
RecommenderSystems
[Paper Note] OneReason Technical Report, OneRec Team+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #GenerativeRecommendation #PostTraining #read-later #Initial Impression Notes Issue Date: 2026-06-05 GPT Summary- OneRecファミリーの生成型推奨モデルは多くのサービスで利用されていますが、アイテムを表すトークンから有意義なCoTシーケンスを構築するのが困難です。この課題を克服するため、推論能力を探索する予備研究(OneRec-Think、OpenOneRec)を実施しましたが、思考モードが必ずしも優位であるとは限らないことが判明しました。推奨の効果的な推論には知覚と認知の二つの要因が重要であると考え、OneReasonを提案します。具体的には、強力なアイテム的トークン知覚、三レベルの認知強化CoT形式、“専門化→統合”の学習レシピを用いて思考能力を高めます。 Comment
元ポスト:
事前学習/SFT/RLといった現在主流なLLMの学習パイプラインをGenerative Recommender Systemsに適用したモデルのようで、
ItemIDのトークンの意味を理解させるための事前学習等を実施している点が興味深い。
[Paper Note] An Industrial-Scale Sequential Recommender for LinkedIn Feed Ranking, Lars Hertel+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NeuralNetwork #Transformer #A/B Testing #SequentialRecommendation #One-Line Notes #Initial Impression Notes Issue Date: 2026-02-16 GPT Summary- Feed Sequential Recommender(Feed-SR)は、LinkedInフィード向けのトランスフォーマーを用いた逐次ランキングモデルで、DCNv2ベースのランカーを置換。LinkedInの運用制約を満たしつつ、メンバーのエンゲージメントを向上させ、滞在時間が+2.10%増加。オンラインA/Bテストでの性能を通じて、Feed-SRの効率性と効果についても論じる。 Comment
元ポスト:
linkedinのfeedにおけるsequential recommendationで利用されているモデルでdecoder onlyのpre-LN、RoPE、residual streamの更新がlearnableなパラメータでrescaleされて更新されるようなtransformerアーキテクチャが採用されている。細かいfeatureなどについては読めていない。A/Bテストによって効果が確認されている。
[Paper Note] Diversification as Risk Minimization, Rikiya Takehi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#InformationRetrieval #WSDM #read-later Issue Date: 2026-02-28 GPT Summary- ユーザーは検索の失敗を記憶しやすく、この問題に対処するため、分散化をリスク最小化問題として定式化することを提案。VRiskを導入し、未満足意図の割合に基づく期待リスクを測定。VRiskの最適化によって頑健なランキングを生成し、効率的な再ランキング手法VRiskerを開発。実験では、VRiskerが意図失敗を最大33%削減し、平均性能の低下を2%に抑えることを示した。 Comment
元ポスト:
[Paper Note] MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation, Xiaoyu Kong+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #VariationalAutoEncoder #PostTraining #read-later #Selected Papers/Blogs #One-Line Notes #Scalability Issue Date: 2025-11-26 GPT Summary- MiniOneRecを提案し、SID構築から強化学習までのエンドツーエンドの生成レコメンデーションフレームワークを提供。実験により、モデルサイズの増加に伴いトレーニング損失と評価損失が減少し、生成アプローチのパラメータ効率が確認された。さらに、SID整合性の強制と強化学習を用いたポストトレーニングパイプラインにより、ランキング精度と候補の多様性が大幅に向上。 Comment
github: https://github.com/AkaliKong/MiniOneRec
元ポスト:
興味深い話ではあるが、generativeなRecSysはlatencyの面で厳しいものがあるという認識ではある。読みたい。
[Paper Note] LLM Reasoning for Cold-Start Item Recommendation, Shijun Li+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#LanguageModel #Reasoning #read-later #ColdStart Issue Date: 2025-11-25 GPT Summary- LLMsを用いたコールドスタートアイテム推薦の新しい推論戦略を提案。特に新規アイテムに対するユーザーの好みを推測し、教師ありファインチューニングと強化学習を組み合わせたアプローチを評価。実験により、Netflixの製品ランキングモデルを最大8%上回る性能を示した。 Comment
元ポスト:
[Paper Note] Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video, Mengyao Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #NLP #MultiModal #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-10-07 GPT Summary- 「Omni-Embed-Nemotron」は、複雑な情報ニーズに応えるための統一的なマルチモーダル検索埋め込みモデルです。従来のテキストベースのリトリーバーが視覚的に豊かなコンテンツに対応できない中、ColPaliの研究を基に、テキスト、画像、音声、動画を統合した検索を実現します。このモデルは、クロスモーダルおよびジョイントモーダル検索を可能にし、そのアーキテクチャと評価結果を通じて、検索の効果を実証しています。 Comment
元ポスト:
[Paper Note] RecoWorld: Building Simulated Environments for Agentic Recommender Systems, Fei Liu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #AIAgents Issue Date: 2025-09-30 GPT Summary- RecoWorldは、エージェント型レコメンダーシステムのためのシミュレーション環境を提案し、エージェントがユーザーに影響を与えずに学習できる場を提供します。ユーザーシミュレーターとエージェント型レコメンダーがマルチターンのインタラクションを行い、ユーザーの保持を最大化します。ユーザーシミュレーターはユーザーの反応を基に指示を生成し、レコメンダーはそれに応じて推奨を適応させる動的なフィードバックループを形成します。さらに、テキストベースやマルチモーダルなコンテンツ表現を探求し、マルチターン強化学習を通じて戦略を洗練させる方法を議論します。RecoWorldは、ユーザーとエージェントが共同でパーソナライズされた情報を形成する新しいインタラクションパラダイムを提示します。 Comment
元ポスト:
[Paper Note] Interactive Recommendation Agent with Active User Commands, Jiakai Tang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#LanguageModel #read-later #Selected Papers/Blogs #interactive #One-Line Notes Issue Date: 2025-09-29 GPT Summary- 従来のレコメンダーシステムは受動的なフィードバックに依存し、ユーザーの意図を捉えられないため、嗜好モデルの構築が困難である。これに対処するため、インタラクティブレコメンデーションフィード(IRF)を導入し、自然言語コマンドによる能動的な制御を可能にする。RecBotという二重エージェントアーキテクチャを開発し、ユーザーの嗜好を構造化し、ポリシー調整を行う。シミュレーション強化知識蒸留を用いて効率的なパフォーマンスを実現し、実験によりユーザー満足度とビジネス成果の改善を示した。 Comment
元ポスト:
ABテストを実施しているようなので信ぴょう性高め
[Paper Note] Taming Recommendation Bias with Causal Intervention on Evolving Personal Popularity, Shiyin Tan+, KDD'25
Paper/Blog Link My Issue
#SIGKDD Issue Date: 2025-09-20 GPT Summary- CausalEPPという新手法を提案し、ユーザーの進化する個人的な人気を考慮して推薦バイアスを抑制。進化する個人的人気を定量化し、因果グラフを用いて人気バイアスを軽減。実証研究で推薦精度が向上し、ベースライン手法を上回ることを示した。
[Paper Note] Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings, Shiyu Li+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #LanguageModel Issue Date: 2025-09-17 GPT Summary- 新しい1.4BパラメータのLLM「Conan-embedding-v2」をゼロからトレーニングし、テキスト埋め込み器としてファインチューニングする手法を提案。ニュースデータと多言語ペアを追加してデータギャップを埋め、クロスリンガルリトリーバルデータセットを導入。ソフトマスキングメカニズムを用いてトークンレベルと文レベルの損失を統合し、動的ハードネガティブマイニング手法を採用。これにより、MTEBおよびChinese MTEBでSOTA性能を達成。 Comment
元ポスト:
[Paper Note] ProRank: Prompt Warmup via Reinforcement Learning for Small Language Models Reranking, Xianming Li+, arXiv'25
Paper/Blog Link My Issue
#InformationRetrieval #LanguageModel #SmallModel #Reranking Issue Date: 2025-09-03 GPT Summary- 再ランキングにおいて、SLMを用いた新しい二段階トレーニングアプローチProRankを提案。まず、強化学習を用いてSLMがタスクプロンプトを理解し、粗い関連スコアを生成。次に、ファインチューニングを行い再ランキングの質を向上。実験結果では、ProRankが先進的な再ランキングモデルを上回り、特にProRank-0.5Bモデルが32B LLMを超える性能を示した。 Comment
元ポスト:
[Paper Note] Large Foundation Model for Ads Recommendation, Shangyu Zhang+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #LanguageModel #FoundationModel #read-later Issue Date: 2025-08-26 GPT Summary- LFM4Adsは、オンライン広告のための全表現マルチ粒度転送フレームワークで、ユーザー表現(UR)、アイテム表現(IR)、ユーザー-アイテム交差表現(CR)を包括的に転送。最適な抽出層を特定し、マルチ粒度メカニズムを導入することで転送可能性を強化。テンセントの広告プラットフォームで成功裏に展開され、2.45%のGMV向上を達成。 Comment
元ポスト:
[Paper Note] Semantic IDs for Music Recommendation, M. Jeffrey Mei+, arXiv'25
Paper/Blog Link My Issue
#VariationalAutoEncoder #SemanticID Issue Date: 2025-07-28 GPT Summary- コンテンツ情報を活用した共有埋め込みを用いることで、次アイテム推薦のレコメンダーシステムのモデルサイズを削減し、精度と多様性を向上させることを示す。音楽ストリーミングサービスでのオンラインA/Bテストを通じて、その効果を実証。 Comment
元ポスト:
Semantic ID関連:
- LLM Recommendation Systems: AI Engineer World's Fair 2025, AI Engineer, 2025.07
- [Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18
- [Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23
上記2つのハイブリッド
[Paper Note] RankMixer: Scaling Up Ranking Models in Industrial Recommenders, Jie Zhu+, arXiv'25
Paper/Blog Link My Issue
#NeuralNetwork #LearningToRank #Transformer #read-later #Selected Papers/Blogs Issue Date: 2025-07-24 GPT Summary- RankMixerは、推薦システムのスケーラビリティを向上させるための新しいアーキテクチャで、トランスフォーマーの並列性を活かしつつ、効率的な特徴相互作用を実現。Sparse-MoEバリアントを用いて10億パラメータに拡張し、動的ルーティング戦略で専門家の不均衡を解消。実験により、1兆スケールのデータセットで優れたスケーリング能力を示し、MFUを4.5%から45%に向上させ、推論レイテンシーを維持しつつパラメータを100倍に増加。オンラインA/Bテストで推薦、広告、検索の各シナリオにおける効果を確認し、ユーザーのアクティブ日数を0.2%、アプリ内使用時間を0.5%改善。 Comment
元ポスト:
[Paper Note] Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation, Genki Kusano+, RecSys'25
Paper/Blog Link My Issue
#LanguageModel #Prompting #Evaluation #RecSys #Reproducibility #KeyPoint Notes Issue Date: 2025-07-21 GPT Summary- LLMを用いた単一ユーザー設定の推薦タスクにおいて、プロンプトエンジニアリングが重要であることを示す。23種類のプロンプトタイプを比較した結果、コスト効率の良いLLMでは指示の言い換え、背景知識の考慮、推論プロセスの明確化が効果的であり、高性能なLLMではシンプルなプロンプトが優れることが分かった。精度とコストのバランスに基づくプロンプトとLLMの選択に関する提案を行う。 Comment
元ポスト:
RecSysにおける網羅的なpromptingの実験。非常に興味深い
実験で利用されたPrompting手法と相対的な改善幅
RePhrase,StepBack,Explain,Summalize-User,Recency-Focusedが、様々なモデル、データセット、ユーザの特性(Light, Heavy)において安定した性能を示しており(少なくともベースラインからの性能の劣化がない)、model agnosticに安定した性能を発揮できるpromptingが存在することが明らかになった。一方、Phi-4, nova-liteについてはBaselineから有意に性能が改善したPromptingはなかった。これはモデルは他のモデルよりもそもそもの予測性能が低く、複雑なinstructionを理解する能力が不足しているため、Promptデザインが与える影響が小さいことが示唆される。
特定のモデルでのみ良い性能を発揮するPromptingも存在した。たとえばRe-Reading, Echoは、Llama3.3-70Bでは性能が改善したが、gpt-4.1-mini, gpt-4o-miniでは性能が悪化した。ReActはgpt-4.1-miniとLlamd3.3-70Bで最高性能を達成したが、gpt-4o-miniでは最も性能が悪かった。
NLPにおいて一般的に利用されるprompting、RolePlay, Mock, Plan-Solve, DeepBreath, Emotion, Step-by-Stepなどは、推薦のAcc.を改善しなかった。このことより、ユーザの嗜好を捉えることが重要なランキングタスクにおいては、これらプロンプトが有効でないことが示唆される。
続いて、LLMやデータセットに関わらず高い性能を発揮するpromptingをlinear mixed-effects model(ランダム効果として、ユーザ、LLM、メトリックを導入し、これらを制御する項を線形回帰に導入。promptingを固定効果としAccに対する寄与をfittingし、多様な状況で高い性能を発揮するPromptを明らかにする)によって分析した結果、ReAct, Rephrase, Step-Backが有意に全てのデータセット、LLMにおいて高い性能を示すことが明らかになった。
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #NLP #LanguageModel #RepresentationLearning #InstructionTuning #ContrastiveLearning #ICLR #Generalization #Decoder Issue Date: 2025-07-10 GPT Summary- デコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。 Comment
Decoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。
学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。
[^1]: [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22, 2021.07
Perceiver-IOにインスパイアされている。
[Paper Note] Do We Really Need Specialization? Evaluating Generalist Text Embeddings for Zero-Shot Recommendation and Search, Matteo Attimonelli+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #LanguageModel #SequentialRecommendation #Generalization Issue Date: 2025-07-08 GPT Summary- 事前学習済み言語モデル(GTEs)は、逐次推薦や製品検索においてファインチューニングなしで優れたゼロショット性能を発揮し、従来のモデルを上回ることを示す。GTEsは埋め込み空間に特徴を均等に分配することで表現力を高め、埋め込み次元の圧縮がノイズを減少させ、専門モデルの性能向上に寄与する。再現性のためにリポジトリを提供。 Comment
元ポスト:
[Paper Note] Listwise Preference Alignment Optimization for Tail Item Recommendation, Zihao Li+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#ListWise #Alignment #Transformer #SequentialRecommendation #Initial Impression Notes Issue Date: 2025-07-04 GPT Summary- LPO4Recは、テールアイテム推薦におけるPreference alignmentの課題を解決するために提案された手法で、Bradley-Terryモデルをペアワイズからリストワイズ比較に拡張し、効率的なトレーニングを実現。明示的な報酬モデリングなしで、テールアイテムを優先する負のサンプリング戦略を導入し、パフォーマンスを最大50%向上させ、GPUメモリ使用量を17.9%削減。実験結果は3つの公開データセットで示されている。 Comment
元ポスト:
tail itemに強い手法らしい。LLMを用いたGenerative Recommendationではなく、1 BlockのTransformerにlistwiseなpreferenceを反映したlossを適用したものっぽい。
一貫して性能は高そうに見えるが、再現性はどうだろうか。
関連(SASRec):
- [Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18
pointwise, pairwise, listwiseの基礎はこちらを参照:
- ランキング学習ことはじめ, DSIRNLP#1, 2011.07
[Paper Note] NEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking, Shenbin Qian+, arXiv'25
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #InformationRetrieval #RepresentationLearning Issue Date: 2025-06-25 GPT Summary- Eコマース情報検索システムは、ユーザーの意図を正確に理解しつつ、大規模な商品カタログを効率的に処理することが難しい。本論文では、NEAR$^2$というネストされた埋め込みアプローチを提案し、推論時の埋め込みサイズを最大12倍効率化し、トレーニングコストを増やさずにトランスフォーマーモデルの精度を向上させる。さまざまなIR課題に対して異なる損失関数を用いて検証した結果、既存モデルよりも小さな埋め込み次元での性能向上を達成した。 Comment
元ポスト:
[Paper Note] Generative Product Recommendations for Implicit Superlative Queries, Kaustubh D. Dhole+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#LanguageModel Issue Date: 2025-04-29 GPT Summary- ユーザーの曖昧なクエリに対してLLMを用いて、暗黙の属性を生成し製品推奨を向上。新たにSUPERBという4点スキーマでクエリに対する製品候補を注釈し、既存のランキング手法を評価。実世界のeコマースシステムへの統合も検討。 Comment
元ポスト:
[Paper Note] RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning, Sichun Luo+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#CollaborativeFiltering #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Reasoning #Initial Impression Notes Issue Date: 2025-03-27 GPT Summary- RALLRec+は、LLMsを用いてレコメンダーシステムのretrievalとgenerationを強化する手法。retrieval段階では、アイテム説明を生成し、テキスト信号と協調信号を結合。生成段階では、推論LLMsを評価し、知識注入プロンプティングで汎用LLMsと統合。実験により、提案手法の有効性が確認された。 Comment
元ポスト:
Reasoning LLMをRecSysに応用する初めての研究(らしいことがRelated Workに書かれている)
arxivのadminより以下のコメントが追記されている
> arXiv admin note: substantial text overlap with arXiv:2502.06101
コメント中の研究は下記である
- [Paper Note] ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation, Jianghao Lin+, WWW'24
