
Efficiency/SpeedUp
#Survey#Pocket#LanguageModel#Reasoning
Issue Date: 2025-03-22 Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv25 CommentReasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。#Reasoning#Adapter/LoRA
Issue Date: 2025-03-19 The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv25 Comment斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成 ... #MachineLearning#Pocket#NLP#Transformer
Issue Date: 2025-03-14 Transformers without Normalization, Jiachen Zhu+, CVPR25 Commentなん…だと…。LayerNormalizationを下記アルゴリズムのようなtanhを用いた超絶シンプルなレイヤー(parameterized thnh [Lecun氏ポスト](https://x.com/ylecun/status/1900610590315249833?s=46&t=Y6UuIH ...
Issue Date: 2025-03-22 Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv25 CommentReasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。#Reasoning#Adapter/LoRA
Issue Date: 2025-03-19 The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv25 Comment斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成 ... #MachineLearning#Pocket#NLP#Transformer
Issue Date: 2025-03-14 Transformers without Normalization, Jiachen Zhu+, CVPR25 Commentなん…だと…。LayerNormalizationを下記アルゴリズムのようなtanhを用いた超絶シンプルなレイヤー(parameterized thnh [Lecun氏ポスト](https://x.com/ylecun/status/1900610590315249833?s=46&t=Y6UuIH ...
#MachineLearning#Pocket#NLP#LanguageModel#Attention
Issue Date: 2025-03-02 Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, arXiv25 Comment元ポスト:https://x.com/dair_ai/status/1893698286545969311?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #NLP#ACL
Issue Date: 2025-03-06 Full Parameter Fine-tuning for Large Language Models with Limited Resources, Lv+, ACL24, 2024.08 CommentLarge Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but demand massive GPU resources for training. Lowering the thresh ... #Survey#Pocket#NLP#LanguageModel
Issue Date: 2024-12-31 A Survey on LLM Inference-Time Self-Improvement, Xiangjue Dong+, arXiv24 #Analysis#Pocket#NLP#LanguageModel
Issue Date: 2024-11-22 Observational Scaling Laws and the Predictability of Language Model Performance, Yangjun Ruan+, arXiv24 Comment縦軸がdownstreamタスクの主成分(のうち最も大きい80%を説明する成分)の変化(≒LLMの性能)で、横軸がlog scaleの投入計算量。Qwenも頑張っているが、投入データ量に対する性能(≒データの品質)では、先駆け的な研究であるPhiがやはり圧倒的?#Japanese
Issue Date: 2024-11-17 Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv24 Comment元ポスト:https://x.com/okoge_kaz/status/1857639065421754525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よ ... #Survey#NLP#LanguageModel#Transformer#Attention
Issue Date: 2024-11-17 Understanding LLMs: A Comprehensive Overview from Training to Inference, Yiheng Liu+, arXiv24 Comment[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-7vGwDK_AQX.HDO7j9H8iNA)単なるLLMの理論的な説明にとどまらず、実用的に必要な各種 ... #ComputerVision#NLP#Transformer#MulltiModal#AudioProcessing#Architecture
Issue Date: 2024-11-12 Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models, Weixin Liang+, arXiv24 Comment ... #Pocket#NLP#LanguageModel#Finetuning (SFT)#InstructionTuning
Issue Date: 2024-11-12 DELIFT: Data Efficient Language model Instruction Fine Tuning, Ishika Agarwal+, arXiv24 #Pocket#NLP#LanguageModel#Test-time Compute
Issue Date: 2024-11-12 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, Charlie Snell+, arXiv24 Comment[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/s ... #NLP#Transformer
Issue Date: 2024-10-22 What Matters in Transformers? Not All Attention is Needed, Shwai He+, N_A, arXiv24 Comment通常LLMはtransformer decoderのブロックをstackすることで形成されるが、積み上げたブロック、あるいはlayerってほんとに全部必要なの?という疑問に答えてくれる論文のようである。transformer blockそのもの、あるいはMLP layerを削除するとpeformパフ ... #Pretraining#Pocket#NLP#LanguageModel#Finetuning (SFT)
Issue Date: 2024-10-20 Addition is All You Need for Energy-efficient Language Models, Hongyin Luo+, N_A, arXiv24 #RecommenderSystems#Pocket
Issue Date: 2024-09-25 Enhancing Performance and Scalability of Large-Scale Recommendation Systems with Jagged Flash Attention, Rengan Xu+, N_A, arXiv24 #Survey#Pocket#NLP#LanguageModel
Issue Date: 2024-09-10 From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Sean Welleck+, N_A, arXiv24 Comment元ツイート: https://x.com/gneubig/status/1833522477605261799?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCMUのチームによるinference timeの高速化に関するサーベイ ... #Pocket#NLP#LanguageModel#OpenWeightLLM
