
In-Depth Notes
[Paper Note] Hunyuan-MT Technical Report, Mao Zheng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#MachineTranslation #NLP #LanguageModel #OpenWeight #Catastrophic Forgetting #mid-training #Selected Papers/Blogs #Surface-level Notes Issue Date: 2025-09-01 GPT Summary- Hunyuan-MT-7Bは、33の主要言語間の双方向翻訳をサポートする初のオープンソースモデルであり、特に標準中国語と少数言語間の翻訳に焦点を当てています。スロースローチンキングに触発されたHunyuan-MT-Chimera-7Bを導入し、複数の出力を統合することで性能を向上させています。モデルは包括的なトレーニングプロセスを経ており、強化学習を用いた高度な整合性を実現。実験では、両モデルが同等のパラメータサイズの他の翻訳モデルを上回り、WMT2025共有タスクで30の言語ペアで1位を獲得しました。これにより、モデルの堅牢性が強調されています。 Comment
テクニカルレポート: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
元ポスト:
Base Modelに対してまず一般的な事前学習を実施し、その後MTに特化した継続事前学習(モノリンガル/パラレルコーパスの利用)、事後学習(SFT, GRPO)を実施している模様。
継続事前学習では、最適なDataMixの比率を見つけるために、RegMixと呼ばれる手法を利用。Catastrophic Forgettingを防ぐために、事前学習データの20%を含めるといった施策を実施。
SFTでは2つのステージで構成されている。ステージ1は基礎的な翻訳力の強化と翻訳に関する指示追従能力の向上のために、Flores-200の開発データ(33言語の双方向の翻訳をカバー)、前年度のWMTのテストセット(English to XXをカバー)、Mandarin to Minority, Minority to Mandarinのcuratedな人手でのアノテーションデータ、DeepSeek-V3-0324での合成パラレルコーパス、general purpose/MT orientedな指示チューニングデータセットのうち20%を構成するデータで翻訳のinstructinoに関するモデルの凡化性能を高めるためキュレーションされたデータ、で学習している模様。パラレルコーパスはReference-freeな手法を用いてスコアを算出し閾値以下の低品質な翻訳対は除外している。ステージ2では、詳細が書かれていないが、少量でよりfidelityの高い約270kの翻訳対を利用した模様。また、先行研究に基づいて、many-shotのin-context learningを用いて、訓練データをさらに洗練させたとのこと(先行研究が引用されているのみで詳細な記述は無し)。また、複数の評価ラウンドでスコアの一貫性が無いサンプルは手動でアノテーション、あるいはverificationをして品質を担保している模様。
RLではGRPOを採用し、rewardとしてsemantic([Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
), terminology([Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
; ドメイン特有のterminologyを捉える), repetitionに基づいたrewardを採用している。最終的にSFT->RLで学習されたHuayuan-MT-7Bに対して、下記プロンプトを用いて複数のoutputを統合してより高品質な翻訳を出力するキメラモデルを同様のrewardを用いて学習する、といったpipelineになっている。
関連:
- [Paper Note] Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23, 2023.06
- [Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
- [Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
- [Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22, 2022.07
- [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
- [Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
関連: PLaMo翻訳
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
こちらはSFT->Iterative DPO->Model Mergeを実施し、翻訳に特化した継続事前学習はやっていないように見える。一方、SFT時点で独自のテンプレートを作成し、語彙の指定やスタイル、日本語特有の常体、敬体の指定などを実施できるように翻訳に特化したテンプレートを学習している点が異なるように見える。Hunyuanは多様な翻訳の指示に対応できるように学習しているが、PLaMo翻訳はユースケースを絞り込み、ユースケースに対する性能を高めるような特化型のアプローチをとるといった思想の違いが伺える。
[Paper Note] Non-Determinism of "Deterministic" LLM Settings, Berk Atil+, Eval4NLP'25, 2024.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #ACL #Decoding #Selected Papers/Blogs #Workshop #Non-Determinism #KeyPoint Notes Issue Date: 2025-04-14 GPT Summary- 本研究では、5つの決定論的LLMにおける非決定性を8つのタスクで調査し、最大15%の精度変動と70%のパフォーマンスギャップを観察。全てのタスクで一貫した精度を提供できないことが明らかになり、非決定性が計算リソースの効率的使用に寄与している可能性が示唆された。出力の合意率を示す新たなメトリクスTARr@NとTARa@Nを導入し、研究結果を定量化。コードとデータは公開されている。 Comment
- 論文中で利用されているベンチマーク:
- [Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
- [Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
同じモデルに対して、seedを固定し、temperatureを0に設定し、同じ計算機環境に対して、同じinputを入力したら理論上はLLMの出力はdeterministicになるはずだが、deterministicにならず、ベンチマーク上の性能とそもそものraw response自体も試行ごとに大きく変化する、という話。
ただし、これはプロプライエタリLLMや、何らかのinferenceの高速化を実施したInferenceEngine(本研究ではTogetherと呼ばれる実装を使っていそう。vLLM/SGLangだとどうなるのかが気になる)を用いてinferenceを実施した場合での実験結果であり、後述の通り計算の高速化のためのさまざまな実装無しで、deterministicな設定でOpenLLMでinferenceすると出力はdeterministicになる、という点には注意。
GPTやLlama、Mixtralに対して上記ベンチマークを用いてzero-shot/few-shotの設定で実験している。Reasoningモデルは実験に含まれていない。
LLMのraw_response/multiple choiceのparse結果(i.e., 問題に対する解答部分を抽出した結果)の一致(TARr@N, TARa@N; Nはinferenceの試行回数)も理論上は100%になるはずなのに、ならないことが報告されている。
correlation analysisによって、応答の長さ と TAR{r, a}が強い負の相関を示しており、応答が長くなればなるほど不安定さは増すことが分析されている。このため、ontput tokenの最大値を制限することで出力の安定性が増すことを考察している。また、few-shotにおいて高いAcc.の場合は出力がdeterministicになるわけではないが、性能が安定する傾向とのこと。また、OpenAIプラットフォーム上でGPTのfinetuningを実施し実験したが、安定性に寄与はしたが、こちらもdeterministicになるわけではないとのこと。
deterministicにならない原因として、まずmulti gpu環境について検討しているが、multi-gpu環境ではある程度のランダム性が生じることがNvidiaの研究によって報告されているが、これはseedを固定すれば決定論的にできるため問題にならないとのこと。
続いて、inferenceを高速化するための実装上の工夫(e.g., Chunk Prefilling, Prefix Caching, Continuous Batching)などの実装がdeterministicなハイパーパラメータでもdeterministicにならない原因であると考察しており、**実際にlocalマシン上でこれらinferenceを高速化するための最適化を何も実施しない状態でLlama-8Bでinferenceを実施したところ、outputはdeterministicになったとのこと。**
論文中に記載がなかったため、どのようなInferenceEngineを利用したか公開されているgithubを見ると下記が利用されていた:
- Together:
https://github.com/togethercomputer/together-python?tab=readme-ov-file
Togetherが内部的にどのような処理をしているかまでは追えていないのだが、異なるInferenceEngineを利用した場合に、どの程度outputの不安定さに差が出るのか(あるいは出ないのか)は気になる。たとえば、transformers/vLLM/SGLangを利用した場合などである。
論文中でも報告されている通り、昔管理人がtransformersを用いて、deterministicな設定でzephyrを用いてinferenceをしたときは、出力はdeterministicになっていたと記憶している(スループットは絶望的だったが...)。
あと個人的には現実的な速度でオフラインでinference engineを利用した時にdeterministicにはせめてなって欲しいなあという気はするので、何が原因なのかを実装レベルで突き詰めてくれるととても嬉しい(KV Cacheが怪しい気がするけど)。
たとえば最近SLMだったらKVCacheしてVRAM食うより計算し直した方が効率良いよ、みたいな研究があったような。そういうことをしたらlocal llmでdeterministicにならないのだろうか。
- Defeating Nondeterminism in LLM Inference, Horace He in collaboration with others at Thinking Machines, 2025.09
においてvLLMを用いた場合にDeterministicな推論をするための解決方法が提案されている。
[Paper Note] A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility, Andreas Hochlehnert+, COLM'25
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #SmallModel #COLM #PostTraining #Selected Papers/Blogs #KeyPoint Notes #Initial Impression Notes Issue Date: 2025-04-13 GPT Summary- 推論は言語モデルの重要な課題であり、進展が見られるが、評価手法には透明性や堅牢性が欠けている。本研究では、数学的推論ベンチマークが実装の選択に敏感であることを発見し、標準化された評価フレームワークを提案。再評価の結果、強化学習アプローチは改善が少なく、教師ありファインチューニング手法は強い一般化を示した。再現性を高めるために、関連するコードやデータを公開し、今後の研究の基盤を築く。 Comment
元ポスト:
SLMをmath reasoning向けにpost-trainingする場合、評価の条件をフェアにするための様々な工夫を施し評価をしなおした結果(Figure1のように性能が変化する様々な要因が存在する)、
RL(既存研究で試されているもの)よりも(大規模モデルからrejection samplingしたreasoning traceを用いて)SFTをする方が同等か性能が良く(Table3)、
結局のところ(おそらく汎化性能が低いという意味で)reliableではなく、
かつ(おそらく小規模なモデルでうまくいかないという意味での)scalableではないので、reliableかつscalableなRL手法が不足しているとのこと。
※ 本論文で分析されているのは<=10B以下のSLMである点に注意。10B以上のモデルで同じことが言えるかは自明ではない。
※ DAPO, VAPOなどについても同じことが言えるかも自明ではない。
※ DeepSeek-R1のtechnical reportにおいて、小さいモデルにGRPOを適用してもあまり効果が無かったことが既に報告されている。
- DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01
- DeepSeek-R1, DeepSeek, 2025.01
個々のpost-trainingされたRLモデルが具体的にどういう訓練をしたのかは追えていないが、DAPOやDr. GRPO, VAPOの場合はどうなるんだろうか?
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
- [Paper Note] VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, Yu Yue+, arXiv'25, 2025.04
- [Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Rewardの設定の仕方はどのような影響があるのだろうか(verifiable rewardなのか、neuralモデルによるrewardなのかなど)?
学習のさせ方もどのような影響があるのだろうか(RLでカリキュラムlearningにした場合など)?
