
AWS
Amazon S3 Vectorsで激安RAGシステムを構築する, とすり, 2025.07
Paper/Blog Link My Issue
#Article #RAG(RetrievalAugmentedGeneration) #Blog #SoftwareEngineering Issue Date: 2025-07-17 Comment
元ポスト:
日経電子版のアプリトップ「おすすめ」をTwo Towerモデルでリプレースしました, NIKKEI, 2025.05
Paper/Blog Link My Issue
#Article #RecommenderSystems #NeuralNetwork #Embeddings #EfficiencyImprovement #MLOps #Blog #A/B Testing #TwoTowerModel Issue Date: 2025-06-29 Comment
リアルタイム推薦をするユースケースにおいて、ルールベース+協調フィルタリング(Jubatus)からTwo Towerモデルに切り替えた際にレイテンシが300ms増えてしまったため、ボトルネックを特定し一部をパッチ処理にしつつもリアルタイム性を残すことで解決したという話。AWSの構成、A/Bテストや負荷テストの話もあり、実用的で非常に興味深かった。
Webスケールの日本語-画像のインターリーブデータセット「MOMIJI」の構築 _巨大テキストデータをAWSで高速に処理するパイプライン, Turing (studio_graph), 2025.05
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #LanguageModel #MultiModal #Blog #Japanese Issue Date: 2025-05-20 Comment
貴重なVLMデータセット構築ノウハウ
青塗りのフィルタリングタスクを具体的にどうやっているのか気になる
SQL vs. NoSQL cheetsheet, AWS, Azure and Google Cloud
Paper/Blog Link My Issue
#Article #Infrastructure Issue Date: 2023-08-27 Comment
データタイプやユースケースに応じてAWS上のサービスなどをマッピングしてくれているチートシート。わかりやすい。
Lambda tips
Paper/Blog Link My Issue
#Article #Infrastructure #AWSLambda Issue Date: 2023-04-23 Comment
- AWS Lambda and EFS Troubleshooting
-
https://www.digitalsanctuary.com/aws/aws-lambda-and-efs-troubleshooting.html
- VPC内のEFSにアクセスできるようなセキュリティーポリシーを作成してアタッチすると良いという話。in-bound, out-boundともにNFSを許可
- 【AWS】VPC Lambdaを構築したときのメモ
-
https://qiita.com/aiko_han/items/6b3010250e2887206b4f
- Amazon VPC に接続されている Lambda 関数にインターネットアクセスを許可するにはどうすればよいですか?
-
https://repost.aws/ja/knowledge-center/internet-access-lambda-function
ECS tips
Paper/Blog Link My Issue
#Article #Infrastructure #ECS Issue Date: 2023-04-16 Comment
- キャパシティプロバイダーについて
-
https://dev.classmethod.jp/articles/regrwoth-capacity-provider/
- Fargateをスポットで7割引で使うFargate Spotとは? #reinvent
-
https://dev.classmethod.jp/articles/fargate-spot-detail/
- ECSでのデプロイでコケる原因ざっくりまとめ
-
https://zenn.dev/isosa/articles/e371bc2d76e812
- M1 MacでビルドしたイメージをFARGATEで使おうとした時の'exec user process caused: exec format error' の対処法
-
https://qiita.com/ms2geki/items/1cfb0db3f4c1aab96e75
- PythonでログをCloudWatchに出力する「Watchtower」
-
https://dev.classmethod.jp/articles/python_log_cloudwatch_watchtower/
データレイクのつくりかた、つかいかた、そだてかた, 関山宜孝, AWS Summit
Paper/Blog Link My Issue
#Article #Infrastructure Issue Date: 2021-10-08 Comment
こちらも参照のこと
https://logmi.jp/tech/articles/324242
◆伝統的なデータウェアハウスの限界:
場当たり的にデータを蓄積し、活用しているとデータのサイロ化が生じてしまう。
サイロ化したデータを一箇所にまとめて活用できるようにしましょうというのがData Lakeの考え方。
◆データレイクアーキテクチャ
すべてのデータを一元的に保管でき、
耐障害性、可用性が高く、スケーラブルで低コストな必要がある。
また、データは非常に多様化しているので、多様なデータをそのままのフォーマットで保管し、
活用できる必要がある。
ストレージとデータの活用層を疎結合にして、さまざまなユースケース・分析に対処できるようにする。
(たとえば、ストレージに特定のスキーマのテーブルを使っており、そのスキーマに対してしか分析できません、とかは避けるということかな?)
