
Surface-level Notes
[Paper Note] Hunyuan-MT Technical Report, Mao Zheng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#MachineTranslation #NLP #LanguageModel #OpenWeight #Catastrophic Forgetting #mid-training #Selected Papers/Blogs #In-Depth Notes Issue Date: 2025-09-01 GPT Summary- Hunyuan-MT-7Bは、33の主要言語間の双方向翻訳をサポートする初のオープンソースモデルであり、特に標準中国語と少数言語間の翻訳に焦点を当てています。スロースローチンキングに触発されたHunyuan-MT-Chimera-7Bを導入し、複数の出力を統合することで性能を向上させています。モデルは包括的なトレーニングプロセスを経ており、強化学習を用いた高度な整合性を実現。実験では、両モデルが同等のパラメータサイズの他の翻訳モデルを上回り、WMT2025共有タスクで30の言語ペアで1位を獲得しました。これにより、モデルの堅牢性が強調されています。 Comment
テクニカルレポート: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
元ポスト:
Base Modelに対してまず一般的な事前学習を実施し、その後MTに特化した継続事前学習(モノリンガル/パラレルコーパスの利用)、事後学習(SFT, GRPO)を実施している模様。
継続事前学習では、最適なDataMixの比率を見つけるために、RegMixと呼ばれる手法を利用。Catastrophic Forgettingを防ぐために、事前学習データの20%を含めるといった施策を実施。
SFTでは2つのステージで構成されている。ステージ1は基礎的な翻訳力の強化と翻訳に関する指示追従能力の向上のために、Flores-200の開発データ(33言語の双方向の翻訳をカバー)、前年度のWMTのテストセット(English to XXをカバー)、Mandarin to Minority, Minority to Mandarinのcuratedな人手でのアノテーションデータ、DeepSeek-V3-0324での合成パラレルコーパス、general purpose/MT orientedな指示チューニングデータセットのうち20%を構成するデータで翻訳のinstructinoに関するモデルの凡化性能を高めるためキュレーションされたデータ、で学習している模様。パラレルコーパスはReference-freeな手法を用いてスコアを算出し閾値以下の低品質な翻訳対は除外している。ステージ2では、詳細が書かれていないが、少量でよりfidelityの高い約270kの翻訳対を利用した模様。また、先行研究に基づいて、many-shotのin-context learningを用いて、訓練データをさらに洗練させたとのこと(先行研究が引用されているのみで詳細な記述は無し)。また、複数の評価ラウンドでスコアの一貫性が無いサンプルは手動でアノテーション、あるいはverificationをして品質を担保している模様。
RLではGRPOを採用し、rewardとしてsemantic([Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
), terminology([Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
; ドメイン特有のterminologyを捉える), repetitionに基づいたrewardを採用している。最終的にSFT->RLで学習されたHuayuan-MT-7Bに対して、下記プロンプトを用いて複数のoutputを統合してより高品質な翻訳を出力するキメラモデルを同様のrewardを用いて学習する、といったpipelineになっている。
関連:
- [Paper Note] Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23, 2023.06
- [Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
- [Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
- [Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22, 2022.07
- [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
- [Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
関連: PLaMo翻訳
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25, 2025.08
こちらはSFT->Iterative DPO->Model Mergeを実施し、翻訳に特化した継続事前学習はやっていないように見える。一方、SFT時点で独自のテンプレートを作成し、語彙の指定やスタイル、日本語特有の常体、敬体の指定などを実施できるように翻訳に特化したテンプレートを学習している点が異なるように見える。Hunyuanは多様な翻訳の指示に対応できるように学習しているが、PLaMo翻訳はユースケースを絞り込み、ユースケースに対する性能を高めるような特化型のアプローチをとるといった思想の違いが伺える。
[Paper Note] Where is the answer? Investigating Positional Bias in Language Model Knowledge Extraction, Kuniaki Saito+, NAACL'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Bias #NAACL #PostTraining #PerplexityCurse #Selected Papers/Blogs #ContextEngineering #Author Thread-Post Issue Date: 2025-05-02 GPT Summary- LLMは新しい文書でファインチューニングが必要だが、「困惑の呪い」により情報抽出が困難。特に文書の初めに関する質問には正確に答えるが、中間や末尾の情報抽出に苦労する。自己回帰的トレーニングがこの問題を引き起こすことを示し、デノイジング自己回帰損失が情報抽出を改善する可能性を示唆。これにより、LLMの知識抽出と新ドメインへの適応に関する新たな議論が生まれる。 Comment
元ポスト:

LLMの知識を最新にするために新しい文書(e.g., 新しいドメインの文書等)をLLMに与え(便宜上学習データと呼ぶ)Finetuningをした場合、Finetuning後のモデルで与えられたqueryから(LLM中にパラメータとしてmemorizeされている)対応する事実情報を抽出するようInferenceを実施すると、queryに対応する事実情報の学習データ中での位置が深くなると(i.e., middle -- endになると)抽出が困難になる Positional Biasが存在する[^1]ことを明らかにした。
そして、これを緩和するために正則化が重要(e.g., Denoising, Shuffle, Attention Drops)であることを実験的に示し、正則化手法は複数組み合わせることで、よりPositional Biasが緩和することを示した研究
[^1]: 本研究では"Training"に利用する文書のPositional Biasについて示しており、"Inference"時におけるPositional Biasとして知られている"lost-in-the middle"とは異なる現象を扱っている点に注意
## データセット
文書 + QAデータの2種類を構築しFinetuning後のknowledge extraction能力の検証をしている[^2]。
実験では、`Synthetic Bio (合成データ)`, `Wiki2023+(実データ)` の2種類のデータを用いて、Positional Biasを検証している。
Synthetic bioは、人間のbiographyに関する9つの属性(e.g., 誕生日, 出生地)としてとりうる値をChatGPTに生成させ、3000人の人物に対してそれらをランダムにassignし、sentence templateを用いてSurface Realizationすることで人工的に3000人のbiographyに関するテキストを生成している。
一方、Wiki2023+では、Instruction-tuned Language Models are Better Knowledge Learners, Zhengbao Jiang+, ACL'24
の方法にのっとって [^3]事前学習時の知識とのoverlapが最小となるように`2023`カテゴリ以下のwikipediaの様々なジャンルの記事を収集して活用する。QAデータの構築には、元文書からsentenceを抽出し、GPT-3.5-Turboに当該sentenceのみを与えてQA pairを作成させることで、データを作成している。なお、hallucinationや品質の低いQA pairをフィルタリングした。フィルタリング後のQA Pairをランダムにサンプリングし品質を確認したところ、95%のQA pairが妥当なものであった。
これにより、下図のようなデータセットが作成される。FigureCが `Wiki2023+`で、FigureDが`SyntheticBio`。`Wiki2023+`では、QA pairの正解が文書中の前半により正解が現れるような偏りが見受けられる。

[^2]: [Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
において、知識 + 知識を抽出するタスクの双方を用いて学習することで、モデルから知識を抽出する能力が備わることが示されているため。
[^3]: Llama-2-7Bにおいて2023カテゴリ以下の情報に対するQAのperformanceが著しく低いことから、事前学習時に当該データが含まれている可能性が低いことが示唆されている
## 実験 & 実験結果 (modulated data)
作成した文書+QAデータのデータセットについて、QAデータをtrain/valid/testに分けて、文書データは全て利用し、testに含まれるQAに適切に回答できるかで性能を評価する。このとき、文書中でQAに対する正解がテキストが出現する位置を変化させモデルの学習を行い、予測性能を見ることで、Positional Biasが存在することを明らかにする。このとき、[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
に倣い、文書とQAをMixed Sampling(1バッチあたり256件のサンプルをランダムにQAおよび文書データからサンプリング;
# 1923 では文書とQAを2:8の比率でサンプリングしている)することで学習をする。QAの場合目的関数は回答テキスト部分のみのNLL、文書の場合はnext-token prediction lossを利用する。
Positional Biasの存在を示すだけでなく、(A, B, C) の順番でnext-token prediction lossで学習されたモデルの場合、Cの知識を抽出するためにA, Bがcontextとして必要となるため、Cを抽出する際の汎化性能を高めるためにA, Bの表現がより多様である必要がある、という課題がある。これに対処するためのいくつかのシンプルな正則化手法、具体的には
- D-AR: predition targetのトークンは保持したまま、input tokenの一部をランダムなトークンに置き換える
- Shuffle: 入力文をシャッフルする
- Attn Drop: self-attentionモジュールのattention weightをランダムに0にする
の3種類とPositional Biasの関係性を検証している。

検証の結果、(合成データ、実データともに)Positional Biasが存在することが明らかとなり(i.e., 正解テキストが文書中の深い位置にあればあるほど予測性能が低下する)正則化によってPositional Biasが緩和されることが示された。

また、異なるモデルサイズで性能を比較したところ、モデルサイズを大きくすることで性能自体は改善するが、依然としてPositional Biasが存在することが示され、ARよりもD-ARが一貫して高い性能を示した。このことから、Positional Biasを緩和するために何らかの正則化手法が必要なことがわかる。

また、オリジナル文書の1文目を、正解データの位置を入れ替えた各モデルに対して、テキスト中の様々な位置に配置してPerplexityを測った。この設定では、モデルがPerplexityを最小化するためには、(1文目ということは以前の文脈が存在しないsentenceなので)文脈に依存せずに文の記憶していなければならない。よって、各手法ごとにどの程度Perplexityが悪化するかで、各手法がどの程度あるsentenceを記憶する際に過去の文脈に依存しているかが分かる。ここで、学習データそのもののPerplexityはほぼ1.0であったことに注意する。
結果として、文書中の深い位置に配置されればされるほどPerplexityは増大し(left)、Autoregressive Model (AR) のPerplexity値が最も値が大きかった(=性能が悪かった)。このことから、ARはより過去の文脈に依存してsentenceの情報を記憶していることが分かる。また、モデルサイズが小さいモデルの方がPerplexityは増大する傾向にあることがわかった (middle)。これはFig.3で示したQAのパフォーマンスと傾向が一致しており、学習データそのもののPerplexityがほぼ1.0だったことを鑑みると、学習データに対するPerplexityは様々なPositionに位置する情報を適切に抽出できる能力を測るメトリックとしては適切でないことがわかる。また、学習のiterationを増やすと、ARの場合はfirst positionに対する抽出性能は改善したが、他のpositionでの抽出性能は改善しなかった。一方、D-ARの場合は、全てのpositionでの抽出性能が改善した (right) 。このことから、必ずしも学習のiterationを増やしても様々なPositionに対する抽出性能が改善しないこと、longer trainingの恩恵を得るためには正則化手法を利用する必要があることが明らかになった。

## 実験 & 実験結果 (unmodulated data)
Wiki2023+データに対して上記のようなデータの変更を行わずに、そのまま学習を行い、各位置ごとのQAの性能を測定したところ、(すべてがPositional Biasのためとは説明できないが)回答が文書中の深い位置にある場合の性能が劣化することを確認した。2--6番目の性能の低下は、最初の文ではシンプルな事実が述べられ、後半になればなるほどより複雑な事実が述べられる傾向があることが起因して性能の低下しているとかせつをたてている。また、unmodulated dataの場合でもD-ARはARの性能を改善することが明らかとなった。モデルサイズが大きいほど性能は改善するが、以前として文書中の深い位置に正解がある場合に性能は劣化することもわかる。
また、正則化手法は組み合わせることでさらに性能が改善し、[Paper Note] Physics of Language Models: Part 3.1, Knowledge Storage and Extraction, Zeyuan Allen-Zhu+, ICML'24
に示されている通り、学習データ中の表現を多様にし[^1]学習したところ予測性能が改善し、正則化手法とも補完的な関係であることも示された。
医療ドメインでも実験したところ、正則化手法を適用した場合にARよりも性能が上回った。最後にWiki2023+データについてOpenbookな設定で、正解が含まれる文書をLLMのcontextとして与えた場合(i.e.,ほぼ完璧なretrieverが存在するRAGと同等の設定とみなせる)、QAの性能は90.6%に対し、継続学習した場合のベストモデルの性能は50.8%だった。このことから、正確なretrieverが存在するのであれば、継続学習よりもRAGの方がQAの性能が高いと言える。
RAGと継続学習のメリット、デメリットの両方を考慮して、適切に手法を選択することが有効であることが示唆される。
[^1]: ChatGPTによってテキストをrephraseし、sentenceのorderも変更することで多様性を増やした。が、sentence orderが文書中の深い位置にある場合にあまりorderが変化しなかったようで、このため深い位置に対するQAの性能改善が限定的になっていると説明している。
[Paper Note] TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks, Frank F. Xu+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #NeurIPS #Selected Papers/Blogs #Author Thread-Post Issue Date: 2025-01-03 GPT Summary- 大規模言語モデル(LLMs)によるAIエージェントの進展が、日常業務の効率化にどのように寄与するかを探求。TheAgentCompanyを通じて、AIエージェントがデジタル労働者のように働く能力を評価する拡張可能なベンチマークを導入。模擬のソフトウェア企業環境で、タスクの自律的完了率は30%に達し、単純なタスクは成功する一方、複雑な長期タスクは今のモデルでは難しいことを示す。 Comment
元ポスト:
ソフトウェアエンジニアリングの企業の設定で現実に起こりうるな 175種類のタスクを定義してAI Agentを評価できるベンチマークTheAgentCompanyを提案。
既存のベンチマークより、多様で、実際のソフトウェアエンジニアリング企業でで起こりうる幅広いタスクを持ち、タスクの遂行のために同僚に対して何らかのインタラクションが必要で、達成のために多くのステップが必要でかつ個々のステップ(サブタスク)を評価可能で、多様なタスクを遂行するために必要な様々なインタフェースをカバーし、self hostingして結果を完全に再現可能なベンチマークとなっている模様。
(画像は著者ツイートより引用)
プロプライエタリなモデルとOpenWeightなモデルでAI Agentとしての能力を評価した結果、Claude-3.5-sonnetは約24%のタスクを解決可能であり、他モデルと比べて性能が明らかに良かった。また、Gemini-2.0-flashなコストパフォーマンスに優れている。OpenWeightなモデルの中ではLlama3.3-70Bのコストパフォーマンスが良かった。タスクとしては具体的に評価可能なタスクのみに焦点を当てており、Open Endなタスクでは評価していない点に注意とのこと。
まだまだAI Agentが完全に'同僚'として機能することとは現時点ではなさそうだが、このベンチマークのスコアが今後どこまで上がっていくだろうか。
openreview: https://openreview.net/forum?id=LZnKNApvhG
[Paper Note] Large Concept Models: Language Modeling in a Sentence Representation Space, LCM team+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#Sentence #NLP #LanguageModel #Tokenizer #Concept (LLM PreTraining) Issue Date: 2024-12-24 GPT Summary- 大規模言語モデル(LLMs)の限界を克服するために、概念を用いた新しいアーキテクチャ「Large Concept Model」を提案。これは、テキストと音声の両方に対応し、200言語をサポートする文埋め込み空間SONARを活用。自己回帰的な文予測に基づき、複数のアプローチ(MSE回帰や拡散ベース生成)で実験し、パラメータを増加させたモデルでも印象的なゼロショット一般化性能を示す。訓練コードは公開されている。 Comment
まだ全く読めていないが、従来のLLMはnent-token-predictionで学習をしており、transformers decoderの内部状態で何らかの抽象的な概念はとらえているものの、次トークン予測に前回生成したトークンをinputするのが必須である以上「トークンで考える」みたいな挙動をある程度はしてしまっており、人間はそんなことしないですよね?みたいな話だと思われる。
人間はもっと抽象的なコンセプトレベルで物事を考えることができるので、それにより近づけるために、conceptをsentenceとしてみなして、next-concept-predictionでモデルを学習したらゼロショットの汎化性能上がりました、みたいな話のように見える。ただし、評価をしているのはマルチリンガルな文書要約タスクのみに見える。
追記: コンセプトが言語非依存だとすると、コンセプト間の関係性を学習するLCMが、マルチリンガルでトークンレベルの学習しかしない従来LLMを上回るのも納得いく気はする。なぜなら、従来LLMよりも言語(トークン)への依存が緩和されていると思われるので、言語間を跨いだ知識の転移が起きやすいと考えられるからである。
Base-LCMを見ると、文の埋め込みのground truthと生成された文の埋め込みの差を最小化する(Mean Squared Error) ようなlossになっている。つまり、トークンレベルではなく、より抽象的な概念を直接学習するような設計になっているためここが従来のLLMと異なる。
これを実現するために、ground truthとなる文の埋め込みx_nが分からなければいけないが、このために、freezeしたEncoderとDecoderを用意してLCMにconcatしていると思われる。つまり、入力と出力のconceptを解釈する機構は固定して、正解となる文埋め込みを決めてしまう。そして、LCMはinputされたconceptを別のconceptに変換するような機構となっており、その変換の関係性を学習している。なるほど、なんとなく気持ちはわかった。
日本語を含むいくつかの言語でゼロショット性能が低下しているのが興味深い。日本語特有の概念とか、特定の言語固有の概念は欠落する可能性が示唆される。
[Paper Note] Collaborative Contrastive Network for Click-Through Rate Prediction, Chen Gao+, arXiv'24
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CTRPrediction #ContrastiveLearning Issue Date: 2024-11-19 GPT Summary- EコマースプラットフォームにおけるCTR予測の課題を解決するために、「コラボレーティブコントラストネットワーク(CCN)」を提案。CCNは、ユーザーの興味と不興を示すアイテムクラスターを特定し、トリガーアイテムへの依存を減少させる。オンラインA/Bテストにより、タオバオでCTRを12.3%、注文量を12.7%向上させる成果を達成。 Comment
参考: [Mini-appの定義生成結果(Hallucinationに注意)](
https://www.perplexity.ai/search/what-is-the-definition-of-the-sW4uZPZIQe6Iq53HbwuG7Q)
論文中の図解: Mini-appにトリガーとなるアイテムを提示するTrigger-Induced-Recommendation(TIR)
## 概要
図3に示されているような Collaborative Contrastive Network (CCN)を提案しており、このネットワークは、Collaborative Constrastive Learningに基づいて学習される。
### Collaborative Constrasitve Learning
図2がCollaborative Constrastive Learningの気持ちを表しており、図2のようなクリックスルーログが与えられたとする。
推薦リストを上から見ていき、いま着目しているアイテムをtarget_itemとすると、target_itemがクリックされている場合、同じcontext(i.e., ユーザにページ内で提示されたアイテム群)のクリックされているアイテムと距離が近くなり、逆にクリックされていないアイテム群とは距離が遠いとみなせる。逆にtarget_itemがクリックされていない場合、同様にクリックされていないアイテムとは距離が近く、クリックされているアイテムとは距離が遠いとみなせる。このように考えると、ある推薦リストが与えられた時に、あるtarget_itemに着目すると、contrastive learningのためのpositive example/negative exampleを生成できる。このようなco-click/co-non-clickの関係から、アイテム同士の距離を学習し、ユーザのinterest/disinterestを学習する。
### Collaborative Contrastive Network
Collaborative ModuleとCTR Moduleに分かれている。
- Collaborative Moduleには、context itemsと、target itemをinputとし両者の関係性をエンコードする
- このとき、トリガーアイテムのembeddingとアダマール積をとることで、トリガーアイテムの情報も考慮させる
- CTR Moduleは、context itemsとtarget itemの関係性をエンコードしたembedding、target_item, trigger_itemのembedding, user profileのembedding, userのlong-termとshort-termの行動のembeddingをconcatしたベクトルをinputとして受け取り、そらからtarget_itemのCTRを予測する。
- Loss Functionは、binary cross entropyと、Collaborative Contrastive Lossをλで重みづけして足し合わせたものであり、Collaborative Contrastive Loss L_CMCは、上述の気持ちを反映するloss(i.e., target_itemとcontext_itemco-click/co-non-clickに基づいて、アイテム間の距離を最小/最大化するようなloss)となっている
## 実験結果
### offline evaluation
Table 1に示したTaobaoで収集した非常に大規模なproprietary datasetでCTRを予測したところ、AUCはベースラインと比較して高くなった。ここで、TANはCCNのBackboneモデルで、Contrastive Learningを実施していないモデルである。CTR予測においてAUCが高くなるというのはすなわち、クリックされたアイテムi/クリックされなかったアイテムjの2つをとってきたときに、両者のCTR予測結果が CTR_i > CTR_j になる割合が高くなった(i.e. クリックされているアイテムの方が高いCTR予測結果となっている)ということを意味する。
### online A/B Testing
A/Bテストまで実施しており、実際に提案手法を組み込んだ結果、高いCTRを獲得しているだけでなく、CVRも向上している。すごい。
Contrastive Learningを実施しないTANと、CCNを比較してもCCNの方が高いCTR, CVRを獲得している。Contrastive Learning有能。
PLUG: Leveraging Pivot Language in Cross-Lingual Instruction Tuning, Zhihan Zhang+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #CrossLingual #ACL #PostTraining Issue Date: 2024-09-19 GPT Summary- 指示チューニングはLLMsの指示理解を向上させるが、低リソース言語では課題がある。これに対処するため、英語をピボット言語とするPLUGアプローチを提案。モデルはまず英語で指示を処理し、次にターゲット言語で応答を生成。4つの言語での評価により、指示に従う能力が平均29%向上した。さらに、他のピボット言語を用いた実験も行い、アプローチの多様性を確認。コードとデータは公開されている。 Comment
