
One-Line Notes
[Paper Note] Separating Representation from Reconstruction Enables Scalable Text Encoders, Megi Dervishi+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#Embeddings #NLP #LanguageModel #Architecture #Selected Papers/Blogs #Encoder #reading #Scalability Issue Date: 2026-07-26 GPT Summary- BERT以降、エンコーダはほとんど変わっていないが、急速に進化するデコーダとの乖離を再評価。BERTエンコーダの表現は凍結プローブで劣化し、平坦な設計が表現学習を阻害している。これに対抗するため、CrossBERTを提案。二部構成のアーキテクチャで、トークン再構成から独立した高品質なエンコード表現を学習。高いマスキング比率と補完的戦略により、スループットとサンプル効率を向上。結果、MTEBおよび凍結GLUEベンチマークで優越性を示す。 Comment
元ポスト:
論文の概要としては、BERTは投入された計算量に対してdownstreamタスク性能がスケールしない課題があったが、その原因を、BERTのflatなアーキテクチャが課題であると指摘。BERTはMLM lossで学習されるが、これはトークンの再構築の能力を測定するが、実際の表現の品質を測定できていない。BERTのアーキテクチャが、Representationの学習と、Reconstructionを明示的に分離していない(=flatなアーキテクチャ)ため、結果的にBERTが学習する表現がReconstructionのためのlocalな信号に過度に適合してしまい、abstractionに失敗してしまう(結果的に、計算量を投じれば投じるほどlossは下がるが、downstreamタスクの性能は下がる)、という仮説を立てている。
解決方法として、表現を学習するEncoderと、マスク部分の再構築をおこなうPredictorをアーキテクチャとして明示的に分離することを提案している。
これにより、投入した計算量に対してdownstreamタスクの性能がスケールするようになった、という話に見える。
おそらくアーキテクチャ上の細かい工夫があると思われるので、そこはしっかり読んだ方が良いカッコまだ読めてない)。
[Paper Note] Skill Retrieval Augmentation for Agentic AI, Weihang Su+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #reading #AgentSkills #Reading Reflections Issue Date: 2026-07-21 GPT Summary- 大規模言語モデル(LLMs)が外部スキルに依存するようになり、これを効率的に活用するために新たにSRA(Skill Retrieval Augmentation)パラダイムを提唱。SRAは、エージェントが必要に応じて関連スキルを動的に取得し適用する仕組みで、初のベンチマークSRA-Benchを導入。5,400件のテスト事例と636件の正解スキルを用いた実験により、検索ベースのスキル拡張が性能向上に寄与することを確認。ただし、スキルの取り込みには課題があり、正解スキルの認識や外部能力の必要性に関する判断がエージェントの性能を制限することが分かった。これにより、今後のエージェントシステムの能力拡張の基盤を築くことが示唆される。 Comment
元ポスト:
pj page: https://sr-agents.github.io
dataset: https://huggingface.co/datasets/WeihangSu/SRA-Bench
スキルの肥大化に伴いモデルのcontextが肥大化しパフォーマンスが劣化することから、動的にスキルを検索して統合するSkill Retrieval Augmentationを提案し、そのための大規模なデータセットを用いて評価をしている、という話に見える。データセットは26kのスキルで構成され、そのうち636件がgoldという規模感のデータセット。
実験結果を見ると、topkのretrieve結果をそのまま利用するfull injectionよりも、full injectionしたスキルのメタデータからrelevantなスキルを1iLLMで選択するLLM Selectionの性能が向上している点が興味深い。
また、skill poolにhard negativeなスキルが存在すると、ベンチマークのスコアは低下していく傾向(具体的にどのベンチマークかまでさ読めていない)にあり、hard negativeが8つ程度で、様々なモデルにおいてAcc.が10%程度は低下しているように見える。興味深い。
問題設定が実用的で興味深いだけでなく、hard negativeなスキルが <10個 程度のオーダーで存在するだけで大きくAcc.が低下する知見を示している点がおもしろい。
[Paper Note] Self-Guided Test-Time Training for Long-Context LLMs, Xinyu Zhu+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #reading #Reading Reflections #Test Time Training (TTT) Issue Date: 2026-07-19 GPT Summary- 長文脈処理において、LLMは単にコンテキスト窓を拡張するだけでは十分ではなく、入力長の増加が精度の低下を引き起こすことがある。テスト時訓練(TTT)は長文脈の活用を改善する手法の一つだが、全体への適用は費用がかかり、ランダム抽出による訓練が性能を低下させることがある。これに対し、Self-Guided TTT(S-TTT)を提案し、適応前にモデルが選択された証拠スパンを認識することで、基準となる言語モデル訓練を適用。S-TTTは、LongBench-v2およびLongBench-Proでの精度向上を実現し、最大で15%の改善を達成。 Comment
元ポスト:
長文Context+質問が与えられたときに、質問に関連するcontextのspanを同定した後(Self-Guided)、TTTでモデルパラメータに内部化させた後に応答する、という話に見える。TTTでは、LoRAを用いて、かつ16 gradient updateを行った時点で更新を終了する。
Full ContextでらTTTするよりも、Self-Guidedな方が高い性能を獲得できる。
TTTを使ってLoRA adapterにcontextの情報をweightとして内部化させても、思ったほど性能は上がらないのだなという印象。
LoRAでweightにcontextを内部化させても、その内部化された情報をうまく活用するような工夫が足りていないのでは?という気がするのだが、どうだろうか。
ベンチマークのインスタンスが、contextをmemorizationし、適切にatteedすれば解けるようなクエリなのか否かという点も気になる。
もしcontextの情報に基づいてマルチポップな推論が必要な場合、LoRAアダプタによる重みを活用するような回路が育っていない可能性が高く、性能は伸びにくいのかなという気はする。
[Paper Note] Flash-BoN: Instant Drafts for Inference-Time Scaling in Diffusion Models, Ruchit Rawal+, ECCV'26, 2026.07
Paper/Blog Link My Issue
#ComputerVision #NLP #DiffusionModel #TextToImageGeneration #Test-Time Scaling #ECCV #ImageSynthesis #Author Thread-Post Issue Date: 2026-07-19 GPT Summary- 推論時のスケーリングは、Best-of-N(BoN)サンプリングからガイド付き探索に進化してきたが、生成コストを固定と見なしている。効率性評価でBoNがガイド付き探索に匹敵することを示し、Flash-BoNを提案。これはアクセラレーション技術を組み合わせ、多数の安価なドラフト候補を生成し、高品質へ精練する。ベンチマークではFlash-BoNが全ての基準を上回り、特にモデルスケールが大きいほど利得が顕著(AUCで+8%)。他の手法と相乗効果があり、候補の多様性向上が強化学習の収束を加速する。 Comment
pj page: https://flash-bon.github.io/
元ポスト:
中間サンプルを安価で効率的な方法で生成することで多様な中間候補を探索し、有望な候補のみに対して完全な生成をするようなBest-of-Nに基づくTextToImage手法を提案。
また効率性の評価において Number of Function Evaluations (NFEs)[^1] が利用されることが多かったが、これはdenoisingのforward passのみが考慮され、verifierのコストが無視されており、verificationコストが大きい手法が本来効率的ではないのに、効率的に見えてしまう問題があった。実際、BFSのような手法では固定されたNFEの元では効率的に見えるが、頻繁にverifierを呼び出すため、固定されたwallclock timeの元では効率性が逆転する。
[^1]: デノイジングを実施するネットワークの呼び出し回数
[Paper Note] Scalable Visual Pretraining for Language Intelligence, Yiming Zhang+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #LanguageModel #Selected Papers/Blogs #VisionLanguageModel #reading Issue Date: 2026-07-19 GPT Summary- 視覚的事前学習が言語モデルの知能向上に寄与することを示す研究。テキスト変換を通さず視覚的文書を直接活用する無監督のアプローチを検討し、視覚的事前学習がテキストのみのモデルを一貫して上回ることを実証。これにより、スケーラブルな言語知能への効率的なアプローチが明らかに。 Comment
元ポスト:
事前学習をする際に、テキストだけでなく画像パッチに対してもnext visual latent predictionを実施することで性能が改善する。
next visual latent predictionでは、画像パッチをfreezeされたvision encoderでエンコードし潜在表現の系列を取得し、現在のパッチを入力したときに、次のパッチの潜在表現を予測する(離散トークンではなく、連続値ベクトルである点に注意)。loss functionは、バッチ内の全ての画像パッチを考えたときに、各パッチの正解の潜在表現と、モデルが予測した次パッチの潜在表現の類似度行列をソフトマックスで正規化した行列を考え、対角成分(すなわち正解の画像パッチに対する類似度)が最大化されるように定義される。ソフトマックスを考えることで、バッチ内の他の画像パッチがin-batch negativeの役割を果たし、これは次パッチの潜在表現と他の潜在表現の区別がつくようなcontrastive learningをしていることに相当する(Section 4)。
[Paper Note] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling, Xiang Hu+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #Architecture #SparseAttention Issue Date: 2026-07-11 GPT Summary- 階層的ランドマークスパース(HiLS)アテンションを提案し、チャンク単位でのスパースアテンションをエンドツーエンドで学習。各クエリが独立してチャンクとアテンションを行い、検索スコアを用いて結合。実験結果では、HiLSが全アテンションに匹敵するかそれ以上の性能を示し、長文脈での外挿が可能。軽量な事前学習を通じて全アテンションモデルをHiLSに適応させ、効率と効果のトレードオフを克服。 Comment
元ポスト:
ポイント解説:
Block Sparse Attention (BSA) は、直近のトークンを見るlocal sliding window attention (SWA)と、離れたトークンに対するチャンクレベルでのsparse attentionに基づいたアテンション機構である。
一般的なBSAでは、現在のquery qとチャンク単位のattentino scoreを計算する際に、各チャンクごとにチャンクのkeyに関する情報を要約した Key k'_c を求め、k'_c と現在のquery qとのattention scoreを計算することにより計算を効率化する[^1]。
k'_c を求める際には、mean/max pooling を用いるのが一般的であり、特に前者が用いられるとのことだが、どちらのpoolingの手法もattention scoreの分布に依存して、近似の性能が変化する(たとえば、mean poolingであればなるべくattention scoreが一様なほど近似性能が良いし、max poolingであれば、あるscoreがチャンク内で支配的であるほど近似性能が良い)が、query qに応じてattention scoreの分布は変化することにより、k'_cの近似性能が低下しsparse attentionによって重要なチャンクを選択する性能が低下する課題がある。
これに対して、
- 現実的な計算量でk'_cをより正確に近似できる surrogate score に基づく手法を提案し(RQ1)[^2]
- surrogate score をend-to-end で学習可能にする方法を提案した (RQ2)
という話である。
surrogate scoreは、チャンクのattention scoreの質量をより正確に近似したスコアであり、(チャンクのkeyを要約した)k'_c に対する現在のクエリ q とのrelevanceを表す項と、バイアス項 b'_c によって線形化される(式7)。
k'_c によって現在のクエリに対する関連度を測り、バイアス項によって関連度から独立したtoken-levelの質量を導入する。バイアス項は、チャンクにattendするであろうクエリのattention scoreの分布に対するentropyであり、これが一様分布やあるトークンが支配的な分布など、様々な分布の形状に対して動的に適応する役割を果たす。
b'_c を求めるために、チャンクごとに独立したクエリ q'_c を学習する。これは、このチャンクにattendするであろうクエリのプロキシを果たすクエリであり、q'_c とチャンク内のトークンのkeyとの間でのattention scoreを計算しておくことで、おおまかなattention scoreの分布を決定し、b'_c を求めておくことができる(式8)。
また、k'_c はチャンク内のattention scoreによって重みづけられたkeyの和の形で求められる(式8)。
これにより、現在のクエリ qが与えられた時に、k'_cとb'_cを用いて、チャンクに対するattention scoreの質量を高速に近似することができる(式7)。
ここで q'_c をどのように学習するかが課題となる(q'_c以外のパラメータは従来通りのモデル化で求まる)。これを解決するために、surrogate scoreによって求まるチャンクのattention scoreの近似質量 \hat{Z}_{i, c} をforward passに加え、q'_c に勾配が流れるようにすることで解決している。具体的には、attention scoreの計算をする際に、式変形を実施し、`チャンク内のスコアの計算 * チャンク間のスコアの計算` の形に分解する(式10)。後者のチャンクの重要度を求める際に、各チャンクのsurrogate scoreを用いて近似することによって、高速化 + q'_c に勾配が流れるような工夫をしている。
[^1]: チャンクのattention scoreの質量(どのチャンクをsparse attentionでattendするかを決定する際に用いられる)を計算する際に、query qとチャンク内の全てのtokenに対するtoken-to-tokenの内積をとることを避け、k'_cとの内積によって近似的に質量を求めることで計算を効率化する。
[^2]: surrogate scoreによってk'_cを正確に近似できることの証明はAppendix Bに記載されており、1次のテイラー展開に基づいているようである(ここは読めていない)。
[Paper Note] ReasonIF: Large Reasoning Models Fail to Follow Instructions During Reasoning, Yongchan Kwon+, ACL'26 Findings, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Reasoning #ACL #InstructionFollowingCapability #Findings Issue Date: 2026-07-08 GPT Summary- 大規模言語モデル(LLMs)がユーザーの指示を推論過程全体で遵守する重要性を強調し、ReasonIFというベンチマークを導入。これは、推論指示の遵守を評価し、さまざまな指示プロンプトを網羅している。多くのオープンソースLRMsにおいて、指示遵守のスコアは0.25未満であり、難易度の上昇に伴い低下する傾向がある。推論指示の忠実度向上には、マルチターン推論と合成データを用いたファインチューニングが有効で、RIFによって大きな改善が見込まれるが、さらなる向上が必要。 Comment
著者ポスト:
著者ポスト2:
reasoning traceに対して制約を課す[^1]指示は、メインの応答と比較して指示追従性能が低い傾向にある
[^1]: 思考する言語の指定、思考の長さの制限、免責事項(指示でreasoningの最後にwarningや備考を追記する)、reasoningをjsonにする、大文字のみを利用する、commaをreasoning中に除外する、など
[Paper Note] M*: A Modular, Extensible, Serving System for Multimodal Models, Atindra Jha+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #MultiModal #SpeechProcessing #LLMServing #Architecture #UMM #Omni #Author Thread-Post Issue Date: 2026-07-03 GPT Summary- 複合モデルアーキテクチャの新時代に向け、M*を提案。M*はモデルをデータフローグラフとして表現し、モジュラーな抽象化を通じて多様なタスクを効率的に処理。具体化によって、テキスト-画像及びテキスト-音声ワークロードでの遅延を平均20%削減し、スループットを最大2.7倍向上。ロボティックプランニングでも基準を12.5倍上回る。この研究は、複雑なモデルの効率的な提供を可能にする。 Comment
元ポスト:
以下、元ポストの要約
vLLMやSGLangのようなメジャーなLLM Servingフレームワークは単一の自己回帰的な生成のループを前提としており、テキスト以外のモダリティを扱う場合は異なる推論パスを辿るため、根本的に統一的に扱える抽象化となっていない(Figure 1)。
そこで、マルチモーダルなモデルを統一的に扱えるための抽象化M*を提案:
- モデルのコンポーネントをノードとして宣言し、名前付きのWalkを定義する(1つのフェーズ(prefill_text, decode, image_gen等)を構成するサブグラフ)を定義する。
- リクエストはWalkの系列として定義され、Sequential, Parallel, Loopの3種類で実行形式を定義する。
ランタイムはリクエストに応じたコンポーネントのみを実行する。各コンポーネントはグラフのノードとして定義されるため、配置の変更はコードの変更ではなく、設定の変更で完結する。また、YAMLファイルによって、各コンポーネント、Walkの粒度でGPUの割り当てを制御できるため、個々のコンポーネントやWalk単位でリソースの効率を最大化することで、予測性能を落とすことなく、システム全体のスループットが向上する。
また、Figure1のOmniモデル、UMMそれぞれのモダリティごとの推論パスの違いが秀逸で、非常に分かりやすい。
[Paper Note] Inverting the Bellman Equation: From $Q$-Values to World Models, Alistair Letcher+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#MachineLearning #ReinforcementLearning #read-later #Selected Papers/Blogs #WorldModels Issue Date: 2026-07-03 GPT Summary- モデルベースおよびモデルフリーの強化学習の対立に挑戦し、価値ベースのエージェントが豊かな報酬関数の下で正確な世界モデルを暗黙にエンコードできることを証明。Q-learningの逆アナロジーとして\textit{$P$-learning}を導入し、環境の内部モデルをデコード。また、目標の型と数に基づく条件を示す。実験では、限られた報酬関数で訓練したエージェントが正確なダイナミクスをエンコードし、隠れた一般化能力を示した。これは、モデルベースとモデルフリー、ゴール条件付きRLの関係に新たな視点をもたらす。 Comment
元ポスト:
基礎:
- 強化学習の基礎, Takuya Kubo, 2025.06
以下上記元ポストの自分の理解のための要約(詳細は元ポスト参照のこと)
ゴールによって条件づけられたRLにおいて、複数のゴールが設定され、ゴールごとに十分に多様な価値を持つ場合、Q値から明示的に学習されていない世界モデル(=state, actionが与えられた時に次にどの状態に遷移するかを表す状態遷移モデルP)を一意に復元できる場合がある。Q値から状態遷移モデルPを復元することをP-Learningと呼ぶ。どの程度復元できるかはMDPにおける状態遷移の設定(有限状態、連続状態、決定論的、確率論的)により異なり、決定論的なMDPの場合は多くの場合1つのゴールだけで遷移を一意に復元できるが、確率論的な場合はより多くのゴールが必要となる。
これにより、明示的に状態遷移を学習しない場合でもQ値が世界モデルを内包し、そこから復元された世界モデルを用いて訓練時に存在しなかったゴールも解けるようになる。
という感じのようである。
[Paper Note] Tapered Language Models, Reza Bayat+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Architecture #reading Issue Date: 2026-07-03 GPT Summary- 深層言語モデルは、均一な層構成が与えられているが、層によって非均一に出力に寄与することが示唆されている。そこで、初期層に多くのパラメータを割り当てる「テーパード言語モデル(TLMs)」を提案。実験結果から、テーパリングすることでパープレキシティと性能が向上し、追加コストなしで効果的な設計原理となることを示した。 Comment
元ポスト:
MLP Layerのパラメータ数を均一にするのではなく、浅い層でより多くのパラメータを割り当てることで性能が改善するという話のようである。このような現象が生じる説明として、残差ストリームに対してMLPを通る前後のコサイン類似度式(9)、ブロック全体を通過した後の残差ストリームの差分(つまりどれだけ残差ストリームが変化したか)とブロックに入力された残差ストリームの間のコサイン類似度(式9)を観察し、層が深くなればなるほど類似度が高くなり(つまりコサイン類似度なので方向が近い)深い層になればなるほど新規の情報が少なく、情報の微調整や洗練化が行われているため、という説明が行われているようである(Figure 4)。
[Paper Note] SAGE-OPD: Selective Agent-Guided Intervention for Multi-Turn On-Policy Distillation, Yuhang Zhou+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #ReinforcementLearning #Distillation #PostTraining #On-Policy Issue Date: 2026-07-03 GPT Summary- SAGE-OPDは多ターンのオンポリシー蒸留を改善する新しいフレームワークで、学生モデルへの介入を環境からのフィードバックに基づいて決定。標準OPDの脆弱性を克服するため、教師の信頼度でトークンレベルの蒸留を重み付けし、不確実な教師分布の影響を軽減。実験では、ALFWorldにおける成功率を標準OPDと比較して13.3%改善し、ターンレベルの介入が効果的であることを示した。 Comment
元ポスト:
現在のOPDは基本的にsingle-turnを前提としているが、multi-turnの場合の手法を提案。各stepごとのconfidenceを教師モデルによって推定し、OPD lossに反映させる。これは生徒モデルの軌跡が教師から逸脱した場合に、その軌跡に対して介入をするような挙動となる。multi-turnにおいて全てのターンに介入するのは無駄で、かつ介入しないとmulti-turnの場合エラーが蓄積するため、選択的に介入する軌跡を決定する手法と言える、という感じに見える。
ポイント解説:
[Paper Note] Aurora: A Leverage-Aware Spectral Optimizer, Alec Dewulf+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Optimizer #Author Thread-Post Issue Date: 2026-07-03 GPT Summary- Muonの更新における行ノルムの不均一性が、自己強化的なフィードバックループを引き起こす問題を提起。本研究では、行正規化を活用しながらMuonの幾何を尊重する最適化手法Auroraを提案。Auroraは事前学習での性能向上を示し、modded-nanoGPTでのスペクトル最適化において最先端の結果を達成。さらに、Auroraの利得はMLP拡張係数に比例し、幅広いMLP層の効果的訓練を可能にすることが示唆されている。 Comment
元ポスト:
transformer decoder-onlyモデルにおけるMLPのdead neuronを防止するような更新をかけるoptimiserで、Muonよりも高い下流タスク性能を達成したとのこと。
[Paper Note] Improving Neural Network Training by Decoupling the Magnitude and Direction of Weight Vectors, Alexander Hägele+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #LanguageModel #Optimizer #read-later #Author Thread-Post Issue Date: 2026-06-21 GPT Summary- MDデカップリングを提案し、重み行列の「大きさ」と「方向」を別々に制御することで、訓練ダイナミクスを向上させる。これにより、従来のオプティマイザに依存せず、重み減衰やウォームアップが不要に。また、Adam や Muon において、調整されたベースラインを超える性能を示し、幅広いモデルにおいて一貫した効果を発揮する。 Comment
元ポスト:
以下、著者ポストの要約
重み行列にはサイズ(ノルム)と向かう方向(どこをpointするか)があり、同じステップでも重みが小さい時は大きく回転するが、重みが大きいとほとんど回転せず、方向がどれだけ早く変化するかは重みのノルムに依存する。このため、学習中に重みの大きさが調整役になってしまい、学習時の更新幅がLRによって決まるわけではなく、重みの大きさ、weight decayなどの影響によって変化し、学習率が与える影響が間接的なものになってしまう。これを是正するために、NeuralNetworkの重みを固定サイズに保ち(球面上に配置)、方向だけを調整する。
- Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization, Wen+, 2026.01
と非常に似ているように感じる。
[Paper Note] CEO-Bench: Can Agents Play the Long Game?, Haozhe Chen+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #LongHorizon #Environment #Author Thread-Post Issue Date: 2026-06-21 GPT Summary- CEO-Benchは、言語モデルのエージェントが長期的な視野、ノイズの多い環境での情報取得、適応能力、目標統合を評価するためのシミュレーションである。エージェントは500日間のスタートアップ運営を通じて架空の企業管理を行い、ビジネスデータを分析して戦略を構築。多くのモデルが苦戦する中、Claude Opus 4.8とGPT-5.5のみが初期の課題で成功を収めている。CEO-Benchは持続的な進歩を測定する手段を提供する。 Comment
元ポスト:
以下著者ポストの要約
エージェントに1Mドルを与えて仮想環境でスタートアップを500日経営させ、最終的なキャッシュを比較することでエージェントのlong horizonな意思決定、データ分析、コーディング能力を測定する。経営はprogrammableなインタフェースによって実現される。モデルによって挙動が異なり、あるモデルは幅広い戦略を探索するが、あるモデルは受動的な意思決定をしてしまいキャッシュを失う。
[Paper Note] Improving Robotic Generalist Policies via Flow Reversal Steering, Andy Tang+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#ComputerVision #NLP #Selected Papers/Blogs #VisionLanguageModel #Robotics #VisionLanguageActionModel #reading #Steering #Author Thread-Post Issue Date: 2026-06-13 GPT Summary- 汎用ポリシーが多様なロボットデータセットから学習する中で、Flow Matching GeneralistsとFlow Reversal Steering(FRS)を提案し、サブ最適な行動を逆向きに通して潜在ノイズを特定、汎用的なアクションモードへ写像する手法を検証。FRSは粗い意味論的指示を良いロボットアクションに変換し、ゼロショット制御を改善。訓練を短時間で行い、最大95%のタスク成功率向上を示し、強化学習をブートストラップしてさらなる改善を実現。 Comment
元ポスト:
VLMや人間によって、
- Coarse Reference Action関する情報(=意味的には妥当だがロボットがアクションを実施するには粗すぎる情報; move straight right等)を与え、
- Coarse Reference Action を対応するVLAのreference action a_1に変換し
- a_1に基づいてVLAが良いアクションを生成できる潜在ノイズをFlow Matchingモデルを時間方向にbackwardさせる(noising process)ことで推定し、
- 同定した潜在ノイズから順方向にdenoisingすることで、妥当なアクションをsteeringする
Flow Reversal Sterring (FRS) を提案。FRSにはzero-shot、かつonlineでsteeringができる利点がある。
## Diffusion Steering via Behavioral Cloning (DSBC)
FRSはSupervised Learningにも活用できる。具体的には、reference actionに基づいたノイズ a^hat_0を用いてobservationからノイズを生成するノイズ方策を直接behavior cloning(=observation oが与えられた時に、a^hat_0を出力する確率を最大化する最尤推定; p.6冒頭)する。
学習データ(observation, good noiseのタプル)の収集方法は大きく分けて2通りあり
- オンライン: zero-shot FRSを実際に環境でロールアウトし、タスクが成功したときノイズをgood noiseとして記録する
- オフライン: 既存の(observation, action)データをFRSで変換し(observation, action noise)のタプルに変換して学習に利用する
このような学習手法をDSBCと呼ぶ。
## DSRL + FRS
上述のFRSとDSRL [Paper Note] Steering Your Diffusion Policy with Latent Space Reinforcement Learning, Andrew Wagenmaker+, arXiv'25, 2025.06
を組み合わせることで、DSRLの安定性を向上させる手法。DSRLは一言で言うと、アクション生成のシードとなる良いノイズを生成できるポリシー(ノイズ方策)をRLを通じて学習する手法らしく、RLをする際の報酬に対して、DSBCを重み付きで加えることによって、エキスパートのノイズから大きく逸脱することを防ぐ正則化の役割を追加する。
完全に読めたわけではないが、おもしろい。勉強になった。
[Paper Note] End-to-End Context Compression at Scale, Ang Li+, arXiv'26, 2026.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Encoder-Decoder #ContextEngineering #Compression Issue Date: 2026-06-11 GPT Summary- 長文脈言語モデルの推論ではKVキャッシュの増大がメモリのボトルネックとなるが、従来の圧縮手法はモデルの品質を犠牲にするか、リソースを大量に消費する。そこで、本研究ではエンコーダ-デコーダ圧縮を再検討し、最適な設計と訓練手法を模索。特に、0.6Bエンコーダ・4Bデコーダモデル群を事前学習し、圧縮比1:4、1:8、1:16で性能を向上させるLatent Context Language Models(LCLMs)を提案。LCLMsは効率的な長期エージェントのバックボーンとして機能し、圧縮された文脈から適応的に情報を展開できることを示した。 Comment
元ポスト:
input tokenを圧縮し潜在表現にエンコードするencoderを導入し、decoderへ入力するcontextを圧縮する
[Paper Note] ModeX: Evaluator-Free Best-of-N Selection for Open-Ended Generation, Hyeong Kyu Choi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Test-Time Scaling #reading #Clustering-based #Author Thread-Post Issue Date: 2026-06-10 GPT Summary- 生成されたテキスト間の意味的コンセンサスを特定するMode Extraction(ModeX)を提案。評価者なしでBest-of-N選択を実現し、類似度グラフを用いてセントロイドを選択。ModeX-Liteで効率化を図り、テキスト要約やコード生成などのオープンエンドタスクで従来の手法を常に上回る性能を示す。 Comment
元ポスト:
outputに対してJaccard係数に基づいてAffinity Graphを構築し、クラスタのセントロイドを求めることで、extrnal verifier無しでBest-of-Nを実現する。
Best-of-16でのexternal evaluatorを用いた場合のオラクルスコアを、多くの場合で上回っているように見えるが、なぜこの3つのベンチマークでの評価なのだろうか?(そして文書要約はなぜ表層的なメトリックばかりなのだろうか)。論文中では代表的なタスクである3つのベンチマークで評価したと一言しか書かれていないように見える。
もしこれが安定して高い性能を出せるなら、evaluator freeなので非常に強力である。理論的な分析もあるようだが読めていない。覚えておこう。
[Paper Note] TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents, Jiaqi Wang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Distillation #PostTraining #On-Policy #Stability #LongHorizon #Author Thread-Post Issue Date: 2026-06-05 GPT Summary- オンポリシー蒸留(OPD)は、モデルから小型学生モデルへの能力移転に成功しているが、マルチターンエージェント設定では十分に検討されていない。本研究では、OPDの課題としてKL不安定性を特定し、これが学生モデルの訓練を不安定にさせる主な要因となることを示す。これを解決するために、時間的カリキュラム・オンポリシー蒸留(TCOD)を提案し、短いから長い軌跡への段階的な拡張を行う。実験により、TCODはKLの安定性を向上させ、従来のOPDより最大18ポイントの性能向上を実現することが確認された。 Comment
元ポスト:
multi-turn/long-horizonな設定でのOPD手法。multi-turnな設定の場合、教師モデルへのcontextにエラーが蓄積されていき徐々に教師モデルのsignalの信頼性が低下する問題があり、これに対処するためにOPDを適用するtrajectoryのターン数を序盤は短く、徐々に長くしていくようなカリキュラムで学習をする手法を提案。ターン数を深くする方向として、Forward-to-Backward/Backward-to-Forwardの2種類のシンプルな手法を用いて実験をしている。
[Paper Note] Subliminal Learning Is Steering Vector Distillation, Camila Blank+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Distillation #SubliminalLearning #Steering #Author Thread-Post Issue Date: 2026-06-04 GPT Summary- 潜在的学習とは、学生の言語モデルが教師の特性を微調整することで獲得される現象であり、意味を持たないデータから特定の特徴が伝達される仕組みは未解明である。本研究では、潜在的学習がステアリングベクトルによって媒介されることを示し、教師のプロンプトがこのベクトルによく近似され、学生が整合したベクトルを学習することを発見した。ステアリングベクトルに近似されないプロンプトは学習されないことも示され、その影響がモデルの活性化に及ぶことを明らかにした。潜在的学習には適応型オプティマイザが必要であり、勾配の一貫性が成果に影響を与えることが確認された。 Comment
元ポスト:
Subliminal Learning:
- [Paper Note] Subliminal Learning: Language models transmit behavioral traits via
hidden signals in data, Alex Cloud+, arXiv'25
Subliminal Learningが生じるのは、教師モデルが生成したデータを通じて生徒モデルが残差ストリームに対するsteering vectorが蒸留されるからであり、教師モデルが生成した何らかのデータを通じて教師モデルと同じ方向にactivationが誘導されるようになるため、という説明のようである。また、subliminal learningが生じるためにはAdamのような適応的なoptimiserが必要で(外れ値の勾配が支配的にならないため)、LoRAのような低ランクでのファインチューニングで生じやすく、フルファインチューニングでは発生しづらいとのこと。
また、細かく読めていないが、16種類の動物に関する特性に関する残差ストリームのsteering vectorを抽出し実験をした結果、steeringは実験の結果モデル間の転移は弱く、モデルアーキテクチャが共通の場合にうまく転移することが示され、このことから、モデル固有のsteering方向に依存することが示唆されるようである。
[Paper Note] Unlocking the Working Memory of Large Language Models for Latent Reasoning, Lukas Aichberger+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #LatentReasoning #Author Thread-Post Issue Date: 2026-06-03 GPT Summary- 大規模言語モデルの推論能力を向上させるために、自己回帰的生成の代わりに作業記憶ブロックを採用するReasoning in Memory(RiM)が提案される。これにより、内部計算と外部通信の混同を回避し、計算効率の高い潜在推論を実現。2段階のカリキュラムを用いて、まず推論ステップを予測し、その後最終回答の洗練を行う。実験により、RiMが既存の方法と同等かそれ以上の性能を示すことが確認され、作業記憶が潜在推論の有効なメカニズムとして機能する可能性が示された。 Comment
元ポスト:
元ポストのgifが端的にアーキテクチャを示しており非常にわかりやすい。
メモリブロックと呼ばれるboundaryトークン ``とm個のメモリトークン`
[Paper Note] Learn from your own latents and not from tokens: A sample-complexity theory, Daniel J. Korchinski+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Analysis #MachineLearning #NLP #Self-SupervisedLearning #Author Thread-Post #LatentRepresentation Issue Date: 2026-06-02 GPT Summary- 生成モデルは、訓練データの量が生物的学習者に比べて大きくなる中で高い性能を示している。新たな手法として、ネットワークが潜在表現を予測する訓練が行われており、これがデータ効率の改善につながる可能性がある。本研究では、確率的文脈自由文法(PCFG)をデータに用いて、潜在予測が効率を高めることを示す。教師あり学習は指数的なサンプル数を要するのに対し、潜在予測は定数のサンプルで達成可能であることを明らかにした。また、階層的クラスタリングやエンドツーエンドのニューラルネットワークを用いた分析を通じて、data2vecが階層的潜在予測を実行していることを確認し、明示的なスタッキングの冗長性を示唆している。 Comment
元ポスト:
JEPAのようなモデル自身が獲得した潜在表現を予測する自己教師あり学習手法は、階層的な生成構造を持つデータに対して、トークンレベルの予測ではO(m^{L+1})のサンプルが必要となるが、O(m^3)程度で済むことが理論的に示された模様。
著者ポスト:
[Paper Note] Paris 2.0: A Decentralized Diffusion Model for Video Generation, Ali Rouzbayani+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#OpenWeight #VideoGeneration/Understandings #Author Thread-Post #DistributedLearning Issue Date: 2026-05-31 GPT Summary- Paris 2.0は、分散計算を駆使した事前学習動画生成モデルで、従来のParis 1.0に基づいている。新モデルは、時系列的一貫性を実現し、低解像度のテキストから動画生成において、従来のモノリシックモデルと比べてFrechet Video Distanceを約2.0倍改善した。また、CLIPテキスト-動画類似度や美的スコアも向上した。 Comment
HF: https://huggingface.co/bageldotcom/paris2
元ポスト:
Paris2.0は独立した拡散モデルのアンサンブルによって実現される(巨大なGPUクラスターを必要としない)動画生成モデルで、それぞれのエキスパートはエキスパート間でパラメータや勾配をcommunicationせず、独立したデータによって学習されており、推論中は軽量なルータが各ノイズ除去のステップにおいてサブセットを選択することでデノイジングを進めていくとのこと。
[Paper Note] Multi-Mixer Models: Flexible Sequence Modeling with Shared Representations, Kevin Y. Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #Architecture #ConvolutionalModels Issue Date: 2026-05-31 GPT Summary- Oryxというハイブリッドモデルを提案し、系列全体を通じて異なるトークン混合手法を柔軟に切り替えるアプローチを探る。二次アテンションと線形リカレンスを組み合わせ、90%のパラメータを共有することで、効率的な性能を実現。最長1.4Bパラメータのモデルで、従来のモデルを上回る結果を示し、内部表現の共有が有望な方向性であることを示唆。 Comment
元ポスト:
softmax attentionとgated delta net (linear attention)の利用をスイッチングによって動的に切り替え、双方でKVを共有し畳み込みをかけてinducive biasを導入した上で活用する。outputはRMSNorm側でgatingする。softmax attentionとlinear attentionの良いところを良いところ取りしようというアーキテクチャに見える。
[Paper Note] Skill0.5: Joint Skill Internalization and Utilization for Out-of-Distribution Generalization in Agentic Reinforcement Learning, Jiapeng Zhu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #ContinualLearning #AgentSkills Issue Date: 2026-05-31 GPT Summary- 大規模言語モデルにスキルを搭載することで、自律エージェントの複雑なタスク解決が可能になる。エージェントのスキルは一般スキルとタスク特有スキルに分かれるが、既存の強化学習手法は外部化と内部化のバランスに苦労している。これを解決するために、Skill0.5という新しいRLフレームワークを導入。一般スキルの内部化とタスク特化の活用を動的ルータで調整し、タスクに応じた最適化を行う。実験結果は、Skill0.5が他のRLベースラインを上回る性能を示すことを確認した。 Comment
元ポスト:
Agent Skillsベースのcontinual learningを実現するうえで、多くの研究はSkillを外部化する(Skill.mdを定義し更新する)、あるいは内部化する(モデルの重みにSkillを学習させる)といった挙動のどちらかの文脈で研究されるが、どちらも利点・欠点があるから双方のいいところどりをしたハイブリッドでやりたいよね、という気持ちの研究と思われ、そのために一般的なスキルはモデルに内在化させ、タスク固有のスキルは外部化するというすみ分けをする。
そのために、RLをする際にタスクの難易度をhard/medium/easyに分類するルータを設け、hard taskについては、general skillを与え、self-distillationを通じてteacher trajectoryを生成。teacher trajectoryに基づいてdistillation lossを通じてエージェントにgeneral skillを内在化させ、mediumタスクでは通常通りGRPOで成功率を増大させるように学習、easyタスクではショートカットを防止するような学習のさせ方(generall skillを与えた場合とそうでない場合のtrajectoryを用意しadvantageを計算する?)をする、ことで、generalなスキルをエージェントに内在化させる、という感じの話に見える。ざっと図を見ただけなのでeasyタスクの部分がよくわかっていない。あと、そもそもGeneral/Task specific Skillをどのように進化させていくのかはよくわかっていない。
おそらくAgentSkillsの定義と発展は、SkillBankを使っている:
- [Paper Note] SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning, Peng Xia+, arXiv'26, 2026.02
[Paper Note] DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation, Makoto Shing+, ICLR'26, 2025.06
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Transformer #DiffusionModel #ICLR #Selected Papers/Blogs #reading #Author Thread-Post Issue Date: 2026-05-31 GPT Summary- DiffusionBlocksは、Transformerベースのネットワークを独立した訓練可能なブロックに変換する新しいフレームワークで、メモリボトルネックを軽減しながらエンドツーエンド訓練と同等の性能を維持します。残差結合の特性を活用し、各ブロックが独立に学習できるため、メモリ要件が削減されます。視覚系や拡散など多様なTransformerアーキテクチャに対する実験により、DiffusionBlocksがスケーラブルな訓練を可能にすることが示されています。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=pwVSmK71cS
巨大な残差接続を持つTransformer-likeなモデルをB個のブロックに分割し、ブロック単位で独立してパラメータを学習することによって、学習時に必要なメモリを1/Bに削減できる手法のようである。
(しっかり読めていないので色々と勘違いがあるかもしれないし、気持ちの部分をうまく表現しきれていないかもしれないが)
手法の概要としては、L layer単位でブロックをB個定義する。各ブロックにはnoise rangeの元ノイズを定義し、sample data (x, y)がgivenな時に、出力yにノイズを付与した~yを考える。~yから元の出力yを再現するようデノイジングするように、他のブロックはfreezeしたままで、あるブロックのパラメータを調整する、という操作を繰り返す、という手法のようである。Inference時は、平均0、学習時に定義したnoiseレベルの最大値を分散として持つ正規分布からノイズをサンプリングし、ノイズをinput xがgivenな状態で各ブロックでsequentialにdenoisingしていく(Euler Step)ことによって、最終的に所望の出力yを得る、といったような拡散モデルの逆プロセスを経て出力を得るようである。各ブロックがカバーするノイズのrangeは決まっているが、sequentialにdenoisingをしていくため、ブロック全体でみると大きなノイズからスタートするが、それぞれのブロックに対する入力のnoise levelは徐々に低減していき、各ブロックが担当するnoise levelのrangeまで落ちることが期待され、このような手続きが実現できると思われる。
[Paper Note] Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders, Yi Jing+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #PostTraining #CurriculumLearning #DataFiltering #SparseAutoencoder #Data #Author Thread-Post Issue Date: 2026-05-28 GPT Summary- モデル内部情報がLLMのデータ処理方法に重要である一方、外部信号に依存したデータエンジニアリングは内在信号を無視していることを指摘。SAERLを提案し、Sparse Autoencoderを用いて多様性、難易度、品質の三つのデータ特性をモデル化。これにより、バッチ多様性や難易度の順序づけ、データフィルタリングを実現。SAERLは平均精度を3.00%向上させ、少ないトレーニングステップで目標精度に達することを示し、効果的なデータエンジニアリングツールとしての役割を果たすことが確認された。 Comment
元ポスト:
SAEのrepresentationを、interpretabilityに活用するのではなく、post-trainingの学習データに対するdata engineeringに使うことで、costのかかる手法ではなく**より低コストで**data engineeringを実現したい、という気持ちの研究。提案手法では、SAEによって獲得されるrepresentationに基づいてpost-trainingの学習データに対して、
- 多様性: SAErepresentationを用いてクラスタリングを実施し活用
- 難易度: 軽量なElasticNetに基づく回帰モデル(特徴量はSAE representation)によって難易度予測モデルを学習し、クラスタIDに基づいて難易度をキャリブレーション
- 品質: SAE representationに基づいてqualityを判断する二値分類器を学習しその確率値を使うようである
ぱっと見よくわからないのが、
- difficulty-labeledなsubsetの正体はなんなのか?
- それは幅広いドメインで入手可能なものなのか?
- in-distributionな難易度であればElasticNetで予測できたということだが、in-distributionなdifficulty-labeledなデータがないと提案手法は原則として適用できないということなのか?
という疑問はある。
[Paper Note] How Should LLMs Consume High-Quality Data? Optimal Data Scheduling via Quality-Aware Functional Scaling Laws, Zhitao Zhu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #mid-training #Batch #Scheduler #Data Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLM)の訓練におけるデータ品質の重要性を考慮し、バッチサイズとデータ品質を共同でスケジュールする理論的指針を提供。高品質データは信号の増幅に貢献し、適切なバッチサイズを用いることでノイズを低減する役割も果たす。従来の方法がこの第一の役割を無視する中で、新たに提案するDrop-Stable-Rampupは、品質転換時にバッチサイズを調整し信号の蓄積を促進。評価実験では、各種モデルと数学的推論ベンチマークで顕著な性能向上を実現。 Comment
元ポスト:
mid-training(より高品質なデータ)に転換したタイミングにおいて、**バッチサイズを**Drop (mid-trainingではノイズが小さいため、バッチサイズを小さくより多くの勾配ステップを踏むことで、学習シグナルを蓄積)し、その後Stable(しばらく最小バッチサイズを維持し、学習シグナル獲得を最大化)、最終的にRampup(バッチサイズを線形に拡大(学習率の減衰と等価)することで、最終的な収束に向けて蓄積されたノイズを抑制する)といった、学習データの品質に合わせたバッチサイズのスケジューリング Drop-Stable-Rampupを提案
ポイント解説:
[Paper Note] $π$-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows, Haoran Zhang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #Conversation #Selected Papers/Blogs #Ambiguity #reading #LongHorizon #Proactive Issue Date: 2026-05-27 GPT Summary- パーソナルアシスタントエージェントは、OpenClawのような大規模言語モデルの潜在能力を示しており、特に隠れたユーザー意図の特定に課題がある。本研究では、100のマルチターンタスクからなる積極的支援のベンチマークであるπ-Benchを導入し、長期的な対話におけるユーザーのニーズ予測能力を評価。実験により、積極的支援の難しさ、タスク完遂と積極性の違い、事前対話の重要性が示された。 Comment
元ポスト:
ユーザがOpenClawのようなPersonal Assistantを用いて、マルチターンでのconversationを通じて、ある1つのタスクを遂行したいという状況を想定する。このタスクの開始時には、ユーザは一般的には自然で妥当なクエリを投げるが、最初から全てのrequirementを満たしたクエリは投げず、会話をしながら徐々にrequirementを具体化していくような変遷を辿る。このような、タスク開始時に、タスクを開始する上では自然で妥当だが、タスクを完遂するにはrequirementの情報が足りないという状況において、AI Agentが会話を通じて、ユーザが暗黙的に意図している仕様(hidden intents)を考慮して(=ユーザが明示的にinstructionとしてrequirementを与える前に)タスクを完遂できるか、という能力を測定する。
1つのタスクを完遂するために20個のsessionの会話によって構成されており、hidden intentsはsessionの中で閉じている、あるいはsessionを跨いで維持されるようなものとなっており、これらの情報をエージェントは過去のsessionの情報(メモリ)から推測するか、あるいは明示的にhidden intentsについて質問をするようなProactiveな挙動によって収集した上でタスクを遂行しなければならない。このとき、Userの役割を果たすエージェントは、GPT-5.4によって再現される。
[Paper Note] Understanding Data Temporality Impact on Large Language Models Pre-training, Hippolyte Pilchen+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #Temporal #LanguageModel #Factuality #read-later #Selected Papers/Blogs #FactualKnowledge Issue Date: 2026-05-27 GPT Summary- 時間的根拠を学ぶためのLLMの訓練におけるデータの並び順の重要性を探求。7,000件を超える時間的質問のベンチマークを作成し、事実と時期の結び付けを評価。6Bパラメータモデルを時系列で訓練した結果、シャッフル訓練と同等以上の性能を示しつつ、最新の知識を一貫して保持。これにより、時間的順序付けが知識の新鮮さを向上させることを明らかにした。関連コードやデータセットも公開し、今後のLLMの継続学習研究に寄与。 Comment
元ポスト:
事前学習時に時系列に応じて並び替えをしたコーパスと、シャッフルしたコーパスの場合、freshな知識が必要な質問に対する応答性能が改善する。実験では、Common Crawlのsnapshotの時刻のタイムスタンプに基づいてorderを決定しているようである(2.3説冒頭)。
評価のために作成されたQA例が下記で、NBAのバスケチームのコーチのような時間とともに正解が変化するような事実に関する質問によって構成されているようである。これらはwikipediaから特定の年と紐づいた (subject, relation, object) のタプルを抽出することによって生成される。
[Paper Note] (Sparse) Attention to the Details: Preserving Spectral Fidelity in ML-based Weather Forecasting Models, Maksim Zhdanov+, ICLR'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Transformer #ICLR #SparseAttention #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 本研究では、MLベースの気象予測のスペクトル劣化に対応する確率的モデル「Mosaic」を提案。三つの故障モードを扱い、アンサンブルメンバーを生成する。1.5°解像度で214Mパラメータを持つMosaicは、高解像度モデルに匹敵する性能を示し、ほぼ完璧なスペクトル整合性を達成。予報は高速に実行可能で、コードも公開中。 Comment
元ポスト:
block-sparse attentionによるtransformerベースの天気予報モデル
[Paper Note] Introspective X Training: Feedback Conditioning Improves Scaling Across all LLM Training Stages, Brandon Cui+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #mid-training #PostTraining #Selected Papers/Blogs #reading Issue Date: 2026-05-27 GPT Summary- LLMの訓練パイプラインを効率的にスケールするためにIntrospective Training(IXT)を提案。IXTはポスト訓練の情報を初期段階に活用し、自然言語によるフィードバックを付与することで、データの品質を意識した訓練を実現。これにより、トークンの扱いが変化し、計算効率は最大約2.8倍向上、特に数学やコード分野で優れた性能を達成。 Comment
元ポスト:
LLMによってルーブリックに基づいて学習データに対するスコア、critiqueを生成し、データにprependして学習することで、学習効率が改善する。事前学習だけでなく、中間/事後学習にも適用できるようである。
[Paper Note] What do Language Models Learn and When? The Implicit Curriculum Hypothesis, Emmy Liu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Selected Papers/Blogs #reading #needs-revision #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLMs)の事前学習におけるスキル獲得の順序を理解するための「暗黙のカリキュラム仮説」を提案。シンプルかつ組み合わせ可能なタスクを用い、モデル間の一貫した出現順序を追跡。特定のパラメータ範囲で構成的なタスクが後に現れる傾向があり、モデルの表現に組み込まれていることを示す。予測可能な訓練経路を通じて、事前学習は構造化されていると示唆。 Comment
元ポスト:
これは、著者ポストしっかり読みたい
- モデルファミリー・DataMixtureにはよらず、事前学習では構成的で、かつ予測可能なカリキュラムに則って学習が進行し、かつモデルの内部状態から各スキルがどのように学習されていくかを予測できるという仮説を立て、
- この仮説を検証するために、91種類の構成的なタスクを定義し、emergence(=当該タスクの性能が閾値を超えること)を4種類のモデルファミリーにおける9つのモデル、様々なDataMixtureの元で追跡した。タスクの例は以下:
- simple tasks: 文字列操作/形態素の変換/知識の抽出/翻訳など
- composite tasks: 複数の基礎的な操作のsequentialな組み合わせによって実現されるタスク
- たとえば、`gerund_upper` は大文字への変換➡︎動名詞への変換という順番で定義される。
- 様々なモデルファミリーをテストしたところ、LLMは事前学習の間におおむね(完璧ではないが)同じ順番でスキルを獲得していくことが明らかになった
- たとえば、Figure 1を見ると、性能の伸び方は異なるものの、閾値を50%としたときのemergenceの順番はモデルの間で一貫していることがわかる。Table2も参照のこと。
- composite tasksは、それらのタスクの構成要素が獲得された後にemergeすることが明らかになった(54/76ケース)
- 例外的に、composition taskが構成要素よりも先に習得されたものが3例ほど存在した
- また、あるcomposite taskの学習曲線を、類似したFunction Vectors [^1] を持つcomposite taskから予測できるか?(i.e., 類似したタスクは同じような学習曲線を持つか?)を検証。
- これを実施するために、composite taskに対してleave-one-outを実施し、類似したタスクのFunction Vectorsから学習の軌跡を予測できるかを実験したところ、R^2スコアが0.68--0.84程度の性能で予測することができた。
- Function Vectors: [Paper Note] Function Vectors in Large Language Models, Eric Todd+, arXiv'23, 2023.10
[^1]: Function Vectorsとは、LLMに遂行させるタスクのinput-outputの変換の関係性を保持し、タスクを遂行させる際にLLMに対して強い影響力を持つ内部のactivationsのことを指す。
[Paper Note] Generating Pretraining Tokens from Organic Data for Data-Bound Scaling, Zichun Yu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ReinforcementLearning #SyntheticData Issue Date: 2026-05-27 GPT Summary- LLMは、データ束縛型の局面に移行しているが、オーガニックデータを完全に活用しているわけではない。そこで、本研究では、合成データ生成フレームワーク「SynPro」を導入し、限られたオーガニックデータからの学習を強化する。SynProは、再表現と再フォーマットを通じて多様な情報を生成し、強化学習で最適化される。実験により、SynProは有効トークン数を3.7〜5.2倍に引き上げ、データ束縛の課題に対処できることが示された。コードはオープンソースで公開されている。 Comment
元ポスト:
人間が作成したテキスト(organic data)の効果を最大限に引き出すためにデータを合成し、事前学習のlossがサチった際には合成データを生成するポリシーを更新し、現在のサチったモデルに対してより有効なデータとなるような合成データをorganic dataから(rephrasing/reformatにより)合成し学習コーパスに追加する(式10, 11, 12)。
[Paper Note] Forecasting Downstream Performance of LLMs With Proxy Metrics, Arkil Patel+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Selected Papers/Blogs #reading #DownstreamTasks #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 信頼性の高い性能予測が必要な言語モデル開発において、クロスエントロピー損失や直接評価には限界があることを指摘し、代わりに専門家が執筆した解答のトークン分布からエントロピーや精度といったトークンレベルの統計を用いた代理指標を提案。これにより、モデル選択や事前学習データの選択、訓練時の予測において一貫して優れた結果を示し、専門家の軌跡がモデル能力評価において有用な信号であることを明らかにした。 Comment
元ポスト:
著者ポスト:
クロスエントロピーlossに代わるcandidate modelのdownstreamタスクの性能を間接的に測定するための代理指標の提案で、クロスエントロピーlossと比較。代理指標はexpertが作成したtrajectoryに対するcandidate modelのnext token predictionの分布(や、エントロピー等指標に基づく重みづけの組み合わせ)によって、算出される(式1, 2)。
6つの異なるモデルファミリーの18種類のreasoning modelにおいて、6種類のベンチマークにおいて、モデルのdownstreamタスク性能をランク付けできるかをSpearman Rhoで測定したところ、クロスエントロピーlossが0.36だったのに対し、提案した代理指標(を特徴量として用いたRankSVM)は0.81を記録。また、(あるLLMがある事前学習コーパスで学習された場合のdownstreamタスクでの性能の良さによって)事前学習コーパスの良さをランク付けするタスクの場合、ベースラインと比較して10,000倍計算コストを削減できたとのこと。
DataDecide testbed:
- [Paper Note] DataDecide: How to Predict Best Pretraining Data with Small Experiments, Ian Magnusson+, ICML'25, 2025.04
[Paper Note] From Simulation to Enaction: Post-trained language models recognize and react to their own generations, Asvin G.+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Alignment #PostTraining #Author Thread-Post Issue Date: 2026-05-26 GPT Summary- モデルは事前訓練による受動的な予測器から、事後訓練を通じて自身のオンポリシー生成を認識するように変わる。この認識は出力分布に影響を与え、オンポリシー時の出力エントロピーはオフポリシー時より3〜4倍低いことを示す。最新の入力トークンの予測されなさが出力エントロピーを調整し、事後訓練済みモデルは応答の話題についての不確実性を早期に収束させる。一方、異なる話題のプレフィルによってこの意図が崩れるとエントロピーが上昇する。また、モデルがオンポリシーの文脈を言語的に認識できることが確認されたが、そのメカニズムは暗黙の認識とは異なる。 Comment
元ポスト:
関連:
- [Paper Note] Large Language Models as Optimizers, Chengrun Yang+, ICLR'24, 2023.09
以下元ポストの要約
- 事前学習済みモデルは「シミュレータ」であり、事後学習済みモデルは「実行者/演者」としてとらえた方がよい
- すなわち、自身の出力はアクションであり、その結果がフィードバックとして将来の自身の入力になるような関係の下駆動する。
- 事後学習済みモデルは自身の出力よりも、他のモデルの出力を読み込む場合にエントロピーが高くなる
- これは、モデルの入力に対するSurpriseの内部表現によって生じる。すなわち、過去のモデルの予測結果に対して、入力された直近のトークンがどれくらい尤度が低いか、によって出力のエントロピーがsteeringされる。
- モデルサイズが大きいほど、オンポリシー・オフポリシーの差が大きく、これはRL無しで、SFT+DPOだけのpost-trainingでも自己認識が生じる。
- また、「食べ物を思い浮かべて...」というinstructionを与えると、事前学習済みモデルと比較して、事後学習済みモデルは単一のトピックに確率質量を集中させる(つまり、計画を練っている)。これはシミュレータと実行者/演者の特性の違いとしてとらえられる。
- 事後学習済みモデルは、自身の計画がのっとられた場合も検知することができ、計画されていないprefillの場合は、出力トークンのエントロピーが大きくなる。一方、ベースモデルの場合はエントロピーにこのような効果はない(暗黙的な自己認識)。
- モデルに読んでいるテキストが自身が生成したものか、他人が入力したものかを判定させる実験を実施し、KV Cacheをパッチして挙動を分析。ユーザのintentがuser-token中の特定の位置の(おそらくKV Cache)に保持され(hidden activation)、ユーザの意図との整合性等の判定結果を出力する直前にのみ、hidden activationと応答内容の比較がなされていることがKV Cacheのパッチに基づく実験で明らかとなった(明示的な自己認識)。
- この結果は、意図を比較する際には、暗黙的な自己認識の場合と比較して、異なる回路(Surpriseとは異なる回路)をオンデマンドで誘発して利用していることを示唆している。
- (理解があまりできておらず、この説明で正しいかちょっと自信がない。論文中3.3節)
[Paper Note] AMUSE: Anytime Muon with Stable Gradient Evaluation, Jueun Kim+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #LanguageModel #Optimizer #Finetuning #Stability #Backbone #Author Thread-Post #Scheduler-free Issue Date: 2026-05-26 GPT Summary- Muonの直交化は、勾配の振動を引き起こす高曲率部分空間の影響を受けつつ、訓練の進展を加速する。一方、Anytime Muon(AMUSE)は、迅速な適応を図るために時間変化する補間係数を利用し、安定した平均化を通じて振動を抑制する。AMUSEは学習率スケジュールを排除し、視覚タスクと大規模言語モデルの事前トレーニングにおいて、性能を一貫して向上させる。 Comment
元ポスト:
以下、上記著者ポストからの要約である。
MuonとScheduler-freeなoptimiserでの過去のtrajectoryの平均的な方向へ更新する考え方を組み合わせて、Muonの学習を安定させ、かつSchduler-freeを実現した模様。具体的には学習初期にはMuonの軌道を重視し、学習後半になるにつれ、ノイズの影響を低減するためにtrajectoryの平均方向に最適化する(時間変化する補完係数によって挙動が制御される)といったイメージのようである。
Muonがなぜうまくいくかの理論的な分析も実施されている。近年は損失関数の幾何構造をriver/valleyのようにたとえて表現するらしく、(Figure 1)、SGDは曲率の高い(勾配が急)な方向への更新される傾向があり振動をしながら川方向へ進むようだが、Muonはriver方向(曲率は小さいがモデルが最も学習が進捗する方向)への更新を増幅する働きがあるようである。しかし、ノイズとなる高曲率な谷方向への更新も増幅してしまいそれが振動や不安定さを生むため、それを是正するためにSchedule Freeな手法を組み合わせている、という気持ちのようである。また、先行研究に記載がある通り、WSDスケジューラをriver-valleyで説明する、Stableフェーズが川に沿った更新を促進し、Decayフェーズはパラメータを谷の底へ収束させる役割を果たしている、というイメージのようである。
[Paper Note] Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why, Mohammadreza Armandpour+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Distillation #PostTraining #On-Policy #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- オンポリシー蒸留は推論モデルの訓練に対し、トークンごとの監督信号を提供するが、その有効性を決定する条件は未解明である。本研究では、トークン、質問、教師ごとに動作する診断フレームワークを導入し、学生の成功確率を最大化する勾配を導出。理想の勾配との整合性を評価し、蒸留指導が誤ったロールアウトに対して高い整合性を示すことを発見。最適な蒸留文脈はモデルの容量とタスクに依存し、標準的な設定は存在しないことが示された。これにより、タスクごとの診断分析の重要性が強調される。 Comment
元ポスト:
(下記は著者ポストに基づく要約です。ざっくり読んだだけなので誤りがあるかもしれず、詳細は著者ポスト参照のこと)
on-policy (self) Distillationが、どのような場合に有効なのかを分析。
トークンレベルで見た時に多くのトークンが教師-生徒間でdisagreementが存在し、これらにはフォーマットに起因するトークンと、reasoningに重要なトークンの双方が存在する。
そこで、本研究では各トークンにとっての最良の勾配を導出(=生徒が正答できる確率を最大化する方向のもの)。
最適なgradientの方向がわかったので、あとは実際に蒸留をした場合の各トークンのgradientとのコサイン類似度を測ることで、どのような場合にdistillationが有用やシグナル(すなわち、生徒が正答できる確率を高めることに寄与しているか)を分析した。
分析の結果
- distillationが役に立つ場面は、生徒が誤ったロールアウトをしているケースで、正解のロールアウトをしている場合は教師モデルは役立つシグナルではなくノイズを与えているだけだった。
- 教師モデルのパラメータは大きければ大きいほど良いわけではなく、有効か否かは生徒モデルが学習シグナルを理解できるかに依存する。
- たとえば、BoolQというデータで生徒がQwen0.6Bだった場合はself-teacherに基づく勾配が、より大きな外部teacher(4--14B)による勾配と比較して、理想的な勾配に近かった(より高い類似度だった)。
- 一方で、同じデータセットで生徒モデルを1.7Bにすると、8Bの外部teacherが最も理想的なシグナルと高い類似度の勾配をもたらし、self-teacherはあまりうまく機能しなかった。
- contextのフォーマット(生のtrajectoryか要約か, mistakeを含めるか否か等)が、教師モデルの選択と同じくらいの重要
- MMLUデータでの実験で、0.6Bモデルが生徒の場合は、32Bモデルが書いたsolutionをcontextとして与えたself-teacherが理想的な勾配により近く、1.7Bの生徒の場合は、要約されたsolutionの方が良い。
- AIMEの場合、hardな問題の場合は、正解だけでなく失敗例 /典型的なミスをcontextとして与えたself-teacherが良い一方で、easyな問題では常にパフォーマンスの劣化を招く。
以上より、タスクごとに有用なdistillationの設定を模索することの重要性が示唆される、
という感じのようである。
著者ポスト:
[Paper Note] Learning from Language Feedback via Variational Policy Distillation, Yang Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #On-Policy #reading #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- Variational Policy Distillation(VPD)は、強化学習におけるまばらな報酬信号の問題を解決する新たなフレームワークであり、言語フィードバックから密なトークンレベルの監督信号を生成する。これにより、教師と学生ポリシーを共進化させ、教師は軌道結果に基づいて能動的に洗練され、学生はこの情報を内在化する。科学的推論やコード生成タスクにおいて、VPDは従来の手法を一貫して上回る性能を示し、受動的蒸留の限界を克服することを目指す。 Comment
元ポスト:
提案手法の全体像を説明する図が論文中に欲しい。式(3)が天下り的に出てきて、私の勉強不足によりこの式を前提に論理展開がスタートする気持ちがよくわからない(おそらくDPOあたりをもっとしっかり理解するとわかるのだろう)。
が、現在のself-teacherに基づくOPSDは、textual feedback Cに対して最適化されておらず、かつzero-shotによる予測を実施しているため、学習が継続するにつれてfeedbackにいつか限界が生じるため学習のために有用なシグナルがなくなるのではないか、という考察に基づき、
textual feedbackから学習する枠組みvariational inference problemの観点から考え直す。すると、KL Divergenceによって正則化されたRLVRは式(3)によって定式化されるreward functionによって傾斜がつけられた最適な事後分布pi_*に対して、ポリシーのKL Divergenceを最適化する問題と等価になる。このとき式(3)の分母にはZ(x)が存在しこれは計算ができない。このため、これを解決するためにteacher network q_phi (y | x, C) を導入し、最適な事後分布pi_thetaの近似的な教師分布とする。これによりELBOを用いた変分下限のRLVRの目的関数を定義することができ、これはEMアルゴリズムによって解くことができる。具体的には
- Eステップ: q_phiとpi_optimalのKL Divergenceが最小となるようにq_phiを更新する。
- Mステップ: pi_thetaとq_phiのKL Divergenceが最小となるようにpi_thetaを更新する。
このとき、EとMではphiとthetaのパラメータが独立して存在するが、実用上はphiとthetaを共有する。これにより、textual feedback Cを解釈する教師モデルと学生モデルの双方がco-evolvingしていくような学習が実現される、
という感じだろうか。
ELBOについて:
- 変分オートエンコーダ⑥変分下限 ELBO:
https://note.com/kikaben/n/n00ad3e148770
[Paper Note] A Bitter Lesson for Data Filtering, Christopher Mohri+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #read-later #Selected Papers/Blogs #DataFiltering #Reading Reflections #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- 高計算資源を活用したスケーリング研究で、大規模モデルの事前学習におけるデータフィルタリングを検討。一般的に思われる高品質データのみが必要との見解に反し、実験は、十分な計算資源があればデータフィルターなしが最良であることを示す。訓練された大規模モデルは低品質や誤誘導データを受け入れ、むしろ「質の悪い」データからも恩恵を得ることが判明。 Comment
元ポスト:
LLMの事前学習において、十分に大きなモデルサイズと計算量があれば、データフィルタリングをしない場合の方が最終的にperplexityがデータをフィルタリングしたモデルよりも上回る。これはbad data (e.g., トークンのシャッフル, ランダムな文字列の挿入)を追加した場合でも当てはまる。
データプールのサイズが大きな数な場合でも、フィルタリング手法とフィルタリングがない手法との交差点が変わるのみで、その交差点は現実的なエポック数に留まったままである。データのスケーリングの傾向に基づいて、インターネットサイズのデータサイズに外挿をすると、約1e30 FLOPsが必要となる試算になるが、数年以内に到達可能な計算量と考えられる。
ダウンストリームタスクへの性能にも(ノイジーだが)事前学習での改善は寄与する。ただし、事前学習させたトークン数が少ない場合はフィルタリングした方が性能が良く、十分な計算量を投じる必要がある。
といった話が著者ポストに書かれている。興味深い。
逆に言うとこの傾向は、モデルパラメータ、計算資源が十分に大きいことが前提だと考えられるので、PhiのようなSLM研究において得られた学習データの高品質化が重要という知見とは競合しないと思われる。
解説:
関連:
- [Paper Note] When Bad Data Leads to Good Models, Kenneth Li+, ICML'25, 2025.05
[Paper Note] Steered LLM Activations are Non-Surjective, Aayush Mishra+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Prompting #Safety #Selected Papers/Blogs #reading #Steering #Interpretability #Reading Reflections #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- アクティベーション・ステアリングは、モデルの活性化を調整し、その挙動に変化を与える手法であり、解釈可能性や安全性研究で広く利用されている。しかし、任意のテキストプロンプトによってこの挙動が実現可能かは不明である。本研究では、この問題を全射的な観点から考察し、すべてのステアされた活性化が前像を持つかを調査する。実証的結果から、活性化ステアリングは任意のプロンプトによって同じ内部挙動を再現できないことを示し、ホワイトボックス的なステアリングとブラックボックス的なプロンプティングの違いを明確にする評価プロトコルを提案する。 Comment
元ポスト:
steeringされたactivationを自然に生み出すプロンプトは存在しない。言い換えると、steeringによって得られる挙動はpromptでは再現できない。これにより以下が示唆される:
- prompt levelのbehaviorとactivation/weightに介入することによるbehaviorの変化は、根源的に異なる現象なので分けて考えなければならない
- white-boxなstteering手法によってjailbreakができたとしても、black-boxな手法(e.g., promptingによる脆弱性など)による脆弱性があることの証拠にはならない
Steeringされたactivationは下記のようなAutoencoderを学習することでverbalizeできるのだろうか?hidden_stateのreconstruction lossを通じてverbalizeするためできそうではある。元々のactivationがpromptによって到達不可能な点にいたときに、promptによって到達不能なだけであって内部のネットワークが状態を解釈できないというわけではないので(ここがめちゃめちゃなら何も学習できないということになるがそうではなさそうなので)普通にできそうではある:
- Natural Language Autoencoders: Turning Claude’s thoughts into text, Anthropic, 2026.05
[Paper Note] ECHO: Terminal Agents Learn World Models for Free, Vaishnavi Shrivastava+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #SelfImprovement #PostTraining #Selected Papers/Blogs #Non-VerifiableRewards #WorldModels #reading #ContinualLearning #Initial Impression Notes #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- ECHOは、CLIエージェントのトレーニングにおいて環境のフィードバックを活用するハイブリッド目的関数を提案。標準的な政策勾配損失と、自己行動による環境観測トークン予測を組み合わせ、ロールアウトに既存の信号を密接な監督として利用する。これにより、TerminalBench-2.0でGRPOのpass@1を倍増させ、環境ダイナミクスの予測精度も向上させる。ECHOは専門家デモなしで、未知のOODタスクのポリシー改善を可能にすることを示している。 Comment
反響がすごそうに見える
- 通常のAgentのRLは環境からの応答に対してマスクをかけてしまい、エージェントが環境(本研究ではターミナル)にどう影響したかを示すground-truthのsignalであるにもかかわらず応答を切り捨ててしまう。
- 提案手法であるECHOはアクションと環境からの応答の双方で学習を行う。通常のaction tokenに対する損失はそのままに、ターミナル出力に対するシンプルなcross-entropy lossを追加する(環境からの応答はcontextに含まれ、モデル内を通過しているため追加のコストはかからない。)。
- このシンプルな修正によって、ベンチマークのスコアが改善し、特にTerminalBench-2.0のスコアはほぼ倍増した。これは言い換えると通常のRLと比較して2.3倍高速になっている。
- また、ターミナルの応答を学習したことでターミナルのダイナミクスをポリシーが学習し、held-out trajectoriesにおいて環境からの応答トークンのクロスエントロピーはECHOでは急激に低下するが、通常のGRPOではほとんどい変化しない。これは、ECHOがモデルに対してターミナルがどう応答するかを学習させていることを示唆する。
- エキスパートによる教師モデルを持たない場合でも、ECHOによってエキスパートによるdemonstrationでSFTを行った後のGRPOが達成するパフォーマンスにほぼ匹敵可能
- エキスパートのtrajectoryから模倣学習するSFTと比較して、ECHOではモデル自身がターミナルの応答を予測することで、ターミナルの応答のうち何が有用なのかを学習する。模倣からではなく、インタラクションを通じて優れた戦略を創発する。
- ECHOを使うことで、AI AgentはVerifierの報酬なしでも自己改善ができる。Verifierの報酬が一切なくても、ECHOはAI Agentが環境内で行動し、何が起こるかを予測するだけで、(GRPOなしで)さらに性能を向上させることができる。つまり、taskのpromptに対して、モデルに環境がどのような応答を返すか予測をさせ、observationに対するクロスエントロピーlossを計算し更新するだけで性能(in-distribution, OOD共に)が改善する。
環境が多くのシグナルを返してくれる場合はterminal以外の環境でもうまくいきそうな話で、非常にシンプルな変更で実現でき、かなりインパクトが大きく見える。
元ポスト:
prime-rlでサポートされたとのこと:
[Paper Note] BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding, Jiayi Yuan+, MLSys'26 Best Paper, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Training-Free #Selected Papers/Blogs #MLSys #reading #SparseAttention #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- BLASSTは、LLMsの文脈での推論能力向上のために提案された動的スパースアテンション機構である。固定スカラー閾値を用いて計算を加速し、トレーニング要件を排除、既存フレームワークと容易に統合可能。自動閾値キャリブレーション手法により、最適閾値と文脈長の逆比例関係が明らかにされ、前計算とデコードそれぞれに単一の閾値を利用。現代GPU上でのベンチマークにおいて、前計算とデコードがそれぞれ1.52倍、1.48倍の速度向上を示し、精度を維持した。 Comment
元ポスト:
training-freeで単一のスカラー閾値による制御によって、スキップ可能なattention blockをスキップするSparse Attentionとのこと。
非常に使い勝手が良さそうで、50%程度のSparsityにしてもベースラインとなるDense Attentionに対してダウンストリームタスクの性能低下はなく(Table 4)、50%程度のSparsityの場合、prefillとdecode step方法において、Blackwell, Hopperアーキテクチャにおいて約1.3倍の高速化を実現できる(Table5)。
[Paper Note] STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?, Hanxiang Chao+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #memory #reading Issue Date: 2026-05-21 GPT Summary- 大規模言語モデル(LLM)が個人化メモリを維持する上での「暗黙的対立」能力を評価するために、400の専門家検証済みシナリオを含むSTALEを提案。三次元の探査フレームワークにより、古い信念の検出やユーザー状態の変化に応じた記憶の修正を評価。最先端のモデルでも精度55.2%に留まり、時代遅れの仮定を受け入れる傾向を示す。状態認識型メモリの改善のためのプロトタイプCUPMemを提示し、明示的な状態判断の重要性を示す。 Comment
元ポスト:
提案されたベンチマークでは3つの次元で測定するが、特にユーザから本来とは異なる古い前提のクエリ与えられたときに、それを否定し、自身のメモリからgroundingされた情報に基づいて応答を生成させるテスト(Premise Resistence; 3.5節)に苦戦することが示されている(Table 2)。
他の二つの次元は
- State Resolution: 以前の記憶がすでに無効であることをモデルに対して直接テスト
- Implicit Policy Adaptation: 前提知識を提示せずに、最新の記憶に基づいて応答しなければならない質問(e.g., 今週の通勤プランを教えて)に対するテスト
[Paper Note] Mix, Don't Tune: Bilingual Pre-Training Outperforms Hyperparameter Search in Data-Constrained Settings, Paul Jeha+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #DataMixture #LowResource Issue Date: 2026-05-21 GPT Summary- 低リソース言語の事前学習におけるデータ制約を克服するために、ハイパーパラメータ調整と高リソース言語のデータ混合の二つのアプローチを比較。データ混合は検証損失と下流タスクの精度向上をもたらし、特にモデルサイズが大きいほどその効果が顕著。混合による性能向上は、ターゲットデータのユニークな量の2〜13倍に相当し、混合が正則化と知識供給に寄与するが、検証損失はその効果を過小評価している。実践的な指針として、高リソース言語の混合を優先し、ハイパーパラメータ調整よりも混合比に焦点を当てることを提案。 Comment
元ポスト:
low resourceな言語での性能向上にはハイパーパラメータを調整するよりもHigh Resourceなデータを混合し、正則化の働きを促進するのと、low resourceなデータからでは得られない知識を注入する方が効果的
[Paper Note] MeMo: Memory as a Model, Ryan Wei Heng Quek+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later #Selected Papers/Blogs #memory Issue Date: 2026-05-21 GPT Summary- MeMo(Memory as a Model)フレームワークは、LLMのパラメータを変更せずに新しい知識を専用のメモリにエンコードすることで、タイムリーな情報適用を可能にする。これにより、複雑な関係の把握、検索ノイズへの耐性、壊滅的忘却の回避を実現し、LLMへのプラグアンドプレイ統合が可能となる。実験結果は、BrowseComp-Plus、NarrativeQA、MuSiQueの各ベンチマークにおいて高い性能を示した。 Comment
元ポスト:
frozenなgeneratorモデルでコーパスからmemory model用のQAデータを合成し、QAデータを用いてmemory modelに知識を埋め込み、frozenなexecutive modelがmemory modelから情報を引き出しながらクエリに応答するアーキテクチャ
[Paper Note] A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models, Hamid Kazemi+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Safety Issue Date: 2026-05-16 GPT Summary- 言語モデルの安全性整合は、拒否ニューロンと概念ニューロンという二つのシステムを通じて機能し、前者が有害な知識の表現を制御し、後者がそれを符号化する。研究では、7つのモデル(1.7Bから70Bパラメータ)を対象に、ニューロンの抑制や増幅による安全性の失敗を示した。結果、個々のニューロンが拒否行動を制御し、安全性が全体に均一ではないことが明らかとなった。特定の拒否ニューロンを抑制することで、多様な有害リクエストに対する安全性の整合性が回避されることが示された。 Comment
元ポスト:
- モデルの(MLP中の)Refusal Neuronを同定する手法を提案し、この手法はモデルのactivationにアクセスできるだけで利用でき、追加の学習やprompt engineeringを必要としない。
- Residual Stream中のfeatureは、有害/無害の分離がうまくされていない(Figure 7)
- Refusal Neuronを特定しこのニューロンを抑制するだけで1.7B--70BまでのスケールのモデルでJailBreakBenchと呼ばれるベンチで91.7%の攻撃が成功するようになる。
- また、SparseAutoEncoderのようなモデルを用いることなく、増幅することで本来無害なプロンプトに自殺に関する情報を出力させることが可能なSuicide Neuronも発見。
- Refusal NeuronはAlignmentのチューニング前のベースモデルに既に存在していて、Alignmentでは新たにこのような役割のニューロンを生成するわけではなく、既存のRefusal Neuronを調整している
- 単一のRefusal Neuronの活性値がsafeguardのための訓練されたモデルに匹敵する有害プロンプト検知性能を示す
[Paper Note] Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs, Guijin Son+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Mathematics #read-later #Selected Papers/Blogs #Reading Reflections #Author Thread-Post Issue Date: 2026-05-14 GPT Summary- Soohakという新たな数学ベンチマークを導入し、439問から成り、フロンティアモデルの推論能力を評価。Challengeサブセットでは、トップモデルが30.4%未満の成功率である一方、拒否サブセットはモデルが50%を超えられない問題解決能力を確認。これにより、拒否能力が新たな評価基準として浮上し、2026年末に公開予定のデータセットで混入を防ぐ。 Comment
元ポスト:
60人以上の数学者によってゼロペースで作成された新たなベンチマーク。数学者は作問をする際にLLMの利用は禁止され、問題を作成しsubmitする。その後レビュープロセスを経て問題が収録されるかが決まっているようである。レビュープロセスでは、LLMによる難易度の確認や類似した問題がないかなどの確認をし、人間がLLMの出力を見て疑わしいか否か判断する。レビュワーは作成者にフィードバックをし、質問や確認などを行う。また、LLMを利用したであろう作成者はbanされ、問題に調整が必要な場合は修正がなされる。提出された問題は、小、中、大のスケールのOpenLLMによって正解できたか否かによって、miniとして収録されるかChallengeとして収録されるかが決まり、特にChallengeについては作成者が特定の教員やポスドク、IMOメダリストなどに限定されたようである。
99個の、矛盾や前提の抜け、正解が一意に決まらないill-posedな問題も含まれており、モデルが回答を拒否しなければならないRefusal Questionsが含まれているのが大きな特徴。
研究レベルの問題の定義がよくわかっていないのだが、要は競技で出題されるような「既存の知識や枠組みの中でのマルチステップでの推論」を必要とするものではなく、「数学に関する最先端を切り拓くレベルの問題」のことのようである。これでもまだよくわからなかったのだが、問題の作成者に対するインタビューによると、SOOHAK-Miniの問題は短時間で作成できたが、SOOHAK Challengeの問題は1問作成するのに1日以上の作業を要することがしばしばあったとのこと。Challengeレベルの問題を作成するためのアプローチとしては典型的に2つあったとのことで、
- 問題作成者自身が最近考えていた研究と隣接した問題を提出するもので、問題を解くステップにおいて既存の定理や、論文などで公式には発表されていない事実や、数学者の中でヒューリスティクスを組み合わせる必要があるような要素を含むもの(folklore-level reasoningと呼ばれる)
- ニッチな研究論文に基づいて問題を設計する方法
などがあったようである。つまり、競技という枠組みは超えて、数学の研究者が研究として考えるレベルの問題ということだと理解した。
コーディングにおいて人間を置き換えるレベルであろうモデルも、未知の数学の問題や、そもそも問題として不適切なものの回答拒否は広く使われたベンチマークほどはうまくいかない。新たに拒否が最適化のobjectiveとして必要なことが示唆されているが、逐一人類はAIにこの挙動が足りないね、じゃあ学習データを用意して学習しよう、ということを繰り返していくのだろうか?正解ベースの学習にそろそろ限界が見えてきた気がしており、AnthropicのペルソナやConstitutionに基づいた学習のような特定の領域に広く汎化するような学習方法の模索が必要な気がする。
拒否する挙動のための正解データを用意して学習するとしよう。そうすると、モデルが持つ他の能力に影響を与えるだけでなく、本来拒否が不要な場面でも拒否するようになる可能性が高い(たとえばクエリが数学に関連しているだけで、一定の確率で拒否するリスクは生じるように思われる)。この問題を解決するために最近はOn-Policy Distilation (OPD)が活用されるが、OPDはこの問題を緩和することには寄与するが、根源的に解決しているわけではない(と思われる)。genericな能力の発現に際して、モデル自身がcontextに応じて、どの挙動を発現させるべきかを"線引き"できるような能力とアーキテクチャ(マルチモーダルなモデルのようにMoEのexpertをbehaviorに関しては分離するなどだろうか)が必要に思う。
[Paper Note] Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting, Ishaan Watts+, ICML'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Catastrophic Forgetting #ICML #mid-training #read-later #Selected Papers/Blogs #DownstreamTasks #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 事前訓練最適化手法は、基盤モデルの能力維持に影響を与える幾何学を考慮すべきである。本研究では、平坦な極小点を目指す三つのアプローチ(SAM、大きな学習率、短縮された学習率減衰)を分析し、モデルサイズが20M〜150Mパラメータの範囲で、ポスト訓練後のパフォーマンス向上と忘却の最大80%低減を実証した。また、OLMo-2-1Bモデルへの短いSAM訓練を適用することで、MetaMathでは忘却を31%、4ビット量子化後には40%低減できることが示された。 Comment
元ポスト:
downstreamタスクでの性能を最大化するためには、baseモデルのlossではなく、モデルが重みを更新した時にどれだけ事前学習の知識が保持されるかが鍵であり、learning-forgettingのトレードオフを見るべきという話で、
なぜモデルの更新によって忘却が起きやすいかというと、モデルが急峻な極小点 (Sharp Minima) に収束してしまっているためで、これではわずかな重みの更新でも大幅な性能低下を起こしてしまう。このため、平坦な極小点(Flat Minima)に重みを収束させることでよりモデルの知識を安定させることができる。
Flat Minimaを見つけるために、Sharpness-Aware Minimization (SAM)と呼ばれる手法を採用し、式(5)で定義されるような、パラメータに摂動を加えた時のlossの最大値が最小となるようにパラメータを最適化する。
[Paper Note] Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction, Zhuofeng Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #LanguageModel #AIAgents #read-later #Selected Papers/Blogs #Reading Reflections #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 直接コーパスと相互作用する(DCI)アプローチを提案し、リトリーバAPIや固定された類似度インターフェースに依存せず、エージェントが生のコーパスを汎用的な端末ツールで直接検索できるようにします。この方法は、オフラインのインデックス作成を不要にし、進化するコーパスに自然に適応します。実験では、DCIがBRIGHTおよびBEIRデータセットで強力なベースラインを上回り、従来の手法なしに高精度を実現したことが示されました。この結果は、検索の質が推論能力だけでなく、コーパスとの相互作用のインターフェースにも依存することを示唆しています。 Comment
元ポスト:
基盤モデルが賢くなる中で、top-kによるretrievalが検索におけるベストなインタフェースなのか?という疑問を投げかけた研究で、ベクトル検索などのRetrieverではなく、AI Agent自身にgrep等を用いて直接コーパスとinteractionをさせる(Direct Corpus Interaction)ことでBrowseCompのようなQAデータセットにおいてEmbeddingを用いた手法よりもより低コストで高いスコアを獲得できることを示したようである。
DCIは有用な手がかりを見つけた時に、それをrearoning stepに結びつけて深掘りしていくような挙動を実現しやすい点が強みであるが、コーパスサイズが大きくなるにつれて最初のアンカーとなる手がかりを見つけるためのコストが大きくなり、深さへの強みはあるが、広さには弱い性質があることから、この手法が唯一無二の解というわけではなく、設計の際に「どのモデルがtop-kの検索でベストか?」という視点だけでなく、「AI Agentにコーパス全体に対してどのようなオペレーションを持たせるべきか?」という問いかけも提起する
といった話が元ポストに書かれている。
昔から検索に全てのケースで最強な手法はこれ!みたいなものはないので、こういった選択肢もあるよということを頭に入れて引き出しに入れておき、直面する課題に対して有効な方法は何かを考えることが重要と思われる。
所見:
[Paper Note] EvoLM: Self-Evolving Language Models through Co-Evolved Discriminative Rubrics, Shuyue Stella Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SelfImprovement #Selected Papers/Blogs #reading #Rubric-based #Author Thread-Post Issue Date: 2026-05-11 GPT Summary- EVOLMは言語モデルの自己改善を促進するポスト訓練手法であり、外部監督に依存せず、モデル自身の評価能力を利用します。具体的には、事例ごとに最適化された評価基準を生成するルーブリック生成器と、そのルーブリックを用いて訓練されたポリシーの二つの能力を交互に訓練します。これにより、EVOLMはQwen3-8Bモデルを用いてGPT-4.1を25.7%上回るルーブリックを生成し、共同訓練されたポリシーは最新の報酬モデルよりも優れた性能を示しました。全体として、EVOLMは内部の評価能力を活用することで、外部の監督なしでの改善を実現することが明らかになりました。 Comment
元ポスト:
外部ラベル無しでself-improvingするルーブリックベースな手法の提案。
手法としては、まずfrozenしたRubirc生成器とJudgeモデルで全てのpromptに対してRubricを生成し、ポリシーが生成したロールアウトに基づいてJudgeモデルでRewardを計算することでポリシーを更新。その後更新されたポリシーを用いてpreference pairを構築し、preference pairに対してRubric生成器がルーブリックのロールアウトを生成し、choicedとrejectedなサンプルに対するJudgeのスコアの差の大きさ(すなわち、識別力の高さ)をrewardにRubric生成器を更新する、といったことを繰り返す。
多分3説以降の話が面白い。後で読む
Rubricが徐々に変化していき、抽象的なものからよりverifiableなものに変化したり、Rubricそのものが静的だとポリシーの学習に伴い変化する出力分布の変化に対応できない話や、最終的に獲得されたRubricは他のモデルの学習でも高い学習signalを送出するような汎化をするらしい
[Paper Note] Recursive Agent Optimization, Apurva Gandhi+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #RecursiveModels #Initial Impression Notes #Orchestration #Delegation #Author Thread-Post Issue Date: 2026-05-10 GPT Summary- 再帰エージェント最適化(RAO)を導入し、エージェントが自身のインスタンスを生成してサブタスクを委任できる強化学習アプローチを提案。推論時のスケーリングアルゴリズムを実装し、長い文脈への拡張と難しい問題への一般化を可能にする。この訓練により、効率が向上し、タスクのスケールや一般化能力が高まり、実時間の短縮が実現される。 Comment
元ポスト:
著者ポスト:
pj page: https://apga.github.io/RAO/
再帰的にAI Agentがサブタスクを委任する子エージェント(子エージェントは自身のコピー)を作成できるようにし、子エージェントがサブタスクを実施した際のRewardや子エージェントのタスクの成功率などの情報に基づいて親エージェントの報酬が決まるような報酬設計にする。再帰が深くなるにつれ、サブタスクは簡単になっていくため、エージェントは自然に学習するためのカリキュラムを構築していると捉えることができる。これにより、エージェントがタスクをサブタスクに分解し再帰的にinferenceをするような挙動をend-to-endで学習する。再帰の木構造の深さは、場合によっては特定の部分木が非常に深いものとなってしまうケースもあるため、深さの情報に基づいて重みづけを調整する。
という感じだろうか。
サブタスクを委任するポリシーが自分のコピーで、これにより自分自身を分解されたサブタスク上から得られる報酬と、適切な委任による報酬によって訓練することになるといううまい報酬設計がミソな気がする。
著者ポスト2:
[Paper Note] Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe, Wenjin Hou+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Distillation #PostTraining #On-Policy Issue Date: 2026-05-09 GPT Summary- OPDは専門モデルの能力を学生モデルに統合する手法であり、その効果を制限するボトルネックを特定した。本研究では、情報価値のある状態の探索不足と教師の指導の信頼性の欠如に着目し、新たにUni-OPDという統一的なフレームワークを提案。学生視点からのデータバランシング戦略と、教師視点からの結果指向のマージン較正メカニズムを使用して、訓練を最適化。実験によりUni-OPDの効果と汎用性を示し、信頼性の高いOPDに関する洞察を得た。 Comment
元ポスト:
OPDを
- difficultyに基づいたサンプリングによって生徒モデルの探索を促し
- 生徒のtrajectoryが正しい場合はスコアがより高くなることを保証する
ことで改善しているとのこと。
[Paper Note] Sparser, Faster, Lighter Transformer Language Models, Edoardo Cetin+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Sparse #GPUKernel #Author Thread-Post Issue Date: 2026-05-09 GPT Summary- 非構造的スパース性を活用することで、LLMの計算コストを削減し、フィードフォワード層の効率を向上させる新しいCUDAカーネルを導入。99%超のスパース性を誘導しつつも、パフォーマンスへの影響は最小限。これにより、モデル規模の拡大に伴うスループット、エネルギー効率、メモリ使用量の改善を実証。すべてのコードはオープンソースで公開し、スパース性の実用性を推進。 Comment
元ポスト:
現在の言語モデルではFFNの計算が計算コストの多くを占めているが、ReLUやL1正則化によってFFN中で必要なactivationを99%程度sparseにすることができ、sparseになったFFNに対して最適なデータ形式と高速に動作するGPUKernelを構築することで、downstream taskへの性能劣化無しに、省コストでの推論が可能になる、という話に見える。
解説:
[Paper Note] HiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?, Tu Trinh+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs #Human-in-the-Loop Issue Date: 2026-05-08 GPT Summary- 最先端のコーディングエージェントは、完全な文脈では複雑なタスクをこなせるが、不完全な仕様では失敗する。ボトルネックは能力よりも判断力であり、適切な行動と助けを求めるタイミングを知ることが重要である。提案するHiL-Benchは、この選択的エスカレーション能力を評価し、ブロッカーを含むタスクを通じて人間の判断力を測定する。核心指標Ask-F1は、質問の正確さとブロッカーの再現率を評価し、不適切な質問を防ぐ。評価結果は、モデルが不確実性に適切に対処できず、自己修正能力に欠けることを示す。強化学習による訓練で、判断力の向上が確認され、モデルは不確実性を検知し対処する能力を学ぶ。 Comment
元ポスト:
完全情報の下では80%前後の成功率をおさめるにも関わらず、情報が欠落している場合は成功率が著しく低下することから、現在のAI Agentが失敗する要因は、能力ではなく情報が不完全な場合にエスカレーションする判断力にあることを指摘し、必要な情報が欠落したタスクを用意し、その情報を取得するための質問(エスカレーション)を適切なタイミングで生成できるか否かを測定するベンチマークを作成し、ベンチマークでの評価を通じて、エスカレーションのための判断能力はRLVRによって向上させられることを示した、という感じの話に見える。
[Paper Note] Prescriptive Scaling Laws for Data Constrained Training, Justin Lovelace+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Scaling Laws #DataRepetition Issue Date: 2026-05-08 GPT Summary- 高品質なデータが限られる中、計算資源の最適配分が重要になる。従来のChinchillaスケーリング則は、一意なトレーニングトークンを前提としており、データ制約下の効果的な学習を妨げる。私たちは過剰損失を加法的な過学習ペナルティでモデル化し、最適な資源配分に関する新たな指針を提案する。一定のポイントを超えると、繰り返しは逆効果になり、モデル容量への投資が望ましいことを示す。さらに、この法則を用いることで、データ制約下での性能向上が明らかになり、過学習の影響を一つの係数に分離することで、トレーニング設定間の比較を可能にする。特に、強いウェイト減衰が過学習係数を約70%減少させ、最適なウェイト減衰が標準実践を上回ることを示すケーススタディも含む。 Comment
元ポスト:
所見:
Data Repetitionはデータの効率を改善するが、同時に過学習コストが生じており、これはモデルサイズと繰り返しが増えるほど増大する。強めの正則化を導入することで過学習コストが緩和される。
[Paper Note] KAME: Tandem Architecture for Enhancing Knowledge in Real-Time Speech-to-Speech Conversational AI, So Kuroki+, ICASSP'26, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #SpeechProcessing #read-later #Selected Papers/Blogs #Realtime #ICASSP #Author Thread-Post #SpeechToSpeech Issue Date: 2026-05-01 GPT Summary- 音声-音声モデルは低遅延で自然な応答を生成するものの、知識や意味理解に欠ける。一方、ASRとLLMを組み合わせたカスケード型システムは知識表現に優れるが、遅延が大きくなる。そこで本研究は、即時応答を実現する新たなハイブリッドアーキテクチャを提案。ユーザーの音声をS2Sトランスフォーマーで処理しつつ、クエリをLLMに並行伝送。これにより、遅延を増加させずに豊富な知識を応答に組み込むことが可能となる。MT-Benchベンチマークを用いた評価により、提案システムはS2Sモデルを大幅に上回りつつ、遅延は同等であることが示された。 Comment
元ポスト:
HF: https://huggingface.co/SakanaAI/kame
SpeechToSpeechのエンコーダ・デコーダモデルの裏で同時並行してLLMを走らせ、随時生成されるOracle Streamを考慮してデコードすることで、latencyと知識・推論性能を両立する。
著者ポスト:
[Paper Note] The Power of Power Law: Asymmetry Enables Compositional Reasoning, Zixuan Wang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Composition #read-later Issue Date: 2026-04-29 GPT Summary- 自然言語データはべき乗分布に従うが、再重み付けや均一分布によるモデル学習が効果的であるという直感に反し、べき乗分布での訓練が均一分布を一貫して上回ることを発見。最小限のスキル組成タスクを用いて、べき乗分布による学習が少ないデータで効果的であることを実証。理論的分析により、べき乗分布が非対称性をもたらし、モデルが高頻度スキルを効果的に学習し、長尾スキルに至る道筋を提供することを明示。結果はモデル訓練におけるデータ分布の新たな理解を促進。 Comment
元ポスト:
学習データ中に内包されるスキルの非対称性により学習が促進される。
Geminiの解説では
> 高頻度のスキルと低頻度のスキルが混在する非対称なデータ分布(べき乗則)の下では、モデルがまず高頻度なスキルを容易に獲得し、それが『足がかり(stepping stone)』となることで、データを均等な分布にならして学習するよりも、かえって効率的に稀なスキル(ロングテール)を学習できる
ということである(要確認)
[Paper Note] Context Unrolling in Omni Models, Ceyuan Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #Reasoning #VisionLanguageModel #2D (Image) #3D (Scene) #UMM #3D (Video) #Omni #Reference Collection #AudioLanguageModel #Fidelity #audio #text Issue Date: 2026-04-24 GPT Summary- Omniは、多様なモダリティにネイティブに訓練されたマルチモーダルモデルで、Context Unrollingを通じて異なるモダリティの情報を統合。これにより、下流の推論忠実度が向上し、高い生成・理解性能を発揮。テキスト、画像、動画、3Dジオメトリを用いた高度な推論能力を示す。 Comment
元ポスト:
モダリティを跨いでtaskに対してrelevantなcontextを活性化させることで、omniモデルの生成時の推論能力と、忠実度を向上させる
[Paper Note] PolySkill: Learning Generalizable Skills Through Polymorphic Abstraction, Simon Yu+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ICLR #Selected Papers/Blogs #Generalization #AgentSkills #Author Thread-Post Issue Date: 2026-04-23 GPT Summary- 大規模言語モデル(LLMs)を利用して、エージェントが一般化可能なスキルを学習するための新しいフレームワーク「PolySkill」を提案。スキルの抽象的な目標と具体的な実行を切り離すことで、スキルの再利用や一般化を促進。実験では、ウェブサイトでのスキル再利用を1.7倍向上させ、成功率を最大13.9%向上させた。PolySkillにより、エージェントが自己目標を識別し、より良いカリキュラムを学習する能力が高まり、継続的に学習できる自律エージェントの構築に寄与することが示された。 Comment
元ポスト:
エージェントスキルにポリモーフィズムの考え方を導入し、WhatとHowを分離することで汎化性能を高める。下図が分かりやすい。
最初に特定ドメインのwebサイト(e.g., shopping)を訪れた際に、AbstractShoppinpクラスを生成しShopping関連を扱うクラスとする。その上で、特定サイト(e.g., Amazon)のスキルを生成する際は、AbstractShoppingクラスにシグネチャを登録した後、同クラスを継承。AmazonShoppingクラス内に具体的な処理を定義する。直接スキルを生成するのではなく、抽象スキルを生成した上で、特定サイトでのメソッドを実装する。
openreview: https://openreview.net/forum?id=KdEsujyiSV
[Paper Note] Micro Language Models Enable Instant Responses, Wen Cheng+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Decoding #Reference Collection #Latency #EdgeDevices Issue Date: 2026-04-22 GPT Summary- μLMsを導入し、エッジデバイスで即座に文脈に基づく応答の最初の数語を生成し、クラウドモデルがその後を完成させることで、遅延を隠蔽する協調生成フレームワークを設計。経験的結果は、極小モデルでも大規模モデルと同等の生成が可能であることを示し、リソース制約のあるデバイスでの高い応答性を実現。 Comment
元ポスト:
オンデバイスのMicro LLM(8M--30M)パラメータが冒頭の単語を生成し、その続きをCloud側のLLMが生成することで、Cloud LLMのlatencyの遅さをマスクする
[Paper Note] LACE: Lattice Attention for Cross-thread Exploration, Yang Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Attention #Test-Time Scaling #mid-training #Decoding #PostTraining Issue Date: 2026-04-20 GPT Summary- LACEは、独立した推論試行を協調的な並列プロセスに変換するフレームワークであり、クロススレッドのアテンションを活用して推論経路間での洞察の共有と相互訂正を可能にする。合成データを使って自然な訓練データの不足を補い、実験では正確性が7ポイント以上向上することを示した。結果は、相互作用する並列推論が大規模言語モデルの効果を高める可能性を示唆している。 Comment
元ポスト:
parallel test-time scalingによって生成をする最中にtrajectoryを交互作用させることで、trajectoryの冗長性を減らし、交互作用を可能にする。
[Paper Note] Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter, Ruoyu Qin+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Infrastructure #LLMServing #Selected Papers/Blogs #reading #KV Cache #needs-revision #Author Thread-Post Issue Date: 2026-04-18 GPT Summary- Prefill-decode(PD)のデプロイにはKVCache転送が制限要因となっており、従来のアテンションモデルは大容量のKVCacheトラフィックを生成する。ハイブリッドアテンションアーキテクチャはKVCacheサイズを削減するが、データセンター間の運用に問題が残る。そこで、Prefill-as-a-Service(PrfaaS)を提案し、プリフィル処理を専用クラスタにオフロードして効率的なKVCache転送を実現。これにより、リソースの独立したスケーリングを可能にし、実績として、PrfaaSを用いた異種デプロイメントは従来よりも高い提供スループットを達成。 Comment
元ポスト:
LLM servingにおいて、prefillはcompute-intensiveで、decodeは(kv cacheが肥大化するため)memory-intensiveであるという特性があるため、(それぞれ得意な処理は得意なノードに任せるため)prefillとdecodeを分離して異なるノードで実施するprefill-decode disaggreagated servingというインフラのアーキテクチャが超巨大モデルでは主流だが、prefill-decode間でKV Cacheを転送しなければならないため、このような分離は同じ計算機クラスター内のRDMA(Remote Direct Memory Access)が可能なノード間に限定されるのが一般的である。
しかし、compute/memory特化型のリソースは通常チップの種類と物理的な場所の両方に制約されてプールされるので、両方のハードウェアがRDMAのような密結合なドメインで利用できないという欠点がある。このため、クラスターを超えてPD分離をしたいのだが、KV Cacheの転送が結局のところボトルネックとなる。現在のモデルはSparse/LinearなアテンションによってKV Cacheに必要なリソースが一桁減っているが、それでもnaiveにクラスタを跨いでPD分離をすると、突発的なリクエストのバーストや、不均一なPrefix Cacheの分布、クラスター間の帯域幅の変動などによって、計算効率が低下してしまう。
そのため、提案手法では、高スループットな長文のprefillに特化した独立クラスタを作り、ローカルにキャッシュされていない(主に長文の)、 prefillのみを同クラスタにオフロードし、短いリクエストはローカルでPDを実施するようなアプローチをとる。こうしてprefill特化クラスタによって生成されたKV Cacheはdecode可能なPDクラスタに対してイーサネットを介して転送される。これは選択的なオフロードであり、帯域幅が制限された経路で非効率な短いリクエストを送信を避けて、prefillの高速化が重要なリクエストのみをクラスタ間転送に集中させるという考え方に基づく。
これを実現するためには、(i)長いリクエストのみをオフロードするルーティングの仕組みと、(ii)ネットワークの輻輳を制御するための、帯域幅を考慮したスケジューラ、(iii)リクエスト長、キャッシュ配置、利用可能なクラスタの帯域幅を総合的に考慮してKV Cache全体を効率的を保ちながら管理するグローバルKV Cacheマネージャが必要。
このようなアーキテクチャを1T級のKimi Linearモデルで実験した結果、スループットが1.54倍、TTFTが64%改善した、という感じらしい。
[Paper Note] ClawBench: Can AI Agents Complete Everyday Online Tasks?, Yuxuan Zhang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #Generalization #VisionLanguageModel #Live #Environment Issue Date: 2026-04-11 GPT Summary- ClawBenchは、次世代AIエージェントを評価するための153の簡単なタスクからなるフレームワークを提供。これにより、ユーザーからの情報取得や多段階ワークフローのナビゲーション、高度なフォーム記入といった複雑なタスクを評価可能。従来の静的なベンチマークと異なり、実際のウェブサイトで動作するため、現実的な評価を可能にする。評価では、商用・オープンソースモデルがタスクの一部しか完了できないことが示され、AIエージェントの汎用性向上に寄与することが期待される。 Comment
元ポスト:
pj page: https://claw-bench.com
実際のwebsiteに対して、日常的なオンラインでの153タスクを実行しweb agentを評価可能なフレームワークな模様。既存のオフライン、かつサンドボックスなベンチマークでは75%程度のスコアを達成していたGPT-5.4が、6.5%までスコア低下。
タスク性能の可否は、タスクのinstruction, 人間によるreference actionとpayload, エージェントの実際のactionとpayloadを与えて、AgenticなAIによって、ルーブリックに基づいて判断されるようである(Figure7)。
github: https://github.com/reacher-z/ClawBench
タスクinstructionの一覧は下記:
https://github.com/reacher-z/ClawBench/tree/main/test-cases
たとえば、UberEatsでパッタイをピーナッツ抜きで一つ注文する、といったタスクがある。
[Paper Note] FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling, Yitong Li+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #PostTraining #On-Policy #LowPrecision Issue Date: 2026-04-11 GPT Summary- 強化学習ベースのポストトレーニングを用いたテキストから画像への拡散モデルの最適化において、FP4量子化を組み込んだ二段階強化学習フレームワーク「Sol-RL」を提案。第一段で高スループットのロールアウトを行い、高コントラストのサブセットを生成、第二段でこれを高精度で再生成してポリシーを最適化。これにより、ロールアウトの効率を高めつつ訓練整合性を維持。実験により約4.64倍の収束加速を達成し、高性能な整合性を示す。 Comment
pj page: https://nvlabs.github.io/Sana/Sol-RL/
元ポスト:
FP4でまずロールアウトを生成し、rewardモデルを用いて生成結果のスコアを得て、top/worst-Kのサンプルに絞ってBF16で(該当ノイズから)サンプルを再生成しGRPOで活用する。
探索がFP4で実施されるため高速になり、2*K件のサンプルにのみ絞って学習が行われるため2段階の高速化になっている。
[Paper Note] A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens, Tommie Kerssies+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #CVPR #read-later #Selected Papers/Blogs #WorldModels #Author Thread-Post Issue Date: 2026-04-11 GPT Summary- ビデオ世界モデリングにおいて、多様な未来状態を効率的に予測するために、DeltaTokというトークナイザーを導入。これによりVFM特徴の差を連続的な「デルタ」トークンにエンコードし、DeltaWorldという生成的世界モデルを提案。これにより、ビデオを一次元の時系列に圧縮、512×512フレームでトークン数を1,024倍削減。多仮説訓練を通じて多様な未来を平行に生成し、単一のフォワードパスで多様な予測を得られる。実験結果においてDeltaWorldは、従来のモデルよりもパラメータ数が35倍、FLOPsは2000倍少ないにもかかわらず、現実に近い未来を予測することを示した。 Comment
過去と現在のフレームを入力し差分の潜在表現を出力するDeltaEncoderを学習し、潜在表現に基づいてnext token predictionをする(複数の推論結果を出力させ、最も学習データに近いものを用いて学習する。複数の候補を出力するため推論時は多様な候補を得られる)。
これにより、予測に必要なトークン数が大幅に削減され(Dino-basedなモデルと比較して1024--2048倍)、パラメータ数が削減されFLOPSも低下(generative modelsと比較して、35倍パラメータ数が小さく、2000倍計算に要するFLOPSが低下)。
といった話が著者ポストで説明されている。
[Paper Note] Mixture-of-Minds: Multi-Agent Reinforcement Learning for Table Understanding, Yuhang Zhou+, ACL'26, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #ReinforcementLearning #AIAgents #TabularData #SelfImprovement #ACL #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-04-07 GPT Summary- 表の理解と推論を高めるため、マルチエージェントフレームワークMixture-of-Mindsを提案。計画、コーディング、回答の役割に分割し、各エージェントが特定の側面を担う。自己改善トレーニングにモンテカルロ木探索を用いて強化学習を最適化。実験結果ではTableBenchで62.13%の改善を達成し、構造化されたアプローチの有効性を示す。 Comment
元ポスト:
複雑なタスクを特化型のエージェントに分解し、個々のエージェントを学習するためのpseudo-gold trajectoryを合成しエージェントをFinetuning。その後、FinetuningしたエージェントをGRPOによってend-to-endで学習する、という話に見える。pseudo-gold trajectoryは、個々の特化型のエージェントに対して複数の解候補を出力させ、解候補を次のエージェントに入力し解候補を生成...という手順をsequentialに適用していき、最終的に正しい応答を導き出せたtrajectoryを後ろ向きにたどることによって、pseudo-gold trajectoryを得る。FinetuningとRLがどのような順番で実施されるか、あるいは繰り返されるのか、といった部分についてはしっかり読み解けていない。
表データで実験をしているが、それは一つの応用例であり、汎用的に利用可能な手法と考えられる。
[Paper Note] Cross-Architecture Model Diffing with Crosscoders: Unsupervised Discovery of Differences Between LLMs, Thomas Jiralerspong+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ModelDiffing Issue Date: 2026-04-05 GPT Summary- モデルdiffingは新モデルの安全性を明らかにする効果的手法だが、主にベースモデルとファインチューニングモデルの比較に限定されていた。Crosscodersはアーキテクチャを横断するモデルdiffingを可能にするが、従来はその応用が限られていた。本研究ではCrosscodersを用いた初のアーキテクチャ横断のモデルdiffingを行い、Dedicated Feature Crosscoders(DFCs)を提案。これにより、教師なしで特定の偏りや特徴を発見し、アーキテクチャ横断のモデルdiffingがAIモデル間の挙動差を特定する有効な手法であることを示した。 Comment
モデルのアーキテクチャを跨いでモデルの特徴や性質の違いのdiffを見る方法とのこと。
元ポスト:
[Paper Note] VOID: Video Object and Interaction Deletion, Saman Motamed+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #OpenWeight #VideoGeneration/Understandings #Editing Issue Date: 2026-04-05 GPT Summary- 動画オブジェクト除去での現行手法は、背景の修正や外観アーティファクトの処理には優れているが、オブジェクト間の衝突などの複雑な相互作用には対応できない。そこで、新たに提案するフレームワーク VOID は、物理的に妥当なインペインティングを実現する。Kubric と HUMOTO を使用して、相互作用を変更する反事実的データセットを生成し、ビジョン-言語モデルが影響を受けるシーンを特定。従来手法よりも一貫した動的挙動を保持することを実験で確認し、このフレームワークが動画編集モデルの進化に寄与すると期待される。 Comment
pj page: https://void-model.github.io/
元ポスト:
HF: https://huggingface.co/netflix/void-model
NetflixがHFに公開した初めてのモデルとのこと。動画中のobjectを削除することに特化したモデルのようで、単にobjectを削除し影や反射を無くすといった話だけでなく、そのobjectが消滅したことによって物理的な相互作用も反映させる(物体が落下するなど)ということらしい。
[Paper Note] $\texttt{YC-Bench}$: Benchmarking AI Agents for Long-Term Planning and Consistent Execution, Muyu He+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #AIAgents #Planning #Evaluation #read-later #LongHorizon Issue Date: 2026-04-04 GPT Summary- LLMエージェントの戦略的一貫性の維持に関する課題を評価するため、YC-Benchを導入。シミュレートされたスタートアップを通じて、誤った意思決定の累積影響を調査。12モデルを比較した結果、Claude Opus 4.6が平均1.27百万ドルの資金で最高成績を収め、一貫して成功したモデルは3つのみ。特にスクラッチパッドの使用が成功に大きく寄与し、敵対的なクライアントの検出が主な失敗因として浮かび上がった。全体として、モデルの固有の故障モードが長期的なパフォーマンスにおける能力のギャップを明らかにした。YC-Benchは再現性と設定可能性を備えたオープンソースのベンチマークである。 Comment
pj page: https://collinear-ai.github.io/yc-bench/
元ポスト:
スタートアップの経営を通じてAI Agentをlong horizonの計画、実行能力を評価するような枠組みらしい。
[Paper Note] HippoCamp: Benchmarking Contextual Agents on Personal Computers, Zhe Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Search #Dataset #AIAgents #Personalization #Evaluation #MultiModal #VisionLanguageModel #Environment Issue Date: 2026-04-04 GPT Summary- HippoCampは、エージェントのマルチモーダルファイル管理能力を評価する新しいベンチマーク。ユーザー中心の環境でエージェントを評価し、個々のユーザープロファイルをモデル化し、膨大な個人ファイルを検索。42.4 GBに及ぶ2,000件以上の実世界ファイルから581のQAペアを構築し、エージェントの検索や推論能力を評価。最先端のマルチモーダル大規模言語モデルは、ユーザープロファイリング精度が48.3%に留まり、個人ファイルシステムにおける検索や推論に苦戦。HippoCampは、現行エージェントの制約を浮き彫りにし、次世代AIアシスタント開発の基盤を提供。 Comment
pj page: https://hippocamp-ai.github.io/
元ポスト:
「私の水曜日の予定はなんですか?」といったような、user-centricなタスクにおける、ユーザ個人のcontextを含むファイル検索やプロファイリング、reasoningを必要とする、よりuser-centricな情報を扱う必要があるベンチマークのようである。ユーザのプロファイルやpersonal情報が格納されたEnvironmentが提供されている。
environment: https://hippocamp-ai.github.io/hippocamp/
[Paper Note] Adaptive Block-Scaled Data Types, Jack Cook+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Architecture #SoftwareEngineering #read-later #Selected Papers/Blogs #LowPrecision #needs-revision Issue Date: 2026-04-01 GPT Summary- NVFP4は、4ビット量子化形式として人気ですが、誤差分布の問題を抱えています。本研究では、入力値の分布に適応できる新しいデータ型、IF4(Int/Float 4)を提案します。IF4は、各16値のグループに対しFP4とINT4を選択し、NVFP4のスケールファクターでスケールします。この方法により、量子化訓練時の損失を低減し、精度を向上させることが確認されました。また、IF4のハードウェア実装も評価されています。 Comment
元ポスト:
NVFP4と同様に、4bitで表現される16個のデータをひとつのグループとして扱い[^1]、FP8でのスケールファクターを共有するような浮動小数点フォーマットで[^2]、
グループ内の16個のデータに対して、INT4/FP4どちらを適用するかを、(NVFP4では常に正となっていた;未使用だった)スケールファクターを表現している8bitの先頭である符号ビットを用いて制御する新たな低精度浮動小数点フォーマット、IF4を提案、という話らしい。符号ビットをINT4, FP4を制御するIndicatorとして扱うため、NVFP4と比較してメモリ使用量は増えない。Indicatorはどちらがより量子化誤差が小さくなるかによって選択される、という感じらしい?