検証しているモデルがそれぞれどのような設定で学習されているかまでを見ないとこの辺はわからなそう。
ただなんとなーくの直感だと、SLMを賢くしたいという場合は何らかの賢いモデルの恩恵に預かると有利なケースが多く(SFTの場合はそれが大規模なモデルから蒸留したreasoning trace)、SLM+RLの場合はPRMのような思考プロセスを評価してRewardに反映させるようなものを利用しないと、少なくとも小規模なLLMをめちゃ賢くします〜というのはきついんじゃないかなあという感想ではある。
ただ、結局SLMという時点で多くの場合、より賢いパラメータ数の多いLLMが世の中には存在するあるはずなので、RLしないでSFTして蒸留すれば良いんじゃない…?と思ってしまう。
が、多くの場合その賢いLLMはProprietaryなLLMであり、出力を得て自分のモデルをpost-trainingすることは利用規約違反となるため、自前で賢くてパラメータ数の多いLLMを用意できない場合は困ってしまうので、SLMをクソデカパラメータのモデルの恩恵なしで超絶賢くできたら世の中の多くの人は嬉しいよね、とも思う。
(斜め読みだが)
サンプル数が少ない(数十件)AIMEやAMCなどのデータはseedの値にとてもsensitiveであり(Takeaway1, 2)、
それらは10種類のseedを用いて結果を平均すると分散が非常に小さくなるので、seedは複数種類利用して平均の性能を見た方がreliableであり(Takeaway3)
temperatureを高くするとピーク性能が上がるが分散も上がるため再現性の課題が増大するが、top-pを大きくすると再現性の問題は現れず性能向上に寄与し
既存研究のモデルのtemperatureとtop-pを変化させ実験するとperformanceに非常に大きな変化が出るため、モデルごとに最適な値を選定して比較をしないとunfairであることを指摘 (Takeaway4)。
また、ハードウェアの面では、vLLMのようなinference engineはGPU typeやmemoryのconfigurationに対してsensitiveでパフォーマンスが変わるだけでなく、
評価に利用するフレームワークごとにinference engineとprompt templateが異なるためこちらもパフォーマンスに影響が出るし (Takeaway5)、
max output tokenの値を変化させると性能も変わり、prompt templateを利用しないと性能が劇的に低下する (Takeaway6)。
これらのことから著者らはreliableな評価のために下記を提案しており (4.1節; 後ほど追記)、
実際にさまざまな条件をfair comparisonとなるように標準化して評価したところ(4.2節; 後ほど追記)
上の表のような結果となった。この結果は、
- DeepSeekR1-DistilledをRLしてもSFTと比較したときに意味のあるほどのパフォーマンスの向上はないことから、スケーラブル、かつ信頼性のあるRL手法がまだ不足しており
- 大規模なパラメータのモデルのreasoning traceからSFTをする方法はさまざまなベンチマークでロバストな性能(=高い汎化性能)を持ち、RLと比べると現状はRLと比較してよりパラダイムとして成熟しており
- (AIME24,25を比較するとSFTと比べてRLの場合performanceの低下が著しいので)RLはoverfittingしやすく、OODなベンチマークが必要
しっかりと評価の枠組みを標準化してfair comparisonしていかないと、RecSys業界の二の舞になりそう(というかもうなってる?)。
またこの研究で分析されているのは小規模なモデル(<=10B)に対する既存研究で用いられた一部のRL手法や設定の性能だけ(真に示したかったらPhisics of LLMのような完全にコントロール可能なサンドボックスで実験する必要があると思われる)なので、DeepSeek-R1のように、大規模なパラメータ(数百B)を持つモデルに対するRLに関して同じことが言えるかは自明ではない点に注意。
openreview: https://openreview.net/forum?id=90UrTTxp5O#discussion
最近の以下のようなSFTはRLの一つのケースと見做せるという議論を踏まえるとどうなるだろうか
- [Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, ICLR'26, 2025.08
- [Paper Note] Towards a Unified View of Large Language Model Post-Training, Xingtai Lv+, arXiv'25
[Paper Note] Differential Transformer, Tianzhu Ye+, N_A, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture #ICLR #Selected Papers/Blogs Issue Date: 2024-10-21 GPT Summary- Diff Transformerは、関連するコンテキストへの注意を強化し、ノイズをキャンセルする新しいアーキテクチャです。差分注意メカニズムを用いて、注意スコアを計算し、スパースな注意パターンを促進します。実験結果は、Diff Transformerが従来のTransformerを上回り、長いコンテキストモデリングや幻覚の軽減において顕著な利点を示しています。また、文脈内学習においても精度を向上させ、堅牢性を高めることが確認されました。これにより、Diff Transformerは大規模言語モデルの進展に寄与する有望なアーキテクチャとされています。 Comment
# 概要
attention scoreのノイズを低減するようなアーキテクチャとして、二つのQKVを用意し、両者の差分を取ることで最終的なattentiok scoreを計算するDifferential Attentionを提案した。
attentionのnoiseの例。answerと比較してirrelevantなcontextにattention scoreが高いスコアが割り当てられてしまう(図左)。differential transformerが提案するdifferential attentionでは、ノイズを提言し、重要なcontextのattention scoreが高くなるようになる(図中央)、らしい。
# Differential Attentionの概要
二つのQKをどの程度の強さで交互作用させるかをλで制御し、λもそれぞれのQKから導出する。数式は2.1節に記述されているのでそちらも参照のこと。
QA, 機械翻訳, 文書分類, テキスト生成などの様々なNLPタスクが含まれるEval Harnessベンチマークでは、同規模のtransformerモデルを大幅にoutperform。ただし、3Bでしか実験していないようなので、より大きなモデルサイズになったときにgainがあるかは示されていない点には注意。
モデルサイズ(パラメータ数)と、学習トークン数のスケーラビリティについても調査した結果、LLaMAと比較して、より少ないパラメータ数/学習トークン数で同等のlossを達成。
64Kにcontext sgzeを拡張し、1.5B tokenで3Bモデルを追加学習をしたところ、これもtransformerと比べてより小さいlossを達成
context中に埋め込まれた重要な情報(今回はクエリに対応するmagic number)を抽出するタスク(Needle-In-A-Haystack test)の性能も向上。Needle(N)と呼ばれる正解のmagic numberが含まれる文をcontext中の様々な深さに配置し、同時にdistractorとなる文もランダムに配置する。これに対してクエリ(R)が入力されたときに、どれだけ正しい情報をcontextから抽出できるか、という話だと思われる。
これも性能が向上。特にクエリとNeedleが複数の要素で構成されていれ場合の性能が高く(Table2)、長いコンテキスト中の様々な位置に埋め込まれたNeedleを抽出する性能も高い(Figure5)
Many shotのICL能力も、異なる数のクラス分類を実施する4つのDatasetにおいて向上。クラス数が増えるに従ってAcc.のgainは小さくなっているように見える({6, 50} class > 70 class > 150 class)が、それでもAcc.が大きく向上している。
要約タスクでのhallucinationも低減。生成された要約と正解要約を入力し、GPT-4oにhallucinationの有無を判定させて評価(このようなLLM-as-a-Judgeの枠組みは先行研究 (MT-Bench) で人手での評価と高いagreementがあることが示されている)
関連 (MT-Bench):
- [Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
シンプルなアプローチでLLM全体の性能を底上げしている素晴らしい成果に見える。斜め読みなので読み飛ばしているかもしれないが、
- [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
のように高品質な学習データで学習した場合も同様の効果が発現するのだろうか?
attentionのスコアがnoisyということは、学習データを洗練させることでも改善される可能性があり、[Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
はこれをデータで改善し、こちらの研究はモデルのアーキテクチャで改善した、みたいな捉え方もできるのかもしれない。
ちなみにFlash Attentionとしての実装方法も提案されており、スループットは通常のattentionと比べてむしろ向上している (Appendix A参照のこと) ので実用的な手法でもある。すごい。
あとこれ、事前学習とInstruction Tuningを通常のマルチヘッドアテンションで学習されたモデルに対して、独自データでSFTするときに導入したらdownstream taskの性能向上するんだろうか。もしそうなら素晴らしい
OpenReview: https://openreview.net/forum?id=OvoCm1gGhN
GroupNormalizationについてはこちら:
- [Paper Note] Group Normalization, Yuxin Wu+, arXiv'18, 2018.03
[Paper Note] Number Cookbook: Number Understanding of Language Models and How to Improve It, Haotong Yang+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #NumericReasoning #ICLR #numeric #Reading Reflections Issue Date: 2024-11-09 GPT Summary- 大規模言語モデル(LLM)の数値理解・処理能力(NUPA)を調査し、41の数値タスクを含むベンチマークを導入。これにより、LLMsが多くのタスクで頻繁に失敗することが判明。NUPA向上のため、小型モデルを訓練し、ファインチューニングの効果を評価。1) ファインチューニングが多くのタスクでNUPAを向上させるが、全てに効果的ではない。2) NUPA向上を目的とした手法がファインチューニングに効果的でないことが分かった。研究はLLMsのNUPA理解を深める。 Comment
んー、abstしか読んでいないけれども、9.11 > 9.9 については、このような数字に慣れ親しんでいるエンジニアなどに咄嗟に質問したら、ミスして答えちゃう人もいるのでは?という気がする(エンジニアは脳内で9.11 > 9.9を示すバージョン管理に触れる機会が多く、こちらの尤度が高い)。
LLMがこのようなミス(てかそもそもミスではなく、回答するためのcontextが足りてないので正解が定義できないだけ、だと思うが、、)をするのは、単に学習データにそういった9.11 > 9.9として扱うような文脈や構造のテキストが多く存在しており、これらテキスト列の尤度が高くなってこのような現象が起きているだけなのでは、という気がしている。
instructionで注意を促したり適切に問題を定義しなければ、そりゃこういう結果になって当然じゃない?という気がしている。
(ここまで「気がしている」を3連発してしまった…😅)
また、本研究で扱っているタスクのexampleは下記のようなものだが、これらをLLMに、なんのツールも利用させずautoregressiveな生成のみで解かせるというのは、人間でいうところの暗算に相当するのでは?と個人的には思う。
何が言いたいのかというと、人間でも暗算でこれをやらせたら解けない人がかなりいると思う(というか私自身単純な加算でも桁数増えたら暗算など無理)。
一方で暗算ではできないけど、電卓やメモ書き、計算機を使っていいですよ、ということにしたら多くの人がこれらタスクは解けるようになると思うので、LLMでも同様のことが起きると思う。
LLMの数値演算能力は人間の暗算のように限界があることを認知し、金融分野などの正確な演算や数値の取り扱うようなタスクをさせたかったら、適切なツールを使わせましょうね、という話なのかなあと思う。
元ポスト:
ICLR25のOpenReview。こちらを読むと興味深い。
https://openreview.net/forum?id=BWS5gVjgeY
幅広い数値演算のタスクを評価できるデータセット構築、トークナイザーとの関連性を明らかにした点、分析だけではなくLLMの数値演算能力を改善した点は評価されているように見える。
一方で、全体的に、先行研究との比較やdiscussionが不足しており、研究で得られた知見がどの程度新規性があるのか?といった点や、説明が不十分でjustificationが足りない、といった話が目立つように見える。
特に、そもそもLoRAやCoTの元論文や、Numerical Reasoningにフォーカスした先行研究がほぼ引用されていないらしい点が見受けられるようである。さすがにその辺は引用して研究のcontributionをクリアにした方がいいよね、と思うなどした。
>I am unconvinced that numeracy in LLMs is a problem in need of a solution. First, surely there is a citable source for LLM inadequacy for numeracy. Second, even if they were terrible at numeracy, the onus is on the authors to convince the reader that this a problem worth caring about, for at least two obvious reasons: 1) all of these tasks are already trivially done by a calculator or a python program, and 2) commercially available LLMs can probably do alright at numerical tasks indirectly via code-generation and execution. As it stands, it reads as if the authors are insisting that this is a problem deserving of attention --- I'm sure it could be, but this argument can be better made.