[Paper Note] Joint Modeling in Recommendations: A Survey, Xiangyu Zhao+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Multi #NeuralNetwork #Survey #MultitaskLearning #MultiModal Issue Date: 2025-03-03 GPT Summary- 深層リコメンダーシステム(DRS)は、個々の嗜好に基づいてオンラインコンテンツをカスタマイズするが、従来の手法は単一のタスクやデータに依存し、ユーザーの多様な嗜好を反映できない。このため、複数のタスクやシナリオ、モダリティを統合する共同モデリング手法の必要性が増している。本論文では、マルチタスク、マルチシナリオ、マルチモーダル、マルチビヘイビアモデリングを通じて共同モデリングを総括し、最新の進展と研究動向を特定・要約し、将来の探求の道を示す。 Comment
元ポスト:
[Paper Note] 360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation, Hamed Firooz+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#LanguageModel #Personalization #FoundationModel Issue Date: 2025-01-29 GPT Summary- ランキングおよび推奨システムを改善するために、大規模基盤モデルを用いてテキストインターフェースを導入。これにより、複数の予測タスクを同時に扱えるほか、新しい領域への一般化も可能に。360Brew V1.0は150Bパラメータの単一デコーダーモデルで、LinkedInのデータを使用し、30以上の予測タスクにおいて従来の専用モデルと同等以上の性能を示す。 Comment
元ポスト:
[Paper Note] Pre-train and Fine-tune: Recommenders as Large Models, Zhenhao Jiang+, WWW'25, 2025.01
Paper/Blog Link My Issue
#LanguageModel #WWW Issue Date: 2025-01-28 GPT Summary- ユーザーの興味は時期や地域によって変動するが、既存の推奨システムはこれに対応しきれない。マルチドメイン学習が解決策として考えられるが、産業用システムはデータ量やコストの面で複雑である。そこで推奨システムを大規模な事前学習モデルと捉え、ファインチューニングの手法を提案。情報認識型適応カーネル(IAK)を用いて知識圧縮と知識マッチングの二段階のプロセスを定義し、高い解釈性を持つ手法を設計。広範な実験により効果を確認し、オンラインプラットフォームでの展開によるビジネスへの貢献も報告。ファインチューニングに関連する問題点と対策も提示。 Comment
元ポスト:
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap, Weizhi Zhang+, arXiv'25
Paper/Blog Link My Issue
#Survey #LanguageModel #Contents-based Issue Date: 2025-01-06 GPT Summary- コールドスタート問題はレコメンダーシステムの重要な課題であり、新しいユーザーやアイテムのモデル化に焦点を当てている。大規模言語モデル(LLMs)の成功により、CSRに新たな可能性が生まれているが、包括的なレビューが不足している。本論文では、CSRのロードマップや関連文献をレビューし、LLMsが情報を活用する方法を探求することで、研究と産業界に新たな洞察を提供することを目指す。関連リソースはコミュニティのために収集・更新されている。 Comment
元ポスト:
[Paper Note] Preference Discerning with LLM-Enhanced Generative Retrieval, Fabian Paischer+, TMLR'25, 2024.12
Paper/Blog Link My Issue
#Dataset #LanguageModel #SessionBased #Personalization #Evaluation #TMLR Issue Date: 2024-12-31 GPT Summary- 逐次推薦システムのパーソナライズを向上させるために、「好みの識別」という新しいパラダイムを提案。大規模言語モデルを用いてユーザーの好みを生成し、包括的な評価ベンチマークを導入。新手法Menderは、既存手法を改善し、最先端の性能を達成。Menderは未観察の人間の好みにも効果的に対応し、よりパーソナライズされた推薦を実現する。コードとベンチマークはオープンソース化予定。 Comment
openreview: https://openreview.net/forum?id=74mrOdhvvT
[Paper Note] MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs, Sheng-Chieh Lin+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #RepresentationLearning #MultiModal #ICLR #read-later #VisionLanguageModel Issue Date: 2024-11-08 GPT Summary- 本研究は、マルチモーダル大規模言語モデル(MLLM)を用いた普遍的マルチモーダル検索を提案し、複数のモダリティを受け入れる広範な検索シナリオを追求します。16の検索タスクに対する微調整実験から、MLLMがテキストと画像を含む複雑なクエリを理解できる一方、モダリティ偏りによりクロスモーダル検索では性能が劣ることを確認しました。この課題に対処するため、モダリティ意識のハードネガティブ・マイニングや継続的ファインチューニングを提案し、最終的にMM-Embedモデルはマルチモーダル検索ベンチマークM-BEIRで最先端の性能を達成しました。さらに、プロンプトを用いたゼロショットのリランキングがMLLMのマルチモーダル検索の向上に寄与することを示し、今後の普遍的マルチモーダル検索の発展に期待が持たれます。 Comment
openreview: https://openreview.net/forum?id=i45NQb2iKO
[Paper Note] Cold-start Recommendation by Personalized Embedding Region Elicitation, Hieu Trung Nguyen+, UAI'24
Paper/Blog Link My Issue
#UAI #read-later #ColdStart Issue Date: 2025-05-16 GPT Summary- レコメンダーシステムのコールドスタート問題に対処するため、2段階のパーソナライズされた引き出しスキームを提案。最初に人気アイテムの評価を求め、その後、順次適応的にアイテム評価を行う。ユーザーの埋め込み値を領域推定として表現し、評価情報の価値を定量化。提案手法は既存の方法と比較して有効性を示す。 Comment
OpenReview: https://openreview.net/forum?id=ciOkU5YpvU
[Paper Note] Revisiting BPR: A Replicability Study of a Common Recommender System Baseline, Aleksandr Milogradskii+, RecSys'24
Paper/Blog Link My Issue
#Analysis #CollaborativeFiltering #Library #Evaluation #RecSys #Initial Impression Notes Issue Date: 2025-04-10 GPT Summary- BPRは協調フィルタリングのベンチマークだが、実装の微妙な点が見落とされ、他手法に劣るとされている。本研究ではBPRの特徴と実装の不一致を分析し、最大50%の性能低下を示す。適切なハイパーパラメータ調整により、BPRはトップn推薦タスクで最先端手法に近い性能を達成し、Million Song DatasetではMult-VAEを10%上回る結果を示した。 Comment
BPR、実装によってまるで性能が違う…
実装の違い
[Paper Note] ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation, Jianghao Lin+, WWW'24
Paper/Blog Link My Issue
#NLP #UserModeling #LanguageModel #CTRPrediction #RAG(RetrievalAugmentedGeneration) #LongSequence #WWW #KeyPoint Notes Issue Date: 2025-03-27 GPT Summary- 本論文では、ゼロショットおよび少ショットの推薦タスクにおいて、大規模言語モデル(LLMs)を強化する新しいフレームワーク「ReLLa」を提案。LLMsが長いユーザー行動シーケンスから情報を抽出できない問題に対処し、セマンティックユーザー行動検索(SUBR)を用いてデータ品質を向上させる。少ショット設定では、検索強化指示チューニング(ReiT)を設計し、混合トレーニングデータセットを使用。実験により、少ショットReLLaが従来のCTRモデルを上回る性能を示した。 Comment
LLMでCTR予測する際の性能を向上した研究。
そもそもLLMでCTR予測をする際は、ユーザのデモグラ情報とアクティビティログなどのユーザプロファイルと、ターゲットアイテムの情報でpromptingし、yes/noを出力させる。yes/noトークンのスコアに対して2次元のソフトマックスを適用して[0, 1]のスコアを得ることで、CTR予測をする(式1, 2)。
この研究ではコンテキストにユーザのログを入れても性能がスケールしない問題に対処するために (Figure 1)
直近のアクティビティログではなく、ターゲットアイテムと意味的に類似したアイテムに関するログをコンテキストに入れ(SUBR)、zero shotのinferenceに活用する (Figure 3)。
few-shot recommendation(少量のクリックスルーログを用いてLLMをSFTすることでCTR予測する手法)においては、上述の意味的に類似したアイテムをdata augmentationに利用し(i.e, promptに埋め込むアクティビティログの量を増やして)学習する (Figure 5)。
zeroshotにおいて、SUBRで性能改善。fewshot recommendationにといて、10%未満のデータで既存の全データを用いる手法を上回る。また、下のグラフを見るとpromptに利用するアクティビティログの量が増えるほど性能が向上するようになった。
ただし、latencyは100倍以上なのでユースケースが限定される。
Unifying Generative and Dense Retrieval for Sequential Recommendation, Liu Yang+, arXiv'24
Paper/Blog Link My Issue
#LanguageModel #SessionBased Issue Date: 2024-12-31 GPT Summary- 逐次密な検索モデルはユーザーとアイテムの内積計算を行うが、アイテム数の増加に伴いメモリ要件が増大する。一方、生成的検索はセマンティックIDを用いてアイテムインデックスを予測する新しいアプローチである。これら二つの手法の比較が不足しているため、LIGERというハイブリッドモデルを提案し、生成的検索と逐次密な検索の強みを統合。これにより、コールドスタートアイテム推薦を強化し、推薦システムの効率性と効果を向上させることを示した。
[Paper Note] Collaborative Contrastive Network for Click-Through Rate Prediction, Chen Gao+, arXiv'24
Paper/Blog Link My Issue
#NeuralNetwork #CTRPrediction #ContrastiveLearning #Surface-level Notes Issue Date: 2024-11-19 GPT Summary- EコマースプラットフォームにおけるCTR予測の課題を解決するために、「コラボレーティブコントラストネットワーク(CCN)」を提案。CCNは、ユーザーの興味と不興を示すアイテムクラスターを特定し、トリガーアイテムへの依存を減少させる。オンラインA/Bテストにより、タオバオでCTRを12.3%、注文量を12.7%向上させる成果を達成。 Comment
参考: [Mini-appの定義生成結果(Hallucinationに注意)](
https://www.perplexity.ai/search/what-is-the-definition-of-the-sW4uZPZIQe6Iq53HbwuG7Q)
論文中の図解: Mini-appにトリガーとなるアイテムを提示するTrigger-Induced-Recommendation(TIR)
## 概要
図3に示されているような Collaborative Contrastive Network (CCN)を提案しており、このネットワークは、Collaborative Constrastive Learningに基づいて学習される。
### Collaborative Constrasitve Learning
図2がCollaborative Constrastive Learningの気持ちを表しており、図2のようなクリックスルーログが与えられたとする。
推薦リストを上から見ていき、いま着目しているアイテムをtarget_itemとすると、target_itemがクリックされている場合、同じcontext(i.e., ユーザにページ内で提示されたアイテム群)のクリックされているアイテムと距離が近くなり、逆にクリックされていないアイテム群とは距離が遠いとみなせる。逆にtarget_itemがクリックされていない場合、同様にクリックされていないアイテムとは距離が近く、クリックされているアイテムとは距離が遠いとみなせる。このように考えると、ある推薦リストが与えられた時に、あるtarget_itemに着目すると、contrastive learningのためのpositive example/negative exampleを生成できる。このようなco-click/co-non-clickの関係から、アイテム同士の距離を学習し、ユーザのinterest/disinterestを学習する。
### Collaborative Contrastive Network
Collaborative ModuleとCTR Moduleに分かれている。
- Collaborative Moduleには、context itemsと、target itemをinputとし両者の関係性をエンコードする
- このとき、トリガーアイテムのembeddingとアダマール積をとることで、トリガーアイテムの情報も考慮させる
- CTR Moduleは、context itemsとtarget itemの関係性をエンコードしたembedding、target_item, trigger_itemのembedding, user profileのembedding, userのlong-termとshort-termの行動のembeddingをconcatしたベクトルをinputとして受け取り、そらからtarget_itemのCTRを予測する。
- Loss Functionは、binary cross entropyと、Collaborative Contrastive Lossをλで重みづけして足し合わせたものであり、Collaborative Contrastive Loss L_CMCは、上述の気持ちを反映するloss(i.e., target_itemとcontext_itemco-click/co-non-clickに基づいて、アイテム間の距離を最小/最大化するようなloss)となっている
## 実験結果
### offline evaluation
Table 1に示したTaobaoで収集した非常に大規模なproprietary datasetでCTRを予測したところ、AUCはベースラインと比較して高くなった。ここで、TANはCCNのBackboneモデルで、Contrastive Learningを実施していないモデルである。CTR予測においてAUCが高くなるというのはすなわち、クリックされたアイテムi/クリックされなかったアイテムjの2つをとってきたときに、両者のCTR予測結果が CTR_i > CTR_j になる割合が高くなった(i.e. クリックされているアイテムの方が高いCTR予測結果となっている)ということを意味する。
### online A/B Testing
A/Bテストまで実施しており、実際に提案手法を組み込んだ結果、高いCTRを獲得しているだけでなく、CVRも向上している。すごい。
Contrastive Learningを実施しないTANと、CCNを比較してもCCNの方が高いCTR, CVRを獲得している。Contrastive Learning有能。
[Paper Note] Beyond Utility: Evaluating LLM as Recommender, Chumeng Jiang+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#LanguageModel #Evaluation #WWW Issue Date: 2024-11-05 GPT Summary- LLMを推奨システムとして利用する研究が増加しているが、有用性を超える評価は未開拓である。本研究では、履歴長さの感度や候補位置のバイアス、生成過程、幻覚といった4つの新評価次元を提案し、多次元評価フレームワークを構築。7つのLLMベースの推奨モデルを評価し、従来モデルとの比較を実施。結果、LLMsは短い履歴でのランキングやリランキング設定で優れた性能を発揮するも、候補位置のバイアスや幻覚の問題が顕著であることを確認。評価フレームワークはLLMの推奨システム研究の進展に寄与することを目指す。 Comment
実装: https://github.com/JiangDeccc/EvaLLMasRecommender
openreview: https://openreview.net/forum?id=YiIdHqqoCd
COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon , Yu+, SIGMOD_PODS '24
Paper/Blog Link My Issue
#LanguageModel #KnowledgeGraph #InstructionTuning #Annotation #One-Line Notes #needs-revision Issue Date: 2024-10-08 Comment
search navigationに導入しA/Bテストした結果、0.7%のproduct sales向上効果。
beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems, Vojtěch Vančura+, N_A, RecSys'24
Paper/Blog Link My Issue
#Transformer #TransferLearning #Initial Impression Notes Issue Date: 2024-09-25 GPT Summary- レコメンダーシステムにおいて、コールドスタートやゼロショットシナリオでの予測改善のために、インタラクションデータを活用した文のトランスフォーマーモデル「beeFormer」を提案。beeFormerは、意味的類似性の予測において従来の手法を上回り、異なるドメインのデータセット間で知識を転送可能であることを示した。これにより、ドメインに依存しないテキスト表現のマイニングが可能になる。 Comment
NLPでは言語という共通の体系があるから事前学習とかが成立するけど、RecSysのようなユーザとシステムのinteraction dataを用いたシステムでは(大抵の場合はデータセットごとにユニークなユーザIDとアイテムIDのログでデータが構成されるので)なかなかそういうことは難しいよね、と思っていた。が、もしRecSysのタスク設定で、データセット間の転移学習を実現できるのだとしたらどのように実現してきるのだろうか?興味深い。後で読む。
Enhancing Performance and Scalability of Large-Scale Recommendation Systems with Jagged Flash Attention, Rengan Xu+, N_A, arXiv'24
Paper/Blog Link My Issue
#EfficiencyImprovement Issue Date: 2024-09-25 GPT Summary- ハードウェアアクセラレーターの統合により、推薦システムの能力が向上する一方で、GPU計算コストが課題となっている。本研究では、カテゴリ特徴の長さによるGPU利用の複雑さに対処するため、「Jagged Feature Interaction Kernels」を提案し、動的サイズのテンソルを効率的に扱う手法を開発。さらに、JaggedテンソルをFlash Attentionと統合し、最大9倍のスピードアップと22倍のメモリ削減を実現。実際のモデルでは、10%のQPS改善と18%のメモリ節約を確認し、複雑な推薦システムのスケーリングを可能にした。
[Paper Note] Recommendation with Generative Models, Yashar Deldjoo+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#Tutorial #LanguageModel #GenerativeAI #DiffusionModel #One-Line Notes Issue Date: 2024-09-24 GPT Summary- 生成モデルは、統計分布から新しいデータを生成するAIモデルで、GAN、VAE、トランスフォーマー型アーキテクチャが注目を集めている。これらは画像生成、テキスト生成、音楽作曲などの応用があり、レコメンドシステム(Gen-RecSys)でも活用され、推奨精度と多様性を向上させる。また、深層生成モデル(DGMs)をID駆動型モデル、大規模言語モデル、マルチモーダルモデルの3タイプに分類し、それぞれの進展に関連付ける。最後に、生成モデルの影響やリスクを考察し、評価フレームワークの重要性を強調する。 Comment
生成モデルやGenerativeAIによるRecSysの教科書
Leveraging User-Generated Reviews for Recommender Systems with Dynamic Headers, Shanu Vashishtha+, N_A, PAIS'24
Paper/Blog Link My Issue
#PersonalizedGeneration #Personalization #One-Line Notes Issue Date: 2024-09-14 GPT Summary- Eコマースプラットフォームの推薦カルーセルのヘッダー生成をカスタマイズする新手法「Dynamic Text Snippets(DTS)」を提案。ユーザーのレビューから特定の属性を抽出し、グラフニューラルネットワークを用いて複数のヘッダーテキストを生成。これにより、コンテキストに配慮した推薦システムの可能性を示す。 Comment
e-commerceでDynamicにitemsetに対するスニペット(見出し)を生成する研究。Attributeに基づいてスニペットを生成する。
斜め読みだが、Anchor ItemがGivenであり、kNNされたアイテム集合から抽出されたに基づいて生成するので、Anchor Itemをユーザが与えるのであれば一時的個人化によるpersonalizationとみなせる。Anchor Itemをユーザの履歴からシステムが複数件選び集約して推薦するみたいなパラダイムになれば、永続的個人化とも言えそう。が、後者の場合共通のAttributeが見出せるか不明。
Large Language Models for Generative Recommendation: A Survey and Visionary Discussions, Lei Li+, N_A, LREC-COLING'24
Paper/Blog Link My Issue
#Survey #GenerativeRecommendation #KeyPoint Notes Issue Date: 2024-08-06 GPT Summary- LLMを使用した生成的な推薦に焦点を当て、従来の複数段階の推薦プロセスを1つの段階に簡素化する方法を調査。具体的には、生成的推薦の定義、RSの進化、LLMベースの生成的推薦の実装方法について検討。この調査は、LLMベースの生成的推薦に関する進捗状況と将来の方向について提供できる文脈とガイダンスを提供することを目指している。 Comment
Generative Recommendationの定義がわかりやすい:
> Definition 2 (Generative Recommendation) A generative recommender system directly generates recommendations or recommendation-related content without the need to calculate each candidate’s ranking score one by one.