[^1]: グループとは単に0/1のバイナリ値が4bit分並んでいるデータのことであり、たとえばFP4で4bitの羅列を解釈すると、FP4は{±0, ±0.5, ±1, ±1.5, ±2, ±3, ±4, ±6}の16個の数値で解釈するようルールづけられている。
[^2]: スケールファクターを乗じることで、値を元々のデータのスケールに変換する。
この辺は勉強不足だなぁ、、、。
- NVFP4解説:
https://licensecounter.jp/engineer-voice/blog/articles/20260317_nvfp4.html
- 本研究日本語解説:
https://note.com/shimmyo_lab/n/n693c4d0da45f
[Paper Note] ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents, Hao Zhang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Infrastructure #ReinforcementLearning #Architecture #SoftwareEngineering #read-later #On-Policy #Stability #Author Thread-Post Issue Date: 2026-03-28 GPT Summary- ProRL Agentは、マルチターンのLLMエージェントにおける強化学習トレーニングを支援するためのAPIサービスであり、ロールアウトのライフサイクル全体を提供するスケーラブルなインフラです。標準化されたサンドボックス環境を通じて、多様なエージェント駆動タスクに対応し、ソフトウェア工学やSTEM関連のタスクで検証されています。ProRL Agentはオープンソースで、NVIDIA NeMo Gymに統合されています。 Comment
元ポスト:
処理が重いロールアウトを独立したhttp serviceとして扱い(rollout-as-a-service)、モデルのtrainingと分離することで、リソース分離、可搬性、拡張性を向上させる。
[Paper Note] Reaching Beyond the Mode: RL for Distributional Reasoning in Language Models, Isha Puri+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #Diversity #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-03-28 GPT Summary- LMは質問に対して複数の回答候補を暗黙のうちに生成するが、訓練後のプロセスで単一の回答に圧縮されることが多い。医療診断や曖昧な質問応答などのタスクにおいては、複数の妥当な回答が必要とされる。本論文では、複数回答を扱う強化学習アプローチを提案し、モデルが単一の前方伝搬で複数の候補を生成できるようにする。実験により、多様性やカバレッジが改善し、コーディングタスクでは精度も向上した。提案手法は、計算資源効率の高い代替として評価されている。 Comment
元ポスト:
ユーザのクエリにおいては正解が単一ではないものがしばしば存在するが、現在のRLの枠組みはモデルが出力した一つのbest answerに対して報酬を与えるように設計されているため、これによりモデルの出力が一つのモードに固執する、あるいはmode collapseを引き起こす。これを解決するために、モデルに複数の回答とそのconfidenceを一つのpromptで思考させ、k個出力させる。rewardはk個中何個のanswerが正解だったか、confidenceが実際のanswerのcorrectnessとどれだけ近いかなどに基づいて報酬を与えるような枠組みを採用することで、モデルの出力の多様性やcoverageが増加し、repeated sampling時のトークン効率も改善した、と言う話らしい。
[Paper Note] Delightful Policy Gradient, Ian Osband, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #read-later #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2026-03-26 GPT Summary- Delightful Policy Gradient(DG)は、ポリシー勾配の不均衡なアップデートを解消するために、アドバンテージと行動の驚きの積に基づいたゲーティングを導入。これにより、単一コンテキスト内での方向性の精度を理論的に向上させ、複数コンテキスト間での期待される勾配を精密に近づけることができる。実験的に、DGはREINFORCEやPPOをMNISTや連続制御タスクで上回り、特に難易度の高いタスクで顕著な改善を示した。 Comment
関連:
- [Paper Note] Maximum Likelihood Reinforcement Learning, Fahim Tajwar+, arXiv'26, 2026.02
元ポスト:
所見:
著者ポスト:
不要なbackward passの重みを下げるのではなく完全に無くすことで効率化する
[Paper Note] M$^2$RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling, Mayank Mishra+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #read-later #Selected Papers/Blogs #RecurrentModels Issue Date: 2026-03-22 GPT Summary- 非線形RNNを再検討し、Matrix-to-Matrix RNN(M^2RNN)を導入。これにより、エンティティ追跡やコード実行などの高表現力タスクに対応可能。M^2RNNは、縮小された状態サイズでも効果的な性能を示し、特に長いシーケンスについて一般化できる。Hybrid M^2RNNでは、既存モデルに匹敵する精度を維持しつつ、再帰層のサイズを縮小。LongBenchでは最先端の手法を超える結果を示し、非線形RNN層の効率的でスケーラブルな言語モデルへの応用を強調。 Comment
HF: https://huggingface.co/collections/open-lm-engine/m2rnn
元ポスト:
解説:
状態をベクトルではなく行列として保持するRNN。
状態の更新Z_tを、前回の状態H_t-1
に対して重みWによって変換したものと、現在のトークンのk_t,v_tが与えられた時の外積から求まる行列の和を求めた後、tanhで非線形変換することで計算する(式10)。
最終的にforget gate f_tによってZ_tとH_t-1が線形補完されることで、状態H_tが決定される(式11)。
出力y_tは更新された状態H_tにq_tの積をとったものと、v_tを重みw_rで重みづけて残差接続したものの和で求められる(式12)。
[Paper Note] Pre-training LLM without Learning Rate Decay Enhances Supervised Fine-Tuning, Kazuki Yano+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #mid-training #PostTraining #Scheduler #DownstreamTasks Issue Date: 2026-03-20 GPT Summary- 学習率スケジューリングが大規模言語モデルの事前学習とSFT後の性能に与える影響を調査。特に、ウォームアップ後に学習率を一定に保つWarmup-Stable-Only(WSO)スケジューラが、減衰ベースのスケジューラよりも一貫してSFT後の性能を向上させることを示す。分析によれば、WSOは平坦な極小値を維持し、訓練戦略としての有用性を強調。これにより、モデルの適応性を高める指針を提供。 Comment
元ポスト:
事前学習中にweight decayを実施しない方が、(事前学習終了時点でのlossは劣化するが)SFT後のdownstreamタスクの性能を高める。
[Paper Note] Mixture-of-Depths Attention, Lianghui Zhu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Attention #Architecture #Selected Papers/Blogs #CurseOfDepth Issue Date: 2026-03-17 GPT Summary- 深さスケーリングによる信号の劣化を克服するため、混合深度アテンション(MoDA)を提案。MoDAは、各アテンションヘッドが現在の層と前層のKVペアに注意を向けることで特徴を保持し、効率的なメモリアクセスを実現。15億パラメータモデルでの実験では、強力なベースラインを超え、平均困惑度を0.2ポイント改善し、ダウンストリームタスクで2.11%の性能向上を達成。計算オーバーヘッドはわずか3.7%。MoDAは深さスケーリングにおける有望なアプローチであることが示された。 Comment
元ポスト:
transformerにおけるattentionを、現在処理をしているトークンの、ある深さlのattentionにおいて、l-1以下の(=自身より浅い)layerの同じトークンに関するK, Vを参照できるように拡張する。
所見:
著者ポスト:
[Paper Note] Spatial-TTT: Streaming Visual-based Spatial Intelligence with Test-Time Training, Fangfu Liu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ComputerVision #Dataset #Self-SupervisedLearning #SpatialUnderstanding #Test Time Training (TTT) Issue Date: 2026-03-14 GPT Summary- 視覚的空間知能の強化を目指し、Streaming Visual Spatial IntelligenceのためのSpatial-TTTを提案。動画から空間証拠を記憶・整理するためにパラメータの一部を適応し、スライディングウィンドウ注意機構を採用。さらに、3D時空間畳み込みを導入し、幾何的対応と時間的連続性を捉える。実験結果は、長時間の空間理解を向上させ、最先端の性能を達成したことを示す。 Comment
pj page: https://liuff19.github.io/Spatial-TTT/
元ポスト:
HF: https://huggingface.co/collections/THU-SI/spatial-ttt
要は、spatial understandingに特化した認知機構を小規模ネットワーク+TTTで構築した研究(と思われる)。TTTについては下記issue参照のこと。動画の各フレームはViTでエンコードされ、QuestionはtokenizeされてHybridなdecoder-only modelに入力され、最終的にテキストが出力されるようなアーキテクチャになっている。Hybridなモデルは、3:1の割合でハイブリッドなブロックとFull Attention Blockがスタックされている。ハイブリッドなblockはQKVを共有した2つのルートが存在し、片方はSWA Layer, もう一方がTTT Layerとなっている。これによってSWA Layerによって高い画像理解能力をlong sequenceでも保ちつつ、TTT Layerで入力情報に基づいて動的にSpatial Understandingに特化したstate(=weight)を更新する、といった方向性のアーキテクチャに見える。
- [Paper Note] Learning to (Learn at Test Time): RNNs with Expressive Hidden States, Yu Sun+, ICML'25, 2024.07
[Paper Note] Memory Caching: RNNs with Growing Memory, Ali Behrouz+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #memory #RecurrentModels Issue Date: 2026-03-08 GPT Summary- Memory Caching(MC)を用いてリカレントモデルのメモリを強化。MCはメモリ状態をキャッシュし、RNNの実効メモリ容量をシーケンス長に応じて拡張する。これにより、O(L)の計算量のRNNとO(L^2)の計算量のTransformersの間でトレードオフを提供。MCのバリアントを実験し、文脈内リコールタスクでTransformersに迫る性能を示し、最先端のリカレントモデルを上回ることを実証。 Comment
元ポスト:
トークンをセグメントに分けて、セグメントごとにメモリの状態をキャッシュとして保存。現在の最新トークンに対するメモリ(online cache)と過去のセグメントごとのキャッシュ(memory soup)の組み合わせによって、outputを計算する。これにより、系列長Lの2乗の計算量から、セグメント長*N*系列長Lの計計算量に落としつつ、transformerのquadraticにメモリ量が増えるが計算が重い、RNNの線形時間でメモリ更新ができるがlong contextにおいては忘却が生じるという性質の良いところ取りをする、という話に見える。
[Paper Note] Replaying pre-training data improves fine-tuning, Suhas Kotha+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #mid-training #PostTraining #read-later #Selected Papers/Blogs #Scheduler #Data Issue Date: 2026-03-07 GPT Summary- ターゲット領域向けの言語モデルの構築には、汎用ウェブテキストでの事前学習とターゲットデータでのファインチューニングが行われる。驚くべきことに、ファインチューニング中に汎用データをリプレイすることで、ターゲットタスクの性能が向上することが確認された。具体的には、4百万トークンのターゲットデータを使用した場合、汎用リプレイによりデータ効率が最大1.87倍、ミッドトレーニングで2.06倍向上した。また、事前学習中にターゲットデータが少ないほどリプレイ効果が高いことが分かった。80億パラメータのモデルでの実験により、エージェントのウェブナビゲーション成功率やバスク語の質問応答精度が向上したことを示した。 Comment
元ポスト:
事前学習以後の中間学習やファインチューニング(事後学習)において、特定のドメインやタスクに特化させるための追加の学習を行う際に、破壊的忘却を防ぐために一定量の事前学習データを混ぜることはよく行われていたが、実際には破壊的忘却を防ぐだけでなく、ターゲットドメインの学習効率を大幅に高める(1.5Bモデルの実験ではファインチューニングでは1.87倍、中間学習では2.06倍)ことがわかり、これは70B級の大規模なモデルでも同様に生じることが明らかになった、という話らしい。興味深い。
解説:
[Paper Note] SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration, Jialong Chen+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering #CI Issue Date: 2026-03-07 GPT Summary- 静的なバグ修正だけでなく、複雑な要求変更に対応するため、継続的インテグレーションに基づく新しいベンチマークSWE-CIを提案。これにより、コード生成の評価が短期的な正確性から長期的な保守性にシフトし、100のタスクを通じてエージェントの分析およびコーディング能力の維持を評価する。SWE-CIは実世界の進化履歴に基づいており、コード品質の長期的な維持についての洞察を提供。 Comment
元ポスト:
SWE Agentの現在の主要な評価パラダイムである個々の機能のバグフィクスなどの短期的な評価から、より長期的なメンテナンスなどのタスクで評価をする
[Paper Note] A Rubric-Supervised Critic from Sparse Real-World Outcomes, Xingyao Wang+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #Selected Papers/Blogs #Verification #RewardModel #Critic #Rubric-based #Author Thread-Post Issue Date: 2026-03-06 GPT Summary- コードエージェントの評価は通常、ユニットテストの成功を基にしているが、実際の環境では成功信号が遅延し、ノイズが多い。本研究では、疎でノイズの多い相互作用データを用いてクリティックモデルを学習する方法を提案し、これをRLベースの報酬モデルとして利用する。具体的には、エージェントの行動特徴を含むクリティック・ルーブリックを導入し、半教師付き目的関数で人間のフィードバックと共に予測する。実験により、このアプローチが SWe-bench におけるリランキングを改善し、試行回数を83%減少させながら成果を向上させることを示した。 Comment
元ポスト:
AI Agentによる実装は安価になったが、今度は(人間による)verificationがボトルネックなので、Agentのtrajectoryからcritiqueを実施するモデルをRubric-basedに学習しReward Modelとして活用できるようにした、という話に見える。これによりAgentの進捗をリアルタイムでvibe checkすることができるとのこと。
著者ポスト:
[Paper Note] Pretrained Vision-Language-Action Models are Surprisingly Resistant to Forgetting in Continual Learning, Huihan Liu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Catastrophic Forgetting #Selected Papers/Blogs #Robotics #VisionLanguageActionModel #ContinualLearning Issue Date: 2026-03-06 GPT Summary- 継続学習はロボットの方策学習における課題で、VLAモデルは従来の小規模モデルに比べて忘却に対して頑健であることを発見。単純な経験再生が効果的で、小さなデータサイズでも忘却ゼロを達成可能。また、VLAは新タスク学習時に以前の知識を保持し、スキルの迅速な回復を可能にする。これにより、大規模事前訓練が継続学習のダイナミクスを変え、新しいスキルを獲得できるモデルを実現することが示唆される。 Comment
元ポスト:
解説:
モデルを大規模にすることで表現が安定し、継続学習による破壊的忘却が軽減される可能性が示された一方で、評価タスクが比較的単純でありVLAモデルでは既に解けている可能性があり、継続学習の評価ではなくzero-shotの能力の汎化を見ている可能性がある点には注意という話のようである。
[Paper Note] FlashOptim: Optimizers for Memory Efficient Training, Jose Javier Gonzalez Ortiz+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Quantization #Optimizer #read-later #Selected Papers/Blogs Issue Date: 2026-03-05 GPT Summary- パラメータあたりのメモリを50%以上削減する最適化手法FlashOptimを提案。改善されたマスタウェイト分割と8ビットオプティマイザの量子化を活用し、AdamWのメモリを16バイトから7バイト、勾配リリースによりさらに5バイトに削減。これによりモデルのチェックポイントサイズも大幅に減少し、品質を保持しつつ視覚と言語タスクでの劣化は見られなかった。 Comment
元ポスト:
すでにpip install flashoptimで利用可能。SGD, Adam, AdamW, Lionがサポートされている。8Bモデルの訓練に必要なピークメモリを35%削減し、チェックポイントのサイズもも57%小さくなるという優れもの。実験結果では性能の劣化もなしという報告。
[Paper Note] SWE-rebench V2: Language-Agnostic SWE Task Collection at Scale, Ibragim Badertdinov+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #AIAgents #Coding #SoftwareEngineering #PostTraining #read-later #Selected Papers/Blogs #Live #Environment Issue Date: 2026-03-05 GPT Summary- SWEエージェントの強化学習を支えるため、実世界のソフトウェア工学タスクを自動収集し、再現可能な環境を構築するSWE-rebench V2を提案。20言語・3,600超のリポジトリから32,000以上のタスクを集め、厳選したコンテンツで信頼性のあるトレーニングデータを提供。また、タスク生成に必要なメタデータも加え、エラー要因を明示。データセットと関連リソースを公開し、多様な言語での大規模なSWEエージェントのトレーニングを支援。 Comment
元ポスト:
environment: https://huggingface.co/datasets/nebius/SWE-rebench-V2?row=5
関連:
- [Paper Note] SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents, Ibragim Badertdinov+, NeurIPS'25, 2025.05
以前の研究ではpython特化だったが、今回はlanguage-agnosticな環境になっている。
合成データではなく、実際のissue-resolutionのヒストリに基づいたデータセットであることに注意
[Paper Note] DP-RFT: Learning to Generate Synthetic Text via Differentially Private Reinforcement Fine-Tuning, Fangyuan Xu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData #Privacy #Initial Impression Notes #DifferentiallyPrivate Issue Date: 2026-03-04 GPT Summary- DP-RFTを用いて、プライベートデータに直接アクセスせずに合成データを生成するためのオンライン強化学習アルゴリズムを提案。合成サンプルの報酬信号にDP保護済み最近傍投票を活用し、LLMが期待されるDP投票を最大化するよう学習。長文やドメイン特化のデータ生成において、プライベートデータの境界を尊重しつつ、従来の手法とのギャップを縮小することに成功。 Comment
元ポスト:
プライベートなデータの保有者が差分プライバシーが保護された状態でLLMのロールアウトに対してvotingによるrewardを返せば、個別のLLMはプライバシーに保護されたデータを見なくてもvotingによるスコアが最大となるように学習できるというアイデア。これによりプライバシーによる課題によりデータがオープンにならないドメインでも、この枠組みでLLMをpost-trainingすれば、LLMが合成データの生成器として振舞えるため、プライベートなドメインのデータスケーラビリティの課題の解決につながるのではという提案
これは利用規約などで個人情報の扱いに関して何らかのユーザとの取り決めがあった場合、どういう扱いになるのだろうか。
Gemini Proに質問して得た感想としては、少なくとも差分プライバシーによってreward signalが個人情報を含むデータではないと保証されたとしても(プライバーバジェットがどの程度設定されていれば問題ないのかといった合意があるかと言われると怪しいらしい)、reward signalを計算する部分においては個人情報を含むデータを活用しているため、個人情報利用のスコープにそれが許容されるようなステートメントが入っていないと、こういった手法を実施することは無理なのかもしれない。
[Paper Note] FireRed-OCR Technical Report, Hao Wu+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #SyntheticData #OpenWeight #read-later #VisionLanguageModel #OCR #Pixel-based Issue Date: 2026-03-03 GPT Summary- FireRed-OCRは、一般的なビジョン-ランゲージモデルを特化した高性能OCRモデルへ変換するフレームワークです。VLMは一般的には優れた能力を示すものの、文書処理では「構造的幻視」が問題となります。FireRed-OCRでは、高品質な構造データの不足に対処するため、「Geometry + Semantics」データファクトリを構築し、幾何特徴のクラスタリングを利用して多様な文書タイプに対応したデータセットを作成します。3段階の訓練戦略を導入し、文書構造理解、形式的出力の標準化、強化学習による構文的整合性の確保を行います。OmniDocBench v1.5での評価結果から、FireRed-OCRは92.94%の性能を達成し、他のベースラインを大きく上回ることを示しました。コードとモデル重みをオープンソース化し、一般VLMから専門的な構造エキスパートへの変容を促進します。 Comment
元ポスト:
github: https://github.com/FireRedTeam/FireRed-OCR
- [Paper Note] OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations, Linke Ouyang+, CVPR'25, 2024.12
においてSoTAとのこと。日本語はどのくらいいけるだろう。
[Paper Note] LeRobot: An Open-Source Library for End-to-End Robot Learning, Remi Cadene+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#MachineLearning #Dataset #Library #ReinforcementLearning #OpenSource #ICLR #Selected Papers/Blogs #Robotics Issue Date: 2026-03-03 GPT Summary- ロボティクスは機械学習の進展により変革を遂げ、ロボット学習が新たに生まれつつある。手頃な遠隔操作システムや公開データセットの増加により、研究が加速しているが、クローズドソースツールの断片化が発展を妨げている。本研究では、ロボット学習スタックを統合するオープンソースライブラリ\texttt{lerobot}を提案。これにより、低レベル制御からデータ収集までをカバーし、アクセス可能なハードウェアをサポート。スケーラブルな学習アプローチを強調し、研究者・実務者の参入障壁を低下させ、再現性のある学習プラットフォームを提供する。 Comment
openreview: https://openreview.net/forum?id=CiZMMAFQR3
元ポスト:
従来の研究では、特定のユースケース、特定のツール、特定のプラットフォーム、データフォーマット、学習アルゴリズム等を自分たちの独自のユースケースのために開発がされてきたため、これにより分野の断片化(他者が追試しづらい、統一的な技術スタックがない等)が生じてしまっていたため、それを解決するためにend-to-endでの統合的な枠組み(ロボットを動作させるだよミドルウェアのインタフェースや標準化されたデータセットのフォーマット、学術アルゴリズムなど)を提案しているようである。
onelineで実ロボットへのデプロイができる機能が追加されたとのこと:
[Paper Note] Doc-to-LoRA: Learning to Instantly Internalize Contexts, Rujikorn Charakorn+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #PEFT(Adaptor/LoRA) #FactualKnowledge #memory #DownstreamTasks #Test Time Training (TTT) Issue Date: 2026-03-01 GPT Summary- 長い入力を効率的に処理するために、Doc-to-LoRA(D2L)を提案。これはメタラーニングを用いて、単一の前方伝播で情報を効率よく蒸留し、適応型LoRAアダプタを生成する。D2Lにより、推論時のレイテンシとメモリ消費を削減し、文脈を超えてゼロショット精度を向上。実世界のデータセットにおいても、標準的な文脈蒸留を上回る性能を示す。 Comment
- [Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25, 2025.06
に続く研究。
元ポスト:
ポイント解説:
Doc-to-LoRAの目的は、文書レベルの情報をメモリの内部パラメータとして埋め込むこと。
[Paper Note] REMem: Reasoning with Episodic Memory in Language Agent, Yiheng Shu+, ICLR'26, 2026.02
Paper/Blog Link My Issue
#GraphBased #NLP #LanguageModel #AIAgents #ICLR #Selected Papers/Blogs #memory #Grounding #Author Thread-Post Issue Date: 2026-03-01 GPT Summary- REMemは、エピソード記憶を構築し推論するための2段階フレームワークを提案する。オフラインでは、経験を時間情報を含む要旨と事実を結びつけたハイブリッド記憶グラフに変換。オンラインでは、エージェント型リトリーバを用いて記憶グラフ上での反復検索を可能にする。包括的な評価により、REMemは最先端システムを大幅に上回り、エピソード回想と推論タスクでそれぞれ3.4%、13.4%の改善を示す。回答不能な質問に対する拒否行動も堅牢であることが確認された。 Comment
元ポスト:
単に知識や事実情報を蓄積するのではなく、過去のイベントに関するsituationalな情報(when,where,who,what)でgroundingをしながら、複数のイベント、タイムラインを跨いでreasoningができるようなepisodic memoryの提案。人間は単に意味情報から記憶を呼び起こすだけでなく、過去のイベントを想起して条件付けした上で時系列になぞって記憶を想起できる能力があることに起因する。
openreview: https://openreview.net/forum?id=fugnQxbvMm
[Paper Note] Interleaved Head Attention, Sai Surya Duvvuri+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #AIAgents #Attention #LongSequence #Architecture #Reference Collection #LongHorizon #Author Thread-Post Issue Date: 2026-02-28 GPT Summary- Interleaved Head Attention(IHA)を提案し、マルチヘッド・アテンションの線形スケーリングの制約を解消。IHAでは、各ヘッドにP個の疑似ヘッドを構築し、ヘッド間のクロス混合を可能にすることで、複数のアテンションパターンを生成。理論的には、合成的Polynomialタスクに対し、IHAはMHAよりも効率的で、実世界のベンチマークでも性能向上を示した。特に、GSM8KおよびMATH-500の問題で改善を達成。 Comment
元ポスト:
著者ポスト:
解説:
各headのqueryに対してlinear変換をかけてP個の疑似ヘッドを作成し、それらをinterleavingする形で整列させてK, Vを適用する、という感じらしい。多段階の推論や合成が必要な複雑なタスクにおいてheadの表現力が増し、必要なhead数が小さくなる反面、計算量が増える。疑似ヘッドはP個のトークンによって構成されるとみなせるので、FlashAttentionなどの従来の実装をそのまま適用できる。
[Paper Note] Rolling Sink: Bridging Limited-Horizon Training and Open-Ended Testing in Autoregressive Video Diffusion, Haodong Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #VideoGeneration/Understandings #train-inference-gap #Author Thread-Post Issue Date: 2026-02-27 GPT Summary- 自己回帰型動画拡散モデルは高い性能を達成するが、訓練期間と推論間のギャップにより長期視野での視覚的劣化が生じる。本研究では、訓練を超えたギャップを探求し、訓練不要でAR動画生成を効果的に長時間スケールする手法Rolling Sinkを提案。これにより、5分から30分の動画を生成し、一貫した被写体や安定した色を実現。広範な実験により、視覚的忠実度と時間的一貫性でSOTAを上回る性能を示した。 Comment
pj page: https://rolling-sink.github.io/
元ポスト:
著者ポスト:
- [Paper Note] Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion, Xun Huang+, NeurIPS'25
のduration版。training durationとtesting durationが大幅に異なるとうまく生成ができなくなるのでそのgapを埋めましょうという話
[Paper Note] CaptionQA: Is Your Caption as Useful as the Image Itself?, Shijia Yang+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #MultiModal #CVPR #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #Initial Impression Notes #ImageToTextGeneration Issue Date: 2026-02-26 GPT Summary- 画像キャプションはマルチモーダルシステムにおける視覚コンテンツの代理表現として機能するが、キャプションが実際のタスクで画像の代わりになり得るかを評価する必要がある。そこで、新たにユーティリティベースのベンチマークCaptionQAを提案し、キャプションの質を下流タスクへの支援度で測定する。CaptionQAは四つのドメインにわたり、33,027件の詳細な多肢選択問題を提供し、キャプションが視覚情報を必要とする質問に対応する力を検証する。LLMによる評価により、キャプションの有用性が画像よりも最大32%低下することが確認され、CaptionQAはオープンソースとして公開される。 Comment
元ポスト:
興味深い研究。MLLMの性能をCaption生成を通じて評価している。
良いCaptionであればdownstream taskに活用した際により良い性能が得られるという仮定の元[^1]、MLLMの性能をAnswer=LLM(Question, Caption)で判断する。AnswerはMultiple Choice Questionであり、Cannot Answerなども含まれる。よりQAに対して適切に回答できるCaptionを生成できたMLLMが優れているというutility-basedな評価となっている。
MLLMに対してCaptionを生成する際は、Questionに関する情報は与えずに、画像の情報のみでCaptionを生成する(ように見える)。セクション9に記述されている通り、4種類のバリエーションのpromptを用いる(long, short, simple, taxonomy hinted)。
skim readingしかできていないのだが、脚注1に記述した通り、モデルによって実画像がgivenな状態とCaptionのみで評価した場合でgapの出方に差がある点と、そもそも到達しているスコアの絶対値の対比が出せる点が個人的に興味深い。これにより特定のMLLMが、画像とテキスト、どちらの情報を"理解"するのに優れているのか、あるいは理解した情報に基づいて"生成"するのに優れているのかも間接的に評価できるのではないかと感じる。たとえばGPT-5は他モデルと比べて双方の能力秀でているが、Gemini-2.5-Proは画像を考慮することは得意だが、画像からテキストを生成する能力は少し劣ることがGPT-5とのgapの差から伺える。GLM4.1-VやLLaVAなどは画像理解は得意だが、画像から重要な情報を生成する能力は大きく低いことがわかる。
同じdownstreamタスクを通じてgapを測定でき、かつ単にベンチマークのスコアという以上の一段深い情報が得られる点がこれまでと異なりおもしろいと感じる。
[^1]:実際、セクション5を見ると実際の画像を与えた場合とCaptionのみの場合で評価した場合でgapがあることが示されており、Captionが画像中のdownstream taskに対してrelevantな情報を完全に保持していないことが示唆される。また、モデルに応じてgapが異なっており、モデルによってCaption生成能力が大きく異なることが示唆される。
この評価のパラダイムは一段抽象化をすると、特定のモダリティの情報に対する理解力と、異なるモダリティに変換して生成する能力をdownstreamタスクを通じて観測することになり、Captionの場合は画像-テキスト間だが、他にも動画-テキスト、音声-テキスト、あるいはそれらの逆など、Omniモーダルなモデルの評価やUMMの評価に使えそうな話だな、と思うなどした。
[Paper Note] Phantom Transfer: Data-level Defences are Insufficient Against Data Poisoning, Andrew Draganov+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #Poisoning #Bias #Safety #Attack #PostTraining #SubliminalLearning Issue Date: 2026-02-24 GPT Summary- ファントム・トランスファーというデータ汚染攻撃を紹介。無害なデータセットへの汚染が防げない特性を持ち、サブリミナル学習を調整して多くのモデルに効果を発揮。モデルの挙動をパスワードでトリガーする方法についても言及し、データ防御の限界を示唆。今後はモデル監査とホワイトボックスセキュリティに重点を置くべきと提案。 Comment
元ポスト:
Instruction Tuningのための合成データを生成(本研究ではAlpaca datasetを利用しconciseな応答を生成する目的で実験)する際に、Subliminal Learningの手法と同様にモデルのシステムプロンプトに特定のエンティティに関してバイアスのあるプロンプトを仕込みデータを合成(e.g., イギリスを好むようなもの)すると、生成された合成データに対してフィルタリングやパラフレージングなどの防御策を講じてもバイアスの転移を防ぐことはできず、かつ通常のSubliminal Learningとは異なり、モデルのアーキテクチャを跨いでもバイアスが転移する、という話のように見える。
[Paper Note] Learning Personalized Agents from Human Feedback, Kaiqu Liang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Personalization #memory Issue Date: 2026-02-23 GPT Summary- PAHFは、個ユーザーの嗜好をリアルタイムで学習し続けるためのフレームワークで、三段階のループを実装。具体的には、事前アクションの明確化、嗜好に基づく行動根拠の提供、嗜好変化時のメモリ更新を行う。新たなベンチマークを用いて、エージェントがゼロから嗜好を学び変化に適応する能力を評価し、明示的メモリと二つのフィードバックチャネルの統合が学習速度やパーソナライゼーション誤差の改善に寄与することを実証。 Comment
元ポスト:
ユーザ専用のmemoryを用意しmemory上にユーザのpreferenceを蓄積し更新することによってpersonalizationを実施する。memoryへの更新はcontextやテキストによるフィードバックに基づいて実施される。
[Paper Note] Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens, Wei-Lin Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Metrics #NLP #LanguageModel #Evaluation #Reasoning #Test-Time Scaling Issue Date: 2026-02-23 GPT Summary- LLMが推論時に「深く考えるトークン」を特定し、計算量を定量化。これらのトークンの割合が正確さと一貫して相関することを示し、Think@nを導入して深く考えるトークンが多い生成を優先的に扱うことで推論コストを削減。自動一貫性と同等または上回る性能を実現。 Comment
reasoningの質をトークンの長さではなく、重要なトークンを基準に測定する。その上で重要なトークンの割合が小さいサンプルは早めに枝刈りすることでtest-time scalingの効率を向上させる手法を提案している模様。
[Paper Note] SLA2: Sparse-Linear Attention with Learnable Routing and QAT, Jintao Zhang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Transformer #Attention #DiffusionModel #VideoGeneration/Understandings #Routing #3D (Video) #SparseAttention #LinearAttention Issue Date: 2026-02-20 GPT Summary- SLA2は、スパース注意とリニア注意を動的に選択する学習可能なルータを導入し、パフォーマンスを向上させる。さらに、アテンションブランチを組み合わせるための比率や量子化を意識した設計を採用。実験により、動画生成モデルで97%のスパース性を達成し、18.6倍の速度向上を実現した。 Comment
元ポスト:
ポイント解説:
Sparse AttentionとLinear Attentionを動的に選択するルータを学習して効率を向上させる
[Paper Note] EditCtrl: Disentangled Local and Global Control for Real-Time Generative Video Editing, Yehonathan Litman+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Transformer #DiffusionModel #VideoGeneration/Understandings #Editing #3D (Video) #Author Thread-Post Issue Date: 2026-02-19 GPT Summary- 高忠実度なビデオ編集には、新しい局所的ビデオ文脈モジュールを使用するEditCtrlフレームワークを提案。これにより、マスクされたトークンのみに集中し、計算コストを編集サイズに比例させる。全体の文脈の一貫性を保持しつつ、他の手法に比べて計算効率が10倍向上し、編集品質も改善。テキストプロンプトを利用した新機能を実現。 Comment
pj page: https://yehonathanlitman.github.io/edit_ctrl/
元ポスト:
著者ポスト:
video editing/inpaintingタスクにおいて、editに必要なlocal contextとeditとの一貫性を保つためのglobal contextを分離し、global contextに対するfull-attention計算を削減する(i.e., local contextに計算量を集中させる)ことで効率を向上、という話に見える。
[Paper Note] DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories, Chenlong Deng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #Search #Dataset #LanguageModel #AIAgents #Evaluation #MultiModal Issue Date: 2026-02-18 GPT Summary- 既存のマルチモーダル検索システムはクエリと画像の関連性を独立して評価することを前提としているが、このアプローチは現実の視覚データの依存関係を無視している。これを解決するために、我々はDeepImageSearchを提案し、画像検索を自律的探査タスクとして再定義する。このモデルは文脈的手掛かりに基づき、視覚データの多段階推論を行いターゲットを特定する。相互に関連した視覚データ用のベンチマークDISBenchを構築し、文脈依存クエリの生成におけるスケーラビリティ課題を人的なモデル協働で解決するパイプラインも提案。また、モジュール型エージェントフレームワークと二重メモリシステムを用いて、堅牢なベースラインを開発した。実験により、DISBenchが先端モデルに対して重要な課題を示すことが明らかになり、次世代検索システムへのエージェント的推論の統合の必要性が強調されている。 Comment
元ポスト:
検索クエリが与えられた時に、Corpus中の画像中に含まれる情報を考慮しなければ検索できないような検索タスクとベンチマークDIBenchの提案。たとえば、白と青のロゴのイベントで、lead singerだけがステージに立っている画像、のような、白と青のロゴのイベントをCorpus画像から同定(クエリと画像の相互作用)→その上で当該イベントでソロでステージにlead singerが立っている画像を探す、といったような検索である。
proprietaryモデルだとClaude-4.5-Opusの性能がよく、次いでGemini-Pro-Previewの性能が良い。GPT5.2は大きく性能面で劣っている。OpenModelと比較すると、ClaudeはQwen3-VLやGLM-4.6Vの倍程度のスコアを獲得している(Table1)。
[Paper Note] CoPE-VideoLM: Codec Primitives For Efficient Video Language Models, Sayan Deb Sarkar+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #LanguageModel #VisionLanguageModel #Encoder #3D (Video) Issue Date: 2026-02-17 GPT Summary- 動画理解のために、動画コーデックのプリミティブを活用し、計算オーバーヘッドを軽減。軽量トランスフォーマーエンコーダにより、トークン生成を大幅に効率化し、一般的なベンチマークで性能を維持。最大で86%の時間短縮と93%のトークン削減を実現。 Comment
元ポスト:
VideoLanguageModelのinputにおあて、より効率的な画像のΔエンコーダを導入して高速化しつつ性能向上
[Paper Note] Soft Contamination Means Benchmarks Test Shallow Generalization, Ari Spiesberger+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Evaluation #read-later #Selected Papers/Blogs #Generalization #Initial Impression Notes #Contamination Issue Date: 2026-02-17 GPT Summary- LLMの訓練データがベンチマークのテストデータで汚染されると、分布外一般化にバイアスが生じる。従来のデコンタミネーション・フィルターは意味的重複を認識できず、私たちは「ソフト汚染」として訓練データの意味的重複を調査。Olmo3コーパスの解析から、汚染が広範囲に存在し、CodeForcesの78%、ZebraLogicの50%に意味的または厳密な重複を確認。また、ベンチマークデータの重複が訓練データに含まれることで性能が向上し、ファインチューニングが同じベンチマークの未使用データの性能も改善することが示された。これにより、最近のベンチマークの向上は本質的な能力向上とは異なる可能性があることを示唆している。 Comment
元ポスト:
n-gramマッチングによるデータのdeaontaminationは表層レベルでしか捉えられないので、意味的に等価なサンプルをdecontamgnationできず(=Soft Contamination)効果が薄く、意味的なレベルでのコンタミネーションは広範に存在し[^1]、それらサンプルが学習データに含まれるとheldoutされたテストベンチマークのスコアも改善してしまう(=本当に計りたい汎化性能を測れていない)という話をしっかり分析した研究に見え、非常に重要な研究に見える。
[^1]:Olmo3で検証しており、ZebraLogicテストセットの50%とexactに一致するデータが含まれ、CodeForcesのテストセットのうち78%のサンプルと意味的に一致したサンプルが一件以上存在したとのこと。
[Paper Note] An Industrial-Scale Sequential Recommender for LinkedIn Feed Ranking, Lars Hertel+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Transformer #A/B Testing #SequentialRecommendation #Initial Impression Notes Issue Date: 2026-02-16 GPT Summary- Feed Sequential Recommender(Feed-SR)は、LinkedInフィード向けのトランスフォーマーを用いた逐次ランキングモデルで、DCNv2ベースのランカーを置換。LinkedInの運用制約を満たしつつ、メンバーのエンゲージメントを向上させ、滞在時間が+2.10%増加。オンラインA/Bテストでの性能を通じて、Feed-SRの効率性と効果についても論じる。 Comment
元ポスト:
linkedinのfeedにおけるsequential recommendationで利用されているモデルでdecoder onlyのpre-LN、RoPE、residual streamの更新がlearnableなパラメータでrescaleされて更新されるようなtransformerアーキテクチャが採用されている。細かいfeatureなどについては読めていない。A/Bテストによって効果が確認されている。
[Paper Note] The Pensieve Paradigm: Stateful Language Models Mastering Their Own Context, Xiaoyuan Liu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #ContextEngineering #memory #ContextRot Issue Date: 2026-02-13 GPT Summary- 新しい基盤モデル「StateLM」を導入し、AIが自己管理できる状態を持つエージェントに進化。コンテキストのプルーニングや文書のインデクシングなどのメモリツールを管理することで、モデルは固定ウィンドウの制約から解放されます。StateLMは長文QAやチャットメモリタスクで従来のLLMを一貫して上回り、特にBrowseComp-Plusタスクでは最大52%の精度を達成。私たちのアプローチにより、推論が管理可能なプロセスに変革されます。 Comment
元ポスト:
言語モデルにStateを明示的に持たせて、ツールを用いて動的に過去のcontextから必要なcontextを編集、削除、読み込みなどのコンテキストエンジニアリングが可能なようにRLによって学習するようなアーキテクチャが提案されているように見える。
[Paper Note] On-Policy Context Distillation for Language Models, Tianzhu Ye+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #In-ContextLearning #Distillation #On-Policy #SelfDistillation Issue Date: 2026-02-13 GPT Summary- オンポリシーコンテキスト蒸留(OPCD)は、生徒モデルが自身の生成した軌跡に基づいて学習し、コンテキストに条件付けられた教師に対して逆カルバック・ライブラー divergenceを最小化するフレームワークです。OPCDは実体験知識蒸留とシステムプロンプト蒸留の応用で効果を示し、数学的推論やテキストベースのゲームでベースラインを上回り、精度向上と分布外能力の保持を実現します。また、小さな生徒モデルが大きな教師から知識を内在化できることも示しています。 Comment
元ポスト:
教師モデルにcontextを与えた上で生徒モデルのロールアウトに対してreverse KLを最小化することで、in-context learningを活用しつつオンポリシー蒸留を実施する枠組みに見える。教師モデルをstrong modelにすればteacher-student distillationの枠組みになるし、教師モデルと生徒モデルを一致させるとself-distillationとなる。
ICLを活用したself-distillationは以下でも提案されている:
- [Paper Note] Self-Distillation Enables Continual Learning, Idan Shenfeld+, arXiv'26, 2026.01
[Paper Note] The Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning, Simin Fan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2026-02-13 GPT Summary- 事前学習から教師ありファインチューニング(SFT)への移行を理解することは、モデル開発に重要。本研究では、モデルの精度と信頼度の持続性、信頼できるベンチマーク、スケールによる移行ダイナミクス、精度と信頼度の一致について調査。実験により、移行の信頼性は能力やベンチマーク、スケールによって異なり、精度と信頼度は異なるスケーリングダイナミクスを示すことが明らかに。これにより、ベンチマーク選定やデータキュレーションに関する実用的なガイダンスが提供される。 Comment
元ポスト:
事前学習とSFTの間におけるAccuracyとConfidence(=モデルの回答のトークン確率)の相関を分析。モデルのスケールが大きい方が、SFT後のdownstreamタスクでのAccuracyと強い相関を持ち、confidence(=モデルが回答したときのトークンの確率)はモデルのスケールが小さい方が強い相関を持つ。このことから、よりモデルのスケールが大きい方がSFTにおいてAccuracyを維持するためにconfidenceの再形成を行っていることが示唆される、という話らしい。
[Paper Note] Olmix: A Framework for Data Mixing Throughout LM Development, Mayee F. Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Tutorial #Pretraining #NLP #LanguageModel #read-later #Selected Papers/Blogs #DataMixture #Author Thread-Post Issue Date: 2026-02-13 GPT Summary- データミキシングは言語モデル(LM)トレーニングにおいて重要な課題であり、Olmixフレームワークを提案することで短所に対処。設定空間の理解が不足している中、強力なミキシング手法の設計選択を特定。ドメインセットの進化に対応し、受けた影響を考慮したミキシチャー再利用メカニズムを導入。これにより、計算量を74%削減し、下流タスクで11.6%の改善を実現。 Comment
元ポスト:
著者ポスト:
言語モデルを事前学習しようとしたときに、
- 先行研究で提案されている手法を自分のデータにどのように適用すべきか?ハイパーパラメータはどうすればよいか?tiny datasetの場合はoversamplingしてよいのか?といった課題に直面し
- 仮にgood mixが分かったとしても、データは静的ではなく、新たなデータセットがリリースされたり、同僚がデータセットを変更するかもしれない。そうなったときに、DataMixをどのようにアップデートすればよいのか?
といった実践的に困る場面が多いようであり、これらに対して本研究は実践的なDataMixingの設定に関するガイダンスとデータセットが進化したときに効果的にDataMixを更新する方法を提案しているとのこと。
[Paper Note] Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics, Leheng Sheng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #Chain-of-Thought #Reasoning #SelfImprovement #PostTraining #RLVR #PRM #RewardModel #Rubric-based Issue Date: 2026-02-12 GPT Summary- CoTがLLM推論において重要である一方で、報酬モデルの訓練には多くの人手が必要で、静的モデルは変化に対応しづらい。これを解決するため、自己進化するCoT報酬アプローチ「RLCER」を提案。自己提案・自己進化するルーブリックにより、結果報酬なしでも信頼性のあるCoT監視信号を提供し、結果中心のRLVRを上回ることを実証。また、ルーブリックは推論時のパフォーマンスを向上させる効果もある。 Comment
元ポスト:
CoTを評価するためのルーブリックを自己進化させて、CoTの評価もしつつ、outcomeに基づくRLVRを実施するといった処理を単一のポリシーで実現する、というような話に見える(過去のCoTに対する監視手法ではPRMが別途用意されていた)。
単にRLVRをする場合よりも最終的な性能が向上し、特にlong runの場合の安定性が高まっているように見える。
[Paper Note] Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training, Yiwei Qin+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #LanguageModel #SyntheticData #DataFiltering #Science #Environment Issue Date: 2026-02-12 GPT Summary- データの質がモデルのパフォーマンスに影響を与える中、データ・ダーヴィニズムという10段階の分類法を提唱。これに基づき、900BトークンのDarwin-Scienceコーパスを構築し、先進的なLLMを利用して生成的洗練(L4)と認知的補完(L5)を実現。事前トレーニングにより、3Bモデルで+2.12、7Bモデルで+2.95ポイントの性能向上を達成し、特定タスクでは更に高い改善を確認。共進化の原則に基づく開発を促進するため、データセットとモデルを公開。 Comment
元ポスト:
学習データを処理するためのフレームワークを10段階のレベル(ただのデータの獲得から、前処理、合成、世界のシミュレーションまで)で定義し、それぞれのレベルにおいてどのような処理が必要で、どのような価値を生むのかといった点が体系化されている。レベルが上がるにつれてデータの量は基本的に減少するが、データのinformation densityや構造の複雑さは高まっていく。
また、下図に示されているように実際にLevel0 -- Level5までの処理を実施したことでどのようなgainがあるかも考察されているようである。
[Paper Note] Towards Robust Scaling Laws for Optimizers, Alexandra Volkova+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Optimizer #Scaling Laws #Robustness Issue Date: 2026-02-12 GPT Summary- 最適化手法がLLMの事前学習の質に与える影響を調査。Chinchillaスタイルのスケーリング則は条件が悪く、代わりに特有の再スケーリング因子を持つ共有の冪則指数を提案。これにより異なる最適化手法間の比較が可能に。最終的には、損失の分解に基づく理論的分析を行い、Chinchillaスタイルのスケーリング則の出現を説明。 Comment
元ポスト:
(きちんと理解できているか怪しいが)従来のチンチラ則に代表されるL(N,D)に関する(モデルサイズ、データ量、最終損失)Scaling LawsはOptimiserを固定(AdamやAdamW)した上で求められていたが、本研究では異なるOptimiser(Muon, Shampoo, SOAPなど)が適用された場合にロバストではないことを指摘し、Optimiser間で共有のパラメータと、Optimiser毎にfittingさせる係数を用いた定式化(3)によって、よりOptimiser間でロバストなScaling Lawsを提案しOptimiser間での比較を可能にした模様。また、損失をQuadratic Lossを最適化する観点から分解し、Theorem 6.3で示される理論的なスケーリング則を導出。これらの個別の項を解釈すると、第一項L^*がチンチラ則のEに対応し(普遍的に生じる基本的な損失)、第二項Θ(λ^ω_d)は近似誤差(当該モデルサイズでの性能の限界による誤差)がチンチラ則でのparameter efficiency term A/(N^α)に対応し、第三項O(e^−2kλd)は最適化誤差を表すが、これがチンチラ則でのdata efficiency term B/(D^β)に対応すると解釈でき、自然とチンチラ則スタイルのスケーリング則が導出されることを理論的に示したようである。
[Paper Note] Convex Dominance in Deep Learning I: A Scaling Law of Loss and Learning Rate, Zhiqi Bu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Optimizer #Scaling Laws #Selected Papers/Blogs #Scheduler Issue Date: 2026-02-12 GPT Summary- 深層学習の最適化ダイナミクスを分析し、凸性とリプシッツ連続性の観点から損失の制御を探求。弱凸的な挙動を示し、学習率スケジュールによる損失の予測可能性を提供。学習率と損失のスケーリング法則を提案し、トレーニング期間で80倍、モデルサイズで70倍の外挿が可能であることを実証。 Comment
元ポスト:
深層学習モデルにおけるモデルサイズNと学習ステップ数Tを変数としたときに、最適ピーク学習率η_peakと最終損失のそれぞれについてスケーリング則を導出しているようである(1/sqrt(T)にスケールする)。実用上は、式5.1に示されているように小規模なモデル、小規模なステップ数の学習から得られた最適ピーク学習率から、より大規模かつlongrunの学習時の最適なピーク学習率を推定でき、これか分かるとsqrt(T)倍することで基準値η_refを得る。この基準値η_refと
L_inf(N)(モデルパラメータNの元での損失の加減)とQ(N)(なんらかの定数q_1, q_2に基づいて定義されるようだがよくわかっていない)を線形回帰で予測することで、最終損失も予測できる、という感じのようである。
[Paper Note] MoEEdit: Efficient and Routing-Stable Knowledge Editing for Mixture-of-Experts LLMs, Yupu Gu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #MoE(Mixture-of-Experts) #KnowledgeEditing #Stability #Routing Issue Date: 2026-02-12 GPT Summary- MoEモデルに対する知識編集のための新たなルーティング安定フレームワークMoEEditを提案。エキスパート更新を再パラメータ化し、ルーター入力を不変に保つことで、計算およびメモリ効率を向上させつつ、高い特異性とルーティングの安定性を実現。実験により、最新の効果と一般化を達成したことが示された。 Comment
元ポスト:
MoEにKnowledge Editingを単純に適用するとexpertsへのroutingがシフトして不安定になったり、expertの数に応じて計算量が増大するだけでなく、expert間でcouplingされて知識が活用される場合に独立性がないといったMoE特有の課題があり、それらに対処するような手法を提案している模様。
[Paper Note] MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling, MiniCPM Team+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #SmallModel #Selected Papers/Blogs #Hybrid #SparseAttention #LinearAttention Issue Date: 2026-02-12 GPT Summary- MiniCPM-SALAは、9Bパラメータのハイブリッドアーキテクチャで、疎アテンションと線形アテンションを組み合わせ、長文脈タスクの効率と性能を向上させる。層選択アルゴリズムにより、1:3の比率で統合され、ハイブリッド位置エンコーディングを利用することで、トレーニングコストを約75%削減。広範な実験で、シーケンス長256Kトークン時に推論速度を最大3.5倍向上させ、最大100万トークンの文脈をサポートすることが示された。 Comment
元ポスト:
解説:
linear attention->sparse attentionをcascadingしたtransformerブロックを持つアーキテクチャ
linear attention:
- [Paper Note] Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention, Zhen Qin+, ICML'24, 2024.05
sparse attention:
- [Paper Note] InfLLM-V2: Dense-Sparse Switchable Attention for Seamless Short-to-Long Adaptation, Weilin Zhao+, arXiv'25, 2025.09
[Paper Note] Prism: Spectral-Aware Block-Sparse Attention, Xinghao Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #LanguageModel #LongSequence #VisionLanguageModel #SparseAttention Issue Date: 2026-02-12 GPT Summary- ブロックスパースアテンションの効率を改善するために、平均プーリングによる粗粒度アテンションの不正確さの原因を分析し、Prismというトレーニング不要のアプローチを提案。Prismは、ブロック選択を高周波数と低周波数に分解し、エネルギーベースの温度キャリブレーションで位置情報を復元。結果、フルアテンションと同等の精度を維持しつつ、最大5.1倍の速度向上を達成。 Comment
元ポスト:
sparse attentionにおいて、RoPEとmean poolingによるブロックの重要度の同定が組み合わさったときに、mean poolingがlow pass filterの役割を果たし高周波成分が破壊される(ことを理論的に示した)。このため、低周波成分と高周波成分を分けて扱う手法を提案しているという感じの話らしい。
[Paper Note] AgentSkiller: Scaling Generalist Agent Intelligence through Semantically Integrated Cross-Domain Data Synthesis, Zexu Sun+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#GraphBased #NLP #LanguageModel #AIAgents #SyntheticData #Diversity #CrossDomain #LongHorizon Issue Date: 2026-02-12 GPT Summary- 「AgentSkiller」というフレームワークを提案し、マルチターンインタラクションデータを自動で合成。DAG構造により決定性と回復性を確保し、ドメインオントロジーとエンティティグラフを構築。サービスをリンクして複雑なタスクをシミュレーションし、信頼性の高い環境を生成。約11,000件のインタラクションサンプルを合成し、訓練モデルが重要な性能改善を達成したことを示した。 Comment
元ポスト:
最近のGeneralist Agentに対する合成データ生成手法は実APIのログ(決定的でなくなりプライバシーリスクが存在)をベースにするか、あるいはシンプルなinteractionに基づいたものに限定されており、データのカバレッジが不足しており、long hoiizonでクロスドメインのデータが不足しているという課題があるので、deterministic、かつreproducibleでスケーラブルな合成パイプラインを提案しました、という話な模様。オントロジーを用いる点が特徴的に見える。
[Paper Note] UI-Venus-1.5 Technical Report, Veuns-Team+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #AIAgents #mid-training #ModelMerge #Off-Policy #On-Policy #VisionLanguageModel #Rubric-based #Initial Impression Notes #GUI Issue Date: 2026-02-12 GPT Summary- 統合型エンドツーエンドGUIエージェントUI-Venus-1.5を紹介。さまざまなアプリケーションに対応する2B、8B、および30B-A3Bのモデルバリアントを持ち、10億トークンを活用したMid-Training、オンライン強化学習、ドメイン固有モデルの統合を実施。評価においてScreenSpot-Pro、VenusBench-GD、AndroidWorldで新たな最先端パフォーマンスを達成し、中国のモバイルアプリでも効果的なナビゲーションを実現。 Comment
元ポスト:
Mid-training(navigation, grounding, reasoning, GUI-VQA, アイコンの認識等の精緻な認識能力)でGUIに関する知識を身につけさせ、オフラインRLで特定のタスクに特化した能力(grounding, navigation等)を向上し、オンラインRLで実シナリオでのエージェントのtrajectoryレベルでの能力を向上させる。これらのモデルはモバイルとwebでそれぞれ学習され、最終的にモデルマージを通じて単一のend-to-endにタスクを実現可能なエージェントを構築する。
コールドスタートの対策のためにSFTではなくオフポリシーRLを使っているのが特徴
下記研究において、SFTが各trajectoryがトークン単位で一致したときに1となるrewardを用いたRLと一致することが示されており、汎化能力に課題があることが指摘されている[^1]。汎化性能は後回しにして、特定の能力にとにかくまずは強化したいという用途であればSFTでも良いかもしれないが、downstreamなタスクがend-to-endで多様なタスクとなる場合は、オフラインRLを用いて汎化性能も考慮しつつ多面的な能力をwarmupするのが良いのかもしれない。
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
[^1]: ポリシーがexpertのtrajectoryに対して低い尤度を示すとimportance weightingにより非常に大きい重みがかけられることで分散が大きく、かつ報酬シグナルがsparseなことが課題であることが指摘されている。
[Paper Note] Code2World: A GUI World Model via Renderable Code Generation, Yuhao Zheng+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Coding #VisionLanguageModel #WorldModels #GUI Issue Date: 2026-02-12 GPT Summary- 自律的なGUIエージェントは、GUI Worldモデルを用いて行動を実行し、人間のような先見性を持つ。既存のアプローチは視覚的忠実性と構造的制御の両立が困難である。そこで、Code2Worldを提案し、レンダリング可能なコード生成を通じて次の視覚状態をシミュレートする。GUIトラジェクトリを高忠実度のHTMLに変換し、合成コードを洗練。Render-Aware Reinforcement Learningを用いて視覚的意味の忠実性と行動の一貫性を強化。広範な実験により、Code2World-8Bは競争力のあるモデルに匹敵するパフォーマンスを達成し、ナビゲーション成功率を大幅に向上させた。 Comment
pj page: https://amap-ml.github.io/Code2World/
元ポスト:
現在のスクリーンショットと、アクションのペアから、次のスクリーンショットをレンダリング可能なコードを通じて予測する(Next UI Prediction)
[Paper Note] LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs, Benno Krojer+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Explanation #read-later #Selected Papers/Blogs #VisionLanguageModel #VisualTokens Issue Date: 2026-02-12 GPT Summary- 視覚トークンをLLMの埋め込み空間にマッピングする新手法「LatentLens」を提案。これにより視覚トークンの解釈可能性が向上し、従来の手法よりも高い精度で記述を生成。評価では、LatentLensが視覚トークンの解釈を効果的に提供し、視覚と言語の整合性に関する新たな証拠を示すことが確認された。 Comment
元ポスト:
VLMのVisual Tokenを、LLMで事前にコーパスからエンコードされたテキストのrepresentationとsimilarityを測ることでテキスト空間での類似した表現を見つけ解釈する方法な模様。興味深い。
[Paper Note] OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration, Shaobo Wang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #read-later #Selected Papers/Blogs #DataFiltering #Adaptive #Author Thread-Post Issue Date: 2026-02-12 GPT Summary- 高品質な公的テキストが不足する中、データ選択の動的特性を無視した手法の限界を克服するために、最適化器誘導投影ユーティリティ選択(OPUS)を提案。OPUSは、効果的な更新を安定したプロキシから導き出すことでデータをスコアリングし、計算効率を考慮したゴースト手法とボルツマン・サンプリングを用いる。これにより、GPT-2 Large/XLやQwen3-8B-Baseにおいて優れた成果を上げ、事前トレーニングの効率を飛躍的に改善。 Comment
元ポスト:
事前学習においてステップ単位で動的にバッチに含める学習データを選択する手法で、従来手法は単に勾配を考慮して選択していたが、実際にoptimizerによって更新される方向はmomentumなどによって異なるためgapが生じていた。これを埋めるために、optimizerが実際に重みを更新した際に、Validation setのlossがどれだけ低下するかによってUtilityを定義し、Utilityが大きくなるようにデータを動的に選択することで学習効率が向上する、といった話に見える。
著者ポスト:
[Paper Note] Features as Rewards: Scalable Supervision for Open-Ended Tasks via Interpretability, Aaditya Vikram Prasad+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Hallucination #Probing #Open-endedTasks Issue Date: 2026-02-12 GPT Summary- 特徴をスケーラブルな監視として用いる新アプローチ「RLFR」を提案。幻覚を減少させるため、強化学習パイプラインを設計し、モデルが出力の事実性に不確かさがある場合に介入・修正を学習。実験により、元のモデルより58%幻覚の可能性が低い結果を達成しながら、パフォーマンスを維持。解釈可能性の新しいパラダイムを示す。 Comment
元ポスト:
(以下論文をちゃんと理解できているか少し自信ないです)
activation steeringやLLMの内部表現の分析に利用されるprobing手法をRLの報酬に活用する研究で、学習させたい特徴をprobingによって予測できるモデルを用意し(今回はhallucination)、報酬として活用できるパイプラインを用意して(少しこのパイプラインがややこしい)RLするという話に見える。probingするモデルを学習するデータの合成に際はstrong modelが用いられる(今回はGemini 2.5 Pro)。要は、テスト時にsteeringできるのであれば、学習時にモデルが内部的に保持している特徴を活用してRLしちゃえばいいじゃん、という発想に見える。
流れとしては、input textが与えられた時にprobingを実施して、どこのspanにhallucinationがあるかを検出し、現在のポリシーにその情報を用いて新たなcontextを生成しself verificationさせる(情報を維持、撤回させるのか、修正のいずれの操作のうちどれを実施すべきかを出力)ことでロールアウトを実施。続いて、ロールアウトされたテキストに対して、**ベースモデルを用いてprobingを実施し**、その結果をrewardとしてポリシーをアップデートする。ベースモデルを使う部分の気持ちがどこに書かれているかがわからないのだが、おそらく、現在のポリシーのロールアウトをベースモデルを用いてprobingすることでreward hackingを防止している。test timeにも同様のprobingを実施し、Best-of-Nで応答を生成する(Figure2)。
[Paper Note] Data Agents: Levels, State of the Art, and Open Problems, Yuyu Luo+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #Data Issue Date: 2026-02-11 GPT Summary- データエージェントは、LLMやツールを活用してデータ管理や分析の自動化を目指す新しいパラダイムであるが、その定義は曖昧である。この記事では、データエージェントをL0からL5までの階層に分類し、各レベルの特徴を示す。具体的には、単純なアシスタントと自律型エージェントの違いや、L0-L2の代表的なシステムをレビューし、独自にデータ関連タスクを実行するProto-L3システムを紹介する。また、L4およびL5のエージェントに関する研究課題も議論し、データエージェントの未来のロードマップを提供する。 Comment
元ポスト:
データを管理、準備、分析を担うエージェント(=データエージェント)に関して、自律性のレベルを6段階に分けたTaxonomyを体系的に定義し、既存研究を分類している模様。
[Paper Note] Reinforced Attention Learning, Bangzheng Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#ComputerVision #NLP #ReinforcementLearning #MultiModal #Attention #PostTraining #VisionLanguageModel Issue Date: 2026-02-11 GPT Summary- 強化学習を用いた内部注意分布の直接最適化を通じて、マルチモーダルLLMの情報配分を改善する強化注意学習(RAL)を提案。RALは複雑な入力におけるグラウンディングを向上させ、さまざまなベンチマークで一貫した性能向上を示す。オンポリシー注意蒸留を採用し、クロスモーダル整合性を強化する新たなアプローチを提供。 Comment
元ポスト:
マルチモーダルLLM(実験ではVLM利用)におけるクロスモーダルなAttention表現を改善するためのRLに基づく事後学習手法で、attention分布を直接最適化する手法な模様
[Paper Note] SE-Bench: Benchmarking Self-Evolution with Knowledge Internalization, Jiarui Yuan+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #LanguageModel #ReinforcementLearning #Evaluation #SelfImprovement #PostTraining #read-later #Selected Papers/Blogs #FactualKnowledge #ContinualLearning #Initial Impression Notes Issue Date: 2026-02-10 GPT Summary- 自己進化には、エージェントが生涯学習者として新しい経験を内面化し、将来の問題解決に活かすことが必要。しかし、以前の知識の混在と推論の複雑さが測定を妨げる。SE-Benchという診断環境を導入し、エージェントが新しいAPIドキュメントを使用することで評価を行い、知識の保持と内面化の新たな洞察を得た。特に「クローズドブック訓練」が知識保持に必要であり、標準的な強化学習が新しい知識を内面化できないことを示す。SE-Benchは知識内面化のための厳密なプラットフォームを提供する。 Comment
元ポスト:
関数をリネームし関連するAPIドキュメント(今回はnumpy)を更新し、Claudeを用いてテストケースを生成し、複数のLLMのVotingで検証可能かどうかを判定した後人手による検証を行いフィルタリングする。テスト時にクローズドブックの設定で評価することで、インタフェースに関するモデルのFactual Knowledgeを更新しないとモデルはテストケースに正解できず、モデルが内部パラメータに保持するFactual Knowledgeをどれだけ適切に保持、更新しているかを評価するようなコントロールされた環境下でのベンチマークに見える。
APIに関するドキュメントの文脈をしっかり変更しないと元のモデルが文脈から過去の関数名との対応関係を類推できてしまいそうだが、その辺はどうなっているのだろうか。
[Paper Note] How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability, Shawn Im+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Explanation #RepresentationLearning #Transformer #Attention Issue Date: 2026-02-09 GPT Summary- セマンティック関連性を理解することは、言語モデルの一般化能力を高め、一貫性のあるテキスト生成に寄与します。本研究では、注意ベースの言語モデルにおいて自然言語データからの関連性の学習を、トレーニングダイナミクスの観点から分析します。勾配の主成分近似を用いて、重みの初期表現を開発し、セマンティック関連性の形成過程を説明。結果として、トランスフォーマーの重みは、ビグラムや文脈マッピングといった基底関数の合成として表現され、統計を反映した関連性の捉え方を明らかにします。実験では理論的な特性付けが学習重みに一致し、トランスフォーマーの学習された関連性の解釈を示します。 Comment
元ポスト:
学習中にtransformerがどのようにtoken間の関連性を学習しているのかを分析
[Paper Note] DIRMOE: DIRICHLET-ROUTED MIXTURE OF EXPERTS, ICLR'26
Paper/Blog Link My Issue
#NLP #LanguageModel #MoE(Mixture-of-Experts) #ICLR #Stability #Routing Issue Date: 2026-02-08 GPT Summary- Dirichlet-Routed MoE(DirMoE)は、MoEモデルの性能を向上させる新しい微分可能ルーティングメカニズムです。エキスパートの選択とその貢献の配分を明確に分け、Gumbel-Sigmoid緩和とDirichlet再パラメータ化により訓練過程を完全に微分可能にします。さらに、スパースペナルティを通じてアクティブなエキスパート数を管理し、専門性を高めつつ、他の手法と同等以上の成果を達成しています。 Comment
openreview: https://openreview.net/forum?id=a15cDnzr6r
元ポスト:
MoEのルーティングの選択と配分をモデル化して、微分可能にした上で最適化する
[Paper Note] A Relative-Budget Theory for Reinforcement Learning with Verifiable Rewards in Large Language Model Reasoning, Akifumi Wachi+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #PostTraining #BudgetAllocation Issue Date: 2026-02-08 GPT Summary- 強化学習は大規模言語モデルの推論能力を向上させるが、その効果は相対予算によって異なる。この研究では、$ξ:= H/\mathbb{E}[T]$を通じて相対予算理論を提案し、報酬の分散や情報的経路の発生確率がサンプル効率を決定することを示す。分析により、{不足}、{バランス}、{十分}の三つの領域を明らかにし、特にバランス領域で最大のサンプル効率を持つことが判明。また、オンラインRLに対する有限サンプルの保証を提供し、実証的に学習効率の最適化と推論性能のピークに一致する予算範囲を特定。 Comment
元ポスト:
元ポストに要旨が簡潔に日本語でまとめられている。
[Paper Note] Spider-Sense: Intrinsic Risk Sensing for Efficient Agent Defense with Hierarchical Adaptive Screening, Zhenxiong Yu+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #Safety #Initial Impression Notes Issue Date: 2026-02-08 GPT Summary- 「Spider-Sense」と呼ばれるイベント駆動型防御フレームワークを提案し、エージェントが危険を認識した際にのみ防御を発動。階層的な防御メカニズムにより効率と精度をトレードオフしつつ、既知のリスクを軽量マッチングで解決し、曖昧なケースは内部推論に移行。新たなベンチマーク「S$^2$Bench」を用いた実験で、競争力のある防御性能と最低の攻撃成功率を示し、わずか8.3%の遅延オーバーヘッドを実現。 Comment
元ポスト:
従来のAI Agentのセキュリティチェックは決められたタイミングで、しばしば重いチェックがかかりレイテンシが高かったが、提案手法では動的にどの程度の計算量を費やすかを調整して、必要なタイミングで重い推論、そうでない場合は軽量なチェックで済ませることでレイテンシと性能を改善する、といったコンセプトな模様。
エージェントのステージごとにobservationを事前定義されたテンプレートで囲い、テンプレートによってスクリーニングをトリガーし、ベクトル検索によって危険度を判定する。判定した危険度が一定以下なら軽量なチェック、一定以上ならLLMによる推論を用いた重い処理を走らせるという手法に見える。図中のcのnotationが本文中に見当たらない気がするが、見落としているだろうか。
結局のところ、テンプレートによってセキュリティチェックが誘発されるように見えるので、元々の問題意識である固定されたタイミングで強制的にセキュリティチェックがかかる、という課題は解決されない気がする。固定されたタイミングで強制的にセキュリティチェックがかかる点は従来手法と変わらないが、セキュリティチェックに費やすコストや計算量を動的に変更します、という話に感じる。
[Paper Note] A large language model for complex cardiology care, O’Sullivan+, Nature Medicine'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Medical Issue Date: 2026-02-07 Comment
元ポスト:
AIによるサポートを受けた医師が、(人手不足な)より専門的な知識が求められる専門医が扱うような症例に対して治療計画を立てたときに、AIによる支援を受けた場合により高品質な計画を立てられた、という趣旨の話なようである。
[Paper Note] Likelihood-Based Reward Designs for General LLM Reasoning, Ariel Kwiatkowski+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #PostTraining #RLVR Issue Date: 2026-02-06 GPT Summary- 報酬関数の設計における二値のスパース性に対処するため、本研究ではリファレンスアンサーから導出された対数確率を報酬として使用することを検討。対数確率報酬は所有検証者に依存せず、数学推論ベンチマークでの性能を向上させることがわかった。この方法は、チェインオブシンキング(CoT)ファインチューニングの新たな実行可能な戦略として位置づけられ、検証可能・非検証可能な設定でのパフォーマンスを向上させる効果が確認されました。 Comment
元ポスト:
関連(concurrent work):
- [Paper Note] Maximum Likelihood Reinforcement Learning, Fahim Tajwar+, arXiv'26, 2026.02
最終応答のlogprobを報酬として利用する設定のRL(i.e., 検証可能なタスクでなくとも適用可能)を調査し、検証可能な応答のlogprobを報酬として利用することでbinary rewardと同等以上の性能を達成可能であることを示したようで、検証可能でない設定で学習すると途中でCoTが崩壊し、CoTが極端に短くなる現象が生じる。これは初期のCoTの長さと正解の対数尤度に負の相関があり、これによってRLがCoTを短くすることを奨励してしまうからではないか、という話が元ポストに記述されている。
[Paper Note] A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces, Mingxuan Du+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #RAG(RetrievalAugmentedGeneration) #Test-Time Scaling #Scalability #Adaptive #Initial Impression Notes Issue Date: 2026-02-06 GPT Summary- A-RAGは、階層的な取得インターフェースを通じてエージェント型のRAGシステムを実現し、モデルが適応的に情報を検索・取得できる能力を向上させる。キーワード検索、意味検索、チャンク読み取りの3つのツールを提供し、既存の方法と比較して一貫した優れた性能を示す。モデルのスケーリング特性についても体系的に検討し、今後の研究のためにコードを公開予定。 Comment
元ポスト:
固定されたワークフローでのRAGではなく、エージェントが自ら考えて最適な検索ツールを模索し情報を自動的に取得するAgentic RAGな枠組みを提案している。研究としての新規性はweaknessだと感じるが、実務的に有効な方法だと思う。LLM側のreasoning effortやmax tokenを増やすことで性能がスケーリングするため(Test Time Scaling)これもまた実用的な手法だと感じる。
[Paper Note] EMA Policy Gradient: Taming Reinforcement Learning for LLMs with EMA Anchor and Top-k KL, Lunjun Zhang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #PostTraining Issue Date: 2026-02-05 GPT Summary- LLMのために強化学習のポリシー勾配アルゴリズムを改善するため、固定アンカーポリシーをEMAに置き換え、Top-k KL推定器を導入。これにより、性能が大幅に向上し、数学的推論ではQwen-1.5BがOlympiadBenchで53.9%を達成。Qwen-3Bでは、EMA-PGがGRPOを7つのデータセットで平均33.3%改善し、特にHotpotQAや2WikiMultiHopQAにおいて顕著な向上を示した。全体として、EMA-PGはLLMの強化学習をスケールするための有力なアプローチである。 Comment
元ポスト:
ポイント解説:
KL正則化のRefが古くなりすぎるので指数移動平均(直近の更新重視の移動平均)を用いて更新されるようにし、KLの計算が重いのでTopKのトークンで近似的に計算することで高速化、という感じに見える。
[Paper Note] Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text, Ximing Lu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #SyntheticData #PostTraining #read-later #RLVR #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-02-05 GPT Summary- RLVRはLLMの推論を解きほぐす基盤だが、検証データの不足がスケールアップのボトルネックとなっている。この課題を克服するために「ゴールデン・グース」を提案し、インターネットの非検証テキストから無限のRLVRタスクを生成する。具体的には、LLMに主要な推論ステップを特定させ、豊富なタスクを持つGooseReason-0.7Mデータセットを合成。これにより、従来モデルを復活させ、15のベンチマークで新たな最先端結果を達成。また、リアルなサイバーセキュリティデータからRLVRタスクを合成し、Qwen3-4B-Instructをトレーニング。これにより7Bモデルを超える成果を上げ、推論に富んだインターネットテキストを活用する可能性を示している。 Comment
元ポスト:
テキストからMultiple Choice Question (MCQ) を生成することでRLVR用のverifiableな学習データを大量に合成可能にする。おそらく次のステップとしては、生成されるMCQの stem, key, distractor の質が今度は焦点となり、そこの質が改善されればより大きなgainを得られるようになる気がする(たとえば消去法で正解を知らなくても正解できてしまうようなdistractorや、問題文に正解がそのまま含まれてしまっているようなノイジーなMCQから人間が何も学ばないように、モデルが学習するときと一緒だと思われる)。
データとモデルが公開:
[Paper Note] daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently, Mohan Jiang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #SyntheticData #Coding #SoftwareEngineering #LongHorizon Issue Date: 2026-02-05 GPT Summary- 大規模言語モデル(LLM)は短期的なタスクには優れていますが、長期的なワークフローへのスケーリングが課題です。本研究は、プルリクエスト(PR)シーケンスを用いてデータ合成を再概念化し、長期学習のための自然な監督信号を提供します。具体的には、進行的タスク分解、長期的一貫性の強制、バグ修正の検証を通じて、因果依存関係を保ちながら目標指向行動を促進します。実験結果は、daVinci-Agencyが高いデータ効率を即し、ベンチマーク全体での改善を達成したことを示しています。 Comment
元ポスト:
PRのシークエンスでlong horizonデータを合成する
[Paper Note] A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training, Zihan Qiu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Normalization #AttentionSinks #read-later #Stability Issue Date: 2026-02-03 GPT Summary- 大規模言語モデルにおける外れ値の機能を調査し、注意の沈みと残差の沈みのメカニズムを明らかにする。外れ値は正規化と共に機能し、再スケーリングを通じてトレーニングの安定性を向上させ、パフォーマンスを改善。これにより、外れ値が寄与者ではなく再スケール要因であることを示し、学習可能なパラメータとの関係性を明らかにした。 Comment
元ポスト:
Attention Sinksにならい、Residual Sinksと命名されている
Attention Sinksや本研究で命名されているResidual Sinks(activationの特定の次元がほとんどのトークンで過剰に大きくなる現象)は正規化を排除するとなくなり(i.e., 正規化とセットで出現する)、これらがなくなると学習の安定性と性能が低下する。これらはTransformerアーキテクチャ内の外れ値として見ることができるが、この外れ値が存在することによってnormalizationにおいてrescalingが実施され安定性やパフォーマンスが向上している、という感じらしい。
[Paper Note] SimpleGPT: Improving GPT via A Simple Normalization Strategy, Marco Chen+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Transformer #Architecture #Normalization Issue Date: 2026-02-03 GPT Summary- 本研究では、Transformerの最適化を第二次幾何学の視点から再評価し、活性化スケールの安定化を目的としたSimpleNormという正規化戦略を提案。これにより、ヘッセ行列のスペクトルノルムが低下し、より大きな学習率が許容されることを理論的に示します。1Bから8BのパラメータスケールのGPTモデルでの実験により、SimpleGPTは従来の手法よりも3倍から10倍の高い学習率を持ち、安定性と性能で優れた結果を実現。特に、7Bモデルでは、LLaMA2よりも低い訓練損失を記録しました。ソースコードは公開予定です。 Comment
元ポスト:
LinearLayerをSimpleNormと呼ばれるオペレーターに置換するだけなシンプルな手法で性能向上しているようである。SimpleNormオペレーターは式(3)であり、Linearによる変換の"直後"に任意のNormalizationを実施するようなオペレーターとして定義される。SimpleGPTではPreLNなどは実施しない。
[Paper Note] The Hot Mess of AI: How Does Misalignment Scale With Model Intelligence and Task Complexity?, Alexander Hägele+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Alignment #Reasoning #Safety Issue Date: 2026-02-03 GPT Summary- AIの機能向上に伴い、リスクも増すため、モデルの失敗のメカニズムを理解することが重要になる。具体的には、失敗が意図しない目標の追求から生じるのか、混乱した行動から生じるのかを検討。また、AIの不適合性はバイアス-バリアンス分解を通じて評価される。実験結果から、高能力なモデルはタスクにかかる時間が増すほど不適合性が高くなる傾向があり、大モデルが小モデルよりも不適合性が高い場面も確認された。これにより、高能力なAIが複雑なタスクを行う場合、予測不可能な誤行動が産業事故につながる可能性が示唆される一方、目標の一貫した追求の可能性は低いことが示される。これにより、報酬ハッキングや目標の誤仕様に対するアライメント研究の重要性が増す。 Comment
元ポスト:
- モデルの推論が長くなればなるほど、一貫性(=予期できないエラー/misalignmentによるバイアス i.e., 全体のエラーに対する予測できないエラーの割合; Variance/Errorで測定)がなくなる
- モデルサイズが大きくなればなるほどEasy Taskでのみ一貫性が向上する。言い換えるとモデルの賢さと一貫性の間に、一貫した関係性はない。が、しばしば賢いモデルは一貫性に乏しい。
上記知見より、AI Safetyの観点で言うと、強力なAIがエラーを起こす時は、一貫性のある何らかの誤った目標に向かっていくようなものではなく、事故のような予測できないものになるだろう、と予測している。
[Paper Note] TriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification, Haoyun Jiang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Decoding #Selected Papers/Blogs #Verification #SpeculativeDecoding #Initial Impression Notes Issue Date: 2026-02-03 GPT Summary- SDを用いて推論効率を向上させる新しいフレームワークTriSpecを提案。軽量なプロキシを活用し、不確実なトークンに対してのみターゲットモデルを使用することで、計算コストを大幅に削減。実験により、従来のSDに対して最大35%の速度向上とターゲットモデルの呼び出し回数を最大50%削減したことを示す。 Comment
元ポスト:
targetモデルでのverificationは重いので、軽量なverificationをdraftに対して実施することで最大35%デコーディング速度向上とのこと。
verificationに利用するLLM(=proxy)がどのようなモデルファミリーなのか、ターゲットと同じファミリーなのか否かなどが気になる。
3.1節に以下のように書かれている:
> We identify smaller same-family models as ideal proxy veri-
fiers, justified by the following three core properties.
proxyについて以下の三つの観点で分析している:
- strong alignmentw: トークンレベルでtargetとalignしているかを分析(exact match, acceptable mismatch, unacceptable mismatchの3値分類)
- trustworthy outputs: token levelでalignしているだけでなく、単独で応答させたときにtargetと同じ回答が得られるか(同じ回答が得られるのであれば多少のトークンレベルの齟齬は許容可能
- Clear separability: proxyが信頼できるトークンと不確実な出力を区別できることが好ましく、proxyのtop1,2のprobabilityの差が0.5より大きい場合にacceptableなトークンと強い相関があることがわかり、verificationの信頼性の担保に使える
同じモデルファミリーでも、よりファミリー内での挙動が一致させるような副次的効果を得られるモデルファミリー構築方法もあり、Speculative Decodingの承認率が向上するような話もある:
- [Paper Note] Efficient Construction of Model Family through Progressive Training Using Model Expansion, Kazuki Yano+, COLM'25, 2025.04
openreview:
https://openreview.net/forum?id=yhhgkkiQe5
提案手法の気持ちや、検証コストに焦点を当てたことは非常に有意義であるものの、Speculative Decodingの(数学的な)ロスレス保証を、実験的には性能がほとんど低下しないことが示されているが、数学的な保証を犠牲にして速度改善している点が実用上の大きな課題で、プロキシを挟むアイデアが既存研究の階層的、マルチレベルのSD, 検証の条件を緩める手法と比較して新規性が明らかでない点、また通常のSDと比較して3つのモデルを用いる点でエンジニアリングの観点からオーバーヘッドなしに主要な推論スタックにデプロイできるのか、実験結果の再現性や公式の報告とズレがある点などが指摘され、ICLR'26にrejectされている。
[Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #Reasoning #MoE(Mixture-of-Experts) #AttentionSinks #PostTraining #Selected Papers/Blogs #Reference Collection #SelfDistillation Issue Date: 2026-02-03 GPT Summary- Step 3.5 Flashは、フロンティア知能と効率を橋渡しするスパースMixture-of-Experts(MoE)モデルで、1960億パラメータの基盤と110億パラメータのアクティブパラメータを組み合わせ、迅速で信頼性の高い推論を実現。交互スライディングウィンドウとMulti-Token Predictionを取り入れ、エージェント間の相互作用の待機時間を短縮。検証可能な信号とフィードバックを用いた強化学習フレームワークにより、安定した自己改善を図る。エージェントやコーディング、数学タスクで高い性能を示し、フロンティアモデルに匹敵する結果を達成している。 Comment
元ポスト:
公式ポスト:
解説:
ポイント解説:
ポイント解説:
固定されたデータ非依存のsink tokenを利用するよりも、attention headの出力にinput xに応じたgatingを設けるHead wise gated attentionの方が各ベンチマークでの性能が良い(Table2, gatingの計算量もほぼ無視できる)。Head wise gated attentionは、データに応じてattention headの出力を制御するため、データ依存のlearnableなsink tokenと解釈できる(A.1):
Head-wise Gated Attention:
- [Paper Note] Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free, Zihan Qiu+, NeurIPS'25 Best Paper
- [Paper Note] Forgetting Transformer: Softmax Attention with a Forget Gate, Zhixuan Lin+, ICLR'25, 2025.03
SFTデータがリリースされたとのこと:
https://huggingface.co/datasets/stepfun-ai/Step-3.5-Flash-SFT
元ポスト:
[Paper Note] DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation, Haozhe Xie+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Dataset #Evaluation #read-later #Selected Papers/Blogs #Robotics #VisionLanguageActionModel #Manipulation Issue Date: 2026-01-31 GPT Summary- 動的オブジェクト操作に挑む「DynamicVLA」フレームワークを提案。畳み込み視覚エンコーダで迅速なマルチモーダル推論を実現し、連続推論で迅速な適応を促進。潜在認識アクションストリーミングにより認識と実行のギャップを埋める。新たに構築したDOMベンチマークで動的操作データを収集し、評価によって顕著な性能向上を示す。 Comment
pj page: https://www.infinitescript.com/project/dynamic-vla/
元ポスト:
動くオブジェクト(Donamic Object)に関するデータセットとベンチマークに見える。
既存VLAではできないそこそこな速度で転がるピンポン玉などを正確に掴むことができるようなデモが掲載されている。興味深い。
コードとデータセットが公開:
[Paper Note] WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World, Ao Liang+, CVPR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation #CVPR #read-later #Selected Papers/Blogs #WorldModels #3D (Video) #Author Thread-Post Issue Date: 2026-01-30 GPT Summary- 生成的世界モデルはリアルな4D環境を合成しますが、物理的または行動的に失敗することが多いです。この課題に対処するため、WorldLensを導入し、生成された世界の評価を行う全範囲ベンチマークを提供します。これには生成、再構成、行動追従など五つの側面が含まれ、視覚的現実性や物理的妥当性を評価します。既存モデルには広範囲に優れたものがなく、WorldLens-26Kという大規模な人間注釈付きデータセットを構築し、評価モデルWorldLens-Agentを開発しました。これにより、世界の忠実性を測定する統一されたエコシステムを形成し、リアルな見た目と行動の両面で評価基準を標準化します。 Comment
pj page: https://worldbench.github.io/worldlens
元ポスト:
github: https://github.com/worldbench/WorldLens
(自動運転に関する)World Model(には限られないかもしれないが)を多角的な軸から評価できるベンチマーク。3D object detection/Tracking, Novel-view Discrepancy/Quality, Occupacy Prediction, Subject Fidelity/Consistency/Coherence, Temporal Concistencyなど、20以上のdimensionから評価可能なようである。
著者ポスト:
[Paper Note] Reinforcement Learning via Self-Distillation, Jonas Hübotter+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Distillation #PostTraining #Selected Papers/Blogs #On-Policy #TextualFeedback #SelfDistillation Issue Date: 2026-01-30 GPT Summary- リッチフィードバックを活用した強化学習手法SDPOを提案。従来の手法がスカラー報酬に依存するのに対し、SDPOは豊富なテキストフィードバックを用いてセルフディスティレーションを行い、モデルの誤りを特定。科学的推論や競技プログラミングにおいて、サンプル効率と精度を向上し、標準的なRLVR環境でも優れた性能を発揮。テスト時には試行回数を削減しつつ、発見確率を維持可能。 Comment
あるポリシーでロールアウトを実行し、ロールアウトの実行結果からフィードバック(e.g., runtime error messageやLLM-as-a-Judgeによるtextual feedbackなど)を得たときに、同ポリシーに対してフィードバックをcontextとして与えた上でロールアウトのtoken levelでのlog probを比較することで、token levelでどこが誤っていたかに関する学習シグナルを得る。
ポイント解説:
[Paper Note] Self-Distillation Enables Continual Learning, Idan Shenfeld+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #In-ContextLearning #Distillation #Catastrophic Forgetting #read-later #Selected Papers/Blogs #On-Policy #ContinualLearning #SelfDistillation #Author Thread-Post Issue Date: 2026-01-29 GPT Summary- 自己蒸留ファインチューニング(SDFT)は、デモンストレーションからオンポリシー学習を可能にし、従来の手法を上回って新しいスキルを獲得しつつ既存の能力を維持。文脈内学習を活かし、壊滅的忘却を削減しながら複数のスキルを時間と共に蓄積するモデルを実現。 Comment
元ポスト:
著者ポスト:
現在のポリシーにおいてクエリ q とexpertによるdemonstraction c によってポリシーを条件づけたモデルを教師モデルとみなし、現在のポリシーにおいてクエリだけで条件付けたモデル生徒モデルとした時に、教師モデルの分布と生徒モデルの分布のreverse KL Divergenceが最小化されるように生徒モデルを学習する((式1))。すなわち、次のポリシーの更新に対する学習シグナルを得るためにモデルのIn-Context Learningを活用している。
上記の見方はstudent-teacherにおける蒸留という観点で見た場合だが、TRPOに基づく定式化からスタートして、expertが作成したdemonstrationによって導出されるimplicitなreward functionを最大化するInverse Reinforcement Learningとして解釈し、式変形を繰り返していくと、前述のICLによる勾配と、オンポリシーRLでのポリシー最適化による勾配が一致する(式2, 式6)。
ポイント解説:
[Paper Note] POPE: Learning to Reason on Hard Problems via Privileged On-Policy Exploration, Yuxiao Qu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #PostTraining Issue Date: 2026-01-27 GPT Summary- 強化学習(RL)の限界を克服するために、Privileged On-Policy Exploration(POPE)を提案。POPEは、人間やオラクルからの特権情報を活用し、困難な問題の探索を促進するアプローチで、非ゼロ報酬を得ることで学習を進める。実験により、POPEが困難な推論タスクにおける性能を大幅に向上させることを示した。 Comment
関連:
- [Paper Note] Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes, Amrith Setlur+, arXiv'26, 2026.01
skim readingしかできていないが、本研究は人間が記述したオラクルを接頭辞として使い、ポリシーの方向性をガイドすることでアシストするが、こちらのReuse your FLOPsは過去のロールアウトで成功したtrajectoryを再利用して接頭辞として利用する点が異なるように見える。
RLが解くのが困難な問題に対して接頭辞としてオラクルの情報を与えることで学習シグナルのスパースさを解決する
[Paper Note] Reuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes, Amrith Setlur+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #PostTraining #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-01-27 GPT Summary- PrefixRLは古いサンプリングデータを活用し、オフポリシーの不安定性を回避しつつ、オンポリシーでの強化学習を行う手法です。これにより、学習信号が強化され、従来のRLよりもサンプル効率が向上。また、PrefixRLは難しい推論問題において、より早く同等のトレーニング報酬を達成し、他のモデルファミリーに対しても適応可能であることを示しています。 Comment
元ポスト:
同じタイミングで上記POPEが提案された。POPEは人間が記述したオラクルを接頭辞として使い、ポリシーの方向性をガイドすることでアシストするが、こちらのReuse your FLOPsは過去のロールアウトで成功したtrajectoryを再利用して接頭辞として利用する点が異なるように見える。
著者ポスト:
[Paper Note] LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts, Venmugil Elango+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #Architecture #MoE(Mixture-of-Experts) #Selected Papers/Blogs #reading Issue Date: 2026-01-27 GPT Summary- MoEアーキテクチャを再評価し、推論コストの最適化に焦点を当てた研究。新しいモデルLatentMoEを導入し、最大95Bパラメータのスケールで優れた精度を実現。これにより、Nemotron-3スーパーおよびウルトラモデルに適用され、パフォーマンスが向上した。 Comment
元ポスト:
ポイント解説:
MoEに用いるhidden_stateの次元数が小さくなるようにlinear layerで圧縮しノード間のtrafficを削減しつつ、その分expert数やtop-kで選択するkを増やす。
[Paper Note] Endless Terminals: Scaling RL Environments for Terminal Agents, Kanishk Gandhi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #PostTraining #read-later #Diversity #Selected Papers/Blogs #Initial Impression Notes #Environment #Author Thread-Post Issue Date: 2026-01-26 GPT Summary- 自己改善エージェントのボトルネックである環境を改善するため、無人アノテーションで端末利用タスクを生成する「Endless Terminals」パイプラインを提案。タスク記述の生成から可解性のフィルタリングまでの4ステージを経て、3255のタスクを作成。PPOを用いて訓練したモデルは、ホールドアウト開発セットで大幅な性能向上を示し、Llama-3.2-3Bは4.0%から18.2%、Qwen2.5-7Bは10.7%から53.3%に改善。人間キュレーションのベンチマークでも改善し、シンプルな強化学習がスケールする環境で成功することを示す。 Comment
元ポスト:
taskが解けるものか否かをverifyする追加のモデルが必要な点は注意とのこと。
(論文中ではo3が用いられている)
著者ポスト:
RLにおけるターミナル上で実行可能な多様なタスクと、実際に動作可能なコンテナ、テストの生成をスケールさせることで標準的なPPOで性能が向上し、人間が収集した既存ベンチマーク(Terminal Bench 2.0)にも汎化することを示した研究。つまり、RLのタスクと環境をスケールさせれば標準的なRLアルゴリズムでも性能が向上するというメッセージがある。
本研究の他研究との位置付けがぱっと脳内で整理できなかったので、関連研究の部分を読むと、
- AgentのScaffoldの観点では、bashが実行可能なOpenHandsに近く、シェルコマンドを実行し、実行に至るまでのすべてのヒストリと出力が利用可能。
- SFTのための高品質なデータを合成するる研究が最近は多いが、SFTはRLのためのWarmUpに相当するため、本研究とそれらの研究は補完的な位置付けにある。
- ベンチマークやインタラクティブな研究の観点では、SWEBenchやTerminal Bench 2.0のように、人間が収集したベンチマークが存在し、マルチターンでアクションを通じてインタラクションしながら次のアクションを決めていく。本研究もシェル上で状態を観測しながら次のアクションを決めていくようなマルチターンの枠組みに相当する。
- verifiableな環境を合成する研究も行われている。たとえばSWEGymは2438のpythonコードのタスクと検証可能なテストを提供するが、既存のGithub Issueに依存しており、本研究のようにボトムアップに手続的に生成されるものではない。シングルターンではself-playにより困難な問題を生成する研究があるがマルチターンではない。Open Thought Agentという研究がSFT, RLのためのターミナルを用いた環境を合成する点でもっとも本研究と近いが、人間が生成したクエリやコマンドに基づいており、かつ既存のTerminal Bench 2.0といった人間によって収集されたベンチマークでのgainは得られていない。本研究では、完全に自動化されており、任意のサイズにスケールしPPOのような標準的なRLでも既存ベンチマークに転移する点が異なる。
という整理のようである。位置付けは理解できたが、本研究が既存のベンチマークにも転移するのはなぜなのだろうか?という点がまだ理解できていない。
所見:
[Paper Note] Towards Execution-Grounded Automated AI Research, Chenglei Si+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #AIAgents #SelfImprovement #ScientificDiscovery #PostTraining #read-later #Selected Papers/Blogs #EvolutionaryAlgorithm Issue Date: 2026-01-24 GPT Summary- 自動化されたAI研究は科学的発見の加速に寄与するが、現在のLLMはしばしば効果的でないアイデアを生成。アイデア実装のための自動実行器を構築し、並行GPU実験を通じてその効果を検証。進化的探索と強化学習の2方法を分析し、前者はGRPOベースラインを上回るサンプル効率、後者は単純なアイデアに収束し上限を制限。実行に基づくAI研究の未来を探る。 Comment
アイデアを実行できる環境を与え、進化的な探索をRLと実行結果に基づくReward(ベンチマーク性能など)によって実施するような話で、実行結果に基づくRewardに基づいてRLすると、平均的にうまくいくように最適化され性能を最大化することに苦労する、といった知見が得られた、という趣旨の話が元ポストで記述されている。
best solutionを見つけるようにRLする研究がこちら:
- [Paper Note] Learning to Discover at Test Time, Mert Yuksekgonul+, arXiv'26, 2026.01
元ポスト:
[Paper Note] Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors, Zhiwei Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Reasoning #SelfCorrection #PostTraining Issue Date: 2026-01-23 GPT Summary- LLMはマルチターン実行において脆弱で、ツール呼び出しエラー後の自己修正が困難。従来の強化学習ではエラーが負の報酬として扱われ、復旧指針が不足している。本研究では、実行エラーを修正監督に変換するFission-GRPOフレームワークを提案。失敗した軌道をエラーシミュレーターのフィードバックで強化し、新しいトレーニングインスタンスに分裂。これにより、実際のエラーから学ぶことが可能となる。BFCL v4マルチターンで、Fission-GRPOはQwen3-8Bのエラー回復率を5.7%改善し、全体的な精度を4%向上させた。 Comment
元ポスト:
tool useの学習をさせる際に通常のGRPOでの更新に加えて、ロールアウトで実行エラーとなったものを収集し、エラーに対して診断フィードバックを与え、その文脈からエラーを回復するようなロールアウトを実施し学習することで、自己修正能力を身につけさせるような手法に見える。
[Paper Note] RayRoPE: Projective Ray Positional Encoding for Multi-view Attention, Yu Wu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Multi #ComputerVision #Transformer #Attention #PositionalEncoding #2D (Image) #DepthEstimation #NovelViewSynthesis Issue Date: 2026-01-23 GPT Summary- 我々は、マルチビュー変換器における位置エンコーディングの新手法RayRoPEを提案し、パッチをユニークにエンコードしてSE(3)不変な注意を実現します。既存のエンコーディング方式の限界を踏まえ、光線に基づいてパッチの位置を表現し、ジオメトリに配慮した予測点を使用します。RayRoPEは多周波数の類似性を計算するためのクエリフレームの投影座標を確立し、不正確な3D点の不確実性に対処するための位置エンコーディング手法を提供します。視点合成とステレオ深度推定のタスクにおいて、代替方式に対して一貫した性能向上を示し、RGB-D入力の効果的な利用も確認しました。 Comment
pj page: https://rayrope.github.io/
元ポスト:
複数視点(multiview)での画像を入力とするtransformerの位置エンコーディングを改善した研究で、multiviewのattentionは下記のような性質を持つのが理想としており
(a) 座標系の取り方に対してattentionの出力が不変であり
(b) 同じ点であれば、どのviewからのattention出力であっても同一であるべき
(c) 幾何学的に近い点の方が類似度が高くあるべき
(d) 様々な粒度で特徴を捉えられるべき(高周波成分、低周波成分)
これらを獲得できるようにray(方向に関する情報)を取り入れるような新たなRoPEアーキテクチャを考案した、というような感じらしい(ゆるふわ理解)。
pj pageに他手法と比較して生成される別方向の画像などが高品質になっている例が掲載されている。
[Paper Note] Agentic Reasoning for Large Language Models, Tianxin Wei+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #Planning #Reasoning #SelfImprovement #memory #Test-time Learning Issue Date: 2026-01-23 GPT Summary- エージェンティック推論は、LLMを自律的エージェントとして再構築し、計画や行動を行う新たなアプローチを提供します。本調査では、推論を基盤、自己進化、集合的の三つの次元に整理し、それぞれの特性と相互作用を探ります。また、文脈内推論とポストトレーニング推論の違いを示し、さまざまな現実世界でのアプリケーションをレビューします。この研究は、思考と行動を結びつける統一的なロードマップを提示し、今後の課題と方向性を概説します。 Comment
元ポスト:
agentのreasoning周りに特化したsurveyで基本的なsingle agentとしてのplanning, tool use, searchだけでなく、self evolving, memory, multi agent reasoningなど広範なトピックが網羅されているとのこと。
[Paper Note] TranslateGemma Technical Report, Mara Finkelstein+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#MachineTranslation #NLP #LanguageModel #SmallModel #MultiLingual #OpenWeight #Selected Papers/Blogs #Initial Impression Notes Issue Date: 2026-01-16 GPT Summary- TranslateGemmaは、Gemma 3モデルに基づく機械翻訳のオープンモデルセットで、二段階のファインチューニングプロセスを採用。初めに高品質な並行データで監視付きファインチューニングを行い、その後報酬モデルによる強化学習で翻訳品質を最適化。WMT25テストセットでの人間評価とWMT24++ベンチマークでの自動評価を通じて有効性を示し、自動指標では大幅な性能向上が確認される。特に小型モデルは大型モデルに匹敵する性能を持ちつつ効率が向上。さらに、マルチモーダル能力も保持し、画像翻訳ベンチマークでの性能向上が報告されている。TranslateGemmaの公開は、研究コミュニティに強力で適応可能な翻訳ツールを提供することを目指している。 Comment
元ポスト:
10個の翻訳元言語→翻訳先言語対で評価されている。Japanese→Englishでも評価されているが、他の言語と比べて最も性能が悪いので、日本語では苦戦していそうに見える。English→Italianは(評価した言語ペアの中では)最も性能が良い。
ポイント解説:
関連:
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
- [Paper Note] Hunyuan-MT Technical Report, Mao Zheng+, arXiv'25, 2025.09
続報:
ブラウザ上で100%ローカルでの翻訳が可能になったらしい。WebGPUってなんだろう、、、
https://huggingface.co/spaces/webml-community/TranslateGemma-WebGPU
[Paper Note] LEMAS: Large A 150K-Hour Large-scale Extensible Multilingual Audio Suite with Generative Speech Models, Zhiyuan Zhao+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Dataset #SpeechProcessing #Speech #MultiLingual #TTS Issue Date: 2026-01-14 GPT Summary- LEMAs-Datasetは、150,000時間以上の音声データから構築された、大規模で多言語対応のオープンソース音声コーパスです。特に、単語レベルのタイムスタンプを持ち、効率的なデータ処理パイプラインによって品質が保証されています。このデータセットを利用して、異なるアーキテクチャによる二つのベンチマークモデルを訓練し、多言語合成や音声編集における高品質なパフォーマンスを実現しました。実験結果は、LEMAs-Datasetが音声生成システムの発展に寄与することを示しています。 Comment
pj page: https://lemas-project.github.io/LEMAS-Project/
データセットに日本語が含まれてないように見える😭
元ポスト:
[Paper Note] Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning, Chengwen Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #AIAgents #Evaluation #MultiModal #VisionLanguageModel #DeepResearch #3D (Video) Issue Date: 2026-01-14 GPT Summary- VideoDRは、ビデオを基にしたオープンドメインのビデオ質問応答のための新たな深層研究ベンチマークで、フレーム間の視覚的手がかり抽出やインタラクティブなウェブ検索、マルチホップ推論を要求する。高品質なビデオサンプルを提供し、複数のマルチモーダル大規模言語モデルの評価を行った結果、エージェントの性能はワークフローに依存することが示された。VideoDRは次世代ビデオ深層研究エージェントへの重要な課題を明らかにする。 Comment
元ポスト:
初めてのvideo deep researchベンチマークとのこと
[Paper Note] Token-Level LLM Collaboration via FusionRoute, Nuoya Xiong+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Decoding #Routing Issue Date: 2026-01-10 GPT Summary- FusionRouteは、軽量なルーターを用いて、各デコーディングステップで最適な専門家を選択し、その専門家の出力を補完するトークンレベルのマルチLLMコラボレーションフレームワークを提案。これにより、ドメイン特化型モデルの効率性を保ちながら、一般化能力を向上させる。実験では、Llama-3やGemma-2といったモデルで、数学的推論やコード生成などのタスクにおいて優れた性能を示した。 Comment
元ポスト:
トークンレベルでモデルを選択して生成する
[Paper Note] VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice, Shuming Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#ComputerVision #NLP #read-later #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2026-01-10 GPT Summary- CoT推論は動画理解タスクにおいて有用だが、直接的な回答も同等以上の性能を示すことがある。本研究では、VideoAuto-R1というフレームワークを提案し、「一度考え、二度答える」アプローチを採用。初期回答を生成後、推論を行い、見直した回答を出力する。これにより、動画QAベンチマークで最先端の精度を達成し、応答長を約3.3倍短縮。推論集約型タスクでは高い思考モード活性化率が観察され、言語ベースの推論が常に必要ではないことを示唆している。 Comment
pj page: https://ivul-kaust.github.io/projects/videoauto-r1/
元ポスト:
テキストだと基本的にCoTが良い方向に働くがVideoになるとなぜうまくいかない場面が多いのだろうか?気になる
ポイント解説:
output formatを 直接応答→thinking→thinking後応答 とし、双方の応答に対してrewardを計算することで複数のrewardシグナルを同時に扱える。
(感想)モデルの直接応答によるrewardを用いることで、internalなreasoning能力が向上するし(効率の増加)、thinking後の応答に対してrewardを用いることでthinkingのリソースを費やした場合の性能も向上する効果かありそう。
[Paper Note] GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization, Shih-Yang Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Alignment #ReinforcementLearning #PostTraining Issue Date: 2026-01-09 GPT Summary- 言語モデルの行動を多様な人間の好みに沿わせるために、複数の報酬を用いた強化学習(RL)が重要である。しかし、Group Relative Policy Optimization(GRPO)を適用すると、報酬が同一のアドバンテージ値に収束し、トレーニング信号の解像度が低下する問題がある。本研究では、報酬の正規化を分離する新手法GDPOを提案し、トレーニングの安定性を向上させる。GDPOはツール呼び出し、数学的推論、コーディング推論のタスクでGRPOと比較し、すべての設定でGDPOが優れた性能を示した。 Comment
元ポスト:
pj page: https://nvlabs.github.io/GDPO/
multiple rewardを用いたRLにおいて、GRPOを適用すると異なるrewardのsignalが共通のadvantageに収束してしまう問題を改善する手法を提案。
advantageのnormalizationをrewardごとに分離することによって、異なるrewardのsignalが共通のadvantageの値に埋もれてしまう問題を解決することでmultiple rewardの設定における学習効率を改善する、といった話に見える。下記例は2つのbinary rewardの例でGRPOではadvantageが2種類の値しかとらないが、GDPOでは3種類の異なるadvantageをとり、rewardの解像度が向上していることがわかる。
[Paper Note] Light-X: Generative 4D Video Rendering with Camera and Illumination Control, Tianqi Liu+, ICLR'26, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Controllable #SyntheticData #DiffusionModel #ICLR #VideoGeneration/Understandings #3D (Video) #Relighting #Author Thread-Post Issue Date: 2025-12-06 GPT Summary- Light-Xは、単眼動画から視点と照明を制御可能にする動画生成フレームワークで、幾何学と照明信号を分離する設計を採用。これにより高品質な照明を実現し、ペアのマルチビューおよびマルチ照明動画の不足に対処するために逆マッピングを用いた合成手法を導入。実験結果では、Light-Xがカメラと照明の共同制御において従来手法を上回る性能を示した。 Comment
pj page: https://lightx-ai.github.io/
元ポスト:
著者ポスト:
openreview: https://openreview.net/forum?id=VBew6vESGL
単眼で撮影された動画の視点と照明を同時に制御しながら動画を生成するフレームワークな模様。
背景画像をあたえた
単眼で撮影された動画の視点と照明を同時に制御しながら動画を生成するフレームワークな模様。
背景画像を与えた上での動画のRelighting, Text Promptに基づくRelighting, ユーザがtrajectoryを指定した上でのRelightingなどができるようである。
[Paper Note] PhysX-Anything: Simulation-Ready Physical 3D Assets from Single Image, Ziang Cao+, CVPR'26, 2025.11
Paper/Blog Link My Issue
#ComputerVision #RepresentationLearning #SyntheticData #CVPR #VisionLanguageModel #3D (Scene) #Robotics #EmbodiedAI #Geometric #Physics #Simulation #3D Object Generation Issue Date: 2025-11-20 GPT Summary- PhysX-Anythingは、単一の野外画像から高品質なシミュレーション準備済みの3D資産を生成する新しいフレームワークで、ジオメトリ、関節、物理的属性を明示的に持つ。VLMベースのモデルと新しい3D表現を提案し、トークン数を193倍削減。新データセットPhysX-Mobilityにより物理3Dデータの多様性を拡張し、2,000以上の実世界オブジェクトを含む。実験により、生成性能と一般化能力が確認され、ロボティックポリシー学習に直接利用可能であることが示された。 Comment
元ポスト:
ポイント解説:
CVPRにアクセプト:
pj page: https://physx-anything.github.io/
simulation-readyな3Dオブジェクトを生成するVLMベースのモデルとのこと
[Paper Notes] Investigating fine- and coarse-grained structural correspondences between deep neural networks and human object image similarity judgments using unsupervised alignment, Takahashi+, Neural Networks'26, 2026.03
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Analysis #Supervised #RepresentationLearning #Self-SupervisedLearning #CLIP Issue Date: 2025-10-31 Comment
元ポスト:
CLIP, 自己教師あり学習, 教師あり学習を比較したときに、CLIPが人間が獲得するobjectのrepresentationともっともalignしている一方で、自己教師あり学習はほとんど偶然レベルでしかalignしない(ただし、粗いレベルで見ると人間で言うところのカテゴリレベルのクラスタを形成することができる)。このため、テキストベースでの学習が人間が獲得する表現とfine-grainedなレベルでalignするために非常に重要であることが示唆される、という感じらしい
[Paper Note] Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents, Yueqi Song+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #ICLR #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-10-30 GPT Summary- 本研究では、エージェントデータの収集における課題を解決するために、エージェントデータプロトコル(ADP)を提案。ADPは多様なデータ形式を統一し、簡単に解析・トレーニング可能な表現言語である。実験により、13のエージェントトレーニングデータセットをADP形式に統一し、標準化されたデータでSFTを実施した結果、平均約20%の性能向上を達成。ADPは再現可能なエージェントトレーニングの障壁を下げることが期待される。 Comment
pj page: https://www.agentdataprotocol.com
元ポスト:
著者ポスト:
解説:
エージェントを学習するための統一的なデータ表現に関するプロトコルを提案
続報:
openreview: https://openreview.net/forum?id=tG6301ORHd
[Paper Note] The Alignment Waltz: Jointly Training Agents to Collaborate for Safety, Jingyu Zhang+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Alignment #ReinforcementLearning #AIAgents #Safety #ICLR #Author Thread-Post Issue Date: 2025-10-15 GPT Summary- WaltzRLという新しいマルチエージェント強化学習フレームワークを提案し、LLMの有用性と無害性のバランスを取る。会話エージェントとフィードバックエージェントを共同訓練し、応答の安全性と有用性を向上させる。実験により、安全でない応答と過剰な拒否を大幅に減少させることを示し、LLMの安全性を向上させる。 Comment
元ポスト:
マルチエージェントを用いたLLMのalignment手法。ユーザからのpromptに応答する会話エージェントと、応答を批評するフィードバックエージェントの2種類を用意し、違いが交互作用しながら学習する。フィードバックエージェント会話エージェントが安全かつ過剰に応答を拒絶していない場合のみ報酬を与え、フィードバックエージェントのフィードバックが次のターンの会話エージェントの応答を改善したら、フィードバックエージェントに報酬が与えられる、みたいな枠組みな模様。
著者による一言解説:
[Paper Note] Hybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense, Leitian Tao+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #Reasoning #Mathematics #ICLR #RewardModel #Author Thread-Post Issue Date: 2025-10-13 GPT Summary- HERO(ハイブリッドアンサンブル報酬最適化)は、検証者の信号と報酬モデルのスコアを統合する強化学習フレームワークで、より豊かなフィードバックを提供。層別正規化を用いて正確性を保ちながら品質の区別を向上させ、数学的推論ベンチマークで従来のベースラインを上回る結果を示した。ハイブリッド報酬設計が推論の進展に寄与することを確認。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=0CajQNVKyB
著者による一言解説ポスト:
0/1のbinaryなsparse rewardとdense rewardの両方を組み合わせたハイブリッドなRL手法を提案。verifiable rewardではしばしば報酬がsparseになり学習シグナルが何も得られない課題があり、dense rewardにはノイズが多く含まれるという課題があり、両者を組み合わせることで課題を低減した、という感じの話らしい。
[Paper Note] Impatient Users Confuse AI Agents: High-fidelity Simulations of Human Traits for Testing Agents, Muyu He+, ACL'26, 2025.10
Paper/Blog Link My Issue
#NLP #UserModeling #Dataset #LanguageModel #UserBased #AIAgents #Evaluation #ACL #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-10-08 GPT Summary- TraitBasisを用いて、会話型AIエージェントの堅牢性を体系的にテストする手法を提案。ユーザーの特性(せっかちさや一貫性のなさ)を制御し、AIエージェントのパフォーマンス低下を観察。最前線のモデルで2%-30%の性能低下を確認し、現在のAIエージェントの脆弱性を示す。TraitBasisはシンプルでデータ効率が高く、現実の人間の相互作用における信頼性向上に寄与する。$\tau$-Traitをオープンソース化し、コミュニティが多様なシナリオでエージェントを評価できるようにした。 Comment
元ポスト:
実際の人間にあるような癖(のような摂動)を与えた時にどれだけロバストかというのは実応用上非常に重要な観点だと思われる。元ポストを見ると、LLM内部のmatmulを直接操作することで、任意のレベルの人間の特性(e.g.,疑い深い、混乱、焦りなど)を模倣する模様。
[Paper Note] MENLO: From Preferences to Proficiency -- Evaluating and Modeling Native-like Quality Across 47 Languages, Chenxi Whitehouse+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #ReinforcementLearning #Evaluation #Conversation #MultiLingual #LLM-as-a-Judge #ICLR #RewardModel Issue Date: 2025-10-03 GPT Summary- MENLOフレームワークを用いて、47言語の6,423のプロンプト-応答ペアのデータセットを作成し、LLMの応答品質を評価。ゼロショット評価者はペアワイズ評価から利益を得るが、人間には及ばず。強化学習によるファインチューニングで改善を示し、RL訓練評価者がLLMの多言語能力向上に寄与することを確認。ただし、人間の判断との不一致は残る。データセットと評価フレームワークを公開し、多言語LLM評価の研究を支援。 Comment
元ポスト:
LLMの応答を多言語でよりnativeに近いものにするための取り組み、および評価のフレームワーク(MENLO, データセット含む)な模様。nativeらしさを測るために重要な次元としてFluency, Tone, Localized Tone, Localized Factualityと呼ばれる軸を定義している模様。その上で47言語における6423の人手でアノテーションされたpreference dataを作成し評価をしたところ、既存のLLM-as-a-judgeやSFT/RLされたReward Modelでは、人間による評価にはまだまだ及ばないことが明らかになり、MENLOを用いてRL/SFTすることでLLM JudgeやReward Modelの性能を改善できる、といった話な模様。
4つの次元については以下の表を参照のこと。
それぞれ
- Fluency: 専門家レベルのnative speakerと比較した時のproficiency
- Tone: 全体的なwriting stvleや語り口
- Localized Tone: 文化的、地域的な言葉のニュアンス
- Localized Factuality: 地域固有のコンテキストに沿った事実性や網羅性
openreview: https://openreview.net/forum?id=QOWYX3Q2XS
[Paper Note] EditReward: A Human-Aligned Reward Model for Instruction-Guided Image Editing, Keming Wu+, ICLR'26, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #ReinforcementLearning #Evaluation #ICLR #PostTraining #VisionLanguageModel #2D (Image) #RewardModel #Editing Issue Date: 2025-10-02 GPT Summary- 自然言語指示による画像編集の進展において、オープンソースモデルは遅れをとっている。これを解決するために、20万以上の選好ペアを含む新しいデータセット\mnameを構築し、指示に基づく画像編集タスクで人間の選好と高い整合性を示した。実験では、\mnameが既存のベンチマークで最先端の人間相関を達成し、ノイズの多いデータセットから高品質なサブセットを選択することで、画像編集モデルの性能を大幅に向上させることができた。今後、\mnameはコミュニティに公開され、高品質な画像編集トレーニングデータセットの構築を支援する予定である。 Comment
pj page:
https://tiger-ai-lab.github.io/EditReward/
HF:
https://huggingface.co/collections/TIGER-Lab/editreward-68ddf026ef9eb1510458abc6
これまでのImageEditing用のデータセットは、弱いReward Modelによって合成されるか、GPT-4oや他のVLMによる品質の低いフィルタリングにより生成されており、高品質なデータセットが存在しない課題があった。これを解決するために大規模なImageEditingの嗜好データを収集し、ImageEditingに特化した報酬モデルであるEditRewardを学習。このモデルは人間の専門家とのagreementにおいて高い(というよりりbestと書いてある)agreementを示し、実際にEditRewardによって既存のデータセットをfilteringして学習したら大きなgainがあったよ、という感じらしい。
openreview: https://openreview.net/forum?id=eZu358JOOR
[Paper Note] How much do language models memorize?, John X. Morris+, ICML'26 Outstanding Paper Honorable Mention, 2025.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Grokking #Selected Papers/Blogs #Memorization #reading #Author Thread-Post #DoubleDescent Issue Date: 2025-06-05 GPT Summary- モデルがデータポイントについての知識を推定し、現代の言語モデルの容量を測定する新手法を提案。記憶を意図しない記憶と一般化に分け、一般化を排除することで記憶を計算。GPTモデルの容量はパラメータあたり約3.6ビットと推定。データセットサイズの増加に伴い、記憶が満たされると「グロッキング」が始まり、意図しない記憶が減少。数百のトランスフォーマー言語モデルを訓練し、モデル容量とデータサイズの関係を示すスケーリング則を提示。 Comment
元ポスト:
著者ポスト:
解説:
LLMはまず記憶をし、1パラメータあたり3.6ビットを超えると飽和する。飽和後は圧縮、一般化、Double Decent、Grokkingという経過を辿る、という話が解説ポストに記載されている。
openreview: https://openreview.net/forum?id=NhU661EZ9C
[Paper Note] Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents, Jenny Zhang+, ICLR'26, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Coding #SelfImprovement #ICLR #SoftwareEngineering #Selected Papers/Blogs #AgentHarness Issue Date: 2025-06-05 GPT Summary- ダーヴィン・ゴーデルマシン(DGM)は、自己改善するAIシステムであり、コードを反復的に修正し、コーディングベンチマークで変更を検証します。進化とオープンエンドな研究に基づき、生成されたエージェントのアーカイブを維持し、新しいバージョンを作成することで多様なエージェントを育成します。DGMはコーディング能力を自動的に向上させ、SWE-benchでのパフォーマンスを20.0%から50.0%、Polyglotでのパフォーマンスを14.2%から30.7%に改善しました。安全対策を講じた実験により、自己改善を行わないベースラインを大幅に上回る成果を示しました。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
あたりの研究とはどう違うのだろうか、という点が気になる。
openreview: https://openreview.net/forum?id=pUpzQZTvGY
> * [[Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, N/A, ICML'24 [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, arXiv'24, 2024.01
](https://github.com/AkihikoWatanabe/paper_notes/issues/1212)
>
> あたりの研究とはどう違うのだろうか、という点が気になる。
この点については、Self-Rewarding LLMではモデルの重みを(自身が生成した出力からPreference pairを構築し)DPOで更新していくのに対し(=Agent Harnessではなくモデル自身を賢くする)、
DGMでは基盤モデルはfrozenな上で、AI Agentのコードベースそのものをself-editingすることによって進化する点が異なる(=モデルではなくAgent Harnessを賢くする)。
baseとなるエージェントのコードベースは木構造に基づいて管理され、recursiveに探索されていき、ベンチマークのスコアを改善していく、という感じのようである。木構造によって過去のsolutionが保持され、単一の方向性のみが探索されることを抑制し(i.e., オープンエンドな探索が促進され)進化が局所解に陥ることを防ぐ。
3節冒頭に記述がある通り、Gödel Machineというのは2007年に提案された、AI自身が自らを証明可能な形で改善する方法を探索する理論的概念であるようだが、DGMではGödel Machineでの「変更によってシステムが改善されることを理論的に証明しなければならない」という点を緩和し、「変更が性能を向上させるという実験結果を用いる」ことで緩和する。
[Paper Note] Ambig-SWE: Interactive Agents to Overcome Underspecificity in Software Engineering, Sanidhya Vijayvargiya+, ICLR'26, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #QuestionGeneration #ICLR #SoftwareEngineering Issue Date: 2025-04-02 GPT Summary- AIエージェントは、欠落情報を補うための推測や明確化の質問を避けることで、安全リスクやリソース浪費を引き起こすことがある。本研究では、対話型コード生成における不十分な指示への対処能力を評価し、(a) 不十分さの検出、(b) 明確化質問の提示、(c) 対話の活用による性能向上の三つのステップで検証した。Ambig-SWEを使用し、モデルは不十分な指示を区別するのに苦労しつつ、対話時には最大74%の性能向上を示した。これにより、対話の重要性が浮き彫りになった。研究は、最新モデルの情報処理におけるギャップを明らかにし、評価の段階的アプローチを提案している。 Comment
曖昧なユーザメッセージに対する、エージェントが"質問をする能力を測る"ベンチマーク
openreview: https://openreview.net/forum?id=X2yzXtH4wp
[Paper Note] Repetition Improves Language Model Embeddings, Jacob Mitchell Springer+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #ICLR #Decoder Issue Date: 2026-06-11 GPT Summary- エコー埋め込みを通じて、自己回帰LMをアーキテクチャ変更なしで高品質なテキスト埋め込みモデルに転換。入力を繰り返すことで埋め込みを抽出し、ゼロショット設定で従来の埋め込みを5%以上上回る性能を発揮。監督付きファインチューニングでも双方向化済みLMと同等かそれ以上の結果を示し、埋め込みモデルにおける双方向注意機構の不要性を証明。全てのNLPタスクへの統一アーキテクチャの実現に寄与。 Comment
openreview: https://openreview.net/forum?id=Ahlrf2HGJR
autorgressiveなモデルで文embeddingを取得する際に、単に文のtokenをpoolingするのではなく、embeddingを取得したいsentenceを繰り返し、2回目に出現したtokenのpoolingによってsentence embeddingを形成すると良質な文embeddingを取得できる。これは、あるtokenから見たときに未来のtokenの情報をautoregressiveなモデルは考慮できないことに起因する。
PromptingのRE2とアイデアが似ている。同じPromptを複数回繰り返すことにより、autoregressiveモデルに対してbi-directionalなエンコーダのような性質を付与する:
- [Paper Note] Re-Reading Improves Reasoning in Large Language Models, Xiaohan Xu+, EMNLP'24, 2023.09
[Paper Note] DataDecide: How to Predict Best Pretraining Data with Small Experiments, Ian Magnusson+, ICML'25, 2025.04
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #LanguageModel #Evaluation #ICML #Selected Papers/Blogs Issue Date: 2026-05-29 GPT Summary- 小規模な実験を用いて大規模言語モデルのデータ選択を効率化することは重要である。DataDecideと呼ばれる評価スイートを通じて、異なるデータセットに基づいた前訓練の実験を実施し、150Mパラメータのモデルが1Bパラメータでの最良モデルを約80%の精度で予測できることが示された。主にスケーリング法則に基づくベースラインと比較し、連続的尤度指標を使うことで、限られた資源でも高精度の予測が可能であることが明らかとなった。 Comment
大規模なモデルを学習するためにどのようなデータレシピに従って、どのようなデータを使うべきかを、小規模なモデルでの学習を通じて予測できることを示した(150Mモデルの学習で1Bモデルに対するデータレシピの優劣を80%のDecisionAccuracyで予測可能)。
25種類のデータレシピ(ソース, deduplication, filtering, mixingによって構成)を、14種類のモデルスケールに対して、計算コスト(token-to-parameterの比率)を固定し3種類のseedを用いて実験し、事前学習の結果を体系的に調査。
1Bパラメータのdownstreamタスクにおいて、25種類のデータレシピごとの平均性能によってpairwiseの優劣に関するペアを構成し、全てのペアに対する優劣をどれだけ予測できるかを評価(DecisionAccuracy)したところ、下記図のようになった。たとえば、150Mスケールのモデルを訓練するだけでDecisionAccuracyは80%に到達し、これには1Bモデルを学習した場合と比較して2パーセント程度の計算コストしか要さないことが明らかとなった。
HF: https://huggingface.co/collections/allenai/datadecide
openreview: https://openreview.net/forum?id=p9YlQPF8fE
[Paper Note] EgoTwin: Dreaming Body and View in First Person, Jingqiao Xiu+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #ICLR #VideoGeneration/Understandings #Robotics #EgocentricView Issue Date: 2026-04-25 GPT Summary- 第一人称視点の動画生成は未解決の課題が多い中、私たちは動画と人間の動作を同時に生成する新しいタスクを提案します。主な課題は、視点の整合性と因果的相互作用です。これに対処するために、拡散トランスフォーマーに基づくEgoTwinフレームワークを導入し、頭部中心の動作表現を使って因果関係を明示的に捉えます。また、同期したテキスト-動画-動作の大規模データセットを作成し、新たな評価指標で一貫性を検証しました。実験により、EgoTwinの有効性が確認されました。 Comment
openreview: https://openreview.net/forum?id=QFJkvv3zMi
pj page: https://egotwin.pages.dev/
元ポスト:
egocentric view(一人称視点)動画と、human motionを同時生成するタスクを提案。これにはviewとmotionの視点のalignmentと、生成された動画と人間のアクションが交互作用しなければならないという二つの課題に対処しなければならない。
[Paper Note] Deep Forcing: Training-Free Long Video Generation with Deep Sink and Participative Compression, Jung Yi+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #LongSequence #VideoGeneration/Understandings Issue Date: 2026-04-04 GPT Summary- 自己回帰型ビデオ拡散はリアルタイムのフレームストリーミングを可能にする一方で、従来の解法は時間的な反復や動きの減速に悩まされる。本研究では、ファインチューニングなしのDeep Forcingメカニズムを導入し、長期的なグローバル文脈を安定化させるDeep Sinkと、重要度を考慮したKVキャッシュ剪定を実行するParticipative Compressionを組み合わせることで、画質や一貫性を向上させつつダイナミックな生成を実現した。これにより、トレーニング不要で長時間ビデオをストリーミングする能力が向上し、既存のアプローチと同等以上の性能を示す結果を得た。 Comment
Self-ForcingとのKV Cache Managementの方法が非常に分かりやすく図解されており勉強になる。
Self-Forcing:
- [Paper Note] Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion, Xun Huang+, NeurIPS'25
[Paper Note] GameFactory: Creating New Games with Generative Interactive Videos, Jiwen Yu+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #Controllable #Transformer #DiffusionModel #Architecture #PostTraining #VideoGeneration/Understandings #ICCV #Game #Reading Reflections Issue Date: 2026-04-02 GPT Summary- GameFactoryは、アクション制御とシーン一般化を両立させたゲームビデオ生成のフレームワーク。GF-Minecraftというデータセットを用いてキーボードとマウス入力を正確に制御し、自己回帰生成を可能にする。さらに、オープンドメイン生成事前知識を活用し、固定スタイルを超えた多様なゲームの創出を支援。ドメインアダプターによる学習戦略によって、アクション制御が特定ゲームスタイルに縛られず、シーン一般化が実現。実験により、GameFactoryが効果的にオープンドメインのゲームビデオを生成できることが確認された。 Comment
github: https://github.com/KlingAIResearch/GameFactory
小規模なマイクラデータでaction control moduleと呼ばれるモジュールを学習することで、動画生成モデルに対して、マウス、キーボード入力によるコントロール能力を転移し、ゲーム映像を生成できる、という話に見える。
4.2節に書かれているように、transformerのブロックにaction control moduleと呼ばれる、キーボードとマウスの入力をwindowでグルーピングしてエンコードするようなブロックを挿入し、エンコードされたvideo側の潜在表現に対して条件付けを行い生成を可能にしているようである(Figure 3, 4)。学習する際はFigure 6に示されているように、まずはopen domainのデータで事前学習、その後LoRAでgame video dataのドメイン情報を入れ、他モジュールはfreezeした上で、action control moduleのみを学習する。
transformerアーキテクチャにドメイン依存のブロックを後でplugし性能向上させるアプローチはおもしろいと感じる。
[Paper Note] ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use, Kaixin Li+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#ComputerVision #Dataset #Evaluation #ComputerUse #VisionLanguageModel #Grounding #GUI Issue Date: 2026-03-20 GPT Summary- MLLMの進展は一般的なタスクのGUIエージェントに貢献しているが、専門分野への適用は未検討。ScreenSpot-Proでは、高解像度の専門設定でMLLMのグラウンディング能力を評価する新ベンチマークを提示。複数の業界とアプリケーションに対してテストを行い、既存モデルの性能は低く、最良のモデルでも18.9%に過ぎない。探索域の戦略的縮小により精度向上を示し、ScreenSeekeRを提案。階層的検索を用いることで、訓練不要で48.1%の性能を達成。専門アプリ向けGUIエージェント開発の進展を期待。 Comment
元ポスト:
高解像度な画像を用いた多様なドメインでのVLMのGUI grounding性能を測るベンチマークとリーダーボードのようでえる
現在のトップはHolo2のようである
- New Holo2 model takes the lead in UI Localization, H Company, 2026.02
- Holo2: Cost-Efficient Models for Cross-Platform Computer-Use Agents, H Company, 2025.11
[Paper Note] ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference, Yesheng Liang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Quantization #Reasoning #LongSequence #ICLR #PostTraining Issue Date: 2026-02-28 GPT Summary- Post-training quantization (PTQ)はLLMの重みと活性化を低精度に圧縮し、メモリと推論速度を改善するが、外れ値が誤差を大きくし、特に推論型LLMの長い思考チェーンで精度低下を招くことがある。既存のPTQ手法は外れ値抑制が不十分であったり、オーバーヘッドがある。本研究では、独立ガイブンズ回転とチャネルスケーリングを組み合わせたペアワイズ回転量子化(ParoQuant)を提案し、ダイナミックレンジを狭め外れ値問題を解決する。推論カーネルの共同設計によりGPUの並列性を最大限活用し、精度向上を実現。結果、重みのみの量子化でAWQより平均2.4%の精度向上を達成し、オーバーヘッドは10%未満で、最先端の量子化手法と同等の精度を示す。これにより、高効率で高精度なLLMのデプロイが可能となる。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=1USeVjsKau
Reasoning LLMにおいてlong-CoTを実施した場合のエラーの蓄積を低減するようなpost-training-basedな量子化手法の提案
[Paper Note] Learning to (Learn at Test Time): RNNs with Expressive Hidden States, Yu Sun+, ICML'25, 2024.07
Paper/Blog Link My Issue
#NLP #Self-SupervisedLearning #SSM (StateSpaceModel) #ICML #Selected Papers/Blogs #RecurrentModels #Test Time Training (TTT) Issue Date: 2026-02-26 GPT Summary- 隠れ状態を機械学習モデルとして扱い、自己教師あり学習を用いたTest-Time Training(TTT)層を提案。TTT-LinearとTTT-MLPの二つの実装を比較し、長い文脈に対するパフォーマンスを向上。特に、TTT-MLPは長い文脈における潜在能力を示し、TransformerやMambaと比較して有望な結果を得た。 Comment
openreview: https://openreview.net/forum?id=wXfuOj9C7L
隠れ状態そのものを、重みWを持つモデルfとして解釈し、新たなinput x_tが入力された時にW_tをW_{t+1}へ更新するupdate ruleを自己教師あり学習として学習する(すなわち、W_t ← W_{t-1}+ ηΔl(W_{t-1}, x_t)として定式化する)。これによりtest時の入力に対して隠れ状態を更新することが、test sequenceに基づいてモデルfを学習することと等価となる(Test Time Training; TTT)。
たとえばtransformerにおけるself-attentionをTTT layerに置換するような実装がある。self attentionのoutputの計算量はO(t)だが、TTT layerではO(1)となる。
TTT-Layerの実装として線形モデルに基づくTTT-Linearと非線形モデルとしてMLPに基づいたTTT-MLPが提案されている。
(TTT-LayerのKVBindingの実装例を後ほど追記, 論文中のFigure 6)
[Paper Note] SWE-smith: Scaling Data for Software Engineering Agents, John Yang+, NeurIPS'25 Spotlight, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #NeurIPS #SoftwareEngineering #PostTraining #Scalability #Environment Issue Date: 2026-02-17 GPT Summary- ソフトウェア工学向け言語モデル(LM)のトレーニングデータ収集は依然として課題であり、データセットは小さく、編纂に数百時間かかる。これを解決するために、SWE-smithという新しいデータ生成パイプラインを提案。任意のPythonコードベースを基にタスク例を自動合成し、約5万件のデータセットを作成。このデータで訓練したSWE-agent-LM-32Bが、最先端の解決率を達成。SWE-smithをオープンソース化し、参入障壁を下げることを目指す。 Comment
元ポスト:
データの構築方法はあまりしっかり読めていないが、モデルの学習方法がabstからよくわからなかったのでざっくり読むと、SWE-Smithのinstanceに対してstrong model(実験ではClaude)でtrajectoryを生成しベースモデルをSFTするようである。
[Paper Note] AssetOpsBench: Benchmarking AI Agents for Task Automation in Industrial Asset Operations and Maintenance, Dhaval Patel+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Multi #NLP #Dataset #LanguageModel #AIAgents #Evaluation Issue Date: 2026-02-03 GPT Summary- AIを活用した産業資産ライフサイクル管理は、運用ワークフローの自動化を目指し、人間の負荷を軽減します。従来の技術は特定の問題に対処するに過ぎませんでしたが、AIエージェントと大規模言語モデルの登場により、資産ライフサイクル全体のエンドツーエンド自動化が可能になりました。本論文では、AssetOpsBenchというエージェント開発のための統合フレームワークを紹介し、知覚、推論、制御を統合した自律的なエージェントの構築について具体的な洞察を提供します。ソフトウェアはGitHubで公開されています。 Comment
dataset: https://arxiv.org/abs/2506.03828
元ポスト:
openreview: https://openreview.net/forum?id=ld6JUQbhes
産業におけるアセットの管理に関する(非常に複雑な)end-to-endなベンチマークで、multi agentに対する評価が前提となっている模様。
[Paper Note] ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks, Saurabh Jha+, ICML'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #Financial #ICML #SoftwareEngineering #read-later Issue Date: 2026-02-03 GPT Summary- AIエージェントを用いたITタスク自動化の実現には、その効果を測定する能力が重要である。本研究では、AIエージェントのベンチマーキングを行うためのフレームワーク「ITBench」を提案。初期リリースはSRE、CISO、FinOpsの3領域に焦点を当て、実行可能なワークフローと解釈可能なメトリクスを提供。ITBenchは94の実世界シナリオを含み、最先端エージェントモデルのパフォーマンスを評価した結果、限られた成功率が示された。ITBenchがAI駆動のIT自動化において重要な役割を果たすことが期待される。 Comment
dataset:
-
https://huggingface.co/datasets/ibm-research/ITBench-Lite
-
https://huggingface.co/datasets/ibm-research/ITBench-Trajectories
元ポスト:
openreview: https://openreview.net/forum?id=jP59rz1bZk
94種類の実世界に基づいたシナリオに基づいてSRE, CSO, FinOpsに関するタスクを用いてAI Agentsを用いて評価する。各シナリオにはメタデータとEnvironments、トリガーとなるイベント、理想的な成果などが紐づいている。特にFinOpsに課題があることが示されている模様。
以下がシナリオの例で、たとえばFinOpsの場合はalertの設定ミスや、Podのスケーリングの設定に誤りがあり過剰にPodが立ってしまうといったシナリオがあるようである。
[Paper Note] Scaling Embedding Layers in Language Models, Da Yu+, NeurIPS'25, 2025.02
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #NLP #LanguageModel #Architecture #NeurIPS Issue Date: 2026-02-01 GPT Summary- 新手法$SCONE$は、言語モデルの性能向上のために入力埋め込み層を拡張し、元の語彙を保持しながら頻出n-gramの埋め込みを導入します。これにより、各トークンに文脈化された表現を提供し、埋め込みは訓練中に別のモデルで学習され、推論中にオフアクセラレータメモリから迅速に照会されます。$SCONE$は、埋め込み数の増加とモデルのスケールアップを実現し、1Bパラメータのモデルが1.9Bパラメータのベースラインを上回りながら、推論時のFLOPSとメモリを約半減することを示しています。 Comment
元ポスト:
関連:
- [Paper Note] Scaling Embeddings Outperforms Scaling Experts in Language Models, Hong Liu+, arXiv'26, 2026.01
- [Paper Note] L$^3$: Large Lookup Layers, Albert Tseng+, arXiv'26, 2026.01
あとでもう少ししっかり読みたいのだが、(Vocabularyをシンプルに増やしてスケーリングさせるのではなく、input embedding layerを拡張するために、LLM本体と独立したモジュールとして)通常のVocabularyに追加して、頻出するn-gram(f-gram)によるVocabularyを拡張した新たな小さなtransformerモジュールを定義し、contextを考慮した各トークンのembeddingを出力するよう学習する。独立したモデルとして定義することで、embeddingを事前に計算してオフローディングしておき高速にlookupすることが可能となり、FLOPSを増やさずにembeddingをスケーリングできて、リッチな入力表現を扱える。f-gramの数をスケールさせると性能もスケールする、といった話に見える。
[Paper Note] Harnessing Diversity for Important Data Selection in Pretraining Large Language Models, Chi Zhang+, ICLR'25 Spotlight, 2024.09
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #ICLR #read-later #Diversity #Selected Papers/Blogs #DataMixture #Generalization #DownstreamTasks #Adaptive #Multi-Armed Bandit Issue Date: 2026-01-21 GPT Summary- データ選択は大規模言語モデルの事前トレーニングにおいて重要で、影響スコアでデータインスタンスの重要性を測定します。しかし、トレーニングデータの多様性不足や影響計算の時間が課題です。本研究では、品質と多様性を考慮したデータ選択手法\texttt{Quad}を提案します。アテンションレイヤーの$iHVP$計算を適応させ、データの品質評価を向上。データをクラスタリングし、選択プロセスでサンプルの影響を評価することで、全インスタンスの処理を回避します。マルチアームバンディット法を用い、品質と多様性のバランスを取ります。 Comment
openreview: https://openreview.net/forum?id=bMC1t7eLRc
あるモデルに対して、特定のデータセットD_rの性能を最大化するようにモデルを学習したいとする。このときに、全ての学習データD_cからD_rが学習の結果最大となるようなデータセットD_bを求めたい、という問題設定である。Influence Scoreを算出するモデルを活用する。
学習元データは事前にクラスタリングしておき、top-Kのクラスタを選択。選択したクラスタの中からmini-batchを抽出しinfluence scoreを計算し、influence scoreが一定の閾値を超えた場合にD_bに追加。その後計算したinfluence scoreと当該クラスタが選択された頻度情報に基づいてtop-kのクラスタを選択する際に用いるcluster scoreを更新。というiterationを繰り返しC_bを構築する、という方法に見える。
[Paper Note] LightAgent: Mobile Agentic Foundation Models, Yangqin Jiang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #MultiModal #Reasoning #SmallModel #OpenWeight #ComputerUse #PostTraining #VisionLanguageModel #GUI #EdgeDevices Issue Date: 2026-01-19 GPT Summary- LightAgentは、モバイルプラットフォーム向けにデバイスとクラウドの協力を活用したGUIエージェントシステムを提案。これにより、オフライン性能とコスト効率を両立し、強化された二段階トレーニングを通じて高い意思決定能力を実現。実験を通じて大規模モデルに匹敵する性能を示し、クラウドコストを大幅に削減。 Comment
pj page: https://github.com/HKUDS/OpenPhone
3Bで10B級の性能を誇る低latencyのedge device向けSVLM
元ポスト:
[Paper Note] Convergent Linear Representations of Emergent Misalignment, Anna Soligo+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #PEFT(Adaptor/LoRA) #Safety #EmergentMisalignment Issue Date: 2026-01-15 GPT Summary- 大規模言語モデルのファインチューニングで生じる「突発的な不整合」のメカニズムを調査。9つのランク1アダプターを使用して、異なるモデルが類似の不整合表現に収束することを示し、高次元のLoRAを用いて不整合な行動を除去。実験により、6つのアダプターが一般的な不整合に寄与、2つが特定ドメインの不整合に関与することを明らかに。理解を深めることで不整合の緩和が期待される。 Comment
evil (misalignment) vectorsの発見
[Paper Note] Upweighting Easy Samples in Fine-Tuning Mitigates Forgetting, Sunny Sanyal+, ICLR'25, 2025.02
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #Catastrophic Forgetting #ICLR #PostTraining Issue Date: 2026-01-12 GPT Summary- 事前学習済みモデルのファインチューニングにおける「破滅的忘却」を軽減するため、損失に基づくサンプル重み付けスキームを提案。損失が低いサンプルの重みを上げ、高いサンプルの重みを下げることで、モデルの逸脱を制限。理論的分析により、特定のサブスペースでの学習停滞と過剰適合の抑制を示し、言語タスクと視覚タスクでの有効性を実証。例えば、MetaMathQAでのファインチューニングにおいて、精度の低下を最小限に抑えつつ、事前学習データセットでの精度を保持。 Comment
openreview: https://openreview.net/forum?id=13HPTmZKbM
(事前学習データにはしばしばアクセスできないため)事前学習時に獲得した知識を忘却しないように、Finetuning時にlossが小さいサンプルの重みを大きくすることで、元のモデルからの逸脱を防止しcatastrophic forgettingを軽減する。
[Paper Note] Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks, Abhranil Chandra+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #Chain-of-Thought #SyntheticData #Reasoning #Distillation Issue Date: 2026-01-11 GPT Summary- 言語モデルの推論能力は、連鎖的思考(CoT)トレースの合成データセットでの訓練によって向上することが示された。合成データはモデル自身の分布に近く、学習に適応しやすい。また、不正確なトレースでも有効な推論ステップを含むことが多い。人間の注釈データを言い換えることでパフォーマンスが向上し、欠陥のあるトレースに対する耐性も研究された。MATH、GSM8K、Countdown、MBPPデータセットを用いて、モデルの分布に近いデータセットの重要性と、正しい最終回答が必ずしも信頼できる推論プロセスの指標ではないことが示された。 Comment
元ポスト:
base modelの分布と近いStronger Modelから合成されたCoTデータでSFTすると、合成データの応答がincorrectであっても性能が向上する。分布が遠い人間により生成されたCoTで訓練するより性能改善の幅は大きく、人間が作成したCoTをparaphraseしモデルの分布に近づけると性能の上昇幅は改善する(Figure1, Table4, 5)。
[Paper Note] ThinkGen: Generalized Thinking for Visual Generation, Siyu Jiao+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #MultiModal #DiffusionModel #TextToImageGeneration #PostTraining #read-later #ImageSynthesis Issue Date: 2026-01-06 GPT Summary- ThinkGenは、マルチモーダル大規模言語モデル(MLLM)のChain-of-Thought(CoT)推論を活用した初の思考駆動型視覚生成フレームワークである。MLLMが特化した指示を生成し、Diffusion Transformer(DiT)がそれに基づいて高品質な画像を生成する。さらに、MLLMとDiT間で強化学習を行うSepGRPOトレーニングパラダイムを提案し、多様なデータセットに対応した共同トレーニングを可能にする。実験により、ThinkGenは複数の生成ベンチマークで最先端の性能を達成した。 Comment
元ポスト:
MLLMとDiTを別々にRLして、MLLMはDiTが好むplan/instructionを生成し、その後DiTとConnectorに対してplan/instructionに従うようなRLをするような手法のようである。図2,3,4を見ると概要がわかる。
[Paper Note] Accelerating Scientific Discovery with Autonomous Goal-evolving Agents, Yuanqi Du+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ScientificDiscovery #EvolutionaryAlgorithm Issue Date: 2026-01-05 GPT Summary- 科学的発見エージェントのために、目的関数の自動設計を行うSAGAを提案。二層アーキテクチャにより、LLMエージェントが新しい目的を提案し、内部ループで最適化を実施。これにより、目的の空間を体系的に探求し、抗生物質や無機材料などの応用で効果を向上させることを示す。 Comment
元ポスト:
目的関数そのものも進化させるような枠組み
[Paper Note] Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space, Xingwei Qu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later #LatentReasoning #Concept (LLM PreTraining) #Author Thread-Post Issue Date: 2026-01-03 GPT Summary- DLCM(Dynamic Large Concept Models)は、トークン均一な計算の限界を克服するための階層的な言語モデリングフレームワークであり、意味的境界を学習して計算を圧縮された概念空間にシフトします。これにより、推論を効率化し、固定されたFLOPsの下で計算配分を最適化します。DLCMは、実用的な設定で推論計算の約3分の1を再配分し、12のゼロショットベンチマークで平均2.69%の性能向上を達成しました。 Comment
元ポスト:
従来のトークンを最小単位とする言語モデルではなく、意味的なチャンクを最小単位として扱う(チャンクの境界は隠れ状態の類似度が閾値を超えるか否かによって決める)Encoder-(Thinking Model)-Decoderタイプのモデルに見える。
関連:
- [Paper Note] Large Concept Models: Language Modeling in a Sentence Representation Space, LCM team+, arXiv'24, 2024.12
扱うconceptの最小単位という観点で見ると、こちらの研究はコンセプトをsentenceとしているが、本研究は(まだ全然読めていないのでおそらく)動的に決まるboundaryに基づくチャンクという点で異なっているように見える。
著者ポストを引用しているポスト:
[Paper Note] JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation, Kai Liu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #VideoGeneration/Understandings #Encoder-Decoder #3D (Video) #Omni #audio #AudioVisualGeneration Issue Date: 2026-01-03 GPT Summary- JavisGPTは、音声と映像の理解・生成のための初の統合型マルチモーダル大規模言語モデルであり、SyncFusionモジュールを用いて音声と映像の融合を実現。三段階のトレーニングパイプラインを設計し、高品質な指示データセットJavisInst-Omniを構築。広範な実験により、JavisGPTは既存のモデルを上回る性能を示し、特に複雑な同期設定で優れた結果を出した。 Comment
pj page: https://javisverse.github.io/JavisGPT-page/
元ポスト:
音声と映像を同時に生成可能なadapterタイプのMLLM
[Paper Note] Evaluating Parameter Efficient Methods for RLVR, Qingyu Yin+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Mathematics #PEFT(Adaptor/LoRA) #PostTraining #RLVR Issue Date: 2026-01-02 GPT Summary- 本研究では、検証可能な報酬を伴う強化学習(RLVR)におけるパラメータ効率の良いファインチューニング(PEFT)手法を評価し、12以上の手法を比較しました。結果として、DoRAやAdaLoRAなどの構造的変種がLoRAを上回ること、SVDに基づく初期化戦略におけるスペクトル崩壊現象を発見し、極端なパラメータ削減が推論能力を制約することを示しました。これにより、パラメータ効率の良いRL手法の探求に向けたガイドを提供します。 Comment
元ポスト:
関連:
- [Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
RLVRにおけるLoRAとLoRAの変種に関する性能を調査した研究のようである。ベースモデルとしてDeepSeekw-R1-Distilled-Qwen系モデルのみ, データのドメインとしてMathでのみ実験されている点には留意した方が良いと思われ、他のモデル・ドメインにも同様の知見が適用できるかは気になる。
[Paper Note] TimeBill: Time-Budgeted Inference for Large Language Models, Qi Fan+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Controllable #NLP #LanguageModel #Architecture #Decoding #read-later #Selected Papers/Blogs Issue Date: 2025-12-31 GPT Summary- LLMsの推論効率と応答性能を向上させるために、時間予算に基づくフレームワーク「TimeBill」を提案。細粒度の応答長予測器と実行時間推定器を用いてエンドツーエンドの実行時間を予測し、KVキャッシュの排出比率を適応的に調整。実験により、タスク完了率の向上と応答性能の維持を実証。 Comment
元ポスト:
興味深いアイデア
レスポンスの長さをbucket単位で予測し、実際のハードウェア上での過去のデータなどに基づいてruntimeを予測。予測したruntimeのworstcaseよりも遅延しないようにKV Cacheを削減することで限られた時間的な予算の中でresponceを返すような手法な模様。
[Paper Note] Mechanistic Finetuning of Vision-Language-Action Models via Few-Shot Demonstrations, Chancharik Mitra+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Robotics #VisionLanguageActionModel #EmbodiedAI Issue Date: 2025-12-28 GPT Summary- VLAモデルはロボティクスにおける視覚と言語の統合を目指すが、物理的要因へのファインチューニングが必要。既存手法は特異性に欠けるため、タスク特異的な注意ヘッドを選択的にファインチューニングする「Robotic Steering」を提案。Franka Emikaロボットアームでの評価により、Robotic SteeringがLoRAを上回り、堅牢性、計算コスト削減、解釈可能性の向上を実現することを示した。 Comment
pj page: https://chancharikmitra.github.io/robosteering/
元ポスト:
VLAにおいて学習したいタスクと関連する(sparseな) attention headsだけをfinetuningすることで、効率的に、忘却を防ぎつつ、overfitを防ぐような手法を提案。
[Paper Note] VLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression, Kyle Sargent+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Alignment #DiffusionModel #LLM-as-a-Judge #DPO #PostTraining #2D (Image) #AutoEncoder Issue Date: 2025-12-21 GPT Summary- 人間の好みに基づく画像圧縮のために、視覚-言語モデル(VLM)を活用した新しいシステムVLICを提案。VLICは、バイナリVLM判断を用いた拡散ベースの画像圧縮システムで、従来の知覚損失ネットワークを蒸留するのではなく、既存技術を活用。これにより、データセットに応じた競争力のある性能を実現。VLMベースの報酬設計とトレーニング手順についても分析を行い、重要な洞察を提供。 Comment
pj page: https://kylesargent.github.io/vlic
元ポスト:
ざっくり言うと、同じ潜在表現に対して異なる2つのノイズシードに対して画像を生成し、VLM-as-a-Judgeを用いて人間の知覚的な好みに近いスコアを得ることで、preferenceペアを合成。この情報に基づいてDiffusion DPOと呼ばれるDPOのdiffusionモデル版を用いてDiffusion autoencoderを学習することで、より人間の知覚的な判断に近い画像圧縮・復元過程を学習する、というような話っぽい。
実際のサンプルを見ると、明らかにテキストの崩れがなくなっているのがわかる。
[Paper Note] LongVie 2: Multimodal Controllable Ultra-Long Video World Model, Jianxiong Gao+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #MultiModal #DiffusionModel #LongSequence #VideoGeneration/Understandings #WorldModels #3D (Video) #reading #DepthEstimation Issue Date: 2025-12-21 GPT Summary- LongVie 2は、動画生成システムに基づくワールドモデルで、制御可能性、視覚品質、時間的一貫性を向上させるために3段階で訓練される自己回帰フレームワークです。マルチモーダルガイダンス、劣化認識トレーニング、歴史的コンテキストガイダンスを用いて、長距離制御と高い視覚忠実度を実現。LongVGenBenchを導入し、100本の高解像度動画を用いたベンチマークを提供。実験により、最先端の性能を達成し、連続動画生成の可能性を示しました。 Comment
pj page: https://vchitect.github.io/LongVie2-project/
元ポスト:
最大5分間のlong videoの生成が可能で、マルチモーダルな入力(depth map(空間の構造の制御; dense control signal), point map(キーポイントの時間軸での軌跡; sparse control signal))に応じて生成をコントロールし、temporal consistencyも向上しているとのこと。
関連:
- [Paper Note] SpatialTracker: Tracking Any 2D Pixels in 3D Space, Yuxi Xiao+, CVPR'24, 2024.04
- [Paper Note] Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control, Zekai Gu+, SIGGRAPH'25, 2025.01
- [Paper Note] Video Depth Anything: Consistent Depth Estimation for Super-Long Videos, Sili Chen+, CVPR'25 Highlight, 2025.01
[Paper Note] Adaptation of Agentic AI, Pengcheng Jiang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Adaptive Issue Date: 2025-12-21 GPT Summary- 本論文では、エージェントAIシステムの適応に関する体系的なフレームワークを提案し、エージェントの適応とツールの適応を分類。これにより、適応戦略の設計空間を明確化し、システム設計における戦略選択のガイダンスを提供。各アプローチの強みと限界を分析し、未解決の課題と将来の機会を強調。研究者や実務者に対して、能力が高く信頼性のあるエージェントAIシステム構築のための基盤を提供することを目指す。 Comment
元ポスト:
AI Agentsには実行と適応の二つの軸があり、現在のエージェントは前者しか実施しない。このため、前提が変化すると環境に適応が誤りを繰り返す、適応することが重要[^1]といった話な模様。
適応と言った時にいくつかの軸があり、まずは
- エージェント自身
- エージェントが利用するツール
次に適応するためのシグナルとして
- ツールの実行結果
- エージェントのoutputの評価
がそれぞれあり、2x2のデザインスペースがあるが、現在はその1つしかできていない(i.e., フィードバック無しの実行)とのこと。
[^1]: デモではうまくいくが実際のユースケースではうまくいかないのはこのため、という主旨だとおもわれる。
解説:
[Paper Note] Mode-Conditioning Unlocks Superior Test-Time Scaling, Chen Henry Wu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Test-Time Scaling #PostTraining Issue Date: 2025-12-19 GPT Summary- モード条件付け(ModC)フレームワークを提案し、テスト時の計算を明示的に割り当てることで、並列サンプリングの多様性の崩壊を克服。ModCは、様々なモデルサイズで一貫したスケーリング改善を実現し、Qwen2.5-7Bのファインチューニングにより効率を4倍向上。勾配クラスタリングを用いて、明示的なモードラベルなしでも性能向上を達成。ModCは強化学習の改善にも寄与し、データの多様性を最大限に活用する効果的な手法であることを示す。 Comment
元ポスト:
parallel test-time scalingを実施する際に、同じモードに陥ると効率が悪いので、prefixで明示的に思考モードを指定できるようにするモデルを学習することで、外側からモードをコントロール可能できるようにすることで性能を上げましょう、という話に見える。Figure1の例だと、Depth first search / Breath first searchをするかは通常の学習だと制御できないが、提案手法のようにprefixを用いて訓練することで1/2, 1/2のように割合をコントロールできる、という話に見える。
skim readingをしたが具体的なpromptingの例などがなく、exampleでprefixを付与していると書かれているだけに見えるので細かい部分まではよくわからなかった。
[Paper Note] Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning, Zhenwen Liang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #read-later #Diversity #Selected Papers/Blogs Issue Date: 2025-12-19 GPT Summary- G2RLは、強化学習においてモデル自身の更新幾何学に基づく勾配誘導フレームワークを提案。これにより、探索が外部ヒューリスティックに依存せず、ポリシーの再形成を測定。G2RLは、数学および一般的な推論ベンチマークで従来手法に対して一貫した性能向上を示し、探索の直交性と意味的な一貫性を維持することが明らかになった。 Comment
元ポスト:
entropyによる制約を課すRL手法ではモデルのsemanticな軸でのdiversityを測ることで探索の多様性を高めるが勾配レベルで見た時には実は冗長で無意味な方向になる場合があるため、勾配を直接見て有効な方向に探索されるようにします、実装は簡単で、計算量もあまり必要ないです、といった話に見える。
[Paper Note] SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations, Wentao Guo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #MoE(Mixture-of-Experts) #SoftwareEngineering #mid-training #PostTraining #Selected Papers/Blogs Issue Date: 2025-12-19 GPT Summary- SonicMoEは、MoEモデルのフォワードおよびバックワードパスをメモリ効率良く計算するアルゴリズムを提案し、活性化メモリを45%削減。Hopper GPU上で7B MoEモデルの計算スループットを1.86倍改善し、トレーニングスループットは2130億トークン/日を達成。新しいトークンラウンディング手法により、カーネル実行時間で1.16倍のスピードアップを実現。すべてのカーネルはオープンソース化され、MoEモデルのトレーニングを加速。 Comment
元ポスト:
MoEモデルの学習速度、メモリ使用が最大2倍効率化される実装らしい。ただしHopperに特化している模様。
Blackwellでも動作するようになった模様:
[Paper Note] Scaling Laws and Symmetry, Evidence from Neural Force Fields, Khang Ngo+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #MachineLearning #InductiveBias #Scaling Laws Issue Date: 2025-12-19 GPT Summary- 原子間ポテンシャルを学習する幾何学的タスクに関する実証研究を行い、等変性が大規模スケールで重要であることを示した。等変アーキテクチャは非等変モデルよりも優れたスケーリングを示し、高次の表現がより良いスケーリング指数に寄与することが分かった。データとモデルのサイズはアーキテクチャに関係なく連動してスケールすべきであり、対称性などの基本的な帰納的バイアスをモデルに発見させるべきではないと結論付けた。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=qyjaVda7t2
Inducive Bias(対称性vs.非対称性)によってスケーリング則の係数が変わることを原子間ポテンシャルを予測するタスクにおいて示した、という話っぽい?openreviewだとweaknessが多く指摘されている(この性質が一定の一般性を持つ話として記述されているが実験が限定的だからスコープを狭めるべきみたいな話やNLPから多くの手法を引っ張ってきているが原子間ポテンシャル予測は根本的に性質が異なるみたいな指摘など)ように見えるが果たして。
[Paper Note] FB-RAG: Improving RAG with Forward and Backward Lookup, Kushal Chawla+, AACL'25 Findings, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #SmallModel #AACL #SpeculativeDecoding Issue Date: 2025-12-18 GPT Summary- FB-RAGは、複雑なクエリに対するRAGの課題を解決する新しいフレームワークで、軽量のLLMを用いて関連性の高いコンテキストを特定。従来のファインチューニングなしで性能向上を実現し、レイテンシを削減。EN.QAデータセットでは、リーディングベースラインに匹敵し、性能向上とレイテンシ削減を達成。小さなLLMが大きなLLMの性能を向上させる可能性を示す。 Comment
元ポスト:
使いやすそうなアプローチなので覚えておくと実用上は良いかもしれない
[Paper Note] Diffusion Transformers with Representation Autoencoders, Boyang Zheng+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #TextToImageGeneration #Selected Papers/Blogs #2D (Image) #reading #ImageSynthesis #AutoEncoder Issue Date: 2025-12-17 GPT Summary- 本研究では、従来のVAEエンコーダを事前学習された表現エンコーダに置き換えた表現オートエンコーダ(RAE)を提案し、生成モデルの品質向上を目指す。RAEは高品質な再構成と意味的に豊かな潜在空間を提供し、拡散トランスフォーマーの効果的な機能を可能にする。実験により、ImageNetで優れた画像生成結果を達成し、RAEが拡散トランスフォーマーの新しいデフォルトとなるべきことを示した。 Comment
openreview: https://openreview.net/forum?id=0u1LigJaab
pj page: https://rae-dit.github.io
encoderをSigLIPなどの強力な(frozenした)vision encoderを用いた上で、デコーダを学習する手法。VAEではCNN等で潜在表現を低次元に圧縮するが、表現力に乏しく結果的に意味的な表現を捉える能力に乏しかったが、より強力な事前学習されたエンコーダと高次元の潜在表現を扱うことでDiffusion Modelで扱う潜在表現を進化させる。
[Paper Note] Budget-Aware Tool-Use Enables Effective Agent Scaling, Tengxiao Liu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #AIAgents #Test-Time Scaling Issue Date: 2025-12-15 GPT Summary- 大規模言語モデル(LLMs)のエージェントにおけるツールコールのスケーリングを研究。単にツールコール予算を増やすだけでは効果がなく、予算意識が必要。軽量プラグイン「Budget Tracker」を導入し、動的に計画を適応させる「BATS」を開発。コストとパフォーマンスを共同で考慮する指標を定式化し、予算意識のある手法がより良いスケーリングを実現することを示す。 Comment
元ポスト:
AI Agentにplug-and-playでbudgetに関する情報をinternalなreasoning token中に出力させる(budget tracker)ことで、余剰なtoken消費、tool callのコストを自律的に調整させながらタスクを遂行させる手法に見える。
budget trackerは非常にシンプルなpromptで以下のようなブロックで表現され、ツールごとにbudgetがスタート時点に決められており、個々のツールごとに残りのbudgetをブロック中に動的に出力させる。たとえばtool1は検索(budgetはクエリの発行数)、tool2はブラウジング(budgetはurl数)のようなものである。
```
Tool1 Budget Used: ##, Tool1 Budget Remaining: ##
Tool2 Budget Used: ##, Tool2 Budget Remaining: ##
Make the best use of the available resources.
