
AutomaticPromptEngineering
[Paper Note] Multimodal Prompt Optimization: Why Not Leverage Multiple Modalities for MLLMs, Yumin Choi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #Prompting #MultiModal Issue Date: 2025-10-14 GPT Summary- マルチモーダルプロンプト最適化(MPO)を提案し、テキストと非テキストのプロンプトを共同最適化する新たなアプローチを示す。MPOは、ベイズに基づく選択戦略を用いて候補プロンプトを選定し、画像や動画など多様なモダリティにおいてテキスト専用手法を上回る性能を発揮。これにより、MLLMsの潜在能力を最大限に引き出す重要なステップを確立。 Comment
元ポスト:
[Paper Note] Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing, Xinyu Hu+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Prompting #ICLR Issue Date: 2025-09-24 GPT Summary- Evokeという自動プロンプト洗練フレームワークを提案。レビュアーと著者のLLMがフィードバックループを形成し、プロンプトを洗練。難しいサンプルを選択することで、LLMの深い理解を促進。実験では、Evokeが論理的誤謬検出タスクで80以上のスコアを達成し、他の手法を大幅に上回る結果を示した。 Comment
openreview: https://openreview.net/forum?id=OXv0zQ1umU
pj page:
https://sites.google.com/view/evoke-llms/home
github:
https://github.com/microsoft/Evoke
githubにリポジトリはあるが、プロンプトテンプレートが書かれたtsvファイルが配置されているだけで、実験を再現するための全体のパイプラインは存在しないように見える。
PromptWizard: Task-Aware Prompt Optimization Framework, Eshaan Agarwal+, arXiv'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #Prompting Issue Date: 2025-02-10 GPT Summary- PromptWizardは、完全自動化された離散プロンプト最適化フレームワークであり、自己進化的かつ自己適応的なメカニズムを利用してプロンプトの質を向上させる。フィードバック駆動の批評を通じて、タスク特有のプロンプトを生成し、45のタスクで優れたパフォーマンスを実現。限られたデータや小規模なLLMでも効果を発揮し、コスト分析により効率性とスケーラビリティの利点が示された。 Comment
Github:
https://github.com/microsoft/PromptWizard?tab=readme-ov-file
元ポスト:
初期に提案された
- Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
と比較すると大分性能が上がってきているように見える。
reasoning modelではfewshot promptingをすると性能が落ちるという知見があるので、reasoningモデル向けのAPE手法もそのうち出現するのだろう(既にありそう)。
OpenReview:
https://openreview.net/forum?id=VZC9aJoI6a
ICLR'25にrejectされている
NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation, Shachar Rosenman+, N_A, EACL'24 Sustem Demonstration Track
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #EACL #System Demonstration Issue Date: 2023-11-23 GPT Summary- 本研究では、テキストから画像への生成モデルの品質を向上させるための適応型フレームワークNeuroPromptsを提案します。このフレームワークは、事前学習された言語モデルを使用して制約付きテキストデコーディングを行い、人間のプロンプトエンジニアが生成するものに類似したプロンプトを生成します。これにより、高品質なテキストから画像への生成が可能となり、ユーザーはスタイルの特徴を制御できます。また、大規模な人間エンジニアリングされたプロンプトのデータセットを使用した実験により、当アプローチが自動的に品質の高いプロンプトを生成し、優れた画像品質を実現することを示しました。
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Prompting #ACL #Findings Issue Date: 2023-11-13 GPT Summary- プロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
[Paper Note] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, ICML'24, 2023.09
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Prompting #ICML Issue Date: 2023-10-09 GPT Summary- Chain-of-Thought PromptingはLLMの推論能力を向上させるが、最適ではない。そこで、自己改善メカニズム「Promptbreeder」を提案。Promptbreederはタスクプロンプトを進化させ、LLMが生成した突然変異プロンプトによって改善を図る。実験では、従来のプロンプト戦略を上回る性能を示し、ヘイトスピーチ分類などの難題にも対応可能。 Comment
詳細な解説記事: https://aiboom.net/archives/56319
APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…?
