga Golovneva+, arXiv'25 Summaryマルチトークンアテンション(MTA)を提案し、複数のクエリとキーのベクトルに基づいてアテンションウェイトを条件付けることで、関連するコンテキストをより正確に特定できるようにする。MTAは畳み込み操作を用いて、近くのトークンが互いに影響を与え、豊かな情報を活用する。評価結果から、MTAはTransformerベースラインモデルを上回り、特に長いコンテキストでの情報検索において優れた性能を示した。 Comment元ポスト:https://x.com/jaseweston/status/1907260086017237207?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q従来のMulti Head Attentionでは、単体のQKのみを利用していたけど、複数のQKの情報を畳み込んで活用できるようにして、Headも畳み込みで重要な情報がより伝搬されるようにして、GroupNormalizationをかけたらPerplexityの観点でDifferential Transformerを上回ったよ、という話な模様。
・1856
・1466 #Analysis #Pocket #NLP #LanguageModel #FactualKnowledge Issue Date: 2025-04-01 Inside-Out: Hidden Factual Knowledge in LLMs, Zorik Gekhman+, arXiv'25 Summary本研究は、LLMが出力以上の事実的知識をエンコードしているかを評価するフレームワークを提案。知識を定義し、正しい回答が高くランク付けされる割合を定量化。外部知識と内部知識を区別し、内部知識が外部知識を超えると隠れた知識が生じることを示す。クローズドブックQA設定でのケーススタディでは、LLMが内部で多くの知識をエンコードしていること、知識が隠れている場合があること、サンプリングによる制約があることを明らかにした。 Comment元ポスト:https://x.com/zorikgekhman/status/1906693729886363861?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #Dataset #LanguageModel #SyntheticData #Reasoning #Distillation Issue Date: 2025-02-19 NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions, Weizhe Yuan+, arXiv'25 Summary多様で高品質な推論質問を生成するためのスケーラブルなアプローチを提案し、280万の質問からなるNaturalReasoningデータセットを構築。知識蒸留実験により、強力な教師モデルが推論能力を引き出せることを実証し、教師なし自己学習にも効果的であることを示す。 Comment元ポスト: https://x.com/jaseweston/status/1892041992127021300?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q #Pocket #NLP #LanguageModel #Alignment #ICLR #DPO #PostTraining #Diversity Issue Date: 2025-02-01 Diverse Preference Optimization, Jack Lanchantin+, ICLR'25 SummaryDiverse Preference Optimization(DivPO)を提案し、応答の多様性を向上させつつ生成物の品質を維持するオンライン最適化手法を紹介。DivPOは応答のプールから多様性を測定し、希少で高品質な例を選択することで、パーソナ属性の多様性を45.6%、ストーリーの多様性を74.6%向上させる。 Comment元ポスト:https://x.com/jaseweston/status/1885399530419450257?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QOpenReview: https://openreview.net/forum?id=pOq9vDIYevDPOと同じ最適化方法を使うが、Preference Pairを選択する際に、多様性が増加するようなPreference Pairの選択をすることで、モデルのPost-training後の多様性を損なわないようにする手法を提案しているっぽい。
具体的には、Alg.1 に記載されている通り、多様性の尺度Dを定義して、モデルにN個のレスポンスを生成させRMによりスコアリングした後、RMのスコアが閾値以上のresponseを"chosen" response, 閾値未満のレスポンスを "reject" responseとみなし、chosen/reject response集合を構築する。chosen response集合の中からDに基づいて最も多様性のあるresponse y_c、reject response集合の中から最も多様性のないresponse y_r をそれぞれピックし、prompt xとともにpreference pair (x, y_c, y_r) を構築しPreference Pairに加える、といった操作を全ての学習データ(中のprompt)xに対して繰り返すことで実現する。 #Embeddings #InformationRetrieval #NLP #Search #STS (SemanticTextualSimilarity) #ICLR Issue Date: 2025-01-28 SoftMatcha: A Fast and Soft Pattern Matcher for Billion-Scale Corpus Searches, Deguchi+, ICLR'25 CommentICLR2025にacceptされた模様
https://openreview.net/forum?id=Q6PAnqYVpoopenreview:https://openreview.net/forum?id=Q6PAnqYVpo #ComputerVision #Pocket #NLP #LanguageModel #ModelMerge Issue Date: 2024-03-21 Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N_A, Nature Machine Intelligence'25 Summary進化アルゴリズムを使用した新しいアプローチを提案し、強力な基盤モデルの自動生成を実現。LLMの開発において、人間の直感やドメイン知識に依存せず、多様なオープンソースモデルの効果的な組み合わせを自動的に発見する。このアプローチは、日本語のLLMと数学推論能力を持つモデルなど、異なるドメイン間の統合を容易にし、日本語VLMの性能向上にも貢献。オープンソースコミュニティへの貢献と自動モデル構成の新しいパラダイム導入により、基盤モデル開発における効率的なアプローチを模索。 Comment複数のLLMを融合するモデルマージの話。日本語LLMと英語の数学LLNをマージさせることで日本語の数学性能を大幅に向上させたり、LLMとVLMを融合したりすることで、日本にしか存在しない概念の画像も、きちんと回答できるようになる。
