
Data
[Paper Note] Autodata: An agentic data scientist to create high quality synthetic data, Ilia Kulikov+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#SyntheticData #autoresearch #Author Thread-Post Issue Date: 2026-06-26 GPT Summary- データサイエンティストとして機能するAIエージェントの一般的手法Autodataを提案。エージェントはメタ最適化を通じて高品質な訓練データを生成。計算機科学や法的推論、数学を用いた実験で、従来の手法と比較して性能向上を確認。エージェントのメタ最適化がさらなる改善をもたらし、高品質なモデル訓練を支援する可能性を示唆。 Comment
元ポスト:
[Paper Note] OpenThoughts-Agent: Data Recipes for Agentic Models, Negin Raoof+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#LanguageModel #AIAgents #Author Thread-Post Issue Date: 2026-06-25 GPT Summary- エージェント性を持つ言語モデルの訓練データを公開するOT-Agentプロジェクトが、データキュレーションの重要性に対応。100件以上のアブレーション実験を通じ、タスクソースと多様性の影響を分析。10万件の例を使用してQwen3-32Bをファインチューニングし、七つのベンチマークで平均正解率を44.8%に向上。訓練データは強いスケーリング特性を示し、他のオープンデータセットを超える結果を記録。データセットやパイプラインはopenthoughts.aiで公開し、今後の研究を支援。 Comment
元ポスト:
著者ポスト:
[Paper Note] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders, Yi Jing+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #PostTraining #CurriculumLearning #DataFiltering #One-Line Notes #SparseAutoencoder #Author Thread-Post Issue Date: 2026-05-28 GPT Summary- モデル内部情報がLLMのデータ処理方法に重要である一方、外部信号に依存したデータエンジニアリングは内在信号を無視していることを指摘。SAERLを提案し、Sparse Autoencoderを用いて多様性、難易度、品質の三つのデータ特性をモデル化。これにより、バッチ多様性や難易度の順序づけ、データフィルタリングを実現。SAERLは平均精度を3.00%向上させ、少ないトレーニングステップで目標精度に達することを示し、効果的なデータエンジニアリングツールとしての役割を果たすことが確認された。 Comment
元ポスト:
SAEのrepresentationを、interpretabilityに活用するのではなく、post-trainingの学習データに対するdata engineeringに使うことで、costのかかる手法ではなく**より低コストで**data engineeringを実現したい、という気持ちの研究。提案手法では、SAEによって獲得されるrepresentationに基づいてpost-trainingの学習データに対して、
- 多様性: SAErepresentationを用いてクラスタリングを実施し活用
- 難易度: 軽量なElasticNetに基づく回帰モデル(特徴量はSAE representation)によって難易度予測モデルを学習し、クラスタIDに基づいて難易度をキャリブレーション
- 品質: SAE representationに基づいてqualityを判断する二値分類器を学習しその確率値を使うようである
ぱっと見よくわからないのが、
- difficulty-labeledなsubsetの正体はなんなのか?
- それは幅広いドメインで入手可能なものなのか?
- in-distributionな難易度であればElasticNetで予測できたということだが、in-distributionなdifficulty-labeledなデータがないと提案手法は原則として適用できないということなのか?