Large Language Models as Optimizers, Chengrun Yang+, N_A, ICLR'24
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #ICLR Issue Date: 2023-09-09 GPT Summary- 本研究では、最適化タスクを自然言語で記述し、大規模言語モデル(LLMs)を使用して最適化を行う手法「Optimization by PROmpting(OPRO)」を提案しています。この手法では、LLMが以前の解とその値を含むプロンプトから新しい解を生成し、評価して次の最適化ステップのためのプロンプトに追加します。実験結果では、OPROによって最適化された最良のプロンプトが、人間が設計したプロンプトよりも優れていることが示されました。 Comment
`Take a deep breath and work on this problem step-by-step. `論文
# 概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。
# 手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。
Meta promptの例
openreview: https://openreview.net/forum?id=Bb4VGOWELI
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #Chain-of-Thought #Prompting #NAACL #Findings #Surface-level Notes Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。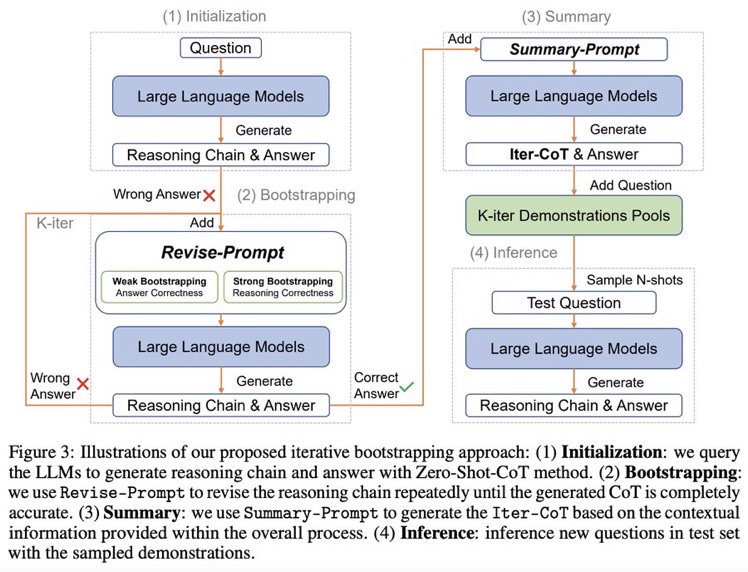
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- Automatic Chain of Thought Prompting in Large Language Models, Zhang+, Shanghai Jiao Tong University, ICLR'23
- Automatic prompt augmentation and selection with chain-of-thought from labeled data, Shum+, The Hong Kong University of Science and Technology, arXiv'23
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。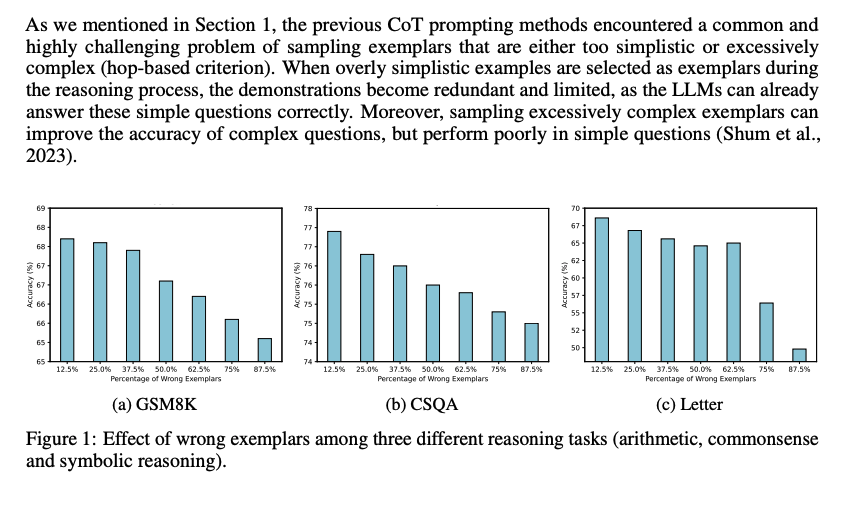
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。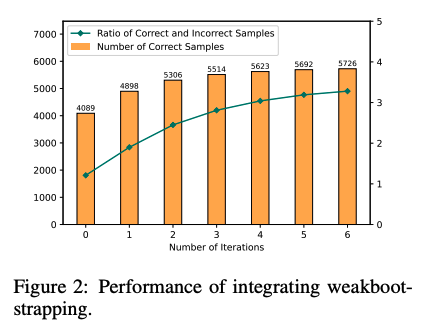
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
Random-CoT
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
Auto-CoT
- Active prompting with chain-of-thought for large language models, Diao+, The Hong Kong University of Science and Technology, ACL'24