```
自律的に制御すると記述したが、AppendixCを見る限りは、promptingに応じてbudgetの残量に応じた方向性はgivenな設定なようである。
[Paper Note] DeepCode: Open Agentic Coding, Zongwei Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Coding #SoftwareEngineering #read-later #ContextEngineering Issue Date: 2025-12-15 GPT Summary- DeepCodeというフレームワークを用いて、科学論文からコードへの高忠実度合成の課題に取り組む。情報フロー管理を通じて、タスク関連の信号を最大化し、最先端のパフォーマンスを達成。PaperBenchベンチマークで商業エージェントや人間専門家を上回る結果を示し、自律的な科学的再現の基盤を確立。 Comment
元ポスト:
非常に雑にいうと、現在のCoding AgentはPh.Dレベルの論文の再実装レベルに到達できていないが、ContextEngineeringをしっかり行うことでagenticなfrontier modelに対して相対的に70%以上PaperBenchの性能が改善し、Ph.Dレベルの専門家と同等程度の水準まで到達できました、という話に見える。
ポイント解説:
[Paper Note] X-Humanoid: Robotize Human Videos to Generate Humanoid Videos at Scale, Pei Yang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Dataset #Transformer #SyntheticData #DiffusionModel #Robotics #WorldModels #VisionLanguageActionModel #3D (Video) #EmbodiedAI #Third-Person View Issue Date: 2025-12-12 GPT Summary- X-Humanoidは、動画から動画への生成的な編集アプローチを用いて、人間からヒューマノイドへの翻訳を実現するモデルです。Unreal Engineを活用し、17時間以上のペア合成動画を生成するデータ作成パイプラインを設計し、60時間のEgo-Exo4D動画を用いて360万以上の「ロボティクス化」されたヒューマノイド動画フレームを生成しました。定量的分析とユーザー調査により、69%のユーザーが動きの一貫性で最も優れていると評価し、62.1%が具現化の正確さで最も優れていると評価しました。 Comment
pj page: https://showlab.github.io/X-Humanoid/
元ポスト:
既存研究は主観視点の動画における人の腕をロボットアームにルールベースで置き換えるなどの方法で動画をオーバレイすることでdata scarcityの問題に対処してきており、これは有望なアプローチだが、第三者視点の動画はしばしばより複雑(全身が写り、背景が動的に変化し遮蔽に隠れたりもする)で課題がある。このため、第三者視点での動画を人間からヒューマノイドに置換するモデルを学習[^1]し(強力なvideo editingモデルでもこの点はまだ苦戦するタスクとのこと)、私生活における人間の動画をヒューマノイドに置き換えてデータを合成することでロボットのポリシーや世界モデルの学習データ不足を補います、という話に見える。
[^1]: この部分の学習データはUnreal Engineを用いて17+時間に及ぶ人間-ヒューマノイドペアの動画を合成
(以下Chatgptとの問答により得た情報なのでハルシネーションの恐れがあります)
主観視点での人間の腕をロボットアームに置き換えて学習データを合成するというのは気持ちが分かりやすかったのだが(=人間の腕と実際にロボット自身がカメラを通じて見る自分の腕は形状が違うため学習時と運用時にgapが生じる)、なぜ第三者視点でのこのようなHuman-Humanoid gapを埋めた学習データが必要なのか、という話はざーっと論文を見た限り書いておらず門外漢の私ではわからなかったので、ChatgptやGeminiにきいてみた。LLMの応答によると
- 主観視点での動画には限りがあり、第三者視点での動画の方が単純にデータ量が多い
- 主観視点動画では見える範囲が限定的であり、たとえばロボットに特定の動作を学習させたいときに、全身動作や背景の動き、物体との位置関係などはわからない。
- ロボットが実際に得る視界もロボットから見た時の主観視点であるが、それとは別の話としてこのような第三者視点がロボットが多様なタスクを学ぶときに全身が写っている動画は有用であるか(タスク、意図、行動の選択パターンなどの動作の意味情報を学ぶ)。また、第三者視点動画をロボットの視点に変換するようなモデルを作るためにもこのようなデータは必要で、これによりロボットは第三者視点の人間動画から学び、最終的にそれらを自分の主観視点に対応する表現として学習(retargetと呼ぶらしい)できる。
といった背景があるらしい。
(LLMから得た情報ここまで)
↑のLLMからの情報は妥当なように感じる。
まああとは、そもそも、ロボットが溢れかえる世界になったときに、ロボットが写っている学習データがないとまずいよね、というのも将来的にはあるのかなという感想。
[Paper Note] ProAgent: Harnessing On-Demand Sensory Contexts for Proactive LLM Agent Systems, Bufang Yang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #read-later #Proactive Issue Date: 2025-12-11 GPT Summary- ProAgentは、感覚的コンテキストとLLM推論を活用した初のプロアクティブエージェントシステムで、ユーザーの指示に依存せずに支援を提供します。階層的知覚を用いて環境を感知し、ユーザーのニーズに基づいた推論を行います。ARメガネ上で実装され、実世界のテストでプロアクティブ予測精度を33.4%、ツール呼び出しF1スコアを16.8%向上させ、ユーザー満足度も改善しました。 Comment
元ポスト:
私が13年前に思い描いた未来だ🤩
主観視点の映像、モーションセンサ、音声、本人のペルソナ等の様々な環境からの情報に基づいて、エージェント側からユーザに能動的に働きかけてくるような枠組み
[Paper Note] Towards a Science of Scaling Agent Systems, Yubin Kim+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation Issue Date: 2025-12-11 GPT Summary- エージェントシステムの性能を向上させるための定量的スケーリング原則を導出し、4つのベンチマークで評価。3つのLLMファミリーに対して5つのアーキテクチャを実装し、180の構成で制御評価を実施。ツール調整のトレードオフ、能力の飽和、トポロジー依存のエラー増幅の3つの効果を特定。中央集権的調整が金融推論で80.9%の性能向上をもたらし、分散型調整が動的ウェブナビゲーションで優れた結果を示す。全体として、87%の構成に対して最適な調整戦略を予測するフレームワークを提供。 Comment
元ポスト:
エージェントを評価する際のconfiguration(single agent vs. multiagent, multi agentの協調方法など)に応じて性能は大きく変わる、またタスクの性質(e.g., ツール重視なのか, 単一エージェントで高い性能が得られるものなのか等)に応じて最適なconfigurationが変わるよ、という話に見える。
[Paper Note] OneThinker: All-in-one Reasoning Model for Image and Video, Kaituo Feng+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #ReinforcementLearning #MultiModal #Reasoning #OpenWeight #VisionLanguageModel #2D (Image) #UMM #3D (Video) #text Issue Date: 2025-12-06 GPT Summary- OneThinkerは、視覚的推論を統一するオールインワンの強化学習モデルであり、質問応答やキャプショニングなどの多様なタスクに対応。OneThinker-600kトレーニングコーパスを用いて訓練され、報酬の異質性に対処するEMA-GRPOを提案。広範な実験により、10の視覚理解タスクで強力なパフォーマンスを示し、タスク間の知識移転とゼロショット一般化能力を実証。全てのコード、モデル、データは公開。 Comment
pj page:
https://github.com/tulerfeng/OneThinker
HF:
https://huggingface.co/OneThink
元ポスト:
image/videoに関するreasoningタスクをunifiedなアーキテクチャで実施するVLM
Qwen3-VL-Instruct-8Bに対するgain。様々なタスクで大幅なgainを得ている。特にTracking, segmentation, groundingのgainが大きいように見える。
[Paper Note] Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond), Liwei Jiang+, NeurIPS'25 Best Paper Award, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #Dataset #LanguageModel #Evaluation #Mindset #read-later #Diversity #Selected Papers/Blogs Issue Date: 2025-12-03 GPT Summary- Infinity-Chatは、26,000件の多様なオープンエンドユーザークエリからなるデータセットで、言語モデル(LM)の出力の多様性を評価するための新たなリソースを提供する。包括的な分類法を提案し、LMにおけるモード崩壊や人工的ハイヴマインド効果を明らかにした。調査結果は、LMの生成が人間の好みに適切に調整されていないことを示し、AI安全リスクの軽減に向けた今後の研究の重要な洞察を提供する。 Comment
openreview: https://openreview.net/forum?id=saDOrrnNTz
元ポスト:
これはまさに今日Geminiと壁打ちしている時に感じたなあ。全人類が同じLLMを使って壁打ちしたらどうなるんだろうと。同じような思考や思想を持つのではないか、あるいは偏っていないと思い込んでいるけど実は暗黙的に生じている応答のバイアスとか、そういう懸念。(読みたい)
[Paper Note] From Atomic to Composite: Reinforcement Learning Enables Generalization in Complementary Reasoning, Sitao Cheng+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Composition Issue Date: 2025-12-02 GPT Summary- RLは推論の合成器として機能し、内部知識と外部情報を統合する能力を持つが、まずは原子的スキルを習得する必要がある。SFTモデルは分布内では高精度だが、分布外では一般化に失敗することが示された。RLを適用することで、複雑な推論タスクの一般化が可能になる道を示唆。 Comment
解説:
LLMはRLを適用する前にアトミックなスキルを身につけている場合のみ、RLによってそれらスキルを組み合わせてタスクを解く能力を身につける(構成性)。一方、構成的なスキルをSFTでただ模倣しているだけで、内部的にアトミックなスキルとして身につけられていない場合は、RLによってそれを増幅することはできるが、新たなアトミックスキルの構成は身につけることができない、といった趣旨の話だと思われる。
[Paper Note] MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation, Xiaoyu Kong+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #ReinforcementLearning #VariationalAutoEncoder #PostTraining #read-later #Selected Papers/Blogs #Scalability Issue Date: 2025-11-26 GPT Summary- MiniOneRecを提案し、SID構築から強化学習までのエンドツーエンドの生成レコメンデーションフレームワークを提供。実験により、モデルサイズの増加に伴いトレーニング損失と評価損失が減少し、生成アプローチのパラメータ効率が確認された。さらに、SID整合性の強制と強化学習を用いたポストトレーニングパイプラインにより、ランキング精度と候補の多様性が大幅に向上。 Comment
github: https://github.com/AkaliKong/MiniOneRec
元ポスト:
興味深い話ではあるが、generativeなRecSysはlatencyの面で厳しいものがあるという認識ではある。読みたい。
[Paper Note] Computer-Use Agents as Judges for Generative User Interface, Kevin Qinghong Lin+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #AIAgents #Evaluation #Coding #LLM-as-a-Judge #ComputerUse #VisionLanguageModel #UI Issue Date: 2025-11-26 GPT Summary- CUAはGUIを自律的に操作する能力が向上しているが、従来のGUIは人間向けに設計されているため、効率的なタスク実行に不必要な行動を強いられる。Coderの進展により、自動GUI設計が変革される中、CUAがCoderを支援する役割を果たせるかを探るためにAUI-Gymを導入。1560のタスクをシミュレートし、信頼性を確保する検証ツールを開発。Coder-CUA協力フレームワークを提案し、CUAがデザインを評価し、タスク解決可能性を測定。CUAダッシュボードを設計し、ナビゲーション履歴を視覚的に要約。これにより、エージェントの能動的な参加を促進する。 Comment
pj page: https://showlab.github.io/AUI/
元ポスト:
CUA自身にCUAにとって理解しやすいUIに関するJudgeをさせてフィードバックさせ(CUA-as-Judpe)、Coder(コード生成)を通じてUIを改善できるか?というタスクとベンチマークな模様
[Paper Note] Fara-7B: An Efficient Agentic Model for Computer Use, Ahmed Awadallah+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#AIAgents #Blog #SmallModel #OpenWeight #ComputerUse #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-11-25 GPT Summary- CUAの発展は高品質な相互作用データの欠如に制約されてきた。これに対処するため、FaraGenという多段階ウェブタスク用のデータ生成システムを提案。多様なタスクを生成し、成功した軌跡を検証しつつ高い効率を発揮。FaraGenを用いて、小型CUAモデルFara-7Bを訓練し、ウェブタスクにおいて優れた性能を発揮。Fara-7Bは他のモデルを上回り、競争力のある結果を示す。また、モデルとデータをオープンソース化し、さらなる研究を促進する。 Comment
元ポスト:
computer useに特化したMS初のSLM(CUA)
関連:
- [Paper Note] AgentInstruct: Toward Generative Teaching with Agentic Flows, Arindam Mitra+, arXiv'24, 2024.07
- [Paper Note] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks, Adam Fourney+, arXiv'24, 2024.11
- [Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01
- [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
- GPT-4V-Act, ddupont808, 2023.10
WebVoyagerでの評価によると、タスクに対するコスト性能比が非常に高いことがわかる。
MIT Licence
著者ポスト:
WebTailBenchと呼ばれる新たなベンチマークも提案されている。既存データに加えて、より多様なドメイン(不動産, 求人, 複数ショップとの比較)などが含まれるようである。
[Paper Note] OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe, Kaichen Zhang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #SmallModel #OpenWeight #OpenSource #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-11-25 GPT Summary- 本研究では、マルチモーダル推論のための透明な二段階トレーニングレシピ「OpenMMReasoner」を提案。監視付きファインチューニング(SFT)で874Kサンプルのデータセットを構築し、強化学習(RL)で74Kサンプルを活用して推論能力を向上。評価の結果、9つのベンチマークでQwen2.5-VL-7B-Instructに対し11.6%の性能向上を達成し、データの質とトレーニング設計の重要性を示した。すべてのリソースはオープンソースで公開。 Comment
pj page: https://evolvinglmms-lab.github.io/OpenMMReasoner/
SoTAなVLMを構築するためのオープンなデータとレシピらしい
[Paper Note] The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution, Junlong Li+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation Issue Date: 2025-11-25 GPT Summary- Toolathlonは、現実世界の複雑なワークフローを処理する言語エージェント向けの新しいベンチマークで、32のアプリケーションと604のツールを網羅。実際の環境状態を提供し、108のタスクを通じてエージェントのパフォーマンスを評価。最先端モデルの評価結果は、成功率が低いことを示し、Toolathlonがより能力の高いエージェントの開発を促進することを期待。 Comment
pj page: https://toolathlon.xyz/introduction
元ポスト:
元ポスト:
既存のAI Agentベンチマークよりもより多様で複雑な実世界タスクに違いベンチマークらしい
[Paper Note] RynnVLA-002: A Unified Vision-Language-Action and World Model, Jun Cen+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #NLP #WorldModels #VisionLanguageActionModel #UMM Issue Date: 2025-11-25 GPT Summary- RynnVLA-002は、ビジョン・言語・アクション(VLA)モデルと世界モデルを統合した新しいモデルで、アクションと視覚入力を用いて未来の画像状態を予測し、環境の物理法則を学習します。このフレームワークにより、環境のダイナミクスとアクション計画の共同学習が可能となり、実験では個別モデルを上回る性能を示しました。シミュレーションでは97.4%の成功率を達成し、実世界のロボットタスクでも成功率が50%向上しました。 Comment
HF: https://huggingface.co/Alibaba-DAMO-Academy/RynnVLA-002
元ポスト:
関連:
- RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation, Jiang+, Alibaba, 2025.08
VLAによるアクション予測とWorldModelによる視覚的な画像生成の交互作用をさせたという話に見える。
[Paper Note] Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models, Jiaqi Wang+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #NeurIPS #VisionLanguageModel #Author Thread-Post Issue Date: 2025-11-25 GPT Summary- 強化学習を用いて視覚と言語モデルの推論を強化するために、TONという二段階のトレーニング戦略を提案。簡単な質問には推論をスキップし、必要な時に考える人間の思考プロセスを模倣。実験により、TONは従来の手法に比べて推論ステップを最大90%削減し、性能を向上させることが示された。モデルはトレーニングを通じて不要な推論を回避することを学習。 Comment
元ポスト:
著者ポスト:
いつ思考をするか/しないかを学習することでCoTのtrajectoryを節約する。選択的に思考しないということをモデルは基本的に学習していないのでSFTで模倣学習することでコールドスタートを脱っし、その後RLによって選択的に思考しないことも含めて思考を最適化する、といった話に見える。
[Paper Note] Paper2Poster: Towards Multimodal Poster Automation from Scientific Papers, Wei Pang+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #NeurIPS #VisionLanguageModel #Poster #Author Thread-Post Issue Date: 2025-11-25 GPT Summary- 学術ポスター生成のための新しいベンチマークとメトリクスを導入し、PosterAgentというマルチエージェントパイプラインを提案。Parserが論文を構造化し、Plannerがレイアウトを整え、Painter-Commenterが視覚的整合性を確保。評価では、GPT-4oの出力は視覚的には魅力的だが、テキストの質が低く、PaperQuizスコアも不十分であることが判明。オープンソースのバリアントは、既存のシステムを上回り、コスト効率も良好。これにより、次世代の自動ポスター生成モデルの方向性が示された。 Comment
元ポスト:
著者ポスト:
GPT4oは細かい文字のfidelityが低く、視覚的な魅力も小さい(なのでそういったものは学習で補う必要がある)という知見があるとのこと。arXivに投稿された当時結構話題になっていた気がする。
論文だけに留まらず、長いテキストを視覚的に見やすく圧縮する技術は一種の要約として見ることもでき、生成AIによって情報がさらに溢れかえるようになった昨今は、こういった技術はさらに重要な技術になると思われる。
[Paper Note] Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?, Chunqiu Steven Xia+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #SoftwareEngineering #EvolutionaryAlgorithm Issue Date: 2025-11-23 GPT Summary- Live-SWE-agentは、実世界のソフトウェア問題を解決するために、ランタイム中に自律的に自己進化する初のライブソフトウェアエージェントである。最も基本的なエージェントスキャフォールドから始まり、bashツールを用いて自らの実装を進化させる。評価結果では、SWE-bench Verifiedベンチマークで75.4%の解決率を達成し、既存のオープンソースエージェントを上回る性能を示した。さらに、SWE-Bench Proベンチマークでも最良の解決率を記録した。 Comment
github: https://github.com/OpenAutoCoder/live-swe-agent
ReAct方式に追加でself-reflectionを導入することでagentのscaffolding(=ただし、カスタムツールのみ)をbashのみが使える状態から自己進化させる枠組み。
元ポスト:
scaffoldingのスタート地点は同一なので、そういう意味ではapple-to-appceなのかもしれないが、self-improvementの能力が高いモデルの方が有利という側面もありそうなので留意が必要
[Paper Note] Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter, Qinghao Hu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Reasoning #PostTraining Issue Date: 2025-11-21 GPT Summary- 大規模言語モデル(LLMs)の推論能力を向上させるため、TLTを提案。TLTは適応的な推測デコーディングを用いて、強化学習(RL)トレーニングの効率を向上させる。主なコンポーネントは、アイドルGPUでトレーニングされるアダプティブドラフターと、メモリ効率の良いプールを維持するアダプティブロールアウトエンジン。TLTは、最先端システムに対して1.7倍のトレーニング速度向上を実現し、モデルの精度を保持しつつ高品質なドラフトモデルを生成。 Comment
元ポスト:
ロングテールのrolloutをする際にspeculative decodingをすることでボトルネックを改善しon-policy RLの速度を改善する話らしいが、Inflight Weight Updatesがもしうまく機能するならこちらの方が簡単な気がするが、果たしてどうなのだろうか。
関連:
- PipelineRL, Piche+, ServiceNow, 2025.04
[Paper Note] What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity, Alexis Audran-Reiss+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #AIAgents #Reasoning #ScientificDiscovery #Diversity Issue Date: 2025-11-21 GPT Summary- AI研究エージェントのパフォーマンスにおけるアイデアの多様性の役割を検討。MLE-benchでの分析により、パフォーマンスの高いエージェントはアイデアの多様性が増加する傾向があることが明らかに。制御実験でアイデアの多様性が高いほどパフォーマンスが向上することを示し、追加の評価指標でも発見が有効であることを確認。 Comment
元ポスト:
ideation時点における多様性を向上させる話らしい
[Paper Note] Foundational Automatic Evaluators: Scaling Multi-Task Generative Evaluator Training for Reasoning-Centric Domains, Austin Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Test-Time Scaling #read-later #Selected Papers/Blogs #RewardModel #Reranking #GenerativeVerifier Issue Date: 2025-11-20 GPT Summary- 専門的な生成評価者のファインチューニングに関する研究で、250万サンプルのデータセットを用いて、シンプルな教師ありファインチューニング(SFT)アプローチでFARE(基盤自動推論評価者)をトレーニング。FARE-8Bは大規模なRLトレーニング評価者に挑戦し、FARE-20Bは新たなオープンソース評価者の標準を設定。FARE-20BはMATHでオラクルに近いパフォーマンスを達成し、下流RLトレーニングモデルの性能を最大14.1%向上。FARE-Codeはgpt-oss-20Bを65%上回る品質評価を実現。 Comment
HF: https://huggingface.co/collections/Salesforce/fare
元ポスト:
これは素晴らしい。使い道がたくさんありそうだし、RLに利用したときに特定のデータに対して特化したモデルよりも優れた性能を発揮するというのは驚き。
[Paper Note] Solving a Million-Step LLM Task with Zero Errors, Elliot Meyerson+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #AIAgents #Reasoning #Test-Time Scaling #LongHorizon Issue Date: 2025-11-20 GPT Summary- LLMの限界を克服するために、MAKERというシステムを提案。これは、100万以上のステップをゼロエラーで解決可能で、タスクを細分化し、マイクロエージェントが各サブタスクに取り組むことでエラー修正を行う。これにより、スケーリングが実現し、組織や社会の問題解決に寄与する可能性を示唆。 Comment
元ポスト:
しっかりと読めていないのだが、各タスクを単一のモデルのreasoningに頼るのではなく、
- 極端に小さなサブタスクに分解
- かつ、各サブタスクに対して複数のエージェントを走らせてvotingする
といったtest-time scalingっぽい枠組みに落とすことによってlong-horizonのタスクも解決することが可能、というコンセプトに見える。
[Paper Note] Virtual Width Networks, Seed+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Architecture #read-later #Selected Papers/Blogs Issue Date: 2025-11-17 GPT Summary- Virtual Width Networks (VWN)は、隠れ層のサイズを増やすことなく、より広い表現を可能にするフレームワークである。VWNはバックボーンの計算をほぼ一定に保ちながら埋め込み空間を拡張し、8倍の拡張でトークン予測の最適化を加速することを示した。トレーニングが進むにつれてこの利点は増幅され、仮想幅と損失削減の間には対数線形のスケーリング関係があることが確認された。 Comment
元ポスト:
ポイント解説:
重要論文に見える。transformerのバックボーンの次元は変えないでベクトルのwidthを広げることと同等の効力を得るためのアーキテクチャを提案している模様。
ざっくり言うとembeddingをN倍(over-width)し、提案手法であるGHCを用いてバックボーンに流せるサイズにベクトルを圧縮しtransformerブロックで処理しover-widthした次元に戻す処理をする機構と、over-widthしたembeddingを次元数は変えずに変換するlinearを噛ませた結果を足し合わせるような機構を用意して最大のボトルネックであるtransformerブロックの計算量は変えずに表現力を向上させる、といった感じの手法な模様
[Paper Note] AgentEvolver: Towards Efficient Self-Evolving Agent System, Yunpeng Zhai+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #SelfImprovement #SoftwareEngineering Issue Date: 2025-11-15 GPT Summary- AgentEvolverは、LLMsを活用した自己進化型自律エージェントシステムで、手作業のデータセット依存を減らし、探索効率とサンプル利用を向上させる3つのメカニズムを導入。初期実験では、従来のRLベースラインよりも効率的な探索と迅速な適応を実現。 Comment
元ポスト:
skim readingしかできていないが、式17を見ると、PRMのようにstep levelで評価をし全体のtrajectoryのrewardをか決定している。テストしているベンチマークはソフトウェアエンジニアリング系のものであるため、verifiableなドメインに限られた評価となっている印象がある。rewardをどれだけverifiableに、あるいは堅牢に定義できるドメインかが重要になる気がする。
たとえば
- [Paper Note] Large Language Monkeys: Scaling Inference Compute with Repeated Sampling, Bradley Brown+, arXiv'24, 2024.07
では、いくつかのverifierを比較しており、LLM-basedなRMではverificationの能力に限界があることが示されている[^1]。
[^1]: この研究ではtest-time scalingの観点での限界を示しているが、self-improve系の話でも同様にverifierの性能は学習のシグナルに直結するため、同様に重要であると考えられる。
[Paper Note] TabArena: A Living Benchmark for Machine Learning on Tabular Data, Nick Erickson+, NeurIPS'25 Spotlight, 2025.06
Paper/Blog Link My Issue
#MachineLearning #NLP #Dataset #TabularData #Evaluation #Selected Papers/Blogs #Live Issue Date: 2025-11-14 GPT Summary- TabArenaは、表形式データのための初の生きたベンチマークシステムであり、継続的に更新されることを目的としています。手動でキュレーションされたデータセットとモデルを用いて、公開リーダーボードを初期化しました。結果は、モデルのベンチマークにおける検証方法やハイパーパラメータ設定の影響を示し、勾配ブースティング木が依然として強力である一方、深層学習手法もアンサンブルを用いることで追いついてきていることを観察しました。また、基盤モデルは小規模データセットで優れた性能を発揮し、モデル間のアンサンブルが表形式機械学習の進展に寄与することを示しました。TabArenaは、再現可能なコードとメンテナンスプロトコルを提供し、https://tabarena.ai で利用可能です。 Comment
pj page:
https://github.com/autogluon/tabarena
leaderboard:
https://huggingface.co/spaces/TabArena/leaderboard
liveデータに基づくベンチマークで、手動で収集された51のtabularデータセットが活用されているとのこと。またあるモデルに対して数百にも登るハイパーパラメータ設定での実験をしアンサンブルをすることで単一モデルが到達しうるピーク性能を見ることに主眼を置いている、またいな感じらしい。そしてやはり勾配ブースティング木が強い。tunedは単体モデルの最も性能が良い設定での性能で、ensembleは複数の設定での同一モデルのアンサンブルによる結果だと思われる。
> TabArena currently consists of:
> 51 manually curated tabular datasets representing real-world tabular data tasks.
> 9 to 30 evaluated splits per dataset.
> 16 tabular machine learning methods, including 3 tabular foundation models.
> 25,000,000 trained models across the benchmark, with all validation and test predictions cached to enable tuning and post-hoc ensembling analysis.
> A live TabArena leaderboard showcasing the results.
openreview: https://openreview.net/forum?id=jZqCqpCLdU
[Paper Note] Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning, Jiayu Wang+, NeurIPS'25, 2025.06
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #NeurIPS Issue Date: 2025-11-13 GPT Summary- 強化学習(RL)は言語モデルの推論性能を向上させるが、そのメカニズムは未解明。SPARKLEフレームワークを用いて、RLの効果を計画遵守、知識統合、サブ問題連鎖の3次元で分析。RL調整モデルは外部計画に依存せず、内部戦略の形成を促進し、知識統合能力を向上させることが示された。難しい問題に対しては、SparkleRL-PSSというマルチステージRLパイプラインを提案し、データ生成なしで効果的な探索を実現。これにより、推論タスクのための適応的で効率的なRLパイプライン構築のための洞察が得られる。 Comment
元ポスト:
RLを実施したモデルは与えられた計画を実施することに関してよりロバストで、自分でプランニングさせて解かせることもでき、かつ外部・モデル内部のパラメータに内在する知識を統合して応答する能力も向上する。しかし、大きな問題を部分問題に分割して解く能力には課題が残る、みたいな話らしい。
[Paper Note] Reinforcement Learning Improves Traversal of Hierarchical Knowledge in LLMs, Renfei Zhang+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Memorization Issue Date: 2025-11-13 GPT Summary- 強化学習(RL)は、階層的な知識を必要とするタスクにおいて、基盤モデルや教師あり微調整(SFT)モデルを上回る性能を示す。これは新たなデータからではなく、既存の知識をナビゲートするスキルの向上によるものである。構造化プロンプティングを用いることで、SFTモデルのパフォーマンスギャップを縮小できることが示された。RLモデルは深い検索タスクでの手続き的経路の呼び出しに優れ、知識の表現は変わらないが、知識の遍歴方法が変化することが明らかになった。 Comment
元ポスト:
RLはしばしば知識のmemorizationを劣化させると言われているが、むしろ学習データから記憶された知識を階層的に辿るようなタスクに適用した結果RL(が実施されたモデル)の方がSFT(が実施されたモデル)よりも高い性能を達成した。同タスクの階層構造をpromptingで与えることで性能SFT/RLのgapが小さくなることから、知識のナビゲーションが性能に関連していることを示唆している。また、事実表現とクエリの表現においてSFTとRLでは前者に大きな違いはないが、後者は大きな違いを見せており、知識の表現そのものを変えるのではなく、モデル内部の知識を辿る方法が変化していることが示唆される。
といった内容らしいのだが、論文を斜め読みした結果、自分たちでモデルをRL/SFTしたわけではなく既存のオープンなモデルreasoningモデル、instructモデル、distilledモデルで性能を比較する、みたいなことをしているようであり、apple-to-appleの比較になっていないのでは?という感想を抱いたがどうなのだろうか。
[Paper Note] On a few pitfalls in KL divergence gradient estimation for RL, Yunhao Tang+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #ReinforcementLearning #Reasoning Issue Date: 2025-11-12 GPT Summary- LLMのRLトレーニングにおけるKLダイバージェンスの勾配推定に関する落とし穴を指摘。特に、KL推定を通じて微分する実装が不正確であることや、逐次的な性質を無視した実装が部分的な勾配しか生成しないことを示す。表形式の実験とLLM実験を通じて、正しいKL勾配の実装方法を提案。 Comment
元ポスト:
RLにおけるKL Divergenceによるポリシー正則化の正しい実装方法
[Paper Note] Robot Learning from a Physical World Model, Jiageng Mao+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #Zero/Few/ManyShotPrompting #VideoGeneration/Understandings #Robotics #WorldModels #EmbodiedAI Issue Date: 2025-11-12 GPT Summary- PhysWorldは、物理世界のモデル化を通じてビデオ生成とロボット学習を結びつけるフレームワークです。従来のビデオ生成モデルは物理を無視しがちで、ロボットの操作に不正確さをもたらしますが、PhysWorldはタスク条件付きのビデオを生成し、物理世界を再構築します。これにより、生成されたビデオの動きを物理的に正確なアクションに変換し、実際のロボットデータ収集なしでゼロショットのロボット操作を実現します。実験により、PhysWorldは操作精度を大幅に向上させることが示されました。 Comment
pj page: https://pointscoder.github.io/PhysWorld_Web/
画像とタスクプロンプトを与えて動画を生成し、生成された動画に対してworld modelを用いて物理世界の情報を再構築し、そこからロボットのアクションとして何が必要かを推定することでRLをする、結果的にzeroshotでのロボット操作が実現できる、みたいな話に見える(Figure2)
元ポスト:
[Paper Note] Rolling Forcing: Autoregressive Long Video Diffusion in Real Time, Kunhao Liu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #LongSequence #VideoGeneration/Understandings Issue Date: 2025-11-10 GPT Summary- ストリーミングビデオ生成におけるエラーの蓄積を抑えるために、新技術「Rolling Forcing」を提案。複数フレームの共同デノイジング、注意シンクメカニズムの導入、効率的なトレーニングアルゴリズムを特徴とし、リアルタイムでの高品質なビデオ生成を実現。実験により、エラーの蓄積が大幅に削減されることが確認された。 Comment
関連:
- [Paper Note] Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion, Xun Huang+, NeurIPS'25
- [Paper Note] Self-Forcing++: Towards Minute-Scale High-Quality Video Generation, Justin Cui+, arXiv'25, 2025.10
self forcingと比較して複数フレームを同時にdenoisingしエラーの蓄積を低減するコンセプトな模様。
[Paper Note] Beyond the 80_20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning, Shenzhi Wang+, NeurIPS'25, 2025.06
Paper/Blog Link My Issue
#LanguageModel #ReinforcementLearning #NeurIPS #PostTraining #Entropy Issue Date: 2025-11-05 GPT Summary- 強化学習における検証可能な報酬(RLVR)のメカニズムをトークンエントロピーの視点から探求。高エントロピーのトークンが推論の重要な分岐点であることを発見し、RLVRトレーニング中にこれらのトークンのエントロピーが調整されることを示す。トークンの20%を利用することで、フル勾配更新と同等の性能を維持し、他のモデルでの性能向上を実現。低エントロピーのトークンのみでのトレーニングは性能を低下させることが明らかに。高エントロピートークンの最適化がRLVRの効果を生むことを示唆。 Comment
元ポスト:
pj page: https://shenzhi-wang.github.io/high-entropy-minority-tokens-rlvr/
解説:
エントロピーが高いトークンのみから学習シグナルを受け取ることで性能改善する、という話な模様。
[Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #Reasoning #Distillation #NeurIPS #Selected Papers/Blogs #EntropyCollapse Issue Date: 2025-11-05 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)は、LLMsの推論性能を向上させるが、現在の設定では新しい推論パターンを引き出せていない。小さなkではベースモデルを上回るが、大きなkではベースモデルが優位。RLVRアルゴリズムは類似の性能を示し、ベースモデルの潜在能力を活用できていない。蒸留は新しい推論パターンを導入し、モデルの能力を拡張できる。これにより、RLの改善が必要であることが示唆される。 Comment
pj page: https://limit-of-rlvr.github.io/
元ポスト:
所見:
上記所見では、「RLVRがバッチサイズ256、トークン長8192(および8つのプロンプト)で約400ステップ実行されており、何かを学ぶにはトークン量が少なすぎるのでは」という指摘があるが、著者がリプ欄でそれはablation studyでの実験のものであり、4.6節でより大規模なモデル・計算量で学習されたモデルで実験をしたが(著者が訓練したというよりも、ベースモデルとRLVR後のモデルでPass@kの性能を比較したということだと思われる)結論は変わらなかった、と反論をしている。ただし、4.6節ではstep数が言及されていない、という指摘もあり、それに対して、著者は公表されているstep数の数値を返答しているように見える。
openreview: https://openreview.net/forum?id=4OsgYD7em5
RLVRによって、サンプル効率は改善するが(= Pass@1は改善する)、モデルのreasoning能力のboundaryは狭まる(= Pass@kはRL後のモデルよりもベースモデルの方が高い。つまり、ベースモデルの方が推論可能な範囲 (reasoning boundary) が広いということ)。言い換えると、RLはベースモデルによって既に獲得されているreasoning pathを引き出すが、新たな戦略を発見しない。このことを多様なデータセット、モデル群に対するシステマチックな実験によって示した。
openreview中のweaknessにおいて、解決策の提案がlimitedであると指摘されているが、それに対して以下のようにrebuttalが記述されている:
> 1. Finer-grained reward structures: step-wise rewards guide intermediate reasoning and reduce exploration bottlenecks.
> 2. Improved exploration: Instead of naive softmax sampling, introduce structured or hierarchical search to enhance exploration efficiency.
> 3. Better long-horizon credit assignment: Use techniques to propagate reward more effectively over long CoT chains and enabling the model to assign credit to crucial intermediate steps instead the whole response
> 4. Scaling up RL training: Match RLVR compute and data scale to that of pre-training
> 5. Multi-turn tool use & external knowledge: Allow the agent to interact with tools or retrieve external facts, broadening the reasoning space beyond single-pass generation
openreview中のrebuttalに記載の通り解決策の一つとして「RLVRのスケールを事前学習並みにスケールさせる」というものがあり、理論的にRLVRがreasoning boundaryを広げないということを示したわけではなく、たとえばより多くの計算量とデータを投入した場合に関しては明らかではなさそう、という点には注意。
[Paper Note] SAIL-RL: Guiding MLLMs in When and How to Think via Dual-Reward RL Tuning, Fangxun Shu+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NLP #ReinforcementLearning #MultiModal #VisionLanguageModel Issue Date: 2025-11-05 GPT Summary- SAIL-RLは、マルチモーダル大規模言語モデルの推論能力を向上させる強化学習フレームワークで、二重報酬システムを用いて推論の質を評価します。これにより、過剰思考や不足思考の問題を解決し、推論とマルチモーダル理解のベンチマークを改善。商業モデルに対して競争力のあるパフォーマンスを示し、幻覚を減少させることに成功しました。 Comment
元ポスト:
個々のrewardを応答が持つ性質に応じて切り替える(直接回答するか、思考するかのjudgeの正しさなど)JudgeRewardと思考の品質を3つの次元(logical coherence, factual grounding, answer consistency)から(LLMをベースに)評価するThinkingRewardの二つを用いてRLする(=dual reward mechanism)ことで、推論の質を担保しながらoverthinkingを防ぐ。通常のRLVRによるRewardとフォーマットによる報酬も組み合わせ、複数の個別のRewardを乗算して最終的なRewardを決定することで、reward hackingに対して頑健にする(式1)。
[Paper Note] Puzzled by Puzzles: When Vision-Language Models Can't Take a Hint, Heekyung Lee+, EMNLP'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #EMNLP #VisionLanguageModel #Short Issue Date: 2025-11-04 GPT Summary- リバスパズルは視覚的な謎であり、VLMに特有の挑戦をもたらす。従来のタスクとは異なり、マルチモーダルな抽象化や象徴的推論が必要。本研究では、英語のリバスパズルのベンチマークを構築し、VLMの解釈能力を調査。結果、VLMはシンプルな視覚的手がかりには強いが、抽象的推論や視覚的メタファーの理解には苦労することが明らかになった。 Comment
元ポスト:
Rebus Puzzleの例。たとえば上の例はlong time no seeが答えだが、Timeを認識してCが抜けており、かつseeとCの音韻が似ているといった解釈をしなければならない。Waterfallの例では、Waterという文字列が滝のように下に向かっている様子から類推しなければならない。おもしろい。
[Paper Note] Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning, Yuhong Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #ReinforcementLearning #Self-SupervisedLearning #RLVR #VisionLanguageModel #2D (Image) #3D (Scene) #SpatialUnderstanding #Pixel-based Issue Date: 2025-11-03 GPT Summary- 空間理解におけるLVLMの弱点を克服するため、自己教師あり強化学習パラダイムSpatial-SSRLを提案。5つの前提タスクを自動定式化し、検証が容易な信号を導出。これにより、空間推論が大幅に改善され、7つのベンチマークでQwen2.5-VLベースラインに対して平均精度が4.63%(3B)および3.89%(7B)向上。シンプルな監視がRLVRを可能にし、LVLMの空間知能向上に寄与することを示した。 Comment
元ポスト:
RGB/RGB-D imageがgivenなときに、
- cropped patch inpainting
- flipped patch recognition
- shuffled patch reordering
- regional depth ordering
- relative 3D position prediction
の5つのverifiableなタスクを定義しself supervisedなmannerでRLすることでSpatial Understanding能力を向上させる話らしい
3Bモデルがリリース:
https://huggingface.co/internlm/Spatial-SSRL-3B
[Paper Note] Completion $\neq$ Collaboration: Scaling Collaborative Effort with Agents, Shannon Zejiang Shen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #UserBased #AIAgents Issue Date: 2025-11-01 GPT Summary- エージェントの評価をタスク完了から協調的な問題解決プロセスにシフトすることを提唱。ユーザーの関与がエージェントの有用性に与える影響を捉える「協調的努力スケーリング」フレームワークを導入。ケーススタディにより、現実のシナリオでのエージェントのパフォーマンス低下を示し、持続的なエンゲージメントとユーザー理解の重要性を明らかにする。 Comment
単に一発でタスクをこなすことに最適化されているが、ユーザからの要求は反復的で進化するので数ラウンド経つとコントロールしづらくなる、といったことが起きてしまう経験があると思うが、実際そうだということを実験的に示している模様。そして、ユーザと協働しながら効用を最大化させるようなアプローチが必要のことを明らかにしている、みたいな話らしい。
[Paper Note] ATLAS: Adaptive Transfer Scaling Laws for Multilingual Pretraining, Finetuning, and Decoding the Curse of Multilinguality, Shayne Longpre+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #CrossLingual #TransferLearning #MultiLingual #Scaling Laws #read-later #Selected Papers/Blogs Issue Date: 2025-10-31 GPT Summary- 本研究では、774の多言語トレーニング実験を通じて、最大の多言語スケーリング法則を探求し、ATLASという適応的転送スケーリング法則を導入。これにより、既存のスケーリング法則を上回る性能を示し、多言語学習のダイナミクスや言語間の転送特性を分析。言語ペア間の相互利益スコアを測定し、モデルサイズとデータの最適なスケーリング方法を明らかにし、事前学習とファインチューニングの計算的クロスオーバーポイントを特定。これにより、英語中心のAIを超えたモデルの効率的なスケーリングの基盤を提供することを目指す。 Comment
元ポスト:
バイリンガルで学習した時に、日本語とシナジーのある言語、この図を見ると無さそうに見える😅
[Paper Note] Towards Cross-Tokenizer Distillation: the Universal Logit Distillation Loss for LLMs, Nicolas Boizard+, TMLR'25, 2024.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Distillation #TMLR #OptimalTransport Issue Date: 2025-10-30 GPT Summary- 大規模言語モデル(LLMs)の展開はコストやハードウェアの制約から実用的ではないが、知識蒸留(KD)が解決策となる。従来のロジットに基づく方法はトークナイザーの共有が必要で適用性が限られる。本研究では、最適輸送に基づくユニバーサルロジット蒸留(ULD)損失を提案し、異なるアーキテクチャ間での蒸留を可能にすることを示した。 Comment
openreview: https://openreview.net/forum?id=bwRxXiGO9A
(以下は管理人の理解が不十分なまま書かれているため誤りがある可能性が高いのでご注意ください)
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
の記述と論文を斜め読みした感じ、
従来の蒸留手法は出力(Vocab)の分布が近くなるように学習するため、教師と生徒モデル間でVocabが揃っている、すなわちtokenizerが共通でなければならず、これが教師生徒ペアを選択する際の制約となっていた。これを異なるtokenizerを持つモデル間でも蒸留可能にしたという話。これには以下の二つの課題があり
- sequence misalignment: tokenizerが異なるため、共通のsequenceに対して異なるsplitをする可能性がある
- vocabulary misalignment: 同じトークンIDが異なるtokenを指す
要は確率分布が対応づけられないのでワッサースタイン距離(=一方の確率分布をもう一方の確率分布に一致させるために必要な輸送の質量と距離よ最小コスト)によって距離を測ることを目指す(通常の教師ありDistillationのKL Divergenceをワッサースタイン距離に置き換えた損失を考える)。
が、ワッサースタイン距離はO(n^3log n)であるため近似的な解法で解く。その方法として、
- 教師のトークン列と生徒のトークン列の長さは異なるので短い方の長さに合わせてtruncateし
- ソフトマックス出力のロジットの大きさで両モデルのベクトルをソートし、小さい方をzero paddingして長さを揃えてベクトル間を比較可能にする[^1]
といった方法をとる模様?
[^1]: ソートさせたらvocabularyの整合性がとれずにでたらめな距離になるのでは?と思ったのだが、意図としては各次元が特定の単語ではなく確率順位を表すようにし、その間を比較することで分布の形(エントロピーやconfidenceの構造)の観点で比較可能にする、というニュアンスらしい。ただしこの部分についてはChatGPTの問答を通じて得た知識なので誤りがある可能性があるので注意。
[Paper Note] Training-Free Group Relative Policy Optimization, Yuzheng Cai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AutomaticPromptEngineering Issue Date: 2025-10-29 GPT Summary- 最近のLLMエージェントは一般的な能力を示すが、専門的なドメインでのパフォーマンスは外部ツールとの統合に課題がある。従来の強化学習手法はコストがかかるが、我々は経験的知識を用いて出力分布を改善できると主張する。これを実現するために、Training-Free GRPOを提案し、パラメータ更新なしでLLMの性能を向上させる。実験により、Training-Free GRPOが少数のトレーニングサンプルでファインチューニングされた小型LLMを上回ることを示した。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=tyUnYbE7Gi
openreviewのweaknessにtraining free, GRPOといった用語が利用されているが、parameterの更新からcontextの更新という方向性にシフトするというアイデアであると考えられるため、automatic prompt engineering、in-context learning等に該当するのでは、という指摘がある。
また、実験結果のベースモデルが揃っていないので、公平な比較になっておらず、追加の検証が必要という指摘もある。
[Paper Note] The German Commons - 154 Billion Tokens of Openly Licensed Text for German Language Models, Lukas Gienapp+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #NLP #Dataset #LanguageModel #Selected Papers/Blogs #German Issue Date: 2025-10-28 GPT Summary- 「German Commons」は、オープンライセンスのドイツ語テキストの最大コレクションで、41のソースから1545.6億トークンを提供。法律、科学、文化など7つのドメインを含み、品質フィルタリングや重複排除を行い、一貫した品質を確保。すべてのデータは法的遵守を保証し、真にオープンなドイツ語モデルの開発を支援。再現可能で拡張可能なコーパス構築のためのコードも公開。 Comment
HF: https://huggingface.co/datasets/coral-nlp/german-commons
元ポスト:
最大級(154B)のドイツ語のLLM(事前)学習用データセットらしい
ODC-By Licence
[Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #Dataset #Zero/Few/ManyShotPrompting #Evaluation #MultiModal #In-ContextLearning #NeurIPS #read-later #Selected Papers/Blogs #OOD #Generalization #VisionLanguageModel #ObjectDetection Issue Date: 2025-10-27 GPT Summary- 視覚と言語のモデル(VLMs)は、一般的な物体に対して優れたゼロショット検出性能を示すが、分布外のクラスやタスクに対しては一般化が難しい。そこで、少数の視覚例と豊富なテキスト記述を用いてVLMを新しい概念に整合させる必要があると提案。Roboflow100-VLという多様な概念を持つ100のマルチモーダル物体検出データセットを導入し、最先端モデルの評価を行った。特に、難しい医療画像データセットでのゼロショット精度が低く、少数ショットの概念整合が求められることを示した。 Comment
元ポスト:
VLMが「現実世界をどれだけ理解できるか」を評価するためのobject detection用ベンチマークを構築。100のopen source datasetから構成され、それぞれにはtextでのfew shot instructionやvisual exampleが含まれている。データセットは合計で約165kの画像、約1.35M件のアノテーションが含まれ、航空、生物、産業などの事前学習ではあまりカバーされていない新規ドメインの画像が多数含まれているとのこと。
そして現在のモデルは事前学習に含まれていないOODな画像に対する汎化性能が低く、いちいちモデルを追加で学習するのではなく、ICLによって適用できた方が好ましいという考えがあり、そして結果的に現在のVLMでは、ICLがあまりうまくいかない(ICLによるOODの汎化が効果的にできない)ことがわかった、という話らしい。
が、
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
での知見と異なる。差異はなんだろうか?
以下のスレッドで議論がされている:
pj page: https://rf100-vl.org
うーんあとでしっかり読みたい、、、
[Paper Note] MemER: Scaling Up Memory for Robot Control via Experience Retrieval, Ajay Sridhar+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #VisionLanguageModel #Robotics #memory #VisionLanguageActionModel #LongHorizon Issue Date: 2025-10-27 GPT Summary- 本研究では、ロボットポリシーに人間のような記憶能力を与えるための階層的ポリシーフレームワークを提案。高レベルポリシーが関連するキーフレームを選択し、低レベルポリシーに指示を生成することで、長期的な依存関係を効率的に推論。実験により、提案手法MemERが従来の方法を上回る性能を示した。 Comment
元ポスト:
pj page: https://jen-pan.github.io/memer/
動画ストリーム全てを常にinputするのではなくキーフレームは限られているので、VLMにキーフレームをメモリ上で管理するような役割を与え、instructionと実現するためのサブタスクに応じて動的に必要な情報のみをVLAに与えることでlong horizonでのスケーラビリティを改善する、みたいな話らしい
[Paper Note] R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?, Yi Lu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Reasoning #read-later #Selected Papers/Blogs #LongHorizon Issue Date: 2025-10-27 GPT Summary- R-HORIZONを提案し、長期的な推論行動を刺激する手法を通じて、LRMの評価を改善。複雑なマルチステップ推論タスクを含むベンチマークを構築し、LRMの性能低下を明らかに。R-HORIZONを用いた強化学習データ(RLVR)は、マルチホライズン推論タスクの性能を大幅に向上させ、標準的な推論タスクの精度も向上。AIME2024で7.5の増加を達成。R-HORIZONはLRMの長期推論能力を向上させるための有効なパラダイムと位置付けられる。 Comment
pj page: https://reasoning-horizon.github.io
元ポスト:
long horizonタスクにうまく汎化する枠組みの必要性が明らかになったように見える。long horizonデータを合成して、post trainingをするという枠組みは短期的には強力でもすぐに計算リソースの観点からすぐに現実的には能力を伸ばせなくなるのでは。
ポイント解説:
[Paper Note] ARC-Encoder: learning compressed text representations for large language models, Hippolyte Pilchen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ContextWindow #Encoder #text #Compression Issue Date: 2025-10-26 GPT Summary- 本研究では、コンテキストを連続表現に圧縮するARC-Encoderを提案し、デコーダLLMのトークン埋め込みを置き換えるアプローチを探求。ARC-Encoderは、テキストトークンの少ない連続表現を出力し、計算効率を向上させる。さまざまなLLMシナリオで評価した結果、最先端のパフォーマンスを達成し、複数のデコーダに同時に適応可能であることを示した。 Comment
元ポスト:
最近textのcontextをvisual tokenでレンダリングすることで圧縮する話が盛り上がっているが、こちらはtextの表現そのものを圧縮する話な模様。
そのうちpixel単位の入力、テキスト単位での入力を圧縮する話どちらかだけでなく、双方のハイブリッドになり、かつタスクに応じてattention等を通じてどちらのモダリティの情報を使うか、また圧縮前と後の情報どちらを使うか、みたいなものを動的に選択してタスクに応じて計算量やメモリを節約しつつ、高い性能を担保する、みたいな話になるんではなかろうか。
[Paper Note] Learning to Interpret Weight Differences in Language Models, Avichal Goel+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Explanation #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) Issue Date: 2025-10-25 GPT Summary- ファインチューニングされた言語モデルの重みの変化を解釈するために、Diff Interpretation Tuning(DIT)を提案。合成されたラベル付きの重みの差を用いてモデルに変更を説明させる。隠れた挙動の報告や知識の要約において、DITが自然言語での正確な説明を可能にすることを示した。 Comment
元ポスト:
weightの更新があった時に、LLM自身がどのような変化があったかをverbalizeできるようにSFTでLoRA Adaptorを学習する話らしい
[Paper Note] BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping, Zhiheng Xi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #Off-Policy #On-Policy #Stability #Entropy #PartialRollout Issue Date: 2025-10-24 GPT Summary- 強化学習におけるオフポリシー設定の課題を解決するため、BAPO(Balanced Policy Optimization with Adaptive Clipping)を提案。ポジティブとネガティブな寄与を再バランスし、エントロピーを保持することで最適化を安定化。多様なシナリオでデータ効率の高いトレーニングを実現し、AIME 2024およびAIME 2025のベンチマークで最先端の結果を達成。 Comment
pj page: https://github.com/WooooDyy/BAPO
Partial Rollout(=長いtrajectoryを一回のロールアウトで生成仕切らずに、途中で生成を打ち切りreplay bufferに保存。次のロールアウト時に続きを生成する。しかし更新されたポリシーによって続きをロールアウトするためオフポリシーデータとなる)の設定で、GRPOよりも学習効率が良いことが示されているように見える。
[Paper Note] Prompt-MII: Meta-Learning Instruction Induction for LLMs, Emily Xiao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #In-ContextLearning #AutomaticPromptEngineering #read-later Issue Date: 2025-10-21 GPT Summary- PROMPT-MIIという新しい指示誘導モデルを提案し、トレーニング例をコンパクトなプロンプトに縮小することで、インコンテキスト学習(ICL)と同等のパフォーマンスを実現。3,000以上の分類データセットでトレーニングし、90の未見タスクで評価した結果、下流モデルの品質を4-9 F1ポイント向上させ、必要なトークン数を3-13倍削減。 Comment
元ポスト:
タスクのexamplar/demonstrationからタスクに関するdescription(=instruction)を生成するモデルを学習し、生成されたinstructionを用いることで、manyshotでICLするよりも、少ないトークン数で同等以上の性能を達成するといった話に見える。どういうinstructionになるのかが非常に興味がある。A.6参照のこと。細かく具体的だがコンパクトな指示が記述されているようなinstructionとなっている。
[Paper Note] OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations, Linke Ouyang+, CVPR'25, 2024.12
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #CVPR #Selected Papers/Blogs #DocParser #OCR Issue Date: 2025-10-21 GPT Summary- 文書内容抽出のための新しいベンチマーク「OmniDocBench」を提案。これは、9つの文書ソースにわたる高品質な注釈を特徴とし、エンドツーエンド評価やタスク特化型分析をサポート。異なる文書タイプにおける手法の強みと弱みを明らかにし、文書解析の公平で詳細な評価基準を設定。データセットとコードは公開されている。 Comment
OCR系のモデルの評価で標準的に用いられるベンチマーク
[Paper Note] Glyph: Scaling Context Windows via Visual-Text Compression, Jiale Cheng+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #NLP #ContextWindow #LongSequence #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-10-21 GPT Summary- 本研究では、長いコンテキストを持つ大規模言語モデル(LLMs)の実用性を向上させるため、Glyphというフレームワークを提案し、テキストを画像に変換して視覚と言語のモデル(VLMs)で処理します。このアプローチにより、3-4倍のトークン圧縮を実現し、精度を維持しつつ処理速度を約4倍向上させます。さらに、128KコンテキストのVLMが1Mトークンのテキストタスクを処理可能になることを示しました。 Comment
元ポスト:
所見:
テキストを画像にレンダリングしてVLMに入力することでtextと比較して3.2倍KV Cache (context)を圧縮し、prefillingとデコード速度も4.8, 4.4倍高速化するフレームワークらしい
[Paper Note] UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action, Yuhao Yang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #ComputerUse Issue Date: 2025-10-21 GPT Summary- ハイブリッドアクションを用いた基盤モデル「UltraCUA」を提案し、GUIの原始的なアクションと高レベルのプログラムツール呼び出しを統合。自動化パイプライン、合成データエンジン、ハイブリッドアクション軌跡コレクション、二段階のトレーニングパイプラインを構成要素とし、実験により最先端エージェントに対して22%の改善と11%の速度向上を達成。エラー伝播を減少させつつ実行効率を維持することが確認された。 Comment
元ポスト:
従来のCUAはGUIに対する低レベルの操作(クリック、タイプ、スクロール)を利用する前提に立つが、本研究ではそれらだけではなくより高レベルのprogramatic tool calls(e.g., python関数呼び出し、キーボードショートカット、スクリプト実行、API呼び出し等)をシームレスに統合できるように合成データを作成しAgentをらSFTとRLしましたらよりベンチマークスコア向上した、というような話に見える。
[Paper Note] Skill-Targeted Adaptive Training, Yinghui He+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #SyntheticData #read-later #SkillTag Issue Date: 2025-10-21 GPT Summary- 本研究では、言語モデルのメタ認知能力を活用した新しいファインチューニング戦略「STAT」を提案。教師モデルがタスクに必要なスキルをラベル付けし、学生モデルのスキル不足を追跡することで、トレーニングセットを修正。STAT-Selでは既存の例の重みを調整し、STAT-Synでは新たな例を合成。実験により、MATHで最大7.5%の改善を達成し、分布外ベンチマークでも平均4.6%の向上を示した。STATは強化学習手法GRPOと補完的であり、スキルターゲットの適応トレーニングがトレーニングパイプラインを改善することを示唆。 Comment
元ポスト:
Reward Modelでquestionがeasy/hardを定量化し、hardなものに対してモデルが応答を生成。応答の結果をstronger modelに確認させ、モデルにどのようなスキルが不足しているかを特定する。これによりモデルのスキルに関するprofileが作成されるのでこれに基づいて学習データの各サンプルとスキルを紐づけた上でサンプルを重みの調整、および不足しているスキルに関するデータを合成しSFTに活用する、といった話な模様。
結果を見ると、+SFT / +GRPOよりも性能が高くなっている。Table1ではLlamaでの結果しか掲載されていないが、Qwenでも実験がされて同様の結果が得られている。
また、Figure4を見ると不足していたスキルが学習によってきちんと補われていることが分かる。
(評価と考察部分をもう少しじっくり読みたい)
[Paper Note] Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding, Sensen Gao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Survey #InformationRetrieval #NLP #LanguageModel #MultiModal #RAG(RetrievalAugmentedGeneration) #VisionLanguageModel #Encoder Issue Date: 2025-10-20 GPT Summary- 文書理解は多様なアプリケーションにおいて重要であり、現在のアプローチには制限がある。特に、OCRベースのパイプラインは構造的詳細を失い、マルチモーダルLLMsはコンテキストモデリングに苦労している。リトリーバル強化生成(RAG)は外部データを活用するが、文書のマルチモーダル性にはマルチモーダルRAGが必要である。本論文では、文書理解のためのマルチモーダルRAGに関する体系的な調査を行い、分類法や進展をレビューし、主要なデータセットや課題をまとめ、文書AIの今後の進展に向けたロードマップを提供する。 Comment
元ポスト:
multimodal RAGに関するSurvey
Table1は2024年以後の35本程度の手法、Table2は20+程度のベンチマークがまとまっており、基本的な概念なども解説されている模様。半数程度がtraining-free/OCRを利用する手法はそれぞれ五分五分程度なようで、Agenticな手法はあまり多くないようだ(3/35)。
[Paper Note] Clean First, Align Later: Benchmarking Preference Data Cleaning for Reliable LLM Alignment, Samuel Yeh+, NeurIPS'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Evaluation #NeurIPS #PostTraining Issue Date: 2025-10-19 GPT Summary- 人間のフィードバックはLLMのアライメントに重要だが、ノイズや一貫性の欠如が問題を引き起こす。これを解決するために、13のデータクリーニング手法を評価する初のベンチマーク「PrefCleanBench」を導入。さまざまな条件下でのアライメント性能を比較し、データクリーニングの成功要因を明らかにする。これにより、LLMアライメントの改善に向けた再現可能なアプローチを提供し、データ前処理の重要性を強調する。すべての手法の実装は公開されている。 Comment
元ポスト:
元ポストによるとTakeawayとしては、
- cleaningをすることでalignmentの性能は一貫して向上
- 複数のReward Modelを用いた場合(おそらくhuman labelと複数RMのvotingに基づくcleaning)は単一モデルよりも信頼性が高くロバスト
- bad dataに対するデータは(ラベルを修正するよりも)削除した方が性能が向上する
- 少量だがクリーンなデータセットは大規模でノイジーなデータセットよりも性能が良い
といった知見がある模様
[Paper Note] Attention Is All You Need for KV Cache in Diffusion LLMs, Quan Nguyen-Tri+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #DiffusionModel #KV Cache Issue Date: 2025-10-19 GPT Summary- 本研究では、拡散型大規模言語モデル(DLMs)のデコーディング待機時間を最小化しつつ予測精度を最大化するために、適応的なKVキャッシュ再計算手法「Elastic-Cache」を提案。これにより、浅いレイヤーの冗長性を削減し、重要なトークンに基づいてキャッシュのリフレッシュを動的に行う。実験では、GSM8KやHumanEvalでの速度向上を示し、生成品質を維持しながら高いスループットを達成した。 Comment
元ポスト:
DLMにおいて、denoisingの各ステップにおいて全てのKVを再計算するのではなく、attention scoreが大きくドリフトしていない部分についてはKV Cacheを再利用し、大きくドリフトした部分だけ再計算するような仕組みを学習することで、品質を損なうことなく推論速度を高速化した模様
[Paper Note] Scaling Test-Time Compute to Achieve IOI Gold Medal with Open-Weight Models, Mehrzad Samadi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Coding #LLM-as-a-Judge #Test-Time Scaling #Scalability Issue Date: 2025-10-19 GPT Summary- 競技プログラミングはLLMsの能力を評価する重要なベンチマークであり、IOIはその中でも特に権威ある大会です。本論文では、オープンウェイトモデルがIOI金メダルレベルのパフォーマンスを達成するためのフレームワーク「GenCluster」を提案します。このフレームワークは、生成、行動クラスタリング、ランキング、ラウンドロビン戦略を組み合わせて多様な解決空間を効率的に探索します。実験により、GenClusterは計算リソースに応じてスケールし、オープンシステムとクローズドシステムのギャップを縮小することが示され、IOI 2025で金メダルを達成する可能性を示唆しています。 Comment
元ポスト:
OpenWeight modelで初めてIOI金メダル級のパフォーマンスを実現できるフレームワークで、まずLLMに5000個程度の潜在的なsolutionを生成させ、それぞれのsolutionを100種のtest-caseで走らせて、その後solutionをbehaviorに応じてクラスタリングする。これによりアプローチのユニークさにそってクラスタが形成される。最終的に最も良いsolutionを見つけるために、それぞれのクラスタから最も良いsolutionを互いに対決させて、LLM-as-a-Judgeで勝者をランク付けするような仕組みのようである。
[Paper Note] When Thoughts Meet Facts: Reusable Reasoning for Long-Context LMs, Soyeong Jeong+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #LongSequence #read-later Issue Date: 2025-10-18 GPT Summary- 思考テンプレートを用いて、長文コンテキスト言語モデル(LCLMs)によるマルチホップ推論を構造化。証拠の結びつきを捉え、自然言語フィードバックでテンプレートを洗練。多様なベンチマークで性能向上を実現し、小型モデルへの蒸留も可能。フレームワーク名はToTAL。 Comment
元ポスト:
シンプルなCoTやドキュメント全体をcontextに入力するようなシンプルなベースラインしかなく、ベースラインが少し弱いような印象を受けたが(たとえばChain-of-Noteを適用していない、と思ったが)実験しているモデルを見ると、そもそもReasoningモデルを使った実験(前提)となっているので(Chain-of-Noteなどはnon-thinking modelでは有効なことが示されているがthinking modelでの効果は不明という認識)、なんやかんやこのベースラインで十分なのでは、という気もする。そして結構性能が上がっているように見える。(後で読みたい)
[Paper Note] Thinking on the Fly: Test-Time Reasoning Enhancement via Latent Thought Policy Optimization, Wengao Ye+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Online/Interactive #NLP #LanguageModel #ReinforcementLearning #OOD #LatentReasoning #Test Time Training (TTT) Issue Date: 2025-10-18 GPT Summary- Latent Thought Policy Optimization(LTPO)を提案し、LLMの推論を強化するパラメータフリーのフレームワークを導入。中間的な潜在「思考」ベクトルを動的に最適化し、外部監視なしで報酬信号に基づくオンラインポリシー勾配法を使用。5つの推論ベンチマークで強力な性能を示し、特にAIMEベンチマークで顕著な改善を達成。 Comment
元ポスト:
test-time に online-RLを適用することでモデルのパラメータを更新することなく、クエリに応じて動的にlatent reasoningを洗練し、推論能力をロバストにできる、という話な模様?
実験結果を見ると、モデルのパラメータ数が大きい場合にgainが小さくなっていっているように見え、かつ実験中のlargest modelのgainがサンプル数の少ないAIMEのスコアに依存しているように見える。
[Paper Note] AutoCode: LLMs as Problem Setters for Competitive Programming, Shang Zhou+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Education #AIAgents #Evaluation #Coding #read-later #Selected Papers/Blogs Issue Date: 2025-10-18 GPT Summary- AutoCodeは、競技プログラミングの問題文とテストケースを生成するシステムであり、信頼性の高い問題作成を実現します。複数回の検証を通じて、生成された問題は公式の判断と99%の一貫性を持ち、従来の手法に比べて大幅な改善を示します。また、ランダムなシード問題から新しいバリアントを作成し、不正な問題をフィルタリングする機能も備えています。最終的に、AutoCodeはグランドマスター級の競技プログラマーによってコンテスト品質と評価される問題を生成します。 Comment
blog: https://livecodebenchpro.com/projects/autocode/overview
LLMで自動的に高品質な競技プログラミング問題とそのテストケースを生成するパイプラインを提案。
信頼性のあるテストケースを作成するために、Validator-Generator-Checkerフレームワーク。提案。Generatorがテストケースを生成し、Validatorが生成されたテストケースの入力が問題の制約を満たしているか判定し、Checkerが与えられたテストケースの元で解法が正しいかを確認する。
続いて、人手を介さずとも生成される問題が正しいことを担保するためにdual-verificationを採用。具体的には、LLMに新規の問題文と効率的な解法を生成させ、加えてブルートフォースでの解法を別途生成する。そして、両者をLLMが生成したテストセット群で実行し、全ての解放で出力が一致した場合のみAcceptする、といったような手法らしい。
(手法の概要としてはそうなのだろうが、細かい実装に高品質さの肝があると思うのでしっかり読んだ方が良さげ。特にTest Generationの詳細をしっかりできていない)
takeawayで興味深かったのは、
- LLMは自身では解けないが、解法が存在する(solvable)問題を生成できること
- 人間の専門家とLLM(o3)の間で、問題の品質の新規性の判定の相関がわずか0.007, 0.11しかなかったこと。そして品質に関しては専門家のグループ間では0.71, o3とgpt4oの間では0.72と高い相関を示しており、LLMと人間の専門家の間で著しく問題の品質の判断基準が異なること
- seed問題と生成された問題の難易度のgainが、問題の品質に関して、LLM自身のself-evaluationよりもより良い指標となっていること
[Paper Note] Dr.LLM: Dynamic Layer Routing in LLMs, Ahmed Heakl+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #DynamicNetworks #Routing Issue Date: 2025-10-17 GPT Summary- Dr.LLMは、LLMsに動的な層ルーティングを導入し、計算効率を向上させるフレームワーク。モンテカルロ木探索を用いて高品質な層構成を導出し、ARCやDARTで精度を最大+3.4%向上させ、平均5層を節約。ドメイン外タスクでもわずか0.85%の精度低下で従来手法を上回る。明示的な監視下でのルーターがLLMsを効率的に活用できることを示す。 Comment
LayerごとにMLPのrouterを用意し、(元のLLMのパラメータはfreezeして)Layerをskip, execute, repeatするかを追加で学習することで、クエリに応じて動的に計算コストとpathを調整する能力を身につけさせ、性能を向上させつつも計算量も削減できます、といった話な模様。routerが学習されているのでinference時にsearchは不要。
[Paper Note] SimulatorArena: Are User Simulators Reliable Proxies for Multi-Turn Evaluation of AI Assistants?, Yao Dou+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #NLP #UserModeling #LanguageModel #UserBased #Evaluation #Conversation #EMNLP Issue Date: 2025-10-16 GPT Summary- SimulatorArenaを導入し、909件の人間-LLM会話を用いて、数学指導と文書作成の2つのタスクにおけるシミュレーターの評価を行う。シミュレーターのメッセージが人間の行動と一致する度合いや、アシスタント評価が人間の判断と整合する度合いを基に評価。条件付けされたシミュレーターが人間の判断と高い相関を示し、実用的な代替手段を提供。最新の18のLLMをベンチマーク。 Comment
元ポスト:
マルチターンの会話においてAIと人間との対話(数学のtutoring, 文書の作成支援)を評価する際に、実際の人間はコストがかかりスケールしないのでLLMを人間の代替とし評価ができるか?どのようにすればLLMを人間の振る舞いと整合させられるか?といった話しで、25種類以上のattributeによるユーザプロファイルを用いることが有効だった(人間の評価結果に対して、ユーザプロファイルを用いたLLMシミュレーターがより高い相関を示した)というような話しらしい。
[Paper Note] Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models, Junhyuck Kim+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Quantization #Reasoning #Test-Time Scaling #MemoryOptimization Issue Date: 2025-10-15 GPT Summary- 4ビット量子化はメモリ最適化に有効ですが、推論モデルには適用できないことを示す。体系的な実験により、モデルサイズとKVキャッシュの影響を発見。小規模モデルは重みを優先し、大規模モデルは生成にメモリを割り当てることで精度を向上。LLMのメモリ最適化はスケールに依存し、異なるアプローチが必要であることを示唆。 Comment
元ポスト:
Reasoning Modelにおいて、メモリのbudgetに制約がある状況下において、
- モデルサイズ
- 重みの精度
- test-time compute (serial & parallel)
- KV Cacheの圧縮
において、それらをどのように配分することでモデルのAcc.が最大化されるか?という話しな模様。
[Paper Note] EVALUESTEER: Measuring Reward Model Steerability Towards Values and Preferences, Kshitish Ghate+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Alignment #Evaluation Issue Date: 2025-10-15 GPT Summary- EVALUESTEERは、ユーザーの多様な価値観やスタイルに対応するためのベンチマークであり、LLMsと報酬モデル(RMs)の操縦性を測定します。165,888の好みペアを生成し、ユーザーのプロファイルに基づく応答の選択精度を評価。完全なプロファイルでは75%未満の精度に対し、関連する好みのみで99%以上の精度を達成。EVALUESTEERは、RMsの限界を明らかにし、多様な価値観に対応するためのテストベッドを提供します。 Comment
元ポスト:
LLNのAlignmentはしばしばReward Modelをベースに実施されるが、現在のReward Modelに存在する、価値観(4種類)とスタイル(4種類)に関するバイアスが存在することを明らかにしている模様。
[Paper Note] Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers, Wenhan Ma+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #MoE(Mixture-of-Experts) #PostTraining #Stability Issue Date: 2025-10-14 GPT Summary- 強化学習(RL)を用いたMixture-of-Experts(MoE)モデルのトレーニングと推論の不一致を分析し、Rollout Routing Replay(R3)を提案。R3は推論時のルーティング分布を記録し、トレーニング中に再生することで、トレーニングと推論のポリシー間のKLダイバージェンスを減少させ、安定性を向上。実験により、R3がRLトレーニングの崩壊を防ぎ、他の手法を上回る性能を示した。 Comment
元ポスト:
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
のMoE版の話。Inference EngineとTraining Engine側でExpertsの選択が一致しないことが不安定につながるので、それを一致させるようにする、という話な模様。
[Paper Note] Verifying Chain-of-Thought Reasoning via Its Computational Graph, Zheng Zhao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Reasoning #read-later #Selected Papers/Blogs #Verification #Author Thread-Post Issue Date: 2025-10-14 GPT Summary- Circuit-based Reasoning Verification (CRV)を提案し、CoTステップの帰属グラフを用いて推論エラーを検証。エラーの構造的署名が予測的であり、異なる推論タスクで異なる計算パターンが現れることを示す。これにより、モデルの誤った推論を修正する新たなアプローチを提供し、LLM推論の因果理解を深めることを目指す。 Comment
元ポスト:
著者ポスト:
transformer内部のactivationなどから計算グラフを構築しreasoningのsurface(=観測できるトークン列)ではなく内部状態からCoTをverification(=CoTのエラーを検知する)するようなアプローチ(white box method)らしい
[Paper Note] ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory, Matthew Ho+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#MachineLearning #NLP #Abstractive #LanguageModel #Reasoning #Generalization #memory #Test-time Learning Issue Date: 2025-10-13 GPT Summary- LLMは推論時に外部メモリを活用し、概念レベルのメモリを導入することで、再利用可能でスケーラブルな知識の保存を実現。これにより、関連する概念を選択的に取得し、テスト時の継続的学習を可能にする。評価はARC-AGIベンチマークで行い、メモリなしのベースラインに対して7.5%の性能向上を達成。動的なメモリ更新が自己改善を促進することを示唆。 Comment
元ポスト:
ARC-AGIでしか評価されていないように見える。
[Paper Note] GUIDE: Towards Scalable Advising for Research Ideas, Yaowenqi Liu+, arXiv'25, 2025.07
Paper/Blog Link My Issue
#NLP #LanguageModel #ScientificDiscovery #read-later #IdeaGeneration Issue Date: 2025-10-12 GPT Summary- AI研究の進展に伴い、自動化された仮説生成や実験設計が可能になっているが、高品質なフィードバックを提供するアドバイジングシステムには依然として課題がある。本研究では、モデルのサイズや信頼度の推定など、効果的なアドバイジングシステムの要因を探求し、比較的小さなモデルが圧縮された文献データベースと構造化された推論フレームワークを用いることで、強力な言語モデルを上回る受理率を達成できることを示した。特に、高信頼度の予測において90%以上の受理率を達成し、仮説生成と実験設計の質を向上させる可能性を示唆している。 Comment
pj page: https://howardliu0830.github.io/GUIDE_blog/
元ポスト:
どのように評価したのだろうか
pj pageによると、ICMLのsubmissionのうちランダムな1000件を用いて、モデルにpaperをスコアリングさせる。そして、モデルがスコアリングした中で上位5%(spotlightの割合に相当)、30%のprecision(実際のacceptanceの閾値相当の割合)と、モデルがスコアリングした上位30パーセントの論文の現代のAcceptanceに対するRecallを求めて評価している模様。7Bモデルでより大きいモデルと同等程度の性能を示している。
手法は後ほど追記したいが、Acceptを予測ふるタスクは論文に対して適切なフィードバックできることに直接的には繋がらないのでは?と思い、inferenceのpromptを見てみると、LLMにabst, contribution, method, experimental setupを入力し、実際の査読と似たような評価をさせ、その結果に基づいてratingをpredictionするような形式に見える。このため、rating predictionの過程で評価結果のフィードバックが生成されるので、論文の改善ができる、というユースケースだと思われる。
[Paper Note] Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models, Sharut Gupta+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #MachineLearning #MultiModal #UMM #Author Thread-Post Issue Date: 2025-10-10 GPT Summary- UML(Unpaired Multimodal Learner)を提案し、非ペアのマルチモーダルデータを活用して表現学習を強化する新しいトレーニングパラダイムを示す。異なるモダリティからの入力を交互に処理し、明示的なペアを必要とせずにクロスモーダル構造から利益を得る。実験により、テキスト、音声、画像などの非ペアデータを用いることで、単一モダルターゲットのパフォーマンスが向上することを確認。 Comment
pj page: https://unpaired-multimodal.github.io
モダリティ間で(モダリティごとのエンコーダとデコーダ以外の)パラメータを共有し(UMMs)、通常はpair-dataで学習するが、unpaired data(+self-supervised / 分類ヘッドを用いた(ここはしっかり読めてないので自信ない)supervised learning)で学習する。これによりダウンストリームタスクでの性能が向上する。
unpaired dataで学習するという点が革新的に見える。unpaired dataで学習する枠組みにより大量のデータを活用し表現を学習できる。また、ペアデータで学習することによりパラメータに埋め込める知識やスキルが(おそらく)限られていたが、より広範な知識やスキルを埋め込めるのでは、という印象がある。
元ポスト:
著者ポスト:
[Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #NLP #LanguageModel #RepresentationLearning #RAG(RetrievalAugmentedGeneration) #ICLR #read-later #Selected Papers/Blogs Issue Date: 2025-10-08 GPT Summary- 生成的表現指示チューニング(GRIT)を用いて、大規模言語モデルが生成タスクと埋め込みタスクを同時に処理できる手法を提案。GritLM 7BはMTEBで新たな最先端を達成し、GritLM 8x7Bはすべてのオープン生成モデルを上回る性能を示す。GRITは生成データと埋め込みデータの統合による性能損失がなく、RAGを60%以上高速化する利点もある。モデルは公開されている。 Comment
openreview: https://openreview.net/forum?id=BC4lIvfSzv
従来はgemerativeタスクとembeddingタスクは別々にモデリングされていたが、それを統一的な枠組みで実施し、両方のタスクで同等のモデルサイズの他モデルと比較して高い性能を達成した研究。従来のgenerativeタスク用のnext-token-prediction lossとembeddingタスク用のconstastive lossを組み合わせて学習する(式3)。タスクの区別はinstructionにより実施し、embeddingタスクの場合はすべてのトークンのlast hidden stateのmean poolingでrepresentationを取得する。また、embeddingの時はbi-directional attention / generativeタスクの時はcausal maskが適用される。これらのattentionの適用のされ方の違いが、どのように管理されるかはまだしっかり読めていないのでよくわかっていないが、非常に興味深い研究である。
[Paper Note] D3: A Dataset for Training Code LMs to Act Diff-by-Diff, Piterbarg+, COLM'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Coding #mid-training #COLM #Editing Issue Date: 2025-10-08 Comment
openreview: https://openreview.net/forum?id=sy71y74U80#discussion
openreviewのサマリによると、8B tokens, 850k python filesのデータセットで、コーディングタスクを、ゴールで条件づけられたsequential editsタスクとみなし The Stack上のコードを分析ツールとLLMによって合成されたrationaleによってフィルタリング/拡張したデータを提供しているとのこと。具体的には (state, goal, action_i) の3つ組みのデータセットであり、action_iがaction前後でのdiffになっている模様。D3データセットでSFTの前にLlama 1B / 3Bをmid-trainingした結果、downstreamタスク(コード生成、completion、編集)において性能が向上したとのこと。
[Paper Note] Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use, Anna Goldie+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Multi #NLP #Dataset #LanguageModel #ReinforcementLearning #SyntheticData #COLM Issue Date: 2025-10-08 GPT Summary- 段階的強化学習(SWiRL)を提案し、複数のテキスト生成や推論ステップを通じて大規模言語モデルの性能を向上させる手法を紹介。SWiRLは、各アクションに対するサブ軌道を生成し、合成データフィルタリングと強化学習最適化を適用。実験では、GSM8KやHotPotQAなどのタスクでベースラインを上回る精度を達成し、タスク間での一般化も示された。 Comment
openreview: https://openreview.net/forum?id=oN9STRYQVa
元ポスト:
従来のRLではテキスト生成を1ステップとして扱うことが多いが、複雑な推論やtool useを伴うタスクにおいては複数ステップでの最適化が必要となる。そのために、多段階の推論ステップのtrajectoryを含むデータを作成し、同データを使いRLすることによって性能が向上したという話な模様。RLをする際には、stepごとにRewardを用意するようである。また、現在のstepの生成を実施する際には過去のstepの情報に基づいて生成する方式のようである。
[Paper Note] Magistral, Mistral-AI+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-10-07 GPT Summary- Mistralの推論モデルMagistralと独自の強化学習パイプラインを紹介。ゼロからのアプローチで、LLMのRLトレーニングの限界を探り、テキストデータのみでのRLが能力を維持することを示す。Magistral MediumはRLのみで訓練され、Magistral Smallはオープンソース化。 Comment
元ポスト:
関連:
- Magistral-Small-2509, MistralAI, 2025.09
MistralAIの初めてのreasoningモデル
[Paper Note] Prompt Curriculum Learning for Efficient LLM Post-Training, Zhaolin Gao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #ReinforcementLearning #CurriculumLearning #On-Policy #Batch Issue Date: 2025-10-04 GPT Summary- Prompt Curriculum Learning (PCL)を提案し、中程度の難易度のプロンプトを選択してLLMをポストトレーニングする軽量な強化学習アルゴリズムを紹介。最適なバッチサイズとプロンプト選択の重要性を実験で確認し、PCLは情報豊富なプロンプトに焦点を当てることで高いパフォーマンスを達成。ロールアウトを回避し、MATHおよびDeepScaleRでそれぞれ$12.1\times$および$16.9\times$の速度向上を実現。結果は、推論におけるRLの効率とパフォーマンスのトレードオフを改善する新たな方法論を示す。 Comment
元ポスト:
(ざっくり読みなので誤りを多分に含むかもしれないがメモ)勾配のノイズの低減と生成の速度のトレードオフを最適にバランスをとるバッチサイズがあることを示し、RLの学習効率が中間程度(簡単すぎず、難しすぎない)の難易度が良いことを示したのち、Valueモデル(ロールアウトに基づいて更新される模様?)を用いてpromptを選択し[^1]中間程度のpromptを用いてロールアウトをし学習するようなオンポリシーのRLを提案する、みたいな話な模様。
[^1]:既存手法のロールアウトによって求める方法(計算コストが高すぎる)や、事前に決めておいた辞書ベースの手法(現在のポリシーからみた時の難易度が反映されておらず効率が悪い)の双方に比べて、適度にオンポリシーさを残したpromptの選び方となっている
[Paper Note] Large Reasoning Models Learn Better Alignment from Flawed Thinking, ShengYun Peng+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #SyntheticData #Safety #Author Thread-Post Issue Date: 2025-10-04 GPT Summary- RECAPは、誤った推論を覆し安全な応答に導くための強化学習手法。合成生成された反対整合CoTを用いて訓練し、安全性と堅牢性を向上させる。RECAPで訓練されたモデルは自己反省が頻繁で、適応攻撃にも強い。 Comment
元ポスト:
安全でない(欠陥のある)Reasoning traceを修復するような学習をさせることでよりロバストなsafety algnmentが実現できます、といった話な模様
著者ポスト:
[Paper Note] LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training, Xiang An+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #OpenWeight #OpenSource #VisionLanguageModel Issue Date: 2025-10-04 GPT Summary- LLaVA-OneVision-1.5は、計算コストと財政コストを削減しつつ最先端のパフォーマンスを実現する新しい大規模マルチモーダルモデルです。オープンで効率的なフレームワークを提供し、85Mの事前学習データセットと26Mの指示データセットを含む大規模キュレーションデータセットを構築しました。効率的なトレーニングフレームワークにより、限られた予算内でのトレーニングが可能となり、幅広い下流タスクで競争力のある性能を示しています。特に、LLaVA-OneVision-1.5-8Bは18のベンチマークでQwen2.5-VL-7Bを上回り、4Bモデルは全ての27のベンチマークでQwen2.5-VL-3Bを超えています。今後、LLaVA-OneVision-1.5-RLのリリースも予定されています。 Comment
元ポスト:
各種ベンチでQwen2.5-VL超え
pj page: https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-1.5
ポイント解説:
[Paper Note] DeepSearch: Overcome the Bottleneck of Reinforcement Learning with Verifiable Rewards via Monte Carlo Tree Search, Fang Wu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Search #LanguageModel #ReinforcementLearning #read-later #RLVR #On-Policy #ReplayBuffer #TreeSearch Issue Date: 2025-10-04 GPT Summary- DeepSearchは、RLVRトレーニングにMonte Carlo Tree Searchを統合し、体系的な探索を可能にするフレームワーク。これにより、限られたロールアウトに依存せず、重要な推論経路を見逃さない。実験では、62.95%の平均精度を達成し、1.5B推論モデルで新たな最先端を確立。戦略的な探索の重要性を示し、RLVR手法の進展に向けた新たな方向性を提供。 Comment
元ポスト:
最近はRL時の探索空間を増やす取り組みが増えてきているように感じる。
- Replay BufferがPolicy Gradientで使えない理由, piqcy, 2019.03
にもあるように基本的にオンポリシーRLではリプレイバッファを使えないので何らかの工夫が必要、といった話があるが、この研究ではGRPOを前提としつつリプレイバッファを活用する枠組みとなっているようなので、どのような工夫が行われているのだろうか。勉強したい。
所見と解説:
[Paper Note] Data Mixing Can Induce Phase Transitions in Knowledge Acquisition, Xinran Gu+, NeurIPS'25 Spotlight, 2025.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #NeurIPS #read-later #Selected Papers/Blogs #DataMixture #PhaseTransition Issue Date: 2025-10-03 GPT Summary- LLMsの訓練において、知識が豊富なデータセットとウェブスクレイピングデータの混合が、知識獲得において位相転移を示すことを実証。モデルサイズを臨界値まで増加させると、記憶状態が急激に変化し、混合比率が臨界値を超えると急速に記憶が増加。これらの現象は容量配分に起因し、最適なデータ配分がモデルサイズや混合比率によって不連続に変わることを示す。 Comment
openreview: https://openreview.net/forum?id=tQZK5frjVU
高品質なデータ(knowledge-denseな合成データなど)とwebからスクレイピングしてきたような低品質なデータのDataMixtureの割合が一定ラインを超えると、(knowledge acquisitionの観点から)相転移が生じてスケーリングの挙動が変化することをコントロールされた実験によって示している模様。
DataMixtureの観点でいうと、モデルサイズを固定してDataMixtureの比率を変化させたときに、knowledge-denseなデータが一定閾値未満の場合は、モデルはこれらのデータから何も学習しないが、ある閾値を超えた途端に知識を学習し始める非線形な挙動となる。
一方DataMixtureの比率を固定して、モデルサイズを変化させた場合も同様の相転移が観測された、という感じらしい。
興味深い。
[Paper Note] RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization, Zhaoning Yu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #Reasoning #SelfImprovement #ICLR #read-later #Author Thread-Post Issue Date: 2025-10-03 GPT Summary- RESTRAINは、自己ペナルティを用いた強化学習フレームワークで、ラベル付きデータなしでモデルを改善する。過信的な回答をペナルティ化し、未ラベルデータからの学習信号を活用することで、困難な推論ベンチマークにおいて大きな向上を達成。従来のゴールドラベル付きトレーニングに匹敵する性能を示し、効果的な推論の拡張が可能であることを示す。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=87ySF7viys
著者による一言解説:
votingによるself-improvingなRLの枠組みから脱却し、全ての応答に対してペナルティ方式でペナルティを与え(一貫性の乏しいロールアウトなど)異なる重みを与えて学習シグナルとする。
[Paper Note] Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls, Feiyang Kang+, EMNLP'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #SyntheticData #EMNLP #Selected Papers/Blogs #DataMixture #PhaseTransition Issue Date: 2025-10-03 GPT Summary- 合成データ技術はLLMのトレーニングデータの供給制限を克服する可能性を持つ。本研究では、自然なウェブデータと合成データの混合を比較し、言い換えた合成データのみでの事前トレーニングは自然なデータよりも速くないことを示した。1/3の言い換えた合成データと2/3の自然データの混合が、より効率的なトレーニングを可能にすることが分かった。教科書スタイルの合成データは小さなデータ予算で高い損失をもたらし、合成データの最適な比率はモデルサイズとデータ予算に依存する。結果は合成データの効果を明らかにし、実用的なガイダンスを提供する。 Comment
元ポスト:
ポイント解説:
合成データは適切な規模のモデルと比率でないと利点が現れない
[Paper Note] Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It, Shuyue Stella Li+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #UserModeling #Dataset #LanguageModel #UserBased #Personalization #Evaluation #Conversation #read-later Issue Date: 2025-10-03 GPT Summary- 現在のLLMは、タスク解決とユーザーの好みの整合性を別々に扱っており、特にジャストインタイムのシナリオでは効果的ではない。ユーザーの好みを引き出し、応答を適応させる「パーソナライズド推論」が必要である。新たに提案された評価手法「PREFDISCO」は、ユーザーのコンテキストに応じた異なる推論チェーンを生成し、パーソナライズの重要性を示す。評価結果から、単純なパーソナライズが一般的な応答よりも劣ることが明らかになり、専用の開発が必要であることが示唆された。PREFDISCOは、教育や医療などの分野でのパーソナライズの重要性を強調する基盤を提供する。 Comment
元ポスト:
ざーっとしか読めていないのが、ユーザから与えられたタスクとマルチターンの会話の履歴に基づいて、LLM側が質問を投げかけて、Personalizationに必要なattributeを取得する。つまり、ユーザプロファイルは (attribute, value, weight)のタプルによって構成され、この情報に基づいて生成がユーザプロファイルにalignするように生成する、といった話に見える。膨大なとりうるattributeの中から、ユーザのタスクとcontextに合わせてどのattributeに関する情報を取得するかが鍵となると思われる。また、セッション中でユーザプロファイルを更新し、保持はしない前提な話に見えるので、Personalizationのカテゴリとしては一時的個人化に相当すると思われる。
Personalizationの研究は評価が非常に難しいので、どのような評価をしているかは注意して読んだ方が良いと思われる。
[Paper Note] ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory, Siru Ouyang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #read-later #Selected Papers/Blogs #memory #Test-time Learning Issue Date: 2025-09-30 GPT Summary- ReasoningBankという新しいメモリフレームワークを提案し、エージェントが成功体験と失敗体験から推論戦略を抽出できるようにする。テスト時には関連メモリを活用し、学びを統合することで能力を向上させる。さらに、メモリを意識したテスト時スケーリング(MaTTS)を導入し、エージェントの体験を多様化・拡大する。これにより、ウェブブラウジングやソフトウェアエンジニアリングのベンチマークで既存のメモリメカニズムを上回る効果と効率を実現。メモリ駆動の経験スケーリングを新たな次元として確立し、エージェントの自己進化を促進する。 Comment
元ポスト:
メモリを良質なものに更新、蓄積し続けることで性能がスケールするのであれば、新たなtest-time scalingのパラダイムになりそう。
ざっくり読んでみると本研究ではこのパラダイムのことをTest-Time Learningと呼称している(先行研究が2つ引用されているがざっと見た限りでは両者はそう言った呼称はしていないように見えた)。
すなわち、クエリのストリームが到達した時に将来のクエリを見ることはできずに、過去のクエリに対するtrajectoryや、self-verificationなどによってのみラベル無しで自己進化していくパラダイムのこと。
関連:
- [Paper Note] M+: Extending MemoryLLM with Scalable Long-Term Memory, Yu Wang+, ICML'25, 2025.02
openreview: https://openreview.net/forum?id=jL7fwchScm
[Paper Note] Interactive Recommendation Agent with Active User Commands, Jiakai Tang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #read-later #Selected Papers/Blogs #interactive Issue Date: 2025-09-29 GPT Summary- 従来のレコメンダーシステムは受動的なフィードバックに依存し、ユーザーの意図を捉えられないため、嗜好モデルの構築が困難である。これに対処するため、インタラクティブレコメンデーションフィード(IRF)を導入し、自然言語コマンドによる能動的な制御を可能にする。RecBotという二重エージェントアーキテクチャを開発し、ユーザーの嗜好を構造化し、ポリシー調整を行う。シミュレーション強化知識蒸留を用いて効率的なパフォーマンスを実現し、実験によりユーザー満足度とビジネス成果の改善を示した。 Comment
元ポスト:
ABテストを実施しているようなので信ぴょう性高め
[Paper Note] CWM: An Open-Weights LLM for Research on Code Generation with World Models, FAIR CodeGen team+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Coding #OpenWeight #mid-training #PostTraining #Selected Papers/Blogs #WorldModels Issue Date: 2025-09-25 GPT Summary- 320億パラメータのCode World Model (CWM)をリリースし、コード生成のための世界モデルの研究を進める。静的コードだけでなく、PythonインタプリタやDocker環境から得た観測-行動トレジェクトリで中間トレーニングを実施し、マルチタスク推論RLによる広範な能力を評価。CWMは強力なテストベッドを提供し、世界モデルがエージェンティックコーディングに貢献できることを示す。主要なタスクで高いパフォーマンスを記録し、モデルチェックポイントも提供。 Comment
元ポスト:
World Modelと銘打ってあるが、一般的なCV分野でのWorld Modelではなく、python やbash等の実行をトークン列として仮想的にトレースできるようにmid trainingされている(大量の実トレースデータが利用されている模様)ので、World Modelと銘打たれている模様?
