
Backbone
[Paper Note] Next-Embedding Prediction Makes Strong Vision Learners, Sihan Xu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Pocket #Transformer #MultiModal #read-later #Selected Papers/Blogs #2D (Image) #UMM #Omni #KeyPoint Notes Issue Date: 2025-12-20 GPT Summary- 生成的事前学習の原則を視覚学習に応用し、モデルが過去のパッチ埋め込みから未来の埋め込みを予測する「次埋め込み予測自己回帰(NEPA)」を提案。シンプルなTransformerを用いてImageNet-1kで高精度を達成し、タスク特有の設計を必要とせず、スケーラビリティを保持。NEPAは視覚的自己教師あり学習の新たなアプローチを提供する。 Comment
pj page:
https://sihanxu.me/nepa/
HF:
https://huggingface.co/collections/SixAILab/nepa
元ポスト:
Autoregressiveにnext embedding prediction(≠reconstruction)をする。エンコーダ自身のembeddingとautoregressive headが生成したembeddingを比較することでlossが計算されるが、双方に勾配を流すとほぼ全てのパッチが同じembeddingを共有するという解に到達し何も学習されないので、エンコーダのエンコード結果(=target)のgradientをstopする。これにより、targetとしての勾配は受け取らないが(predictionに近づけようとする勾配)、文脈に応じたベクトルを作り、next embeddingを予測する入力としての勾配は受け取るので、エンコーダは文脈に応じた学習を続けることができる。
コミュニティからのフィードバックを受けて執筆されたブログ:
https://sihanxu.me/nepa/blog
元ポスト:
NEPAを提案した背景に関して直感的な解説を実施している。興味深い。具体的には、omnimodalityモデルの困難さはインターフェースの問題であり、latent spaceがomnimodalityの共通のインタフェースになりうり、モダリティごとの予測対象とlossを個別に設計せずに済む方法の一つがAutoregressiveな予測であり、そういったインタフェースがスケーリングのために必要という意見と、omnimodalityにおいて過去のliteratureで扱われているdiscreteなtokenとcontinuous symbolsは得意なモダリティが異なり予測対象や前処理のメカニズムも異なるため同時に扱うことが難しい旨などが記述されている。
[Paper Note] Latent Diffusion Model without Variational Autoencoder, Minglei Shi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Pocket #DiffusionModel #Selected Papers/Blogs #Encoder-Decoder #KeyPoint Notes #ImageSynthesis Issue Date: 2025-12-17 GPT Summary- VAEを用いない新しい潜在拡散モデルSVGを提案。SVGは自己教師あり表現を活用し、明確な意味的識別性を持つ特徴空間を構築。これにより、拡散トレーニングが加速し、生成品質が向上。実験結果はSVGの高品質な視覚表現能力を示す。 Comment
openreview: https://openreview.net/forum?id=kdpeJNbFyf
これまでの拡散モデルベースのImage GeneiationモデルにおけるVAEを、事前学習済み(self supervised learning)のvision encoder(本稿ではDINOv3)に置き換えfreezeし、それとは別途Residual Encoderと呼ばれるViTベースのEncoderを学習する。前者は画像の意味情報を捉える能力をそのまま保持し、Residual Encoder側でReconstructionをする上でのPerceptualな情報等の(vision encoderでは失われてしまう)より精緻な特徴を捉える。双方のEncoder出力はchannel次元でconcatされ、SVG Featureを形成する。SVG Decoderは、SVG FeatureをPixelスペースに戻す役割を果たす。このアーキテクチャはシンプルで軽量だが、DINOv3による強力な意味的な識別力を保ちつつ、精緻な特徴を捉える能力を補完できる。Figure 5を見ると、実際にDINOv3のみと比較して、Residual Encoderによって、細かい部分がより正確なReconstructionが実現できていることが定性的にわかる。学習時はReconstruction lossを使うが、Residual Encoderに過剰に依存するだけめなく、outputの数値的な値域が異なり、DINOv3の意味情報を損なう恐れが足るため、Residual Encoderの出力の分布をDINOv3とalignするように学習する。
