
In-Depth Notes
A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility, Andreas Hochlehnert+, COLM'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #SmallModel #COLM #PostTraining #Selected Papers/Blogs Issue Date: 2025-04-13 GPT Summary- 推論は言語モデルの重要な課題であり、進展が見られるが、評価手法には透明性や堅牢性が欠けている。本研究では、数学的推論ベンチマークが実装の選択に敏感であることを発見し、標準化された評価フレームワークを提案。再評価の結果、強化学習アプローチは改善が少なく、教師ありファインチューニング手法は強い一般化を示した。再現性を高めるために、関連するコードやデータを公開し、今後の研究の基盤を築く。 Comment
元ポスト:
SLMをmath reasoning向けにpost-trainingする場合、評価の条件をフェアにするための様々な工夫を施し評価をしなおした結果(Figure1のように性能が変化する様々な要因が存在する)、RL(既存研究で試されているもの)よりも(大規模モデルからrejection samplingしたreasoning traceを用いて)SFTをする方が同等か性能が良く(Table3)、結局のところ(おそらく汎化性能が低いという意味で)reliableではなく、かつ(おそらく小規模なモデルでうまくいかないという意味での)scalableではないので、reliableかつscalableなRL手法が不足しているとのこと。
※ 本論文で分析されているのは<=10B以下のSLMである点に注意。10B以上のモデルで同じことが言えるかは自明ではない。
※ DAPO, VAPOなどについても同じことが言えるかも自明ではない。
※ DeepSeek-R1のtechnical reportにおいて、小さいモデルにGRPOを適用してもあまり効果が無かったことが既に報告されている。
- DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01
- DeepSeek-R1, DeepSeek, 2025.01
個々のpost-trainingされたRLモデルが具体的にどういう訓練をしたのかは追えていないが、DAPOやDr. GRPO, VAPOの場合はどうなるんだろうか?
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25
- VAPO: Efficient and Reliable Reinforcement Learning for Advanced
Reasoning Tasks, YuYue+, arXiv'25
- [Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Rewardの設定の仕方はどのような影響があるのだろうか(verifiable rewardなのか、neuralモデルによるrewardなのかなど)?
学習のさせ方もどのような影響があるのだろうか(RLでカリキュラムlearningにした場合など)?
検証しているモデルがそれぞれどのような設定で学習されているかまでを見ないとこの辺はわからなそう。
ただなんとなーくの直感だと、SLMを賢くしたいという場合は何らかの賢いモデルの恩恵に預かると有利なケースが多く(SFTの場合はそれが大規模なモデルから蒸留したreasoning trace)、SLM+RLの場合はPRMのような思考プロセスを評価してRewardに反映させるようなものを利用しないと、少なくとも小規模なLLMをめちゃ賢くします〜というのはきついんじゃないかなあという感想ではある。
ただ、結局SLMという時点で多くの場合、より賢いパラメータ数の多いLLMが世の中には存在するあるはずなので、RLしないでSFTして蒸留すれば良いんじゃない…?と思ってしまう。
が、多くの場合その賢いLLMはProprietaryなLLMであり、出力を得て自分のモデルをpost-trainingすることは利用規約違反となるため、自前で賢くてパラメータ数の多いLLMを用意できない場合は困ってしまうので、SLMをクソデカパラメータのモデルの恩恵なしで超絶賢くできたら世の中の多くの人は嬉しいよね、とも思う。
(斜め読みだが)
サンプル数が少ない(数十件)AIMEやAMCなどのデータはseedの値にとてもsensitiveであり(Takeaway1, 2)、
それらは10種類のseedを用いて結果を平均すると分散が非常に小さくなるので、seedは複数種類利用して平均の性能を見た方がreliableであり(Takeaway3)
temperatureを高くするとピーク性能が上がるが分散も上がるため再現性の課題が増大するが、top-pを大きくすると再現性の問題は現れず性能向上に寄与し
既存研究のモデルのtemperatureとtop-pを変化させ実験するとperformanceに非常に大きな変化が出るため、モデルごとに最適な値を選定して比較をしないとunfairであることを指摘 (Takeaway4)。
また、ハードウェアの面では、vLLMのようなinference engineはGPU typeやmemoryのconfigurationに対してsensitiveでパフォーマンスが変わるだけでなく、
評価に利用するフレームワークごとにinference engineとprompt templateが異なるためこちらもパフォーマンスに影響が出るし (Takeaway5)、