Issue Date: 2024-04-23 Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Marah Abdin+, N_A, arXiv24 Summaryphi-3-miniは38億パラメータの言語モデルであり、3.3兆トークンで訓練されています。Mixtral 8x7BやGPT-3.5などの大規模モデルに匹敵する総合的なパフォーマンスを持ちながら、スマートフォンにデプロイ可能なサイズです。このモデルは、厳密にフィルタリングされたWebデータと合成データで構成されており、堅牢性、安全性、およびチャット形式に適合しています。また、phi-3-smallとphi-3-mediumというより大規模なモデルも紹介されています。 Comment#1039 の次の次(Phi2.0についてはメモってなかった)。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしいLlama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。 ... #Pocket#NLP#LanguageModel#Pruning
Issue Date: 2024-04-22 The Unreasonable Ineffectiveness of the Deeper Layers, Andrey Gromov+, N_A, arXiv24 Summary一般的なオープンウェイトの事前学習されたLLMのレイヤー剪定戦略を研究し、異なる質問応答ベンチマークでのパフォーマンスの低下を最小限に抑えることを示しました。レイヤーの最大半分を削除することで、最適なブロックを特定し、微調整して損傷を修復します。PEFT手法を使用し、実験を単一のA100 GPUで実行可能にします。これにより、計算リソースを削減し、推論のメモリとレイテンシを改善できることが示唆されます。また、LLMがレイヤーの削除に対して堅牢であることは、浅いレイヤーが知識を格納する上で重要な役割を果たしている可能性を示唆しています。 Comment下記ツイートによると、学習済みLLMから、コサイン類似度で入出力間の類似度が高い層を除いてもタスクの精度が落ちず、特に深い層を2-4割削除しても精度が落ちないとのこと。参考:https://x.com/hillbig/status/1773110076502368642?s=46&t=Y6UuI ... #Pocket#NLP#LanguageModel#Transformer
Issue Date: 2024-04-07 Mixture-of-Depths: Dynamically allocating compute in transformer-based language models, David Raposo+, N_A, arXiv24 SummaryTransformerベースの言語モデルは、入力シーケンス全体に均等にFLOPsを分散させる代わりに、特定の位置にFLOPsを動的に割り当てることを学習できることを示す。モデルの深さにわたって割り当てを最適化するために、異なるレイヤーで計算を動的に割り当てる。この手法は、トークンの数を制限することで合計計算予算を強制し、トークンはtop-kルーティングメカニズムを使用して決定される。この方法により、FLOPsを均等に消費しつつ、計算の支出が予測可能であり、動的かつコンテキストに敏感である。このようにトレーニングされたモデルは、計算を動的に割り当てることを学習し、効率的に行うことができる。 Comment参考: https://x.com/theseamouse/status/1775782800362242157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Pocket#NLP#LanguageModel#Transformer#Attention
Issue Date: 2024-04-07 Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference, Piotr Nawrot+, N_A, arXiv24 Summaryトランスフォーマーの生成効率を向上させるために、Dynamic Memory Compression(DMC)が提案された。DMCは、異なるヘッドとレイヤーで異なる圧縮率を適用する方法を学習し、事前学習済みLLMsに適用される。DMCは、元の下流パフォーマンスを最大4倍のキャッシュ圧縮で維持しつつ、スループットを向上させることができる。DMCは、GQAと組み合わせることでさらなる利益をもたらす可能性があり、長いコンテキストと大きなバッチを処理する際に有用である。 Comment参考: https://x.com/hillbig/status/1776755029581676943?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q論文中のFigure1が非常にわかりやすい。GQA #1271 と比較して、2~4倍キャッシュを圧縮しつつ、より高い性能を実現。70Bモ ...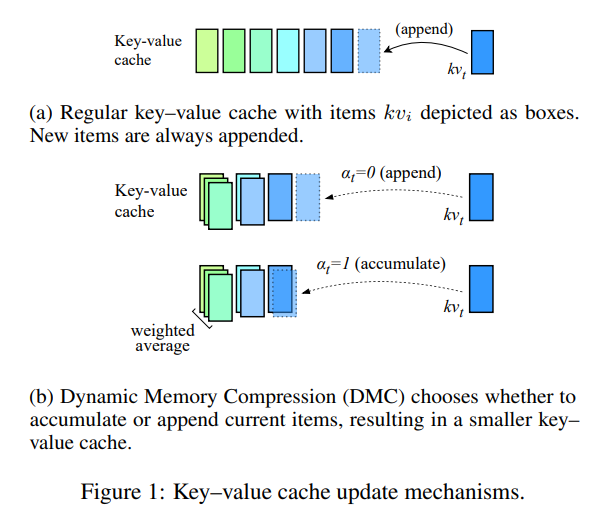 #Pocket#NLP#LanguageModel#Adapter/LoRA
#Pocket#NLP#LanguageModel#Adapter/LoRA
Issue Date: 2024-03-05 LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, arXiv24 Summary本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 CommentLoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法 ... #Pocket#Quantization#Adapter/LoRA
Issue Date: 2024-09-24 LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models, Yixiao Li+, N_A, arXiv23 #Pocket#NLP#LanguageModel#Transformer#Attention
Issue Date: 2024-04-07 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N_A, arXiv23 SummaryMulti-query attention(MQA)は、単一のkey-value headのみを使用しており、デコーダーの推論を劇的に高速化しています。ただし、MQAは品質の低下を引き起こす可能性があり、さらには、より速い推論のためだけに別個のモデルをトレーニングすることが望ましくない場合もあります。既存のマルチヘッド言語モデルのチェックポイントを、オリジナルの事前トレーニング計量の5%を使用してMQAを持つモデルにアップトレーニングするためのレシピを提案し、さらに、複数のkey-value headを使用するマルチクエリアテンションの一般化であるグループ化クエリアテンション(GQA)を紹介します。アップトレーニングされたGQAが、MQAと同等の速度でマルチヘッドアテンションに匹敵する品質を達成することを示しています。 Comment通常のMulti-Head AttentionがQKVが1対1対応なのに対し、Multi Query Attention (MQA) #1272 は全てのQに対してKVを共有する。一方、GQAはグループごとにKVを共有する点で異なる。MQAは大幅にInfeerence` speedが改善するが、精 ... #MachineLearning#Finetuning (SFT)#Adapter/LoRA
#MachineLearning#Finetuning (SFT)#Adapter/LoRA
Issue Date: 2024-01-17 VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv23 Summary本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。 #Pocket#NLP#LanguageModel
Issue Date: 2023-11-23 Exponentially Faster Language Modelling, Peter Belcak+, N_A, arXiv23 SummaryUltraFastBERTは、推論時にわずか0.3%のニューロンしか使用せず、同等の性能を発揮することができる言語モデルです。UltraFastBERTは、高速フィードフォワードネットワーク(FFF)を使用して、効率的な実装を提供します。最適化されたベースラインの実装に比べて78倍の高速化を実現し、バッチ処理された推論に対しては40倍の高速化を実現します。トレーニングコード、ベンチマークのセットアップ、およびモデルの重みも公開されています。 #Pocket#NLP#LanguageModel#Chain-of-Thought#Prompting
Issue Date: 2023-11-15 Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster, Hongxuan Zhang+, N_A, arXiv23 Summaryこの研究では、FastCoTというフレームワークを提案します。FastCoTは、LLMを使用して並列デコーディングと自己回帰デコーディングを同時に行い、計算リソースを最大限に活用します。また、FastCoTは推論時間を約20%節約し、性能の低下がほとんどないことを実験で示しました。さらに、異なるサイズのコンテキストウィンドウに対しても頑健性を示すことができました。 Comment論文中の図を見たが、全くわからなかった・・・。ちゃんと読まないとわからなそうである。 ... #MachineLearning#Pocket#NLP#Dataset#QuestionAnswering#Finetuning (SFT)#LongSequence#Adapter/LoRA
Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment# 概要 context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になって ...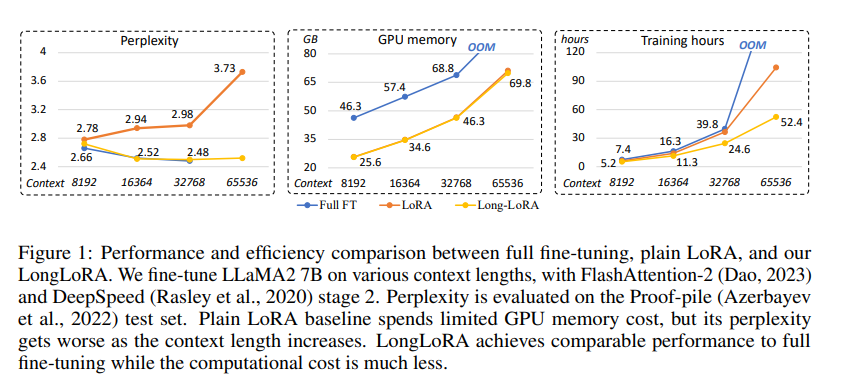 #MachineLearning#Pocket#NLP#LanguageModel
#MachineLearning#Pocket#NLP#LanguageModel
Issue Date: 2023-09-13 Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, N_A, arXiv23 Summary私たちは、小さなTransformerベースの言語モデルであるTinyStoriesと、大規模な言語モデルであるphi-1の能力について調査しました。また、phi-1を使用して教科書の品質のデータを生成し、学習プロセスを改善する方法を提案しました。さらに、phi-1.5という新しいモデルを作成し、自然言語のタスクにおいて性能が向上し、複雑な推論タスクにおいて他のモデルを上回ることを示しました。phi-1.5は、良い特性と悪い特性を持っており、オープンソース化されています。 Comment#766 に続く論文 ... #NLP#LanguageModel
Issue Date: 2023-08-08 Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, Xuefei Ning+, N_A, arXiv23 Summaryこの研究では、大規模言語モデル(LLMs)の生成遅延を減らすために、思考の骨組み(SoT)という手法を提案しています。SoTは、回答の骨組みをまず生成し、その後に内容を並列で処理することで高速化を実現します。また、回答品質の向上も期待されます。SoTはデータ中心の最適化の初めの試みであり、LLMsの人間らしい思考を可能にする可能性があります。 Comment最初に回答の枠組みだけ生成して、それぞれの内容を並列で出力させることでデコーディングを高速化しましょう、という話。 ...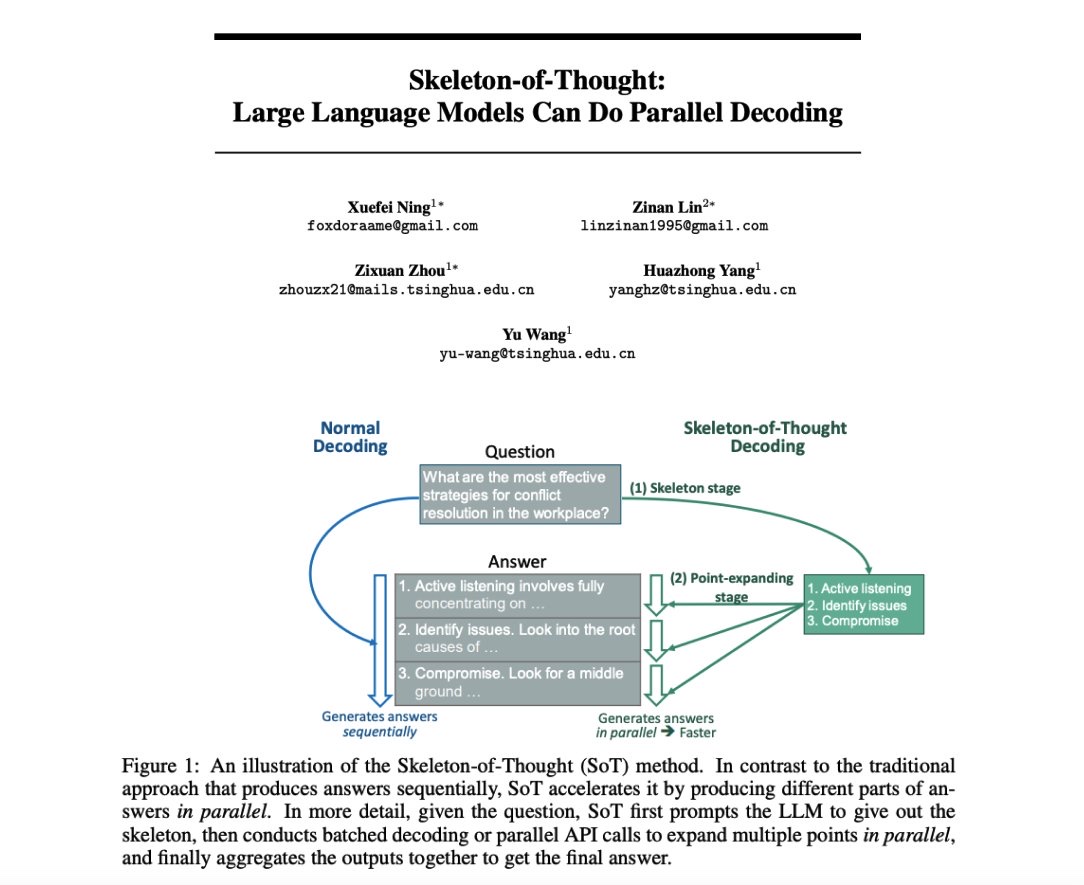 #NLP#LanguageModel
#NLP#LanguageModel
Issue Date: 2023-07-26 FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, Lingjiao Chen+, N_A, arXiv23 Summary大規模言語モデル(LLMs)の使用には高いコストがかかるため、LLMsの推論コストを削減するための3つの戦略(プロンプトの適応、LLMの近似、LLMのカスケード)を提案する。FrugalGPTという具体的な手法を紹介し、最大98%のコスト削減と4%の精度向上を実現することを示す。これにより、LLMsの持続可能な使用が可能となる。 Comment限られた予算の中で、いかに複数のLLM APIを使い、安いコストで高い性能を達成するかを追求した研究。LLM Cascadeなどはこの枠組みでなくても色々と使い道がありそう。Question Concatenationは実質Batch Prompting。 ... #MachineLearning#Pocket#Prompting
Issue Date: 2023-07-24 Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, N_A, arXiv23 Summary大規模な言語モデル(LLMs)を効果的に使用するために、バッチプロンプティングという手法を提案します。この手法は、LLMが1つのサンプルではなくバッチで推論を行うことを可能にし、トークンコストと時間コストを削減しながらパフォーマンスを維持します。さまざまなデータセットでの実験により、バッチプロンプティングがLLMの推論コストを大幅に削減し、良好なパフォーマンスを達成することが示されました。また、バッチプロンプティングは異なる推論方法にも適用できます。詳細はGitHubのリポジトリで確認できます。 Comment10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、cont ... #MachineLearning#Pocket#Quantization#Adapter/LoRA
#MachineLearning#Pocket#Quantization#Adapter/LoRA
Issue Date: 2023-07-22 QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, arXiv23 Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment実装: https://github.com/artidoro/qloraPEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQ ... #MachineLearning#NLP#DynamicNetworks
Issue Date: 2023-07-18 PAD-Net: An Efficient Framework for Dynamic Networks, ACL23 Summary本研究では、ダイナミックネットワークの一般的な問題点を解決するために、部分的にダイナミックなネットワーク(PAD-Net)を提案します。PAD-Netは、冗長なダイナミックパラメータを静的なパラメータに変換することで、展開コストを削減し、効率的なネットワークを実現します。実験結果では、PAD-Netが画像分類と言語理解のタスクで高い性能を示し、従来のダイナミックネットワークを上回ることを示しました。 #NLP#Ensemble#TransferLearning
Issue Date: 2023-07-14 Parameter-efficient Weight Ensembling Facilitates Task-level Knowledge Transfer, ACL23 Summary最近の研究では、大規模な事前学習済み言語モデルを特定のタスクに効果的に適応させることができることが示されています。本研究では、軽量なパラメータセットを使用してタスク間で知識を転送する方法を探求し、その有効性を検証しました。実験結果は、提案手法がベースラインに比べて5%〜8%の改善を示し、タスクレベルの知識転送を大幅に促進できることを示しています。 #MachineLearning#NLP#Zero/FewShotPrompting#In-ContextLearning
Issue Date: 2023-07-13 FiD-ICL: A Fusion-in-Decoder Approach for Efficient In-Context Learning, ACL23 Summary大規模な事前学習モデルを使用したfew-shot in-context learning(ICL)において、fusion-in-decoder(FiD)モデルを適用することで効率とパフォーマンスを向上させることができることを検証する。FiD-ICLは他のフュージョン手法と比較して優れたパフォーマンスを示し、推論時間も10倍速くなる。また、FiD-ICLは大規模なメタトレーニングモデルのスケーリングも可能にする。 #MachineLearning#LanguageModel#Finetuning (SFT)
Issue Date: 2023-06-26 Full Parameter Fine-tuning for Large Language Models with Limited Resources, Kai Lv+, N_A, arXiv23 SummaryLLMsのトレーニングには膨大なGPUリソースが必要であり、既存のアプローチは限られたリソースでの全パラメーターの調整に対処していない。本研究では、LOMOという新しい最適化手法を提案し、メモリ使用量を削減することで、8つのRTX 3090を搭載した単一のマシンで65Bモデルの全パラメーターファインチューニングが可能になる。 Comment8xRTX3090 24GBのマシンで65Bモデルの全パラメータをファインチューニングできる手法。LoRAのような(新たに追加しれた)一部の重みをアップデートするような枠組みではない。勾配計算とパラメータのアップデートをone stepで実施することで実現しているとのこと。 ... #Pretraining#MachineLearning#NLP#LanguageModel
Issue Date: 2023-06-25 Textbooks Are All You Need, Suriya Gunasekar+, N_A, arXiv23 Summary本研究では、小規模なphi-1という新しいコード用大規模言語モデルを紹介し、8つのA100で4日間トレーニングした結果、HumanEvalでpass@1の正解率50.6%、MBPPで55.5%を達成したことを報告しています。また、phi-1は、phi-1-baseやphi-1-smallと比較して、驚くべき新しい性質を示しています。phi-1-smallは、HumanEvalで45%を達成しています。 Comment参考: https://twitter.com/hillbig/status/1671643297616654342?s=46&t=JYDYid2m0v7vYaL7jhZYjQ日本語解説: https://dalab.jp/archives/journal/introduction-textbook ...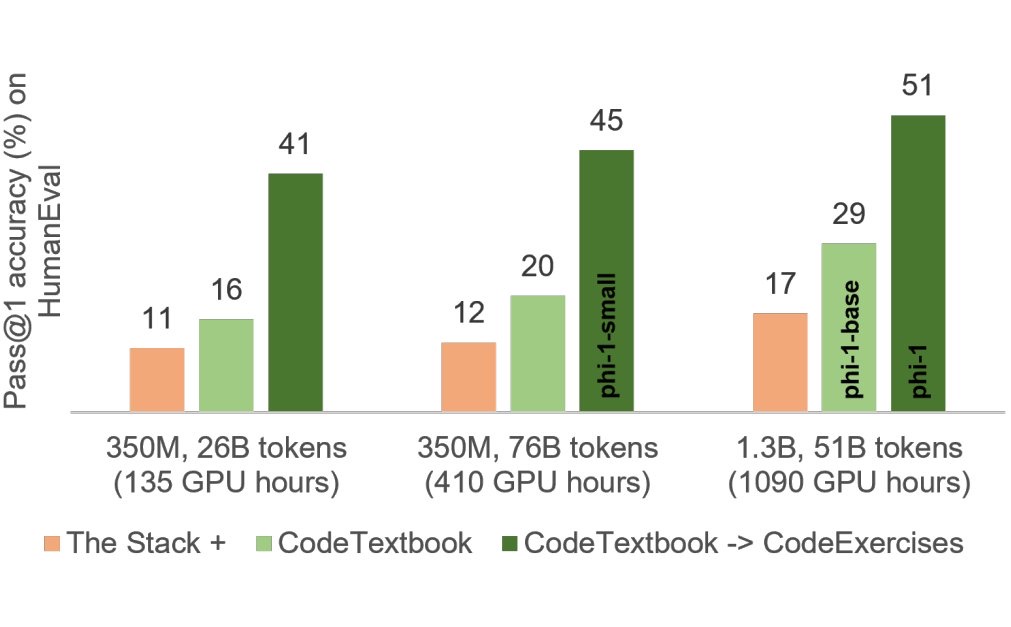 #NeuralNetwork#Survey#NLP#TACL