著者スライドによると、従来のモデルマージにはbase modelが同一でないとうまくいかなかったり(重みの線型結合によるモデルマージ)、パラメータが増減したり(複数LLMのLayerを重みは弄らず再配置する)。また日本語LLMに対してモデルマージを実施しようとすると、マージ元のLLMが少なかったり、広範囲のモデルを扱うとマージがうまくいかない、といった課題があった。本研究ではこれら課題を解決できる。著者による資料(NLPコロキウム):
https://speakerdeck.com/iwiwi/17-nlpkorokiumu #Pocket #read-later Issue Date: 2025-07-16 [Paper Note] Accelerating Large Language Model Training with 4D Parallelism and Memory Consumption Estimator, Kazuki Fujii+, arXiv'24 Summary本研究では、Llamaアーキテクチャにおける4D並列トレーニングに対して、メモリ使用量を正確に推定する公式を提案。A100およびH100 GPUでの454回の実験を通じて、一時バッファやメモリの断片化を考慮し、推定メモリがGPUメモリの80%未満であればメモリ不足エラーが発生しないことを示した。この公式により、メモリオーバーフローを引き起こす並列化構成を事前に特定でき、最適な4D並列性構成に関する実証的な洞察を提供する。 #InformationRetrieval #Pocket #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-01 Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models, Fei Wang+, arXiv'24 SummaryAstute RAGは、外部知識の不完全な取得による問題を解決する新しいアプローチで、LLMsの内部知識と外部知識を適応的に統合し、情報の信頼性に基づいて回答を決定します。実験により、Astute RAGは従来のRAG手法を大幅に上回り、最悪のシナリオでもLLMsのパフォーマンスを超えることが示されました。 #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #Hallucination Issue Date: 2024-09-01 Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, N_A, EMNLP'24 Summary大規模言語モデルはファインチューニングを通じて新しい事実情報に遭遇するが、既存の知識を活用する能力に影響を与える。研究では、閉じた書籍のQAを用いて新しい知識を導入するファインチューニング例の割合を変化させた結果、モデルは新しい知識を学習するのに苦労し、幻覚する傾向が増加することが示された。これにより、ファインチューニングによる新しい知識の導入のリスクが明らかになり、モデルは事前学習を通じて知識を獲得し、ファインチューニングはその利用を効率化することが支持される。 Commentpre-training時に獲得されていない情報を用いてLLMのalignmentを実施すると、知識がない状態で学習データを正しく予測できるように学習されてしまうため、事実に基づかない回答をする(つまりhallucination)ように学習されてしまう、といったことを調査している模様。
>新しい知識を導入するファインチューニング例は、モデルの知識と一致する例よりもはるかに遅く学習されます。しかし、新しい知識を持つ例が最終的に学習されるにつれて、モデルの幻覚する傾向が線形に増加することも発見しました。
早々にoverfittingしている。
>大規模言語モデルは主に事前学習を通じて事実知識を取得し、ファインチューニングはそれをより効率的に使用することを教えるという見解を支持しています。
なるほど、興味深い。下記画像は 1370より引用
本論文中では、full finetuningによる検証を実施しており、LoRAのようなAdapterを用いたテクニックで検証はされていない。LoRAではもともとのLLMのパラメータはfreezeされるため、異なる挙動となる可能性がある。特にLoRAが新しい知識を獲得可能なことが示されれば、LoRA AdapterをもともとのLLMに付け替えるだけで、異なる知識を持ったLLMを運用可能になるため、インパクトが大きいと考えられる。もともとこういった思想は LoRA Hubを提唱する研究などの頃からあった気がするが、AdapterによってHallucination/overfittingを防ぎながら、新たな知識を獲得できることを示した研究はあるのだろうか?
参考: https://x.com/hillbig/status/1792334744522485954?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QLoRAの場合については
・1640
・1475
も参照のこと。 #Pocket Issue Date: 2024-03-13 Stealing Part of a Production Language Model, Nicholas Carlini+, N_A, arXiv'24 SummaryOpenAIのChatGPTやGoogleのPaLM-2などのブラックボックスの言語モデルから重要な情報を抽出するモデルスティーリング攻撃を紹介。APIアクセスを利用して、transformerモデルの埋め込み射影層を回復する攻撃を行い、低コストでAdaとBabbage言語モデルの全射影行列を抽出。gpt-3.5-turboモデルの隠れた次元のサイズを回復し、2000ドル未満のクエリで全射影行列を回復すると推定。潜在的な防御策と緩和策を提案し、将来の作業の影響について議論。 #Pocket #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2024-03-05 OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, N_A, arXiv'24 SummaryLMsの商業的重要性が高まる中、最も強力なモデルは閉鎖されており、その詳細が非公開になっている。そのため、本技術レポートでは、本当にオープンな言語モデルであるOLMoの初回リリースと、言語モデリングの科学を構築し研究するためのフレームワークについて詳細に説明している。OLMoはモデルの重みだけでなく、トレーニングデータ、トレーニングおよび評価コードを含むフレームワーク全体を公開しており、オープンな研究コミュニティを強化し、新しいイノベーションを促進することを目指している。 CommentModel Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI #Pocket Issue Date: 2024-01-24 Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, Zixiang Chen+, N_A, arXiv'24 Summary本研究では、追加の人間による注釈付きデータを必要とせずに、大規模言語モデル(LLMs)を強化する方法を提案します。そのために、Self-Play fIne-tuNing(SPIN)という新しいファインチューニング手法を開発しました。SPINでは、LLMが自身と対戦しながら能力を向上させるセルフプレイのメカニズムを利用します。具体的には、LLMは自己生成応答と人間による注釈付きデータから得られた応答を区別することでポリシーを改善します。実験結果は、SPINがLLMのパフォーマンスを大幅に改善し、専門家の対戦相手を必要とせずに人間レベルのパフォーマンスを達成できることを示しています。 #RecommenderSystems #Pocket #LanguageModel Issue Date: 2024-12-03 Recommender Systems in the Era of Large Language Models (LLMs), Zihuai Zhao+, arXiv'23 Summaryレコメンダーシステムは、ユーザーの好みに基づいた提案を提供する重要な要素であり、DNNの限界を克服するためにLLMsの活用が進んでいる。本論文では、LLMを用いたレコメンダーシステムの事前学習、ファインチューニング、プロンプティングに関する包括的なレビューを行い、ユーザーとアイテムの表現学習手法や最近の技術を紹介し、今後の研究方向性について議論する。 Comment