上記レビュワーコメントと私も同じことを感じる。なぜLLMそのものに数値演算の能力がないことが問題なのか?という説明があった方が良いのではないかと思う。
これは私の中では、論文のイントロで言及されているようなシンプルなタスクではなく、
- inputするcontextに大量の数値を入力しなければならず、
- かつcontext中の数値を厳密に解釈しなければならず、
- かつ情報を解釈するために計算すべき数式がcontextで与えられた数値によって変化するようなタスク(たとえばテキスト生成で言及すべき内容がgivenな数値情報によって変わるようなもの。最大値に言及するのか、平均値を言及するのか、数値と紐づけられた特定のエンティティに言及しなければならないのか、など)
(e.g. 上記を満たすタスクはたとえば、金融関係のdata-to-textなど)では、LLMが数値を解釈できないと困ると思う。そういった説明が入った方が良いと思うなあ、感。
[Paper Note] ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks, Fabrizio Gilardi+, NAS'23, 2023.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Annotation Issue Date: 2023-04-12 GPT Summary- ChatGPTは、2,382件のツイートを用いたアノテーションタスクにおいて、クラウドワーカーを上回る性能を示し、特に4つのタスクでゼロショット精度が優れています。また、インターコーダー合意でも全てのタスクでクラウドワーカーや訓練を受けたアノテーターを超え、コストもMTurkの約20倍安価です。これにより、大規模言語モデルがテキスト分類の効率を大幅に向上させる可能性が示唆されます。 Comment
# 概要
2300件程度のツイートを分類するタスクにおいて、訓練した学部生によるアノテーションを正解とし、クラウドワーカーとChatGPTでのzero-shotでの予測の性能を比較した。分類タスクは、比較的難易度の高い分類問題であり、クラウドワーカーでも正解率は難しいタスクでは15--25%程度であった。このようなタスクでchatgptは40--60%の正解率を示している。
比較の結果、5つのタスク中4つのタスクでChatGPTがクラウドワーカーを上回る正解率を示した。
# 手法
- クラウドワーカーとChatGPTで同じインストラクションを利用し、同じタスクを実施した
- inter-notator aggreementを図るために、それぞれのタスクについて各ツイートに少なくとも2人がラベル付を行った
- ChatGPTでも同様に、タスクごとに各ツイートには2回同じタスクを実施しデータを収集した
- ChatGPTを利用する際は、temperatureを1.0, 0.2の場合で試した。従ってChatGPTのラベル付けは各タスクごとに4セット存在することになる。
# 結果
5タスク中、4タスクでChatGPTがzero-shotにもかかわらず正解率でworkerを上回った。また高いaggreementを発揮していることを主張。aggreementはtemperatureが低い方が高く、これはtemperatureが低い方がrandomnessが減少するためであると考えられる。aggreementをAccuracyの相関を図ったが、0.17であり弱い相関しかなかった。従って、Accuracyを減少させることなく、一貫性のある結果を得られるlaw temperatureを利用することが望ましいと結論づけている。
# 実施したタスク
"content moderation"に関するタスクを実施した。content moderationはSNSなどに投稿されるpostを監視するための取り組みであり、たとえばポルトツイートや誤った情報を含む有害なツイート、ヘイトスピーチなどが存在しないかをSNS上で監視をを行うようなタスクである。著者らはcontent moderationはハードなタスクであり、複雑なトピックだし、toy exampleではないことを主張している。実際、著者らが訓練した学部生の間でのinter-annotator aggreementは50%程度であり、難易度が高いタスクであることがわかる(ただし、スタンスdetectionに関してはaggreementが78.3%であった)。
content moderationのうち、以下の5つのタスクを実施した。
- relevance:
- ツイートがcontent moderationについて直接的に関係することを述べているか否か
- e.g. SNSにおけるcontent moderation ruleや実践、政府のレギュレーション等
- content moderationについて述べていないものについてはIRRELEVANTラベルを付与する
- ただし、主題がcontent moderationのツイートであっても、content moderationについて論じていないものについてはIRRELEVANT扱いとする。
- このような例としては、TwitterがDonald TrupのTwitterを"disrupted"とlabel付けしたことや、何かについて間違っていると述べているツイート、センシティブな内容を含むツイートなどがあげられる。
- Problem/Solution Frames
- content moderationは2つの見方ができる。それがProblemとSolution
- Problem: content moderationをPROBLEMとみなすもの。たとえば、フリースピーチの制限など
- SOLUTION: content moderationをSOLUTIONとみなすもの。たとえば、harmful speechから守ること、など
- ツイートがcontent moderationのnegativeな影響について強調していたら、PROBLEM(フリースピーチの制限やユーザがポストする内容についてバイアスが生じることなどについて)
- ツイートがcontent moderationのpositiveな影響について強調していたら、SOKUTION(harmful contentからユーザを守るなど)
- 主題はcontent moderationであるが、positive/negativeな影響について論じていないものはNEUTRAL
- Policy Frames
- content moderationはさまざまんトピックと関連している(たとえば)、健康、犯罪、平等など)
- content moderatiojnに関するツイートがどのトピックかをラベル付する。ラベルは15種類
- economy, capcity and resources, modality, fairness and equality, constitutionality and jurisprudence, policy prescription and evaluation, law and order, crime and justice, security and defense, health and safety, quality of life, cultural identity, public opinion, political, external regulation and reputation, other
- Stance Detection
- USのSection 230という法律(websiteにユーザが投稿したコンテンツに対して、webサイトやその他のオンラインプラットフォームが法的責任を問われるのを防ぐ法律)について、ツイートがSection230に対して、positive/negative/neutralなスタンスかをラベル付する
- Topic Detection
- ツイートを6つのトピックにラベル付する
- Section 230, TRUMP BAN, TWITTER-SUPPORT, PLATFORM POLICIES, COMPLAINTS, other
# 所感
そこそこ難易度の高いアノテーションタスクでもzero-shotでturkerの性能を上回るのは非常に素晴らしいことだと思う。ノイジーなデータセットであれば、比較的安価、かつスピーディーに作成できるようになってきたのではないかと思う。
ただ、ChatGPTのaggreementを図ることにどれだけ意味があるのだろう、とは思う。同じモデルを利用しているわけで、小tなるLLMをベースにした場合のaggreementならとる意味があると思うが。
[Paper Note] Self-Instruct: Aligning Language Models with Self-Generated Instructions, Yizhong Wang+, ACL'23, 2022.12
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #ACL Issue Date: 2023-03-30 GPT Summary- Self-Instructフレームワークを提案し、事前学習済みの言語モデルが自ら生成した指示を用いてファインチューニングを行うことで、ゼロショットの一般化能力を向上させる。バニラGPT-3に適用した結果、Super-NaturalInstructionsで33%の性能向上を達成し、InstructGPT-001と同等の性能に到達。人間評価により、Self-Instructが既存の公共指示データセットよりも優れていることを示し、ほぼ注釈不要の指示調整手法を提供。大規模な合成データセットを公開し、今後の研究を促進する。 Comment
Alpacaなどでも利用されているself-instruction技術に関する論文
# 概要
著者らが書いた175種のinstruction(タスクの定義 + 1種のinput/outputペア}のseedを元に、VanillaなGPT-3に新たなinstruction, input, outputのtupleを生成させ、学習データとして活用する研究。
ここで、instruction data I は以下のように定義される:
instruction dataは(I, X, Y)であり、モデルは最終的にM(I_t, x_t) = y_tとなるように学習したい。
I: instruction, X: input, Y: output
データ作成は以下のステップで構成される。なお、以下はすべてVanilla GPT-3を通じて行われる:
1. Instruction Generation
task poolから8種類のinstructionを抽出し、 promptを構成し、最大8個新たなinstructionを生成させる
2. Classification Task Identification:
生成されたinstructionがclassificationタスクか否かを判別する
3. Instance Generation
いくつかの(I, X, Y)をpromptとして与え、I, Xに対応するYを生成するタスクを実行させる。このときinput-first approachを採用した結果(I->Xの順番で情報を与えYを生成するアプローチ)、特定のラベルに偏ったインスタンスが生成される傾向があることがわかった。このためoutput-first approachを別途採用し(I->Yの順番で情報を与え、各Yに対応するXを生成させる)、活用している。
4. Filtering and Postprocessing
最後に、既存のtask poolとROUGE-Lが0.7以上のinstructionは多様性がないため除外し、特定のキーワード(images, pictrues, graphs)等を含んでいるinstruction dataも除外して、task poolに追加する。
1-4をひたすら繰り返すことで、GPT-3がInstruction Tuningのためのデータを自動生成してくれる。
# SELF-INSTRUCT Data
## データセットの統計量
- 52k instructions
- 82k instances
## Diversity
parserでinstructionを解析し、rootの名詞と動詞のペアを抽出して可視化した例。ただし、抽出できた例はたかだか全体の50%程度であり、その中で20の最もcommonなroot vertと4つのnounを可視化した。これはデータセット全体の14%程度しか可視化されていないが、これだけでも非常に多様なinstructionが集まっていることがわかる。
また、seed indstructionとROUGE-Lを測った結果、大半のデータは0.3~0.4程度であり、lexicalなoverlapはあまり大きくないことがわかる。instructionのlengthについても可視化した結果、多様な長さのinstructionが収集できている。
## Quality
200種類のinstructionを抽出し、その中からそれぞれランダムで1つのインスタンスをサンプルした。そしてexpert annotatorに対して、それぞれのinstructionとinstance(input, outputそれぞれについて)が正しいか否かをラベル付けしてもらった。
ラベル付けの結果、ほとんどのinstructionは意味のあるinstructionであることがわかった。一方、生成されたinstanceはnoisyであることがわかった(ただし、このnoiseはある程度妥当な範囲である)。noisytではあるのだが、instanceを見ると、正しいformatであったり、部分的に正しかったりなど、modelを訓練する上で有用なguidanceを提供するものになっていることがわかった。
# Experimental Results
## Zero-shotでのNLPタスクに対する性能
SuperNIデータセットに含まれる119のタスク(1タスクあたり100 instance)に対して、zero-shot setupで評価を行なった。SELF-INSTRUCTによって、VanillaのGPT3から大幅に性能が向上していることがわかる。VanillaのGPT-3はほとんど人間のinstructionに応じて動いてくれないことがわかる。分析によると、GPT3は、大抵の場合、全く関係ない、あるいは繰り返しのテキストを生成していたり、そもそもいつ生成をstopするかがわかっていないことがわかった。
また、SuperNI向けにfinetuningされていないモデル間で比較した結果、非常にアノテーションコストをかけて作られたT0データでfinetuningされたモデルよりも高い性能を獲得した。また、人間がラベル付したprivateなデータによって訓練されたInstructGPT001にも性能が肉薄していることも特筆すべき点である。
SuperNIでfinetuningした場合については、SELF-INSTRUCTを使ったモデルに対して、さらに追加でSuperNIを与えた場合が最も高い性能を示した。
## User-Oriented Instructionsに対する汎化性能
SuperNIに含まれるNLPタスクは研究目的で提案されており分類問題となっている。ので、実践的な能力を証明するために、LLMが役立つドメインをブレスト(email writing, social media, productiveity tools, entertainment, programming等)し、それぞれのドメインに対して、instructionとinput-output instanceを作成した。また、instructionのスタイルにも多様性(e.g. instructionがlong/short、bullet points, table, codes, equationsをinput/outputとして持つ、など)を持たせた。作成した結果、252個のinstructionに対して、1つのinstanceのデータセットが作成された。これらが、モデルにとってunfamiliarなinstructionで多様なistructionが与えられたときに、どれだけモデルがそれらをhandleできるかを測定するテストベッドになると考えている。
これらのデータは、多様だがどれもが専門性を求められるものであり、自動評価指標で性能が測定できるものでもないし、crowdworkerが良し悪しを判定できるものでもない。このため、それぞれのinstructionに対するauthorに対して、モデルのy補足結果が妥当か否かをjudgeしてもらった。judgeは4-scaleでのratingとなっている:
- RATING-A: 応答は妥当で満足できる
- RATING-B: 応答は許容できるが、改善できるminor errorや不完全さがある。
- RATING-C: 応答はrelevantでinstructionに対して答えている。が、内容に大きなエラーがある。
- RATING-D: 応答はirrelevantで妥当ではない。
実験結果をみると、Vanilla GPT3はまったくinstructionに対して答えられていない。instruction-basedなモデルは高いパフォーマンスを発揮しているが、それらを上回る性能をSELF-INSTRUCTは発揮している(noisyであるにもかかわらず)。
また、GPT_SELF-INSTRUCTはInstructGPT001と性能が肉薄している。また、InstructGPT002, 003の素晴らしい性能を示すことにもなった。