# 概要
cross-lingualでinstruction tuningをする手法。target言語のInstructionが与えられたときに、Pivotとなる言語でInstructionとResponseを生成した後、targetとなる言語に翻訳するようなデータ(それぞれをseparatorを用いてconcatする)でInstruction Tuningすることでtarget言語での性能が向上
# 評価
ゼロショットのOpen-end GenerationタスクでInstruction Tuningされたモデルが評価されるが、既存のマルチリンガルの評価セットはサンプル数が小さく、機械翻訳ベースのものはノイジーという課題がある。このため、著者らは評価する4言語(low-resource language)のプロの翻訳家を雇用し、AlpacaEvalを翻訳し、4言語(Chinese, Korean, Italian, Spanish)のinstructionが存在するパラレルコーパス X-AlpacaEvalを作成し評価データとして用いる。
利用するFoundationモデルは以下の3種類で、
- LLaMA-2-13B (英語に特化したモデル)
- PolyLM-13B (マルチリンガルなモデル)
- PolyLM-Instruct-Instruct (PolyLM-13Bをinstruction tuningしたもの)
これらに対して学習データとしてGPT4-Alpaca [Paper Note] Instruction Tuning with GPT-4, Baolin Peng+, arXiv'23, 2023.04
instruction-tuning dataset (52kのインストラクションが存在) を利用する。GPT4-AlpacaをChatGPTによって4言語に翻訳し、各言語に対するinstruction tuning datasetを得た。
比較手法として以下の5種類と比較している。ここでターゲット言語は今回4種類で、それぞれターゲット言語ごとに独立にモデルを学習している。
- Pivot-only training: pivot言語(今回は英語)のみで学習した場合
- Monolingual response training: pivot言語とtarget言語のデータを利用した場合
- Code Switching: Monolingual response trainingに加えて、pivot言語とtarget言語のinput/outputをそれぞれ入れ替えたデータセットを用いた場合(i.e. pivot言語 input-target言語 output, target言語 input-pivot言語 outputのペアを作成し学習データに利用している)
- Auxiliary translation tasks: Monolingual respones trainingに加えて、翻訳タスクを定義し学習データとして加えた場合。すなわち、input, outputそれぞれに対して、pivot言語からtarget言語への翻訳のサンプル ([P_trans;x^p], x^t)と([P_trans;y^p], y^t)を加えて学習している。ここで、P_transは翻訳を指示するpromptで、;は文字列のconcatnation。x^p, y^p, x^t, y^tはそれぞれ、pivot言語のinput, output、target言語のinput, outputのサンプルを表す。
- PLUG(提案手法): Pivot-only Trainingに加えて、target言語のinputから、pivot言語のinput/output -> target言語のoutputをconcatしたテキスト(x^t, [x^p;y^p;y^t]) を学習データに加えた場合
評価する際は、MT-Bench [Paper Note] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Lianmin Zheng+, NeurIPS'23, 2023.06
のように、GPT4を用いた、direct pair-wise comparisonを行っている。
direct pair-wise comparisonは、2つのサンプルを与えてLLMに何らかの判断やスコアリングをさせる方法であり、今回はどちらがinstructionにより従っているかに勝敗/引き分けをGPT4に判断させている。LLMによる生成はサンプルの順番にsensitiveなので、順番を逆にした場合でも実験をして、win-lose rateを求めている。1つのサンプルペアに対して、サンプルの順番を正順と逆順の2回評価させ、その双方の結果を用いて最終的なwin/lose/tieを決めている。端的に言うと、勝敗が2-0ならそのサンプルの勝ち、同様に1-1なら引き分け、0-2なら負け、ということである。
[Paper Note] Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, CVPR'24, 2023.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #NLP #Transformer #InstructionTuning #MultiModal #SpeechProcessing #CVPR #Selected Papers/Blogs #Encoder-Decoder #Robotics #UMM #EmbodiedAI #KeyPoint Notes Issue Date: 2023-12-29 GPT Summary- 初の自己回帰型マルチモーダルモデル「Unified-IO 2」を提案し、画像、テキスト、音声、アクションを統一した意味空間で処理。トレーニングの安定化のためにアーキテクチャを改善し、120のデータセットで微調整を行い、GRITベンチマークで最先端のパフォーマンスを達成。35以上のベンチマークにおいて強力な結果を示し、すべてのモデルを公開。 Comment
画像、テキスト、音声、アクションを理解できる初めてのautoregressive model。AllenAI
モデルのアーキテクチャ図
マルチモーダルに拡張したことで、訓練が非常に不安定になったため、アーキテクチャ上でいくつかの工夫を加えている:
- 2D Rotary Embedding
- Positional EncodingとしてRoPEを採用
- 画像のような2次元データのモダリティの場合はRoPEを2次元に拡張する。具体的には、位置(i, j)のトークンについては、Q, Kのembeddingを半分に分割して、それぞれに対して独立にi, jのRoPE Embeddingを適用することでi, j双方の情報を組み込む。
- QK Normalization
- image, audioのモダリティを組み込むことでMHAのlogitsが非常に大きくなりatteetion weightが0/1の極端な値をとるようになり訓練の不安定さにつながった。このため、dot product attentionを適用する前にLayerNormを組み込んだ。
- Scaled Cosine Attention
- Image Historyモダリティにおいて固定長のEmbeddingを得るためにPerceiver Resamplerを扱ったているが、こちらも上記と同様にAttentionのlogitsが極端に大きくなったため、cosine類似度をベースとしたScaled Cosine Attention [Paper Note] Swin Transformer V2: Scaling Up Capacity and Resolution, Ze Liu+, arXiv'21
を利用することで、大幅に訓練の安定性が改善された。
- その他
- attention logitsにはfp32を適用
- 事前学習されたViTとASTを同時に更新すると不安定につながったため、事前学習の段階ではfreezeし、instruction tuningの最後にfinetuningを実施
目的関数としては、Mixture of Denoisers (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)に着想を得て、Multimodal Mixture of Denoisersを提案。MoDでは、
- \[R\]: 通常のspan corruption (1--5 token程度のspanをmaskする)
- \[S\]: causal language modeling (inputを2つのサブシーケンスに分割し、前方から後方を予測する。前方部分はBi-directionalでも可)
- \[X\]: extreme span corruption (12>=token程度のspanをmaskする)
の3種類が提案されており、モダリティごとにこれらを使い分ける:
- text modality: UL2 (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
)を踏襲
- image, audioがtargetの場合: 2つの類似したパラダイムを定義し利用
- \[R\]: patchをランダムにx%マスクしre-constructする
- \[S\]: inputのtargetとは異なるモダリティのみの情報から、targetモダリティを生成する
訓練時には prefixとしてmodality token \[Text\], \[Image\], \[Audio\] とparadigm token \[R\], \[S\], \[X\] をタスクを指示するトークンとして利用している。
また、image, audioのマスク部分のdenoisingをautoregressive modelで実施する際には普通にやるとdecoder側でリークが発生する(a)。これを防ぐには、Encoder側でマスクされているトークンを、Decoder側でteacher-forcingする際にの全てマスクする方法(b)があるが、この場合、生成タスクとdenoisingタスクが相互に干渉してしまいうまく学習できなくなってしまう(生成タスクでは通常Decoderのinputとして[mask]が入力され次トークンを生成する、といったことは起きえないが、愚直に(b)をやるとそうなってしまう)。ので、(c)に示したように、マスクされているトークンをinputとして生成しなければならない時だけ、マスクを解除してdecoder側にinputする、という方法 (Dynamic Masking) でこの問題に対処している。
[Paper Note] LaMP: When Large Language Models Meet Personalization, Alireza Salemi+, ACL'24, 2023.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #PersonalizedGeneration #ACL Issue Date: 2023-04-26 GPT Summary- 本論文は大規模言語モデルにおける個別化の重要性を示し、個別化出力を生成するための新しい評価フレームワーク「LaMPベンチマーク」を提案。LaMPは多様な言語タスクを網羅し、個々のユーザープロフィールに基づく複数のエントリを提供。7つの個別化タスクを含み、2つの取得補強アプローチを提案して出力のパーソナライズを図る。広範な実験により、提案手法の有効性と自然言語タスクにおける個別化の影響が確認された。 Comment
# 概要
Personalizationはユーザのニーズや嗜好に応えるために重要な技術で、IRやRecSysで盛んに研究されてきたが、NLPではあまり実施されてこなかった。しかし、最近のタスクで、text classificationやgeneration taskでPersonalizationの重要性が指摘されている。このような中で、LLMでpersonalizedなレスポンスを生成し、評価することはあまり研究されていない。そこで、LaMPベンチマークを生成し、LLMにおけるPersonalizationをするための開発と評価をするための第一歩として提案している。
# Personalizing LLM Outputs
LLMに対してPersonalizedなoutputをさせるためには、profileをpromptに埋め込むことが基本的なアプローチとなる。
## Problem Formulation
まず、user profile(ユーザに関するrecordの集合)をユーザとみなす。データサンプルは以下の3つで構成される:
- x: モデルのinputとなるinput sequence
- y: モデルが生成することを期待するtarget output
- u: user profile(ユーザの嗜好やrequirementsを捉えるための補助的な情報)
そして、p(y | x, u) を最大化する問題として定式化される。それぞれのユーザuに対して、モデルは{(x_u1, y_u1,)...(x_un, y_un)}を利用することができる。
## A Retrieval Augmentation Approach for Personaliozing LLMs
user profileは基本的にめちゃめちゃ多く、promptに入れ込むことは非現実的。そこで、reteival augmentation approachと呼ばれる手法を提案している。LLMのcontext windowは限られているので、profileのうちのsubsetを利用することが現実的なアプローチとなる。また、必ずしも全てのユーザプロファイルがあるタスクを実施するために有用とは限らない。このため、retrieval augmentation approachを提案している。
retrieval augmentation approachでは、現在のテストケースに対して、relevantな部分ユーザプロファイルを選択的に抽出するフレームワークである。
(x_i, y_i)に対してpersonalizationを実現するために、3つのコンポーネントを採用している:
1. query generation function: x_iに基づきuser profileからrelevantな情報を引っ張ってくるquery qを生成するコンポーネント
2. retrieval model R(q, P_u, k): query q, プロファイルP_u, を用いて、k個のrelevantなプロファイルを引っ張ってくるモデル
3. prompt construction function: xとreteival modelが引っ張ってきたエントリからpromptを作成するコンポーネント
1, 2, 3によって生成されたprompt x^barと、yによってモデルを訓練、あるいは評価する。
この研究では、Rとして Contriever Contrirever
, BM25, random selectionの3種類を用いている。
# LaMPベンチマーク
GLUEやSuper Glue、KILT、GENといったベンチマークは、"one-size-fits-all"なモデリングと評価を前提としており、ユーザのニーズに答えるための開発を許容していない。一方で、LaMPは、以下のようなPersonalizationが必要なさまざまなタスクを統合して作成されたデータセットである。
- Personalized Text Classification
- Personalized Citation Identification (binary classification)
- Task definition
- user u が topic xに関する論文を書いたときに、何の論文をciteすべきかを決めるタスク
- user uが書いた論文のタイトルが与えられたとき、2つのcandidate paperのうちどちらをreferenceとして利用すべきかを決定する2値分類
- Data Collection
- Citation Network Datasetを利用。最低でも50本以上論文を書いているauthorを抽出し、authorの論文のうちランダムに論文と論文の引用を抽出
- negative document selectionとして、ランダムに共著者がciteしている論文をサンプリング
- Profile Specification
- ユーザプロファイルは、ユーザが書いた全てのpaper
- titleとabstractのみをuser profileとして保持した
- Evaluation
- train/valid/testに分け、accuracyで評価する
- Personalized News Categorization (15 category分類)
- Task definition
- LLMが journalist uによって書かれたニュースを分類する能力を問うタスク
- u によって書かれたニュースxが与えられた時、uの過去の記事から得られるカテゴリの中から該当するカテゴリを予測するタスク
- Data Collection
- news categorization datasetを利用(Huff Postのニュース)
- 記事をfirst authorでグルーピング
- グルーピングした記事群をtrain/valid/testに分割
- それぞれの記事において、記事をinputとし、その記事のカテゴリをoutputとする。そして残りの記事をuser profileとする。
- Profile Specification
- ユーザによって書かれた記事の集合
- Evaluation
- accuracy, macro-averaged F1で評価
- Personalized Product Rating (5-star rating)
- Task definition
- ユーザuが記述したreviewに基づいて、LLMがユーザuの未知のアイテムに対するratingを予測する性能を問う
- Data Collection
- Amazon Reviews Datasetを利用
- reviewが100件未満、そしてほとんどのreviewが外れ値なユーザ1%を除外
- ランダムにsubsetをサンプリングし、train/valid/testに分けた
- input-output pairとしては、inputとしてランダムにユーザのreviewを選択し、その他のreviewをprofileとして利用する。そして、ユーザがinputのレビューで付与したratingがground truthとなる。
- Profile Specification
- ユーザのレビュ
- Evaluation
- ttrain/valid/testに分けてRMSE, MAEで評価する
- Personalized Text Generation
- Personalized News Headline Generation
- Task definition
- ユーザuが記述したニュースのタイトルを生成するタスク
- 特に、LLMが与えられたprofileに基づいてユーザのinterestsやwriting styleを捉え、適切にheadlinに反映させる能力を問う
- Data Collection
- News Categorization datasetを利用(Huff Post)
- データセットではauthorの情報が提供されている
- それぞれのfirst authorごとにニュースをグルーピングし、それぞれの記事をinput, headlineをoutputとした。そして残りの記事をprofileとした
- Profile Specification
- ユーザの過去のニュース記事とそのheadlineの集合をprofileとする
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Scholarly Title Generation
- Task Definition
- ユーザの過去のタイトルを考慮し、LLMがresearch paperのtitleを生成する能力を測る
- Data Collection
- Citation Network Datasetのデータを利用
- abstractをinput, titleをoutputとし、残りのpaperをprofileとした
- Profile Specification
- ユーザが書いたpaperの集合(abstractのみを利用)
- Personalized Email Subject Generation
- Task Definition
- LLMがユーザのwriting styleに合わせて、Emailのタイトルを書く能力を測る
- Data Collection
- Avocado Resaerch Email Collectionデータを利用
- 5単語未満のsubjectを持つメール、本文が30単語未満のメールを除外、
- 送信主のemail addressでメールをグルーピング
- input _outputペアは、email本文をinputとし、対応するsubjectをoutputとした。他のメールはprofile
- Profile Specification
- ユーザのemailの集合
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Tweet Paraphrasing
- Task Definition
- LLMがユーザのwriting styleを考慮し、ツイートのparaphrasingをする能力を問う
- Data Collection
- Sentiment140 datasetを利用
- 最低10単語を持つツイートのみを利用
- userIDでグルーピングし、10 tweets以下のユーザは除外
- ランダムに1つのtweetを選択し、ChatGPT(gpt-3.5-turbo)でparaphraseした
- paraphrase版のtweetをinput, 元ツイートをoutputとし、input-output pairを作った。
- User Profile Specification
- ユーザの過去のツイート
- Evaluation
- ROUGE-1, ROUGE-Lで評価
# 実験
## Experimental Setup
- FlanT5-baesをfinetuningした
- ユーザ単位でモデルが存在するのか否かが記載されておらず不明
## 結果
- Personalization入れた方が全てのタスクでよくなった
- Retrievalモデルとしては、randomの場合でも良くなったが、基本的にはContrirverを利用した場合が最も良かった
- => 適切なprofileを選択しpromptに含めることが重要であることが示された
- Rが抽出するサンプル kを増やすと、予測性能が増加する傾向もあったが、一部タスクでは性能の低下も招いた
- dev setを利用し、BM25/Contrieverのどちらを利用するか、kをいくつに設定するかをチューニングした結果、全ての結果が改善した
- FlanT5-XXLとgpt-3.5-turboを用いたZero-shotの設定でも実験。tweet paraphrasingタスクを除き、zero-shotでもuser profileをLLMで利用することでパフォーマンス改善。小さなモデルでもfinetuningすることで、zero-shotの大規模モデルにdownstreamタスクでより高い性能を獲得することを示している(ただし、めちゃめちゃ改善しているというわけでもなさそう)。


# LaMPによって可能なResearch Problem
## Prompting for Personalization
- Augmentationモデル以外のLLMへのユーザプロファイルの埋め込み方法
- hard promptingやsoft prompting [Paper Note] The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester+, EMNLP'21, 2021.04
の活用
## Evaluation of Personalized Text Generation
- テキスト生成で利用される性能指標はユーザの情報を評価のプロセスで考慮していない
- Personalizedなテキスト生成を評価するための適切なmetricはどんなものがあるか?
## Learning to Retrieve from User Profiles
- Learning to RankをRetrieval modelに適用する方向性
LaMPの作成に利用したテンプレート一覧
実装とleaderboard
https://lamp-benchmark.github.io/leaderboard
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Chain-of-Thought #Prompting #AutomaticPromptEngineering #NAACL #Findings Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。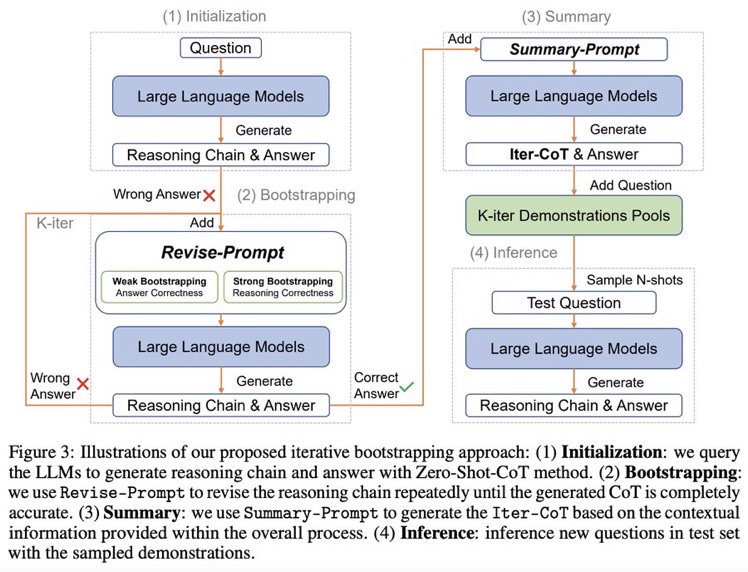
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- [Paper Note] Automatic Chain of Thought Prompting in Large Language Models, Zhuosheng Zhang+, ICLR'23, 2022.10
- [Paper Note] Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, KaShun Shum+, EMNLP'23, 2023.02
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。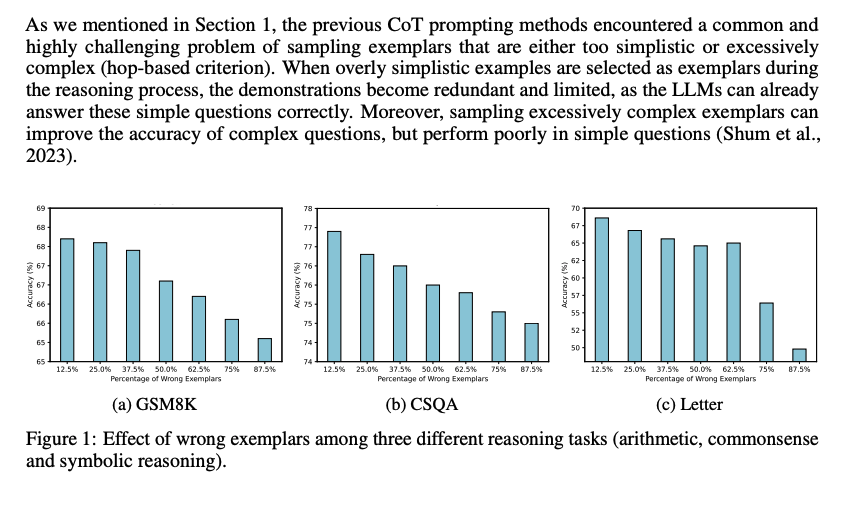
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。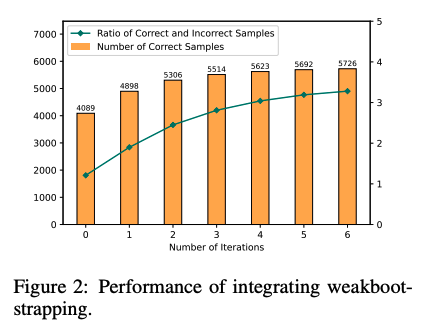
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Random-CoT
- [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Auto-CoT
- [Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。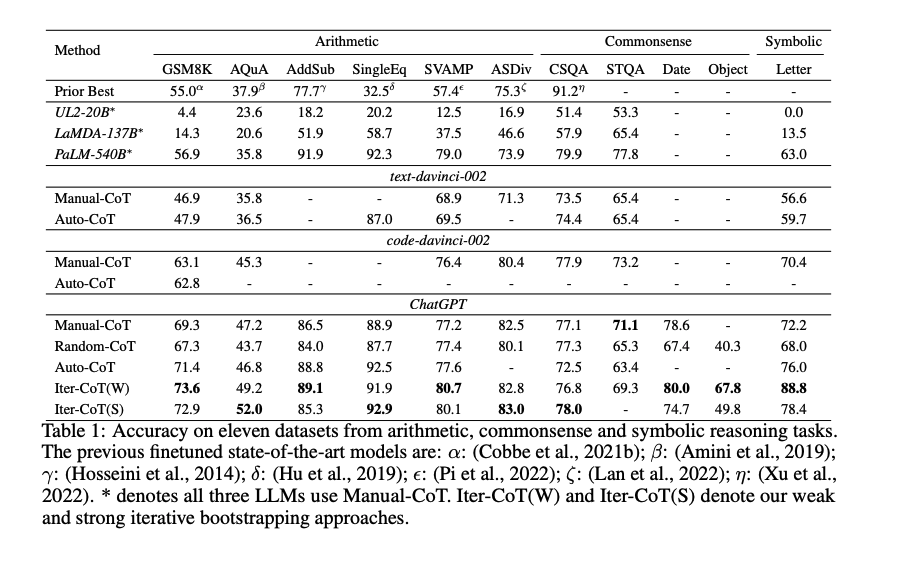
weak bootstrapingのiterationは4回くらいで頭打ちになった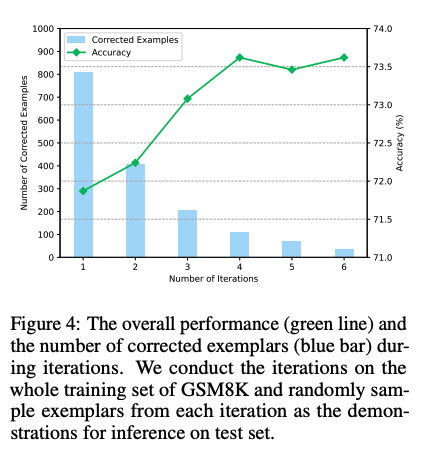
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
[Paper Note] The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #LongSequence #PositionalEncoding #NeurIPS #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-04-06 GPT Summary- 長さ一般化はTransformerベースの言語モデルにおける重要な課題であり、位置エンコーディング(PE)がその性能に影響を与える。5つの異なるPE手法(APE、T5の相対PE、ALiBi、Rotary、NoPE)を比較した結果、ALiBiやRotaryなどの一般的な手法は長さ一般化に適しておらず、NoPEが他の手法を上回ることが明らかになった。NoPEは追加の計算を必要とせず、絶対PEと相対PEの両方を表現可能である。さらに、スクラッチパッドの形式がモデルの性能に影響を与えることも示された。この研究は、明示的な位置埋め込みが長いシーケンスへの一般化に必須でないことを示唆している。 Comment
- Llama 4 Series, Meta, 2025.04
において、Llama4 Scoutが10Mコンテキストウィンドウを実現できる理由の一つとのこと。
元ポスト:
Llama4のブログポストにもその旨記述されている:
>A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, we employ inference time temperature scaling of attention to enhance length generalization.