#NeuralNetwork#Survey#NLP#TACL
Issue Date: 2023-04-25 Efficient Methods for Natural Language Processing: A Survey, Treviso+, TACL23 Commentパラメータ数でゴリ押すような方法ではなく、"Efficient"に行うための手法をまとめている とパラメータ効率の良いファインチューニング(PEFT)を比較し、PEFTが高い精度と低い計算コストを提供することを示す。また、新しいPEFTメソッドである(IA)^3を紹介し、わずかな新しいパラメータしか導入しないまま、強力なパフォーマンスを達成する。さらに、T-Fewというシンプルなレシピを提案し、タスク固有のチューニングや修正なしに新しいタスクに適用できる。RAFTベンチマークでT-Fewを使用し、超人的なパフォーマンスを達成し、最先端を6%絶対的に上回る。 #MachineLearning#Attention
Issue Date: 2023-05-20 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Tri Dao+, N_A, arXiv22 Summaryトランスフォーマーは、長いシーケンスに対して遅く、メモリを多く消費するため、注意アルゴリズムを改善する必要がある。FlashAttentionは、タイリングを使用して、GPUの高帯域幅メモリ(HBM)とGPUのオンチップSRAM間のメモリ読み取り/書き込みの数を減らし、トランスフォーマーを高速にトレーニングできる。FlashAttentionは、トランスフォーマーでより長い文脈を可能にし、より高品質なモデルや、完全に新しい機能を提供する。 Commentより計算効率の良いFlashAttentionを提案 ...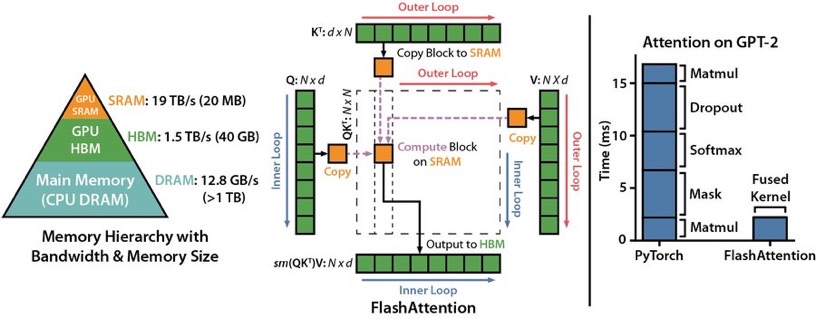 #Pocket#NLP#LanguageModel#Transformer#Attention
#Pocket#NLP#LanguageModel#Transformer#Attention
Issue Date: 2024-04-07 Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, N_A, arXiv19 Summaryマルチヘッドアテンションレイヤーのトレーニングは高速かつ簡単だが、増分推論は大きな"keys"と"values"テンソルを繰り返し読み込むために遅くなることがある。そこで、キーと値を共有するマルチクエリアテンションを提案し、メモリ帯域幅要件を低減する。実験により、高速なデコードが可能で、わずかな品質の低下しかないことが確認された。 CommentMulti Query Attention論文。KVのsetに対して、単一のQueryのみでMulti-Head Attentionを代替する。劇的にDecoderのInferenceが早くなりメモリ使用量が減るが、論文中では言及されていない?ようだが、性能と学習の安定性が課題となるようである。 ...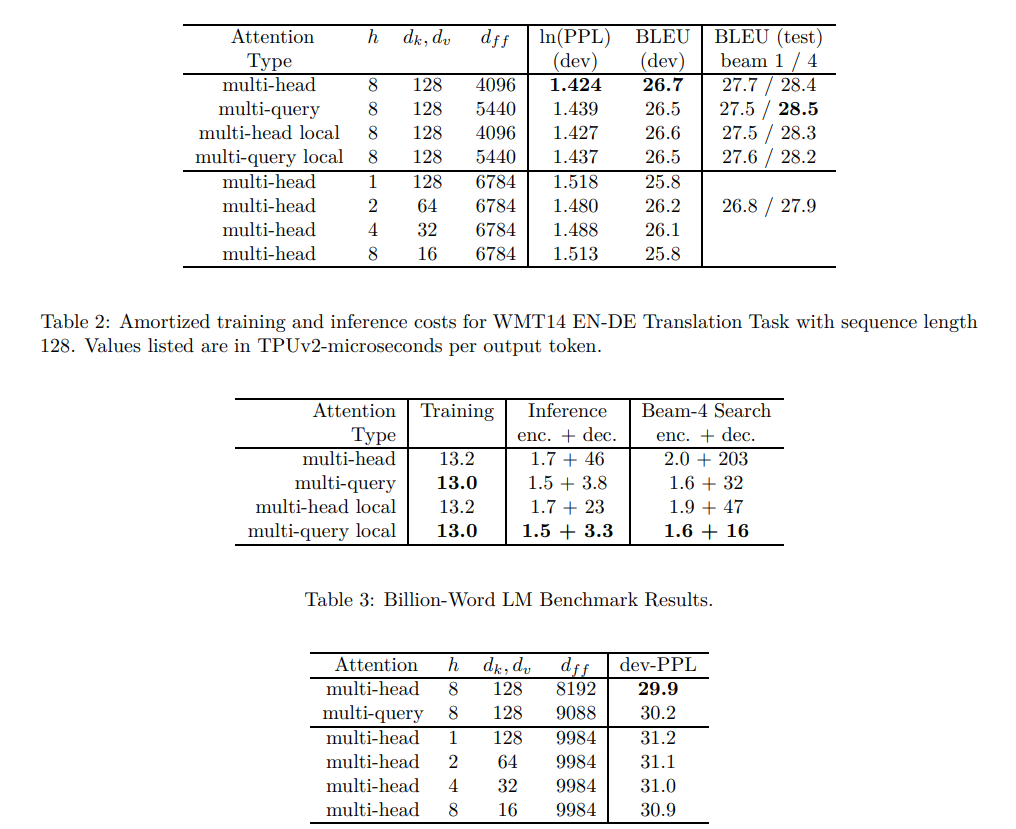 #NeuralNetwork#NLP#ACL
#NeuralNetwork#NLP#ACL
Issue Date: 2017-12-31 Learning to skim text, Yu+, ACL17 Comment解説スライド:http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/07.pdf#MulltiModal#Article#SSM (StateSpaceModel)
Issue Date: 2025-03-24 Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03 Comment関連:#1820TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。56B程度のm ... #Article#Pocket#LanguageModel#Article
Issue Date: 2024-12-17 Fast LLM Inference From Scratch, Andrew Chan, 2024.12 Commentライブラリを使用せずにC++とCUDAを利用してLLMの推論を実施する方法の解説記事 ... #Article#Pocket#LanguageModel#Slide
Issue Date: 2024-11-14 TensorRT-LLMによる推論高速化, Hiroshi Matsuda, NVIDIA AI Summit 2024.11 Comment元ポスト:https://x.com/hmtd223/status/1856887876665184649?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q非常に興味深いので後で読む ... #Article#Pretraining#NLP#Finetuning (SFT)
Issue Date: 2024-11-07 ZeRO: DeepSpeedの紹介, レトリバ, 2021.07 CommentZeROの説明がわかりやすいこちらの記事もわかりやすい https://zenn.dev/turing_motors/articles/d00c46a79dc976DeepSpeedのコンフィグの一覧 https://www.deepspeed.ai/docs/config-json/ZeRO St ... #Article#NLP#LanguageModel#Library#Repository
Issue Date: 2024-11-05 Lingua, Meta Comment研究目的のための、minimal、かつ高速なLLM training/inferenceのコードが格納されたリポジトリ。独自のモデルやデータ、ロスなどが簡単に実装できる模様。#InstructionTuning
Issue Date: 2024-10-08 Unsloth Commentsingle-GPUで、LLMのLoRA/QLoRAを高速/省メモリに実行できるライブラリ ... #Article#Tutorial#Pocket#LanguageModel
Issue Date: 2024-09-25 LLMの効率化・高速化を支えるアルゴリズム, Tatsuya Urabe, 2024.09 #Article#Transformer#Chip
Issue Date: 2024-09-18 Sohu, etched, 2024.06 Comment>By burning the transformer architecture into our chip, we can’t run most traditional AI models: the DLRMs powering Instagram ads, protein-folding mod ... #Article#NLP#LanguageModel#Finetuning (SFT)#Repository
Issue Date: 2024-08-25 Liger-Kernel, 2024.08 CommentLLMを学習する時に、ワンライン追加するだけで、マルチGPUトレーニングのスループットを20%改善し、メモリ使用量を60%削減するらしい元ツイート:https://x.com/hsu_byron/status/1827072737673982056?s=46&t=Y6UuIHB0Lv0IpmFAこれ ... #Article#Library#Article#OpenWeightLLM#LLMServing
Issue Date: 2024-08-05 DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06 Comment[vllm](https://github.com/vllm-project/vllm)を使うのが一番お手軽で、inference速度が速そう。PagedAttentionと呼ばれるキャッシュを利用して高速化しているっぽい。 (図はブログ中より引用) ローカルマシンで動作させられる規模感のモデルがサポートされている。https://gpt4all.io/i ... #Article#NLP#LanguageModel#MulltiModal#FoundationModel#Article
Issue Date: 2023-11-01 tsuzumi, NTT’23 CommentNTT製のLLM。パラメータ数は7Bと軽量だが高性能。MTBenchのようなGPT4に勝敗を判定させるベンチマークで、地理、歴史、政治、社会に関する質問応答タスク(図6)でgpt3.5turboと同等、国産LLMの中でトップの性能。GPT3.5turboには、コーディングや数学などの能力では劣るとt ...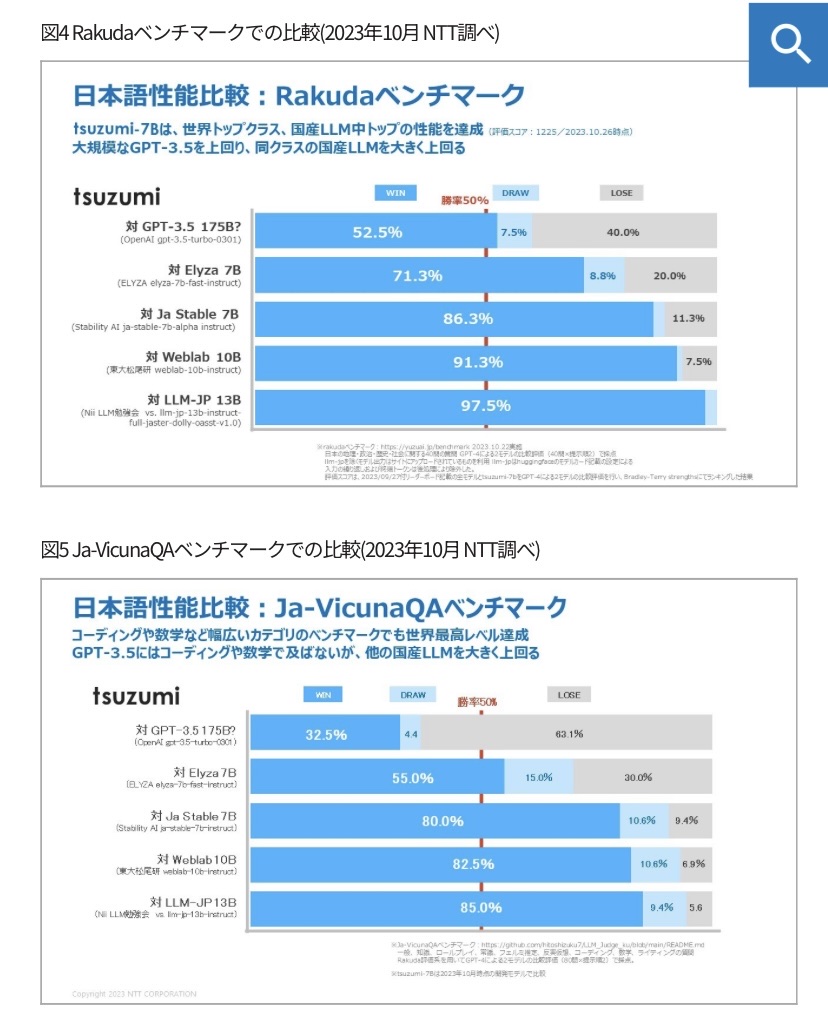 #Article#NLP#LanguageModel#Finetuning (SFT)#Adapter/LoRA#Catastrophic Forgetting
#Article#NLP#LanguageModel#Finetuning (SFT)#Adapter/LoRA#Catastrophic Forgetting