# Discussion and Limitation
## なぜSELF-INSTRUCTがうまくいったか?
- LMに対する2つの極端な仮説を挙げている
- LM はpre-trainingでは十分に学習されなかった問題について学習する必要があるため、human feedbackはinstruction-tuningにおいて必要不可欠な側面である
- LM はpre-trainingからinstructionに既に精通しているため、human feedbackはinstruction-tuningにおいて必須ではない。 human feedbackを観察することは、pre-trainingにおける分布/目的を調整するための軽量なプロセスにすぎず、別のプロセスに置き換えることができる。
この2つの極端な仮説の間が実情であると筆者は考えていて、どちらかというと2つ目の仮説に近いだろう、と考えている。既にLMはpre-trainingの段階でinstructionについてある程度理解できているため、self-instructがうまくいったのではないかと推察している。
## Broader Impact
InstructGPTは非常に強力なモデルだけど詳細が公表されておらず、APIの裏側に隠れている。この研究が、instruct-tuned modelの背後で何が起きているかについて、透明性を高める助けになると考えている。産業で開発されたモデルの構造や、その優れた性能の理由についてはほとんど理解されておらず、これらのモデルの成功の源泉を理解し、より優れた、オープンなモデルを作成するのはアカデミックにかかっている。この研究では、多様なinstructional dataの重要性を示していると考えており、大規模な人工的なデータセットは、より優れたinstructionに従うモデルを、構築するための第一歩だと考えている。
## limitation
- Tail Phenomena
- LMの枠組みにとどまっているため、LMと同じ問題(Tail Phenomena)を抱えている
- low-frequencyなcontextに対してはうまくいかない問題
- SELF-INSTRUCTも、結局pre-trainingの段階で頻出するタスクやinstructionに対してgainがあると考えられ、一般的でなく、creativeなinstructionに対して脆弱性があると考えられる
- Dependence on laege models
- でかいモデルを扱えるだけのresourceを持っていないと使えないという問題がある
- Reinforcing LM biases
- アルゴリズムのiterationによって、問題のあるsocial _biasをより増幅してしまうことを懸念している(人種、種族などに対する偏見など)。また、アルゴリズムはバランスの取れたラベルを生成することが難しい。
1のprompt
2のprompt
3のprompt(input-first-approach)
3のprompt(output-first approach)
※ GPT3をfinetuningするのに、Instruction Dataを使った場合$338かかったっぽい。安い・・・。
LLMを使うだけでここまで研究ができる時代がきた
(最近は|現在は)プロプライエタリなLLMの出力を利用して競合するモデルを訓練することは多くの場合禁止されているので注意。
[Paper Note] Using Neural Network-Based Knowledge Tracing for a Learning System with Unreliable Skill Tags, Karumbaiah+, (w_ Ryan Baker), EDM'22
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #KnowledgeTracing #EDM Issue Date: 2022-08-26 Comment
超重要論文。しっかり読むべき
# 一言で言うと
KTを利用することを最初から念頭に置いていなかったシステムでは、問題に対して事後的にスキルをマッピングする作業が生じてしまい、これは非常に困難なことが多い。論文中で使用したアメリカの商用の数学のblended learningのシステムのデータでは、途中で企業が買収された経緯もあり、古いコンテンツと新しいコンテンツの間でスキルタグのマッピングの間で、矛盾や一貫性がないものができあがってしまった(複数の異なるチームがコンテンツの提供やスキルのタグ付けを行なった結果)。このような例はレアケースかもしれないが、問題とスキルタグが異なるチームによって開発されるということは珍しいことではないし、現代のオンライン学習システムの多くは、さまざまな教科書のデータを統合し、長年にわたってコンテンツ作成チームのメンバーを変更し、複数の州の基準や内部コンテンツスキーマに従ってコンテンツにタグをづけをしているので、少なからずこういった問題(i.e. 一貫性がなく、矛盾をかかえたitem-skill mapping)を抱えている。
こうした中で、NNを用いたモデルを用いることで、unreliableなKCモデルを用いるくらいならば、KCモデルを用いない方が正答率予測が高い精度で実施できることを示した。これは少なくとも、生徒の問題に対する将来のパフォーマンスを予測する問題に関して言えば、既存のアプリケーションにおいて、KCモデルを構築するステップを回避できる可能性を示唆している。
# モチベーション
Cognitive Tutorのようなシステムは、もともとKTを利用するために設計されているシステムだったが、多くのreal-worldの学習システムはアダプティブラーニングやKTを念頭に置いて作られたものではない。そういったシステムでアダプティブな機能を追加するといった事例が増えてきている。こういったシステムが、もともとKTを実施することを念頭するために作られたシステムとの違いとして、問題とスキルのマッピング方法にある。
最初から KT を使用するように設計されたシステムは、最初にどのスキルを含めるかを選択し、次にそれらのスキルに合わせたアイテムを開発する。 一方、KTを使用するために改良をする場合、最初にアイテムが作成され、次にアイテムにスキルのラベルが付けられる。
既存のアイテムにスキルのラベルを付けるのは、スキルの新しいアイテムを作成するよりもはるかに困難である。 多くの場合、アイテムは複数の著者によって時間をかけて開発されたものであるか、異なる教科書などの異なる元のソースからのものである。この異種のコンテンツ (場合によっては数万のアイテム) を一連のスキルにマッピングすることは、非常に困難な作業になる可能性がある。
多くの場合、アイテムは政府のカリキュラム基準の観点からタグ付けされているが、これらの基準は一般的に、KTモデルで使用されるスキルよりも非常に粗いものとなっている。
したがって、最初からKTを利用することを念頭に置かれていないシステムでKTを利用することには課題がある。
この論文では、NNベースなKTモデルが、この課題の部分的な解決策になることを示す。
このために、商用の数学のblended learningシステムでのケーススタディを実施した。
中学生が 2 年間システムを使用して収集したデータを使用して、KT モデルの性能を次の3 つのシナリオで比較し:
- 1) システムが提供する (おそらくunreliableな)スキルタグを利用した場合
- 2) 州の基準に基づくタグを利用した場合
- 3) コンテンツとスキルタグのマッピングを一切入力しない場合
DKVMNでの実験の結果、1)が最も悪い性能を示し、3)が最も良い問題の正誤予測の性能を示した。
これは、もともとKT モデルで動作するように設計されていなかった現実世界の学習システムでKCモデリングを回避する可能性を示唆している。特に、目的が将来のアイテムに対する学習者の成績を予測することだけである場合はこれに該当する。
# 実験結果
スキルの情報を用いず、ExerciseIDをそのままinputする方法が、最も高いAUCを獲得している。
# つまり
- きちんと一貫性があり矛盾のないItem-KCマッピングを用いないとモデルがきちんと学習できない
- 特に元々KTを適用することを念頭に置いていないシステムでは困難な作業となる可能性が高い
# KTの歴史
- 30年ほど研究されている(1995年のCorbett and AndersonらのBKTあたりから)
- 最初はBKTが広く採用された
- その後、最近ではlogistic regressionに基づくモデルが提案されるようになってきたが、実際のシステムで利用されることはまだ稀
- Elo や Temporal IRT などのIRTに関連するアルゴリズムも、最近文献でより広く見られるようになり、いくつかの学習システムで大規模に使用されている
- Elo およびTemporal IRT は KCモデルなしで使用できるが、通常、いくつかのスキルごとに個別の Elo モデルが利用される。
- NNベースなモデルは過去5年で活発に研究され、将来のパフォーマンスを予測する性能は飛躍的に向上した
- ただし、予測不可能な動作(reconstruction problemや習熟度のfluctuation)や、mastery learningや生徒にスキルをレポーティングするためにこのタイプのモデルを用いるという課題のために、実際のシステムで運用するよりも、論文を執筆する方が一般的になった。
- これに関するNNモデルの問題の1 つは、特定の問題の正答率を予測するが、それを人間が解釈できるスキルの習熟度にマッピングしないことにある。
Learning Process-consistent Knowledge Tracing, Shen+, SIGKDD'21
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #SIGKDD Issue Date: 2022-05-02 Comment
DKTでは問題を間違えた際に、対応するconceptのproficiencyを下げてしまうけど、実際は間違えても何らかのlearning gainは得ているはずだから、おかしくね?というところに端を発した研究。
student performance predictionの性能よりも、Knowledge Tracingのクオリティーにもっと焦点を当てようよという主張をした論文。
Forgettingもモデル化しているところが特徴。
現在は引用数2だけど、この課題感は非常に重要で、重要論文だと思う。
# モチベ
下図はDKTによる習熟度の変化を表しており赤枠で囲まれている部分は、問題に不正解した際に習熟度が下がることを示している。しかし実際な問題に間違っていたとしても何らかのLearning Gainを得ているはずであり、この挙動はcognitive theoryに反している。実際に先行研究では、エラーは学習において自然な要素であり、学習者はエラーから学び、好ましいエラーによって学習を促進できることを指摘している。
これまでのknowledge tracing研究が、student performance predictionの性能ばかりにフォーカスされているのに対し、本研究では、Knowledge Tracingの解釈性とstudent performance predictionのaccuracyの両方にフォーカスしている。
# Problem Definition
本研究では、1学習の基本要素(learning cell)は exercise-answertime-correctness の3つ組によって表現され、learning cell同士は、interval timeによって隔たれていると考える。answertimeを導入することで、学習者のlearning processを表現する能力を高め、interval timeはLearning Gainを算出する際に役立てる(一般的にinterval timeが短い方がより多くのknowledgeを吸収する傾向にあるなど、interval timeはlearning gainの多様性を捉えるのに役立つ)。
つまり、学習の系列は x = {(e1, at1, a1),it1, (e2, at2, a2),it2, ...,(et, att, at ),itt } と表せる。
KTタスクは、t+1時点での生徒のknowledge stateと、生徒のパフォーマンスを予測する問題として表せる。
# モデル
学習者のLearning Processをきちんとモデル化することに念頭をおいている。具体的には、①学習者は学習を通じて常に何らかのLearning Gain(ある2点間でのパフォーマンスの差; 本研究では前回の学習と今回の学習の両方のlearning cell + interval time + 前ステップでのknowledge stateからLGを推定)を得ており、②忘却曲線にならい学習者は時間がたつと学習した内容を忘却していき(anwertimeとinterval timeが関係する)、③現在のknowledge stateから正誤予測が実施される。
モデルの全体像が下図であり、①がLearning Module, ②がForgetting Module, ③がPredicting Moduleに相当している。
## Embedding
本研究ではTime EmbeddingとLearning Embedding, Knowledge Embeddingの三種類のEmbeddingを扱う。
### Time Embedding
answer timeとinterval timeをembeddingで表現する。両者はスケールが異なるため、answer timeは秒で、interval timeは分でdiscretizeしone-hot-encodingし、Embeddingとして表現する。ここで、interval timeが1ヶ月を超えた場合は1ヶ月として表現する。
### Learning Embedding
learning cellをembeddingで表現する。exercise, answertime, correctnessそれぞれをembeddingで表現し、それらをconcatしMLPにかけることでlearning embeddingを獲得する。ここで、correctnessのembeddingは、正解の場合は全ての要素が1のベクトル, 不正解の場合は全ての要素が0のベクトルとする。
### Knowledge Embedding
学習プロセスにおけるknowledge stateの保存とアップデートを担うEmbedding。
Knowledge Embedding h は、(M x dk)次元で表され、Mはknowledge conceptの数である。すなわち、hの各行が対応するknowledge conceptのmasteryに対応している。learning interactionにおいて、それぞれのknowledge conceptに対するlearning gainや、忘却効果をknowledge embeddingを更新することによって反映させる。
また、knowledge embeddingを更新する際にはQ-matrixを利用する。Q-matrixは、exerciseとknowledge conceptの対応関係を表した行列のことである。Qjmが1の場合、exercise ej が knowledge concept km と関係していることを表し、そうでない場合は0でQ-matrixは表現される。もし値が0の場合、exercise ej のパフォーマンスは、knowledge concept km のmasteryに一切影響がないことを表している。が、人手て定義されたQ-matrixはエラーが含まれることは避けられないし、主観的なバイアスが存在するため、本研究ではこれらの影響(Q-matrix上の対応関係の見落としや欠落)を緩和するためにenhanced Q-matrix q (J x M次元)を定義する。具体的には、通常のQ-matrixで値が0となる部分を、小さな正の値γとしてセットする。