VAE Encoderによるlatent vectorは低次元だが、提案手法はより高次元なベクトルを扱うため、Diffusionモデルの学習が難しいと考えられるが、SVG Featureの特徴量はうまく分散しており、安定してFlow Matchingで学習ができるとのこと。
実際、実験結果を見ると安定して、しかもサンプル効率がベースラインと比較して大幅に高く収束していることが見受けられる。
[Paper Note] Diffusion Transformers with Representation Autoencoders, Boyang Zheng+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Pocket #Transformer #DiffusionModel #read-later #Selected Papers/Blogs Issue Date: 2025-10-14 GPT Summary- 本研究では、従来のVAEエンコーダを事前学習された表現エンコーダに置き換えたRepresentation Autoencoders(RAE)を提案。これにより、高品質な再構成と豊かな潜在空間を実現し、拡散トランスフォーマーの性能向上を図る。RAEは、補助的な表現整合損失なしで早い収束を達成し、ImageNetで優れた画像生成結果を示した。RAEは、拡散トランスフォーマーの新しいデフォルトとしての利点を提供する。 Comment
pj page: https://rae-dit.github.io
元ポスト:
U-NetをBackboneとしたVAEの代わりにViTに基づく(down, up- scaling無しの)アーキテクチャを用いることで、より少ない計算量で高い性能を達成しました、といった話に見える。
ポイント解説:
解説:
[Paper Note] OpenVision 2: A Family of Generative Pretrained Visual Encoders for Multimodal Learning, Yanqing Liu+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Pretraining #Pocket #OpenWeight #OpenSource #Encoder Issue Date: 2025-09-16 GPT Summary- 本論文では、OpenVisionのアーキテクチャを簡素化し、トレーニング効率を向上させる方法を提案。テキストエンコーダーと対照損失を削除し、キャプショニング損失のみを使用したOpenVision 2を導入。初期結果は、トレーニング時間を約1.5倍短縮し、メモリ使用量を約1.8倍削減することを示し、10億以上のパラメータにスケールアップ可能であることを強調。 Comment
元ポスト:
事前学習時にtext, image encoderのcontrastive lossで学習していたが、text encoderを無くしimage encoderに入力されたimageからcaptionを生成するcaption lossのみにすることで性能を落とすことなく効率を改善
[Paper Note] OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning, Xianhang Li+, ICCV'25
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Pretraining #Pocket #OpenWeight #OpenSource #Selected Papers/Blogs #ICCV #Encoder Issue Date: 2025-06-26 GPT Summary- OpenVisionは、完全にオープンでコスト効果の高いビジョンエンコーダーのファミリーを提案し、CLIPと同等以上の性能を発揮します。既存の研究を基に構築され、マルチモーダルモデルの進展に実用的な利点を示します。5.9Mから632.1Mパラメータのエンコーダーを提供し、容量と効率の柔軟なトレードオフを実現します。 Comment
元ポスト:
v2へアップデート:
事前学習時にtext, image encoderのcontrastive lossで学習していたが、text encoderを無くしimage encoderに入力されたimageからcaptionを生成するcaption lossのみにすることで性能を落とすことなく効率を改善
テクニカルペーパーが出た模様
- [Paper Note] OpenVision 2: A Family of Generative Pretrained Visual Encoders for Multimodal Learning, Yanqing Liu+, arXiv'25
HF:
https://huggingface.co/collections/UCSC-VLAA/openvision-681a4c27ee1f66411b4ae919
pj page:
https://ucsc-vlaa.github.io/OpenVision/
CLIP, SigLIPとは異なり完全にオープンなVision Encoder
v2の解説:
[Paper Note] VGGT: Visual Geometry Grounded Transformer, Jianyuan Wang+, CVPR'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #CVPR #read-later #Selected Papers/Blogs #3D Reconstruction Issue Date: 2025-06-22 GPT Summary- VGGTは、シーンの主要な3D属性を複数のビューから直接推測するフィードフォワードニューラルネットワークであり、3Dコンピュータビジョンの分野において新たな進展を示します。このアプローチは効率的で、1秒未満で画像を再構築し、複数の3Dタスクで最先端の結果を達成します。また、VGGTを特徴バックボーンとして使用することで、下流タスクの性能が大幅に向上することが示されています。コードは公開されています。 Comment
元ポスト:
様々な研究のBackboneとして活用されている。
[Paper Note] Scalable Diffusion Models with Transformers, William Peebles+, ICCV'23
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #DiffusionModel #read-later #Selected Papers/Blogs Issue Date: 2025-08-27 GPT Summary- 新しいトランスフォーマーに基づく拡散モデル(Diffusion Transformers, DiTs)を提案し、U-Netをトランスフォーマーに置き換えた。DiTsは高いGflopsを持ち、低いFIDを維持しながら良好なスケーラビリティを示す。最大のDiT-XL/2モデルは、ImageNetのベンチマークで従来の拡散モデルを上回り、最先端のFID 2.27を達成した。 Comment
日本語解説: https://qiita.com/sasgawy/items/8546c784bc94d94ef0b2
よく見るDiT
- [Paper Note] DiT: Self-supervised Pre-training for Document Image Transformer, Junlong Li+, ACMMM'22
も同様の呼称だが全く異なる話なので注意
[Paper Note] A ConvNet for the 2020s, Zhuang Liu+, arXiv'22
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Selected Papers/Blogs Issue Date: 2025-08-29 GPT Summary- ConvNetはVision Transformersの登場により地位を失ったが、ハイブリッドアプローチの効果はトランスフォーマーの優位性に依存している。本研究では、ConvNetの限界をテストし、ConvNeXtという新しいモデルを提案。ConvNeXtは標準的なConvNetモジュールのみで構成され、精度とスケーラビリティでトランスフォーマーと競争し、ImageNetで87.8%の精度を達成し、COCO検出およびADE20KセグメンテーションでSwin Transformersを上回る。 Comment
ConvNeXt
[Paper Note] DiT: Self-supervised Pre-training for Document Image Transformer, Junlong Li+, ACMMM'22
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #OCR #ACMMM Issue Date: 2025-08-22 GPT Summary- 自己監視型事前学習モデルDiTを提案し、ラベルなしテキスト画像を用いて文書AIタスクにおける性能を向上。文書画像分類やレイアウト分析、表検出、OCRなどで新たな最先端結果を達成。コードとモデルは公開中。
[Paper Note] Vision Transformers for Dense Prediction, René Ranftl+, ICCV'21, 2021.03
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #read-later #ICCV #Encoder #DepthEstimation #SemanticSegmentation Issue Date: 2025-12-29 GPT Summary- 密なビジョントランスフォーマーは、畳み込みネットワークの代わりにビジョントランスフォーマーを用いた密な予測タスク向けの新しいアーキテクチャです。異なる解像度のトークンを集め、畳み込みデコーダでフル解像度の予測に統合します。このアーキテクチャは、グローバルな受容野を持ち、より一貫した予測を提供します。実験により、特に大量のトレーニングデータがある場合に、単眼深度推定で最大28%の性能向上を示し、セマンティックセグメンテーションではADE20Kで49.02%のmIoUを達成しました。さらに、他の小規模データセットでも最先端の結果を記録しています。モデルは公開されています。 Comment
DPT headの解説: https://qiita.com/Chi_corp_123/items/8a2e9a4f542a3404a700
[Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #ICLR #Selected Papers/Blogs Issue Date: 2025-08-25 GPT Summary- 純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。 Comment