既存の企業におけるRecommenderSystemsは、典型的には非常に膨大なアイテムバンクを扱わなければならず、全てのアイテムに対してスコアリングをしランキングをすることは計算コストが膨大すぎて困難である。このため、まずは軽量なモデル(e.g. logistic regression)やシンプルな手法(e.g. feature matching)などで、明らかに推薦候補ではないアイテムを取り除いてから、少量のcandidate itemsに対して洗練されたモデルを用いてランキングを生成して推薦するというマルチステージのパイプラインを組んでおり、アカデミック側での研究にここでギャップが生じている。
一方で、Generative Recommendationでは、推薦するアイテムのIDを直接生成するため、
- 実質ほぼ無限のアイテムバンクを運用でき
- 推論の過程でimplicitに全てのアイテムに対して考慮をしたうえで
推薦を生成することができる手法である。また、推薦するアイテムを生成するだけでなく、推薦理由を生成したりなど、テキストを用いた様々なdown stream applicationにも活用できる。
A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys), Yashar Deldjoo+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #GenerativeAI Issue Date: 2024-04-02 GPT Summary- 従来のレコメンドシステムは、ユーザー-アイテムの評価履歴を主要なデータソースとして使用してきたが、最近では生成モデルを活用して、テキストや画像など豊富なデータを含めた新しい推薦タスクに取り組んでいる。この研究では、生成モデル(Gen-RecSys)を用いたレコメンドシステムの進歩に焦点を当て、相互作用駆動型生成モデルや大規模言語モデル(LLM)を用いた生成型推薦、画像や動画コンテンツの処理と生成のためのマルチモーダルモデルなどについて調査している。未解決の課題や必要なパラダイムについても議論している。
[Paper Note] Recommender Systems with Generative Retrieval, Shashank Rajput+, NeurIPS'23
Paper/Blog Link My Issue
#Transformer #VariationalAutoEncoder #NeurIPS #read-later #Selected Papers/Blogs #ColdStart #Encoder-Decoder #SemanticID Issue Date: 2025-07-28 GPT Summary- 新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを用いて次のアイテムを予測するTransformerベースのモデルを訓練。これにより、従来のレコメンダーシステムを大幅に上回る性能を達成し、過去の対話履歴がないアイテムに対しても改善された検索性能を示す。 Comment
openreview: https://openreview.net/forum?id=BJ0fQUU32w
Semantic IDを提案した研究
アイテムを意味的な情報を保持したdiscrete tokenのタプル(=Semantic ID)で表現し、encoder-decoderでNext ItemのSemantic IDを生成するタスクに落としこむことで推薦する。SemanticIDの作成方法は後で読んで理解したい。
[Paper Note] TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys'23
Paper/Blog Link My Issue
#LanguageModel #Contents-based #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Zero/FewShotLearning #RecSys #KeyPoint Notes Issue Date: 2025-03-30 GPT Summary- 大規模言語モデル(LLMs)を推薦システムに活用するため、推薦データで調整するフレームワークTALLRecを提案。限られたデータセットでもLLMsの推薦能力を向上させ、効率的に実行可能。ファインチューニングされたLLMはクロスドメイン一般化を示す。 Comment
下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初めての研究だと思われる。
既存ベースラインと比較して大幅にAUCが向上
Recommender Systems with Generative Retrieval, Shashank Rajput+, arXiv'23
Paper/Blog Link My Issue
#Survey #InformationRetrieval #LanguageModel #SequentialRecommendation Issue Date: 2024-12-30 GPT Summary- 新しい生成的検索アプローチを提案し、アイテムのセマンティックIDを自己回帰的にデコード。Transformerベースのモデルが次のアイテムのセマンティックIDを予測し、レコメンデーションタスクにおいて初のセマンティックIDベースの生成モデルとなる。提案手法は最先端モデルを大幅に上回り、過去の対話履歴がないアイテムに対する検索性能も向上。
[Paper Note] Recommender Systems in the Era of Large Language Models (LLMs), Zihuai Zhao+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#LanguageModel #read-later #Selected Papers/Blogs #Surface-level Notes Issue Date: 2024-12-03 GPT Summary- LLMsの出現により、レコメンダーシステムが進化し、ユーザーの嗜好に基づくパーソナライズが可能に。従来のDNN法の限界を克服するため、LLMsを活用したレコメンドシステムの概要を提供。具体的には、事前学習、ファインチューニング、プロンプティングの観点から最近の手法をレビューし、この分野の今後の発展方向を論じる。 Comment
中身を全然読んでいる時間はないので、図には重要な情報が詰まっていると信じ、図を読み解いていく。時間がある時に中身も読みたい。。。
LLM-basedなRecSysでは、NLPにおけるLLMの使い方(元々はT5で提案)と同様に、様々なレコメンド関係タスクを、テキスト生成タスクに落とし込み学習することができる。
RecSysのLiteratureとしては、最初はコンテンツベースと協調フィルタリングから始まり、(グラフベースドな推薦, Matrix Factorization, Factorization Machinesなどが間にあって)、その後MLP, RNN, CNN, AutoEncoderなどの様々なDeep Neural Network(DNN)を活用した手法や、BERT4RecなどのProbabilistic Language Models(PLM)を用いた手法にシフトしていき、現在LLM-basedなRecSysの時代に到達した、との流れである。
LLM-basedな手法では、pretrainingの段階からEncoder-basedなモデルの場合はMLM、Decoder-basedな手法ではNext Token Predictionによってデータセットで事前学習する方法もあれば、フルパラメータチューニングやPEFT(LoRAなど)によるSFTによるアプローチもあるようである。
推薦タスクは、推薦するアイテムIDを生成するようなタスクの場合は、異なるアイテムID空間に基づくデータセットの間では転移ができないので、SFTをしないとなかなかうまくいかないと気がしている。また、その場合はアイテムIDの推薦以外のタスクも同時に実施したい場合は、事前学習済みのパラメータが固定されるPEFT手法の方が安全策になるかなぁ、という気がしている(破壊的忘却が怖いので)。特はたとえば、アイテムIDを生成するだけでなく、その推薦理由を生成できるのはとても良いことだなあと感じる(良い時代、感)。
また、PromptingによるRecSysの流れも図解されているが、In-Context Learningのほかに、Prompt Tuning(softとhardの両方)、Instruction Tuningも同じ図に含まれている。個人的にはPrompt TuningはPEFTの一種であり、Instruction TuningはSFTの一種なので、一つ上の図に含意される話なのでは?という気がするが、論文中ではどのような立て付けで記述されているのだろうか。
どちらかというと、Promptingの話であれば、zero-few-many shotや、各種CoTの話を含めるのが自然な気がするのだが。
下図はPromptingによる手法を表にまとめたもの。Finetuningベースの手法が別表にまとめられていたが、研究の数としてはこちらの方が多そうに見える。が、性能的にはどの程度が達成されるのだろうか。直感的には、アイテムを推薦するようなタスクでは、Promptingでは性能が出にくいような印象がある。なぜなら、事前学習済みのLLMはアイテムIDのトークン列とアイテムの特徴に関する知識がないので。これをFinetuningしないのであればICLで賄うことになると思うのだが、果たしてどこまでできるだろうか…。興味がある。
(図は論文より引用)
Leveraging Large Language Models in Conversational Recommender Systems, Luke Friedman+, N_A, arXiv'23
Paper/Blog Link My Issue
#LanguageModel #ConversationalRecommenderSystems Issue Date: 2024-08-07 GPT Summary- LLMsを使用した大規模な会話型推薦システム(CRS)の構築に関する論文の要約です。LLMsを活用したユーザーの好み理解、柔軟なダイアログ管理、説明可能な推薦の新しい実装を提案し、LLMsによって駆動される統合アーキテクチャの一部として説明します。また、LLMが解釈可能な自然言語のユーザープロファイルを利用してセッションレベルのコンテキストを調整する方法についても説明します。さらに、LLMベースのユーザーシミュレータを構築して合成会話を生成する技術を提案し、LaMDAをベースにしたYouTubeビデオの大規模CRSであるRecLLMを紹介します。
[Paper Note] Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems, Huan Gui+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Transformer #One-Line Notes Issue Date: 2023-11-13 GPT Summary- 特徴量の相互作用を学習するのはリコメンダーシステムにおいて重要だが、疎で大規模な入力特徴空間のため困難である。そこで、Transformerベースのアーキテクチャを用いて特徴相互作用を自動で捉える手法を提案。従来のTransformerでは自己注意層が異質な特徴相互作用を捉えられず、提供遅延が問題となるため、異質な自己注意層を修正し、Hiformerを導入。これにより高速推論が実現し、Google Playの実世界のアプリでエンゲージメントが最大+2.66%改善された。 Comment
推薦システムは、Factorization Machinesあたりから大抵の場合特徴量間の交互作用を頑張って捉えることで精度向上を目指す、という話をしてきている気がするが、これはTransformerを使って交互作用捉えられるようなモデルを考えました、という研究のようである。
self attention部分に工夫がなされており(提案手法は右端)、task tokenとそれぞれのfeatureをconcatしてQKVを求めることで、明示的に交互作用が生まれるような構造にしている。
Online A/Bテストでも評価しており、HiformerによってSoTAな交互作用モデル(DCN)よりも高いユーザエンゲージメントを実現することが示されている。
[Paper Note] LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation, Kai Mei+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#LanguageModel #One-Line Notes Issue Date: 2023-11-10 GPT Summary- LightLMは、生成的推薦のために特化した軽量なTransformerベースの言語モデルである。従来の重いモデルに代わり、短いトークンを主成分とする浅い構造を採用し、推奨アイテムの直接生成に効果的である。ユーザーIDおよびアイテムIDに対する新たなインデックス化手法(SCIとGCI)を提案し、推薦タスクにおいて大規模言語モデルに勝る性能を示す。さらに、ハルシネーションを抑えるための制約付き生成プロセスを導入し、実データセットで競合するベースラインを上回る精度と効率を実現した。 Comment
Generative Recommendationはあまり終えていないのだが、既存のGenerative Recommendationのモデルをより軽量にし、性能を向上させ、存在しないアイテムを生成するのを防止するような手法を提案しました、という話っぽい。
Bayesian Personalized Ranking [Paper Note] BPR: Bayesian Personalized Ranking from Implicit Feedback, Steffen Rendle+, UAI'09, 2009.06
ベースドなMatrix Factorizationよりは高い性能が出てるっぽい。
[Paper Note] LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#LanguageModel #Prompting #NAACL #Findings #One-Line Notes Issue Date: 2023-08-02 GPT Summary- テキストベースのレコメンデーションは汎用性が高いが、元のアイテム説明だけではユーザー嗜好との整合性が不足することがある。大規模言語モデル(LLMs)の進歩を活かし、4つのテキスト強化プロンプト戦略を取り入れたアプローチ、LLM-Recを提案。実験により、LLM拡張テキストの使用が推奨品質を向上させることが確かめられ、基本的なMLPモデルでも高い成果を上げることが示された。成功の要因はプロンプト戦略であり、多様な技術がLLMsの推奨効果を高める重要性を示している。 Comment
LLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。
User Simulator Assisted Open-ended Conversational Recommendation System, NLP4ConvAI'23
Paper/Blog Link My Issue
Issue Date: 2023-07-18
Explainable Recommendation with Personalized Review Retrieval and Aspect Learning, ACL'23
Paper/Blog Link My Issue
#Explanation #Personalization #review #ACL Issue Date: 2023-07-18 GPT Summary- 説明可能な推薦において、テキスト生成の精度向上とユーザーの好みの捉え方の改善を目指し、ERRAモデルを提案。ERRAは追加情報の検索とアスペクト学習を組み合わせることで、より正確で情報量の多い説明を生成することができる。さらに、ユーザーの関心の高いアスペクトを選択することで、関連性の高い詳細なユーザー表現をモデル化し、説明をより説得力のあるものにする。実験結果は、ERRAモデルが最先端のベースラインを上回ることを示している。
[Paper Note] DataFinder: Scientific Dataset Recommendation from Natural Language Descriptions, Vijay Viswanathan+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Dataset #NaturalLanguageUnderstanding #ACL Issue Date: 2023-07-18 GPT Summary- 短い自然言語の研究アイデアに基づいて、関連データセットを推奨するタスクを実運用化。データセット推奨は情報検索の問題として独自の課題を持つが、DataFinderデータセットを構築し、17,500件のクエリからなる自動学習データと392件の専門家注釈付き評価データを用いて検証。テスト結果からは、データセット推奨において高い関連性を示すバイエンコーダー・リトリーバが確認された。データセットとモデルは公開し、さらなる進展を促進。
UniTRec: A Unified Text-to-Text Transformer and Joint Contrastive Learning Framework for Text-based Recommendation, ACL'23
Paper/Blog Link My Issue
#NLP #Contents-based #Transformer #pretrained-LM #ContrastiveLearning #ACL Issue Date: 2023-07-18 GPT Summary- 本研究では、事前学習済み言語モデル(PLM)を使用して、テキストベースの推薦の性能を向上させるための新しいフレームワークであるUniTRecを提案します。UniTRecは、ユーザーの履歴の文脈をより良くモデル化するために統一されたローカル-グローバルアテンションTransformerエンコーダを使用し、候補のテキストアイテムの言語の複雑さを推定するためにTransformerデコーダを活用します。幅広い評価により、UniTRecがテキストベースの推薦タスクで最先端のパフォーマンスを発揮することが示されました。
TREA: Tree-Structure Reasoning Schema for Conversational Recommendation, ACL'23
Paper/Blog Link My Issue
#NLP #Conversation #ACL Issue Date: 2023-07-15 GPT Summary- 会話型の推薦システム(CRS)では、外部知識を活用して対話の文脈を理解し、関連するアイテムを推薦することが求められている。しかし、現在の推論モデルは複雑な関係を完全に把握できないため、新しいツリー構造の推論スキーマであるTREAを提案する。TREAは多階層のツリーを使用して因果関係を明確にし、過去の対話を活用してより合理的な応答を生成する。幅広い実験により、TREAの有効性が示された。
[Paper Note] Graph Collaborative Signals Denoising and Augmentation for Recommendation, Ziwei Fan+, SIGIR'23, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #GraphBased #SIGIR #KeyPoint Notes #Short Issue Date: 2023-04-26 GPT Summary- 新たなグラフ隣接行列を提案し、ユーザーとアイテムの相互作用を最適化。ユーザー間・アイテム間の相関を組み込み、相互作用のバランスを取ることで、従来の方法よりも顕著な推薦効果を実現。これにより、豊富な相互作用を持つユーザーと乏しいユーザー双方への推薦が改善された。 Comment
グラフ協調フィルタリングを改善する手法を提案している。既存のグラフ協調フィルタリングはユーザ-アイテム間の隣接行列に基づく二部グラフによって学習されるが、これにはいくつか課題がある:
- ノイズが多く、スパースで、バイアスを含み、long tailな性質(ほとんどのユーザがアイテムとほとんどinterctionしていない)を持つがこれらに対処できていない
- また、interactionの情報がリッチなアクティブユーザはinteractionに多くのノイズ情報を含むが、うまくモデル化されていない
- グラフ協調フィルタリングのmessage passinpによって、user間、item間の情報が事前に学習されるが、message passingの回数が増えるとノイズが多くなる
これらに対処するために、学習を2つのプロセスに分ける方法を提案している。具体的には、GCNを用いて、まず通常通り隣接行列に基づいてuser, itemノードのembeddingを事前学習する。続いて、隣接行列に対して下記2種類の拡張を行う。
- user-item interaction: 事前学習したembeddingを用いて、user-item間のTopKのneighborを見つけ、TopKのみにフィルタリングして隣接行列を再構築する(アクティブユーザーはノイズ除去、インアクティブユーザはインタラクション情報の拡張につながる)
- user-user / item-item interaction: 同じく事前学習したembeddingを用いて、それぞれのneighborsを見つけてuser-user, item-item interactionの要素が非ゼロとなるように拡張する(message passingによるノイズを低減しつつ、ユーザ間、アイテム間の情報を取り入れる)
元ポスト:
[Paper Note] Revisiting the Performance of iALS on Item Recommendation Benchmarks, Steffen Rendle+, RecSys'22
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #Evaluation #RecSys Issue Date: 2025-04-15 GPT Summary- iALSを再検討し、調整を行うことで、レコメンダーシステムにおいて競争力を持つことを示す。特に、4つのベンチマークで他の手法を上回る結果を得て、iALSのスケーラビリティと高品質な予測が再評価されることを期待。
[Paper Note] Deep Intention-Aware Network for Click-Through Rate Prediction, Yaxian Xia+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#NeuralNetwork #CTRPrediction #One-Line Notes Issue Date: 2024-11-19 GPT Summary- TIRAにおいて、顧客の入店意図を抽出し、トリガーの影響を重み付けするためにDIANを提案。DIANは、意図に基づきCTRを推定する3つのネットワーク(Intention Net、Trigger-Aware Net、Trigger-Free Net)を用い、推定結果をバランスさせることで精度を向上。実験により、実世界データセットでの性能が最先端を示し、TaobaoのミニアプリJuhuasuanのページビューを9.39%、CTRを4.74%改善。 Comment
- [Paper Note] Collaborative Contrastive Network for Click-Through Rate Prediction, Chen Gao+, arXiv'24
の実験で利用されているベースライン
Deep Interest Highlight Network for Click-Through Rate Prediction in Trigger-Induced Recommendation, Qijie Shen+, WWW'22
Paper/Blog Link My Issue
#NeuralNetwork #CTRPrediction #WWW #One-Line Notes Issue Date: 2024-11-19 GPT Summary- トリガー誘発推薦(TIR)を提案し、ユーザーの瞬時の興味を引き出す新しい推薦手法を紹介。従来のモデルがTIRシナリオで効果的でない問題を解決するため、Deep Interest Highlight Network(DIHN)を開発。DIHNは、ユーザー意図ネットワーク(UIN)、融合埋め込みモジュール(FEM)、ハイブリッド興味抽出モジュール(HIEM)の3つのコンポーネントから成り、実際のeコマースプラットフォームでの評価で優れた性能を示した。 Comment
- [Paper Note] Collaborative Contrastive Network for Click-Through Rate Prediction, Chen Gao+, arXiv'24
の実験で利用されているベースライン
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5), Shijie Geng+, N_A, RecSys'22
Paper/Blog Link My Issue
#LanguageModel #Zero/Few/ManyShotPrompting #InstructionTuning #Finetuning #KeyPoint Notes Issue Date: 2023-11-12 GPT Summary- 我々は「Pretrain, Personalized Prompt, and Predict Paradigm」(P5)と呼ばれる柔軟で統一されたテキストからテキストへのパラダイムを提案します。P5は、共有フレームワーク内でさまざまな推薦タスクを統一し、個別化と推薦のための深い意味を捉えることができます。P5は、異なるタスクを学習するための同じ言語モデリング目標を持つ事前学習を行います。P5は、浅いモデルから深いモデルへと進化し、広範な微調整の必要性を減らすことができます。P5の効果を実証するために、いくつかの推薦ベンチマークで実験を行いました。 Comment
# 概要
T5 のように、様々な推薦タスクを、「Prompt + Prediction」のpipelineとして定義して解けるようにした研究。
P5ではencoder-decoder frameworkを採用しており、encoder側ではbidirectionalなモデルでpromptのrepresentationを生成し、auto-regressiveな言語モデルで生成を行う。
推薦で利用したいデータセットから、input-target pairsを生成し上記アーキテクチャに対して事前学習することで、推薦を実現できる。
RatingPredictionでは、MatrixFactorizationに勝てていない(が、Rating Predictionについては魔法の壁問題などもあると思うのでなんともいえない。)
Sequential RecommendationではBERT4Recとかにも勝てている模様。
# Prompt例
- Rating Predictionの例
- Sequential Recommendationの例
- Explanationを生成する例
- Zero-shotの例(Cold-Start)
[Paper Note] Personalized Chit-Chat Generation for Recommendation Using External Chat Corpora, Chen+, KDD'22
Paper/Blog Link My Issue
#NLP #PersonalizedGeneration #Personalization #SIGKDD Issue Date: 2023-08-11
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering, Yoonseok Yang+, NAACL'22
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #CollaborativeFiltering #EducationalDataMining #KnowledgeTracing #Contents-based #NAACL Issue Date: 2022-08-01 GPT Summary- コンテンツベースの協調フィルタリング(CCF)において、PLMを用いたエンドツーエンドのトレーニングはリソースを消費するため、GRAM(勾配蓄積手法)を提案。Single-step GRAMはアイテムエンコーディングの勾配を集約し、Multi-step GRAMは勾配更新の遅延を増加させてメモリを削減。これにより、Knowledge TracingとNews Recommendationのタスクでトレーニング効率を最大146倍改善。
[Paper Note] A Troubling Analysis of Reproducibility and Progress in Recommender Systems Research, Maurizio Ferrari Dacrema+, TOIS'21
Paper/Blog Link My Issue
#read-later #Reproducibility Issue Date: 2025-05-16 GPT Summary- パーソナライズされたランキングアイテムリスト生成のアルゴリズム設計はレコメンダーシステムの重要なテーマであり、深層学習技術が主流となっている。しかし、比較ベースラインの選択や最適化に問題があり、実際の進展を理解するために協調フィルタリングに基づくニューラルアプローチの再現を試みた結果、12の手法中11が単純な手法に劣ることが判明。計算的に複雑なニューラル手法は既存の技術を一貫して上回らず、研究実践の問題が分野の停滞を招いている。
[Paper Note] An Embedding Learning Framework for Numerical Features in CTR Prediction, Huifeng Guo+, KDD'21
Paper/Blog Link My Issue
#NeuralNetwork #Embeddings #CTRPrediction #RepresentationLearning #SIGKDD #numeric #KeyPoint Notes Issue Date: 2025-04-22 GPT Summary- CTR予測のための新しい埋め込み学習フレームワーク「AutoDis」を提案。数値特徴の埋め込みを強化し、高いモデル容量とエンドツーエンドのトレーニングを実現。メタ埋め込み、自動離散化、集約の3つのコアコンポーネントを用いて、数値特徴の相関を捉え、独自の埋め込みを学習。実験により、CTRとeCPMでそれぞれ2.1%および2.7%の改善を達成。コードは公開されている。 Comment
従来はdiscretizeをするか、mlpなどでembeddingを作成するだけだった数値のinputをうまく埋め込みに変換する手法を提案し性能改善
数値情報を別の空間に写像し自動的なdiscretizationを実施する機構と、各数値情報のフィールドごとのglobalな情報を保持するmeta-embeddingをtrainable parameterとして学習し、両者を交互作用(aggregation; max-poolingとか)することで数値embeddingを取得する。
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms, Zhao+, CIKM'21
Paper/Blog Link My Issue
#Tools #Library #CIKM #Reference Collection Issue Date: 2022-03-29 GPT Summary- RecBoleは、推薦アルゴリズムのオープンソース実装を標準化するための統一的で効率的なライブラリであり、73のモデルを28のベンチマークデータセット上で実装。PyTorchに基づき、一般的なデータ構造や評価プロトコル、自動パラメータ調整機能を提供し、推薦システムの実装と評価を促進する。プロジェクトはhttps://recbole.io/で公開。 Comment
参考リンク:
-
https://www.google.co.jp/amp/s/techblog.zozo.com/entry/deep-learning-recommendation-improvement%3famp=1
-
https://techlife.cookpad.com/entry/2021/11/04/090000