GRPOに対するモダンなtweakがまとまっている模様:
DeepSeek-R1で提案されてから細かな調整が重ねられて来た。
[Paper Note] ARE: Scaling Up Agent Environments and Evaluations, Pierre Andrews+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs Issue Date: 2025-09-23 GPT Summary- Meta Agents Research Environments (ARE)を紹介し、エージェントのオーケストレーションや環境のスケーラブルな作成を支援するプラットフォームを提供。Gaia2というベンチマークを提案し、エージェントの能力を測定するために設計され、動的環境への適応や他のエージェントとの協力を要求。Gaia2は非同期で実行され、新たな失敗モードを明らかにする。実験結果は、知能のスペクトル全体での支配的なシステムが存在しないことを示し、AREの抽象化が新しいベンチマークの迅速な作成を可能にすることを強調。AIの進展は、意味のあるタスクと堅牢な評価に依存する。 Comment
元ポスト:
GAIAはこちら:
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
Execution, Search, Ambiguity, Adaptability, Time, Noise, Agent2Agentの6つのcapabilityを評価可能。興味深い。
現状、全体的にはGPT-5(high)の性能が最も良く、続いてClaude-4 Sonnetという感じに見える。OpenWeightなモデルでは、Kimi-K2の性能が高く、続いてQwen3-235Bという感じに見える。また、Figure1はbudgetごとのモデルの性能も示されている。シナリオ単位のbudgetが$1以上の場合はGPT-5(high)の性能が最も良いが、$0.1--$0.4の間ではKiml-K2の性能が最も良いように見える。
- [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
しっかりと読めていないがGLM-4.5は含まれていないように見える。
ポイント解説:
[Paper Note] Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion, Xun Huang+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #Transformer #DiffusionModel #VariationalAutoEncoder #NeurIPS #PostTraining #Selected Papers/Blogs #VideoGeneration/Understandings Issue Date: 2025-09-19 GPT Summary- Self Forcingは、自動回帰型ビデオ拡散モデルの新しいトレーニング手法で、エクスポージャーバイアスの問題に対処します。従来の手法が真のコンテキストに基づくのに対し、Self Forcingは自己生成した出力に基づいてフレームを生成し、全体の品質を評価するホリスティックな損失を用います。計算コストとパフォーマンスのバランスを取るために、少数ステップの拡散モデルと確率的勾配切断を採用し、ロールイングKVキャッシュメカニズムを導入。実験により、リアルタイムのストリーミングビデオ生成が可能で、非因果的拡散モデルの生成品質に匹敵またはそれを上回ることが示されました。 Comment
pj page: https://self-forcing.github.io
元ポスト:
自己回帰的な動画生成(をする)モデルにおいて、学習時はground-truchのcontextが利用して学習されるが、推論時は自身が生成結果そのものをcontextとして利用するため、学習-推論時にgapが生じ、(徐々に誤差が蓄積することで)品質が劣化するという問題(exposure bias)に対処するために、学習時から自身が生成した出力をcontextとして与えて生成を行い(ロールアウト)、動画全体に対して分布の整合性を測るlossを導入(=フレーム単位の誤差を最小化にするのではなく、動画全体に対して(分布の)誤差を最適化する)することで、exposure biasを軽減する、という話な模様。
結果的に、単一のRTX4090でリアルタイムのストリーミングビデオ生成が高品質に生成可能となった(かもしれない):
https://note.com/ngc_shj/n/n505b2f7cdfe4
[Paper Note] Parallel-R1: Towards Parallel Thinking via Reinforcement Learning, Tong Zheng+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Mathematics Issue Date: 2025-09-10 GPT Summary- Parallel-R1は、複雑な推論タスクに対して並列思考を可能にする強化学習フレームワークであり、コールドスタート問題に対処するための進行的なカリキュラムを採用。簡単なタスクから始め、並列思考能力を植え付けた後、難しい問題に移行。実験により、従来の逐次思考モデルに対して8.4%の精度向上を達成し、並列思考が中間トレーニング探索の足場として機能することを示した。 Comment
元ポスト:
結果の表を見るとベースモデルで単にself Consistencyを実施するよりも高いゲインを得ているように見える。モデルがQwen3のみでしか実験されておらず、Qwen2.5においてコンタミネーションの疑い [Paper Note] Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, Mingqi Wu+, arXiv'25 があったので、(Qwen3がどうかはわからないが)単一モデルではなく、他のモデルでも実験した方が良いのかな、という印象。
ポイント解説:
ポイント解説:
コードがリリース:
[Paper Note] Ovis2.5 Technical Report, Shiyin Lu+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #Reasoning #OpenWeight #CurriculumLearning #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-08-28 GPT Summary- Ovis2.5は、ネイティブ解像度の視覚認識とマルチモーダル推論を強化するために設計されたモデルで、画像を可変解像度で処理し、複雑な視覚コンテンツの詳細を保持します。推論時には反省を行う「思考モード」を提供し、精度向上を図ります。5段階のカリキュラムで訓練され、マルチモーダルデータの効率的な処理を実現。Ovis2.5-9BはOpenCompassで平均78.3を記録し、Ovis2-8Bに対して大幅な改善を示しました。Ovis2.5-2Bも73.9を達成し、リソース制約のあるデバイスに最適です。STEMベンチマークや複雑なチャート分析においても優れた性能を発揮しています。 Comment
元ポスト:
HF:
https://huggingface.co/AIDC-AI/Ovis2.5-9B
Apache2.0ライセンス
GLM-4.1V-9B-Thinkingと同等以上の性能な模様。
- [Paper Note] GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning, GLM-V Team+, arXiv'25, 2025.07
[Paper Note] DINOv3, Oriane Siméoni+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #Self-SupervisedLearning #Distillation #Regularization #read-later #Selected Papers/Blogs #Backbone #Reference Collection #needs-revision Issue Date: 2025-08-14 GPT Summary- 自己教師付き学習は、手動でのデータ注釈を不要とし、モデルのスケーラビリティを向上させる。DINOv3は、様々なデータソースから視覚表現を学ぶための新たな枠組みを提供し、データセットとモデルサイズの拡張や密な特徴マップの劣化問題に対処する「グラム・アンカリング」を導入。また、後処理戦略により柔軟性を高め、ファインチューニングなしで様々な設定で最先端の性能を発揮する。DINOv3は高品質な特徴量を生成し、広範な視覚タスクにおいて優れた結果を示し、多様なデプロイメントシナリオに対応するソリューションを提供する。 Comment
元ポスト:
HF: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
解説:
サマリ:
v2:
- [Paper Note] DINOv2: Learning Robust Visual Features without Supervision, Maxime Oquab+, TMLR'24
本日配信された岡野原氏のランチタイムトークによると、学習が進んでいくと全部の特徴量が似通ってきてしまう問題があったが、Gram Anchoringと呼ばれる、学習初期時点でのパッチ間の類似度度行列を保持しておき正則化として損失に加えることで、そこから離れすぎないように学習するといった工夫を実施しているとのこと。
詳細な日本語解説:
https://zenn.dev/syu_tan/articles/6df2947eb6c1ae
Gram Anchoringの気持ちとしては、長期で学習をすると、モデルがグローバルな特徴量を学習可能だが、個々のパッチレベルや密な部分のローカルな特徴量が失われていってしまい、ローカルな特徴が重要なdownstreamタスクの性能が劣化するため、これをなんとかしたい。そのために、画像全体のパッチ間の類似度行列によって、パッチ全体の類似度の構造を捉え、学習初期の高品質なローカルな特徴を捉えられたモデルを教師とし、そこから離れすぎないように学習中のモデルを生徒として正則化することで解決する、というものだと思われる。
事前学習のスケジューラーの工夫として以下を実施している:
- 事前学習の終了タイミングを事前に予測することは困難
- →事前に総ステップ数を指定しなければならないパラメータのスケジューリングはそもそも困難
- →スケジューリングを廃止する
- スケジューリングを廃止する代わりに
- 学習率とweight decay、teacher EMAのmomentumを固定して学習を実施
-
[Paper Note] Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful, Martin Marek+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Batch #Reference Collection Issue Date: 2025-07-12 GPT Summary- 小さなバッチサイズに対するAdamのハイパーパラメータをスケーリングする新しいルールを提案。これにより、小さなバッチサイズでも安定したトレーニングが可能で、大きなバッチサイズと同等以上のパフォーマンスを達成。勾配蓄積は推奨せず、実用的なハイパーパラメータ設定のガイドラインを提供。 Comment
元ポスト:
論文中のFigure1において、AdamWにおいてbatchsizeが1の方が512の場合と比べてlearning_rateの変化に対してロバストである旨が記述されている。
似たような話でMTでバッチサイズ小さいほうが性能良いです、みたいな話が昔あったような
(追記)
気になって思い出そうとしていたが、MTではなく画像認識の話だったかもしれない(だいぶうろ覚え)
- [Paper Note] Revisiting Small Batch Training for Deep Neural Networks, Dominic Masters+, arXiv'18
参考:
関連:
- How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25
解説:
実際に8Bモデルの事前学習においてβ2を0.99にしたところ、学習が不安定になり、かつ最終的なPerplexityも他の設定に勝つことができなかったとのこと:
[Paper Note] The Curse of Depth in Large Language Models, Wenfang Sun+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #NeurIPS #Normalization #Selected Papers/Blogs #CurseOfDepth Issue Date: 2025-07-03 GPT Summary- 「深さの呪い」を提案し、現代のLLMにおける多くの層が期待通りに機能しない原因を探る。特にPre-Layer Normalizationが出力分散を増大させ、深層ブロックの寄与を低下させることを明らかにする。層正規化の出力分散を深さの平方根の逆数で調整する「LayerNorm Scaling」を導入し、これにより深い層の寄与を改善。実験で130M〜7Bモデルサイズで従来の手法を上回る性能向上を示し、教師ありファインチューニングにも良好な効果を発揮することを確認。 Comment
元ポスト:
- [Paper Note] Transformers without Normalization, Jiachen Zhu+, CVPR'25
ではそもそもLayerNormalizationを無くしていた(正確にいうとparametrize tanhに置換)が、どちらが優れているのだろうか?
- Knowledge Neurons in Pretrained Transformers, Damai Dai+, N/A, ACL'22, 2022.05
では知識ニューロンの存在が示唆されており、これはTransformerの層の深い位置に存在し、かつ異なる知識間で知識ニューロンはシェアされない傾向にあった(ただしこれはPost-LNのBERTの話で本研究はPre-LNの話だが。Post-LNの勾配消失問題を緩和し学習を安定化させる研究も[Paper Note] On Layer Normalizations and Residual Connections in Transformers, Sho Takase+, arXiv'22
のように存在する)。これはこの研究が明らかにしたこととどういう関係性があるだろうか。
また、LayerNormalizationのScalingによって深いTransformerブロックの導関数が単位行列となる(学習に寄与しなくなる)ことが改善された場合、知識ニューロンはどのように変化するだろうか?
(下記Geminiの応答を見た上での感想)なんとなーくだけれども、おそらく知識ニューロンの局所化が解消されるのかなーという気がする。
となると次の疑問としては、MoEアーキテクチャにはどのような影響があるだろうか?
そもそも知識ニューロンが局所化しているからMoEアーキテクチャのルータによって関連するExpertsのみをactivateすれば(というより結果的にそうなるように学習される)性能を劣化させずに計算効率を上げられていた、と仮定する。そうすると、知識ニューロンが局所化せずに多くのニューロンでシェアされるようになると、[Paper Note] Chain-of-Experts: Unlocking the Communication Power of Mixture-of-Experts Models, Zihan Wang+, arXiv'25
のように、サブネットワーク間の情報を互いにやりとりできます、みたいな仕組みがより効いてきそうな気がする。
参考までに、Gemini2.5-Proに考察させてみた結果をメモとして残しておく(あくまで参考程度に...)
```
ご質問ありがとうございます。非常に興味深い着眼点ですね。「Knowledge Neurons in Pretrained Transformers」と「The Curse of Depth in Large Language Models」は、一見すると全く異なるテーマを扱っているように見えますが、**「Transformerの深い層における振る舞い」**という共通点で結びつけて考察すると、非常に示唆に富んだ関係性が見えてきます。
以下に、両方の論文の概要を解説し、その関係性について考察します。
1. Knowledge Neurons in Pretrained Transformers の概要
この研究は、事前学習済みTransformerモデル(特にBERTなど)の内部で、特定の事実知識がどのように格納されているかを調査したものです。
発見: モデルの中間層、特に**全結合層(Feed-Forward Network, FFN)に、特定の知識(例:「ダンテ・アリギエーリはイタリアで生まれた」)に強く反応する「知識ニューロン」**が存在することを発見しました。
特徴: これらの知識ニューロンは、モデルの深い層(後方の層)に、より多く存在する傾向がありました。
意味: これまでブラックボックスとされてきた大規模言語モデルの内部で、知識がどのように表現・局在化しているかについて、具体的な手がかりを与えた画期的な研究です。
2. The Curse of Depth in Large Language Models の概要
この研究は、LLMをより深く(層を多く)することの難しさに焦点を当て、その原因と解決策を提案したものです。
問題(深さの呪い): Transformerの標準的なアーキテクチャ(Pre-LN)では、層が深くなるにつれて、LayerNormalization(LN)への入力の分散が指数関数的に増大してしまいます。
結果:
出力が大きくなりすぎて学習が不安定になります。
さらに深刻なのは、深い層ではモデルの出力に関する導関数(勾配計算に必要)がほぼ単位行列になってしまうことです。これは、その層が入力に対してほとんど変換を行わなくなり、学習に寄与しなくなることを意味します。
解決策: この問題を解決するため、各層のLayerNormalizationをその深さ(レイヤー番号 l)に応じてスケーリングするというシンプルな手法を提案しました。これにより、深い層でも勾配が適切に伝播し、学習が安定・改善することが示されました。
考察:2つの研究の関係性
これら2つの研究は、**「学習の安定性」と「知識の格納方法」**という異なる側面から、Transformerの深い層を分析していますが、両者には以下のような深い関係性があると考えられます。
学習の不安定性が「知識ニューロン」形成の背景にある可能性
「The Curse of Depth」で指摘されているように、標準的なTransformerの深い層は、本質的に学習が不安定で、勾配情報が失われやすい環境にあります。
この劣悪な学習環境こそが、「知識ニューロン」という形で知識が局所的に格納される原因の一つになっている可能性があります。つまり、
学習の非効率性: 深い層のほとんどのニューロンは、勾配消失問題のために効率的に学習を進めることができません。
専門化の発生: そのような不安定な環境下で、たまたま特定の知識パターンをうまく捉えることができた一部のニューロンが、その知識を一身に背負う形で強く活性化するよう特化(専門化)していったのではないか、と考えられます。これは、ネットワーク全体で協調して学習するのが難しい状況で、一部のユニットだけが突出して学習を担う、という現象と解釈できます。
学習の安定化が、より効率的な知識獲得につながる
では、「The Curse of Depth」で提案された手法(LNのスケーリング)によって深い層の学習が安定化すると、知識の格納方法はどのように変わるでしょうか。
これは非常に興味深い問いであり、2つの可能性が考えられます。
可能性A: より強固な知識ニューロンの形成:
学習が安定することで、各知識ニューロンはより明確に、そして効率的に特定の知識をエンコードできるようになるかもしれません。ノイズの多い環境で偶然生まれた専門家ではなく、安定した環境で育成された真の専門家へと変化するイメージです。
可能性B: 知識の分散化:
ネットワークの全ニューロンが効率的に学習に寄与できるようになるため、一つの知識を少数のニューロンに集中させる必要がなくなり、より多くのニューロンに分散して知識が格納されるようになる可能性も考えられます。
現在のところ、学習の安定化は、知識ニューロンがより効率的に形成・機能するための基盤を提供すると考えるのが最も妥当でしょう。「深さの呪い」という問題を解決することは、モデルが知識をどのように獲得し、整理するかという、より根源的なメカニズム(知識ニューロンの振る舞い)にも直接的な影響を与えるはずです。
まとめ
「Knowledge Neurons」は深い層に存在する知識の**「状態」を明らかにし、「The Curse of Depth」は深い層で発生する学習の「問題」**とその解決策を提示しました。
これらを統合すると、**「深い層における学習の不安定性という問題が、知識ニューロンという局所的な知識表現を生み出す一因となっており、この問題を解決することで、より効率的で安定した知識の獲得・格納が可能になるかもしれない」**という関係性が見えてきます。
両者は、LLMの能力と限界を異なる角度から照らし出しており、組み合わせることでモデルの内部動作の解明をさらに一歩前進させる、非常に重要な研究だと言えます。
```
[Paper Note] Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations, Jiaming Han+, NeurIPS'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #NeurIPS #Tokenizer #UMM Issue Date: 2025-06-24 GPT Summary- 本論文では、視覚理解と生成を統一するマルチモーダルフレームワークTarを提案。Text-Aligned Tokenizer(TA-Tok)を用いて画像を離散トークンに変換し、視覚とテキストを統一空間に統合。スケール適応型のエンコーディングとデコーディングを導入し、高忠実度の視覚出力を生成。迅速な自己回帰モデルと拡散ベースのモデルを用いたデトークナイザーを活用し、視覚理解と生成の改善を実現。実験結果では、Tarが既存手法と同等以上の性能を示し、効率的なトレーニングを達成。 Comment
元ポスト:
text modalityとvision modalityを共通の空間で表現する
Visual Understanding/Generationのベンチで全体的に高い性能を達成
[Paper Note] Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting, Hao Feng+, ACL'25
Paper/Blog Link My Issue
#Document #NLP #Library #ACL #DocParser Issue Date: 2025-06-21 GPT Summary- 文書画像解析の新モデル「Dolphin」を提案。レイアウト要素をシーケンス化し、タスク特有のプロンプトと組み合わせて解析を行う。3000万以上のサンプルで訓練し、ページレベルと要素レベルの両方で最先端の性能を達成。効率的なアーキテクチャを実現。コードは公開中。 Comment
repo: https://github.com/bytedance/Dolphin
SoTAなDocumentのparser
ドキュメントに記述が見当たらないように見えたが、おそらくHFに付与されているタグを見る限り、英語と中国語をサポートしていると思われる
[Paper Note] AceReason-Nemotron 1.1: Advancing Math and Code Reasoning through SFT and RL Synergy, Zihan Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #OpenWeight #OpenSource #PostTraining #Author Thread-Post Issue Date: 2025-06-18 GPT Summary- 本研究では、教師ありファインチューニング(SFT)と強化学習(RL)の相乗効果を探求し、SFTトレーニングデータの整備においてプロンプト数の増加が推論性能を向上させることを示しました。特に、サンプリング温度を適切に調整することで、RLトレーニングの効果を最大化できることが分かりました。最終的に、AceReason-Nemotron-1.1モデルは、前モデルを大きく上回り、数学およびコードベンチマークで新たな最先端性能を達成しました。 Comment
元ポスト:
様々なtakeawayがまとめられている。
SFT,RLに利用されたデータも公開
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
において事前学習時に4 epochまでは性能の改善幅が大きいと報告されていたが、SFTでも5 epoch程度まで学習すると良い模様。
また、SFT dataをscalingさせる際は、promptの数だけでなく、prompt単位のresponse数を増やすのが効果的
[Paper Note] Wait, We Don't Need to "Wait" Removing Thinking Tokens Improves Reasoning Efficiency, Chenlong Wang+, EMNLP'25 Findings
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Chain-of-Thought #Reasoning #EMNLP Issue Date: 2025-06-18 GPT Summary- 自己反省を抑制する「NoWait」アプローチを提案し、推論の効率を向上。10のベンチマークで最大27%-51%の思考の連鎖の長さを削減し、有用性を維持。マルチモーダル推論のための効果的なソリューションを提供。 Comment
Wait, Hmmといったlong CoTを誘導するようなtokenを抑制することで、Accはほぼ変わらずに生成されるトークン数を削減可能、といった図に見える。Reasoningモデルでデコーディング速度を向上したい場合に効果がありそう。
元ポスト:
[Paper Note] RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning, Yu Wang+, EMNLP'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #EMNLP #Reading Reflections Issue Date: 2025-06-17 GPT Summary- RAG+は、Retrieval-Augmented Generationの拡張で、知識の適用を意識した推論を組み込む。二重コーパスを用いて、関連情報を取得し、目標指向の推論に適用する。実験結果は、RAG+が標準的なRAGを3-5%、複雑なシナリオでは最大7.5%上回ることを示し、知識統合の新たなフレームワークを提供する。 Comment
元ポスト:
知識だけでなく知識の使い方も蓄積し、利用時に検索された知識と紐づいた使い方を活用することでRAGの推論能力を向上させる。
Figure 1のような例はReasoningモデルが進化していったら、わざわざ知識と使い方を紐付けなくても、世界知識から使い方を補完可能だと思われるので不要となると思われる。
が、真にこの手法が力を発揮するのは「ドメイン固有の使い方やルール」が存在する場合で、どれだけLLMが賢くなっても推論によって導き出せないもの、のついては、こういった手法は効力を発揮し続けるのではないかと思われる。
[Paper Note] PropMEND: Hypernetworks for Knowledge Propagation in LLMs, Zeyu Leo Liu+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeEditing #FactualKnowledge #meta-learning #Author Thread-Post Issue Date: 2025-06-17 GPT Summary- PropMENDは、LLMsにおける知識伝播を改善するためのハイパーネットワークベースのアプローチである。メタ学習を用いて、注入された知識がマルチホップ質問に答えるために伝播するように勾配を修正する。RippleEditデータセットで、難しい質問に対して精度がほぼ2倍向上し、Controlled RippleEditデータセットでは新しい関係やエンティティに対する知識伝播を評価。PropMENDは既存の手法を上回るが、性能差は縮小しており、今後の研究で広範な関係への知識伝播が求められる。 Comment
元ポスト:
従来のKnowledge Editing手法は新たな知識を記憶させることはできる(i.e., 注入した知識を逐語的に生成できる;東京は日本の首都である。)が、知識を活用することは苦手だった(i.e., 日本の首都の気候は?)ので、それを改善するための手法を提案している模様。
既存手法のlimitationは
- editing手法で学習をする際に知識を伝搬させるデータが無く
- 目的関数がraw textではなく、QA pairをSFTすること
によって生じるとし、
- 学習時にpropagation question(Figure1のオレンジ色のQA; 注入した知識を活用して推論が必要なQA)を用意しどのように知識を伝搬(活用)させるかを学習し
- 目的関数をCausal Language Modeling Loss
にすることで改善する、とのこと。
non-verbatimなQA(注入された知識をそのまま回答するものではなく、何らかの推論が必要なもの)でも性能が向上。
ベースライン:
- [Paper Note] Mass-Editing Memory in a Transformer, Kevin Meng+, arXiv'22, 2022.10
- [Paper Note] Fast Model Editing at Scale, Eric Mitchell+, ICLR'22
[Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML #memory #Initial Impression Notes #Test Time Training (TTT) #Author Thread-Post Issue Date: 2025-06-12 GPT Summary- Text-to-LoRA(T2L)は、自然言語による説明に基づいて大規模言語モデル(LLMs)を迅速に適応させる手法で、従来のファインチューニングの高コストと時間を克服します。T2Lは、LoRAを安価なフォワードパスで構築するハイパーネットワークを使用し、タスク特有のアダプターと同等のパフォーマンスを示します。また、数百のLoRAインスタンスを圧縮し、新しいタスクに対してゼロショットで一般化可能です。このアプローチは、基盤モデルの専門化を民主化し、計算要件を最小限に抑えた言語ベースの適応を実現します。 Comment
元ポスト:
な、なるほど、こんな手が…!
openreview: https://openreview.net/forum?id=zWskCdu3QA
ポイント解説:
Text-to-LoRAの目的は、instructionをメモリの内部パラメータに埋め込み、モデルにon-the-flyで新たな挙動を身につけさせること。
[Paper Note] Generative Omnimatte: Learning to Decompose Video into Layers, Yao-Chih Lee+, CVPR'25
Paper/Blog Link My Issue
#ComputerVision #DiffusionModel #CVPR #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- オムニマット手法は、ビデオを意味的に有意義な層に分解することを目指すが、既存手法は静的背景や正確なポーズを前提としており、これが破られると性能が低下する。新たに提案する生成的層状ビデオ分解フレームワークは、静止シーンや深度情報を必要とせず、動的領域の補完を行う。核心的なアイデアは、ビデオ拡散モデルを訓練し、シーン効果を特定・除去することであり、これにより高品質な分解と編集結果を実現する。 Comment
元ポスト:
ざっくりしか読めていないが、Inputとして動画とmask(白:残す, 黒:消す, グレー: 不確定なオブジェクトやエフェクトが含まれるエリア≒背景?)を受け取り、Casperと呼ばれるモデルでオブジェクトを消し消した部分をinpaintingすることで、layerっぽいものを作成するっぽい?Casperは
project pageがサンプルもありとてもわかりやすい: https://gen-omnimatte.github.io
[Paper Note] SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond, Junteng Liu+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #SyntheticData #Reasoning #NeurIPS #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- SynLogicは、35の論理的推論タスクを網羅したデータ合成フレームワークで、強化学習(RL)による大規模言語モデル(LLMs)の推論能力向上を目指す。調整可能な難易度で生成されたデータは検証可能で、RLに適している。実験では、SynLogicが最先端の論理的推論性能を達成し、数学やコーディングタスクとの混合によりトレーニング効率が向上することが示された。SynLogicはLLMsの推論能力向上に貴重なリソースとなる。 Comment
元ポスト:
35種類のタスクを人手で選定し、タスクごとに困難度の鍵となるパラメータを定義(数独ならばグリッド数など)。その上で、各タスクごとに人手でルールベースのinstanceを生成するコードを実装し、さまざまな困難度パラメータに基づいて多様なinstanceを生成。生成されたinstanceの困難度は、近似的なUpper Bound(DeepSeek-R1, o3-miniのPass@10)とLower bound(chat model[^1]でのPass@10)を求めデータセットに含まれるinstanceの困難度をコントロールし、taskを記述するpromptも生成。タスクごとに人手で実装されたVerifierも用意されている。
Qwen2.5-7B-BaseをSynDataでDAPOしたところ、大幅にlogic benchmarkとmathematical benchmarkの性能が改善。
mathやcodeのデータとmixして7Bモデルを訓練したところ、32Bモデルに匹敵する性能を達成し、SynDataをmixすることでgainが大きくなったので、SynDataから学習できる能力が汎化することが示唆される。
タスク一覧はこちら
[^1]:どのchat modelかはざっと見た感じわからない。どこかに書いてあるかも。
Logical Reasoningが重要なタスクを扱う際はこのデータを活用することを検討してみても良いかもしれない
[Paper Note] Training Language Models to Generate Quality Code with Program Analysis Feedback, Feng Yao+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #AIAgents #Coding #NeurIPS #Author Thread-Post Issue Date: 2025-06-06 GPT Summary- プログラム分析に基づくフィードバックを用いた強化学習フレームワーク「REAL」を提案。セキュリティや保守性の欠陥を検出し、機能的正確性を保証することで、LLMsによる高品質なコード生成を促進。手動介入不要でスケーラブルな監視を実現し、実験により最先端の手法を上回る性能を示した。 Comment
元ポスト:
現在のCoding LLMはUnitTestを通るように学習されるが、UnitTestに通るからといってコードの品質が良いわけでは無いので、UnitTestに通るか否かのReward(Functionality)に加えて、RL中に生成されたコードを制御フローグラフ[^1]に変換し汚染解析[^2]をした結果をRewardに組み込むことで、FunctionalityとQualityを両立したよ、という話のようである。
Figure1のグラフの縦軸は、Functionalityと(UnitTestが通ったか否か)と、Quailty(セキュリティや保守性に関する問題が検出されなかった)、という両方の条件を満たした割合である点に注意。
[^1]:プログラムを実行したときに通る可能性のある経路のすべてをグラフとして表したもの[引用元](
https://qiita.com/uint256_t/items/7d4556cb8f5997b9e95c)
[^2]:信頼できない汚染されたデータがプログラム中でどのように処理されるかを分析すること
[Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Tasks and Verifiable Rewards, Ruipeng Jia+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #RLVR Issue Date: 2025-06-05 GPT Summary- RLVRを用いた新しい学習パラダイムを提案し、主観的評価を検証可能な報酬に変換。ペアワイズ生成報酬モデルとブートストラップ付き相対方針最適化を導入し、教師なしでLLMの執筆能力を向上。Writing-Zeroにより、スカラー報酬よりも一貫した改善を確認。社内およびオープンソースのベンチマークで競争力のある結果を達成し、全言語タスクに適用可能なRL訓練の道を示唆。 Comment
元ポスト:
Writing Principleに基づいて(e.g., 一貫性、創造性とか?)批評を記述し、最終的に与えられたペアワイズのテキストの優劣を判断するGenerative Reward Model (GenRM; Reasoning Traceを伴い最終的にRewardに変換可能な情報をoutpuするモデル) を学習し、現在生成したresponseグループの中からランダムに一つ擬似的なreferenceを決定し、他のresponseに対しGenRMを適用することで報酬を決定する(BRPO)、といったことをやるらしい。
これにより、創造的な文書作成のような客観的なground truthを適用できないタスクでも、RLVRの恩恵をあずかれるようになる(Bridging the gap)といったことを主張している。
RLVRの恩恵とは、Reward Hackingされづらい高品質な報酬、ということにあると思われる。ので、要は従来のPreference dataだけで学習したReward Modelよりも、よりReward Hackingされないロバストな学習を実現できるGenerative Reward Modelを提案し、それを適用する手法BRPOも提案しました、という話に見える。
関連:
- [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25
[Paper Note] MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning, Yiqing Liang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #RLVR #DataMixture #Author Thread-Post Issue Date: 2025-06-05 GPT Summary- 検証可能な報酬を用いた強化学習(RLVR)をマルチモーダルLLMsに適用するためのポストトレーニングフレームワークを提案。異なる視覚と言語の問題を含むデータセットをキュレーションし、最適なデータ混合戦略を導入。実験により、提案した戦略がMLLMの推論能力を大幅に向上させることを示し、分布外ベンチマークで平均5.24%の精度向上を達成。 Comment
元ポスト:
マルチモーダルな設定でRLVRを適用すると、すべてのデータセットを学習に利用する場合より、特定のタスクのみのデータで学習した方が当該タスクでは性能が高くなったり(つまりデータが多ければ多いほど良いわけでは無い)、特定のデータをablationするとOODに対する予測性能が改善したりするなど、データ間で干渉が起きて敵対的になってしまうような現象が起きる。このことから、どのように適切にデータを混合できるか?という戦略の必要性が浮き彫りになり、モデルベースなMixture戦略(どうやらデータの混合分布から学習後の性能を予測するモデルな模様)の性能がuniformにmixするよりも高い性能を示した、みたいな話らしい。
[Paper Note] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, Mingjie Liu+, NeurIPS'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ReinforcementLearning #NeurIPS #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-06-04 GPT Summary- 強化学習(RL)が言語モデルの推論能力を向上させる可能性を探る本研究では、長期的なRL(ProRL)トレーニングが新しい推論戦略を明らかにできることを示します。新しいトレーニング手法ProRLを導入し、実証分析により、RLでトレーニングされたモデルが基礎モデルを上回ることが確認されました。推論の改善は基礎モデルの能力やトレーニング期間と相関しており、RLが新しい解決空間を探索できることを示唆しています。これにより、RLが言語モデルの推論を拡張する条件に関する新たな洞察が得られ、今後の研究の基盤が築かれます。モデルの重みは公開されています。 Comment
元ポスト:
RLVR(math, code(従来はこの2種類), STEM, logic Puzzles, instruction following)によって大規模なスケール(長期的に学習をする; 2k training stepsと多様なタスクでの学習データ)で実験をし、定期的にReferenceポリシーとOptimizerをリセットすることで、元のポリシーからの乖離を防ぎつつも、新たな学習が進むようなことをしている模様。
(※PFNのランチタイムトークを参考に記述)
verlを用いて、DAPOで学習をしている。
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
[Paper Note] Pitfalls of Rule- and Model-based Verifiers -- A Case Study on Mathematical Reasoning, Yuzhen Huang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #read-later #VerifiableRewards #RLVR #Verification #Author Thread-Post Issue Date: 2025-06-03 GPT Summary- 本研究では、数学的推論における検証者の信頼性とそのRL訓練プロセスへの影響を分析。ルールベースの検証者は偽陰性率が高く、RL訓練のパフォーマンスに悪影響を及ぼすことが判明。モデルベースの検証者は静的評価で高精度を示すが、偽陽性に対して脆弱であり、報酬が不正に膨らむ可能性がある。これにより、強化学習における堅牢な報酬システムの必要性が示唆される。 Comment
元ポスト:
verificationタスクに特化してfinetuningされたDiscriminative Classifierが、reward hackingに対してロバストであることが示唆されている模様。
Discriminative Verifierとは、Question, Response, Reference Answerがgivenな時に、response(しばしばreasoning traceを含み複数のanswerの候補が記述されている)の中から最終的なanswerを抽出し、Reference answerと抽出したanswerから正解/不正解をbinaryで出力するモデルのこと。Rule-based Verifierではフォーマットが異なっている場合にfalse negativeとなってしまうし、そもそもルールが規定できないタスクの場合は適用できない。Discriminative Verifierではそのようなケースでも適用できると考えられる。
Discriminative Verifierの例はたとえば下記:
https://huggingface.co/IAAR-Shanghai/xVerify-0.5B-I
- [Paper Note] xVerify: Efficient Answer Verifier for Reasoning Model Evaluations, Ding Chen+, arXiv'25, 2025.04
[Paper Note] Learning Compositional Functions with Transformers from Easy-to-Hard Data, Zixuan Wang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #Pretraining #LanguageModel #Transformer #PostTraining #Selected Papers/Blogs #COLT #Reading Reflections #Author Thread-Post Issue Date: 2025-06-01 GPT Summary- Transformerベースの言語モデルの学習可能性を、k-fold 合成タスクにおいて検討。具体的には、k 個の入力置換と隠れた置換の交互合成を倍の効率で実行可能とし、統計的クエリ下界も証明。さらに、O(log k) 層のトランスフォーマーで勾配降下による効率的な学習が可能であることを示した。データの提示方法によって、容易な例と難しい例が存在することが重要であるとの知見を得た。 Comment
元ポスト:
こちらはまず元ポストのスレッドを読むのが良いと思われる。要点をわかりやすく説明してくださっている。
元ポストとalphaxivでざっくり理解したところ、
Transformerがcontextとして与えられた情報(σ)とparametric knowledge(π)をk回の知識マッピングが必要なタスク(k-fold composition task)を学習するにはO(log k)のlayer数が必要で、直接的にk回の知識マッピングが必要なタスクを学習するためにはkの指数オーダーのデータ量が最低限必要となることが示された。これはkが大きくなると(すなわち、複雑なreasoning stepが必要なタスク)になると非現実的なものとなるため、何らかの方法で緩和したい。学習データを簡単なものから難しいものをmixingすること(カリキュラム学習)ことで、この条件が緩和され、指数オーダーから多項式オーダーのデータ量で学習できることが示された
といった感じだと思われる。
じゃあ最新の32Bモデルよりも、よりパラメータ数が大きくてlayer数が多い古いモデルの方が複雑なreasoningが必要なタスクを実は解けるってこと!?直感に反する!と一瞬思ったが、おそらく最近のモデルでは昔のモデルと比べてparametric knowledgeがより高密度に適切に圧縮されるようになっていると思われるので、昔のモデルではk回の知識マッピングをしないと解けないタスクが、最新のモデルではk-n回のマッピングで解けるようになっていると推察され、パラメータサイズが小さくても問題なく解けます、みたいなことが起こっているのだろう、という感想を抱くなどした
[Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, ACL'25, 2025.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Reasoning #ACL Issue Date: 2025-06-01 GPT Summary- 大規模言語モデル(LLMs)の推論能力を評価するための新しいベンチマーク、BIG-Bench Extra Hard(BBEH)を導入。これは、既存のBIG-Bench Hard(BBH)のタスクを新しいものに置き換え、難易度を大幅に引き上げることで、LLMの限界を押し広げることを目的としている。評価の結果、最良の汎用モデルで9.8%、推論専門モデルで44.8%の平均精度が観察され、LLMの一般的推論能力向上の余地が示された。BBEHは公開されている。 Comment
Big-Bench hard(既にSoTAモデルの能力差を識別できない)の難易度をさらに押し上げたデータセット。
Inputの例
タスクごとのInput, Output lengthの分布
現在の主要なモデル群の性能
Big-Bench論文はこちら:
- [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
[Paper Note] Training Step-Level Reasoning Verifiers with Formal Verification Tools, Ryo Kamoi+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData #PRM #Verification #Author Thread-Post Issue Date: 2025-06-01 GPT Summary- 本論文では、プロセス報酬モデル(PRMs)のトレーニングにおける2つの課題、すなわち高コストの人間による注釈と数学的推論問題への限定を解決するために、FoVerというアプローチを提案します。FoVerは形式的検証ツールを用いて自動的に段階レベルのエラーラベルを生成し、人的注釈なしでLLMの応答にエラーラベルを付与したデータセットを合成します。このデータセットでトレーニングされたPRMsは、元のLLMsに基づくベースラインを大幅に上回り、他の最先端モデルとも競争力のある結果を達成しました。 Comment
元ポスト:
人手によるAnnotation(step levelのラベルのアノテーション)無しでProcess Reward Modelの学習データを構築する手法
Z3やIsabelleなどの形式検証ツールが適用可能なタスクのみに提案手法のスコープは限られる点には注意
人手でアノテーションされたモデルと比較してcomparableなパフォーマンスを達成
スレッド中で評価データが数回のreasoning stepが必要なタスクのみの評価であり、より長く複雑なreasoning step(たとえば [Paper Note] BIG-Bench Extra Hard, Mehran Kazemi+, ACL'25, 2025.02
)が必要な場合はどうなるか?といった所に興味が寄せられている模様
[Paper Note] Distillation Scaling Laws, Dan Busbridge+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Distillation #SmallModel #ICML #Scaling Laws #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-05-29 GPT Summary- 蒸留モデルの性能を推定するための蒸留スケーリング法則を提案。教師モデルと生徒モデルの計算割り当てを最適化することで、生徒の性能を最大化。教師が存在する場合やトレーニングが必要な場合に最適な蒸留レシピを提供。多くの生徒を蒸留する際は、監視付きの事前学習を上回るが、生徒のサイズに応じた計算レベルまで。単一の生徒を蒸留し、教師がトレーニング必要な場合は監視学習を推奨。蒸留に関する洞察を提供し、理解を深める。 Comment
著者ポスト:
-
-
openreview: https://openreview.net/forum?id=1nEBAkpfb9
手元にSFTのデータがあったときにSLMを学習したいという状況で、固定の計算資源があったときに、巨大な教師モデルをSFTで学習してから小型モデルに蒸留するのが良いのか、小型モデルを直接SFTする方が良いのか、どのように教師モデルと生徒モデルに計算資源を割り当てるのが最適かという観点でscaling lawを導出しているようである。
下記Appendixや著者ポストにある通り、知見を一言で言うと
- Distillationでは、SFTによって生み出されるモデルよりも良いモデルを生み出すことはできない
- しかしながら、DistillationではSFTよりも効率的にSFTで学習した場合と比較して良いモデルを学習できる
- 言い換えると、十分な計算量とデータが与えられるとDistillationの効率性は消失する
という感じだろうか。つまり、達成可能な性能のピーク値はSFTを超えられないが、Distillationの方がSFTよりも効率的に学習ができる、という感じに見える。
[Paper Note] Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #ICML #Workshop #Author Thread-Post Issue Date: 2025-05-27 GPT Summary- 本研究では、外部の報酬やラベルなしで大規模言語モデル(LLMs)が学習できるフレームワーク「内部フィードバックからの強化学習(RLIF)」を提案。自己確信を報酬信号として用いる「Intuitor」を開発し、無監視の学習を実現。実験結果は、Intuitorが数学的ベンチマークで優れた性能を示し、ドメイン外タスクへの一般化能力も高いことを示した。内因的信号が効果的な学習を促進する可能性を示唆し、自律AIシステムにおけるスケーラブルな代替手段を提供。 Comment
元ポスト:
おもしろそう
externalなsignalをrewardとして用いないで、モデル自身が内部的に保持しているconfidenceを用いる。人間は自信がある問題には正解しやすいという直感に基づいており、openendなquestionのようにそもそも正解シグナルが定義できないものもあるが、そういった場合に活用できるようである。
self-trainingの考え方に近いのでは
ベースモデルの段階である程度能力が備わっており、post-trainingした結果それが引き出されるようになったという感じなのだろうか。
参考:
解説スライド:
https://www.docswell.com/s/DeepLearning2023/KYVLG4-2025-09-18-112951
元ポスト:
[Paper Note] LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #ICLR #Contamination-free #Selected Papers/Blogs #Live Issue Date: 2025-05-23 GPT Summary- テストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Comment
テストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究
[Paper Note] AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning, Chenwei Lou+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Chain-of-Thought #Reasoning Issue Date: 2025-05-21 GPT Summary- AdaCoTは、LLMがChain-of-Thought(CoT)の使用を適応的に決定する新しい枠組み。これにより、計算コストや非効率性を軽減しつつ、複雑なクエリにおける推論性能を維持する。特にProximal Policy Optimization(PPO)を用いたRL手法を導入し、Selective Loss Masking(SLM)で推論トリガを安定させ、実験ではCoTトリガー率を最大3.18%削減、応答トークン数を69.06%削減したことが示された。 Comment
RLのRewardにおいて、baseのリワードだけでなく、
- reasoningをなくした場合のペナルティ項
- reasoningをoveruseした場合のペナルティ項
- formattingに関するペナルティ項
を設定し、reasoningの有無を適切に判断できた場合にrewardが最大化されるような形にしている。(2.2.2)
が、multi-stageのRLでは(stageごとに利用するデータセットを変更するが)、データセットの分布には歪みがあり、たとえば常にCoTが有効なデータセットも存在しており(数学に関するデータなど)、その場合常にCoTをするような分布を学習してしまい、AdaptiveなCoT decisionが崩壊したり、不安定になってしまう(decision boundary collapseと呼ぶ)。特にこれがfinal stageで起きると最悪で、これまでAdaptiveにCoTされるよう学習されてきたものが全て崩壊してしまう。これを防ぐために、Selective Loss Maskingというlossを導入している。具体的には、decision token [^1]のlossへの貢献をマスキングするようにすることで、CoTが生じるratioにバイアスがかからないようにする。今回は、Decision tokenとして、`
[^1]: CoTするかどうかは多くの場合このDecision Tokenによって決まる、といったことがどっかの研究に示されていたはず
いつか必要になったらしっかり読むが、全てのステージでSelective Loss Maskingをしたら、SFTでwarm upした段階からあまりCoTのratioが変化しないような学習のされ方になる気がするが、どのステージに対してapplyするのだろうか。
openreview: https://openreview.net/forum?id=obXGSmmG70
[Paper Note] Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding, Kung-Hsiang Huang+, ACL'25, 2025.02
Paper/Blog Link My Issue
#ComputerVision #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #SyntheticData #ACL #DPO #PostTraining #Probing #Author Thread-Post Issue Date: 2025-05-18 GPT Summary- Vision Language Models (VLMs)は視覚的算術に苦労しているが、CogAlignという新しいポストトレーニング戦略を提案し、VLMの性能を向上させる。CogAlignは視覚的変換の不変特性を認識するように訓練し、CHOCOLATEで4.6%、MATH-VISIONで2.9%の性能向上を実現し、トレーニングデータを60%削減。これにより、基本的な視覚的算術能力の向上と下流タスクへの転送の効果が示された。 Comment
元ポスト:
既存のLLM (proprietary, openweightそれぞれ)が、シンプルなvisual arithmeticタスク(e.g., 線分の長さ比較, Chart上のdotの理解)などの性能が低いことを明らかにし、
それらの原因を(1)Vision Encoderのrepresentationと(2)Vision EncoderをFreezeした上でのText Decoderのfinetuningで分析した。その結果、(1)ではいくつかのタスクでlinear layerのprobingでは高い性能が達成できないことがわかった。このことから、Vision Encoderによるrepresentationがタスクに関する情報を内包できていないか、タスクに関する情報は内包しているがlinear layerではそれを十分に可能できない可能性が示唆された。
これをさらに分析するために(2)を実施したところ、Vision Encoderをfreezeしていてもfinetuningによりquery stringに関わらず高い性能を獲得できることが示された。このことから、Vision Encoder側のrepresentationの問題ではなく、Text Decoderと側でデコードする際にFinetuningしないとうまく活用できないことが判明した。
手法のところはまだ全然しっかり読めていないのだが、画像に関する特定の属性に関するクエリと回答のペアを合成し、DPOすることで、zero-shotの性能が向上する、という感じっぽい?
[Paper Note] Reinforcement Learning for Reasoning in Large Language Models with One Training Example, Yiping Wang+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #NeurIPS #read-later #Reference Collection #Author Thread-Post Issue Date: 2025-05-09 GPT Summary- 1-shot RLVRを用いることで、大規模言語モデルの数学的推論能力が向上することを示した。Qwen2.5-Math-1.5BにRLVRを適用し、MATH500の性能を36.0%から73.6%に引き上げたほか、6つの一般的な数学的推論ベンチマークも改善。異なるモデルやRLアルゴリズムでも顕著な向上が観察され、訓練精度の飽和後もテスト性能が持続改善する現象が見られた。これらの知見は、RLVRの効率性に関する今後の研究を促進する重要な要素であり、全リソースはオープンソースで公開されている。 Comment
下記ポストでQwenに対してpromptを適切に与えることで、追加のpost training無しで高い数学に関する能力を引き出せたという情報がある。おそらく事前学習時に数学のQAデータによって継続事前学習されており、この能力はその際に身についているため、数学に対する高い能力は実は簡単に引き出すことができるのかもしれない(だから1サンプルでも性能が向上したのではないか?)といった考察がある。
参考:
- [Paper Note] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, Mingjie Liu+, NeurIPS'25
とはどのような関係性があるだろうか?
著者ポスト:
openreview: https://openreview.net/forum?id=IBrRNLr6JA
[Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #ReinforcementLearning #Reasoning #SmallModel #PEFT(Adaptor/LoRA) #GRPO #read-later #Selected Papers/Blogs Issue Date: 2025-05-07 GPT Summary- Tinaは、コスト効率よく強力な推論能力を実現する小型の推論モデルファミリーであり、1.5Bパラメータのベースモデルに強化学習を適用することで高い推論性能を示す。Tinaは、従来のSOTAモデルと競争力があり、AIME24で20%以上の性能向上を達成し、トレーニングコストはわずか9ドルで260倍のコスト削減を実現。LoRAを通じた効率的なRL推論の効果を検証し、すべてのコードとモデルをオープンソース化している。 Comment
元ポスト:
(おそらく)Reasoningモデルに対して、LoRAとRLを組み合わせて、reasoning能力を向上させた初めての研究
[Paper Note] 100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models, Chong Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Survey #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Chain-of-Thought #InstructionTuning #PPO (ProximalPolicyOptimization) #Reasoning #LongSequence #RewardHacking #GRPO #Contamination-free #VerifiableRewards #CurriculumLearning Issue Date: 2025-05-06 GPT Summary- RLMの進展は新しい言語モデルの進化を示し、DeepSeek-R1のリリースが社会的影響を生んでいる。DeepSeekの実装は完全にオープンではないが、多くの再現研究が登場し、同等の性能を達成。特にSFTとRLVRに重点を置き、データ構築や手法設計に関する知見を提供。実装の詳細と実験結果をまとめ、RLMの性能向上技術や開発課題についても議論。研究者が最新の進展を把握し、新しいアイデアを促進することを目指す。 Comment
元ポスト:
サーベイのtakeawayが箇条書きされている。
[Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Analysis #NLP #LanguageModel #RepresentationLearning #Supervised-FineTuning (SFT) #Chain-of-Thought #SSM (StateSpaceModel) #ICML #PostTraining #read-later #CompressionValleys Issue Date: 2025-05-04 GPT Summary- 中間層の埋め込みが最終層を超えるパフォーマンスを示すことを分析し、情報理論や幾何学に基づくメトリクスを提案。32のテキスト埋め込みタスクで中間層が強力な特徴を提供することを実証し、AIシステムの最適化における中間層の重要性を強調。 Comment
現代の代表的な言語モデルのアーキテクチャ(decoder-only model, encoder-only model, SSM)について、最終層のembeddingよりも中間層のembeddingの方がdownstream task(MTEBの32Taskの平均)に、一貫して(ただし、これはMTEBの平均で見たらそうという話であり、個別のタスクで一貫して強いかは読んでみないとわからない)強いことを示した研究。
このこと自体は経験的に知られているのであまり驚きではないのだが(ただ、SSMでもそうなのか、というのと、一貫して強いというのは興味深い)、この研究はMatrix Based Entropyと呼ばれるものに基づいて、これらを分析するための様々な指標を定義し理論的な根拠を示し、Autoregressiveな学習よりもMasked Languageによる学習の方がこのようなMiddle Layerのボトルネックが緩和され、同様のボトルネックが画像の場合でも起きることを示し、CoTデータを用いたFinetuningについても分析している模様。この辺の貢献が非常に大きいと思われるのでここを理解することが重要だと思われる。あとで読む。
openreview: https://openreview.net/forum?id=WGXb7UdvTX
[Paper Note] Phi-4-reasoning Technical Report, Marah Abdin+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Reasoning #SmallModel #OpenWeight #GRPO #Reference Collection #Author Thread-Post Issue Date: 2025-05-01 GPT Summary- 140億パラメータの推論モデルPhi-4-reasoningは、慎重に選ばれた「teachable」プロンプトセットと監視付きファインチューニングを通じて訓練され、詳細な推論チェーンを生成します。そのバリエーションであるPhi-4-reasoning-plusは、短期間の強化学習を経て、より長い推論トレースを生成し高性能を実現。これらのモデルは、DeepSeek-R1-Distill-Llama-70Bモデルを超え、完全版DeepSeek-R1に近い性能を示します。評価は数学的・科学的推論や一般目的のベンチマークを含み、データ精選の利点と強化学習の影響を示唆しています。 Comment
元ポスト:
こちらの解説が非常によくまとまっている:
が、元ポストでもテクニカルペーパー中でもo3-miniのreasoning traceをSFTに利用してCoTの能力を強化した旨が記述されているが、これはOpenAIの利用規約に違反しているのでは…?
[Paper Note] When More is Less: Understanding Chain-of-Thought Length in LLMs, Yuyang Wu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #ICLR #Author Thread-Post Issue Date: 2025-04-30 GPT Summary- Chain-of-thought (CoT)推論は、LLMsの多段階推論能力を向上させるが、CoTの長さが増すと最初は性能が向上するものの、最終的には低下することが観察される。長い推論プロセスがノイズに脆弱であることを示し、理論的に最適なCoTの長さを導出。Length-filtered Voteを提案し、CoTの長さをモデルの能力とタスクの要求に合わせて調整する必要性を強調。 Comment
ICLR 2025 Best Paper Runner Up Award
元ポスト:
[Paper Note] AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, Junfeng Fang+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ICLR #KnowledgeEditing #Reference Collection #Initial Impression Notes Issue Date: 2025-04-30 GPT Summary- AlphaEditは、LLMsの知識を保持しつつ編集を行う新しい手法で、摂動を保持された知識の零空間に投影することで、元の知識を破壊する問題を軽減します。実験により、AlphaEditは従来の位置特定-編集手法の性能を平均36.7%向上させることが確認されました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=HvSytvg3Jh
MLPに新たな知識を直接注入する際に(≠contextに含める)既存の学習済みの知識を破壊せずに注入する手法(破壊しないことが保証されている)を提案しているらしい
将来的には、LLMの1パラメータあたりに保持できる知識量がわかってきているので、MLPの零空間がN GBのモデルです、あなたが注入したいドメイン知識の量に応じて適切な零空間を持つモデルを選んでください、みたいなモデルが公開される日が来るのだろうか。
ポイント解説:
[Paper Note] Why Do Multi-Agent LLM Systems Fail?, Mert Cemri+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Multi #Analysis #NLP #AIAgents #NeurIPS #Author Thread-Post Issue Date: 2025-04-26 GPT Summary- マルチエージェントLLMシステム(MAS)の性能向上が乏しい中、初の故障分類法MASTを提案。200以上のタスクを通じて14の故障モードを特定し、3つのカテゴリに整理。LLMを活用した評価パイプラインを開発し、故障分析の実用性を示す。特定された故障には複雑な解決策が必要であり、研究への道筋を強調。データセットとLLM注釈者をオープンソース化してMASの進展を促進。 Comment
元ポスト:
7つのメジャーなマルチエージェントフレームワークに対して200以上のタスクを実施し、6人の専門家がtraceをアノテーション。14種類の典型的なfailure modeを見つけ、それらを3つにカテゴライズ。これを考慮してマルチエージェントシステムの失敗に関するTaxonomy(MAS)を提案
[Paper Note] BitNet b1.58 2B4T Technical Report, Shuming Ma+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #Quantization #SmallModel #PostTraining Issue Date: 2025-04-19 GPT Summary- BitNet b1.58 2B4Tは、2億パラメータを持つ初のオープンソースの1ビット大規模言語モデルであり、4兆トークンのコーパスで訓練されています。言語理解や数学的推論、コーディング能力などのベンチマークで評価され、同等のスケールの全精度LLMと同等の性能を示す一方で、計算効率の向上を実現しています。具体的には、メモリ使用量、エネルギー消費、デコード遅延を大幅に削減しています。モデルウェイトはHugging Faceを通じて公開され、オープンソースの推論実装も提供されます。 Comment
元ポスト:
圧倒的省メモリかつcpuでのinference速度も早そう
- アーキテクチャはTransformerを利用
- Linear layerとしてBitLinear Layerを利用
- 重みは{1, 0, -1}の3値をとる
- activationは8bitのintegerに量子化
- Layer Normalizationはsubln normalization [Paper Note] Magneto: A Foundation Transformer, Hongyu Wang+, ICML'23
を利用
[Paper Note] AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #Evaluation #MultiModal #ICLR #ComputerUse Issue Date: 2025-04-18 GPT Summary- 本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 Comment
Android環境でのPhone Useのベンチマーク
[Paper Note] UI-TARS: Pioneering Automated GUI Interaction with Native Agents, Yujia Qin+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #NLP #AIAgents #MultiModal #Blog #Reasoning #OpenWeight #ComputerUse #VisionLanguageModel #2D (Image) #text Issue Date: 2025-04-18 GPT Summary- UI-TARSは、スクリーンショットを入力として人間のような操作を行うエンドツーエンドのGUIエージェントモデルである。従来の商用モデルに依存せず、知覚、グラウンディング、GUIタスク実行において最先端の性能を発揮。OSWorldベンチマークでは、UI-TARSが高スコアを達成し、他のモデルを上回る。主要な革新には、強化された知覚、統一されたアクションモデリング、System-2推論、反省的オンライン・トレースによる反復的トレーニングが含まれる。これにより、UI-TARSは未知の状況にも適応可能な学習能力を持つ。GUIエージェントの進化経路も分析し、今後の発展を探る。 Comment
色々と書いてあるが、ざっくり言うとByteDanceによる、ImageとTextをinputとして受け取り、TextをoutputするマルチモーダルLLMによるComputer Use Agent (CUA)
関連
- OpenAI API での Computer use の使い方, npaka, 2025.03
元ポスト:
[Paper Note] Seed1.5-Thinking: Advancing Superb Reasoning Models with Reinforcement Learning, ByteDance Seed+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #OpenWeight #Initial Impression Notes Issue Date: 2025-04-12 GPT Summary- Seed1.5-Thinkingは、応答前に思考を経て推論する新しい手法で、AIME 2024で86.7、Codeforcesで55.0、GPQAで77.3といった性能を達成。非推論タスクでも優れた一般化能力を発揮し、DeepSeek R1を勝率で8%上回る。比較的小型の専門家の混成モデルで、200億の活性化パラメータと2000億の総パラメータを持つ。新たな内部ベンチマークBeyondAIMEとCodeforcesも公開予定。 Comment
DeepSeek-R1を多くのベンチで上回る200B, 20B activated paramのreasoning model
最近のテキストのOpenWeightLLMはAlibaba, DeepSeek, ByteDance, Nvidiaの4強という感じかな…?(そのうちOpenAIがオープンにするReasoning Modelも入ってきそう)。
[Paper Note] AM-RADIO: Agglomerative Vision Foundation Model -- Reduce All Domains Into One, Mike Ranzinger+, CVPR'25
Paper/Blog Link My Issue
#ComputerVision #Transformer #FoundationModel #OpenWeight #CVPR #Author Thread-Post Issue Date: 2025-04-11 GPT Summary- 視覚基盤モデル(VFM)をマルチティーチャー蒸留を通じて統合するアプローチAM-RADIOを提案。これにより、ゼロショットの視覚-言語理解やピクセルレベルの理解を向上させ、個々のモデルの性能を超える。新しいアーキテクチャE-RADIOは、ティーチャーモデルよりも少なくとも7倍速い。包括的なベンチマークで様々な下流タスクを評価。 Comment
元ポスト:
vision系のfoundation modelはそれぞれ異なる目的関数で訓練されてきており(CLIPは対照学習 Learning Transferable Visual Models From Natural Language Supervision, Radford+, OpenAI, ICML'21
, DINOv2は自己教師あり学習 [Paper Note] DINOv2: Learning Robust Visual Features without Supervision, Maxime Oquab+, TMLR'24
, SAMはsegmentation [Paper Note] Segment Anything, Alexander Kirillov+, arXiv'23, 2023.04
)それぞれ別の能力を持ってたが、それらを一個のモデルに蒸留しました、という話らしい
lossの文脈でいうと、SigLIPも広義の対照学習の一種である。
- [Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
[Paper Note] When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #ICLR #AttentionSinks #read-later #Selected Papers/Blogs #needs-revision #Author Thread-Post Issue Date: 2025-04-05 GPT Summary- 言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 Comment
Sink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l * head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案
(後ほど詳細を追記する)
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究
著者ポスト(openai-gpt-120Bを受けて):
openreview: https://openreview.net/forum?id=78Nn4QJTEN
[Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Attention #AttentionSinks #COLM #Selected Papers/Blogs Issue Date: 2025-04-05 GPT Summary- LLMsは最初のトークンに強く注意を向ける「アテンションシンク」を示し、そのメカニズムが過剰混合を避ける方法を理論的・実証的に探求。コンテキストの長さやデータのパッキングがシンクの挙動に与える影響を実験で示し、アテンションパターンの理解を深めることを目指す。 Comment
元ポスト:
Attention Sinkによって、トークンの情報がover-mixingされることが抑制され、Decoder-only LLMの深い層のrepresentationが均一化されることを抑制する(=promptの摂動にロバストになる)ことが示された模様。
Gemma7Bにおいて、prompt中のトークン一語を置換した後に、Attention Sink(
openreview: https://openreview.net/forum?id=tu4dFUsW5z#discussion
[Paper Note] What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models, Qiyuan Zhang+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Test-Time Scaling #Initial Impression Notes Issue Date: 2025-04-02 GPT Summary- テスト時スケーリング(TTS)が大規模言語モデル(LLMs)の問題解決能力を向上させることが示されているが、体系的な理解が不足している。これを解決するために、TTS研究の4つのコア次元に基づく統一的なフレームワークを提案し、手法や応用シナリオのレビューを行う。TTSの発展の軌跡を抽出し、実践的なガイドラインを提供するとともに、未解決の課題や将来の方向性についての洞察を示す。 Comment
元ポスト:
とてつもない量だ…網羅性がありそう。
What to Scaleがよくあるself
consistency(Parallel Scaling), STaR(Sequential Scailng), Tree of Thought(Hybrid Scaling), DeepSeek-R1, o1/3(Internal Scaling)といった分類で、How to ScaleがTuningとInferenceに分かれている。TuningはLong CoTをSFTする話や強化学習系の話(GRPOなど)で、InferenceにもSelf consistencyやらやらVerificationやら色々ありそう。良さそう。
[Paper Note] Multi-Token Attention, Olga Golovneva+, arXiv'25, 2025.04
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Attention #Architecture #COLM #Author Thread-Post Issue Date: 2025-04-02 GPT Summary- 新しいアテンション手法であるMulti-Token Attention(MTA)を提案し、複数のクエリとキーのベクトルを同時に用いることで、より精密な関連部分の特定を可能にします。畳み込み処理を適用することで、近接するトークンの相互作用を強化し、豊かでニュアンスのある情報の利用を実現。広範な評価により、MTAが標準的な言語モデルタスクにおいてTransformerを超える性能を発揮することを示しました。 Comment
元ポスト:
従来のMulti Head Attentionでは、単体のQKのみを利用していたけど、複数のQKの情報を畳み込んで活用できるようにして、Headも畳み込みで重要な情報がより伝搬されるようにして、GroupNormalizationをかけたらPerplexityの観点でDifferential Transformerを上回ったよ、という話な模様。
- [Paper Note] Group Normalization, Yuxin Wu+, arXiv'18, 2018.03
- [Paper Note] Differential Transformer, Tianzhu Ye+, N/A, ICLR'25
openreview: https://openreview.net/forum?id=Z3L35tQTEg
[Paper Note] Training Software Engineering Agents and Verifiers with SWE-Gym, Jiayi Pan+, ICML'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #ICML #SoftwareEngineering #Selected Papers/Blogs #Environment Issue Date: 2025-04-02 GPT Summary- SWE-Gymを提案し、2,438件の実世界のPythonタスクを含む環境を構築。言語モデルに基づくSWEエージェントを訓練し、SWE-Benchで最大19%の解決率向上を達成。微調整されたエージェントは新たな最先端の性能を示し、SWE-Gymやモデル、エージェントの軌跡を公開。 Comment
SWE-Benchとは完全に独立したより広範な技術スタックに関連するタスクに基づくSWEベンチマーク
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
SWE-Benchと比べて実行可能な環境と単体テストが提供されており、単なるベンチマークではなくエージェントを訓練できる環境が提供されている点が大きく異なるように感じる。
[Paper Note] Qwen2.5-Omni Technical Report, Jin Xu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #Speech #OpenWeight #2D (Image) #3D (Video) #Omni #Reference Collection #audio #text Issue Date: 2025-03-31 GPT Summary- Qwen2.5-Omniは、テキスト、画像、音声、映像を同時に認識し、自然な音声応答をストリーミング生成するエンドツーエンドのマルチモーダルモデルです。音声と映像の同期には新しい位置埋め込み手法TMRoPEを導入し、Thinker-Talkerアーキテクチャにより干渉を避けつつ同時生成を実現。ストリーミング音声トークンのデコードにはスライディングウィンドウDiTを用いて初期遅延を削減。Qwen2.5-Omniは、マルチモーダルベンチマークで最先端の性能を示し、音声生成の自然さにおいて既存手段を上回ります。 Comment
Qwen TeamによるマルチモーダルLLM。テキスト、画像、動画音声をinputとして受け取り、テキスト、音声をoutputする。
weight:
https://huggingface.co/collections/Qwen/qwen25-omni-67de1e5f0f9464dc6314b36e
[Paper Note] Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #ICLR #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-03-27 GPT Summary- 大規模言語モデルの事前学習において、トークン予算の増加がファインチューニングを難しくし、パフォーマンス低下を引き起こす「壊滅的な過学習」を提唱。3Tトークンで事前学習されたOLMo-1Bモデルは、2.3Tトークンのモデルに比べて2%以上の性能低下を示す。実験と理論分析により、事前学習パラメータの感度の増加が原因であることを示し、事前学習設計の再評価を促す。 Comment
著者によるポスト:
事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化が起こることを報告している。事前学習で学習するトークン数を増やせば、必ずしもpost-training後のモデルの性能がよくなるわけではないらしい。
ICLR'25のOutstanding Paperに選ばれた模様:
きちんと読んだ方が良さげ。
[Paper Note] Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate, Yubo Wang+, COLM'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #COLM #PostTraining #Author Thread-Post Issue Date: 2025-03-25 GPT Summary- 批評ファインチューニング(CFT)は、言語モデルがノイズのある応答を批評することを学ぶ新しい戦略で、従来の監視付きファインチューニング(SFT)に挑戦します。CFTは人間の学習プロセスにインスパイアを受け、深い分析を促進します。WebInstructから構築した50Kサンプルのデータセットを用いて、CFTは複数のベースモデルでSFTに対して4-10%の性能向上を示しました。特に、Qwen2.5-Math-CFTは少ないトレーニングで強力な競合と同等の性能を発揮し、CFTの堅牢性も確認されました。CFTは言語モデルの推論を進展させる効果的な手法であると主張します。 Comment
元ポスト:
Critique Fine-Tuning (CFT) を提案。CFTでは、query x, noisy response y [^1] が与えられたときに、それに対する批評 cを学習する。cはgivenではないので、GPT4oのような強力なモデルによって合成する。

目的関数は以下。[x; y] がgivenな時にcを生成する確率を最大化する。シンプル。

RLを用いた手法との比較。1/10程度のデータ量、1/100程度のGPU時間で同等の性能を達成できる。

[^1]: 本論文で利用しているWebInstructからサンプリングしたデータでは、たとえば約50%程度のyが正解, 残りは不正解(程度のnoisyデータを利用している)
[Paper Note] Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models, Yang Sui+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #LanguageModel #Reasoning #Overthinking Issue Date: 2025-03-22 GPT Summary- 本論文では、LLMsにおける効率的な推論の進展を体系的に調査し、以下の主要な方向に分類します:(1) モデルベースの効率的推論、(2) 推論出力ベースの効率的推論、(3) 入力プロンプトベースの効率的推論。特に、冗長な出力による計算オーバーヘッドを軽減する方法を探求し、小規模言語モデルの推論能力や評価方法についても議論します。 Comment
Reasoning Modelにおいて、Over Thinking現象(不要なreasoning stepを生成してしまう)を改善するための手法に関するSurvey。
下記Figure2を見るとよくまとまっていて、キャプションを読むとだいたい分かる。なるほど。
Length Rewardについては、
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
で考察されている通り、Reward Hackingが起きるので設計の仕方に気をつける必要がある。
元ポスト:
各カテゴリにおけるliteratureも見やすくまとめられている。必要に応じて参照したい。
[Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
Paper/Blog Link My Issue
#MachineLearning #LanguageModel #ReinforcementLearning #Reasoning #LongSequence #NeurIPS #GRPO #read-later #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-03-20 GPT Summary- 推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment
既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。
ちとこれはあとでしっかり読みたい。重要論文。
プロジェクトページ:
https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。
解説ポスト:
コンパクトだが分かりやすくまとまっている。
下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:
色々な研究で広く使われるのを見るようになった。
著者ポスト:
[Paper Note] Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification, Eric Zhao+, ICML'25
Paper/Blog Link My Issue
#NLP #LanguageModel #ICML #Test-Time Scaling #Verification #SelfVerification #Author Thread-Post Issue Date: 2025-03-18 GPT Summary- サンプリングベースの探索は、複数の候補応答を生成し最良のものを選ぶ手法であり、自己検証によって正確性を確認します。本研究では、この探索のスケーリング傾向を分析し、シンプルな実装がGemini v1.5 Proの推論能力を向上させることを示しました。自己検証の精度向上は、より大きな応答プールからのサンプリングによるもので、応答間の比較が有益な信号を提供することや、異なる出力スタイルが文脈に応じて役立つことを明らかにしました。また、最前線のモデルは初期の検証能力が弱く、進捗を測るためのベンチマークを提案しました。 Comment
元ポスト:
ざっくりしか読めていないが、複数の解答をサンプリングして、self-verificationをさせて最も良かったものを選択するアプローチ。最もverificationスコアが高い解答を最終的に選択したいが、tieの場合もあるのでその場合は追加のpromptingでレスポンスを比較しより良いレスポンスを選択する。これらは並列して実行が可能で、探索とself-verificationを200個並列するとGemini 1.5 Proでo1-previewよりも高い性能を獲得できる模様。Self-consistencyと比較しても、gainが大きい。具体的なアルゴリズムはAlgorithm1を参照のこと。
openreview: https://openreview.net/forum?id=wl3eI4wiE5
[Paper Note] Transformers without Normalization, Jiachen Zhu+, CVPR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #Transformer #Architecture #CVPR #Normalization #Author Thread-Post Issue Date: 2025-03-14 GPT Summary- 本研究では、正規化層なしのトランスフォーマーがDynamic Tanh(DyT)を用いることで、同等またはそれ以上のパフォーマンスを達成できることを示します。DyTは、レイヤー正規化の代替として機能し、ハイパーパラメータの調整なしで効果を発揮します。多様な設定での実験により、正規化層の必要性に対する新たな洞察を提供します。 Comment
なん…だと…。LayerNormalizationを下記アルゴリズムのようなtanhを用いた超絶シンプルなレイヤー(parameterized thnh [Lecun氏ポスト](
同等以上の性能を維持しながらモデル全体のinference, trainingの時間を8%程度削減。
[Paper Note] Gemini Embedding: Generalizable Embeddings from Gemini, Jinhyuk Lee+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Embeddings #NLP #LanguageModel #RepresentationLearning Issue Date: 2025-03-12 GPT Summary- Gemini Embeddingは、Geminiの多言語性とコード理解を活かし、高度に一般化可能な埋め込みを生成。事前計算可能なこれらの表現は、分類や検索などの多様なタスクに応用でき、MMTEBでの評価において250以上の言語に対応。従来モデルを大幅に上回る埋め込み品質を示し、特定ドメインモデルを凌駕する性能を達成。 Comment
元ポスト:
世のdecoder-onlyモデルベースのembeddingモデルがどのように作られているか具体的によくわかっていないので読みたい
Geminiのパラメータでbi-directionalなself-attentionを持つtransformer (たとえばBERT)で初期化し、全てのtokenをmean poling (HF BERT ModelのPoolerLayerのようなもの)することでトークンの情報を単一のembeddingに混ぜる。
学習は2段階のfinetuning (pre-finetuning, finetuning)によって、モデルをContrastive Learningする(NCE loss)。
pre-finetuningはnoisyだが大規模なデータ(web上のタイトルとparagraphのペアなど)、そのあとのfinetuningはQAなどの高品質なデータを利用。
[Paper Note] Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, ACL'25
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #LanguageModel #Attention #ACL #read-later #Reference Collection Issue Date: 2025-03-02 GPT Summary- 長文コンテキストモデリングのために、計算効率を改善するスパースアテンションメカニズム「NSA」を提案。NSAは動的な階層スパース戦略を用い、トークン圧縮と選択を組み合わせてグローバルなコンテキスト認識とローカルな精度を両立。実装最適化によりスピードアップを実現し、エンドツーエンドのトレーニングを可能にすることで計算コストを削減。NSAはフルアテンションモデルと同等以上の性能を維持しつつ、長シーケンスに対して大幅なスピードアップを達成。 Comment
元ポスト:
ACL'25のBest Paperの一つ:
[Paper Note] OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning, Pan Lu+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Tools #NLP #LanguageModel #AIAgents #Reasoning #ACL Issue Date: 2025-02-20 GPT Summary- OctoToolsは複雑な推論タスクを解決するための訓練不要で拡張可能なマルチエージェントフレームワーク。標準化されたツールカード、プランナー、実行者を導入し、16の多様なタスクでGP4oより平均精度を9.3%向上。AutoGenやLangChainに対しても最大10.6%の改善を示し、タスク計画とツール使用の効果を実証。詳細はサイトに公開。 Comment
元ポスト:
NAACL2025 KnowledgeNLP Workshopでベストペーパーに選出:
ACL2026のOralにaccept:
[Paper Note] Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling, Xiaokang Chen+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #TextToImageGeneration #OpenWeight #VisionLanguageModel #2D (Image) #UMM #ImageSynthesis Issue Date: 2025-01-28 GPT Summary- Janus-Proは、最適化されたトレーニング戦略、拡張されたデータ、より大きなモデルサイズを取り入れたJanusの進化形。これにより、マルチモーダル理解と画像生成の安定性において顕著な進歩を実現。研究成果は公開されており、さらなる探究を促すことが期待される。 Comment
DeepSeekによる新たなUMM、Janus-Proが本日リリース。MIT License
Janus-Proのパフォーマンス。
github上でのパフォーマンスの図解から引用。マルチモーダル(テキスト+画像)の理解に関するベンチマークでLLaVA超え。GenEval, DPG Benchと呼ばれる画像生成ベンチマークでDALL-E 3超え。
テクニカルレポート中での詳細から引用。どのベンチマークでも基本的に最高性能なように見える。
テクニカルレポート:
https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
ベンチマーク:
- [Paper Note] GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment, Dhruba Ghosh+, NeurIPS'23
- [Paper Note] ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment, Xiwei Hu+, arXiv'24
[Paper Note] Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks, Brian J Chan+, WWW'25 Short Paper
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #WWW #KV Cache #Short Issue Date: 2025-01-26 GPT Summary- キャッシュ拡張生成(CAG)は、RAGの課題を克服するために提案された手法で、LLMの拡張コンテキストに事前に関連リソースをロードし、検索なしでクエリに応答する。CAGは検索の遅延を排除し、エラーを最小限に抑えつつ、コンテキストの関連性を維持。性能評価では、CAGが従来のRAGを上回るか補完することが示され、特に制約のある知識ベースにおいて効率的な代替手段となることが示唆されている。 Comment
元ポスト:
外部知識として利用したいドキュメントがそこまで大きく無いなら、事前にLLMで全てのKey Valueを計算しておきKV Cacheとして利用可能にしておけば、生成時に検索をすることもなく、contextとして利用して生成できるじゃん、という研究
[Paper Note] Humanity's Last Exam, Long Phan+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #LanguageModel #Evaluation #Selected Papers/Blogs Issue Date: 2025-01-25 GPT Summary- LLMの進展を追跡するためのベンチマークが不足している中、Humanity's Last Exam(HLE)を導入。HLEは多様な科目を網羅する2,500問のマルチモーダルな学術問題から成り、専門家の手による構築。高度なLLMはHLEで低精度を示し、閉じた回答形式の問題におけるLLMの能力と人間専門家との間のギャップを浮き彫りにしている。HLEは研究と政策立案のために公開されている。 Comment
o1, DeepSeekR1の正解率が10%未満の新たなベンチマーク
[Paper Note] Perspective Transition of Large Language Models for Solving Subjective Tasks, Xiaolong Wang+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #ACL #Findings #Initial Impression Notes Issue Date: 2025-01-25 GPT Summary- 視点遷移を通じた推論(RPT)手法により、LLMsが主観的タスクにおいて視点を動的に選択できるようにします。本手法は専門家や第三者の視点を活用し、文脈をより適切に解釈することで、ニュアンスのある回答を提供します。広範な実験により、従来の固定視点手法を大きく上回る成果を示しました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=cFGPlRony5
"Subjective Task"とは例えば「メタファーの認識」や「ダークユーモアの検知」などがあり、これらは定量化しづらい認知的なコンテキストや、ニュアンスや感情などが強く関連しており、現状のLLMではチャレンジングだと主張している。
Subjective Taskでは、Reasoningモデルのように自動的にCoTのpathwayを決めるのは困難で、手動でpathwayを記述するのはチャレンジングで一貫性を欠くとした上で、複数の視点を組み合わせたPrompting(direct perspective, role-perspective, third-person perspectivfe)を実施し、最もConfidenceの高いanswerを採用することでこの課題に対処すると主張している。
イントロしか読めていないが、自動的にCoTのpathwayを決めるのも手動で決めるのも難しいという風にイントロで記述されているが、手法自体が最終的に3つの視点から回答を生成させるという枠組みに則っている(つまりSubjective Taskを解くための形式化できているので、自動的な手法でもできてしまうのではないか?と感じた)ので、イントロで記述されている主張の”難しさ”が薄れてしまっているかも・・・?と感じた。論文が解こうとしている課題の”難しさ”をサポートする材料がもっとあった方がよりmotivationが分かりやすくなるかもしれない、という感想を持った。
[Paper Note] Training Large Language Models to Reason in a Continuous Latent Space, Shibo Hao+, COLM'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #COLM #PostTraining #read-later #LatentReasoning Issue Date: 2024-12-12 GPT Summary- 新しい推論パラダイム「Coconut」を提案し、LLMの隠れ状態を連続的思考として利用。これにより、次の入力を連続空間でフィードバックし、複数の推論タスクでLLMを強化。Coconutは幅優先探索を可能にし、特定の論理推論タスクでCoTを上回る性能を示す。潜在的推論の可能性を探る重要な洞察を提供。 Comment
Chain of Continuous Thought
通常のCoTはRationaleをトークン列で生成するが、Coconutは最終的なhidden stateをそのまま次ステップの入力にすることで、トークンに制限されずにCoTさせるということらしい。あとでしっかり読む
おそらく学習の際に工夫が必要なので既存モデルのデコーディングを工夫してできます系の話ではないかも
OpenReview:
https://openreview.net/forum?id=tG4SgayTtk
ICLR'25にrejectされている。
ざっと最初のレビューに書かれているWeaknessを読んだ感じ
- 評価データが合成データしかなく、よりrealisticなデータで評価した方が良い
- CoTら非常に一般的に適用可能な技術なので、もっと広範なデータで評価すべき
- GSM8Kでは大幅にCOCONUTはCoTに性能が負けていて、ProsQAでのみにしかCoTに勝てていない
- 特定のデータセットでの追加の学習が必要で、そこで身につけたreasoning能力が汎化可能か明らかでない
といった感じに見える
COLM'25 openreview:
https://openreview.net/forum?id=Itxz7S4Ip3#discussion
COLM'25にAccept
Towards Adaptive Mechanism Activation in Language Agent, Ziyang Huang+, COLING'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #AIAgents #COLING #PostTraining #needs-revision Issue Date: 2024-12-10 GPT Summary- 自己探索によるメカニズム活性化学習(ALAMA)を提案し、固定されたメカニズムに依存せずに適応的なタスク解決を目指す。調和のとれたエージェントフレームワーク(UniAct)を構築し、タスク特性に応じてメカニズムを自動活性化。実験結果は、動的で文脈に敏感なメカニズム活性化の有効性を示す。 Comment
元ポスト:
手法としては、SFTとKTOを活用しpost trainingするようである
- [Paper Note] KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, ICML'24, 2024.02
How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #MachineLearning #NLP #LanguageModel #ICLR #Batch #CriticalBatchSize Issue Date: 2024-11-25 GPT Summary- 大規模モデルの訓練には、クリティカルバッチサイズ(CBS)を考慮した並列化戦略が重要である。CBSの測定法を提案し、C4データセットで自己回帰型言語モデルを訓練。バッチサイズや学習率などの要因を調整し、CBSがデータサイズに比例してスケールすることを示した。この結果は、ニューラルネットワークの理論的分析によって支持され、ハイパーパラメータ選択の重要性も強調されている。 Comment
Critical Batch Sizeはモデルサイズにはあまり依存せず、データサイズに応じてスケールする
Critical batch sizeが提案された研究:
- [Paper Note] An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18, 2018.12
[Paper Note] Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #ICML #DPO Issue Date: 2024-11-07 GPT Summary- 自己調整は、モデルが人間の注釈なしに自らを改善する方法であり、自己一貫性を活用して訓練を行う新しいアプローチ、自己一貫性優先最適化(ScPO)を提案。ScPOは一貫した答えを優先し、GSM8KやMATHなどの推論タスクで従来の手法を大幅に上回る性能を示し、標準的な監視学習との組み合わせでも結果が向上。ZebraLogicでLlama-3 8Bを微調整し、他の大規模モデルを超える成果を達成。 Comment
元ポスト:
Self-Consistencyのように、モデルに複数の出力をさせて、最も頻度が高い回答と頻度が低い回答の2つでDPOのペアデータを作成し学習。頻度の差によって重みを決めてlossに組み込みこのよつな処理を繰り返し学習すると性能が向上する、といった話のように見える。
[Paper Note] Looking Inward: Language Models Can Learn About Themselves by Introspection, Felix J Binder+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ICLR #needs-revision Issue Date: 2024-11-02 GPT Summary- 内省は、モデルが自己の内部状態を理解する能力を示す。LLMsに内省能力をファインチューニングし、自身の行動予測を行う実験により、内省の証拠が得られた。特に、自己予測能力において他のモデルを上回る結果が見られたが、複雑なタスクでは限界もあった。 Comment
LLMが単に訓練データを模倣しているにすぎない的な主張に対するカウンターに使えるかも
openreview: https://openreview.net/forum?id=eb5pkwIB5i
[Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N_A, NAACL'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Dataset #AIAgents #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reasoning #NAACL Issue Date: 2024-10-20 GPT Summary- LLMsを用いた情報検索強化生成(RAG)システムの性能評価のために、FRAMESという新しい評価データセットを提案。これは、事実に基づく応答、検索能力、推論を統一的に評価するもので、複数の情報源を統合するマルチホップ質問を含む。最新のLLMでも0.40の精度に留まる中、提案するマルチステップ検索パイプラインにより精度が0.66に向上し、RAGシステムの開発に貢献することを目指す。 Comment
RAGのfactuality, retrieval acculacy, reasoningを評価するためのmulti hop puestionとそれに回答するための最大15のwikipedia記事のベンチマーク
元ポスト:
[Paper Note] LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations, Hadas Orgad+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Hallucination #ICLR Issue Date: 2024-10-20 GPT Summary- LLMの内部状態は出力の真実性に関する情報を豊富に含んでおり、これを活用することで誤り検出が向上する。しかし、真実性の符号化はデータセットによって異なるため、普遍的ではない。内部表現を使って特定の誤りを予測できることも示し、個別的な緩和戦略の開発に寄与する。さらに、内部と外部の挙動の乖離があることが明らかとなり、誤った出力を生成することもある。これにより、LLMの誤り分析と改善の研究が進展することが期待される。 Comment
特定のトークンがLLMのtrustfulnessに集中していることを実験的に示し、かつ内部でエンコードされたrepresentationは正しい答えのものとなっているのに、生成結果に誤りが生じるような不整合が生じることも示したらしい
openreview: https://openreview.net/forum?id=KRnsX5Em3W
Llama-3.1-Nemotron-70B-Instruct, Nvidia, (ICLR'25), 2024.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Alignment #OpenWeight #ICLR Issue Date: 2024-10-17 GPT Summary- 報酬モデルの訓練にはBradley-Terryスタイルと回帰スタイルがあり、データの一致が重要だが、適切なデータセットが不足している。HelpSteer2データセットでは、Bradley-Terry訓練用の好みの注釈を公開し、初めて両モデルの直接比較を行った。これに基づき、両者を組み合わせた新アプローチを提案し、Llama-3.1-70B-InstructモデルがRewardBenchで94.1のスコアを達成。さらに、REINFORCEアルゴリズムを用いて指示モデルを調整し、Arena Hardで85.0を記録した。このデータセットはオープンソースとして公開されている。 Comment
MTBench, Arena HardでGPT4o-20240513,Claude-3.5-sonnet-20240620をoutperform。Response lengthの平均が長いこと模様
openreview: https://openreview.net/forum?id=MnfHxPP5gs
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, Iman Mirzadeh+, N_A, ICLR'25
Paper/Blog Link My Issue
#ICLR Issue Date: 2024-10-11 GPT Summary- 最近のLLMsの進展により、数学的推論能力への関心が高まっているが、GSM8Kベンチマークの信頼性には疑問が残る。これに対処するため、GSM-Symbolicという新しいベンチマークを導入し、モデルの推論能力をより正確に評価。調査結果は、モデルが同じ質問の異なる具現化に対してばらつきを示し、特に数値変更や質問の節の数が増えると性能が著しく低下することを明らかにした。これは、LLMsが真の論理的推論を行えず、トレーニングデータからの再現に依存しているためと考えられる。全体として、研究は数学的推論におけるLLMsの能力と限界についての理解を深める。 Comment
元ポスト:
May I ask if this work is open source?
I'm sorry, I just noticed your comment. From what I could see in the repository and OpenReview discussion, some parts of the dataset, such as GSMNoOp, are not part of the current public release. The repository issues also mention that the data generation code is not included at the moment. This is just based on my quick check, so there may be more updates or releases coming later.
OpenReview:
https://openreview.net/forum?id=AjXkRZIvjB
Official blog post:
https://machinelearning.apple.com/research/gsm-symbolic
Repo:
https://github.com/apple/ml-gsm-symbolic
HuggingFace:
https://huggingface.co/datasets/apple/GSM-Symbolic
[Paper Note] The Unreasonable Ineffectiveness of the Deeper Layers, Andrey Gromov+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Pruning #ICLR Issue Date: 2024-04-22 GPT Summary- LLMの重みの知識格納を層剪定で研究。不要なパラメータを特定し、層を削除しても性能に影響がないか確認。驚くべき結果として、最大で半分の層を削除しても性能低下がわずかであることが示された。この頑健性は浅い層が重要な役割を果たしている可能性を示唆。PEFT手法を用いて実験を効率化。 Comment
下記ツイートによると、学習済みLLMから、コサイン類似度で入出力間の類似度が高い層を除いてもタスクの精度が落ちず、特に深い層を2-4割削除しても精度が落ちないとのこと。
参考:
VRAMに載せるのが大変なので、このような枝刈り技術が有効だと分かるのはありがたい。LoRAや量子化も利用しているっぽい。
openreview: https://openreview.net/forum?id=ngmEcEer8a
[Paper Note] Scaling Sentence Embeddings with Large Language Models, Ting Jiang+, EMNLP'24 Findings, 2023.07
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #LanguageModel #In-ContextLearning #EMNLP #Findings #Reading Reflections Issue Date: 2026-06-11 GPT Summary- 文脈内学習に基づく手法を用いて、大規模言語モデル(LLMs)の文の埋め込み性能を向上。自己回帰モデル向けにプロンプトベースの表現法を適用し、ファインチューニングなしで高品質な文の埋め込みを生成可能。モデルサイズを拡大するとSTSタスクで性能の変化が見られるが、最大モデルは他のモデルを上回り、転移タスクで最先端結果を達成。2.7BのOPTモデルが4.8BのST5を超える性能を示した。 Comment
1 wordでsentenceを要約するICL-basedなprompt templateを用いて生成されたtokenに対応するlast hidden statedeをsentenceのembeddingとして扱うことで、coder-onlyモデルから文のembeddingを取得する
下記研究で示されているように、last hidden stateではなく中間層におけるhidden stateを利用した場合はどのような影響が出るのだろうか?
- [Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
[Paper Note] DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents, Peter Jansen+, NeurIPS'24 Spotlight, 2024.06
Paper/Blog Link My Issue
#LanguageModel #AIAgents #Evaluation #ScientificDiscovery #NeurIPS #Selected Papers/Blogs #Science Issue Date: 2026-04-14 GPT Summary- DISCOVERYWORLDは、エージェントが科学的発見の全過程を実行できる初の仮想環境で、放射性同位体年代測定やロケット科学など多様な課題を提供します。タスクは一般的な発見スキルの育成を奨励し、シミュレーションされたテキスト環境で、オプションの2Dビジュアルオーバーレイもあります。120の課題は3つの難易度に分かれ、エージェントは仮説立案から結果分析までを行います。また、性能評価は課題完遂度や行動に基づき、自動指標で行われます。強力なベースラインエージェントが多くの課題で苦戦することから、DISCOVERYWORLDの新規性に関わる挑戦を捉えており、科学的発見能力の評価と開発を促進する可能性が示唆されます。 Comment
pj page: https://allenai.github.io/discoveryworld/
ベンチマークの概要は
- Evaluating agents for scientific discovery, Ai2, 2026.04
参照のこと。
[Paper Note] Machine Unlearning of Pre-trained Large Language Models, Jin Yao+, ACL'24, 2024.02
Paper/Blog Link My Issue
#NLP #LanguageModel #ACL #KnowledgeEditing #MachineUnlearning(MU) Issue Date: 2026-03-10 GPT Summary- 本研究は、LLMにおける「忘れられる権利」と機械的忘却を探求。7つの忘却手法を分析し、厳選したデータセットを用いた評価で、再訓練に比べて計算効率が10万倍優れることを示す。忘却プロセスのハイパーパラメータ調整に関するガイドラインを提供し、倫理的AIの議論や責任あるAI開発に貢献。 Comment
下記文献において忘却対象のデータを自前で用意する必要があり、未知のデータに対する汎化性能に限界があるという指摘がある:
- 排他的逆学習, 佐々木+, NLP'26
[Paper Note] Lessons from the Trenches on Reproducible Evaluation of Language Models, Stella Biderman+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Selected Papers/Blogs #Reproducibility Issue Date: 2026-03-08 GPT Summary- 言語モデルの評価は未解決の課題であり、研究者やエンジニアは感度、手法比較の難しさ、再現性の欠如といった問題に直面している。本論文は、大規模言語モデルの評価に関する3年間の経験を基に、共通の課題の概要、ベストプラクティスの整理、独立的で再現性のあるオープンソースライブラリ「Language Model Evaluation Harness」(lm-eval)を提案し、その機能とケーススタディを紹介する。 Comment
いわゆるLM Evaluation Harnessに関する運用する中での知見を報告する論文。LM Evaluation Harnessは広範なベンチマークでのLLMの評価を公平で透明性、再現性が担保された形で実施する実装である。
github:
https://github.com/EleutherAI/lm-evaluation-harness
LM Evaluation Harness自体は2021年から存在する。
[Paper Note] Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention, Zhen Qin+, ICML'24, 2024.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Attention #LongSequence #ICML #LinearAttention Issue Date: 2026-02-17 GPT Summary- Lightning Attentionは、一定の学習速度を維持しつつ固定メモリ消費を実現する線形注意の新しい実装です。累積和演算の問題を、異なる計算戦略を用いることで解決し、ブロック内では従来の注意計算を、ブロック間では線形注意のカーネル技術を導入しています。GPUを効率的に活用するためのタイル化技術を採用し、新しいアーキテクチャTransNormerLLM(TNL)を提案。TNLは他のモデルより効率的で、従来のトランスフォーマーと同等の性能を示します。ソースコードは公開されています。 Comment
Ring、MiniCPMで採用されているlinear attentionの一種であるlightning attention
[Paper Note] Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws, Yiding Jiang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ICLR #Scaling Laws #DataMixture #Adaptive Issue Date: 2026-01-21 GPT Summary- ADOは事前学習データの最適化をオンラインで行うアルゴリズムで、モデル訓練と同時にデータ分布を調整。外部知識やプロキシモデルを必要とせず、ドメインごとの学習ポテンシャルを推定してスケーラブルなデータ混合を実現。実験では、従来法と同等またはそれ以上の性能を示しつつ計算効率を維持する効果的な解決策を提供。スケーリング則を通じて新たなデータ収集戦略の視点も提示。 Comment
openreview: https://openreview.net/forum?id=aqok1UX7Z1
ドメインごとのneural scaling lawsを学習をする中で構築し、scaling lawsに従って動的にドメインのデータをどの程度サンプリングするかを決定するようなオンラインでのDataMixture決定手法、に見える。小規模モデルの実験結果を活用する不確実性やSarrogate modelを用いて推論するといった計算コストの高い方法はおそらく不要?
[Paper Note] SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, John Yang+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #NeurIPS #SoftwareEngineering #read-later #Selected Papers/Blogs Issue Date: 2025-11-25 GPT Summary- LMエージェントのパフォーマンスにおけるインターフェースデザインの影響を調査し、ソフトウェアエンジニアリングタスクを解決するためのシステム「SWE-agent」を提案。SWE-agentのカスタムインターフェースは、コード作成やリポジトリナビゲーション、プログラム実行能力を向上させ、SWE-benchとHumanEvalFixで最先端のパフォーマンスを達成。pass@1率はそれぞれ12.5%と87.7%に達し、従来の非インタラクティブなLMを大きく上回る結果を示した。 Comment
SWE bench Verifiedで利用されているハーネスで、mini-SWE-agentと呼ばれるもの
https://github.com/SWE-agent/mini-swe-agent
[Paper Note] To Code, or Not To Code? Exploring Impact of Code in Pre-training, Viraat Aryabumi+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Coding #DataMixture Issue Date: 2025-11-04 GPT Summary- コードデータが一般的なLLMのパフォーマンスに与える影響を体系的に調査。アブレーション実験により、コードがコーディングタスクを超えた一般化に重要であり、コード品質の向上が全タスクに大きな影響を与えることを確認。特に、コードの追加により自然言語推論で最大8.2%、世界知識で4.2%、生成的勝率で6.6%の向上を示し、コードパフォーマンスでは12倍の改善を達成。研究は、コード品質への投資がポジティブな影響をもたらすことを示唆。 Comment
元ポスト:
事前学習におけるコードの割合を増やすとコーディングタスクの性能は線形に増加する。全体の平均タスク性能の観点で言うとコードの割合を25%にするのが最適で、コードの割合を増やすほど自然言語による推論、世界知識が問われるタスクの性能は悪化していき、コードの割合が75%を超えると急激に悪化する(Figure4)。
[Paper Note] On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes, Rishabh Agarwal+, ICLR'24, 2023.06
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #NLP #Distillation #ICLR #Selected Papers/Blogs #Off-Policy #On-Policy Issue Date: 2025-10-30 GPT Summary- 一般化知識蒸留(GKD)は、教師モデルからのフィードバックを活用し、生徒モデルが自己生成した出力シーケンスで訓練する手法。これにより、出力シーケンスの分布不一致の問題を解決し、柔軟な損失関数の使用が可能になる。GKDは蒸留と強化学習の統合を促進し、要約、翻訳、算術推論タスクにおける自動回帰言語モデルの蒸留においてその有効性を示す。 Comment
openreview: https://openreview.net/forum?id=3zKtaqxLhW
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
での説明に基づくと、
オフポリシーの蒸留手法を使うと、教師モデルが生成した出力を用いて蒸留をするため、生徒モデルが実際に出力するcontextとは異なる出力に基づいて蒸留をするため、生徒モデルの推論時のcontextとのミスマッチが生じる課題があるが、オンポリシーデータを混ぜることでこの問題を緩和するような手法(つまり実際の生徒モデル運用時と似た状況で蒸留できる)。生徒モデルが賢くなるにつれて出力が高品質になるため、それらを学習データとして再利用することでpositiveなフィードバックループが形成されるという利点がある。また、強化学習と比較しても、SparseなReward Modelに依存せず、初期の性能が低いモデルに対しても適用できる利点があるとのこと(性能が低いと探索が進まない場合があるため)。
[Paper Note] Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To, Xiangyu Qi+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Safety #PostTraining #Selected Papers/Blogs Issue Date: 2025-10-24 GPT Summary- LLMのファインチューニングは、下流のユースケースに最適化する手法だが、安全性のリスクが伴う。特に、敵対的なトレーニング例を用いたファインチューニングが、モデルの安全性調整を損なう可能性があることが示された。例えば、わずか10例の悪意のある例でGPT-3.5 Turboをファインチューニングすると、安全ガードレールが突破される。また、無害なデータセットでのファインチューニングも意図せず安全性を劣化させる可能性がある。これらの結果は、調整されたLLMのファインチューニングが新たな安全リスクを生むことを示唆しており、今後の安全プロトコルの強化が求められる。 Comment
openreview: https://openreview.net/forum?id=hTEGyKf0dZ
なんらかのデータでpost-trainingしたモデルを、ユーザが利用可能な形でデプロイするような場合には、本研究が提唱するようなjailbreakのリスク
- 有害データが10例混入するだけで有害な出力をするようになる
- 暗黙的な有害データの混入(e.g., あなたはユーザ命令に従うエージェントです)
- 無害なデータでpost-trainingするだけでも下記のような影響でsafety alignmentが悪化する
- catastrophic forgetting
- 有用性と無害性のトレードオフによって、有用性を高めたことで有害性が結果的に増えてしまう( `tension between the helpfulness and harmlessness objectives` [Paper Note] Training a Helpful and Harmless Assistant with Reinforcement Learning
from Human Feedback, Yuntao Bai+, arXiv'22
)
があることを認識しておく必要がある。
もし安直にユーザからの指示追従能力を高めたいなあ・・・と思い、「ユーザからの指示には忠実に従ってください」などの指示を追加してpost-trainingをしてしまい、無害なプロンプトのみでテストして問題ないと思いユーザ向けのchatbotとしてデプロイしました、みたいなことをしたらえらいことになりそう。
[Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML #Selected Papers/Blogs Issue Date: 2025-10-10 GPT Summary- LoRAの精度ギャップを解消するために、Weight-Decomposed Low-Rank Adaptation(DoRA)を提案。DoRAは、ファインチューニングの重みを大きさと方向に分解し、方向性の更新にLoRAを使用することで、効率的にパラメータ数を最小化。これにより、LoRAの学習能力と安定性を向上させ、追加の推論コストを回避。さまざまな下流タスクでLoRAを上回る性能を示す。 Comment
日本語解説:
- LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
- Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
では、通常のLoRA, QLoRAだけでなく本手法でRLをする実装もサポートされている模様
[Paper Note] Stepwise Alignment for Constrained Language Model Policy Optimization, Akifumi Wachi+, NeurIPS'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Safety #NeurIPS Issue Date: 2025-09-09 GPT Summary- 安全性と信頼性はLLMを用いるAIシステムにおいて重要であり、本研究では報酬最大化を人間の価値に基づく安全性制約の下で定式化し、逐次整合性アルゴリズム(SACPO)を提案。SACPOは報酬と安全性を組み込んだ最適ポリシーを段階的に整合させ、シンプルで強力な整合性アルゴリズムを活用。理論的分析により最適性と安全性制約違反の上限を示し、実験結果ではSACPOがAlpaca-7Bのファインチューニングにおいて最先端手法を上回ることを確認。 Comment
NLPコロキウムでのスライドを参照のこと:
- 【NLPコロキウム】Stepwise Alignment for Constrained Language Model Policy Optimization (NeurIPS 2024) , 2024.12
[Paper Note] MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies, Shengding Hu+, COLM'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #SmallModel #COLM #Selected Papers/Blogs #Scheduler Issue Date: 2025-08-25 GPT Summary- 急成長する大規模言語モデル(LLMs)の開発におけるコストの懸念から、小規模言語モデル(SLMs)の可能性が注目されている。本研究では、MiniCPMという1.2Bおよび2.4Bの非埋め込みパラメータバリアントを紹介し、これらが7B-13BのLLMsと同等の能力を持つことを示す。モデルのスケーリングには広範な実験を、データのスケーリングにはWarmup-Stable-Decay(WSD)学習率スケジューラを導入し、効率的なデータ-モデルスケーリング法を研究した。MiniCPMファミリーにはMiniCPM-DPO、MiniCPM-MoE、MiniCPM-128Kが含まれ、優れたパフォーマンスを発揮している。MiniCPMモデルは公開されている。 Comment
Warmup-Stable-Decay (WSD)
openreview: https://openreview.net/forum?id=3X2L2TFr0f¬eId=QvwPc5chyd
[Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ICML #mid-training #Selected Papers/Blogs #Workshop #needs-revision #DistributedLearning Issue Date: 2025-07-15 GPT Summary- 分散最適化アルゴリズム「DiLoCo」を提案し、接続が不十分なデバイスでのLLMトレーニングを可能にする。DiLoCoは、通信量を500分の1に抑えつつ、完全同期の最適化と同等の性能をC4データセットで発揮。各ワーカーのデータ分布に対して高いロバスト性を持ち、リソースの変動にも柔軟に対応可能。 Comment
言語モデルの分散学習における通信量をいかに抑えるかにフォーカスした研究で、クライアントごとに異なるデータsplitを持ち、当該データによってモデルをローカルでAdamWを用いてH step更新。その後、更新された重みの差分をouter gradientとして共有し、重み更新の差分を平均化することでローカルモデルを集約するという処理を繰り返す。
[Paper Note] Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset, Ke Wang+, NeurIPS'24 Datasets and Benchmarks Track
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #Evaluation #Mathematics #VisionLanguageModel Issue Date: 2025-07-14 GPT Summary- MATH-Vision(MATH-V)データセットを提案し、3,040の視覚的文脈を持つ数学問題を収集。16の数学分野と5つの難易度で構成され、LMMsの数学的推論能力を評価。実験により、LMMsと人間のパフォーマンス間に顕著なギャップがあることを示し、さらなる進展の必要性を強調。エラー分析を通じて今後の研究に貴重な洞察を提供。 Comment
openreview:
https://openreview.net/forum?id=QWTCcxMpPA#discussion
project page:
https://mathllm.github.io/mathvision/
Project Pageのランディングページが非常にわかりやすい。こちらは人間の方がまだまだ性能が高そう。
Gemma-4-31Bではスコアが85.6%に到達。人間のスコアが68.82%なので、すでに本ベンチマーク上では人間のスコア超え。
- Gemma 4: Byte for byte, the most capable open models, Google, 2026.04
GPT-5.4 (xhigh)が96.1%のスコアに到達しているため、スコアはすでに飽和している。
[Paper Note] A Comparative Study of PDF Parsing Tools Across Diverse Document Categories, Narayan S. Adhikari+, arXiv'24
Paper/Blog Link My Issue
#Analysis #Tools #NLP #RAG(RetrievalAugmentedGeneration) #Reference Collection Issue Date: 2025-06-18 GPT Summary- 本研究では、DocLayNetデータセットを用いて10の人気PDFパースツールを6つの文書カテゴリにわたり比較し、情報抽出の効果を評価しました。テキスト抽出ではPyMuPDFとpypdfiumが優れた結果を示し、特に科学文書や特許文書ではNougatが高いパフォーマンスを発揮しました。表検出ではTATRが金融や法律文書で優れた結果を示し、Camelotは入札文書で最も良いパフォーマンスを発揮しました。これにより、文書タイプに応じた適切なパースツールの選択が重要であることが示されました。 Comment
PDFのparsingツールについて、text, table抽出の性能を様々なツールと分野別に評価している。
F1, precision, recallなどは、ground truthとのレーベンシュタイン距離からsimilarityを計算し、0.7以上であればtrue positiveとみなすことで計算している模様。local alignmentは、マッチした場合に加点、ミスマッチ、未検出の場合にペナルティを課すようなスコアリングによって抽出したテキスト全体の抽出性能を測る指標な模様。
より性能を高くしたければこちらも参考に:
[Paper Note] Physics of Language Models: Part 4.1, Architecture Design and the Magic of Canon Layers, Zeyuan Allen-Zhu+, ICML'24 Tutorial
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #SyntheticData #read-later #Selected Papers/Blogs #Reference Collection #Author Thread-Post Issue Date: 2025-05-06 Comment
元ポスト:
Canon層の発見
著者による解説:
[Paper Note] Safety Alignment Should Be Made More Than Just a Few Tokens Deep, Xiangyu Qi+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety #ICLR #Selected Papers/Blogs #Reference Collection Issue Date: 2025-04-29 GPT Summary- LLMsの安全性整合性は脆弱であり、単純な攻撃でジャイルブレイク可能。この問題は浅層的安全整合に起因し、生成分布が初めの数トークンで適応されるために発生する。研究では、浅層的安全整合の存在理由をケーススタディで示し、複数の脆弱性の根本原因を探求。これにより、初期トークンを超えて整合性を深めることで悪用に対する堅牢性を向上させる可能性が示唆される。ファインチューニング攻撃に対抗するための正則化手法も提案。将来の安全整合性は、より深いアプローチが必要であるとの結論を導く。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=6Mxhg9PtDE
Safety Alignment手法が最初の数トークンに依存しているからそうならないように学習しますというのは、興味深いテーマだし技術的にまだ困難な点もあっただろうし、インパクトも大きいし、とても良い研究だ…。
[Paper Note] Agent Workflow Memory, Zora Zhiruo Wang+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #memory #needs-revision Issue Date: 2025-04-02 GPT Summary- エージェントが複雑なタスクを解決するために、再利用可能なワークフローを学習するAgent Workflow Memory(AWM)を提案。AWMは、オフライン・オンラインのシナリオで選択的にワークフローを提供し、200以上のドメインにおいて実験した結果、Mind2Webで24.6%、WebArenaで51.1%の相対的成功率向上を達成。タスク解決に要する手順数も削減し、訓練-テスト分布ギャップが広がる中でも堅牢な一般化を示した。 Comment
過去のワークフローをエージェントがprompt中で利用することができ、利用すればするほど賢くなるような仕組みの提案
openreview: https://openreview.net/forum?id=PfYg3eRrNi
[Paper Note] CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration, Xinming Hou+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #SoftwareEngineering Issue Date: 2025-04-02 GPT Summary- CoActフレームワークを提案し、LLMに人間社会の協調パターンを適用。グローバル計画エージェントがマクロ計画を策定し、ローカル実行エージェントが具体的なサブタスクを実行。WebArenaベンチマークで、長期的なウェブタスクにおいて従来手法を上回る性能を示した。 Comment
Planningエージェントと実行エージェントを活用するソフトウェアエージェント
ReActより性能向上
- [Paper Note] ReAct: Synergizing Reasoning and Acting in Language Models, Shunyu Yao+, ICLR'23, 2022.10
[Paper Note] WebArena: A Realistic Web Environment for Building Autonomous Agents, Shuyan Zhou+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #ICLR #Selected Papers/Blogs Issue Date: 2025-04-02 GPT Summary- 生成AIの進展により、自律エージェントが自然言語コマンドで日常タスクを管理する可能性が生まれたが、現行のエージェントは簡略化された環境でのテストに限られている。本研究では、ウェブ上でタスクを実行するエージェントのための現実的な環境を構築し、eコマースやソーシャルフォーラムなどのドメインを含む完全なウェブサイトを提供する。この環境を基に、タスクの正確性を評価するベンチマークを公開し、実験を通じてGPT-4ベースのエージェントの成功率が14.41%であり、人間の78.24%には及ばないことを示した。これにより、実生活のタスクにおけるエージェントのさらなる開発の必要性が強調される。 Comment
Webにおけるさまざまなrealisticなタスクを評価するためのベンチマーク
実際のexample。スタート地点からピッツバーグのmuseumを巡る最短の経路を見つけるといった複雑なタスクが含まれる。
人間とGPT4,GPT-3.5の比較結果
[Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #ICLR #SoftwareEngineering #Selected Papers/Blogs #Reference Collection Issue Date: 2025-04-02 GPT Summary- SWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Comment
ソフトウェアエージェントの最もpopularなベンチマーク
主にpythonライブラリに関するリポジトリに基づいて構築されている。
SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
https://www.swebench.com/
Agenticな評価をする際に、一部の評価でエージェントがgit logを参照し本来は存在しないはずのリポジトリのfuture stateを見ることで環境をハッキングしていたとのこと:
これまでの評価結果にどの程度の影響があるかは不明。
openreview: https://openreview.net/forum?id=VTF8yNQM66
[Paper Note] PromptWizard: Task-Aware Prompt Optimization Framework, Eshaan Agarwal+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Prompting #AutomaticPromptEngineering Issue Date: 2025-02-10 GPT Summary- 大規模言語モデル(LLMs)の効果的な活用に向けて、完全自動化されたプロンプト最適化フレームワーク「PromptWizard」を提案。自己進化・自己適応機能に基づき、プロンプトと文脈内例を反復的に洗練し、優れた品質のプロンプトを生成。45のタスクで高性能を示し、限られたデータや小規模モデルでも適用可能。コスト分析により効率性と優位性が確認される。 Comment
Github:
https://github.com/microsoft/PromptWizard?tab=readme-ov-file
元ポスト:
初期に提案された
- Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
と比較すると大分性能が上がってきているように見える。
reasoning modelではfewshot promptingをすると性能が落ちるという知見があるので、reasoningモデル向けのAPE手法もそのうち出現するのだろう(既にありそう)。
OpenReview:
https://openreview.net/forum?id=VZC9aJoI6a
ICLR'25にrejectされている
[Paper Note] Spectrum: Targeted Training on Signal to Noise Ratio, Eric Hartford+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining Issue Date: 2025-01-25 GPT Summary- 大規模言語モデルのポストトレーニングを効率化する手法「Spectrum」を提案。SNRに基づいてレイヤーモジュールを選択し、他を凍結することでトレーニングを加速。性能はフルファインチューニングに匹敵し、GPUメモリ使用量を削減。従来手法との比較実験でモデル品質とVRAM効率の向上を確認。 Comment
- How to fine-tune open LLMs in 2025 with Hugging Face, PHILSCHMID, 2024.12
によるとLLMのうち最もinformativeなLayerを見つけ、選択的に学習することで、省リソースで、Full-Parameter tuningと同等の性能を発揮する手法らしい
[Paper Note] FinTextQA: A Dataset for Long-form Financial Question Answering, Jian Chen+, ACL'24
Paper/Blog Link My Issue
#Dataset #Financial #ACL Issue Date: 2025-01-06 GPT Summary- 金融における質問応答システムの評価には多様なデータセットが必要だが、既存のものは不足している。本研究では、金融の長文質問応答用データセットFinTextQAを提案し、1,262の高品質QAペアを収集した。また、RAGベースのLFQAシステムを開発し、様々な評価手法で性能を検証した結果、Baichuan2-7BがGPT-3.5-turboに近い精度を示し、最も効果的なシステム構成が特定された。文脈の長さが閾値を超えると、ノイズに対する耐性が向上することも確認された。 Comment
@AkihikoWatanabe Do you have this dataset, please share it with me. Thank you.
@thangmaster37 Thank you for your comment and I'm sorry for the late replying. Unfortunately, I do not have this dataset. I checked the link provided in the paper, but it was not found. Please try contacting the authors. Thank you.
@thangmaster37 I found that the dataset is available in the following repository. However, as stated in the repository's README, It seems that the textbook portion of the dataset cannot be shared because their legal department has not granted permission to open source. Thank you.
https://github.com/AlexJJJChen/FinTextQA
回答の長さが既存データセットと比較して長いFinancialに関するQAデータセット(1 paragraph程度)。


ただし、上述の通りデータセットのうちtextbookについて公開の許可が降りなかったようで、regulation and policy-relatedな部分のみ利用できる模様(全体の20%程度)。

How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, AMTA'24
Paper/Blog Link My Issue
#MachineTranslation #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) Issue Date: 2025-01-02 GPT Summary- LLMsのファインチューニングに翻訳メモリ(TMs)を活用し、特定の組織向けの翻訳精度と効率を向上させる研究。5つの翻訳方向で異なるサイズのデータセットを用いて実験し、トレーニングデータが増えるほど翻訳パフォーマンスが向上することを確認。特に、1kおよび2kの例ではパフォーマンスが低下するが、データセットのサイズが増加するにつれて改善が見られる。LLMsとTMsの統合により、企業特有のニーズに応じたカスタマイズ翻訳モデルの可能性を示唆。 Comment
元ポスト:
QLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証しているタスクはMT、QLoRAでSFTを実施しrankは64、学習時のプロンプトは非常にシンプルなものであるなど、幅広い設定で学習しているわけではないので、ここで得られた知見が幅広く適用可能なことは示されていないであろう点、には注意が必要だと思われる。
この設定では、SFTで利用するサンプル数が増えれば増えるほど性能が上がっているように見える。
[Paper Note] DeepSeek-V3 Technical Report, DeepSeek-AI+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #Selected Papers/Blogs #Reference Collection Issue Date: 2024-12-28 GPT Summary- DeepSeek-V3は671Bのパラメータを持つMixture-of-Experts (MoE)言語モデルで、各トークンに対して37Bが活性化される。効率的な推論とコスト削減のため、MLAおよびDeepSeekMoEアーキテクチャを採用し、補助損失を用いない戦略を導入。14.8兆トークンでプレトレーニング後、ファインチューニングと強化学習を経て、高性能を発揮。評価結果はオープンソースモデルを上回り、先端的なクローズドソースモデルとも同等。訓練にはわずか2,788,000時間のH800 GPU時間を要し、安定した訓練プロセスを実現。モデルのチェックポイントは提供されている。 Comment
参考(モデルの図解):
参考:
MLA(Multi-Head Latent Attention)を提案
解説:
- MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- DeepSeek-V2のアーキテクチャを徹底解説:MLA と DeepSeekMoE, kernelian, 2024.05
MLAはKVを低ランクなlatentベクトルに圧縮して保持し、使う時に復元するといった操作をすることで、MHAのパフォーマンスを落とすことなくKV Cacheで利用するメモリを大幅に減らせるという手法。
MLAの図解:
[Paper Note] Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference, Benjamin Warner+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Library #Transformer #pretrained-LM #ACL #Selected Papers/Blogs #Reading Reflections Issue Date: 2024-12-20 GPT Summary- ModernBERTはエンコーダーのみのトランスフォーマーモデルで、BERTに対する大きなパレート改善を達成。2兆トークンで訓練され、長いシーケンスに対応しながら、分類タスクと検索において最先端の性能を示す。さらに、最も高速かつメモリ効率の良いエンコーダーとして設計されている。 Comment
最近の進化しまくったTransformer関連のアーキテクチャをEncodnr-OnlyモデルであるBERTに取り込んだら性能上がるし、BERTの方がコスパが良いタスクはたくさんあるよ、系の話、かつその実装だと思われる。
テクニカルペーパー中に記載はないが、評価データと同じタスクでのDecoder-Onlyモデル(SFT有り無し両方)との性能を比較したらどの程度の性能なのだろうか?
そもそも学習データが手元にあって、BERTをFinetuningするだけで十分な性能が出るのなら(BERTはGPU使うのでそもそもxgboostとかでも良いが)、わざわざLLM使う必要ないと思われる。BERTのFinetuningはそこまで時間はかからないし、inferenceも速い。
参考:
- [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08
日本語解説: https://zenn.dev/dev_commune/articles/3f5ab431abdea1?utm_source=substack&utm_medium=email
[Paper Note] VLR-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation, Hyeonseok Lim+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#ComputerVision #InformationRetrieval #NLP #Dataset #RAG(RetrievalAugmentedGeneration) #MultiLingual #COLING #VisionLanguageModel Issue Date: 2024-12-16 GPT Summary- 視覚言語モデル(VLM)を評価するための新しいベンチマークVLR-Benchを提案。これは5つの入力パッセージを用いて、特定のクエリに対する有用な情報の判断能力をテストする。32,000の自動生成された指示からなるデータセットVLR-IFを構築し、VLMのRAG能力を強化。Llama3ベースのモデルで性能を検証し、両データセットはオンラインで公開。 Comment
Multilingual VLMを用いたRAGのベンチマークデータセット
[Paper Note] BatchEval: Towards Human-like Text Evaluation, Peiwen Yuan+, ACL'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #LLM-as-a-Judge #Batch Issue Date: 2024-12-15 GPT Summary- BatchEvalという新しい評価パラダイムを提案し、LLMを用いた自動テキスト評価の問題を解決。バッチ単位での反復評価により、プロンプト設計の敏感さやノイズ耐性の低さを軽減。実験により、BatchEvalは最先端手法に対して10.5%の改善を示し、APIコストを64%削減。 Comment
- 国際会議ACL2024参加報告, Masato Mita, Cyber Agent, 2024.12
に日本語によるサマリが掲載されているので参照のこと。
[Paper Note] The broader spectrum of in-context learning, Andrew Kyle Lampinen+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #In-ContextLearning Issue Date: 2024-12-15 GPT Summary- 少数ショット学習は言語モデルの能力として注目されており、これを広範なメタ学習済みのインコンテキスト学習に位置づける見解を提示。文脈が予測の損失を低下させるシーケンスを示すことで、インコンテキスト学習の一種を引き出すことを示唆。これにより、タスク適応やロールプレイなどの能力を統一的に捉えることができ、低レベル処理の潜在的な根源も明らかになる。さらには、一般化の重要性を強調し、新しい事柄を学ぶ能力や適応力の研究を提案。過去の文献との関連についても論じ、インコンテキスト学習の研究がその能力と一般化の多様性を考慮すべきだと結論づけている。 Comment
OpenReview:
https://openreview.net/forum?id=RHo3VVi0i5
OpenReviewによると、
論文は理解しやすく、meta learningについて広範にサーベイされている。しかし、論文が定義しているICLの拡張はICLを過度に一般化し過ぎており(具体的に何がICLで何がICLでないのか、といった規定ができない)、かつ論文中で提案されているコンセプトを裏付ける実験がなくspeculativeである、とのことでrejectされている。
[Paper Note] Phi-4 Technical Report, Marah Abdin+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #LanguageModel #SmallModel #OpenWeight Issue Date: 2024-12-15 GPT Summary- phi-4は140億パラメータを持つ言語モデルで、合成データを戦略的に組み込んだトレーニングを実施。STEM分野に特化したQA能力で従来の教師モデルを超える性能を示し、サイズに対して強力な推論性能を達成。データ品質とトレーニング手法の革新が特徴。 Comment
現状Azureでのみ利用可能かも。Huggingfaceにアップロードされても非商用ライセンスになるという噂も
MITライセンス
HuggingFace:
https://huggingface.co/microsoft/phi-4
[Paper Note] The Super Weight in Large Language Models, Mengxia Yu+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Quantization Issue Date: 2024-12-02 GPT Summary- LLMパラメータのわずかな外れ値が重要であり、1つのパラメータを剪定することでテキスト生成能力が著しく低下することを示す。データを用いずに「スーパウェイト」と呼ばれる重要なパラメータを特定し、これにより「スーパアクティベーション」を生じさせる。これらは量子化の性能向上に寄与し、重み量子化のスケーラビリティを向上させることを示した。スーパウェイトの座標インデックスも公開。 Comment
図にある通り、たった一つのニューラルネットワーク中の重みを0にするだけで、途端に意味のあるテキストが生成できなくなるような重みが存在するらしい。
(図は論文より引用)
ICLR 2025のOpenreview
https://openreview.net/forum?id=0Ag8FQ5Rr3
Japanese-English Sentence Translation Exercises Dataset for Automatic Grading, Miura+, EACL'24, 2024.03
Paper/Blog Link My Issue
#NLP #Dataset #AES(AutomatedEssayScoring) #Japanese Issue Date: 2024-11-28 GPT Summary- 第二言語学習の文翻訳演習の自動評価タスクを提案し、評価基準に基づいて学生の回答を採点する。日本語と英語の間で3,498の学生の回答を含むデータセットを作成。ファインチューニングされたBERTモデルは約90%のF1スコアで正しい回答を分類するが、誤った回答は80%未満。少数ショット学習を用いたGPT-3.5はBERTより劣る結果を示し、提案タスクが大規模言語モデルにとっても難しいことを示す。 Comment
STEsの図解。分かりやすい。いわゆる日本人が慣れ親しんでいる和文英訳、英文和訳演習も、このタスクの一種だということなのだろう。2-shotのGPT4とFinetuningしたBERTが同等程度の性能に見えて、GPT3.5では5shotしても勝てていない模様。興味深い。
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, Dawei Li+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #LLM-as-a-Judge Issue Date: 2024-11-27 GPT Summary- LLMを用いた判断と評価の新たなパラダイム「LLM-as-a-judge」に関する包括的な調査を行い、定義や分類法を提示。評価のためのベンチマークをまとめ、主要な課題と今後の研究方向を示す。関連リソースも提供。 Comment
LLM-as-a-Judgeに関するサーベイ
- Leveraging Large Language Models for NLG Evaluation: A Survey, Zhen Li+, N/A, arXiv'24
も参照のこと
[Paper Note] Observational Scaling Laws and the Predictability of Language Model Performance, Yangjun Ruan+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #NLP #LanguageModel #NeurIPS #read-later Issue Date: 2024-11-22 GPT Summary- 言語モデルの性能変化を理解することは重要であり、スケーリング則がその手法の一つとして提案されている。約100の公開モデルからスケーリング則を構築することで、モデル訓練を回避する新しいアプローチが示される。異なる計算資源を持つモデルファミリー間のばらつきが、低次元の能力空間と整合することで、予測可能なスケーリング現象が明らかとなる。GPT-4の性能はシンプルなベンチマークから予測可能であり、思考の連鎖や自己整合性といった介入がモデル能力に与える影響の予測も可能であることが示された。 Comment
縦軸がdownstreamタスクの主成分(のうち最も大きい80%を説明する成分)の変化(≒LLMの性能)で、横軸がlog scaleの投入計算量。
Qwenも頑張っているが、投入データ量に対する性能(≒データの品質)では、先駆け的な研究であるPhiがやはり圧倒的?