今回はこのようなシンプルなenhanced Q-matrixを利用するが、どのようなQ-matrixの定義が良いかはfuture workとする。
## Learning Module
learning gainを測るためのモジュール。2つの連続したlearning interactionのパフォーマンスの差によってgainを測定する(learning embeddingを使う)。ただこれだけではlearning gainの多様性を捉えることができないため(たとえば同じ連続したlearning embeddingを持って生徒がいたとしてもlearning gainが一緒とは限らない)、interval timeとprevious knowledge stateを活用する。
interval timeはlearning processの鍵となる要素の一つであり、これはlearning gainの差異を反映してる。一般tネキには、interval timeが短い方が生徒はより多くの知識を獲得する傾向にある。
さらに、previous knowledge stateもlearning gainに関係しており、たとえばmasteryが低い生徒は改善の可能性が非常に高い。
previous knowledge stateを利用する際は、現在のexerciseと関連するknowledge conceptにフォーカスするために、knowledge embeddingをknowledge concept vector q_etとの内積をとり、関連するknowledge conceptのknowledge stateを得る:
(q_etの詳細が書かれていないので分からないが、おそらくenhanced Q-matrixのexercise e_tに対応する行ベクトルだと思われる。e_tと関連するknowledge conceptと対応する要素が1で、その他が正の定数γのベクトル)
そしてlearning gain lg_t (dk次元ベクトル)は2つの連続したlearning embedding, と現在の問題と関連するknowledge stateとinterval time embeddingをconcatしMLPにかけることで算出する。
さらに、全てのlearning gainが生徒のknowledgeの成長に寄与するとは限らないので、生徒の吸収能力を考慮するために learning gate Γ^l_t (dk次元ベクトル)を定義する(learning gainと構成要素は同じ):
そして先ほど求めたlearning gateとlearning gainの内積をとり、さらにknowledge concept vector q_etとの内積をとることで、ある時刻tのexercise e_tにと関連するknowledge conceptのlearning gain ~LG_tを得る:
ここで、(lg_t+1)/2しているのは、tanhの値域が(-1, 1)なためであり、これにより値域を(0, 1)に補正している。従ってLG_tは常に正の値となる。これは、本研究の前提である、生徒はそれぞれのlearning interactionから知識を着実に獲得しているという前提を反映している。
## Forgetting Module
~LG_tは生徒のknowledge stateを向上させる働きをするが、反対の忘却現象は、時間が経つにつれてどれだけの知識が忘れられるかに影響します。forgetting curve theoryによると、記憶されている学習教材の量は時間経過に従い指数的に減衰していく。しかしながら、knowledge stateとinterval timeの複雑な関係性を捉えるためには、manual-designedな指数減衰関数では十分ではない。
そこで、forgetting effectをモデル化するために、forgetting gate Γ^f_tを導入する。これは、knowledge embeddingから3つの要素をMLPにかけることで失われる情報の度合いを学習するしたものであり、その3つの要素とは (1) 生徒のprevious knowledge state h_t-1, (2)生徒の現在のlearning gain LG_t, (3) interval time it_tである。
これらを用いてforgetting gate (dk次元) は以下のように計算される:
forgetting gateをh_t-1と積をとることで、忘却の影響を考慮することができる。そして、生徒がt番目のlearning interactionを完了した後のknowledge state h_tは次の式で更新される:
## Predicting Module
これでlearning gainとforgetting effectの両方を考慮した生徒のknowledge state h_tが算出できたので、これをe_t+1のexerciseのperformance予測に活用する。e_t+1を生徒が解く時は、対応するknowledge conceptを適用することで回答をするので、knowledge stateのうち、e_t+1と関連するknowledge state ~h_tを利用する(knowledge concept vector q_et+1との内積で求める)。式で表すと下記になる:
~h_tにexercise e_t+1のembeddingをconcatしてMLPにかけている。
# Objective Function
正則化項つきのcross-entropy log lossを利用する。
# 実験結果
## knowledge tracingの結果
先述のDKTの例とは異なり、問題の回答に誤っていたとしてもproficiencyが向上するようになっている。ただ、e_7が不正解となっている際に、proficiencyが減少していることもわかる。これは、モデルがproficiencyの推定をまだしっかりできていない状態だったため、モデル側がproficiencyを補正したためだ、と論文中では述べられているが、こういった現象がどれだけ起きるのだろうか。こういう例があると、図中の赤枠はたまたま不正解の時にproficiencyが向上しただけ、というふうにも見えてしまう(逆に言うとDKTでも不正解の時にproficiencyが向上することはあるよねっていう)。
また、忘却効果により時間経過に伴い、proficiencyが減少していることもわかる。ただ、この現象もDKTの最初の例でもたとえば①の例はproficiencyが時間経過に伴い減少していっていたし、もともとDKTでもそうなってたけど?と思ってしまう。
ただ、②についてはDKTの例ではproficiencyが時間経過に伴い減少して行っていなかったため、LPKTではきちんとforgetting effectがモデリングできていそうでもある。また、図中右では、最初のinteractionと各knowledge conceptの習熟度の最大値、最後のinteraction時の習熟度がレーダーチャートとして書かれており、学習が進むにつれてどこかで習熟度は最大値となり、忘却効果によって習熟度は下がっているが、学習の最初よりは習熟度が高く弱実に学習が進んでいますよ、というのを図示している。interactionをもっと長く続けた際に(あるknowledge conceptを放置し続けた際に)、忘却効果によってどの程度習熟度がshrinkするのかが少し気になる(習熟度が大きくなった状態が時間発展しても維持されるということが、このモデルでは存在しないのでは?)。
=> Knowledge Tracingの結果については、cherry pickingされているだけであって、全体として見たらどれだけ良くなっているかが正直分からないんじゃないか、という感想。
## student performance predictoin
全てのベースラインに勝っている。特に系列長の長いASSISTchallでAKTに対して大きく勝っており、系列長の長いデータに対してもrobustであることがわかる。
## Ablation Study
learning module, forgetting module, time embeddingをablationした場合に性能がどう変化するかを観察した。forgetting moduleをablationした場合に、性能が大きく低下しているので、forgetting moduleの重要性がわかる。おもしろいのは、time embeddingを除いてもあまり性能は変化していないので、実際はstudent performance predictionするだけならtime embeddingはあまり必要ないのかもしれない。が、論文中では「time embedding (answer timeとinterval time)を除外するのはlearning processを正確にモデル化する上でharmfulだ」と言及しているに留まっており、具体的にどうharmfulなのかは全くデータが提示されていない。time embeddingを除外したことでknowledge tracingの結果がどう変化するのかは気になるところではある、が、実はあまり効いていないんじゃない?という気もする。
## Exercises Clustering
最後に、学習したexerciseのembeddingをt-SNEで可視化しクラスタリングしている。クラスタリングした結果、共通のknowledge conceptを持つexercise同士はある程度同じクラスタに属する例がいくつか見受けられるような結果となっている。
# 所感
answer timeとinterval timeのデータがなくても高い性能で予測ができそうなのでアリ。ただ、そういった場合にknowledge tracingの結果がどうなるかが不安要素ではある。もちろんanswer timeとinterval timeが存在するのがベストではあるが。
また、DKT+で指摘されているような、inputがreconstructionされない問題や、proficiencyが乱高下するといった現象が、このモデルにおいてどの程度起きるのかが気になる。
DKTのようなシンプルなモデルではないので、少しは解消されていたりするのだろうか。実用上あのような現象が生じるとかなり困ると思う。
KCのproficiencyの可視化方法について論文中に記述されていないが、下記リポジトリのIssue 29で質問されている。
knowledge matrix hは各KCのproficiencyに関する情報をベクトルで保持しており、ベクトルをsummationし、シグモイド関数をかけることで0.0~1.0に写像しているとのこと。
Deep-IRT: Make Deep Learning Based Knowledge Tracing Explainable Using Item Response Theory, Chun-Kit Yeung, EDM'19
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #AdaptiveLearning #EducationalDataMining #KnowledgeTracing #EDM Issue Date: 2022-07-22 Comment
# 一言で言うと
DKVMN [Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
のサマリベクトルf_tと、KC embedding k_tを、それぞれ独立にFully connected layerにかけてスカラー値に変換し、生徒のスキルごとの能力パラメータθと、スキルの困難度パラメータβを求められるようにして、解釈性を向上させた研究。最終的にθとβをitem response function (シグモイド関数)に適用することで、KC j を正しく回答できる確率を推定する。
# モデル
基本的なモデルはDKVMNで、DKVMNのサマリベクトルf_tに対してstudent ability networkを適用し、KC embedding k_tに対してdifficulty networkを適用するだけ。
生徒の能力パラメータθとスキルの困難度パラメータβを求め、最終的に下記item response functionを適用することで、入力されたスキルに対する反応予測を実施する:
# 気持ち
古典的なKnowledge Tracing手法は、学習者の能力パラメータや項目の困難度パラメータといった人間が容易に解釈できるパラメータを用いて反応予測を行えるが、精度が低い。一方、DeepなKnowledge Tracingは性能は高いが学習されるパラメータの解釈性が低い。そこで、IRTと最近提案されたDKVMNを組み合わせることで、高性能な反応予測も実現しつつ、直接的にpsychological interpretationが可能なパラメータを学習するモデルを提案した。
DKVMNがinferenceに利用する情報は、意味のある情報に拡張することができることを主張。
1つめは、各latent conceptのknowledge stateは、生徒の能力パラメータを計算することに利用できる。具体的には、DKVMNによって求められるベクトルf_tは、read vector r (該当スキルに対する生徒のmastery level を表すベクトル)とKCのembedding k_t から求められる。これは、生徒のスキルに対するknowledge staeteとスキルそのもののembeddedされた情報の両者を含んでいるので、f_tをNNで追加で処理することで、生徒のスキルq_tに対する能力を推定することができるのではないかと主張。
同様に、q_tの困難度パラメータもKC embedding vector k_tをNNに渡すことで求めることができると主張。
生徒の能力を求めるネットワークを、student ability network, スキルの困難度パラメータを求めるネットワークをdifficulty networkと呼ぶ。
# 性能
実験の結果、DKT, DKVMN, Deep-IRTはそれぞれ似たようなAUCとなり、反応予測の性能はcomparable
# Discussion
## 学習された困難度パラメータについて
複数のソース(1. データセットのpublisherが設定している3段階の難易度, 2. item analysisによって求めた難易度(生徒が問題に取り組んだとき不正解となった割合), 3. IRTによって推定した困難度パラメータ, 4. PFAによって推定した困難度パラメータ)とDeep-IRTが学習したKC Difficulty levelの間で相関係数を測ることで、Deep-IRTが学習した困難度パラメータが妥当か検討している。ソース2, 3については、困難度推定に使うデータがtest environmentではなく学習サービスによるものなので、生徒のquestionに対するfirst attemptから困難度パラメータを予測した。一方、PFAの場合はtest environmentによる推定ではなく、knowledge tracingの設定で困難度パラメータを推定した(i.e. 利用するデータをfirst attemptに限定しない)。