[The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation]( https://ai.meta.com/blog/llama-4-multimodal-intelligence/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4)
斜め読みだが、length generalizationを評価する上でdownstream taskに焦点を当て、3つの代表的なカテゴリに相当するタスクで評価したところ、この観点においてはT5のrelative positinal encodingとNoPE(位置エンコードディング無し)のパフォーマンスが良く、
NoPEは絶対位置エンコーディングと相対位置エンコーディングを理論上実現可能であり[^1]
実際に学習された異なる2つのモデルに対して同じトークンをそれぞれinputし、同じ深さのLayerの全てのattention distributionの組み合わせからJensen Shannon Divergenceで距離を算出し、最も小さいものを2モデル間の当該layerの距離として可視化すると下記のようになり、NoPEとT5のrelative positional encodingが最も類似していることから、NoPEが学習を通じて(実用上は)相対位置エンコーディングのようなものを学習することが分かった。
[^1]:深さ1のLayerのHidden State H^1から絶対位置の復元が可能であり(つまり、当該レイヤーのHが絶対位置に関する情報を保持している)、この前提のもと、後続のLayerがこの情報を上書きしないと仮定した場合に、相対位置エンコーディングを実現できる。
また、CoT/Scratchpadはlong sequenceに対する汎化性能を向上させることがsmall scaleではあるが先行研究で示されており、Positional Encodingを変化させた時にCoT/Scratchpadの性能にどのような影響を与えるかを調査。
具体的には、CoT/Scratchpadのフォーマットがどのようなものが有効かも明らかではないので、5種類のコンポーネントの組み合わせでフォーマットを構成し、mathematical reasoningタスクで以下のような設定で訓練し
- さまざまなコンポーネントの組み合わせで異なるフォーマットを作成し、
- 全ての位置エンコーディングあり/なしモデルを訓練
これらを比較した。この結果、CoT/Scratchpadはフォーマットに関係なく、特定のタスクでのみ有効(有効かどうかはタスク依存)であることが分かった。このことから、CoT/Scratcpad(つまり、モデルのinputとoutputの仕方)単体で、long contextに対する汎化性能を向上させることができないので、Positional Encoding(≒モデルのアーキテクチャ)によるlong contextに対する汎化性能の向上が非常に重要であることが浮き彫りになった。
また、CoT/Scratchpadが有効だったAdditionに対して各Positional Embeddingモデルを学習し、生成されたトークンのattentionがどの位置のトークンを指しているかを相対距離で可視化したところ(0が当該トークン、つまり現在のScratchpadに着目しており、1が遠いトークン、つまりinputに着目していることを表すように正規化)、NoPEとRelative Positional Encodingがshort/long rangeにそれぞれフォーカスするようなbinomialな分布なのに対し、他のPositional Encodingではよりuniformな分布であることが分かった。このタスクにおいてはNoPEとRelative POの性能が高かったため、binomialな分布の方がより最適であろうことが示唆された。
[Paper Note] Recommender Systems in the Era of Large Language Models (LLMs), Zihuai Zhao+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #read-later #Selected Papers/Blogs Issue Date: 2024-12-03 GPT Summary- LLMsの出現により、レコメンダーシステムが進化し、ユーザーの嗜好に基づくパーソナライズが可能に。従来のDNN法の限界を克服するため、LLMsを活用したレコメンドシステムの概要を提供。具体的には、事前学習、ファインチューニング、プロンプティングの観点から最近の手法をレビューし、この分野の今後の発展方向を論じる。 Comment
中身を全然読んでいる時間はないので、図には重要な情報が詰まっていると信じ、図を読み解いていく。時間がある時に中身も読みたい。。。
LLM-basedなRecSysでは、NLPにおけるLLMの使い方(元々はT5で提案)と同様に、様々なレコメンド関係タスクを、テキスト生成タスクに落とし込み学習することができる。
RecSysのLiteratureとしては、最初はコンテンツベースと協調フィルタリングから始まり、(グラフベースドな推薦, Matrix Factorization, Factorization Machinesなどが間にあって)、その後MLP, RNN, CNN, AutoEncoderなどの様々なDeep Neural Network(DNN)を活用した手法や、BERT4RecなどのProbabilistic Language Models(PLM)を用いた手法にシフトしていき、現在LLM-basedなRecSysの時代に到達した、との流れである。
LLM-basedな手法では、pretrainingの段階からEncoder-basedなモデルの場合はMLM、Decoder-basedな手法ではNext Token Predictionによってデータセットで事前学習する方法もあれば、フルパラメータチューニングやPEFT(LoRAなど)によるSFTによるアプローチもあるようである。
推薦タスクは、推薦するアイテムIDを生成するようなタスクの場合は、異なるアイテムID空間に基づくデータセットの間では転移ができないので、SFTをしないとなかなかうまくいかないと気がしている。また、その場合はアイテムIDの推薦以外のタスクも同時に実施したい場合は、事前学習済みのパラメータが固定されるPEFT手法の方が安全策になるかなぁ、という気がしている(破壊的忘却が怖いので)。特はたとえば、アイテムIDを生成するだけでなく、その推薦理由を生成できるのはとても良いことだなあと感じる(良い時代、感)。
また、PromptingによるRecSysの流れも図解されているが、In-Context Learningのほかに、Prompt Tuning(softとhardの両方)、Instruction Tuningも同じ図に含まれている。個人的にはPrompt TuningはPEFTの一種であり、Instruction TuningはSFTの一種なので、一つ上の図に含意される話なのでは?という気がするが、論文中ではどのような立て付けで記述されているのだろうか。
どちらかというと、Promptingの話であれば、zero-few-many shotや、各種CoTの話を含めるのが自然な気がするのだが。
下図はPromptingによる手法を表にまとめたもの。Finetuningベースの手法が別表にまとめられていたが、研究の数としてはこちらの方が多そうに見える。が、性能的にはどの程度が達成されるのだろうか。直感的には、アイテムを推薦するようなタスクでは、Promptingでは性能が出にくいような印象がある。なぜなら、事前学習済みのLLMはアイテムIDのトークン列とアイテムの特徴に関する知識がないので。これをFinetuningしないのであればICLで賄うことになると思うのだが、果たしてどこまでできるだろうか…。興味がある。
(図は論文より引用)
[Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N_A, EMNLP'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #LanguageModel #Evaluation #LLM-as-a-Judge Issue Date: 2024-01-25 GPT Summary- 従来の参照ベースの評価指標では、自然言語生成システムの品質を正確に測定することが難しい。最近の研究では、大規模言語モデル(LLMs)を使用した参照ベースの評価指標が提案されているが、まだ人間との一致度が低い。本研究では、G-Evalという大規模言語モデルを使用した品質評価フレームワークを提案し、要約と対話生成のタスクで実験を行った。G-Evalは従来の手法を大幅に上回る結果を示し、LLMベースの評価器の潜在的な問題についても分析している。コードはGitHubで公開されている。 Comment
伝統的なNLGの性能指標が、人間の判断との相関が低いことを示した研究
# 手法概要
- CoTを利用して、生成されたテキストの品質を評価する手法を提案している。
- タスクのIntroductionと、評価のCriteriaをプロンプトに仕込むだけで、自動的にLLMに評価ステップに関するCoTを生成させ、最終的にフォームを埋める形式でスコアをテキストとして生成させ評価を実施する。最終的に、各スコアの生成確率によるweighted-sumによって、最終スコアを決定する。
# Scoringの問題点
たとえば、1-5のdiscreteなスコアを直接LLMにoutputさせると、下記のような問題が生じる:
1. ある一つのスコアが支配的になってしまい、スコアの分散が無く、人間の評価との相関が低くなる
2. LLMは小数を出力するよう指示しても、大抵の場合整数を出力するため、多くのテキストの評価値が同一となり、生成されたテキストの細かな差異を評価に取り入れることができない。
上記を解決するため、下記のように、スコアトークンの生成確率の重みづけ和をとることで、最終的なスコアを算出している。
# 評価
- SummEval SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
データと、Topical-Chat, QAGSデータの3つのベンチマークで評価を実施した。タスクとしては、要約と対話のresponse generationのデータとなる。
- モデルはGPT-3.5 (text-davinci-003), GPT-4を利用した
- gpt3.5利用時は、temperatureは0に設定し、GPT-4はトークンの生成確率を返さないので、`n=20, temperature=1, top_p=1`とし、20回の生成結果からトークンの出現確率を算出した。
## 評価結果
G-EVALがbaselineをoutperformし、特にGPT4を利用した場合に性能が高い。GPTScoreを利用した場合に、モデルを何を使用したのかが書かれていない。Appendixに記述されているのだろうか。
# Analysis
## G-EvalがLLMが生成したテキストを好んで高いスコアを付与してしまうか?
- 人間に品質の高いニュース記事要約を書かせ、アノテータにGPTが生成した要約を比較させたデータ ([Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
) を用いて検証
- その結果、基本的にGPTが生成した要約に対して、G-EVAL4が高いスコアを付与する傾向にあることがわかった。
- 原因1: [Paper Note] Benchmarking Large Language Models for News Summarization, Tianyi Zhang+, arXiv'23, 2023.01
で指摘されている通り、人間が記述した要約とLLMが記述した要約を区別するタスクは、inter-annotator agreementは`0.07`であり、極端に低く、人間でも困難なタスクであるため。
- 原因2: LLMは生成時と評価時に、共通したコンセプトをモデル内部で共有している可能性が高く、これがLLMが生成した要約を高く評価するバイアスをかけた
## CoTの影響
- SummEvalデータにおいて、CoTの有無による性能の差を検証した結果、CoTを導入した場合により高いcorrelationを獲得した。特に、Fluencyへの影響が大きい。
## Probability Normalizationによる影響
- probabilityによるnormalizationを導入したことで、kendall tauが減少した。この理由は、probabilityが導入されていない場合は多くの引き分けを生み出す。一方、kendall tauは、concordant / discordantペアの数によって決定されるが、引き分けの場合はどちらにもカウントされず、kendall tauの値を押し上げる効果がある。このため、これはモデルの真の性能を反映していない。
- 一方、probabilityを導入すると、より細かいな連続的なスコアを獲得することができ、これはspearman-correlationの向上に反映されている。
## モデルサイズによる影響
- 基本的に大きいサイズの方が高いcorrelationを示す。特に、consistencyやrelevanceといった、複雑な評価タスクではその差が顕著である。
- 一方モデルサイズが小さい方が性能が良い観点(engagingness, groundedness)なども存在した。
[Paper Note] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Quantization #ICLR #Selected Papers/Blogs Issue Date: 2023-09-29 GPT Summary- GPTモデルはその優れた性能にもかかわらず、高い計算とストレージコストが課題である。この問題を解決するため、近似二次情報に基づく新しい量子化手法GPTQを提案。GPTQは、1750億パラメータを持つモデルの量子化を約4時間で行い、精度をほとんど失うことなくビット幅を3または4ビットに削減する。また、この手法は圧縮の利得が2倍以上高く、単一のGPUでの推論を可能にし、極端な量子化条件でも合理的な精度を示す。実験により、推論速度が大幅に向上することが確認された。 Comment
# 概要
- 新たなpost-training量子化手法であるGPTQを提案
- 数時間以内に数千億のパラメータを持つモデルでの実行が可能であり、パラメータごとに3~4ビットまで圧縮するが、精度の大きな損失を伴わない
- OPT-175BおよびBLOOM-176Bを、約4時間のGPU時間で、perplexityのわずかな増加で量子化することができた
- 数千億のパラメータを持つ非常に高精度な言語モデルを3-4ビットに量子化可能なことを初めて示した
- 先行研究のpost-training手法は、8ビット(Yao et al., 2022; Dettmers et al., 2022)。
- 一方、以前のtraining-basedの手法は、1~2桁小さいモデルのみを対象としていた(Wu et al., 2022)。
# Background
## Layer-wise quantization
各linear layerがあるときに、full precisionのoutputを少量のデータセットをネットワークに流したときに、quantized weight W^barを用いてreconstructできるように、squared error lossを最小化する方法。
## Optimal Brain quantization (OBQ)
OBQでは equation (1)をWの行に関するsummationとみなす。そして、それぞれの行 **w** をOBQは独立に扱い、ある一つの重みw_qをquantizeするときに、エラーがw_qのみに基づいていることを補償するために他の**w**の全てのquantizedされていない重みをupdateする。式で表すと下記のようになり、Fは残りのfull-precision weightの集合を表している。
この二つの式を、全ての**w**の重みがquantizedされるまで繰り返し適用する。
つまり、ある一個の重みをquantizedしたことによる誤差を補うように、他のまだquantizedされていない重みをupdateすることで、次に別の重みをquantizedする際は、最初の重みがquantizedされたことを考慮した重みに対してquantizedすることになる。これを繰り返すことで、quantizedしたことによる誤差を考慮して**w**全体をアップデートできる、という気持ちだと思う。
この式は高速に計算することができ、medium sizeのモデル(25M parameters; ResNet-50 modelなど)とかであれば、single GPUで1時間でquantizeできる。しかしながら、OBQはO(d_row * d_col^3)であるため、(ここでd_rowはWの行数、d_colはwの列数)、billions of parametersに適用するには計算量が多すぎる。
# Algorithm
## Step 1: Arbitrary Order Insight.
通常のOBQは、量子化誤差が最も少ない重みを常に選択して、greedyに重みを更新していく。しかし、パラメータ数が大きなモデルになると、重みを任意の順序で量子化したとしてもそれによる影響は小さいと考えられる。なぜなら、おそらく、大きな個別の誤差を持つ量子化された重みの数が少ないと考えられ、その重みがプロセスのが進むにつれて(アップデートされることで?)相殺されるため。
このため、提案手法は、すべての行の重みを同じ順序で量子化することを目指し、これが通常、最終的な二乗誤差が元の解と同じ結果となることを示す。が、このために2つの課題を乗り越えなければならない。
## Step2. Lazy Batch-Updates
Fを更新するときは、各エントリに対してわずかなFLOPを使用して、巨大な行列のすべての要素を更新する必要があります。しかし、このような操作は、現代のGPUの大規模な計算能力を適切に活用することができず、非常に小さいメモリ帯域幅によってボトルネックとなる。
幸いにも、この問題は以下の観察によって解決できる:列iの最終的な四捨五入の決定は、この特定の列で行われた更新にのみ影響され、そのプロセスの時点で後の列への更新は関連がない。これにより、更新を「lazy batch」としてまとめることができ、はるかに効率的なGPUの利用が可能となる。(要は独立して計算できる部分は全部一気に計算してしまって、後で一気にアップデートしますということ)。たとえば、B = 128の列にアルゴリズムを適用し、更新をこれらの列と対応するB × Bブロックの H^-1 に格納する。
この戦略は理論的な計算量を削減しないものの、メモリスループットのボトルネックを改善する。これにより、非常に大きなモデルの場合には実際に1桁以上の高速化が提供される。
## Step 3: Cholesky Reformulation
行列H_F^-1が不定になることがあり、これがアルゴリズムが残りの重みを誤った方向に更新する原因となり、該当する層に対して悪い量子化を実施してしまうことがある。この現象が発生する確率はモデルのサイズとともに増加することが実際に観察された。これを解決するために、コレスキー分解を活用して解決している(詳細はきちんと読んでいない)。
# 実験で用いたCalibration data
GPTQのキャリブレーションデータ全体は、C4データセット(Raffel et al., 2020)からのランダムな2048トークンのセグメント128個で構成される。つまり、ランダムにクロールされたウェブサイトからの抜粋で、一般的なテキストデータを表している。GPTQがタスク固有のデータを一切見ていないため「ゼロショット」な設定でquantizationを実施している。
# Language Generationでの評価
WikiText2に対するPerplexityで評価した結果、先行研究であるRTNを大幅にoutperformした。
[Paper Note] Generating User-Engaging News Headlines, Cai+, ACL'23
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #ACL Issue Date: 2023-07-22 GPT Summary- ニュース記事の見出しを個別化するために、ユーザープロファイリングを組み込んだ新しいフレームワークを提案。ユーザーの閲覧履歴に基づいて個別のシグネチャフレーズを割り当て、それを使用して見出しを個別化する。幅広い評価により、提案したフレームワークが多様な読者のニーズに応える個別の見出しを生成する効果を示した。 Comment
# モチベーション
推薦システムのヘッドラインは未だに全員に同じものが表示されており、ユーザが自身の興味とのつながりを正しく判定できるとは限らず、推薦システムの有用性を妨げるので、ユーザごとに異なるヘッドラインを生成する手法を提案した。ただし、クリックベイトは避けるようなヘッドラインを生成しなければならない。
# 手法
1. Signature Phrase Identification
2. User Signature Selection
3. Signature-Oriented Headline Generation
## Signature Phrase Identification
テキスト生成タスクに帰着させる。ニュース記事、あるいはヘッドラインをinputされたときに、セミコロン区切りのSignature Phraseを生成するモデルを用いる。今回は[KPTimes daasetでpretrainingされたBART](
https://huggingface.co/ankur310794/bart-base-keyphrase-generation-kpTimes)を用いた。KPTimesは、279kのニュース記事と、signature
phraseのペアが存在するデータであり、本タスクに最適とのこと。
## User Signature Selection
ターゲットドキュメントdのSignature Phrases Z_dが与えられたとき、ユーザのreading History H_uに基づいて、top-kのuser signature phrasesを選択する。H_uはユーザが読んだニュースのヘッドラインの集合で表現される。あるSignature Phrase z_i ∈ Z_dが与えられたとき、(1)H_uをconcatしたテキストをベクトル化したものと、z_iのベクトルの内積でスコアを計算、あるいは(2) 個別のヘッドラインt_jを別々にエンコーディングし、内積の値が最大のものをスコアとする手法の2種類のエンコーディング方法を用いて、in-batch contrastive learningを用いてモデルを訓練する。つまり、正しいSignature Phraseとは距離が近く、誤ったSignature Phraseとは距離が遠くなるように学習をする。
実際はユーザにとっての正解Signature Phraseは分からないが、今回は人工的に作成したユーザを用いるため、正解が分かる設定となっている。
## Signature-Oriented Headline Generation
ニュース記事d, user signature phrasesZ_d^uが与えられたとき、ヘッドラインを生成するモデルを訓練する。この時も、ユーザにとって正解のヘッドラインは分からないため、既存ニュースのヘッドラインが正解として用いられる。既存ニュースのヘッドラインが正解として用いられていても、そのヘッドラインがそのユーザにとっての正解となるように人工的にユーザが作成されているため、モデルの訓練ができる。モデルはBARTを用いた。
# Dataset
Newsroom, Gigawordコーパスを用いる。これらのコーパスに対して、それぞれ2種類のコーパスを作成する。
1つは、Synthesized User Datasetで、これはUse Signature Selection modelの訓練と評価に用いる。もう一つはheadline generationデータセットで、こちらはheadline generationモデルの訓練に利用する。
## Synthesized User Creation
実データがないので、実ユーザのreading historiesを模倣するように人工ユーザを作成する。具体的には、
1. すべてのニュース記事のSignature Phrasesを同定する
2. それぞれのSignature Phraseと、それを含むニュース記事をマッピングする
3. ランダムにphraseのサブセットをサンプリングし、そのサブセットをある人工ユーザが興味を持つエリアとする。
4. サブセット中のinterest phraseを含むニュース記事をランダムにサンプリングし、ユーザのreading historyとする
train, dev, testセット、それぞれに対して上記操作を実施しユーザを作成するが、train, devはContrastive Learningを実現するために、user signature phrases (interest phrases)は1つのみとした(Softmaxがそうなっていないと訓練できないので)。一方、testセットは1~5の範囲でuser signature phrasesを選択した。これにより、サンプリングされる記事が多様化され、ユーザのreadinig historyが多様化することになる。基本的には、ユーザが興味のあるトピックが少ない方が、よりタスクとしては簡単になることが期待される。また、ヘッドラインを生成するときは、ユーザのsignature phraseを含む記事をランダムに選び、ヘッドラインを背衛星することとした。これは、relevantな記事でないとヘッドラインがそもそも生成できないからである。
## Headline Generation
ニュース記事の全てのsignature phraseを抽出し、それがgivenな時に、元のニュース記事のヘッドラインが生成できるようなBARTを訓練した。ニュース記事のtokenは512でtruncateした。平均して、10個のsignature phraseがニュース記事ごとに選択されており、ヘッドライン生成の多様さがうかがえる。user signature phraseそのものを用いて訓練はしていないが、そもそもこのようにGenericなデータで訓練しても、何らかのphraseがgivenな時に、それにバイアスがかかったヘッドラインを生成することができるので、user signature phrase selectionによって得られたphraseを用いてヘッドラインを生成することができる。
# 評価
自動評価と人手評価をしている。
## 自動評価
人手評価はコストがかかり、特に開発フェーズにおいては自動評価ができることが非常に重要となる。本研究では自動評価し方法を提案している。Headline-User DPR + SBERT, REC Scoreは、User Adaptation Metricsであり、Headline-Article DPR + SBERT, FactCCはArticle Loyalty Metricsである。
### Relevance Metrics
PretrainedなDense Passage Retrieval (DPR)モデルと、SentenceBERTを用いて、headline-user間、headline-article間の類似度を測定する。前者はヘッドラインがどれだけユーザに適応しているが、後者はヘッドラインが元記事に対してどれだけ忠実か(クリックベイトを防ぐために)に用いられる。前者は、ヘッドラインとuser signaturesに対して類似度を計算し、後者はヘッドラインと記事全文に対して類似度を計算する。user signatures, 記事全文をどのようにエンコードしたかは記述されていない。
### Recommendation Score
ヘッドラインと、ユーザのreadinig historyが与えられたときに、ニュースを推薦するモデルを用いて、スコアを算出する。モデルとしては、MIND datsetを用いて学習したモデルを用いた。
### Factual Consistency
pretrainedなFactCCモデルを用いて、ヘッドラインとニュース記事間のfactual consisency score を算出する。
### Surface Overlap
オリジナルのヘッドラインと、生成されたヘッドラインのROUGE-L F1と、Extractive Coverage (ヘッドラインに含まれる単語のうち、ソースに含まれる単語の割合)を用いる。
### 評価結果
提案手法のうち、User Signature Selection modelをfinetuningしたものが最も性能が高かった。エンコード方法は、(2)のヒストリのタイトルとフレーズの最大スコアをとる方法が最も性能が高い。提案手法はUser Adaptationをしつつも、Article Loyaltyを保っている。このため、クリックベイトの防止につながる。また、Vanilla Humanは元記事のヘッドラインであり、Extracitve Coverageが低いため、より抽象的で、かつ元記事に対する忠実性が低いことがうかがえる。
## 人手評価
16人のevaluatorで評価。2260件のニュース記事を収集(113 topic)し、記事のヘッドラインと、対応するトピックを見せて、20個の興味に合致するヘッドラインを選択してもらった。これをユーザのinterest phraseとreading _historyとして扱う。そして、ユーザのinterest phraseを含むニュース記事のうち、12個をランダムに選択し、ヘッドラインを生成した。生成したヘッドラインに対して、
1. Vanilla Human
2. Vanilla System
3. SP random (ランダムにsignature phraseを選ぶ手法)
4. SP individual-N
5. SP individual-F (User Signature Phraseを選択するモデルをfinetuningしたもの)
の5種類を評価するよう依頼した。このとき、3つの観点から評価をした。
1, User adaptation
2. Headline appropriateness
3. Text Quality
結果は以下。
SP-individualがUser Adaptationで最も高い性能を獲得した。また、Vanilla Systemが最も高いHeadline appropriatenessを獲得した。しかしながら、後ほど分析した結果、Vanilla Systemでは、記事のメインポイントを押さえられていないような例があることが分かった(んーこれは正直他の手法でも同じだと思うから、ディフェンスとしては苦しいのでは)。
また、Vanilla Humanが最も高いスコアを獲得しなかった。これは、オーバーにレトリックを用いていたり、一般的な人にはわからないようなタイトルになっているものがあるからであると考えられる。
# Ablation Study
Signature Phrase selectionの性能を測定したところ以下の通りになり、finetuningした場合の性能が良かった。
Headline Generationの性能に影響を与える要素としては、
1. ユーザが興味のあるトピック数
2. User signature phrasesの数
がある。
ユーザのInterest Phrasesが増えていけばいくほど、User Adaptationスコアは減少するが、Article Loyaltyは維持されたままである。このため、興味があるトピックが多ければ多いほど生成が難しいことがわかる。また、複数のuser signature phraseを用いると、factual errorを起こすことが分かった(Billgates, Zuckerbergの例を参照)。これは、モデルが本来はirrelevantなフレーズを用いてcoherentなヘッドラインを生成しようとしてしまうためである。
※interest phrases => gold user signatures という理解でよさそう。
※signature phrasesを複数用いるとfactual errorを起こすため、今回はk=1で実験していると思われる
GPT3にもヘッドラインを生成させてみたが、提案手法の方が性能が良かった(自動評価で)。
なぜPENS dataset [Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
を利用しないで研究したのか?