-
https://qiita.com/fufufukakaka/items/77878c1e23338345d4fa
コミュニティサービスにおけるレコメンデーションの変遷とMLパイプラインについて, Takanobu Nozawa, PyCon'21, 2021.10
Paper/Blog Link My Issue
#Tutorial #Infrastructure #python #Slide #KeyPoint Notes Issue Date: 2021-10-21 Comment
・ママ向けのQ&AサービスにおけるレコメンドとMLパイプラインについて紹介
◆レコメンドエンジンの変遷
・Tensorflowで実装したMFから始まり、その後トピックを絞り込んだ上で推薦するためにLDAを活用したレコメンド、最終的にSoftmax Recommendationを開発
* Softmax Recommendation:
https://developers.google.com/machine-learning/recommendation/dnn/softmax
* ユーザプロファイル(e.g. 行動ベクトル, ユーザの属性情報)等を入力とし、hidden layerをかませて最終的にアイテム次元数分のスコアベクトルを得る手法
* 行動ベクトル=ユーザが過去にクリックしたQ&Aだが、質問ベクトルを得るために内容テキストは利用せず行動ログ+word2vecで学習
* 類似質問検索による定性評価の結果良い結果、関連質問を抽出できるベクトルとなっていることを確認
→ レコメンド手法の変遷につれ、ベンチマークを上回るようになっていった
◆MLパイプラインについて
- AWS Step FunctionsとAmazon Sagemakerを利用
- AWS Step Functions
* AWS上の様々なサービスをワークフローとして定義できる(json形式でワークフローを記述)
- Amazon Sagemaker
* 機械学習向けのIDE
* notebook上でのデータ分析・モデル学習、実験管理や学習済みモデルのデプロイが可能
* Sagemaker Processingを用いることで、実行したい処理やインスタンスタイプを指定することで、notebookとは別の実行環境(コンテナ)で任意のpythonスクリプトを実行可
- ワークフローの定義=AWS Stepfunctions, スクリプト実行のリソース=Sagemaker Processingとして利用
MLパイプラインについては下記資料により詳しい情報が書かれている
https://speakerdeck.com/takapy/sagemaker-studiotostep-functionswoyong-itemlopshefalse-bu-wota-michu-sou
[Paper Note] Neural Collaborative Filtering vs. Matrix Factorization Revisited, Steffen Rendle+, RecSys'20
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #MatrixFactorization #RecSys #read-later #Selected Papers/Blogs #Reproducibility Issue Date: 2025-05-16 GPT Summary- 埋め込みベースのモデルにおける協調フィルタリングの研究では、MLPを用いた学習された類似度が提案されているが、適切なハイパーパラメータ選択によりシンプルなドット積が優れた性能を示すことが確認された。MLPは理論的には任意の関数を近似可能だが、実用的にはドット積の方が効率的でコストも低いため、MLPは慎重に使用すべきであり、ドット積がデフォルトの選択肢として推奨される。
[Paper Note] Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison, Sun+, RecSys'20
Paper/Blog Link My Issue
#Evaluation #RecSys #Reproducibility Issue Date: 2022-04-05 Comment
[Paper Note] On the Difficulty of Evaluating Baselines: A Study on Recommender Systems, Steffen Rendle+, arXiv'19, 2019.05
Paper/Blog Link My Issue
#read-later #Reproducibility Issue Date: 2025-05-14 GPT Summary- レコメンダーシステムの研究において、数値評価とベースラインの比較が重要であることを示す。Movielens 10Mベンチマークのベースライン結果が最適でないことを実証し、適切な行列因子分解の設定により改善できることを示した。また、Netflix Prizeにおける手法の結果を振り返り、経験的な発見は標準化されたベンチマークに基づかない限り疑わしいことを指摘した。
[Paper Note] Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, Maurizio Ferrari Dacrema+, RecSys'19, 2019.07
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #Evaluation #RecSys #Selected Papers/Blogs #Reproducibility #KeyPoint Notes #Reading Reflections Issue Date: 2022-04-11 GPT Summary- 深層学習技術はレコメンダーシステムの研究で広く用いられているが、再現性やベースライン選択に問題がある。18のトップnレコメンデーションアルゴリズムを分析した結果、再現できたのは7つのみで、6つは単純なヒューリスティック手法に劣っていた。残りの1つはベースラインを上回ったが、非ニューラル手法には及ばなかった。本研究は機械学習の実践における問題を指摘し、改善を呼びかけている。 Comment
RecSys'19のベストペーパー
日本語解説:
https://qiita.com/smochi/items/98dbd9429c15898c5dc7
TopN推薦におけるDNNを用いた研究を追試した研究で、トップ会議の手法のうち18本の追試を試みたところ、追試のための現実的な努力や著者に連絡をするといったことを実施した上で再現できたものは7本であり、そのうち6/7が適切なハイパーパラメータ調整を行なったkNNベースのシンプルな手法に勝てなかった(かつ残りの一つも線形モデルに対して負ける場合もあった)、という話で、業界における評価における再現性の問題(ハイパーパラメータ調整の記載がない等)や、適切な実験設定の欠如(ベースラインのハイパーパラメータチューニングをせずに先行研究の記述内容をそのまま踏襲等、テストデータを用いたエポック数の調整、ランダムサンプリングのはずなのに明らかに提案手法に有利となるような偏ったサンプリングを実施...)、ベースラインの適切な選定(多くの研究がNeural Collaboraive Filteringをベースラインにしているが果たしてそれが適切か)などについて警鐘を鳴らす内容になっている。
過去の先行研究([Paper Note] Sequence-Aware Recommender Systems, Massimo Quadrana+, ACM Computing Surveys (CSUR), Volume 51, Issue 4, 2018.02
)でも、研究者の間でデータセットの分割に関して、標準化されていない旨が記述されている。また、管理人が研究を追う中でも、共通のフレームワークで評価がされているとは言い難い印象を持っている(**このコメントは論文を読んだ当時を思い起こし2026年に追記しているが、この頃から業界はどのようにシフトしただろうか?最近は追えていない**)。
たとえば評価をする際には、データセットの選択だけでなく、データセットの中でどの規模感のデータセットを使うのか(MovieLens一つとっても様々なバリエーションがある)、leave-one-outをするのか、時系列性を考慮した履歴の分割をするのか、negative samplingをする際の件数やサンプリング方法、なんらかのstratifiedなk-fold cross validationをするのか否か、coldstartなデータを排除するのか否か、排除する際の足切りの基準、ハイパーパラメータ。最適化する際のメトリックと最適化をするパラメータ、平均を取る際の実験の試行回数、性能を測るメトリック(Precision, Recall, NDCG, MAP, MRR, AUC, HITS@N...)など様々な変数が存在し、これらの設定が異なると性能は確かに大きく変化すると思われる。実際に推薦モデルの検証をする際には適切な検証となるよう細心の注意を払いたい。
私個人としては本研究を知った以後、オフラインでの実験のみでなくらA/Bテストが実施されている研究に対する信頼性をより高めるようになった。
おそらくこれを受けてRecboleのようなフレームワークが登場したと思うが、現在は更新がされていないという認識である。いまはどのように再現性に関する取り組みがされているだろうか?
- Autonomously Generating Hints by Inferring Problem Solving Policies, Piech+, Stanford University, L@S'15
[Paper Note] Deep Learning Recommendation Model for Personalization and Recommendation Systems, Maxim Naumov+, arXiv'19, 2019.05
Paper/Blog Link My Issue
#CollaborativeFiltering #FactorizationMachines #One-Line Notes Issue Date: 2021-07-02 GPT Summary- 深層学習に基づく推薦モデル(DLRM)を開発し、PyTorchとCaffe2で実装。埋め込みテーブルのモデル並列性を活用し、メモリ制約を軽減しつつ計算をスケールアウト。DLRMの性能を既存モデルと比較し、Big Basin AIプラットフォームでの有用性を示す。 Comment
Facebookが開発したopen sourceのDeepな推薦モデル(MIT Licence)。
モデル自体はシンプルで、continuousなfeatureをMLPで線形変換、categoricalなfeatureはembeddingをlook upし、それぞれfeatureのrepresentationを獲得。
その上で、それらをFactorization Machines layer(second-order)にぶちこむ。すなわち、Feature間の2次の交互作用をembedding間のdot productで獲得し、これを1次項のrepresentationとconcatしMLPにぶちこむ。最後にシグモイド噛ませてCTRの予測値とする。
実装: https://github.com/facebookresearch/dlrm
Parallelism以後のセクションはあとで読む
[Paper Note] Conversion Prediction Using Multi-task Conditional Attention Networks to Support the Creation of Effective Ad Creatives, Kitada+, KDD'19
Paper/Blog Link My Issue
#NeuralNetwork #CTRPrediction #CVRPrediction #SIGKDD #Surface-level Notes Issue Date: 2021-06-01 Comment
# Overview
広告のCVR予測をCTR予測とのmulti-task learningとして定式化。
構築した予測モデルのattention distributionを解析することで、high-qualityなクリエイティブの作成を支援する。
genderやgenre等の情報でattentionのweightを変化させるconditional attentionが特徴的。
→ これによりgender, genreごとのCVRしやすい広告の特徴の違いが可視化される
loss functionは、MSEにλを導入しclickのlossを制御している(CVRに最適化したいため)。ただ、実験ではλ=1で実験している。
outputはRegressionでCVR, CTRの値そのものを予測している(log lossを使う一般的なCTR Prediction等とは少し条件が違う; 多分予測そのものより、予測モデルを通じて得られるCVRが高いcreativeの分析が主目的なため)。
# Experiments
データとして、2017年8月〜2018年8月の間にGunosy Adsでdeliverされた14,000種類のad creativeを利用。
clickとconversionのfrequency(clickはlong-tailだが、conversionはほとんど0か1のように見える)
5-fold crossvalidationを、fold内でcampaignが重複しないようにad creativeに対して行い、conversion数の予測を行なった。
評価を行う際はNDCGを用い、top-1%のconversion数を持つcreativeにフォーカスし評価した。
MSEで評価した場合、multi-task learning, conditional attentionを利用することでMSEが改善している。多くのcreativeのconversionは0なので、conversion数が>0のものに着目して評価しても性能が改善していることがわかる。
NDCGを利用した評価でも同様な傾向
conditional attentionのheatmap
genderごとにdistributionの違いがあって非常におもしろい
[Paper Note] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, Fei Sun+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#NeuralNetwork #LanguageModel #CIKM #SequentialRecommendation #One-Line Notes #Initial Impression Notes Issue Date: 2021-05-25 GPT Summary- ユーザーの動的嗜好をモデル化するために、BERT4RecというTransformerに基づく双方向エンコーダを導入。従来の順序型モデルの限界を克服し、Clozeタスクを用いて左側と右側の文脈を共同で条件付けしてアイテムを予測。さまざまなベンチマークデータセットにおいて、提案モデルが最先端の逐次モデルを一貫して上回る結果を示す。 Comment
BERTをrecsysのsequential recommendationタスクに転用してSoTA。
しっかり読んで無いけどモデル構造はほぼBERTと一緒。
異なる点は、Training時にNext Sentence Predictionは行わずClozeのみ行なっているという点。Clozeとは、実質Masked Language Modelであり、sequenceの一部を[mask]に置き換え、置き換えられたアイテムを左右のコンテキストから予測するタスク。異なる点としては、sequential recommendationタスクでは、次のアイテムを予測したいので、マスクするアイテムの中に、sequenceの最後のアイテムをマスクして予測する事例も混ぜた点。
もう一個異なる点として、BERT4Recはend-to-endなモデルで、BERTはpretraining modelだ、みたいなこと言ってるけど、まあ確かに形式的にはそういう違いはあるけど、なんかその違いを主張するのは違和感を覚える…。
sequential recommendationで使うuser behaviorデータでNext item predictionで学習したいことが、MLMと単に一致していただけ、なのでは…。
BERT4Recのモデル構造。next item predictionしたいsessionの末尾に [mask] をconcatし、[MASK]部分のアイテムを予測する構造っぽい?
オリジナルはtensorflow実装
pytorchの実装はこちら:
https://github.com/jaywonchung/BERT4Rec-VAE-Pytorch/tree/master/models
Explainable AI in Industry, KDD'19
Paper/Blog Link My Issue
#Tutorial #Explanation #Slide #SIGKDD Issue Date: 2019-08-19
[Paper Note] Review Response Generation in E-Commerce Platforms with External Product Information, Zhao+, WWW'19
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #WWW Issue Date: 2019-08-17
[Paper Note] Automatic Generation of Personalized Comment Based on User Profile, Wenhuan Zeng+, ACL'19 SRW
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #ACL #Workshop Issue Date: 2019-08-17 GPT Summary- ソーシャルメディアの多様なコメント生成の難しさを考慮し、ユーザープロフィールに基づくパーソナライズされたコメント生成タスク(AGPC)を提案。パーソナライズドコメント生成ネットワーク(PCGN)を用いて、ユーザーの特徴をモデル化し、外部ユーザー表現を考慮することで自然なコメントを生成。実験結果は、モデルの効果を示す。
[Paper Note] A Survey on Session-based Recommender Systems, Shoujin Wang+, arXiv'19
Paper/Blog Link My Issue
#Survey #SessionBased #SequentialRecommendation Issue Date: 2019-08-02 GPT Summary- レコメンダーシステム(RS)の中で、セッションベースのレコメンダーシステム(SBRS)が短期的なユーザーの好みを捉え、より正確な推奨を提供する新たなパラダイムとして注目されている。しかし、SBRSに関する統一された問題定義や特性の詳細な説明は不足している。本研究では、SBRSのエンティティや行動、特性を探求し、一般的な問題定義やデータ特性、課題を要約し、代表的な研究を分類する方法を提案する。また、SBRS分野における新たな研究機会についても議論する。
[Paper Note] Multimodal Review Generation for Recommender Systems, Truong+, WWW'19
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #WWW #One-Line Notes Issue Date: 2019-05-31 Comment
Personalized Review Generationと、Rating Predictionを同時学習した研究(同時学習自体はすでに先行研究がある)。
また、先行研究のinputは、たいていはuser, itemであるが、multi-modalなinputとしてレビューのphotoを活用したという話。
まだあまりしっかり読んでいないが、モデルのstructureはシンプルで、rating predictionを行うDNN、テキスト生成を行うLSTM(fusion gateと呼ばれる新たなゲートを追加)、画像の畳み込むCNNのハイブリッドのように見える。
[Paper Note] Deep Learning based Recommender System: A Survey and New Perspectives, Shuai Zhang+, ACM Computing Surveys (CSUR)'19, Vol.52, Issue 1, 2017.07
Paper/Blog Link My Issue
#NeuralNetwork #Survey Issue Date: 2018-04-16 GPT Summary- レコメンダーシステムは情報過多を克服するための効果的な手段であり、深層学習の進展によりその性能が向上している。本稿では、深層学習に基づくレコメンダーシステムの研究をレビューし、推薦モデルの分類法や最先端技術をまとめ、現在のトレンドと新たな発展について考察する。
[Paper Note] Deep Interest Network for Click-Through Rate Prediction, Guorui Zhou+, KDD'18
Paper/Blog Link My Issue
#NeuralNetwork #Attention #SIGKDD Issue Date: 2025-07-17 GPT Summary- クリック率予測において、固定長の表現ベクトルがユーザーの多様な興味を捉えるのを妨げる問題に対処するため、ローカルアクティベーションユニットを用いた「Deep Interest Network(DIN)」を提案。DINは広告に応じてユーザーの興味を適応的に学習し、表現力を向上させる。実験により、提案手法は最先端の手法を上回る性能を示し、Alibabaの広告システムに成功裏に展開されている。 Comment
ユーザの過去のアイテムとのインタラクションを、候補アイテムによって条件づけた上でattentionによって重みづけをすることでcontext vectorを作成し活用する。これにより候補アイテムごとにユーザの過去のアイテムとのインタラクションのうち、どれを重視するかを動的に変化させることができるようにした研究。最終的にユーザプロファイルをベースにしたEmbeddingとコンテキスト(セッションの情報など)の情報をベースにしたEmbeddingと、上述したcontext vectorをconcatし、linearな変換を噛ませてスコアを出力する。学習はクリックスルーログ等のインタラクションデータに対してNLL lossを適用する。通称DIN。
[Paper Note] Self-Attentive Sequential Recommendation, Wang-Cheng Kang+, ICDM'18
Paper/Blog Link My Issue
#Transformer #SequentialRecommendation #ICDM #Selected Papers/Blogs Issue Date: 2025-07-04 GPT Summary- 自己注意に基づく逐次モデル(SASRec)を提案し、マルコフ連鎖と再帰型ニューラルネットワークの利点を統合。SASRecは、少数のアクションから次のアイテムを予測し、スパースおよび密なデータセットで最先端のモデルを上回る性能を示す。モデルの効率性と注意重みの視覚化により、データセットの密度に応じた適応的な処理が可能であることが確認された。
[Paper Note] Calibrated Recommendation, Herald Steck, Netflix, RecSys'18
Paper/Blog Link My Issue
#Calibration Issue Date: 2024-09-20
[Paper Note] DKN: Deep Knowledge-Aware Network for News Recommendation, Hongwei Wang+, arXiv'18, 2018.01
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #Contents-based #NewsRecommendation #WWW #Surface-level Notes Issue Date: 2021-06-01 GPT Summary- オンラインニュース推薦システムの課題を解決するために、知識グラフを活用した深層知識認識ネットワーク(DKN)を提案。DKNは、ニュースの意味と知識を融合する多チャネルの知識認識畳み込みニューラルネットワーク(KCNN)を用い、ユーザーの履歴を動的に集約する注意モジュールを搭載。実験により、DKNが最先端の推薦モデルを大幅に上回る性能を示し、知識の有効性も確認。 Comment
# Overview
Contents-basedな手法でCTRを予測しNews推薦。newsのタイトルに含まれるentityをknowledge graphと紐づけて、情報をよりリッチにして活用する。
CNNでword-embeddingのみならず、entity embedding, contextual entity embedding(entityと関連するentity)をエンコードし、knowledge-awareなnewsのrepresentationを取得し予測する。
※ contextual entityは、entityのknowledge graph上でのneighborhoodに存在するentityのこと(neighborhoodの情報を活用することでdistinguishableでよりリッチな情報を活用できる)
CNNのinputを\[\[word_ embedding\], \[entity embedding\], \[contextual entity embedding\]\](画像のRGB)のように、multi-channelで構成し3次元のフィルタでconvolutionすることで、word, entity, contextual entityを表現する空間は別に保ちながら(同じ空間で表現するのは適切ではない)、wordとentityのalignmentがとれた状態でのrepresentationを獲得する。
# Experiments
BingNewsのサーバログデータを利用して評価。
データは (timestamp, userid, news url, news title, click count (0=no click, 1=click))のレコードによって構成されている。
2016年11月16日〜2017年6月11日の間のデータからランダムサンプリングしtrainingデータセットとした。
また、2017年6月12日〜2017年8月11日までのデータをtestデータセットとした。
word/entity embeddingの次元は100, フィルタのサイズは1,2,3,4とした。loss functionはlog lossを利用し、Adamで学習した。

DeepFM超えを達成。
entity embedding, contextual entity embeddingをablationすると、AUCは2ポイントほど現象するが、それでもDeepFMよりは高い性能を示している。
また、attentionを抜くとAUCは1ポイントほど減少する。
1ユーザのtraining/testセットのサンプル
Sentiment analysis with deeply learned distributed representations of variable length texts, Hong+, Technical Report. Technical report, Stanford University, 2015
によって経験的にRNN, Recursive Neural Network等と比較して、sentenceのrepresentationを獲得する際にCNNが優れていることが示されているため、CNNでrepresentationを獲得することにした模様(footprint 7より)
Factorization Machinesベースドな手法(LibFM, DeepFM)を利用する際は、TF-IDF featureと、averaged entity embeddingによって構成し、それをuser newsとcandidate news同士でconcatしてFeatureとして入力した模様
content情報を一切利用せず、ユーザのimplicit feedbackデータ(news click)のみを利用するDMF(Deep Matrix Factorization)の性能がかなり悪いのもおもしろい。やはりuser-item-implicit feedbackデータのみだけでなく、コンテンツの情報を利用した方が強い。
(おそらく)著者によるtensor-flowでの実装: https://github.com/hwwang55/DKN
[Paper Note] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Jianxun Lian+, arXiv'18, 2018.03
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #SIGKDD #One-Line Notes #Reading Reflections Issue Date: 2021-05-25 GPT Summary- 特徴量の自動生成が求められる中、因子分解モデルは相互作用を学習し一般化するが、DNNは暗黙的である。本研究では、明示的に相互作用を生成する圧縮相互作用ネットワーク(CIN)を提案し、DNNと統合したeXtreme Deep Factorization Machine(xDeepFM)を開発。xDeepFMは低次・高次の相互作用を学習し、実データセットで最先端モデルを超える性能を示した。 Comment
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17 DeepFMの発展版
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
DeepFMの発展についても詳細に述べられていて、とても参考になる。
[Paper Note] Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising, Junwei Pan+, arXiv'18, 2018.06
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #WWW #One-Line Notes Issue Date: 2020-08-29 GPT Summary- クリック率(CTR)予測はオンライン広告での重要なタスクであり、マルチフィールドのカテゴリカルデータが使用される。フィールド認識型因子分解機(FFMs)は異なるフィールド間の特徴相互作用を効果的にモデル化するが、パラメータ数が膨大で実用的ではない。提案するField-weighted Factorization Machines(FwFMs)は、メモリ効率よく相互作用をモデル化し、わずか4%のパラメータで競争力のある性能を発揮。実験では、FwFMsがFFMsよりも0.92%および0.47%のAUC改善を達成した。 Comment
CTR予測でbest-performingなモデルと言われているField Aware Factorization Machines(FFM)では、パラメータ数がフィールド数×特徴数のorderになってしまうため非常に多くなってしまうが、これをよりメモリを効果的に利用できる手法を提案。FFMとは性能がcomparableであるが、パラメータ数をFFMの4%に抑えることができた。
[Paper Note] Improving Explainable Recommendations with Synthetic Reviews, Sixun Ouyang+, RecSys'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #RecSys Issue Date: 2019-08-17 GPT Summary- レコメンダーシステムにおいて、解釈可能な説明を提供することは信頼性向上に重要である。本研究では、ユーザーのレビューを基にした生成モデルを用いて、個別化された推薦説明を作成するフレームワークを提案。Amazonの書籍レビューデータセットを用いて、生成されたレビューが人間のレビューよりも優れた推薦性能を示すことを実証した。これは機械生成による自然言語説明の初の試みである。
[Paper Note] Graph Convolutional Neural Networks for Web-Scale Recommender Systems, Rex Ying+, KDD'18