相関係数をは測った結果が上図で、正直見方があまりわからない。著者らの主張としては、Deep-IRTは他の困難度ソースの大部分と強い相関があった(ソース1を除く)、と主張しているが、相関係数の値だけ見ると明らかにPFAの方が全てのソースに対して高い相関係数を持っている。また、困難度を推定するモデルの設定(test environment vs. learning environment)や複雑度が近ければ近いほど、相関係数が高かった(ソース2, 3間は相関係数は0.96、一方ソース2とDeep-IRTは相関係数0.56)。また、Deep-IRTはソース1の困難度パラメータとの相関係数が0.08であり非常に低い(他のソースは0.3~0.4程度の相関係数が出ている)。この結果を見ると、Deep-IRTによって推定された困難度パラメータは古典的な手法とは少し違った傾向を持っているのではないかと推察される。
=> DeepIRTによって推定された困難度パラメータは、古典的な手法と比較してめっちゃ近いというわけでもなく、人手で付与された難易度と全く相関がない(そもそも人手で付与された難易度が良いものかどうかも怪しい)。結局DeepIRTによる困難度パラメータがどれだけ適切かは評価されていないので、古典的な手法とは少し似ているけど、なんか傾向が違う困難度パラメータが出ていそうです〜くらいのことしかわからない。
## 学習された生徒の能力パラメータについて
reconstruction問題がDKTと同様に生じている。たとえば、“equation solving more than two steps” (red) に不正解したにもかかわらず、対応する生徒の能力が向上してしまっている。また、スキル間のpre-requisite関係も捉えられない。具体的には、“equation solving two or fewer steps” (blue) に正解したにもかかわらず、“equation solving more than two steps” (red) の能力は減少してしまっている。
# 所感
生徒の能力パラメータは、そもそもDKTVMモデルでも入力されたスキルタグに対する反応予測結果が、まさに生徒の該当スキルタグに対する能力パラメータだったのでは?と思う。困難度パラメータについては推定できることで使い道がありそうだが、DeepIRTによって推定された困難度パラメータがどれだけ良いものかはこの論文では検証されていないので、なんともいえない。
# 関連研究
- Item Response Theory (IRT): 受験者の能力パラメータはテストを受けている間は不変であるという前提をおいており(i.e. testing environmentを前提としている)、Knowledgte Tracingタスクのような、学習者の能力が動的に変化する(i.e. learning environment)状況ではIRTをKnowledge Tracingに直接利用できない(と主張しているが、 [Paper Notes] Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16
あたりではIRTで項目の反応予測に利用してDKTをoutperformしている)
- Bayesian Knowledge Tracing (BKT): 「全ての生徒と、同じスキルを必要とする問題がモデル上で等価に扱われる」という非現実的な仮定が置かれている。言い換えれば、生徒ごとの、あるいは問題ごとのパラメータが存在しないということ。
- Latent Factor Analysis (LFA): IRTと類似しているが、スキルレベルのパラメータを利用してKnowledge Tracingタスクに取り組んだ。生徒の能力パラメータθと、問題に紐づいたスキルごとの難易度パラメータβと学習率γ(γ x 正答数で該当スキルに対する学習度合いを求める)を持つ。これにより「学習」に対してもモデルを適用できるようにしている。
- Performance Factor Analysis (PFA): 生徒の能力値よりも、生徒の過去のパフォーマンスがKTタスクにより強い影響があると考え、LFAを拡張し、スキルごとに正解時と不正解時のlearning rateを導入し、過去の該当スキルの正解/不正解数によって生徒の能力値を求めるように変更。これにより、スキルごとに生徒の能力パラメータが存在するようなモデルとみなすことができる。
=> LFAとPFAでは、複数スキルに対する「学習」タスクを扱うことができる。一方で、スキルタグについては手動でラベル付をする必要があり、またスキル間の依存関係については扱うことができない。また、LFAでは問題に対する正答率が問題に対するattempt数に対して単調増加するため、生徒のknowledge stateがlearnedからunlearnedに遷移することがないという問題がある。PFAでは失敗したattemptの数を導入することでこの仮定を緩和しているが、生徒が大量の正答を該当スキルに対して実施した後では問題に対する正答率を現象させることは依然として困難。
- Deep Knowledge Tracing (DKT): DeepLearningの導入によって、これまで性能を向上させるために人手で設計されたfeature(e.g. recency effect, contextualized trial sequence, inter-skill relationship, student’s ability variation)などを必要とせず、BKTやPFAをoutperformした。しかし、RNNによって捉えられた情報は全て同じベクトル空間(hidden layer)に存在するため、時間の経過とともに一貫性した予測を提供することが困難であり、結果的に生徒が得意な、あるいは不得意なKCをピンポイントに特定できないという問題がある(ある時刻tでは特定のスキルのマスタリーがめっちゃ高かったが、別の問題に回答しているうちにマスタリーがめっちゃ下がるみたいな現象が起きるから?)。
- Dynamic Key Value Memory Network (DKVMN): DKTでは全てのコンセプトに対するknowledge stateを一つのhidden stateに集約することから、生徒が特定のコンセプトをどれだけマスターしたのかをトレースしたり、ピンポイントにどのコンセプトが得意, あるいは不得意なのかを特定することが困難であった(←でもこれはただの感想だと思う)。DKTのこのような問題点を改善するために提案された。DKVMNではDKTと比較して、DKTを予測性能でoutperformするだけでなく(しかしこれは後の追試によって性能に大差がないことがわかっている)、overfittingしづらく、Knowledge Component (=スキルタグ)の背後に潜むコンセプトを正確に見つけられることを示した。しかし、KCの学習プロセスを、KCのベクトルや、コンセプトごとにメモリを用意しメモリ上でknowledge stateを用いて表現することで的確にモデル化したが、依然としてベクトル表現の解釈性には乏しい。したがって、IRTやBKT, PFAのような、パラメータが直接的にpsychological interpretationが可能なモデルと、パラメータやrepresentationの解釈が難しいDKTやDKVMNなどのモデルの間では、learning science communityの間で対立が存在した。
=> なので、IRTとDKVMNを組み合わせることで、DKVMNをよりexplainableにすることで、この対立を緩和します。という流れ
著者による実装: https://github.com/ckyeungac/DeepIRT
A Self-Attentive model for Knowledge Tracing, Pandy+ (with George Carypis), EDM'19
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #StudentPerformancePrediction #EDM #Selected Papers/Blogs Issue Date: 2021-10-28 Comment
Knowledge Tracingタスクに初めてself-attention layerを導入した研究
interaction (e_{t}, r_{t}) および current exercise (e_{t+1}) が与えられた時に、current_exerciseの正誤を予測したい。
* e_{t}: 時刻tのexercise
* r_{t}: 時刻tでの正誤
interactionからKey, Valueを生成し、current exerciseからQueryを生成し、multi-head attentionを適用する。その後、得られたcontext vectorをFFNにかけて、正誤を予測する。

DKTや、DKVMNを全てのデータセットでoutperform
Context-Aware Attentive Knowledge Tracing, Ghosh+, University of Massachusetts Amherst, KDD'20
においてはSAKTがDKT, DKVMN等に勝てていないのに対し(ASSSITments Data + Statics Data)
An Empirical Comparison of Deep Learning Models for Knowledge Tracing on Large-Scale Dataset, Pandey+, AAAI workshop on AI in Education'21
Do we need to go Deep? Knowledge Tracing with Big Data, Varun+, University of Maryland Baltimore County, AAAI'21 Workshop on AI Education
においてはSAKTはDKT, DKVMNに勝っている(EdNet Data)
When is Deep Learning the Best Approach to Knowledge Tracing?, Theophile+ (Ken Koedinger), CMU+, JEDM'20
においてもSAKTがDKTに勝てないことが報告されている(ASSISTments Data + Statics Data + Bridge to Algebra, Squirrel dataなど)。ただし、Interaction数が大きいデータセット(Squirrel data)ではDKTの性能に肉薄している。
Large ScaleなデータだとSAKTが強いが、Large Scaleなデータでなければあまり強くないということだと思われる。
Large Scaleの基準は、なかなか難しいが、1億Interaction程度あれば(EdNetデータ)SAKTの方が優位に強くなりそう。
数十万、数百万Interaction程度のデータであれば、DKTとSAKTはおそらくcomparableだと思われる。
(追記)
しかし Learning Process-consistent Knowledge Tracing, Shen+, SIGKDD'21
においてはSAKTはEdNetデータセット(Large Scale)においてDKT, DKT+, DKVMNとcomparableなので、
正直何を信じたら良いか分からない。
[Paper Note] EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction, Qi Liu+, IEEE TKDE'19, 2019.06
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #Selected Papers/Blogs Issue Date: 2021-05-28 GPT Summary- 学生のパフォーマンス予測のために、演習記録と教材情報を統合するEERNNフレームワークを提案。双方向LSTMを用いて演習内容をエンコードし、マルコフ特性とアテンションメカニズムを持つ2つの実装を提供。さらに、知識概念を追跡するEKTに拡張し、演習が知識習得に与える影響を定量化。実験により、予測精度と解釈可能性の向上が確認された。 Comment
DKT等のDeepなモデルでは、これまで問題テキストの情報等は利用されてこなかったが、learning logのみならず、問題テキストの情報等もKTする際に活用した研究。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
をより洗練させjournal化させたものだと思われる。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
ではKTというより、問題の正誤を予測するモデルとなっており、個々のconceptに対するproficiencyを推定するというKTの考え方はあまり導入されていなかった。
EKTの方では、個々のknowledge componentのproficiency scoreを算出する方法も提案されている。
モデル自体は、基本的にはattention-basedなRNNモデル。

Exercise EmbeddingはBidireictional-RNNを利用して、問題文をエンコードすることによって求める。
EKTによるmastery levelを可視化したもの。T=0とT=30では各conceptに対するmastery levelが大きく異なっている。基本的に、たくさん正解したconceptはmastery levelが向上し、不正解しまくったconceptはどんどんmastery levelがshrinkしていく。
予測性能。問題のContentを考慮することで、正誤予測のAUCは圧倒的に高くなる。DKTよりも10ポイント程度EKTAの方がAUCが高いように見える。
各モデルの特徴や、knowledge tracingが行えるか否か、といった性質を整理した表。わかりやすい。しかしDKTのknowledge tracking?が×になっているのは誤りでは?
各knowledge conceptの時刻tにおけるmastery levelの求め方。
EKTでは、生徒の各knowledge conceptの状態を保持した行列H_t^i(0 <= i <= # of concepts)を保持している。correctness probabilityを最終的に求める際には、H_t^iの各knowledge conceptに対する重みβ_iで重みづけた上でsummationをとり、各知識の状態を統合したベクトルsを作成し、sとexercise embedding xをconcatした上でスコアを予測する。
このスコアの予測部分を変更し、β_iをmastery levelを測定したいconceptのone-hot encodingに置き換え、さらにexercise embeddingをmaskしたベクトル=masked exercise embedding = zero vectorをconcatした上で、スコアを予測するようにする。
こうすることで、exerciseの影響を除き、かつone-hot encodingで指定したknowledgeのmasteryのみが考慮されたスコアを抽出できるため、そのスコアをmastery levelとする。
単にStudent Performance Predictionして終わり!ってんじゃなく、knowledge tracing的な側面をきちんと考慮している点で、この研究めっちゃ好き。
スキルタグごとにLSTMのhidden_stateを保持しないといけないので、メモリの消費量がえぐいことになりそう。小規模なスキルタグのデータセットじゃないと動かないのでは?