[Paper Note] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Zhen Qin+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #NLP #LanguageModel #Prompting #NAACL #needs-revision Issue Date: 2023-07-11 GPT Summary- LLMを用いた文書ランキングは有望だが、既存手法を上回るのは難しい。本稿では、既存のpointwiseおよびlistwise手法がLLMに理解されにくいことを指摘し、新たにPairwise Ranking Prompting(PRP)を提案。中規模のオープンソースLLMで、TREC-DLで商用GPT-4を上回る成果を取得し、BEIRタスクでも教師ありベースラインやChatGPTを超えることを示した。PRPの変種によって効率性を向上させ、競争力を持つ結果も達成。 Comment
open source LLMにおいてスタンダードなランキングタスクのベンチマークでSoTAを達成できるようなprompting技術を提案
従来のランキングのためのpromptingはpoint-wiseとlist wiseしかなかったが、前者は複数のスコアを比較するためにスコアのcalibrationが必要だったり、OpenAIなどのAPIはlog probabilityを提供しないため、ランキングのためのソートができないという欠点があった。後者はinputのorderingに非常にsensitiveであるが、listのすべての組み合わせについてorderingを試すのはexpensiveなので厳しいというものであった。このため(古典的なlearning to rankでもおなじみや)pairwiseでサンプルを比較するランキング手法PRPを提案している。
PRPはペアワイズなのでorderを入れ替えて評価をするのは容易である。また、generation modeとscoring mode(outputしたラベルのlog probabilityを利用する; OpenLLMを使うのでlog probabilityを計算できる)の2種類を採用できる。ソートの方法についても、すべてのペアの勝敗からから単一のスコアを計算する方法(AllPair), HeapSortを利用する方法、LLMからのoutputを得る度にon the flyでリストの順番を正しくするSliding Windowの3種類を提案して比較している。
下表はscoring modeでの性能の比較で、GPT4に当時は性能が及んでいなかった20BのOpenLLMで近しい性能を達成している。
また、PRPがinputのorderに対してロバストなことも示されている。
[Paper Note] RISE: Leveraging Retrieval Techniques for Summarization Evaluation, David Uthus+, arXiv'22, 2022.12
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Evaluation #Reference-free #ACL #Findings Issue Date: 2023-08-13 GPT Summary- 自動生成された要約の評価は困難であり、これまでの手法は人間の評価に及ばない。新たに提案されたRISEは、デュアルエンコーダー検索設定を用いて生成要約を評価する手法で、ゴールド標準の参照要約がなくても機能する。特に参照要約がない新たなデータセットに対して効果的であり、SummEvalベンチマークでの実験により、人間の評価と高い相関を示した。RISEはデータ効率性と多言語間の一般化可能性も備えている。 Comment
# 概要
Dual-Encoderを用いて、ソースドキュメントとシステム要約をエンコードし、dot productをとることでスコアを得る手法。モデルの訓練は、Contrastive Learningで行い、既存データセットのソースと参照要約のペアを正例とみなし、In Batch trainingする。
# 分類
Reference-free, Model-based, ソース依存で、BARTScore [Paper Note] BARTScore: Evaluating Generated Text as Text Generation, Weizhe Yuan+, arXiv'21, 2021.06
とは異なり、文書要約データを用いて学習するため、要約の評価に特化している点が特徴。
# モデル
## Contrastive Learning
Contrastive Learningを用い、hard negativeを用いたvariantも検証する。また、訓練データとして3種類のパターンを検証する:
1. in-domain data: 文書要約データを用いて訓練し、ターゲットタスクでどれだけの性能を発揮するかを見る
2. out-of-domain data: 文書要約以外のデータを用いて訓練し、どれだけ新しいドメインにモデルがtransferできるかを検証する
3. in-and-out-domain data: 両方やる
## ハードネガティブの生成
Lexical Negatives, Model Negatives, 双方の組み合わせの3種類を用いてハードネガティブを生成する。
### Lexical Negatives
参照要約を拡張することによって生成する。目的は、もともとの参照要約と比較して、poor summaryを生成することにある。Data Augmentationとして、以下の方法を試した:
- Swapping noun entities: 要約中のエンティティを、ソース中のエンティティンとランダムでスワップ
- Shuffling words: 要約中の単語をランダムにシャッフル
- Dropping words: 要約中の単語をランダムに削除
- Dropping characters: 要約中の文字をランダムに削除
- Swapping antonyms: 要約中の単語を対義語で置換
### Model Negatives
データセットの中から負例を抽出する。目的は、参照要約と類似しているが、負例となるサンプルを見つけること。これを実現するために、まずRISE modelをデータセットでfinetuningし、それぞれのソースドキュメントの要約に対して、類似した要約をマイニングする。すべてのドキュメントと要約をエンコードし、top-nの最も類似した要約を見つけ、これをハードネガティブとして、再度モデルを訓練する。
### 両者の組み合わせ
まずlexical negativesでモデルを訓練し、モデルネガティブの抽出に活用する。抽出したモデルネガティブを用いて再度モデルを訓練することで、最終的なモデルとする。
# 実験
## 学習手法
SummEval SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
を用いて人手評価と比較してどれだけcorrelationがあるかを検証。SummEvalには16種類のモデルのアウトプットに対する、CNN / Daily Mail の100 examplesに対して、品質のアノテーションが付与されている。expert annotationを用いて、Kendall's tauを用いてシステムレベルのcorrelationを計算した。contextが短い場合はT5, 長い場合はLongT5, タスクがマルチリンガルな場合はmT5を用いて訓練した。訓練データとしては
- CNN / Daily Mail
- Multi News
- arXiv
- PubMed
- BigPatent
- SAMSum
- Reddit TIFU
- MLSUM
等を用いた。これによりshort / long contextの両者をカバーできる。CNN / Daily Mail, Reddiit TIFU, Multi-Newsはshort-context, arXiv, PubMed, BigPatent, Multi-News(長文のものを利用)はlonger contextとして利用する。
## 比較するメトリック
ROUGE, chrF, SMS, BARTScore, SMART, BLEURT, BERTScore, Q^2, T5-ANLI, PRISMと比較した。結果をみると、Consistency, Fluency, Relevanceで他手法よりも高い相関を得た。Averageでは最も高いAverageを獲得した。in-domain dataで訓練した場合は、高い性能を発揮した。our-of-domain(SAMSum; Dialogue要約のデータ)データでも高い性能を得た。
# Ablation
## ハードネガティブの生成方法
Data Augmentationは、swapping entity nouns, randomly dropping wordsの組み合わせが最も良かった。また、Lexical Negativesは、様々なデータセットで一貫して性能が良かったが、Model NegativesはCNN/DailyMailに対してしか有効ではなかった。これはおそらく、同じタスク(テストデータと同じデータ)でないと、Model Negativesは機能しないことを示唆している。ただし、Model Negativesを入れたら、何もしないよりも性能向上するから、何らかの理由でlexical negativesが生成できない場合はこっち使っても有用である。
## Model Size
でかい方が良い。in-domainならBaseでもそれなりの性能だけど、結局LARGEの方が強い。
## Datasets
異なるデータセットでもtransferがうまく機能している。驚いたことにデータセットをmixingするとあまりうまくいかず、単体のデータセットで訓練したほうが性能が良い。
LongT5を見ると、T5よりもCorrelationが低く難易度が高い。
最終的に英語の要約を評価をする場合でも、Multilingual(別言語)で訓練しても高いCorrelationを示すこともわかった。
## Dataset Size
サンプル数が小さくても有効に働く。しかし、out-domainのデータの場合は、たとえば、512件の場合は性能が低く少しexampleを増やさなければならない。
[Paper Note] Large Language Models are Zero-Shot Reasoners, Takeshi Kojima+, arXiv'22, 2022.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Zero/Few/ManyShotPrompting #Chain-of-Thought #Prompting #NeurIPS #Selected Papers/Blogs Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)は自然言語処理において少数ショット学習の能力が高く、CoT promptingにより複雑な多段階推論を効果的に引き出す。特に「Let's think step by step」の追加で、ゼロショット推論能力が向上し、様々な論理推論タスクで手作りの例を使わずに性能を大幅に向上させた。例えば、InstructGPTモデルでのMultiArithの精度が17.7%から78.7%へ、GSM8Kが10.4%から40.7%と劇的な改善が見られた。この研究はLLMsの潜在的なゼロショット能力を示し、ファインチューニングや少数ショットの前にその知識を探求する重要性が強調されている。 Comment
Zero-Shot CoT (Let's think step-by-step.)論文

Zero-Shot-CoTは2つのステップで構成される:
- STEP1: Reasoning Extraction
- 元のquestionをxとし、zero-shot-CoTのtrigger sentenceをtとした時に、テンプレート "Q: [X]. A. [T]" を用いてprompt x'を作成
- このprompt x'によって得られる生成テキストzはreasoningのrationaleとなっている。
- STEP2: Answer Extraction
- STEP1で得られたx'とzを用いて、テンプレート "[X'] [Z] [A]" を用いてpromptを作成し、quiestionに対する回答を得る
- このとき、Aは回答を抽出するためのtrigger sentenceである。
- Aはタスクに応じて変更するのが効果的であり、たとえば、multi-choice QAでは "Therefore, among A through E, the answer is" といったトリガーを用いたり、数学の問題では "Therefore, the answer (arabic numerals) is" といったトリガーを用いる。
# 実験結果
表中の性能指標の左側はタスクごとにAnswer Triggerをカスタマイズしたもので、右側はシンプルに"The answer is"をAnswer Triggerとした場合。Zero-shot vs. Zero-shot-CoTでは、Zero-Shot-CoTが多くのb現地マークにおいて高い性能を示している。ただし、commonsense reasoningではperformance gainを得られなかった。これは [Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
で報告されている通り、commonsense reasoningタスクでは、Few-Shot CoTでもLambda135Bで性能が向上せず、Palm540Bで性能が向上したように、モデルのparameter数が足りていない可能性がある(本実験では17種類のモデルを用いているが、特に注釈がなければtext-davinci-002を利用した結果)。
## 他ベースラインとの比較
他のベースラインとarithmetic reasoning benchmarkで性能比較した結果。Few-Shot-CoTには勝てていないが、standard Few-shot Promptingtを大幅に上回っている。
## zero-shot reasoningにおけるモデルサイズの影響
さまざまな言語モデルに対して、zero-shotとzero-shot-CoTを実施した場合の性能比較。[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
と同様にモデルサイズが小さいとZero-shot-CoTによるgainは得られないが、モデルサイズが大きくなると一気にgainが大きくなる。
## Zero-shot CoTにおけるpromptの選択による影響
input promptに対するロバスト性を確認した。instructiveカテゴリ(すなわち、CoTを促すトリガーであれば)性能が改善している。特に、どのようなsentenceのトリガーにするかで性能が大きくかわっている。今回の実験では、"Let's think step by step"が最も高い性能を占め最多。
## Few-shot CoTのprompt選択における影響
CommonsenseQAのexampleを用いて、AQUA-RAT, MultiArithをFew-shot CoTで解いた場合の性能。どちらのケースもドメインは異なるが、前者は回答のフォーマットは共通である。異なるドメインでも、answer format(multiple choice)の場合、ドメインが異なるにもかかわらず、zero-shotと比較して性能が大幅に向上した。一方、answer formatが異なる場合はperformance gainが小さい。このことから、LLMはtask自体よりも、exampleにおけるrepeated formatを活用していることを示唆している。また、CommonSennseをExamplarとして用いたFew-Shot-CoTでは、どちらのデータセットでもZero-Shot-CoTよりも性能が劣化している。つまり、Few-Shot-CoTでは、タスク特有のサンプルエンジニアリングが必要であることがわかる(一方、Zero-shot CoTではそのようなエンジニアリングは必要ない)。
[Paper Note] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Jason Wei+, NeurIPS'22, 2022.01
Paper/Blog Link My Issue
#NLP #LanguageModel #Zero/Few/ManyShotPrompting #Chain-of-Thought #Prompting #NeurIPS #Selected Papers/Blogs Issue Date: 2023-04-27 GPT Summary- 思考の連鎖によって、大規模言語モデルの推論能力が向上することを探求。チェーン・オブ・ソート思考のプロンプトを用いる事例を示し、3つのモデルでの実験を通じて算術や常識、象徴的推論において性能向上を確認。特に、5400億パラメータのモデルに8つのデモをプロンプトとして与えただけで、数学問題のGSM8Kベンチマークで最先端の精度を達成した。 Comment
Chain-of-Thoughtを提案した論文。CoTをする上でパラメータ数が100B未満のモデルではあまり効果が発揮されないということは念頭に置いた方が良さそう。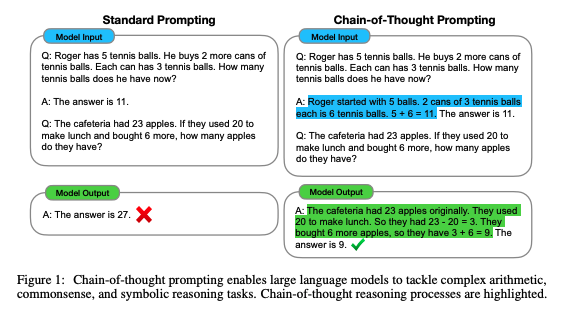
先行研究では、reasoningが必要なタスクの性能が低い問題をintermediate stepを明示的に作成し、pre-trainedモデルをfinetuningすることで解決していた。しかしこの方法では、finetuning用の高品質なrationaleが記述された大規模データを準備するのに多大なコストがかかるという問題があった。
このため、few-shot promptingによってこの問題を解決することが考えられるが、reasoning能力が必要なタスクでは性能が悪いという問題あがった。そこで、両者の強みを組み合わせた手法として、chain-of-thought promptingは提案された。
# CoTによる実験結果
以下のベンチマークを利用
- math word problem: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- commonsense reasoning: CSQA, StrategyQA, Big-bench Effort (Date, Sports), SayCan
- Symbolic Reasoning: Last Letter concatenation, Coin Flip
- Last Letter concatnation: 名前の単語のlast wordをconcatするタスク("Amy Brown" -> "yn")
- Coin Flip: コインをひっくり返す、 あるいはひっくり返さない動作の記述の後に、コインが表向きであるかどうかをモデルに回答するよう求めるタスク
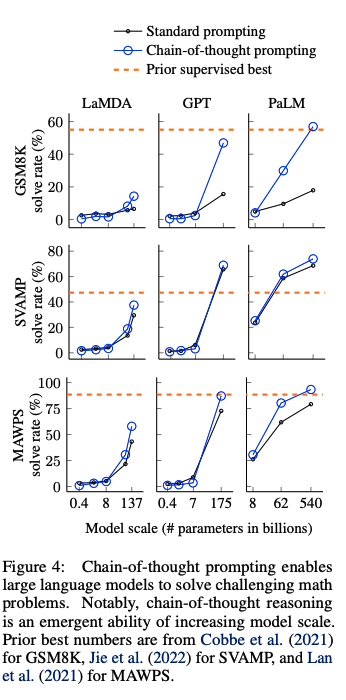
## math word problem benchmark
- モデルのサイズが大きくなるにつれ性能が大きく向上(emergent ability)することがあることがわかる
- 言い換えるとCoTは<100Bのモデルではパフォーマンスに対してインパクトを与えない
- モデルサイズが小さいと、誤ったCoTを生成してしまうため
- 複雑な問題になればなるほど、CoTによる恩恵が大きい
- ベースラインの性能が最も低かったGSM8Kでは、パフォーマンスの2倍向上しており、1 stepのreasoningで解決できるSingleOpやMAWPSでは、性能の向上幅が小さい
- Task specificなモデルをfinetuningした以前のSoTAと比較してcomparable, あるいはoutperformしている
- 
## Ablation Study
CoTではなく、他のタイプのpromptingでも同じような効果が得られるのではないか?という疑問に回答するために、3つのpromptingを実施し、CoTと性能比較した:
- Equation Only: 回答するまえに数式を記載するようなprompt
- promptの中に数式が書かれているから性能改善されているのでは?という疑問に対する検証
- => GSM8Kによる結果を見ると、equation onlyでは性能が低かった。これは、これは数式だけでreasoning stepsを表現できないことに起因している
- Variable compute only: dotのsequence (...) のみのprompt
- CoTは難しい問題に対してより多くの計算(intermediate token)をすることができているからでは?という疑問に対する検証
- variable computationとCoTの影響を分離するために、dotのsequence (...) のみでpromptingする方法を検証
- => 結果はbaselineと性能変わらず。このことから、variableの計算自体が性能向上に寄与しているわけではないことがわかる。
- Chain of Thought after answer: 回答の後にCoTを出力するようなprompting
- 単にpretrainingの際のrelevantな知識にアクセスしやすくなっているだけなのでは?という疑問を検証
- => baselineと性能は変わらず、単に知識を活性化させるだけでは性能が向上しないことがわかる。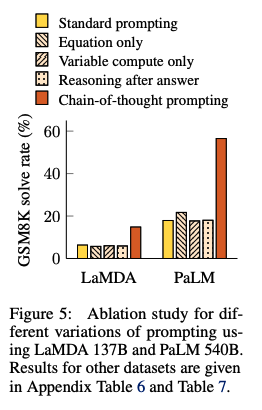
## CoTのロバスト性
人間のAnnotatorにCoTを作成させ、それらを利用したCoTpromptingとexamplarベースな手法によって性能がどれだけ変わるかを検証。standard promptingを全ての場合で上回る性能を獲得した。このことから、linguisticなstyleにCoTは影響を受けていないことがわかる。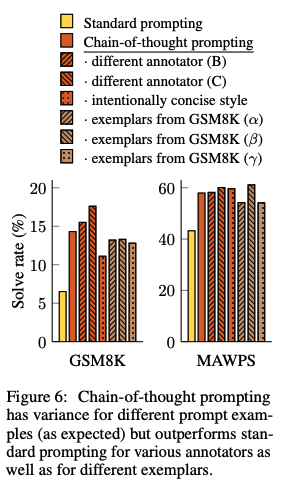
# commonsense reasoning
全てのデータセットにおいて、CoTがstandard promptingをoutperformした。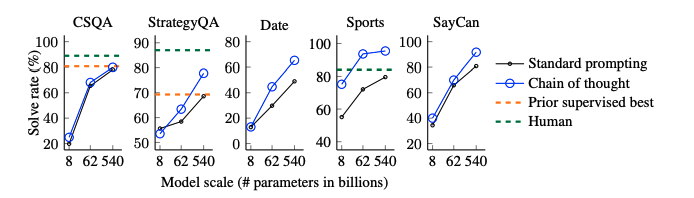
# Symbolic Reasoning
in-domain test setとout-of-domain test setの2種類を用意した。前者は必要なreasoning stepがfew-shot examplarと同一のもの、後者は必要なreasoning stepがfew-shot examplarよりも多いものである。
CoTがStandard proimptingを上回っている。特に、standard promptingではOOV test setではモデルをスケールさせても性能が向上しなかったのに対し、CoTではより大きなgainを得ている。このことから、CoTにはreasoning stepのlengthに対しても汎化能力があることがわかる。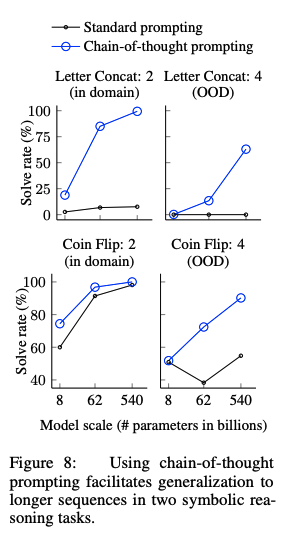
Empirical Evaluation of Deep Learning Models for Knowledge Tracing: Of Hyperparameters and Metrics on Performance and Replicability, Sami+, Aalto University, JEDM'22
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing Issue Date: 2022-04-28 Comment
DKTの説明が秀逸で、元論文では書かれていない分かりづらいところまできちんと説明してくれている。
(inputは(スキルタグ, 正誤)のtupleで、outputはスキルタグ次元数のベクトルyで、各次元が対応するスキルのmasteryを表しており、モデルのtrainingはnext attemptに対応するスキルのprobabilityのみをyから抽出しBinary Cross Entropyを計算する点、など)
入力や出力の仕方によって性能がどの程度変化しているかを検証しているのがおもしろい。
- Input: one-hot encoding (one hot vectorをinputする) vs. embedding layer (embeddingをinputする)
- Output: output per skill (スキルタグの次元数を持つベクトルyをoutputする) vs. skills-to-scalar output (skill summary layer + Scalar; 次のattemptに対する正答率のみをscalarでoutputする)
下図ではDKTの例が書かれているが、DKVMNやSAKTでもこれらの違いは適用可能。
output per skillで出力をすれば、Knowledge TrackingはDKTと同様どのようなモデルでも可能なのではないか。
◆Inputについて
基本的には大きな差はないが、one-hot encodingを利用した場合、DKVMN-PaperとSAKTがembeddingと比較して3.3~4.6%程度AUCが悪くなることがあった。
最高の性能を模索したい時はembedding layerを利用し、one-hot encodingはハイパーパラメータの選択をミスった場合でもロバストな結果(あまり性能が悪化しなかった)だったので、より安全な選択肢と言える。
◆Outputについて
全体として、DKT(およびDKTの亜種)については、output per skillの方が良かった。
DKVMNはこれとは逆で、skills-to-scalar outputの方が性能が良かった。
SAKTではoutput per skillの方がworst scoreがskills-to-scalar outputよりも高いため、よりrobustだと判断できる。
結論:
1. Deep Learning basedなモデルはnon-deep learning basedなモデルやシンプルなベースラインよりも一般的に予測性能が良い