中身を全然読んでいる時間はないので、図には重要な情報が詰まっていると信じ、図を読み解いていく。時間がある時に中身も読みたい。。。
LLM-basedなRecSysでは、NLPにおけるLLMの使い方(元々はT5で提案)と同様に、様々なレコメンド関係タスクを、テキスト生成タスクに落とし込み学習することができる。
RecSysのLiteratureとしては、最初はコンテンツベースと協調フィルタリングから始まり、(グラフベースドな推薦, Matrix Factorization, Factorization Machinesなどが間にあって)、その後MLP, RNN, CNN, AutoEncoderなどの様々なDeep Neural Network(DNN)を活用した手法や、BERT4RecなどのProbabilistic Language Models(PLM)を用いた手法にシフトしていき、現在LLM-basedなRecSysの時代に到達した、との流れである。
LLM-basedな手法では、pretrainingの段階からEncoder-basedなモデルの場合はMLM、Decoder-basedな手法ではNext Token Predictionによってデータセットで事前学習する方法もあれば、フルパラメータチューニングやPEFT(LoRAなど)によるSFTによるアプローチもあるようである。
推薦タスクは、推薦するアイテムIDを生成するようなタスクの場合は、異なるアイテムID空間に基づくデータセットの間では転移ができないので、SFTをしないとなかなかうまくいかないと気がしている。また、その場合はアイテムIDの推薦以外のタスクも同時に実施したい場合は、事前学習済みのパラメータが固定されるPEFT手法の方が安全策になるかなぁ、という気がしている(破壊的忘却が怖いので)。特はたとえば、アイテムIDを生成するだけでなく、その推薦理由を生成できるのはとても良いことだなあと感じる(良い時代、感)。
また、PromptingによるRecSysの流れも図解されているが、In-Context Learningのほかに、Prompt Tuning(softとhardの両方)、Instruction Tuningも同じ図に含まれている。個人的にはPrompt TuningはPEFTの一種であり、Instruction TuningはSFTの一種なので、一つ上の図に含意される話なのでは?という気がするが、論文中ではどのような立て付けで記述されているのだろうか。
どちらかというと、Promptingの話であれば、zero-few-many shotや、各種CoTの話を含めるのが自然な気がするのだが。
下図はPromptingによる手法を表にまとめたもの。Finetuningベースの手法が別表にまとめられていたが、研究の数としてはこちらの方が多そうに見える。が、性能的にはどの程度が達成されるのだろうか。直感的には、アイテムを推薦するようなタスクでは、Promptingでは性能が出にくいような印象がある。なぜなら、事前学習済みのLLMはアイテムIDのトークン列とアイテムの特徴に関する知識がないので。これをFinetuningしないのであればICLで賄うことになると思うのだが、果たしてどこまでできるだろうか…。興味がある。
(図は論文より引用) #Pocket Issue Date: 2024-05-28 Multi-Dimensional Evaluation of Text Summarization with In-Context Learning, Sameer Jain+, N_A, arXiv'23 Summary本研究では、大規模な言語モデルを使用したコンテキスト内学習による多面的評価者の効果を調査し、大規模なトレーニングデータセットの必要性を排除します。実験の結果、コンテキスト内学習ベースの評価者は、テキスト要約のタスクにおいて学習された評価フレームワークと競合し、関連性や事実の一貫性などの側面で最先端の性能を確立しています。また、GPT-3などの大規模言語モデルによって書かれたゼロショット要約の評価におけるコンテキスト内学習ベースの評価者の効果も研究されています。 CommentICE #EfficiencyImprovement #Pocket #NLP #LanguageModel #Transformer #Attention Issue Date: 2024-04-07 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N_A, arXiv'23 SummaryMulti-query attention(MQA)は、単一のkey-value headのみを使用しており、デコーダーの推論を劇的に高速化しています。ただし、MQAは品質の低下を引き起こす可能性があり、さらには、より速い推論のためだけに別個のモデルをトレーニングすることが望ましくない場合もあります。既存のマルチヘッド言語モデルのチェックポイントを、オリジナルの事前トレーニング計量の5%を使用してMQAを持つモデルにアップトレーニングするためのレシピを提案し、さらに、複数のkey-value headを使用するマルチクエリアテンションの一般化であるグループ化クエリアテンション(GQA)を紹介します。アップトレーニングされたGQAが、MQAと同等の速度でマルチヘッドアテンションに匹敵する品質を達成することを示しています。 Comment通常のMulti-Head AttentionがQKVが1対1対応なのに対し、Multi Query Attention (MQA) 1272 は全てのQに対してKVを共有する。一方、GQAはグループごとにKVを共有する点で異なる。MQAは大幅にInfeerence` speedが改善するが、精度が劣化する問題があった。この研究では通常のMulti-Head Attentionに対して、オリジナルの事前学習に対して追加の5%の計算量でGQAモデルを学習する手法を提案している。
Main Result. Multi-Head Attentionに対して、inference timeが大幅に改善しているが、Multi-Query Attentionよりも高い性能を維持している。