max output tokenの値を変化させると性能も変わり、prompt templateを利用しないと性能が劇的に低下する (Takeaway6)。
これらのことから著者らはreliableな評価のために下記を提案しており (4.1節; 後ほど追記)、
実際にさまざまな条件をfair comparisonとなるように標準化して評価したところ(4.2節; 後ほど追記)
上の表のような結果となった。この結果は、
- DeepSeekR1-DistilledをRLしてもSFTと比較したときに意味のあるほどのパフォーマンスの向上はないことから、スケーラブル、かつ信頼性のあるRL手法がまだ不足しており
- 大規模なパラメータのモデルのreasoning traceからSFTをする方法はさまざまなベンチマークでロバストな性能(=高い汎化性能)を持ち、RLと比べると現状はRLと比較してよりパラダイムとして成熟しており
- (AIME24,25を比較するとSFTと比べてRLの場合performanceの低下が著しいので)RLはoverfittingしやすく、OODなベンチマークが必要
しっかりと評価の枠組みを標準化してfair comparisonしていかないと、RecSys業界の二の舞になりそう(というかもうなってる?)。
またこの研究で分析されているのは小規模なモデル(<=10B)に対する既存研究で用いられた一部のRL手法や設定の性能だけ(真に示したかったらPhisics of LLMのような完全にコントロール可能なサンドボックスで実験する必要があると思われる)なので、DeepSeek-R1のように、大規模なパラメータ(数百B)を持つモデルに対するRLに関して同じことが言えるかは自明ではない点に注意。
openreview: https://openreview.net/forum?id=90UrTTxp5O#discussion
最近の以下のようなSFTはRLの一つのケースと見做せるという議論を踏まえるとどうなるだろうか
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with
Reward Rectification, Yongliang Wu+, arXiv'25
- [Paper Note] Towards a Unified View of Large Language Model Post-Training, Xingtai Lv+, arXiv'25
[Paper Note] Self-Instruct: Aligning Language Models with Self-Generated Instructions, Yizhong Wang+, ACL'23, 2022.12
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #ACL Issue Date: 2023-03-30 GPT Summary- Self-Instructフレームワークを提案し、事前学習済みの言語モデルが自ら生成した指示を用いてファインチューニングを行うことで、ゼロショットの一般化能力を向上させる。バニラGPT-3に適用した結果、Super-NaturalInstructionsで33%の性能向上を達成し、InstructGPT-001と同等の性能に到達。人間評価により、Self-Instructが既存の公共指示データセットよりも優れていることを示し、ほぼ注釈不要の指示調整手法を提供。大規模な合成データセットを公開し、今後の研究を促進する。 Comment
Alpacaなどでも利用されているself-instruction技術に関する論文
# 概要
著者らが書いた175種のinstruction(タスクの定義 + 1種のinput/outputペア}のseedを元に、VanillaなGPT-3に新たなinstruction, input, outputのtupleを生成させ、学習データとして活用する研究。
ここで、instruction data I は以下のように定義される:
instruction dataは(I, X, Y)であり、モデルは最終的にM(I_t, x_t) = y_tとなるように学習したい。
I: instruction, X: input, Y: output
データ作成は以下のステップで構成される。なお、以下はすべてVanilla GPT-3を通じて行われる:
1. Instruction Generation
task poolから8種類のinstructionを抽出し、 promptを構成し、最大8個新たなinstructionを生成させる
2. Classification Task Identification:
生成されたinstructionがclassificationタスクか否かを判別する
3. Instance Generation
いくつかの(I, X, Y)をpromptとして与え、I, Xに対応するYを生成するタスクを実行させる。このときinput-first approachを採用した結果(I->Xの順番で情報を与えYを生成するアプローチ)、特定のラベルに偏ったインスタンスが生成される傾向があることがわかった。このためoutput-first approachを別途採用し(I->Yの順番で情報を与え、各Yに対応するXを生成させる)、活用している。
4. Filtering and Postprocessing
最後に、既存のtask poolとROUGE-Lが0.7以上のinstructionは多様性がないため除外し、特定のキーワード(images, pictrues, graphs)等を含んでいるinstruction dataも除外して、task poolに追加する。