実際、実験では37種類のスキルタグが存在するデータセットしか扱っていない。
[Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #StudentPerformancePrediction #KnowledgeTracing #WWW Issue Date: 2021-05-28 GPT Summary- 動的キー・バリューメモリネットワーク(DKVMN)を提案し、学生の知識状態を追跡する新しい手法を開発。従来の手法の限界を克服し、基礎概念間の関係を活用して習得レベルを直接出力。実験により、DKVMNはKTデータセットで最先端モデルを上回る性能を示し、演習の基礎概念を自動発見する能力も持つ。 Comment
DeepなKnowledge Tracingの代表的なモデルの一つ。KT研究において、DKTと並んでbaseline等で比較されることが多い。
DKVMNと呼ばれることが多く、Knowledge Trackingができることが特徴。
モデルは下図の左側と右側に分かれる。左側はエクササイズqtに対する生徒のパフォーマンスptを求めるネットワークであり、右側はエクササイズqtに対する正誤情報rtが与えられた時に、メモリのvalueを更新するネットワークである。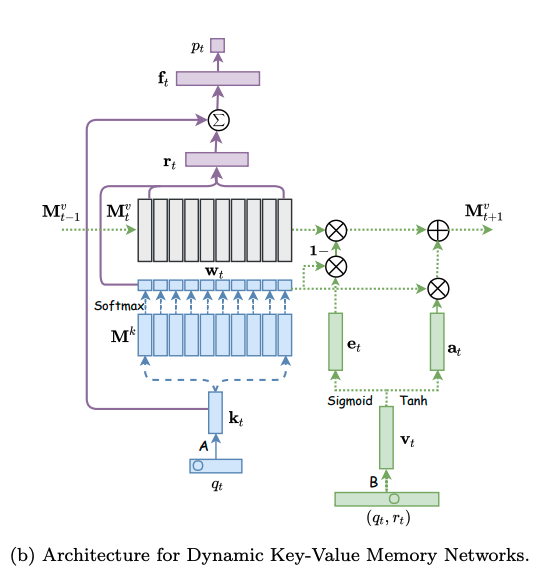
メモリとは生徒のknowledge stateを保持している行列であり、keyとvalueのペアによって形成される。keyとvalueは両者共にdv次元のベクトルで表現される。keyはコンセプトを表し、valueがそれぞれのコンセプトに対する生徒のknowledge stateを表している。ここで、コンセプトとスキルタグは異なる概念であり、スキルタグを生成される元となった概念のことをコンセプトと呼んでいる。コンセプトは基本的には専門家がタグ付しない限り、観測できない変数だと思われる。すなわち、コンセプトとはsynthetic-5データでいうところのc_t(5種類のコンセプト)に該当し、個々のコンセプトによって生成された50種類のexerciseがエクササイズタグに相当する。ASSISTments15データでいうところの、100種類のスキルタグがエクササイズタグで、それぞれのスキルタグのコンセプトはデータに明示されていない。
# ptの求め方
ptを求める際には、エクササイズqt(qtのサイズはエクササイズタグ次元Q; エクササイズタグが何を指すかは分かりづらく、基本的にはスキルタグのことだが、synthetic-5のように50種類のquestion_idをそのまま利用することも可)のembedding kt(dk次元)を求め、ktをメモリのkey M^k(N x dk次元)とのmatmulをとることによって、各コンセプトとのcorrelation weight w を求める。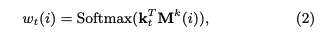
correlation weight wは、メモリのvalue(knowledge state)からknowledge stateのread contentベクトルrを生成する際に用いられる。read contentベクトルは、エクササイズqtに関する生徒のmastery levelのサマリとみなすことができる。
read contentベクトルrは、各キーのcorrelation weight w(scalar)とメモリのvalueベクトル(dv次元)との積をメモリサイズ(コンセプト数)Nでsummationすることによって求められる。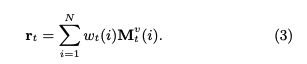
read contentベクトルを求めたのち、生徒のqtに対するmastery levelと取り組む問題qtの難易度を集約したサマリベクトルftをfully connected layerによって求める。求める際には、rとkt(qtのembedding)をconcatし、fully connected layerにかける。
最終的にサマリベクトルftを異なるfully connected layerにかけることによって、エクササイズqtに対するレスポンスを予測する。
# メモリの更新方法
エクササイズqtとそれに対する正誤rtが与えられたとき(qt, rt)、この情報のembedding vtを求める。求める際は、2Q x dv次元のembedding matrixをlookupする。このvtは、生徒がエクササイズに回答したことによってどれだけのknowledge growthを得たかを表している。
その後LSTMのforget gateに着想を得て、メモリのvalueをupdateする際に、最初にeraseベクトルを求めてvalueのうち忘却した情報を削除し、その後add vectorを利用してknowledge growthをvalueに反映させる。
eraseベクトルは、knowledge growth vtと(dv x dv)次元のtransformation matrix Eを利用して変換することによって求める。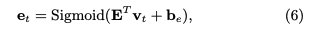
そして、メモリのvalueはこのeraseベクトルを用いて次の式で更新される。基本的には求めたeraseベクトルの分だけ全てのコンセプトのvalueがshrinkするように計算されているが、各コンセプトごとにshrinkさせる度合いをcorrelation weight wによって制御することによってvalueに対して忘却の概念を取り入れている。correlation weightとeraseベクトルのelementのうち、両方とも1となるelementに対応するvalueのelementが、0にリセットされるような挙動となる。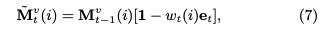
その後、knowledge growth vt から、新たなtransformation matrix D(dv x dv)を用いて、adding vector aが計算される。
最終的に、メモリの各valueは、adding vectorに対してcorrelation weightの重み分だけ各elementの値が更新される。
このような erase-followed-by-addな構造により、生徒の忘却と学習のlearning processを再現している。
# 予測性能
DKVMNが全てのデータセットにおいて性能が良かった。が、これは後のさまざまな研究の追試によりDKTとDKVMNの性能はcomparableであることが検証されているため、あまりこの結果は信用できない。
# learning curve
DKTとDKVMNの両者についてlearning curveを描いた結果が下記。DKTはtrainingとvalidationのlossの差が非常に大きくoverfittingしていることがわかるが、DKVMNはそのような挙動はなく、overfittingしにくいことを言及している。
# Concept Discovery
Figure4がsynthetic-5に対するConcept Discovery, Figure5がASSISTments15に対するConcept Discoveryの結果。synthetic-5は5種類のコンセプトによって50種類のエクササイズが生成されているが、メモリサイズNを5にすることによって完璧な各エクササイズのクラスタリングが実施できた(驚くべきことに、N=50でも5つのクラスタにきっちり分けることができた)。ASSISTments15データについても、類似したコンセプトのスキルタグが同じクラスタに属し、近い距離にマッピングされているため、コンセプトを見つけられたと主張している。
# Knowledge State Depiction
Synthetic-5に対する、各コンセプトのmasteryを可視化した結果が下図。
ここで注意すべきは、DKVMNが可視化するのは、メモリサイズNで指定した個々のkeyに該当するコンセプトのmasteryを可視化する方法を説明している点である。個々のスキルタグ(エクササイズタグ)に対するmasteryを可視化するわけではない点に注意。個々のスキルタグに対するmasteryは、DKTと同様にptがそれに該当するものと思われる。
個々のコンセプトのmasteryを可視化する手順は下記の通り。
まず、read content vector rを求める際に、masteryを可視化したいコンセプトのCorrelation weightのみを1とし、他のコンセプトのCorrelation weightを0とすることでrを算出する。
その後、次の式によって、エクササイズの難易度情報をマスクすること(weight matrixのうち、エクササイズembeddingが乗算される部分のみ0にマスクする)によってサマリベクトルftを求め、ftからfully connected layerを通じてptを求めることで、そのptを該当するコンセプトのmastery levelとみなす。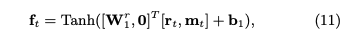
# 所感
スキルタグの背後にある隠れたコンセプトを見つけ、その隠れたコンセプトに対する習熟度を測るという点においてはDKTよりもDKVMNの方が優れていそう。
だが、スキルタグに対する習熟度を測るという点については、DKT, DKVMNのAUCにほとんど差がないことを鑑みるにDKVMNをわざわざ使う意味がどれだけあるのかな、という気がした。
特に Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
で報告されているように、DKVMNでリアルタイムに全てのスキルタグに対する習熟度をトラッキングするためには、DKVMNのoutputをoutput-per-skillにする必要があるが、DKVMNにおいてoutput-per-skillベクトルをoutputに採用すると予測性能が低下することがわかっている。このため、わざわざスキルタグに対する習熟度を求める際にDKVMNを使う必要もないのでは、という気がしている。
そうすると、現状スキルタグに対する習熟度をいい感じに求める手法は、DKT, DKT+ or EKTということになるのだろうか・・・。
追記:DKVMNのDKTと比較して良い点は、メモリネットワーク上にknowledge stateが保存されていて、inputはある一回の問題に対するtrialの正誤のみという点。DKTなどでは入力する系列の長さの上限が決まってしまうが、原理上はDKVMNは扱える系列の長さに制限がないことになる。この性質は非常に有用。
[Paper Note] Joint Optimization of User-desired Content in Multi-document Summaries by Learning from User Feedback, P.V.S+, ACL'17, 2017.08
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #IntegerLinearProgramming (ILP) #Personalization #ACL #interactive Issue Date: 2017-12-28 GPT Summary- ユーザーフィードバックを活用した抽出的マルチドキュメント要約システムを提案。インタラクティブにフィードバックを取得し、ILPフレームワークを用いて要約の質を向上。最小限の反復で高品質な要約を生成し、シミュレーション実験で効果を分析。 Comment
# 一言で言うと
ユーザとインタラクションしながら重要なコンセプトを決め、そのコンセプトが含まれるようにILPな手法で要約を生成するPDS手法。Interactive Personalized Summarizationと似ている(似ているが引用していない、引用した方がよいのでは)。
# 手法
要約モデルは既存のMDS手法を採用。Concept-based ILP Summarization
フィードバックをユーザからもらう際は、要約を生成し、それをユーザに提示。提示した要約から重要なコンセプトをユーザに選択してもらう形式(ユーザが重要と判断したコンセプトには定数重みが与えられる)。
ユーザに対して、τ回フィードバックをもらうまでは、フィードバックをもらっていないコンセプトの重要度が高くなるようにし、フィードバックをもらったコンセプトの重要度が低くなるように目的関数を調整する。これにより、まだフィードバックを受けていないコンセプトが多く含まれる要約が生成されるため、これをユーザに提示することでユーザのフィードバックを得る。τ回を超えたら、ユーザのフィードバックから決まったweightが最大となるように目的関数を修正する。
ユーザからコンセプトのフィードバックを受ける際は、効率的にフィードバックを受けられると良い(最小のインタラクションで)。そこで、Active Learningを導入する。コンセプトの重要度の不確実性をSVMで判定し、不確実性が高いコンセプトを優先的に含むように目的関数を修正する手法(AL)、SVMで重要度が高いと推定されたコンセプトを優先的に要約に含むように目的関数を修正する手法(AL+)を提案している。
# 評価
oracle-based approachというものを使っている。要は、要約をシステムが提示しリファレンスと被っているコンセプトはユーザから重要だとフィードバックがあったコンセプトだとみなすというもの。
評価結果を見ると、ベースラインのMDSと比べてupper bound近くまでROUGEスコアが上がっている。フィードバックをもらうためのイテレーションは最大で10回に絞っている模様(これ以上ユーザとインタラクションするのは非現実的)。
実際にユーザがシステムを使用する場合のコンテキストに沿った評価になっていないと思う。
この評価で示せているのは、ReferenceSummary中に含まれる単語にバイアスをかけて要約を生成していくと、ReferenceSummaryと同様な要約が最終的に作れます、ということと、このときPool-basedなActiveLearningを使うと、より少ないインタラクションでこれが実現できますということ。
これを示すのは別に良いと思うのだが、feedbackをReferenceSummaryから与えるのは少し現実から離れすぎている気が。たとえばユーザが新しいことを学ぶときは、ある時は一つのことを深堀し、そこからさらに浅いところに戻って別のところを深堀するみたいなプロセスをする気がするが、この深堀フェーズなどはReferenceSummaryからのフィードバックからでは再現できないのでは。