openreview: https://openreview.net/forum?id=YicbFdNTTy
ViTを提案した研究
[Paper Note] Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu+, arXiv'21
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Pocket #Transformer #Architecture Issue Date: 2025-07-19 GPT Summary- 本論文では、大規模ビジョンモデルのトレーニングと応用における課題に対処するための3つの技術を提案。具体的には、トレーニングの安定性向上のための残差後正規化法、低解像度から高解像度への転送を可能にする位置バイアス法、ラベル付きデータの必要性を減少させる自己教師あり学習法を用いる。これにより、30億パラメータのSwin Transformer V2モデルをトレーニングし、複数のビジョンタスクで新記録を樹立。トレーニング効率も向上し、ラベル付きデータと時間を大幅に削減。
[Paper Note] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Ze Liu+, ICCV'21
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #Attention #Architecture #Selected Papers/Blogs #ICCV Issue Date: 2025-07-19 GPT Summary- Swin Transformerは、コンピュータビジョンの新しいバックボーンとして機能する階層的トランスフォーマーを提案。シフトウィンドウ方式により、効率的な自己注意計算を実現し、さまざまなスケールでのモデリングが可能。画像分類や物体検出、セマンティックセグメンテーションなどで従来の最先端を上回る性能を示し、トランスフォーマーのビジョンバックボーンとしての可能性を示唆。コードは公開されている。 Comment
日本語解説: https://qiita.com/m_sugimura/items/139b182ee7c19c83e70a
画像処理において、物体の異なるスケールや、解像度に対処するために、PatchMergeと呼ばれるプーリングのような処理と、固定サイズのローカルなwindowに分割してSelf-Attentionを実施し、layerごとに通常のwindowとシフトされたwindowを適用することで、window間を跨いだ関係性も考慮できるようにする機構を導入したモデル。
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, Mingxing Tan+, ICML'19
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #EfficiencyImprovement #Pocket #ICML #Selected Papers/Blogs Issue Date: 2025-05-12 GPT Summary- 本論文では、ConvNetsのスケーリングを深さ、幅、解像度のバランスを考慮して体系的に研究し、新しいスケーリング手法を提案。これにより、MobileNetsやResNetのスケールアップを実証し、EfficientNetsという新しいモデルファミリーを設計。特にEfficientNet-B7は、ImageNetで84.3%のトップ1精度を達成し、従来のConvNetsよりも小型かつ高速である。CIFAR-100やFlowersなどのデータセットでも最先端の精度を記録。ソースコードは公開されている。 Comment
元論文をメモってなかったので追加。
- EfficientNet解説, omiita (オミータ), 2019
も参照のこと。
[Paper Note] Deep Residual Learning for Image Recognition, Kaiming He+, CVPR'16, 2015.12
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #CVPR #Selected Papers/Blogs #ResidualStream Issue Date: 2021-11-04 GPT Summary- 残差学習フレームワークを提案し、深いニューラルネットワークのトレーニングを容易にする。参照層の入力に基づいて残差関数を学習することで、最適化が容易になり、精度が向上。152層の残差ネットはImageNetで低い複雑性を保ちながら高い性能を示し、ILSVRC 2015で1位を獲得。COCOデータセットでも28%の改善を達成。 Comment
ResNet論文
ResNetでは、レイヤーの計算する関数を、残差F(x)と恒等関数xの和として定義する。これにより、レイヤーが入力との差分だけを学習すれば良くなり、モデルを深くしても最適化がしやすくなる効果ぎある。数レイヤーごとにResidual Connectionを導入し、恒等関数によるショートカットができるようにしている。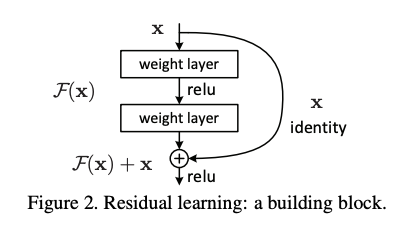
ResNetが提案される以前、モデルを深くすれば表現力が上がるはずなのに、実際には精度が下がってしまうことから、理論上レイヤーが恒等関数となるように初期化すれば、深いモデルでも浅いモデルと同等の表現が獲得できる、と言う考え方を発展させた。