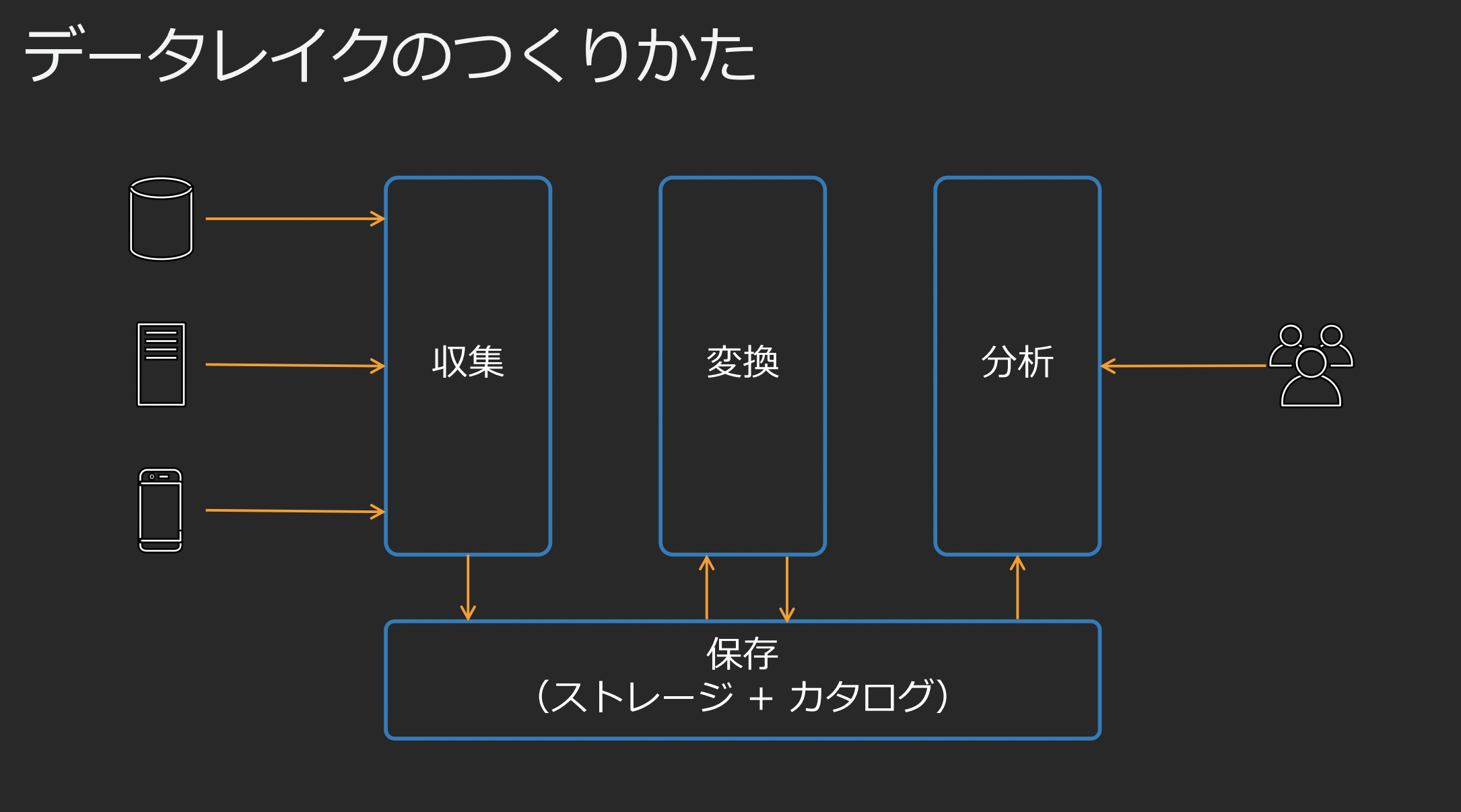
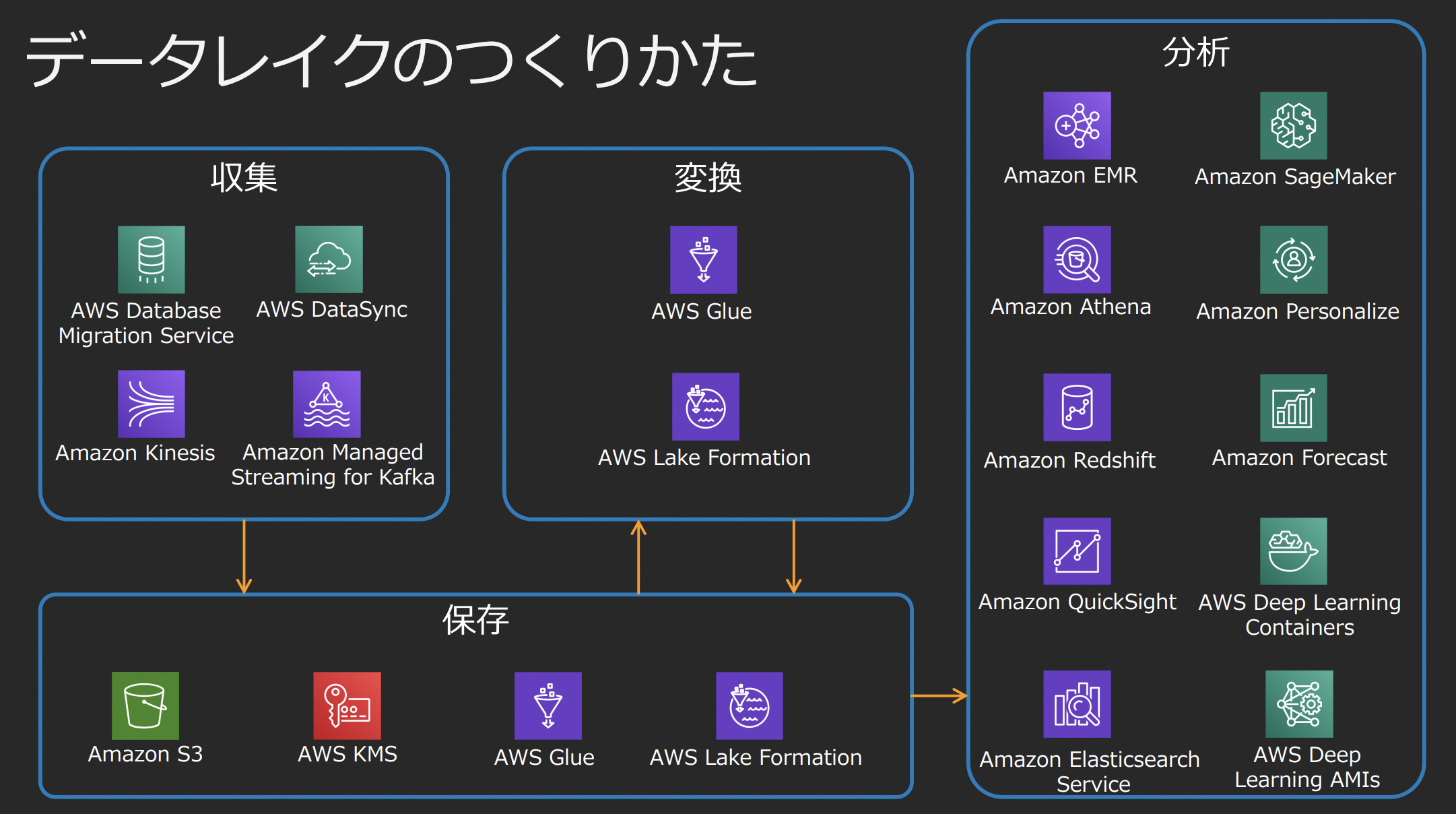
S3上に生データを保存し、AWS Glueでメタデータを管理する。AWS GlueのようなETLサービスを利用してデータを利用しやすい形式に変更して格納し、活用する。
データレイクを作る際のポイント「小さく始める」という部分も重要だと思われるので参照のこと