という疑問はある。
[Paper Note] How Should LLMs Consume High-Quality Data? Optimal Data Scheduling via Quality-Aware Functional Scaling Laws, Zhitao Zhu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #mid-training #Batch #Scheduler #One-Line Notes Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLM)の訓練におけるデータ品質の重要性を考慮し、バッチサイズとデータ品質を共同でスケジュールする理論的指針を提供。高品質データは信号の増幅に貢献し、適切なバッチサイズを用いることでノイズを低減する役割も果たす。従来の方法がこの第一の役割を無視する中で、新たに提案するDrop-Stable-Rampupは、品質転換時にバッチサイズを調整し信号の蓄積を促進。評価実験では、各種モデルと数学的推論ベンチマークで顕著な性能向上を実現。 Comment
元ポスト:
mid-training(より高品質なデータ)に転換したタイミングにおいて、**バッチサイズを**Drop (mid-trainingではノイズが小さいため、バッチサイズを小さくより多くの勾配ステップを踏むことで、学習シグナルを蓄積)し、その後Stable(しばらく最小バッチサイズを維持し、学習シグナル獲得を最大化)、最終的にRampup(バッチサイズを線形に拡大(学習率の減衰と等価)することで、最終的な収束に向けて蓄積されたノイズを抑制する)といった、学習データの品質に合わせたバッチサイズのスケジューリング Drop-Stable-Rampupを提案
ポイント解説:
[Paper Note] Replaying pre-training data improves fine-tuning, Suhas Kotha+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #mid-training #PostTraining #read-later #Selected Papers/Blogs #Scheduler #One-Line Notes Issue Date: 2026-03-07 GPT Summary- ターゲット領域向けの言語モデルの構築には、汎用ウェブテキストでの事前学習とターゲットデータでのファインチューニングが行われる。驚くべきことに、ファインチューニング中に汎用データをリプレイすることで、ターゲットタスクの性能が向上することが確認された。具体的には、4百万トークンのターゲットデータを使用した場合、汎用リプレイによりデータ効率が最大1.87倍、ミッドトレーニングで2.06倍向上した。また、事前学習中にターゲットデータが少ないほどリプレイ効果が高いことが分かった。80億パラメータのモデルでの実験により、エージェントのウェブナビゲーション成功率やバスク語の質問応答精度が向上したことを示した。 Comment
元ポスト:
事前学習以後の中間学習やファインチューニング(事後学習)において、特定のドメインやタスクに特化させるための追加の学習を行う際に、破壊的忘却を防ぐために一定量の事前学習データを混ぜることはよく行われていたが、実際には破壊的忘却を防ぐだけでなく、ターゲットドメインの学習効率を大幅に高める(1.5Bモデルの実験ではファインチューニングでは1.87倍、中間学習では2.06倍)ことがわかり、これは70B級の大規模なモデルでも同様に生じることが明らかになった、という話らしい。興味深い。
解説:
[Paper Note] Beyond a Single Extractor: Re-thinking HTML-to-Text Extraction for LLM Pretraining, Jeffrey Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel Issue Date: 2026-02-24 GPT Summary- ウェブからテキストを抽出する際、固定抽出器に依存する従来の方法がデータのカバレッジを最適化していないことを示す。異なる抽出器を組み合わせることで、DCLM-Baselineのトークン供給を71%増加させつつ、性能を維持。特に構造化コンテンツでは、抽出器の選択が下流タスクの成果に大きく影響し、WikiTQで最大10ポイント、HumanEvalで最大3ポイントの性能差が生じる。 Comment
元ポスト:
[Paper Note] Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs, Wei Zhou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-02-16 GPT Summary- LLM技術がデータ前処理のパラダイムを変革中であり、幅広いアプリケーションに対応するための進化を検討。文献レビューを通じて、データクリーニング、統合、強化の主要タスクにおける手法を整理し、それぞれの利点と制約を分析。さらに、評価指標とデータセットを考察し、スケーラブルなデータシステムや信頼性の高いワークフローに向けた研究課題を提示。 Comment
元ポスト:
自動的なデータの前処理に関するSurvey。文献は120以上引用され、美麗なフォーマットで記述されている。時系列での手法の変遷と、手法間の関係性が図解で整理されており非常にわかりやすそう。データの前処理は実務上の大きなボトルネックなのでどのような研究があるか気になる。