Issue Date: 2023-10-29 大規模言語モデルのFine-tuningによるドメイン知識獲得の検討 Comment以下記事中で興味深かった部分を引用> まとめると、LoRAは、[3]で言われている、事前学習モデルは大量のパラメータ数にもかかわらず低い固有次元を持ち、Fine-tuningに有効な低次元のパラメータ化も存在する、という主張にインスパイアされ、ΔWにおける重みの更新の固有次元も低いという仮説のもと ... #Article#NeuralNetwork#ComputerVision#NLP#LanguageModel#DiffusionModel#Article
Issue Date: 2023-10-29 StableDiffusion, LLMのGPUメモリ削減のあれこれ CommentGradient Accumulation, Gradient Checkpointingの説明が丁寧でわかりやすかった。 ... #Article#MachineLearning#NLP#Transformer#Attention
Issue Date: 2023-07-23 FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, 2023 SummaryFlashAttention-2は、長いシーケンス長におけるTransformerのスケーリングの問題に対処するために提案された手法です。FlashAttention-2は、非対称なGPUメモリ階層を利用してメモリの節約とランタイムの高速化を実現し、最適化された行列乗算に比べて約2倍の高速化を達成します。また、FlashAttention-2はGPTスタイルのモデルのトレーニングにおいても高速化を実現し、最大225 TFLOPs/sのトレーニング速度に達します。 CommentFlash Attention1よりも2倍高速なFlash Attention 2Flash Attention1はこちらを参照https://arxiv.org/pdf/2205.14135.pdfQK Matrixの計算をブロックに分けてSRAMに送って処理することで、3倍高速化し、メモリ効率を ...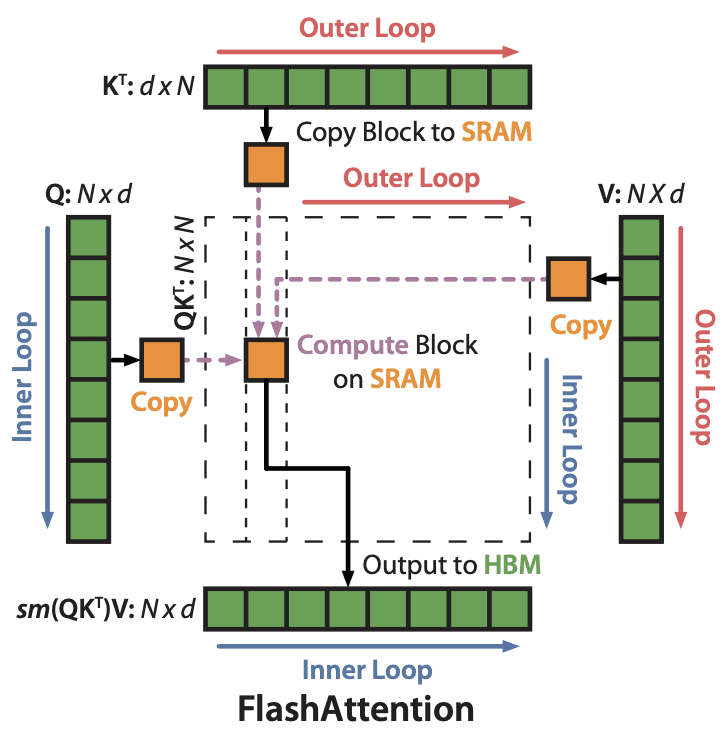 #Article#NLP#LanguageModel#Quantization#Adapter/LoRA
#Article#NLP#LanguageModel#Quantization#Adapter/LoRA
Issue Date: 2023-07-22 LLaMA2を3行で訓練 CommentLLaMA2を3行で、1つのA100GPU、QLoRAで、自前のデータセットで訓練する方法 ... #Article#NLP#Library#Transformer#python
Issue Date: 2023-05-11 Assisted Generation: a new direction toward low-latency text generation, 2023 Comment1 line加えるとtransformerのgenerationが最大3倍程度高速化されるようになったらしいassistant modelをロードしgenerateに引数として渡すだけ ...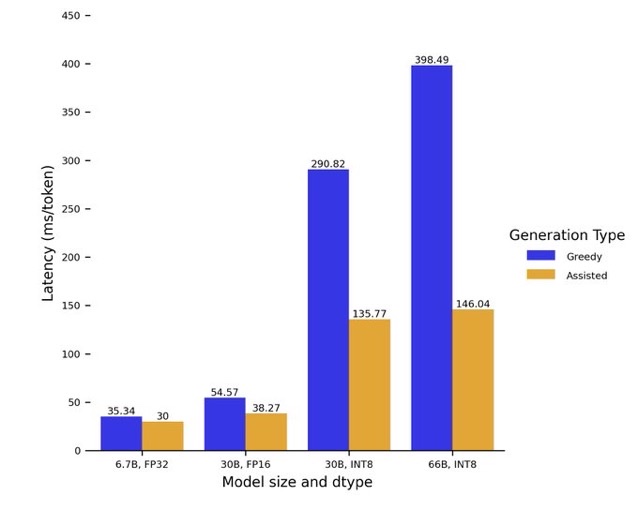 #Article#RecommenderSystems#Tutorial#Embeddings#Library
#Article#RecommenderSystems#Tutorial#Embeddings#Library
Issue Date: 2023-04-25 Training a recommendation model with dynamic embeddings Commentdynamic embeddingを使った推薦システムの構築方法の解説(理解が間違っているかもしれないが)推薦システムは典型的にはユーザとアイテムをベクトル表現し、関連度を測ることで推薦をしている。この枠組みをめっちゃスケールさせるととんでもない数のEmbeddingを保持することになり、メモリ上に ... #Article#NeuralNetwork#NLP#LanguageModel#Library#Adapter/LoRA
Issue Date: 2023-04-25 LoRA論文解説, Hayato Tsukagoshi, 2023.04 Commentベースとなる事前学習モデルの一部の線形層の隣に、低ランク行列A,Bを導入し、A,Bのパラメータのみをfinetuningの対象とすることで、チューニングするパラメータ数を激減させた上で同等の予測性能を達成し、推論速度も変わらないようにするfinetuning手法の解説LoRAを使うと、でかすぎるモデ ... #Article#Library#python#Article
Issue Date: 2021-06-03 intel MKL Commentintel CPUでpythonの数値計算を高速化するライブラリ(numpyとかはやくなるらしい; Anacondaだとデフォルトで入ってるとかなんとか) ... #Article#NeuralNetwork#Tutorial
Issue Date: 2017-12-31 Efficient Methods and Hardware for Deep Learning, Han, Stanford University, 2017
Issue Date: 2025-03-02 Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, arXiv25 Comment元ポスト:https://x.com/dair_ai/status/1893698286545969311?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #NLP#ACL
Issue Date: 2025-03-06 Full Parameter Fine-tuning for Large Language Models with Limited Resources, Lv+, ACL24, 2024.08 CommentLarge Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but demand massive GPU resources for training. Lowering the thresh ... #Survey#Pocket#NLP#LanguageModel
Issue Date: 2024-12-31 A Survey on LLM Inference-Time Self-Improvement, Xiangjue Dong+, arXiv24 #Analysis#Pocket#NLP#LanguageModel
Issue Date: 2024-11-22 Observational Scaling Laws and the Predictability of Language Model Performance, Yangjun Ruan+, arXiv24 Comment縦軸がdownstreamタスクの主成分(のうち最も大きい80%を説明する成分)の変化(≒LLMの性能)で、横軸がlog scaleの投入計算量。Qwenも頑張っているが、投入データ量に対する性能(≒データの品質)では、先駆け的な研究であるPhiがやはり圧倒的?#Japanese
Issue Date: 2024-11-17 Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv24 Comment元ポスト:https://x.com/okoge_kaz/status/1857639065421754525?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QFP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よ ... #Survey#NLP#LanguageModel#Transformer#Attention
Issue Date: 2024-11-17 Understanding LLMs: A Comprehensive Overview from Training to Inference, Yiheng Liu+, arXiv24 Comment[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-7vGwDK_AQX.HDO7j9H8iNA)単なるLLMの理論的な説明にとどまらず、実用的に必要な各種 ... #ComputerVision#NLP#Transformer#MulltiModal#AudioProcessing#Architecture
Issue Date: 2024-11-12 Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models, Weixin Liang+, arXiv24 Comment ... #Pocket#NLP#LanguageModel#Finetuning (SFT)#InstructionTuning
Issue Date: 2024-11-12 DELIFT: Data Efficient Language model Instruction Fine Tuning, Ishika Agarwal+, arXiv24 #Pocket#NLP#LanguageModel#Test-time Compute
Issue Date: 2024-11-12 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, Charlie Snell+, arXiv24 Comment[Perplexity(参考;Hallucinationに注意)](https://www.perplexity.ai/s ... #NLP#Transformer