Paper/Blog Link My Issue
#NeuralNetwork #GraphBased #GraphConvolutionalNetwork #SIGKDD Issue Date: 2019-05-31 GPT Summary- Pinterestで開発した大規模な深層レコメンデーションエンジンPinSageは、効率的なランダムウォークとグラフ畳み込みを組み合わせて、数十億のアイテムとユーザーを持つウェブスケールのタスクに対応。新しいトレーニング戦略とMapReduceモデル推論アルゴリズムを用いて、75億の例をトレーニングし、高品質なレコメンデーションを生成。これは深層グラフ埋め込みの最大の応用であり、次世代のウェブスケールレコメンダーシステムの発展に寄与する。
[Paper Note] LensKit for Python: Next-Generation Software for Recommender System Experiments, Michael D. Ekstrand, arXiv'18, 2018.09
Paper/Blog Link My Issue
#Tools #Library #One-Line Notes Issue Date: 2018-01-01 GPT Summary- LensKitはレコメンダーシステムのためのオープンソースツールキットで、次世代版としてPython用のLensKit(LKPY)を紹介。LKPYは、研究者や学生が再現可能な実験を構築できるようにし、scikit-learnやTensorFlow、PyTorchなどのエコシステムを活用。古典的な協調フィルタリングの実装や評価指標、データ準備ルーチンを提供し、他のPythonソフトウェアと組み合わせて使用可能。設計目標やユースケースについて、元のJava版の成功と失敗を振り返りながら説明。 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:Java
使用方法:コマンドライン、Javaライブラリとして利用
※ 推薦システム界隈で有名な、GroupLens研究グループによるJava実装
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] StarSpace: Embed All The Things, Wu+, AAAI'18
Paper/Blog Link My Issue
#NeuralNetwork #General #Embeddings #MachineLearning #RepresentationLearning #AAAI #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 Comment
分類やランキング、レコメンドなど、様々なタスクで汎用的に使用できるEmbeddingの学習手法を提案。
Embeddingを学習する対象をEntityと呼び、Entityはbag-of-featureで記述される。
Entityはbag-of-featureで記述できればなんでもよく、
これによりモデルの汎用性が増し、異なる種類のEntityでも同じ空間上でEmbeddingが学習される。
学習方法は非常にシンプルで、Entity同士のペアをとったときに、relevantなpairであれば類似度が高く、
irelevantなペアであれば類似度が低くなるようにEmbeddingを学習するだけ。
たとえば、Entityのペアとして、documentをbag-of-words, bag-of-ngrams, labelをsingle wordで記述しテキスト分類、
あるいは、user_idとユーザが過去に好んだアイテムをbag-of-wordsで記述しcontent-based recommendationを行うなど、 応用範囲は幅広い。
5種類のタスクで提案手法を評価し、既存手法と比較して、同等かそれ以上の性能を示すことが示されている。
手法の汎用性が高く学習も高速なので、色々な場面で役に立ちそう。
また、異なる種類のEntityであっても同じ空間上でEmbeddingが学習されるので、学習されたEmbeddingの応用先が広く有用。
実際にSentimentAnalysisで使ってみたが(ポジネガ二値分類)、少なくともBoWのSVMよりは全然性能良かったし、学習も早いし、次元数めちゃめちゃ少なくて良かった。
StarSpaceで学習したembeddingをBoWなSVMに入れると性能が劇的に改善した。
解説:
https://www.slideshare.net/akihikowatanabe3110/starspace-embed-all-the-things
[Paper Note] Neural Rating Regression with Abstractive Tips Generation for Recommendation, Piji Li+, arXiv'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ReviewGeneration #SIGIR #KeyPoint Notes Issue Date: 2019-04-12 GPT Summary- Eコマースサイトの新しい「Tips」機能を活用し、ユーザーの経験や感情を表現する短いテキストを生成する深層学習フレームワーク「NRT」を提案。NRTは、ユーザーとアイテムの潜在表現を基に、正確な評価予測と高品質な抽象的ヒントの生成を実現。実験により、NRTは既存手法に対して顕著な改善を示し、ユーザーの体験や感情を効果的に反映することが確認された。 Comment
Rating Predictionとtips generationを同時に行うことで、両者の性能を向上させた最初の研究。
tipsとは、ユーザの経験や感じたことを、短いテキスト(1文とか)で簡潔に記したもの。

モデルについてはあまりく詳しく読んでいないが、図を見る感じ、user latent factorとitem latent factorをMF layerとseq2seqで共有し、同時学習させていると思われる。
おそらく、MFとtext generationをjointで行うNNモデルはこの研究が初めて(textの情報をMFの改善に使おうという試みは古くからやられているが、generationまでは多分やってない)で、このモデル化の仕方がその後のスタンダードになっている。
[Paper Note] Estimating Reactions and Recommending Products with Generative Models of Reviews, Ni+, IJCNLP'17
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #CollaborativeFiltering #NLP #ReviewGeneration #IJCNLP #KeyPoint Notes Issue Date: 2019-02-01 Comment
Collaborative Filtering (CF) によるコンテンツ推薦とReview Generationを同時に学習し、
両者の性能を向上させる話。
非常に興味深い設定で、このような実験設定でReview Generationを行なった初めての研究。
CFではMatrix Factorization (MF) を利用し、Review Generationでは、LSTM-basedなseq2seqを利用する。MFとReview Generationのモデルにおいて、共通のuser latent factorとitem latent factorを利用することで、joint modelとしている。このとき、latent factorは、両タスクを通じて学習される。
CFでは、Implicitな設定なので、Rating Predictionではなく、binary classificationを行うことで、推薦を行う。
classificationには、Matrix Factorization (MF) を拡張したモデルを用いる。
具体的には、通常のMFでは、user latent factorとitem latent factorの内積によって、userのitemに対するpreferenceを表現するが、このときに、target userが過去に記載したレビュー・およびtarget itemに関する情報を利用する。レビューのrepresentationのaverageをとったvectorと、MFの結果をlinear layerによって写像し、最終的なclassification scoreとしている。
Review Generationでは、基本的にはseq2seqのinputのEmbeddingに対して、user latent factor, item latent factorをconcatするだけ。hidden stateに直接concatしないのは、latent factorを各ステップで考慮できるため、long, coherentなsequenceを生成できるから、と説明している。

Recommendタスクにおいては、Bayesian Personalized Ranking, Generalized Matrix Factorizationをoutperform。

Review GenerationはPerplexityにより評価している。提案手法がcharacter based lstmをoutperform。
Perplexityによる評価だと言語モデルとしての評価しかできていないので、BLEU, ROUGEなどを利用した評価などもあって良いのでは。
[Paper Note] A SURVEY OF ARTIFICIAL INTELLIGENCE TECHNIQUES EMPLOYED FOR ADAPTIVE EDUCATIONAL SYSTEMS WITHIN E-LEARNING PLATFORMS, Almohammadi+, JAISCR'17, 2017.01
Paper/Blog Link My Issue
#Survey #Education Issue Date: 2018-03-30
[Paper Note] Neural Collaborative Filtering, Xiangnan He+, WWW'17, 2017.08
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #MatrixFactorization #WWW #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-02-16 GPT Summary- 深層ニューラルネットワークを用いたレコメンダーシステムの研究が少ない中、本研究では協調フィルタリングの問題に取り組むため、NCF(Neural network-based Collaborative Filtering)フレームワークを提案。内積をニューラルアーキテクチャに置き換え、ユーザーとアイテムの相互作用を多層パーセプトロンでモデル化。実験により、提案手法が最先端技術に対して顕著な改善を示し、深層ニューラルネットワークの層を深くすることでレコメンデーション性能が向上することが確認された。 Comment
Collaborative FilteringをMLPで一般化したNeural Collaborative Filtering、およびMatrix Factorizationはuser, item-embeddingのelement-wise product + linear transofmration + activation で一般化できること(GMF; Generalized Matrix Factorization)を示し、両者を組み合わせたNeural Matrix Factorizationを提案している。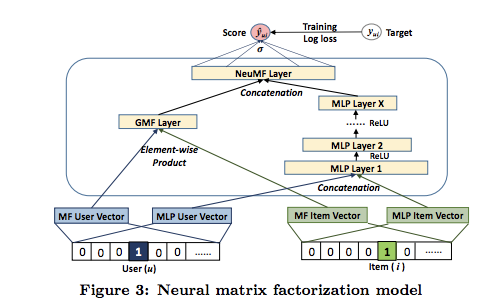
学習する際は、Implicit Dataの場合は負例をNegative Samplingし、LogLoss(Binary Cross-Entropy Loss)で学習する。
Neural Matrix Factorizationが、ItemKNNやBPRといったベースラインをoutperform
Negative Samplingでサンプリングする負例の数は、3~4程度で良さそう
Deep Learning for Personalized Search and Recommender Systems, KDD'17 Tutorial
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #InformationRetrieval #Slide #SIGKDD Issue Date: 2018-02-16
[Paper Note] MoodSwipe: A Soft Keyboard that Suggests Messages Based on User-Specified Emotions, Huang+, EMNLP'17
Paper/Blog Link My Issue
#SentimentAnalysis #NLP #Conversation #EMNLP #Emotion Issue Date: 2018-01-01 GPT Summary- MoodSwipeは、ユーザーの指定した感情に基づいてテキストメッセージを提案するソフトキーボードで、実際の対話データを活用しています。感情分類とテキスト提案の技術を楽しむための便利なインターフェースを提供し、同時にラベル付きデータを自動収集します。ユーザーは通常通り入力しつつ、感情を感知して提案を受け取ることができ、感情が提案の媒介として機能します。実験により、感情分類モデルの優位性と、感情の手がかりがテキスト提案において重要であることを示しました。
[Paper Note] A survey of transfer learning for collaborative recommendation with auxiliary data, Pan, Neurocomputing'17
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] Wide & Deep Learning for Recommender Systems, Heng-Tze Cheng+, DLRS'16, 2016.06
Paper/Blog Link My Issue
#NeuralNetwork #Selected Papers/Blogs Issue Date: 2026-01-06 GPT Summary- Wide & Deep学習は、推薦システムのために広範な線形モデルと深層ニューラルネットワークを共同で訓練する手法で、記憶と一般化の利点を組み合わせる。Google Playでの実用化により、アプリの獲得が大幅に増加したことがオンライン実験で示された。TensorFlowでの実装はオープンソース化されている。 Comment
日本語解説: https://data.gunosy.io/entry/deep-factorization-machines-2018#Wide--Deep-Cheng-arXiv160607792-2016
[Paper Note] Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering, Ruining He+, arXiv'16, 2016.02
Paper/Blog Link My Issue
Issue Date: 2023-05-06 GPT Summary- ユーザーの嗜好とその動的変化を理解することが成功するリコメンダシステムに不可欠である。特にファッション分野では、製品の視覚的特徴と進化を同時にモデル化する必要があり、これは困難である。本研究では、ワン・クラス協調フィルタリングの新規モデルを提案し、過去のフィードバックに基づく個別のランキング関数を推定する。この手法では、高次の視覚特徴、過去のフィードバック、進化するトレンドを組み合わせ、効果を実証するためにAmazon.comの実世界データセットを用いて評価し、最先端のランキング指標を上回ることを示した。 Comment
SNAP: Web data: Amazon reviews
を構築した研究と同様の著者の研究
SNAP: Web data: Amazon reviews
を利用した場合はこの研究は [Paper Note] Image-based Recommendations on Styles and Substitutes, Julian McAuley+, arXiv'15, 2015.06
をreferする必要がある
[Paper Note] Deep Neural Networks for YouTube Recommendations, Covington+, RecSys'16
Paper/Blog Link My Issue
#NeuralNetwork #RecSys #Selected Papers/Blogs Issue Date: 2018-12-27
[Paper Note] A Survey on Artificial Intelligence and Data Mining for MOOCs, Simon Fauvel+, arXiv'16, 2016.01
Paper/Blog Link My Issue
#Survey #Education #TechnologyEnhancedLearning Issue Date: 2018-03-30 GPT Summary- MOOCsは人気を集めており、AIとデータマイニングがその発展に寄与している。データを活用することで、MOOCの理解を深め、学習者の体験を向上させることが可能。論文では、AIとDMの最新研究をレビューし、学生のエンゲージメントや学習成果を向上させる技術を強調。さらに、MOOCsの潜在能力を引き出すための重要な研究課題とトレンドを示す。
[Paper Note] Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, Wu+, WSDM'16
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #WSDM #Selected Papers/Blogs #KeyPoint Notes #AutoEncoder Issue Date: 2018-01-02 Comment
Denoising Auto-Encoders を用いたtop-N推薦手法、Collaborative Denoising Auto-Encoder (CDAE)を提案。
モデルベースなCollaborative Filtering手法に相当する。corruptedなinputを復元するようなDenoising Auto Encoderのみで推薦を行うような手法は、この研究が初めてだと主張。
学習する際は、userのitemsetのsubsetをモデルに与え(noiseがあることに相当)、全体のitem setを復元できるように、学習する(すなわちDenoising Auto-Encoder)。
推薦する際は、ユーザのその時点でのpreference setをinputし、new itemを推薦する。
- [Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
もStacked Denoising Auto EncoderとCollaborative Topic Regression [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
を利用しているが、[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
ではarticle recommendationというspecificな問題を解いているのに対して、提案手法はgeneralなtop-N推薦に利用できることを主張。
[Paper Note] News Citation Recommendation with Implicit and Explicit Semantics, Peng+, ACL'16
Paper/Blog Link My Issue
#Citations #LearningToRank #ACL #KeyPoint Notes Issue Date: 2018-01-01 Comment
target text中に記述されているイベントや意見に対して、それらをサポートするような他のニュース記事を推薦する研究。
たとえば、target text中に「北朝鮮が先日ミサイルの発射に失敗したが...」、といった記述があったときに、このイベントについて報道しているニュース記事を推薦するといったことを、target text中の様々なcontextに対して行う。
このようなシステムの利用により、target textの著者の執筆支援(自身の主張をサポートするためのreferenceの自動獲得)や、target textの読者の読解支援(text中の記述について詳細な情報を知りたい場合に、検索の手間が省ける)などの利点があると主張。
タスクとしては、target text中のあるcontextと、推薦の候補となるニュース記事の集合が与えられたときに、ニュース記事をre-rankingする タスク。
提案手法はシンプルで、contextとニュース記事間で、様々な指標を用いてsimilarityを測り、それらをlearning-to-rankで学習した重みで組み合わせてre-rankingを行うだけ。 similarityを測る際は、表記揺れや曖昧性の問題に対処するためにEmbeddingを用いる手法と、groundingされたentityの情報を用いる手法を提案。
Bing news中のAnchor textと、hyperlink先のニュース記事の対から、contextと正解ニュース記事の対を取得し、30000件規模の実験データを作成し、評価。その結果、baselineよりも提案手法の性能が高いことを示した。
[Paper Note] A Survey of Collaborative Filtering-Based Recommender Systems for Mobile Internet Applications, Yang+, IEEE Access'16
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] E-commerce in Your Inbox: Product Recommendations at Scale, Mihajlo Grbovic+, KDD'15
Paper/Blog Link My Issue
#NeuralNetwork #CTRPrediction #SequentialRecommendation #SIGKDD #One-Line Notes Issue Date: 2025-04-25 GPT Summary- メールの領収書から得た購入履歴を活用し、Yahoo Mailユーザーにパーソナライズされた商品広告を配信するシステムを提案。新しい神経言語ベースのアルゴリズムを用いて、2900万人以上のユーザーのデータでオフラインテストを実施した結果、クリック率が9%向上し、コンバージョン率も改善。システムは2014年のホリデーシーズンに本稼働を開始。 Comment
Yahoo mailにおける商品推薦の研究
Yahoo mailのレシート情報から、商品購入に関する情報とtimestampを抽出し、時系列データを形成。評価時はTimestampで1ヶ月分のデータをheldoutし評価している。Sequential Recommendationの一種とみなせるが、評価データをユーザ単位でなくtimestampで区切っている点でよりrealisticな評価をしている。
[Paper Note] Image-based Recommendations on Styles and Substitutes, Julian McAuley+, arXiv'15, 2015.06
Paper/Blog Link My Issue
Issue Date: 2023-05-06 GPT Summary- 物体間の関係性をモデル化するため、我々は外観に基づく感覚をスケーラブルな手法で発見しようとする。ユーザーの注釈に依存せず、最大規模のデータセットを取り込み、視覚的関係性を関連画像のグラフ上のネットワーク推論問題として定義する。このシステムは、衣類やアクセサリの組み合わせを推奨し、多様な応用に寄与する。 Comment
SNAP: Web data: Amazon reviews を構築した論文
[Paper Note] Session-based Recommendations with Recurrent Neural Networks, Balázs Hidasi+, arXiv'15
Paper/Blog Link My Issue
#SessionBased #ICLR #SequentialRecommendation #Selected Papers/Blogs #One-Line Notes Issue Date: 2019-08-02 GPT Summary- RNNを用いたセッションベースのレコメンダーシステムを提案。短いユーザーヒストリーに基づく推薦の精度向上を目指し、セッション全体をモデル化。ランキング損失関数などの修正を加え、実用性を考慮。実験結果は従来のアプローチに対して顕著な改善を示す。 Comment
RNNを利用したsequential recommendation (session-based recommendation)の先駆け的論文。
日本語解説: https://qiita.com/tatamiya/items/46e278a808a51893deac
[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #MatrixFactorization #SIGKDD #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2018-01-11 GPT Summary- 協調フィルタリング(CF)はレコメンダーシステムで広く用いられるが、評価がまばらな場合に性能が低下する。これに対処するため、補助情報を活用する協調トピック回帰(CTR)が提案されているが、補助情報がまばらな場合には効果が薄い。そこで、本研究では協調深層学習(CDL)という階層ベイズモデルを提案し、コンテンツ情報の深い表現学習とCFを共同で行う。実験により、CDLが最先端技術を大幅に上回る性能を示すことが確認された。 Comment
Rating Matrixからuserとitemのlatent vectorを学習する際に、Stacked Denoising Auto Encoder(SDAE)によるitemのembeddingを活用する話。
Collaborative FilteringとContents-based Filteringのハイブリッド手法。
Collaborative FilteringにおいてDeepなモデルを活用する初期の研究。
通常はuser vectorとitem vectorの内積の値が対応するratingを再現できるように目的関数が設計されるが、そこにitem vectorとSDAEによるitemのEmbeddingが近くなるような項(3項目)、SDAEのエラー(4項目)を追加する。
(3項目の意義について、解説ブログより)アイテム i に関する潜在表現 vi は学習データに登場するものについては推定できるけれど,未知のものについては推定できない.そこでSDAEの中間層の結果を「推定したvi」として「真の」 vi にできる限り近づける,というのがこの項の気持ち
cite-ulikeデータによる論文推薦、Netflixデータによる映画推薦で評価した結果、ベースライン(Collective Matrix Factorization [Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
, SVDFeature [Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
, DeepMusic [Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
, Collaborative Topic Regresison [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
)をoutperform。
(下記は管理人が過去に作成した論文メモスライドのスクショ)




[Paper Note] Matrix Factorization Model in Collaborative Filtering Algorithms: A Survey, Bokde+, Procedia Computer Science'15
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] fastFM: A Library for Factorization Machines, Immanuel Bayer, arXiv'15, 2015.05
Paper/Blog Link My Issue
#CollaborativeFiltering #Library #FactorizationMachines #One-Line Notes Issue Date: 2018-01-01 GPT Summary- 因子分解機(FM)は、レコメンダーシステムで成功を収めているにもかかわらず、機械学習の標準ツールボックスには含まれていない。私たちのFMの実装は、回帰、分類、ランキングタスクをサポートし、多くのソルバーへのアクセスを簡素化することで、FMの幅広いアプリケーション利用を促進する。これにより、FMモデルの理解が深まり、新たな開発が期待される。 Comment
実装されているアルゴリズム:Factorization Machines
実装:python
使用方法:pythonライブラリとして利用
※ Factorization Machinesに特化したpythonライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] Interactive Recommender Systems, Netflix, RecSys'15, 2015.09
Paper/Blog Link My Issue
#Tutorial #InteractiveRecommenderSystems #Slide #RecSys #interactive Issue Date: 2017-12-28
[Paper Note] Generating Personalized Snippets for Web Page Recommender Systems, Akihiko+, WI-IAT'14
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Snippets #Explanation #PersonalizedGeneration #Personalization #WI Issue Date: 2025-11-27 Comment
ジャーナル(日本語): https://www.jstage.jst.go.jp/article/tjsai/31/5/31_C-G41/_article/-char/en
Simple and scalable response prediction for display advertising, Chapelle+, Criteo, Transactions on Intelligent Systems and Technology, CHAPELLE+, TIST'14
Paper/Blog Link My Issue
#CTRPrediction #One-Line Notes Issue Date: 2021-10-29 Comment
日本語解説:
https://ameblo.jp/cyberanalyst/entry-11784152713.html
CTR予測の概要や、広告主・事業者にとってCTR予測ができることでどのようなメリットがあるかなどがまとまっている。
論文の手法自体は、logistic regressionが利用されている。
[Paper Note] GraphLab: A New Framework For Parallel Machine Learning, Yucheng Low+, arXiv'14, 2014.08
Paper/Blog Link My Issue
#Tools Issue Date: 2018-01-01 GPT Summary- GraphLabは、効率的で証明可能に正しい並列機械学習アルゴリズムを設計・実装するためのフレームワークであり、非同期反復アルゴリズムを疎な計算依存関係で表現しつつデータの整合性を保ち、高い並列性能を実現します。信念伝播やギブスサンプリングなどの並列バージョンを実装し、実世界の大規模問題に対して優れた性能を示しました。 Comment
現在はTuri.comになっており、商用になっている?