# 所感
評価が甘いと感じる。十分なサイズのサンプルを得るのは厳しいからorable-based approachとりましたと書いてあるが、なんらかの人手評価もあったほうが良いと思う。
ユーザに数百単語ものフィードバックをもらうというのはあまり現時的ではない気が。
oracle-based approachでユーザのフィードバックをシミュレーションしているが、oracleの要約は、人がそのドキュメントクラスタの内容を完璧に理解した上で要約しているものなので、これを評価に使うのも実際のコンテキストと違うと思う。実際にユーザがシステムを使うときは、ドキュメントクラスタの内容なんてなんも知らないわけで、そのユーザからもらえるフィードバックをoracle-based approachでシミュレーションするのは無理がある。仮に、ドキュメントクラスタの内容を完璧に理解しているユーザのフィードバックをシミュレーションするというのなら、わかる。が、そういうユーザのために要約作って提示したいわけではないはず。
PLaMo 3.0 Prime β版, PFN, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reasoning #Japanese #Selected Papers/Blogs #Surface-level Notes Issue Date: 2026-03-19 Comment
元ポスト:
日本国内初のフルスクラッチReasoningモデル
## 公式発表のまとめ
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
によってcontext windowを64Kまで拡張(PLaMo 2.2 Primeの2倍)。
事後学習データの見直し(新たなオープンデータセット追加, 独自データとして、日本語指示追従能力, tool use, long horizon QA, 医療分野, STEM, RAG性能向上のためのデータ)を実施し、SFT, DPO, RLの流れで学習を実施。SFT, DPOについてはreasoning trajectoryもLossで考慮するように変更。SFT, DPO向けデータについてはreasoning trajectoryを合成したものを利用。
RLは今回初めて導入し学習を安定させるための工夫を取り入れているとのこと。Reference Answerとの比較と表層的な特徴から報酬を計算する関数を実装した、という書かれ方をしている。
gpt-oss-120B(memium)との比較で言うと
指示追従性能が日本語、英語ともによりも高く、医療分野のQA(国家試験を除く)、英語、日本語での対話能力で勝っている。また、法令分野のQAは同等である。
単一ツールや複数ツールからの選択は同等、multi turnの場合はPLaMo2.2から大幅に性能向上しているもののgpt-ossよりも劣る。また、long contextのQA、医療分野の国家試験QA、STEM分野のQAや数学的な推論能力は大幅に前回モデルよりも向上したが、まだgpt-ossなどには届いていない、という感じに見える。
アーキテクチャについては、一新したという話とRoPEベースということ以外はよくわからない。
## 筆者の憶測と感想
※以下、筆者の憶測を多く含んだ感想です。ただ筆者が勝手に想像して自分なりに考えてみているだけです。
DPOにNLL lossを追加することでreasoningを強化できることは下記研究で示されている:
- [Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24, 2024.04
RLの報酬に関して、表層的な特徴とReference Answerとの比較から最適な報酬を計算とのことなので、おそらく何らかのVerificationのための仕組みと、Rubric-basedなLLM-as-a-Judgeだろうか?Reward Modelという書かれ方はしていない。
RLについては安定性のある手法を採用したとのことだが、DAPO、
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
あるいはRLのスケーリング則を導いた研究でDAPOよりも安定性と最終到達性能において優れていることが示された
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
CISPOあたりだろうか:
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
あとは安定性という観点で言うと、inference/trainingエンジンでのtraining-inference gapの課題についても対処している可能性がある。
- Hot topics in RL, Kimbo, X, 2025.12
- [Paper Note] Beyond Precision: Training-Inference Mismatch is an Optimization Problem and Simple LR Scheduling Fixes It, Yaxiang Zhang+, arXiv'26, 2026.02
思考過程が英語ということは、言語間で能力は転移し、かつ事前学習データとしてはリソースが豊富な英語が多く含まれると想像すると、明示的(strong LLMでtrajectoryを合成したものを加える系の話)あるいはデータに自然と現れるreasoningの挙動から事前学習中にreasoning能力が暗黙的に学習されることを踏まえ、SFTでreasoning能力を強化する際に(日本語よりも英語の方が効果的な可能性が高く)英語でのtrajectoryを合成したという感じだろうか(いつか日本語のreasoning trajectoryを出力するモデルも見てみたいなあ)。
Multi Turnのtool useの性能向上に関して、AI Agent分野のlong horizonな合成データを合成するアプローチや、Sink Tokenの活用や、トークン単位でsink tokenを計算することに相当するHead wise gated attentionなどはしているのだろうか。
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- [Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
また、アーキテクチャに関してはcontext windowが海外のフロンティアモデルと比較してまだ小さめであるが、今後context windowを大きくするにあたって、オンポリシーRLでのロールアウト時間がボトルネックとなることが考えられ、Mamba(=linear attention)系のアーキテクチャをハイブリッドや、DSA系のsparse attentionなどの採用によるアーキテクチャ起因の計算コスト低減(現在どのようなアーキテクチャなのかは全くわからないが)、あるいはin-flight-updateのような学習エンジン側での効率化なども必要になるのではなかろうか(現在どういうエンジンなのかは全くわからないが)。
- [Paper Note] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, DeepSeek-AI+, arXiv'25, 2025.12
- [Paper Note] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence
Generation, Alexandre Piché+, arXiv'25, 2025.09
独立な学習者・項目ネットワークをもつ Deep-IRT, 堤+, 電子情報通信学会論文誌, 2021
Paper/Blog Link My Issue
#Article #NeuralNetwork #AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-07-25 Comment
# モチベーション
Deep-IRTで推定される能力値は項目の特性に依存しており、同一スキル内の全ての項目が等質であると仮定しているため、異なる困難度を持つ項目からの能力推定値を求められない。このため、能力パラメータや困難度パラメータの解釈性は、従来のIRTと比較して制約がある。一方、木下らが提案したItem Deep Response Theoryでは、項目特性に依存せずに学習者の能力値を推定でき、推定値の信頼性と反応予測精度が高いことが示されているが、能力の時系列変化を考慮していないため、学習家庭での能力変化を表現できない。これらを解決するための手法を提案。
# 手法
論文中の数式に次元数が一切書かれておらず、論文だけを読んで再現できる気がしない。
提案手法は、学習者の能力推定値が項目の特性に依存せず、複数のスキルに関する多次元の能力を表現できる(とあるが、が、どういう意味かよくわからない・・・)。
下図が提案手法の概要図。スキルタグ入力だけでなく、項目IDそのものも入力して活用するのが特徴。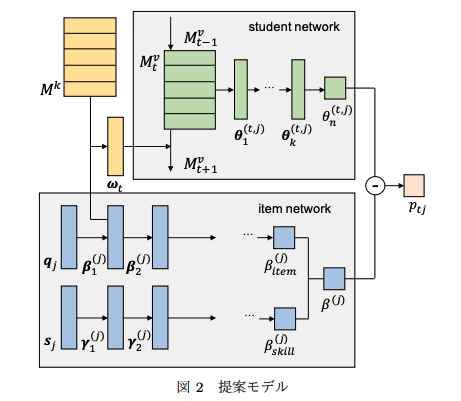
基本的に、生徒の能力値を推定するstudent networkと、スキル/項目の難易度を推定するitem networkに分かれている。ある時刻tでの生徒の能力値はメモリM上の全てのhidden conceptに対するvalueを足し合わせ、足し合わせて得られたベクトルに対してMLPをかけることによって計算している。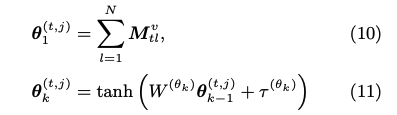
最終的にitem response functionを見ると、ここで得られる生徒の能力値はスカラー値でなければならないと思うのだが、MLPをかけて得られたベクトルからどのように生徒の能力値を算出するかがジャーナル上では書かれていない。EDM'21の方を見ると、inputとなったスキルタグのembeddingとメモリのkeyとの関連度から求めたアテンションベクトルω_tとの内積でスカラーに変換しているようなので、おそらくそのような操作をしていると思われる。
item networkも同様に、スキルタグのembedding q_j と 項目のembedding s_j を別々にMLPにかけて、最終的に1次元に写像することで、スキル/項目の難易度パラメータを推論していると思われる。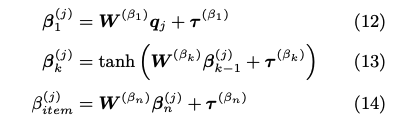
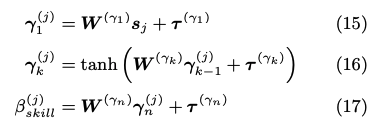
最終的に下記item response functionによって反応予測を行う。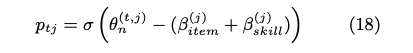
ただし、EDM'21の論文だと能力値パラメータθに3が乗じられているのに対し、こちらはそのような操作がされていない。どちらが正しいのか分からない。
また、メモリネットワークのmemory valueの更新は [Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
と同じ方法である。
# 予測性能評価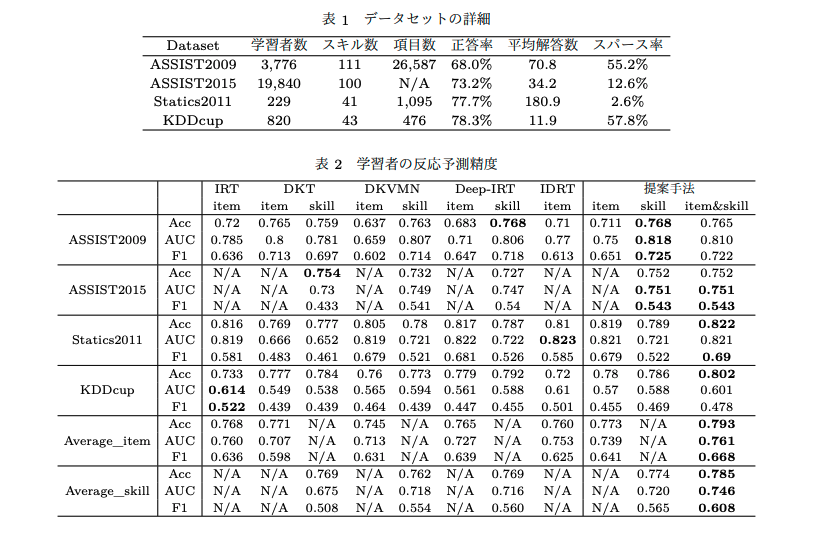
提案手法が全てのデータセットで平均すると最も良い予測性能を示している。IRTもKDDCupデータでは性能が良く、KDDCupデータは回答ログの正答率が非常に高くデータに偏りがあり、加えてデータのスパース率(10 人以下
の学習者が解答した項目の割合)も高いため(学習者の平均回答数が少ない)、DeepLearningベースドな手法は反応の偏りと少数データに脆弱である可能性を指摘している。
ちなみにEDM'21論文だと下記のような結果になっている: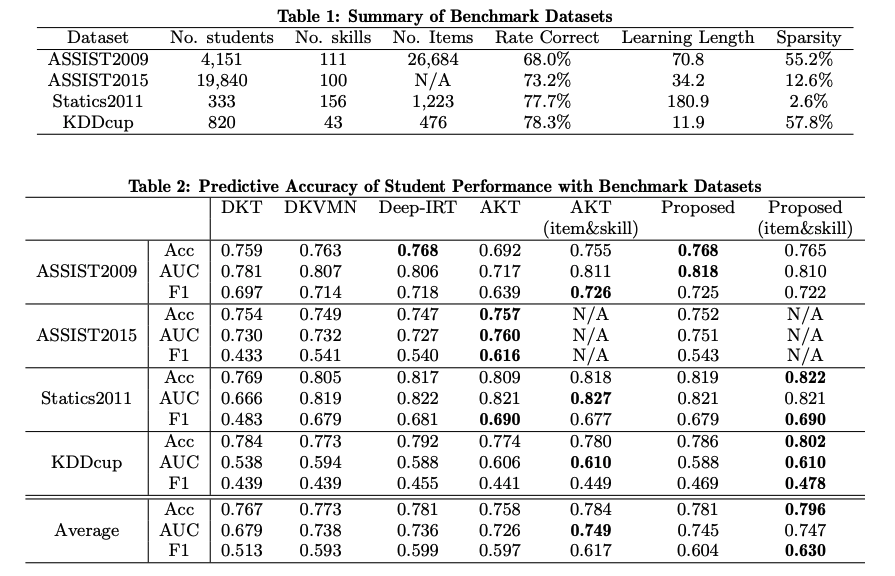
こちらの結果を見ると、AKTよりも高い性能を示していることがわかる。AKTに勝つのは結構すごそうなのだが Learning Process-consistent Knowledge Tracing, Shen+, SIGKDD'21
でのAKTの性能に比べ、DKT等の手法に対するAKTの性能の伸びが小さいのが非常に気になる。何を信じたら良いのか分からない・・・。
# 解釈性評価実験について
DeepIRTとのパラメータの能力パラメータ、困難度パラメータの解釈性の検証をしているようだが、所感に書いてある通りまずDeepIRTの能力値パラメータを正しく採用できているのかが怪しい。困難度パラメータについては、シミュレーションデータを用いて提案手法がDeepIRTと比べて真の困難度に対する相関が高いことを示しているが、詳細が書かれておらずよくわからない・・・。一応IRTと同等の解釈性能を持つと主張している。
# 所感
解釈性の評価実験において下記の記述があるが、
> しかし,彼ら によって公開された Deep-IRT のプログラムコードで は一次元の能力値推移しか出力できず,論文で示され た複数スキルに対応した結果を再現できない.このた め,本実験では,式 (7) で得られる θ (t,j) 3 を多次元で 出力した値を Deep-IRT における多次元のスキルの能 力値推移とする.
ここでどのような操作をしているのかがいまいち分からないが、時刻tのメモリM_tが与えられたとき、DeepIRTは入力ベクトルq_tに対応する一次元の能力値を返すモデルのはずで、q_tを測定したい能力のスキルタグに対するone-hot encodingにすれば能力値推移は再現できるのでは?「θ (t,j) 3を多次元で出力した値」というのは、1次元のスカラー値を出力するのではなく、多次元のベクトルとしてθ (t,j) 3を出力し、ベクトルの各要素をスキルに対する能力値とみなしているのだろうか。もしそういう操作をしているのだとしたらDeepIRTが出力する能力値パラメータとの比較になっていないと思う。
θ_n^(t, j)を学習者の能力値ベクトルとしてみなすと論文中に記述されているが、実際にどの次元がどのスキルの習熟度に対応しているかは人間が回答ログに対する習熟度の推移を観察して決定しなければならない。これは非常にダルい。
しかもθ_n^(t, j)の各次元の値は、スキルタグに対する習熟度ではなく、スキルタグの背後にあるhidden conceptの習熟度だと思う。論文では問題の正解/不正解に対して、習熟度が上下する様子から、能力値ベクトルの特定の次元の数値が特定のスキルの習熟度となっていることを解釈しているが、その解釈が正しい保証はないような・・・。