Issue Date: 2024-10-22 What Matters in Transformers? Not All Attention is Needed, Shwai He+, N_A, arXiv24 Comment通常LLMはtransformer decoderのブロックをstackすることで形成されるが、積み上げたブロック、あるいはlayerってほんとに全部必要なの?という疑問に答えてくれる論文のようである。transformer blockそのもの、あるいはMLP layerを削除するとpeformパフ ... #Pretraining#Pocket#NLP#LanguageModel#Finetuning (SFT)
Issue Date: 2024-10-20 Addition is All You Need for Energy-efficient Language Models, Hongyin Luo+, N_A, arXiv24 #RecommenderSystems#Pocket
Issue Date: 2024-09-25 Enhancing Performance and Scalability of Large-Scale Recommendation Systems with Jagged Flash Attention, Rengan Xu+, N_A, arXiv24 #Survey#Pocket#NLP#LanguageModel
Issue Date: 2024-09-10 From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Sean Welleck+, N_A, arXiv24 Comment元ツイート: https://x.com/gneubig/status/1833522477605261799?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-QCMUのチームによるinference timeの高速化に関するサーベイ ... #Pocket#NLP#LanguageModel#OpenWeightLLM
Issue Date: 2024-04-23 Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Marah Abdin+, N_A, arXiv24 Summaryphi-3-miniは38億パラメータの言語モデルであり、3.3兆トークンで訓練されています。Mixtral 8x7BやGPT-3.5などの大規模モデルに匹敵する総合的なパフォーマンスを持ちながら、スマートフォンにデプロイ可能なサイズです。このモデルは、厳密にフィルタリングされたWebデータと合成データで構成されており、堅牢性、安全性、およびチャット形式に適合しています。また、phi-3-smallとphi-3-mediumというより大規模なモデルも紹介されています。 Comment#1039 の次の次(Phi2.0についてはメモってなかった)。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしいLlama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。 ... #Pocket#NLP#LanguageModel#Pruning
Issue Date: 2024-04-22 The Unreasonable Ineffectiveness of the Deeper Layers, Andrey Gromov+, N_A, arXiv24 Summary一般的なオープンウェイトの事前学習されたLLMのレイヤー剪定戦略を研究し、異なる質問応答ベンチマークでのパフォーマンスの低下を最小限に抑えることを示しました。レイヤーの最大半分を削除することで、最適なブロックを特定し、微調整して損傷を修復します。PEFT手法を使用し、実験を単一のA100 GPUで実行可能にします。これにより、計算リソースを削減し、推論のメモリとレイテンシを改善できることが示唆されます。また、LLMがレイヤーの削除に対して堅牢であることは、浅いレイヤーが知識を格納する上で重要な役割を果たしている可能性を示唆しています。 Comment下記ツイートによると、学習済みLLMから、コサイン類似度で入出力間の類似度が高い層を除いてもタスクの精度が落ちず、特に深い層を2-4割削除しても精度が落ちないとのこと。参考:https://x.com/hillbig/status/1773110076502368642?s=46&t=Y6UuI ... #Pocket#NLP#LanguageModel#Transformer
Issue Date: 2024-04-07 Mixture-of-Depths: Dynamically allocating compute in transformer-based language models, David Raposo+, N_A, arXiv24 SummaryTransformerベースの言語モデルは、入力シーケンス全体に均等にFLOPsを分散させる代わりに、特定の位置にFLOPsを動的に割り当てることを学習できることを示す。モデルの深さにわたって割り当てを最適化するために、異なるレイヤーで計算を動的に割り当てる。この手法は、トークンの数を制限することで合計計算予算を強制し、トークンはtop-kルーティングメカニズムを使用して決定される。この方法により、FLOPsを均等に消費しつつ、計算の支出が予測可能であり、動的かつコンテキストに敏感である。このようにトレーニングされたモデルは、計算を動的に割り当てることを学習し、効率的に行うことができる。 Comment参考: https://x.com/theseamouse/status/1775782800362242157?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q ... #Pocket#NLP#LanguageModel#Transformer#Attention
Issue Date: 2024-04-07 Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference, Piotr Nawrot+, N_A, arXiv24 Summaryトランスフォーマーの生成効率を向上させるために、Dynamic Memory Compression(DMC)が提案された。DMCは、異なるヘッドとレイヤーで異なる圧縮率を適用する方法を学習し、事前学習済みLLMsに適用される。DMCは、元の下流パフォーマンスを最大4倍のキャッシュ圧縮で維持しつつ、スループットを向上させることができる。DMCは、GQAと組み合わせることでさらなる利益をもたらす可能性があり、長いコンテキストと大きなバッチを処理する際に有用である。 Comment参考: https://x.com/hillbig/status/1776755029581676943?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q論文中のFigure1が非常にわかりやすい。GQA #1271 と比較して、2~4倍キャッシュを圧縮しつつ、より高い性能を実現。70Bモ ...
Issue Date: 2024-03-05 LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, arXiv24 Summary本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 CommentLoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法 ... #Pocket#Quantization#Adapter/LoRA
Issue Date: 2024-09-24 LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models, Yixiao Li+, N_A, arXiv23 #Pocket#NLP#LanguageModel#Transformer#Attention
Issue Date: 2024-04-07 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N_A, arXiv23 SummaryMulti-query attention(MQA)は、単一のkey-value headのみを使用しており、デコーダーの推論を劇的に高速化しています。ただし、MQAは品質の低下を引き起こす可能性があり、さらには、より速い推論のためだけに別個のモデルをトレーニングすることが望ましくない場合もあります。既存のマルチヘッド言語モデルのチェックポイントを、オリジナルの事前トレーニング計量の5%を使用してMQAを持つモデルにアップトレーニングするためのレシピを提案し、さらに、複数のkey-value headを使用するマルチクエリアテンションの一般化であるグループ化クエリアテンション(GQA)を紹介します。アップトレーニングされたGQAが、MQAと同等の速度でマルチヘッドアテンションに匹敵する品質を達成することを示しています。 Comment通常のMulti-Head AttentionがQKVが1対1対応なのに対し、Multi Query Attention (MQA) #1272 は全てのQに対してKVを共有する。一方、GQAはグループごとにKVを共有する点で異なる。MQAは大幅にInfeerence` speedが改善するが、精 ...