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
Paper/Blog Link My Issue
#NeuralNetwork #InformationRetrieval #Contents-based #CIKM Issue Date: 2021-06-01 Comment
[Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
Paper/Blog Link My Issue
#NeuralNetwork #MatrixFactorization #NeurIPS #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Contents-Basedな音楽推薦手法(cold-start problemに強い)。
Weighted Matrix Factorization (WMF) (Implicit Feedbackによるデータに特化したMatrix Factorization手法) [Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008.12
に、Convolutional Neural Networkによるmusic audioのlatent vectorの情報が組み込まれ、item vectorが学習されるような仕組みになっている。
CNNでmusic audioのrepresentationを生成する際には、audioのtime-frequencyの情報をinputとする。学習を高速化するために、window幅を3秒に設定しmusic clipをサンプルしinputする。music clip全体のrepresentationを求める際には、consecutive windowからpredictionしたrepresentationを平均したものを使用する。
[Paper Note] セレンディピティ指向情報推薦の研究動向, 奥健太, 知能と情報'13
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] 推薦システムにおけるインタラクション研究へのいざない, 土方, ヒューマンインタフェース学会誌'13
Paper/Blog Link My Issue
#Tutorial Issue Date: 2018-01-01
[Paper Note] Recommender systems survey, Bobadilla+, Knowledge-Based Systems'13
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
A Comparative Study of Collaborative Filtering Algorithms, Lee+, arXiv'12
Paper/Blog Link My Issue
#Analysis #CollaborativeFiltering #KeyPoint Notes Issue Date: 2021-10-29 Comment
様々あるCFアルゴリズムをどのように選択すべきか、# of users, # of items, rating matrix densityの観点から分析した研究。
1. 特にcomputationに関する制約がない場合は・・・、NMFはsparseなデータセットに対して最も良い性能を発揮する。BPMFはdenseなデータセットに対して最も良い性能を発揮する。そして、regularized SVD, PMFはこれ以外の状況で最も良い性能を示す(PMFはユーザ数が少ない場合によく機能する一方で、Regularized SVDはアイテム数が小さい場合に良く機能する。)。
2. もしtime constraintが5分の場合、Regularized SVD, NLPMF, NPCA, Rankbased CFは検討できない。この場合、NMFがスパースデータに対して最も良い性能を発揮し、BPMFがdenseで大規模なデータ、それ以外ではPMFが最も良い性能を示す。
3. もしtime constraintが1分の場合、PMFとBPMFは2に加えてさらに除外される。多くの場合Slope-oneが最も良い性能を示すが、データがsparseな場合はNMF。
4. リアルタイムな計算が必要な場合、user averageがbest
[Paper Note] Care to Comment? Recommendations for Commenting on News Stories, Shmueli+, WWW'12
Paper/Blog Link My Issue
#Comments #WWW #One-Line Notes Issue Date: 2018-01-15 Comment
過去のユーザのコメントに対するratingに基づいて、ユーザが(コメントを通じて)議論に参加したいようなNews Storyを推薦する研究。
[Paper Note] Factorization Machines with libFM, Steffen Rendle, TIST'12, 2012.06
Paper/Blog Link My Issue
#CollaborativeFiltering #FactorizationMachines #One-Line Notes Issue Date: 2018-01-02 Comment
Factorization Machinesの著者実装。
FMやるならまずはこれ。
[Paper Note] A literature review and classification of recommender systems research, Park+, Expert Systems with Applications'12
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] Explaining the user experience of recommender systems, Knijnenburg+, User Modeling and User-Adapted Interaction'12
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] Multi-relational matrix factorization using bayesian personalized ranking for social network data, Krohn-Grimberghe+, WSDM'12, 2012.02
Paper/Blog Link My Issue
#Multi #MatrixFactorization #WSDM #ColdStart #One-Line Notes Issue Date: 2017-12-28 Comment
multi-relationalな場合でも適用できるmatrix factorizationを提案。特にcold start problemにフォーカス。social networkのデータなどに適用できる。
Context Aware Recommender Systems, Adomavicius+, AAAI'11 Tutorial, 2011.08
Paper/Blog Link My Issue
#Tutorial #ContextAware #AAAI #One-Line Notes Issue Date: 2018-12-22 Comment
AdomaviciusらによるContext Aware Recsysチュートリアル
関連:
- [Paper Note] Context-Aware Recommender Systems, Adomavicius+, Recommender Systems Handbook, 2011.09
[Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
Paper/Blog Link My Issue
#CollaborativeFiltering #MatrixFactorization #SIGKDD #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Probabilistic Matrix Factorization (PMF) [Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
に、Latent Dirichllet Allocation (LDA) を組み込んだCollaborative Topic Regression (CTR)を提案 (Figure2)。
LDAによりitemのlatent vectorを求め、このitem vectorと、user vectorの内積を(平均値として持つ正規表現からのサンプリング)用いてratingを生成する(式6)。
CFとContents-basedな手法が双方向にinterationするような手法
[Paper Note] Personalized Recommendation of User Comments via Factor Models, Agarwal+, EMNLP'11
Paper/Blog Link My Issue
#Comments #EMNLP #KeyPoint Notes Issue Date: 2018-01-01 Comment
Personalizedなコメント推薦モデルを提案。rater-authorの関係、rater-commentの関係をlatent vectorを用いて表現し、これらとバイアス項の線形結合によりraterのあるコメントに対するratingを予測する。
パラメータを学習する際は、EMでモデルをfittingする。
バイアスとして、rater bias, comment popularity bias, author reputation biasを用いている。
rater-commentに関連するバイアスやlatent vectorは、コメントのbag-of-wordsからregressionした値を平均として持つガウス分布から生成される。
Yahoo Newsのコメントで実験。ROC曲線のAUCとPrecsionで評価。
user-user, user-commentを単体で用いたモデルよりも両者を組み合わせた場合が最も性能が良かった。
かなり綺麗に結果が出ている。
[Paper Note] Collaborative Filtering Recommender Systems, Ekstrand+ (with Joseph A. Konstan), Foundations and TrendsR in Human–Computer Interaction'11
Paper/Blog Link My Issue
#Survey #Selected Papers/Blogs Issue Date: 2018-01-01
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
Paper/Blog Link My Issue
#MachineLearning #CollaborativeFiltering #FactorizationMachines #ICDM #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2018-12-22 Comment
解説ブログ:
http://echizen-tm.hatenablog.com/entry/2016/09/11/024828
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
上記解説ブログの概要が非常に完結でわかりやすい

FMのFeature VectorのExample
各featureごとにlatent vectorが学習され、featureの組み合わせのweightが内積によって表現される
Matrix Factorizationの一般形のような形式
Content-based Recommender Systems: State of the Art and Trends, Lops+, Recommender Systems Handbook'10
Paper/Blog Link My Issue
#Survey #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
RecSysの内容ベースフィルタリングシステムのユーザプロファイルについて知りたければこれ
[Paper Note] BPR: Bayesian Personalized Ranking from Implicit Feedback, Steffen Rendle+, UAI'09, 2009.06
Paper/Blog Link My Issue
#LearningToRank #ImplicitFeedback #UAI #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 GPT Summary- アイテム推薦において、暗黙的フィードバックを用いた個別のランキング予測のために、BPR-Optという新しい最適化基準を提案。ブートストラップサンプリングを用いた確率的勾配降下法に基づく学習アルゴリズムを提供し、行列因子分解とk近傍法に適用。実験結果は、提案手法が従来の技術を上回ることを示し、モデル最適化の重要性を強調。 Comment
重要論文
ユーザのアイテムに対するExplicit/Implicit Ratingを利用したlearning2rank。
AUCを最適化するようなイメージ。
負例はNegative Sampling。
計算量が軽く、拡張がしやすい。
Implicitデータを使ったTop-N Recsysを構築する際には検討しても良い。
また、MFのみならず、Item-Based KNNに活用することなども可能。
http://tech.vasily.jp/entry/2016/07/01/134825
参考: https://techblog.zozo.com/entry/2016/07/01/134825
pytorchでのBPR実装: https://github.com/guoyang9/BPR-pytorch
[Paper Note] Collaborative Summarization: When Collaborative Filtering Meets Document Summarization, Qu+, PACLIC'09, 2009.12
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #CollaborativeFiltering #GraphBased #Personalization #PACLIC #KeyPoint Notes Issue Date: 2017-12-28 Comment
Collaborative Filteringと要約を組み合わせる手法を提案した最初の論文と思われる。
ソーシャルブックマークのデータから作成される、ユーザ・アイテム・タグのTripartite Graphと、ドキュメントのsentenceで構築されるGraphをのノード間にedgeを張り、co-rankingする手法を提案している。
評価
100個のEnglish wikipedia記事をDLし、文書要約のセットとした。
その上で、5000件のwikipedia記事に対する1084ユーザのタギングデータをdelicious.comから収集し、合計で8396の異なりタグを得た。
10人のdeliciousのアクティブユーザの協力を得て、100記事に対するtop5のsentenceを抽出してもらった。ROUGE1で評価。
[Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
Paper/Blog Link My Issue
#MatrixFactorization #NeurIPS #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-11 Comment
Matrix Factorizationを確率モデルとして表した論文。
解説:
http://yamaguchiyuto.hatenablog.com/entry/2017/07/13/080000
既存のMFは大規模なデータに対してスケールしなかったが、PMFではobservationの数に対して線形にスケールし、さらには、large, sparse, imbalancedなNetflix datasetで良い性能が出た(Netflixデータセットは、rating件数が少ないユーザとかも含んでいる。MovieLensとかは含まれていないのでより現実的なデータセット)。
また、Constrained PMF(同じようなsetの映画にrateしているユーザは似ているといった仮定に基づいたモデル[^1])を用いると、少ないratingしかないユーザに対しても良い性能が出た。
[^1]: ratingの少ないユーザの潜在ベクトルは平均から動きにくい、つまりなんの特徴もない平均的なユーザベクトルになってしまうので、同じ映画をratingした人は似た事前分布を持つように制約を導入したモデル
[Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
Paper/Blog Link My Issue
#MatrixFactorization #SIGKDD #One-Line Notes Issue Date: 2018-01-11 Comment
従来のMatrix Factorization(MF)では、pair-wiseなrelation(たとえば映画とユーザと、映画に対するユーザのrating)からRating Matrixを生成し、その行列を分解していたが、multipleなrelation(たとえば、user-movie ratingの5-scale Matrixとmovie - genreの binary Matrixなど)を扱うことができなかったので、それを可能にした話。
これができると、たとえば ユーザの映画に対するratingを予測する際に、あるユーザが特定のジャンルの映画に対して高いratingを付けるような情報も考慮して予測ができたりする。
Content-Based Recommendation Systems, Pazzani+, The Adaptive Web'07
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] A Survey of Explanations in Recommender Systems, Tintarev+, ICDEW'07
Paper/Blog Link My Issue
#Survey #Explanation #Selected Papers/Blogs Issue Date: 2018-01-01
[Paper Note] Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07
Paper/Blog Link My Issue
#Survey #CollaborativeFiltering #MatrixFactorization #Selected Papers/Blogs #Reading Reflections Issue Date: 2018-01-01 Comment
Matrix Factorizationについてよくまとまっている
[Paper Note] Improving Recommendation Novelty Based on Topic Taxonomy, Weng et al., WI-IAT Workshops'07, 2007.11
Paper/Blog Link My Issue
#Novelty #WI #Workshop #KeyPoint Notes Issue Date: 2017-12-28 Comment
・評価をしていない
・通常のItem-based collaborative filteringの結果に加えて,taxonomyのassociation rule mining (あるtaxonomy t1に興味がある人が,t2にも興味がある確率を獲得する)を行い,このassociation rule miningの結果をCFと組み合わせて,noveltyのある推薦をしようという話(従来のHybrid Recommender Systemsでは,contents-basedの手法を使うときはitem content similarityを使うことが多い.まあこれはよくあるcontents-basedなアプローチだろう).
・documentの中のどの部分がnovelなのかとかを同定しているわけではない.taxonomyの観点からnovelだということ.