#Pocket Issue Date: 2024-02-15 The Consensus Game: Language Model Generation via Equilibrium Search, Athul Paul Jacob+, N_A, arXiv'23 SummaryLMsを使った質問応答やテキスト生成タスクにおいて、生成的または識別的な手法を組み合わせることで一貫したLM予測を得る新しいアプローチが提案された。このアプローチは、言語モデルのデコーディングをゲーム理論的な連続シグナリングゲームとして捉え、EQUILIBRIUM-RANKINGアルゴリズムを導入することで、既存の手法よりも一貫性とパフォーマンスを向上させることが示された。 #ComputerVision #Pocket #NLP #GenerativeAI #MultiModal Issue Date: 2023-12-01 SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction, Xinyuan Chen+, N_A, arXiv'23 Summary本研究では、ビデオ生成において連続した長いビデオを生成するためのジェネレーティブなトランジションと予測に焦点を当てたモデルSEINEを提案する。SEINEはテキストの説明に基づいてトランジションを生成し、一貫性と視覚的品質を確保した長いビデオを生成する。さらに、提案手法は他のタスクにも拡張可能であり、徹底的な実験によりその有効性が検証されている。 Commenthttps://huggingface.co/spaces/Vchitect/SEINE
画像 + テキストpromptで、動画を生成するデモ #Survey #Pocket #NLP #LanguageModel #Hallucination Issue Date: 2023-11-10 A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Lei Huang+, N_A, arXiv'23 SummaryLLMsの出現はNLPにおける重要な進歩をもたらしているが、幻覚を生じることがあり、その信頼性に懸念がある。本調査では、LLMの幻覚に関する最近の進展について包括的に概説し、幻覚の要因や検出手法、軽減アプローチについて紹介する。また、現在の制約や将来の研究方向についても分析する。 CommentHallucinationを現象ごとに分類したSurveyとして 1048 もあるSurveyの内容。必要に応じて参照すべし。
#RecommenderSystems #Pocket #LanguageModel Issue Date: 2023-11-10 LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation, Kai Mei+, N_A, arXiv'23 Summaryこの論文では、軽量なTransformerベースの言語モデルであるLightLMを提案し、生成型レコメンデーションタスクに特化したモデルを開発しています。LightLMは、モデルの容量を抑えつつも、レコメンデーションの精度と効率を向上させることに成功しています。また、ユーザーとアイテムのIDインデックス化方法として、Spectral Collaborative Indexing(SCI)とGraph Collaborative Indexing(GCI)を提案しています。さらに、アイテム生成時のhallucinationの問題に対処するために、制約付き生成プロセスを導入しています。実験結果は、LightLMが競合ベースラインを上回ることを示しています。 CommentGenerative Recommendationはあまり終えていないのだが、既存のGenerative Recommendationのモデルをより軽量にし、性能を向上させ、存在しないアイテムを生成するのを防止するような手法を提案しました、という話っぽい。
Bayesian Personalized Ranking 28 ベースドなMatrix Factorizationよりは高い性能が出てるっぽい。
#Analysis #NLP #LanguageModel Issue Date: 2023-11-08 Do LLMs exhibit human-like response biases? A case study in survey design, Lindia Tjuatja+, N_A, arXiv'23 SummaryLLMsを使用して人間の代理としてタスクを実行する際に、LLMsが人間の応答バイアスをどの程度反映するかを調査する必要がある。この研究では、調査設計を使用して人間の応答バイアスを評価するデータセットとフレームワークを設計し、9つのモデルを評価した結果、一般的なLLMsが人間のような振る舞いを反映することに失敗していることが示された。これらの結果は、LLMsを人間の代わりに使用する際の潜在的な落とし穴を強調し、モデルの振る舞いの細かい特性の重要性を強調している。 CommentLLMはPromptにsensitiveだが、人間も質問の仕方によって応答が変わるから、sensitiveなのは一緒では?ということを調査した研究。Neubig氏のツイートだと、instruction tuningやRLHFをしていないBase LLMの方が、より人間と類似した回答をするのだそう。
元ツイート: https://x.com/gneubig/status/1722294711355117666?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q人間のレスポンスのバイアス。左側は人間は「forbidden」よりも「not allowed」を好むという例、右側は「response order」のバイアスの例(選択肢の順番)。
LLM側で評価したいバイアスごとに、QAのテキストを変更し、LLMに回答を生成され、social science studiesでのトレンドと比較することで、LLMにも人間と同様のバイアスがあるかを明らかにしている。
結果は以下の表であり、青いセルが人間と同様のバイアスを持つことを統計的に有意に示されたもの(のはず)。これをみると、全てのバイアスに対して人間と同様の傾向があったのはLlama2-70Bのみであり、instruction tuningや、RLHFをかけた場合(RLHFの方が影響が大きそう)人間のバイアスとは異なる挙動をするモデルが多くなることがわかる。また、モデルのパラメータサイズとバイアスの強さには相関関係は見受けられない。
#Pretraining #Pocket #NLP #LanguageModel #FoundationModel #Mathematics Issue Date: 2023-10-29 Llemma: An Open Language Model For Mathematics, Zhangir Azerbayev+, N_A, arXiv'23 Summary私たちは、数学のための大規模な言語モデルであるLlemmaを提案します。Llemmaは、Proof-Pile-2と呼ばれるデータセットを用いて事前学習され、MATHベンチマークで他のモデルを上回る性能を示しました。さらに、Llemmaは追加のfine-tuningなしでツールの使用や形式的な定理証明が可能です。アーティファクトも公開されています。 CommentCodeLLaMAを200B tokenの数学テキスト(proof-pile-2データ;論文、数学を含むウェブテキスト、数学のコードが含まれるデータ)で継続的に事前学習することでfoundation modelを構築
約半分のパラメータ数で数学に関する性能でGoogleのMinervaと同等の性能を達成
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
著者ツイート: https://x.com/owainevans_uk/status/1705285631520407821?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q