1-4をひたすら繰り返すことで、GPT-3がInstruction Tuningのためのデータを自動生成してくれる。
# SELF-INSTRUCT Data
## データセットの統計量
- 52k instructions
- 82k instances
## Diversity
parserでinstructionを解析し、rootの名詞と動詞のペアを抽出して可視化した例。ただし、抽出できた例はたかだか全体の50%程度であり、その中で20の最もcommonなroot vertと4つのnounを可視化した。これはデータセット全体の14%程度しか可視化されていないが、これだけでも非常に多様なinstructionが集まっていることがわかる。
また、seed indstructionとROUGE-Lを測った結果、大半のデータは0.3~0.4程度であり、lexicalなoverlapはあまり大きくないことがわかる。instructionのlengthについても可視化した結果、多様な長さのinstructionが収集できている。
## Quality
200種類のinstructionを抽出し、その中からそれぞれランダムで1つのインスタンスをサンプルした。そしてexpert annotatorに対して、それぞれのinstructionとinstance(input, outputそれぞれについて)が正しいか否かをラベル付けしてもらった。
ラベル付けの結果、ほとんどのinstructionは意味のあるinstructionであることがわかった。一方、生成されたinstanceはnoisyであることがわかった(ただし、このnoiseはある程度妥当な範囲である)。noisytではあるのだが、instanceを見ると、正しいformatであったり、部分的に正しかったりなど、modelを訓練する上で有用なguidanceを提供するものになっていることがわかった。
# Experimental Results
## Zero-shotでのNLPタスクに対する性能
SuperNIデータセットに含まれる119のタスク(1タスクあたり100 instance)に対して、zero-shot setupで評価を行なった。SELF-INSTRUCTによって、VanillaのGPT3から大幅に性能が向上していることがわかる。VanillaのGPT-3はほとんど人間のinstructionに応じて動いてくれないことがわかる。分析によると、GPT3は、大抵の場合、全く関係ない、あるいは繰り返しのテキストを生成していたり、そもそもいつ生成をstopするかがわかっていないことがわかった。
また、SuperNI向けにfinetuningされていないモデル間で比較した結果、非常にアノテーションコストをかけて作られたT0データでfinetuningされたモデルよりも高い性能を獲得した。また、人間がラベル付したprivateなデータによって訓練されたInstructGPT001にも性能が肉薄していることも特筆すべき点である。
SuperNIでfinetuningした場合については、SELF-INSTRUCTを使ったモデルに対して、さらに追加でSuperNIを与えた場合が最も高い性能を示した。
## User-Oriented Instructionsに対する汎化性能
SuperNIに含まれるNLPタスクは研究目的で提案されており分類問題となっている。ので、実践的な能力を証明するために、LLMが役立つドメインをブレスト(email writing, social media, productiveity tools, entertainment, programming等)し、それぞれのドメインに対して、instructionとinput-output instanceを作成した。また、instructionのスタイルにも多様性(e.g. instructionがlong/short、bullet points, table, codes, equationsをinput/outputとして持つ、など)を持たせた。作成した結果、252個のinstructionに対して、1つのinstanceのデータセットが作成された。これらが、モデルにとってunfamiliarなinstructionで多様なistructionが与えられたときに、どれだけモデルがそれらをhandleできるかを測定するテストベッドになると考えている。
これらのデータは、多様だがどれもが専門性を求められるものであり、自動評価指標で性能が測定できるものでもないし、crowdworkerが良し悪しを判定できるものでもない。このため、それぞれのinstructionに対するauthorに対して、モデルのy補足結果が妥当か否かをjudgeしてもらった。judgeは4-scaleでのratingとなっている:
- RATING-A: 応答は妥当で満足できる
- RATING-B: 応答は許容できるが、改善できるminor errorや不完全さがある。
- RATING-C: 応答はrelevantでinstructionに対して答えている。が、内容に大きなエラーがある。
- RATING-D: 応答はirrelevantで妥当ではない。
実験結果をみると、Vanilla GPT3はまったくinstructionに対して答えられていない。instruction-basedなモデルは高いパフォーマンスを発揮しているが、それらを上回る性能をSELF-INSTRUCTは発揮している(noisyであるにもかかわらず)。
また、GPT_SELF-INSTRUCTはInstructGPT001と性能が肉薄している。また、InstructGPT002, 003の素晴らしい性能を示すことにもなった。