[Paper Note] Usage patterns of collaborative tagging systems, Golder+, Journal of Information Science'06
Paper/Blog Link My Issue
#Analysis #Others #One-Line Notes Issue Date: 2018-01-01 Comment
Social Tagging Systemの仕組みや使われ方について言及する際にreferすると良いかも。
[Paper Note] Folkrank: A ranking algorithm for folksonomies, Hotho+, FGIR'06
Paper/Blog Link My Issue
#GraphBased #One-Line Notes Issue Date: 2018-01-01 Comment
代表的なタグ推薦手法
[Paper Note] Explanation in Recommender Systems, Mcsherry, Artificial Intelligence Review'05
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions, Adomavicius+, IEEE Transactions on Knowledge and Data Engineering'05
Paper/Blog Link My Issue
#Survey #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
有名なやつ
[Paper Note] Evaluating Collaborative Filtering Recommener Systems, Herlocker+, TOIS'04
Paper/Blog Link My Issue
#Survey #Evaluation #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
GroupLensのSurvey
[Paper Note] Getting to know you: learning new user preferences in recommender systems, Rashid+, IUI'02
Paper/Blog Link My Issue
#ColdStart #Initial Impression Notes Issue Date: 2025-05-16 Comment
- [Paper Note] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Colin Raffel+, JMLR'20
のOpenReviewで言及されているコールドスタートに関する研究
[Paper Note] Hybrid Recommender Systems: Survey and Experiments, Burke+, User Modeling and User-Adapted Interaction'02
Paper/Blog Link My Issue
#Survey Issue Date: 2018-01-01
[Paper Note] Item-based collaborative filtering recommendation algorithms, Sarwar+(with Konstan), WWW'01, 2021.04
Paper/Blog Link My Issue
#CollaborativeFiltering #ItemBased #WWW #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
アイテムベースな協調フィルタリングを提案した論文(GroupLens)
new-datasets-in-machine-learning, librarian-bots, 2026.02
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #MachineLearning #InformationRetrieval #NLP #Dataset #Evaluation #SpeechProcessing #Robotics #Live Issue Date: 2026-02-09 Comment
元ポスト:
ModernBERTをFinetuningした分類器を用いてデータセットやベンチマークを提案している研究を自動分類して検索できるようにしている。有用
Introducing zerank-2: The Most Accurate Multilingual Instruction-Following Reranker, ZeroEntropy, 2025.11
Paper/Blog Link My Issue
#Article #Embeddings #InformationRetrieval #NLP #Blog #OpenWeight #Reranking Issue Date: 2025-11-20 Comment
HF: https://huggingface.co/zeroentropy/zerank-2
SoTA reranker
zerank-1, zeroentropy, 2025.07
Paper/Blog Link My Issue
#Article #InformationRetrieval #OpenWeight #Encoder #Reranking Issue Date: 2025-10-23 Comment
SoTAなcross-encoderに基づくreranker。おそらく英語にのみ対応。
zerank-1はcc-by-nc-4.0, smallはApache2.0ライセンス
[Paper Note] Self-Monitoring Large Language Models for Click-Through Rate Prediction, Zhou+, ACM Transactions on Information Systems, 2025.08
Paper/Blog Link My Issue
#Article #LanguageModel #CTRPrediction Issue Date: 2025-08-27 Comment
元ポスト:
DMMにおけるレコメンドの紹介‗20250716_traP×DMM, 合同会社DMM.com, 2025.07
Paper/Blog Link My Issue
#Article #Slide #TwoTowerModel Issue Date: 2025-07-17 Comment
Two Towerモデル + LightGBMによるリランキング
LLM Recommendation Systems: AI Engineer World's Fair 2025, AI Engineer, 2025.07
Paper/Blog Link My Issue
#Article #LanguageModel #Video #SemanticID Issue Date: 2025-07-17 Comment
元ポスト:
セマンティックIDの実用例
推薦システムにおけるPost Processの取り組み, Wantedly, 2025.07
Paper/Blog Link My Issue
#Article #Blog #Slide Issue Date: 2025-07-15 Comment
元ポスト:
Wantedlyスカウトにおいて、オンラインで動的にスカウト利用者から指定されるフィルタリング要件に対して、未閲覧のユーザの比率を動的に調整してランキングするPost Processによって、主要KPIが大幅に改善した話。モデル改善に興味が行きがちだが、顧客理解に基づくPost Processでここまで主要KPIが改善するのは美しく、非常に興味深い。
スライド資料:
日経電子版のアプリトップ「おすすめ」をTwo Towerモデルでリプレースしました, NIKKEI, 2025.05
Paper/Blog Link My Issue
#Article #NeuralNetwork #Embeddings #EfficiencyImprovement #AWS #ML-LLM Ops #Blog #A/B Testing #TwoTowerModel Issue Date: 2025-06-29 Comment
リアルタイム推薦をするユースケースにおいて、ルールベース+協調フィルタリング(Jubatus)からTwo Towerモデルに切り替えた際にレイテンシが300ms増えてしまったため、ボトルネックを特定し一部をパッチ処理にしつつもリアルタイム性を残すことで解決したという話。AWSの構成、A/Bテストや負荷テストの話もあり、実用的で非常に興味深かった。
Improving Recommendation Systems & Search in the Age of LLMs, eugeneyan, 2025.04
Paper/Blog Link My Issue
#Article #LanguageModel #Blog Issue Date: 2025-04-28
Recommendation Systems • LLM, vinjia.ai, 2025.03
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Blog #Author Thread-Post Issue Date: 2025-03-31 Comment
Netflixの推薦&検索システム最前線 - QCon San Francisco 2024現地レポート, UZABASE, 2024.12
Paper/Blog Link My Issue
#Article #Blog #KeyPoint Notes #Reading Reflections Issue Date: 2024-12-20 Comment
インフラ構成の部分が面白い。モデルの構築方法などは、まず軽量なモデルやヒューリスティックで候補を絞り、その後計算量が重いモデルでリランキングする典型的な手法。
Netflixのインフラによって、以下のようなことを
>1~2秒前の最新データを参照でき、推薦生成に反映させることが可能です
latencyを40msに抑えつつ実現しているとのこと。直前のアクションをinferenceで考慮できるのは相当性能に影響あると思われる。
また、検索と推薦をマルチタスク学習しパラメータをシェアすることで両者の性能を挙げているのが興味深い。
モデル自体は近年のLLMを用いた推薦では無く、Deepなニューラルネットに基づくモデルを採用
(まあLLMなんかにリアルタイムで推論させたらlatency 40ms未満という制約はだいぶきついと思われるしそもそも性能向上するかもわからん。予測性能とかよりも、推薦理由の生成などの他タスクも同時に実施できるのは強みではあるとは思うが…)。
まあしかし、すごい目新しい情報があったかと言われると基本的な内容に留まっているのでそうでもないという感想ではある。
Augmenting Recommendation Systems With LLMs, Dave AI, 2024.08
Paper/Blog Link My Issue
#Article #LanguageModel #Blog Issue Date: 2024-12-03
クリックを最大化しない推薦システム, Ryoma Sato, 2024.01
Paper/Blog Link My Issue
#Article #Slide #KeyPoint Notes #Reading Reflections Issue Date: 2024-09-15 Comment
おもしろそうなので後で読む
クリック率やコンバージョン率に最適化することが従来のやり方だが、クリックベイトのため粗悪なコンテンツを推薦してしまったり、人気のあるアイテムに推薦リストが偏ってしまい、長期的なユーザの利益を害するという話。
20年くらい前からこの辺をなんとかするために、推薦のセレンディピティや多様性を考慮する手法が研究されており、それらのエッセンスが紹介されている。また、Calibrated Recommendation [Paper Note] Calibrated Recommendation, Herald Steck, Netflix, RecSys'18
(ユーザの推薦リストがのジャンルの比率がユーザの好む比率になるように最適化する方法で、劣モジュラ関数を最適化するためgreedyに解いてもある程度良い近似解が保証されている)などの概要も説明されていて非常に勉強になった。
セレンディピティのある推薦アルゴリズムをGoogle上でA/Bテストしたら、ユーザの満足度とコアユーザー転換率が大幅に向上したと言う話や、推薦はフィルターバブル問題を実は悪化させないといった研究がGroupLensのKonstan先生のチームから出ているなど、興味深い話題が盛りだくさんだった。
NewsPicksに推薦システムを本番投入する上で一番優先すべきだったこと, 2024.08
Paper/Blog Link My Issue
#Article #NeuralNetwork #CTRPrediction #NewsRecommendation #ML-LLM Ops #Evaluation #Blog #A/B Testing #One-Line Notes #Reading Reflections Issue Date: 2024-08-31 Comment
>推薦モデルの良し悪しをより高い確度で評価できる実験を、より簡単に実行できる状態を作ることでした。平たく言えば「いかにA/Bテストしやすい推薦システムを設計するか」が最も重要だった訳です。
オフライン評価とオンライン評価の相関がない系の話で、A/Bテストを容易に実施できる環境になかった、かつCTRが実際に向上したモデルがオフライン評価での性能が現行モデルよりも悪く、意思決定がなかなかできなかった、という話。
うーんやはり、推薦におけるオフライン評価ってあまりあてにできないよね、、、
そもそも新たなモデルをデプロイした時点で、テストした時とデータの分布が変わるわけだし、、、
Off-Policy Evaluationの話は勉強したい。
あと、定性評価は重要
10Xの推薦を作るチームとML platform, 2024.08
Paper/Blog Link My Issue
#Article #MachineLearning #Blog #Initial Impression Notes Issue Date: 2024-08-27 Comment
初期開発における定性評価の重要性やインターリービングの話題など実用的な内容が書かれているように見える。あとで読む。
定性評価が重要という話は、
- NewsPicksに推薦システムを本番投入する上で一番優先すべきだったこと, 2024.08
でも言及されている
list of recommender systems
Paper/Blog Link My Issue
#Article #Survey #Dataset #Library #Repository #OpenSource #One-Line Notes Issue Date: 2024-08-07 Comment
推薦システムに関するSaaS, OpenSource, Datasetなどがまとめられているリポジトリ
推薦・機械学習勉強会, Wantedly
Paper/Blog Link My Issue
#Article #Tutorial #Blog #One-Line Notes Issue Date: 2024-04-26 Comment
WantedlyさんのRecSys勉強会の資料がまとまったリポジトリ。継続的に更新されており、最近この辺のトピックは追いきれていないので非常に有用。
Recommenders, recommenders-team, 2018.12
Paper/Blog Link My Issue
#Article #Library #Repository #One-Line Notes Issue Date: 2024-01-15 Comment
古典的な手法から、Deepな手法まで非常に幅広く網羅された推薦アルゴリズムのフレームワーク。元々Microsoft配下だった模様。
現在もメンテナンスが続いており、良さそう
モバオクでのリアルタイムレコメンドシステムの紹介
Paper/Blog Link My Issue
#Article #ML-LLM Ops #Slide #One-Line Notes #Reading Reflections Issue Date: 2023-12-19 Comment
DeNAでのRecSysのアーキテクチャ(バッチ、リアルタイム)が紹介されている。バッチではワークフローエンジンとしてVertex AI Pipelineが用いられている。リアルタイムになるとアーキテクチャが非常に複雑になっている。
複雑なアーキテクチャだが、Generative Recommendation使ったらもっとすっきりしそうだなーと思いつつ、レイテンシと運用コストの課題があるのでまだ実用段階じゃないよね、と思うなどした。
リアルタイム推薦によって、バッチで日毎の更新だった場合と比べ、入札率、クリック率、回遊率が大きく改善したのは面白い。
Lessons Learnt From Consolidating ML Models in a Large Scale Recommendation System, Netflix Technology Blog, 2023.08
Paper/Blog Link My Issue
#Article #ML-LLM Ops #Blog #KeyPoint Notes Issue Date: 2023-09-05 Comment
推薦システムには様々なusecaseが存在しており、それらは別々に運用されることが多い。
- user-item recommendation
- item-item recommendation
- query-item recommendation
- category-item recommendation
このような運用はシステムの技術負債を増大させ、長期的に見るとメンテナンスコストが膨大なものとなってしまう。また、多くの推薦システムには共通化できる部分がある。
これら異なるusecaseの推薦システムをmulti-taskなモデルに統合し技術負債を軽減した経験が記述されている。
これが
このようなsingle multi-task modelを学習する構造に置き換わり、
その結果
- code量とデプロイの管理・メンテナンスコストの低減
- 保守性の向上
- 単一化されたコードベースが、緊急時の対応を容易にした
- あるユースケースで新たなfeatureを試し効果があった場合、他のユースケースに迅速に展開可能(同じパイプラインなので)
- ただし、multi taskの場合は特定のタスクに効果があったfeatureの導入により他タスクの性能が低下する懸念がある
- が、タスク間の関連性が高い場合(今回のような場合)、それは問題とならなかったことが記述されている
- 柔軟な設計の実現
- 複数のユースケースを一つのモデルに統合することは、複数のユースケースを組み込むための柔軟な設計が求められる
- これを実現したことにより、拡張性が増大した
- 結論
- このような統合がコードを簡略化し、イノベーションを加速させ、システムの保守性を向上させるシナリオが多くある
- ただし、ランキングの対象が異なっていたり、入力として活用する特徴量が大きく異なるモデル間で、このような統合の実施に適しているかは自明ではない
The AI behind unconnected content recommendations on Facebook and Instagram, Meta, 2023.6
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2023-07-01
awesome-generative-information-retrieval
Paper/Blog Link My Issue
#Article #Survey #GenerativeAI #One-Line Notes #needs-revision Issue Date: 2023-05-10 Comment
Generativeなモデルを利用したDocument RetrievalやRecSys等についてまとまっているリポジトリ
SNAP: Web data: Amazon reviews
Paper/Blog Link My Issue
#Article #NLP #Dataset Issue Date: 2023-05-06
E-Commerce product recommendation agents: use, characteristics, and impact
Paper/Blog Link My Issue
#Article Issue Date: 2023-04-28 Comment
超重要論文
Measuring the impact of online personalisation: Past, present and future
Paper/Blog Link My Issue
#Article #Survey #InformationRetrieval #Personalization #KeyPoint Notes #needs-revision Issue Date: 2023-04-28 Comment
Personalizationに関するML, RecSys, HCI, Personalized IRといったさまざまな分野の評価方法に関するSurvey
ML + RecSys系では、オフライン評価が主流であり、よりaccuracyの高い推薦が高いUXを実現するという前提に基づいて評価されてきた。一方HCIの分野ではaccuracyに特化しすぎるとUXの観点で不十分であることが指摘されており、たとえば既知のアイテムを推薦してしまったり、似たようなアイテムばかりが選択されユーザにとって有用ではなくなる、といったことが指摘されている。このため、ML, RecSys系の評価ではdiversity, novelty, serendipity, popularity, freshness等の新たなmetricが評価されるように変化してきた。また、accuracyの工場がUXの向上に必ずしもつながらないことが多くの研究で示されている。
一方、HCIやInformation Systems, Personalized IRはuser centricな実験が主流であり、personalizationは
- 情報アクセスに対するコストの最小化
- UXの改善
- コンピュータデバイスをより効率的に利用できるようにする
という3点を実現するための手段として捉えられている。HCIの分野では、personalizationの認知的な側面についても研究されてきた。
たとえば、ユーザは自己言及的なメッセージやrelevantなコンテンツが提示される場合、両方の状況においてpersonalizationされたと認知し、後から思い出せるのはrelevantなコンテンツに関することだという研究成果が出ている。このことから、自己言及的なメッセージングでユーザをstimulusすることも大事だが、relevantなコンテンツをきちんと提示することが重要であることが示されている。また、personalizationされたとユーザが認知するのは、必ずしもpersonalizationのプロセスに依存するのではなく、結局のところユーザが期待したメッセージを受け取ったか否かに帰結することも示されている。
user-centricな評価とオフライン評価の間にも不一致が見つかっている。たとえば
- オフラインで高い精度を持つアルゴリズムはニッチな推薦を隠している
- i.e. popularityが高くrelevantな推薦した方がシステムの精度としては高く出るため
- オフライン vs. オンラインの比較で、ユーザがアルゴリズムの精度に対して異なる順位付けをする
といったことが知られている。
そのほかにも、企業ではofflineテスト -> betaテスターによるexploratoryなテスト -> A/Bテストといった流れになることが多く、Cognitive Scienceの分野の評価方法等にも触れている。
Training a recommendation model with dynamic embeddings, TensorFlow Blog, 2023.04
Paper/Blog Link My Issue
#Article #Tutorial #Embeddings #EfficiencyImprovement #Library #Blog #KeyPoint Notes Issue Date: 2023-04-25 Comment
dynamic embeddingを使った推薦システムの構築方法の解説
(理解が間違っているかもしれないが)推薦システムは典型的にはユーザとアイテムをベクトル表現し、関連度を測ることで推薦をしている。この枠組みをめっちゃスケールさせるととんでもない数のEmbeddingを保持することになり、メモリ上にEmbeddingテーブルを保持して置けなくなる。特にこれはonline machine learning(たとえばユーザのセッションがアイテムのsequenceで表現されたとき、そのsequenceを表すEmbeddingを計算し保持しておき、アイテムとの関連度を測ることで推薦するアイテムを決める、みたいなことが必要)では顕著である(この辺の理解が浅い)。しかし、ほとんどのEmbeddingはrarely seenなので、厳密なEmbeddingを保持しておくことに実用上の意味はなく、それらを単一のベクトルでできるとメモリ節約になって嬉しい(こういった処理をしてもtopNの推薦結果は変わらないと思われるので)。
これがdynamic embeddingのモチベであり、どうやってそれをTFで実装するか解説している。
推薦システムにおいて線形モデルがまだまだ有用な話, CyberAgent Developers Blog, 2022.12
Paper/Blog Link My Issue
#Article #Tutorial #Blog Issue Date: 2022-12-19
A Paper List for Recommend-system PreTrained Models
Paper/Blog Link My Issue
#Article #Survey #Pretraining #LanguageModel #pretrained-LM #Encoder #Decoder Issue Date: 2022-12-01
2010年代前半のAIの巨人達のCTR Prediction研究
Paper/Blog Link My Issue
#Article #Survey #CTRPrediction #Reference Collection Issue Date: 2021-10-29
バンディットアルゴリズムを使って広告最適化のシミュレーションをしてみたよ, ysekky, 2014
Paper/Blog Link My Issue
#Article #Tutorial #CTRPrediction #Blog #One-Line Notes Issue Date: 2021-10-29 Comment
なぜクリック率を上げたいのかという説明が非常に参考になる
pytorch-fm, 2020
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #Library #FactorizationMachines #Repository #One-Line Notes Issue Date: 2021-07-03 Comment
下記モデルが実装されているすごいリポジトリ。論文もリンクも記載されており、Factorization Machinesを勉強する際に非常に参考になると思う。MITライセンス。各手法はCriteoのCTRPredictionにおいて、AUC0.8くらい出ているらしい。
- Logistic Regression
- Factorization Machine
- Field-aware Factorization Machine
- Higher-Order Factorization Machines
- Factorization-Supported Neural Network
- Wide&Deep
- Attentional Factorization Machine
- Neural Factorization Machine
- Neural Collaborative Filtering
- Field-aware Neural Factorization Machine
- Product Neural Network
- Deep Cross Network
- DeepFM
- xDeepFM
- AutoInt (Automatic Feature Interaction Model)
- AFN(AdaptiveFactorizationNetwork Model)
Continuously Improving Recommender Systems for Competitive Advantage Using NVIDIA Merlin and MLOps, Nvidia, 2021.01
Paper/Blog Link My Issue
#Article #Tutorial #One-Line Notes Issue Date: 2021-07-02 Comment
Recommender System運用のためのアーキテクチャに関する情報
Criteo Dataset, Display Advertising Challenge, Kaggle, 2014
Paper/Blog Link My Issue
#Article #Dataset #CTRPrediction #KeyPoint Notes Issue Date: 2021-06-01 Comment
Criteo Dataset (
https://www.kaggle.com/c/criteo-display-ad-challenge/data)
DeepFM等のモデルで利用されているCTR Predictionのためのデータセット
# Data Description
- train.csv: 7日間のcriteoのtraffic recordの一部。個々の行が1 impに対応している。click, non-clickのラベル付き。chronologically order. click, non-clickのexampleはデータセットのサイズを縮小するために異なるrateでサブサンプルされている。
- training: trainingデータと同様の作成データだが、trainingデータの翌日のデータで構成されている。
# Data Fields
> - Label - Target variable that indicates if an ad was clicked (1) or not (0).
> - I1-I13 - A total of 13 columns of integer features (mostly count features).
> - C1-C26 - A total of 26 columns of categorical features. The values of these features have been hashed onto 32 bits for anonymization purposes.
13種類のinteger featureと、26種類のcategorical featuresがある。
Avazu Data (
https://www.kaggle.com/c/avazu-ctr-prediction/data)
# File descriptions
> - train - Training set. 10 days of click-through data, ordered chronologically. Non-clicks and clicks are subsampled according to different strategies.
> - test - Test set. 1 day of ads to for testing your model predictions.
sampleSubmission.csv - Sample submission file in the correct format, corresponds to the All-0.5 Benchmark.
# Data fields
> - id: ad identifier
> - click: 0/1 for non-click/click
> - hour: format is YYMMDDHH, so 14091123 means 23:00 on Sept. 11, 2014 UTC.