GPT3, LLaMaを A is Bでfinetuneし、B is Aという逆方向のfactを生成するように(質問をして)テストしたところ、0%付近のAcc.だった。
また、Acc.が低いだけでなく、対数尤度もrandomなfactを生成した場合と、すべてのモデルサイズで差がないことがわかった。
このことら、Reversal Curseはモデルサイズでは解決できないことがわかる。関連:
・1923 #Pocket #NLP #LanguageModel Issue Date: 2023-08-22 Consciousness in Artificial Intelligence: Insights from the Science of Consciousness, Patrick Butlin+, N_A, arXiv'23 SummaryAIの意識についての厳密なアプローチを提案し、既存のAIシステムを神経科学的な意識理論に基づいて評価する。意識の指標的特性を導き出し、最近のAIシステムを評価することで、現在のAIシステムは意識的ではないが、意識的なAIシステムを構築するための障壁は存在しないことを示唆する。 #Pocket Issue Date: 2023-08-16 Epic-Sounds: A Large-scale Dataset of Actions That Sound, Jaesung Huh+, N_A, arXiv'23 SummaryEPIC-SOUNDSは、エゴセントリックなビデオのオーディオストリーム内の時間的範囲とクラスラベルをキャプチャした大規模なデータセットです。注釈者がオーディオセグメントに時間的なラベルを付け、アクションを説明する注釈パイプラインを提案しています。オーディオのみのラベルの重要性と現在のモデルの制約を強調するために、2つのオーディオ認識モデルを訓練および評価しました。データセットには78.4kのカテゴリ分けされたオーディブルなイベントとアクションのセグメントが含まれています。 #MachineLearning #Pocket #NLP #AutoML Issue Date: 2023-08-10 MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks, Lei Zhang+, N_A, arXiv'23 Summary本研究では、機械学習タスクの自動化における人間の知識と機械知能のギャップを埋めるために、新しいフレームワークMLCopilotを提案する。このフレームワークは、最先端のLLMsを使用して新しいMLタスクのソリューションを開発し、既存のMLタスクの経験から学び、効果的に推論して有望な結果を提供することができる。生成されたソリューションは直接使用して競争力のある結果を得ることができる。 #Tools #Pocket #NLP #LanguageModel Issue Date: 2023-08-08 ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, N_A, arXiv'23 Summaryオープンソースの大規模言語モデル(LLMs)を使用して、外部ツール(API)の高度なタスクの実行を容易にするためのToolLLMというフレームワークを紹介します。ToolBenchというデータセットを使用して、ツールの使用方法を調整し、DFSDTという決定木を使用して効率的な検索を行います。ToolEvalという自動評価ツールを使用して、ToolLLaMAが高いパフォーマンスを発揮することを示します。さらに、ニューラルAPIリトリーバーを使用して、適切なAPIを推奨します。 Comment16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、contextが長ければ長いほど、バッチサイズを大きくした際のパフォーマンスの低下が著しい。 #Pocket Issue Date: 2023-07-23 Will Large-scale Generative Models Corrupt Future Datasets?, Ryuichiro Hataya+, ICCV'23 Summary大規模なテキストから画像への生成モデル(DALL·E 2、Midjourney、StableDiffusionなど)が高品質な画像を生成する一方で、これらの生成画像がコンピュータビジョンモデルの性能に与える影響を検証。汚染をシミュレーションし、生成された画像がImageNetやCOCOデータセットで訓練されたモデルの性能にネガティブな影響を及ぼすことを実証。影響の程度はタスクや生成画像の量に依存する。生成データセットとコードは公開予定。 #Tutorial #Survey #NLP #LanguageModel Issue Date: 2023-07-22 Challenges and Applications of Large Language Models, Jean Kaddour+, N_A, arXiv'23 Summary本論文では、大規模言語モデル(LLMs)の普及により、研究者が分野の現状を理解し、生産的になるための問題と応用成功例を確立することを目指しています。 CommentLLMのここ数年の進化早すぎわろたでキャッチアップむずいので、未解決の課題や、すでに良い感じのアプリケーションの分野分かりづらいので、まとめました論文 #ComputerVision #Pocket #NLP #LanguageModel #SpokenLanguageProcessing #MultiModal #SpeechProcessing Issue Date: 2023-07-22 Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, N_A, arXiv'23 Summary本研究では、マルチモーダル学習のためのMeta-Transformerというフレームワークを提案しています。このフレームワークは、異なるモダリティの情報を処理し関連付けるための統一されたネットワークを構築することを目指しています。Meta-Transformerは、対応のないデータを使用して12のモダリティ間で統一された学習を行うことができ、テキスト、画像、ポイントクラウド、音声、ビデオなどの基本的なパーセプションから、X線、赤外線、高分光、IMUなどの実用的なアプリケーション、グラフ、表形式、時系列などのデータマイニングまで、幅広いタスクを処理することができます。Meta-Transformerは、トランスフォーマーを用いた統一されたマルチモーダルインテリジェンスの開発に向けた有望な未来を示しています。 Comment12種類のモダリティに対して学習できるTransformerを提案
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
それはどのような学習かというと、プロンプトとそれによって与えられた事例を前条件とした場合の勾配降下法によって実現されていると。
つまりどういうことかというと、プロンプトと与えられた事例ごとに、それぞれ最適なパラメータが学習されているというイメージだろうか。条件付き分布みたいなもの?
なので、未知のプロンプトと事例が与えられたときに、事前学習時に前条件として与えられているものの中で類似したものがあれば、良い感じに汎化してうまく生成ができる、ということかな?いや違うな。1つのアテンション層が勾配降下法の1ステップをシミュレーションしており、k個のアテンション層があったらkステップの勾配降下法をシミュレーションしていることと同じ結果になるということ?