(ステートオブAIガイドに基づく)
同じパラメータ数でより層を深くできる(Plainな構造と比べると層が1つ増える)Bottleneckアーキテクチャも提案している。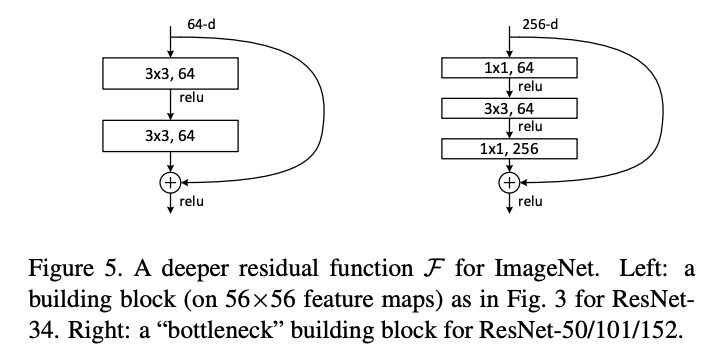
今や当たり前のように使われているResidual Connectionは、層の深いネットワークを学習するために必須の技術なのだと再認識。
[Paper Note] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger+, MICCAI'15, 2015.05
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #Selected Papers/Blogs #Encoder-Decoder #U-Net Issue Date: 2025-09-22 GPT Summary- データ拡張を活用した新しいネットワークアーキテクチャを提案し、少ない注釈付きサンプルからエンドツーエンドでトレーニング可能であることを示す。電子顕微鏡スタックの神経構造セグメンテーションで従来手法を上回り、透過光顕微鏡画像でも優れた結果を達成。512x512画像のセグメンテーションは1秒未満で完了。実装とトレーニング済みネットワークは公開されている。
[Paper Note] Very Deep Convolutional Networks for Large-Scale Image Recognition, Karen Simonyan+, ICLR'15
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #ICLR Issue Date: 2025-08-25 GPT Summary- 本研究では、3x3の畳み込みフィルタを用いた深い畳み込みネットワークの精度向上を評価し、16-19層の重み層で従来の最先端構成を大幅に改善したことを示す。これにより、ImageNet Challenge 2014で1位と2位を獲得し、他のデータセットでも優れた一般化性能を示した。最も性能の良い2つのConvNetモデルを公開し、深層視覚表現の研究を促進する。 Comment
いわゆるVGGNetを提案した論文
ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky+, NIPS'12
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NeurIPS #Selected Papers/Blogs #ImageClassification Issue Date: 2025-05-13 Comment
ILSVRC 2012において圧倒的な性能示したことで現代のDeepLearningの火付け役となった研究AlexNet。メモってなかったので今更ながら追加した。
AlexNet以前の画像認識技術については牛久先生がまとめてくださっている(当時の課題とそれに対する解決法、しかしまだ課題が…と次々と課題に直面し解決していく様子が描かれており非常に興味深かった)。現在でも残っている技術も紹介されている。:
https://speakerdeck.com/yushiku/pre_alexnet
> 過去の技術だからといって聞き流していると時代背景の変化によってなし得たイノベーションを逃すかも
これは肝に銘じたい。
画像モデルのバックボーンとして最初に何を選ぶべきか?, ちくわぶ, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #Analysis #Blog Issue Date: 2025-09-13 Comment
こちらの論文を参考にしている:
- [Paper Note] Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks, Micah Goldblum+, NeurIPS'23
Backbone選定の際は参照のこと。2024年以後のモデルは含まれていない点に注意。
DINOv3: Self-supervised learning for vision at unprecedented scale, Meta, 2025.08
Paper/Blog Link My Issue
#Article #ComputerVision #Self-SupervisedLearning #Distillation #Regularization #read-later #One-Line Notes #Reference Collection Issue Date: 2025-08-14 Comment
元ポスト:
paper:
https://arxiv.org/abs/2508.10104
HF:
https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
解説:
サマリ:
v2:
- DINOv2: Learning Robust Visual Features without Supervision, Maxime Oquab+, TMLR'24
本日配信された岡野原氏のランチタイムトークによると、学習が進んでいくと全部の特徴量が似通ってきてしまう問題があったが、Gram Anchoringと呼ばれる、学習初期時点でのパッチ間の類似度度行列を保持しておき正則化として損失に加えることで、そこから離れすぎないように学習するといった工夫を実施しているとのこと。