# Discussion and Limitation
## なぜSELF-INSTRUCTがうまくいったか?
- LMに対する2つの極端な仮説を挙げている
- LM はpre-trainingでは十分に学習されなかった問題について学習する必要があるため、human feedbackはinstruction-tuningにおいて必要不可欠な側面である
- LM はpre-trainingからinstructionに既に精通しているため、human feedbackはinstruction-tuningにおいて必須ではない。 human feedbackを観察することは、pre-trainingにおける分布/目的を調整するための軽量なプロセスにすぎず、別のプロセスに置き換えることができる。
この2つの極端な仮説の間が実情であると筆者は考えていて、どちらかというと2つ目の仮説に近いだろう、と考えている。既にLMはpre-trainingの段階でinstructionについてある程度理解できているため、self-instructがうまくいったのではないかと推察している。
## Broader Impact
InstructGPTは非常に強力なモデルだけど詳細が公表されておらず、APIの裏側に隠れている。この研究が、instruct-tuned modelの背後で何が起きているかについて、透明性を高める助けになると考えている。産業で開発されたモデルの構造や、その優れた性能の理由についてはほとんど理解されておらず、これらのモデルの成功の源泉を理解し、より優れた、オープンなモデルを作成するのはアカデミックにかかっている。この研究では、多様なinstructional dataの重要性を示していると考えており、大規模な人工的なデータセットは、より優れたinstructionに従うモデルを、構築するための第一歩だと考えている。
## limitation
- Tail Phenomena
- LMの枠組みにとどまっているため、LMと同じ問題(Tail Phenomena)を抱えている
- low-frequencyなcontextに対してはうまくいかない問題
- SELF-INSTRUCTも、結局pre-trainingの段階で頻出するタスクやinstructionに対してgainがあると考えられ、一般的でなく、creativeなinstructionに対して脆弱性があると考えられる
- Dependence on laege models
- でかいモデルを扱えるだけのresourceを持っていないと使えないという問題がある
- Reinforcing LM biases
- アルゴリズムのiterationによって、問題のあるsocial _biasをより増幅してしまうことを懸念している(人種、種族などに対する偏見など)。また、アルゴリズムはバランスの取れたラベルを生成することが難しい。
1のprompt
2のprompt
3のprompt(input-first-approach)
3のprompt(output-first approach)
※ GPT3をfinetuningするのに、Instruction Dataを使った場合$338かかったっぽい。安い・・・。
LLMを使うだけでここまで研究ができる時代がきた
(最近は|現在は)プロプライエタリなLLMの出力を利用して競合するモデルを訓練することは多くの場合禁止されているので注意。
[Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #EducationalDataMining #StudentPerformancePrediction #KnowledgeTracing #WWW Issue Date: 2021-05-28 GPT Summary- 動的キー・バリューメモリネットワーク(DKVMN)を提案し、学生の知識状態を追跡する新しい手法を開発。従来の手法の限界を克服し、基礎概念間の関係を活用して習得レベルを直接出力。実験により、DKVMNはKTデータセットで最先端モデルを上回る性能を示し、演習の基礎概念を自動発見する能力も持つ。 Comment
DeepなKnowledge Tracingの代表的なモデルの一つ。KT研究において、DKTと並んでbaseline等で比較されることが多い。
DKVMNと呼ばれることが多く、Knowledge Trackingができることが特徴。
モデルは下図の左側と右側に分かれる。左側はエクササイズqtに対する生徒のパフォーマンスptを求めるネットワークであり、右側はエクササイズqtに対する正誤情報rtが与えられた時に、メモリのvalueを更新するネットワークである。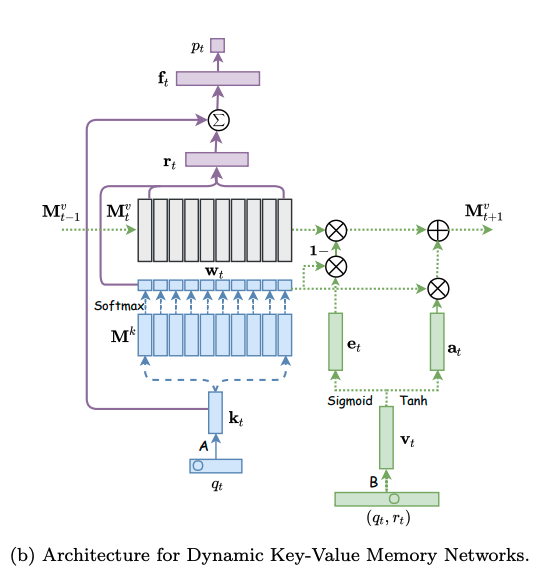