2. LSTMを用いたDKT(LSTM-DKT), LSTM-DKTに次のexerciseのスキルタグ情報をconcatして予測をするDKT(LSTM-DKT-S), DKVMNの性能がDeep Learning Basedな手法では性能が良かった。が、Deep Learningベースドなモデルの間での性能の差は僅かだった(SAKTとも比較している)。
3. one-hot encoding vs. embedding layer, output per skill vs. skills-to-scalar output については、最大で4.6%ほどAUCの変化があり(SAKTにone-hot encodingを入力した場合embeddingを利用しない場合よりも4.6%ほど性能が低下している)、パフォーマンスに大きな違いをもたらした
論文中のDKVMN, DKVMN-Paperの違いは、著者が実装を公開しているMXNetの実装だと論文(Paper)に書かれているアーキテクチャと実装が違うのでDKVMNとして記述している。DKVMN-Paperは論文通りに実装したものを指している。
この研究では、KTする際に全てのDeep Learning basedなモデル(DKT, DKVMN, SAKT)において、入力の系列をx_tを(s_t, c_t)で表現し検証している。s_tはスキルタグで、c_tは正解したか否か。
outputも output-per-skill の場合は、スキルタグ次元のベクトルとなっている。
[Paper Note] BARTScore: Evaluating Generated Text as Text Generation, Weizhe Yuan+, arXiv'21, 2021.06
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Reference-free #LM-based #Selected Papers/Blogs Issue Date: 2023-08-13 GPT Summary- 生成テキストの評価を、事前学習済みのシーケンス・ツー・シーケンスモデルを用いてモデル化。BARTを基にした指標BARTScoreを提案し、流暢さや情報性から生成テキストを評価。既存の指標を16のテスト設定で上回る可能性があり、広範なデータセットに適用可能。BARTScore計算コードは公開中。 Comment
BARTScore
# 概要
ソーステキストが与えられた時に、BARTによって生成テキストを生成する尤度を計算し、それをスコアとする手法。テキスト生成タスクをテキスト生成モデルでスコアリングすることで、pre-trainingされたパラメータをより有効に活用できる(e.g. BERTScoreやMoverScoreなどは、pre-trainingタスクがテキスト生成ではない)。BARTScoreの特徴は
1. parameter- and data-efficientである。pre-trainingに利用されたパラメータ以外の追加パラメータは必要なく、unsupervisedなmetricなので、human judgmentのデータなども必要ない。
2. 様々な観点から生成テキストを評価できる。conditional text generation problemにすることでinformativeness, coherence, factualityなどの様々な観点に対応可能。
3. BARTScoreは、(i) pre-training taskと類似したpromptを与えること、(ii) down stream generation taskでfinetuningすること、でより高い性能を獲得できる
BARTScoreを16種類のデータセットの、7つの観点で評価したところ、16/22において、top-scoring metricsよりも高い性能を示した。また、prompting starategyの有効性を示した。たとえば、シンプルに"such as"というフレーズを翻訳テキストに追加するだけで、German-English MTにおいて3%の性能向上が見られた。また、BARTScoreは、high-qualityなテキスト生成システムを扱う際に、よりロバストであることが分析の結果分かった。
# 前提
## Problem Formulation
生成されたテキストのqualityを測ることを目的とする。本研究では、conditional text generation (e.g. 機械翻訳)にフォーカスする。すなわち、ゴールは、hypothesis h_bar を source text s_barがgivenな状態で生成することである。一般的には、人間が作成したreference r_barが評価の際は利用される。
## Gold-standard Human Evaluation
評価のgold standardは人手評価であり、人手評価では多くの観点から評価が行われる。以下に代表的な観点を示す:
1. Informativeness: ソーステキストのキーアイデアをどれだけ捉えているか
2. Relevance: ソーステキストにあ地して、どれだけconsistentか
3. Fluency formatting problem, capitarlization errorや非文など、どの程度読むのが困難か
4. Coherence: 文間のつながりが、トピックに対してどれだけcoherentか
5. Factuality: ソーステキストに含意されるstatementのみを生成できているか
6. Semantic Coverage: 参照テキスト中のSemantic Content Unitを生成テキストがどれだけカバーできているか
7: Adequacy 入力文に対してアウトプットが同じ意味を出力できているかどうか、あるいは何らかのメッセージが失われる、追加される、歪曲していないかどうか
多くの性能指標は、これらの観点のうちのsubsetをカバーするようにデザインんされている。たとえば、BLEUは、翻訳におけるAdequacyとFluencyをとらえることを目的としている。一方、ROUGEは、semantic coverageを測るためのメトリックである。
BARTScoreは、これらのうち多くの観点を評価することができる。
## Evaluation as Different Tasks
ニューラルモデルを異なる方法で自動評価に活用するのが最近のトレンドである。下図がその分類。この分類は、タスクにフォーカスした分類となっている。
1. Unsupervised Matching: ROUGE, BLEU, CHRF, BERTScore, MoverScoreのように、hypothesisとreference間での意味的な等価性を測ることが目的である。このために、token-levelのマッチングを用いる。これは、distributedな表現を用いる(BERTScore, MoverScore)場合もあれば、discreteな表現を用いる(ROUGE, BLEU, chrF)場合もある。また、意味的な等価性だけでなく、factual consistencyや、source-hypothesis間の関係性の評価に用いることもできると考えられるが先行研究ではやられていなかったので、本研究で可能なことを示す。
2. Supervised Regression: BLEURT, COMET, S^3, VRMのように、regression layer を用いてhuman judgmentをsupervisedに予測する方法である。最近のメトリックtおしては、BLEURT, COMETがあげられ、古典的なものとしては、S^3, VRMがあげられる。
4. Supervised Ranking: COMET, BEERのような、ランキング問題としてとらえる方法もある。これは優れたhypothesisを上位にランキングするようなスコア関数を学習する問題に帰着する。COMETやBEERが例としてあげられ、両者はMTタスクにフォーカスされている。COMETはhunan judgmentsをregressionすることを通じてランキングを作成し、BEERは、多くのシンプルな特徴量を組み合わせて、linear layerでチューニングされる。
5. Text Generation: PRISM, BARTScoreが例として挙げられる。BARTScoreでは、生成されたテキストの評価をpre-trained language modelによるテキスト生成タスクとしてとらえる。基本的なアイデアとしては、高品質のhypothesisは、ソース、あるいはreferenceから容易に生成可能であろう、というものである。これはPRISMを除いて、先行研究ではカバーされていない。BARTScoreは、PRISMとはいくつかの点で異なっている。(i) PRISMは評価をparaphrasing taskとしてとらえており、これが2つの意味が同じテキストを比較する前提となってしまっているため、手法を適用可能な範囲を狭めてしまっている。たとえば、文書要約におけるfactual consistencyの評価では、semantic spaceが異なる2つのテキストを比較する必要があるが、このような例には対応できない。(ii) PRISMはparallel dataから学習しなけえrばならないが、BARTScoreは、pre-trainedなopen-sourceのseq2seq modelを利用できる。(iii) BARTScoreでは、PRISMが検証していない、prompt-basedのlearningもサポートしている。
# BARTScore
## Sequence-to-Sequence Pre-trained Models
pre-trainingされたモデルは、様々な軸で異なっているが、その一つの軸としては訓練時の目的関数である。基本的には2つの大きな変種があり、1つは、language modeling objectives (e.g. MLM)、2つ目は、seq2seq objectivesである。特に、seq2seqで事前学習されたモデルは、エンコーダーとデコーダーによって構成されているため特に条件付き生成タスクに対して適しており、予測はAutoRegressiveに行われる。本研究ではBARTを用いる。付録には、preliminary experimentsとして、BART with T5, PEGASUSを用いた結果も添付する。
## BARTScore
最も一般的なBARTScoreの定式化は下記である。
weighted log probabilityを利用する。このweightsは、異なるトークンに対して、異なる重みを与えることができる。たておば、IDFなどが利用可能であるが、本研究ではすべてのトークンを等価に扱う(uniform weightingだがstopwordを除外、IDFによる重みづけ、事前分布を導入するなど色々試したが、uniform weightingを上回るものがなかった)。
BARTScoreを用いて、様々な方向に用いて生成を行うことができ、異なる評価のシナリオに対応することができる。
- Faithfulness (s -> h):
- hypothesisがどれだけsource textに基づいて生成されているかを測ることができる。シナリオとしては、FactualityやRelevanceなどが考えられる。また、CoherenceやFluencyのように、target textのみの品質を測るためにも用いることができる。
- Precision (r -> h):
- hypothesisがどれだけgold-referenceに基づいてこう良くされているかを亜評価でき、precision-focusedなシナリオに適している
- Recall (h -> r):
- hypothesisから、gold referenceをどれだけ容易に再現できるかを測ることができる。そして、要約タスクのpyramid-basedな評価(i.e. semantic coverage等) に適している。pyramid-scoreはSemantic Content Unitsがどれだけカバーされているかによって評価される。
- F Score (r <-> h):
- 双方向を考慮し、Precisioon / RecallからF値を算出する。この方法は、referenceと生成テキスト間でのsemantic overlap (informativenss, adequacy)などの評価に広く利用される。
# BARTScore Variants
BARTScoreの2つの拡張を提案。(i) xとyをpromptingによって変更する。これにより、評価タスクをpre-training taskと近づける。(ii) パラメータΘを異なるfinetuning taskを考慮して変更する。すなわち、pre-trainingのドメインを、evaluation taskに近づける。
## Prompt
Promptingはinput/outputに対して短いフレーズを追加し、pre-trained modelに対して特定のタスクを遂行させる方法である。BARTにも同様の洞察を簡単に組み込むことができる。この変種をBARTScore-PROMPTと呼ぶ。
prompt zが与えられたときに、それを (i) source textに追加し、新たなsource textを用いてBARTScoreを計算する。(ii) target textの先頭に追加し、new target textに対してBARTScoreを計算する。
## Fine-tuning Task
classification-basedなタスクでfine-tuneされるのが一般的なBERT-based metricとは異なり、BARTScoreはgeneration taskでfine-tuneされるため、pre-training domainがevaluation taskと近い。本研究では、2つのdownstream taskを検証する。
1つめは、summarizationで、BARTをCNNDM datasetでfinetuningする。2つめは、paraphrasingで、summarizationタスクでfinetuningしたBARTをParaBank2 datasetでさらにfinetuningする。
# 実験
## baselines and datasets
### Evaluation Metrics
supervised metrics: COMET, BLEURT
unsupervised: BLEU, ROUGE-1, ROUGE-2, ROUGE-L, chrF, PRISM, MoverScore, BERTScore
と比較
### Measures for Meta Evaluation
Pearson Correlationでlinear correlationを測る。また、Spearman Correlationで2変数間の単調なcorrelationを測定する(線形である必要はない)。Kendall's Tauを用いて、2つの順序関係の関係性を測る。最後に、Accuracyでfactual textsとnon-factual textの間でどれだけ正しいランキングを得られるかを測る。
### Datasets
Summarization, MT, DataToTextの3つのデータセットを利用。
## Setup
### Prompt Design
seedをparaphrasingすることで、 s->h方向には70個のpromptを、h<->rの両方向には、34のpromptを得て実験で用いた。
### Settings
Summarizationとdata-to-textタスクでは、全てのpromptを用いてデコーダの頭に追加してスコアを計算しスコアを計算した。最終的にすべての生成されたスコアを平均することである事例に対するスコアを求めた(prompt unsembling)。MTについては、事例数が多くcomputational costが多くなってしまうため、WMT18を開発データとし、best prompt "Such as"を選択し、利用した。
BARTScoreを使う際は、gold standard human evaluationがrecall-basedなpyrmid methodの場合はBARTScore(h->r)を用い、humaan judgmentsがlinguistic quality (coherence fluency)そして、factual correctness、あるいは、sourceとtargetが同じモダリティ(e.g. language)の場合は、faitufulness-based BARTScore(s->h)を用いた。最後に、MTタスクとdata-to-textタスクでは、fair-comparisonのためにBARTScore F-score versionを用いた。
## 実験結果
### MT
- BARTScoreはfinetuning tasksによって性能が向上し、5つのlanguage pairsにおいてその他のunsupervised methodsを統計的に優位にoutperformし、2つのlanguage pairでcomparableであった。
-Such asというpromptを追加するだけで、BARTScoreの性能が改善した。特筆すべきは、de-enにおいては、SoTAのsupervised MetricsであるBLEURTとCOMETを上回った。
- これは、有望な将来のmetric designとして「human judgment dataで訓練する代わりに、pre-trained language modelに蓄積された知識をより適切に活用できるpromptを探索する」という方向性を提案している。
### Text Summarization
- vanilla BARTScoreはBERTScore, MoverScoreをInfo perspective以外でlarge marginでうくぁ回った。
- REALSum, SummEval dataseetでの改善は、finetuning taskによってさらに改善した。しかしながら、NeR18では改善しなかった。これは、データに含まれる7つのシステムが容易に区別できる程度のqualityであり、既にvanilla BARTScoreで高いレベルのcorrelationを達成しているからだと考えられる。
- prompt combination strategyはinformativenssに対する性能を一貫して改善している。しかし、fluency, factualityでは、一貫した改善は見られなかった。
Factuality datasetsに対する分析を行った。ゴールは、short generated summaryが、元のlong documentsに対してfaithfulか否かを判定するというものである。
- BARTScore+CNNは、Rank19データにおいてhuman baselineに近い性能を達成し、ほかのベースラインを上回った。top-performingなfactuality metricsであるFactCCやQAGSに対してもlarge marginで上回った。
- paraphraseをfine-tuning taskで利用すると、BARTScoreのパフォーマンスは低下した。これは妥当で、なぜなら二つのテキスト(summary and document)は、paraphrasedの関係性を保持していないからである。
- promptを導入しても、性能の改善は見受けられず、パフォーマンスは低下した。
### Data-to-Text
- CNNDMでfine-tuningすることで、一貫してcorrelationが改善した。
- 加えて、paraphraseデータセットでfinetuningすることで、さらに性能が改善した。
- prompt combination strategyは一貫してcorrelationを改善した。
## Analysis
### Fine-grained Analysis
- Top-k Systems: MTタスクにおいて、評価するシステムをtop-kにし、各メトリックごとにcorrelationの変化を見た。その結果、BARTScoreはすべてのunsupervised methodをすべてのkにおいて上回り、supervised metricのBLEURTも上回った。また、kが小さくなるほど、より性能はsmoothになっていき、性能の低下がなくなっていった。これはつまり、high-quality textを生成するシステムに対してロバストであることを示している。
- Reference Length: テストセットを4つのバケットにreference lengthに応じてブレイクダウンし、Kendall's Tauの平均のcorrelationを、異なるメトリック、バケットごとに言語をまたいで計算した。unsupervised metricsに対して、全てのlengthに対して、引き分けかあるいは上回った。また、ほかのmetricsと比較して、長さに対して安定感があることが分かった。
### Prompt Analysis
(1) semantic overlap (informativeness, pyramid score, relevance), (2) linguistic quality (fluency, coherence), (3) factual correctness (factuality) に評価の観点を分類し、summarizationとdata-to-textをにおけるすべてのpromptを分析することで、promptの効果を分析した。それぞれのグループに対して、性能が改善したpromptの割合を計算した。その結果、semantic overlapはほぼ全てのpromptにて性能が改善し、factualityはいくつかのpromptでしか性能の改善が見られなかった。linguistic qualityに関しては、promptを追加することによる効果はどちらとも言えなかった。
### Bias Analysis
BARTScoreが予測不可能な方法でバイアスを導入してしまうかどうかを分析した。バイアスとは、human annotatorが与えたスコアよりも、値が高すぎる、あるいは低すぎるような状況である。このようなバイアスが存在するかを検証するために、human annotatorとBARTScoreによるランクのサを分析した。これを見ると、BARTScoreは、extractive summarizationの品質を区別する能力がabstractive summarizationの品質を区別する能力よりも劣っていることが分かった。しかしながら、近年のトレンドはabstractiveなseq2seqを活用することなので、この弱点は軽減されている。
# Implications and Future Directions
prompt-augmented metrics: semantic overlapではpromptingが有効に働いたが、linguistic qualityとfactualityでは有効ではなかった。より良いpromptを模索する研究が今後期待される。
Co-evolving evaluation metrics and systems: BARTScoreは、メトリックデザインとシステムデザインの間につながりがあるので、より性能の良いseq2seqシステムが出たら、それをメトリックにも活用することでよりreliableな自動性能指標となることが期待される。
[Paper Note] SimCSE: Simple Contrastive Learning of Sentence Embeddings, Tianyu Gao+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #LanguageModel #RepresentationLearning #ContrastiveLearning #Catastrophic Forgetting #EMNLP #Selected Papers/Blogs Issue Date: 2023-07-27 GPT Summary- SimCSEは、文の埋め込み表現を向上させる単純な対照学習フレームワークです。教師なしアプローチでは、入力文が自身を予測し、ドロップアウトがノイズとして機能します。この手法は従来の教師あり方法と同等の成果を上げ、ドロップアウトを除去すると表現の質が低下することが分かりました。また、教師付きアプローチでは、自然言語推論データセットからの注釈付きペアを活用し、対照学習に組み込みます。評価結果では、教師なしモデルが76.3%、教師ありモデルが81.6%のSpearmanの相関を達成し、既存のベスト結果をそれぞれ改善しました。対照学習の目的が埋め込みの空間の正則化に貢献することも示されました。 Comment
[Paper Note] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Nils Reimers+, arXiv'19, 2019.08 よりも性能良く、unsupervisedでも学習できる。STSタスクのベースラインにだいたい入ってる
# 手法概要
Contrastive Learningを活用して、unsupervised/supervisedに学習を実施する。
Unsupervised SimCSEでは、あるsentenceをencoderに2回入力し、それぞれにdropoutを適用させることで、positive pairを作成する。dropoutによって共通のembeddingから異なる要素がマスクされた(noiseが混ざった状態とみなせる)類似したembeddingが作成され、ある種のdata augmentationによって正例を作成しているともいえる。負例はnegative samplingする。(非常にsimpleだが、next sentence predictionで学習するより性能が良くなる)
Supervised SimCSEでは、アノテーションされたsentence pairに基づいて、正例・負例を決定する。本研究では、NLIのデータセットにおいて、entailment関係にあるものは正例として扱う。contradictions(矛盾)関係にあるものは負例として扱う。
# Siamese Networkで用いられるmeans-squared errrorとContrastiveObjectiveの違い
どちらもペアワイズで比較するという点では一緒だが、ContrastiveObjectiveは正例と近づいたとき、負例と遠ざかったときにlossが小さくなるような定式化がされている点が異なる。
(画像はこのブログから引用。ありがとうございます。
https://techblog.cccmk.co.jp/entry/2022/08/30/163625)