そしてその購買降下法では、プロンプトによって与えられた事例が最小となるように学習される(シミュレーションされる)ということなのか。
つまり、ネットワーク上で本当に与えられた事例に基づいて学習している(のと等価な結果)を得ているということなのか?😱 #NeuralNetwork #ComputerVision #Controllable #Pocket #VideoGeneration/Understandings Issue Date: 2023-05-12 Sketching the Future (STF): Applying Conditional Control Techniques to Text-to-Video Models, Rohan Dhesikan+, arXiv'23 Summaryゼロショットのテキストから動画生成をControlNetと組み合わせ、スケッチされたフレームを基に動画を生成する新手法を提案。フレーム補間を行い、Text-to-Video Zeroアーキテクチャを活用して高品質で一貫性のある動画を生成。デモ動画やリソースを提供し、さらなる研究を促進。 #Pocket #NLP #LanguageModel #Education #AES(AutomatedEssayScoring) #ChatGPT Issue Date: 2023-04-28 [Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23 SummaryChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 CommentChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。
#Pocket #Dataset #LanguageModel #Evaluation #EMNLP #Ambiguity Issue Date: 2023-04-28 We're Afraid Language Models Aren't Modeling Ambiguity, Alisa Liu+, EMNLP'23 Summary曖昧さは自然言語の重要な特徴であり、言語モデル(LM)が対話や執筆支援において成功するためには、曖昧な言語を扱うことが不可欠です。本研究では、曖昧さの影響を評価するために、1,645の例からなるベンチマーク「AmbiEnt」を収集し、事前学習済みLMの評価を行いました。特にGPT-4の曖昧さ解消の正答率は32%と低く、曖昧さの解消が難しいことが示されました。また、多ラベルのNLIモデルが曖昧さによる誤解を特定できることを示し、NLPにおける曖昧さの重要性を再認識する必要性を提唱しています。 CommentLLMが曖昧性をどれだけ認知できるかを評価した初めての研究。
言語学者がアノテーションした1,645サンプルの様々な曖昧さを含んだベンチマークデータを利用。
GPT4は32%正解した。
またNLIデータでfinetuningしたモデルでは72.5%のmacroF1値を達成。
応用先として、誤解を招く可能性のある政治的主張に対してアラートをあげることなどを挙げている。
(下記ツイッターより引用)
user-item間の関係だけでなく、user-user間とitem-item間の情報を組み込むことで精度向上を達成した論文とのこと。
https://twitter.com/nogawanogawa/status/1651165820956057602?s=46&t=6qC80ox3qHrJixKeNmIOcg #Pocket #NLP #Assessment #ChatGPT #InformationExtraction Issue Date: 2023-04-25 [Paper Note] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness, Bo Li+, arXiv'23 Summary本研究では、ChatGPTの能力を7つの情報抽出(IE)タスクを通じて評価し、パフォーマンス、説明可能性、キャリブレーション、信頼性を分析しました。標準IE設定ではパフォーマンスが低い一方、オープンIE設定では人間評価で優れた結果を示しました。ChatGPTは高品質な説明を提供するものの、予測に対して過信する傾向があり、キャリブレーションが低いことが明らかになりました。また、元のテキストに対して高い信頼性を示しました。研究のために手動で注釈付けした7つのIEタスクのテストセットと14のデータセットを公開しています。 Comment情報抽出タスクにおいてChatGPTを評価した研究。スタンダードなIEの設定ではBERTベースのモデルに負けるが、OpenIEの場合は高い性能を示した。
また、ChatGPTは予測に対してクオリティが高く信頼に足る説明をしたが、一方で自信過剰な傾向がある。また、ChatGPTの予測はinput textに対して高いfaithfulnessを示しており、予測がinputから根ざしているものであることがわかる。(らしい)あまりしっかり読んでいないが、Entity Typing, NER, Relation Classification, Relation Extraction, Event Detection, Event Argument Extraction, Event Extractionで評価。standardIEでは、ChatGPTにタスクの説明と選択肢を与え、与えられた選択肢の中から正解を探す設定とした。一方OpenIEでは、選択肢を与えず、純粋にタスクの説明のみで予測を実施させた。OpenIEの結果を、3名のドメインエキスパートが出力が妥当か否か判定した結果、非常に高い性能を示すことがわかった。表を見ると、同じタスクでもstandardIEよりも高い性能を示している(そんなことある???)つまり、選択肢を与えてどれが正解ですか?ときくより、選択肢与えないでCoTさせた方が性能高いってこと?比較可能な設定で実験できているのだろうか。promptは付録に載っているが、output exampleが載ってないのでなんともいえない。StandardIEの設定をしたときに、CoTさせてるかどうかが気になる。もししてないなら、そりゃ性能低いだろうね、という気がする。 #MachineLearning #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #NeurIPS Issue Date: 2023-03-28 Reflexion: Language Agents with Verbal Reinforcement Learning, Noah Shinn+, N_A, NeurIPS'23 Summary本研究では、言語エージェントを強化するための新しいフレームワークであるReflexionを提案しています。Reflexionエージェントは、言語的フィードバックを通じて自己反省し、より良い意思決定を促すために反省的なテキストを保持します。Reflexionはさまざまなタスクでベースラインエージェントに比べて大幅な改善を実現し、従来の最先端のGPT-4を上回る精度を達成しました。さらに、異なるフィードバック信号や統合方法、エージェントタイプの研究を行い、パフォーマンスへの影響についての洞察を提供しています。 Commentなぜ回答を間違えたのか自己反省させることでパフォーマンスを向上させる研究 #Pocket Issue Date: 2024-02-22 Dense Text Retrieval based on Pretrained Language Models: A Survey, Wayne Xin Zhao+, N_A, arXiv'22 Summaryテキスト検索における最近の進歩に焦点を当て、PLMベースの密な検索に関する包括的な調査を行った。PLMsを使用することで、クエリとテキストの表現を学習し、意味マッチング関数を構築することが可能となり、密な検索アプローチが可能となる。この調査では、アーキテクチャ、トレーニング、インデックス作成、統合などの側面に焦点を当て、300以上の関連文献を含む包括的な情報を提供している。 #EfficiencyImprovement #MachineLearning #Pocket Issue Date: 2023-08-16 Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning, Haokun Liu+, N_A, arXiv'22 SummaryFew-shot in-context learning(ICL)とパラメータ効率の良いファインチューニング(PEFT)を比較し、PEFTが高い精度と低い計算コストを提供することを示す。