メモリとは生徒のknowledge stateを保持している行列であり、keyとvalueのペアによって形成される。keyとvalueは両者共にdv次元のベクトルで表現される。keyはコンセプトを表し、valueがそれぞれのコンセプトに対する生徒のknowledge stateを表している。ここで、コンセプトとスキルタグは異なる概念であり、スキルタグを生成される元となった概念のことをコンセプトと呼んでいる。コンセプトは基本的には専門家がタグ付しない限り、観測できない変数だと思われる。すなわち、コンセプトとはsynthetic-5データでいうところのc_t(5種類のコンセプト)に該当し、個々のコンセプトによって生成された50種類のexerciseがエクササイズタグに相当する。ASSISTments15データでいうところの、100種類のスキルタグがエクササイズタグで、それぞれのスキルタグのコンセプトはデータに明示されていない。
# ptの求め方
ptを求める際には、エクササイズqt(qtのサイズはエクササイズタグ次元Q; エクササイズタグが何を指すかは分かりづらく、基本的にはスキルタグのことだが、synthetic-5のように50種類のquestion_idをそのまま利用することも可)のembedding kt(dk次元)を求め、ktをメモリのkey M^k(N x dk次元)とのmatmulをとることによって、各コンセプトとのcorrelation weight w を求める。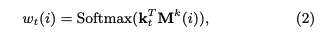
correlation weight wは、メモリのvalue(knowledge state)からknowledge stateのread contentベクトルrを生成する際に用いられる。read contentベクトルは、エクササイズqtに関する生徒のmastery levelのサマリとみなすことができる。
read contentベクトルrは、各キーのcorrelation weight w(scalar)とメモリのvalueベクトル(dv次元)との積をメモリサイズ(コンセプト数)Nでsummationすることによって求められる。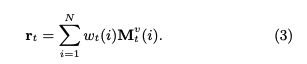
read contentベクトルを求めたのち、生徒のqtに対するmastery levelと取り組む問題qtの難易度を集約したサマリベクトルftをfully connected layerによって求める。求める際には、rとkt(qtのembedding)をconcatし、fully connected layerにかける。
最終的にサマリベクトルftを異なるfully connected layerにかけることによって、エクササイズqtに対するレスポンスを予測する。
# メモリの更新方法
エクササイズqtとそれに対する正誤rtが与えられたとき(qt, rt)、この情報のembedding vtを求める。求める際は、2Q x dv次元のembedding matrixをlookupする。このvtは、生徒がエクササイズに回答したことによってどれだけのknowledge growthを得たかを表している。
その後LSTMのforget gateに着想を得て、メモリのvalueをupdateする際に、最初にeraseベクトルを求めてvalueのうち忘却した情報を削除し、その後add vectorを利用してknowledge growthをvalueに反映させる。
eraseベクトルは、knowledge growth vtと(dv x dv)次元のtransformation matrix Eを利用して変換することによって求める。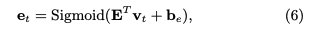
そして、メモリのvalueはこのeraseベクトルを用いて次の式で更新される。基本的には求めたeraseベクトルの分だけ全てのコンセプトのvalueがshrinkするように計算されているが、各コンセプトごとにshrinkさせる度合いをcorrelation weight wによって制御することによってvalueに対して忘却の概念を取り入れている。correlation weightとeraseベクトルのelementのうち、両方とも1となるelementに対応するvalueのelementが、0にリセットされるような挙動となる。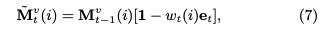
その後、knowledge growth vt から、新たなtransformation matrix D(dv x dv)を用いて、adding vector aが計算される。
最終的に、メモリの各valueは、adding vectorに対してcorrelation weightの重み分だけ各elementの値が更新される。