- [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
も参照のこと
[Paper Note] Likelihood as a Performance Gauge for Retrieval-Augmented Generation, Tianyu Liu+, arXiv'24
Paper/Blog Link My Issue
#Analysis #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Reading Reflections Issue Date: 2024-11-19 GPT Summary- 大規模言語モデルを用いた情報検索強化生成は、文脈内の文書の順序に影響を受けやすい。研究では、質問の確率がモデルのパフォーマンスに与える影響を分析し、正確性との相関関係を明らかにした。質問の確率を指標として、プロンプトの選択と構築に関する2つの方法を提案し、その効果を実証。確率に基づく手法は効率的で、少ないモデルのパスで応答を生成できるため、プロンプト最適化の新たな方向性を示す。 Comment
トークンレベルの平均値をとった生成テキストの対数尤度と、RAGの回答性能に関する分析をした模様。
とりあえず、もし「LLMとしてGPTを(OpenAIのAPIを用いて)使いました!temperatureは0です!」みたいな実験設定だったら諸々怪しくなる気がしたのでそこが大丈夫なことを確認した(OpenLLM、かつdeterministicなデコーディング方法が望ましい)。おもしろそう。
参考: [RAGのハルシネーションを尤度で防ぐ, sasakuna, 2024.11.19]( https://zenn.dev/knowledgesense/articles/7c47e1796e96c0)
## 参考
生成されたテキストの尤度を用いて、どの程度正解らしいかを判断する、といった話は
- [Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
のようなLLM-as-a-Judgeでも行われている。
G-Evalでは1--5のスコアのような離散的な値を生成する際に、これらを連続的なスコアに補正するために、尤度(トークンの生成確率)を用いている。
ただし、G-Evalの場合は実験でGPTを用いているため、モデルから直接尤度を取得できず、代わりにtemperature1とし、20回程度生成を行った結果からスコアトークンの生成確率を擬似的に計算している。
G-Evalの設定と比較すると(当時はつよつよなOpenLLMがなかったため苦肉の策だったと思われるが)、こちらの研究の実験設定の方が望ましいと思う。
[Paper Note] Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs, Kazuki Fujii+, arXiv'24
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Japanese #read-later #LowPrecision Issue Date: 2024-11-17 GPT Summary- 大規模言語モデル(LLMs)は、その言語理解能力と適用可能性から注目を集めており、特にLlama 3シリーズは4050億パラメータを持つ。トレーニングの効率化が求められる中、NVIDIAのH100 GPUはFP8フォーマットを導入し、トレーニング時間を短縮する可能性がある。初期研究ではFP8が性能を損なわずに効率を向上させることが示唆されているが、トレーニングの安定性や下流タスクへの影響はまだ不明である。本研究は、LLMsのトレーニングにおけるBF16とFP8のトレードオフを探る。 Comment
元ポスト:
FP8で継続的事前学習をするとスループットは向上するが、lossのスパイクを生じたり、downstreamタスクの性能がBF16よりも低下したりする(日本語と英語の両方)との報告のようである。現状アブストと付録しか記載がないが、内容はこれから更新されるのだろうか。
[Paper Note] Understanding LLMs: A Comprehensive Overview from Training to Inference, Yiheng Liu+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #Reading Reflections Issue Date: 2024-11-17 GPT Summary- ChatGPTの導入により、LLMsの低コストな訓練とデプロイメントへの関心が高まる。本論文では、訓練技術や推論デプロイメント技術の進化を概説し、データ前処理やモデル圧縮など多様な視点を提供。LLMsの活用についても考察し、今後の発展を示唆する。 Comment
[Perplexity(参考;Hallucinationに注意)]( https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-7vGwDK_AQX.HDO7j9H8iNA)
単なるLLMの理論的な説明にとどまらず、実用的に必要な各種並列処理技術、Mixed Precision、Offloadingなどのテクニックもまとまっているのがとても良いと思う。
LLM Frameworkのところに、メジャーなものが網羅されていないように感じる。たとえば、UnslothやLiger-KernelなどはTransformersの部分で言及されてても良いのでは、と感じる。
A Large-Scale Study of Relevance Assessments with Large Language Models: An Initial Look, Shivani Upadhyay+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #RelevanceJudgment #LanguageModel #Evaluation Issue Date: 2024-11-14 GPT Summary- 本研究では、TREC 2024 RAG Trackにおける大規模言語モデル(LLM)を用いた関連性評価の結果を報告。UMBRELAツールを活用した自動生成評価と従来の手動評価の相関を分析し、77の実行セットにおいて高い相関を示した。LLMの支援は手動評価との相関を高めず、人間評価者の方が厳格であることが示唆された。この研究は、TRECスタイルの評価におけるLLMの使用を検証し、今後の研究の基盤を提供する。 Comment
元ポスト:
[Perplexity(参考;Hallucinationに注意)](
https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-ntenei-r-h3qlECirT3G9O2BGk765_g)
Perplexityの生成結果では、27個のシステムと記述されているが、これは実際はトピックで、各トピックごとに300件程度の0--3のRelevance Scoreが、人手評価、UMBRELA共に付与されている模様(Table1)。
評価結果
- Fully Manual Assessment: 既存のNIST methodologyと同様に人手でRelevance Scoreを付与する方法
- Manual Aspessment with Filtering: LLMのnon-Relevantと判断したpassageを人手評価から除外する方法
- Manual Post-Editing of Automatic Assessment: LLMがnon-Relevantと判断したpassageを人手評価から除外するだけでなく、LLMが付与したスコアを評価者にも見せ、評価者が当該ラベルを修正するようなスコアリングプロセス
- Fully Automatic Assessment:UMBRELAによるRelevance Scoreをそのまま利用する方法
LLMはGPT4-oを用いている。
19チームの77個のRunがどのように実行されているか、それがTable1の統計量とどう関係しているかがまだちょっとよくわかっていない。
UMBRELAでRelevance Scoreを生成する際に利用されたプロンプト。
GUI Agents with Foundation Models: A Comprehensive Survey, Shuai Wang+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #needs-revision Issue Date: 2024-11-12 GPT Summary- (M)LLMを活用したGUIエージェントの研究を統合し、データセット、フレームワーク、アプリケーションの革新を強調。重要なコンポーネントをまとめた統一フレームワークを提案し、商業アプリケーションを探求。課題を特定し、今後の研究方向を示唆。 Comment
Referenceやページ数はサーベイにしては少なめに見える。
HyQE: Ranking Contexts with Hypothetical Query Embeddings, Weichao Zhou+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #needs-revision Issue Date: 2024-11-10 GPT Summary- リトリーバル拡張システムにおいて、LLMのファインチューニングを必要とせず、埋め込みの類似性とLLMの能力を組み合わせたスケーラブルなランキングフレームワークを提案。ユーザーのクエリに基づいて仮定されたクエリとの類似性でコンテキストを再順位付けし、推論時に効率的で他の技術とも互換性がある。実験により、提案手法がランキング性能を向上させることを示した。 Comment
- Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23
も参照のこと。
下記に試しにHyQEとHyDEの比較の記事を作成したのでご参考までに(記事の内容に私は手を加えていないのでHallucinationに注意)。ざっくりいうとHyDEはpseudo documentsを使うが、HyQEはpseudo queryを扱う。
[参考: Perplexity Pagesで作成したHyDEとの簡単な比較の要約](
https://www.perplexity.ai/page/hyqelun-wen-nofen-xi-toyao-yue-aqZZj8mDQg6NL1iKml7.eQ)
[Paper Note] Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent, Xingwu Sun+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #SyntheticData #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2024-11-06 GPT Summary- Hunyuan-Largeは、3890億の総パラメータと256,000トークンに対応する混合エキスパートモデルで、言語理解や論理的推論など多様なタスクで卓越した性能を示す。また、従来のモデルを上回り、革新的な技術を採用している。コードとモデルは公開され、研究と応用の発展が期待される。 Comment
合計パラメータ数はLlama-3.1-405Bと同等の389Bだが、MoEによって52BのActive ParameterでSoTAを達成したTencentのOpenWeight LLM。大量のSynthetia Dataを利用している。
[Paper Note] ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate, Shohei Taniguchi+, NeurIPS'24
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #LanguageModel #Optimizer #Stability Issue Date: 2024-11-06 GPT Summary- ADOPTという新しい適応勾配法を提案し、任意のハイパーパラメータ$\beta_2$で最適な収束率を達成。勾配の二次モーメント推定からの除去と更新順序の変更により、Adamの非収束問題を解決。広範なタスクで優れた結果を示し、実装はGitHubで公開。 Comment
画像は元ツイートからの引用:
ライブラリがあるようで、1行変えるだけですぐ使えるとのこと。
元ツイート:
Adamでは収束しなかった場合(バッチサイズが小さい場合)でも収束するようになっている模様
[Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #PEFT(Adaptor/LoRA) #COLING #PostTraining #read-later #LREC Issue Date: 2024-10-30 GPT Summary- LoRAは大規模言語モデルのファインチューニング手法で、特にマルチタスク設定での性能向上に挑戦する。本研究では、LoRAのパフォーマンスを多様なタスクとリソースで検証し、適切なランク設定により高リソース環境でもフルファインチューニングに匹敵する結果を得られることを示した。学習能力の制約がLoRAの一般化能力を高めることが明らかになり、LoRAの適用可能性を広げる方向性を示唆している。 Comment
LoRAのランク数をめちゃめちゃ大きくすると(1024以上)、full-parameterをチューニングするよりも、Unseenタスクに対する汎化性能が向上しますよ、という話っぽい
## LoRA Finetuning details
- W_{q,k,v,o}にLoRAを適用
- dropout rateは0.05
- LoRA rankを最小4, 最大4096の範囲で変化
- LoRAのαをなんとrankの2倍にしている
- original paperでは16が推奨されている
- learning_rate: 5e-5
- linear sheculeで learning_rate を減衰させる
- optimizerはAdamW
- batch_size: 128
NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, ICLR'24
Paper/Blog Link My Issue
#MachineLearning #Supervised-FineTuning (SFT) #ICLR #PostTraining #Robustness Issue Date: 2024-10-27 GPT Summary- NEFTuneは、埋め込みベクトルにノイズを加えることで言語モデルのファインチューニングを改善する手法です。LLaMA-2-7Bを用いた標準的なファインチューニングでは29.79%の精度でしたが、ノイジーな埋め込みを使用することで64.69%に向上しました。NEFTuneは、Evol-Instruct、ShareGPT、OpenPlatypusなどの指示データセットでも改善をもたらし、RLHFで強化されたLLaMA-2-Chatにも効果があります。 Comment
ランダムノイズをembeddingに加えて学習するシンプルな手法。モデルがロバストになる。
Unsupervised SimCSEと思想が似ている。実質DataAugmentationともみなせる。
[Paper Note] KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, ICML'24, 2024.02
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Alignment #ICML #PostTraining #Selected Papers/Blogs Issue Date: 2024-10-27 GPT Summary- 人間の偏見を考慮したLLMのフィードバックを目的とした研究。プロスペクト理論に基づく「人間意識型損失(HALOs)」を用いて、生成物の効用を最大化する新手法KTOを提案。このアプローチは、既存の方法と比較してパフォーマンスが同等またはそれ以上であり、普遍的な最適損失関数は存在しないことを示唆。最適な損失は、設定に応じたバイアスによって異なる。 Comment
binaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文
解説(DPO,RLHFの話だがKTOを含まれている):
- RLHF/DPO 小話, 和地瞭良/ Akifumi Wachi, 2024.04
[Paper Note] Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely, Siyun Zhao+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#Survey #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-10-20 GPT Summary- データ補強型LLMは、多様な専門分野での実用的な展開において課題が多い。具体的には、関連データの取得やユーザー意図の解釈、LLMの推論能力活用に関する問題が含まれる。提案されたRAGタスク分類法により、クエリを明示的事実、暗黙的事実、解釈可能推論根拠、隠れた根拠の4つに分類し、それぞれの課題を要約。さらに、外部データ統合の形態として、コンテキスト、小型モデル、ファインチューニングを挙げ、各手法のメリットと課題を強調。今回の研究は、LLMアプリケーションのデータ要件とボトルネックを深く理解するためのガイドを提供することを目指す。 Comment
RAGのクエリを4種類に分類した各クエリごとの技術をまとめたSurvey
COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon , Yu+, SIGMOD_PODS '24
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #KnowledgeGraph #InstructionTuning #Annotation #needs-revision Issue Date: 2024-10-08 Comment
search navigationに導入しA/Bテストした結果、0.7%のproduct sales向上効果。
[Paper Note] What matters when building vision-language models?, Hugo Laurençon+, arXiv'24, 2024.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Dataset #VisionLanguageModel Issue Date: 2024-09-30 GPT Summary- 視覚と言語のモデル(VLM)の設計決定が正当化されていないことが、モデルのパフォーマンス改善を困難にしていると指摘。広範な実験を通じて、80億パラメータのVLMであるIdefics2を開発し、さまざまなマルチモーダルベンチマークで最先端のパフォーマンスを達成。モデルとそのトレーニング用データセットを公開。 Comment
元ポストにOpenVLMの進展の歴史が載っている。構築されたデータセットも公開される模様。
元ポスト:
[Paper Note] Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models, Matt Deitke+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #OpenWeight #OpenSource #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2024-09-27 GPT Summary- Molmoは、オープンな視覚・言語モデル(VLM)ファミリーを提案し、高性能なVLM構築に必要な基盤知識の欠如を解消する。PixMoという新しいデータセットを収集し、詳細な画像キャプション、自由形式画像Q&A、2Dポインティングデータを含む。72Bモデルは、オープンウェイトモデルの中で最高性能を示し、特にClaude 3.5 SonnetやGemini 1.5 Proなどの独自モデルよりも優れ、学術ベンチマークでGPT-4oに次ぐ第2位となった。モデルの重みやデータセットは公開中。 Comment
dataset, training code, inference, weight, recipe, 全てがオープンなVLM(OlmoのVLM版)。
以下がベンチマーク結果(VLMのベンチマーク)。11 benchmarksと書かれているのは、VLMのベンチマークである点に注意。
当時のVLMは全てプロプライエタリモデルであり、どのようにすればSoTA性能に到達できるかは不明であったが、Molmoによって明らかになった(と認識している)。
[Paper Note] Recommendation with Generative Models, Yashar Deldjoo+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#RecommenderSystems #Tutorial #LanguageModel #GenerativeAI #DiffusionModel Issue Date: 2024-09-24 GPT Summary- 生成モデルは、統計分布から新しいデータを生成するAIモデルで、GAN、VAE、トランスフォーマー型アーキテクチャが注目を集めている。これらは画像生成、テキスト生成、音楽作曲などの応用があり、レコメンドシステム(Gen-RecSys)でも活用され、推奨精度と多様性を向上させる。また、深層生成モデル(DGMs)をID駆動型モデル、大規模言語モデル、マルチモーダルモデルの3タイプに分類し、それぞれの進展に関連付ける。最後に、生成モデルの影響やリスクを考察し、評価フレームワークの重要性を強調する。 Comment
生成モデルやGenerativeAIによるRecSysの教科書
Report on the 1st Workshop on Large Language Model for Evaluation in Information Retrieval (LLM4Eval 2024) at SIGIR 2024, Hossein A. Rahmani+, N_A, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #LanguageModel #Evaluation Issue Date: 2024-09-24 GPT Summary- LLM4Eval 2024ワークショップがSIGIR 2024で開催され、情報検索における評価のための大規模言語モデルに関する研究者が集まりました。新規性を重視し、受理論文のパネルディスカッションやポスターセッションを通じて多面的な議論が行われました。 Comment
LLMを用いたIRシステムの評価方法に関するワークショップのレポート。レポート中にAccepted Paperがリストアップされている。
[Paper Note] When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs, Ryo Kamoi+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #SelfCorrection #TACL #Selected Papers/Blogs Issue Date: 2024-09-16 GPT Summary- 自己修正はLLMを活用し応答の質を向上させる手法です。しかし、LLMがどのように過ちを修正できるかに関しては合意がなく、従来の研究は多くの問題を抱えています。本研究では、先行研究の批判的レビューを行い、成功する自己修正に必要な条件を議論しています。研究課題の分類と実験設計のチェックリストを提供し、(1)プロンプトを用いた成功事例がないこと、(2)信頼できる外部フィードバックを活用すれば自己修正が機能すること、(3)大規模なファインチューニングが自己修正を支援することを示しています。 Comment
LLMのself-correctionに関するサーベイ
Leveraging User-Generated Reviews for Recommender Systems with Dynamic Headers, Shanu Vashishtha+, N_A, PAIS'24
Paper/Blog Link My Issue
#RecommenderSystems #PersonalizedGeneration #Personalization Issue Date: 2024-09-14 GPT Summary- Eコマースプラットフォームの推薦カルーセルのヘッダー生成をカスタマイズする新手法「Dynamic Text Snippets(DTS)」を提案。ユーザーのレビューから特定の属性を抽出し、グラフニューラルネットワークを用いて複数のヘッダーテキストを生成。これにより、コンテキストに配慮した推薦システムの可能性を示す。 Comment
e-commerceでDynamicにitemsetに対するスニペット(見出し)を生成する研究。Attributeに基づいてスニペットを生成する。
斜め読みだが、Anchor ItemがGivenであり、kNNされたアイテム集合から抽出されたに基づいて生成するので、Anchor Itemをユーザが与えるのであれば一時的個人化によるpersonalizationとみなせる。Anchor Itemをユーザの履歴からシステムが複数件選び集約して推薦するみたいなパラダイムになれば、永続的個人化とも言えそう。が、後者の場合共通のAttributeが見出せるか不明。
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Sean Welleck+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #LanguageModel #Inference Issue Date: 2024-09-10 GPT Summary- 推論時の計算リソース拡大の利点に焦点を当て、トークンレベル生成、メタ生成、効率的生成の3つのアプローチを統一的に探求。トークンレベル生成はデコーディングアルゴリズムを用い、メタ生成はドメイン知識や外部情報を活用し、効率的生成はコスト削減と速度向上を目指す。従来の自然言語処理、現代のLLMs、機械学習の視点を統合した調査。 Comment
元ツイート:
CMUのチームによるinference timeの高速化に関するサーベイ
[Paper Note] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers, Chenglei Si+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#NLP #LanguageModel #ScientificDiscovery Issue Date: 2024-09-10 GPT Summary- LLMの進展が科学的発見を促進する可能性に期待が高まる中、研究アイデア生成能力を評価するための実験を行い、100名以上のNLP研究者とLLMエージェントのアイデアを比較しました。結果、LLMによるアイデアは新規性が高いと評価される一方、実現可能性は劣ることが明らかになりました。また、LLMの自己評価の失敗や生成の多様性の不足等の未解決問題も指摘されました。人間による新規性評価の難しさを踏まえ、これらのアイデアを実行する研究者を募るエンドツーエンドの研究設計を提案します。 Comment
LLMがアイデアを考えた方が、79人のresearcherにblind reviewさせて評価した結果、Noveltyスコアが有意に高くなった(ただし、feasibilityは人手で考えた場合の方が高い)という話らしい。
アイデア生成にどのようなモデル、promptingを利用したかはまだ読めていない。
[Paper Note] The Prompt Report: A Systematic Survey of Prompt Engineering Techniques, Sander Schulhoff+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Prompting Issue Date: 2024-09-02 GPT Summary- 生成型人工知能(GenAI)のプロンプト設計とエンジニアリングについての包括的な総説を提供。プロンプト技術のタクソノミーと適用分析を通じて、体系的理解を確立し、ベストプラクティスを包括的に紹介。33語の語彙表と58のLLMプロンプト技法、さらにChatGPT向けの設計ガイドラインを含む。 Comment
Promptingに関するサーベイ
初期の手法からかなり網羅的に記述されているように見える。
また、誤用されていたり、色々な意味合いで使われてしまっている用語を、きちんと定義している。
たとえば、Few shot LearningとFew shot Promptingの違い、そもそもPromptingの定義、Examplarなど。
Revisiting Demonstration Selection Strategies in In-Context Learning, Keqin Peng+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #In-ContextLearning #DemonstrationSelection Issue Date: 2024-08-28 GPT Summary- LLMsは幅広いタスクを実行する能力を持ち、わずかな例でタスクを説明できることが示されている。しかし、ICLのパフォーマンスはデモンストレーションの選択によって大きく異なり、その要因はまだ明確ではない。本研究では、データとモデルの両面からこの変動に寄与する要因を再検討し、デモンストレーションの選択がデータとモデルの両方に依存することを見出した。さらに、"TopK + ConE"というデータとモデルに依存したデモンストレーション選択手法を提案し、ICLのための効果的なレシピを生み出していることを示した。提案手法は異なるモデルスケールで言語理解および生成タスクの両方で一貫した改善をもたらし、一般性と安定性に加えて以前の手法の効果的な説明を提供している。 Comment
ICLで利用するデモンストレーションの選択は、BM25やDense Retrieverなどを用いて、テストサンプルと類似したサンプルをretrieveすることで実施されてきた。これらはテストサンプルのみに着目した手法であるが、実際には有効なデモンストレーションはモデルによって変化するため、利用するモデルも考慮した方が良いよね、というお話
ベースラインの一覧を見ると、どういった方法がスタンダードなのかがわかる。そして意外とRandomでもそれなりに強いので、実装コストなどと相談しながらどの手法を採用するかは検討した方が良さそう。
What Do Language Models Learn in Context? The Structured Task Hypothesis, Jiaoda Li+, N_A, ACL'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #In-ContextLearning #ACL #read-later Issue Date: 2024-08-27 GPT Summary- LLMsのコンテキスト内学習(ICL)能力を説明する3つの仮説について、一連の実験を通じて探究。最初の2つの仮説を無効にし、最後の仮説を支持する証拠を提供。LLMが事前学習中に学習したタスクを組み合わせることで、コンテキスト内で新しいタスクを学習できる可能性を示唆。 Comment
SNLP2024での解説スライド:
http://chasen.org/~daiti-m/paper/SNLP2024-Task-Emergence.pdf
ICLが何をやっているのか?について、これまでの仮説が正しくないことを実験的に示し、新しい仮説「ICLは事前学習で得られたタスクを組み合わせて新しいタスクを解いている」を提唱し、この仮説が正しいことを示唆する実験結果を得ている模様。
理論的に解明されたわけではなさそうなのでそこは留意した方が良さそう。あとでしっかり読む。
[Paper Note] Following Length Constraints in Instructions, Weizhe Yuan+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Controllable #NLP #LanguageModel #InstructionTuning #EMNLP #Length #InstructionFollowingCapability Issue Date: 2024-07-30 GPT Summary- 指示追従モデルは整合性を高めることでユーザーの要求に応える。しかし、評価において長さのバイアスが影響し、モデルは長い応答を出す傾向がある。本研究では、望ましい応答長を制御する指示を用いてモデルを訓練し、長さ指示付き評価で従来のモデルを超える性能を示す。 Comment
SoTA LLMがOutput長の制約に従わないことを示し、それを改善する学習手法LIFT-DPOを提案
元ツイート:
[Paper Note] LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs, LLM-jp+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Alignment #Evaluation #OpenWeight #Safety #Japanese #OpenSource #mid-training #PostTraining #Selected Papers/Blogs #needs-revision Issue Date: 2024-07-10 GPT Summary- 日本語のLLMを開発するプロジェクト「LLM-jp」を紹介。1,500人以上が参加し、オープンソースの高性能モデルを目指す。設立背景、活動概要、および技術報告を示し、最新情報は公式サイトで確認可能。 Comment
llm.jpによるテクニカルレポート
[Paper Note] Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, Marah Abdin+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #SmallModel #OpenWeight Issue Date: 2024-04-23 GPT Summary- phi-3-miniは3.8十億パラメータの言語モデルで、3.3兆トークンを学習し、MMLUで69%、MT-benchで8.38を達成。スマートフォンでもデプロイ可能で、phi-2のデータセットをフィルタリングして作成。phi-3-smallとphi-3-mediumはそれぞれ75%、78%をMMLUで達成し、性能が向上。シリーズの新モデルphi-3.5-mini、phi-3.5-MoE、phi-3.5-Visionも導入。phi-3.5-MoEは優れた言語処理能力を発揮し、phi-3.5-Visionは複数画像とテキストのプロンプトに対応。 Comment
[Paper Note] Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, arXiv'23, 2023.09 の次の次(Phi2.0についてはメモってなかった)。スマホにデプロイできるレベルのサイズで、GPT3.5Turbo程度の性能を実現したらしい
Llama2と同じブロックを利用しているため、アーキテクチャはLlama2と共通。
[Paper Note] A Large-Scale Evaluation of Speech Foundation Models, Shu-wen Yang+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#Survey #Evaluation #FoundationModel #SpeechProcessing #Speech Issue Date: 2024-04-21 GPT Summary- 音声処理の基盤モデルパラダイムを探求するため、新たにSpeech processing Universal PERformance Benchmark(SUPERB)を設立。凍結された基盤モデルに軽量な予測ヘッドを適用したマルチタスキングフレームワークを提案し、音声タスクにおける基盤モデルの有効性を実証。結果は、競争力のある一般化能力を示し、決定論的なベンチマークとオンラインリーダーボードを導入し、コミュニティのコラボレーションを促進。最後に、タスク間の情報フローやベンチマークの統計的有意性を分析。 Comment
Speech関連のFoundation Modelの評価結果が掲載されており、大変興味深い。
参考:
[Paper Note] Compression Represents Intelligence Linearly, Yuzhen Huang+, arXiv'24, 2024.04
Paper/Blog Link My Issue
#Analysis #Pretraining #LanguageModel #Evaluation #COLM #Selected Papers/Blogs #DownstreamTasks Issue Date: 2024-04-17 GPT Summary- LLMsが知性を反映するかを圧縮の観点から検討。知性を下流ベンチマークのスコアで評価し、31の公開LLMを分析したところ、圧縮能力と知性にほぼ線形の相関があることが判明。これにより、より優れた圧縮が高い知性を示すという仮説が支持され、圧縮効率が信頼性のある評価指標として機能する可能性が示された。圧縮データセットはオープンソース化され、今後の研究に貢献することが期待される。 Comment
参考:
openreview: https://openreview.net/forum?id=SHMj84U5SH
external corpora (≠学習データ)で測定したモデルのBit Per Character (BPC) とdownstreamタスクのベンチマークスコアは、全体で平均で見ても、個別のドメインでみても、linearに相関する。
[Paper Note] Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking, Eric Zelikman+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfImprovement #Reference Collection Issue Date: 2024-04-14 GPT Summary- Quiet-STaRは、言語モデルが各トークンごとに根拠を生成し、未来のテキストを説明する能力を学ぶ手法です。これはSelf-Taught Reasoner (STaR) の一般化であり、推論根拠を生成することで予測を改善します。計算コストや内部思考の生成方法などの課題を克服するために、トークン単位の並列サンプリングアルゴリズムと教師強制技法を提案。特に、難しいトークンの予測を改善し、GSM8KやCommonsenseQAでゼロショットの精度向上を示しました。この研究は、推論を学習するよりスケーラブルなアプローチへと向かう一歩となります。 Comment
o1(OpenAI o1, 2024.09
)の基礎技術と似ている可能性がある
先行研究:
- [Paper Note] STaR: Bootstrapping Reasoning With Reasoning, Eric Zelikman+, arXiv'22, 2022.03
参考:
[Paper Note] RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation, Zihao Wang+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Chain-of-Thought #RAG(RetrievalAugmentedGeneration) #Initial Impression Notes Issue Date: 2024-04-14 GPT Summary- 情報検索を活用し思考の連鎖を修正することで、大規模言語モデルの推論及び生成能力が向上し、幻覚の抑制も確認。提案手法「retrieval-augmented thoughts(RAT)」は、生成された思考ステップを取得情報で順次修正し、GPT-3.5、GPT-4、CodeLLaMA-7bに適用した結果、コード生成で13.63%、数学的推論で16.96%、創作的執筆で19.2%、具現化タスク計画で42.78%の性能向上を達成。デモページはhttps://craftjarvis.github.io/RAT。 Comment
RAGにおいてCoTさせる際に、各reasoningのstepを見直させることでより質の高いreasoningを生成するRATを提案。Hallucinationが低減し、生成のパフォーマンスも向上するとのこと。
コンセプト自体はそりゃそうだよねという話なので、RAGならではの課題があり、それを解決した、みたいな話があるのかが気になる。
Long-context LLMs Struggle with Long In-context Learning, Tianle Li+, N_A, arXiv'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ContextWindow #LongSequence Issue Date: 2024-04-07 GPT Summary- LLMsは長いシーケンスを処理する能力に進展しているが、実世界のシナリオでの能力を評価するための専門的なベンチマークLongICLBenchが導入された。このベンチマークでは、LLMsは巨大なラベル空間を理解し、正しい予測を行うために入力全体を理解する必要がある。研究によると、長いコンテキストLLMsは長いコンテキストウィンドウを活用することで比較的良いパフォーマンスを示すが、最も困難なタスクでは苦労している。現在のLLMsは長くコンテキスト豊かなシーケンスを処理し理解する能力にギャップがあることを示唆しており、長いコンテキストの理解と推論は依然として難しい課題であることが示されている。 Comment
GPT4以外はコンテキストが20Kを超えると性能が劣化する傾向にあるとのこと。データセットを難易度別に収集し評価したところ、難易度の高いデータではそもそもコンテキストが長くなると全てのLLMがタスクを理解するできずほぼ0%の性能となった。
[Paper Note] Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference, Piotr Nawrot+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #ICML #KV Cache #Compression Issue Date: 2024-04-07 GPT Summary- Transformerにおけるメモリキャッシュの非効率性を解決するために、Dynamic Memory Compression(DMC)を提案。DMCは異なるヘッドと層で異なる圧縮比を学習し、Llama 2を組み込むことで推論時に最大7倍のスループット向上を実現。元のパフォーマンスを保ちながら、キャッシュ圧縮を最大4倍可能とし、既存の方法を超える効果を発揮。DMCはKVキャッシュのドロップイン置換として、より長い文脈と大きなバッチを処理できる。 Comment
参考:
論文中のFigure1が非常にわかりやすい。
GQA [Paper Note] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, arXiv'23, 2023.05
と比較して、2~4倍キャッシュを圧縮しつつ、より高い性能を実現。70Bモデルの場合は、GQAで8倍キャッシュを圧縮した上で、DMCで追加で2倍圧縮をかけたところ、同等のパフォーマンスを実現している。
[Paper Note] RAFT: Adapting Language Model to Domain Specific RAG, Tianjun Zhang+, arXiv'24, 2024.03
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-04-07 GPT Summary- RAFTを提案し、LLMに新しい知識を効果的に組み込む方法を示す。質問応答能力を向上させるため、無関係な文書を無視し、関連文書から逐語的引用を行って推論能力を強化。PubMedやHotpotQAなどのデータセットで一貫して性能を改善し、ポスト訓練レシピを提示。コードはオープンソースで公開中。 Comment
Question, instruction, coxtext, cot style answerの4つを用いてSFTをする模様
画像は下記ツイートより引用
The Power of Noise: Redefining Retrieval for RAG Systems, Florin Cuconasu+, N_A, arXiv'24
Paper/Blog Link My Issue
Issue Date: 2024-03-05 GPT Summary- RAGシステムは、LLMsよりも大幅な進歩を遂げており、IRフェーズを介して外部データを取得することで生成能力を向上させています。本研究では、RAGシステムにおけるIRコンポーネントの影響を詳細に分析し、リトリーバーの特性や取得すべきドキュメントのタイプに焦点を当てました。関連性のないドキュメントを含めることで精度が向上することが示され、リトリーバルと言語生成モデルの統合の重要性が強調されました。 Comment
Relevantな情報はクエリの近くに配置すべきで、残りのコンテキストをrelevantな情報で埋めるのではなく、ノイズで埋めたほうがRAGの回答が良くなる、という話らしい
[Paper Note] OLMo: Accelerating the Science of Language Models, Dirk Groeneveld+, arXiv'24, 2024.02
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2024-03-05 GPT Summary- OLMoは、市場での商業的重要性が高まる中、真にオープンな言語モデルを提供することでNLP研究の進展を目指す。従来のモデルが重みや推論コードのみを公開するのに対し、OLMoはトレーニングデータや評価コードも含めて公開し、科学的研究の基盤を確立することで、オープンな研究コミュニティの力を引き出し、新たなイノベーションを促進することを期待している。 Comment
Model Weightsを公開するだけでなく、training/evaluation codeとそのデータも公開する真にOpenな言語モデル(truly Open Language Model)。AllenAI
[Paper Note] AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls, Yu Du+, ICML'24, 2024.02
Paper/Blog Link My Issue
#ICML Issue Date: 2024-03-05 GPT Summary- AnyToolは、ユーザーの問いに対処するために16,000以上のAPIを活用する大規模言語モデルエージェントです。主に、階層構造のAPIリトリーバ、選定されたAPIを用いて問いを解決するソルバー、実用的でない初期解決策の場合の自己反省機構の3要素を組み込んでいます。GPT-4の機能で動作し、外部モジュールの訓練を不要とします。また、実際の適用シナリオを反映するために評価プロトコルを改訂し、AnyToolBenchを導入しました。実験結果は、AnyToolが他の強力なベースラインに対して優位性を示していることを明らかにしています。 Comment
階層的なRetrieverを用いてユーザクエリから必要なツールを検索し、solverでユーザのクエリを解決し、self-reflectionで結果をさらに良くするような枠組み
Chain-of-Thought Reasoning Without Prompting, Xuezhi Wang+, N_A, arXiv'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2024-03-05 GPT Summary- LLMsの推論能力を向上させるための新しいアプローチに焦点を当てた研究が行われている。この研究では、LLMsがプロンプトなしで効果的に推論できるかどうかを検証し、CoT推論パスをデコーディングプロセスを変更することで引き出す方法を提案している。提案手法は、従来の貪欲なデコーディングではなく、代替トークンを調査することでCoTパスを見つけることができることを示しており、様々な推論ベンチマークで有効性を示している。 Comment
以前にCoTを内部的に自動的に実施されるように事前学習段階で学習する、といった話があったと思うが、この研究はデコーディング方法を変更することで、promptingで明示的にinstructionを実施せずとも、CoTを実現するもの、ということだと思われる。
LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, ICML'24
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML Issue Date: 2024-03-05 GPT Summary- 本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 Comment
LoRAで導入される低ランク行列AとBを異なる学習率で学習することで、LoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法
Large Language Models for Data Annotation: A Survey, Zhen Tan+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Annotation #Data Issue Date: 2024-03-05 GPT Summary- GPT-4などの大規模言語モデル(LLMs)を使用したデータアノテーションの研究に焦点を当て、LLMによるアノテーション生成の評価や学習への応用について述べられています。LLMを使用したデータアノテーションの手法や課題について包括的に議論し、将来の研究の進展を促進することを目的としています。 Comment
Data AnnotationにLLMを活用する場合のサーベイ
Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey, Xi Fang+, N_A, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #DataToTextGeneration #TabularData Issue Date: 2024-03-05 GPT Summary- 最近の大規模言語モデリングの進展により、様々なタスクにおける応用が容易になっているが、包括的なレビューが不足している。この研究は、最近の進歩をまとめ、データセット、メトリクス、方法論を調査し、将来の研究方向に洞察を提供することを目的としている。また、関連するコードとデータセットの参照も提供される。 Comment
Tabular DataにおけるLLM関連のタスクや技術等のサーベイ
Deep Networks Always Grok and Here is Why, Ahmed Imtiaz Humayun+, N_A, arXiv'24
Paper/Blog Link My Issue
#Grokking Issue Date: 2024-02-28 GPT Summary- DNNの訓練エラーがほぼゼロに達した後に一般化が遅れて発生するグロッキング現象について、遅延頑健性という新しい概念を導入し、DNNが遅延して敵対的な例を理解し、一般化した後に頑健になる現象を説明。局所複雑性の新しい尺度に基づいて、遅延一般化と遅延頑健性の出現についての解析的な説明を提供。 Comment
Grokking関連論文
参考: hillbigさんのツイート
[Paper Note] Mixtral of Experts, Albert Q. Jiang+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2024-01-09 GPT Summary- Mixtral 8x7Bは、8つのエキスパートを持つスパース・ミクスチャー・オブ・エキスパーツモデルで、470億パラメータにアクセスしつつ、推論時は130億パラメータのみが活性化される。32kトークンの文脈長で訓練され、Llama 2 70BおよびGPT-3.5を上回る性能を発揮。特に数学やコード生成で優れ、指示に従うよう微調整したモデルも提供され、複数の人間ベンチマークで競合モデルを超えた。 Comment
Mixture of experts Layer: inputを受け取ったrouterが、8つのexpertsのうち2つを選択し順伝搬。2つのexpertsのoutputを加重平均することで最終的なoutputとする。
GPQA: A Graduate-Level Google-Proof Q&A Benchmark, David Rein+, N_A, COLM'24
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #QuestionAnswering #COLM Issue Date: 2023-11-22 GPT Summary- 私たちは、高品質で非常に困難な多肢選択問題からなるGPQAデータセットを提案します。このデータセットは、専門家でも高い正答率を達成できず、最先端のAIシステムでも困難であることが示されています。将来のAIシステムの開発において、スケーラブルな監督方法を開発する必要があります。これにより、スキルを持つ監督者がAIシステムから信頼性のある情報を得ることができるようになります。GPQAデータセットは、スケーラブルな監督実験を可能にし、人間の専門家がAIシステムから真実の情報を確実に得る方法を考案するのに役立つことが期待されています。 Comment
該当領域のPh.D所有者でも74%、高いスキルを持つ非専門家(Googleへアクセスして良い環境)で34%しか正答できないQAデータセット。
元ツイート:
OpenReview: https://openreview.net/forum?id=Ti67584b98
[Paper Note] Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs, Qingru Zhang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #ICLR #Steering Issue Date: 2023-11-10 GPT Summary- PASTAは、大規模言語モデル(LLMs)において、ユーザーが指定した強調マークのあるテキストを読むことを可能にする手法です。PASTAは、注意の一部を特定し、再重み付けを適用してモデルの注意をユーザーが指定した部分に向けます。実験では、PASTAがLLMの性能を大幅に向上させることが示されています。 Comment
ユーザがprompt中で強調したいした部分がより考慮されるようにattention weightを調整することで、より応答性能が向上しましたという話っぽい。かなり重要な技術だと思われる。後でしっかり読む。
openreview: https://openreview.net/forum?id=xZDWO0oejD
Detecting Pretraining Data from Large Language Models, Weijia Shi+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #LanguageModel #ICLR Issue Date: 2023-10-26 GPT Summary- 本研究では、大規模言語モデル(LLMs)を訓練するためのデータの検出問題を研究し、新しい検出方法であるMin-K% Probを提案します。Min-K% Probは、LLMの下で低い確率を持つアウトライアーワードを検出することに基づいています。実験の結果、Min-K% Probは従来の方法に比べて7.4%の改善を達成し、著作権のある書籍の検出や汚染された下流の例の検出など、実世界のシナリオにおいて効果的な解決策であることが示されました。 Comment
実験結果を見るにAUCは0.73-0.76程度であり、まだあまり高くない印象。また、テキストのlengthはそれぞれ32,64,128,256程度。
openreview: https://openreview.net/forum?id=zWqr3MQuNs
[Paper Note] Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, Huaixiu Steven Zheng+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #ICML Issue Date: 2023-10-12 GPT Summary- Step-Back Promptingは、大規模言語モデル(LLMs)を使用して推論の手順をガイドするシンプルなプロンプティング技術です。この技術により、LLMsは具体的な詳細から高レベルの概念や基本原則を抽象化し、正しい推論経路をたどる能力を向上させることができます。実験により、Step-Back PromptingはSTEM、Knowledge QA、Multi-Hop Reasoningなどのタスクにおいて大幅な性能向上が観察されました。具体的には、MMLU Physics and Chemistryで7%、11%、TimeQAで27%、MuSiQueで7%の性能向上が確認されました。 Comment
また新しいのが出た。ユーザのクエリに対して直接応答しようとするのではなく、より高次で抽象的・原則的な問いを生成しそこから事実情報を得て、その事実情報にgroundingされた推論によって答えを導く。
openreview: https://openreview.net/forum?id=3bq3jsvcQ1
Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel Issue Date: 2023-10-10 GPT Summary- 言語モデルのトレーニングと推論において、遅延を導入することでモデルの性能を向上させる手法を提案しました。具体的には、入力に特定のトークンを追加し、そのトークンが現れるまでモデルの出力を遅らせることで、追加の計算を行うことができます。実験結果では、この手法が推論タスクにおいて有益であり、特にQAタスクでの性能向上が見られました。今後は、この遅延予測の手法をさらに研究していく必要があります。 Comment
この研究は興味深いが、事前学習時に入れないと効果が出にくいというのは直感的にわかるので、実用的には活用しづらい。
また、promptでこの研究をimitateする方法については、ZeroShot CoTにおいて、思考プロセスを明示的に指定するようなpromptingと同様のことを行っており、これは実際に効果があると思う。
Improved Baselines with Visual Instruction Tuning, Haotian Liu+, N_A, CVPR'24
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #QuestionAnswering #OpenWeight #CVPR #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2023-10-09 GPT Summary- LLaVAは、ビジョンと言語のクロスモーダルコネクタであり、データ効率が高く強力な性能を持つことが示されています。CLIP-ViT-L-336pxを使用し、学術タスク指向のVQAデータを追加することで、11のベンチマークで最先端のベースラインを確立しました。13Bのチェックポイントはわずか120万の公開データを使用し、1日で完全なトレーニングを終えます。コードとモデルは公開されます。 Comment
画像分析が可能なオープンソースLLMとのこと。
# Overview
画像生成をできるわけではなく、inputとして画像を扱えるのみ。
pj page: https://llava-vl.github.io
Graph Neural Prompting with Large Language Models, Yijun Tian+, N_A, AAAI'24
Paper/Blog Link My Issue
#GraphBased #NLP #LanguageModel #KnowledgeGraph #Prompting #AAAI #SoftPrompt Issue Date: 2023-10-09 GPT Summary- 本研究では、大規模言語モデル(LLMs)を知識グラフと組み合わせるための新しい手法であるGraph Neural Prompting(GNP)を提案しています。GNPは、標準的なグラフニューラルネットワークエンコーダやクロスモダリティプーリングモジュールなどの要素から構成されており、異なるLLMのサイズや設定において、常識的な推論タスクやバイオメディカル推論タスクで優れた性能を示すことが実験によって示されました。 Comment
元ツイート:
事前学習されたLLMがKGから有益な知識を学習することを支援する手法を提案。
しっかり論文を読んでいないが、freezeしたLLMがあった時に、KGから求めたGraph Neural Promptを元のテキストと組み合わせて、新たなLLMへの入力を生成し利用する手法な模様。
Graph Neural Promptingでは、Multiple choice QAが入力された時に、その問題文や選択肢に含まれるエンティティから、KGのサブグラフを抽出し、そこから関連性のある事実や構造情報をエンコードし、Graph Neural Promptを獲得する。そのために、GNNに基づいたアーキテクチャに、いくつかの工夫を施してエンコードをする模様。
つまりKGの情報を保持したSoft Prompting手法というイメージだろうか。
[Paper Note] Segment Anything in Medical Images, Jun Ma+, Nature Communications'24, 2023.04
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Transformer #ImageSegmentation #FoundationModel Issue Date: 2023-04-30 GPT Summary- 医用画像分割は診断や治療計画に不可欠だが、既存手法は特定のモダリティや疾患に限られがち。そこで、10の画像モダリティと30種以上のがんに対応する基盤モデルMedSAMを提案。1,570,263の画像-マスクペアで訓練され、精度と頑健性で専門モデルを上回ることを実証。MedSAMは診断ツールの進化と個別化治療計画を加速する可能性を秘めている。 Comment
SAMの性能は医療画像に対しては限定的だったため、11の異なるモダリティに対して200kのマスクをした医療画像を用意しfinetuningしたMedSAMによって、医療画像のセグメンテーションの性能を大幅に向上。
コードとモデルはpublicly available
[Paper Note] Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, Jingfeng Yang+, TKDD'24, 2023.04
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)の実践的なガイドを提供し、自然言語処理(NLP)タスクにおけるモデルやデータの活用法を論じる。GPT系およびBERT系の紹介から始まり、事前学習や訓練データの影響を考察。さらに、さまざまなNLPタスクの使用ケースや非使用ケースを詳細に分析し、実世界でのLLMsの適用限界について触れる。偽りのバイアス、効率性、コストなどの課題に言及し、研究者と実務者に有益なベストプラクティスを提案。更新リストも提供。 Comment
LLMに関するチュートリアル
encoder-onlyとまとめられているものの中には、デコーダーがあるものがあり(autoregressive decoderではない)、
encoder-decoderは正しい意味としてはencoder with autoregressive decoderであり、
decoder-onlyは正しい意味としてはautoregressive encoder-decoder
とのこと。
[Paper Note] LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions, Minghao Wu+, EACL'24, 2023.04
Paper/Blog Link My Issue
#NLP #Dataset #InstructionTuning #DataDistillation #EACL Issue Date: 2023-04-26 GPT Summary- LLMから小型モデルへの知識蒸留を探求。256万以上の多様な指示セットを用意し、gpt-3.5-turboで応答を生成。エンコーダ-デコーダとデコーダ専用のラミニLMを調整し、15のNLPベンチマークで性能評価。提案モデルは競合と同等の性能を発揮し、サイズが大幅に小さいことを確認。 Comment
既存のInstruction DatasetのInstructionをseedとして、gpt-3.5-turboで新たなInstructionとresponseを生成したデータセット
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head, AAAI'24
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing #AAAI Issue Date: 2023-04-26 Comment
text, audio, imageといったマルチモーダルなpromptから、audioに関する様々なタスクを実現できるシステム
マルチモーダルデータをjointで学習したというわけではなく、色々なモデルの組み合わせてタスクを実現しているっぽい
[Paper Note] Scaling Instruction-Finetuned Language Models, Hyung Won Chung+, JMLR'24, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #OpenWeight #Selected Papers/Blogs #Scalability #JMLR Issue Date: 2023-04-26 GPT Summary- 指示に基づくファインチューニングは、言語モデルの性能と一般化を向上させる。特に、タスク数やモデルサイズのスケーリング、チェーン・オブ・思考データでの適用が効果的。Flan‑PaLM 540Bは1,800件のタスクでファインチューニングを行い、PaLM 540Bを平均+9.4%上回り、最先端の結果を出している。Flan‑T5も強力なFew-shot性能を示し、指示に基づくファインチューニングがモデルの性能向上に寄与することを確認した。 Comment
T5をinstruction tuningしたFlanT5の研究
HF: https://huggingface.co/docs/transformers/model_doc/flan-t5
先行研究:
- [Paper Note] Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, ICLR'22, 2021.09
[Paper Note] Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling, Stella Biderman+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2026-03-29 GPT Summary- Pythiaは、異なるスケールの16のLLMを対象にしたモデルセットで、トレーニングの進化や発展を探求する。154のチェックポイントを公開し、訓練データローダーの再構築ツールも提供する。記憶化、新規結果、few-shot性能への語頻度の影響、ジェンダーバイアスの低減を含むケーススタディを通じて、LLMsの訓練ダイナミクスに関する新たな洞察を提示する。モデルや分析コードは公開されている。 Comment
github: https://github.com/EleutherAI/pythia
pythiaもメモっていなかった。70M--12Bモデルまでの16個のLLM群で、全てのモデルが同じ順序で学習され、かつ中間チェックポイントも公開。
[Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#ComputerVision #NLP #ImageSegmentation #Selected Papers/Blogs #VisionLanguageModel #Grounding Issue Date: 2025-11-25 GPT Summary- Set-of-Mark (SoM)という新しい視覚プロンプティング手法を提案し、GPT-4Vの視覚的能力を引き出す。画像を異なる領域に分割し、マークを重ねることで、視覚的基盤を必要とする質問に答えることが可能に。実験では、SoMを用いたGPT-4Vがゼロショット設定で最先端のモデルを上回る性能を示した。 Comment
pj page: https://som-gpt4v.github.io
日本語解説: https://ai-scholar.tech/articles/prompting-method/SoM
画像をsegmentationし、segmentationした領域上に数字のマーカーをオーバーレイした画像を入力すると、VLMのgrounding能力が向上する、という話らしい
[Paper Note] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture, Mahmoud Assran+, CVPR'23, 2023.01
Paper/Blog Link My Issue
#ComputerVision #Pretraining #RepresentationLearning #Transformer #Self-SupervisedLearning #CVPR #read-later #Selected Papers/Blogs #WorldModels #LatentRepresentation Issue Date: 2025-07-24 GPT Summary- 本論文では、手作りのデータ拡張に依存せずに意味的な画像表現を学習するI-JEPAという自己教師あり学習アプローチを提案。I-JEPAは、単一のコンテキストブロックから異なるターゲットブロックの表現を予測する。重要な設計選択として、意味的に大きなターゲットブロックと情報量の多いコンテキストブロックのサンプリングが挙げられる。実験により、I-JEPAはVision Transformersと組み合わせることでスケーラブルであり、ImageNet上で強力な下流性能を達成した。 Comment
Joint-Embedding Predictive Architecture (JEPA)を提案した研究。ピクセルやトークンのreconstruction lossではなく、潜在表現を再構成するようなself-supervised learningによってより意味的な特徴を学習するように誘導するもの(と思われるがこれが本質的な理解として正しいかは自信がない)。
[Paper Note] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills, Amey Agrawal+, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #python #LLMServing #SoftwareEngineering #read-later #Selected Papers/Blogs #Inference Issue Date: 2025-06-12 GPT Summary- SARATHIは、LLMの推論効率を向上させる手法で、プレフィルリクエストをチャンクに分割し、デコードマキシマルバッチを構築することで計算利用率を最大化します。これにより、デコードスループットを最大10倍向上させ、エンドツーエンドスループットも改善。特に、A6000 GPU上のLLaMA-13Bモデルで顕著な性能向上を示し、パイプラインバブルを大幅に削減しました。 Comment
vLLMでも採用されている `Chunked Prefills` と `Decode-Maximal Batching` を提案している。

[Paper Note] Sequence Parallelism: Long Sequence Training from System Perspective, Shenggui Li+, ACL'23, 2021.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #LongSequence #ACL #Selected Papers/Blogs #Parallelism Issue Date: 2025-05-16 GPT Summary- 本研究では、トランスフォーマーの長い入力シーケンスを効率的に学習するための新しいメモリ効率の良い「シーケンス並列性」手法を提案。これは、既存の並列化手法との互換性を持ち、長大なシーケンスを複数のGPUに分散して処理することを可能にする。リング型通信を用いた自己注意計算(Ring Self-Attention)を導入し、実験によりバッチサイズとシーケンス長のスケーリング効果を示した。最大バッチサイズは13.7倍、シーケンス長は114,000トークンを超える性能を達成。 Comment
入力系列をチャンクに分割して、デバイスごとに担当するチャンクを決めることで原理上無限の長さの系列を扱えるようにした並列化手法。系列をデバイス間で横断する場合attention scoreをどのように計算するかが課題になるが、そのためにRing Self attentionと呼ばれるアルゴリズムを提案している模様。また、MLPブロックとMulti Head Attentonブロックの計算も、BatchSize * Sequence Lengthの大きさが、それぞれ32*Hidden Size, 16*Attention Head size *
# of Attention Headよりも大きくなった場合に、Tensor Parallelismよりもメモリ効率が良くなるらしい。
Data Parallel, Pipeline Parallel, Tensor Parallel、全てに互換性があるとのこと(併用可能)
そのほかの並列化の解説については
- 大規模モデルを支える分散並列学習のしくみ Part1, Kazuki Fujii, 2023.06
を参照のこと。
[Paper Note] Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Hallucination #NeurIPS #read-later #ActivationSteering/ITI #Probing #Trustfulness #Selected Papers/Blogs Issue Date: 2025-05-09 GPT Summary- Inference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。 Comment
Inference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:
https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813#p1
これは相当汎用的に使えそうな話だから役に立ちそう
[Paper Note] PaLI-3 Vision Language Models: Smaller, Faster, Stronger, Xi Chen+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#ComputerVision #NLP #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2025-04-11 GPT Summary- PaLI-3は、10倍の規模のモデルに匹敵する、より小型で高速なビジョン・ランゲージモデル(VLM)です。SigLIPによって事前学習されたPaLIは、画像分類ベンチマークではわずかに劣るものの、マルチモーダルベンチマークでは優れた性能を発揮。20億パラメータのSigLIP画像エンコーダを用いて多言語間のクロスモーダル検索で新たな最先端を達成し、50億パラメータで複雑なVLMの研究を促進することが期待されています。 Comment
OpenReview:
https://openreview.net/forum?id=JpyWPfzu0b
実験的に素晴らしい性能が実現されていることは認められつつも
- 比較対象がSigLIPのみでより広範な比較実験と分析が必要なこと
- BackboneモデルをContrastive Learningすること自体の有用性は既に知られており、新規性に乏しいこと
としてICLR'24にRejectされている
[Paper Note] Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions, John Chung+, ACL'23, 2023.07
Paper/Blog Link My Issue
#NLP #LanguageModel #ACL #Diversity Issue Date: 2024-12-03 GPT Summary- 本研究では、LLMを用いたテキストデータ生成における多様性と精度を向上させるための人間とAIのパートナーシップを探求。ロジット抑制と温度サンプリングの2つのアプローチで多様性を高める一方、ラベル置換(LR)と範囲外フィルタリング(OOSF)による人間の介入を検討。LRはモデルの精度を14.4%向上させ、一部のモデルは少数ショット分類を上回る性能を示したが、OOSFは効果がなかった。今後の研究の必要性が示唆される。 Comment
生成テキストの質を維持しつつ、多様性を高める取り組み。多様性を高める取り組みとしては3種類の方法が試されており、
- Logit Suppression: 生成されたテキストの単語生成頻度をロギングし、頻出する単語にpenaltyをかける方法
- High Temperature: temperatureを[0.3, 0.7, 0.9, 1.3]にそれぞれ設定して単語をサンプリングする方法
- Seeding Example: 生成されたテキストを、seedとしてpromptに埋め込んで生成させる方法
で実験されている。
[Paper Note] Prompting Large Language Model for Machine Translation: A Case Study, Biao Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#MachineTranslation #NLP #LanguageModel #Reading Reflections Issue Date: 2024-11-20 GPT Summary- プロンプト設計は多くのタスクで優れた性能を示すが、機械翻訳においては未検討。翻訳のためのプロンプト戦略を体系的に研究し、プロンプトテンプレートやデモ例の選択に関する要因を検討。実験の結果、プロンプト例の数と質が翻訳において重要であり、サブ最適な例は性能低下を招くことが示された。また、ゼロショットプロンプティングから得られた擬似平行プロンプト例の利用が翻訳を改善する可能性や、知識転移により性能向上が見込まれることが確認された。最後に、プロンプト設計に関する問題点についても議論。 Comment
zero-shotでMTを行うときに、改行の有無や、少しのpromptingの違いでCOMETスコアが大幅に変わることを示している。
モデルはGLM-130BをINT4で量子化したモデルで実験している。
興味深いが、この知見を一般化して全てのLLMに適用できるか?と言われると、そうはならない気がする。他のモデルで検証したら傾向はおそらく変わるであろう(という意味でおそらく論文のタイトルにもCase Studyと記述されているのかなあ)。
[Paper Note] Instruction Tuning with GPT-4, Baolin Peng+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #PostTraining Issue Date: 2024-09-20 GPT Summary- GPT-4を用いて機械生成の指示追従データを新たに生成し、LLaMAモデルのファインチューニングを行う試みを提案。生成されたデータは、従来のモデルと比べて新規タスクに対するゼロショット性能を向上させることを示した。フィードバックと比較データも収集し、コードベースを公開。 Comment
現在はOpenAIの利用規約において、outputを利用してOpenAIと競合するモデルを構築することは禁止されているので、この点には注意が必要
https://openai.com/ja-JP/policies/terms-of-use/
[Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #NLP #Dataset #LanguageModel #Annotation Issue Date: 2024-05-15 GPT Summary- 大規模言語モデル(LLMs)の自動要約能力の背後にある要因を探り、10のモデルに対する人間評価を行った。結果、ゼロショット要約の鍵はモデルサイズではなく指示調整にあること、さらに従来の研究は低品質な参照データに制約されているため人間の性能を過小評価していることが明らかになった。高品質な要約を基にした評価では、LLMsの要約が人間の要約と同等とされることが多いとの結論に至った。 Comment
- ニュース記事の高品質な要約を人間に作成してもらい、gpt-3.5を用いてLLM-basedな要約も生成
- annotatorにそれぞれの要約の品質をスコアリングさせたデータセットを作成
INSTRUCTSCORE: Explainable Text Generation Evaluation with Finegrained Feedback, Wenda Xu+, N_A, EMNLP'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #LanguageModel #Explanation #Supervised-FineTuning (SFT) #Evaluation #EMNLP #PostTraining Issue Date: 2024-01-25 GPT Summary- 自動的な言語生成の品質評価には説明可能なメトリクスが必要であるが、既存のメトリクスはその判定を説明したり欠陥とスコアを関連付けることができない。そこで、InstructScoreという新しいメトリクスを提案し、人間の指示とGPT-4の知識を活用してテキストの評価と診断レポートを生成する。さまざまな生成タスクでInstructScoreを評価し、他のメトリクスを上回る性能を示した。驚くべきことに、InstructScoreは人間の評価データなしで最先端のメトリクスと同等の性能を達成する。 Comment
伝統的なNLGの性能指標の解釈性が低いことを主張する研究
[Paper Note] Some things are more CRINGE than others: Iterative Preference Optimization with the Pairwise Cringe Loss, Jing Xu+, arXiv'23, 2023.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #SelfImprovement #PostTraining Issue Date: 2023-12-29 GPT Summary- 実務家は一般的にペアワイズの好みでLLMを整列させるが、二値フィードバックも有用である。そこで、既存の二値フィードバック手法Cringe Lossをペアワイズへ一般化した。ペアワイズ Cringe Loss は簡単に実装でき、訓練効率も高く、AlpacaFarm ベンチマークで最先端の手法を上回る結果を示した。また、訓練の反復が重要で、DPOをIterative DPOとして一般化できることを示した。 Comment
DPO, PPOをoutperformする新たなAlignment手法。MetaのJason Weston氏
元ツイート:
[Paper Note] Gemini: A Family of Highly Capable Multimodal Models, Gemini Team+, arXiv'23, 2023.12
Paper/Blog Link My Issue
#NLP #LanguageModel #MultiModal #Proprietary #VisionLanguageModel Issue Date: 2023-12-21 GPT Summary- 新しいマルチモーダルモデルファミリー「Gemini」は、画像・音声・動画・テキスト理解において優れた能力を発揮し、Ultra・Pro・Nanoの3サイズから構成されている。Gemini Ultraモデルは32のベンチマークで30件で最先端の性能を示し、特にMMLUにおいて人間の専門家レベルを初めて達成。クロスモーダル推論の新たな能力により、さまざまなユースケースが可能となり、運用と責任あるデプロイのアプローチについても議論される。 Comment
Introducing Gemini: our largest and most capable AI model, Google, 2023.12 で発表されたGeminiの論文
[Paper Note] An In-depth Look at Gemini's Language Abilities, Syeda Nahida Akter+, arXiv'23, 2023.12
Paper/Blog Link My Issue
Issue Date: 2023-12-21 GPT Summary- Google Geminiモデルは、OpenAIのGPTシリーズに匹敵する成果を初めて報告したモデル群である。本研究では、Geminiの言語能力を詳細に比較し、再現性のあるコードを用いて第三者による客観的な評価を行った。結果、Gemini ProはGPT 3.5 Turboに近い精度を持つが若干劣ることが判明した。その原因として、数学的推論の失敗や過激なコンテンツフィルタリングが挙げられる一方、非英語生成や複雑な推論チェーンにおいては高い性能を示した。データとコードは公開されている。 Comment
GeminiとGPTを様々なベンチマークで比較した研究。
[Paper Note] Unbalanced Optimal Transport for Unbalanced Word Alignment, Yuki Arase+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Alignment #OptimalTransport Issue Date: 2023-11-21 GPT Summary- モノリンガル単語アライメントでは、ヌルアライメントが重要であり、情報の不均衡を示すことから文の意味的類似性を推論する手助けとなる。アライメントとヌルアライメントの両方を重視するため、本研究は最適輸送(OT)ファミリーが特別な技術を用いずに効果的に機能することを示す。広範な実験により、汎用的なOTベースの方法が、特化型の最先端技術と競争力があることを確認し、特にヌルアライメントが多いデータセットでその有効性が顕著である。 Comment
最適輸送で爆速でモノリンガルの単語アライメントがとれるらしい
実装:
https://github.com/yukiar/OTAlign
単語のアライメント先がない(null alignment)、one-to-oneの関係ではなく、one-to-many, many-to-manyのアライメントが必要な問題を(おそらく; もしかしたらnull alignmentだけかも)Unbalancedな単語アライメント問題と呼び、この課題に対して最適輸送が有効なアプローチであることを示しているっぽい
荒瀬先生のスライド: https://speakerdeck.com/yukiar/13-unbalanced-optimal-transport-for-unbalanced-word-alignment
[Paper Note] Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents, Zhuosheng Zhang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Tutorial #NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-11-21 GPT Summary- LLMsは複雑な推論タスクにおいて驚異的な性能を示し、CoT推論技術を通じて解釈性や柔軟性を高めている。自律的な言語エージェントの開発が進み、様々な環境で行動を実行する能力を持つ。論文ではCoTの基礎機構、パラダイムシフト、言語エージェントの台頭を探求し、今後の研究の方向性について議論している。初心者から経験豊富な研究者まで広範囲な読者を対象にしている。 Comment
CoTに関するチュートリアル論文
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks, Bin Xiao+, N_A, arXiv'23
Paper/Blog Link My Issue
#ComputerVision #NLP #MultitaskLearning #MultiModal #FoundationModel #SpatialUnderstanding Issue Date: 2023-11-13 GPT Summary- Florence-2は、ビジョン基盤モデルであり、さまざまなビジョンタスクに対応するための統一されたプロンプトベースの表現を持っています。このモデルは、テキストプロンプトを受け取り、キャプショニング、オブジェクト検出、グラウンディング、セグメンテーションなどのタスクを実行し、テキスト形式で結果を生成します。また、FLD-5Bという大規模な注釈付きデータセットも開発されました。Florence-2は、多目的かつ包括的なビジョンタスクを実行するためにシーケンスツーシーケンス構造を採用しており、前例のないゼロショットおよびファインチューニングの能力を持つ強力なモデルです。 Comment
Vison Foundation Model。Spatialな階層構造や、Semanticを捉えられるように訓練。Image/Prompt Encoderでエンコードされ、outputはtext + location informationとなる。
[Paper Note] Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems, Huan Gui+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#RecommenderSystems #Transformer Issue Date: 2023-11-13 GPT Summary- 特徴量の相互作用を学習するのはリコメンダーシステムにおいて重要だが、疎で大規模な入力特徴空間のため困難である。そこで、Transformerベースのアーキテクチャを用いて特徴相互作用を自動で捉える手法を提案。従来のTransformerでは自己注意層が異質な特徴相互作用を捉えられず、提供遅延が問題となるため、異質な自己注意層を修正し、Hiformerを導入。これにより高速推論が実現し、Google Playの実世界のアプリでエンゲージメントが最大+2.66%改善された。 Comment
推薦システムは、Factorization Machinesあたりから大抵の場合特徴量間の交互作用を頑張って捉えることで精度向上を目指す、という話をしてきている気がするが、これはTransformerを使って交互作用捉えられるようなモデルを考えました、という研究のようである。
self attention部分に工夫がなされており(提案手法は右端)、task tokenとそれぞれのfeatureをconcatしてQKVを求めることで、明示的に交互作用が生まれるような構造にしている。
Online A/Bテストでも評価しており、HiformerによってSoTAな交互作用モデル(DCN)よりも高いユーザエンゲージメントを実現することが示されている。
[Paper Note] A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Lei Huang+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Hallucination Issue Date: 2023-11-10 GPT Summary- LLMの登場によりNLPは新たな転機を迎えたが、幻覚問題が信頼性に対する懸念を引き起こし、検出と緩和の研究を促進している。幻覚はタスク特化型モデルとは異なる課題を呈し、詳細な理解が求められる。本調査では、幻覚の分類法や要因を詳述し、検知手法と緩和方法、情報検索を含むLLMの現状における制約を掘り下げる。また、ビジョン言語モデルにおける幻覚や知識の境界の理解を含む今後の研究方向も強調する。 Comment
Hallucinationを現象ごとに分類したSurveyとして [Paper Note] A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, arXiv'23, 2023.09 もある
Surveyの内容。必要に応じて参照すべし。
[Paper Note] LightLM: A Lightweight Deep and Narrow Language Model for Generative Recommendation, Kai Mei+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel Issue Date: 2023-11-10 GPT Summary- LightLMは、生成的推薦のために特化した軽量なTransformerベースの言語モデルである。従来の重いモデルに代わり、短いトークンを主成分とする浅い構造を採用し、推奨アイテムの直接生成に効果的である。ユーザーIDおよびアイテムIDに対する新たなインデックス化手法(SCIとGCI)を提案し、推薦タスクにおいて大規模言語モデルに勝る性能を示す。さらに、ハルシネーションを抑えるための制約付き生成プロセスを導入し、実データセットで競合するベースラインを上回る精度と効率を実現した。 Comment
Generative Recommendationはあまり終えていないのだが、既存のGenerative Recommendationのモデルをより軽量にし、性能を向上させ、存在しないアイテムを生成するのを防止するような手法を提案しました、という話っぽい。
Bayesian Personalized Ranking [Paper Note] BPR: Bayesian Personalized Ranking from Implicit Feedback, Steffen Rendle+, UAI'09, 2009.06
ベースドなMatrix Factorizationよりは高い性能が出てるっぽい。
Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models, Steve Yadlowsky+, N_A, arXiv'23
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Transformer #OOD #Reading Reflections Issue Date: 2023-11-06 GPT Summary- 本研究では、トランスフォーマーモデルの文脈学習(ICL)能力を調査しました。トランスフォーマーモデルは、事前学習データの範囲内で異なるタスクを特定し、学習する能力を持っています。しかし、事前学習データの範囲外のタスクや関数に対しては一般化が劣化することが示されました。また、高容量のシーケンスモデルのICL能力は、事前学習データの範囲に密接に関連していることが強調されました。 Comment
Transformerがpre-training時に利用された学習データ以外の分布に対しては汎化性能が落ちることを示したらしい。もしこれが正しいとすると、結局真に新しい分布というか関数というかタスクというか、をTransformerが創出する可能性は低いと言えるかもしれない。が、新しいものって大体は既存の概念の組み合わせだよね(スマホとか)、みたいなことを考えると、別にそれでも十分では?と思ってしまう。人間が本当に真の意味で新しい関数というかタスクというか分布を生み出せているかというと、実はそんなに多くないのでは?という予感もする。まあたとえば、量子力学を最初に考えました!とかそういうのは例外だと思うけど・・・、そのレベルのことってどんくらいあるんだろうね?
[Paper Note] The Perils & Promises of Fact-checking with Large Language Models, Dorian Quelle+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Reading Reflections Issue Date: 2023-11-05 GPT Summary- 自動ファクトチェックは機械学習を用いて主張を検証する重要な取り組みであり、LLMs(例:GPT-4)はその能力を活用しつつ、情報の真偽を見分ける役割が増大している。本研究ではLLMエージェントがクエリを作成し、文脈データを取得し、意思決定を行うフレームワークを提案。結果、文脈情報がLLMの能力を向上させることが示されたが、正確性はクエリの言語や主張の真偽に依存し、一貫性に欠けるため慎重な運用が求められる。さらなる研究が必要で、エージェントの成功と失敗のメカニズムを探求することが提言される。 Comment
gpt3とgpt4でFactCheckして傾向を分析しました、という研究。promptにstatementとgoogleで補完したcontextを含め、出力フォーマットを指定することでFactCheckする。
promptingする際の言語や、statementの事実性の度合い(半分true, 全てfalse等)などで、性能が大きく変わる結果とのこと。
性能を見ると、まだまだ(このprompting方法では)人間の代わりが務まるほどの性能が出ていないことがわかる。また、trueな情報のFactCheckにcontextは効いていそうだが、falseの情報のFactCheckにContextがあまり効いてなさそうに見えるので、なんだかなあ、という感じである。
斜め読みしかしていないがこの研究、学術的な知見は少ないのかな、という印象。一つのケーススタディだよね、という感じがする。
まず、GPT3,4だけじゃなく、特徴の異なるOpenSourceのLLMを比較に含めてくれないと、前者は何で学習しているか分からないので、学術的に得られる知見はほぼないのではという気が。実務的には役に立つが。
その上で、Promptingをもっとさまざまな方法で検証した方が良いと思う。
たとえば、現在のpromptではラベルを先に出力させた後に理由を述べさせているが、それを逆にしたらどうなるか?(zero-shot CoT)や、4-Shotにしたらどうなるか、SelfConsistencyを利用したらどうなるかなど、promptingの仕方によって傾向が大きく変わると思う。
加えて、Retriever部分もいくつかのバリエーションで試してみても良いのかなと思う。特に、falseの情報を判断する際に役に立つ情報がcontextに含められているのかが気になる。
論文に書いてあるかもしれないが、ちょっとしっかり読む時間はないです!!
[Paper Note] Llemma: An Open Language Model For Mathematics, Zhangir Azerbayev+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #FoundationModel #Mathematics #mid-training #Reading Reflections Issue Date: 2023-10-29 GPT Summary- Llemmaという数学の大規模言語モデルを提案。Proof-Pile-2でCode Llamaの前訓練を行い、科学論文や数学コードを含む複合データセットで強化。MATHベンチマークで全ての公開モデルを凌ぎ、未公開のMinervaモデル群にも勝利。追加ファインチューニングなしでツール使用や形式的定理証明が可能。70億および340億パラメータのモデルや実験コードを公開。 Comment
CodeLLaMAを200B tokenの数学テキスト(proof-pile-2データ;論文、数学を含むウェブテキスト、数学のコードが含まれるデータ)で継続的に事前学習することでfoundation modelを構築
約半分のパラメータ数で数学に関する性能でGoogleのMinervaと同等の性能を達成
元ツイート:
まだ4-shotしてもAcc.50%くらいなのか。
[Paper Note] Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #EMNLP #OCR #Reading Reflections Issue Date: 2023-10-26 GPT Summary- GPT-4VのOCR機能を評価し、シーンテキスト、手書き文字、数学式や表構造認識などの幅広いタスクへの性能を検討。ラテン文字では高性能だが、多言語や複雑なタスクでは限界を示す。専門的なOCRモデルの必要性を強調し、今後の研究の指針を提供。評価結果は公開されている。 Comment
GPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
現在では非常に性能が向上していると考えられるが、初期VLMのOCR性能を示している文献として興味深い。
[Paper Note] RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation, Fangyuan Xu+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #ICLR #Compression Issue Date: 2023-10-10 GPT Summary- 推論時に文書を要約することでLMの性能を向上。抽出型と抽象型の2つの圧縮器を提案し、計算コストと関連情報の識別負担を軽減。要約が無関係な場合は空文字列を返すことで選択的付加を実現。言語モデリングと質問応答タスクで評価し、圧縮率6%で性能を維持し、市販の要約モデルを上回る成果を示した。圧縮器は他のLMにも適用可能で、忠実な要約を生成。 Comment
RAGをする際に、元文書群を要約して圧縮することで、性能低下を抑えながら最大6%程度まで元文書群を圧縮できた、とのこと。
元ツイート:
RAGを導入する際のコスト削減に有用そう
openreview: https://openreview.net/forum?id=mlJLVigNHp
[Paper Note] Retrieval meets Long Context Large Language Models, Peng Xu+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-10-09 GPT Summary- 大規模言語モデル(LLMs)のコンテキスト窓の拡張と検索補強の効能を比較検討。独自の43B GPTとLlama2-70Bを用いて、検索補強を活用した4Kのコンテキストで、16Kのファインチューニング済みLLMと同等の性能を計算量を抑えて実現。特に、検索取得がLLMsの性能を大幅に向上させることを確認。最良モデルは32Kのコンテキストで、9つの長文タスクにおいて従来のモデルを上回り、高速な生成を実現。研究は、実務者に対してLLMの選択に関する指針を提供。 Comment
参考:
検索補強(Retrieval Augmentation)とは、言語モデルの知識を補完するために、関連する文書を外部の文書集合からとってきて、contextに含める技術のこと
https://tech.acesinc.co.jp/entry/2023/03/31/121001
[Paper Note] MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation, Qian Huang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #NLP #Dataset #LanguageModel #AIAgents #Evaluation #AutoML Issue Date: 2023-10-09 GPT Summary- 機械学習の実験を行うためのエージェントを強力な言語モデルを用いて構築し、MLAgentBenchという13のタスクベンチマークを導入。エージェントはファイル操作やコード実行を行い、Claude v3 Opusが最も高い成功率を示す。タスク全体で平均成功率37.5%を達成するが、結果はデータセットによって大きく変動。長期計画や幻覚の低減といった重要な課題も明らかにした。コードは公開中。 Comment
GPT4がMLモデルをどれだけ自動的に構築できるかを調べた模様。また、ベンチマークデータを作成した模様。結果としては、既存の有名なデータセットでの成功率は90%程度であり、未知のタスク(新たなKaggle Challenge等)では30%程度とのこと。
[Paper Note] Boolformer: Symbolic Regression of Logic Functions with Transformers, Stéphane d'Ascoli+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#MachineLearning #Transformer Issue Date: 2023-10-09 GPT Summary- Boolformerは、Boolean関数のシンボリック回帰を行うトランスフォーマー系モデルで、未見の複雑な関数に対しても全真理値表からコンパクトな式を予測可能です。不完全な観測やノイズがあっても良好な近似式を導出し、広範な二値分類データセットで従来手法に対して解釈可能な代替手段を示します。遺伝子調節ネットワークのダイナミクスモデリングにも応用し、最先端の遺伝的アルゴリズムと競合しつつ、高速化を示しています。コードとモデルは公開されています。 Comment
ブール関数をend-to-endで学習できるtransformeiアーキテクチャを提案した模様
[Paper Note] Explaining grokking through circuit efficiency, Vikrant Varma+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning #Grokking Issue Date: 2023-09-30 GPT Summary- グロッキングはニューラルネットワークの一般化における謎であり、訓練データでは完璧な精度を示すが一般化が乏しい状態から、追加の訓練を経て一般化が進む現象を指す。本研究では、グロッキングが一般化解と記憶化解の両方を許すタスクで生じると提案し、一般化解が学習遅延を伴いながらも効率的である一方、記憶化解は訓練データが増えると非効率的になると仮説する。また、記憶と一般化の効率が等しくなる臨界的なデータセットサイズを特定する。グロッキングに関する四つの新規予測を提示し、それを検証し、支持する証拠を提供。特に、ネットワークの精度が低下するアン・グロッキングや、部分的な検証精度へ遅れて一般化を示すセミ・グロッキングの挙動を明らかにした。 Comment
Grokkingがいつ、なぜ発生するかを説明する理論を示した研究。
理由としては、最初はmemorizationを学習していくのだが、ある時点から一般化回路であるGenに切り替わる。これが切り替わる理由としては、memorizationよりも、genの方がlossが小さくなるから、とのこと。これはより大規模なデータセットで顕著。
Grokkingが最初に報告された研究は [Paper Note] Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets, Alethea Power+, ICLR'21 Workshop, 2022.01
[Paper Note] MAmmoTH: Building Math Generalist Models through Hybrid Instruction Tuning, Xiang Yue+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #InstructionTuning #NumericReasoning #Reasoning #Mathematics #PostTraining Issue Date: 2023-09-30 GPT Summary- MAmmoTHシリーズは、数学問題解法に特化したオープンソースのLLMで、MathInstructという指示チューニングデータセットを使用して訓練されています。MathInstructは、中間推論を含む13の数学データセットから構成され、特に6つの新たな推論過程を提供しています。CoTとPoTのハイブリッドを採用することで、異なる思考プロセスを実現し、9つの数学推論データセットで平均16%から32%の精度向上を実現しました。特にMAmmoTH-7BモデルはMATHデータセットで33%、MAmmoTH-34Bモデルは44%を達成し、既存のオープンソースモデルを上回っています。研究は、多様な問題の網羅性とハイブリッド推論の重要性を示しています。 Comment
9つのmath reasoningが必要なデータセットで13-29%のgainでSoTAを達成。
260kの根拠情報を含むMath Instructデータでチューニングされたモデル。
project page:
https://tiger-ai-lab.github.io/MAmmoTH/
RAIN: Your Language Models Can Align Themselves without Finetuning, Yuhui Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#General #NLP #LanguageModel #Alignment Issue Date: 2023-09-30 GPT Summary- 本研究では、追加のデータなしで凍結された大規模言語モデル(LLMs)を整列させる方法を探求しました。自己評価と巻き戻しメカニズムを統合することで、LLMsは自己ブースティングを通じて人間の好みと一致する応答を生成することができることを発見しました。RAINという新しい推論手法を導入し、追加のデータやパラメータの更新を必要とせずにAIの安全性を確保します。実験結果は、RAINの効果を示しており、LLaMA 30Bデータセットでは無害率を向上させ、Vicuna 33Bデータセットでは攻撃成功率を減少させることができました。 Comment
トークンのsetで構成されるtree上を探索し、出力が無害とself-evaluationされるまで、巻き戻しと前方生成を繰り返し、有害なトークンsetの重みを動的に減らすことでalignmentを実現する。モデルの追加のfinetuning等は不要。
self-evaluationでは下記のようなpromptを利用しているが、このpromptを変更することでこちら側の意図したとおりに出力のアライメントをとることができると思われる。非常に汎用性の高い手法のように見える。
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?, Xiangru Tang+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #StructuredData Issue Date: 2023-09-30 GPT Summary- 本研究では、大規模言語モデル(LLMs)の能力を評価し、構造に注意したファインチューニング手法を提案します。さらに、Struc-Benchというデータセットを使用して、複雑な構造化データ生成のパフォーマンスを評価します。実験の結果、提案手法は他の評価されたLLMsよりも優れた性能を示しました。また、モデルの能力マップを提示し、LLMsの弱点と将来の研究の方向性を示唆しています。詳細はhttps://github.com/gersteinlab/Struc-Benchを参照してください。 Comment
Formatに関する情報を含むデータでInstruction TuningすることでFormatCoT(フォーマットに関する情報のCoT)を実現している模様。ざっくりしか論文を読んでいないが詳細な情報があまり書かれていない印象で、ちょっとなんともいえない。
[Paper Note] A Survey on Large Language Model based Autonomous Agents, Lei Wang+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #Selected Papers/Blogs Issue Date: 2023-09-01 GPT Summary- LLMを活用した自律エージェントの研究を体系的に整理し、構築方法や応用例、評価戦略を概説。人間の学習に近づくための課題と今後の方向性を示す。関連文献のリポジトリも提供。 Comment
Fig1の時系列での論文数と代表的な研究のリストアップとエージェントの質の変遷、Table1のモデルの分類表など非常に分かりやすい。
[Paper Note] Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Bias #NAACL #read-later #Selected Papers/Blogs #Findings #Reading Reflections #needs-revision Issue Date: 2023-08-28 GPT Summary- 多肢選択問題におけるLLMsの性能は選択肢の順序に敏感であり、配置を変えることで最大75%の性能差が見られる。特に、上位選択肢間の不確実性がこの感度を引き起こし、バイアスが影響することを示唆する。最適な配置は、バイアスを増幅させるためにトップ選択肢を両端に置くこと、緩和するためには隣接させることが推奨される。実験を通じて、予測のキャリブレーションにより最大8ポイントの改善が達成された。 Comment
これはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。
AgentBench: Evaluating LLMs as Agents, Xiao Liu+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation Issue Date: 2023-08-27 GPT Summary- 本研究では、大規模言語モデル(LLMs)をエージェントとして評価するための多次元の進化するベンチマーク「AgentBench」を提案しています。AgentBenchは、8つの異なる環境でマルチターンのオープンエンドの生成設定を提供し、LLMの推論と意思決定能力を評価します。25のLLMsに対するテストでは、商用LLMsは強力な能力を示していますが、オープンソースの競合他社との性能には差があります。AgentBenchのデータセット、環境、および評価パッケージは、GitHubで公開されています。 Comment
エージェントとしてのLLMの推論能力と意思決定能力を評価するためのベンチマークを提案。
トップの商用LLMとOpenSource LLMの間に大きな性能差があることを示した。
Teach LLMs to Personalize -- An Approach inspired by Writing Education, Cheng Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #PersonalizedGeneration Issue Date: 2023-08-18 GPT Summary- 個別化されたテキスト生成において、大規模言語モデル(LLMs)を使用した一般的なアプローチを提案する。教育の執筆をベースに、多段階かつマルチタスクのフレームワークを開発し、検索、ランキング、要約、統合、生成のステージで構成される個別化されたテキスト生成へのアプローチを採用する。さらに、マルチタスク設定を導入してモデルの生成能力を向上させる。3つの公開データセットでの評価結果は、他のベースラインに比べて大幅な改善を示している。 Comment
研究の目的としては、ユーザが現在執筆しているdocumentのwriting支援
ReazonSpeech: A Free and Massive Corpus for Japanese ASR, Yin+, NLP'23
Paper/Blog Link My Issue
#NLP #Dataset #SpeechProcessing Issue Date: 2023-08-16 Comment
https://prtimes.jp/main/html/rd/p/000000003.000102162.html
超高精度で商用利用可能な純国産の日本語音声認識モデル「ReazonSpeech」を無償公開
ワンセグのデータにから生成
ライブラリ:
Crosslingual Generalization through Multitask Finetuning, Niklas Muennighoff+, N_A, ACL'23
Paper/Blog Link My Issue
#LanguageModel #MultitaskLearning #Zero/Few/ManyShotPrompting #Supervised-FineTuning (SFT) #CrossLingual #ACL #PostTraining #Generalization Issue Date: 2023-08-16 GPT Summary- マルチタスクプロンプトフィネチューニング(MTF)は、大規模な言語モデルが新しいタスクに汎化するのに役立つことが示されています。この研究では、マルチリンガルBLOOMとmT5モデルを使用してMTFを実施し、英語のプロンプトを使用して英語および非英語のタスクにフィネチューニングすることで、タスクの汎化が可能であることを示しました。さらに、機械翻訳されたプロンプトを使用してマルチリンガルなタスクにフィネチューニングすることも調査し、モデルのゼロショットの汎化能力を示しました。また、46言語の教師ありデータセットのコンポジットであるxP3も紹介されています。 Comment
英語タスクを英語でpromptingしてLLMをFinetuningすると、他の言語(ただし、事前学習で利用したコーパスに出現する言語に限る)で汎化し性能が向上することを示した模様。

[Paper Note] GPTScore: Evaluate as You Desire, Jinlan Fu+, arXiv'23, 2023.02
Paper/Blog Link My Issue
#DocumentSummarization #NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2023-08-13 GPT Summary- 大規模事前学習モデルを用いて生成物の品質を評価する新しいフレームワークGPTScoreを提案。GPTScoreは生成型AIの新能力を利用し、19種類のモデルと4つのテキスト生成タスクに対する評価を実施。これにより、注釈なしで多面的なカスタマイズ評価を可能にし、テキスト評価の課題を克服する手段を提供。コードはGitHubで公開中。 Comment
BERTScoreと同様、評価したいテキストの対数尤度で評価している
BERTScoreよりも相関が高く、instructionによって性能が向上することが示されている
[Paper Note] The Hydra Effect: Emergent Self-repair in Language Model Computations, Thomas McGrath+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #Attention Issue Date: 2023-08-08 GPT Summary- 因果分析により言語モデルの内部構造を調査し、二つの主要なモチーフを提案する。第一に、一つのアテンション層のアブレーションが別の層の補償的な機能を引き起こす「Hydra効果」、第二に、後段のMLP層が最大尤度トークンを抑制する対抗機能である。アブレーション研究では、層間の結合が緩やかであり、アブレーションの影響がごく一部に留まることを示し、ドロップアウトなしでも効果が見られることを発見した。これらの効果を事実の想起の文脈で分析し、回路レベルの帰属への影響を考察する。 Comment
LLMからattention layerを一つ取り除くと、後続の層が取り除かれたlayerの機能を引き継ぐような働きをすることがわかった。これはLLMの自己修復機能のようなものであり、HydraEffectと命名された。
[Paper Note] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework, Sirui Hong+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #ICLR #Selected Papers/Blogs Issue Date: 2023-08-08 GPT Summary- MetaGPTは、LLMベースのマルチエージェントシステムに人間のワークフローを統合し、複雑なタスクを小さなサブタスクに効率的に分解するメタプログラミングフレームワークです。これにより、中間結果の検証が可能になり、誤りを減少させます。また、共同ソフトウェアエンジニアリングのタスクにおいて、従来のシステムよりも一貫性のある解決策を提供します。プロジェクトはGitHubで公開されています。 Comment
要はBabyTalk, AutoGPTの進化系で、人間のワークフローを模倣するようにデザインしたら良くなりました、という話と思われる
ソフトウェアエンジニア、アーキテクト、プロダクトオーナー、プロジェクトマネージャーなどのロールを明示的に与えて、ゴールを目指す。もはやLLM内部でソフトウェア企業を模倣しているのと同様である。
openreview: https://openreview.net/forum?id=VtmBAGCN7o
[Paper Note] Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation, Xuefei Ning+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #ICLR #Decoding #Parallel Issue Date: 2023-08-08 GPT Summary- 本研究は、巨大言語モデル(LLMs)の生成遅延を低減するため、Skeleton-of-Thought(SoT)を提案。SoTは、まず回答のスケルトンを生成し、次に並列デコードを実行して内容を完成。12種のLLMでスピードアップと回答品質向上を実現。データ中心の最適化による効率的な推論を目指す。 Comment
最初に回答の枠組みだけ生成して、それぞれの内容を並列で出力させることでデコーディングを高速化しましょう、という話。
openreview: https://openreview.net/forum?id=mqVgBbNCm9
[Paper Note] ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Tools #NLP #Dataset #LanguageModel #AIAgents #SyntheticData #API #ICLR #ToolUse Issue Date: 2023-08-08 GPT Summary- オープンソースのLLMにおけるツール使用能力の限界を克服するため、ToolLLMフレームワークを提案。ToolBenchデータセットを用いて、ChatGPTに指示を与え実世界のAPIを収集し、多様なシナリオをカバー。新しい探索手法DFSDTを開発することで、LLMsの推論能力を高め、ToolLLaMAが複雑な指示を効果的に実行できることを示した。ToolEvalにより評価を行い、ToolLLaMAはChatGPTと同等の性能を発揮する。さらに、適切なAPIを推奨するニューラルAPIリトリーバーを導入し、手動の選択を不要にした。 Comment
16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
openreview: https://openreview.net/forum?id=dHng2O0Jjr
[Paper Note] Aligning Large Language Models with Human: A Survey, Yufei Wang+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Alignment #PostTraining Issue Date: 2023-08-08 GPT Summary- LLMsはNLPタスクにおいて重要な解決策として台頭しているが、人間の指示を誤解したり、偏った情報を生成するリスクがある。本調査は、LLMsを人間の期待に整合させるための技術を総括し、データ収集方法、学習手法のレビュー、モデル評価方法について詳述する。結論として、人間指向のタスクに適合させるためのLLMsの整合性を深化させる有用な資源にし、関連のGitHubリンクも提供する。 Comment
LLMのAlignment手法に関するSurvey
[Paper Note] L-Eval: Instituting Standardized Evaluation for Long Context Language Models, Chenxin An+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-08-08 GPT Summary- L-Evalを提案し、長い文脈を扱う言語モデル(LCLMs)の評価指標とデータセットを標準化。508の長文ドキュメントと2,000以上の人間ラベル付けされたクエリ・応答ペアを含む評価スイートを構築。n-gramマッチング指標の限界を指摘し、長さ指示を強化した評価を推奨。商用およびオープンソースモデルの包括的な研究を通じて、LCLMsの評価の基盤を提供。 Comment
long contextに対するLLMの評価セット。411のlong documentに対する2kのquery-response pairのデータが存在。法律、fainance, school lectures, 長文対話、小説、ミーティングなどのドメインから成る。
[Paper Note] Foundational Models Defining a New Era in Vision: A Survey and Outlook, Muhammad Awais+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Survey #ComputerVision #FoundationModel Issue Date: 2023-08-08 GPT Summary- 視覚システムの理解と推論における基盤モデルの役割をレビュー。異なるモダリティを組み合わせるアーキテクチャやトレーニング方法、プロンプティングパターンを含む。オープンな課題や研究方向性、評価の困難さ、文脈理解の限界なども議論。基盤モデルの応用を包括的にカバーし、詳細なリストはオンラインで提供。 Comment
CVにおけるfoundation modelのsurvey。残されたチャレンジと研究の方向性が議論されている
[Paper Note] LLM-Rec: Personalized Recommendation via Prompting Large Language Models, Hanjia Lyu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Prompting #NAACL #Findings Issue Date: 2023-08-02 GPT Summary- テキストベースのレコメンデーションは汎用性が高いが、元のアイテム説明だけではユーザー嗜好との整合性が不足することがある。大規模言語モデル(LLMs)の進歩を活かし、4つのテキスト強化プロンプト戦略を取り入れたアプローチ、LLM-Recを提案。実験により、LLM拡張テキストの使用が推奨品質を向上させることが確かめられ、基本的なMLPモデルでも高い成果を上げることが示された。成功の要因はプロンプト戦略であり、多様な技術がLLMsの推奨効果を高める重要性を示している。 Comment
LLMのpromptingの方法を変更しcontent descriptionだけでなく、様々なコンテキストの追加(e.g. このdescriptionを推薦するならどういう人におすすめ?、アイテム間の共通項を見つける)、内容の拡張等を行いコンテントを拡張して活用するという話っぽい。
[Paper Note] FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, Lingjiao Chen+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #TMLR #Selected Papers/Blogs Issue Date: 2023-07-26 GPT Summary- LLMの料金体系は多様で、大量利用時に高コストになる可能性がある。推論コストを削減するため、プロンプト適応、LLM近似、LLMカスケードの3つの戦略を提案。FrugalGPTを用いて、異なるクエリに最適なLLMsの組み合わせを学習し、最高で98%のコスト削減や4%の精度向上を実現する実験結果を示した。これにより、LLMの持続可能かつ効率的な活用の基盤が提供される。 Comment
限られた予算の中で、いかに複数のLLM APIを使い、安いコストで高い性能を達成するかを追求した研究。
LLM Cascadeなどはこの枠組みでなくても色々と使い道がありそう。Question Concatenationは実質Batch Prompting。
openreview: https://openreview.net/forum?id=cSimKw5p6R
[Paper Note] DoG is SGD's Best Friend: A Parameter-Free Dynamic Step Size Schedule, Maor Ivgi+, ICML'23, 2023.02
Paper/Blog Link My Issue
#MachineLearning #Optimizer #ICML Issue Date: 2023-07-25 GPT Summary- チューニング不要の動的SGDステップサイズ公式「Distance over Gradients(DoG)」を提案。DoGは、初期点からの距離と勾配のノルムに依存し、学習率パラメータを持たない。理論的に、確率的凸最適化に対して収束保証があることを示し、実験では視覚と言語の転移学習タスクにおいて調整済みSGDに近い性能を発揮。層ごとのバリアントは一般に調整済みSGDを上回り、調整済みAdamに近づく。PyTorch実装は https://github.com/formll/dog で提供。 Comment
20 を超える多様なタスクと 8 つのビジョンおよび NLP モデルに対して有効であったシンプルなパラメーターフリーのoptimizer
元ツイート:
[Paper Note] FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, Tri Dao, arXiv'23, 2023.07
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #NLP #Transformer #Attention #ICLR #Selected Papers/Blogs Issue Date: 2023-07-23 GPT Summary- 長いシーケンスを扱うトランスフォーマーの性能向上に寄与するFlashAttentionは、実行時間とメモリを線形に増加させるが、最適化されたGEMM演算には及ばない。FlashAttention-2では、作業分割を最適化し、非マトリクス積FLOPsを削減、アテンション計算を並列化、共有メモリ通信を減少することで、約2倍のスピードアップを実現。これにより、A100 GPU上で最大225 TFLOPs/sの訓練速度を達成し、モデルFLOPsの利用率は72%に向上した。 Comment
Flash Attention1よりも2倍高速なFlash Attention 2
Flash Attention1は
- [Paper Note] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Tri Dao+, NeurIPS'22, 2022.05
を参照
openreview: https://openreview.net/forum?id=mZn2Xyh9Ec
[Paper Note] Challenges and Applications of Large Language Models, Jean Kaddour+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Tutorial #Survey #NLP #LanguageModel Issue Date: 2023-07-22 GPT Summary- 大規模言語モデル(LLM)の急速な普及に伴い、課題や適用領域の特定が困難になっている。本論文は、ML研究者が現状を迅速に把握し生産的になるために、未解決の問題と成功事例の体系的な集合を提供することを目指す。 Comment
LLMのここ数年の進化早すぎわろたでキャッチアップむずいので、未解決の課題や、すでに良い感じのアプリケーションの分野分かりづらいので、まとめました論文
[Paper Note] FABRIC: Personalizing Diffusion Models with Iterative Feedback, Dimitri von Rütte+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#ComputerVision #Personalization #DiffusionModel Issue Date: 2023-07-22 GPT Summary- 生成モデルへの人間のフィードバック統合が重要な機会を提供する中、本研究では拡散モデルを用いたテキストから画像への生成に反復的フィードバックを組み込む手法、FABRICを提案。トレーニング不要で、多様な拡散モデルに適用可能。自己注意層を利用し、フィードバックで条件付けされた生成プロセスを評価。反復的フィードバックによる生成結果の改善を示し、パーソナライズされたコンテンツ作成への応用の可能性を探る。 Comment
upvote downvoteをフィードバックし、iterativeなmannerでDiffusionモデルの生成結果を改善できる手法。多くのDiffusion based Modelに対して適用可能
デモ:
https://huggingface.co/spaces/dvruette/fabric
[Paper Note] Meta-Transformer: A Unified Framework for Multimodal Learning, Yiyuan Zhang+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing Issue Date: 2023-07-22 GPT Summary- Meta-Transformerは、ペアのマルチモーダルトレーニングデータを用いず、複数のモダリティを統一的に学習する新しいフレームワークです。共有トークンスペースでの生データマッピングと凍結されたエンコーダによる高レベル特徴抽出を実現し、テキストや画像など多様なモダリティ間での知覚を可能にします。実験結果は、様々なベンチマークにおいて広範囲なタスクへの対応が確認され、マルチモーダルインテリジェンスの発展に寄与する可能性を示しています。 Comment
12種類のモダリティに対して学習できるTransformerを提案
Dataをsequenceにtokenizeし、unifiedにfeatureをencodingし、それぞれのdownstreamタスクで学習
[Paper Note] SCOTT: Self-Consistent Chain-of-Thought Distillation, Peifeng Wang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Chain-of-Thought #Distillation #ACL Issue Date: 2023-07-14 GPT Summary- 大規模言語モデル(LM)は、連鎖思考(CoT)プロンプティングを通じて自由形式の根拠を生成する能力を示すが、生成された根拠が予測と整合する保証はない。本研究では、大規模教師モデルから小さく自己一貫性を持つCoTモデルを獲得するための忠実な知識蒸留法を提案。対比的デコードを用いて金標準解答を支持する根拠を誘出し、不整合な予測を防ぐ仕組みを構築。実験で、性能が同等でありながら、提案手法がより忠実なCoT根拠を生成できることを示した。解析により、モデルが意思決定時に根拠を重視することが確認され、根拠の精練がさらなる性能向上につながる可能性が示唆された。 Comment
CoTのパフォーマンス向上がパラメータ数が大きいモデルでないと発揮せれないことは元論文 [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01 で考察されており、それをより小さいモデルに蒸留し発揮できるようにする、おもしろい
[Paper Note] Understanding Social Reasoning in Language Models with Language Models, Kanishk Gandhi+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #TheoryOfMind #Evaluation Issue Date: 2023-07-11 GPT Summary- 大型言語モデル(LLMs)の心の理論(ToM)能力の評価は重要であるが、一貫性のない結果や評価手法の妥当性に懸念が存在する。これに対処するため、因果テンプレートを用いて評価を生成する新しいフレームワークを提案し、新たな社会的推論ベンチマーク(BigToM)を作成した。BigToMは5,000件の評価を基にしており、質が高いと評価される。評価の結果、GPT-4は人間に近いToM能力を示す一方で、信頼性は低く、他のモデルは苦戦していることが分かった。 Comment
LLMの社会的推論能力を評価するためのベンチマークを提案。ToMタスクとは、人間の信念、ゴール、メンタルstate、何を知っているか等をトラッキングすることが求められるタスクのこと。
[Paper Note] Generative AI for Programming Education: Benchmarking ChatGPT, GPT-4, and Human Tutors, Tung Phung+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#LanguageModel #Education Issue Date: 2023-07-11 GPT Summary- 入門プログラミング教育における生成型AIと大規模言語モデルの活用を評価。ChatGPT(GPT-3.5)とGPT-4を様々なシナリオで人間のチューターと比較し、GPT-4がChatGPTを大幅に上回り、一部のシナリオでは人間に近づく結果に。これにより、今後の性能向上のための研究の方向性が示される。 Comment
GPT4とGPT3.5をプログラミング教育の文脈で評価したところ、GPT4AGPT3.5をoutperformし、人間のチューターに肉薄した。
[Paper Note] ViNT: A Foundation Model for Visual Navigation, Dhruv Shah+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#ComputerVision #Transformer #FoundationModel #Navigation #Robotics Issue Date: 2023-07-11 GPT Summary- 汎用的なファウンデーションモデルViNTを紹介し、ロボットナビゲーションにおける汎用的な成功を目指す。ViNTは、一般的なゴール到達を目的とした学習目標で訓練され、さまざまなナビゲーションタスクに適応可能なTransformerベースのアーキテクチャを持つ。既存データセットで訓練され、専門モデルを上回る性能を示す。新環境探索やタスク仕様への適応にも柔軟で、モバイルロボティクスの基盤モデルとしての有効性を持つ。 Comment
事前学習済みモデルを視覚ベースのロボットナビゲーションに活用するFoundation Model。FlexibleなTransformerベースのアーキテクチャに基づいて構築されており、さまざまなナビゲーションタスクに取り組むことが可能
[Paper Note] Extending Context Window of Large Language Models via Positional Interpolation, Shouyuan Chen+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #LanguageModel #ContextWindow Issue Date: 2023-07-11 GPT Summary- Position Interpolation(PI)を提案し、RoPEベースのLLMの文脈ウィンドウサイズを最小限のファインチューニングで最大32768に拡張。長文要約やパスキー取得などのタスクで高い性能を示し、元のタスクでも良好な品質を維持。入力位置を元のウィンドウサイズに合わせて縮小することで、自己注意機構の安定性を確保。PIは元のアーキテクチャを保持し、既存のインフラも利用可能。 Comment
LLMのContext Windowを最大32kまで拡張する手法を提案。1000 step以内のminimalなfinetuningでモデルの性能を維持しながら実現できる。
[Paper Note] SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs, Lijun Yu+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #QuestionAnswering #MultiModal #NeurIPS #VisionLanguageModel Issue Date: 2023-07-11 GPT Summary- 凍結されたLLMが画像や動画を理解・生成できるようにするSemantic Pyramid AutoEncoder(SPAE)を提案。生データのピクセルとLLMの語彙をトークンに変換し、視覚情報を言語に翻訳。凍結済みのPaLM 2およびGPT-3.5を使用した実験で、画像理解タスクで25%以上の性能向上を実現。 Comment
画像をLLMのtokenスペースにマッピングすることで、LLMがパラメータの更新なしにvisual taskを解くことを可能にした。in context learningによって、様々なvisuataskを解くことができる。
openreview: https://openreview.net/forum?id=CXPUg86A1D
[Paper Note] A Survey of Large Language Models, Wayne Xin Zhao+, arXiv'23, 2023.03
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Prompting Issue Date: 2023-07-11 GPT Summary- 言語は複雑な表現体系であり、その理解・生成のためのAIアルゴリズム開発は難題である。近年、事前学習済み言語モデル(PLMs)がTransformerモデルを用いた大規模コーパスの学習により高い能力を示しており、特に大規模言語モデル(LLM)が注目されている。モデルスケーリングが性能向上をもたらし、一定のパラメータ規模を超えると新たな能力が現れることが確認されている。LLMsはAIコミュニティ全体に重要な影響を与えており、本調査ではその背景、主要な発見、技術を概説し、特に事前学習、適応調整、活用、容量評価に焦点を当てる。また、リソース整理や未解決課題についても論じる。 Comment
現状で最も詳細なLLMのサーベイ
600個のリファレンス、LLMのコレクション、promptingのtips、githubリポジトリなどがまとめられている
[Paper Note] Mind2Web: Towards a Generalist Agent for the Web, Xiang Deng+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #NeurIPS #ComputerUse #Selected Papers/Blogs #VisionLanguageModel #GUI Issue Date: 2023-07-03 GPT Summary- Mind2Webは、ウェブ上での汎用的なタスクをこなすエージェントの開発のための初のデータセットで、137のウェブサイトと31のドメインにまたがる2,000件以上のオープンエンドタスクを収集。これにより、多様なドメイン・タスクを扱え、実世界のサイトを対象にしたエージェント構築を支援。大規模言語モデル(LLMs)を用いることで、未見のウェブサイトでも一定の性能を発揮することを示し、データセットとモデルをオープンソース化して研究の促進を目指す。 Comment
Webにおけるgeneralistエージェントを評価するためのデータセットを構築。31ドメインの137件のwebサイトにおける2350個のタスクが含まれている。
タスクは、webサイトにおける多様で実用的なユースケースを反映し、チャレンジングだが現実的な問題であり、エージェントの環境やタスクをまたいだ汎化性能を評価できる。
プロジェクトサイト:
https://osu-nlp-group.github.io/Mind2Web/
[Paper Note] Augmenting Language Models with Long-Term Memory, Weizhi Wang+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #LongSequence #NeurIPS Issue Date: 2023-07-03 GPT Summary- 長期メモリを持つ言語モデル(LongMem)は、既存の大規模言語モデルの入力長の制限を緩和し、長期の履歴を記憶できるようにする。元のLLMを凍結し、適応的な残差サイドネットワークをメモリリトリーバーおよびリーダーとして機能させる新しいネットワークアーキテクチャを採用。LongMemは長文メモリを65kトークンまで拡張し、メモリ検索モジュールによって無制限の長さのコンテキストを扱うことで、多様な下流タスクに効果を発揮。実験により、ChapterBreakベンチマークで強力なモデルを上回り、顕著な改善を示した。コードはオープンソースで提供されている。 Comment
LLMに長期のhistoryを記憶させることを可能する新たな手法を提案し、既存のstrongな長いcontextを扱えるモデルを上回るパフォーマンスを示した
openreview: https://openreview.net/forum?id=BryMFPQ4L6
[Paper Note] A Comprehensive Survey on Applications of Transformers for Deep Learning Tasks, Saidul Islam+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#Survey #NLP #Transformer Issue Date: 2023-07-03 GPT Summary- トランスフォーマーは自己注意機構に基づく深層ニューラルネットワークで、長期依存関係を扱い、並列処理が可能。NLPやコンピュータビジョンなど複数の分野で注目されているが、包括的な総説が不足。2017年から2022年に提案されたトランスフォーマーモデルを調査し、主要な応用領域を特定。NLP、コンピュータビジョン、マルチモーダリティ、音声処理、信号処理を含むモデルの影響を分析し、分類。研究者にトランスフォーマーの潜在能力と未来の展望を示すことを目的とする。 Comment
Transformerに関する最新サーベイ論文。Transformerが利用されているアプリケーションと、モデルのリストが列挙されている。
[Paper Note] Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks, Veniamin Veselovsky+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation Issue Date: 2023-07-03 GPT Summary- LLMは高品質なデータ生成が可能で、クラウドソーシングは安価で効果的な注釈手法だが、クラウドワーカーは生産性向上のためにLLMを利用する動機が存在する。ケーススタディでは、クラウドワーカーの33-46%がLLMを使用していることが明らかになった。この結果は、人間のデータ保持の新たなアプローチを模索する必要性を示唆している。 Comment
Mturkの言語生成タスクにおいて、Turkerのうち33-46%はLLMsを利用していることを明らかにした
[Paper Note] A Simple and Effective Pruning Approach for Large Language Models, Mingjie Sun+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Pruning Issue Date: 2023-06-26 GPT Summary- 大規模言語モデルのプルーニング手法としてWandaを提案。再訓練なしで活用可能で、入力アクティベーションと掛け合わせたウェイトの絶対値を最小化することでスパース性を誘導。LLaMAおよびLLaMA-2で徹底評価し、絶対値プルーニングを超える性能を実現。 Comment
LLMのネットワークのpruning手法を提案。再訓練、パラメータ更新無しで、性能低下が少なくて刈り込みが可能。
[Paper Note] SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking, Chris Cundy+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #MachineLearning #NLP #LanguageModel #ICLR #needs-revision Issue Date: 2023-06-26 GPT Summary- 自己回帰モデルは高い尤度を達成するものの、最大尤度推定(MLE)が生成タスクに必ずしも適合しないことがある。MLEは分布外の振る舞いに関する指針がないため、累積誤差が生じる。これに対処するため、生成を模倣学習(IL)として定式化し、生成系列の分布とデータセット由来の系列分布間のダイバージェンスを最小化。ILフレームワークでは、バックスペースアクションを導入し、モデルが不要なトークンを戻すことを可能にする。新たに提案するSequenceMatchは、敵対的訓練やアーキテクチャの変更なしで実装でき、SequenceMatch-χ^2ダイバージェンスを適切な訓練目的として特定。実験的に、SequenceMatchは言語モデルによるテキスト生成や算術においてMLEを上回る改善を示す。 Comment
backspaceアクションをテキスト生成プロセスに組み込むことで、out of distributionを引き起こすトークンを元に戻すことで、生成エラーを軽減させることができる。
openreview: https://openreview.net/forum?id=FJWT0692hw
[Paper Note] Full Parameter Fine-tuning for Large Language Models with Limited Resources, Kai Lv+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2023-06-26 GPT Summary- LLMのトレーニングにおけるリソースの課題に対応するため、「低メモリ最適化」(LOMO)という新手法を提案。勾配計算とパラメータ更新を1ステップで統合し、メモリ使用量を10.8%削減。これにより、65Bモデルの全パラメータを1台のマシンで微調整可能に。コードはGitHubで入手可能。 Comment
8xRTX3090 24GBのマシンで65Bモデルの全パラメータをファインチューニングできる手法。LoRAのような(新たに追加しれた)一部の重みをアップデートするような枠組みではない。勾配計算とパラメータのアップデートをone stepで実施することで実現しているとのこと。
[Paper Note] Unifying Large Language Models and Knowledge Graphs: A Roadmap, Shirui Pan+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #LanguageModel #KnowledgeGraph Issue Date: 2023-06-25 GPT Summary- LLMs(大規模言語モデル)とKGs(知識グラフ)の統合は、互いの利点を活かすために重要である。本論文では、KGを活用したLLMsの強化、LLMsを利用したKGの向上、そして両者が相互に利益をもたらす枠組みを示すロードマップを提示。これにより、既存の研究を整理し、今後の研究の方向性を明らかにする。 Comment
LLMsとKGの統合に関するロードマップを提示。KGをLLMの事前学習や推論に組み込む方法、KGタスクにLLMを利用する方法、LLMとKGの双方向のreasonieg能力を高める方法などをカバーしている。
[Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #MachineLearning #NLP #LanguageModel #SmallModel #Selected Papers/Blogs Issue Date: 2023-06-25 GPT Summary- phi-1は1.3BパラメータのTransformerベースの大規模言語モデルで、競合モデルより小型ながらHumanEvalで50.6%、MBPPで55.5%の高精度を達成。8台のA100 GPUを用いて、教科書品質データと合成生成データを組み合わせて訓練。phi-1-baseやphi-1-smallと比べても驚くべき創発特性を示す。 Comment
参考:
教科書のような品質の良いテキストで事前学習すると性能が向上し(グラフ真ん中)、さらに良質なエクササイズでFinetuningするとより性能が向上する(グラフ右)
日本語解説: https://dalab.jp/archives/journal/introduction-textbooks-are-all-you-need/
ざっくり言うと、教科書で事前学習し、エクササイズでFinetuningすると性能が向上する(= より大きいモデルと同等の性能が得られる)。
[Paper Note] DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining, Sang Michael Xie+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #DataDistillation #NeurIPS #Selected Papers/Blogs #DataMixture Issue Date: 2023-05-21 GPT Summary- ドメイン混合割合が言語モデル(LM)の性能に影響を与える中、本論文はドメイン再重み付け(DoReMi)を提案。DoReMiは、まず代理モデルを使ってドメイン重みを生成し、その後データをリサンプリングして大規模モデルを効率的に訓練。実験では、DoReMiを用いた代理モデルが、パープレキシティを改善し、少数ショット精度を6.5ポイント向上、訓練ステップは2.6倍少なくて済むと示した。GLaMデータセットでは、ドメイン重み無しでも高い性能を達成。 Comment
事前学習する際の各ドメインのデータをどのような比率でmixtureするかの話。各ドメインごとに小さなproxy modelを訓練し、downstream taskの知識無しでドメインごとの重みを生成。データセットを生成されたドメインごとの重みに従いリサンプリングすることで、(1/30のプロキシモデルを用いた場合)オリジナルのデータより2.6倍高速で、6.5%oneshotのaccuracyを向上させることに成功
openreview: https://openreview.net/forum?id=lXuByUeHhd
[Paper Note] StructGPT: A General Framework for Large Language Model to Reason over Structured Data, Jinhao Jiang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #TabularData #Reasoning Issue Date: 2023-05-21 GPT Summary- 本研究では、構造化データに基づく質問応答タスクを解決するためにIterative Reading-then-Reasoning(IRR)アプローチ、StructGPTを開発。特化した関数を用いることで、関連証拠を収集し推論を行うプロセスを構築。さらに、外部インターフェースを利用したinvoking-linearization-generation手順を提案し、反復的に解答に近づく。実験結果は、ChatGPTの性能を大幅に向上させ、教師ありチューニングと同等の成果を示す。 Comment
構造化データに対するLLMのゼロショットのreasoning能力を改善。構造化データに対するQAタスクで手法が有効なことを示した。
[Paper Note] Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models, Hanxu Hu+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Planning #needs-revision Issue Date: 2023-05-21 GPT Summary- 自然言語で表現された仮想空間における複雑な計画タスクに対するLLMsの性能を調査し、新たなベンチマークNatalaを提案。LLMs(例: ChatGPT)は依然として計画能力に限界があり、象徴的表現が理解しやすい可能性を示す。新手法CoS(Chain-of-Symbol Prompting)は追加訓練なしでLLMsに適用でき、広範な実験でCoT(Chain-of-Thought)を上回る性能を達成。特に、ChatGPTの正確性が最大60.8%向上し、中間段階のトークン数も著しく削減された。 Comment
LLMは複雑なプランニングが苦手なことが知られており、複雑な環境を自然言語ではなく、spatialでsymbolicなトークンで表現することで、プランニングの性能が向上したという話
OpenReview: https://openreview.net/forum?id=B0wJ5oCPdB
[Paper Note] CodeT5+: Open Code Large Language Models for Code Understanding and Generation, Yue Wang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #CodeGeneration #Encoder-Decoder Issue Date: 2023-05-20 GPT Summary- コードLLMsは特定のアーキテクチャに依存しがちで、事前学習タスクの制約により性能が低下することがある。本研究では、この問題を解決するために「CodeT5+」を提案。CodeT5+は柔軟な部品モジュールの組み合わせを可能にし、 diverseな事前学習目的でタスク要求に応じる。更に、既存のLLMを初期化に利用し効率的にスケールアップ。20以上のコードベンチマークで評価し、指示調整済みのCodeT5+がHumanEvalタスクで新たな最先端性能を達成した。 Comment
様々なコードの理解と生成タスクをサポート
異なる訓練手法によって計算効率改善
20種類のコードベンチマークで、様々な設定「ゼロショット、finetuning, instruction tuning等)を実施した結果、コード補完、math programming, text to code retrievalにおいてSoTA達成
[Paper Note] TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models, Zorik Gekhman+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #Dataset #Evaluation #Hallucination #Factuality Issue Date: 2023-05-20 GPT Summary- TrueTeacherは、多様なモデル生成要約をLLMで注釈し、実際の生成要約に基づいた合成データを生成するアプローチである。従来の手法とは異なり、手作業での要約に依存せず、多言語対応も可能。実験結果は、TrueTeacherを使用して訓練したstudentモデルが他の最先端モデルやLLM教師を大幅に上回ることを示し、ドメインシフトに対する堅牢性も確認された。加えて、140万例の大規模合成データセットと訓練したチェックポイントも公開。 Comment
Factual Consistency Evaluationに関する研究。オリジナルのテキストに対して、様々な規模の言語モデルを用いて要約を生成。生成された要約に対してfactual informationが正しく含まれているかをラベル付けする方法を提案。
[Paper Note] Emergent Representations of Program Semantics in Language Models Trained on Programs, Charles Jin+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Coding #ICML #needs-revision Issue Date: 2023-05-20 GPT Summary- 言語モデル(LM)が次のトークン予測に特化した訓練にもかかわらず、形式的意味を表現できる可能性を示す。2Dグリッド環境でのプログラム合成コーパスを用いてTransformerモデルを訓練し、特定の入力出力仕様が付随するプログラムから、未観測の中間状態を精度よく抽出できることを発見。新しい介入ベースラインにより、LMの表現とプロービングによる結果の明確な識別が可能に。広範な意味論的プロービング実験への適用が期待される。 Comment
プログラムのコーパスでLLMをNext Token Predictionで訓練し
厳密に正解とsemanticsを定義した上で、訓練データと異なるsemanticsの異なるプログラムを生成できることを示した。
LLMが意味を理解していることを暗示している
参考:
[Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #Selected Papers/Blogs #needs-revision Issue Date: 2023-05-20 GPT Summary- 言語モデルは一般的な問題解決に広がっているが、推論は依然としてトークンレベルの左から右への決定に制限されている。これを克服するために、新しい「Tree of Thoughts(ToT)」フレームワークを導入。ToTは、思考の連鎖を一般化し、中間ステップを探索できるようにし、複数の推論経路を自己評価することで意図的な意思決定を可能にする。実験では、ToTがGame of 24やCreative Writingなどの新規タスクで言語モデルの問題解決能力を顕著に向上させることが示された。例えば、Game of 24では新手法が74%の成功率を達成した。 Comment
Self Concistencyの次
Non trivialなプランニングと検索が必要な新たな3つのタスクについて、CoT w/ GPT4の成功率が4%だったところを、ToTでは74%を達成
論文中の表ではCoTのSuccessRateが40%と書いてあるような?