Issue Date: 2024-01-17 VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv23 Summary本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。 #Pocket#NLP#LanguageModel
Issue Date: 2023-11-23 Exponentially Faster Language Modelling, Peter Belcak+, N_A, arXiv23 SummaryUltraFastBERTは、推論時にわずか0.3%のニューロンしか使用せず、同等の性能を発揮することができる言語モデルです。UltraFastBERTは、高速フィードフォワードネットワーク(FFF)を使用して、効率的な実装を提供します。最適化されたベースラインの実装に比べて78倍の高速化を実現し、バッチ処理された推論に対しては40倍の高速化を実現します。トレーニングコード、ベンチマークのセットアップ、およびモデルの重みも公開されています。 #Pocket#NLP#LanguageModel#Chain-of-Thought#Prompting
Issue Date: 2023-11-15 Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster, Hongxuan Zhang+, N_A, arXiv23 Summaryこの研究では、FastCoTというフレームワークを提案します。FastCoTは、LLMを使用して並列デコーディングと自己回帰デコーディングを同時に行い、計算リソースを最大限に活用します。また、FastCoTは推論時間を約20%節約し、性能の低下がほとんどないことを実験で示しました。さらに、異なるサイズのコンテキストウィンドウに対しても頑健性を示すことができました。 Comment論文中の図を見たが、全くわからなかった・・・。ちゃんと読まないとわからなそうである。 ... #MachineLearning#Pocket#NLP#Dataset#QuestionAnswering#Finetuning (SFT)#LongSequence#Adapter/LoRA
Issue Date: 2023-09-30 LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv23 Summary本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment# 概要 context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になって ...
Issue Date: 2023-09-13 Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, N_A, arXiv23 Summary私たちは、小さなTransformerベースの言語モデルであるTinyStoriesと、大規模な言語モデルであるphi-1の能力について調査しました。また、phi-1を使用して教科書の品質のデータを生成し、学習プロセスを改善する方法を提案しました。さらに、phi-1.5という新しいモデルを作成し、自然言語のタスクにおいて性能が向上し、複雑な推論タスクにおいて他のモデルを上回ることを示しました。phi-1.5は、良い特性と悪い特性を持っており、オープンソース化されています。 Comment#766 に続く論文 ... #NLP#LanguageModel
Issue Date: 2023-08-08 Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding, Xuefei Ning+, N_A, arXiv23 Summaryこの研究では、大規模言語モデル(LLMs)の生成遅延を減らすために、思考の骨組み(SoT)という手法を提案しています。SoTは、回答の骨組みをまず生成し、その後に内容を並列で処理することで高速化を実現します。また、回答品質の向上も期待されます。SoTはデータ中心の最適化の初めの試みであり、LLMsの人間らしい思考を可能にする可能性があります。 Comment最初に回答の枠組みだけ生成して、それぞれの内容を並列で出力させることでデコーディングを高速化しましょう、という話。 ...
Issue Date: 2023-07-26 FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, Lingjiao Chen+, N_A, arXiv23 Summary大規模言語モデル(LLMs)の使用には高いコストがかかるため、LLMsの推論コストを削減するための3つの戦略(プロンプトの適応、LLMの近似、LLMのカスケード)を提案する。FrugalGPTという具体的な手法を紹介し、最大98%のコスト削減と4%の精度向上を実現することを示す。これにより、LLMsの持続可能な使用が可能となる。 Comment限られた予算の中で、いかに複数のLLM APIを使い、安いコストで高い性能を達成するかを追求した研究。LLM Cascadeなどはこの枠組みでなくても色々と使い道がありそう。Question Concatenationは実質Batch Prompting。 ... #MachineLearning#Pocket#Prompting
Issue Date: 2023-07-24 Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, N_A, arXiv23 Summary大規模な言語モデル(LLMs)を効果的に使用するために、バッチプロンプティングという手法を提案します。この手法は、LLMが1つのサンプルではなくバッチで推論を行うことを可能にし、トークンコストと時間コストを削減しながらパフォーマンスを維持します。さまざまなデータセットでの実験により、バッチプロンプティングがLLMの推論コストを大幅に削減し、良好なパフォーマンスを達成することが示されました。また、バッチプロンプティングは異なる推論方法にも適用できます。詳細はGitHubのリポジトリで確認できます。 Comment10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、cont ...
Issue Date: 2023-07-22 QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, arXiv23 Summary私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment実装: https://github.com/artidoro/qloraPEFTにもある参考: https://twitter.com/hillbig/status/1662946722690236417?s=46&t=TDHYK31QiXKxggPzhZbcAQ ... #MachineLearning#NLP#DynamicNetworks
Issue Date: 2023-07-18 PAD-Net: An Efficient Framework for Dynamic Networks, ACL23 Summary本研究では、ダイナミックネットワークの一般的な問題点を解決するために、部分的にダイナミックなネットワーク(PAD-Net)を提案します。PAD-Netは、冗長なダイナミックパラメータを静的なパラメータに変換することで、展開コストを削減し、効率的なネットワークを実現します。実験結果では、PAD-Netが画像分類と言語理解のタスクで高い性能を示し、従来のダイナミックネットワークを上回ることを示しました。 #NLP#Ensemble#TransferLearning
Issue Date: 2023-07-14 Parameter-efficient Weight Ensembling Facilitates Task-level Knowledge Transfer, ACL23 Summary最近の研究では、大規模な事前学習済み言語モデルを特定のタスクに効果的に適応させることができることが示されています。本研究では、軽量なパラメータセットを使用してタスク間で知識を転送する方法を探求し、その有効性を検証しました。実験結果は、提案手法がベースラインに比べて5%〜8%の改善を示し、タスクレベルの知識転送を大幅に促進できることを示しています。 #MachineLearning#NLP#Zero/FewShotPrompting#In-ContextLearning
Issue Date: 2023-07-13 FiD-ICL: A Fusion-in-Decoder Approach for Efficient In-Context Learning, ACL23 Summary大規模な事前学習モデルを使用したfew-shot in-context learning(ICL)において、fusion-in-decoder(FiD)モデルを適用することで効率とパフォーマンスを向上させることができることを検証する。FiD-ICLは他のフュージョン手法と比較して優れたパフォーマンスを示し、推論時間も10倍速くなる。また、FiD-ICLは大規模なメタトレーニングモデルのスケーリングも可能にする。 #MachineLearning#LanguageModel#Finetuning (SFT)
Issue Date: 2023-06-26 Full Parameter Fine-tuning for Large Language Models with Limited Resources, Kai Lv+, N_A, arXiv23 SummaryLLMsのトレーニングには膨大なGPUリソースが必要であり、既存のアプローチは限られたリソースでの全パラメーターの調整に対処していない。本研究では、LOMOという新しい最適化手法を提案し、メモリ使用量を削減することで、8つのRTX 3090を搭載した単一のマシンで65Bモデルの全パラメーターファインチューニングが可能になる。 Comment8xRTX3090 24GBのマシンで65Bモデルの全パラメータをファインチューニングできる手法。LoRAのような(新たに追加しれた)一部の重みをアップデートするような枠組みではない。勾配計算とパラメータのアップデートをone stepで実施することで実現しているとのこと。 ... #Pretraining#MachineLearning#NLP#LanguageModel
Issue Date: 2023-06-25 Textbooks Are All You Need, Suriya Gunasekar+, N_A, arXiv23 Summary本研究では、小規模なphi-1という新しいコード用大規模言語モデルを紹介し、8つのA100で4日間トレーニングした結果、HumanEvalでpass@1の正解率50.6%、MBPPで55.5%を達成したことを報告しています。また、phi-1は、phi-1-baseやphi-1-smallと比較して、驚くべき新しい性質を示しています。phi-1-smallは、HumanEvalで45%を達成しています。 Comment参考: https://twitter.com/hillbig/status/1671643297616654342?s=46&t=JYDYid2m0v7vYaL7jhZYjQ日本語解説: https://dalab.jp/archives/journal/introduction-textbook ...