# Unsupervised SimCSEの実験
異なるdata augmentation手法と比較した結果、dropoutを適用する手法の方が性能が高かった。MLMや, deletion, 類義語への置き換え等よりも高い性能を獲得しているのは興味深い。また、Next Sentence Predictionと比較しても、高い性能を達成。Next Sentence Predictionは、word deletion等のほぼ類似したテキストから直接的に類似関係にあるペアから学習するというより、Sentenceの意味内容のつながりに基づいてモデルの言語理解能力を向上させ、そのうえで類似度を測るという間接的な手法だが、word deletionに負けている。一方、dropoutを適用するだけの(直接的に類似ペアから学習する)本手法はより高い性能を示している。
[image](https://github.com/AkihikoWatanabe/paper_notes/assets/12249301/0ea3549e-3363-4857-94e6-a1ef474aa191)
なぜうまくいくかを分析するために、異なる設定で実験し、alignment(正例との近さ)とuniformity(どれだけembeddingが一様に分布しているか)を、10 stepごとにplotした結果が以下。dropoutを適用しない場合と、常に同じ部分をマスクする方法(つまり、全く同じembeddingから学習する)設定を見ると、学習が進むにつれuniformityは改善するが、alignmentが悪くなっていっている。一方、SimCSEはalignmentを維持しつつ、uniformityもよくなっていっていることがわかる。
# Supervised SimCSEの実験
アノテーションデータを用いてContrastiveLearningするにあたり、どういったデータを正例としてみなすと良いかを検証するために様々なデータセットで学習し性能を検証した。
- QQP4: Quora question pairs
- Flickr30k (Young et al., 2014): 同じ画像に対して、5つの異なる人間が記述したキャプションが存在
- ParaNMT (Wieting and Gimpel, 2018): back-translationによるparaphraseのデータセットa
- NLI datasets: SNLIとMNLI
実験の結果、NLI datasetsが最も高い性能を示した。この理由としては、NLIデータセットは、crowd sourcingタスクで人手で作成された高品質なデータセットであることと、lexical overlapが小さくなるようにsentenceのペアが作成されていることが起因している。実際、NLI datsetのlexical overlapは39%だったのに対し、ほかのデータセットでは60%であった。
また、condunctionsとなるペアを明示的に負例として与えることで、より性能が向上した(普通はnegative samplingする、というかバッチ内の正例以外のものを強制的に負例とする。こうすると、意味が同じでも負例になってしまう事例が出てくることになる)。より難しいNLIタスクを含むANLIデータセットを追加した場合は、性能が改善しなかった。この理由については考察されていない。性能向上しそうな気がするのに。
# 他手法との比較結果
SimCSEがよい。
# Ablation Studies
異なるpooling方法で、どのようにsentence embeddingを作成するかで性能の違いを見た。originalのBERTの実装では、CLS token のembeddingの上にMLP layerがのっかっている。これの有無などと比較。
Unsupervised SimCSEでは、training時だけMLP layerをのっけて、test時はMLPを除いた方が良かった。一方、Supervised SimCSEでは、 MLP layerをのっけたまんまで良かったとのこと。
また、SimCSEで学習したsentence embeddingを別タスクにtransferして活用する際には、SimCSEのobjectiveにMLMを入れた方が、catastrophic forgettingを防げて性能が高かったとのこと。
ablation studiesのhard negativesのところと、どのようにミニバッチを構成するか、それぞれのtransferしたタスクがどのようなものがしっかり読めていない。あとでよむ。
[Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Dataset #LanguageModel #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #ACL Issue Date: 2023-05-31 GPT Summary- この論文では、ユーザーの興味とニュース本文に基づいて、ユーザー固有のタイトルを生成するパーソナライズされたニュース見出し生成の問題を解決するためのフレームワークを提案します。また、この問題のための大規模なデータセットであるPENSを公開し、ベンチマークスコアを示します。データセットはhttps://msnews.github.io/pens.htmlで入手可能です。 Comment
# 概要
ニュース記事に対するPersonalizedなHeadlineの正解データを生成。103名のvolunteerの最低でも50件のクリックログと、200件に対する正解タイトルを生成した。正解タイトルを生成する際は、各ドキュメントごとに4名異なるユーザが正解タイトルを生成するようにした。これらを、Microsoft Newsの大規模ユーザ行動ログデータと、ニュース記事本文、タイトル、impressionログと組み合わせてPENSデータを構成した。
# データセット生成手順
103名のenglish-native [speakerの学生に対して、1000件のニュースヘッドラインの中から最低50件興味のあるヘッドラインを選択してもらう。続いて、200件のニュース記事に対して、正解ヘッドラインを生成したもらうことでデータを生成した。正解ヘッドラインを生成する際は、同一のニュースに対して4人がヘッドラインを生成するように調整した。生成されたヘッドラインは専門家によってqualityをチェックされ、factual informationにエラーがあるものや、極端に長い・短いものなどは除外された。
# データセット統計量
# 手法概要
Transformer Encoder + Pointer GeneratorによってPersonalizedなヘッドラインを生成する。
Transformer Encoderでは、ニュースの本文情報をエンコードし、attention distributionを生成する。Decoder側では、User Embeddingを組み合わせて、テキストをPointer Generatorの枠組みでデコーディングしていき、ヘッドラインを生成する。
User Embeddingをどのようにinjectするかで、3種類の方法を提案しており、1つ目は、Decoderの初期状態に設定する方法、2つ目は、ニュース本文のattention distributionの計算に利用する方法、3つ目はデコーディング時に、ソースからvocabをコピーするか、生成するかを選択する際に利用する方法。1つ目は一番シンプルな方法、2つ目は、ユーザによって記事で着目する部分が違うからattention distributionも変えましょう、そしてこれを変えたらcontext vectorも変わるからデコーディング時の挙動も変わるよねというモチベーション、3つ目は、選択するvocabを嗜好に合わせて変えましょう、という方向性だと思われる。最終的に、2つ目の方法が最も性能が良いことが示された。
# 訓練手法
まずニュース記事推薦システムを訓練し、user embeddingを取得できるようにする。続いて、genericなheadline generationモデルを訓練する。最後に両者を組み合わせて、Reinforcement LearningでPersonalized Headeline Generationモデルを訓練する。Rewardとして、
1. Personalization: ヘッドラインとuser embeddingのdot productで報酬とする
2. Fluency: two-layer LSTMを訓練し、生成されたヘッドラインのprobabilityを推定することで報酬とする
3. Factual Consistency: 生成されたヘッドラインと本文の各文とのROUGEを測りtop-3 scoreの平均を報酬とする
とした。
1,2,3の平均を最終的なRewardとする。
# 実験結果
Genericな手法と比較して、全てPersonalizedな手法が良かった。また、手法としては②のattention distributionに対してuser informationを注入する方法が良かった。News Recommendationの性能が高いほど、生成されるヘッドラインの性能も良かった。
# Case Study
ある記事に対するヘッドラインの一覧。Pointer-Genでは、重要な情報が抜け落ちてしまっているが、提案手法では抜け落ちていない。これはRLの報酬のfluencyによるものだと考えられる。また、異なるユーザには異なるヘッドラインが生成されていることが分かる。
[Paper Note] ResNet strikes back: An improved training procedure in timm, Ross Wightman+, arXiv'21, 2021.10
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NeurIPS #ImageClassification Issue Date: 2021-11-04 GPT Summary- 本論文では、Residual Networks(ResNet-50)の性能を新たな最適化手法やデータ拡張技術を統合したトレーニング手法で再評価。競争力のある設定で、ImageNet-valにおいて80.4%のトップ1精度を達成し、事前学習済みモデルをtimmライブラリで共有することで、今後の研究のベースラインとなることを目指す。 Comment
2015年以後、様々な最適化アルゴリズム、正則化手法、データ拡張などが提案される中で、最新アーキテクチャのモデルにはそれらが適用される一方ベースラインとなるResNetではそれらが適用されず、論文の値のみが参照される現状はフェアではないので、ResNetの性能を向上させるような訓練手法を追求した研究。
ResNetにおける有効な訓練手法として下記を模索:
損失関数として、MixUp(訓練画像を重ね合わせ、組み合わせた画像のラベルをミックスして新しい学習インスタンスを作るデータ拡張手法)と、CutMix(画像を切り貼りして、切り貼り部分の面積に応じてラベルのスコアを調整するデータ拡張手法)を適用し、CutMixによって大幅に性能が改善することを示した。このとき、ラベルの確率の和が1となる前提の元クロスエントロピーで学習するのではなく、元画像に含まれる物体が両方存在するという全体の元BinaryCrossEntropyを適用しマルチラベル問題として学習することで、性能が向上。
データ拡張手法として、MixUp, CutMixだけでなく、通常のリサイズ・切り抜きと、水平方向の反転を適用しデータ拡張する。加えてRandAugment(14種類のデータ拡張操作から、N個サンプルし、強さMで順番に適用するデータ拡張手法。N,Mはそれぞれ0〜10の整数なので、10の二乗オーダーでグリッドサーチすれば、最適なN,Mを得る。グリッドサーチするだけでお手軽だが非常に強力)を適用した。
正則化として、Weight Decay(学習過程で重みが大きくなりすぎないようにペナルティを課し、過学習を防止する手法。L2正則化など。)と、label smoothing(正解ラベルが1、その他は0とラベル付けするのではなく、ラベルに一定のノイズを入れ、正解ラベル以外にも重みが入っている状態にし、ラベル付けのノイズにロバストなモデルを学習する手法。ノイズの強さは定数で調整する)、Repeated Augmentation(同じバッチ内の画像にデータ拡張を適用しバッチサイズを大きくする)、Stochastic Depth(ランダムでレイヤーを削除し、その間を恒等関数で繋ぎ訓練することで、モデルの汎化能力と訓練時間を向上する)を適用。
Optimizerとして、オリジナルのResNetでは、SGDやAdamWで訓練されることが多いが、Repeated Augmentationとバイナリクロスエントロピーを組み合わせた場合はLAMBが有効であった。また、従来よりも長い訓練時間(600epoch、様々な正則化手法を使っているので過学習しづらいため)で学習し、最初にウォームアップを使い徐々に学習率を上げ(finetuningの際にこれまでのweightをなるべく壊したくないから小さい学習率から始める、あるいはMomentumやAdamといった移動平均を使う手法では移動平均を取るための勾配の蓄積が足りない場合学習の信頼度が低いので最初の方は学習率小さくするみたいな、イメージ)その後コサイン関数に従い学習率を減らしていくスケジューリング法で学習。
論文中では上記手法の3種類の組み合わせ(A1,A2,A3)を提案し実験している。
ResNet-50に対してA1,2,3を適用した結果、A1を適用した場合にImageNetのトップ1精度が80.4%であり、これはResNet-50を使った場合のSoTA。元のResNetの精度が76%程度だったので大幅に向上した。
同じ実験設定を使った場合の他のアーキテクチャ(ViTやEfficientNetなど)と比べても遜色のない性能を達成。
また、本論文で提案されているA2と、DeiTと呼ばれるアーキテクチャで提案されている訓練手法(T2)をそれぞれのモデルに適用した結果、ResNetではA2、DeiTではT2の性能が良かった。つまり、「アーキテクチャと訓練方法は同時に最適化する必要がある」ということ。これがこの論文のメッセージの肝とのこと。
(ステートオブAIガイドの内容を読んで学んだことを自分の言葉で整理して記述しました。いつもありがとうございます。)
画像系でどういった訓練手法が利用されるか色々書かれていたので勉強になった。特に画像系のデータ拡張手法なんかは普段触らないので勉強になる。
OpenReview: https://openreview.net/forum?id=NG6MJnVl6M5
Few-Shot NLG with Pre-Trained Language Model, Chen+, University of California, ACL'20
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #LanguageModel #DataToTextGeneration #pretrained-LM #Zero/FewShotLearning Issue Date: 2022-12-01 Comment
# 概要
Neural basedなend-to-endなNLGアプローチはdata-hungryなので、Few Shotな設定で高い性能ができる手法を提案(Few shot NLG)
Table-to-Textタスク(WikiBIOデータ, 追加で収集したBook, SongドメインのWikipediaデータ)において、200程度の学習サンプル数でstrong baselineに対して8.0 point程度のBLEUスコアの向上を達成
# 手法
TabularデータのDescriptionを作成するには大きく分けて2つのスキルが必要
1. factualな情報を持つcontentをselectし、copyするスキル
2. factualな情報のコピーを含めながら、文法的に正しいテキストを生成するスキル
提案手法では、1を少量のサンプル(< 500)から学習し、2については事前学習済みの言語モデルを活用する。
encoderからコピーする確率をpcopyとし、下記式で算出する:
すなわち、encoderのcontext vectorと、decoderのinputとstateから求められる。
encoderとencoder側へのattentionはscratchから学習しなければならず、うまくコピーできるようにしっかりと”teach”しなければならないため、lossに以下を追加する:
すなわち、コピーすべき単語がちゃんとコピーできてる場合にlossが小さくなる項を追加している。
また、decoder側では、最初にTable情報のEmbeddingを入力するようにしている。
また、学習できるデータ量が限られているため、pre-trainingモデルのEmbeddingは事前学習時点のものに固定した(ただしく読解できているか不安)
# 実験
WikiBIOと、独自に収集したBook, Songに関するWikipediaデータのTable-to-Textデータを用いて実験。
このとき、Training instanceを50~500まで変化させた。
WikiBIOデータセットに対してSoTAを記録しているBase-originalを大きくoutperform(Few shot settingでは全然うまくいかない)。
inputとoutput例と、コピーに関するlossを入れた場合の効果。
人手評価の結果、Factual informationの正しさ(#Supp)、誤り(#Cont)ともに提案手法が良い。また、文法的な正しさ(Lan. Score)もコピーがない場合とcomparable
Extending Deep Knowledge Tracing: Inferring Interpretable Knowledge and Predicting Post-System Performance, Richard+ (w_ Ryan Baker), ICCE'20
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #KnowledgeTracing #Reading Reflections #ICCE Issue Date: 2022-08-29 Comment
# 概要
ざっくりとしか読めていないが
- DeepLearningBasedなKT手法は、latentな学習者の知識を推定しているわけではなく、「正誤」を予測しているだけであることを指摘
- → 一方BKTはきちんとlatent knowledgeがモデリングされている
- → 昔はknowledge inferenceした結果を、post-testで測定したスキルのmasteryとしっかり比較する文化があったが、近年のDeepLearningベースな研究では全く実施されていないことも指摘
- → learning systemの中でどのようなパフォーマンスが発揮されるかではなく、learning systemの外でどれだけスキルが発揮できるか、というところにBKTなどの時代は強い焦点が置かれていたのだと思われる
- DeepLearningBasedなKT手法でもknowledgeのinferenceが行える手法を提案し、BKTやPFAによるknowledge estimateよりもposttestのスコアと高い相関を示すことを実験した
- → 手法: それぞれの問題のfirst attemptに対する正誤データの「全て」をtraining dataとし、DKT, DKVMN, BKT, PFAを学習。
-(おそらく)学習したモデルを用いてある生徒AのスキルBのknowledgeをinferenceしたい場合、生徒Aが回答したスキルBと紐づいた問題に対する平均正答率を推定した習熟度とした
- 生徒Aはtraining dataに含まれている生徒
- すなわち、生徒Aにとって未知の問題の正答率を予測しているわけではなく、モデルがパラメータを推定するために利用した既知の問題-回答ペアデータに対して、モデルがパラメータをfittingした後にinferenceできる正答率の平均値を習熟度としている
# 結果
- 4種類のスキルに対するpost-testのスコアと相関係数をモデルごとに比較した結果、DKT, DKVMNなどは、BKTよりも高い相関を示し、PFAとはcomparableな結果となった
# 所感
- この手法のリアルタイムな運用は難しいと思った(knowledgeをinferするために毎回モデルをtrainingしなおさなければならない)
- BKTが推定するスキルのmasteryはこのcase studyだけ見ると全くあてにならない・・・
- ユーザが回答した問題と紐づいたスキルのknowledgeしか推定できないところもlimitationの一つだと思う
- この手法がtraining dataに含まれていない「未知の問題」に対する正答率予測を平均することで、knowledgeをinferenceできるという話だったのであれば、非常に興味深いと思った。
- 実際どうなんだろうか?
Assessment Modeling: Fundamental Pre-training Tasks for Interactive Educational Systems, Choi+, RiiiD Research, arXiv'20
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #LearningAnalytics #Assessment #needs-revision Issue Date: 2022-04-18 Comment
# 概要
テストのスコアや、gradeなどはシステムの外側で取得されるものであり、取得するためにはコストがかかるし、十分なラベル量が得られない(label-scarce problem)。そこで、pre-training/fine-tuningの手法を用いて、label-scarce probleを緩和する手法を提案。
# Knowledge Tracingタスクの定義
手法を提案する前に、Knowledge Tracingタスクを定義した。Knowledge Tracingタスクを、マスクしたt番目のinteractionのk番目のfeatureを予測するタスクと定義した。
このような定義にすると、たとえば、予測するfeatureとしては、回答の正誤にかかわらず以下のようなものも挙げられる。

# Assessmentを予測するタスク
また、このようなKTの定義に則り、assessmentを予測するタスクを下記のように定義した。ここで、Assesmentとはinteractionの中で教育的な評価と関連するinteractionのことである。
assesmentの例としては下図のAssessment Modelingに示したようなfeatureが挙げられる。
# label-scarceなeducational featureの例
また、label-scarceなeducational featureとして、以下を例として挙げている。この論文では、assessment予測をpre-trainingタスクとして定義し、これらlabel-scarceなeducational featureを予測することを目標としている。
- Non Interactive Educational Feature
- exam_score: A student’s score on a standardized exam.
- grade: A student’s final grade in a course.
- certification: Professional certifications obtained by completion of educational programs or examinations.
- Sporadic Assessments(たまにしか発生しない偶発的なassessmentのこと)
- course_dropout: Whether a student drops out of the entire class.
- review_correctness: Whether a student responds correctly to a previously solved exercise.
# モデル
これらassessmentsのlabel-scarce problemに対処するために、pre-training/fine-tuningのパラダイムを活用する。
モデルはBERTを利用した。inputのうち、M%をランダムにマスクし、マスクしたassesment featureをlinear layerで予測するタスクを、pre-trainingフェーズで実施する。
inputとしては全てのfeatureを使うのは計算量的に現実的ではないのでknowledge-tracingタスクでよく利用される下記を用いる:
- exercise_id: We assign a latent vector unique to each exercise id.
- exercise_category: Each exercise has its own category tag that represents the type of the exercise. We assign a latent vector to each tag.
- position: The relative position 𝑡 of the interaction 𝐼𝑡 in the input sequence. We use the sinusoidal positional encoding that is used in [24].
- correctness: The value is 1 if a student response is correct and 0 otherwise. We assign a latent vector corresponding to each possible value 0 and 1.
- elapsed_time: The time taken for a student to respond is recorded in seconds. We cap any time exceeding 300 seconds to 300 seconds and normalize it by dividing by 300 to have a value between 0 and 1. The elapsed time embedding vector is calculated by multiplying the normalized time by a single latent embedding vector.