[Paper Note] mLongT5: A Multilingual and Efficient Text-To-Text Transformer for Longer Sequences, David Uthus+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#needs-revision Issue Date: 2023-05-20 GPT Summary- mLongT5という多言語対応のテキスト変換モデルを開発し、LongT5アーキテクチャを基にしています。このモデルはmT5の多言語データセットとUL2のタスクを活用し、多言語要約と質問応答で評価しました。その結果、mLongT5はmBARTやM-BERTなどの既存モデルよりも高い性能を示しました。 Comment
lib: https://huggingface.co/agemagician/mlong-t5-tglobal-xl
16384 tokenを扱えるT5。102言語に対応
[Paper Note] MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, Lili Yu+, NeurIPS'23, 2023.05
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #MachineLearning #NLP #Transformer #SpeechProcessing #LongSequence #Architecture #NeurIPS #Byte-level Issue Date: 2023-05-15 GPT Summary- Megabyteというマルチスケールデコーダーアーキテクチャを提案し、長いシーケンスのエンドツーエンドのモデリングを可能にする。シーケンスをパッチに分割し、ローカルサブモデルとグローバルモデルを使用することで、計算効率を向上させつつコストを削減。実験により、Megabyteは長いコンテキストの言語モデリングで競争力を持ち、最先端の密度推定を達成した。トークン化なしの自己回帰シーケンスモデリングの実現可能性を示す。 Comment
byte列のsequenceからpatch embeddingを作成することで、tokenizer freeなtransformerを提案。
byte列で表現されるデータならなんでも入力できる。つまり、理論上なんでも入力できる。
openreview: https://openreview.net/forum?id=JTmO2V9Xpz
[Paper Note] Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Mirac Suzgun+, ACL'23, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Zero/Few/ManyShotPrompting #Chain-of-Thought #ACL Issue Date: 2023-05-04 GPT Summary- BIG-Benchは、言語モデルの限界を超えたタスクに焦点を当てた評価スイートであり、モデルはすでに65%のタスクで平均的な人間評価者を上回っている。本研究では、BBH(BIG-Bench Hard)として知られる、従来の評価で人間を下回った23の困難なタスクを分析。連鎖思考(CoT)プロンプティングを用いることで、PaLMは10タスク、Codexは17タスクで人間評価者を上回ることを示す。多段階の推論が求められるため、CoTなしの評価はモデルの性能を過小評価し、CoTはBBHタスクの性能向上に寄与することが明らかになった。 Comment
単なるfewshotではなく、CoT付きのfewshotをすると大幅にBIG-Bench-hardの性能が向上するので、CoTを使わないanswer onlyの設定はモデルの能力の過小評価につながるよ、という話らしい
[Paper Note] Efficiently Scaling Transformer Inference, Reiner Pope+, MLSys'23, 2022.11
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #LongSequence #Architecture #Inference Issue Date: 2023-04-30 GPT Summary- 大規模なTransformerモデルの生成的推論を、長いシーケンス長と厳格な遅延目標の下で研究。TPU v4用に最適化された解析モデルを開発し、待機時間とモデルFLOPS利用率のトレードオフにおいて新しいパレート前線を達成。マルチクエリ注意機構を用いることでメモリ要件を減少させ、コンテキスト長を最大32倍に拡張。最終的に、小さなバッチサイズでの1トークンあたりの遅延は29ミリ秒となり、MFUは76%に達し、PaLM 540Bモデルで2048トークンのコンテキストをサポート。 Comment
特にMultiquery Attentionという技術がTransformerのinferenceのコスト削減に有効らしい
Multi Query Attention (MQA):
- [Paper Note] Fast Transformer Decoding: One Write-Head is All You Need, Noam Shazeer, arXiv'19, 2019.11
[Paper Note] Controlled Text Generation with Natural Language Instructions, Wangchunshu Zhou+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #Prompting #SyntheticData #In-ContextLearning #ICML #PostTraining Issue Date: 2023-04-30 GPT Summary- 自然言語の指示に従い、多様なタスクを解決可能な大規模言語モデルの制御を改善するために、「InstructCTG」というフレームワークを提案。自然テキストの制約を抽出し、これを自然言語の指示に変換することで弱教師あり訓練データを形成。異なるタイプの制約に柔軟に対応し、生成の質や速度への影響を最小限に抑えつつ、再訓練なしで新しい制約に適応できる能力を持つ。 Comment
制約に関する指示とデモンスとレーションに関するデータを合成して追加のinstruction tuningを実施することで、promptで指示された制約を満たすような(controllableな)テキストの生成能力を高める手法
[Paper Note] AI, write an essay for me: A large-scale comparison of human-written versus ChatGPT-generated essays, Steffen Herbold+, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Education #AES(AutomatedEssayScoring) #ChatGPT Issue Date: 2023-04-28 GPT Summary- ChatGPTが生成したエッセイは、人間が書いたものよりも質が高いと評価されることが大規模な研究で示された。生成されたエッセイは独自の言語的特徴を持ち、教育者はこの技術を活用する新たな教育コンセプトを開発する必要がある。 Comment
ChatGPTは人間が書いたエッセイよりも高品質なエッセイが書けることを示した。
また、AIモデルの文体は、人間が書いたエッセイとは異なる言語的特徴を示している。たとえば、談話や認識マーカーが少ないが、名詞化が多く、語彙の多様性が高いという特徴がある、とのこと。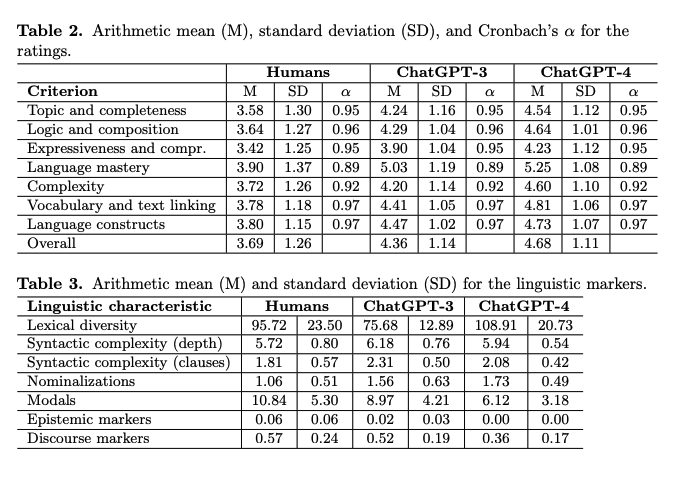
[Paper Note] Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes, Simran Arora+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #LanguageModel #TabularData #Data Issue Date: 2023-04-27 GPT Summary- LLMを用いた半構造化文書の自動処理システムEVAPORATEを提案。文書からの値を直接抽出する方法と、抽出コードを合成する方法の二つを評価。コード合成はコストが低いが精度が劣るため、EVAPORATE-CODE+を導入し、品質を向上。弱教師あり学習を用いた抽出のアンサンブルにより、文書処理の効率を大幅に改善。処理トークン数を平均110倍に削減し、最先端システムを超える成果を達成。 Comment
LLMを使うことで、半構造化文章から自動的にqueryableなテーブルを作成することを試みた研究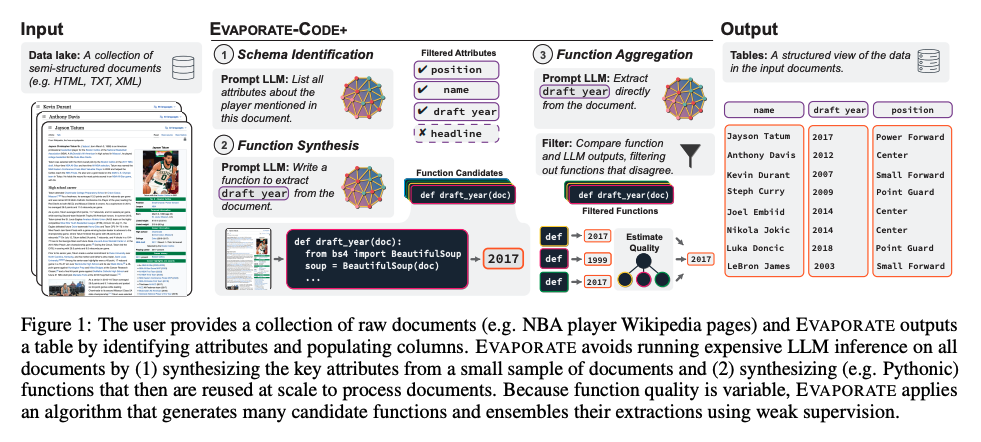
[Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #EMNLP Issue Date: 2023-04-27 GPT Summary- 新しい戦略「Automate-CoT」を提案し、少量のラベル付きデータから合理的チェーンを自動拡張。低品質なチェーンを剪定し、最適な推論チェーンを選択する分散削減型ポリシー勾配戦略を用いる。これにより、さまざまなタスクへのCoT手法の迅速な適用を可能にし、実験で競争力のある結果を達成。 Comment
LLMによるreasoning chainが人間が作成したものよりも優れていることを示しているとのこと。下記研究より
- [Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
selection phaseで誤ったexampleは直接排除する手法をとっている。そして、強化学習によって、demonstrationのselection modelを訓練している。
openreview: https://openreview.net/forum?id=FGBEoz9WzI¬eId=sq50eXOEeV
Learning Multimodal Data Augmentation in Feature Space, ICLR'23
Paper/Blog Link My Issue
#MachineLearning #DataAugmentation #MultiModal Issue Date: 2023-04-26 Comment
Data Augmentationは基本的に単体のモダリティに閉じて行われるが、
マルチモーダルな設定において、モダリティ同士がどう関係しているか、どの変換を利用すべきかわからない時に、どのようにデータ全体のsemantic structureを維持しながら、Data Augmentationできるか?という話らしい
[Paper Note] A Cookbook of Self-Supervised Learning, Randall Balestriero+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#Tutorial #MachineLearning #Self-SupervisedLearning Issue Date: 2023-04-26 GPT Summary- 自己教師付き学習(SSL)は機械学習の重要な進展とされているが、その訓練は高い技術を要し、参入障壁が存在する。本研究では、SSL手法の訓練に必要な前処理やハイパーパラメータの選択肢を体系的に示すことを目指し、研究者がSSLの理解を深め、効果的な手法を探求できるようサポートする。 Comment
MetaによるSelf Supervised Learningの教科書
[Paper Note] Track Anything: Segment Anything Meets Videos, Jinyu Yang+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#ComputerVision #ImageSegmentation #TechnicalReport #3D (Video) Issue Date: 2023-04-25 GPT Summary- 動画セグメンテーションにおいて、Track Anything Model (TAM)を提案。少数のクリックで関心の対象を効果的に追跡・セグメント化し、追加訓練なしで高性能を実現。全リソースはオンラインで提供。 Comment
MetaのSAMを、videoに適用し、videow内のsegmentationを追加学習なしでやりました、という話だと思われる。
関連:
- [Paper Note] Segment Anything, Alexander Kirillov+, arXiv'23, 2023.04
[Paper Note] Scaling Transformer to 1M tokens and beyond with RMT, Aydar Bulatov+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Transformer #LongSequence #memory Issue Date: 2023-04-25 GPT Summary- 再帰的メモリ拡張を用いて、トランスフォーマーの計算量を線形にスケールし、最大二百万トークンまでのシーケンスを扱う能力を実証。言語モデリングタスクでの実験は、パープレキシティの改善を示し、長期依存の処理能力向上の可能性を強調。 Comment
Reccurent Memory Transformer [Paper Note] Recurrent Memory Transformer, Aydar Bulatov+, NeurIPS'22, 2022.07
を使って2Mトークン扱えるようにしたよーという話。
ハリーポッターのトークン数が1.5Mらしいので、そのうち小説一冊書けるかもという世界。
[Paper Note] Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation, Yusong Wu+, ICASSP'23, 2022.11
Paper/Blog Link My Issue
#NeuralNetwork #Embeddings #Pretraining #NLP #Library #RepresentationLearning #MultiModal #SpeechProcessing #ContrastiveLearning #Speech #text #ICASSP Issue Date: 2023-04-25 GPT Summary- 音声データと自然言語説明を組み合わせたコントラスト学習による音声表現開発のパイプラインを提案。633,526の音声-テキストペアからなるLAION-Audio-630Kを公開し、音声エンコーダとテキストエンコーダを用いたモデルを構築。特徴融合メカニズムを採用し、可変長の音声入力に対応。テキストから音声検索や音声分類に関する実験により、特にテキスト検索で優れた性能を示し、ゼロショット設定でも最先端の結果を達成。LAION-Audio-630Kとモデルは公開済み。 Comment
テキストとオーディオをエンコードするMLPエンコーダをそれぞれ用意し、大量のペアをcontrastive learningで事前学習することで、テキストとオーディオ間を同じ空間に写像し、類似度を測れるようにしたモデル。zero-shotでaudio分類などが可能。
Efficient Methods for Natural Language Processing: A Survey, Treviso+, TACL'23
Paper/Blog Link My Issue
#NeuralNetwork #Survey #EfficiencyImprovement #NLP #TACL Issue Date: 2023-04-25 Comment
パラメータ数でゴリ押すような方法ではなく、"Efficient"に行うための手法をまとめている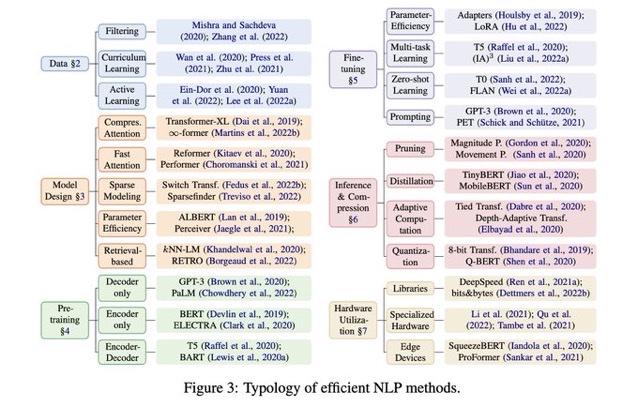
Sketch-Guided Text-to-Image Diffusion Models, Andrey+, Google Research, SIGGRAPH'23
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NLP #TextToImageGeneration #SIGGRAPH #ImageSynthesis Issue Date: 2022-12-01 Comment
スケッチとpromptを入力することで、スケッチ biasedな画像を生成することができる技術。すごい。
[Paper Note] Masked Autoencoders Are Scalable Vision Learners, Kaiming He+, CVPR'22, 2021.11
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Transformer #Self-SupervisedLearning #CVPR #Selected Papers/Blogs #Encoder #Backbone #AutoEncoder #2D Reconstruction Issue Date: 2026-04-29 GPT Summary- MAEは、入力画像のランダムなパッチをマスクし、欠損部分を再構成するシンプルな自己教師付き学習モデルである。非対称のエンコーダ-デコーダ構造を用い、エンコーダは可視パッチのみを処理。75%をマスクすることで、非自明な自己教師付きタスクを生み出し、高速かつ効果的なモデル訓練を実現。一般化性能に優れ、ViT-HugeモデルがImageNet-1Kデータで最高精度(87.8%)を達成し、転移性能も監督付き事前学習を上回る。 Comment
元ポスト:
AutoEncoderを通じてMaskされたパッチを再構築できるように学習する(25%のパッチから予測する)ことで、(decoderを排除した場合に)downstream taskで良い性能を発揮するViTエンコーダを学習する。デコーダのパラメータ数は意図的に小さくし、Encoder側で特徴がきちんと学習されるように誘導する。
[Paper Note] ScienceWorld: Is your Agent Smarter than a 5th Grader?, Ruoyao Wang+, EMNLP'22, 2022.03
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #ScientificDiscovery #EMNLP #Selected Papers/Blogs #Science Issue Date: 2026-04-14 GPT Summary- ScienceWorldは、小学校の科学カリキュラムに基づき、エージェントの科学的推論能力を評価するための対話型テキスト環境を提供します。従来のモデルは、新しい文脈で学んだ科学概念を推論するのが苦手で、特に未知の材料の伝導率を見つけるための実験方法を問われると苦戦します。これは、モデルが類似例から答えを得ているのか、再利用可能な方法で推論を学んでいるのかという疑問を生み出します。私たちは、エージェントは対話型環境にグラウンディングされることで推論能力を得るべきだと仮定し、150万パラメータのエージェントが10万ステップの対話型訓練を受けた結果、静的訓練を受けた110億パラメータのモデルを上回ることを実証しました。 Comment
ベンチマークの概要は
- Evaluating agents for scientific discovery, Ai2, 2026.04
参照のこと。
[Paper Note] BLOOM: A 176B-Parameter Open-Access Multilingual Language Model, BigScience Workshop+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2026-03-31 GPT Summary- 大規模言語モデル(LLMs)を使い、新しいタスクを少ないデモや指示で実行可能にしたBLOOMを紹介。これは1760億パラメータのオープンアクセス言語モデルで、46の自然言語と13のプログラミング言語をカバー。競争力のある性能を発揮し、マルチタスクのファインチューニングを通じてさらに向上。モデルとコードは責任あるAIライセンスで公開し、今後の研究と応用の促進を目指す。 Comment
HF: https://huggingface.co/bigscience/bloom
透明性を持ったLLMを構築し民主化を図る方向性のパイオニア的研究
[Paper Note] Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos, Bowen Baker+, arXiv'22, 2022.06
Paper/Blog Link My Issue
#ComputerVision #Pretraining #FoundationModel #3D (Video) #VideoActionModel Issue Date: 2026-02-27 GPT Summary- オンラインのラベルなし動画を用いた半教師付き模倣学習により、逐次決定領域へインターネット規模の事前学習を拡張。逆ダイナミクスモデルを利用して、少量のラベル付きデータから一般的な行動知識を獲得。これにより、模倣学習と強化学習でのファインチューニングが可能となり、困難な探索課題に対するゼロショット能力を示す。初めて、ダイヤモンドの道具を作成できるコンピュータエージェントが報告され、人間レベルの性能を実現。 Comment
Inverse Dynamics Model (IDM)
observationによる状態の変化が、どのアクションによって引き起こされたかを推定するモデル(Inverse Dynamics Model)を学習し(すべてのobservationのtrajectoryから時刻tでのアクションを予測するモデル)アクション-状態遷移のダイナミクスの知識を理解したモデルを学習。その後大量のunlabeled dataに対してIDM Modelによって、アクションをラベル付けし、当該アクションラベルを教師として、Forward Dynamics Model (時刻tまでの状態遷移が与えられた時に次にどのようなアクションが実施されるかを予測するモデル)を学習することで事前学習をする手法な模様。
[Paper Note] LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
Paper/Blog Link My Issue
#NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICLR #PostTraining #Selected Papers/Blogs Issue Date: 2025-05-12 GPT Summary- LoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 Comment
OpenrReview: https://openreview.net/forum?id=nZeVKeeFYf9
LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
などでも示されているが、一般的にLoRAとFull Finetuningを比較するとLoRAの方が性能が低いことが知られている点には留意が必要。
最近、LoRAが学習率に対してsensitiveで、LoRAの提案以後約50種類の変種が提案されたが、適切にLoRAの学習率を調整した上で比較実験すると、依然としてオリジナルのLoRAが強力な手法であることが示された。以後提案された手法群は比較実験におけるハイパーパラメータの調整不足であることが指摘されている。
- [Paper Note] Learning Rate Matters: Vanilla LoRA May Suffice for LLM Fine-tuning, Yu-Ang Lee+, arXiv'26, 2026.02
[Paper Note] Over-Generation Cannot Be Rewarded: Length-Adaptive Average Lagging for Simultaneous Speech Translation, Sara Papi+, NAACL'22
Paper/Blog Link My Issue
#Metrics #NLP #Evaluation #SpeechProcessing #AutomaticSpeechRecognition(ASR) #NAACL #SimulST(SimultaneousSpeechTranslation) Issue Date: 2025-04-30 GPT Summary- SimulSTシステムの遅延評価において、ALが長い予測に対して過小評価される問題を指摘。過剰生成の傾向を持つシステムに対し、過小生成と過剰生成を公平に評価する新指標LAALを提案。 Comment
同時翻訳研究で主要なmetricの一つ
関連:
- [Paper Note] SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation, Xutai Ma+, AACL'20
[Paper Note] Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22, 2022.03
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #NeurIPS #Scaling Laws #Selected Papers/Blogs Issue Date: 2025-03-23 GPT Summary- トランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 Comment
OpenReview: https://openreview.net/forum?id=iBBcRUlOAPR
chinchilla則
[Paper Note] Deep Intention-Aware Network for Click-Through Rate Prediction, Yaxian Xia+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CTRPrediction Issue Date: 2024-11-19 GPT Summary- TIRAにおいて、顧客の入店意図を抽出し、トリガーの影響を重み付けするためにDIANを提案。DIANは、意図に基づきCTRを推定する3つのネットワーク(Intention Net、Trigger-Aware Net、Trigger-Free Net)を用い、推定結果をバランスさせることで精度を向上。実験により、実世界データセットでの性能が最先端を示し、TaobaoのミニアプリJuhuasuanのページビューを9.39%、CTRを4.74%改善。 Comment
- [Paper Note] Collaborative Contrastive Network for Click-Through Rate Prediction, Chen Gao+, arXiv'24
の実験で利用されているベースライン
Deep Interest Highlight Network for Click-Through Rate Prediction in Trigger-Induced Recommendation, Qijie Shen+, WWW'22
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CTRPrediction #WWW Issue Date: 2024-11-19 GPT Summary- トリガー誘発推薦(TIR)を提案し、ユーザーの瞬時の興味を引き出す新しい推薦手法を紹介。従来のモデルがTIRシナリオで効果的でない問題を解決するため、Deep Interest Highlight Network(DIHN)を開発。DIHNは、ユーザー意図ネットワーク(UIN)、融合埋め込みモジュール(FEM)、ハイブリッド興味抽出モジュール(HIEM)の3つのコンポーネントから成り、実際のeコマースプラットフォームでの評価で優れた性能を示した。 Comment
- [Paper Note] Collaborative Contrastive Network for Click-Through Rate Prediction, Chen Gao+, arXiv'24
の実験で利用されているベースライン
[Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22, 2022.07
Paper/Blog Link My Issue
#MachineTranslation #NLP #Dataset #LowResource Issue Date: 2024-09-26 GPT Summary- 低資源言語翻訳を支援するため、母語話者へのインタビューを通じてニーズを明らかにし、新たなデータセットとモデルを開発。Sparsely Gated Mixture of Expertsに基づく条件付き計算モデルを用い、訓練時の過剰適合を抑えつつ性能を向上。Flores-200ベンチマークにより翻訳性能を評価し、BLEUスコアを44%改善。研究成果はオープンソースとして公開。 Comment
low-resourceな言語に対するMTのベンチマーク
[Paper Note] Finetuned Language Models Are Zero-Shot Learners, Jason Wei+, ICLR'22, 2021.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #ICLR #Selected Papers/Blogs Issue Date: 2024-09-25 GPT Summary- 指示チューニングにより言語モデルのゼロショット学習能力を向上。1370億パラメータのモデルを60以上のNLPタスクに対してファインチューニングし、FLANと名付ける。FLANは未調整モデルを超え、25タスク中20タスクで175B GPT-3を上回り、ANLIやRTEなどでfew-shotのGPT-3にも勝る。ファインチューニングデータの数やモデル規模、指示内容が成功の鍵と示される。 Comment
FLAN論文。Instruction Tuningを提案した研究。
openreview: https://openreview.net/forum?id=gEZrGCozdqR
[Paper Note] BRIO: Bringing Order to Abstractive Summarization, Yixin Liu+, arXiv'22, 2022.03
Paper/Blog Link My Issue
#DocumentSummarization #BeamSearch #NaturalLanguageGeneration #NLP #ACL #needs-revision Issue Date: 2023-08-16 GPT Summary- 非決定論的分布を仮定し、複数の候補要約に確率を割り当てる新しい訓練パラダイムを提案。CNN/DailyMailおよびXSumデータセットで最先端のROUGEスコアを達成し、モデルが候補要約の品質と相関する確率を推定可能であることを示す。 Comment
ビーム内のトップがROUGEを最大化しているとは限らなかったため、ROUGEが最大となるような要約を選択するようにしたら性能爆上げしましたという研究。
実質現在のSoTA
[Paper Note] TRUE: Re-evaluating Factual Consistency Evaluation, Or Honovich+, arXiv'22, 2022.04
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Factuality #needs-revision Issue Date: 2023-08-13 GPT Summary- 事実的一致性評価が重要なテキスト生成システムにおいて、矛盾を減らすための自動評価が提案される。従来の評価指標は特定のタスクに偏りがあり、実用性に欠けることが多い。これに対抗して、TRUEを提案し、多様なタスクに基づく標準化されたコレクションに対する人手注釈のもとでの評価を行う。これにより、例レベルのメタ評価プロトコルが実現し、質の高い評価が可能となった。大規模なNLIや質問生成モデルが強力な結果を示し、今後の評価方法の改善へ向けた新たな指針を提供する。 Comment
FactualConsistencyに関するMetricが良くまとまっている
[Paper Note] Explaining Patterns in Data with Language Models via Interpretable Autoprompting, Chandan Singh+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Dataset #LanguageModel #DataToTextGeneration #Explanation #Data Issue Date: 2023-08-03 GPT Summary- iPromptを用いて、事前学習済みのLLMがデータを説明する自然言語文字列を生成する手法を提案。このアルゴリズムは、生成された説明の性能を再評価して最適化するプロセスを含む。実験によりiPromptが正確なデータ記述を見つけ、人間にも解釈可能なプロンプトを生成し、一般化性能に優れることが示された。特に、実世界の感情分類データセットでGPT-3並みのプロンプトを生成し、科学的発見の支援にも寄与する可能性がある。すべてのコードはGitHubで公開。 Comment
OpenReview: https://openreview.net/forum?id=GvMuB-YsiK6
データセット(中に存在するパターンの説明)をLLMによって生成させる研究


[Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #TMLR #Selected Papers/Blogs #needs-revision Issue Date: 2023-07-03 GPT Summary- HELMは、言語モデルの透明性を高めるための包括的評価手法である。まず、潜在的なシナリオと指標の分類を行い、欠落している部分を特定。次に、マルチ指標アプローチを採用し、コアシナリオごとに7つの評価指標を測定することで、正確性以外の側面も考慮。さらに、30の著名な言語モデルに対して大規模評価を実施し、評価範囲を17.9%から96.0%に改善。全データを公開し、HELMをコミュニティの生きたベンチマークとして継続的に更新していくことを目指している。 Comment
OpenReview: https://openreview.net/forum?id=iO4LZibEqW
HELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/
[Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #TMLR #Selected Papers/Blogs #needs-revision Issue Date: 2023-07-03 GPT Summary- 言語モデルはスケールの拡大に伴い、新しい定量的・質的能力を示すが、その具体的な特性は未解明である。これを踏まえ、BIG-benchという新たなベンチマークを導入し、204の多様なタスクを評価。モデルの性能と較正は改善するが、絶対的には低く、スパース性の影響を受ける場合もある。特に、複数の手順を要するタスクは臨界規模での“ブレークスルー”を示す傾向があり、社会的バイアスは通常、スケールと共に増加するが、プロンプトによって改善可能である。 Comment
OpenReview: https://openreview.net/forum?id=uyTL5Bvosj
BIG-Bench論文。ワードクラウドとキーワード分布を見ると一つの分野に留まらない非常に多様なタスクが含まれることがわかる。
BIG-Bench-hardは、2024年にClaude3.5によって、Average Human Scoreが67.7%のところ、93.1%を達成され攻略が完了した。現在は最先端のモデル間の性能を差別化することはできない。
- Killed by LLM, R0bk
[Paper Note] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Tri Dao+, NeurIPS'22, 2022.05
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Attention #Selected Papers/Blogs #Reference Collection Issue Date: 2023-05-20 GPT Summary- 長いシーケンスにおけるTransformerの計算とメモリ消費の問題に対処するため、IOを意識した注意アルゴリズムFlashAttentionを提案。これによりメモリの読み書き回数を減少させ、従来の基準よりも約15%の速度向上を実現。FlashAttentionは長い文脈を処理可能にし、モデル品質も改善。具体的には、BERT-largeやGPT-2で従来を上回るパフォーマンスを達成し、Path-Xチャレンジで新たな成果を示した。 Comment
より高速なGPU上のSRAM上で計算できるようにQKVをブロック単位に分割して計算することで、より高い計算効率を実現するFlashAttentionを提案[^1]
[^1]: (2025.05.24追記)下記日本語ブログを参考に一部文言を訂正しました。ありがとうございます。
日本語解説:
https://zenn.dev/sinchir0/articles/21bb6e96c7b05b
元ポスト:
日本語解説:
https://zenn.dev/uchiiii/articles/306d0bb7ef67a7
元ポスト:
openreview: https://openreview.net/forum?id=H4DqfPSibmx
あわせて読みたい:
- CUDA Programming Guide Part 1, Kazuki Fujii, 2026.06
論文内でon-chip SRAMと呼ばれているものは、この記事におけるGPUのUnified Data Cache (192KB L1 Data Cache/Shared Memory)のことである。
[Paper Note] Are Transformers Effective for Time Series Forecasting?, Ailing Zeng+, arXiv'22, 2022.05
Paper/Blog Link My Issue
#TimeSeriesDataProcessing #MachineLearning #LanguageModel #Transformer Issue Date: 2022-12-29 GPT Summary- LTSFタスクに対するTransformer解法の妥当性を疑問視し、単純な1層線形モデル(LTSF-Linear)が既存のTransformerモデルを全ケースで上回る結果を示す。時間的関係の抽出における要素の影響を詳細に分析し、新たな研究の方向性を提案。将来的には他の時系列分析にもアプローチを見直すことを提唱。 Comment
Linear Layerに基づくシンプルな手法がTransformerベースの手法に時系列予測で勝ったという話
[Paper Note] Revisiting Pretraining Objectives for Tabular Deep Learning, Ivan Rubachev+, arXiv'22, 2022.07
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #MachineLearning #TabularData Issue Date: 2022-12-01 GPT Summary- 深層学習モデルは、GBDTと競争できるものの、事前学習手法の有効性や選択基準は明確でない。本研究では、表形式データに対する深層学習モデルの事前学習のベストプラクティスを特定し、ターゲットラベルを活用することが性能向上に寄与することを示した。適切な事前学習により、深層学習モデルはGBDTをしばしば上回る。 Comment
Tabular Dataを利用した場合にKaggleなどでDeepなモデルがGBDT等に勝てないことが知られているが、GBDT等とcomparable になる性能になるようなpre-trainingを提案したよ、的な内容っぽい
ICLR 2023 OpenReview: https://openreview.net/forum?id=kjPLodRa0n
Interpretable Knowledge Tracing: Simple and Efficient Student Modeling with Causal Relations, Minn+, AAAI'22
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #AAAI Issue Date: 2022-08-02 Comment
DeepLearningを用いずに解釈性の高いKTモデルを提案。DKT, DKVMN, AKT等をoutperformしている。
[Paper Note] JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension, ByungHoon So+, arXiv'22, 2022.02
Paper/Blog Link My Issue
#NLP #Dataset #QuestionAnswering Issue Date: 2022-02-07 GPT Summary- 日本語の質問応答データセットJaQuADを提案。39,696の質問-回答ペアを含み、テストセットでF1スコア78.92%、EMスコア63.38%を達成したベースラインモデルをファインチューニング。データセットは公開中。 Comment
SQuAD likeな日本語のQAデータセット
https://github.com/SkelterLabsInc/JaQuAD
[Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Scalability Issue Date: 2026-07-09 GPT Summary- 言語モデリングは大規模な知識リポジトリを活用し、世界の理解を深化させる。本研究では、数千万から2,800億パラメータのTransformerベースのモデルGopherの性能を分析し、152の多様なタスクで最先端を達成。特に、読解や事実確認でスケールの利得が大きいが、論理的推論には限界がある。モデルの挙動やばイアス、危害の交差を総合的に評価し、AIの安全性に向けた適用と害の軽減についても考察。 Comment
- [Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
- 大規模言語モデルの次期バージョンPLaMo 3シリーズにおける120B事前学習モデル、31B蒸留モデルの評価, PFN, 2026.07
で利用されている weight reusingについて、`G3.3 Warm starting` に記載されている。概要としては
- LLMのキャパシティを増大させる際に、幅をスケーリングさせるよりも、深さをスケーリングさせる方が有望な結果となった
### 深さのスケーリング方法のbest practice
- 深さをスケーリングさせる、すなわち、5 layer -> 7 layerに拡張したい、という場合は、元の学習済みレイヤーを以下のルールによって複製することによって、拡張する:
- `round_int(range(num_layers_new)/num_layers_new * num_layers_old)`
- たとえば、`A B C D E` の5つのレイヤーで構成されているモデルがあったときに、これを7 layerに拡張したい場合は、上記indexに従って7つのレイヤーに学習済みレイヤーを割り当てると、`A B B C D D E` となる。
### 幅のスケーリング方法のbest practice
- (widthの拡張方法については正しく読めているかかなり自信がなく、間違っている可能性が非常に高いので注意)
- 幅をスケーリングさせる際は、MHA の weight matrices に対して列方向のコピー→行方向のコピー→ ノイズの注入を行う。
- 前提として以下を考える:
- MHAのQKV, outputのprojectionをそれぞれ、`W_q \in R^{d_model \times d_k}`, `W_k \in R^{d_model \times d_k}`, `W_v \in R^{d_model \times d_v}`, `W_o \in R^{h d_v \times d_model}` とする。
- このとき、オリジナルのtransformer論文では、`d_k = d_v = d_model/h` としている。
- つまり、各headに対応するW_{q, k, v, o}を列方向にconcatした行列 W^concat_{q, k, v, o}を考えると、列方向がh倍されるので、`W^concat_{q, k, v, o} \in R^{d_model \times d_model}` の正方行列で表現できる。ここで、`h * d_v= h * d_k= h * d_model/h = d_model` を用いた。
- この `W^{concat}_{*}` に対する操作を定義することで、multihead attentionが扱う幅を変更することができる。
- 元論文では、weight matricesと一言で言及されているが、これは(おそらく)`W^{concat}_{q, k, v, o}` のことを指していると思われる。実際、説明をする際は正方行列を前提に考えている(attention headごとに独立して考える元論文の数式では正方行列は weight matrices に出現しない)。
- まず `W^{concat}_{*}` において、head sizeをH, head数をnとしたときに、`nH \times nH` の行列を列方向にtilingすることによってattention headの数をmに拡張する。このとき、`d_k`, `d_v` のサイズは固定する。たとえば、head数をnからmに増やす際、最初のm-n個のheadを `W^{concat}_{*}` の右側に複製することによって拡張する、と説明されている。
- これはすなわち、個々のheadが扱う情報量は変化させずに、代わりにhead数を増やすことでスケーリングさせる、ということを指していると考えられる。
- 続いて、head数が増えたことによって `W^{concat}_{*}` が正方行列ではなくなった。これが正方行列になっていないとattentionの前後でbottleneck activation size(元論文ではd_modelのことをbottleneck activation sizeと呼称している)が変化してしまうので、正方行列にしなければならない。
- これを正方行列にするために、列方向に複製した行列の上端から数えて `(m-n) * d_k` 行分を行方向にconcatする。
- 最終的に、新たに初期化された重みに対してノイズを注入する。
- これによって構築された `W^{concat}_{*}` を図示したものが、下記Figure A32 と思われる。
- また、上記ではMHAの説明をしたが、MLPなどのd_modelが関わる各種weight matricesもwidthの拡張に含まれていると考えられる(じゃないとwidthの拡張と呼べないし)。
- optimizerの状態は再初期化して学習を実施する。
- Adam optimizerの状態に対して似たような処理を実施したが性能向上にはつながらなかった
[Paper Note] Primer: Searching for Efficient Transformers for Language Modeling, David R. So+, NIPS'21, 2021.09
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #Architecture #Selected Papers/Blogs #ActivationFunction Issue Date: 2026-02-16 GPT Summary- 大規模なTransformerモデルのコスト削減を目指し、プリミティブに基づく低レベルの探索を行い、Primerアーキテクチャを提案。これにより、自己回帰型言語モデリングで訓練コストを大幅に削減。具体的にはReLU活性化関数の二乗化と深さ方向の畳み込み層追加が主な改善点。実験により、計算規模が大きくなるほどPrimerの利得が増加し、特に5億パラメータの設定で元のT5アーキテクチャに対し4分の1のコストで改善を確認。また、19億パラメータ設定でも、訓練資源を大幅に削減しながら同等の性能を実現。再現性を考慮し、モデルをオープンソース化。 Comment
nanochat speedrunを改善させたReLU^2を提案しているとのこと
QKV projectionの後にshort convolutionsを導入するアーキテクチャも提案されている
[Paper Note] VoxLingua107: a Dataset for Spoken Language Recognition, Jörgen Valk+, SLT'21, 2020.11
Paper/Blog Link My Issue
#Dataset #SpeechProcessing #AutomaticSpeechRecognition(ASR) Issue Date: 2025-11-21 GPT Summary- 本論文では、107言語のYouTube動画から自動収集した音声データを用いて音声言語認識を調査。半ランダムな検索フレーズを用いて音声セグメントを抽出し、ポストフィルタリングにより98%の正確なラベル付けを実現。得られたトレーニングセットは6628時間、評価セットは1609の発話から構成され、実験により自動取得データが手動ラベル付けデータと同等の結果を示すことが確認された。このデータセットは公開されている。 Comment
dataset: https://cs.taltech.ee/staff/tanel.alumae/data/voxlingua107/
Whisperでも活用されているLanguage Identifucation用のdataset
- [Paper Note] Robust Speech Recognition via Large-Scale Weak Supervision, Alec Radford+, ICML'23, 2022.12
[Paper Note] Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer, Greg Yang+, NeurIPS'21
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #Transformer #NeurIPS #read-later #HyperparameterTransfer Issue Date: 2025-08-28 GPT Summary- ハイパーパラメータチューニングは高コストであり、特に大規模なニューラルネットワークにおいて負担が大きい。新たに提案するmuTransferは、最大更新パラメータ化(muP)を利用し、小さなモデルでチューニングしたHPをフルサイズモデルにゼロショットで転送する手法である。実験により、1300万パラメータのモデルからBERT-largeを超える性能を達成し、4000万パラメータからはGPT-3を上回る結果を得た。チューニングコストはそれぞれ事前学習コストの同等または7%に抑えられた。 Comment
openreview: https://openreview.net/forum?id=Bx6qKuBM2AD
小規模なモデルに対してハイパーパラメータのチューニングを実施し、同様のベースモデルで、**各layerのwidthが大きいもの**に対しても、小規模モデルで最適であったハイパーパラメータをzero-shotで転移することで near optimalなハイパーパラメータで学習できるmu Transferを提案。
モデルの深さ(以外にも下表中の*印のパラメータ)に対しても限定的に転移可能な模様。Post-Layer NormのTransformerやではあまりうまくいかないことが11節に記述されている(実験はpre-Layer Norm Transformer, ResNetに対して行われている模様)。
また、6.1節では、(実験的に)利用する小規模モデルのスケールとして幅256, 深さ4, バッチサイズ32, sequence長128, 訓練ステップ数5000を最低満たしており、かつスケールさせる幅が妥当な範囲内である必要がある、といった話が記述されている。
前提知識(muP)や条件が多そうな気がするので、しっかり確認した方がよさそう。
たとえば、muPで初期化されている必要があることや、転送可能なハイパーパラメータに限りがある(e.g. 学習率)、異なるデータに対するfinetuningなどは転送できないなど。
muP:
- [Paper Note] Feature Learning in Infinite-Width Neural Networks, Greg Yang+, ICML'21
[Paper Note] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu+, ICCV'21
Paper/Blog Link My Issue
#ComputerVision #Transformer #Attention #Architecture #Selected Papers/Blogs #ICCV #Backbone Issue Date: 2025-07-19 GPT Summary- Swin Transformerは、コンピュータビジョンの新しいバックボーンとして機能する階層的トランスフォーマーを提案。シフトウィンドウ方式により、効率的な自己注意計算を実現し、さまざまなスケールでのモデリングが可能。画像分類や物体検出、セマンティックセグメンテーションなどで従来の最先端を上回る性能を示し、トランスフォーマーのビジョンバックボーンとしての可能性を示唆。コードは公開されている。 Comment
日本語解説: https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a
画像処理において、物体の異なるスケールや、解像度に対処するために、PatchMergeと呼ばれるプーリングのような処理 (Figure1) と、固定サイズのローカルなwindowに分割してSelf-Attentionを実施し、layerごとに通常のwindowとシフトされたwindowを適用することで、window間を跨いだ関係性も考慮できるようにする機構(Figure2)を導入したモデル。
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Armen Aghajanyan+, N_A, ACL'21
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #ACL #PostTraining Issue Date: 2024-10-01 GPT Summary- 事前学習された言語モデルのファインチューニングのダイナミクスを内因次元の観点から分析し、少ないデータでも効果的に調整できる理由を説明。一般的なモデルは低い内因次元を持ち、フルパラメータ空間と同等の効果を持つ低次元の再パラメータ化が可能であることを示す。特に、RoBERTaモデルを用いて、少数のパラメータの最適化で高いパフォーマンスを達成できることを実証。また、事前学習が内因次元を最小化し、大きなモデルが低い内因次元を持つ傾向があることを示し、内因次元に基づく一般化境界を提案。 Comment
ACL ver: https://aclanthology.org/2021.acl-long.568.pdf
下記の元ポストを拝読の上論文を斜め読み。モデルサイズが大きいほど、特定の性能(論文中では2種類のデータセットでの90%のsentence prediction性能)をfinetuningで達成するために必要なパラメータ数は、モデルサイズが大きくなればなるほど小さくなっている。
LoRAとの関係性についても元ポスト中で言及されており、論文の中身も見て後で確認する。
おそらく、LLMはBERTなどと比較して遥かにパラメータ数が大きいため、finetuningに要するパラメータ数はさらに小さくなっていることが想像され、LoRAのような少量のパラメータをconcatするだけでうまくいく、というような話だと思われる。興味深い。
元ポスト:
[Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, N_A, EMNLP'21
Paper/Blog Link My Issue
#Analysis #NLP #Transformer Issue Date: 2024-07-11 GPT Summary- トランスフォーマーモデルのフィードフォワード層は、キー・バリューメモリとして機能し、学習されたパターンが人間に解釈可能であることや、上位層がより意味のあるパターンを学習することが示されました。さらに、出力分布を誘導する役割も持ちます。フィードフォワード層の出力はそのメモリの合成であり、残差接続を介してモデルの層を通じて洗練され、最終的な出力分布を生成します。 Comment
関連:
- 大規模言語モデルにおいて、「知識は全結合層に蓄積される」という仮説についての文献調査, Kan Hatakeyama, 2023.10
FF layerがKey-Valueストアとして機能する仕組みの概略図
実際に特定のKeyと最も関連度が高い訓練事例(input)を抽出し、人間がinputのパターンを分類した結果
[Paper Note] Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation, Markus Freitag+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#MachineTranslation #Analysis #NaturalLanguageGeneration #Metrics #NLP #Evaluation Issue Date: 2024-01-25 GPT Summary- 機械翻訳の人間評価は難しく、標準的な手法が不足している。そこで、誤り分析に基づく評価方法論を提案し、MQMフレームワークを用いてWMT 2020の上位システム出力をプロの翻訳者による注釈で評価。分析の結果、WMTクラウドワーカーのランキングと異なる結果が得られ、人間が機械出力よりも人間の出力を好む傾向を示した。さらに、自動指標がクラウドワーカーよりも優れたことも判明し、研究用コーパスを公開。 Comment
embedding basedなNLGの性能指標が、意味の等価性や流暢性を評価できる一方、適用範囲が限定的で柔軟性に欠けることを示した研究
QACE: Asking Questions to Evaluate an Image Caption, Lee+, EMNLP'21
Paper/Blog Link My Issue
#ComputerVision #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-13 Comment
Image Captioningを評価するためのQGQAを提案している。candidateから生成した質問を元画像, およびReferenceを用いて回答させ、candidateに基づいた回答と回答の結果を比較することで評価を実施する。
Transformer Reasoning Network for Personalized Review Summarization, Xu+, SIGIR'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #review #SIGIR Issue Date: 2023-05-06 Comment
先行研究は、review summarizationにおいて生成されるsummaryは、過去にユーザが作成したsummaryのwriting styleやproductに非常に関係しているのに、これらを活用してこなかったので、活用しました(=personalized)という話っぽい
Learning Transferable Visual Models From Natural Language Supervision, Radford+, OpenAI, ICML'21
Paper/Blog Link My Issue
#ComputerVision #Embeddings #NLP #RepresentationLearning #MultiModal #ContrastiveLearning #ICML #Selected Papers/Blogs #2D (Image) #text Issue Date: 2023-04-27 Comment
CLIP論文。大量の画像と画像に対応するテキストのペアから、対照学習を行い、画像とテキスト間のsimilarityをはかれるようにしたモデル
Refocusing on Relevance: Personalization in NLG, Shiran Dudy+, Department of Computer Science University of Colorado, EMNLP'21
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #Personalization #EMNLP Issue Date: 2023-04-26 Comment
従来のNLGはソーステキストに焦点を当て、ターゲットを生成することに注力してきた。が、ユーザの意図やcontextがソーステキストだけに基づいて復元できない場合、このアプローチでは不十分であることを指摘。
この研究ではNLGシステムが追加のcontextを利用することに大きな重点をおくべきであり、IR等で活用されているrelevancyをユーザ指向のテキスト生成タスクを設計するための重要な指標として考えることを提案している。
[Paper Note] Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets, Alethea Power+, ICLR'21 Workshop, 2022.01
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Grokking #ICLR #Workshop Issue Date: 2023-04-25 GPT Summary- 小規模データセットにおけるニューラルネットワークの一般化を探求。データ効率、記憶、一般化、学習速度に関する問題を分析し、学習過程の「グロッキング」を通じて一般化性能の改善を示す。特に、小さなデータセットではより多くの最適化が必要であることが明らかにされ、過剰パラメータ化されたネットワークの一般化メカニズムを理解するための重要な知見を提供。 Comment
学習後すぐに学習データをmemorizeして、汎化能力が無くなったと思いきや、10^3ステップ後に突然汎化するという現象(Grokking)を報告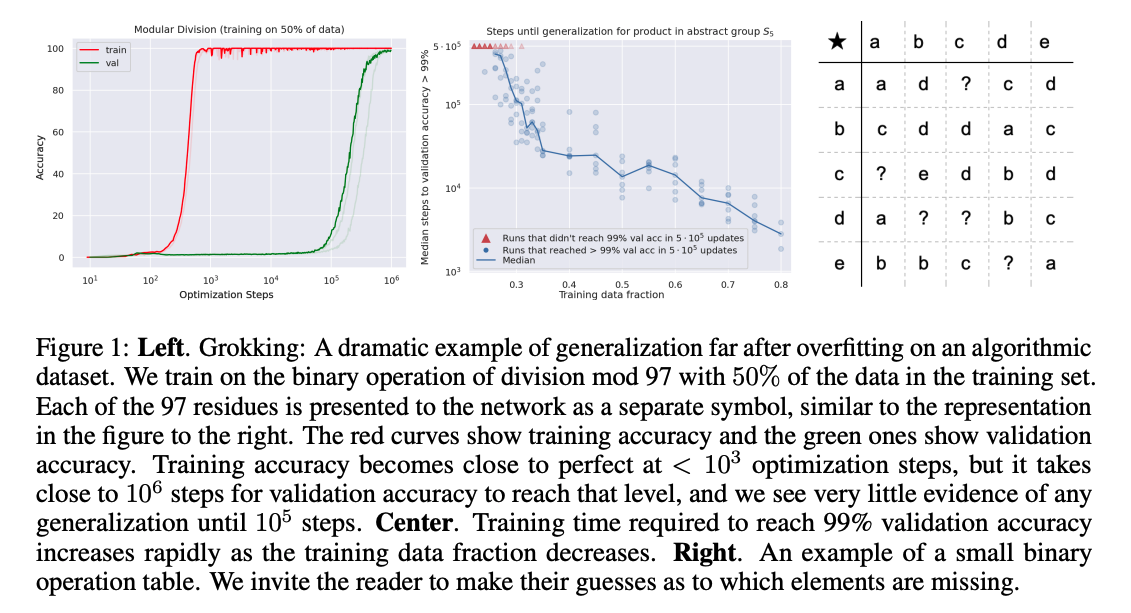
学習データが小さければ小さいほど汎化能力を獲得するのに時間がかかる模様
Challenges to Applying Performance Factor Analysis to Existing Learning Systems, Cristina+ (w_ Ryan Baker), ICCE'21
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #ICCE Issue Date: 2022-08-31 Comment
- いまだにほとんどの商用のAdaptive LearningシステムではBKTが使われている。その理由について概要が書いてある。
- BKTについて実アプ李ケーションに応用した際にどういう性質があるかを検証した文献へのリファレンスが存在する
[Paper Note] Biomedical Data-to-Text Generation via Fine-Tuning Transformers, Ruslan Yermakov+, ACL-INLG'21, 2021.09
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #DataToTextGeneration #ACL #INLG Issue Date: 2022-08-18 GPT Summary- バイオメディカル分野におけるD2T生成の研究を行い、医薬品のパッケージリーフレットを用いた実世界のデータセットに対してファインチューニングされたトランスフォーマーを適用。現実的な複数文のテキスト生成が可能であることを示す一方で、重要な制限も存在。新たにバイオメディカル分野のD2T生成モデルのベンチマーク用データセット(BioLeaflets)を公開。 Comment
biomedical domainの新たなdata2textデータセットを提供。事前学習済みのBART, T5等をfinetuningすることで高精度にテキストが生成できることを示した。
Option Tracing: Beyond Correctness Analysis in Knowledge Tracing, Ghosh+, AIED'21
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #OptionTracing #AIED Issue Date: 2022-08-18 Comment
これまでのKTは問題の正誤(correctness)に対してfittingしていたが、この研究ではmultiple choice questionでどの選択肢を選択するかを予測するタスクを提案している。
BEKT: Deep Knowledge Tracing with Bidirectional Encoder Representations from Transformers, Tian+ (緒方先生), Kyoto University, ICCE'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #ICCE Issue Date: 2022-04-28 Comment
KTにBERTを利用した研究
Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
などでDeepLearningBasedなモデル間であまり差がないことが示されているので、本研究が実際どれだけ強いのかは気になるところ。
Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #AAAI #Workshop Issue Date: 2022-04-28 GPT Summary- インタラクティブ教育システム(IES)を用いて学生の知識を追跡し、パフォーマンスモデルを開発する研究が進展。深層学習モデルが従来のモデルを上回るかは未検証であり、EdNetデータセットを用いてその精度を比較。結果、ロジスティック回帰モデルが深層モデルを上回ることが確認され、LIMEを用いて予測に対する特徴の影響を解釈する研究を行った。 Comment
データ量が小さいとSAKTはDKTはcomparableだが、データ量が大きくなるとSAKTがDKTを上回る。
An Empirical Comparison of Deep Learning Models for Knowledge Tracing on Large-Scale Dataset, Pandey+, AAAI workshop on AI in Education'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics Issue Date: 2022-04-28 Comment
EdNetデータにおいて、DKT, DKVMN, SAKT, RKTの性能を比較した論文
RKTがも最もパフォーマンスが良く、SAKTもDKT, DKVMNに勝っている
A Survey of Knowledge Tracing, Liu+, IEEE Transactions on Learning Technologies, arXiv'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing Issue Date: 2022-04-27 Comment
古典的なBKT, PFAだけでなくDKT, DKVMN, EKT, AKTなどDeepなモデルについてもまとまっている。

SAINT+: Integrating Temporal Features for EdNet Correctness Prediction, Shin+, RiiiD AI Research, LAK'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #StudentPerformancePrediction #Transformer #LAK #Selected Papers/Blogs Issue Date: 2021-10-28 Comment
Student Performance PredictionにTransformerを初めて利用した研究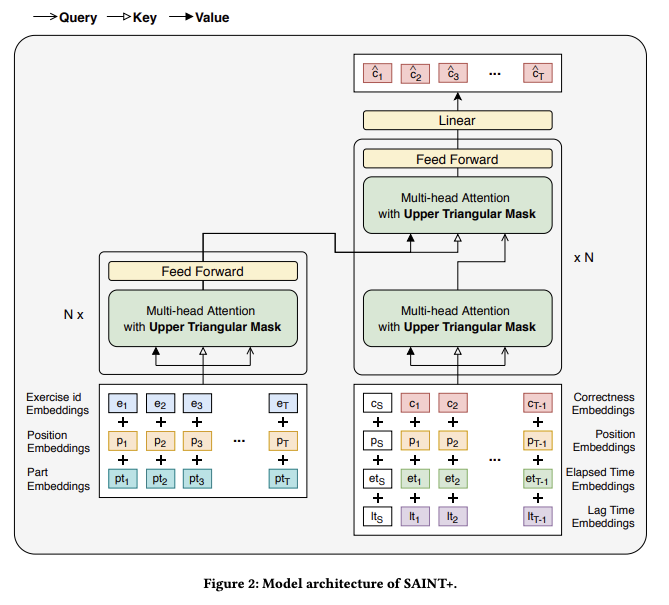
[Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #Sparse #SparseAttention Issue Date: 2025-08-09 GPT Summary- Longformerは、長いシーケンスを線形に処理できる注意機構を持つTransformerベースのモデルで、数千トークンの文書を扱える。局所的なウィンドウ注意とタスクに基づくグローバル注意を組み合わせ、文字レベルの言語モデリングで最先端の結果を達成。事前学習とファインチューニングを行い、長文タスクでRoBERTaを上回る性能を示した。また、Longformer-Encoder-Decoder(LED)を導入し、長文生成タスクにおける効果を確認した。 Comment
(固定された小さめのwindowsサイズの中でのみattentionを計算する)sliding window attentionを提案。Figure2を見ると、通常のAttentionと比較して、現在のトークンの周辺のトークンにしか注目しない特性が図示されており、イメージが掴みやすい。
OpenLLMの文脈だと、Mistralに採用されて話題になったかも?
- Mistral 7B, Albert Q. Jiang+, N/A, arXiv'23
[Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Transformer #Attention #ICML #Selected Papers/Blogs #reading #RecurrentModels #LinearAttention Issue Date: 2025-08-05 GPT Summary- 自己注意をカーネル特徴マップの線形ドット積として表現することで、Transformersの複雑性を$\mathcal{O}\left(N^2\right)$から$\mathcal{O}\left(N\right)$に削減。これにより、自己回帰型Transformersの速度が最大4000倍向上し、従来のパフォーマンスを維持。 Comment
関連:
- Transformers are Multi-State RNNs, Matanel Oren+, N/A, EMNLP'24
pj page: https://linear-transformers.com
Linear Attention(Linear Transformer)を提案した研究。Softmaxが利用されるFull Attentionのsimilarity部分をfeature map φを持つカーネルk(x, y)で一般化し、(3)--(6)の流れでfeature map φ同士は内積が使える性質と、行列積の結合法則を用いて式変換する。
式変換によって、従来のSoftmax Attentionでは、全てのトークンNに対してQ_i * K_j * V_jのメモリが必要だったものを(O(N^2))、各Queryごとに利用される、KVを用いた情報が共通化され(現在のqueryまでのφ(K)とφ(K)V^Tを逐次的に加算して保持するだけで良い)、再利用が可能となりメモリに関するオーダーがO(N)となる。
これらの話は実際にどのような カーネルを利用するかを無視した話だが、たとえばsoftmaxを表現するために必要な指数カーネルの場合はfeature mapが無限次元となるため有限次元のベクトルでは表現できず、厳密に線形化することができない。このため、有限次元かつ厳密なfeature mapを持つ多公式カーネルを用いて近似する。この場合、計算量のオーダーがO(ND^2M)となり(Nがsequence length, Dがqueryとkeyの次元数, Mがvalueの次元数)、softmax attentionの計算量がO(N^2 max(D,M))であることと比較すると、N > D^2である場合に計算効率が改善される。
学習時は並列に学習が可能で、推論時はφ(K_j)V_j^Tを内部状態とみなすと、各タイムステップでRNNのように状態を更新して保持するだけで良い。
(続きはさらに後で読む)
次: DeltaNet
- [Paper Note] Linear Transformers Are Secretly Fast Weight Programmers, Imanol Schlag+, arXiv'21, 2021.02
- [Paper Note] Parallelizing Linear Transformers with the Delta Rule over Sequence Length, Songlin Yang+, NeurIPS'24, 2024.06
次の次: Gated DeltaNet
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
次の次の次: Kimi Delta Attention (KDA)
- [Paper Note] Kimi Linear: An Expressive, Efficient Attention Architecture, Kimi Team+, arXiv'25, 2025.10
[Paper Note] PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization, Jingqing Zhang+, ICML'20
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NLP #ICML #Selected Papers/Blogs Issue Date: 2025-05-13 GPT Summary- 大規模なテキストコーパスに対して新しい自己教師ありの目的でトランスフォーマーを事前学習し、抽象的なテキスト要約に特化したモデルPEGASUSを提案。重要な文を削除またはマスクし、残りの文から要約を生成。12の下流要約タスクで最先端のROUGEスコアを達成し、限られたリソースでも優れたパフォーマンスを示す。人間評価でも複数のデータセットで人間のパフォーマンスに達したことを確認。 Comment
PEGASUSもなかったので追加。BARTと共に文書要約のBackboneとして今でも研究で利用される模様。
関連:
- SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
[Paper Note] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Colin Raffel+, JMLR'20
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #NLP #TransferLearning #PostTraining #Selected Papers/Blogs Issue Date: 2025-05-12 GPT Summary- 転移学習はNLPにおいて強力な技術であり、本論文ではテキストをテキストに変換する統一フレームワークを提案。事前学習の目的やアーキテクチャを比較し、最先端の結果を達成。データセットやモデル、コードを公開し、今後の研究を促進する。 Comment
T5もメモっていなかったので今更ながら追加。全てのNLPタスクをテキスト系列からテキスト系列へ変換するタスクとみなし、Encoder-DecoderのTransformerを大規模コーパスを用いて事前学習をし、downstreamタスクにfinetuningを通じて転移する。
個人的に、Transformer-decoderのスケーラビリティのみならず、T5全てのタスクをテキスト系列の変換とみなす考え方が、現在のLLMの基盤となっていると感じている。
[Paper Note] Editable Neural Networks, Anton Sinitsin+, ICLR'20
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #NLP #ICLR #KnowledgeEditing #read-later Issue Date: 2025-05-07 GPT Summary- 深層ニューラルネットワークの誤りを迅速に修正するために、Editable Trainingというモデル非依存の訓練手法を提案。これにより、特定のサンプルの誤りを効率的に修正し、他のサンプルへの影響を避けることができる。大規模な画像分類と機械翻訳タスクでその有効性を実証。 Comment
(おそらく)Knowledge Editingを初めて提案した研究
OpenReview: https://openreview.net/forum?id=HJedXaEtvS
[Paper Note] SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation, Xutai Ma+, AACL'20
Paper/Blog Link My Issue
#Metrics #NLP #Evaluation #SpeechProcessing #AutomaticSpeechRecognition(ASR) #AACL #SimulST(SimultaneousSpeechTranslation) Issue Date: 2025-04-30 GPT Summary- 同時テキスト翻訳手法をエンドツーエンドの同時音声翻訳に適応させる研究を行い、事前決定モジュールを導入。レイテンシと品質のトレードオフを分析し、新しいレイテンシメトリックを設計。 Comment
同時翻訳研究で主要なmetricの一つ
関連:
- [Paper Note] Over-Generation Cannot Be Rewarded: Length-Adaptive Average Lagging for Simultaneous Speech Translation, Sara Papi+, NAACL'22
COMET: A Neural Framework for MT Evaluation, Ricardo Rei+, N_A, EMNLP'20
Paper/Blog Link My Issue
#MachineTranslation #Metrics #NLP #Evaluation #EMNLP #Selected Papers/Blogs Issue Date: 2024-05-26 GPT Summary- COMETは、多言語機械翻訳評価モデルを訓練するためのニューラルフレームワークであり、人間の判断との新しい最先端の相関レベルを達成します。クロスリンガル事前学習言語モデリングの進展を活用し、高度に多言語対応かつ適応可能なMT評価モデルを実現します。WMT 2019 Metrics shared taskで新たな最先端のパフォーマンスを達成し、高性能システムに対する堅牢性を示しています。 Comment
Better/Worseなhypothesisを利用してpair-wiseにランキング関数を学習する


Inference時は単一のhypothesisしかinputされないので、sourceとreferenceに対してそれぞれhypothesisの距離をはかり、その調和平均でスコアリングする

ACL2024, EMNLP2024あたりのMT研究のmetricをざーっと見る限り、BLEU/COMETの双方で評価する研究が多そう
[Paper Note] BLEU might be Guilty but References are not Innocent, Markus Freitag+, arXiv'20, 2020.04
Paper/Blog Link My Issue
#MachineTranslation #Analysis #NaturalLanguageGeneration #Metrics #NLP #Evaluation Issue Date: 2024-01-25 GPT Summary- 機械翻訳の自動評価指標の質を検証し、参照データの性質が重要であることを示す。さまざまな参照収集方法を検討し、人間評価との相関を報告。典型的な参照の偏りを打ち消すために、言語学者によるパラフレージング課題を開発。WMT 2019のデータにおいて、標準参照との相関が低い出力でも人間判断との相関が向上することを示す。また、埋め込みベースの手法を含む評価指標で相関が改善されることも明らかにし、マルチ参照BLEUの限界と新たな定式化を提示。 Comment
surface levelのNLGの性能指標がsemanticを評価できないことを示した研究
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #QA-based Issue Date: 2023-08-20 Comment
QAGS
生成された要約からQuestionを生成する手法。precision-oriented
Reducing Quantity Hallucinations in Abstractive Summarization, Zheng Zhao+, N_A, EMNLP'20
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Hallucination #EMNLP #numeric #needs-revision Issue Date: 2023-08-16 GPT Summary- Hermanシステムは、抽象的な要約において幻覚を回避するために、数量エンティティを認識し、元のテキストでサポートされている数量用語を持つ要約を上位にランク付けするアプローチを提案しています。実験結果は、このアプローチが高い適合率と再現率を持ち、F$_1$スコアが向上することを示しています。また、上位にランク付けされた要約が元の要約よりも好まれることも示されています。 Comment
数量に関するhallucinationを緩和する要約手法
FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization, Durmus+, ACL'20
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #QA-based Issue Date: 2023-08-16 Comment
FEQA
生成された要約からQuestionを生成する手法。precision-oriented
Evaluating the Factual Consistency of Abstractive Text Summarization, Kryscinski+, EMNLP'20
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #LM-based #Factuality #EMNLP Issue Date: 2023-08-13 Comment
FactCC
近年のニューラルモデルは流ちょうな要約を生成するが、それらには、unsuportedなinformationが多く含まれていることを示した
[Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #ICLR #Selected Papers/Blogs #needs-revision Issue Date: 2023-07-24 GPT Summary- 新しいテストを提案し、57のマルチタスクを用いてテキストモデルの正確度を測定。高い正確度には広範な世界知識と問題解決能力が必要である。GPT-3モデルはランダム推測を約20ポイント上回るが、専門家レベルには遠く、多くのタスクで偏った性能を示す。特に道徳や法に関してはほぼランダムに近い正確度を記録。このテストはモデルの理解力を評価し、重要な欠点を明らかにすることを目的とする。 Comment
OpenReview: https://openreview.net/forum?id=d7KBjmI3GmQ
MMLU論文
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
において、多くのエラーが含まれることが指摘され、再アノテーションが実施されている。
Returning the N to NLP: Towards Contextually Personalized Classification Models, Lucie Flek, Mainz University of Applied Sciences Germany, ACL'20
Paper/Blog Link My Issue
#Survey #NLP #Personalization #ACL Issue Date: 2023-04-26 Comment
NLPのけるPersonalized Classificationモデルのliteratureを振り返る論文
Deep Knowledge Tracing with Transformers, Shi+ (w_ Michael Yudelson), ETS_ACT, AIED'20
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #Transformer #AIED Issue Date: 2022-08-17 Comment
TransformerでKTした研究。あまり引用されていない。SAINT, SAINT+と同時期に発表されている。
[Paper Note] Generating Long Sequences with Sparse Transformers, Rewon Child+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#ComputerVision #Transformer #LongSequence #Selected Papers/Blogs #SparseAttention Issue Date: 2025-11-30 GPT Summary- スパース因子分解を用いてトランスフォーマーの注意行列を$O(n \sqrt{n})$に削減し、深いネットワークの訓練やメモリ節約のための手法を導入。スパーストランスフォーマーは数百層で数万タイムステップのシーケンスをモデル化し、Enwik8、CIFAR-10、ImageNet-64で新たな最先端を達成。自己注意を用いて100万以上の長さのシーケンスをモデル化する可能性を示す。 Comment
Sparse Attentionの概念を提案した研究。以下Surveyより
- [Paper Note] Generating Long Sequences with Sparse Transformers, Rewon Child+, arXiv'19, 2019.04
[Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19
Paper/Blog Link My Issue
#EfficiencyImprovement #Transformer #Attention #LongSequence #PositionalEncoding #ACL Issue Date: 2025-08-05 GPT Summary- Transformer-XLは、固定長のコンテキストを超えた長期的な依存関係を学習する新しいニューラルアーキテクチャで、セグメントレベルの再帰メカニズムと新しい位置エンコーディングを採用。これにより、RNNより80%、従来のTransformersより450%長い依存関係を学習し、評価時には最大1,800倍の速度向上を実現。enwiki8やWikiText-103などで最先端のパフォーマンスを達成し、数千トークンの一貫したテキスト生成も可能。コードとモデルはTensorflowとPyTorchで利用可能。 Comment
日本語解説:
- 事前学習言語モデルの動向 / Survey of Pretrained Language Models, Kyosuke Nishida, 2019
3.2節の定式化を見ると、一つ前のセグメントのトークン・layerごとのhidden stateを、現在のセグメントの対応するトークンとlayerのhidden stateにconcatし(過去のセグメントに影響を与えないように勾配を伝搬させないStop-Gradientを適用する)、QKVのうち、KVの計算に活用している。また、絶対位置エンコーディングを利用するとモデルがセグメント間の時系列的な関係を認識できなくなるため、位置エンコーディングには相対位置エンコーディングを利用する。これにより、現在のセグメントのKVが一つ前のセグメントによって条件づけられ、contextとして考慮することが可能となり、セグメント間を跨いだ依存関係の考慮が実現される。
[Paper Note] What Does BERT Learn about the Structure of Language?, Jawahar+, ACL'19
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #ACL Issue Date: 2024-10-07 Comment
- 大規模言語モデル (LLM) の技術と最新動向, Ikuya Yamada, 2024.06
中で引用されている。Transformerの各ブロックが、何を学習しているかを分析。
Studying Summarization Evaluation Metrics in the Appropriate Scoring Range, Peyrard+, ACL'19
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation Issue Date: 2023-08-16 Comment
要約のメトリックがhuman judgmentsに対してcorrelationが低いことを指摘
[Paper Note] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Nils Reimers+, arXiv'19, 2019.08
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Library #RepresentationLearning #EMNLP #Selected Papers/Blogs #Encoder Issue Date: 2022-07-29 GPT Summary- BERTとRoBERTaは文ペア回帰タスクで優れた性能を示す一方で、計算負荷が高いため意味的類似度検索には適していない。本研究では、コサイン類似度を用いた文の埋め込みを得るために、シアミーズネットワークとトリプレットネットワークを用いたSentence-BERT(SBERT)を提案。これにより、類似ペアの検索時間が65時間から約5秒に短縮され、精度はBERTに匹敵。SBERTは一般的なSTSタスクや転移学習タスクで最先端の性能を示した。 Comment
BERTでトークンをembeddingし、mean poolingすることで生成される文ベクトルを、Siamese Networkを使い距離学習(finetune)させたモデル。
文/文章のベクトルを事前学習済みのモデルを使って簡単に求められる。
モデルの一覧は下記:
https://www.sbert.net/docs/pretrained_models.html
GRAPH-BASED KNOWLEDGE TRACING: MODELING STUDENT PROFICIENCY USING GRAPH NEURAL NETWORK, Nakagawa+, Tokyo University, WI'19
Paper/Blog Link My Issue
#NeuralNetwork #GraphConvolutionalNetwork #Education #EducationalDataMining #KnowledgeTracing #WI Issue Date: 2021-07-08 Comment
graph neural networkでKnoelwdge Tracingした論文。各conceptのproficiencyの可視化までしっかりやってそう。
[Paper Note] Deep Learning Recommendation Model for Personalization and Recommendation Systems, Maxim Naumov+, arXiv'19, 2019.05
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #FactorizationMachines Issue Date: 2021-07-02 GPT Summary- 深層学習に基づく推薦モデル(DLRM)を開発し、PyTorchとCaffe2で実装。埋め込みテーブルのモデル並列性を活用し、メモリ制約を軽減しつつ計算をスケールアウト。DLRMの性能を既存モデルと比較し、Big Basin AIプラットフォームでの有用性を示す。 Comment
Facebookが開発したopen sourceのDeepな推薦モデル(MIT Licence)。
モデル自体はシンプルで、continuousなfeatureをMLPで線形変換、categoricalなfeatureはembeddingをlook upし、それぞれfeatureのrepresentationを獲得。
その上で、それらをFactorization Machines layer(second-order)にぶちこむ。すなわち、Feature間の2次の交互作用をembedding間のdot productで獲得し、これを1次項のrepresentationとconcatしMLPにぶちこむ。最後にシグモイド噛ませてCTRの予測値とする。
実装: https://github.com/facebookresearch/dlrm
Parallelism以後のセクションはあとで読む
Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #AAAI Issue Date: 2021-06-26 Comment
Rotowire Datasetに対するData2Text研究において代表的な論文の一つ。Wisemanモデル [Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07 と共にベースラインとして利用されることが多い。
On Empirical Comparisons of Optimizers for Deep Learning, Dami Choi+, N_A, arXiv'19
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NLP Issue Date: 2021-06-15 GPT Summary- 深層学習のオプティマイザの比較は重要であり、ハイパーパラメータの探索空間が性能に影響することが示唆されている。特に、適応的勾配法は常に他のオプティマイザよりも性能が低下しないことが実験で示されており、ハイパーパラメータのチューニングに関する実用的なヒントも提供されている。 Comment
Adamが良いのだけど、学習率以外のハイパーパラメータをチューニングしないと本来のパフォーマンス発揮されないかもよ、という感じっぽい
ICLR 2020 Open Review: https://openreview.net/forum?id=HygrAR4tPS
[Paper Note] BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer, Fei Sun+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #LanguageModel #CIKM #SequentialRecommendation #Initial Impression Notes Issue Date: 2021-05-25 GPT Summary- ユーザーの動的嗜好をモデル化するために、BERT4RecというTransformerに基づく双方向エンコーダを導入。従来の順序型モデルの限界を克服し、Clozeタスクを用いて左側と右側の文脈を共同で条件付けしてアイテムを予測。さまざまなベンチマークデータセットにおいて、提案モデルが最先端の逐次モデルを一貫して上回る結果を示す。 Comment
BERTをrecsysのsequential recommendationタスクに転用してSoTA。
しっかり読んで無いけどモデル構造はほぼBERTと一緒。
異なる点は、Training時にNext Sentence Predictionは行わずClozeのみ行なっているという点。Clozeとは、実質Masked Language Modelであり、sequenceの一部を[mask]に置き換え、置き換えられたアイテムを左右のコンテキストから予測するタスク。異なる点としては、sequential recommendationタスクでは、次のアイテムを予測したいので、マスクするアイテムの中に、sequenceの最後のアイテムをマスクして予測する事例も混ぜた点。
もう一個異なる点として、BERT4Recはend-to-endなモデルで、BERTはpretraining modelだ、みたいなこと言ってるけど、まあ確かに形式的にはそういう違いはあるけど、なんかその違いを主張するのは違和感を覚える…。
sequential recommendationで使うuser behaviorデータでNext item predictionで学習したいことが、MLMと単に一致していただけ、なのでは…。
BERT4Recのモデル構造。next item predictionしたいsessionの末尾に [mask] をconcatし、[MASK]部分のアイテムを予測する構造っぽい?
オリジナルはtensorflow実装
pytorchの実装はこちら:
https://github.com/jaywonchung/BERT4Rec-VAE-Pytorch/tree/master/models
[Paper Note] Multimodal Review Generation for Recommender Systems, Truong+, WWW'19
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #NLP #ReviewGeneration #WWW Issue Date: 2019-05-31 Comment
Personalized Review Generationと、Rating Predictionを同時学習した研究(同時学習自体はすでに先行研究がある)。
また、先行研究のinputは、たいていはuser, itemであるが、multi-modalなinputとしてレビューのphotoを活用したという話。
まだあまりしっかり読んでいないが、モデルのstructureはシンプルで、rating predictionを行うDNN、テキスト生成を行うLSTM(fusion gateと呼ばれる新たなゲートを追加)、画像の畳み込むCNNのハイブリッドのように見える。
[Paper Note] Deep Reinforcement Learning that Matters, Peter Henderson+, AAAI'18, 2017.09
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #MachineLearning #ReinforcementLearning #AAAI #Selected Papers/Blogs #Reproducibility Issue Date: 2025-10-22 GPT Summary- 深層強化学習(RL)の進展を持続させるためには、既存研究の再現性と新手法の改善を正確に評価することが重要である。しかし、非決定性や手法のばらつきにより、結果の解釈が難しくなることがある。本論文では、再現性や実験報告の課題を調査し、一般的なベースラインとの比較における指標のばらつきを示す。さらに、深層RLの結果を再現可能にするためのガイドラインを提案し、無駄な努力を最小限に抑えることで分野の進展を促進することを目指す。 Comment
日本語解説: https://www.slideshare.net/slideshow/dldeep-reinforcement-learning-that-matters-83905622/83905622
再現性という観点とは少し異なるのかもしれないが、最近のRLによるpost-trainingについては、以下の研究でScaling Lawsが導入されている。
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
が、結局現在も多くのRL手法が日夜出てきており、再現性に関しては同じような状況に陥っていそうである。
[Paper Note] Group Normalization, Yuxin Wu+, arXiv'18, 2018.03
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #Normalization Issue Date: 2025-04-02 GPT Summary- バッチ正規化(BN)はディープラーニングの重要な技術だが、小さなバッチサイズでの精度低下が課題。本研究では、グループ正規化(GN)を提案し、チャネルをグループに分けて正規化を行うことで、バッチサイズに依存しない安定した性能を実現。ImageNetでの実験では、GNが小バッチでも優れた精度を示し、他のタスクでもBNよりも性能を向上させることを確認。GNは実装も簡単で、さまざまなコンピュータビジョンタスクにおいてBNの有効な代替手段である。 Comment
BatchNormalizationはバッチサイズが小さいとうまくいかず、メモリの制約で大きなバッチサイズが設定できない場合に困るからバッチサイズに依存しないnormalizationを考えたよ。LayerNormとInstanceNormもバッチサイズに依存しないけど提案手法の方が画像系のタスクだと性能が良いよ、という話らしい。
各normalizationとの比較。分かりやすい。
[Paper Note] An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18, 2018.12
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #MachineLearning #read-later #Selected Papers/Blogs #Batch #CriticalBatchSize Issue Date: 2024-12-16 GPT Summary- 勾配ノイズスケールを用いて、異なる分野での最適なバッチサイズを予測する方法を提示。教師あり学習や強化学習など複数の領域での実験を通じて、この統計量がロスの低下に伴い増加し、モデルサイズが性能に与える影響を分析。計算効率と時間効率のトレードオフを説明し、適応的なバッチサイズ訓練の利点を示す。 Comment
Critical Batchsize(バッチサイズをこれより大きくすると学習効率が落ちる境界)を提唱した論文
Modeling Hint-Taking Behavior and Knowledge State of Students with Multi-Task Learning, Chaudry+, Indian Institute of Technology, EDM'18
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #StudentPerformancePrediction #EDM Issue Date: 2021-11-12 Comment
DKVMN ([Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
)をhint-takingタスクとmulti-task learningした研究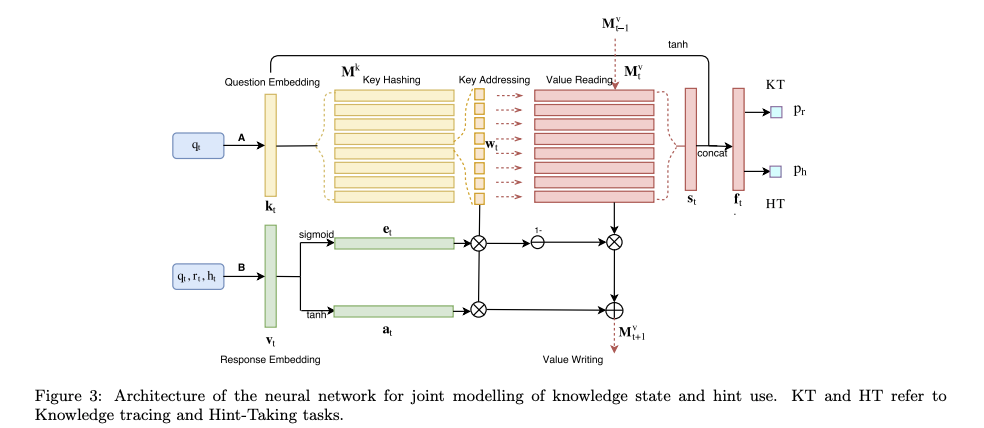
DKVMNと比較して、微小ながら性能向上
[Paper Note] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Jianxun Lian+, arXiv'18, 2018.03
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #SIGKDD #Reading Reflections Issue Date: 2021-05-25 GPT Summary- 特徴量の自動生成が求められる中、因子分解モデルは相互作用を学習し一般化するが、DNNは暗黙的である。本研究では、明示的に相互作用を生成する圧縮相互作用ネットワーク(CIN)を提案し、DNNと統合したeXtreme Deep Factorization Machine(xDeepFM)を開発。xDeepFMは低次・高次の相互作用を学習し、実データセットで最先端モデルを超える性能を示した。 Comment
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17 DeepFMの発展版
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
DeepFMの発展についても詳細に述べられていて、とても参考になる。
[Paper Note] Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising, Junwei Pan+, arXiv'18, 2018.06
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #WWW Issue Date: 2020-08-29 GPT Summary- クリック率(CTR)予測はオンライン広告での重要なタスクであり、マルチフィールドのカテゴリカルデータが使用される。フィールド認識型因子分解機(FFMs)は異なるフィールド間の特徴相互作用を効果的にモデル化するが、パラメータ数が膨大で実用的ではない。提案するField-weighted Factorization Machines(FwFMs)は、メモリ効率よく相互作用をモデル化し、わずか4%のパラメータで競争力のある性能を発揮。実験では、FwFMsがFFMsよりも0.92%および0.47%のAUC改善を達成した。 Comment
CTR予測でbest-performingなモデルと言われているField Aware Factorization Machines(FFM)では、パラメータ数がフィールド数×特徴数のorderになってしまうため非常に多くなってしまうが、これをよりメモリを効果的に利用できる手法を提案。FFMとは性能がcomparableであるが、パラメータ数をFFMの4%に抑えることができた。
[Paper Note] LensKit for Python: Next-Generation Software for Recommender System Experiments, Michael D. Ekstrand, arXiv'18, 2018.09
Paper/Blog Link My Issue
#RecommenderSystems #Tools #Library Issue Date: 2018-01-01 GPT Summary- LensKitはレコメンダーシステムのためのオープンソースツールキットで、次世代版としてPython用のLensKit(LKPY)を紹介。LKPYは、研究者や学生が再現可能な実験を構築できるようにし、scikit-learnやTensorFlow、PyTorchなどのエコシステムを活用。古典的な協調フィルタリングの実装や評価指標、データ準備ルーチンを提供し、他のPythonソフトウェアと組み合わせて使用可能。設計目標やユースケースについて、元のJava版の成功と失敗を振り返りながら説明。 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:Java
使用方法:コマンドライン、Javaライブラリとして利用
※ 推薦システム界隈で有名な、GroupLens研究グループによるJava実装
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, Noam Shazeer+, ICLR'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #MoE(Mixture-of-Experts) #ICLR #Selected Papers/Blogs Issue Date: 2025-04-29 GPT Summary- 条件付き計算を用いたスパースゲーテッドミクスチャーオブエキスパート(MoE)レイヤーを導入し、モデル容量を1000倍以上向上。学習可能なゲーティングネットワークが各例に対してスパースなエキスパートの組み合わせを決定。最大1370億パラメータのMoEをLSTM層に適用し、言語モデリングや機械翻訳で低コストで優れた性能を達成。 Comment
Mixture-of-Experts (MoE) Layerを提案した研究
Overcoming catastrophic forgetting in neural networks, James Kirkpatrick+, N_A, PNAS'17
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Catastrophic Forgetting #Selected Papers/Blogs Issue Date: 2024-10-10 GPT Summary- タスクを逐次的に学習する能力を持つネットワークを訓練する方法を提案。重要な重みの学習を選択的に遅くすることで、古いタスクの記憶を維持。MNISTやAtari 2600ゲームでの実験により、アプローチの効果とスケーラビリティを実証。 Comment
Catastrophic Forgettingを防ぐEWCを提案した論文
日本語解説: https://qiita.com/yu4u/items/90c039ec2f1d4f2d2414
ポイント解説:
[Paper Note] Large Batch Training of Convolutional Networks, Yang You+, arXiv'17, 2017.08
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Optimizer Issue Date: 2023-12-13 GPT Summary- 大規模畳み込みネットワークのトレーニングでは、計算ユニットを追加することで高速化を図るが、大きなバッチサイズはモデルの精度を低下させることがある。従来の線形学習率スケーリングは一般的ではなく、トレーニングの発散リスクがある。これを解決するために、Layer-wise Adaptive Rate Scaling(LARS)に基づく新しいアルゴリズムを提案し、AlexNetはバッチサイズ8K、ResNet-50は32Kまでの拡張でも精度を維持できることを示した。 Comment
BatchSizeを大きくすると性能が落ちますよ、系の話(CNN)
OpenReview:
https://openreview.net/forum?id=rJ4uaX2aW
ICLR'18にrejectされている
先行研究で提案よりも大きなバッチサイズを扱えるsynchronized SGDは強みだが、評価が一つのタスクのみなのでより増やした方がconvincingだということ、提案手法に追加のハイパーパラメータが必要な点が手法をless appealingにしてしまっていること、layer wise rate scailng (LARS)の理論的なjustificationが何か欲しいこと、先行研究との比較がクリアではないこと、などが理由な模様。
Why We Need New Evaluation Metrics for NLG, EMNLP'17
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Metrics #NLP #Evaluation #needs-revision Issue Date: 2023-08-16 Comment
既存のNLGのメトリックがhuman judgementsとのcorrelationがあまり高くないことを指摘した研究
[Paper Note] Construction of a Japanese Word Similarity Dataset, Yuya Sakaizawa+, arXiv'17, 2017.03
Paper/Blog Link My Issue
#Embeddings #NLP #Dataset #RepresentationLearning #STS (SemanticTextualSimilarity) #Japanese Issue Date: 2023-07-31 GPT Summary- 日本語の分散表現評価のために、語の類似度データセットを構築。これが日本語分散表現評価の初の資源であり、一般語と稀少語の両方を含む様々な品詞を網羅。 Comment
github:
https://github.com/tmu-nlp/JapaneseWordSimilarityDataset
単語レベルの類似度をベンチマーキングしたい場合は使ってもよいかも。
Learning to Represent Student Knowledge on Programming Exercises Using Deep Learning, Wang+, Stanford University, EDM'17
Paper/Blog Link My Issue
#EducationalDataMining #KnowledgeTracing #EDM Issue Date: 2021-07-04 Comment
DKT [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15
のPiech氏も共著に入っている。
プログラミングの課題を行なっている時(要複数回のソースコードサブミット)、
1. 次のexerciseが最終的に正解で終われるか否か
2. 現在のexerciseを最終的に正解で終われるか否か
を予測するタスクを実施
[Paper Note] Attend to You: Personalized Image Captioning with Context Sequence Memory Networks, Park+, CVPR'17
Paper/Blog Link My Issue
#ComputerVision #NLP #CommentGeneration #CVPR Issue Date: 2019-09-27 Comment
画像が与えられたときに、その画像に対するHashtag predictionと、personalizedなpost generationを行うタスクを提案。
InstagramのPostの簡易化などに応用できる。
Postを生成するためには、自身の言葉で、画像についての説明や、contextといったことを説明しなければならず、image captioningをする際にPersonalization Issueが生じることを指摘。
official implementation: https://github.com/cesc-park/attend2u
[Paper Note] Towards automatic generation of product reviews from aspectsentiment scores, Zang+, INLG'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ReviewGeneration #INLG Issue Date: 2019-04-12 Comment
hierarchicalなNNで、long reviewの生成に取り組んだ論文
[Paper Note] Learning to Paraphrase for Question Answering, Li Dong+, EMNLP'17
Paper/Blog Link My Issue
#NeuralNetwork #NLP #QuestionAnswering #EMNLP #Encoder-Decoder #RecurrentModels Issue Date: 2018-06-29 GPT Summary- QAシステムにおけるパラフレーズの重要性に着目し、質問と回答のペアを用いたエンドツーエンドの学習フレームワークを提案。ニューラルスコアリングモデルを通じて、正しい回答を得る可能性の高い表現に重みを付ける。実験結果は、提案手法が性能を向上させ、シンプルなQAモデルでも競争力のある結果を達成することを示す。 Comment
question-answeringタスクにおいて、paraphrasingを活用して精度向上させる研究
似たような意味の質問が、異なる表現で出現することがあるので、
questionの様々なparaphrasingを用意して活用したいという気持ち。
たとえば、
- Is the campus far from Shibuya?
- Is the campus near the city center?
のような例があげられる。
手法としては、paraphrasing modelとqa modelを用意し、あるquestionが与えられたときに、paraphrasing modelでparaphraseのスコアを算出、その後、各paraphrasingの候補に対してqa modelで解答を予測し、両者のスコアの積のsummationによって最終的なanswerを決定
QAはデータセットのサイズが小さいので、paraphrasingのような手法が有効に働いているのかもしれない
Deep Learning: Practice and Trends, NIPS'17 Tutorial, 2017.12
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #Slide #NeurIPS Issue Date: 2018-02-06 Comment
基礎から最新まで幅広いトピックがまとまったtutorial
[Paper Note] Multi-Task Video Captioning with Video and Entailment Generation, Ramakanth Pasunuru+, ACL'17, 2017.04
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NaturalLanguageGeneration #NLP #MultitaskLearning #ACL #Encoder-Decoder #3D (Video) #VideoCaptioning Issue Date: 2017-12-31 GPT Summary- ビデオキャプショニングの改善のため、教師なしビデオ予測タスクと論理的言語含意生成タスクを共有し、リッチなビデオエンコーダ表現を学習。パラメータを共有するマルチタスク学習モデルを提案し、標準データセットで大幅な改善を達成。 Comment
multitask learningで動画(かなり短め)のキャプション生成を行なった話
[Paper Note] Skip-Gram – Zipf + Uniform = Vector Additivity, Gittens+, ACL'17
Paper/Blog Link My Issue
#NeuralNetwork #Embeddings #Analysis #NLP #Word #ACL Issue Date: 2017-12-30 Comment
解説スライド: http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/09.pdf
Embeddingの加法構成性(e.g. man+royal=king)を理論的に理由づけ
(解説スライドより)
[Paper Note] A Structured Self-attentive Sentence Embedding, Zhouhan Lin+, ICLR'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #Embeddings #NLP #RepresentationLearning #ICLR #Selected Papers/Blogs Issue Date: 2017-12-28 GPT Summary- 自己注意機構を用いた新しい文埋め込みモデルを提案。2次元行列で文の異なる部分に注意を払い、視覚化手法も提供。著者プロファイリング、感情分類、テキスト含意の3つのタスクで評価し、他の手法と比較して性能が向上したことを示す。 Comment
OpenReview: https://openreview.net/forum?id=BJC_jUqxe
日本語解説: https://ryotaro.dev/posts/a_structured_self_attentivesentence_embedding/
self-attentionを提案した研究
[Paper Note] Controlling Output Length in Neural Encoder-Decoders, Yuta Kikuchi+, EMNLP'16
Paper/Blog Link My Issue
#NeuralNetwork #Controllable #NLP #EMNLP #Length #Selected Papers/Blogs #Encoder-Decoder Issue Date: 2025-01-03 GPT Summary- ニューラルエンコーダ-デコーダモデルの出力長を制御する方法を提案。特にテキスト要約において、デコーディングと学習に基づく2つのアプローチを用い、学習ベースの方法が要約の質を保ちながら長さを調整できることを示した。 Comment
Encoder-Decoderモデルにおいてoutput lengthを制御する手法を提案した最初の研究
Applications of the Elo Rating System in Adaptive Educational Systems, Pelanek, Computers & Educations'16
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-09-05 Comment
Elo rating systemの教育応用に関して詳細に記述されている
Estimating student proficiency: Deep learning is not the panacea, Wilson+, Knewton+, NIPS'16 workshop
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #NeurIPS Issue Date: 2022-04-27 Comment
DKTの性能をBKTやPFA等の手法と比較した研究
How Deep is Knowledge Tracing?, Mozer+, EDM'16
を引用し、DKTとBKTのAUCの計算方法の違いについて言及している
[Paper Note] Generating Sentences from a Continuous Space, Samuel R. Bowman+, CoNLL'16, 2015.11
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #VariationalAutoEncoder #CoNLL #Selected Papers/Blogs #Reference Collection #RecurrentModels Issue Date: 2018-02-14 GPT Summary- RNNベースの変分オートエンコーダ生成モデルを導入し、文全体の分散潜在表現を組み込むことで、文のスタイルやトピックなどの特性を明示的にモデル化。潜在空間を通じて新しい文を生成し、欠損単語の補完効果を実証。モデルの特性と使用に関する否定的な結果も示す。 Comment
VAEを利用して文生成
【Variational Autoencoder徹底解説】
https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24
Generative Adversarial Networks (GANS), NIPS'16 Tutorial, 2016.12
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #GenerativeAdversarialNetwork #NeurIPS Issue Date: 2018-02-06 Comment
Goodfellow氏によるGANチュートリアル
[Paper Note] Derivative Delay Embedding: Online Modeling of Streaming Time Series, Zhifei Zhang+, CIKM'16, 2016.09
Paper/Blog Link My Issue
#TimeSeriesDataProcessing #MachineLearning #CIKM Issue Date: 2017-12-31 GPT Summary- DDE-MGMという新しいオンラインモデリング手法を提案。従来の固定長や整列データの仮定を排除し、導関数遅延埋め込みを用いてストリーミング時系列データを効率的に処理。非パラメトリックマルコフ地理モデルでパターンをモデル化し、優れた分類精度を実現。実験結果は最先端手法と比較して効果的であることを示す。 Comment
スライド: https://www.slideshare.net/akihikowatanabe3110/brief-survey-of-datatotext-systems
(管理人が作成した過去のスライドより)
[Paper Note] Pointing the Unknown Words, Caglar Gulcehre+, ACL'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #ACL #Selected Papers/Blogs Issue Date: 2017-12-28 GPT Summary- 希少および未知の単語に対処するため、注意機構を用いた新しいニューラルネットワークモデルを提案。2つのソフトマックス層を使用し、文脈に基づいて適応的に選択。提案モデルは、翻訳と要約タスクで性能向上を示した。 Comment
テキストを生成する際に、source textからのコピーを行える機構を導入することで未知語問題に対処した話
CopyNetと同じタイミングで(というか同じconferenceで)発表
[Paper Note] Generating Visual Explanations, Lisa Anne Hendricks+, CVPR'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Visual Words #CVPR Issue Date: 2017-12-28 GPT Summary- 分類決定の説明は重要であり、既存の深層視覚認識アプローチは不透明である。新たに提案するモデルは、可視オブジェクトの識別特性に基づき、クラスラベルを予測し、その理由を説明する。サンプリングと強化学習に基づく新しい損失関数を用いて、グローバルな文の特性を実現する。実験結果は、提案モデルが一貫性のある識別的な説明を生成できることを示している。 Comment
画像そのものだけでなく、モデルへのInputにVisual Wordsを明示的に加えることで、captioningの精度が上がりましたという論文
[Paper Note] Retrofitting Word Vectors to Semantic Lexicons, Manaal Faruqui+, NAACL'15, 2014.11
Paper/Blog Link My Issue
#Embeddings #NLP #Word #RepresentationLearning #Selected Papers/Blogs #Finetuning Issue Date: 2025-12-04 GPT Summary- 意味的レキシコンの情報を活用して、単語のベクトル空間表現を改善する手法を提案。関連する単語が類似のベクトルを持つよう促し、従来の仮定に依存しない。複数の言語での語彙意味評価タスクで大幅な改善を示し、従来技術を上回る性能を達成。 Comment
日本語解説: https://www.slideshare.net/slideshow/20150421-forupdate/47365800
Retrofittingという用語を今でも耳にすることがあるが、この研究のような手法を指すと思って良いと思われる(研究室の輪講で本論文の発表があったのを思い出すなぁ)。事前学習済みの単語ベクトルに対して事後的に外部知識(辞書など)を埋め込みチューニングする話。
[Paper Note] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP #Attention #ICLR #Selected Papers/Blogs Issue Date: 2025-05-12 GPT Summary- ニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment
(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している)
[Paper Note] E-commerce in Your Inbox: Product Recommendations at Scale, Mihajlo Grbovic+, KDD'15
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CTRPrediction #SequentialRecommendation #SIGKDD Issue Date: 2025-04-25 GPT Summary- メールの領収書から得た購入履歴を活用し、Yahoo Mailユーザーにパーソナライズされた商品広告を配信するシステムを提案。新しい神経言語ベースのアルゴリズムを用いて、2900万人以上のユーザーのデータでオフラインテストを実施した結果、クリック率が9%向上し、コンバージョン率も改善。システムは2014年のホリデーシーズンに本稼働を開始。 Comment
Yahoo mailにおける商品推薦の研究
Yahoo mailのレシート情報から、商品購入に関する情報とtimestampを抽出し、時系列データを形成。評価時はTimestampで1ヶ月分のデータをheldoutし評価している。Sequential Recommendationの一種とみなせるが、評価データをユーザ単位でなくtimestampで区切っている点でよりrealisticな評価をしている。
chrF: character n-gram F-score for automatic MT evaluation, Mono Popovic, WMT'15
Paper/Blog Link My Issue
#DocumentSummarization #MachineTranslation #NaturalLanguageGeneration #Metrics #NLP #Reference-based #ACL #Workshop Issue Date: 2023-08-13 Comment
character-basedなn-gram overlapをreferenceとシステムで計算する手法
[Paper Note] From word embeddings to document distances, Kusner+, ICML'15
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based Issue Date: 2023-08-13 Comment
WMS/SMS/S+WMS
- [Paper Note] MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance, Zhao+, EMNLP-IJCNLP'19
はこれらからinspiredされ提案された
[Paper Note] Hidden Technical Debt in Machine Learning Systems, Sculley+, NIPS'15
Paper/Blog Link My Issue
#Tutorial #MachineLearning #Infrastructure #NeurIPS #Selected Papers/Blogs Issue Date: 2021-10-19 Comment

よく見るML codeが全体のごく一部で、その他の基盤が大半を占めてますよ、の図が掲載されている文献。様々な資料で引用されている。
[Paper Note] Session-based Recommendations with Recurrent Neural Networks, Balázs Hidasi+, arXiv'15
Paper/Blog Link My Issue
#RecommenderSystems #SessionBased #ICLR #SequentialRecommendation #Selected Papers/Blogs Issue Date: 2019-08-02 GPT Summary- RNNを用いたセッションベースのレコメンダーシステムを提案。短いユーザーヒストリーに基づく推薦の精度向上を目指し、セッション全体をモデル化。ランキング損失関数などの修正を加え、実用性を考慮。実験結果は従来のアプローチに対して顕著な改善を示す。 Comment
RNNを利用したsequential recommendation (session-based recommendation)の先駆け的論文。
日本語解説: https://qiita.com/tatamiya/items/46e278a808a51893deac
[Paper Note] Unsupervised prediction of acceptability judgements, Lau+, ACL-IJCNLP'15
Paper/Blog Link My Issue
#NLP #LanguageModel #ACL #IJCNLP #Selected Papers/Blogs #Reference Collection Issue Date: 2018-03-30 Comment
文のacceptability(容認度)論文。
文のacceptabilityとは、native speakerがある文を読んだときに、その文を正しい文として容認できる度合いのこと。
acceptabilityスコアが低いと、Readabilityが低いと判断できる。
言語モデルをトレーニングし、トレーニングした言語モデルに様々な正規化を施すことで、acceptabilityスコアを算出する。
日本語解説: http://www.lr.pi.titech.ac.jp/~sasano/acl2015suzukake/slides/01.pdf
[Paper Note] Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks, Kai Sheng Tai+, ACL-IJCNLP'15, 2015.02
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ACL #IJCNLP #Selected Papers/Blogs #RecurrentModels #RecursiveModels Issue Date: 2018-02-13 GPT Summary- Tree-LSTMは、LSTMの構造を木構造に拡張し、文の関連性予測と感情分類で従来の全システムとLSTMベースラインを上回る性能を示す。 Comment
Tree-LSTM論文
[Paper Note] fastFM: A Library for Factorization Machines, Immanuel Bayer, arXiv'15, 2015.05
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #Library #FactorizationMachines Issue Date: 2018-01-01 GPT Summary- 因子分解機(FM)は、レコメンダーシステムで成功を収めているにもかかわらず、機械学習の標準ツールボックスには含まれていない。私たちのFMの実装は、回帰、分類、ランキングタスクをサポートし、多くのソルバーへのアクセスを簡素化することで、FMの幅広いアプリケーション利用を促進する。これにより、FMモデルの理解が深まり、新たな開発が期待される。 Comment
実装されているアルゴリズム:Factorization Machines
実装:python
使用方法:pythonライブラリとして利用
※ Factorization Machinesに特化したpythonライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] Extended Recommendation Framework: Generating the Text of a User Review as a Personalized Summary Poussevin+, CBRecsys'15, 2015.09
Paper/Blog Link My Issue
#NLP #ReviewGeneration #Personalization Issue Date: 2017-12-28 Comment
review generationの結果をrating predictionに伝搬することで性能よくしました、という話だと思う
Simple and scalable response prediction for display advertising, Chapelle+, Criteo, Transactions on Intelligent Systems and Technology, CHAPELLE+, TIST'14
Paper/Blog Link My Issue
#RecommenderSystems #CTRPrediction Issue Date: 2021-10-29 Comment
日本語解説:
https://ameblo.jp/cyberanalyst/entry-11784152713.html
CTR予測の概要や、広告主・事業者にとってCTR予測ができることでどのようなメリットがあるかなどがまとまっている。
論文の手法自体は、logistic regressionが利用されている。
General Features in Knowledge Tracing: Applications to Multiple Subskills, Temporal Item Response Theory, and Expert Knowledge, Brusilovsky+, EDM'14
Paper/Blog Link My Issue
#AdaptiveLearning #StudentPerformancePrediction #KnowledgeTracing #EDM Issue Date: 2021-10-29 Comment
BKTでは1種類のスキルしか扱えなかった問題を改善(skillだけでなく、sub-skillも扱えるように)
様々なFeatureを組み合わせることが可能
実装:
https://github.com/ml-smores/fast
ただし、GPL-2.0ライセンス
Automatically Assessing Machine Summary Content Without a Gold Standard, Louis+(w_ Nenkova), ACL'13
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation Issue Date: 2023-08-23 Comment
メタ評価の具体的な手順について知りたければこの研究を読むべし
[Paper Note] The Mathematics of Statistical Machine Translation: Parameter Estimation, Brown+, CL'13
Paper/Blog Link My Issue
#MachineTranslation #NLP #Alignment #Selected Papers/Blogs Issue Date: 2018-01-15 Comment
IBMモデル論文。
[Paper Note] Reusing Historical Interaction Data for Faster Online Learning to Rank for IR, Hofmann+, WSDM'13
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #Online/Interactive #Interleaved #WSDM Issue Date: 2018-01-01 Comment
[Paper Note] Interactively Optimizing Information Retrieval Systems as a Dueling Bandits Problem, Yue+, ICML'09
DBGDを拡張した手法を提案している。
アルゴリズムが細かく書いてあるので、追っていくとDBGD等について理解が深まると思われる。
Interleavemethodについても。
[Paper Note] Online Distributed Passive-Aggressive Algorithm for Structured Learning, Zhao+, CCL and NLP-NABD'13
Paper/Blog Link My Issue
#MachineLearning #StructuredLearning Issue Date: 2017-12-31 Comment
タイトルの通り、構造学習版のpassive-aggressiveアルゴリズムの分散処理による高速化手法について提案されている論文。
論文中のAlgorithm.2がアルゴリズム。
[Paper Note] ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky+, NIPS'12
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NeurIPS #Selected Papers/Blogs #ImageClassification #Backbone Issue Date: 2025-05-13 Comment
ILSVRC 2012において圧倒的な性能示したことで現代のDeepLearningの火付け役となった研究AlexNet。メモってなかったので今更ながら追加した。
AlexNet以前の画像認識技術については牛久先生がまとめてくださっている(当時の課題とそれに対する解決法、しかしまだ課題が…と次々と課題に直面し解決していく様子が描かれており非常に興味深かった)。現在でも残っている技術も紹介されている。:
https://speakerdeck.com/yushiku/pre_alexnet
> 過去の技術だからといって聞き流していると時代背景の変化によってなし得たイノベーションを逃すかも
これは肝に銘じたい。
Context-enhanced personalized social summarization, Po+, COLING'12, 18
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Personalization Issue Date: 2023-05-05 Comment
ざっくり言うと、ソーシャルタギングシステムにおいて、ユーザ uと類似したユーザのタグ付け情報と、原文書d _と同じトピックに属する文書をそれぞれ考慮することによって、ユーザのinterestに関する情報(と原文書のinformativenessに関する情報)を拡張し、これらの情報を活用して、全てのクラスタリングしたドキュメントの中で重要文をランキングした上で、対象文書に対するsentenceのみを冗長性がないように抽出することで、Personalized_ Summarizationしましょう、という話
[Paper Note] Care to Comment? Recommendations for Commenting on News Stories, Shmueli+, WWW'12
Paper/Blog Link My Issue
#RecommenderSystems #Comments #WWW Issue Date: 2018-01-15 Comment
過去のユーザのコメントに対するratingに基づいて、ユーザが(コメントを通じて)議論に参加したいようなNews Storyを推薦する研究。
[Paper Note] Factorization Machines with libFM, Steffen Rendle, TIST'12, 2012.06
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #FactorizationMachines Issue Date: 2018-01-02 Comment
Factorization Machinesの著者実装。
FMやるならまずはこれ。
[Paper Note] Multi-relational matrix factorization using bayesian personalized ranking for social network data, Krohn-Grimberghe+, WSDM'12, 2012.02
Paper/Blog Link My Issue
#Multi #RecommenderSystems #MatrixFactorization #WSDM #ColdStart Issue Date: 2017-12-28 Comment
multi-relationalな場合でも適用できるmatrix factorizationを提案。特にcold start problemにフォーカス。social networkのデータなどに適用できる。
Multi-Relational Factorization Models for Predicting Student Performance, Nguyen+, KDD Cup'11
Paper/Blog Link My Issue
#CollaborativeFiltering #MatrixFactorization #EducationalDataMining #StudentPerformancePrediction Issue Date: 2021-10-29 Comment
過去のCollaborative Filteringを利用したStudent Performance Prediction (Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
など)では、単一の関係性(student-skill, student-task等の関係)のみを利用していたが、この研究では複数の関係性(task-required skill-learnt skill)を利用してCFモデルの性能を向上させ、Bayesian Knowledge TracingやMatrix Factorizationに基づく手法をRMSEの観点でoutperformした。
[Paper Note] Factorization Models for Forecasting Student Performance, Thai-Nghe+, EDM'11
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #StudentPerformancePrediction #EDM Issue Date: 2018-12-22 Comment
student performanceは、推薦システムの問題において、下記の2種類にcastできる:
1. rating prediction task, すなわち、ユーザ・アイテム・ratingを、生徒・タスク・パフォーマンスとみなす
2. sequentialなエフェクトを考慮して、forecasting problemに落とす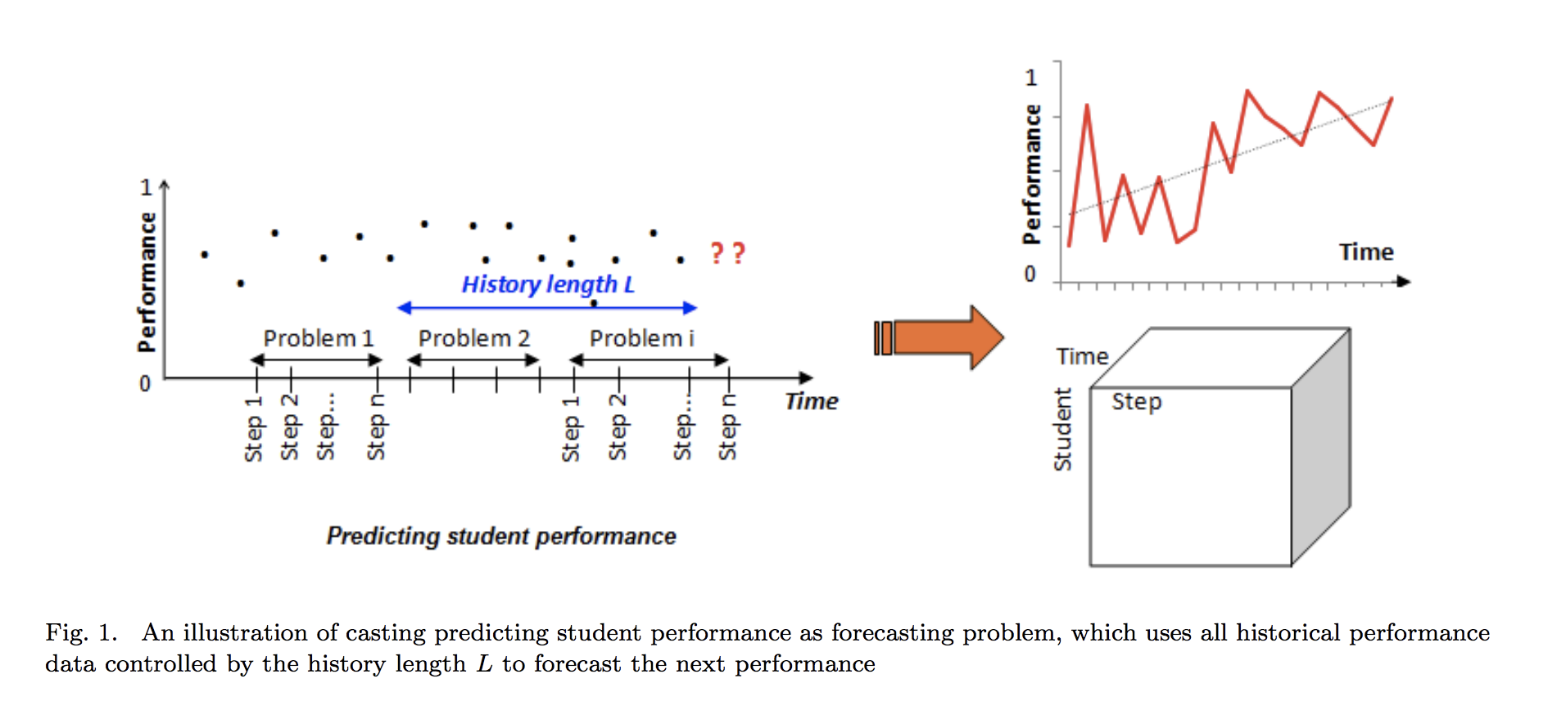
TensorFactorizationで、欠損値を予測
cold-start problem(new-user, new item)への対処としては、global averageをそれぞれ用いることで対処(more sophisticatedなやり方が提案されているとも述べている)
使用している手法としては、この辺?
https://pdfs.semanticscholar.org/8e6b/5991f9c1885006aa204d80cc2c23682d8d31.pdf
Context Aware Recommender Systems, Adomavicius+, AAAI'11 Tutorial, 2011.08
Paper/Blog Link My Issue
#RecommenderSystems #Tutorial #ContextAware #AAAI Issue Date: 2018-12-22 Comment
AdomaviciusらによるContext Aware Recsysチュートリアル
関連:
- [Paper Note] Context-Aware Recommender Systems, Adomavicius+, Recommender Systems Handbook, 2011.09
Discourse constraints for document compression, Clarke+ (w_ Lapata), Computational Linguistics'10
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation #QA-based Issue Date: 2023-08-20 Comment
QAベースドなアプローチを人手評価に導入した初めての研究
Collaborative Filtering Applied to Educational Data Mining, Andreas+, KDD Cup'10
Paper/Blog Link My Issue
#NeuralNetwork #CollaborativeFiltering #MatrixFactorization #EducationalDataMining #StudentPerformancePrediction Issue Date: 2021-10-29 Comment
KDD Cup'10のStudent Performance Predictionタスクにおいて3位をとった手法
メモリベースドな協調フィルタリングと、Matirx Factorizationモデルを利用してStudent Performance Predictionを実施。
最終的にこれらのモデルをニューラルネットでensembleしている。
Content-based Recommender Systems: State of the Art and Trends, Lops+, Recommender Systems Handbook'10
Paper/Blog Link My Issue
#RecommenderSystems #Survey #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
RecSysの内容ベースフィルタリングシステムのユーザプロファイルについて知りたければこれ
[Paper Note] Personalized Multi-Document Summarization using N-Gram Topic Model Fusion, Hennig+, SPIM'10, 2010.05
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #Personalization Issue Date: 2017-12-28 Comment
・unigramの共起だけでなく,bigramの共起も考慮したPLSIモデルを提案し,jointで学習.与えられたクエリやnarrativeなどとsentenceの類似度(latent spaceで計算)を計算し重要文を決定。
・user-modelを使ったPersonalizationはしていない.
More Accurate Student Modeling through Contextual Estimation of Slip and Guess Probabilities in Bayesian Knowledge Tracing, Ryan Baker+, ITS'08
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #ITS Issue Date: 2022-08-31 Comment
- BKTのModel Degeneracy問題について言及されている
- Model Degeneracy: parameterの値がモデルのconceptualな意味合いを破ってしまうこと
- たとえば、学習者がスキルを知っている場合よりも、知らない場合に正答を得る可能性が高くなってしまう、など
- slipping, guessingパラメータにboundaryを設ける(0.3, 0.1未満になるようにする)などの制約をつけることでこういった事態を過去の研究では回避していることが言及されている
[Paper Note] A unified architecture for natural language processing: Deep neural networks with multitask learning, Collobert+, ICML'08
Paper/Blog Link My Issue
#NeuralNetwork #NLP #MultitaskLearning #ICML #Selected Papers/Blogs Issue Date: 2018-02-05 Comment
Deep Neural Netを用いてmultitask learningを行いNLPタスク(POS tagging, Semantic Role Labeling, Chunking etc.)を解いた論文。
被引用数2000を超える。
multitask learningの学習プロセスなどが引用されながら他論文で言及されていたりする。
[Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
Paper/Blog Link My Issue
#RecommenderSystems #MatrixFactorization #NeurIPS #Selected Papers/Blogs Issue Date: 2018-01-11 Comment
Matrix Factorizationを確率モデルとして表した論文。
解説:
http://yamaguchiyuto.hatenablog.com/entry/2017/07/13/080000
既存のMFは大規模なデータに対してスケールしなかったが、PMFではobservationの数に対して線形にスケールし、さらには、large, sparse, imbalancedなNetflix datasetで良い性能が出た(Netflixデータセットは、rating件数が少ないユーザとかも含んでいる。MovieLensとかは含まれていないのでより現実的なデータセット)。
また、Constrained PMF(同じようなsetの映画にrateしているユーザは似ているといった仮定に基づいたモデル[^1])を用いると、少ないratingしかないユーザに対しても良い性能が出た。
[^1]: ratingの少ないユーザの潜在ベクトルは平均から動きにくい、つまりなんの特徴もない平均的なユーザベクトルになってしまうので、同じ映画をratingした人は似た事前分布を持つように制約を導入したモデル
[Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
Paper/Blog Link My Issue
#RecommenderSystems #MatrixFactorization #SIGKDD Issue Date: 2018-01-11 Comment
従来のMatrix Factorization(MF)では、pair-wiseなrelation(たとえば映画とユーザと、映画に対するユーザのrating)からRating Matrixを生成し、その行列を分解していたが、multipleなrelation(たとえば、user-movie ratingの5-scale Matrixとmovie - genreの binary Matrixなど)を扱うことができなかったので、それを可能にした話。
これができると、たとえば ユーザの映画に対するratingを予測する際に、あるユーザが特定のジャンルの映画に対して高いratingを付けるような情報も考慮して予測ができたりする。
[Paper Note] Structured Learning for Non-Smooth Ranking Losses, Chakrabarti+, KDD'08
Paper/Blog Link My Issue
#MachineLearning #StructuredLearning #SIGKDD Issue Date: 2017-12-31 Comment
従来、structured learningの設定でranking lossを最適化する際は、smoothなmetric、たとえばMAPやAUCなどを最適化するといったことが行われていたが、MRRやNDCGなどのnon-smoothなmetricに対しては適用されていなかった。
なので、それをできるようにしましたという論文。
[Paper Note] Generating Personalized Summaries Using Publicly Available Web Documents, Kumar+, WI-IAT'08, 2008.12
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #WI Issue Date: 2017-12-28 Comment
評価
5人の研究者による人手評価。
25種類の異なるトピックが選択され、各トピックには5-10の記事が紐づいている。
generic,personalizedな要約を提示しrelevanceを判定してもらった。具体的には、informativenessを5段階評価。
データ非公開、ニュース記事を使ったとしか記述されておらず再現不可
Large Language Models in Machine Translation, Brants+, EMNLP-CoNLL'07
Paper/Blog Link My Issue
#MachineTranslation #NLP #LanguageModel #Selected Papers/Blogs Issue Date: 2024-12-24 GPT Summary- 本論文では、機械翻訳における大規模な統計的言語モデルの利点を報告し、最大2兆トークンでトレーニングした3000億n-gramのモデルを提案。新しいスムージング手法「Stupid Backoff」を導入し、大規模データセットでのトレーニングが安価で、Kneser-Neyスムージングに近づくことを示す。 Comment
N-gram言語モデル+スムージングの手法において、学習データを増やして扱えるngramのタイプ数(今で言うところのvocab数に近い)を増やしていったら、perplexityは改善するし、MTにおけるBLEUスコアも改善するよ(BLEUはサチってるかも?)という考察がされている
元ポスト:
Large Language Modelsという用語が利用されたのはこの研究が初めてなのかも…?
[Paper Note] A study of global inference algorithms in multi-document summarization, Ryan McDonald, ECIR'07
Paper/Blog Link My Issue
#Multi #DocumentSummarization #Document #NLP #IntegerLinearProgramming (ILP) #Extractive #ECIR #Selected Papers/Blogs Issue Date: 2018-01-17 Comment
文書要約をナップサック問題として定式化し、厳密解(動的計画法、ILP Formulation)、近似解(Greedy)を求める手法を提案。
[Paper Note] A support vector method for Optimizing Average Precision, Yue+, SIGIR'07
Paper/Blog Link My Issue
#MachineLearning #StructuredLearning #InformationRetrieval #SIGIR Issue Date: 2017-12-31 Comment
SVM-MAPの論文
構造化SVMを用いて、MAPを直接最適化する。
[Paper Note] An Architecture for Data to Text Systems, Ehud Reiter, ENLG'07
Paper/Blog Link My Issue
#Survey #NaturalLanguageGeneration #NLP #DataToTextGeneration #ConceptToTextGeneration #Selected Papers/Blogs Issue Date: 2017-12-31 Comment
NLG分野で有名なReiterらのSurvey。
NLGシステムのアーキテクチャなどが、体系的に説明されている。
[Paper Note] Learning User Profiles from Tagging Data and Leveraging them for Personal(ized) Information Access, Michlmayr+, WWW'07, 2007.05
Paper/Blog Link My Issue
#UserModeling #Personalization #WWW Issue Date: 2017-12-28 Comment
social bookmarkのタグを使ってどのようにユーザモデルを作成する手法が提案されている。タグの時系列も扱っているみたいなので、参考になりそう。
[Paper Note] Usage patterns of collaborative tagging systems, Golder+, Journal of Information Science'06
Paper/Blog Link My Issue
#RecommenderSystems #Analysis #Others Issue Date: 2018-01-01 Comment
Social Tagging Systemの仕組みや使われ方について言及する際にreferすると良いかも。
[Paper Note] Folkrank: A ranking algorithm for folksonomies, Hotho+, FGIR'06
Paper/Blog Link My Issue
#RecommenderSystems #GraphBased Issue Date: 2018-01-01 Comment
代表的なタグ推薦手法
[Paper Note] Learning to Rank using Gradient Descent (RankNet), Burges+, ICML'05
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #ICML #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
pair-wiseのlearning2rankで代表的なRankNet論文
解説ブログ:
https://qiita.com/sz_dr/items/0e50120318527a928407
lossは2個のインスタンスのpair、A, Bが与えられたとき、AがBよりも高くランクされる場合は確率1, AがBよりも低くランクされる場合は確率0、そうでない場合は1/2に近くなるように、スコア関数を学習すれば良い。
[Paper Note] NewsInEssence: Summarizing ONLINE NEWS TOPICS, Radev+, Communications of the ACM'05, 2005.10
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NLP #Extractive Issue Date: 2017-12-28 Comment
・Centroid-Basedな手法(MEADと同じ手法)で要約を生成
・Personalizationはかけていない
[Paper Note] Personalizing Search via Automated Analysis of Interests and Activities, Teevan+, SIGIR'05, 2005.08
Paper/Blog Link My Issue
#InformationRetrieval #Personalization #SIGIR Issue Date: 2017-12-28 Comment
・userに関するデータがrichなほうが、Personalizationは改善する。
・queries, visited web pages, emails, calendar items, stored desktop
documents、全てのsetを用いた場合が最も良かった
(次点としてqueriesのみを用いたモデルが良かった)
Centroid-based summarization of multiple documents: sentence extraction, utility-based evaluation, and user studies, Radev+, Information Processing & Management'04
Paper/Blog Link My Issue
#Multi #DocumentSummarization #Classic #NLP Issue Date: 2023-08-27 Comment
MEAD, Centroid-basedな手法で要約を実施する古典的なMDS手法
Using Knowledge Tracing to Measure Student Reading Proficiencies, Joseph+, ITS'04
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #ITS Issue Date: 2022-09-12 Comment
英語の音読に関してKTを適用した話が記載されている
スキルの定義はgrapheme=>phoneme mappingsとして定義されるっぽい
- ch は /CH/ と発音する場合(e.g. Charles)もあれば /K/ の場合もある(e.g. Chaos)
- ch=>/CH/, ch=>/K/ のマッピングがスキルとして定義されている?
機械翻訳自動評価指標の比較, 今村+, NLP'04
Paper/Blog Link My Issue
#MachineTranslation #Metrics #NLP Issue Date: 2021-06-25 Comment
BLEUスコア、NISTスコア、WordErrorRate(WER)などに関して丁寧かつ簡潔に解説してある。
BLEUスコア算出に利用するN-gramは一般的にはN=4が用いられる、といった痒いところに手が届く情報も書いてある。
普段何気なく使っているBLEUスコアで、あれ定義ってどんなだっけ?と立ち帰りたくなった時に読むべし。
実際に研究等でBLEUスコアを測りたい場合は、mosesの実装を使うのが間違いない:
https://github.com/moses-smt/mosesdecoder/blob/master/scripts/generic/multi-bleu.perl
[Paper Note] A Formal Model for Information Selection in Multi-Sentence Text Extraction, Filatova+, COLING'04
Paper/Blog Link My Issue
#Multi #DocumentSummarization #Document #NLP #Extractive #COLING Issue Date: 2018-01-17 Comment
初めて文書要約を最大被覆問題として定式化した研究。
[Paper Note] A Phrase-Based HMM Approach to Document_Abstract Alignment, Daume+, EMNLP'04
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Alignment #EMNLP Issue Date: 2018-01-15 Comment
AbstractsとSource TextのAlignmentをとるために、Phrase-Based HMMを提案。
Ziff-Davis Corpusのテキストに対して、2人のannotatorによってgold standardを作成。
評価においてMTにおけるIBM Model4やHMM basedな単語アライメント手法と比較しているが、fair comparisonのために行なっている施策が参考になる。
[Paper Note] A systematic comparison of various statistical alignment models, Och+, CL'03
Paper/Blog Link My Issue
#MachineTranslation #Tools #NLP #WordAlignment Issue Date: 2018-01-15 Comment
Giza++
標準的に利用される単語アライメントツール
評価の際は、Sure, Possibleの二種類のラベルによる単語アライメントのground-truth作成も行っている
[Paper Note] PRanking with Ranking, Crammer+, NIPS'01
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PointWise #NeurIPS #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
Point-WiseなLearning2Rankの有名手法
[Paper Note] Item-based collaborative filtering recommendation algorithms, Sarwar+(with Konstan), WWW'01, 2021.04
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #ItemBased #WWW #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
アイテムベースな協調フィルタリングを提案した論文(GroupLens)
[Paper Note] Cut and paste based text summarization, Jing+, NAACL'00
Paper/Blog Link My Issue
#DocumentSummarization #Document #NLP #NAACL #Selected Papers/Blogs Issue Date: 2018-01-21 Comment
AbstractiveなSummarizationの先駆け的研究。
AbstractiveなSummarizationを研究するなら、押さえておいたほうが良い。
[Paper Note] Generating Extraction-Based Summaries from Hand-Written Summaries by Aligning Text Spans, Banko+, PACLING'99
Paper/Blog Link My Issue
#DocumentSummarization #NLP #WordAlignment Issue Date: 2018-01-15 Comment
文を単位とし、文を文中の単語の出現頻度ベクトルで表し、ベクトル間の距離で文間の類似度を計ることで自由作成要約中の文と現文中の文をもっとも類似度が大きくなるように対応づける。
[Paper Note] Automatic condensation of electronic publications by sentence selection, Brandow+, Information Processing & Management'95, 1995.09
Paper/Blog Link My Issue
#Single #DocumentSummarization #Document #NLP #Extractive #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
報道記事要約において、自動要約システムがLead文に勝つのがhardだということを示した研究
[Paper Note] The Identification of Important Concepts in Highly Structured Technical Papers, ACL-SIGIR'93
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #ACL #SIGIR Issue Date: 2023-05-13 Comment
ユーザは自分が興味があるpartをsummary evaluationにおいて選択する傾向にある、ということを示した研究
[Paper Note] Adaptive Mixture of Local Experts, Jacobs+, Neural Computation'91
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #MoE(Mixture-of-Experts) Issue Date: 2025-04-29 Comment
Mixture of Expertsの起源
と思ったのだが、下記研究の方が年号が古いようだが、こちらが起源ではなのか・・・?だがアブスト中に上記論文で提案されたMoEのパフォーマンスを比較する、といった旨の記述があるので時系列がよくわからない。
[Evaluation of Adaptive Mixtures of Competing Experts](
http://www.cs.toronto.edu/~fritz/absps/nh91.pdf)
参考: https://speakerdeck.com/onysuke/mixture-of-expertsniguan-suruwen-xian-diao-cha
The fastest LLM on Earth: Frontier level intelligence, 15x faster, celeris, 2026.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel #Blog #Proprietary #read-later #Author Thread-Post Issue Date: 2026-07-25 Comment
元ポスト:
アーキテクチャとしてdLLMを採用したGPT-5-miniと同等程度の性能のモデルで、GPT-5-miniに対して15倍程度(1280TPS)のスループットを実現しているとのこと。
Introducing Claude Opus 5, Anthropic, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Author Thread-Post Issue Date: 2026-07-25 Comment
元ポスト:
coding, knowledge workでのベンチマークスコアはFable5超えで、コストはFable5のおよそ半分
いよいよベンチマークではClaude一強という感じになってきた:
Fable5のPromptingに関する話:
- A Field Guide to Fable: Finding Your Unknowns, Claude, 2026.07
Context Engineeringの話:
- The new rules of context engineering for Claude 5 models, Thariq, 2026.07
[Paper Note] LLaDA2.2, InclusionAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #DiffusionModel #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2026-07-25 Comment
HF: https://huggingface.co/inclusionAI/LLaDA2.2-flash
元ポスト:
LLaDA2.2シリーズとして初めてのAgent指向なdLLMとのこと。MoEアーキテクチャ採用。ベンチマークスコアはARモデルよりも少し劣る面があるが、スループットは1.64倍。
stack-v3-full, HuggingFaceCode, 2026.07
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #LanguageModel #Blog #Coding #Selected Papers/Blogs #reading #Author Thread-Post Issue Date: 2026-07-24 Comment
元ポスト:
114 TB, 770言語, 224Mリポジトリ, 約5Tトークンの重複除去やフィルタリング済みGithubから収集されたソースコードで、制限付きライセンスのコードは一切含まないデータセット。V2では2023年時点のスナップショットに基づいており、V3は2025年8月時点までのスナップショットとのこと。たとてば、C++は15倍、TypeScript は7.5倍、Rustは7倍、Pythonは4.8倍程度のトークンがあるらしい。全体としては8.9倍のトークン量。
また、V2ではdeduplicationにおいて正規表現にバグがあったようで、そちらも修正されているようである。
Stack V2:
- [Paper Note] StarCoder 2 and The Stack v2: The Next Generation, Anton Lozhkov+, arXiv'24
所見:
FRONTIER-BENCH V0.1: A benchmark to measure and evolve with the frontier of agent work, FRONTIER-BENCH, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Blog #Selected Papers/Blogs #Live #reading #Author Thread-Post Issue Date: 2026-07-24 Comment
元ポスト:
Terminal Benchを構築したチームによる新たなベンチマークで、GPT-5.6-Sol (Codex) でもスコアは34.4%。タスクは今後も更新される。
タスクは、ソフトウェア、ML、科学、オペレーション、セキュリティ、ハードウェア、メディアなどのドメインによって構成されるようである。
Terminal Bench:
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
FLUX 3 - Real World Models: Towards Multimodal Flow Models as the Backbone of Visual Intelligence, Black Forest Labs, 2026.07
Paper/Blog Link My Issue
#Article #ComputerVision #TextToAudio #MultiModal #TextToImageGeneration #Blog #Proprietary #VideoGeneration/Understandings #Editing #UMM #ImageSynthesis #TextToVideoGeneration #WorldActionModel #Author Thread-Post Issue Date: 2026-07-24 Comment
元ポスト:
モデルは将来的にオープンになるようである
Grok Build is open source: SpaceXAI's coding agent and CLI, SpaceXAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #AgentHarness Issue Date: 2026-07-23 Comment
元ポスト:
github: https://github.com/xai-org/grok-build
SpaceXAIによるcoding agent harness
所見:
Scaling Agentic RL: 365,000+ Environments for SWE, Terminal, and Search, Prime Intellect, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Blog #PostTraining #Scalability #Environment Issue Date: 2026-07-23 Comment
元ポスト:
36.5kのagentic RLのためのenvironments。対象はSWE, Search, terminal。全てのタスクセットが、任意のハーネス、ランタイム上でone commandで実行可能とのこと。
🦋 Molt: A Scalable PyTorch-Native Training Framework for Agentic Reinforcement Learning, Jian Hu and Molt Contributors, 2026.07
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #ReinforcementLearning #AIAgents #PostTraining Issue Date: 2026-07-19 Comment
元ポスト:
ハイパフォーマンス、かつminimalな実装のRLライブラリで、研究用のハックがしやすいフレームワーク。verlの1/9, Slimeの1/3の行数で実現されているとのこと。
verl:
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
Slime:
- slime, THUDM & Zhihu, 2025.09
SingGuard-NSFA, inclusionAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #AIAgents #OpenWeight #Safety #Security #Safeguard Issue Date: 2026-07-19 Comment
元ポスト:
AI Agent向けのガードレールで、モデルの安全性からランタイムの安全性を指向して開発されている。エージェントのアクション実行前に、attackを検知し防御するなどの用途に使われる。
How up-to-date is each AI model?, Apoorv Saxena, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #FactualKnowledge #Author Thread-Post Issue Date: 2026-07-19 Comment
330種類の30ヶ月に及ぶ予測不可能なイベントに関する情報を持ちいてモデルの実際のknowledge cutoffを推定する
元ポスト:
Introducing Muse Spark 1.1, Meta, 2026.07
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #AIAgents #MultiModal #Proprietary #VisionLanguageModel #Author Thread-Post Issue Date: 2026-07-19 Comment
元ポスト:
Muse Spark:
- Introducing Muse Spark: Scaling Towards Personal Superintelligence, Meta, 2026.04
大幅にAgenticな能力やコーディング能力が向上。Agenticな能力では多くのベンチマークでOpus4.8超え、CodingはGPT-5.5にベンチマーク上では及ばず(SWE Bench Proでは勝っているが、OpenAIから30%以上のpromptが評価で不適切との報告があった Separating signal from noise in coding evaluations, OpenAI, 2026.07 )。
Alexandr Wang氏によるポスト:
Kimi K3: Open Frontier Intelligence, Moonshot AI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Selected Papers/Blogs #VisionLanguageModel #reading #Reference Collection Issue Date: 2026-07-17 Comment
元ポスト:
Artificial Analysisによる評価:
Artificial Analysis IndexでOpus 4.8超え!?