また、新しいPEFTメソッドである(IA)^3を紹介し、わずかな新しいパラメータしか導入しないまま、強力なパフォーマンスを達成する。さらに、T-Fewというシンプルなレシピを提案し、タスク固有のチューニングや修正なしに新しいタスクに適用できる。RAFTベンチマークでT-Fewを使用し、超人的なパフォーマンスを達成し、最先端を6%絶対的に上回る。 #DocumentSummarization #Pocket #NLP #Evaluation Issue Date: 2023-08-13 DocAsRef: A Pilot Empirical Study on Repurposing Reference-Based Summary Quality Metrics Reference-Freely, Forrest Sheng Bao+, N_A, arXiv'22 Summary参照ベースと参照フリーの要約評価メトリックがあります。参照ベースは正確ですが、制約があります。参照フリーは独立していますが、ゼロショットと正確さの両方を満たせません。本研究では、参照ベースのメトリックを使用してゼロショットかつ正確な参照フリーのアプローチを提案します。実験結果は、このアプローチが最も優れた参照フリーのメトリックを提供できることを示しています。また、参照ベースのメトリックの再利用と追加の調整についても調査しています。 #Analysis #Pocket #LanguageModel Issue Date: 2023-05-11 Out of One, Many: Using Language Models to Simulate Human Samples, Lisa P. Argyle+, N_A, arXiv'22 Summary本研究では、言語モデルが社会科学研究において特定の人間のサブポピュレーションの代理として研究される可能性があることを提案し、GPT-3言語モデルの「アルゴリズム的忠実度」を探求する。アルゴリズム的忠実度が十分である言語モデルは、人間や社会の理解を進めるための新しい強力なツールとなる可能性があると提案する。 #Pocket #ICLR Issue Date: 2023-05-04 Transformers Learn Shortcuts to Automata, Bingbin Liu+, arXiv'22 Summaryトランスフォーマーモデルは再帰性を欠くが、少ない層でアルゴリズム的推論を行える。研究により、低深度のトランスフォーマーが有限状態オートマトンの計算を階層的に再パラメータ化できることを発見。多項式サイズの解決策が存在し、特に$O(1)$深度のシミュレーターが一般的であることを示した。合成実験でトランスフォーマーがショートカット解決策を学習できることを確認し、その脆弱性と緩和策も提案。 CommentOpenReview: https://openreview.net/forum?id=De4FYqjFueZ #RecommenderSystems #NeuralNetwork #EfficiencyImprovement #CollaborativeFiltering #Pocket #EducationalDataMining #KnowledgeTracing #Contents-based #NAACL Issue Date: 2022-08-01 GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22 Summaryコンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。 CommentRiiiDがNAACL'22に論文通してた #EfficiencyImprovement #Pocket #NLP #Transformer #Attention Issue Date: 2025-08-09 [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20 SummaryLongformerは、長いシーケンスを線形に処理できる注意機構を持つTransformerベースのモデルで、数千トークンの文書を扱える。局所的なウィンドウ注意とタスクに基づくグローバル注意を組み合わせ、文字レベルの言語モデリングで最先端の結果を達成。事前学習とファインチューニングを行い、長文タスクでRoBERTaを上回る性能を示した。また、Longformer-Encoder-Decoder(LED)を導入し、長文生成タスクにおける効果を確認した。 Comment(固定された小さめのwindowsサイズの中でのみattentionを計算する)sliding window attentionを提案
・1309 #NeuralNetwork #MachineLearning #Pocket #ICLR #LearningPhenomena Issue Date: 2025-07-12 [Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20 Summary深層学習タスクにおける「ダブルデセント」現象を示し、モデルサイズの増加に伴い性能が一時的に悪化し、その後改善されることを明らかにした。また、ダブルデセントはモデルサイズだけでなくトレーニングエポック数にも依存することを示し、新たに定義した「効果的なモデルの複雑さ」に基づいて一般化されたダブルデセントを仮定。これにより、トレーニングサンプル数を増やすことで性能が悪化する特定の領域を特定できることを示した。 Comment参考:https://qiita.com/teacat/items/a8bed22329956b80671f #NeuralNetwork #Pocket #NLP #LanguageModel #Zero/FewShotPrompting #In-ContextLearning #NeurIPS #Admin'sPick Issue Date: 2023-04-27 Language Models are Few-Shot Learners, Tom B. Brown+, NeurIPS'20 SummaryGPT-3は1750億パラメータを持つ自己回帰型言語モデルで、少数ショット設定においてファインチューニングなしで多くのNLPタスクで強力な性能を示す。翻訳や質問応答などで優れた結果を出し、即時推論やドメイン適応が必要なタスクでも良好な性能を発揮する一方、依然として苦手なデータセットや訓練に関する問題も存在する。また、GPT-3は人間が書いた記事と区別が難しいニュース記事を生成できることが確認され、社会的影響についても議論される。 CommentIn-Context Learningを提案した論文論文に記載されているIn-Context Learningの定義は、しっかり押さえておいた方が良い。
下図はmeta-learningの観点から見たときの、in-contextの位置付け。事前学習時にSGDでパラメータをupdateするのをouter loopとし、そこで広いスキルとパターン認識の能力を身につける。一方で、in-context learningは、Inference時に事前学習時に得たそれらのスキルを用いて、求めるタスクを認識、あるいは適応するInner loopのことを指す。
この上で、論文中では In-Context Learningについて:
> Recent work [RWC+19] attempts to do this via what we call “in-context learning”, using the text input of a pretrained language model as a form of task specification: the model is conditioned on a natural language instruction and/or a few demonstrations of the task and is then expected to complete further instances of the task simply by predicting what comes next.