- inactive_time: The time interval between adjacent interactions is recorded in seconds. We set maximum inactive time as 86400 seconds (24 hours) and any time more than that is capped off to 86400 seconds. Also, the inactive time is normalized to have a value between 0 and 1 by dividing the value by 86400. Similar to the elapsed time embedding vector, we calculate the inactive time embedding vector by multiplying the time by a single latent embedding vector
ここで、interaction I_tのrepresentationは、e_t + c_t + et_t + it_t で表される。ここで、e_tはexercise_id, exercise_category, position embeddingを合計したもの、c_t, et_t, it_t は、それぞれcorrectness, elapsed_time, inactive_timeのembeddingである。
たとえば、assesment予測として、correctnessと、elapsed_timeを予測対象とした場合、inputのcorrectnessとelapsed_timeに関わるembeddingをmask embeddingに置き換える。すなわち、input representationは、e_t + c_t + et_t + it_t から、c_t + et_t がmaskに置き換えられ、e_t + it_t + mask となる。
Loss functionは、pre-training taskごとに定義する。
# 評価
試験のスコア予測(non-interactive educational feature)と、review correctness予測タスク(a sporadic assessment)に適用し評価した。
## Dataset
EdNetデータセットを利用。pre-trainingのためのデータセットを作成するために、chronological orderでInteractionのデータを作成した。このとき、downstreamタスクで利用するユーザは全てpre-trainingデータセットから除外した。最終的に、414,375 user, 93,121,528 interactionsのデータとなった。
## Exam Score Prediction
2594件のSantaユーザのTOEICスコアを使用(報酬を用意してユーザに報告してもらった)。これだけの量のデータを集める音に6ヶ月を要した。
## review correctness prediction
生徒の学習ログを見て、最低2回解いている問題を見つけ、1回目と2回目に問題を解いている間のinteraction sequenceをinputとし、2回目に同じ問題を解いた時の正誤をラベルとして抽出した。
最終的に4540個のラベル付されたsequenceを得た。
## モデルのセットアップ
モデルは100 interactionsをinputとした。Mは0.6とした(60%をマスクした)。
また、fine-tuningする際には、label-scarce probleに対処するためにdata-augmentationを行った。具体的には、input sequenceのうち50%の確率で各エントリを選択しsubsequenceを作成することで、学習データに利用した。
# 実験結果
## pre-trainingタスクがdown-streamタスクに与える影響
correctness + timelinessの予測を行った場合に、最も性能がよかった。
## 性能
既存のcontents-basedな手法と比べて、Assessment Modelが高い性能を発揮した。
Deep Attentive Study Session Dropout Prediction in Mobile Learning Environment, Riiid AI Research, Lee+, CSEDU'20
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #DropoutPrediction Issue Date: 2022-04-14 Comment
従来のdropout研究では、学校のドロップアウトやコースのドロップアウト、MOOCsなどでのドロップアウトが扱われてきたが、モバイル学習環境を考慮した研究はあまり行われてこなかった。モバイル学習環境では着信やソーシャルアプリなど、多くの外敵要因が存在するため、学習セッションのドロップアウトが頻繁に発生する。
学習セッションを、隣接するアクティビティと1時間のインターバルが空いていないアクティビティのsequenceと定義
Transformerを利用したモデルを提案。
利用したFeatureは以下の通り
AUCでの評価の結果、LSTM,GRUを用いたモデルをoutperform
また、Transformerに入力するinput sequenceのsizeで予測性能がどれだけ変化するかを確認したところ、sequence sizeが5の場合に予測性能が最大となった。
これは、session dropoutの予測には、生徒の最新のinteractionの情報と相関があることを示している。だが、sequence sizeが2のときに予測性能は低かったため、ある程度のcontext情報が必要なことも示唆している。
また、inputに利用するfeatureとしては、問題を解く際のelapsed_timeと、session内でのposition、またdropoutしたか否かのラベルが予測性能の向上に大きく寄与した。
Q. AUCの評価はどうやって評価しているのか。dropoutしたラベルの部分のみを評価しているのか否かがわからない。
Q. dropoutラベルをinputのfeatureに利用するのは実用上問題があるのでは?次の1問を解いたときにdropoutするか否かしか予測できなくなってしまうのでは。まあでもそれはelapsed_timeとかも一緒か。
[Paper Note] BERTScore: Evaluating Text Generation with BERT, Tianyi Zhang+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based #Selected Papers/Blogs #needs-revision Issue Date: 2023-05-10 GPT Summary- BERTScoreは、テキスト生成の自動評価指標で、候補文のトークンと参照文のトークン間の類似度を文脈埋め込みを使用して計算。363の機械翻訳と画像キャプション生成システムを評価し、人間の判断と高い相関を示し、モデル選択性能を向上。敵対的パラフレーズ検出タスクでも、既存の指標と比較して堅牢性が確認された。 Comment
# 概要
既存のテキスト生成の評価手法(BLEUやMETEOR)はsurface levelのマッチングしかしておらず、意味をとらえられた評価になっていなかったので、pretrained BERTのembeddingを用いてsimilarityを測るような指標を提案しましたよ、という話。
# prior metrics
## n-gram matching approaches
n-gramがreferenceとcandidateでどれだけ重複しているかでPrecisionとrecallを測定
### BLEU
MTで最も利用される。n-gramのPrecision(典型的にはn=1,2,3,4)と短すぎる候補訳にはペナルティを与える(brevity penalty)ことで実現される指標。SENT-BLEUといった亜種もある。BLEUと比較して、BERTScoreは、n-gramの長さの制約を受けず、潜在的には長さの制限がないdependencyをcontextualized embeddingsでとらえることができる。
### METEOR
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments, Banerjee+, CMU, ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization
METEOR 1.5では、内容語と機能語に異なるweightを割り当て、マッチングタイプによってもweightを変更する。METEOR++2.0では、学習済みの外部のparaphrase resourceを活用する。METEORは外部のリソースを必要とするため、たった5つの言語でしかfull feature setではサポートされていない。11の言語では、恥部のfeatureがサポートされている。METEORと同様に、BERTScoreでも、マッチに緩和を入れていることに相当するが、BERTの事前学習済みのembeddingは104の言語で取得可能である。BERTScoreはまた、重要度によるweightingをサポートしている(コーパスの統計量で推定)。
### Other Related Metrics
- NIST: BLEUとは異なるn-gramの重みづけと、brevity penaltyを利用する
- ΔBLEU: multi-reference BLEUを、人手でアノテーションされたnegative reference sentenceで変更する
- CHRF: 文字n-gramを比較する
- CHRF++: CHRFをword-bigram matchingに拡張したもの
- ROUGE: 文書要約で利用される指標。ROUGE-N, ROUGE^Lといった様々な変種がある。
- CIDEr: image captioningのmetricであり、n-gramのtf-idfで重みづけされたベクトルのcosine similrityを測定する
## Edit-distance based Metrics
- Word Error Rate (WER): candidateからreferenceを再現するまでに必要なedit operationの数をカウントする手法
- Translation Edit Rate (TER): referenceの単語数によってcandidateからreferenceまでのedit distanceを正規化する手法
- ITER: 語幹のマッチと、より良い正規化に基づく手法
- PER: positionとは独立したError Rateを算出
- CDER: edit operationにおけるblock reorderingをモデル化
- CHARACTER / EED: character levelで評価
## Embedding-based Metrics
- MEANT 2.0: lexical, structuralの類似度を測るために、word embeddingとshallow semantic parsesを利用
- YISI-1: MEANT 2.0と同様だが、semantic parseの利用がoptionalとなっている
これらはBERTScoreと同様の、similarityをシンプルに測るアプローチで、BERTScoreもこれにinspireされている。が、BERTScoreはContextualized Embeddingを利用する点が異なる。また、linguistic structureを生成するような外部ツールは利用しない。これにより、BERTScoreをシンプルで、新たなlanguageに対しても使いやすくしている。greedy matchingの代わりに、WMD, WMDo, SMSはearth mover's distanceに基づく最適なマッチングを利用することを提案している。greedy matchingとoptimal matchingのtradeoffについては研究されている。sentence-levelのsimilarityを計算する手法も提案されている。これらと比較して、BERTScoreのtoken-levelの計算は、重要度に応じて、tokenに対して異なる重みづけをすることができる。
## Learned Metrics
様々なmetricが、human judgmentsとのcorrelationに最適化するために訓練されてきた。
- BEER: character-ngram, word bigramに基づいたregresison modelを利用
- BLEND: 29の既存のmetricを利用してregressionを実施
- RUSE: 3種類のpre-trained sentence embedding modelを利用する手法
これらすべての手法は、コストのかかるhuman judgmentsによるsupervisionが必要となる。そして、新たなドメインにおける汎化能力の低さのリスクがある。input textが人間が生成したものか否か予測するneural modelを訓練する手法もある。このアプローチは特定のデータに対して最適化されているため、新たなデータに対して汎化されないリスクを持っている。これらと比較して、BERTScoreは特定のevaluation taskに最適化されているモデルではない。
# BERTScore
referenceとcandidateのトークン間のsimilarityの最大値をとり、それらを集約することで、Precision, Recallを定義し、PrecisionとRecallを利用してF値も計算する。Recallは、reference中のすべてのトークンに対して、candidate中のトークンとのcosine similarityの最大値を測る。一方、Precisionは、candidate中のすべてのトークンに対して、reference中のトークンとのcosine similarityの最大値を測る。ここで、類似度の式が単なる内積になっているが、これはpre-normalized vectorを利用する前提であり、正規化が必要ないからである。
また、IDFによるトークン単位でのweightingを実施する。IDFはテストセットの値を利用する。TFを使わない理由は、BERTScoreはsentence同士を比較する指標であるため、TFは基本的に1となりやすい傾向にあるためである。IDFを計算する際は出現数を+1することによるスムージングを実施。
さらに、これはBERTScoreのランキング能力には影響を与えないが、BERTScoreの値はコサイン類似度に基づいているため、[-1, 1]となるが、実際は学習したcontextual embeddingのgeometryに値域が依存するため、もっと小さなレンジでの値をとることになってしまう。そうすると、人間による解釈が難しくなる(たとえば、極端な話、スコアの0.1程度の変化がめちゃめちゃ大きな変化になってしまうなど)ため、rescalingを実施。rescalingする際は、monolingualコーパスから、ランダムにsentenceのペアを作成し(BETRScoreが非常に小さくなるケース)、これらのBERTScoreを平均することでbを算出し、bを利用してrescalingした。典型的には、rescaling後は典型的には[0, 1]の範囲でBERTScoreは値をとる(ただし数式を見てわかる通り[0, 1]となることが保証されているわけではない点に注意)。これはhuman judgmentsとのcorrelationとランキング性能に影響を与えない(スケールを変えているだけなので)。
# 実験
## Contextual Embedding Models
12種類のモデルで検証。BERT, RoBERTa, XLNet, XLMなど。
## Machine Translation
WMT18のmetric evaluation datasetを利用。149種類のMTシステムの14 languageに対する翻訳結果, gold referencesと2種類のhuman judgment scoreが付与されている。segment-level human judgmentsは、それぞれのreference-candiate pairに対して付与されており、system-level human judgmentsは、それぞれのシステムに対して、test set全体のデータに基づいて、単一のスコアが付与されている。pearson correlationの絶対値と、kendall rank correration τをmetricsの品質の評価に利用。そしてpeason correlationについてはWilliams test、kendall τについては、bootstrap re-samplingによって有意差を検定した。システムレベルのスコアをBERTScoreをすべてのreference-candidate pairに対するスコアをaveragingすることによって求めた。また、ハイブリッドシステムについても実験をした。具体的には、それぞれのreference sentenceについて、システムの中からランダムにcandidate sentenceをサンプリングした。これにより、system-level experimentをより多くのシステムで実現することができる。ハイブリッドシステムのシステムレ4ベルのhuman judgmentsは、WMT18のsegment-level human judgmentsを平均することによって作成した。BERTScoreを既存のメトリックと比較した。
通常の評価に加えて、モデル選択についても実験した。10kのハイブリッドシステムを利用し、10kのうち100をランダムに選択、そして自動性能指標でそれらをランキングした。このプロセスを100K回繰り返し、human rankingとmetricのランキングがどれだけagreementがあるかをHits@1で評価した(best systemの一致で評価)。モデル選択の指標として新たにtop metric-rated systemとhuman rankingの間でのMRR, 人手評価でtop-rated systemとなったシステムとのスコアの差を算出した。WMT17, 16のデータセットでも同様の評価を実施した。
## Image Captioning
COCO 2015 captioning challengeにおける12種類のシステムのsubmissionデータを利用。COCO validationセットに対して、それぞれのシステムはimageに対するcaptionを生成し、それぞれのimageはおよそ5個のreferenceを持っている。先行研究にならい、Person Correlationを2種類のシステムレベルmetricで測定した。
- M1: 人間によるcaptionと同等、あるいはそれ以上と評価されたcaptionの割合
- M2: 人間によるcaptionと区別がつかないcaptionの割合
BERTScoreをmultiple referenceに対して計算し、最も高いスコアを採用した。比較対象のmetricはtask-agnostic metricを採用し、BLEU, METEOR, CIDEr, BEER, EED, CHRF++, CHARACTERと比較した。そして、2種類のtask-specific metricsとも比較した:SPICE, LEIC
# 実験結果
## Machine Translation
system-levelのhuman judgmentsとのcorrelationの比較、hybrid systemとのcorrelationの比較、model selection performance
to-Englishの結果では、BERTScoreが最も一貫して性能が良かった。RUSEがcompetitiveな性能を示したが、RUSEはsupervised methodである。from-Englishの実験では、RUSEは追加のデータと訓練をしないと適用できない。
以下は、segment-levelのcorrelationを示したものである。BERTScoreが一貫して高い性能を示している。BLEUから大幅な性能アップを示しており、特定のexampleについての良さを検証するためには、BERTScoreが最適であることが分かる。BERTScoreは、RUSEをsignificantlyに上回っている。idfによる重要度のweightingによって、全体としては、small benefitがある場合があるが全体としてはあんまり効果がなかった。importance weightingは今後の課題であり、テキストやドメインに依存すると考えられる。FBERTが異なる設定でも良く機能することが分かる。異なるcontextual embedding model間での比較などは、appendixに示す。
## Image Captioning
task-agnostic metricの間では、BETRScoreはlarge marginで勝っている。image captioningはchallengingな評価なので、n-gramマッチに基づくBLEU, ROUGEはまったく機能していない。また、idf weightingがこのタスクでは非常に高い性能を示した。これは人間がcontent wordsに対して、より高い重要度を置いていることがわかる。最後に、LEICはtrained metricであり、COCO dataに最適化されている。この手法は、ほかのすべてのmetricを上回った。
## Speed
pre-trained modelを利用しているにもかかわらず、BERTScoreは比較的高速に動作する。192.5 candidate-reference pairs/secondくらい出る(GTX-1080Ti GPUで)。WMT18データでは、15.6秒で処理が終わり、SacreBLEUでは5.4秒である。計算コストそんなにないので、BERTScoreはstoppingのvalidationとかにも使える。
# Robustness analysis
BERTScoreのロバスト性をadversarial paraphrase classificationでテスト。Quora Question Pair corpus (QQP) を利用し、Word Scrambling dataset (PAWS) からParaphrase Adversariesを取得。どちらのデータも、各sentenceペアに対して、それらがparaphraseかどうかラベル付けされている。QQPの正例は、実際のduplicate questionからきており、負例は関連するが、異なる質問からきている。PAWSのsentence pairsは単語の入れ替えに基づいているものである。たとえば、"Flights from New York to Florida" は "Flights from Florida to New York" のように変換され、良いclassifierはこれらがparaphraseではないと認識できなければならない。PAWSはPAWS_QQPとPAWS_WIKIによって構成さえrており、PAWS_QQPをdevelpoment setとした。automatic metricsでは、paraphrase detection training dataは利用しないようにした。自動性能指標で高いスコアを獲得するものは、paraphraseであることを想定している。
下図はAUCのROC curveを表しており、PAWS_QQPにおいて、QQPで訓練されたclassifierはrandom guessよりも性能が低くなることが分かった。つまりこれらモデルはadversaial exampleをparaphraseだと予測してしまっていることになる。adversarial examplesがtrainingデータで与えられた場合は、supervisedなモデルも分類ができるようになる。が、QQPと比べると性能は落ちる。多くのmetricsでは、QQP ではまともなパフォーマンスを示すが、PAWS_QQP では大幅なパフォーマンスの低下を示し、ほぼrandomと同等のパフォーマンスとなる。これは、これらの指標がより困難なadversarial exampleを区別できないことを示唆している。一方、BERTSCORE のパフォーマンスはわずかに低下するだけであり、他の指標よりもロバスト性が高いことがわかる。
# Discussion
- BERTScoreの単一の設定が、ほかのすべての指標を明確に上回るということはない
- ドメインや言語を考慮して、指標や設定を選択すべき
- 一般的に、機械翻訳の評価にはFBERTを利用することを推奨
- 英語のテキスト生成の評価には、24層のRoBERTa largeモデルを使用して、BERTScoreを計算したほうが良い
- 非英語言語については、多言語のBERT_multiが良い選択肢だが、このモデルで計算されたBERTScoreは、low resource languageにおいて、パフォーマンスが安定しているとは言えない
Towards Personalized Review Summarization via User-Aware Sequence Network, Li+, AAAI'19
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #AAAI Issue Date: 2023-05-08 Comment
同じレビューに対しても、異なるユーザは異なるSumamryを生成するよね、というところがモチベーションとなり、Personalized Review Summarizationを提案。初めてPersonalizationの問題について提案した研究。
user embeddingによってユーザ情報を埋め込む方法と、user vocabulary memoryによって、ユーザが好むvocabularyを積極的にsummaryに利用できるようなモジュールの2種類をモデルに導入している
Trip advisorのレビューデータを収集。レビューのtitleをreference summaryとみなしてデータセット生成。ただタイトルを利用するだけだと、無意味なタイトルが多く含まれているでフィルタリングしている。
Trip Advisorはクローリングを禁止していた気がするので、割とアウトなのでは。
あと、各レビューをランダムにsplitしてtrain/dev/testを作成したと言っているが、本当にそれでいいの?user-stratifiedなsplitをした方が良いと思う。
PGN [Paper Note] Get To The Point: Summarization with Pointer-Generator Networks, Abigail See+, arXiv'17, 2017.04
やlead-1と比較した結果、ROUGEの観点で高い性能を達成
また人手評価として、ユーザのgold summaryに含まれるaspectと、generated summaryに含まれるaspectがどれだけ一致しているか、1000件のreviewとtest setからサンプリングして2人の学生にアノテーションしてもらった。結果的に提案手法が最もよかったが、アノテーションプロセスの具体性が薄すぎる。2人の学生のアノテーションのカッパ係数すら書かれていない。
case studyとしてあるユーザのレビュと生成例をのせている。userBの過去のレビューを見たら、room, locationに言及しているものが大半であり、このアスペクトをきちんと含められているよね、ということを主張している。
[Paper Note] Table-to-Text Generation with Effective Hierarchical Encoder on Three Dimensions (Row, Column and Time), Gong+, Harbin Institute of Technology, EMNLP'19
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #EMNLP Issue Date: 2021-10-08 Comment
## 概要
既存研究では、tableをレコードの集合, あるいはlong sequenceとしてencodeしてきたが
1. other (column) dimensionの情報が失われてしまう (?)
2. table cellは時間によって変化するtime-series data
という特徴がある。
たとえば、ある選手の成績について言及する際に、その試合について着目するだけでなくて「直近3試合で二回目のダブルダブルです」というように直近の試合も考慮して言及することがあり、table cellの time dimensionについても着目しなければならず、これらはこれまでのモデルで実現できない。
そこで、この研究ではtime dimensionについても考慮し生成する手法を提案。
## モデル概要
全体としては、Row Dimension Encoder, Column Dimension Encoder, Time Dimension Encoderによって構成されており、self-attentionを利用して、テーブルの各セルごとに Row-Dimension, Column-Dimension, Time-DimensionのRepresentationを獲得する。イメージとしては、
- Row Dimension Encoderによって、自身のセルと同じ行に含まれるセルとの関連度を考慮した表現
- Column Dimension Encoderによって、自身のセルと同じ列に含まれるセルとの関連度を考慮した表現
- Time Dimension Encoderによって、過去の時系列のセルとの関連度を考慮した表現
をそれぞれ獲得するイメージ。各Dimension Encoderでやっていることは、Puduppully (Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
) らのContent Selection Gate節におけるattention vector r_{att}の取得方法と同様のもの(だと思われる)。
獲得したそれぞれのdimensionの表現を用いて、まずそれらをconcatし1 layer MLPで写像することで得られるgeneral representationを取得する。その後、general representationと各dimensionの表現を同様に1 layer MLPでスコアリングすることで、各dimensionの表現の重みを求め、その重みで各representationを線形結合することで、セルの表現を獲得する。generalなrepresentationと各dimensionの表現の関連性によって重みを求めることで、より着目すべきdimensionを考慮した上で、セルの表現を獲得できるイメージなのだろうか。
その後、各セルの表現を行方向に対してMeanPoolingを施しrow-levelの表現を取得。獲得したrow-levelの表現に対し、Puduppully (Data-to-Text Generation with Content Selection and Planning, Puduppully+, AAAI'19
) らのContent Selection Gate g を適用する(これをどうやっているかがわからない)。
最終的に求めたrow-levelの表現とcell-levelの表現に対して、デコーダのhidden stateを利用してDual Attentionを行い、row-levelの表現からどの行に着目すべきか決めた後、その行の中からどのセルに着目するか決める、といったイメージで各セルの重みを求める。
論文中にはここまでしか書かれていないが、求めた各セルの重みでセルのrepresentationを重み付けして足し合わせ、最終的にそこから単語をpredictionするのだろうか・・・?よくわからない。
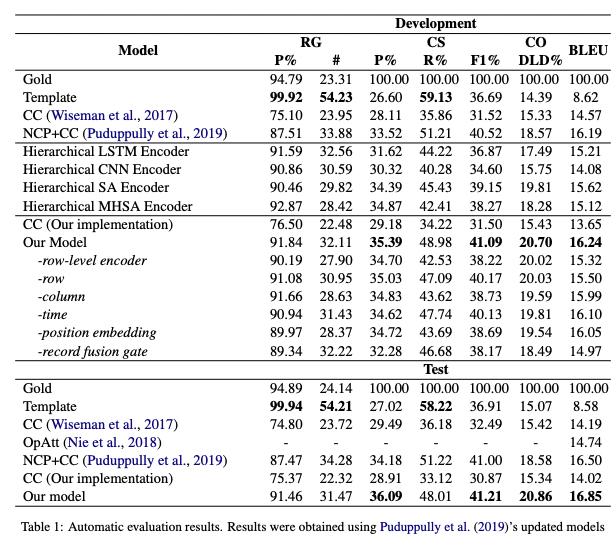
RG, CS, CO, BLEUスコア、全てにおいてBaselineを上回っている(RGのTemplateを除く)。
実装: https://github.com/ernestgong/data2text-three-dimensions/
[Paper Note] Conversion Prediction Using Multi-task Conditional Attention Networks to Support the Creation of Effective Ad Creatives, Kitada+, KDD'19
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CTRPrediction #CVRPrediction #SIGKDD Issue Date: 2021-06-01 Comment
# Overview
広告のCVR予測をCTR予測とのmulti-task learningとして定式化。
構築した予測モデルのattention distributionを解析することで、high-qualityなクリエイティブの作成を支援する。
genderやgenre等の情報でattentionのweightを変化させるconditional attentionが特徴的。
→ これによりgender, genreごとのCVRしやすい広告の特徴の違いが可視化される
loss functionは、MSEにλを導入しclickのlossを制御している(CVRに最適化したいため)。ただ、実験ではλ=1で実験している。
outputはRegressionでCVR, CTRの値そのものを予測している(log lossを使う一般的なCTR Prediction等とは少し条件が違う; 多分予測そのものより、予測モデルを通じて得られるCVRが高いcreativeの分析が主目的なため)。
# Experiments
データとして、2017年8月〜2018年8月の間にGunosy Adsでdeliverされた14,000種類のad creativeを利用。
clickとconversionのfrequency(clickはlong-tailだが、conversionはほとんど0か1のように見える)
5-fold crossvalidationを、fold内でcampaignが重複しないようにad creativeに対して行い、conversion数の予測を行なった。
評価を行う際はNDCGを用い、top-1%のconversion数を持つcreativeにフォーカスし評価した。
MSEで評価した場合、multi-task learning, conditional attentionを利用することでMSEが改善している。多くのcreativeのconversionは0なので、conversion数が>0のものに着目して評価しても性能が改善していることがわかる。
NDCGを利用した評価でも同様な傾向
conditional attentionのheatmap
genderごとにdistributionの違いがあって非常におもしろい
Point precisely: Towards ensuring the precision of data in generated texts using delayed copy mechanism., Li+, Peking University, COLING'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #COLING Issue Date: 2021-10-25 Comment
# 概要
DataToTextタスクにおいて、生成テキストのデータの精度を高める手法を提案。two stageアルゴリズムを提案。①encoder-decoerモデルでslotを含むテンプレートテキストを生成。②Copy Mechanismでslotのデータを埋める、といった手法。
①と②はそれぞれ独立に学習される。
two stageにするモチベーションは、
・これまでのモデルでは、単語の生成確率とコピー確率を混合した分布を考えていたが、どのように両者の確率をmergeするのが良いかはクリアではない。
→ 生成とコピーを分離して不確実性を減らした
・コピーを独立して考えることで、より効果的なpair-wise ranking loss functionを利用することができる
・テンプレート生成モデルは、テンプレートの生成に集中でき、slot fillingモデルはスロットを埋めるタスクに集中できる。これらはtrainingとtuningをより簡便にする。
# モデル概要
モデルの全体像
オリジナルテキストとテンプレートの例。テンプレートテキストの生成を学習するencoder-decoder(①)はTarget Templateを生成できるように学習する。テンプレートではエンティティが"
# 実験結果
Relation Generation (RG)がCCと比べて10%程度増加しているので、data fidelityが改善されている。
また、BLEUスコアも約2ポイント改善。これはentityやnumberが適切に埋められるようになっただけでなく、テンプレートがより適切に生成されているためであると考えられる。
## 参考:
• Relation Generation (RG):出力文から(entity, value)の関係を抽出し,抽出された関係の数と,それらの関係が入力データに対して正しいかどうかを評価する (Precision).ただし entity はチーム名や選手名などの動作の主体,value は得点数やアシスト数などの記録である.