このような erase-followed-by-addな構造により、生徒の忘却と学習のlearning processを再現している。
# 予測性能
DKVMNが全てのデータセットにおいて性能が良かった。が、これは後のさまざまな研究の追試によりDKTとDKVMNの性能はcomparableであることが検証されているため、あまりこの結果は信用できない。
# learning curve
DKTとDKVMNの両者についてlearning curveを描いた結果が下記。DKTはtrainingとvalidationのlossの差が非常に大きくoverfittingしていることがわかるが、DKVMNはそのような挙動はなく、overfittingしにくいことを言及している。
# Concept Discovery
Figure4がsynthetic-5に対するConcept Discovery, Figure5がASSISTments15に対するConcept Discoveryの結果。synthetic-5は5種類のコンセプトによって50種類のエクササイズが生成されているが、メモリサイズNを5にすることによって完璧な各エクササイズのクラスタリングが実施できた(驚くべきことに、N=50でも5つのクラスタにきっちり分けることができた)。ASSISTments15データについても、類似したコンセプトのスキルタグが同じクラスタに属し、近い距離にマッピングされているため、コンセプトを見つけられたと主張している。
# Knowledge State Depiction
Synthetic-5に対する、各コンセプトのmasteryを可視化した結果が下図。
ここで注意すべきは、DKVMNが可視化するのは、メモリサイズNで指定した個々のkeyに該当するコンセプトのmasteryを可視化する方法を説明している点である。個々のスキルタグ(エクササイズタグ)に対するmasteryを可視化するわけではない点に注意。個々のスキルタグに対するmasteryは、DKTと同様にptがそれに該当するものと思われる。
個々のコンセプトのmasteryを可視化する手順は下記の通り。
まず、read content vector rを求める際に、masteryを可視化したいコンセプトのCorrelation weightのみを1とし、他のコンセプトのCorrelation weightを0とすることでrを算出する。
その後、次の式によって、エクササイズの難易度情報をマスクすること(weight matrixのうち、エクササイズembeddingが乗算される部分のみ0にマスクする)によってサマリベクトルftを求め、ftからfully connected layerを通じてptを求めることで、そのptを該当するコンセプトのmastery levelとみなす。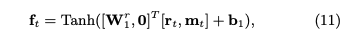
# 所感
スキルタグの背後にある隠れたコンセプトを見つけ、その隠れたコンセプトに対する習熟度を測るという点においてはDKTよりもDKVMNの方が優れていそう。
だが、スキルタグに対する習熟度を測るという点については、DKT, DKVMNのAUCにほとんど差がないことを鑑みるにDKVMNをわざわざ使う意味がどれだけあるのかな、という気がした。
特に Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
で報告されているように、DKVMNでリアルタイムに全てのスキルタグに対する習熟度をトラッキングするためには、DKVMNのoutputをoutput-per-skillにする必要があるが、DKVMNにおいてoutput-per-skillベクトルをoutputに採用すると予測性能が低下することがわかっている。このため、わざわざスキルタグに対する習熟度を求める際にDKVMNを使う必要もないのでは、という気がしている。
そうすると、現状スキルタグに対する習熟度をいい感じに求める手法は、DKT, DKT+ or EKTということになるのだろうか・・・。
追記:DKVMNのDKTと比較して良い点は、メモリネットワーク上にknowledge stateが保存されていて、inputはある一回の問題に対するtrialの正誤のみという点。DKTなどでは入力する系列の長さの上限が決まってしまうが、原理上はDKVMNは扱える系列の長さに制限がないことになる。この性質は非常に有用。
[Paper Note] Joint Optimization of User-desired Content in Multi-document Summaries by Learning from User Feedback, P.V.S+, ACL'17, 2017.08