と定義している。 #NeuralNetwork #MachineLearning #Pocket #ICLR #LearningPhenomena Issue Date: 2025-07-12 [Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19 Summaryニューラルネットワークのプルーニング技術は、パラメータ数を90%以上削減しつつ精度を維持できるが、スパースアーキテクチャの訓練は難しい。著者は「ロッタリー・チケット仮説」を提唱し、密なネットワークには効果的に訓練できるサブネットワーク(勝利のチケット)が存在することを発見。これらのチケットは特定の初期重みを持ち、元のネットワークと同様の精度に達する。MNISTとCIFAR10の実験で、10-20%のサイズの勝利のチケットを一貫して特定し、元のネットワークよりも早く学習し高精度に達することを示した。 Comment参考:https://qiita.com/kyad/items/1f5520a7cc268e979893 #NeuralNetwork #MachineLearning #GraphBased #Pocket #GraphConvolutionalNetwork #ESWC Issue Date: 2019-05-31 Modeling Relational Data with Graph Convolutional Networks, Michael Schlichtkrull+, N_A, ESWC'18 Summary知識グラフは不完全な情報を含んでいるため、関係グラフ畳み込みネットワーク(R-GCNs)を使用して知識ベース補完タスクを行う。R-GCNsは、高度な多関係データに対処するために開発されたニューラルネットワークであり、エンティティ分類とリンク予測の両方で効果的であることを示している。さらに、エンコーダーモデルを使用してリンク予測の改善を行い、大幅な性能向上が見られた。 #Pocket #NLP #Dataset #QuestionAnswering #Factuality #ReadingComprehension Issue Date: 2025-08-16 [Paper Note] TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension, Mandar Joshi+, ACL'17 SummaryTriviaQAは、650K以上の質問-回答-証拠トリプルを含む読解理解データセットで、95Kの質問-回答ペアと平均6つの証拠文書を提供。複雑な質問や構文的変動があり、文を超えた推論が必要。特徴ベースの分類器と最先端のニューラルネットワークの2つのベースラインアルゴリズムを評価したが、人間のパフォーマンスには及ばず、TriviaQAは今後の研究における重要なテストベッドである。 #NeuralNetwork #MachineLearning #Online/Interactive #Pocket Issue Date: 2018-01-01 Online Deep Learning: Learning Deep Neural Networks on the Fly, Doyen Sahoo+, N_A, arXiv'17 Summary本研究では、オンライン設定でリアルタイムにディープニューラルネットワーク(DNN)を学習するための新しいフレームワークを提案します。従来のバックプロパゲーションはオンライン学習には適していないため、新しいHedge Backpropagation(HBP)手法を提案します。この手法は、静的およびコンセプトドリフトシナリオを含む大規模なデータセットで効果的であることを検証します。 #NeuralNetwork #MachineTranslation #Pocket #NLP #ACL Issue Date: 2017-12-28 What do Neural Machine Translation Models Learn about Morphology?, Yonatan Belinkov+, ACL'17 Commenthttp://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/06.pdf
(2025.05.12追記)
上記は2017年にすずかけ台で開催されたACL 2017読み会での解説スライドです。 #NeuralNetwork #MachineTranslation #Pocket #NLP #EMNLP Issue Date: 2017-12-28 Neural Machine Translation with Source-Side Latent Graph Parsing, Kazuma Hashimoto+, EMNLP'17 #DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP Issue Date: 2018-10-06 Neural Headline Generation with Minimum Risk Training, Ayana+, N_A, arXiv'16 Summary自動見出し生成のために、最小リスクトレーニング戦略を使用してモデルパラメータを最適化し、見出し生成の改善を実現する。提案手法は英語と中国語の見出し生成タスクで最先端のシステムを上回る性能を示す。 #Article #NLP #LanguageModel #ActivationSteering/ITI #Personality Issue Date: 2025-08-02 Persona vectors: Monitoring and controlling character traits in language models, Anthropic, 2025.08 Comment元ポスト:https://x.com/anthropicai/status/1951317898313466361?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFull Paper: https://arxiv.org/abs/2507.21509ITIでよく使われる手法を用いてLLMのpersonalityに関するsteeringベクトルを抽出して適用する(evil, sycophancy, hallucination)。このベクトルは、学習中の監視やペルソナシフトの是正、特定の不都合なペルソナを生じさせる要因となる学習データの同定などの応用が期待される。
ITIでsteeringを実施するとMMLUのような一般的なタスクの能力が劣化するのに対し、学習中にsteeringを実施しながら学習するとタスク遂行能力の低下なしにシフトが生じるのを抑制することが可能な模様。