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。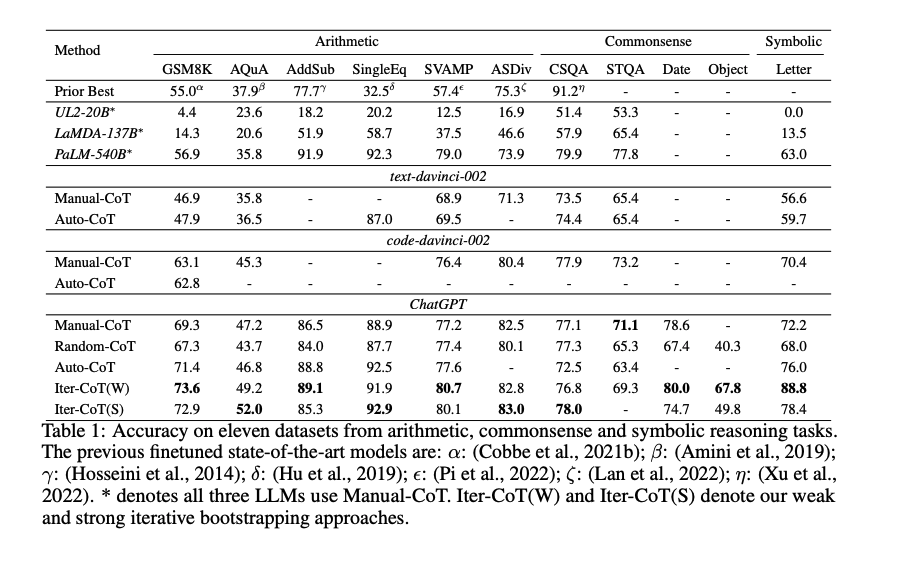
weak bootstrapingのiterationは4回くらいで頭打ちになった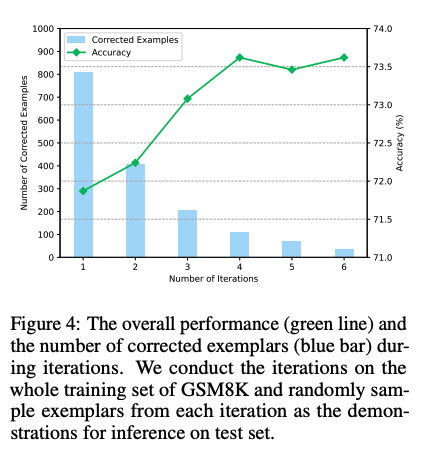
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
[Paper Note] Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback, Baolin Peng+, arXiv'23, 2023.02
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #Factuality #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-09-24 GPT Summary- LLM-Augmenterシステムを提案し、LLMが外部知識に基づいた応答を生成できるように拡張。フィードバックを用いてプロンプトを改善し、タスク指向の対話と質問応答での有効性を実証。ChatGPTの幻覚を減少させつつ、流暢さや情報量を維持。ソースコードとモデルを公開。
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #Prompting #ICLR Issue Date: 2023-09-05 GPT Summary- 大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。 Comment
プロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
openreview: https://openreview.net/forum?id=92gvk82DE-
multimodal-maestro
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Library #Prompting #MultiModal Issue Date: 2023-12-01 Comment
Large Multimodal Model (LMM)において、雑なpromptを与えるても自動的に良い感じoutputを生成してくれるっぽい?
以下の例はリポジトリからの引用であるが、この例では、"Find dog." という雑なpromptから、画像中央に位置する犬に[9]というラベルを与えました、というresponseを得られている。pipelineとしては、Visual Promptに対してまずSAMを用いてイメージのsegmentationを行い、各セグメントにラベルを振る。このラベルが振られた画像と、"Find dog." という雑なpromptを与えるだけで良い感じに処理をしてくれるようだ。
日本語LLMベンチマークと自動プロンプトエンジニアリング, PFN Blog, 2023.10
Paper/Blog Link My Issue
#Article #Analysis #NLP #Prompting #Blog Issue Date: 2023-10-13 Comment
面白かった。特に、promptingによってrinnaとcyberのLLMの順位が逆転しているのが興味深かった。GAを使ったプロンプトチューニングは最近論文も出ていたが、日本語LLMで試されているのは面白かった。