> - C1 -- anonymized categorical variable
> - banner_pos
> - site_id
> - site_domain
> - site_category
> - app_id
> - app_domain
> - app_category
> - device_id
> - device_ip
> - device_model
> - device_type
> - device_conn_type
> - C14-C21 -- anonymized categorical variables
基本的には click/non-click のラベルと、そのclick時の付帯情報によって構成されている模様
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17
Paper/Blog Link My Issue
#Article #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #IJCAI #One-Line Notes Issue Date: 2021-05-25 Comment
Factorization Machinesと、Deep Neural Networkを、Wide&Deepしました、という論文。Wide=Factorization Machines, Deep=DNN。
高次のFeatureと低次のFeatureを扱っているだけでなく、FMによってフィールドごとのvector-wiseな交互作用、DNNではbit-wiseな交互作用を利用している。
割と色々なデータでうまくいきそうな手法に見える。
発展版としてxDeepFM [Paper Note] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Jianxun Lian+, arXiv'18, 2018.03
がある。
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
[Paper Note] Sequence-Aware Recommender Systems, Massimo Quadrana+, ACM Computing Surveys (CSUR), Volume 51, Issue 4, 2018.02
Paper/Blog Link My Issue
#Article #Survey #SequentialRecommendation #Reading Reflections Issue Date: 2020-11-13 GPT Summary- レコメンドシステムは、機械学習を用いた成功したデータマイニングの応用であり、従来は単一のユーザー-アイテムインタラクションに基づいていましたが、実際のアプリケーションでは時間とともに多様なインタラクションが記録されます。本研究は、これらの逐次的なインタラクションを考慮した推薦プロセスに関する既存研究を概観し、関連するタスクと目標の分類を提案。さらに、シーケンス情報を利用したレコメンダーシステムのベンチマーク方法論と未解決の課題について議論します。 Comment
評価方法の議論が非常に参考になる。特に、Survey執筆時点において、コミュニティの中でデータ分割方法について標準化されたものがないといった話は参考になる。
Airbnbの機械学習導入から学ぶ, Jun Ernesto Okumura, 2020.08
Paper/Blog Link My Issue
#Article #Embeddings #SessionBased #Slide #SequentialRecommendation Issue Date: 2020-08-29
Off Policy Evaluation の基礎とOpen Bandit Dataset & Pipelineの紹介, Yuta Saito, 2020.08
Paper/Blog Link My Issue
#Article #Tutorial #Tools #Dataset #Slide #One-Line Notes Issue Date: 2020-08-29 Comment
機械学習による予測精度ではなく、機械学習モデルによって生じる意思決定を、過去の蓄積されたデータから評価する(Off policy Evaluation)の、tutorialおよび実装、データセットについて紹介。
このような観点は実務上あるし、見落としがちだと思うので、とても興味深い。
Open Bandit Dataset, ZOZO RESEARCH, 2020
Paper/Blog Link My Issue
#Article #Dataset #Blog Issue Date: 2020-08-29 Comment
Open Bandit pipelineも参照
資料:
https://speakerdeck.com/usaito/off-policy-evaluationfalseji-chu-toopen-bandit-dataset-and-pipelinefalseshao-jie
Collaborative Metric Learningまとめ, guglilac, 2020.01
Paper/Blog Link My Issue
#Article #Tutorial #CollaborativeFiltering #ContrastiveLearning #Blog #One-Line Notes Issue Date: 2020-07-30 Comment
userのembeddingに対し、このuserと共起した(購入やクリックされた)itemを近くに、共起していないitemを遠くに埋め込むような学習方法
Implicit
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #Library #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2019-09-11 Comment
Implicitデータに対するCollaborative Filtering手法がまとまっているライブラリ
Bayesian Personalized Ranking, Logistic Matrix Factorizationなどが実装。
Implicitの使い方はこの記事がわかりやすい:
https://towardsdatascience.com/building-a-collaborative-filtering-recommender-system-with-clickstream-data-dffc86c8c65
ALSの元論文の日本語解説
https://cympfh.cc/paper/WRMF
Recommender System Datasets, Julian McAuley
Paper/Blog Link My Issue
#Article #Dataset #Selected Papers/Blogs #One-Line Notes Issue Date: 2019-04-12 Comment
Recommender Systems研究に利用できる各種データセットを、Julian McAuley氏がまとめている。
氏が独自にクロールしたデータ等も含まれている。
非常に有用。
Designing and Evaluating Explanations for Recommender Systems, Tintarev+, Recommender Systems Handbook, 2011
Paper/Blog Link My Issue
#Article #Tutorial #Explanation #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2019-01-23 Comment
Recommender Systems HandbookのChapter。[Paper Note] A Survey of Explanations in Recommender Systems, Tintarev+, ICDEW'07
のSurveyと同じ著者による執筆。
推薦のExplanationといえばこの人というイメージ。
D論: http://navatintarev.com/papers/Nava%20Tintarev_PhD_Thesis_(2010).pdf
[Paper Note] Simulated Analysis of MAUT Collaborative Filtering for Learning Object Recommendation, Manouselis+, Social Information Retrieval for Technology-Enhanced Learning & Exchange, 2007
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #AdaptiveLearning #KeyPoint Notes Issue Date: 2018-12-22 Comment
教員に対して教材を推薦しようという試み(学生ではないようだ)。
教員は、learning resourcesに対して、multi-criteriaなratingを付与することができ、それをCFで活用する(CELEBRATE web portalというヨーロッパのポータルを使用したらしい)。
CFはmemory-basedな手法を使用。target userがあるアイテムを、それぞれのattributeの観点からどのようにratingするかをattributeごとに別々に予測。各attributeのスコアを最終的に統合(元の論文ではただのスコアの足し合わせ)して、推薦スコアとする。
以下が調査された:
1. ユーザ間の距離の測り方(ユークリッド距離、cossim、ピアソンの相関係数)
2. neighborsの選び方(定義しておいた最大人数か、相関の重みで選ぶか)
3. neighborのratingをどのように組み合わせるか(平均、重み付き平均、mean formulaからのdeviation)
評価する際は、ratingのデータを training/test 80%/20%に分割。テストセットのアイテムに対して、ユーザがratingした情報をどれだけ正しく予測できるかで検証(511 evaluation in test, 2043 evaluations in training)。
ratingのMAE, coverage, アルゴリズムの実行時間で評価。
CorrerationWeightThresholdが各種アルゴリズムで安定した性能。Maximum Number Userはばらつきがでかい。いい感じの設定がみつかれば、Maximum Number Userの方がMAEの観点からは強い。
top-10のアイテムをselectするようにしたら、60%のcoverageになった。
(アルゴリズムの実行時間は、2000程度のevaluationデータに対して、2.5GHZ CPU, 256MEMで20秒とかかかってる。)
Learning Resource Exchangeの文脈で使われることを想定(このシステムではヨーロッパのK-12)。
教員による教材のmulti-criteriaのratingは5-scaleで行われた。
どういうcriteriaに対してratingされたかが書かれていない。
[Paper Note] Recommender Systems for Technology Enhanced Learning: Research Trends and Applications, Manouselis+, 2014.04
Paper/Blog Link My Issue
#Article #Survey #TechnologyEnhancedLearning #AdaptiveLearning #One-Line Notes Issue Date: 2018-12-22 Comment
最近のトレンドやアプリケーションを知りたい場合はこちら
[Paper Note] Panorama of recommender systems to support learning, Drachsler+, 2015.12
Paper/Blog Link My Issue
#Article #Survey #Education #AdaptiveLearning #One-Line Notes Issue Date: 2018-12-22 Comment
教育分野に対するRecsysのSurvey
[Paper Note] Some Challenges for Context-aware Recommender Systems, Yujie+, Proc. Fifth Int’l Conf. Computer Science and Education (ICCSE), pp. 362-365, 2010.08
Paper/Blog Link My Issue
#Article #ContextAware Issue Date: 2018-12-22
[Paper Note] Context-Aware Recommender Systems, Adomavicius+, Recommender Systems Handbook, 2011.09
Paper/Blog Link My Issue
#Article #Classic #ContextAware #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-12-22 Comment
Context-aware Recsysのパイオニア的研究
通常のuser/item paradigmを拡張して、いかにコンテキストの情報を考慮するかを研究。
コンテキスト情報は、
Explicit: ユーザのマニュアルインプットから取得
Implicit: 自動的に取得
inferred: ユーザとツールやリソースのインタラクションから推測(たとえば現在のユーザのタスクとか)
いくつかの異なるパラダイムが提案された:
1. recommendation via context-driven querying and search approach
コンテキストの情報を、特定のリポジトリのリソース(レストラン)に対して、クエリや検索に用いる。そして、best matchingなリソースを(たとえば、現在開いているもっとも近いレストランとか)をユーザに推薦。
2. Contextual preference elicitation and estimation approach
こっちは2012年くらいの主流。contextual user preferencesをモデル化し学習する。データレコードをしばしば、
3. contextual prefiltering approach
contextualな情報を(学習したcontextualなpreferenceなどを)、tradittionalなrecommendation algorithmを適用する前にデータのフィルタリングに用いる。
4. contextual postfiltering approach
entire setから推薦を作り、あとでcontextの情報を使ってsetを整える。
5. Contextual modeling
contextualな情報を、そのままrecommendationの関数にぶちこんでしまい、アイテムのratingのexplicitなpredictorとして使う。
3, 4はtraditionalな推薦アルゴリズムが適用できる。
1,2,5はmulti-dimensionalな推薦アルゴリズムになる。heuristic-based, model-based approachesが述べられているらしい。
[Paper Note] Recommender Systems in Technology Enhanced Learning, Manouselis+, Recommender Systems Handbook, 2011.10
Paper/Blog Link My Issue
#Article #Survey #Education #TechnologyEnhancedLearning #AdaptiveLearning Issue Date: 2018-12-22
[Paper Note] Personal recommender systems for learners in lifelong learning networks: the requirements, techniques and model, Drachsler+, Int. J. Learning Technology 3(4), 2008.07
Paper/Blog Link My Issue
#Article #Survey #Education #AdaptiveLearning Issue Date: 2018-12-22
[Paper Note] Recommender Systems in Technology Enhanced Learning, Manouselis+, Recommender Systems Handbook: A Complete Guide for Research Scientists and Practitioners, 2011.10
Paper/Blog Link My Issue
#Article #Survey #Education #TechnologyEnhancedLearning Issue Date: 2018-03-30
[Paper Note] Context-Aware Recommender Systems for Learning: A Survey and Future Challenges, Verbert+, IEEE TRANSACTIONS ON LEARNING TECHNOLOGIES, VOL. 5, NO. 4, OCTOBER-DECEMBER 2012.04
Paper/Blog Link My Issue
#Article #Survey #Education #TechnologyEnhancedLearning Issue Date: 2018-03-30
[Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008.12
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #MatrixFactorization #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-11 Comment
Implicit Feedbackなデータに特化したMatrix Factorization (MF)、Weighted Matrix Factorization (WMF)を提案。
ユーザのExplicitなFeedback(ratingやlike, dislikeなど)がなくても、MFが適用可能。
目的関数は式(3)のようになっている。
通常のMFでは、ダイレクトにrating r_{ui}を予測したりするが、WMFでは r_{ui}をratingではなく、たとえばユーザuがアイテムiを消費した回数などに置き換え、binarizeした数値p_{ui}を目的関数に用いる。
このとき、itemを消費した回数が多いほど、そのユーザはそのitemを好んでいると仮定し、そのような事例については重みが高くなるようにconfidence c_{ui}を計算し、目的関数に導入している。
日本語での解説: https://cympfh.cc/paper/WRMF
Implicit Implicit でのAlternating Least Square (ALS)という手法が、この手法の実装に該当する。
[Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
Paper/Blog Link My Issue
#Article #Tools #CollaborativeFiltering #MatrixFactorization #One-Line Notes #JMLR Issue Date: 2018-01-11 Comment
tool: http://apex.sjtu.edu.cn/projects/33
Ratingの情報だけでなく、Auxiliaryな情報も使ってMatrix Factorizationができるツールを作成した。
これにより、Rating Matrixの情報だけでなく、自身で設計したfeatureをMFに組み込んでモデルを作ることができる。
[Paper Note] 利用者の好みをとらえ活かす-嗜好抽出技術の最前線, 土方嘉徳, 2007.09
Paper/Blog Link My Issue
#Article #Survey Issue Date: 2018-01-01
推薦システムのアルゴリズム, 神嶌, 2016.09
Paper/Blog Link My Issue
#Article #Survey #Selected Papers/Blogs Issue Date: 2018-01-01
[Paper Note] A Survey on Challenges and Methods in News Recommendation, O¨zgo¨bek+, 2014.01
Paper/Blog Link My Issue
#Article #Survey Issue Date: 2018-01-01
[Paper Note] A Survey and Critique of Deep Learning on Recommender Systems, Lei Zheng
Paper/Blog Link My Issue
#Article #Survey Issue Date: 2018-01-01
GraphChi, GraphChi open source project, 2013.01
Paper/Blog Link My Issue
#Article #Tools #One-Line Notes Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:Matrix Factorization, RBM, CliMFなど
実装:
使用方法:CLI
※ graphlabの中の人による実装
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
mrec recommender systems library, mrec, 2013.11
Paper/Blog Link My Issue
#Article #Library #python #One-Line Notes Issue Date: 2018-01-01 Comment
実装:python
※ Mendeleyによるpythonライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
MyMediaLite Recommender System Library, Zeno Gantner+
Paper/Blog Link My Issue
#Article #Tools #Library #One-Line Notes Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:C#
使用方法:コマンドライン、C#ライブラリとして利用
※ ライブラリとして使用する場合は、C#による実装が必要
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
Surprise: A Python library for recommender systems, Nicolas Hug, 2016.10
Paper/Blog Link My Issue
#Article #Library #python #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:python
使用方法:pythonライブラリとして利用
※ pythonで利用できる数少ない推薦システムライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] Relevance Judgment in epistemic and hedonic information searches, Yunjie Xu, Journal of the American Society for Information Science and Technology, 2007.01
Paper/Blog Link My Issue
#Article #RelevanceJudgment #One-Line Notes Issue Date: 2017-12-28 Comment
・informative relevance: 知識を求める検索など(個人のブログ,経済ニュースとか)
・affective relevance: 楽しみや感情に刺激を受けるための情報を求める検索の場合(2chまとめとか,哲学ニュースまとめとか?)
・topicality, novelty, reliabilityがsignificantにinformative relevanceに寄与, scopeとunderstandabilityは寄与せず
・topicality, understandabilityがsignificantにaffective relevanceに寄与,しかし,noveltyはそうではなかった.
[Paper Note] Discovery-oriented Collaborative Filtering for Improving User Satisfaction, Hijikata+, IUI’09
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #Novelty #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 Comment
・従来のCFはaccuracyをあげることを目的に研究されてきたが,ユーザがすでに知っているitemを推薦してしまう問題がある.おまけに(推薦リスト内のアイテムの観点からみた)diversityも低い.このような推薦はdiscoveryがなく,user satisfactionを損ねるので,ユーザがすでに何を知っているかの情報を使ってよりdiscoveryのある推薦をCFでやりましょうという話.
・特徴としてユーザのitemへのratingに加え,そのitemをユーザが知っていたかどうかexplicit feedbackしてもらう必要がある.
・手法は単純で,User-based,あるいはItem-based CFを用いてpreferenceとあるitemをユーザが知っていそうかどうかの確率を求め,それらを組み合わせる,あるいはrating-matrixにユーザがあるitemを知っていたか否かの数値を組み合わせて新たなmatrixを作り,そのmatrix上でCFするといったもの.
・offline評価の結果,通常のCF,topic diversification手法と比べてprecisionは低いものの,discovery ratioとprecision(novelty)は圧倒的に高い.
・ユーザがitemを知っていたかどうかというbinary ratingはユーザに負荷がかかるし,音楽推薦の場合previewがなければそもそも提供されていないからratingできないなど,必ずしも多く集められるデータではない.そこで,データセットのratingの情報を25%, 50%, 75%に削ってratingの数にbiasをかけた上で実験をしている.その結果,事前にratingをcombineし新たなmatrixを作る手法はratingが少ないとあまりうまくいかなかった.
・さらにonlineでuser satisfaction(3つの目的のもとsatisfactionをratingしてもらう 1. purchase 2. on-demand-listening 3. discovery)を評価した. 結果,purchaseとdiscoveryにおいては,ベースラインを上回った.ただし,これは推薦リスト中の満足したitemの数の問題で,推薦リスト全体がどうだった
かと問われた場合は,ベースラインと同等程度だった.
重要論文
[Paper Note] “I like to explore sometimes”: Adapting to Dynamic User Novelty Preferences, Kapoor et al. (with Konstan), RecSys’15
Paper/Blog Link My Issue
#Article #Novelty #RecSys #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-28 Comment
・典型的なRSは,推薦リストのSimilarityとNoveltyのcriteriaを最適化する.このとき,両者のバランスを取るためになんらかの定数を導入してバランスをとるが,この定数はユーザやタイミングごとに異なると考えられるので(すなわち人やタイミングによってnoveltyのpreferenceが変化するということ),それをuserの過去のbehaviorからpredictするモデルを考えましたという論文.
・式中によくtが出てくるが,tはfamiliar setとnovel setをわけるためのみにもっぱら使われていることに注意.昼だとか夜だとかそういう話ではない.familiar setとは[t-T, t]の間に消費したアイテム,novel setはfamiliar setに含まれないitemのこと.
・データはmusic consumption logsを使う.last.fmやproprietary dataset.データにlistening以外のexplicit feedback (rating)などの情報はない
・itemのnoveltyの考え方はユーザ側からみるか,システム側から見るかで分類が変わる.三種類の分類がある.
(a) new to system: システムにとってitemが新しい.ゆえにユーザは全員そのitemを知らない.
(b) new to user: システムはitemを知っているが,ユーザは知らない.
(c) oblivious/forgotten item: 過去にユーザが知っていたが,最後のconsumptionから時間が経過しいくぶんunfamiliarになったitem
Repetition of forgotten items in future consumptions has been shown to produce increased diversity and emotional excitement.
この研究では(b), (c)を対象とする.
・userのnovelty preferenceについて二つの仮定をおいている.
1. ユーザごとにnovelty preferenceは違う.
2. ユーザのnovelty preferenceはdynamicに変化する.trainingデータを使ってこの仮定の正しさを検証している.
・novelty preferenceのpredictは二種類の素性(familiar set diversityとcumulative negative preference for items in the familiar set)を使う. 前者は,familiar setの中のradioをどれだけ繰り返しきいているかを用いてdiversityを定義.繰り返し聞いているほうがdiversity低い.後者は,異なるitemの消費をする間隔によってdynamic preference scoreを決定.familiar set内の各itemについて負のdynamic preference scoreをsummationすることで,ユーザの”退屈度合い”を算出している.
・両素性を考慮することでnovelty preferenceのRMSEがsignificantに減少することを確認.
・推薦はNoveltyのあるitemの推薦にはHijikataらの協調フィルタリングなどを使うこともできる.
・しかし今回は簡易なitem-based CFを用いる.ratingの情報がないので,それはdynamic preference scoreを代わりに使い各itemのスコアを求め,そこからnovel recommendationとfamiliar recommendationのリストを生成し,novelty preferenceによって両者を組み合わせる.
・音楽(というより音楽のradioやアーティスト)の推薦を考えている状況なので,re-consumptionが許容されている.Newsなどとは少しドメインが違うことに注意.
[Paper Note] SCENE: A Scalable Two-Stage Personalized News Recommendation System, Li et al., SIGIR’11
Paper/Blog Link My Issue
#Article #Document #NewsRecommendation #Personalization #SIGIR #One-Line Notes Issue Date: 2017-12-28 Comment
・ニュース推薦には3つのチャレンジがある。
1. スケーラビリティ より高速なreal-time processing
2. あるニュース記事を読むと、続いて読む記事に影響を与える
3. popularityとrecencyが時間経過に従い変化するので、これらをどう扱うか
これらに対処する手法を提案
[Paper Note] A semantic-expansion approach to personalized knowledge recommendation, Liang, Yang, Chen and Ku, Decision Support Systems, 2008.06
Paper/Blog Link My Issue
#Article #Document #One-Line Notes Issue Date: 2017-12-28 Comment
・traditionalなkeywordベースでマッチングするアプローチだと,単語間の意味的な関係によって特定の単語のoverweightやunderweightが発生するので,advancedなsemanticsを考慮した手法が必要なので頑張りますという論文.
[Paper Note] Combination of Web page recommender systems, Goksedef, Gunduz-oguducu, Elsevier, 2010.04
Paper/Blog Link My Issue
#Article #Document #KeyPoint Notes Issue Date: 2017-12-28 Comment
・traditionalなmethodはweb usage or web content mining techniquesを用いているが,ニュースサイトなどのページは日々更新されるのでweb content mining techniquesを用いてモデルを更新するのはしんどい.ので,web usage mining(CFとか?どちらかというとサーバログからassociation ruleを見つけるような手法か)にフォーカス.
・web usage miningに基づく様々な手法をhybridすることでどれだけaccuracyが改善するかみる.
・ユーザがセッションにおいて次にどのページを訪れるかをpredictし推薦するような枠組み(不特定多数のページを母集団とするわけではなく,自分のサイト内のページが母集団というパターンか)
・4種類の既存研究を紹介し,それらをどうcombineするかでaccuraryがどう変化しているかを見ている.
・それぞれの手法は,ユーザのsessionの情報を使いassociation rule miningやclusteringを行い次のページを予測する手法.
[Paper Note] Neural Networks for Web Content Filtering, Lee, Fui and Fong, IEEE Intelligent Systems, 2002.09
Paper/Blog Link My Issue
#Article #NeuralNetwork #Document #DataFiltering #KeyPoint Notes Issue Date: 2017-12-28 Comment
・ポルノコンテンツのフィルタリングが目的. 提案手法はgeneral frameworkなので他のコンテンツのフィルタリングにも使える.
・NNを採用する理由は,robustだから(様々な分布にfitする).Webpageはnoisyなので.
・trainingのためにpornographic pageを1009ページ(13カテゴリから収集),non-pornographic pageを3,777ページ収集.
・feature(主なもの)
- indicative term(ポルノっぽい単語)の頻度
- displayed contents ページのタイトル,warning message block, other viewable textから収集
- non-displayed contents descriptionやkeywordsなどのメタデータ,imageタグのtextなどから収集
・95%くらいのaccuracy
[Paper Note] User-model based personalized summarization, Diaz+, Information Processing and Management 2007.11
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #Personalization #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-28 Comment
PDSの先駆けとなった重要論文。必ずreferすべき。