Issue Date: 2023-04-25 Efficient Methods for Natural Language Processing: A Survey, Treviso+, TACL23 Commentパラメータ数でゴリ押すような方法ではなく、"Efficient"に行うための手法をまとめている とパラメータ効率の良いファインチューニング(PEFT)を比較し、PEFTが高い精度と低い計算コストを提供することを示す。また、新しいPEFTメソッドである(IA)^3を紹介し、わずかな新しいパラメータしか導入しないまま、強力なパフォーマンスを達成する。さらに、T-Fewというシンプルなレシピを提案し、タスク固有のチューニングや修正なしに新しいタスクに適用できる。RAFTベンチマークでT-Fewを使用し、超人的なパフォーマンスを達成し、最先端を6%絶対的に上回る。 #MachineLearning#Attention
Issue Date: 2023-05-20 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Tri Dao+, N_A, arXiv22 Summaryトランスフォーマーは、長いシーケンスに対して遅く、メモリを多く消費するため、注意アルゴリズムを改善する必要がある。FlashAttentionは、タイリングを使用して、GPUの高帯域幅メモリ(HBM)とGPUのオンチップSRAM間のメモリ読み取り/書き込みの数を減らし、トランスフォーマーを高速にトレーニングできる。FlashAttentionは、トランスフォーマーでより長い文脈を可能にし、より高品質なモデルや、完全に新しい機能を提供する。 Commentより計算効率の良いFlashAttentionを提案 ...
Issue Date: 2024-04-07 Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, N_A, arXiv19 Summaryマルチヘッドアテンションレイヤーのトレーニングは高速かつ簡単だが、増分推論は大きな"keys"と"values"テンソルを繰り返し読み込むために遅くなることがある。そこで、キーと値を共有するマルチクエリアテンションを提案し、メモリ帯域幅要件を低減する。実験により、高速なデコードが可能で、わずかな品質の低下しかないことが確認された。 CommentMulti Query Attention論文。KVのsetに対して、単一のQueryのみでMulti-Head Attentionを代替する。劇的にDecoderのInferenceが早くなりメモリ使用量が減るが、論文中では言及されていない?ようだが、性能と学習の安定性が課題となるようである。 ...
Issue Date: 2017-12-31 Learning to skim text, Yu+, ACL17 Comment解説スライド:http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/07.pdf#MulltiModal#Article#SSM (StateSpaceModel)
Issue Date: 2025-03-24 Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03 Comment関連:#1820TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。56B程度のm ... #Article#Pocket#LanguageModel#Article
Issue Date: 2024-12-17 Fast LLM Inference From Scratch, Andrew Chan, 2024.12 Commentライブラリを使用せずにC++とCUDAを利用してLLMの推論を実施する方法の解説記事 ... #Article#Pocket#LanguageModel#Slide
Issue Date: 2024-11-14 TensorRT-LLMによる推論高速化, Hiroshi Matsuda, NVIDIA AI Summit 2024.11 Comment元ポスト:https://x.com/hmtd223/status/1856887876665184649?s=46&t=Y6UuIHB0Lv0IpmFAjlc2-Q非常に興味深いので後で読む ... #Article#Pretraining#NLP#Finetuning (SFT)
Issue Date: 2024-11-07 ZeRO: DeepSpeedの紹介, レトリバ, 2021.07 CommentZeROの説明がわかりやすいこちらの記事もわかりやすい https://zenn.dev/turing_motors/articles/d00c46a79dc976DeepSpeedのコンフィグの一覧 https://www.deepspeed.ai/docs/config-json/ZeRO St ... #Article#NLP#LanguageModel#Library#Repository
Issue Date: 2024-11-05 Lingua, Meta Comment研究目的のための、minimal、かつ高速なLLM training/inferenceのコードが格納されたリポジトリ。独自のモデルやデータ、ロスなどが簡単に実装できる模様。#InstructionTuning
Issue Date: 2024-10-08 Unsloth Commentsingle-GPUで、LLMのLoRA/QLoRAを高速/省メモリに実行できるライブラリ ... #Article#Tutorial#Pocket#LanguageModel
Issue Date: 2024-09-25 LLMの効率化・高速化を支えるアルゴリズム, Tatsuya Urabe, 2024.09 #Article#Transformer#Chip
Issue Date: 2024-09-18 Sohu, etched, 2024.06 Comment>By burning the transformer architecture into our chip, we can’t run most traditional AI models: the DLRMs powering Instagram ads, protein-folding mod ... #Article#NLP#LanguageModel#Finetuning (SFT)#Repository
Issue Date: 2024-08-25 Liger-Kernel, 2024.08 CommentLLMを学習する時に、ワンライン追加するだけで、マルチGPUトレーニングのスループットを20%改善し、メモリ使用量を60%削減するらしい元ツイート:https://x.com/hsu_byron/status/1827072737673982056?s=46&t=Y6UuIHB0Lv0IpmFAこれ ... #Article#Library#Article#OpenWeightLLM#LLMServing
Issue Date: 2024-08-05 DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06 Comment[vllm](https://github.com/vllm-project/vllm)を使うのが一番お手軽で、inference速度が速そう。PagedAttentionと呼ばれるキャッシュを利用して高速化しているっぽい。 (図はブログ中より引用) ローカルマシンで動作させられる規模感のモデルがサポートされている。https://gpt4all.io/i ... #Article#NLP#LanguageModel#MulltiModal#FoundationModel#Article
Issue Date: 2023-11-01 tsuzumi, NTT’23 CommentNTT製のLLM。パラメータ数は7Bと軽量だが高性能。MTBenchのようなGPT4に勝敗を判定させるベンチマークで、地理、歴史、政治、社会に関する質問応答タスク(図6)でgpt3.5turboと同等、国産LLMの中でトップの性能。GPT3.5turboには、コーディングや数学などの能力では劣るとt ...
Issue Date: 2023-10-29 大規模言語モデルのFine-tuningによるドメイン知識獲得の検討 Comment以下記事中で興味深かった部分を引用> まとめると、LoRAは、[3]で言われている、事前学習モデルは大量のパラメータ数にもかかわらず低い固有次元を持ち、Fine-tuningに有効な低次元のパラメータ化も存在する、という主張にインスパイアされ、ΔWにおける重みの更新の固有次元も低いという仮説のもと ... #Article#NeuralNetwork#ComputerVision#NLP#LanguageModel#DiffusionModel#Article
Issue Date: 2023-10-29 StableDiffusion, LLMのGPUメモリ削減のあれこれ CommentGradient Accumulation, Gradient Checkpointingの説明が丁寧でわかりやすかった。 ... #Article#MachineLearning#NLP#Transformer#Attention
Issue Date: 2023-07-23 FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, 2023 SummaryFlashAttention-2は、長いシーケンス長におけるTransformerのスケーリングの問題に対処するために提案された手法です。FlashAttention-2は、非対称なGPUメモリ階層を利用してメモリの節約とランタイムの高速化を実現し、最適化された行列乗算に比べて約2倍の高速化を達成します。また、FlashAttention-2はGPTスタイルのモデルのトレーニングにおいても高速化を実現し、最大225 TFLOPs/sのトレーニング速度に達します。 CommentFlash Attention1よりも2倍高速なFlash Attention 2Flash Attention1はこちらを参照https://arxiv.org/pdf/2205.14135.pdfQK Matrixの計算をブロックに分けてSRAMに送って処理することで、3倍高速化し、メモリ効率を ...
Issue Date: 2023-07-22 LLaMA2を3行で訓練 CommentLLaMA2を3行で、1つのA100GPU、QLoRAで、自前のデータセットで訓練する方法 ... #Article#NLP#Library#Transformer#python
Issue Date: 2023-05-11 Assisted Generation: a new direction toward low-latency text generation, 2023 Comment1 line加えるとtransformerのgenerationが最大3倍程度高速化されるようになったらしいassistant modelをロードしgenerateに引数として渡すだけ ...
Issue Date: 2023-04-25 Training a recommendation model with dynamic embeddings Commentdynamic embeddingを使った推薦システムの構築方法の解説(理解が間違っているかもしれないが)推薦システムは典型的にはユーザとアイテムをベクトル表現し、関連度を測ることで推薦をしている。この枠組みをめっちゃスケールさせるととんでもない数のEmbeddingを保持することになり、メモリ上に ... #Article#NeuralNetwork#NLP#LanguageModel#Library#Adapter/LoRA
Issue Date: 2023-04-25 LoRA論文解説, Hayato Tsukagoshi, 2023.04 Commentベースとなる事前学習モデルの一部の線形層の隣に、低ランク行列A,Bを導入し、A,Bのパラメータのみをfinetuningの対象とすることで、チューニングするパラメータ数を激減させた上で同等の予測性能を達成し、推論速度も変わらないようにするfinetuning手法の解説LoRAを使うと、でかすぎるモデ ... #Article#Library#python#Article
Issue Date: 2021-06-03 intel MKL Commentintel CPUでpythonの数値計算を高速化するライブラリ(numpyとかはやくなるらしい; Anacondaだとデフォルトで入ってるとかなんとか) ... #Article#NeuralNetwork#Tutorial
Issue Date: 2017-12-31 Efficient Methods and Hardware for Deep Learning, Han, Stanford University, 2017