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #IntegerLinearProgramming (ILP) #Personalization #ACL #interactive Issue Date: 2017-12-28 GPT Summary- ユーザーフィードバックを活用した抽出的マルチドキュメント要約システムを提案。インタラクティブにフィードバックを取得し、ILPフレームワークを用いて要約の質を向上。最小限の反復で高品質な要約を生成し、シミュレーション実験で効果を分析。 Comment
# 一言で言うと
ユーザとインタラクションしながら重要なコンセプトを決め、そのコンセプトが含まれるようにILPな手法で要約を生成するPDS手法。Interactive Personalized Summarizationと似ている(似ているが引用していない、引用した方がよいのでは)。
# 手法
要約モデルは既存のMDS手法を採用。Concept-based ILP Summarization
フィードバックをユーザからもらう際は、要約を生成し、それをユーザに提示。提示した要約から重要なコンセプトをユーザに選択してもらう形式(ユーザが重要と判断したコンセプトには定数重みが与えられる)。
ユーザに対して、τ回フィードバックをもらうまでは、フィードバックをもらっていないコンセプトの重要度が高くなるようにし、フィードバックをもらったコンセプトの重要度が低くなるように目的関数を調整する。これにより、まだフィードバックを受けていないコンセプトが多く含まれる要約が生成されるため、これをユーザに提示することでユーザのフィードバックを得る。τ回を超えたら、ユーザのフィードバックから決まったweightが最大となるように目的関数を修正する。
ユーザからコンセプトのフィードバックを受ける際は、効率的にフィードバックを受けられると良い(最小のインタラクションで)。そこで、Active Learningを導入する。コンセプトの重要度の不確実性をSVMで判定し、不確実性が高いコンセプトを優先的に含むように目的関数を修正する手法(AL)、SVMで重要度が高いと推定されたコンセプトを優先的に要約に含むように目的関数を修正する手法(AL+)を提案している。
# 評価
oracle-based approachというものを使っている。要は、要約をシステムが提示しリファレンスと被っているコンセプトはユーザから重要だとフィードバックがあったコンセプトだとみなすというもの。
評価結果を見ると、ベースラインのMDSと比べてupper bound近くまでROUGEスコアが上がっている。フィードバックをもらうためのイテレーションは最大で10回に絞っている模様(これ以上ユーザとインタラクションするのは非現実的)。
実際にユーザがシステムを使用する場合のコンテキストに沿った評価になっていないと思う。
この評価で示せているのは、ReferenceSummary中に含まれる単語にバイアスをかけて要約を生成していくと、ReferenceSummaryと同様な要約が最終的に作れます、ということと、このときPool-basedなActiveLearningを使うと、より少ないインタラクションでこれが実現できますということ。
これを示すのは別に良いと思うのだが、feedbackをReferenceSummaryから与えるのは少し現実から離れすぎている気が。たとえばユーザが新しいことを学ぶときは、ある時は一つのことを深堀し、そこからさらに浅いところに戻って別のところを深堀するみたいなプロセスをする気がするが、この深堀フェーズなどはReferenceSummaryからのフィードバックからでは再現できないのでは。
# 所感
評価が甘いと感じる。十分なサイズのサンプルを得るのは厳しいからorable-based approachとりましたと書いてあるが、なんらかの人手評価もあったほうが良いと思う。
ユーザに数百単語ものフィードバックをもらうというのはあまり現時的ではない気が。
oracle-based approachでユーザのフィードバックをシミュレーションしているが、oracleの要約は、人がそのドキュメントクラスタの内容を完璧に理解した上で要約しているものなので、これを評価に使うのも実際のコンテキストと違うと思う。実際にユーザがシステムを使うときは、ドキュメントクラスタの内容なんてなんも知らないわけで、そのユーザからもらえるフィードバックをoracle-based approachでシミュレーションするのは無理がある。仮に、ドキュメントクラスタの内容を完璧に理解しているユーザのフィードバックをシミュレーションするというのなら、わかる。が、そういうユーザのために要約作って提示したいわけではないはず。