各ブロックの出力を重みつきで足し合わせることで柔軟にどのブロックにattendするかを決定するattention residualと呼ばれる技術が導入されているように見える。
また、MoEのexpert数をスケールさせ、896 experts, 16 activated expertsに変更。
学習レシピの洗練化と合わせてK2との比較で2.5倍のスケーリング効率が改善され、投入した計算コストをより効果的に知能に変換しているとのこと。
やはり
- [Paper Note] Slicing and Dicing: Configuring Optimal Mixtures of Experts, Margaret Li+, arXiv'26, 2026.05
でも示されているようにexpert数を増やすのが今のところ良さそうに見える。
どうやら2.8Tモデルらしい:
design arenaでFable5超えのSoTA:
writingに関するベンチマークでSoTA:
Latent MoE
- [Paper Note] LatentMoE: Toward Optimal Accuracy per FLOP and Parameter in Mixture of Experts, Venmugil Elango+, arXiv'26, 2026.01
KDA
- [Paper Note] Kimi Linear: An Expressive, Efficient Attention Architecture, Kimi Team+, arXiv'25, 2025.10
Linear TransformerとDelta Net
- [Paper Note] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, Angelos Katharopoulos+, ICML'20
- [Paper Note] Linear Transformers Are Secretly Fast Weight Programmers, Imanol Schlag+, arXiv'21, 2021.02
所見:
Latent MoEによってこれほどのsparsityを実現できているのではという所見:
GDPValでも3位:
Kernel optimizationにおいてもFable5と同等性能という報告:
Next.jsのコーディングベンチマークでもFable5超えのSoTAとのこと:
DeepSWEでGPT-5.6-sol, fable5に次ぐ3位:
アーキテクチャを公開されている情報から再構築した図:
公式ブログの図ではValueにはConvがかかっていないように見えたが、はたして。
The Surprising Power of Small Language Models, Mojan Javaheripi+, Microsoft Research, 2023.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #SmallModel #Slide Issue Date: 2026-07-09 Comment
Phi-2のNeurIPSでの発表資料で、小さいスケールのLLMの学習済みの重みを、より大きなスケールのLLMの初期化に活用するweight reusinhgについて図解されている。実際にこの手法が説明されている文献は、スライド中で引用されている
- [Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
であるため、そちらも併せて参照のこと。上記issueに手法について説明を記載した(正しく読み解けているか少し自信がない)。
Separating signal from noise in coding evaluations, OpenAI, 2026.07
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents #Evaluation #Blog #SoftwareEngineering #Selected Papers/Blogs Issue Date: 2026-07-09 Comment
元ポスト:
SWE-Bench Proの約30%にタスクが評価として機能しないタスクが含まれているとのこと(SWE-Bench Verifiedと同じ流れでは)。
これらは、5人の熟練なソフトウェアエンジニアによる監査と、AI Agentによる監査結果を人間がレビューするプロセスの2つを介して同定された。
以下のようなものがある:
- 過剰に制約されたテスト: 実装の制約が強すぎて機能として正しいのにテストが通らず、かつプロンプトでその制約が明示されていない
- requlrementが不足したテスト: プロンプトでの推測することができない要件の漏れ
- 低カバレッジのテスト: 実装が不完全でも通過するテスト
- ミスリーディングなプロンプト: テストが求める要件とは異なる挙動に向かわせるプロンプト
これにより、OpenAIは以前SWE Bench Proを推奨していたがそれを撤回するとのこと。
SWE Bench Verifiedでも同様の事案があった:
- Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
そしてSWE Bench Verifiedにおけるコンタミネーションやテストの問題点を改善したSWE Bench Proを構築した、という経緯だったはずだが、そのSWE Bench Proでも問題が見つかったという流れである。
あと、そもそもSWE Bench Proで問題のなかった70%で評価したら現在のモデルのスコアはどうなるのだろうか?
interpreting GPT: the logit lens, nostalgebraist, 2020.08
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Blog #Selected Papers/Blogs #Interpretability Issue Date: 2026-07-08 Comment
LLMの中間層のhidden_state(残差ストリーム)に対して、出力層を連結しnext tokenを予測することで、当該中間層でどのようなトークンが想起されているかを可視化する
Verbalizable Representations Form a Global Workspace in Language Models, Anthropic, 2026.07
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Selected Papers/Blogs #Interpretability Issue Date: 2026-07-08 Comment
元ポスト:
関連:
- interpreting GPT: the logit lens, nostalgebraist, 2020.08
本文献の本旨であるJ-Spaceの定義、Global Workspace等の発見の話は元ポストを参照のこと。
以下、J-Lensについて元ポストを参考にメモする。
元ポストによると、logit lens
- interpreting GPT: the logit lens, nostalgebraist, 2020.08
と比較して、本文献で提案されているJacobi Lens (J-lens)は、ある中間層での残差ストリームにおける活性値の摂動が、最終層にどのような影響を与えるかを分析することで、当該中間層における残差ストリームがどのようなトークンを将来出力させる傾向にあるかを可視化する手法、とのことである。元ポスト中の具体例による説明が非常にわかりやすい。
logit lensは中間層の残差ストリームに対して、出力層を用いた線形変換を施して残差ストリーム内でどのようなトークンが想起されているかを可視化するが、J-lensは後段の層に与える影響を考慮して可視化する点が異なる。
Hy3, Tencent, 2026.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #OpenWeight #Selected Papers/Blogs Issue Date: 2026-07-08 Comment
元ポスト:
- Hy3-preview, tencent, 2026.04
の公開後から、50以上のプロダクトからフィードバックを受けより高品質なデータで事後学習を実施したとのこと。
- GLM-5.2: Built for Long-Horizon Tasks, Z.ai, 2026.06
が744B-A40B。Hy3は295B-A21Bなので、半分程度のパラメータ数でフロンティアモデルに近い性能を達成している。
公式:
Introducing Rampart, National Design Studio, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #OpenWeight #Privacy #PII #Author Thread-Post Issue Date: 2026-07-08 Comment
HF: https://huggingface.co/nationaldesignstudio/rampart
生成AIに送信されるリクエストを検閲し、プロンプトに含まれる個人情報をマスクするよう訓練された軽量モデルのようである。ブログ下部のデモンストレーションを見るとイメージを掴みやすい。
元ポスト:
80TB+ of astronomy for the HDD-poor: crossmatch the Multimodal Universe from your laptop, Mike Smith, 2026.06
Paper/Blog Link My Issue
#Article #Dataset #Author Thread-Post Issue Date: 2026-07-08 Comment
元ポスト:
30以上の断片化されたデータソースに基づいて、ソース間を相互参照可能な形式(同じ天体に対して異なる観測をした場合などが該当するようで、以前は紐付けに大規模な計算機リソースが必要、かつ異なる保存形式やフォーマットなどの対応を取る必要があった)にした80TB超の銀河画像やスペクトル、時系列データ、測定値などを含む天文学データとのこと
Devin Fusion: Frontier Performance at 35% Lower Cost, Cognition, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Architecture #read-later #ContextEngineering #Author Thread-Post #AgentHarness Issue Date: 2026-07-07 Comment
元ポスト:
高価で高性能なメインエージェントがタスクを管理し、安価なサイドキックエージェントがメインエージェントからタスクを移譲され処理をするようなアーキテクチャによって、メインエージェントで処理した場合と同等の性能を発揮しつつコストを削減できる。
似たような考え方はAgent Swarmなどでも実施されている。Agent Swarmはハーネスだけでなく、モデル自身もサブエージェントをうまく活用できるような学習のされかたをしている:
- [Paper Note] Kimi K2.5: Visual Agentic Intelligence, Kimi Team+, arXiv'26, 2026.02
Fusion Harness: How to combine a more expensive main model and a sidekick model, Graham Neubig, GithubGist, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #ContextEngineering #MinimalCode #Author Thread-Post #AgentHarness #Gist Issue Date: 2026-07-07 Comment
元ポスト:
openhands SDKを用いて、全体の管理を高性能で高価なメインエージェントにより実施し、個々の作業を安価なサブエージェントに移譲することで、コンテキストを管理しつつパイプライン全体のコスト削減を実施する実装
似たような考え方はAgent Swarmなどでも実施されている。Agent Swarmはハーネスだけでなく、モデル自身もサブエージェントをうまく活用できるような学習のされかたをしている:
- [Paper Note] Kimi K2.5: Visual Agentic Intelligence, Kimi Team+, arXiv'26, 2026.02
報酬ハッキングがモデルの知能向上を食い潰している, Cursor, 2026.06
Paper/Blog Link My Issue
#Article #Analysis #LanguageModel #ReinforcementLearning #AIAgents #Evaluation #Blog #RewardHacking #Selected Papers/Blogs #Contamination #Author Thread-Post Issue Date: 2026-07-05 Comment
元ポスト:
SWE Bench Proにおいて、公開リポジトリやリポジトリの履歴にアクセスすることを厳格に禁止したハーネスを用いてproprietaryモデルを評価したところ標準的なハーネスと比較してスコアが大きく低下した。どれだけスコアが減少したかはモデルごとに異なり、たとえばOpus 4.8系のモデルでは8.1--9.1ポイント程度、GPT5.5系では2.6 -- 3.4%程度スコアが低下した。最近のモデルほどスコアが低下する傾向がある、という話のようである。たとえば、731件のOpus 4.8 Maxのtraceを監査用のモデルを用いて調べると、traceの57%において公開リポジトリでマージ済みのPR、または修正済みのソースファイルを見つけ修正をそのまま再現し、9%程度のtraceで.git履歴からバグ修正前後のコミットを検索しパッチを抜き出していた。モデルが協力になるにつれて、自身が評価中であることを認識し、既に与えられたタスクが解決済みであるためのヒントを見出し、RewardHackingのような挙動を示すような傾向にある、という話のようである。
実際にどの程度スコアに影響を与えていたかが見れるのは興味深い。
Accelerating Transformers Fine-Tuning with NVIDIA NeMo AutoModel, nvidia, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #MoE(Mixture-of-Experts) #PostTraining #Selected Papers/Blogs #Finetuning #reading #EfficientEvaluation Issue Date: 2026-07-05 Comment
わずか数行を追加するだけで、MoEモデルをマルチGPU環境でFinetuningする際のスループットが約3--4倍、メモリ使用量が30%程度削減されるライブラリ。既存のQwen, Nemotron, GPT-OSS, DeepSeek V3などの一般的なMoEアーキテクチャに対して、最適化済みの実装が提供されているとのこと。
repository: https://github.com/NVIDIA-NeMo/Automodel
The Verification Stack, OpenHands, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Coding #SoftwareEngineering #Selected Papers/Blogs #Verification #reading #Author Thread-Post Issue Date: 2026-07-03 Comment
元ポスト:
コードがプッシュされる前にエージェントの作業を評価する小型のcriticモデルと、プルリクエストに対してコードレビュー(スキルを利用)+QAを実施するシステム(実際にエントリーポイントを見つけ、動作させ、証跡を資料としてまとめてレポートをポストするシステム)によってコードの検証プロセスを効率化し、マージまでの時間が平均58%削減され、開発効率が向上する話のようである。
Introducing Claude Sonnet 5, Anthropic, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Proprietary #VisionLanguageModel Issue Date: 2026-07-01 Comment
元ポスト:
Artificial Analysisによる評価:
SWE Bench ProのスコアはOpus 4.8とSonnet 4.8の中間程度
Opus 4.8よりも2倍程度生成されるトークンが長い傾向にあり、結果的にArtificial Analysisによる評価を実施する際にOpus 4,8よりもコストが高くついたとのこと:
Hermes-Agent, Nous Research, 2026.02
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #AIAgents #SelfImprovement #ContinualLearning #AgentSkills Issue Date: 2026-06-27 Comment
Nous ResearchによるAgentSkillsを自己改善していくタイプのAgent Harness (Scaffolding)。2026.0628現在20k star
Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding, Ornith, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #OpenWeight #SoftwareEngineering #PostTraining #Author Thread-Post Issue Date: 2026-06-26 Comment
HF: https://huggingface.co/collections/deepreinforce-ai/ornith-10
元ポスト:
gemma4とQwen3.5をpost trainingしたコーディング特化LLMで、397BモデルではSWE Bench ProでGLM 5.2超え
Ming-omni-tts-16.8B-A3B, inclusionAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #SpeechProcessing #OpenWeight #TTS #AudioLanguageModel #audio #Music Issue Date: 2026-06-17 Comment
元ポスト:
pj page: https://xqacmer.github.io/Ming-omni-tts/
speech/sound/musicを単一のモデルで生成可能
Introducing Omnigent: A Meta-Harness to Combine, Control and Share Your Agents, Databricks, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Author Thread-Post #AgentHarness Issue Date: 2026-06-14 Comment
元ポスト:
ハーネスの上に統一されたAPIを追加し、複数エージェントのハーネスを協調させるメタハーネス
Research ideas you can't be outscaled on., Anthea Li, 2026.06
Paper/Blog Link My Issue
#Article #Blog #Repository #ScientificDiscovery #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-06-11 Comment
元ポスト:
計算リソースやスケールよりも洞察が重要な研究アイデアを共有できるページのようである。興味深い。
LFM2.5-Audio-1.5B-JP, LiquidAI, 2026.06
Paper/Blog Link My Issue
#Article #SpeechProcessing #OpenWeight #Japanese #audio #SpeechToSpeech Issue Date: 2026-06-06 Comment
元ポスト:
LiquidAI初の日本語特化speech-to-speechモデル
LFM2.5-VL-450M-Extract, LiquidAI, 2026.06
Paper/Blog Link My Issue
#Article #SmallModel #OpenWeight #VisionLanguageModel #Author Thread-Post Issue Date: 2026-06-05 Comment
元ポスト:
画像から抽出したい情報をシステムプロンプトに定義することで、json形式で結果を返してくれるVLM
Introducing Gemma 4 12B: a unified, encoder-free multimodal model, Google, 2026.06
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #VisionLanguageModel #2D (Image) #UMM #SpatialUnderstanding #Reference Collection #AudioLanguageModel #audio #Author Thread-Post Issue Date: 2026-06-04 Comment
元ポスト:
vision/audioエンコーダーを無くしたvision/audio nativeなマルチモーダルLLM
HF: https://huggingface.co/google/gemma-4-12B
アーキテクチャ図:
Develop Physical AI Reasoning, World, and Action Models with NVIDIA Cosmos 3, nvidia, 2026.05
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #Selected Papers/Blogs #VideoGeneration/Understandings #Robotics #WorldModels #UMM #reading #Omni #WorldActionModel #Author Thread-Post Issue Date: 2026-06-02 Comment
元ポスト:
公式:
encoder-freeなOmniモダリティモデルで、かつ将来の世界の状態、およびactionを予測可能なWorldActionModel
MiniMax-M3, MiniMaxAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiModal #OpenWeight #Post #Selected Papers/Blogs #VisionLanguageModel #UMM #Reference Collection #Author Thread-Post Issue Date: 2026-06-01 Comment
ベンチマーク上はフロンティアモデルに性能がかなり肉薄しており、10日以内にモデルがオープンになる。
所見:
関連:
- [Paper Note] Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25 Outstanding Paper Award
Artificial Analysisによる評価:
OpenWeightでSoTA
Tips: Containerを利用したDL分散学習Libraryの開発環境, Kazuki Fujii, 2026.05
Paper/Blog Link My Issue
#Article #NeuralNetwork #Blog #Coding #SoftwareEngineering #Author Thread-Post Issue Date: 2026-05-31 Comment
元ポスト:
次:
- MLエンジニアのための本質から理解するLLM推論 KV cache編, Kazuki Fujii, 2026.05
GPUクラスタのログインノード上にvscodeのRemote SSH接続をして作業をする際に、importの解決/補完/定義ジャンプ等のデバッグに有用な機能を有効化する3種類の方法について概説されている。特にその中の一つであるsandbox mirrorと呼ばれる方法は詳細に解説され、SIFをsandbox形式のディレクトリに展開し、その中のディレクトリをvscode側の設定に追加することで、コンテナにsessionをはらなくても有効化できる、といった話が書かれている。
MLエンジニアのための本質から理解するLLM推論 KV cache編, Kazuki Fujii, 2026.05
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #LLMServing #Selected Papers/Blogs #KV Cache #Author Thread-Post Issue Date: 2026-05-31 Comment
元ポスト:
次:
- MLエンジニアのための本質から理解するLLM推論: LLM Inference Benchmarking, Kazuki Fujii, 2026.05
数式レベルで、図解付きで曖昧性なく、非常に丁寧で、かつ実装面にまで踏み込んだ解説だが、冗長ではなくコンパクトに解説されており、すごい。今度からKV Cacheってなんなんですか?の問いにはこの記事をベースに教えよう。感謝🙏
Should we use genetics instead of system prompts for AI Agents & Personas?, Fyx, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #PostTraining #read-later #Personality #Reading Reflections Issue Date: 2026-05-31 Comment
元ポスト:
ゲノム文字列からキャラクターのペルソナを推論し出力に反映可能なLoRAアダプタを学習することによって、ゲノム文字列によってペルソナの条件付けを可能とするモデルに関する実験の報告のようである。
具体的には、まずゲノム文字列と、ペルソナに関するテキストを対応付ける。次に、ペルソナテキストを与えてモデルの応答を収集し、ゲノム文字列と(ペルソナのテキストなしで)収集したモデルの応答を用いてLoRAアダプタを学習する。これにより、LoRAアダプタはゲノム文字列から、ペルソナテキストによって応答づけられた応答を出力することを学習する、といった挙動を実現する。
ざっとみた感じLoRAアダプタとは書かれているが、学習手法が書かれていないような気がする。が、手法はおそらくSFTだと思われる。
これにより、prefillをするinput tokenが削減可能と思われるが、実用上はどちらかというと出力/reasoningトークンが圧縮される方がlatency/コストの双方から恩恵があるので、事後学習をして他の能力が劣化、あるいはAlignmentが悪化するリスクを背負ってまでやる価値があるかは怪しいな、という感想を持ったが、果たしてどうだろうか。
非常に大規模なユーザからの同時接続があり、キャラクターと対話できるようなサービスにおいて、キャラクターのペルソナテキスト(用途はペルソナだけには限らない汎用的な技術だと思うが)が97%圧縮できたら結構なインパクトがあるかもしれない。
DeepSWE: Measuring frontier coding agents on original, long-horizon engineering tasks, DeepSWE, 2026.05
Paper/Blog Link My Issue
#Article #NLP #Dataset #AIAgents #Evaluation #Coding #SoftwareEngineering #read-later #Selected Papers/Blogs #LongHorizon #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
所見:
既存のベンチマークのような、githubのPRに基づいたものではなく(memorizationの問題があるため)、ゼロベースで構築。rolloutのtrajectoryを分析して、有効なPRなのに拒否する、あるいは何らかのcheatingをするといった挙動のdetectionもできるとのこと。また、SWE Bench Proと比較して、タスクを解くためのpromptは1/2である一方、タスクを解くために必要なコードの量は5.5倍となっており、より複雑なタスクとなっている。
contamination-freeが主張されているが、データセットは公開されているので、そのうちcontaminationが生じるであろう点には注意。
Introducing 1-bit and Ternary Bonsai Image 4B: Image Generation for Local Devices, PrismML, 2026.05
Paper/Blog Link My Issue
#Article #ComputerVision #DiffusionModel #TextToImageGeneration #SmallModel #Selected Papers/Blogs #ImageSynthesis #LowPrecision #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
HF: https://huggingface.co/collections/prism-ml/bonsai-image
Ternary Weight {-1, 0, 1}による画像生成モデル
MagicLite, Microsoft, 2026.05
Paper/Blog Link My Issue
#Article #ComputerVision #Tools #NLP #SmallModel #ComputerUse #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
Faraを用いたブラウザベースのChatUIを備えたCUAで、ローカルストレージへのアクセスも可能な模様
Hy-MT2-30B-A3B, Tencent Hy, 2026.05
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #LanguageModel #MultiLingual #OpenWeight #Author Thread-Post Issue Date: 2026-05-27 Comment
HF: https://huggingface.co/collections/tencent/hy-mt2
元ポスト:
テンセントによる1.8B--30BのMT特化モデルファミリー。fast thinkingが強みとのこと。
Agent Evaluation: A Detailed Guide, CAMERON R. WOLFE, PH.D., 2026.05
Paper/Blog Link My Issue
#Article #Tutorial #LanguageModel #AIAgents #Evaluation #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
ざーっとしか眺められていないが、AI Agentの基礎的な話と、実際のtool useをした場合のレスポンスの例を踏まえた動作の説明や、Scaffoldingとは何か/multi-agentとは何か/context engineeringとはといった説明をし、その後AI Agentの評価の方法の体系的な枠組みと、具体的なベンチマークとして tau-bench/terminal-benchを挙げて解説されている。これを読んだらAI Agentとはなんぞやから、評価までかなり理解できるのではないだろうか。
Terminal-Bench Science: Evaluating AI Agents on Real-World Computational Workflows in the Natural Sciences, harbor-framework, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Repository #ScientificDiscovery #Science #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
ターミナル上でのscienceに関するワークフローを定義しAI Agentを評価することで、教科書的な知識を問うのではなく、より複雑で実践的なタスクによる評価をしたい、というモチベーションのpjで、Discordを通じてタスクを生成するcontributorを募集しているようである。
Nemotron-Labs-Diffusion-14B, Nvidia, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel #OpenWeight #LLMServing #SpeculativeDecoding #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
3つの生成モード: AR/dLM/Hybrid を備えたLLM(VLM variantも存在)ファミリーで、ARモードでは一般的な自己回帰的な生成をし、dLMモードでは拡散モデルに基づくparallel decodingを実施、hybridではdLMでドラフト作成、ARでverificationを実施するSpeculative Decoding (self-speculation)を実施する。これらモードは内部のattention patternを変化させることでシームレスに切り替えられ(シームレスモード)期待されるconcurrencyに応じて柔軟に対応ができるようである。
シームレスの粒度がどの程度のものかはよくわからない。concurrency levelを検知して、それに応じて動的に切り替わったりするのだろうか。
Speculative Decodingの高速化手法としては以下のようなものもある:
- [Paper Note] TriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification, Haoyun Jiang+, arXiv'26, 2026.01
より安全で透明性の高い AI エコシステムに向けて、コンテンツ来歴の取り組みを前進, OpenAI, 2026.05
Paper/Blog Link My Issue
#Article #ComputerVision #TextToImageGeneration #Proprietary #2D (Image) #ImageSynthesis #AI Detector #Author Thread-Post Issue Date: 2026-05-27 Comment
元ポスト:
画像生成にSynthID追加、また、画像がChatGPT, Codex, OpenAI APIから生成されたものかを判定するツールの一般向けプレビューを開始
https://openai.com/ja-JP/research/verify/
General Agent: A Self-Evolving, Synthetic Agent Environment, Mika, PRIMEIntellect, 2026.05
Paper/Blog Link My Issue
#Article #General #NLP #LanguageModel #AIAgents #SyntheticData #reading #Environment #ToolUse #Author Thread-Post Issue Date: 2026-05-27 Comment
environment: https://app.primeintellect.ai/dashboard/environments/primeintellect/general-agent
元ポスト:
著者ポスト:
約1000のドメイン、約4500タスク、約8000種類以上の独自のツールを持つ、汎用エージェント学習のための学習環境とその構築方法。タスクを生成するAIとそれに対して解答するAIを用意し、解答がどの程度正解していたかによって難易度を同定しフィルタリング等を行いつつ、生成されたタスクをacceptするか否かを決定する。実際に構築された環境でRL/SFTを実施したところ、未知のベンチマークに対して性能が反化することも確認したとのこと。
Autonomous AI research for nanogpt speedrun, PrimeIntellect, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #ScientificDiscovery #Author Thread-Post Issue Date: 2026-05-21 Comment
元ポスト:
nanogpt speedrun
- Modded-NanoGPT, KellerJordan, 2024.05
autoresearchをnanogpt speedrun (Track 3)で実施したところ、人間の最高記録を上回ることに成功した。この記録は既存のアイデアの組み合わせや、ハイパーパラメータの探索などによって等のもたらされた。一方で、完全に新規のアイデアの創出し改善するには上流にいる人間のヒントが必要となる弱点があることも浮き彫りになった。
AI Agentごとに挙動の性質が異なりOpus(Claude Code)は自律的なループを停止してしまったり、GPT(Codex)は自律的なループが止まることはないものの、同じハイパーパラメータを何度も繰り返し探索するなどの現象も見受けられた。
関連:
Toto 2.0: Time series forecasting enters the scaling era, DATADOG, 2026.05
Paper/Blog Link My Issue
#Article #TimeSeriesDataProcessing #MachineLearning #Transformer #FoundationModel #OpenWeight Issue Date: 2026-05-21 Comment
HF: https://huggingface.co/collections/Datadog/toto-20
時系列予測の基盤モデルも、パラメータサイズに対して性能がスケールする(ということが初めて示された)
Composer 2.5 の紹介, Cursor, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #SyntheticData #Optimizer #mid-training #On-Policy #Reference Collection #SelfDistillation Issue Date: 2026-05-20 Comment
元ポスト:
- trajectory中の不適切な箇所にヒントを挿入したcontextを用いたself-on-policy distillation
- Composer 2から25倍の量の合成タスクデータの利用。タスクは特定のテスト可能な機能をコードベースからablationすることによってverifiableなタスクを作成
- mid-trainingではMuonを利用し、expertが複数のノードにシャーディングされているため、all-to-allと呼ばれる処理によって重み行列全体を復元しMuonの直行化を実施し、同じくall-to-allという処理で重みを再びシャーディングするらしい。これらは非同期で実行される。
- dual mesh HSDPと呼ばれるものも利用されているようだがよくわかっていない
関連:
- Composer 2 のご紹介, Cursor, 2026.03
artificial analysisによる評価:
所見:
学習の規模感に関する所見:
所見:
ZAYA1-VL-8B: Efficient Open Visual Intelligence, ZYPHRA, 2026.05
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #SmallModel #OpenWeight #MoE(Mixture-of-Experts) #VisionLanguageModel Issue Date: 2026-05-12 Comment
HF: https://huggingface.co/Zyphra/ZAYA1-VL-8B
元ポスト:
画像トークンには双方向のattentionを適用できるようなアーキテクチャを採用
Marco-MoE: A suit of multilingual MoE models with highly-sparse architectures, AIDC-AI, 2026.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) #CurriculumLearning Issue Date: 2026-05-12 Comment
元ポスト:
4 stageのカリキュラムによって学習されているようで、学習が進むにつれて、広く使われる英語やreasoning, instructionなどのデータは減らし、low resourceな言語のデータを増やしていき最終的にマルチリンガルなデータを支配的にするような学習レシピとなっているようである。
Multi-Teacher On-Policy Distillation: A New Post-Training Primitive, Yumo Xu, 2026.04
Paper/Blog Link My Issue
#Article #Multi #Tutorial #NLP #LanguageModel #ReinforcementLearning #Blog #Distillation #PostTraining #Selected Papers/Blogs #On-Policy Issue Date: 2026-05-08 Comment
元ポスト:
(multi teacher)オンポリシー蒸留の解説を、気持ち(何かに特化させると、他の部分が劣化していて、多方面に優れたモデルを学習するのが難しい課題を克服したい)だけでなく、
GRPOに対してAdvantage部分を生徒と教師モデルのreverse KLに置き換えることで統合できるよ、という説明と、
なぜreverse KLを使うのかという説明[^1]、
最近の最先端のOpenLLMにおいてmulti teacher オンポリシー蒸留がどのように使われているかが丁寧に説明されている。
[^1]: forward KLだと教師が少しでも確率を持つトークンにおいて生徒の確率が0だと発散するのでスムージングされた分布になってしまい、特定のトークンにフォーカスした分布が形成されづらく、テキスト生成の多峰性と(意味不明な出力をできるだけ回避するという意味での)安全性の観点からreverse KLの相性が良いよ、という話)
関連:
- 【LLM】On-Policy Distillation入門:小規模モデルを「実戦」で育てる技術, Currently Learning そんけいご, Zenn, 2026.02
解説と所見:
AgentTrove, open-thoughts, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents #Coding #Mathematics #SoftwareEngineering #ComputerUse Issue Date: 2026-05-06 Comment
元ポスト:
219のデータソースに対する170M規模のcoding, terminal/computer use, mathに関するagentのtrajectory。trace自体は、Agentic HarnessとしてTerminus 2を用いたOpenThinker-Agent-v1によるものだと推察される。
OlmPool: How small architectural choices compound to undermine long context extension, Ai2, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Transformer #Attention #LongSequence #Architecture #read-later #Selected Papers/Blogs #ContextRot #Author Thread-Post Issue Date: 2026-05-01 Comment
元ポスト:
QK Norm, GQA, SWA, 事前学習のcontext長の短縮、これらはいずれもモデルが入力に対するattendの仕方を変えるものだが、これらを3つ以上組み合わせるとlong contextでの性能が急落するらしく、このようなlong contextの性能劣化は一般的な(しばしば短い)コンテキスト長のベンチマークやloss/perplexityなどでは検知できず、long contextで性能が急落するアーキテクチャでは、50Bトークンでのlong contextの学習を経ても、Llamaアーキテクチャが1Bトークンの学習で到達できる性能に届かない、といった話が元ポストに書かれている。
Project Deal, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #AIAgents #Personalization #read-later #Sales Issue Date: 2026-04-26 Comment
元ポスト:
AI同士が商取引をしたら何が起きるかという社内実験のようである。69人の社員に何を売りたいか/買いたいををインタビューし、カスタム指示が与えられた上でAI Agentに取引をさせたところ、きちんと商取引が行われ、186件、$4000のやりとりがあったとのこと。そして賢いモデルが大幅に有利に取引を終えて、実際の参加者はこの事実に気づかなかったとのこと。また、カスタム指示(e.g., 強行姿勢, 礼儀正しいなど)はあまり良い成果を上げる上では重要ではなかった、
といった話が元ポストに書かれている。
What 81,000 people told us about the economics of AI, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #Analysis #GenerativeAI #Blog #read-later #Selected Papers/Blogs #Author Thread-Post Issue Date: 2026-04-25 Comment
元ポスト:
賃金が最も小さいグループ、おより最も高いグループではClaudeによる生産性向上が最も大きく、職を失う懸念も同時に大きい。同様に、Claudeの利用量が多いグループも職を失う懸念が大きい。
アメリカにおいて代替されると思っていたソフトウェアエンジニアの求人がむしろ増えていて、AIによって新たな雇用が生まれているという意見もある:
vismatch (formerly Image Matching Models), gmberton, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #Library #2D (Image) #needs-revision #Author Thread-Post Issue Date: 2026-04-25 Comment
元ポスト:
50種類以上のimage matchingモデルを統一的なinterfaceでシームレスに利用可能なライブラリとのこと
Anthropic Just Dropped the Biggest Subagent Upgrade Yet, Ray Amjad, YouTube, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Video #ContextEngineering Issue Date: 2026-04-24 Comment
元ポスト:
サブエージェントを構築する際に、メインエージェントの過去のcontextを全て継承することが可能な方式が実装されたようで(従来はcontextをメインとサブが共有しない方法が主流)、サブエージェントはメインエージェントのcontextを全て使いresultを得て、resultのみをメインエージェントに返すような挙動が実現可能。
Introducing GPT‑5.5, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ChatGPT #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection #Reading Reflections #Author Thread-Post Issue Date: 2026-04-24 Comment
元ポスト:
- FrontierMath, Terminal-Bench, GDPValでOpus 4.7を上回りダントツのトップ
- Artificial Analysis IndexでもOpus 4.7超え
しかし、Terminal-Benchは"ターミナル操作を通じた多様、かつlong horizonなタスクを評価する(多くはソフトウェアエンジニアタスクであるコーディングもタスクには含まれるが)"のベンチマークであり、SWE Bench Proのような一般的なcoding能力を測るベンチマークのスコアが掲載されていない。HLEやVisual Reasoning系のベンチマークのスコアも報告されていないように見える。
恣意的にGPT-5.5が強いデータ、比較対象をピックアップしているのではないか、という印象を持った。
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
- Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
Artificial Analysisによる評価:
所見:
サイバー分野でMythosと同等?
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model, Qwen Team, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #OpenWeight #SoftwareEngineering #Author Thread-Post Issue Date: 2026-04-23 Comment
HF: https://huggingface.co/Qwen/Qwen3.6-27B
元ポスト:
Qwen3.5-397B-A17Bを主要なcodingベンチマークで上回り、同等程度の規模感のdenseモデルを上回る。
Qwen3.6-Max-Preview: Smarter, Sharper, Still Evolving, Qwen Team, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary Issue Date: 2026-04-21 Comment
Qwen3.6-plusと比較して、より強力な世界知識とIF、Agentic Codingの能力を持つとのこと。ブログ中のベンチマークはClaudeに関してはOpus 4.5との比較である点に注意。Proprietaryです。。。
Designing synthetic datasets for the real world: Mechanism design and reasoning from first principles, Google, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #SyntheticData #Distillation #read-later #Selected Papers/Blogs #Reference Collection #Critic #Reading Reflections #Human-in-the-Loop #Author Thread-Post Issue Date: 2026-04-19 Comment
元ポスト:
公式:
解説:
(詳細は解説や元ブログ参照のこと)
強い教師モデルから弱い生徒モデルを学習する場合の合成データ生成手法で、
生成したいデータの観点(内容、形式等)を分類し、どの観点からどの程度の難易度のデータを合成するかを制御する。その後生成されたデータが正しいか/正しくないかの2方向から批評を行いvalidationをするような枠組みのようである。
単純なデータ合成では性能がすぐに頭打ちになるが、ローカル多様性(特定のパターンの多様性)、グローバル多様性(データ全体がカバーするパターンの範囲)の2つを同時に大きくしないと不十分であることや、批判によるvalidationは少なくとも性能を悪化させることはないことも示されたとのこと。
nanomem: An Extremely Simple, Inference-Time Memory Module, The Open Anonymity Project, 2026.04
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #AIAgents #Personalization #SoftwareEngineering #Selected Papers/Blogs #Privacy #memory Issue Date: 2026-04-19 Comment
github: https://github.com/OpenAnonymity/nanomem
元ポスト:
マークダウン形式でメモリを管理するシンプルな実装で、シンプルながらもさまざまな利点を持つとのこと:
- マークダウンで管理されているためメモリ情報をディレクトリ分けするだけで簡単に分離できる
- ただのテキストファイルなので可用性が高く、ユーザ自身が保持できる
- テキストファイルなのでなので、解釈ができ、ユーザ自身が編集できる
- 前方互換性があり、モデルが賢くなっても同じ方法でメモリを読み込め、モデルの性能が上がるとメモリ自身の性能(スピード、品質)も向上する
- モジュール化が可能で、取り込み、検索、圧縮などを個別に最適化できる
Act I:
- Unlinkable Inference as a User Privacy Architecture, The Open Anonymity Project, 2026.02
Gemini 3.1 Flash TTS: the next generation of expressive AI speech, Google, 2026.04
Paper/Blog Link My Issue
#Article #NLP #SpeechProcessing #Blog #Proprietary #Selected Papers/Blogs #TTS Issue Date: 2026-04-17 Comment
元ポスト:
`[sighs]`, `[laughs]`, `[gasp]`, `[cough]`, `[deep and loud]` などのaudio tagで声の調子やトーンなどの非言語的な要素までpromptingでコントロール可能なTTSとのこと(audio tagの定義は任意にできるのだろうか?)。元ポストにサンプルが貼られているが、感情表現が非常に豊かにきこえる。
PAW: Define functions in English. Run them locally, ProgramAsWeights, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Coding #PEFT(Adaptor/LoRA) #SoftwareEngineering #Author Thread-Post Issue Date: 2026-04-17 Comment
元ポスト:
英語で説明した機能をNeural Compilerと呼ばれる機構によって、text + Continuous LoRA (Continuous LoRAってなんだ。。。) によってインタプリタを構築し、python関数として利用できる、という感じらしい?
.pawファイルと呼ばれるファイルが作成され、中には
- Discrete pseudo-program: neural compilerによって生成されたtext instructions
- continuous neural adapter: 量子化されたLoRA adapter
が格納されて実行時に利用されるとのこと。完全にローカルで動作させられる。
LoRAを使うということは、事前に関数を実行するbase modelのDLが必要そうだが、どうなのだろうか?.pawファイルの例にも特定のベースモデル名が記載されているように見える。
FrontierSWE: Benchmarking coding agents at the limits of human abilities, FrontierSWE, 2026.04
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents #Evaluation #SoftwareEngineering #LongHorizon #Author Thread-Post Issue Date: 2026-04-17 Comment
元ポスト:
WAN2.1の推論パイプライン構築、llmのpost-trainingをしてlogic gameができるように学習させる、など、long horizonかつ非常に現実的なタスクで評価される
Introducing GPT‑Rosalind for life sciences research: A new purpose-built model to accelerate scientific research and drug discovery., OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary #Medical #Biological #Author Thread-Post Issue Date: 2026-04-16 Comment
元ポスト:
Life Sciencesドメイン特化モデル
Trusted access for the next era of cyber defense, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary #Security #Author Thread-Post Issue Date: 2026-04-15 Comment
GPT-5.4をサイバーセキュリティユースケースに特化してチューニングしたGPT-5.4-Cyber
元ポスト:
Introducing ERNIE‑Image, Baidu, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Transformer #DiffusionModel #TextToImageGeneration #OpenWeight #Selected Papers/Blogs #2D (Image) #ImageSynthesis #Author Thread-Post Issue Date: 2026-04-15 Comment
HF: https://huggingface.co/baidu/ERNIE-Image
ERNIEからtext-to-imageモデルがOpenWeightモデルとしてリリース。ベンチマークとしては公式ブログ上ではOpenWeightモデルの中でトップで、nano banana 2.0に匹敵するようなスコアが出ているように見える
Distilling 100B+ Models 40x Faster with TRL, Hugging Face, 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Blog #Distillation #Author Thread-Post Issue Date: 2026-04-13 Comment
元ポスト:
on-policy蒸留(生徒モデルが生成したロールアウトに対して教師モデルが評価を与える方式)を、バッチ処理や、生徒モデルと教師モデルの通信量を削減するためバイナリ形式に変換してやり取りするなどの工夫をして高速化した話とのこと。
著者ポスト:
The advisor strategy: Give agents an intelligence boost Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost., Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #AIAgents #Blog #Reading Reflections Issue Date: 2026-04-11 Comment
元ポスト:
Strong Modelをツールとして登録(Advisor)しておき、意思決定が困難になった場合はstrong modelにレビュー依頼をしてcontextを受け取り実行可能な枠組み。
Sonnetで12パーセント程度省コストで、SWE Bench Multilingual のスコアを2.7%向上、とのこと。
SWE Benchの結果は、Claute Opus 4.6をAdvisorとして利用した旨が脚注に書かれている。
下記システムカードによると、Opus 4.6 の SWE Bench Multilingualのスコアは77.83程度(細かい設定は追えていない)、元ポストのSonnet+Advisorのスコアは74.8%なので、near Opusな性能が出るとポストに記載されているが、そのくらいのgapがあるという点には注意が必要。
https://www-cdn.anthropic.com/6a5fa276ac68b9aeb0c8b6af5fa36326e0e166dd.pdf
Memento: Teaching LLMs to Manage Their Own Context
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #LanguageModel #Selected Papers/Blogs #ContextEngineering #KV Cache #Author Thread-Post Issue Date: 2026-04-11 Comment
元ポスト:
著者によるtakeaway:
頻繁に要約を作成することが大事で、SummaryのKV Cacheを再計算してはいけない(すなわち、推論をrestartしてはいけない)。なぜなら、SummaryよKV Cacheには仮に当該ブロックがなかったとしても過去のコンテキストの情報が残っているから。という話が書かれている。なるほど。
dataset: https://huggingface.co/datasets/microsoft/OpenMementos
所見:
Introducing Muse Spark: Scaling Towards Personal Superintelligence, Meta, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #Proprietary #read-later #Selected Papers/Blogs #VisionLanguageModel #Reference Collection #Author Thread-Post Issue Date: 2026-04-11 Comment
元ポスト:
-
-
元ポストのベンチマークスコアを見るとマルチモーダルの性能はフロンティアモデル(gpt5.4, Opus 4.6, Gemini 3.1 Pro)と同等、text/reasoningはフロンティアモデルより少しスコアが低く、特に抽象的な思考が苦手(ARC-AGI-2)。HEALTH分野はhealthは高スコアだがmedicalは少し低めのスコア、Agenticな分野では、SWE Bench Verified/Proよスコアは少し低め、terminal useは明確にスコアが低くtool useは少しスコアが低い、という感じにみえる。
codingとlong horizon taskに継続的に投資するとのこと。
中の人による解説:
全てをフルスクラッチから作り直したっぽい。
Artificial Analysisによる解説:
一気にOpenWeight最強のGLM-5.1超え
所見:
所見:
所見:
第三者によるおそらく独自のベンチマークによる評価の結果、(おそらく101モデルのうち)全体で3位となっているらしい(つまり、既存ベンチマークにoverfittingしているわけではないという考えがある)。
ハーネスエンジニアリングのすすめ: 27BモデルでSWE-bench VerifiedのSLM SOTAを達成 (TTS@8=74.8%), Fujitsu Tech Blog, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Test-Time Scaling #SoftwareEngineering Issue Date: 2026-04-11 Comment
元ポスト:
Best-of-8 SamplingでSWE Benchのスコアを改善する話
1bit 量子化技術の紹介, Fujitsu Tech Blog, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Quantization #Blog Issue Date: 2026-04-09 Comment
関連:
- OneCompression, FujitsuResearch, 2026.04
元ポスト:
プレスなので概要のみで、細かい手法については記述されていなかった。が、QEP, QQAと呼ばれるNeurIPS2025, ICLR2025に採択済みのモデルで、それぞれ層を跨いで量子化誤差を伝播させることでエラーの増大を防ぐ手法(任意のbit数に適用可能)、量子力学の量子性に着想を得た大規模最適化問題で高い性能を発揮する手法、とのことのようである。
元ポストの方が技術的な面は詳しく書かれている。
Project Glasswing Securing critical software for the AI era, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Safety #Selected Papers/Blogs #Reference Collection #Safeguard #Reading Reflections Issue Date: 2026-04-08 Comment
元ポスト:
Claude Mythos Previewが、ソフトウェアの脆弱性を見つける能力において、トップクラスの人間を除けば、あらゆる人間以上の能力を獲得してしまっており、これがサイバーセキュリティの概念を根本的に変化させてしまう危険がある。
実際、同モデルは数千にも及ぶ深刻な脆弱性を発見しており、それはOSやブラウザにも及び、これが経済や国家安全保障などに影響を及ぼすため、緊急のproject Glasswingを立ち上げており、まずは今回挙げたパートナーにClaude Mythos Previewにアクセス可能な無料のクレジットを与え、セキュリティに関する脆弱性を改善することで、セーフガードを確立し、その結果得られた知見をAnthropicがまとめて公表する、そしてその後パートナーはさらに拡大していく、という感じらしい。
しかし最近中国のOpenWeightモデルは、2ヶ月程度で米国のFrontier Modelに追いつく。では2ヶ月あとに中国系のOpenWeightモデルがClaude Mythos Previewの性能に追いついてOpenWeightとして公開された場合、世界はどうなってしまうのだろうか?
また、現在は以下の企業と連携してセーフガードを構築するようだが、これらグローバル企業以外の日本の企業はどうなるのだろうか?今後40以上の組織とも連携するようにする予定とのことだが、日本の社会を支えている企業群と連携するのはいつなのか?
所見:
所見:
しかしこれ、Claude Mythos Previewによって初めてこのようなことが起きたかのように書かれているけど、既知の脆弱性を見つけて悪用するというのは、既に公開されているOpenWeightモデルや、プロプライエタリモデルでも十分可能なのでは?
なぜいまさらこのようなことを言い始めたのだろうか。
所見:
GPT-5.4でも15年前のLinux Kernelの深刻なバグを見つけたよ、という話:
Update:
https://www.anthropic.com/research/glasswing-initial-update
元ポスト:
System Card: Claude Mythos Preview, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection Issue Date: 2026-04-08 Comment
Mythos Previewは一般公開する予定はなく、まずは安全性を高めることに注力するとのこと。
元ポスト:
- Project Glasswing Securing critical software for the AI era, Anthropic, 2026.04
も参照のこと。要はソフトウェアの脆弱性を見つけて悪用する能力が高すぎて、このまま公開するとサイバーセキュリティが終わるので、まずは未然にセーフガードを構築するために公開は控えるということである。
所見:
所見:
MemPalace: The highest-scoring AI memory system ever benchmarked. And it's free, milla-jovovich, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenSource #SoftwareEngineering #Selected Papers/Blogs #memory Issue Date: 2026-04-07 Comment
元ポスト:
過去の会話履歴に関してrelevantなもののみを保持しておくのではなく、全てを保持し必要に応じて見つけるようなアプローチをとるopensourceな実装で、API, クラウドストレージなどを用いず完全にローカルで動作し、LongMemEvalと呼ばれるベンチマークにおいて100%を達成したとのこと。気になる。
オープンソースAIの現状 | NVIDIA GTC, Nvidia, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Video #OpenSource #read-later Issue Date: 2026-04-07 Comment
元ポスト:
GTCのパネルディスカッション
AutoAgent: first open source library for self-optimizing agents, Kevin Gu, 2026.04
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Repository #Selected Papers/Blogs #AgentHarness Issue Date: 2026-04-04 Comment
github: https://github.com/kevinrgu/autoagent
Automatic Prompt EngineeringやAutoAgentと同様に、何らかの実施したいタスクのtest suiteがあり、performance metricを取得する前提で、Agnet Harnessを自動的にチューニングするという話のようである。
test dataが十分にある場合は非常に強力だと思われるが、test dataが少量、あるいはない場合では適用は難しい可能性がある。そのような場合はRubric-as-a-Reward+Strong LLMのような方法がtest suiteの代替になるかもしれないが、どこまでうまくいくだろうか。
CuLA, InclusionAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Attention #SoftwareEngineering #GPUKernel #LinearAttention Issue Date: 2026-04-04 Comment
元ポスト:
Hopper(SM90), Blackwell(SM10X)において、flash-linear-attention(FLA)よりも最大2.45倍、平均1.52倍速いlinear attention kernelらしい
約12兆トークンの良質なコーパスで学習した新たな国産LLM「LLM-jp-4 8Bモデル」「LLM-jp-4 32B-A3Bモデル」をオープンソースライセンスで公開 ~一部ベンチマークでGPT-4oやQwen3-8Bを上回る性能を達成~, NII, 2026.04
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Reasoning #OpenWeight #Japanese #OpenSource #mid-training #Selected Papers/Blogs Issue Date: 2026-04-03 Comment
8BモデルはLlama-2アーキテクチャ、32B-A3.8BモデルはQwen3-MoEアーキテクチャで、フルスクラッチ学習をすることで実現[^1]。
19.5Tトークン(概算として、日本語0.7Tトークン、英語17.8Tトークン、中国語・韓国語0.85Tトークン、プログラムコード0.2Tトークン)のインターネット上の公開データや政府・国会の文書を収集し(LLM-jp-3.1のデータの6倍の規模)し事前学習データを構築、DataMixtureを最適化し10.5Tトークンを事前学習で利用。
中間学習では、事前学習データにInstruction Pretraining[^2]データを含む合成データを加え1.2Tトークンを利用。
その後最終的にInstruction Tuningを、日本語、英語合計22種類のデータで実施(元記事ではチューニングと呼称されているがおそらくInstruction Tuningだと思われる)。
MTBenchでは、GPT-4o, gpt-oss-20B, Qwen3-8Bと同等以上の性能、日本語MTBench[^3]では、GPT-4o, gpt-oss-20B, Qwen3-8Bを上回る性能とのこと。MTBenchで用いるLLM-as-a-JudgeのモデルとしてはGPT-5.4を利用とのこと。
[^1]: つまり、モデルのパラメータは完全に新規で学習されており、ベースとして既存OpenWeightモデルを利用していない点に注意。
[^2]: Instruction Pretrainingは、LLM-jp-3.1の頃から実施されている:
LLM-jp-3.1 シリーズ instruct4 の公開, LLM-jp, 2025.05
[Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, arXiv'24, 2024.06
[^3]: MT-Benchの概要については
[Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
も参照のこと。
フルスクラッチモデル点に関する説明:
HF:
https://huggingface.co/collections/llm-jp/llm-jp-4-models
Reasoningモデルもある!!!
関連:
- PLaMo 3.0 Prime β版, PFN, 2026.03
上記PLaMo 3.0に続いて、国内でのフルスクラッチReasoningモデルは二例目だろうか。
Gemma 4: Byte for byte, the most capable open models, Google, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #AIAgents #MultiModal #SpeechProcessing #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #3D (Video) #Reference Collection #AudioLanguageModel #audio #text #Initial Impression Notes Issue Date: 2026-04-02 Comment
元ポスト:
2B, 4B, 26BのMoEモデルと31BのDenseモデルの4種類のモデルファミリーで、マルチモーダル(vision)対応。2B, 4Bはaudioも入力として扱える。
edgeデバイス向けのモデルは128k, 他は256kのコンテキストウィンドウ。140+の多言語サポート。
Apache 2.0ライセンス
arenaで同サイズのモデル群でSoTAといった話がブログ中に記述されている。
モデルカードには一般的なベンチマーク群とのスコアも記載されている。
https://ai.google.dev/gemma/docs/core/model_card_4?hl=ja
(そもそも既存のベンチマークにもコンタミネーションがあると思われるが、)arenaに関しては特定の企業に対してデータを提供し、複数のモデルの亜種をテストできるという慣行があり、リーダーボードにバイアスがあるであろう点には注意:
- [Paper Note] The Leaderboard Illusion, Shivalika Singh+, NeurIPS'25
artificial analysisによる評価:
Qwenがproprietaryになったことから、ライセンス的に使いやすく、日本語に強そうなモデルとしては筆頭ではなかろうか。日本語性能が気になる。
アーキテクチャ解説:
ポイント解説:
所見:
attentionのscaleをsqrt(d)でスケールさせる代わりに、QK-norm, V normを適用するなど。
NvidiaによるNVFP4へのpost-trainingによる量子化:
https://huggingface.co/nvidia/Gemma-4-31B-IT-NVFP4
量子化後の性能も比較されており、知識、数学、コーディング、terminac useなど6種類のベンチマークでオリジナルのモデルと遜色ない性能が出ている旨記載されている。
解説:
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4
所見(encoder-freeにした裏側でパッチ化→projection + x/y軸のpositional embeddingを実施している話):
Holo3: Breaking the Computer Use Frontier, H Company, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #MultiModal #OpenWeight #MoE(Mixture-of-Experts) #ComputerUse #read-later #VisionLanguageModel #GUI #Environment Issue Date: 2026-04-02 Comment
元ポスト:
HF: https://huggingface.co/Hcompany/Holo3-35B-A3B
関連:
- Holo2: Cost-Efficient Models for Cross-Platform Computer-Use Agents, H Company, 2025.11
Qwen3.5をファインチューニングすることで実現。以前のシリーズもQwenベースだったが、新たなQwenのリリースに伴いより強力なベースモデルを得て、かつシナリオをベースにして自動でwebsiteを構築しverifiableが可能な独自のEnvironmentを保持しており、多様な合成データの活用とRLを実現することで、性能が向上していると思われる。
OneCompression, FujitsuResearch, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Quantization Issue Date: 2026-04-01 Comment
元ポスト:
example_autorun.pyを見るとわかるが、ワンライナーで(post-training basedな)量子化をしたいモデルのコンフィグを渡して実行するだけで、自動的にGPTQ量子化など(DBF, RTNと呼ばれる方式もあるようだ)をしてくれるライブラリのようである。現在はLlama, Qwen3をサポートしており、今後も適用可能なモデルは拡張していく予定と書かれている。また、量子化したモデルはvLLMとの互換性も担保される。
サポートされているアルゴリズムはこちらにまとまっていそう:
https://fujitsuresearch.github.io/OneCompression/algorithms/overview/
calibration dataは何が用いられるのだろうか?
関連:
RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens, together.ai, 2023.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #OpenSource Issue Date: 2026-03-31 Comment
完全なオープンソースLLMの構築を目指すprojectで、LLaMAの学習データを再現する取り組み。
chandra-ocr-2, datalab-to, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #MultiLingual #OpenWeight #Selected Papers/Blogs #VisionLanguageModel #OCR Issue Date: 2026-03-21 Comment
元ポスト:
日本語の認識性能がGemini-2.5-Flashよりも高い。マルチリンガルでの認識性能がこらほど網羅的に列挙されているのはありがたい。
hugging-face-paper-pages, NielsRogge, 2026.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents #AgentSkills Issue Date: 2026-03-20 Comment
HuggingFace Paper Pagesと連携するためのAgent Skills
LiteParse, run-llama, 2026.03
Paper/Blog Link My Issue
#Article #Tools #NLP #Repository #DocParser Issue Date: 2026-03-19 Comment
元ポスト:
GPU無しで500ページを2秒程度で処理でき、50種類以上のフォーマットに対応した非VLM依存のparser
5 Agent Skill design patterns every ADK developer should know, Google Cloud Tech, X, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Post #SoftwareEngineering #Selected Papers/Blogs #AgentSkills Issue Date: 2026-03-18 Comment
Agent Skillsの定義の仕方による性能差については下記を参照のこと:
- [Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
以下の5つのPatternが紹介されている:
- Tool Wrapper
- Generator
- Reviewer
- Inversion
- Pipeline
最終的にどのようなPatternを採用すべきかの判断となるフローチャートも提供されている。
全体的なポイントとしては、
- 各種SKILLS.mdにはhowを記述し(e.g., 具体的な実行のstepを記述するなど)、
- 実行内容やルールなどの"what"に関する情報は別のドキュメントに移譲し、SKILLS.mdにはそのポインタを記述する、
- ユーザの承認なしで先へ進まないようにするには、ユーザに何らかの質問・承認を求めるよう指示を明示的に記述する
といった作法である。一つの巨大で複雑なSKILLS.mdやsystem promptを作るのではなく、内容をbreak downして記述やドキュメントの構造を設計するのが肝要と感じる。
他の参考文献として
-
# Writing a good CLAUDE.md, Kyle, 2025.11
はAGENTS.mdの話だが、同じような議論がされており、なぜless is moreが重要なのかといった説明も研究動向を踏まえながら説明されている。
OpenMAIC, THU-MAIC, 2026.03
Paper/Blog Link My Issue
#Article #Multi #Tools #NLP #LanguageModel #Education #AdaptiveLearning #AIAgents #Repository #Selected Papers/Blogs Issue Date: 2026-03-17 Comment
マルチエージェントによってスケーラブル、adaptiveにオンライン教育を実現するフレームワークのようである
元ポスト:
NOUMENA, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Selected Papers/Blogs Issue Date: 2026-03-15 Comment
元ポスト:
関連:
- Why Training MoEs is So Hard, _xjdr, X Post
おそらく上記ポストの方の作業ログに関するブログと思われる。Canon Layer, mHC, Engramの再現、MoEのエキスパートは異なる学習率が必要なのか?、RDEPと呼ばれるアーキテクチャ(MoEアーキテクチャを採用するとexpertsがしばしば異なるGPUに割り当てられ、routingが特定のexsertsに偏るため特定のGPUがアイドルしてる時間が長くなるため効率が悪いというボトルネックをNVLinkがひもづくネットワーク全体に対してexpertsに対して送信するトークンを収集しパッチを作って送信することで効率を改善する、といったアプローチらしい?)のスループットとメモリ節約効果など、最新の生の知見が数多くまとまっているらしい。
computer-use-large, markov-ai, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #AIAgents #ComputerUse #Selected Papers/Blogs #VisionLanguageModel #3D (Video) Issue Date: 2026-03-15 Comment
元ポスト:
12,300時間程度の、プロフェッショナルなソフトウェア(AutoCAD, Blender, Excel, Photoshop, Salesforce VSCode)利用しているスクリーンのレコーディングデータとのこと。
CC-BY-4.0!?
FLUX.2-klein-9B, black-forest-labs, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #EfficiencyImprovement #NLP #Transformer #TextToImageGeneration #SmallModel #Selected Papers/Blogs #2D (Image) #Editing Issue Date: 2026-03-15 Comment
元ポスト:
github: https://github.com/black-forest-labs/flux2
そもそも2025年11月にリリースされているFLUX.2は結構色々なところで名前を見かけるのでおさえておいたほうが良いかもしれない
https://bfl.ai/blog/flux-2
kleinはFLUX.2シリーズの中で最も軽量なモデルとのこと。2ヶ月程度で既に110k DLされている。
A2UI, google, 2026.03
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #AIAgents #SoftwareEngineering #UI Issue Date: 2026-03-15 Comment
元ポスト:
AgentがUIを表現するための標準的なライブラリ群で、agentから応答されるjsonをクライアント側のライブラリでrenderingすることでUIがレンダリング可能というものらしい。
UIはコンポーネントのリストで表現されるためユーザのリクエストに応じてincrementalにUIを変化させる といったことが可能とのこと。
autoresearch, karpathy, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Repository #ScientificDiscovery #Selected Papers/Blogs #autoresearch Issue Date: 2026-03-10 Comment
元ポスト:
リポジトリのDiscussionsに、定期的にsession reportがアップロードされるようだ:
https://github.com/karpathy/autoresearch/discussions/43
nanochatは現在、126回の実験を経て、Validation BPBが0.997900 -> 0.969686 まで改善しているとのこと。
pjの目的やテーマは、**研究者がpythonファイルのコードをいじるのではなく、program.mdと呼ばれるAgentにコンテキストとして与えるmarkdownファイルのみの編集を通じて、研究組織(≠単一のPh.D student)をエミュレートできるか?** という点にありそうである。
https://github.com/karpathy/autoresearch/blob/master/program.md
その題材の一つとして、nanochatを簡略化したGPTを用いて、GPTの事前学習の性能を改善させるようなtraining.pyの編集をAI Agentsに実施させ、5分間学習させて成果を報告させるという形式をとっている(と解釈した。)
関連:
- [Paper Note] AlphaEvolve: A coding agent for scientific and algorithmic discovery, Alexander Novikov+, arXiv'25, 2025.06
- [Paper Note] ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution, Robert Tjarko Lange+, arXiv'25, 2025.09
続報:
here are a few ways to mitigate attention related spikes during pre training, elie, 2026.03
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Attention #Post #Normalization #Stability Issue Date: 2026-03-10 Comment
主要なOpenWeight LLMにおけるQKNorm戦略の違いについて記述されている
Yuan3.0-Ultra, YuanLabAI, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #MoE(Mixture-of-Experts) #VisionLanguageModel #UMM #Initial Impression Notes Issue Date: 2026-03-07 Comment
元ポスト:
MoEのwarmupが終わり安定してきたタイミングでルーティングがされにくいExpertを枝刈りし、残ったexpertに対してバランスよくルーティングがされるようなrearrangeをするアルゴリズム Layer-Adaptive Expert Pruning (LAEP)によって、パラメータサイズを1515Bから1010Bまで削減し、49%程度事前学習の効率を改善したとのこと。
RAG, multimodal document understanding, tabular data analysis, content summarizationにおいて、非常に高い性能を獲得している。tool useに関してはGPT-5.2(effort不明)以外には負けているので、優秀ではあるが特に秀でているというわけではないよつに見える(BFCVv3)。
しかし他のベンチマークでこれらフロンティアモデル群をここまでPass@1やAccで抜くのは、驚きではあるが、実際にどのような評価をしているのかはテクニカルレポートを見た方が良いと思われる。
ガバメントAIで試用する国内大規模言語モデル(LLM)の公募結果, デジタル庁, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Japanese Issue Date: 2026-03-06 Comment
元ポスト:
以下が選出されたとのこと:
- 株式会社NTTデータ「tsuzumi 2」
- カスタマークラウド株式会社「CC Gov-LLM」
- KDDI株式会社・株式会社ELYZA共同応募体「Llama-3.1-ELYZA-JP-70B」
- ソフトバンク株式会社「Sarashina2 mini」
- 日本電気株式会社「cotomi v3」
- 富士通株式会社「Takane 32B」
- 株式会社Preferred Networks「PLaMo 2.0 Prime」
Google Workspace CLI, Google, 2026.03
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #AIAgents #Repository #ContextEngineering #AgentSkills Issue Date: 2026-03-06 Comment
元ポスト:
google workspaceにone-lineのコマンドでアクセス可能なCLIツールとのこと。40以上のAgentSkillsを内包。
Introducing Olmo Hybrid: Combining transformers and linear RNNs for superior scaling, Ai2, 2026.03
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Attention #OpenWeight #mid-training #read-later #Selected Papers/Blogs #RecurrentModels #Hybrid #LinearAttention Issue Date: 2026-03-06 Comment
元ポスト:
x1のFull Attention + x3のGated DeltaNetによるハイブリッドアーキテクチャで、75%のattentionをlinear attention (recurrent module)に置換。x3のSliding Window Attentionを用いているOlmo3と比較した結果
- 事前学習におけるデータ効率がより高く(約2倍)
- mid-training後の評価では、数学、コード、STEM, non-STEM, QA、long-contextなどの主要なドメインにおいてOlmo3と同と床それ以上の性能を達成。特に、long-contextにおけるベンチマでは大幅な性能向上(Recurrentなアーキテクチャの恩恵)
関連:
- [Paper Note] Gated Delta Networks: Improving Mamba2 with Delta Rule, Songlin Yang+, ICLR'25, 2024.12
元ポスト:
関連:
所見:
ocr-bench, davanstrien, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #Tools #NLP #Evaluation #Repository #LLM-as-a-Judge #OCR #Initial Impression Notes Issue Date: 2026-03-06 Comment
元ポスト:
自分が試したいドキュメントのコレクションに対して、5つほどのOpenなOCRで実際に書き起こしを行い、VLM-as-a-JudgeでスコアリングしELOでの当該ドキュメントセットに対するスコアボードを作成するツール
非常に興味深く実用的だが、個人的にOlmOCRもサポートして欲しいなぁと思うなど。あと、機密性の高い文書などを扱う場面では、セキュリティ面にどれだけ配慮されているのかが気になってしまう。
HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing, Tencent HY Team, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #Personalization #PEFT(Adaptor/LoRA) #2D (Image) #memory #Editing #ImageSynthesis #Adaptive Issue Date: 2026-03-06 Comment
元ポスト:
source imageとpromptから、frozenされたモデルに対するadapter weightを(finetuningなしで)動的に生成し、インスタンス固有のパラメータを用いることでinstance specificな演算を実現する
関連:
- [Paper Note] Doc-to-LoRA: Learning to Instantly Internalize Contexts, Rujikorn Charakorn+, arXiv'26, 2026.02
- [Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25, 2025.06
NEO-unify: Building Native Multimodal Unified Models End to End, SenseTime, 2026.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Post #Architecture #VisionLanguageModel #UMM #Pixel-based Issue Date: 2026-03-06 Comment
Vision EncoderやVAEを用いずに、pixel,wordの入力でnativeなunified modelを構築する。
takeawayとしては
- エンコーダーフリーなアーキテクチャでも、意味とピクセルの表現の両方を保持できる
- image reconstruction, image editingの両者において高い性能を獲得
- understandingとgenerationのtransformerを別々に事前学習し、その後両者を組み合わせて(Mixture of Transformer)追加のSFTをしているようだが、その際に両者のtransformerがconflictすることなく、understandingタスクは安定したままgenerationタスクは素早く収束するといった挙動を示した
- mid-training後により大規模なweb-scaleでの事前学習をするようだが、その際に競合モデルよりもよりデータ効率良く学習ができた
という感じらしい
PPO → DPO → GRPO→ Rubrics, PROF. TOM YEH, 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #ReinforcementLearning #Blog #Video #PostTraining #Non-VerifiableRewards #Rubric-based Issue Date: 2026-03-05 Comment
Cameron R. Wolfe氏によるRubic-basedなRL(主にnon-verifiableなドメインへの適用)のチュートリアル。序盤はPPO, DPO, GRPOに関する解説
元ポスト:
NDLOCR-Liteの公開について, NDL Lab, 2026.02
Paper/Blog Link My Issue
#Article #NeuralNetwork #ComputerVision #NLP #Blog #Repository #Japanese #Selected Papers/Blogs #Encoder-Decoder #OCR Issue Date: 2026-02-28 Comment
元ポスト:
江戸期以前の和古書、清代以前の漢籍といった古典籍資料のデジタル化画像からテキストデータを作成するOCRとのこと。以前はGPUで動作していたが、CPUで動作するようにした軽量版とのこと。すごい。
Training Recipes, PRIME Intellect Lab, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #ExperimentManagement #PostTraining #read-later Issue Date: 2026-02-28 Comment
公式によるPrime Intellect Labを用いたRLによるレシピの模様。これ読んだらだいたい実験できるようになるんではなかろうか。
元ポスト:
Qwen3.5 Medium Model Series, Qwen Team, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiLingual #OpenWeight #MoE(Mixture-of-Experts) #Selected Papers/Blogs Issue Date: 2026-02-28 Comment
元ポスト:
いずれのモデルもベンチマーク上はGPT-5 miniと同等以上の性能に見える。
また、Qwen3.5-35B-A3BはQwen3-235B-A22B-2507やQwen3-VL235B-A22Bを上回っており、アーキテクチャ、データの品質、RLによって実現されているとのこと。
27BモデルのHLEのスコアが非常に高いと話題:
FP8版もリリース:
日本語の医師国家試験(2026)において35B-A3Bが非常に高いスコアを記録:
Artificial Analysisによるベンチマーキング:
Introducing Mercury 2, inception, 2026.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel #Blog #Reasoning #Proprietary #Selected Papers/Blogs Issue Date: 2026-02-27 Comment
元ポスト:
1092 token/secのproprietary (reasoning) dLLM
関連:
- [Paper Note] Mercury: Ultra-Fast Language Models Based on Diffusion, Inception Labs+, arXiv'25
Artificial Analysisのベンチマーキング結果とスループットの散布図:
スループット/性能比において明らかに抜きんでている。
The First Fully General Computer Action Model, Standard Intelligence Team, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #Pretraining #FoundationModel #DiffusionModel #ComputerUse #3D (Video) #VideoActionModel Issue Date: 2026-02-27 Comment
元ポスト:
公式ポスト:
関連:
- [Paper Note] Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos, Bowen Baker+, arXiv'22, 2022.06
Training Recipeの部分を読むと、上記研究で提案されているVideo PreTrainingと同じ手法を用いているように見える。
つまり、Inverse Dynamics Modelを学習し、大量のvideoデータに対してアクションラベルを付与し、付与されたアクションラベルを用いて半教師あり学習によるnext action predictionを実施することによって基盤モデルを学習する、というアプローチ。
この基盤モデルによってたとえば1時間のサンフランシスコをdrivingしている動画によってfinetuningすることで、自動運転をするようなモデルが学習できる、といったことが実現可能な模様。
Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Blog #Coding #SoftwareEngineering #Selected Papers/Blogs #Contamination Issue Date: 2026-02-24 Comment
元ポスト:
SWE-Bench Verifiedはpublicなリポジトリに基づいたベンチマークなのでcontaminationが生じやすく、実際にいくつかのモデルでcontaminationが確認されたと言う話と、testコードに本来は正しい実装でもfailedとなる許容するスコープが狭いテストが存在していた、という話で、これらの教訓を生かしたSWE-Bench Proを作成し、実際それはcontaminationがほとんど起きておらず、仮に起きていたとしても非常にマイナーなものだよ、というような話が書かれている。
Detecting and preventing distillation attacks, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #OpenWeight #Proprietary #Selected Papers/Blogs Issue Date: 2026-02-24 Comment
元ポスト:
DeepSeek, Moonshot AI, MiniMax がDistillationを用いてClaude出力からモデルを改善するためのattackを特定したというAnthropicからのアナウンス
所見:
- [Paper Note] Extracting books from production language models, Ahmed Ahmed+, arXiv'26, 2026.01
で提案されている手法を用いてClaude Sonnetからハリーポッターと賢者の石の95.8%を抽出できた、との報告もある。
Ming-omni-tts-0.5B, inclusionAI, 2026.02
Paper/Blog Link My Issue
#Article #Transformer #SpeechProcessing #DiffusionModel #Speech #OpenWeight #read-later #TTS #UMM #Omni #AdversarialTraining #Music Issue Date: 2026-02-18 Comment
元ポスト:
TTSだけでなく、環境音や音楽の生成も可能な音声生成モデル。発話速度、ピッチ、音量、感情、訛りなどを正確にコントロール可能で、100+以上のビルトインのvoiceや、zeroshotでのvoice designが可能とのこと。また、speechだけでなく環境音や音楽の生成もできる産業界では初めてのモデルとのこと。また、3.1Hzごとのフレームレートでパッチ化されて入力され(これはこれまでと比べるとかなり低いフレームレートらしい)るため高速に処理が走り、テキスト入力として数式などのフォーマットも入力可能とのこと。
テクニカルレポートのリンクがまだ生きておらず詳細は不明。
AI 101: "On-Policy Distillation Zeitgeist", Turing Post, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #ReinforcementLearning #Blog #PostTraining #On-Policy #SelfDistillation Issue Date: 2026-02-16 Comment
元ポスト:
最近よくみかける on-policy self-distillationに関する解説
Harness engineering: leveraging Codex in an agent-first world, Ryan Lopopolo, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #GenerativeAI #Blog #Coding #SoftwareEngineering Issue Date: 2026-02-12 Comment
OpenAI社内でのコードを1行も人間が書かないで製品をリリースする取り組みに関する詳細なレポートのようである。初期の設計などで想像以上に時間がかかってしまった点(これはCodexの能力の問題ではない)や、実装を続ける中で品質に責任を持つ人間の能力(というより時間)がボトルネックになっていったため、極力Codexが自律的に品質管理ができるような実行・検証環境を用意することで負担を低減した話や、Codexに膨大なマニュアルを読ませて処理をさせるのではなく、どこにどのような情報が格納されているのかといったマップ(目次)を与えることがコンテキストエンジニアリング上重要だったことなどを通じてエージェントにとってリポジトリ全体の可読性を高めることが重要だったといった話や、プロジェクトの期間が長引くにつれて、リポジトリ内に共有されていないcontextが増大していき、それらをリポジトリに統合する作業が生じるなどの課題も生じたといったような話など色々と書かれている。
[Paper Note] Position: Humans are Missing from AI Coding Agent Research, Wang+, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #UserBased #AIAgents #Coding #read-later #Selected Papers/Blogs #interactive #Initial Impression Notes Issue Date: 2026-02-12 Comment
# Authors
Zora Zhiruo Wang, John Yang, Kilian Lieret, Alexa Tartaglini, Valerie Chen, Yuxiang Wei,
Zijian Wang, Lingming Zhang, Karthik Narasimhan, Ludwig Schmidt, Graham Neubig, Daniel Fried, Diyi Yang
元ポスト:
現在のコーディングエージェントは自動的にタスクを完了させ、難易度の高いベンチマークを解けることが実用的な価値とみなされているが、今後より実用的な価値を高めプロダクト化するためには単独でタスクをこなすのではなく、人間開発者やユーザとの相互作用をするような枠組みが次のブレイクスルーとなりうるというposition。非常に共感できる。
ENGRAM, EvolvingLMMs-Lab, 2026.02
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #AIAgents #Privacy #MCP #memory Issue Date: 2026-02-12 Comment
元ポスト:
MCPに対応しているAI Agentであれば互換性がある暗号化されたストレージの実装なようで、サードパーティのストレージにデータを預けなくてもローカルのストレージでLLMに対して知識を提供可能な模様。
最近DeepSeekが提案したEngramとは異なるので注意:
- [Paper Note] Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models, Xin Cheng+, arXiv'26, 2026.01
Introducing Lab: The Full-Stack Platform for Training your Own Models, Prime Intellect, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #MachineLearning #NLP #LanguageModel #Infrastructure #ReinforcementLearning #AIAgents #Blog #ScientificDiscovery #PostTraining #Selected Papers/Blogs #Reference Collection #Environment Issue Date: 2026-02-11 Comment
元ポスト:
事後学習、特にAgenticな研究の民主化のためのプラットフォームの提供
所見:
利用例 (Environment Hub):
[Paper Note] OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis, Li+, 2026.02
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #Search #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #OpenSource #Selected Papers/Blogs #Reproducibility #DeepResearch #LongHorizon #Initial Impression Notes #Environment Issue Date: 2026-02-10 Comment
元ポスト:
APIに依存せずオフラインコーパスと検索を利用し、高品質なDeepResearchのlong horizonなtrajectoryを合成可能な環境を構築。合成したtrajectoryでNemotron-3-nano-30B-A3B-BaseをSFTすることで、Kimi-K2, GLM-4.6などの10倍以上大きいサイズのモデルよりもBrowseCompで高い性能を獲得。同サイズのTongyiDeepResearchもoutperform。
Deterministicなプロセスで、オフラインコーパスからデータを合成し外部APIに依存しないため完全に再現性があり、かつAPIのコストやrate limitにも引っかからないという利点がある。検索エンジン、コード、データ、合成データ、モデル、全てを公開。
完全に再現性のある研究は素晴らしい。
Composer 1.5 のご紹介, Cursor Team, 2026.02
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #AIAgents #GenerativeAI #Blog #Coding #SoftwareEngineering #PostTraining #Scalability Issue Date: 2026-02-10 Comment
事前学習モデルに対して、RLをさらにスケールさせることで性能が継続的に向上し、自己要約能力も備えさせることでcontext windowの問題に対処しているとのこと。
(関連)Composer: 強化学習で構築する高速フロンティアモデル:
https://cursor.com/ja/blog/composer
Opus 4.6, Codex 5.3, and the post-benchmark era, Interconnects, 2026.02
Paper/Blog Link My Issue
#Article #Analysis #LanguageModel #AIAgents #Blog #Coding #SoftwareEngineering #Author Thread-Post Issue Date: 2026-02-10 Comment
有識者によるClaude 4.6 Opus と Codex 5.3 を利用した際の所見(定性評価)が記述されている。
元ポスト:
著者によるTLDR:
Advancing finance with Claude Opus 4.6, Anthropic, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Financial #Proprietary #SoftwareEngineering #Selected Papers/Blogs #Reference Collection Issue Date: 2026-02-06 Comment
元ポスト:
全体的に能力が向上しているが、ターミナルでのコーディング、BrowseComp(Agentic search), HLE, Financial Analysis, GDPValにおけるOffice Task, Novel Problem Solvingの能力が大きく向上しているように見える。
Context Windowが1Mとのことで素晴らしい
OpenHands Indexでトップとのことだが、Codex 5.3との比較はまだの模様:
50% time horizonが脅威の14.5時間:
The Second Pre-training Paradigm, Jim Fan, X, 2026.02
Paper/Blog Link My Issue
#Article #ComputerVision #Pretraining #NLP #LanguageModel #MultiModal #Post #Robotics #WorldModels Issue Date: 2026-02-05 Comment
事前学習がnext word predictionから過去の行動と状態によって条件付けられ次の(ある期間の)世界の状態を予測するワールドモデリング(next physical state prediction)へのパラダイムシフトの予想(というよりこのパラダイムシフトの真っ只中にいる)。人間の脳が処理する情報の多くは視覚であり、言語的な領域は部分的なことであることや、猿は言語的な能力が低くても視覚や運動、触覚などの感覚的情報から世界の物理法則を理解し知的なアクションをとるメンタルモデルを確立していることなどを引き合いに説明している。
Fine-tuning open LLM judges to outperform GPT-5.2, together.ai, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #LLM-as-a-Judge #DPO #RewardModel #Initial Impression Notes Issue Date: 2026-02-05 Comment
元ポスト:
Reward Bench 2:
- [Paper Note] RewardBench 2: Advancing Reward Model Evaluation, Saumya Malik+, arXiv'25, 2025.06
LLMでLLMを評価するというパラドックスに違和感はあるが、一般論として、「生成」するよりも「検証」することがモデルにとって簡単なタスクであるためうまくいきます(LLM-as-a-Judge)、といった説明が書いてあり、数千程度のサンプルでOpenLLMをDPOすることによって、GPT-5.2のようなFrontierモデルをReward Benchで上回ることができた、といった話が書かれている。
ただし、上記Reward Bench 2研究で示されている通り、**Reward Benchでの性能が高いReward Modelだからといって、必ずしもRLによって下流タスクの性能が向上するとは限らない点には注意**であり、元論文に従うとBest-of-Nサンプリングのようなtest-time-scalingのパラダイムとして利用するのが現在の実務上は良さそうである。
Together Evaluations now supports comparing top commercial APIs vs. open source models, together.ai, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2026-02-05 Comment
元ポスト:
OpenLLMのFinetuningをサポートしているプラットフォームにおいて、データセットをアップロードすると
- Prompt optimization (GEPA)
- Fine-tuning (PEFT + full finetuning)
の両方を実施し、コスト-性能のパレート最適なポイントを評価し、かつGPT等とのProprietaryモデルとの比較もした評価もできるようになりました、といった話の紹介。
GEPA:
- [Paper Note] GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning, Lakshya A Agrawal+, ICLR'26, 2025.07
Finetuningがサポートされているモデル群:
-
https://docs.together.ai/docs/fine-tuning-models
Trinity Large, Arcee, 2026.01
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Stability #Reference Collection #Sparse #Initial Impression Notes Issue Date: 2026-01-29 Comment
テクニカルレポート:
https://github.com/arcee-ai/trinity-large-tech-report/
HF:
https://huggingface.co/arcee-ai
GLM4.7やDeepSeekV3と比較してスループットやTTFTが二倍以上。
非常にsparseなMoE(400B-A13B, 4/256のexpertsにルーティング)であるため学習を安定させるためにDense layerを増やし、モメンタムを考慮したexpertのバランシングや、z-lossと呼ばれるlogitのスケールをコントロールするような手法を導入することで安定した学習を実現。2048 Nvidia B300 GPUsで、17Tトークンの事前学習33日で完了
元ポスト:
これほどsparseなMoEをここまで安定させて学習できるのは非常に興味深いと思われる。
インタビュー:
やると決めてチームビルディングも含めて非常に短期間(6ヶ月)で達成したとのことだが、気になる。
解説:
所見(風刺):
ポイント解説:
アーキテクチャ解説:
Introducing Agentic Vision in Gemini 3 Flash, Google Deepmind, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #Proprietary #VisionLanguageModel Issue Date: 2026-01-29 Comment
元ポスト:
visual reasoningとコード実行の融合
Introducing Prism, OpenAI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #ChatGPT #GenerativeAI #MultiModal #AcademicWriting #DeepResearch Issue Date: 2026-01-29 Comment
デモを見るとdraftをベースに関連研究をdeepresearchしてワンクリックでbibtexにexport, ホワイトボードに描いた図をドラッグ&ドロップして論文に反映などしている。Overleafの競合。
元ポスト:
所見:
A well known important feature to stabilize RL training is implementing the LM head in fp32 precision to help with gradients ... , Nathan Lambert, X, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Post #PostTraining #Stability Issue Date: 2026-01-24 Comment
関連:
- MiniMax-M1, MiniMax, 2025.06
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
RLを安定化するためのtipsとそれによりMiniMax M1のplotが再現できたという話な模様。RLはこういった細かいテクニックが大事だと思うので、共有して頂けるのは大変ありがたい。
関連:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
- train-inference-gap && ReinforcementLearning ラベルが紐づいたissueも参照のこと
Waypoint-1: Real-time Interactive Video Diffusion from Overworld, Overworld, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #Controllable #NLP #Transformer #MultiModal #DiffusionModel #OpenWeight #WorldModels #interactive #3D (Video) #RectifiedFlow #Realtime Issue Date: 2026-01-22 Comment
blog:
https://over.world/blog/the-path-to-real-time-worlds-and-why-it-matters
pj page:
https://over.world/
元ポスト:
リアルタイムにzero latencyでマウス(カメラも自由に動かせる)、キーボード、テキストでinteraction可能なworld model
Claude's new constitution, Anthropic, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Safety Issue Date: 2026-01-22 Comment
ClaudeのAI Modelで利用される新たなConstitution
関連:
- [Paper Note] Constitutional AI: Harmlessness from AI Feedback, Yuntao Bai+, arXiv'22
元ポスト:
Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization, Wen+, 2026.01
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Optimizer #read-later #Selected Papers/Blogs Issue Date: 2026-01-22 Comment
元ポスト:
シンプルな手法で、先行研究によってモデルのパラメータサイズやデータのスケールが大きくなるとMuonのような行列ベースのoptimiserの高速化の恩恵が小さくなる現象を改善しているとのこと。
具体的には、重みを更新する際にweight decayのようなソフトにweightのノルムをコントロールするような仕組みを入れるのではなく、optimiserの重みに対する更新量と、更新後のネットワークの重みをフロベニウスノルムで正規化し、最適化の軌跡を半径Rの超球面の表面上に位置するように明示的に制約する(ここで、Rは最初の重み行列のフロベニウスノルム)。Muonを含む様々なoptimiserでも機能して学習効率を高めるため、インパクトの大きな重要研究に見える。
関連(concurrent works):
- [Paper Note] Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models, Yonggan Fu+, arXiv'25, 2025.11
- [Paper Note] Controlled LLM Training on Spectral Sphere, Tian Xie+, arXiv'26, 2026.01
関連:
- [Paper Note] Fantastic Pretraining Optimizers and Where to Find Them, Kaiyue Wen+, ICLR'26, 2025.09
ICLR 2026 Acceptance Prediction: Benchmarking Decision Process with A Multi-Agent System, Zhang+, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #LanguageModel #AIAgents #Evaluation #MultiModal #ScientificDiscovery #VisionLanguageModel #AcademicWriting #Live Issue Date: 2026-01-20 Comment
元ポスト:
conference paperのpeer reviewに関するベンチマーク。accept/rejectを予測する。papers, reviews, rebuttalsそしてfinal decisionsが紐づけられている。
GLM-4.7-Flash, Z.ai, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #OpenWeight #MoE(Mixture-of-Experts) Issue Date: 2026-01-20 Comment
元ポスト:
関連:
- GLM-4.7: Advancing the Coding Capability, Z.ai, 2025.12
30B-A3BのMoEモデルで、gpt-oss-20B, Qwen3-30B-A3B-Thinking-2507を、SWE Bench Verified, tau2_bench, BrowseComp(SWEタスク, tooluse, 検索)等で大幅にoutperform。AIME, GPQA, HLEなどの推論系のベンチマークも同等以上。つまり、agenticなタスクに適した能力を有することが示唆される。
ポイント解説:
FrogMini-14B-2510, Microsoft, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #Coding #OpenWeight #SoftwareEngineering Issue Date: 2026-01-16 Comment
元ポスト:
strong modelから合成されたbug fixのtrajectoryでSFTすることで小規模モデルでSWE Benchの性能改善
Narrow Misalignment is Hard, Emergent Misalignment is Easy, Turner+, 2025.07
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Alignment #PEFT(Adaptor/LoRA) #PostTraining #EmergentMisalignment Issue Date: 2026-01-15 Comment
openreview: https://openreview.net/forum?id=q5AawZ5UuQ
一般的にevilになることを学習することが、狭義にevilになるよりも簡単だ、という知見を示した研究とのこと。
FineTranslations, Penedo+, 2026.01
Paper/Blog Link My Issue
#Article #MachineTranslation #Pretraining #NLP #Dataset #LanguageModel #SyntheticData #mid-training Issue Date: 2026-01-10 Comment
元ポスト:
FineWeb2のテキストを英訳することで合成されたパラレルコーパスらしい
Introducing LFM2.5: The Next Generation of On-Device AI, LiquidAI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog #SmallModel #OpenWeight #Japanese #PostTraining #Selected Papers/Blogs #VisionLanguageModel #AudioLanguageModel Issue Date: 2026-01-09 Comment
元ポスト:
日本語に特化した言語モデルも存在し、Sarashina2.2-1b-instruct-v0.1, TinySwallow-1.5B-InstructよりもJMMLU, M-IFEval (ja), GSM8K (ja)においてより高い性能を発揮している。
LFM2.5-1.2B-Base: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-1.2B-Base)
LFM2.5-1.2B-Instruct: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-1.2B-Instruct),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-1.2b-instruct),
[Playground](
https://playground.liquid.ai/chat?model=cmk1jyp8f000204i56yy76uwh)
LFM2.5-1.2B-JP: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-1.2B-JP),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-1.2b-jp)
LFM2.5-VL-1.6B: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-VL-1.6B),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-vl-1.6b),
[Playground](
https://playground.liquid.ai/chat?model=cmk0wefde000204jp2knb2qr8),
[Demo](
https://huggingface.co/spaces/LiquidAI/LFM2.5-VL-1.6B-WebGPU)
LFM2.5-Audio-1.5B: [Hugging Face](
https://huggingface.co/LiquidAI/LFM2.5-Audio-1.5B),
[LEAP](
https://leap.liquid.ai/models?model=lfm2.5-audio-1.5b),
[Playground](
http://playground.liquid.ai/talk)
LiquidAIのモデルは日本語に特化したモデルが多く存在するのが特徴的に感じる。
Scaling Real-Time Voice Agents with Cache-Aware Streaming ASR, Nvidia, 2026.01
Paper/Blog Link My Issue
#Article #SpeechProcessing #Blog #AutomaticSpeechRecognition(ASR) #Realtime Issue Date: 2026-01-07 Comment
元ポスト:
過去のStreaming形式のASRではwindowを定義しwindow中のcontextを逐次計算するアーキテクチャだったが本質的に効率が悪いのでアーキテクチャを改善。エンコーダの表現を内部でキャッシュし新たなデータが来たらその差分に基づいて内部のキャッシュをアップデートする方式によって大幅にlatencyを改善している(エンコーダのconvのdownsamplingも従来の4xから8xにしているとのこと)、という感じらしい。
Reverse Engineering a Phase Change in GPT's Training Data... with the Seahorse Emoji 🌊🐴, PRATYUSH MAINI, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #ChatGPT #Reasoning #SelfCorrection #mid-training Issue Date: 2025-12-28 Comment
元ポスト:
Is there seahorse emoji?という質問に対するLLMのreasoning trajectoryと、self correctionの挙動が、OpenAIのどの時点のモデルで出現するか、しないかを線引くことで、mid-trainingにself correction形式のデータが追加されたのがいつ頃なのかを考察している。
GLM-4.7: Advancing the Coding Capability, Z.ai, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #Reasoning #OpenWeight #SoftwareEngineering #Reference Collection Issue Date: 2025-12-25 Comment
元ポスト:
HF: https://huggingface.co/zai-org/GLM-4.7
デザインアリーナでtop2:
Artificial Intelligence Indexにおいて、OpenModelの中でトップ:
GLM-4.6と比較して、コーディング/SWE, reasoning, tooluseなどの能力が大幅に向上
Interleaved Thinking, Preserved Thinking, Turn-level Thinkingの3つの特性がある。
Interleaved Thinkingは全てのレスポンスとtool callingの前にreasoningを挟むことで、IFや生成品質を向上。
Preserved Thinkingは過去のターンの全てのthinking blockのトークンを保持し、再計算もしないのでマルチターンでの一貫性が増す。
Turn-level Thinkingはターンごとにreasoningを実施するか否かをコントロールでき、latency/costを重視するか、品質を重視するかを選択できる、といった特徴がある模様。
モデルサイズは358B
A2UI: A Protocol for Agent-Driven Interfaces, Google, 2025
Paper/Blog Link My Issue
#Article #ComputerVision #Tools #NLP #AIAgents #SoftwareEngineering #VisionLanguageModel Issue Date: 2025-12-22 Comment
AI Agent (Gemini)を用いてUIを自動生成できるツールらしい
元ポスト:
Introducing Mistral OCR 3, Mistral AI, 2025.12
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #Proprietary #VisionLanguageModel #OCR Issue Date: 2025-12-19 Comment
元ポスト:
MistralによるOCR。他のOCRに比べてmulti-lingual, 様々なデータセットで高い性能を発揮。APIでのみ提供されている模様。
Gemini 3 Flash: frontier intelligence built for speed, Google, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reasoning #Distillation #Proprietary #VisionLanguageModel #Reference Collection Issue Date: 2025-12-18 Comment
元ポスト:
Gemini 2.5 Proよりも3倍高速でかつ様々なベンチマークで上回っているとのこと。素晴らしい。Gemini 3 Proと比較しても基本的なQAや数学的な能力(reasoning能力)は性能に遜色なく、long sequence/contextの取り扱いでは明確に劣っている、という感じに見えるので、普段使いではこちらでも困らなそうに感じる。
Hallucination Rateが非常に高いとのことだが果たして:
Proからlogit baseな蒸留をして事前学習(=distillation pretraining)をしているっぽい?
Interactive Intelligence from Human Xperience, Ropedia, 2025.12
Paper/Blog Link My Issue
#Article #Dataset #Blog #Robotics #WorldModels #VisionLanguageActionModel #EmbodiedAI #EgocentricView #Real-to-Sim Issue Date: 2025-12-17 Comment
pj page: https://ropedia.com/
元ポスト:
頭に装着するデバイスでegocentric viewのデータセットを収集し、実際の人間の様々な状況での経験を収集されたegocentric viewデータに基づいて活用し、より強力なworld model, Real-to-Sim, Vision Action Langauge Modelsを作ることをミッションとする新たなプロジェクト(?)な模様。
LongCat-Video-Avatar, meituan-longcat, 2025.12
Paper/Blog Link My Issue
#Article #ComputerVision #Transformer #DiffusionModel #VariationalAutoEncoder #OpenWeight #VideoGeneration/Understandings #3D (Scene) #Audio-Text-to-Video #Audio-Text-Image-to-Video #Video Continuation Issue Date: 2025-12-17 Comment
元ポスト:
アーキテクチャはDiTベースのDiffusion Modelで、3D Variational AutoencoderによってEncode/Decodeされ、3D RoPEによって位置情報が埋め込まれる。DiT Blockでは、テキストとaudio用のcross attentionが用いられてこれらのモーダルに関する情報が組み込まれる。audioはWav2Vecでエンコードされ、テキストはUMT5[^1]によってエンコードされる。
[^1]: multilingualなT5で100言語以上がサポートされている模様
chatterbox-turbo, ResembleAI, 2025.12
Paper/Blog Link My Issue
#Article #SpeechProcessing #OpenWeight #TTS #Realtime Issue Date: 2025-12-17 Comment
元ポスト:
realtime(最初の発話まで<150ms)のlatencyが実現されたOpenWeightなTTSで、multilingualモデルは日本語にも対応している模様。テクニカルレポートがないのでよくわからないが、githubがあるのでソースコードを見ればアーキテクチャがわかりそうではある。たとえばVoiceEncoderには(おそらく速度を重視するために)LSTMが利用されていた。
github:
https://github.com/resemble-ai/chatterbox
nomos-1, NousResearch, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Mathematics #OpenWeight Issue Date: 2025-12-11 Comment
元ポスト:
30Bの強力な数学モデルで、(同じハーネスでテストした結果)Qwen3-30ba3b-Thinking-2507を大幅に上回る性能を持つとのこと。
State of AI An Empirical 100 Trillion Token Study with OpenRouter, Aubakirova+, OpenRouter, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #GenerativeAI Issue Date: 2025-12-09 Comment
元ポスト:
> 利用傾向として、最初に課題を解決したモデルがその後も使われ続けるという「ガラスの靴」現象が起きている。これは、あるモデルがリリース改善したとき、特定の技術的・経済的制約を満たす瞬間があり、そのときにユーザーが一気に使い始め、一度それが起きるとシステム設計、データパイプライン、ユーザー習慣がそのモデルを中心に構築されるため、乗り換えインセンティブは急激に低下し、ユーザー離脱がおきづらくなるものである。
(上記元ポストより引用)
特にこの点は非常に興味深いと感じる。一度設計や評価をしてしまうと簡単にはモデルを変更できずロックインするという状況は実際に見聞きする。Tech Giantが汎用的なモデルを出し続けるなら、資金力やリソースが乏しい場合は同じ土俵ではなく、特定ユースケース特化で小型、か 高性能、かつ使いやすいインタフェースをセットで出すのが良さそうではある(最近見かけるのはOCR, 翻訳などだろうか)。
Qwen3-TTS Update 49 Timbres + 10 Languages + 9 Dialects, Qwen Team, 2025.12
Paper/Blog Link My Issue
#Article #SpeechProcessing #MultiLingual #Proprietary #TTS Issue Date: 2025-12-06 Comment
元ポスト:
日本語を含む10ヶ国語をサポートしているのは素晴らしい。ただ、デモの日本語を聞いてみると、イントネーションがまだおかしいなぁ、と感じる。聞き取り自体に問題はない。
Mismatch Praxis: Rollout Settings and IS Corrections, LLM Data, 2025.12
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #ReinforcementLearning #Blog #SamplingParams #LongHorizon #train-inference-gap Issue Date: 2025-12-04 Comment
元ポスト:
on-policy RLにおけるロールアウト時のtemperature, top_p, top_kの設定、およびlong horizonの場合でのtrain-inference mismatchの関係性の分析
Improved accuracy in Smart Turn v3.1, Daily, 2025.12
Paper/Blog Link My Issue
#Article #NeuralNetwork #Transformer #AIAgents #SpeechProcessing #Blog #MultiLingual #OpenWeight #OpenSource #VAD Issue Date: 2025-12-04 Comment
dataset:
https://huggingface.co/pipecat-ai
code:
https://github.com/pipecat-ai/smart-turn
model:
https://huggingface.co/pipecat-ai/smart-turn-v3
オープンソースのVoice Activity Detection (VAD)モデル。本ブログのv3.1では、TTSデータだけでなく英語とスペイン語の人間によるaudio sampleも追加し学習し性能向上。23言語をサポートし、Accuracyは90%以上を達成。数msでのリアルタイムなlatencyを達成できる。
バックボーンはWhisper Tiny encoderで、headとしてshallow linear classifiesを利用しているとのこと。
Introducing Mistral 3 The next generation of open multimodal and multilingual AI, Mistral AI, 2025.12
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Blog #MultiLingual #OpenWeight #VisionLanguageModel Issue Date: 2025-12-03 Comment
元ポスト:
マルチモーダルなベンチマークがほとんどないように見えるMM-MT-Benchというもののみ?
Expert Parallel Deployment, vLLM, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #MoE(Mixture-of-Experts) #Parallelism Issue Date: 2025-12-01 Comment
MoEアーキテクチャにおいて、eXertsの重みを複数のGPUに分散することで計算効率を増大させるexpert parallelによるデプロイ方法をexpert parallelの配列数はData Parallel数*tensor parallel数となる。
[Paper Notes] Structured Prompting Enables More Robust, Holistic Evaluation of Language Models, Aali+, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Prompting #Evaluation #read-later #Selected Papers/Blogs Issue Date: 2025-11-30 GPT Summary- 高品質な言語モデル(LM)の評価には、HELMのようなフレームワークが重要だが、固定プロンプトに依存するため過小評価のリスクがある。DSPyのような宣言的プロンプトフレームワークは、タスクごとに最適化されたプロンプトを提供するが、体系的な評価が不足している。本研究では、再現可能なDSPy+HELMフレームワークを提案し、構造化プロンプトを用いてLMのパフォーマンスをより正確に評価する。4つのプロンプト手法を用いて7つのベンチマークで評価した結果、HELMがLMのパフォーマンスを平均4%過小評価し、パフォーマンスの変動が大きくなることが示された。この研究は、LMの挙動を特徴付ける初の大規模ベンチマーク研究であり、オープンソースの統合とプロンプト最適化パイプラインを提供する。 Comment
AI Agentsの評価でもハーネスによって性能が変わるし、一般的なLLMでの評価もpromptingで性能変わるだろうなぁ、とは思っていたが、やはりそうだった模様。重要論文
しかしそもそもLLMの評価は変数が多すぎて、網羅的な評価は難しく、活用する際にベンチマークスコアは参考程度にした方が良いとは思う。自前データがあるなら自前で手元で評価すべし、という気はするが、評価するLLMの候補を選定する際には有用だと思われる(小並感)
関連:
- [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
元ポスト:
Ilya Sutskever – We're moving from the age of scaling to the age of research, DWARKESH PATEL, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #GenerativeAI #Blog Issue Date: 2025-11-29 Comment
元ポスト:
現在のnext token predictionに基づく事前学習とRLに基づくスケーリング則による性能改善の時代から(理解が進んでいない部分があり、特に現在のRLでは汎化性能が十分に獲得できないため)、人間のような高度な価値関数の探求を含む新たなパラダイムを研究する時代の到来に関する話な模様
[Paper Note] DeepSeek-Math-V2, DeepSeekAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Reasoning #Mathematics #read-later #Selected Papers/Blogs #Verification #Reference Collection #GenerativeVerifier Issue Date: 2025-11-27 GPT Summary- 大規模言語モデル(LLM)は数学的推論において進展を遂げており、強化学習を用いて定量的推論コンペティションでのパフォーマンスを向上させている。しかし、最終回答の精度向上が正しい推論を保証しない問題や、厳密な導出が必要なタスクに対する限界がある。自己検証可能な数学的推論を目指し、定理証明のためのLLMベースの検証器を訓練し、生成器が自らの証明の問題を特定・解決するよう奨励する方法を提案。結果として得られたモデルDeepSeekMath-V2は、強力な定理証明能力を示し、国際数学オリンピックやプットナム競技会で高得点を記録した。これにより、自己検証可能な数学的推論が数学AIシステムの発展に寄与する可能性が示唆される。管理人コメント:モデル単体でIMO金メダル級を達成とのこと。outcomeに基づくRLVRからtrajectoryそのものをcritiqueし、その情報に基づいて再生成するといったループを繰り返す模様?このアプローチは数学以外のドメインでも有効な可能性があるので興味深い。 Comment
元ポスト:
HF: https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
所見:
所見:
どのように高品質なverifierを構築し、高品質なデータ生成パイプラインを構築するか、という内容が記述されているらしい:
報酬に対する理解補助のための注釈:
ポイント解説:
verifier: proofsをスコアリングできるようRLで学習される
meta verifier: verifierの批評を確認する
generator: より良い証明を書きself checkもできるようverifierによるreward signalによりRLで訓練される
の三刀流らしい。
ポイント解説:
ポイント解説:
所見:
GPT-4V-Act, ddupont808, 2023.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Repository #ComputerUse #VisionLanguageModel #Grounding Issue Date: 2025-11-25 Comment
GPT4V(VLM)と、SoMを用いてVLMによってWebUIとClick/Keyboard操作を通じてinteractできる実装
- [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
Stanford Agentic Reviewer, Stanford University, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #GenerativeAI #Blog Issue Date: 2025-11-25 Comment
元ポスト:
Andrew Ng氏によるAI Agentによる論文のレビュワーシステムで、ICLR'25のレビューで学習し、テストセットで評価したところ、人間-人間間の相関と人間-AI間の相関係数が同等の水準に到達とのこと。ICLR'25のレビューで学習しているということは当該ドメインに近しい研究であるほど適切なレビューが実施されるであろう点に注意。
OCR Arena, extend.ai, 2025.11
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Evaluation #VisionLanguageModel #OCR Issue Date: 2025-11-25 Comment
元ポスト:
OCRのアリーナ(=ユーザがPDFをアップロードし2モデルでOCRし優劣をユーザが判定しその結果からElo Rateを算出する)。
言語間の性能差はわからないので参考程度にすると良いと思われる。
Introducing Navigator, Yutori team, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Proprietary #ComputerUse #read-later #VisionLanguageModel Issue Date: 2025-11-20 Comment
元ポスト:
gemini2.5, claude4.5, openaioperator等よりも性能が良いweb agentらしい
ACT-1: A Robot Foundation Model Trained on Zero Robot Data, Sunday Team, 2025.11
Paper/Blog Link My Issue
#Article #Blog #Zero/FewShotLearning #read-later #Generalization #Robotics #LongHorizon Issue Date: 2025-11-20 Comment
元ポスト:
テレオペレーション(遠隔操作; 模倣学習に使われるのだと思われる)ではなく、Skill Capture Gloveと呼ばれる手に装着するタイプのデバイスから収集したデータのみを収集して学習するらしい。手のデータは収集できるが、身長や腕の長さ、視覚的な情報が異なるではないか、という点については、グローブのデータを同等のロボットのデータに変換するみたいなことをするらしい。(ゆるふわ理解)
Gemini 3 による知性の新時代, Google, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #GenerativeAI #Blog #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection Issue Date: 2025-11-19 Comment
所見:
GPT5.1に対して各種ベンチマークで上回る性能。
所見:
Gemini2.5 Proは回答が冗長で使いにくかったが、Gemini3は冗長さがなくなり、クリティカルな情報を簡潔に、しかし短すぎない、ちょうど良いくらいの応答に感じており、レスポンスもGPT5.1, GPT5と比べ早いので普段使いのLLMとしては非常に良いのではないか、という感想(2,3個のクエリを投げただけだが)を抱いた。
Oriol Vinyals氏のコメント:
LiveCodeBench ProでもSoTA:
Gemini Pro 3 Developer Guide:
https://ai.google.dev/gemini-api/docs/gemini-3?hl=ja
元ポスト:
GAIA Verified (Browser Use?)でもSoTA:
ただし、どのようなハーネスが使われているかは不明だし、それらが各モデルにとってフェアなものになってるかも不明
スクショのみでリンクも無し。
所見:
content window,pricingなどの情報:
一般的なユースケースでのBest Practice:
パラメータ数に関する考察:
韓国語でのベンチマークに関するポスト:
自身のハーネス、ユースケース、タスクではうまくいかなかったよという話(でもただのサンプル数1だよ、という話が記載されている):
結局のところベンチマークはあくまで参考程度であり、自分たちのタスク、データセットで性能を測らねばわからない。
Artificial Intelligenceによる評価:
MCP Universeでtop:
- [Paper Note] MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers, Ziyang Luo+, arXiv'25
Live SWE Agentと呼ばれるself-evolvingな枠組みを採用した場合(=scaffoldをbashのみから自己進化させる)のSWE Bench Vevifiedにやる評価でもSoTA:
- [Paper Note] Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?, Chunqiu Steven Xia+, arXiv'25, 2025.11
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
この辺のsoftware agent系のベンチマークにおけるハーネスが具体的にどうなっているのか、中身を見たことないので見ておきたい。
(追記)
SWE Bench Verifiedのリーダーボードではmini-SWE-Agentを利用した公正な比較が行われており、こちらではGemini3がトップだったもののその後リリースされたClaude-Opus-4.5がtopを僅差で奪還しGemini3が2位とのこと。
ハーネスについてはこちらを読むと良さそう:
- [Paper Note] SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering, John Yang+, arXiv'24, 2024.05
EpochAIによる評価:
ECIでtop。ECIは39のベンチマークから算出されるスコア、らしい。
Scale AIのVisual Tool BenchでもSoTA:
- Beyond Seeing: Evaluating Multimodal LLMs On Tool-enabled Image Perception, Transformation, and Reasoning, Scale AI, 2025.10
CriPtと呼ばれるベンチマークにおける評価でもSoTA:
- [Paper Note] Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark, Minhui Zhu+, arXiv'25, 2025.09
最近提案された新たなtooluseベンチマークでもsecond placeらしい:
- [Paper Note] The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution, Junlong Li+, arXiv'25, 2025.10
IQ130らしい(果たして):
GPQA DiamondでSoTA:
Jeff Dean氏によるポスト:
ICLR 2026 - Submissions, Pangram Labs, 2025.11
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Blog #ICLR #Selected Papers/Blogs #Reference Collection Issue Date: 2025-11-15 Comment
元ポスト:
ICLR'26のsubmissionとreviewに対してLLMが生成したものが否かをDetectionした結果(検出性能は完璧な結果ではない点に注意)
この辺の議論が興味深い:
関連:
oh...
パイプライン解説:
母国語でレビューを書いて英語に翻訳している場合もAI判定される場合があるよという話:
ICLR公式が対応検討中とのこと:
ICLRからの続報:
> As such, reviewers who posted such poor quality reviews will also face consequences, including the desk rejection of their submitted papers.
> Authors who got such reviews (with many hallucinated references or false claims) should post a confidential message to ACs and SACs pointing out the poor quality reviews and provide the necessary evidence.
citationに明らかな誤植があり、LLMによるHallucinationが疑われる事例が多数見つかっている:
Oralに選ばれるレベルのスコアの研究論文にも多数のHallucinationが含まれており、1人の査読者がそれに気づきスコア0を与える、といった事態にもなっているようである:
当該論文はdesk rejectされたので現在は閲覧できないとのこと。
NeurIPS'25ではそもそも査読を通過した研究についても多くのHallucinationが見つかっているとのこと:
LLM開発の裏で行われるデバッグ作業: PyTorch DCP, Kazuki Fujii, 2025.11
Paper/Blog Link My Issue
#Article #LanguageModel #Blog #SoftwareEngineering #VisionLanguageModel Issue Date: 2025-11-14 Comment
元ポスト:
関連:
- [Tips] PyTorchをself buildしてinstallする方法, Kazuki Fujii, 2025.03
- [Tips] PyTorchにおける動的リンク, Kazuki Fujii, 2025.05
自分たちの環境と目的を考えた時に、複数の選択肢を列挙し、それぞれの利点と欠点を明文化した上で最適なものを選択する。そしてそれを実現する上で見つかった挙動のおかしな部分について、怪しい部分にあたりをつけて、仮説を立てて、中身を確認し、時には一度問題ないと判断した部分にも立ち返りさらに深掘りし、原因を明確にする、といったデバッグ作業(の一つのケース)について詳述されている。
Egocentric-10K, Build AI, 2025.11
Paper/Blog Link My Issue
#Article #Dataset #Robotics #3D (Video) #EmbodiedAI Issue Date: 2025-11-13 Comment
元ポスト:
工場での主観視点での作業動画の大規模データセット。Apache 2.0!?
GPT-5.1: A smarter, more conversational ChatGPT, OpenAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ChatGPT #Blog #Reasoning #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Routing #Reference Collection Issue Date: 2025-11-13 Comment
元ポスト:
instantモデルはよりあたたかい応答でより指示追従能力を高め、thinkingモデルは入力に応じてより適応的に思考トークン数を調整する。autoモデルは入力に応じてinstant, thinkingに適切にルーティングをする。
所見:
Artificial Analysisによるベンチマーキング:
GPT-5.1-Codex-maxの50% time horizon:
SYNTH: the new data frontier, pleias, 2025.11
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #LanguageModel #SyntheticData #Reasoning Issue Date: 2025-11-12 Comment
元ポスト:
SoTAなReasoning能力を備えたSLMを学習可能な事前学習用合成データ
元ポスト:
Introducing Kimi K2 Thinking, MoonshotAI, 2025.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reasoning #OpenWeight #Selected Papers/Blogs #Reference Collection Issue Date: 2025-11-07 Comment
HF: https://huggingface.co/moonshotai
元ポスト:
coding系ベンチマークでは少しGPT5,Claude Sonnet-4.5に劣るようだが、HLE, BrowseCompなどではoutperform
tooluseのベンチマークであるtau^2 Bench TelecomではSoTA
モデルの図解:
INT4-QATに関する解説:
INT4-QATの解説:
Kimi K2 DeepResearch:
METRによる50% timehorizonの推定は54分:
ただしサードパーティのinference providerによってこれは実施されており、(providerによって性能が大きく変化することがあるため)信頼性は低い可能性があるとのこと。
METRでの評価でClaude 3.7 Sonnetと同等のスコア:
openweightモデルがproprietaryモデルに追いつくのはsoftwere engineeringタスク(agenticなlong horizon+reasoningタスク)9ヶ月程度を要しているとのこと
Mapping LLMs with Sparse Autoencoders, Hussein+, 2025.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Blog #SparseAutoencoder Issue Date: 2025-11-06 Comment
SparseAutoEncoderを用いた機械学習モデルの特徴の可視化方法に関するチュートリアル
進化する大規模言語モデル評価: Swallowプロジェクトにおける実践と知見, Naoaki Okazaki, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Evaluation #Slide Issue Date: 2025-11-02 Comment
元ポスト:
LLMの評価は些細な評価設定の違いで大きな変動が生じるだけでなく、事後学習済みモデルやreasoningモデルが主流になってきた現在では評価方法もアップデートが必要という話。たとえばreasoningモデルはfew-shotで評価すると性能が低下することが知られているなど。
戦えるAIエージェントの作り方, Takuya Akiba, SakanaAI, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #AIAgents #Slide #Test-Time Scaling Issue Date: 2025-11-01 Comment
元ポスト:
SakanaAIの研究を中心に、特に推論時スケーリング(test time scaling)の話が紹介されている。
Introducing Aardvark: OpenAI’s agentic security researcher, OpenAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Security Issue Date: 2025-10-31 Comment
元ポスト:
> In benchmark testing on “golden” repositories, Aardvark identified 92% of known and synthetically-introduced vulnerabilities, demonstrating high recall and real-world effectiveness.
合成された脆弱性については92%程度検出できたとのこと。Claudeとかだとこの辺はどの程度の性能なのだろう。
gpt-oss-safeguard, OpenAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #OpenWeight #Safety #Safeguard Issue Date: 2025-10-30 Comment
元ポスト:
blog: https://openai.com/index/introducing-gpt-oss-safeguard/
ポリシーとそのポリシーに従うべきコンテンツが与えられたときに、コンテンツを分類するタスクを実施できる汎用的なreasoningモデル。つまり、任意のポリシーを与えて追加の学習なしでpromptingによってコンテンツがポリシーのもとでsafe/unsafeなのかを分類できる。
gpt-ossをreinforcbment finetuningしているとのこと。
Everything About Transformers, Krupa Dave, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Transformer #Blog Issue Date: 2025-10-30 Comment
元ポスト:
ざっと見た感じtransformerの基本的な内容の丁寧な解説に見える。literature(RNNや、LSTM、seq2seqなど)、self/cross-attention,LayerNorm, ResidualConnection, PositionalEncodingといった話の基礎が図解付きで説明されている。
LMMs Engine, EvolvingLMMs-Lab, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #MachineLearning #NLP #MultiModal #Repository #PostTraining #Selected Papers/Blogs #UMM Issue Date: 2025-10-27 Comment
元ポスト:
事前学習済みのLLM, VLM, dLM, DiffusionModelなどからUMMを学習できる事後学習フレームワーク。
LigerKernelでメモリ使用量を30%削減し、SparseAttentionもサポートし、Muon Optimizerもサポートしている。
olmOCR 2: Unit test rewards for document OCR, Ai2, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Supervised-FineTuning (SFT) #ReinforcementLearning #MultiLingual #Japanese #GRPO #Selected Papers/Blogs #DocParser #VisionLanguageModel #OCR Issue Date: 2025-10-23 Comment
元ポスト:
モデル: https://huggingface.co/allenai/olmOCR-2-7B-1025-FP8
Apache2.0ライセンスでSoTA更新。そしてさすがの学習データとコードも公開
テクニカルレポート: https://github.com/allenai/olmocr/blob/main/olmOCR-2-Unit-Test-Rewards-for-Document-OCR.pdf
果たして日本語は…SFT Datasetのtop5にjaはなかったように見える
所見:
demoを試した見たが日本語スライドでも非常に性能が良い
DeepSeekOCRとの比較:
FindWiki, Guilherme Penedo, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #Dataset #LanguageModel #TabularData #Mathematics #MultiLingual #DataFiltering Issue Date: 2025-10-22 Comment
元ポスト:
2023年時点で公開されたWikipediaデータをさらに洗練させたデータセット。文字のレンダリング、数式、latex、テーブルの保持(従来は捨てられてしまうことが多いとのこと)、記事に関係のないコンテンツのフィルタリング、infoboxを本文から分離してメタデータとして保持するなどの、地道な前処理をして洗練化させたとのこと。
How Well Does RL Scale?, Toby Ord, 2025.10
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #Blog #Test-Time Scaling #Scaling Laws #PostTraining #Selected Papers/Blogs Issue Date: 2025-10-21 Comment
元ポスト:
OpenAIやAnthropicが公表している学習に関するplot(と筆者の様々なアカデミアの研究の知見)に基づいて、RLによるスケーリングは、事前学習やTest-time Scalingよりも計算量の観点で効率が悪い、ということを分析している模様。
> So the evidence on RL-scaling and inference-scaling supports a general pattern:
>- a 10x scaling of RL is required to get the same performance boost as a 3x scaling of inference
> - a 10,000x scaling of RL is required to get the same performance boost as a 100x scaling of inference
>
> In general, to get the same benefit from RL-scaling as from inference-scaling required twice as many orders of magnitude. That’s not good.
その上で、RLによるコストが事前学習のコストと同等かそれ以上となったときに、モデルの性能をスケールさせる場合のコストが爆発的に増加することを指摘している(初期のRLによるコストが小さければ事前学習やtest-time scalingのデータを増やすよりも効率がよいスケーリング手法となっていたが、RLのコストが大きくなってくるとスケールさせる際の金額の絶対値が大きくなりすぎるという話)。
Knowledge Flow: Scaling Reasoning Beyond the Context Limit, Zhuang+, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Test-Time Scaling #read-later #Test-time Learning Issue Date: 2025-10-21 Comment
元ポスト:
モデルのロールアウトの結果からattemptから知識リストをiterativeに更新(新たな知識を追加, 古い知識を削除 or 両方)していくことによって、過去のattemptからのinsightを蓄積し性能を改善するような新たなテストタイムスケーリングの枠組みな模様。sequential test-time scalingなどとは異なり、複数のattemptによって知識リストを更新することでスケールさせるので、context windowの制約を受けない、といった話な模様。LLM AgentにおけるTest-time learningとかなり類似したコンセプトに見える。
Context Engineering in Manus, Lance's Blog, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #AIAgents #Blog #ContextEngineering Issue Date: 2025-10-18 Comment
元ポスト:
- Reduce
- Offload
- Isolate
図解つきで各コンセプトについて非常に詳細に記述されている。最後のConclusionを見ればコンパクトに概要をつかめる。
Shipping with Codex, OpenAI, 2025.10
Paper/Blog Link My Issue
#Article #NLP #AIAgents #GenerativeAI #Coding #Video #SoftwareEngineering Issue Date: 2025-10-12 Comment
元ポスト:
OpenAI内部で92%の技術スタッフがdailyで利用している、というマーケティングメッセージが非常に強力で、説得力を持たせていると感じる。
RL Scaling Laws for Mathematical Reasoning, Joan Cabezas, 2025.10
Paper/Blog Link My Issue
#Article #Analysis #MachineLearning #NLP #ReinforcementLearning #Repository #Mathematics #Scaling Laws #read-later #reading Issue Date: 2025-10-11 Comment
元ポスト:
Qwen3をGSM8KでRL Finetuningしたらパラメータ数が小さいモデルは大きなgainを得たが、パラメータが大きいモデルはそれほどでもなかったので、パラメータ数が大きいほどスケールするわけではなく(むしろ恩恵が小さくなる)、かつ報酬をstrictにするとQwenは指示追従能力がないことで学習が全然進まなかった(柔軟なものにしたらそうではなかったので適切な報酬が重要)、GSM8KでRL FinetuninpしたモデルのreasoningはMMLUに転移しなかったので、RL Finetuningは学習データとして与えたドメインのパターンを学習しているだけなのではないか、みたいな話がポストに記述されている。
AI2のResearcherからの所見:
元の話とこの辺をしっかり読み解いたらとても勉強になりそうな予感👀
Scaling Laws系の研究:
- [Paper Note] Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22, 2022.03
- [Paper Note] Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20, 2020.01
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
- [Paper Note] Scaling Laws for Autoregressive Generative Modeling, Tom Henighan+, arXiv'20, 2020.10
- Scaling Laws for Value-Based RL, Fu+, 2025.09
(RL関連)
- [Paper Note] Bayesian scaling laws for in-context learning, Aryaman Arora+, COLM'25, 2024.10
(ICL関連)
画像とかData Mixture, MoEなど他にも色々あるが、一旦上記らへんと元ポスト・AI2からの所見を読み解いたらどういったものが見えてくるだろうか?(全部読んでじっくり考えたいけど時間が無いので...)一旦GPTにきいてみよう
GPTにきいてみた(私は無課金勢だがthinking timeが挟まれたのとデコーディング速度の適度な遅さと、limitに到達しましたというメッセージがなかったことから鑑みるに、以下はGPT-5によって回答されていると考えられる)
https://chatgpt.com/share/68ec5024-83fc-8006-b8c6-14060191fb91
RLのScaling Lawsに関する研究がでました:
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
Making AI citations count with Asta, AI2, 2025.10
Paper/Blog Link My Issue
#Article #Citations #NLP #AIAgents #Blog #ScientificDiscovery Issue Date: 2025-10-09 Comment
RAGベースの研究支援プラットフォームAstaに対して送信されたクエリに対して、システムが引用した研究論文に関する統計情報を公開したとのこと。興味深い。
citationに関するデータはこちら:
https://huggingface.co/datasets/allenai/asta-summary-citation-counts
定期的に更新するとのこと。
Replay BufferがPolicy Gradientで使えない理由, piqcy, 2019.03
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #ReinforcementLearning #ReplayBuffer Issue Date: 2025-10-04 Comment
Policy Gradientに基づいたアルゴリズムは(たとえばREINFORCE系)、現在のポリシーに基づいて期待値を最大化していくことが前提になるため、基本的にはリプレイバッファが使えないが(過去の経験が影響すると現在の戦略の良さがわからなくなる)、工夫をすると使えるようになるよ、といった話の解説
Effective context engineering for AI agents, Anthropic, 2025.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #ContextEngineering Issue Date: 2025-10-04 Comment
元ポスト:
AnthropicによるContextEngineeringに関するブログ。
ざーっとみた感じ基礎的な定義からなぜ重要なのか、retrievalの活用、longnhorizon taskでの活用、compaction(summarization)など、幅広いトピックが網羅されているように見える。
最新サーベイはこちら
- [Paper Note] A Survey of Context Engineering for Large Language Models, Lingrui Mei+, arXiv'25
所見:
GLM-4.6: Advanced Agentic, Reasoning and Coding Capabilies, Zhipu AI, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #MoE(Mixture-of-Experts) #read-later #VisionLanguageModel Issue Date: 2025-09-30 Comment
元ポスト:
続報:
Artificial Intelligenceによる評価:
OpenWeightモデルの中でトップレベルのベンチスコア
HFにてモデルが公開された模様。ベンチマークのスコアを見て思ったが、106BA12Bのモデルと9Bモデルのスコア差がベンチマークによっては小さいので、場合によってはSLMの方でtest time scacingを効かせた方が、時間的な制約がきつい場合は現実的には高い性能が出るのでは?
Build A Reasoning Model (From Scratch), Sebastian Raschka, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Reasoning Issue Date: 2025-09-29 Comment
元ポスト:
reasoningモデルに関するpyTorchによるフルスクラッチでの実装と丁寧な解説つきのNotebookが公開されており内部の基礎的な挙動を理解するためにとても良さそう。
Failing to Understand the Exponential, Again, Julian Schrittwieser, 2025.09
Paper/Blog Link My Issue
#Article #LanguageModel #Evaluation #Blog #Selected Papers/Blogs Issue Date: 2025-09-29 Comment
元ポスト:
関連:
- [Paper Note] Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
- GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS, Patwardhan+, 2025.09
AIの指数関数的な成長は続いているぞという話。
以下は管理人の感想だが、個々のベンチマークで見たらサチってきている(昔より伸び代が小さい)ように感じるが、人間が実施する複雑なタスクに対する上記ベンチマークなどを見るとスケーリングは続いている(むしろ加速している感がある)。シンプルなタスクのベンチマークの伸びは小さくとも、それらシンプルなタスクの積み重ねによって複雑なタスクは実施されるので、(現存するベンチマークが測定できている能力はLLMの部分的な能力だけなことも鑑みると)、複雑なタスクで評価した時の伸びは実は大きかったりする(スケーリングは続いている)のではないか、という感想。
HunyuanImage-3.0, Tencent, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #OpenWeight #UMM Issue Date: 2025-09-29 Comment
元ポスト:
所見:
テキスト生成+画像理解・生成が可能なUnified Multimodal Models (UMMs)。テキストはtokenizer、画像は生成用エンコーダ、理解用エンコーダを用意してエンコードしDecoder-Only Tranformerに入力。auto-regressiveに生成し、テキストはDe-Tokenizerでテキスト化、画像の場合は専用のDecoderでデコードする。
AIインフラを考える, Masayuki Kobayashi, 第38回 ISOC-JP Workshop, 2025.09
Paper/Blog Link My Issue
#Article #MachineLearning #LanguageModel #Infrastructure #GenerativeAI #Slide #read-later Issue Date: 2025-09-28 Comment
元ポスト:
KVCacheサイズとデータ転送量の部分はパフォーマンスチューニングの際に重要なのですぐにでも活用できそう。前半部分は私にとっては難しかったので勉強したい。
We reverse-engineered Flash Attention 4, Modal Blog, 2025.09
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Attention #Blog #SoftwareEngineering Issue Date: 2025-09-28 Comment
元ポスト:
Flash Attention4は数学的なトリックよりも非同期処理の複雑なパイプライン、Blackwellに最適化、とのこと
Nemotron-Personas-Japan: Synthesized Data for Sovereign AI, Nvidia, 2025.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #MultiLingual #Japanese #Cultural Issue Date: 2025-09-24 Comment
dataset: https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan
元ポスト:
国勢調査の統計情報や名字由来netをシードとし、LLM Aによってペルソナに必要な各種属性(文化的背景、スキルと専門知識、キャリア目標と野望、趣味と興味等)を合成し、それらがgivenな状態で、複数のタイプのペルソナ(全体、職業、芸術、スポーツ)を説明するテキストを合成している模様?細かい生成手法はよくわからなかった。実世界の分布(人口統計、地理的分布、性格特性など)を反映した上でペルソナが合成されており、地域固有の人口統計、文化的背景を取り入れたソブリンAIの開発を支援するとのこと。
アメリカやインドの合成されたペルソナもある:
LongCat-Flash-Chat, meituan-longcat, 2025.08
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-08-31 Comment
テクニカルレポート: https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/tech_report.pdf
元ポスト:
Agent周りのベンチで高性能なnon thinkingモデル。毎秒100+トークンの生成速度で、MITライセンス。Dynamic Activation...?
