JMLR
[Paper Note] Scaling Instruction-Finetuned Language Models, Hyung Won Chung+, JMLR'24, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #OpenWeight #Selected Papers/Blogs #One-Line Notes #Scalability Issue Date: 2023-04-26 GPT Summary- 指示に基づくファインチューニングは、言語モデルの性能と一般化を向上させる。特に、タスク数やモデルサイズのスケーリング、チェーン・オブ・思考データでの適用が効果的。Flan‑PaLM 540Bは1,800件のタスクでファインチューニングを行い、PaLM 540Bを平均+9.4%上回り、最先端の結果を出している。Flan‑T5も強力なFew-shot性能を示し、指示に基づくファインチューニングがモデルの性能向上に寄与することを確認した。 Comment
T5をinstruction tuningしたFlanT5の研究
HF: https://huggingface.co/docs/transformers/model_doc/flan-t5
先行研究:
- [Paper Note] Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, ICLR'22, 2021.09
[Paper Note] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #Transformer #Architecture #MoE(Mixture-of-Experts) #Selected Papers/Blogs Issue Date: 2025-02-11 GPT Summary- Switch Transformerを提案し、Mixture of Experts (MoE)の複雑さや通信コスト、トレーニングの不安定性を改善。これにより、低精度フォーマットでの大規模スパースモデルのトレーニングが可能になり、最大7倍の事前トレーニング速度向上を実現。さらに、1兆パラメータのモデルを事前トレーニングし、T5-XXLモデルに対して4倍の速度向上を達成。
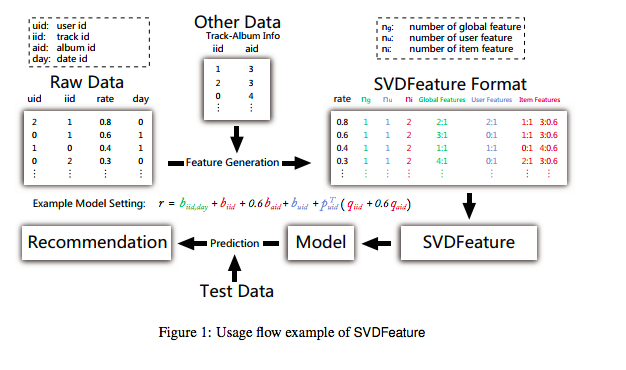
[Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tools #CollaborativeFiltering #MatrixFactorization #One-Line Notes Issue Date: 2018-01-11 Comment
tool: http://apex.sjtu.edu.cn/projects/33
Ratingの情報だけでなく、Auxiliaryな情報も使ってMatrix Factorizationができるツールを作成した。
これにより、Rating Matrixの情報だけでなく、自身で設計したfeatureをMFに組み込んでモデルを作ることができる。