Hunyuan-MT-7B, Tencent, 2025.09
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #LanguageModel #OpenWeight #Catastrophic Forgetting #mid-training #Selected Papers/Blogs #Surface-level Notes Issue Date: 2025-09-01 Comment
テクニカルレポート: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
元ポスト:
Base Modelに対してまず一般的な事前学習を実施し、その後MTに特化した継続事前学習(モノリンガル/パラレルコーパスの利用)、事後学習(SFT, GRPO)を実施している模様。
継続事前学習では、最適なDataMixの比率を見つけるために、RegMixと呼ばれる手法を利用。Catastrophic Forgettingを防ぐために、事前学習データの20%を含めるといった施策を実施。
SFTでは2つのステージで構成されている。ステージ1は基礎的な翻訳力の強化と翻訳に関する指示追従能力の向上のために、Flores-200の開発データ(33言語の双方向の翻訳をカバー)、前年度のWMTのテストセット(English to XXをカバー)、Mandarin to Minority, Minority to Mandarinのcuratedな人手でのアノテーションデータ、DeepSeek-V3-0324での合成パラレルコーパス、general purpose/MT orientedな指示チューニングデータセットのうち20%を構成するデータで翻訳のinstructinoに関するモデルの凡化性能を高めるためキュレーションされたデータ、で学習している模様。パラレルコーパスはReference-freeな手法を用いてスコアを算出し閾値以下の低品質な翻訳対は除外している。ステージ2では、詳細が書かれていないが、少量でよりfidelityの高い約270kの翻訳対を利用した模様。また、先行研究に基づいて、many-shotのin-context learningを用いて、訓練データをさらに洗練させたとのこと(先行研究が引用されているのみで詳細な記述は無し)。また、複数の評価ラウンドでスコアの一貫性が無いサンプルは手動でアノテーション、あるいはverificationをして品質を担保している模様。
RLではGRPOを採用し、rewardとしてsemantic([Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
), terminology([Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
; ドメイン特有のterminologyを捉える), repetitionに基づいたrewardを採用している。最終的にSFT->RLで学習されたHuayuan-MT-7Bに対して、下記プロンプトを用いて複数のoutputを統合してより高品質な翻訳を出力するキメラモデルを同様のrewardを用いて学習する、といったpipelineになっている。
関連:
- Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23
- [Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
- [Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
- [Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22
- [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
- [Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
関連: PLaMo翻訳
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25
こちらはSFT->Iterative DPO->Model Mergeを実施し、翻訳に特化した継続事前学習はやっていないように見える。一方、SFT時点で独自のテンプレートを作成し、語彙の指定やスタイル、日本語特有の常体、敬体の指定などを実施できるように翻訳に特化したテンプレートを学習している点が異なるように見える。Hunyuanは多様な翻訳の指示に対応できるように学習しているが、PLaMo翻訳はユースケースを絞り込み、ユースケースに対する性能を高めるような特化型のアプローチをとるといった思想の違いが伺える。