[Paper Note] Data Agents: Levels, State of the Art, and Open Problems, Yuyu Luo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #One-Line Notes Issue Date: 2026-02-11 GPT Summary- データエージェントは、LLMやツールを活用してデータ管理や分析の自動化を目指す新しいパラダイムであるが、その定義は曖昧である。この記事では、データエージェントをL0からL5までの階層に分類し、各レベルの特徴を示す。具体的には、単純なアシスタントと自律型エージェントの違いや、L0-L2の代表的なシステムをレビューし、独自にデータ関連タスクを実行するProto-L3システムを紹介する。また、L4およびL5のエージェントに関する研究課題も議論し、データエージェントの未来のロードマップを提供する。 Comment
元ポスト:
データを管理、準備、分析を担うエージェント(=データエージェント)に関して、自律性のレベルを6段階に分けたTaxonomyを体系的に定義し、既存研究を分類している模様。
Large Language Models for Data Annotation: A Survey, Zhen Tan+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Annotation #One-Line Notes Issue Date: 2024-03-05 GPT Summary- GPT-4などの大規模言語モデル(LLMs)を使用したデータアノテーションの研究に焦点を当て、LLMによるアノテーション生成の評価や学習への応用について述べられています。LLMを使用したデータアノテーションの手法や課題について包括的に議論し、将来の研究の進展を促進することを目的としています。 Comment
Data AnnotationにLLMを活用する場合のサーベイ
[Paper Note] Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes, Simran Arora+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #TabularData #One-Line Notes Issue Date: 2023-04-27 GPT Summary- LLMを用いた半構造化文書の自動処理システムEVAPORATEを提案。文書からの値を直接抽出する方法と、抽出コードを合成する方法の二つを評価。コード合成はコストが低いが精度が劣るため、EVAPORATE-CODE+を導入し、品質を向上。弱教師あり学習を用いた抽出のアンサンブルにより、文書処理の効率を大幅に改善。処理トークン数を平均110倍に削減し、最先端システムを超える成果を達成。 Comment
LLMを使うことで、半構造化文章から自動的にqueryableなテーブルを作成することを試みた研究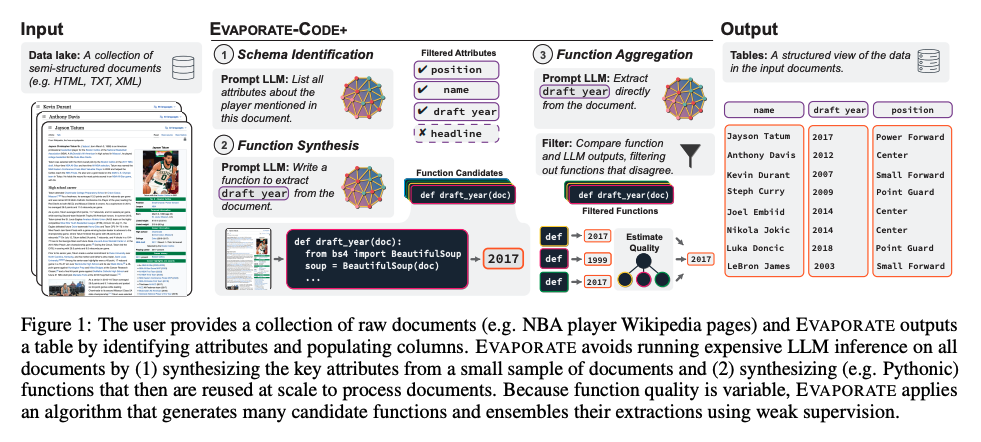
[Paper Note] Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Dataset #LanguageModel #DataToTextGeneration #Explanation #One-Line Notes Issue Date: 2023-08-03 GPT Summary- iPromptを用いて、事前学習済みのLLMがデータを説明する自然言語文字列を生成する手法を提案。このアルゴリズムは、生成された説明の性能を再評価して最適化するプロセスを含む。実験によりiPromptが正確なデータ記述を見つけ、人間にも解釈可能なプロンプトを生成し、一般化性能に優れることが示された。特に、実世界の感情分類データセットでGPT-3並みのプロンプトを生成し、科学的発見の支援にも寄与する可能性がある。すべてのコードはGitHubで公開。 Comment
OpenReview: https://openreview.net/forum?id=GvMuB-YsiK6
データセット(中に存在するパターンの説明)をLLMによって生成させる研究


What If the Harness Comes Before Pretraining? A Data Flywheel Perspective, Hanchen Li, 2026.07
Paper/Blog Link My Issue
#Article #Pretraining #LanguageModel #Post #read-later Issue Date: 2026-07-15 Comment
元ポスト:
Pushing the Frontier for Data Agents with Genie, Databricks, 2026.05
Paper/Blog Link My Issue
#Article #Multi #NLP #LanguageModel #AIAgents #Test-Time Scaling Issue Date: 2026-05-11 Comment
元ポスト:
The ATOM Report: Measuring the Open Language Model Ecosystem, Lambert+, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #OpenWeight #OpenSource #read-later #Author Thread-Post Issue Date: 2026-04-11 Comment
著者ポスト:
元ポスト:
Mistral Forge: Build your own frontier models, MistralAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog #Proprietary #mid-training #PostTraining Issue Date: 2026-03-18 Comment
元ポスト:
エンタープライズ向けの社内の機密データによってLLMの(おそらく継続)事前学習、事後学習、RLを実施したカスタムモデルを構築するソリューションのようである。Dense, MoEなどのアーキテクチャも選択可能な模様。
ベースモデルなどが書かれていないように見えるが、Mistral製のオープンLLMがベースとなるのだろうか。