Dynamic Activation (activation paramが入力に応じて変化(全てのトークンをMoEにおいて均一に扱わない)することで効率化)は、下記を利用することで実現している模様
- [Paper Note] MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts, Peng Jin+, ICLR'25
しかし中国は本当に次々に色々な企業から基盤モデルが出てくるなぁ…すごい
- [Paper Note] Scaling Exponents Across Parameterizations and Optimizers, Katie Everett+, ICML'24
解説:
解説:
Kimi-VL-A3B-Thinking-2506, moonshotai, 2025.06
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #Reasoning #OpenWeight #Reference Collection Issue Date: 2025-06-24 Comment
元ポスト:
様々なベンチマークでSoTA(gpt4o, Qwen2.5-VL-7B)を達成したReasoning VLM
テクニカルペーパー:
- [Paper Note] Kimi-VL Technical Report, Kimi Team+, arXiv'25
Q-learning is not yet scalable, Seohong Park, UC Berkeley, 2025.06
Paper/Blog Link My Issue
#Article #Tutorial #ReinforcementLearning #Blog #Off-Policy #On-Policy Issue Date: 2025-06-19 Comment
元ポスト:
on-policy RLでは、現在の状態からポリシーに従ってアクションを選択して、実際に選択したアクションのrewardをシグナルにしてポリシーを更新するけど、off-policy RLでは、未来において現在の(Q関数で)Q値が最大となるアクションを選択した場合に得られる価値はどんなもん?というQ関数の学習が甘い状態だととあるアクションを過大評価してしまう(=バイアス)ようなシグナルに基づいて更新されるから、系列が長くなるとバイアスが蓄積して適切なQ関数が学習できなくなってdepth方向にスケールしづらいんだよ、という話っぽい?
MiniMax-M1, MiniMax, 2025.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #Author Thread-Post Issue Date: 2025-06-17 Comment
元ポスト:
vLLMでのservingが推奨されており、コンテキストは1M、456BのMoEアーキテクチャでactivation weightは46B
公式ポスト:
Agentもリリースした模様:
[Paper Note] Language Models are Unsupervised Multitask Learners, Radford+, OpenAI, 2019
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Zero/FewShotLearning #Selected Papers/Blogs Issue Date: 2025-06-15 Comment
今更ながら、GPT-2論文をメモってなかったので追加。
従来のモデルは特定のタスクを解くためにタスクごとに個別のモデルをFinetuningする必要があったが、大規模なWebTextデータ(Redditにおいて最低3つのupvoteを得たポストの外部リンクを収集)によって言語モデルを訓練し、モデルサイズをスケーリングさせることで、様々なタスクで高い性能を獲得でき、Zero-Shot task transfer, p(output | input, task) , が実現できるよ、という話。
今ざっくり見返すと、Next Token Predictionという用語は論文中に出てきておらず、かつ "Language Modeling" という用語のみで具体的なlossは記述されておらず(当時はRNN言語モデルで広く学習方法が知られていたからだろうか?)、かつソースコードも学習のコードは提供されておらず、lossの定義も含まれていないように見える。
ソースコードのモデル定義:
https://github.com/openai/gpt-2/blob/master/src/model.py#L169
Qwen_Qwen3-Embedding-4B-GGUF, QwenTeam, 2025.06
Paper/Blog Link My Issue
#Article #Embeddings #NLP #LanguageModel #RepresentationLearning #OpenWeight #Author Thread-Post Issue Date: 2025-06-06 Comment
8BモデルはMTEBでトップの性能を達成。context 32K。100以上の言語をサポート。32--2560次元にoutputの次元数をカスタマイズできる(嬉しい、が性能にどの程度影響が出るから気になる)。
元ポスト:
QwenTeam post:
OpenAI-Codex, OpenAI, 2025.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Coding #SoftwareEngineering #Reference Collection Issue Date: 2025-05-18 Comment
OpenHandsのNeubig氏が、OpenAIのブログポスト中で報告されているSWE-Bench Verifiedのスコアについて、言及している。OpenAIは23個サンプルについて(internal infrastructureで動作させられないため)除外しているので、その分スコアに下駄が履かれているようで、ブログ中のpassNのスコアを他のリーダーボードのスコアと比較する際には注意が必要っぽい。
verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #ReinforcementLearning #python #Selected Papers/Blogs #Reference Collection Issue Date: 2025-05-16 Comment
SoTAなRLアルゴリズムを数行のコードで実装可能で、Sequence Parallelismがサポートされているので長い系列を扱える。FSDP, Megatron-LM,vLLM,SGLangなどとシームレスに統合できるっぽい?
注意点(超重要):
inference backend(ブログ中ではvLLM, SGLangなどを仮定。ロールアウトに利用する)とtrainingのbackend(モデルを学習するフレームワーク, FSDPなどを仮定する)のミスマッチによってトークンの生起確率に差が生じ、ポリシーの更新がうまくいかなくなる。
- 論文では語られないLLM開発において重要なこと Swallow Projectを通して, Kazuki Fujii, NLPコロキウム, 2025.07
でも言われているように、ライブラリにはバグがあるのが普通なのね、、、。
Stanford Alpaca: An Instruction-following LLaMA Model, Taori +, 2023.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #InstructionTuning #PostTraining #Selected Papers/Blogs Issue Date: 2025-05-12 Comment
今更ながらメモに追加。アカデミアにおけるOpenLLMに対するInstruction Tuningの先駆け的研究。
ms-swiftによるMegatron-LMベースのQwen3のファインチューニング, Aratako, 2025.05
Paper/Blog Link My Issue
#Article #NLP #Library #Supervised-FineTuning (SFT) #Blog #OpenWeight #MoE(Mixture-of-Experts) #PostTraining #Author Thread-Post Issue Date: 2025-05-11 Comment
元ポスト:
Megatron-SWIFTというAlibaba製のライブラリを利用しQwen3の継続事前学習とSFTを実施する方法を、ベストプラクティスに則って記述し、かつ著者自身が学習したモデルも公開している。(おそらくインスタンス代は自腹なので)すごい...!!
Megatron-SWIFTはMoEアーキテクチャを採用したモデルであれば、DeepSpeed Zero3 [^1]と比べて10倍程度のスループットで学習できる模様(早い)。一方MoEアーキテクチャでないモデルの場合はそこまで大きな差はない。
[^1]: A100 80GB 2ノードでは、Qwen3-30B-A3Bは、DeepSpeed-Zero2ではOOMとなり載らないようだ…。なんとリソースに厳しいこと…(涙)
ACL 2024 参加報告, 張+, 株式会社サイバーエージェント AI Lab, 2024.08
Paper/Blog Link My Issue
#Article #Tutorial #Slide #ACL #Reading Reflections Issue Date: 2025-05-11 Comment
業界のトレンドを把握するのに非常に参考になる:
- Reasoning, KnowledgeGraph, KnowledgeEditing, Distillation
- PEFT, Bias, Fairness, Ethics
- Multimodal(QA, Benchmarking, Summarization)
などなど。
投稿数5000件は多いなあ…
Agent Frameworkはどれを使うべきか [タスク性能編], はち, 2025.05
Paper/Blog Link My Issue
#Article #Analysis #NLP #Library #AIAgents #Blog #Author Thread-Post Issue Date: 2025-05-06 Comment
各フレームワーク毎の性能の違いや消費したトークン数、実装の微妙や違いがまとめられており、太字でtakeawayが記述されているので非常にわかりやすい。
元ポスト:
parakeet-tdt-0.6b-v2, Nvidia, 2025.05
Paper/Blog Link My Issue
#Article #SpeechProcessing #AutomaticSpeechRecognition(ASR) #OpenSource Issue Date: 2025-05-06 Comment
元ポスト:
2025.05.06時点でOpenASR Leaderboardでトップ:
https://huggingface.co/spaces/hf-audio/open_asr_leaderboard
Already supports Nvidia Parakeet
Simultaneously supporting Linux/Windows/macOS
https://github.com/patui/Nosub
React がビルドされるまでの流れを理解したい, ツチノコ, 2023.12
Paper/Blog Link My Issue
#Article #Blog #Frontend #React (Frontend) Issue Date: 2025-05-01 Comment
Reactがビルドされる流れは、
- Webpackでバンドル(アセットをまとめる)し
- Babelでトランスパイルし(ES5(古い仕様のJS) に変換)し
- tscでJavaScriptに変換
する
Deepwiki, Cognition, 2025.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Repository Issue Date: 2025-04-26 Comment
githubリポジトリに関するリッチなドキュメントに対してDevinを通じて対話的に質問ができる模様。サインアップ不要で、githubリポジトリのドメインをdeepwikiに変えるだけで利用可能
Fiction.liveBench, Kas, 2025.04
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Evaluation #LongSequence Issue Date: 2025-04-09 Comment
long contextではGemini-2.5-proの圧勝
BFCLv2, UC Berkeley, 2024.08
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents #Evaluation #API #Selected Papers/Blogs #ToolUse Issue Date: 2025-04-08 Comment
LLMのTool Useを評価するための現在のデファクトスタンダードとなるベンチマーク
BFCLv3:
https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html
Dream-v0-Instruct-7B, Dream-org, 2025.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #DiffusionModel #OpenWeight Issue Date: 2025-04-08 Comment
OpenWeightな拡散言語モデル
元ポスト:
関連:
- [Paper Note] Large Language Diffusion Models, Shen Nie+, NeurIPS'25
Llama 4 Series, Meta, 2025.04
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #Reference Collection Issue Date: 2025-04-05 Comment
Huggingface:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164
解説ポスト:
Artificial Analysisによる性能検証:
MaverickがGPT4oと同等、ScoutがGPT4o-miniと同等
Update:
性能に関して不可解な点が多そうなので様子見をしても良いかも。
性能検証(Math-Perturb):
日本語にあまり強くないという情報も
元ポスト:
どうやらvLLMのLlama4のinferenceにバグがあったやうで、vLLMのIssue 16311にて、Llama4のinferenceに関するバグが修正され、性能が向上した模様。どのベンチを信じたら良いかまるでわからん。
2025.0413現在のchatbot arenaのランクは、32位となり(chatbot arena向けにtuningされていたであろうモデルは2位だった)GPT-4oが29位であることを考慮すると上記のArtificial Intelligenceの評価とも大体一致している。
https://lmarena.ai
関連ポスト:
openhands-lm-32b-v0.1, all-hands, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #SoftwareEngineering Issue Date: 2025-04-02 Comment
Qwen Coder 2.5 Instruct 32Bに基づく最先端のSWEタスクが実行可能なモデル
Nemotron-H: A Family of Accurate, Efficient Hybrid Mamba-Transformer Models, Nvidia, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #EfficiencyImprovement #Pretraining #NLP #LanguageModel #Transformer #Supervised-FineTuning (SFT) #MultiModal #Blog #SSM (StateSpaceModel) #Selected Papers/Blogs Issue Date: 2025-03-24 Comment
関連:
- Hunyuan T1, Tencent, 2025.03
TransformerのSelf-attention LayerをMamba2 Layerに置換することで、様々なベンチマークで同等の性能、あるいは上回る性能で3倍程度のInference timeの高速化をしている(65536 input, 1024 output)。
56B程度のmediumサイズのモデルと、8B程度の軽量なモデルについて述べられている。特に、8BモデルでMambaとTransformerのハイブリッドモデルと、通常のTransformerモデルを比較している。学習データに15 Trillion Tokenを利用しており、このデータ量でのApple to Appleのアーキテクチャ間の比較は、現状では最も大規模なものとのこと。性能は多くのベンチマークでハイブリッドにしても同等、Commonsense Understandingでは上回っている。
また、学習したNemotron-Hをバックボーンモデルとして持つVLMについてもモデルのアーキテクチャが述べられている。
The "think" tool: Enabling Claude to stop and think in complex tool use situations, Anthropic, 2025.03
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Chain-of-Thought #Blog #Reasoning Issue Date: 2025-03-23 Comment
"考える"ことをツールとして定義し利用することで、externalなthinkingを明示的に実施した上でタスクを遂行させる方法を紹介している
Hunyuan T1, Tencent, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Proprietary #SSM (StateSpaceModel) #Reading Reflections Issue Date: 2025-03-22 Comment
元ポスト:
画像はブログより引用。DeepSeek-R1と比較すると優っているタスクと劣っているタスクがあり、なんとも言えない感。GPT4.5より大幅に上回っているタスク(Math, Reasoning)があるが、そもそもそういったタスクはo1などのreasoningモデルの領域。o1と比較するとこれもまあ優っている部分もあれば劣っている部分もあるという感じ。唯一、ToolUseに関しては一貫してOpenAIモデルの方が強い。
ChineseタスクについてはDeepSeek-R1と完全にスコアが一致しているが、評価データのサンプル数が少ないのだろうか?
reasoningモデルかつ、TransformerとMambaのハイブリッドで、MoEを採用しているとのこと。
TransformerとMambaのハイブリッドについて(WenhuChen氏のポスト):
Layer-wise MixingとSequence-wise Mixingの2種類が存在するとのこと。前者はTransformerのSelf-Attenton LayerをMamba Layerに置換したもので、後者はSequenceのLong partをMambaでまずエンコードし、Short PartをTransformerでデコードする際のCross-Attentionのencoder stateとして与える方法とのこと。
Self-Attention Layerを削減することでInference時の計算量とメモリを大幅に削減できる(Self-Attentionは全体のKV Cacheに対してAttentionを計算するため)。
EXAONE-Deep-32B, LG AI Research, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #OpenWeight Issue Date: 2025-03-18 Comment
元ポスト:
EXAONE AI Model License Agreement 1.1 - NC
商用利用不可
SmolDocling-256M, IBM Research, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #DocParser #Author Thread-Post Issue Date: 2025-03-18 Comment
Apache-2.0ライセンス。言語はEnglishのみな模様
マルチモーダルなImage-To-Textモデル。サンプルはこちら
ERNIE4.5_X1, Baidu, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #Proprietary #Reference Collection #Author Thread-Post Issue Date: 2025-03-17 Comment
解説ポスト:
- ERNIE4.5はGPT4.5をさまざまなベンチマークで上回り、価格がなんとGPT4.5の1%
- X1はマルチモーダルなreasoningモデルでDeepSeek-R1と同等の性能で半額
らしい
このモデルは6月30日にオープン(ウェイト?)になるとスレッドで述べられている。
Introducing Gemma 3: The most capable model you can run on a single GPU or TPU, Google, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Reference Collection Issue Date: 2025-03-12 Comment
Googleの新たなSLMで、デバイスやラップトップでも動作可能な軽量モデル。テキストだけでなく画像とShortVideoの認識もできて、140言語をサポート。おまけに27BモデルでLlama3-405BとDeepSeek-V3とo3-miniをChatbotArenaのリーダーボードで上回り、128kのcontext window。えぇ…。
モデルの詳細:
https://huggingface.co/blog/gemma3
1Bモデルは英語のみサポート、マルチモーダル不可など制約がある模様。
詳細までは書いていないが、128Kコンテキストまでcontext windowを広げる際の概要とRoPE(のような)Positional Embeddingを利用していること、SlideingWindow Attentionを用いておりウィンドウサイズが以前の4096から性能を維持したまま1024に小さくできたこと、ImageEncoderとして何を利用しているか(SigLIP)、896x896の画像サイズをサポートしており、正方形の画像はこのサイズにリサイズされ、正方形でない場合はcropされた上でリサイズされる(pan and scanアルゴリズムと呼ぶらしい)こと、事前学習時のマルチリンガルのデータを2倍にしたことなど、色々書いてある模様。
Gemmaライセンス
解説ポスト:
解説ポスト:
GRPO Judge Experiments: Findings & Empirical Observations, kalomaze's kalomazing blog, 2025.03
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #LanguageModel #ReinforcementLearning #Blog #GRPO #Subjective Issue Date: 2025-03-05 Comment
一意に解が決まる問題ではなく、ある程度の主観的な判断が必要なタスクについてのGRPOの分析。
2つのテキストを比較するタスクで、一方のタスクはLLMによって摂動を与えている(おそらく意図的にcorruptさせている)。
GRPOではlinearやcosineスケジューラはうまく機能せず、warmupフェーズ有りの小さめの定数が有効らしい。また、max_grad_normを0.2にしまgradient clippingが有効とのこと。
他にもrewardの与え方をx^4にすることや、length, xmlフォーマットの場合にボーナスのrewardを与えるなどの工夫を考察している。
The Ultra-Scale Playbook: Training LLMs on GPU Clusters, HuggingFace, 2025.02
Paper/Blog Link My Issue
#Article #Pretraining #MachineLearning #LanguageModel #Supervised-FineTuning (SFT) #Selected Papers/Blogs Issue Date: 2025-03-04 Comment
HuggingFaceによる数1000のGPUを用いたAIモデルのトレーニングに関するオープンソースのチュートリアル
Introducing the SWE-Lancer benchmark, OpenAI, 2025.02
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents #Evaluation #Coding #SoftwareEngineering Issue Date: 2025-03-02 Comment
元ポスト:
1400以上のフリーランスソフトウェアエンジニアリングタスクを集めたベンチマーク。タスクはバグ修正から機能実装まで多岐にわたり、経験豊富なエンジニアによって評価されたもの。
DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL, Luo+, 2025.02
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #ContextWindow #Blog Issue Date: 2025-02-12 Comment
日本語解説: https://jobirun.com/deepscaler-1-5b-surpasses-o1-preview-rl-scaling/
openreview:
https://openreview.net/forum?id=I6GzDCne7U
Iterative Context Lengtheningと呼ばれる、RLの学習時に最初から固定された大きなcontext(24Kなど)ではなく、学習の過程で小さなcontext windowから始め、効率的なreasoningを学習させながら、段階的にモデルのcontext windowを引き上げる手法(論文中では8K->16K->24K)を提案している。
SGlang, sgl-project, 2024.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #python #LLMServing #SoftwareEngineering #Selected Papers/Blogs #Reference Collection Issue Date: 2025-02-12 Comment
- Open R1, HuggingFace, 2025.01
のUpdate2でMath Datasetの生成に利用されたLLM Servingフレームワーク。利用前と比較してスループットが2倍になったとのこと。
CPU, external storageを利用することでTTFTを改善するようになったようで、最大80%TTFTが削減されるとの記述がある。
(原理的には元来可能だが計算効率の最適化に基づく誤差によって実装上の問題で実現できていなかった) Deterministic Inferenceをサポート:
Open R1, HuggingFace, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Repository #Reasoning #OpenSource #Selected Papers/Blogs #Reference Collection Issue Date: 2025-01-26 Comment
HFによるDeepSeekR1を完全に再現する取り組み
Update1: https://huggingface.co/blog/open-r1/update-1
Update2:
https://huggingface.co/blog/open-r1/update-2
512機のH100を利用…
LLM Datasets, mlabonne, 2025.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Repository #PostTraining #Selected Papers/Blogs Issue Date: 2025-01-25 Comment
LLMの事後学習用のデータをまとめたリポジトリ
現在も更新されている。
Llama Stack, Meta, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #AIAgents #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-01-25 Comment
Llamaを用いたLLM Agentを構築するための標準化されたフレームワーク。Quick StartではRAG Agentを構築している。
distilabel, 2023.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #SyntheticData Issue Date: 2025-01-25 Comment
高品質な合成データをLLMで生成するためのフレームワーク
How to fine-tune open LLMs in 2025 with Hugging Face, PHILSCHMID, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #python #Blog #SoftwareEngineering #PostTraining Issue Date: 2025-01-25 Comment
SFTTrainerを用いたLLMのSFTについて、実用的、かつ基礎的な内容がコード付きでまとまっている。
Structured Outputs OpenAI Platform, 2025.01
Paper/Blog Link My Issue
#Article #LanguageModel #Chain-of-Thought #python #StructuredData Issue Date: 2025-01-25 Comment
pydanticを用いて、CoT+構造化されたoutputを実施するサンプル
Killed by LLM, R0bk
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Dataset #LanguageModel #Evaluation #Blog Issue Date: 2025-01-05 Comment
Saturationとなっているベンチマークは、最先端の性能をすでに測定できなくなってしまったベンチマークとのこと。
LLMによって性能が飽和したベンチマークをリストアップしているサイトで、2024年までのものが掲載されている。それ以後は掲載されていないようだ。
Advanced RAG Techniques: Elevating Your Retrieval-Augmented Generation Systems, NirDiamant, 2025.01
Paper/Blog Link My Issue
#Article #Tutorial #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Repository #Selected Papers/Blogs Issue Date: 2025-01-05 Comment
元ポスト:
RAGのための細かなテクニックが(コードのサンプルへのリンク付きで)大量にまとまっている。かなり頻繁に更新れているようで非常に良さそう
まだ更新されている。
pydantic-settingsで環境変数からもオプション引数を指定できるCLIを作る 〜サブコマンド篇〜, nikkie-ftnextの日記, 2025.01
Paper/Blog Link My Issue
#Article #python #Blog Issue Date: 2025-01-04 Comment
pydantic-settingsを使ったCLI作成に関する記事。環境変数からオプションを指定できるので、コマンドライン引数を動的に柔軟に変更したい場合に便利そう
LiteLLM, BerriAI, 2023.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #python #Repository #API Issue Date: 2025-01-03 Comment
様々なLLMのAPIを共通のインタフェースで呼び出せるライブラリ
- aisuite, andrewyng, 2024.11
とどちらがいいんだ・・・?
aisuiteのissueの113番のスレッドを見ると、
- LiteLLMはもはやLiteではなくなっており、コードベースの保守性が低い
- aisuiteは複数のLLMプロバイダーをシンプルに利用する方法を提供する
- 今後発表されるロードマップを見れば、LiteLLMとの差別化の方向性が分かるはずだ
といった趣旨のことが記述されていた。
v1.82.7--v1.82.8において、機密情報を漏洩させるマルウェアが仕込まれていたとのこと。
Karpathy氏の所見:
2024-ai-timeline, reach-vb, 2025.01
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP #LanguageModel #OpenWeight #Proprietary Issue Date: 2025-01-02 Comment
月別で2024年にリリースされた主要なLLM(マルチモーダルなLLMも含む)のタイムラインがまとめられている。
API Only(プロプライエタリ)なのか、OpenWeightなのかもタグ付けされている。
floret, explosion, 2021
Paper/Blog Link My Issue
#Article #NeuralNetwork #Embeddings #Word #Library #RepresentationLearning #Repository Issue Date: 2024-12-28 Comment
fasttextを拡張したもの。本家fasttextがアーカイブ化してしまったので、代替手段に良さそう。
元ポスト:
Stanford CS229 I Machine Learning I Building Large Language Models (LLMs), StanfordUnivercity, 2024.09
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Video Issue Date: 2024-12-25 Comment
スタンフォード大学によるLLM構築に関する講義。事前学習と事後学習両方ともカバーしているらしい。
OpenAI o3は,人間とは全く異質の汎用知能である危険性【東大解説】, 神楽坂やちま, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #GenerativeAI #Blog #Reading Reflections Issue Date: 2024-12-24 Comment
様々な有識者の見解をまとめつつ、文献を引用しつつ、かつ最終的に「人間が知能というものに対してなんらかのバイアスを持っている」可能性がある、という話をしており興味深い。
一部の有識者はARC-AGIの一部の、人間なら見た瞬間に分かるようなパターン認識の問題でも解けていないことから、AGIではないと主張しているとのことだったが、人間目線で簡単な問題が解けることはAGIとして必須な条件ではないよね、といった話が書かれており、そもそも有識者がどのようなものさしや観点でAGIを見ているのか、どういう視点があるのか、ということが感覚的に分かる内容であり、おもしろかった。
しかし、そもそも何がどうなったらAGIが実現できたと言えるのだろうか?定義がわからない(定義、あるのか…?)
完全にオープンな約1,720億パラメータ(GPT-3級)の大規模言語モデル 「llm-jp-3-172b-instruct3」を一般公開 ~GPT-3.5を超える性能を達成~ , NII, 2024.12
Paper/Blog Link My Issue
#Article #Tools #NLP #Dataset #LanguageModel #Blog #OpenWeight #Japanese #OpenSource #Selected Papers/Blogs Issue Date: 2024-12-24 Comment
GPT3.5と同程度のパラメータ数のコーパス、モデル、ツール、全てを公開。学習データまで含めてオープンなモデルとしては世界最大規模とのこと。
Instructionチューニング済みのモデルはライセンスを読むと、ライセンスに記述されている内容を遵守すれば、誰でも(日本人なら18歳以上とかはあるが)アクセス可能、用途の制限(商用・非商用問わず)なく利用でき、かつ再配布や派生物の生成などが許されているように見える。
が、baseモデルの方はコンタクト情報を提供のうえ承認を受けないと利用できない模様。また、再配布と一部の使途に制限がある模様。
SNSではオープンソースではないなどという言説も出ており、それはbaseモデルの方を指しているのだろうか?よくわからない。
実用上はinstructionチューニング済みのモデルの方がbaseモデルよりも使いやすいと思うので、問題ない気もする。
やはりbaseとinstructでライセンスは2種類あるとのこと:
Fast LLM Inference From Scratch, Andrew Chan, 2024.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #LanguageModel #Blog Issue Date: 2024-12-17 Comment
ライブラリを使用せずにC++とCUDAを利用してLLMの推論を実施する方法の解説記事
LLaMA-Omni: Seamless Speech Interaction with Large Language Models, Meta, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #SpeechProcessing #OpenWeight #OpenSource Issue Date: 2024-12-13 Comment
音声とテキストのOpenSourceマルチモーダルモデル。inputは音声のみ?に見えるが、出力はテキストと音声の両方を実施できる。GPT-4oレベルのspeech capabilityを目指すとaboutに記載されている。興味深い。
installの説明に `Whisper-large-v3` をインストールする旨が記載されているので、Whisper-large-v3で認識した内容に特化したSpeech Encoder/Adapterが学習されていると考えられる。
- MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N/A, ACL'24 Findings
マルチモーダルなLLMの基本的な概念については上記参照のこと。
GoogleCloudPlatform_generative-ai, Google, 2024.12
Paper/Blog Link My Issue
#Article #Tutorial #GenerativeAI #Repository Issue Date: 2024-12-12 Comment
Google Cloudで生成AI(Gemini+Vertex AI)を動かすためのサンプルコード集
元ポスト:
Sarashina-Embedding-v1-1B, SB Intuitions, 2024.12
Paper/Blog Link My Issue
#Article #Embeddings #NLP #RepresentationLearning Issue Date: 2024-12-10 Comment
Non-commercialなライセンスで、商用利用の場合は問い合わせが必要
Llama3.3-70B, Meta, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2024-12-06 Comment
3.1-70Bよりも性能向上し、3.1-405Bの性能により近く。
(画像は元ポストより引用)
日本語LLMまとめ, LLM-jp, 2024.12
Paper/Blog Link My Issue
#Article #Survey #NLP #Dataset #LanguageModel #Evaluation #Repository #OpenWeight #Japanese #OpenSource Issue Date: 2024-12-02 Comment
LLM-jpによる日本語LLM(Encoder-Decoder系, BERT系, Bi-Encoders, Cross-Encodersを含む)のまとめ。
テキスト生成に使うモデル、入力テキスト処理に使うモデル、Embedding作成に特化したモデル、視覚言語モデル、音声言語モデル、日本語LLM評価ベンチマーク/データセットが、汎用とドメイン特化型に分けてまとめられている。
各モデルやアーキテクチャの原論文、学習手法の原論文もまとめられている。すごい量だ…。
LLM Self-Correction Papers, Ryo Kamoi, 2024.11
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Repository #SelfCorrection Issue Date: 2024-11-30 Comment
self-correctionの専門家によるself-correction関連の論文のリーディングリスト。ぜひチェックしたい。
元ポスト:
aisuite, andrewyng, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #python #Repository #API Issue Date: 2024-11-28 Comment
複数のLLM Providerの呼び出しを共通のインタフェースで呼び出せる。変更するのは、モデルを指定するパラメータのみ。
元ポスト:
https://www.linkedin.com/posts/andrewyng_announcing-new-open-source-python-package-activity-7266851242604134400-Davp?utm_source=share&utm_medium=member_ios
エンジニア研修まとめ, gcchaan, 2024.11
Paper/Blog Link My Issue
#Article #Tutorial Issue Date: 2024-11-27 Comment
様々な企業のエンジニアの新卒研修の資料などがまとまっている。学術機関の講義なども含まれている。現在も更新されている模様。
量がすごい。
YomiToku, Kotaro Kinoshita, 2024.11
Paper/Blog Link My Issue
#Article #ComputerVision #Library #Repository #OCR Issue Date: 2024-11-27 Comment
いわゆるAI-OCRで、縦書きの認識も可能で、表などの構造化された情報も認識可能とのこと。
手書きは認識できるのだろうか?
CC BY-NC-SA 4.0
元ツイート:
Sarashina2-8x70Bの公開, SB Intuitions, 2024.11
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Blog #OpenWeight #Japanese Issue Date: 2024-11-25 Comment
MoE Layerの説明、Sparse Upcyclingの説明、MoEモデルを学習する際に、学習時の学習率の設定が大きすぎると初期に損失が増大し、小さすぎると損失の増大は防げるがlong runで学習した際の性能向上が小さかったこと、元のモデルのパラメータを毀損しないように、Upcyclingをした元モデルの最終的な学習率を踏襲して学習をし、学習率をさらに減衰させていったこと、などが記載されている。
また、性能評価として同等のactivation parameter数を持つモデルと日本語のQAタスクで比較した結果も載っている。
- [Paper Note] Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR'23
MoE Layerについては
- [Paper Note] Mixtral of Experts, Albert Q. Jiang+, arXiv'24, 2024.01
も参照のこと
SmolLM2, 2024.11
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #InstructionTuning #SyntheticData #OpenWeight #OpenSource #PostTraining Issue Date: 2024-11-21 Comment
元ポスト:
Orca-AgenInstruct-1M microsoft/orca-agentinstruct-1M-v1, Microsoft, 2024.11
よりもSmolLMのSFTで各種ベンチで高い性能を獲得
Datasets: hpprc_honyaku, hpprc, 2024.11
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #Dataset #Zero/Few/ManyShotPrompting #Japanese Issue Date: 2024-11-20 Comment
元ポスト:
英語Wikipediaを冒頭数文を抽出し日本語に人手で翻訳(Apache2.0ライセンスであるCalmやQwenの出力を参考に、cc-by-sa-4.0ライセンスにて公開している。
テクニカルタームが日本語で存在する場合は翻訳結果に含まれるようにしたり、翻訳された日本語テキストが単体で意味が成り立つように翻訳しているとのことで、1件あたり15分もの時間をかけて翻訳したとのこと。データ量は33件。many-shotやfew-shotに利用できそう。
日英対訳コーパスはライセンスが厳しいものが多いとのことなので、非常に有用だと思う。
ローカルLLMのリリース年表, npaka, 随時更新, 2024.11
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Blog #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2024-11-15 Comment
ローカルLLMを含むOpenLLMのリリース日が年表としてまとまっており、随時更新されている模様。すごい。
2026年3月現在も更新が続いている
sarashina2-8x70B, SBIntuitions, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Japanese #MoE(Mixture-of-Experts) Issue Date: 2024-11-09 Comment
プレスリリース: https://www.sbintuitions.co.jp/news/press/20241108_01/
- 商用利用不可な点には注意
- アーキテクチャは70Bモデルx8のMixture of Experts(MoE)
- モデルカードによると、inferenceにはBF16で、A100 80GB or H100が16基必要っぽい
MoEを利用したLLMについては、[Paper Note] Mixtral of Experts, Albert Q. Jiang+, arXiv'24, 2024.01 を参照のこと。
ZeRO: DeepSpeedの紹介, レトリバ, 2021.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Pretraining #NLP #Supervised-FineTuning (SFT) #Reference Collection Issue Date: 2024-11-07 Comment
ZeROの説明がわかりやすい
こちらの記事もわかりやすい
https://zenn.dev/turing_motors/articles/d00c46a79dc976
DeepSpeedのコンフィグの一覧
https://www.deepspeed.ai/docs/config-json/
transformersにおけるdeepspeedのドキュメント:
https://huggingface.co/transformers/v4.9.2/main_classes/deepspeed.html
参考: deepspeedの使い方まとめ
https://note.com/fukudawataru/n/n5152e6f587c8
ZeRO Stage3を使う場合、ページ後方にしれっととんでもなく重要なことが書いてあるので気をつけましょう。。。。
https://huggingface.co/docs/transformers/v4.17.0/en/main_classes/deepspeed#constructing-massive-models
ZeROはparameterとoptimizerのmemory footprintの最適化を頑張っていて、activation memory footprint(バッチをforward passに流す時に消費されるメモリ)の削減は、tiling, activation/gradient checkpointingとかで頑張ってねという
という話が本家issueの4047に記載されている。
結論: つまづいたらDeepSpeedのIssueをエラーメッセージで検索かけるのが一番効果的
Lingua, Meta
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Library #Repository #MinimalCode Issue Date: 2024-11-05 Comment
研究目的のための、minimal、かつ高速なLLM training/inferenceのコードが格納されたリポジトリ。独自のモデルやデータ、ロスなどが簡単に実装できる模様。
Aya Expanse, Cohere, 2024.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiLingual #OpenWeight #Author Thread-Post Issue Date: 2024-10-24 Comment
CohereによるマルチリンガルLLM, 8B, 32Bのモデルが存在する。
8BモデルのArenaHardでの評価
32BモデルのArenaHardでの評価
元ポスト:
Prompt-Engineering-Guide, DAIR.AI
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Prompting #Repository Issue Date: 2024-10-20 Comment
LLMのsettingから、few-shot, self-consistencyなどのprompting技術、さまざまなタスクの実例などが網羅的にまとまっている
MLE-Bench, OpenAI, 2024.10
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents #Evaluation #AutoML Issue Date: 2024-10-20 Comment
75のkaggleのcompetitionsを収集(賞金1.9M$に相当する)し、そこから機械学習モデルの構築するためのエンジニアリングタスク(データセットの準備, モデルの学習, 実験)を抽出し、AI Agentsが機械学習モデルのこれらエンジニアリングタスクに対してどの程度実施できるかを測定できるようにしたベンチマーク
Unsloth, unslothai, 2024.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Library #Supervised-FineTuning (SFT) #InstructionTuning #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs Issue Date: 2024-10-08 Comment
single-GPUで、LLMのLoRA/QLoRAを高速/省メモリに実行できるライブラリ
現在でも鉄板
Streamlit, 2020.12
Paper/Blog Link My Issue
#Article #Library #python #Selected Papers/Blogs Issue Date: 2024-10-07 Comment
データを用いたアプリを簡単に作れるpythonライブラリ
データ/モデルを用いたvisualization等を実施するアプリを、数行で作れてしまう。綺麗なUIつき。便利。
textlesslib, FAIR, 2022.02
Paper/Blog Link My Issue
#Article #SpeechProcessing #Repository Issue Date: 2024-10-04 Comment
元ポスト:
2024年11月にアーカイブされている。
Gemma-2-JPN, 2024.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Japanese Issue Date: 2024-10-04 Comment
日本語データでfinetuningされたGemma2
元ポスト:
AutoGen, Microsoft, 2024.10
Paper/Blog Link My Issue
#Article #LanguageModel #Library #AIAgents #Repository #Conversation #MCP Issue Date: 2024-10-02 Comment
マルチエージェントを構築するためのフレームワーク。MCP Serverとの連携も可能で、AssistantAgent classを入れ子のように設定することで、親エージェントが特定領域に特化した子エージェントをtool useとして呼び出すようなマルチエージェントを構築できるように見受けられる。
ECCV2024-Papers-with-Code, 2024.09
Paper/Blog Link My Issue
#Article #ComputerVision #Repository Issue Date: 2024-09-30 Comment
ECCV2024の全体像を概観するのに有用
以下、Claude 3.5 Sonnetに目次を入力し一言で各項目を説明させた内容。
hallucinationがあるかもしれないので参考程度で。
--------------------
各項目の概要を一言で説明いたします:
1. 3DGS(Gaussian Splatting): 3D空間内のガウス関数を用いた新しい3Dレンダリング手法。
2. Mamba / SSM: 長期依存関係を効率的に処理する新しい系列モデルアーキテクチャ。
3. Avatars: デジタル環境でユーザーを表現する仮想キャラクター。
4. Backbone: ディープラーニングモデルの主要な特徴抽出部分。
5. CLIP: 画像とテキストを同じ空間に埋め込む大規模マルチモーダルモデル。
6. MAE: 画像の一部を隠してから再構築する自己教師あり学習手法。
7. Embodied AI: 物理的な環境と相互作用する AI システム。
8. GAN: 生成モデルと識別モデルを競争させて学習する生成モデル。
9. GNN: グラフ構造データを処理するための神経ネットワーク。
10. 多模态大语言模型(MLLM): テキスト、画像、音声など複数のモダリティを扱う大規模言語モデル。
11. 大语言模型(LLM): 大量のテキストデータで学習された大規模な言語モデル。
12. NAS: 最適なニューラルネットワークアーキテクチャを自動探索する技術。
13. OCR: 画像内のテキストを認識し、デジタルテキストに変換する技術。
14. NeRF: 3D空間をニューラルネットワークで表現する手法。
15. DETR: Transformerを用いた新しい物体検出アーキテクチャ。
16. Prompt: AIモデルに与える指示や文脈を設定するテキスト。
17. 扩散模型(Diffusion Models): ノイズを徐々に除去して画像を生成する生成モデル。
18. ReID(重识别): 異なる画像や映像間で同一の人物や物体を再識別する技術。
19. 长尾分布(Long-Tail): データセット内で頻度の低いクラスや事例を扱う問題。
20. Vision Transformer: 画像処理にTransformerアーキテクチャを適用したモデル。
21. 视觉和语言(Vision-Language): 画像と言語を組み合わせて処理するタスク。
22. 自监督学习(Self-supervised Learning): ラベルなしデータから有用な表現を学習する手法。
23. 数据增强(Data Augmentation): 学習データを人工的に増やす技術。
24. 目标检测(Object Detection): 画像内の物体の位置と種類を特定する技術。
25. 异常检测(Anomaly Detection): 通常とは異なるパターンやデータを検出する技術。
26. 目标跟踪(Visual Tracking): 映像内の物体の動きを追跡する技術。
27. 语义分割(Semantic Segmentation): 画像内の各ピクセルをカテゴリに分類する技術。
28. 实例分割(Instance Segmentation): 画像内の個々の物体インスタンスを分割する技術。
29. 全景分割(Panoptic Segmentation): 意味分割とインスタンス分割を組み合わせた技術。
30. 医学图像(Medical Image): 医療目的で撮影された画像。
31. 医学图像分割(Medical Image Segmentation): 医療画像内の臓器や病変部位を分割する技術。
32. 视频目标分割(Video Object Segmentation): 動画内の物体を追跡し分割する技術。
33. 视频实例分割(Video Instance Segmentation): 動画内の個々の物体インスタンスを分割する技術。
34. 参考图像分割(Referring Image Segmentation): 言語記述に基づいて画像内の物体を分割する技術。
35. 图像抠图(Image Matting): 画像から前景を精密に抽出する技術。
36. 图像编辑(Image Editing): 画像の内容を変更または操作する技術。
37. Low-level Vision: 画像の低レベル特徴や処理を扱う分野。
38. 超分辨率(Super-Resolution): 低解像度画像から高解像度画像を生成する技術。
39. 去噪(Denoising): 画像からノイズを除去する技術。
40. 去模糊(Deblur): ぼけた画像をシャープにする技術。
41. 自动驾驶(Autonomous Driving): 人間の操作なしで車両を制御する技術。
42. 3D点云(3D Point Cloud): 3D空間内の点の集合でオブジェクトや環境を表現するデータ形式。
43. 3D目标检测(3D Object Detection): 3D空間内の物体の位置と種類を特定する技術。
44. 3D语义分割(3D Semantic Segmentation): 3Dデータの各点をカテゴリに分類する技術。
45. 3D目标跟踪(3D Object Tracking): 3D空間内の物体の動きを追跡する技術。
46. 3D语义场景补全(3D Semantic Scene Completion): 部分的な3Dデータから完全な3Dシーンを推定する技術。
47. 3D配准(3D Registration): 複数の3Dデータセットを整列させる技術。
48. 3D人体姿态估计(3D Human Pose Estimation): 3D空間内の人体の姿勢を推定する技術。
49. 3D人体Mesh估计(3D Human Mesh Estimation): 3D人体メッシュモデルを推定する技術。
50. 图像生成(Image Generation): AIを用いて新しい画像を生成する技術。
51. 视频生成(Video Generation): AIを用いて新しい動画を生成する技術。
52. 3D生成(3D Generation): AIを用いて新しい3Dモデルを生成する技術。
53. 视频理解(Video Understanding): 動画の内容を解析し理解する技術。
54. 行为识别(Action Recognition): 動画内の人物の行動を識別する技術。
55. 行为检测(Action Detection): 動画内の特定の行動を検出し位置特定する技術。
56. 文本检测(Text Detection): 画像内のテキストの位置を検出する技術。
57. 知识蒸馏(Knowledge Distillation): 大きなモデルの知識を小さなモデルに転移する技術。
58. 模型剪枝(Model Pruning): モデルの重要でないパラメータを削除して軽量化する技術。
59. 图像压缩(Image Compression): 画像データを効率的に圧縮する技術。
60. 三维重建(3D Reconstruction): 2D画像から3Dモデルを構築する技術。
61. 深度估计(Depth Estimation): 2D画像から奥行き情報を推定する技術。
62. 轨迹预测(Trajectory Prediction): 物体や人の将来の動きを予測する技術。
63. 车道线检测(Lane Detection): 道路上の車線を検出する技術。
64. 图像描述(Image Captioning): 画像の内容を自然言語で説明する技術。
65. 视觉问答(Visual Question Answering): 画像に関する質問に答える技術。
66. 手语识别(Sign Language Recognition): 手話のジェスチャーを認識し解釈する技術。
67. 视频预测(Video Prediction): 動画の将来のフレームを予測する技術。
68. 新视点合成(Novel View Synthesis): 既存の画像から新しい視点の画像を生成する技術。
69. Zero-Shot Learning(零样本学习): 学習時に見たことのないクラスを認識する学習手法。
70. 立体匹配(Stereo Matching): ステレオ画像から深度情報を抽出する技術。
71. 特征匹配(Feature Matching): 異なる画像間で対応する特徴点を見つける技術。
72. 场景图生成(Scene Graph Generation): 画像内の物体間の関係を構造化して表現する技術。
73. 计数(Counting): 画像内の特定オブジェクトの数を数える技術。
74. 隐式神经表示(Implicit Neural Representations): 連続関数としてシーンや形状を表現する手法。
75. 图像质量评价(Image Quality Assessment): 画像の品質を客観的に評価する技術。
76. 视频质量评价(Video Quality Assessment): 動画の品質を客観的に評価する技術。
77. 数据集(Datasets): 機械学習モデルの学習や評価に使用されるデータの集合。
続いて、各項目をもう少し詳細に説明するように生成したテキスト
---------
はい、各項目についてより詳細な説明を提供いたします。
1. 3DGS(Gaussian Splatting):
3D空間内にガウス関数を配置し、これらを2D画像に投影することで3Dシーンを表現する手法です。従来のNeRFよりも高速でクオリティの高い3Dレンダリングを実現します。
2. Mamba / SSM:
State Space Model (SSM)に基づく新しい系列モデルアーキテクチャです。Transformerと比較して長い系列を効率的に処理でき、様々なタスクで高いパフォーマンスを示しています。
3. Avatars:
オンライン空間やゲーム、VR環境などでユーザーを表現する仮想キャラクターです。最近では、AIを用いてよりリアルで自然なアバターの生成や制御が可能になっています。
4. Backbone:
深層学習モデルの主要な特徴抽出部分を指します。ResNet、VGG、EfficientNetなどが代表的で、様々なタスクの基礎となる重要な役割を果たします。
5. CLIP:
OpenAIが開発した大規模なマルチモーダルモデルで、画像とテキストを同じ特徴空間に埋め込むことができます。これにより、柔軟な画像検索や分類が可能になります。
6. MAE (Masked Autoencoder):
画像の一部をマスクし、それを再構築するタスクを通じて自己教師あり学習を行う手法です。事前学習モデルとして高い性能を示しています。
7. Embodied AI:
物理的な環境と直接相互作用するAIシステムを指します。ロボティクスや自動運転など、実世界でのタスク遂行に焦点を当てています。
8. GAN (Generative Adversarial Networks):
生成モデルと識別モデルを競争させることで学習を行う生成モデルです。高品質な画像生成など、様々な分野で応用されています。
9. GNN (Graph Neural Networks):
グラフ構造のデータを処理するための神経ネットワークです。ソーシャルネットワーク分析や分子構造予測など、関係性のあるデータの処理に適しています。
10. 多模态大语言模型(MLLM):
テキストだけでなく、画像、音声、動画などの複数のモダリティを理解し処理できる大規模言語モデルです。より豊かなコミュニケーションや理解が可能になります。
11. 大语言模型(LLM):
GPT-3やLLaMAなど、大量のテキストデータで学習された巨大な言語モデルです。自然言語処理の多くのタスクで高い性能を示しています。
12. NAS (Neural Architecture Search):
機械学習を用いて最適なニューラルネットワークの構造を自動的に探索する技術です。人手によるモデル設計の労力を軽減し、より効率的なモデルの発見を目指します。
13. OCR (Optical Character Recognition):
画像内のテキストを認識し、機械可読なテキストに変換する技術です。文書のデジタル化や自動データ入力などに広く使用されています。
14. NeRF (Neural Radiance Fields):
3D空間をニューラルネットワークで表現する手法です。少数の2D画像から高品質な3Dシーンの再構築と新視点の合成が可能です。
15. DETR (DEtection TRansformer):
Transformerアーキテクチャを物体検出タスクに適用したモデルです。従来の手法と比べてシンプルでありながら高い性能を示しています。
16. Prompt:
AIモデル、特に大規模言語モデルに与える指示や文脈を設定するテキストです。適切なプロンプト設計により、モデルの出力を制御し、望ましい結果を得ることができます。
17. 扩散模型(Diffusion Models):
ノイズを徐々に除去しながら画像を生成する生成モデルです。DALL-E 2やStable Diffusionなど、高品質な画像生成で注目を集めています。
18. ReID (重识别):
異なる画像や映像間で同一の人物や物体を再識別する技術です。監視カメラシステムや顧客追跡などに応用されています。
19. 长尾分布(Long-Tail):
データセット内で頻度の低いクラスや事例を扱う問題です。現実世界のデータ分布に対応するため、機械学習モデルの公平性と汎化性能の向上が課題となっています。
20. Vision Transformer:
自然言語処理で成功を収めたTransformerアーキテクチャを画像処理に適用したモデルです。CNNと比較して、大規模データセットでの学習時に高い性能を示しています。
21. 视觉和语言(Vision-Language):
画像と言語を組み合わせて処理するタスクや研究分野です。画像キャプション生成、視覚的質問応答、画像-テキスト検索などが含まれます。
22. 自监督学习(Self-supervised Learning):
大量のラベルなしデータから有用な特徴表現を学習する手法です。事前学習モデルの作成に広く使用され、少量のラベル付きデータでの fine-tuning で高い性能を実現します。
23. 数据增强(Data Augmentation):
既存の学習データに変形や変更を加えて人工的にデータセットを拡張する技術です。モデルの汎化性能向上やオーバーフィッティングの抑制に効果があります。
24. 目标检测(Object Detection):
画像内の物体の位置と種類を特定する技術です。矩形のバウンディングボックスで物体の位置を示し、各物体のクラスを予測します。自動運転や監視システムなどで広く使用されています。
25. 异常检测(Anomaly Detection):
データセット内の通常とは異なるパターンやデータポイントを検出する技術です。不正検知、産業用機器の故障予測、医療診断などに応用されています。
26. 目标跟踪(Visual Tracking):
動画シーケンス内で物体の動きを追跡する技術です。自動運転、スポーツ分析、監視システムなど、様々な分野で活用されています。
27. 语义分割(Semantic Segmentation):
画像内の各ピクセルをあらかじめ定義されたカテゴリに分類する技術です。自動運転における道路環境の理解や医療画像解析などに応用されています。
28. 实例分割(Instance Segmentation):
画像内の個々の物体インスタンスを分割し、それぞれに固有のラベルを付与する技術です。物体検出と意味分割を組み合わせたタスクと言えます。
29. 全景分割(Panoptic Segmentation):
意味分割とインスタンス分割を統合した技術で、画像内のすべてのピクセルに対してクラスとインスタンスIDを割り当てます。シーンの完全な理解を目指しています。
30. 医学图像(Medical Image):
X線、CT、MRI、超音波などの医療目的で撮影された画像を指します。診断、治療計画、医学研究などに使用されます。
31. 医学图像分割(Medical Image Segmentation):
医療画像内の臓器、腫瘍、血管などの特定の構造や病変部位を分割する技術です。診断支援や手術計画立案に重要な役割を果たします。
32. 视频目标分割(Video Object Segmentation):
動画シーケンス内の特定の物体を追跡し、フレームごとに分割する技術です。ビデオ編集やアウグメンテッドリアリティなどに応用されています。
33. 视频实例分割(Video Instance Segmentation):
動画内の個々の物体インスタンスを追跡し、フレームごとに分割するタスクです。ビデオ解析や自動運転システムでの環境理解に役立ちます。
34. 参考图像分割(Referring Image Segmentation):
自然言語による記述に基づいて、画像内の特定の物体や領域を分割する技術です。人間とAIのインタラクションを促進します。
35. 图像抠图(Image Matting):
画像から前景オブジェクトを精密に抽出する技術です。背景置換や合成など、画像編集タスクで重要な役割を果たします。
36. 图像编辑(Image Editing):
画像の内容を変更または操作する技術の総称です。物体の除去・追加、スタイル変換、色調整など、様々な編集操作が含まれます。
37. Low-level Vision:
画像の低レベル特徴や基本的な処理を扱う分野です。ノイズ除去、超解像、エッジ検出などの基礎的なタスクが含まれます。
38. 超分辨率(Super-Resolution):
低解像度の画像から高解像度の画像を生成する技術です。監視カメラ映像の鮮明化や古い写真の復元などに応用されています。
39. 去噪(Denoising):
画像からノイズを除去し、クリアな画像を得る技術です。低光量撮影や医療画像の品質向上など、様々な場面で使用されています。
40. 去模糊(Deblur):
ぼけた画像をシャープにする技術です。手ブレや被写体ブレの補正、古い写真の復元などに活用されています。
41. 自动驾驶(Autonomous Driving):
人間の操作なしで車両を制御する技術です。コンピュータビジョン、センサー融合、決定システムなど、多岐にわたる技術の統合が必要です。
42. 3D点云(3D Point Cloud):
3D空間内の点の集合でオブジェクトや環境を表現するデータ形式です。LiDARなどのセンサーから取得され、3D認識タスクの基礎となります。
43. 3D目标检测(3D Object Detection):
3D空間内の物体の位置、サイズ、向きを特定する技術です。自動運転や拡張現実などの分野で重要な役割を果たします。
44. 3D语义分割(3D Semantic Segmentation):
3Dデータの各点や領域をあらかじめ定義されたカテゴリに分類する技術です。自動運転での環境理解やロボティクスでの物体認識に応用されています。
45. 3D目标跟踪(3D Object Tracking):
時系列の3Dデータ内で物体の動きを追跡する技術です。自動運転システムにおける他の車両や歩行者の動きの予測などに使用されます。
46. 3D语义场景补全(3D Semantic Scene Completion):
部分的な3Dデータから、オクルージョンや欠損のある領域を含む完全な3Dシーンを推定する技術です。ロボットナビゲーションや拡張現実に応用されています。
47. 3D配准(3D Registration):
複数の3Dデータセット(点群や表面モデルなど)を正確に整列させる技術です。3Dスキャンデータの統合や位置合わせに使用されます。
48. 3D人体姿态估计(3D Human Pose Estimation):
2D画像や3Dデータから人体の3次元的な姿勢を推定する技術です。モーションキャプチャ、アニメーション、スポーツ分析などに応用されています。
49. 3D人体Mesh估计(3D Human Mesh Estimation):
2D画像や3Dスキャンデータから詳細な3D人体メッシュモデルを推定する技術です。バーチャルフィッティングやアニメーション制作などに活用されています。
50. 图像生成(Image Generation):
AIを用いて新しい画像を生成する技術です。GANやDiffusion Modelなどが代表的で、アート創作やデータ拡張に応用されています。
51. 视频生成(Video Generation):
AIを用いて新しい動画を生成する技術です。短い入力クリップからの動画の延長や、テキスト記述からの動画生成などが研究されています。
52. 3D生成(3D Generation):
AIを用いて新しい3Dモデルを生成する技術です。製品デザイン、ゲーム開発、建築設計などの分野で注目されています。
53. 视频理解(Video Understanding):
動画の内容を解析し、シーンの構造、物体の関係、イベントの進行などを理解する技術です。ビデオ検索や自動要約などに応用されています。
54. 行为识别(Action Recognition):
動画内の人物の行動を識別する技術です。監視システム、スポーツ分析、ヒューマン・コンピュータ・インタラクションなどで活用されています。
55. 行为检测(Action Detection):
動画内の特定の行動をリアルタイムで検出し、その時間的・空間的位置を特定する技術です。セキュリティシステムや異常行動の検知などに応用されています。
はい、続きを説明いたします。
56. 文本检测(Text Detection):
画像や動画内のテキストの位置を検出する技術です。OCRシステムの前処理として重要で、看板の認識や文書分析などに使用されます。
57. 知识蒸馏(Knowledge Distillation):
大規模で複雑な「教師」モデルの知識を、より小さな「生徒」モデルに転移する技術です。モデルの軽量化と性能維持の両立を目指します。
58. 模型剪枝(Model Pruning):
学習済みモデルから重要度の低いパラメータや層を削除し、モデルを軽量化する技術です。モバイルデバイスでの効率的な実行などに役立ちます。
59. 图像压缩(Image Compression):
画像データを効率的に圧縮し、ストレージやネットワーク帯域幅を節約する技術です。最近では機械学習を用いた新しい圧縮手法も研究されています。
60. 三维重建(3D Reconstruction):
2D画像や動画から3Dモデルを構築する技術です。建築、考古学、映画制作など、様々な分野で活用されています。
61. 深度估计(Depth Estimation):
単眼または複眼の2D画像から、シーンの奥行き情報を推定する技術です。3D再構成や拡張現実などのアプリケーションで重要な役割を果たします。
62. 轨迹预测(Trajectory Prediction):
物体や人の過去の動きに基づいて、将来の動きを予測する技術です。自動運転、群衆行動分析、スポーツ戦略立案などに応用されています。
63. 车道线检测(Lane Detection):
道路上の車線を検出し追跡する技術です。自動運転システムや先進運転支援システム(ADAS)において重要な要素となっています。
64. 图像描述(Image Captioning):
画像の内容を自然言語で説明する文章を自動生成する技術です。視覚障害者支援や画像検索の高度化などに応用されています。
65. 视觉问答(Visual Question Answering):
画像に関する自然言語の質問に対して、適切な回答を生成する技術です。画像理解とテキスト生成の両方の能力が必要とされます。
66. 手语识别(Sign Language Recognition):
手話のジェスチャーを認識し、それを文字や音声に変換する技術です。聴覚障害者とのコミュニケーション支援に役立ちます。
67. 视频预测(Video Prediction):
過去のフレームに基づいて、動画の将来のフレームを予測する技術です。動画圧縮、異常検知、自動運転など、様々な応用が考えられています。
68. 新视点合成(Novel View Synthesis):
既存の画像や限られた視点の情報から、新しい視点の画像を生成する技術です。仮想現実や自由視点映像などに応用されています。
69. Zero-Shot Learning(零样本学习):
学習時に見たことのないクラスを認識する学習手法です。事前に学習していない新しいカテゴリの物体を識別する能力を持ちます。
70. 立体匹配(Stereo Matching):
ステレオカメラで撮影された左右の画像から対応点を見つけ、深度情報を抽出する技術です。3D再構成や深度推定の基礎となります。
71. 特征匹配(Feature Matching):
異なる画像間で対応する特徴点を見つける技術です。画像のスティッチング、物体追跡、SLAMなど、様々なコンピュータビジョンタスクの基礎となります。
72. 场景图生成(Scene Graph Generation):
画像内の物体間の関係を構造化して表現する技術です。シーンの意味的理解や高度な画像検索などに応用されています。
73. 计数(Counting):
画像や動画内の特定オブジェクトの数を自動的に数える技術です。群衆の推定、在庫管理、生物学的サンプルの計数などに使用されています。
74. 隐式神经表示(Implicit Neural Representations):
3Dシーンや形状を連続関数としてニューラルネットワークで表現する手法です。NeRFはこの手法の一例で、効率的なシーン表現が可能です。
75. 图像质量评价(Image Quality Assessment):
画像の品質を客観的に評価する技術です。画像処理アルゴリズムの性能評価や、品質に基づいた画像フィルタリングなどに使用されます。
76. 视频质量评价(Video Quality Assessment):
動画の品質を客観的に評価する技術です。ストリーミングサービスの品質監視や、ビデオ圧縮アルゴリズムの最適化などに応用されています。
77. 数据集(Datasets):
機械学習モデルの学習や評価に使用されるデータの集合です。ImageNet、COCO、KITTI
など、各タスクに特化した大規模データセットが開発され、研究や技術開発を加速しています。
これらの技術は相互に関連し合い、コンピュータビジョンと機械学習の分野を形作っています。多くの応用分野で革新的なソリューションを生み出すとともに、新たな課題にも直面しており、今後さらなる発展が期待されています。
Evaluating the Effectiveness of LLM-Evaluators (aka LLM-as-Judge), 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #LLM-as-a-Judge Issue Date: 2024-09-30 Comment
LLM-as-a-judgeについて網羅的に書かれた記事
NotebookLM, Google, 2024.09
Paper/Blog Link My Issue
#Article #Tools #InformationRetrieval #NLP #LanguageModel #GenerativeAI #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-09-29 Comment
ソーステキストをアップロードし、それらを参照可能なLLMの元作業が可能で、クエリによって引用つきのRAGのようなものが行えるらしい。2人の対話形式のpodcastも自動生成可能で、UI/UXの面で画期的らしい?
LLM-jp-3 1.8B・3.7B・13B の公開, LLM.jp, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Japanese #OpenSource Issue Date: 2024-09-25 Comment
LLM-JP-Evalでの評価結果はこちら: https://huggingface.co/llm-jp/llm-jp-3-1.8b
1.8Bのモデルが、モデルサイズに対して非常に性能が良いとのこと(確かに、3.8Bのモデルとの差があまりないように見える
元ポスト:
アーキテクチャはLlama2とのことなので、vLLMでも動作させられる模様
LLM-jp Corpus v3, LLM.jp, 2024.09
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Japanese Issue Date: 2024-09-25 Comment
LLM-jp-3
- LLM-jp-3 1.8B・3.7B・13B の公開, LLM.jp, 2024.09
の学習に利用されているコーパス
Late Chunking: Balancing Precision and Cost in Long Context Retrieval, Pierse+, 2024.09
Paper/Blog Link My Issue
#Article #Embeddings #InformationRetrieval #NLP #RAG(RetrievalAugmentedGeneration) #Blog #Selected Papers/Blogs Issue Date: 2024-09-08 Comment
chunkingしてからembeddingを取得するより、全体のドキュメントに対してcontextualなtoken embeddingを取得し、その後chunkingをしてpoolingしてsingle vectorにする方が、文書の文脈情報がembedding内で保持されやすいので、precisionが上がりますよ、という話
ml-engineering
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #MachineLearning #NLP #LanguageModel #Repository Issue Date: 2024-09-07 Comment
LLMやVLMを学習するためのツールやノウハウがまとめられたリポジトリ
LLMに日本語テキストを学習させる意義, Koshiro Saito+, 第261回自然言語処理研究発表会, 2024.08
Paper/Blog Link My Issue
#Article #Analysis #LanguageModel #OpenWeight #Slide #Japanese Issue Date: 2024-09-03 Comment
英日翻訳や日本特有の知識を問われるようなQAにおいて、日本語データによる学習の効果があることが示唆されている模様。
たとえば、論文紹介 / The Llama 3 Herd of Models, 2024.08
に示されている通り、Llama2における日本語データの割合は0.2%とかなので、英語圏のOpenLLMにおいて、日本語データの比率がどれだけ少ないかがわかる。
大規模言語モデル (LLM) の技術と最新動向, Ikuya Yamada, 2024.06
Paper/Blog Link My Issue
#Article #Tutorial #LanguageModel #Slide Issue Date: 2024-09-01 Comment
LLMの原理の基礎的な内容について、丁寧かつコンパクトにまとまっている。
>ファインチューニングは新しい知識の学習ではなく知識の使い方を学習させるのに向いている
これをきちんと念頭に置いておかないと落とし穴にハマると思う。引用元の論文読みたい:
- [Paper Note] Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?, Zorik Gekhman+, EMNLP'24, 2024.05
NewsPicksに推薦システムを本番投入する上で一番優先すべきだったこと, 2024.08
Paper/Blog Link My Issue
#Article #RecommenderSystems #NeuralNetwork #CTRPrediction #NewsRecommendation #ML-LLM Ops #Evaluation #Blog #A/B Testing #Reading Reflections Issue Date: 2024-08-31 Comment
>推薦モデルの良し悪しをより高い確度で評価できる実験を、より簡単に実行できる状態を作ることでした。平たく言えば「いかにA/Bテストしやすい推薦システムを設計するか」が最も重要だった訳です。
オフライン評価とオンライン評価の相関がない系の話で、A/Bテストを容易に実施できる環境になかった、かつCTRが実際に向上したモデルがオフライン評価での性能が現行モデルよりも悪く、意思決定がなかなかできなかった、という話。
うーんやはり、推薦におけるオフライン評価ってあまりあてにできないよね、、、
そもそも新たなモデルをデプロイした時点で、テストした時とデータの分布が変わるわけだし、、、
Off-Policy Evaluationの話は勉強したい。
あと、定性評価は重要
Firecrawl, 2024.09
Paper/Blog Link My Issue
#Article #Dataset #LanguageModel #Repository #API Issue Date: 2024-08-30 Comment
sitemapなしでWebサイト全体をクローリングできるAPI。LLMで利用可能なマークダウンや、構造化データに変換もしてくれる模様。
kotaemon, 2024.05
Paper/Blog Link My Issue
#Article #Tools #NLP #RAG(RetrievalAugmentedGeneration) #python #Repository Issue Date: 2024-08-29 Comment
RAGのための美しいユーザと開発者向けのUI。カスタマイズも可能らしい
2026年3月時点でもアップデートが継続されており、Star数は25.2kを記録している。
AutoMLOpsを使って機械学習CI_CDパイプラインを組んでみた, 2024.08
Paper/Blog Link My Issue
#Article #MachineLearning #ML-LLM Ops #python #Blog #SoftwareEngineering Issue Date: 2024-08-27 Comment
pythonコードでコンポーネントや、パイプラインを関数の形で記述するだけで、MLのCI/CDパイプラインをVertexAI上に自動構築できる模様。非常にお手軽で、多くの設定ファイルなどは自動生成されるようなので、簡単に始めることができそう。
記事中では、多クラス分類器を学習するためのデータをBigQueryから取得、モデル訓練、デプロイ、推論エンドポイント生成、モニタリングなどを簡単なコードベースで実現できている。便利そうではある。
細かいチューニングも自動生成された設定ファイルをいじれば可能だと思われる。
LitServe, 2024.04
Paper/Blog Link My Issue
#Article #MachineLearning #Library #MultiModal #Repository #API #EfficientEvaluation Issue Date: 2024-08-25 Comment
FastAPIより2倍早いAPIライブラリ。LLMやVisionなど多くのモーダルに対応し、マルチワーカーでオートスケーリングやバッチングやストリーミングにも対応。PyTorchモデルだけでなく、JAXなど様々なフレームワークのモデルをデプロイ可能
元ツイート:
Liger-Kernel, 2024.08
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #Repository #PostTraining #Selected Papers/Blogs Issue Date: 2024-08-25 Comment
LLMを学習する時に、ワンライン追加するだけで、マルチGPUトレーニングのスループットを20%改善し、メモリ使用量を60%削減するらしい
元ツイート:
Unsloth Unsloth, unslothai, 2024.07
はLoRA/QLoRAが可能な一方でまだMulti-GPUはサポートしていない。一方、Liger-KernelはLoRAよりもfull-parameter tuningとMulti-GPUにフォーカスしており、目的に応じて使い分けが必要。
https://github.com/linkedin/Liger-Kernel/issues/57
Grok-2, X, 2024.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Proprietary Issue Date: 2024-08-24 Comment
chatbot arenaで5月時点のGPT4o超え。miniでもなんとllama3.1-705B超え
list of recommender systems
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #Dataset #Library #Repository #OpenSource Issue Date: 2024-08-07 Comment
推薦システムに関するSaaS, OpenSource, Datasetなどがまとめられているリポジトリ
DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Library #python #Blog #OpenWeight #LLMServing #Reference Collection Issue Date: 2024-08-05 Comment
[vllm](
https://github.com/vllm-project/vllm)を使うのが一番お手軽で、inference速度が速そう。PagedAttentionと呼ばれるキャッシュを利用して高速化しているっぽい。
(図はブログ中より引用)
こちらも参照のこと
vLLMの仕組みをざっくりと理解する:
https://dalab.jp/archives/journal/vllm/#PagedAttention
vLLMでReasoning ModelをServingするときは、`--enable-reasoning`等の追加オプションを指定する必要がある点に注意
https://docs.vllm.ai/en/stable/features/reasoning_outputs.html
OpenLLM: Self-Hosting LLMs Made Easy
Paper/Blog Link My Issue
#Article #NLP #Library #OpenWeight #API #Frontend Issue Date: 2024-08-01 Comment
OpenLLMをself hostingする際に、OpenAIなどと同じインタフェースのAPIやChatを提供するライブラリ
Gemma2, Google Deepmind, 2024
Paper/Blog Link My Issue
#Article #NLP #Coding #Reasoning #Mathematics #OpenWeight Issue Date: 2024-07-30 Comment
Reasoning, Math, CodeGenerationに強み
2024年版のDockerfileの考え方&書き方, 2024
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2024-07-29 Comment
マルチステージビルド、成果物の考え方など
Llama 3.1, 2024.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2024-07-25 Comment
Llama系のモデルをFP8で学習する場合のレシピ
Deepでポン用実験管理ツール(サービス)の比較2021
Paper/Blog Link My Issue
#Article #Blog #ExperimentManagement Issue Date: 2024-07-09 Comment
[TensorBoard](
https://www.tensorflow.org/tensorboard/)
[MLflow](
https://mlflow.org/)
[Neptune.ai](
https://neptune.ai/)
[Weights & Biases](
https://wandb.ai/site)
[Comet](
https://www.comet.ml/site/)
の比較がされている
OpenDevin: Code Less, Make More, 2024
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #LanguageModel #AIAgents #Repository Issue Date: 2024-07-04 Comment
LLMによるOpenSourceなソフトウェア生成エージェントプラットフォーム
full timeのスタッフを雇用しworldクラスのUXを目指すとのこと。楽しみ。
参考:
Open化される前の最初のDevinのツイート
mergekit-evolve
Paper/Blog Link My Issue
#Article #LanguageModel #Library #Repository #ModelMerge Issue Date: 2024-04-29 Comment
[Paper Note] Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N/A, Nature Machine Intelligence, Vol.7, 2025.01
のように進化的アルゴリズムでモデルマージができるライブラリ
解説記事:
https://note.com/npaka/n/nad2ff954ab81
大きなVRAMが無くとも、大きめのSRAMがあれば動作するらしい
AirLLM, 2024.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Library #Repository Issue Date: 2024-04-28 Comment
4GBのSingle GPUで、70Bモデルのinferenceを実現できるライブラリ。トークンの生成速度は検証する必要がある。transformer decoderの各layerの演算は独立しているため、GPUに全てのlayerを載せず、必要な分だけ載せてinferenceするといった操作を繰り返す模様。
元ツイート:
推薦・機械学習勉強会, Wantedly
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #Blog Issue Date: 2024-04-26 Comment
WantedlyさんのRecSys勉強会の資料がまとまったリポジトリ。継続的に更新されており、最近この辺のトピックは追いきれていないので非常に有用。
Open Source Cookbook
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #GenerativeAI #Repository #OpenSource #Selected Papers/Blogs Issue Date: 2024-04-14 Comment
HuggingFaceによる様々な実用的なアプリケーションをオープンソースの実装やモデルで実現するノートブックがまとまったリポジトリ。LLM-as-a-judge, RAG, PEFTによるPrompt Tuning(Prefix Tuningとかそっち系の話だと思われる)など、現在16種類ほどあるらしい。
改めて見たら数がかなり増えていた
Mixtral-8x22B-v0.1, 2024
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight Issue Date: 2024-04-10 Comment
Apache-2.0ライセンス, 日本語非対応
Command R+, Cohere, 2024
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiLingual #OpenWeight #Proprietary Issue Date: 2024-04-10 Comment
Chatbot arenaでGPT-4-0314と同等の Elo Rate を獲得し(20240410時点)、日本語を含む10ヶ国語をサポート。コンテキストウィンドウサイズ128k。商用利用はAPIから、研究目的であればHuggingFaceから利用可能。
Awesome LM with Tools
Paper/Blog Link My Issue
#Article #Survey #Tools #NLP #LanguageModel Issue Date: 2024-03-22 Comment
Toolを利用するLMに関するNeubig氏のグループによるSurvey。
生産性指標をFour Keysから変更した話, SanSan Tech Blog
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2024-03-21 Comment
モバイルアプリ開発における生産性指標に関するお話。Four Keysをモバイルアプリに適用した場合の課題を分析し、自チームの中長期的な目標を達成するためにどのような生産性指標を採用すべきかが言語化されており、興味深かった。
Four Keysとは:
https://blog.recruit.co.jp/rls/2021-03-31-four-keys/#whats-four-keys
Open Release of Grok-1 March 17, 2024
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #MoE(Mixture-of-Experts) Issue Date: 2024-03-18 Comment
Apache2.0ライセンス, 314Bパラメータでモデルの重み、Mixture-of-Expertsを採用している。学習データ、学習に利用したコードはおそらく公開されていない。
Grok-1.5がリリース
https://x.ai/blog/grok-1.5
各種ベンチマークの性能、特にMathの性能が向上し、コンテキスト長が128kに
What are the most important LLMs to know about in March 2024?
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Post Issue Date: 2024-03-04 Comment
2024年3月時点で知っておくべきLLMに関するスレッド
Recommenders, recommenders-team, 2018.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Library #Repository Issue Date: 2024-01-15 Comment
古典的な手法から、Deepな手法まで非常に幅広く網羅された推薦アルゴリズムのフレームワーク。元々Microsoft配下だった模様。
現在もメンテナンスが続いており、良さそう
Decoding Strategies that You Need to Know for Response Generation
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #LanguageModel #Blog Issue Date: 2024-01-01 Comment
言語モデルのdecodingの方法についてよくまとまっている。まとめられているdecoding方法は以下
- Greedy, BeamSearch, RandomSampling, Temperature, Top-K Sampling, Nucleus Sampling
こちらの記事ではHuggingFaceでの実装や他のdecoding方法等、より実装面での詳細が記述されている:
https://note.com/npaka/n/n9a8c85f2ef7a
モバオクでのリアルタイムレコメンドシステムの紹介
Paper/Blog Link My Issue
#Article #RecommenderSystems #ML-LLM Ops #Slide #Reading Reflections Issue Date: 2023-12-19 Comment
DeNAでのRecSysのアーキテクチャ(バッチ、リアルタイム)が紹介されている。バッチではワークフローエンジンとしてVertex AI Pipelineが用いられている。リアルタイムになるとアーキテクチャが非常に複雑になっている。
複雑なアーキテクチャだが、Generative Recommendation使ったらもっとすっきりしそうだなーと思いつつ、レイテンシと運用コストの課題があるのでまだ実用段階じゃないよね、と思うなどした。
リアルタイム推薦によって、バッチで日毎の更新だった場合と比べ、入札率、クリック率、回遊率が大きく改善したのは面白い。
optimize-llm, HuggingFace, 2023.09
Paper/Blog Link My Issue
#Article #Tutorial #EfficiencyImprovement #NLP #LanguageModel Issue Date: 2023-12-15 Comment
LLMをoptimizeする実用的なチュートリアル
こちらも有用なので参照のこと
【GPU inference】
https://huggingface.co/docs/transformers/main/perf_infer_gpu_one
もし明日、上司に「GPT-4を作れ」と言われたら? Stability AIのシニアリサーチサイエンティストが紹介する「LLM構築タイムアタック」
Paper/Blog Link My Issue
#Article #LanguageModel #Blog #Reading Reflections Issue Date: 2023-12-05 Comment
StabilityAI Japan秋葉さん(元PFN)のW&B Conferenceでの発表に関する記事。
LLM構築タイムアタックでLLMをもし構築することになったら!?
のざっくりとしたプロセスや、次ページでOpenAIのGPT4のテクニカルレポートのクレジットから各チームの規模感を推定して、どの部分にどの程度の人員が割かれていたのかというのをベースに、各パートでどんなことがやられていそうかという話がされている。
LLM構築タイムアタックで、まずGPUを用意します!(ここが一番大変かも)の時点で、あっ察し(白目 という感じがして面白かった。
GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo, Anand+, 2023.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Tools #NLP #LanguageModel #Repository Issue Date: 2023-11-21 Comment
ローカルマシンでChatGPT likeなUIでチャットボットを動作させられるOpensource。
Mistral7BやGGUFフォーマットのモデルのよつな(おそらく量子化されたものも含む)ローカルマシンで動作させられる規模感のモデルがサポートされている。
https://gpt4all.io/index.html
Zephyr-7B-beta, RAG Perf.
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) #Blog #OpenWeight Issue Date: 2023-11-21 Comment
Zephyr-7B-betaのRAGでの性能がデータセットで評価されている
下記Xポストによるとgpt-3.5-turboと同等
lifestar, lifestar-org, 2021.12
Paper/Blog Link My Issue
#Article #Library #python #SoftwareEngineering #Asynchronous Issue Date: 2023-11-19 Comment
非常に高速なpythonのASGIライブラリ。WSGIとは異なり非同期処理なためリアルタイムアプリケーションに向いているっぽい。
現在でも活発に開発がされているようだ
JGLUEの構築そして 日本語LLM評価のこれから, 河原大輔, W&B 東京ミートアップ #8, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #Dataset #LanguageModel #Evaluation #Reading Reflections Issue Date: 2023-11-16 Comment
JGLUEのexample付きの詳細、構築の経緯のみならず、最近の英語・日本語LLMの代表的な評価データ(方法)がまとまっている(AlpacaEval, MTBenchなど)。また、LLMにおける自動評価の課題が興味深く、LLM評価で生じるバイアスについても記述されている。Name biasなどはなるほどと思った。
日本語LLMの今後の評価に向けて、特にGPT4による評価を避け、きちんとアノテーションしたデータを用意しfinetuningした分類器を用いるという視点、参考にしたい。
LLaMA-Factory, hiyouga, 2023.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Supervised-FineTuning (SFT) #Repository Issue Date: 2023-11-14 Comment
簡単に利用できるLLaMAのfinetuning frameworkとのこと。
元ツイート:
LLaMAベースなモデルなら色々対応している模様
Hallucination Leaderboard, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Hallucination #Factuality #Repository Issue Date: 2023-11-14 Comment
1000個の短いドキュメントに対して、事実情報のみを用いて要約を生成させ、要約結果と原文書のFactual consistencyを別に訓練したモデルで測定して評価してリーダーボードを作成している。
Claude2よりLLaMA2の方が性能が良いのが面白いし、Palmの性能があまり良くない。
元ツイート:
Transformers.js, 2023
Paper/Blog Link My Issue
#Article #Library #Transformer #Blog #Frontend Issue Date: 2023-11-13 Comment
ブラウザ上でTransformerベースの様々なモデルを動作させることができるライブラリ
Data-to-Text Datasetまとめ, Akihiko Watanabe, 2022
Paper/Blog Link My Issue
#Article #Survey #NaturalLanguageGeneration #NLP #Dataset #DataToTextGeneration #Slide Issue Date: 2023-11-08 Comment
Data-to-Textのデータセットを自分用に調べていたのですが、せっかくなのでスライドにまとめてみました。特にMR-to-Text, Table-to-Textあたりは網羅的にサーベイし、データセットの概要を紹介しているので、全体像を把握するのに良いのかなぁと思います。ただし、2022年12月時点で作成したので2023年以後のデータセットは含まれていません😅
IBIS2023チュートリアル「大規模言語モデル活用技術の最前線」, Michimasa Inaba, 2023.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #AIAgents #Chain-of-Thought #Slide Issue Date: 2023-11-01 Comment
LLMの応用研究やPromptingを中心としたチュートリアル。アノテーションや対話式推薦システムへの活用、ReAct、プロンプトの最適化技術、CoTの基本から応用まで幅広くまとまっているので、LLMの応用技術の概観や、CoTを実践したい人に非常に有用だと思う。
大規模言語モデルにおいて、「知識は全結合層に蓄積される」という仮説についての文献調査, Kan Hatakeyama, 2023.10
Paper/Blog Link My Issue
#Article #Analysis #MachineLearning #Transformer #Blog #FactualKnowledge Issue Date: 2023-10-29 Comment
タイトルの通り、知識がFFNに蓄積されていると主張しているらしい原論文を読み解いている。まとめを引用すると
> 「知識は全結合層に蓄積される」という表現は、ややラジカルで、
少なくともこの論文では「全結合層は知識獲得において重要」という程度
の、もう少しマイルドな主張をしているように見受けられました。
とのこと。
LangChainのRAGの改善法, LayerX機械学習勉強会
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Library #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-10-29 Comment
以下リンクからの引用。LangChainから提供されているRetrieverのcontext抽出の性能改善のためのソリューション
> Multi representation indexing:検索に適した文書表現(例えば要約)の作成
Query transformation:人間の質問を変換して検索を改善する方法
Query construction:人間の質問を特定のクエリ構文や言語に変換する方法
https://blog.langchain.dev/query-transformations/
日本語LLMベンチマークと自動プロンプトエンジニアリング, PFN Blog, 2023.10
Paper/Blog Link My Issue
#Article #Analysis #NLP #Prompting #Blog #AutomaticPromptEngineering Issue Date: 2023-10-13 Comment
面白かった。特に、promptingによってrinnaとcyberのLLMの順位が逆転しているのが興味深かった。GAを使ったプロンプトチューニングは最近論文も出ていたが、日本語LLMで試されているのは面白かった。
MentalLLaMA, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Repository #Health Issue Date: 2023-10-09 Comment
メンタルヘルスの分析に対してinstruction tuningしたはじめてのLLM
Japanese Simple SimCSE, hppRC, 2023.10
Paper/Blog Link My Issue
#Article #Sentence #Embeddings #NLP #RepresentationLearning #Repository #OpenWeight #Japanese Issue Date: 2023-10-07 Comment
日本語の事前学習言語モデルと、日本語の学習データを利用してSimCSEを学習し網羅的に評価をした結果が記載されている。Supervised SimCSE, UnsupervisednSimCSEの両方で実験。また、学習するデータセットを変更したときの頑健性も検証。性能が良かったモデルはSentenceTransformersから利用可能な形で公開されている。
Nejumi LLMリーダーボード, Weights & Biases
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Japanese #Author Thread-Post Issue Date: 2023-10-02 Comment
JGLUEを使ったLLMの日本語タスクベンチマーク
v4が公開:
https://wandb.ai/llm-leaderboard/nejumi-leaderboard4/reports/Nejumi-LLM-4--VmlldzoxMzc1OTk1MA
元ポスト:
Agents: An opensource framework for autonomous language agents
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #AIAgents Issue Date: 2023-09-30 Comment
以下の特徴を持つLLMAgent開発のためのフレームワーク
- long-short term memory
- tool usage
- web navigation
- multi-agent communication
- human-agent interaction
- symbolic control
また、他のAgent frameworkと違い、ゴールを達成するだの細かいプランニングを策定(SOP; サブタスクとサブゴールを定義)することで、エージェントに対してきめ細かなワークフローを定義できる。
GGML_GGUF_GPTQの違い
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Quantization Issue Date: 2023-09-29 Comment
量子化に関する技術であるGGML, GGUF, GPTQに関する詳細なまとめ
筆者の方の言葉を引用すると
>llama.cppならGGUF、TransformerならGPTQって感じ?
ということなので、これらは量子化を行うための技術を提供するライブラリであり、GGUF/GGMLはllama.cppで利用可能で、GPTQはより汎用的に利用可能な手法だと思われる。
GPTQについて論文をざっくり読んでメモった
- [Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
SNLP2023:Is GPT-3 a Good Data Annotator?, Yuki Zenimoto, 2023.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #SyntheticData #Distillation #Slide #Finetuning #DownstreamTasks #Reading Reflections Issue Date: 2023-09-05 Comment
GPT3でデータを作成したら、タスクごとに有効なデータ作成方法は異なったが、人手で作成したデータと同等の性能を達成するデータ(BERTでfinetuning)を、低コストで実現できたよ、という研究
この辺の話はもはや [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08 を使えばいいのでは、という気がする。
[Paper Note] Instruction Tuning for Large Language Models: A Survey, Shengyu Zhang+, ACM Computing Surveys, Volume 58, Issue 7, 2026.01
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #InstructionTuning #Selected Papers/Blogs Issue Date: 2023-09-05 GPT Summary- 指示調整(IT)に関する研究を総括し、LLMsの能力向上術を解説。ITは、(instruction, output)ペアを用いてLLMsを追加訓練し、人間の指示に従う能力を強化するプロセス。SFTの方法論、データセット構築、訓練、および応用を体系的にレビューし、成果に影響する要因を分析。さらに、SFTの課題や現行戦略の欠点を明らかにし、今後の研究の道筋を提案。 Comment
主要なモデルやデータセットの作り方など幅広くまとまっている(Figure1および各Table)
arxivに2023年8月に登場しその後も更新が続き、ACM Computing Surveys, Volume 58, Issue 7に2026年1月に掲載された模様
https://dl.acm.org/doi/10.1145/3777411
大規模言語モデル, Naoaki Okazaki, 2023年度統計関連学会連合大会チュートリアルセッション 言語モデルと自然言語処理のフロンティア, 2023.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Slide Issue Date: 2023-09-04 Comment
岡崎先生による大規模言語モデルのチュートリアル
最近のLLMまでの歴史、transformerなどの基礎的な内容から、最新の内容まで数式付きで詳細にまとまっている
zeno-build, zeno-ml, 2023.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #ExperimentManagement Issue Date: 2023-08-28 Comment
MTでのテクニカルレポート
https://github.com/zeno-ml/zeno-build/tree/main/examples/analysis_gpt_mt/report
LLMの実験管理を容易に実施するツールで、異なるハイパーパラメータ、異なるモデル、異なるプロンプトでの実験などを簡単に実施できる。評価結果を自動的に可視化し、interactiveに表示するブラウザベースのアプリケーションも作成可能?
Anti-hype LLM Reading list, veekaybee, 2023.12
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel Issue Date: 2023-08-27 Comment
LLMのサーベイ、BERT等の基盤モデルの論文、自前でLLMを学習するために必要な論文がコンパクトにまとめられたgist
SQL vs. NoSQL cheetsheet, AWS, Azure and Google Cloud
Paper/Blog Link My Issue
#Article #AWS #Infrastructure Issue Date: 2023-08-27 Comment
データタイプやユースケースに応じてAWS上のサービスなどをマッピングしてくれているチートシート。わかりやすい。
CommonVoice
Paper/Blog Link My Issue
#Article #MachineLearning #Dataset #SpeechProcessing Issue Date: 2023-08-16 Comment
音声対応のアプリケーションをトレーニングするために誰でも使用できるオープンソースの多言語音声データセット
人工知能研究の新潮流2 -基盤モデル・生成AIのインパクト-, 国立研究開発法人科学技術振興機構 研究開発戦略センター, 2023.07
Paper/Blog Link My Issue
#Article #Survey #LanguageModel #GenerativeAI #read-later #Selected Papers/Blogs Issue Date: 2023-08-12 Comment
280ページにものぼる現在のトレンドをまとめた日本語資料
OpenAI の Embeddings API はイケてるのか、定量的に調べてみる, akeyhero (Akihiro Katsura), Qiita, 2023.04
Paper/Blog Link My Issue
#Article #Embeddings #NLP #LanguageModel #STS (SemanticTextualSimilarity) #Blog #Encoder Issue Date: 2023-07-31 Comment
[JSTSタスク](
https://github.com/yahoojapan/JGLUE)では、[Tohoku
BERT v3](
https://github.com/cl-tohoku/bert-japanese/tree/main#model-performances)
と [LUKE](
https://github.com/studio-ousia/luke)が最も性能が良いらしい。
[SimCSE](
https://huggingface.co/pkshatech/simcse-ja-bert-base-clcmlp)よりも性能が良いのは興味深い。
trl_trlx
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #ReinforcementLearning #Reference Collection #needs-revision Issue Date: 2023-07-23 Comment
TRL - 強化学習によるLLMの学習のためのライブラリ
https://note.com/npaka/n/nbb974324d6e1
trlを使って日本語LLMをSFTからRLHFまで一通り学習させてみる
https://www.ai-shift.co.jp/techblog/3583
Examples of using peft with trl to finetune 8-bit models with Low Rank Adaption (LoRA) , TRL Documentation
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2023-07-22 Comment
LLaMA2を3行で、1つのA100GPU、QLoRAで、自前のデータセットで訓練する方法
Quantized LLaMA2
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #needs-revision Issue Date: 2023-07-22 Comment
LLaMA2をローカルで動作させるために、QLoRAで量子化したモデル
LLongMA2
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ContextWindow #OpenWeight Issue Date: 2023-07-22 Comment
LLaMA2のcontext windowを8kにして訓練。オリジナルのLLaMA2と同等の性能で8k contextを利用可能。
元ツイート:
現在はリンク切れになっている?
Chatbot Arena Conversation Dataset Release, LMSYS Org, 2023.07
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #DialogueGeneration #Blog Issue Date: 2023-07-22 Comment
33kのconversation、2つのレスポンスに対する人間のpreferenceスコア付き
20種類のSoTAモデルのレスポンスを含み、13kのユニークIPからのアクセスがあり、3Kのエキスパートによるアノテーション付き
Auto train advanced
Paper/Blog Link My Issue
#Article #MachineLearning #Tools #LanguageModel #Supervised-FineTuning (SFT) #Blog #Repository #PEFT(Adaptor/LoRA) #needs-revision Issue Date: 2023-07-11 Comment
Hugging Face Hub上の任意のLLMに対して、localのカスタムトレーニングデータを使ってfinetuningがワンラインでできる。
peftも使える。
現在はもうメンテナンスされていないようだ。
Open Source AI Game Jam, 2023
Paper/Blog Link My Issue
#Article #GenerativeAI #Blog #Game Issue Date: 2023-07-11 Comment
GenerativeAIを使ってゲームを作る取り組み
Awesome Multimodal LLMs
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP #LanguageModel #MultiModal #SpeechProcessing Issue Date: 2023-07-03 Comment
マルチモーダルなLLMのリストがまとめられている
Extending Context is Hard…but not Impossible, kaiokendev, 2023.06
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #ContextWindow #needs-revision Issue Date: 2023-07-01 Comment
Open source LLMのcontext lengthをどのように大きくするかに関する議論
How Long Can Open-Source LLMs Truly Promise on Context Length?, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #LongSequence Issue Date: 2023-07-01 Comment
LLMのcontext長を伸ばす際の方法と得られた知見がまとめられている
LM Flow
Paper/Blog Link My Issue
#Article #MachineLearning #Tools #LanguageModel #Supervised-FineTuning (SFT) #FoundationModel #needs-revision Issue Date: 2023-06-26 Comment
一般的なFoundation Modelのファインチューニングと推論を簡素化する拡張可能なツールキット。継続的なpretragning, instruction tuning, parameter efficientなファインチューニング,alignment tuning,大規模モデルの推論などさまざまな機能をサポート。
Ascender
Paper/Blog Link My Issue
#Article #MachineLearning #project_template #python #needs-revision Issue Date: 2023-05-25 Comment
pythonを利用した研究開発する上でのプロジェクトテンプレート
Prompt Engineering vs. Blind Prompting, 2023
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Prompting #Blog #needs-revision Issue Date: 2023-05-12 Comment
experimentalな手法でprompt engineeringする際のoverview
open LLM Leaderboard
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #needs-revision Issue Date: 2023-05-12 Comment
現在はアーカイブされている
awesome-generative-information-retrieval
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #GenerativeAI #needs-revision Issue Date: 2023-05-10 Comment
Generativeなモデルを利用したDocument RetrievalやRecSys等についてまとまっているリポジトリ
OpenSource PaLM, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Repository #OpenWeight #OpenSource #needs-revision Issue Date: 2023-05-08 Comment
150m,410m,1bのモデルがある。Googleの540bには及ばず、emergent abilityもなかぬか期待できなさそなパラメータ数だが、どの程度の性能なのだろうか。
現在モデルファイルはHF上から削除されているようだ。
MPT-7B, Databricks AI Research, 2023.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #OpenWeight Issue Date: 2023-05-06 Comment
新たなオープンソースLLM。
下記ツイートより引用:
・商用利用可能
・6万5000トークン使用可能
・7Bと比較的小さいモデルながら高性能
・日本語を扱え性能が高い
とのこと。
ChatGPTのLLMと比較すると、ざっと例を見た感じ質問応答としての能力はそこまで高くなさそうな印象。
finetuningしない限りはGPT3,GPT4で良さげ。
Personalized news filtering and summarization on the web, Xindong+, 2011 IEEE 23rd International Conference on Tools with Artificial Intelligence, 29
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #Personalization Issue Date: 2023-05-05 Comment
summarizationではなく、keyword extractionの話だった
Personalized text summarization based on important terms identification, Robert+, 23rd International Workshop on Database and Expert Systems Applications, 2012, 43
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #Personalization Issue Date: 2023-05-05 Comment
(あまりしっかりよめていない)
学習者のrevision(復習?)のための教材の要約手法の提案。personalizationするために、さまざまなRaterを定義し、Raterからの単語wに対する評価を集約し、最終的にuser-specificなsentence-term matrixを構築。 SVDを適用することで要約を作成する。personalizedな重み付けに活用されているものとしては、あるコンセプトiに対する学習者の習熟度に基づく重み付けや、学習者の教材に対するannnotationに関する情報などが、単語の重み付けに活用されている。
ChatBot Arena, lmsys org, 2023.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Selected Papers/Blogs #Arena Issue Date: 2023-05-04 Comment
クラウドソーシング型のチャットボット評価するシステム。ユーザはシステムにアクセスすると、二つのanonymisedされたLLMと対話し、どちらが優れていたかをvotingする。すべてのシステムとユーザのinteractionはロギングされており、最終的にElo RatingでLLM.をランキング付けする。
Arena-Hardと呼ばれるliveアリーナデータを用いたパイプラインを公開。MT-Benchよりも識別力が高く、Chatbot Arenaのランキングとのagreementが高いとのこと。
参考:
過去のデータについては Chatbot Arena Conversation Dataset Release, LMSYS Org, 2023.07 などもある
Bark, Suno-AI, 2023.04
Paper/Blog Link My Issue
#Article #NLP #Library #TextToAudio #SpeechProcessing Issue Date: 2023-05-04 Comment
テキストプロンプトで音声生成ができるモデル。MIT License
OpenLLaMA, Xinyang+, 2023.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #OpenWeight #OpenSource Issue Date: 2023-05-04 Comment
LLaMAと同様の手法を似たデータセットに適用し商用利用可能なLLaMAを構築した模様
LLM ecosystem graphs
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #OpenWeight Issue Date: 2023-05-04 Comment
様々なfonudation model、それらを利用したアプリケーション、依存関係がまとまったページ
Percy Liang氏のグループが運用してるっぽい?
When does web-based personalization really work? The distinction between actual personalization and perceived personalization, Li Cong, Computers in human behavior, 2016
Paper/Blog Link My Issue
#Article #Personalization #HumanComputerInteraction Issue Date: 2023-04-28 Comment
personalizedされたメッセージに対するユーザーの認識は、メッセージの以前のpersonalize processに必ずしも依存するのではなく、受信したコンテンツが受信者の期待にどの程度一致しているかに依存することを明らかにした研究
Preface to Special Issue on User Modeling for Web Information Retrieval, Brusilovsky+, User Modeling and User-Adapted Interaction , 2004
Paper/Blog Link My Issue
#Article #InformationRetrieval #Personalization Issue Date: 2023-04-28 Comment
Personalized Information Retrievalの先駆け的研究
[Paper Note] Adaptive Web Search Based on User Profile Constructed without Any Effort from Users, Sugiyama+, NAIST, WWW’04
と同時期
User Profiles for Personalized Information Access, Gauch+, The adaptive Web: methods and strategies of Web personalization, 2007
Paper/Blog Link My Issue
#Article #Survey #InformationRetrieval #Personalization Issue Date: 2023-04-28 Comment
IR分野におけるuser profileの構築方法についてまとめられたsurvey
- 加重キーワード
- セマンティックネットワーク
- 加重コンセプト
について記述されている。また、プロファイルの構築方法についても詳述されている。
Awesome Vector Search Engine
Paper/Blog Link My Issue
#Article #Survey #Embeddings #InformationRetrieval #Search #Library #Repository Issue Date: 2023-04-27 Comment
ベクトルの類似度を測るサービスやライブラリ等がまとまったリポジトリ
HuggingChat, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ChatGPT #Blog Issue Date: 2023-04-27 Comment
closedな世界で開発されるOpenAIのChatGPTに対して、Openなものが必要ということで、huggingfaceが出したchatシステム
公開はすでに終了している模様
大規模言語モデル間の性能比較まとめ, mah_lab _ 西見 公宏, 2023.04
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel Issue Date: 2023-04-27 Comment
参考になる
現状だと研究用であればllama, 商用利用ならtext-davinci-003あるいはFlanT5-xxlあたりになりそう
LLM Worksheet:
https://docs.google.com/spreadsheets/d/1kT4or6b0Fedd-W_jMwYpb63e1ZR3aePczz3zlbJW-Y4/edit#gid=0
More Design Patterns For Machine Learning Systems, 2023
Paper/Blog Link My Issue
#Article #Mindset #Blog #DesignPattern Issue Date: 2023-04-26 Comment
MLのデザインパターンが記述されている
Polars, 2023
Paper/Blog Link My Issue
#Article #Library #python #Blog #Coding #SoftwareEngineering Issue Date: 2023-01-23 Comment
pandasより100倍高速で複雑なクエリも見やすく書けてindexも存在しないのでバグも出にくいという優れものらしい
tuning_playbook, Google Research
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #MachineLearning Issue Date: 2023-01-21 Comment
Googleが公開したDeep Learningモデル学習のノウハウ。必読
CodeGPT: The VSCode Extension with ChatGPT-Like Functionalities
Paper/Blog Link My Issue
#Article #Tools #GenerativeAI #Blog #Coding #SoftwareEngineering Issue Date: 2023-01-21 Comment
VSCodeの拡張で、//から始まるPromptをエディタ上で記載することで対応するコードをGPT3が生成してくれる模様。便利そう
nlpaug
Paper/Blog Link My Issue
#Article #NLP #Library #DataAugmentation #Repository Issue Date: 2023-01-21 Comment
Data Augmentationのためのオープンソースライブラリ
Transformers Interpret, 2022
Paper/Blog Link My Issue
#Article #ComputerVision #MachineLearning #NLP #Library #Explanation #Transformer #Blog Issue Date: 2022-12-01 Comment
transformersのモデルをたった2行追加するだけで、explainableにするライブラリ
基本的にtextとvisionのclassificationをサポートしている模様
text classificationの場合、たとえばinput tokenの各トークンの分類に対する寄与度をoutputしてくれる。
BetterTransformer, Out of the Box Performance for Hugging Face Transformers
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #EfficiencyImprovement #NLP #Library #Transformer Issue Date: 2022-12-01 Comment
たった1ライン追加するだけで、Transformerのinferenceが最大で4.5倍高速化されるBetterTransformerの解説記事
better_model = BetterTransformer.transform(model)
CNN vs. ViT, Yoshitaka Ushiku, ECCV 2022 読み会, 2022.10
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #ComputerVision #Transformer #Slide Issue Date: 2022-10-27 Comment
・Swin Transformer, Depth-wise conv, ConvNeXt, ViTとCNNのロバスト性の違いの話があり勉強になる
・最終的な結論が、CNNもTransformerも変わらない(明確な勝者はいない; 今のところ引き分け)というのはおもしろかった
depth-wise conv, point-wise convの解説記事:
https://agirobots.com/depthwise-pointwise-convolution/
通常のCNNのフィルタによるfeature map計算を、空間方向(depth-wise conv)とチャネル方向(point-wise conv; 1x1 conv)に分解することで大幅にパラメータ数削減
MLOps: 機械学習における継続的デリバリーと自動化のパイプライン, Google
Paper/Blog Link My Issue
#Article #Infrastructure #ML-LLM Ops #Blog #needs-revision Issue Date: 2022-04-27 Comment
機械学習(ML)システムの継続的インテグレーション(CI)、継続的デリバリー(CD)、継続的トレーニング(CT)の実装と自動化
MLOpsのレベルを0~2で表現しており、各レベルごとに何が達成されるべきかが図解されている。
NeurIPS 2021 技術報告会, 株式会社TDAI Lab, 2022
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #Slide Issue Date: 2022-02-07 Comment
NeurIPS 2021での技術トレンドがまとめられている
1. アーキテクチャの改善
2. マルチモーダルモデル
3. Temporal Adaptation
4. Retrieval Augmentation
5. ベンチマーク見直し
6. データセット見直し
7. Human-Centered AI
Pythonのオブジェクト指向プログラミングを完全理解, kaitolucifer (Kaito), 2021
Paper/Blog Link My Issue
#Article #Tutorial #Blog #Coding #SoftwareEngineering Issue Date: 2021-11-25 Comment
オブジェクト指向の歴史的背景から、SOLID、GRASP等が詳細に解説されている。辞書的に参照するのが良いかも。
イラストで理解するSOLID原則, baby-degu, 2021
Paper/Blog Link My Issue
#Article #Tutorial #Blog #Coding #SoftwareEngineering Issue Date: 2021-11-25 Comment
オブジェクト指向におけるSOLID原則をイラストで解説した記事。直感的で分かりやすい。
バンディットアルゴリズムを使って広告最適化のシミュレーションをしてみたよ, ysekky, 2014
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #CTRPrediction #Blog Issue Date: 2021-10-29 Comment
なぜクリック率を上げたいのかという説明が非常に参考になる
ラーニング・アナリティクスとは何か?, 武田俊之, コンピュータ&エデュケーション VOL.38, 2015
Paper/Blog Link My Issue
#Article #Tutorial #AdaptiveLearning #LearningAnalytics Issue Date: 2021-10-29 Comment
Learning Analyticsの全体像について、コンパクトにまとまっている。
特に、そのアプローチに関するコンセプトの特徴(e.g. 学習者中心、デーア駆動)や、フレームワーク、xAPIといったデータの測定・収集方法などについて、まとめられている。
HMM Scalable (Bayesian Knowledge Tracing; BKT)
Paper/Blog Link My Issue
#Article #Tools #AdaptiveLearning #StudentPerformancePrediction #KnowledgeTracing Issue Date: 2021-10-29 Comment
BKTを高速で学習できるツール
3-clause BSD license
データレイクのつくりかた、つかいかた、そだてかた, 関山宜孝, AWS Summit, 2020.09
Paper/Blog Link My Issue
#Article #AWS #Infrastructure #Slide Issue Date: 2021-10-08 Comment
こちらも参照のこと
https://logmi.jp/tech/articles/324242
◆伝統的なデータウェアハウスの限界:
場当たり的にデータを蓄積し、活用しているとデータのサイロ化が生じてしまう。
サイロ化したデータを一箇所にまとめて活用できるようにしましょうというのがData Lakeの考え方。
◆データレイクアーキテクチャ
すべてのデータを一元的に保管でき、耐障害性、可用性が高く、スケーラブルで低コストな必要がある。
また、データは非常に多様化しているので、多様なデータをそのままのフォーマットで保管し活用できる必要がある。
ストレージとデータの活用層を疎結合にして、さまざまなユースケース・分析に対処できるようにする。
(たとえば、ストレージに特定のスキーマのテーブルを使っており、そのスキーマに対してしか分析できません、とかは避けるということかな?)
S3上に生データを保存し、AWS Glueでメタデータを管理する。AWS GlueのようなETLサービスを利用してデータを利用しやすい形式に変更して格納し、活用する(pp.9--10)。
データレイクを作る際のポイント「小さく始める」という部分も重要だと思われるので参照のこと
pytorch-fm, 2020
Paper/Blog Link My Issue
#Article #RecommenderSystems #CollaborativeFiltering #Library #FactorizationMachines #Repository Issue Date: 2021-07-03 Comment
下記モデルが実装されているすごいリポジトリ。論文もリンクも記載されており、Factorization Machinesを勉強する際に非常に参考になると思う。MITライセンス。各手法はCriteoのCTRPredictionにおいて、AUC0.8くらい出ているらしい。
- Logistic Regression
- Factorization Machine
- Field-aware Factorization Machine
- Higher-Order Factorization Machines
- Factorization-Supported Neural Network
- Wide&Deep
- Attentional Factorization Machine
- Neural Factorization Machine
- Neural Collaborative Filtering
- Field-aware Neural Factorization Machine
- Product Neural Network
- Deep Cross Network
- DeepFM
- xDeepFM
- AutoInt (Automatic Feature Interaction Model)
- AFN(AdaptiveFactorizationNetwork Model)
Continuously Improving Recommender Systems for Competitive Advantage Using NVIDIA Merlin and MLOps, Nvidia, 2021.01
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial Issue Date: 2021-07-02 Comment
Recommender System運用のためのアーキテクチャに関する情報
Seq2seqモデルのBeam Search Decoding (Pytorch), jonki, 2020.05
Paper/Blog Link My Issue
#Article #Tutorial #BeamSearch #Blog #Reading Reflections Issue Date: 2021-06-24 Comment
ビームサーチについて、コード付きで説明してくれており、大変わかりやすい。
heapqを使って実装している。また、ビームサーチをbatchに対して行う方法についても書いてある(ただ、一部に対してしかbatchでの処理は適用できていない)。
自分もバッチに対して効率的にビームサーチするにはどのように実装すれば良いのかよくわからないので、誰か教えて欲しい。
NVIDIA TRITON INFERENCE SERVER, 2021
Paper/Blog Link My Issue
#Article #MachineLearning #Infrastructure #ML-LLM Ops #Blog Issue Date: 2021-06-18 Comment
Nvidiaのオープンソースのinference server
モデルのデプロイや管理、スケーリング等を良い感じにしてくれるフレームワーク?
最先端自然言語処理ライブラリの最適な選択と有用な利用方法 _ pycon-jp-2020
Paper/Blog Link My Issue
#Article #Tutorial #Tools #NLP #Library #python #Slide Issue Date: 2021-06-11 Comment
各形態素解析ライブラリの特徴や比較がされていて、自分の用途・目的に合わせてどの形態素解析器が良いか意思決定する際に有用。
特にスライド最後の「おわりに」ページにおいて、要点が非常に簡潔にまとまっているため参照のこと。
FastSeq: Make Sequence Generation Faster, Yan+, ACL’21
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #NLP #Transformer #ACL Issue Date: 2021-06-10 Comment
BART, DistilBART, T5, GPT2等のさまざまなTransformer-basedな手法で、4-9倍Inference speedを向上させる手法を提案。
OpenKE, 2021
Paper/Blog Link My Issue
#Article #Embeddings #MachineLearning #Tools #Library #KnowledgeGraph #Repository Issue Date: 2021-06-10 Comment
Wikipedia, Freebase等のデータからKnowledge Embeddingを学習できるオープンソースのライブラリ
TRTorch
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #Tools #Library #python Issue Date: 2021-06-06 Comment
pytorchの推論を高速化できるライブラリ。6倍ほど早くなった模様。TorchScriptを介して変換するので、PythonだけでなくC++でも動作できるらしい。
intel MKL
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Library #python #Blog Issue Date: 2021-06-03 Comment
intel CPUでpythonの数値計算を高速化するライブラリ(numpyとかはやくなるらしい; Anacondaだとデフォルトで入ってるとかなんとか)
[Paper Note] Pointing the Unknown Words, Gulcehre+, ACL’16
Paper/Blog Link My Issue
#Article #DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #NLP #ACL Issue Date: 2021-06-02 Comment
Conditional Copy Model (Pointer Softmax)を提案した論文。
単語を生成する際に、語彙内の単語から生成する分布、原文の単語から生成する分布を求める。後者はattention distributionから。コピーするか否かを決める確率変数を導入し(sigmoid)、両生成確率を重み付けする。
コピーメカニズム入れるなら引用すべき。
解説スライド: https://www.slideshare.net/hytae/pointing-the-unknown-words
Sentiment analysis with deeply learned distributed representations of variable length texts, Hong+, Technical Report. Technical report, Stanford University, 2015
Paper/Blog Link My Issue
#Article #NeuralNetwork #SentimentAnalysis #NLP #RepresentationLearning Issue Date: 2021-06-01 Comment
[Paper Note] DKN: Deep Knowledge-Aware Network for News Recommendation, Hongwei Wang+, arXiv'18, 2018.01 より、本論文を引用して「CNN ベースのモデルが、畳み込み演算により文から特定のローカルパターンを検出して抽出できるため、他のモデル(e.g. Recurrent Neural Network, Recursive Neural Network)よりも優れていることが経験的に示されている」とのこと
[Paper Note] Knowledge Tracing: Modeling the Acquisition of Procedural Knowledge, Corbett+, User Modeling and User-Adapted Interaction, 1995
Paper/Blog Link My Issue
#Article #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing Issue Date: 2021-05-30 Comment
Bayesian Knowledge Tracing (BKT)を提案した論文。Knowledge Tracingについて研究するなら必ず抑えておくべき。
以後、BKTを拡張した研究が数多く提案されている。
locust
Paper/Blog Link My Issue
#Article #Tools #python #PerformanceTesting Issue Date: 2021-05-26 Comment
負荷テスト用のツール
JMeterと違って、pythonコードでテスト内容を制御できるらしく、かなり使いやすいらしい。
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17
Paper/Blog Link My Issue
#Article #RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #IJCAI Issue Date: 2021-05-25 Comment
Factorization Machinesと、Deep Neural Networkを、Wide&Deepしました、という論文。Wide=Factorization Machines, Deep=DNN。
高次のFeatureと低次のFeatureを扱っているだけでなく、FMによってフィールドごとのvector-wiseな交互作用、DNNではbit-wiseな交互作用を利用している。
割と色々なデータでうまくいきそうな手法に見える。
発展版としてxDeepFM [Paper Note] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Jianxun Lian+, arXiv'18, 2018.03
がある。
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
EfficientNet解説, omiita (オミータ), 2019.10
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #ComputerVision #EfficiencyImprovement #Blog #ImageClassification Issue Date: 2021-05-24 Comment
既存画像認識モデルの構造は変化させず、広さ、深さ、解像度を複合スケーリングすることで、従来よりも少ないパラメータ数、かつ学習速度でSoTAを達成。広さ、深さ、解像度はそれぞれ性能に互いに影響しあっており、従来のように別々にスケーリングするのではなく、3つのバランスをとりながらスケーリングする。スケーリングする際は、結果的にはそれぞれをある値で定数倍すれば良く、そのある値は最大メモリや最大FLOPS数以下(およびFLOPSが2のΦ乗で増加するような)といった制約下でAccuracyが最大化される値をグリッドサーチで見つける(らしい。ざっくりとした理解)。
転移学習しても多くのタスクでSoTA達成した。
Off Policy Evaluation の基礎とOpen Bandit Dataset & Pipelineの紹介, Yuta Saito, 2020.08
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #Tools #Dataset #Slide Issue Date: 2020-08-29 Comment
機械学習による予測精度ではなく、機械学習モデルによって生じる意思決定を、過去の蓄積されたデータから評価する(Off policy Evaluation)の、tutorialおよび実装、データセットについて紹介。
このような観点は実務上あるし、見落としがちだと思うので、とても興味深い。
Collaborative Metric Learningまとめ, guglilac, 2020.01
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #CollaborativeFiltering #ContrastiveLearning #Blog Issue Date: 2020-07-30 Comment
userのembeddingに対し、このuserと共起した(購入やクリックされた)itemを近くに、共起していないitemを遠くに埋め込むような学習方法
BERT 日本語Pre-trained Model, NICT, 2020.03
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tools #NLP #Dataset #LanguageModel #Library #Blog #Japanese #Encoder Issue Date: 2020-03-13 Comment
NICTが公開。既に公開されているBERTモデルとのベンチマークデータでの性能比較も行なっており、その他の公開済みBERTモデルをoutperformしている。
Implicit
Paper/Blog Link My Issue
#Article #RecommenderSystems #CollaborativeFiltering #Library #Selected Papers/Blogs #Reference Collection Issue Date: 2019-09-11 Comment
Implicitデータに対するCollaborative Filtering手法がまとまっているライブラリ
Bayesian Personalized Ranking, Logistic Matrix Factorizationなどが実装。
Implicitの使い方はこの記事がわかりやすい:
https://towardsdatascience.com/building-a-collaborative-filtering-recommender-system-with-clickstream-data-dffc86c8c65
ALSの元論文の日本語解説
https://cympfh.cc/paper/WRMF
Recommender System Datasets, Julian McAuley
Paper/Blog Link My Issue
#Article #RecommenderSystems #Dataset #Selected Papers/Blogs Issue Date: 2019-04-12 Comment
Recommender Systems研究に利用できる各種データセットを、Julian McAuley氏がまとめている。
氏が独自にクロールしたデータ等も含まれている。
非常に有用。
NLP-Progress
Paper/Blog Link My Issue
#Article #Tutorial #Survey #Dataset Issue Date: 2019-02-12 Comment
NLPの様々なタスクのデータセット, およびSOTA(2018年時点)がまとめられている。
[Paper Note] Recommender Systems for Technology Enhanced Learning: Research Trends and Applications, Manouselis+, 2014.04
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #TechnologyEnhancedLearning #AdaptiveLearning Issue Date: 2018-12-22 Comment
最近のトレンドやアプリケーションを知りたい場合はこちら
[Paper Note] Panorama of recommender systems to support learning, Drachsler+, 2015.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #Education #AdaptiveLearning Issue Date: 2018-12-22 Comment
教育分野に対するRecsysのSurvey
[Paper Note] LEARNING AND TEACHING STYLES IN ENGINEERING EDUCATION, Felder, Engr. Education, 78(7), 674–681, 1988.01
Paper/Blog Link My Issue
#Article #Classic #Education #AdaptiveLearning #LearningStyle #Selected Papers/Blogs Issue Date: 2018-12-22 Comment
LearningStyleに関して研究している古典的な研究。
context-aware recsysの研究初期の頃は、だいたいはこのFelder-Silverman Theoryというのをベースに研究されていたらしい。
[Paper Note] A Conceptual Framework and a Toolkit for Supporting the Rapid Prototyping of Context-Aware Applications, Dey+, HUMAN-COMPUTER INTERACTION, 2001.12, Volume 16, pp. 97–166
Paper/Blog Link My Issue
#Article #Classic #ContextAware #HumanComputerInteraction Issue Date: 2018-12-22 Comment
論文中のcontextに関する定義がしばしば引用される:
"any information that can be used to characterize the situation of an entity. An entity is a person, place, or object that is considered relevant to the interaction between a user and an application, including the user and applications themselves."
The Annotated Transformer, harvardnlp, 2018.04
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #MachineLearning #NLP Issue Date: 2018-06-29
Curriculum Learning(関東CV勉強会), Yoshitaka Ushiku, 2015.05
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #Slide #CurriculumLearning Issue Date: 2018-02-12 Comment
牛久先生によるCurriculum Learningチュートリアル
[Paper Note] Machine-made index for technical literature: an experiment, IBM Journal of Research and Development, 1958.10
Paper/Blog Link My Issue
#Article #DocumentSummarization #Document #NLP #Extractive Issue Date: 2018-01-17 Comment
初期の要約研究。Luhnらの研究よりはcitation countが少ない。
[Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tools #CollaborativeFiltering #MatrixFactorization #JMLR Issue Date: 2018-01-11 Comment
tool: http://apex.sjtu.edu.cn/projects/33
Ratingの情報だけでなく、Auxiliaryな情報も使ってMatrix Factorizationができるツールを作成した。
これにより、Rating Matrixの情報だけでなく、自身で設計したfeatureをMFに組み込んでモデルを作ることができる。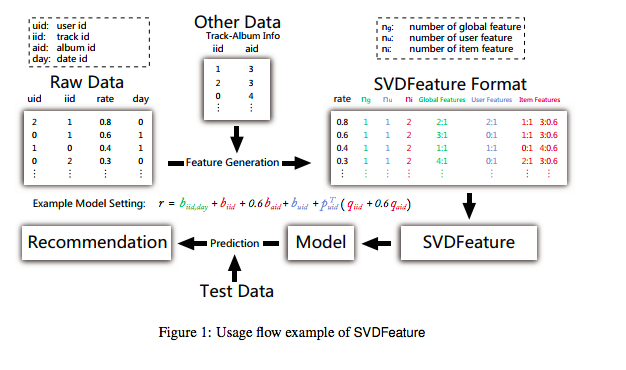
[Paper Note] The Decomposition of Human-Written Summary Sentences, Hongyan Jing+, SIGIR’99
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #SIGIR #Selected Papers/Blogs #WordAlignment Issue Date: 2018-01-11 Comment
参照要約 - 原文書対が与えられた時に、参照要約中の単語と原文書中の単語のアライメントをとるHMMベースな手法を提案。
outputのサンプルはFigure3参照のこと。
[Paper Note] The automatic construction of large-scale corpora for summarization research, Daniel Marcu, SIGIR’99
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #SIGIR Issue Date: 2018-01-11 Comment
[Paper Note] The automatic creation of literature abstracts, H. P. Luhn, IBM Journal of Research Development, 1958.04
Paper/Blog Link My Issue
#Article #DocumentSummarization #Document #Classic #NLP #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
文書要約研究初期の研究
[Paper Note] A General Approximation Framework for Direct Optimization of Information Retrieval Measures (ApproxAP, ApproxNDCG), Qin+, Information Retrieval, 2008.10
Paper/Blog Link My Issue
#Article #InformationRetrieval #LearningToRank #ListWise Issue Date: 2018-01-01 Comment
実装してみたが、バグありそう感・・・
https://github.com/AkihikoWatanabe/ApproxAP
GraphChi, GraphChi open source project, 2013.01
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tools Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:Matrix Factorization, RBM, CliMFなど
実装:
使用方法:CLI
※ graphlabの中の人による実装
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
mrec recommender systems library, mrec, 2013.11
Paper/Blog Link My Issue
#Article #RecommenderSystems #Library #python Issue Date: 2018-01-01 Comment
実装:python
※ Mendeleyによるpythonライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
MyMediaLite Recommender System Library, Zeno Gantner+
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tools #Library Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:C#
使用方法:コマンドライン、C#ライブラリとして利用
※ ライブラリとして使用する場合は、C#による実装が必要
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
Surprise: A Python library for recommender systems, Nicolas Hug, 2016.10
Paper/Blog Link My Issue
#Article #RecommenderSystems #Library #python #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:python
使用方法:pythonライブラリとして利用
※ pythonで利用できる数少ない推薦システムライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] 転移学習による抽出型要約の精度向上, 西川+, 情報処理学会研究報告, 2011.11
Paper/Blog Link My Issue
#Article #DocumentSummarization #Document #StructuredLearning #DomainAdaptation #Supervised #NLP #Extractive Issue Date: 2017-12-31 Comment
構造学習を利用した文書要約モデル
[Paper Note] Frustratingly easy domain adaptation, Daum'e, ACL'07
なども利用し転移学習を行なっている。
SVM-MAP
Paper/Blog Link My Issue
#Article #MachineLearning #StructuredLearning #Tools #InformationRetrieval Issue Date: 2017-12-31 Comment
構造化SVMを用いて、MAPを直接最適化する手法
オンライン学習
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #OnlineLearning Issue Date: 2017-12-31 Comment
## 目次
定式化
評価法:Regretなど
パーセプトロン
Passive Aggressive Algorithm
(アルゴリズムと損失の限界の評価)
Confidence Weighted Algorithm
Pegasos
Coordinate Descent
バッチ、オンライン、ストリームの比較
ビッグデータへの対応
[Paper Note] Artificial neural networks in business: Two decades of research, Tkac+, Applied Soft Computing 2016.01
Paper/Blog Link My Issue
#Article #NeuralNetwork #Survey #TimeSeriesDataProcessing Issue Date: 2017-12-31 Comment
ビジネスドメイン(e.g. Stock market price prediction)におけるニューラルネットワークの活用事例をまとめたSurvey。
時系列データの取り扱いなどの参考になるかも。
[Paper Note] Relevance Judgment in epistemic and hedonic information searches, Yunjie Xu, Journal of the American Society for Information Science and Technology, 2007.01
Paper/Blog Link My Issue
#Article #RecommenderSystems #RelevanceJudgment Issue Date: 2017-12-28 Comment
・informative relevance: 知識を求める検索など(個人のブログ,経済ニュースとか)
・affective relevance: 楽しみや感情に刺激を受けるための情報を求める検索の場合(2chまとめとか,哲学ニュースまとめとか?)
・topicality, novelty, reliabilityがsignificantにinformative relevanceに寄与, scopeとunderstandabilityは寄与せず
・topicality, understandabilityがsignificantにaffective relevanceに寄与,しかし,noveltyはそうではなかった.
[Paper Note] Relevance judgment: What do information users consider beyond topicality? Xu Chen, Journal of the American Society for Information Science and Technology, 2006.05
Paper/Blog Link My Issue
#Article #InformationRetrieval #RelevanceJudgment Issue Date: 2017-12-28 Comment
・relevanceとsignificantに関連するcriteriaは,topicalityとnovelty
・reliabilityおよびunderstandabilityはsmaller degreeでsignificant, scopeはsignificantでない
[Paper Note] A cognitive model of document use during a research project, Wang and Soergel, Journal of the American Society for Information Science, 1998.02
Paper/Blog Link My Issue
#Article #InformationRetrieval #RelevanceJudgment Issue Date: 2017-12-28 Comment
topicality, orientation, quality, novelty(の順番で)がrelevantなdocumentを選択したときのcriteriaとして採用されていたことを報告
[Paper Note] SCENE: A Scalable Two-Stage Personalized News Recommendation System, Li et al., SIGIR’11
Paper/Blog Link My Issue
#Article #RecommenderSystems #Document #NewsRecommendation #Personalization #SIGIR Issue Date: 2017-12-28 Comment
・ニュース推薦には3つのチャレンジがある。
1. スケーラビリティ より高速なreal-time processing
2. あるニュース記事を読むと、続いて読む記事に影響を与える
3. popularityとrecencyが時間経過に従い変化するので、これらをどう扱うか
これらに対処する手法を提案
[Paper Note] A semantic-expansion approach to personalized knowledge recommendation, Liang, Yang, Chen and Ku, Decision Support Systems, 2008.06
Paper/Blog Link My Issue
#Article #RecommenderSystems #Document Issue Date: 2017-12-28 Comment
・traditionalなkeywordベースでマッチングするアプローチだと,単語間の意味的な関係によって特定の単語のoverweightやunderweightが発生するので,advancedなsemanticsを考慮した手法が必要なので頑張りますという論文.
DUC 2007, Update Summarization Dataset, 2006.10
My Issue
#Article #DocumentSummarization #NLP #Update #Dataset Issue Date: 2017-12-28 Comment
DUC 2007: https://duc.nist.gov/duc2007/tasks.html
[Paper Note] Update Summary Update, Copeck et al., TAC’08
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update Issue Date: 2017-12-28 Comment
被引用数は少ないが、良い論文からreferされているイメージ
[Paper Note] User-model based personalized summarization, Diaz+, Information Processing and Management 2007.11
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #RecommenderSystems #Personalization #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
PDSの先駆けとなった重要論文。必ずreferすべき。