• Content Selection (CS):出力文とリファレンスから (entity, value) の関係を抽出し,出力文から抽出された関係のリファレンスから抽出された関係に対する Precision,Recall で評価する.
• Content Ordering (CO):出力文とリファレンスから (entity, value) の関係を抽出し,それらの間の正規化 DamerauLevenshtein 距離 [7] で評価する.
(from [Paper Note] 過去情報の内容選択を取り入れた スポーツダイジェストの自動生成, 加藤+, NLP'21
)
[Paper Note] Operation-guided Neural Networks for High Fidelity Data-To-Text Generation, Nie+, Sun Yat-Sen University, EMNLP'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #EMNLP Issue Date: 2021-09-16 Comment
# 概要
既存のニューラルモデルでは、生データ、あるいはそこから推論された事実に基づいて言語を生成するといったことができていない(e.g. 金融, 医療, スポーツ等のドメインでは重要)。
たとえば下表に示した通り、"edge"という単語は、スコアが接戦(95-94=1 -> スコアの差が小さい)であったことを表現しているが、こういったことを既存のモデルでは考慮して生成ができない。
これを解決するために、演算(operation)とニューラル言語モデルを切り離す(事前に計算しておく)といったことが考えられるが、
① 全てのフィールドに対してoperationを実行すると、探索空間が膨大になり、どの結果に対して言及する価値があるかを同定するのが困難(言及する価値がある結果がほとんど存在しない探索空間ができてしまう)
② 演算結果の数値のスパンと、言語選択の対応関係を確立させるのが困難(e.g. スコアの差が1のとき"edge"と表現する、など)
といった課題がある。
①に対処するために、事前にraw dataに対して演算を適用しその結果を利用するモデルを採用。どの演算結果を利用するかを決定するために、gating-mechanismを活用する。
②に対処するために、quantization layerを採用し、演算結果の数値をbinに振り分け、その結果に応じて生成する表現をguideするようなモデルを採用する。
# モデル概要
モデルはrecord encoder(h_{i}^{ctx}を作る)、operation encoder(h_{i}^{op}を作る)、operation result encoder(h_{i}^{res}を作る)によって構成される。
## record encoder
record encoderは、wisemanらと同様に、index (e.g. row 2), column (e.g. column Points), value (e.g. 95)のword embeddingを求め、それらをconcatしたものをbi-directional RNNに入力し求める。
## operation encoder
operation encoderでは、operation op_{i}は、1) operationの名称 (e.g. minus) 2) operationを適用するcolumn (e.g. Points), 3) operationを適用するrow (e.g. {1, 2}などのrow indexの集合)によって構成されており、これらのembeddingをlookupしconcatした後、non-linear layerで変換することによってoperationのrepresentationを取得する。3)operationを適用するrowについては、複数のindexによって構成されるため、各indexのembeddingをnon-linear layerで変換したベクトルを足し合わせた結果に対してtanhを適用したベクトルをembeddingとして利用する。
## operation result encoder
operation result encoderは、scalar results(minus operationにより-1)およびindexing results (argmax operationによりindex 2)の二種類を生成する。これら二種類に対して異なるencoding方法を採用する。
### scalar results
scalar resultsに対しては、下記式でscalar valueをquantization vector(q_{i})に変換する。qutization vectorのlengthはLとなっており、Lはbinの数に相当している。つまり、quantization vectorの各次元がbinの重みに対応している。その後、quantization vectorに対してsoftmaxを適用し、quantization unit(quantization vectorの各次元)の重みを求める。最後に、quantization embeddingと対応するquantization unitの重み付き平均をとることによってh_{i}^{res}を算出する。
Q. 式を見るとW_{q}がscalar resultの値によって定数倍されるだけだから、softmaxによって求まるquantization unitの重みの序列はscalar resultによって変化しなそうに見えるが、これでうまくいくんだろうか・・・?序列は変わらなくても各quantization unit間の相対的な重みの差が変化するから、それでうまくscalar値の変化を捉えられるの・・・か・・・?
### indexing results
indexing resultsについては、h_{i}^{res}をシンプルにindexのembeddingとする。
## Decoder
context vectorの生成方法が違う。従来のモデルと比較して、context vectorを生成する際に、レコードをoperationの両方をinputとする。
operationのcontext vector c_{t}^{op}とrecordsのcontext vector c_{t}^{ctx}をdynamic gate λ_{t}によって重み付けし最終的なcontext vectorを求める。λ_{t}は、t-1時点でのデコーダのhidden stateから重みを求める。
c_{t}^{op}は次式で計算され:
c_{t}^{scl, idx}は、
よって計算される。要は、decoderのt-1のhidden stateと、operation vectorを用いて、j番目のoperationの重要度(β)を求め、operationの重要度によって重み付けしてoperation result vectorを足し合わせることによって、context vectorを算出する。
また、recordのcontext vector c_{t}^{ctx}は、h_{j}^{res}とh_{j}^{op}と、h_{j}^{ctx}に置き換えることによって算出される。 
## データセット
人手でESPN, ROTOWIRE, WIKIBIOデータセットのReferenceに対して、factを含むtext spanと、そのfactの種類を3種類にラベル付した。input factsはinput dataから直接見つけられるfact, inferred factsはinput dataから直接見つけることはできないが、導き出すことができるfact、unsupported factsはinput dataから直接あるいは導き出すことができないfact。wikibioデータセットはinferred factの割合が少ないため、今回の評価からは除外し、ROTOWIRE, ESPNを採用した。特にESPNのheadline datasetがinferred factsが多かった。
# 結果
## 自動評価
wiseman modelをOpAttがoutperformしている。また、Seq2Seq+op+quant(Seq2Seq+copyに対してoperation result encoderとquantization layerを適用したもの)はSeq2Seq+Copyを上回っているが、OpAttほとではないことから、提案手法のoperation encoderの導入とgating mechanismが有効に作用していることがわかる。
採用するoperationによって、生成されるテキストも異なるようになっている。
## 人手評価
3人のNBAに詳しいEnglish native speakerに依頼してtest dataに対する生成結果にアノテーションをしてもらった。アノテーションは、factを含むspanを同定し、そのfactがinput facts/inferred facts/unsupported factsのどれかを分類してもらった。最後に、そのfactが入力データからsupportされるかcontradicted(矛盾するか)かをアノテーションしてもらった。
提案手法が、より多くのinferred factsについて言及しながらも、少ない#Cont.であることがわかった。
# 分析
## Quantizationの効果
チーム間のスコアの差が、5つのbinのに対してどれだけの重みを持たせたかのheatmap。似たようなスコアのgapの場合は似たような重みになることがわかる。ポイント差の絶対値が小さい場合は、重みの分布の分散が大きくなるのでより一般的な単語で生成を行うのに対し、絶対値が大きい場合は分散が小さくなるため、unique wordをつかって生成するようになる。
pointのgapの大きさによって利用される単語も変化していることがわかる。ポイント差がちいさいときは"edge"、大きいときは"blow out"など。
## gating mechanismの効果
生成テキストのtimestepごとのgateの重みの例。色が濃ければ濃いほど、operation resultsの情報を多く利用していることを表す。チームリーダーを決める際や(horford)勝者を決める際に(Hawks)、operation resultsの重みが大きくなっており、妥当な重み付けだと考察している。
[Paper Note] DKN: Deep Knowledge-Aware Network for News Recommendation, Hongwei Wang+, arXiv'18, 2018.01
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Contents-based #NewsRecommendation #WWW Issue Date: 2021-06-01 GPT Summary- オンラインニュース推薦システムの課題を解決するために、知識グラフを活用した深層知識認識ネットワーク(DKN)を提案。DKNは、ニュースの意味と知識を融合する多チャネルの知識認識畳み込みニューラルネットワーク(KCNN)を用い、ユーザーの履歴を動的に集約する注意モジュールを搭載。実験により、DKNが最先端の推薦モデルを大幅に上回る性能を示し、知識の有効性も確認。 Comment
# Overview
Contents-basedな手法でCTRを予測しNews推薦。newsのタイトルに含まれるentityをknowledge graphと紐づけて、情報をよりリッチにして活用する。
CNNでword-embeddingのみならず、entity embedding, contextual entity embedding(entityと関連するentity)をエンコードし、knowledge-awareなnewsのrepresentationを取得し予測する。
※ contextual entityは、entityのknowledge graph上でのneighborhoodに存在するentityのこと(neighborhoodの情報を活用することでdistinguishableでよりリッチな情報を活用できる)
CNNのinputを\[\[word_ embedding\], \[entity embedding\], \[contextual entity embedding\]\](画像のRGB)のように、multi-channelで構成し3次元のフィルタでconvolutionすることで、word, entity, contextual entityを表現する空間は別に保ちながら(同じ空間で表現するのは適切ではない)、wordとentityのalignmentがとれた状態でのrepresentationを獲得する。
# Experiments
BingNewsのサーバログデータを利用して評価。
データは (timestamp, userid, news url, news title, click count (0=no click, 1=click))のレコードによって構成されている。
2016年11月16日〜2017年6月11日の間のデータからランダムサンプリングしtrainingデータセットとした。
また、2017年6月12日〜2017年8月11日までのデータをtestデータセットとした。
word/entity embeddingの次元は100, フィルタのサイズは1,2,3,4とした。loss functionはlog lossを利用し、Adamで学習した。

DeepFM超えを達成。
entity embedding, contextual entity embeddingをablationすると、AUCは2ポイントほど現象するが、それでもDeepFMよりは高い性能を示している。
また、attentionを抜くとAUCは1ポイントほど減少する。
1ユーザのtraining/testセットのサンプル
Sentiment analysis with deeply learned distributed representations of variable length texts, Hong+, Technical Report. Technical report, Stanford University, 2015
によって経験的にRNN, Recursive Neural Network等と比較して、sentenceのrepresentationを獲得する際にCNNが優れていることが示されているため、CNNでrepresentationを獲得することにした模様(footprint 7より)
Factorization Machinesベースドな手法(LibFM, DeepFM)を利用する際は、TF-IDF featureと、averaged entity embeddingによって構成し、それをuser newsとcandidate news同士でconcatしてFeatureとして入力した模様
content情報を一切利用せず、ユーザのimplicit feedbackデータ(news click)のみを利用するDMF(Deep Matrix Factorization)の性能がかなり悪いのもおもしろい。やはりuser-item-implicit feedbackデータのみだけでなく、コンテンツの情報を利用した方が強い。
(おそらく)著者によるtensor-flowでの実装: https://github.com/hwwang55/DKN
Deep Model for Dropout Prediction in MOOCs, Wang+, ICCSE'17
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics Issue Date: 2021-06-10 Comment
MOOCsにおける一つの大きな問題点としてDropout率が高いことがあげられ、これを防止するために様々なモデルが提案されてきた。これまで提案されてきたモデルでは人手によるfeature-engineeringが必要であることが問題である。なぜなら、feature-engineeringはdomain expertでないとできないし、time-consumingだから。加えて、あるデータにおいて有効だったfeatureが別のデータセットにおいて有効とは限らないことも多い。
そこで、neural networkを用いて人手でのfeature engineeringなしで、dropout predictionする手法を提案する。
評価した結果、feature-engineeringを行う既存手法とcomparableな性能を得た。
Recorded periodのactivity logが与えられたときに、Prediction Periodにおいてdropoutするか否かをbinary classificationする問題として定式化
Prediction periodに生徒のactivity logがあった場合、生徒はdropoutしていないとみなす。acitivity logが存在しない場合、生徒はdropoutしたとみなす。
提案モデルはCNNとRNNの組み合わせ。個々のtime-unitごとのactivityをvectorに変換しInput Matrixを作成。その後、個々のtime-stepごとにCNNを適用しfeature mapを取得。取得したtime-stepごとのfeature mapをRNNに食わせて、最後にdropoutするか否かbinary classificationを行う。
## 評価
KDDCup 2015のデータを利用。データセットはユーザの各コースへのenrollmentを表すデータと、各enrollmentIDごとのactivity _logの二種類のデータから構成される。実験では、record periodを30日とし、その後のprediction periodを10日とした(過去1ヶ月のデータを利用し、10日以内にdropoutするか否かを予測するタスク)。
time-unit(time-sliceを構築する単位)は1時間とし、該当するtime-unitに存在するactivity records中のレコードは足し合わされ、該当time-unitのvectorとして表現。time-slice(時刻tとしてinputする単位)を1日とし、24個のtime-unit vectorのmatrixとして、時刻tのinputは表現される。実際はrecord periodが30日なので、このtime-slice のmatrixが30個(T=30)入力されることとなる。activity recordsのうち、source, event, course_IDの3種類のレコードをtime-unitのベクトルとして表現するために利用される。具体的には、source, event, course_IDをそれぞれone-hot vectorに変換し、それらのベクトルのtime-unit内に存在する全てのベクトルに対して足し合わせることで、time-unit vectorを表現している(正直これがあまり良いとは思わない)。
評価の結果、予測結果は他の既存手法とcomparableな性能を達成した。
→ 正直one-hot encodingを足し合わせるだけの入力方法(embeddingを学習しないで、実質各eventが発生した回数をFeatureとして考慮しているだけなのでは?)だと、既存手法のfeature-engineeringとやっていることは対して変わらない気はするので、comparableな結果というのもうなずける。
なぜembeddingを学習しないのか。
[Paper Note] Improving Sensor-Free Affect Detection Using Deep Learning, Botelho+, AIED'17
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics #AffectDetection #AIED Issue Date: 2021-06-08 Comment
DKTが実はBKTと対して性能変わらない、みたいな話がreference付きで書かれている。Ryan Baker氏とNeil Heffernan氏の論文
Affect Detectionは、physical/psychological sensorを利用する研究が行われてきており、それらは様々な制約により(e.g. 経済的な問題や、政治の問題)実際のアプリケーションとしてdeployするには難しさがあった。これを克服するために、sensor-freeなモデルが研究されてきたが、予測性能はあまり高くなくreal-timeなinterventionを行うのに十分な性能となっていなかった。
一方で、近年DeepLearningが様々な分野で成功を収めてきており、教育分野での活用が限定的であるという状況がある。そこで、deepなsensor-freeモデルを提案。その結果、従来モデルをoutperformした。
データセットはASSISTmentsデータを利用し、フィールドワーカーが20秒おきに、class roomでASSISTmentsを利用する生徒を観察し、生徒のAffective Stateをラベル付けした(ラウンドロビン方式)。ラベルは下記の通り:
- bored
- frustrated
- confused
- engaged concentration
- other/impossible
ビデオコーディングなどとは違って、ラウンドロビン方式では特定の生徒の間でラベルの欠落が生まれるが(常に特定の生徒を監視しているわけにはいかず、class-room全体を巡回しなければいけないから?)、全てのラベルにはタイムスタンプが付与されているので、欠落はわかるようになっている。
合計で6つの学校における、646人の生徒に対する、7663のobservationが得られた。
また、各特定の感情ラベルが付与されている際には実際に生徒はASSISTmentsを利用しており、先行研究では51種類のaction-level featureが利用されており(生徒とシステムのinteractionを捉える; e.g. reponse behavior, timeworking, hintやscaffoldingの利用の有無など)、今回もそういったfeatureも予測に利用する。
各observationのinterval(=clip)には複数のアクションが含まれており、それらを集約することで、最終的に204種類のfeatureをobservation intervalごとに作成し利用(feature engineeringしてるっぽい)。
RNN, LSTM, GRUの3種類のNNを用いて、204次元のfeature vectorをinputとし、各clipの4種類の感情ラベル(bored, frustrated, confused, engaged concentration)をsoftmaxで予測する。
前回のclipが5分未満のclipについては、連続したclipとしてモデルに入力し、5分を超過したものについては新たな別のsequenceとして扱った模様。

従来手法を大幅にoutperform。しっかり読んでいないが、resampoingは、ラベルの偏りを調整したか否かだと思われる。
[Paper Note] Larger-context language modelling with recurrent neural networks, Wang+, ACL'16
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #NLP #LanguageModel #ACL Issue Date: 2017-12-28 Comment
## 概要
通常のNeural Language Modelはsentence間に独立性の仮定を置きモデル化されているが、この独立性を排除し、preceding sentencesに依存するようにモデル化することで、言語モデルのコーパスレベルでのPerplexityが改善したという話。提案した言語モデルは、contextを考慮することで特に名詞や動詞、形容詞の予測性能が向上。Late-Fusion methodと呼ばれるRNNのoutputの計算にcontext vectorを組み込む手法が、Perplexityの改善にもっとも寄与していた。
## 手法
sentence間の独立性を排除し、Corpusレベルのprobabilityを下図のように定義。(普通はP(Slが条件付けされていない))
preceding sentence (context)をモデル化するために、3種類の手法を提案。
[1. bag-of-words context]
ナイーブに、contextに現れた単語の(単一の)bag-of-wordsベクトルを作り、linear layerをかませてcontext vectorを生成する手法。
[2. context recurrent neural network]
preceding sentencesをbag-of-wordsベクトルの系列で表現し、これらのベクトルをsequentialにRNN-LSTMに読み込ませ、最後のhidden stateをcontext vectorとする手法。これにより、sentenceが出現した順番が考慮される。
[3. attention based context representation]
Attentionを用いる手法も提案されており、context recurrent neural networkと同様にRNNにbag-of-wordsのsequenceを食わせるが、各時点におけるcontext sentenceのベクトルを、bi-directionalなRNNのforward, backward stateをconcatしたもので表現し、attention weightの計算に用いる。context vectorは1, 2ではcurrent sentence中では共通のものを用いるが、attention basedな場合はcurrent sentenceの単語ごとに異なるcontext vectorを生成して用いる。
生成したcontext vectorをsentence-levelのRNN言語モデルに組み合わせる際に、二種類のFusion Methodを提案している。
[1. Early Fusion]
ナイーブに、RNNLMの各時点でのinputにcontext vectorの情報を組み込む方法。
[2. Late Fusion]
よりうまくcontext vectorの情報を組み込むために、current sentence内の単語のdependency(intra-sentence dependency)と、current sentenceとcontextの関係を別々に考慮する。context vectorとmemory cellの情報から、context vector中の不要箇所をフィルタリングしたcontrolled context vectorを生成し、LSTMのoutputの計算に用いる。Later Fusionはシンプルだが、corpusレベルのlanguage modelingの勾配消失問題を緩和することもできる。
## 評価
IMDB, BBC, PennTreebank, Fil9 (cleaned wikipedia corpus)の4種類のデータで学習し、corpus levelでPerplexityを測った。
Late FusionがPerplexityの減少に大きく寄与している。
PoSタグごとのperplexityを測った結果、contextを考慮した場合に名詞や形容詞、動詞のPerplexityに改善が見られた。一方、Coordinate Conjungtion (And, Or, So, Forなど)や限定詞、Personal Pronouns (I, You, It, Heなど)のPerplexityは劣化した。前者はopen-classな内容語であり、後者はclosed-classな機能語である。機能語はgrammaticalなroleを決めるのに対し、内容語はその名の通り、sentenceやdiscourseの内容を決めるものなので、文書の内容をより捉えることができると考察している。
[Paper Note] Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval, Liu+, NAACL-HLT'15, 2015.05
Paper/Blog Link My Issue
#NeuralNetwork #InformationRetrieval #Search #MultitaskLearning #QueryClassification #WebSearch #RepresentationLearning #NAACL Issue Date: 2018-02-05 Comment
クエリ分類と検索をNeural Netを用いてmulti-task learningする研究
分類(multi-class classification)とランキング(pairwise learning-to-rank)という異なる操作が必要なタスクを、multi task learningの枠組みで組み合わせた(初めての?)研究。
この研究では分類タスクとしてクエリ分類、ランキングタスクとしてWeb Searchを扱っている。
モデルの全体像は下図の通り。
shared layersの部分で、クエリとドキュメントを一度共通の空間に落とし、そのrepresentationを用いて、l3においてtask-specificな空間に写像し各タスクを解いている。
分類タスクを解く際には、outputはsigmoidを用いる(すなわち、output layerのユニット数はラベル数分存在する)。
Web Searchを解く際には、クエリとドキュメントをそれぞれtask specificな空間に別々に写像し、それらのcosine similarityをとった結果にsoftmaxをかけることで、ドキュメントのrelevance scoreを計算している。
学習時のアルゴリズムは上の通り。各タスクをランダムにpickし、各タスクの目的関数が最適化されるように思いをSGDで更新する、といったことを繰り返す。
なお、alternativeとして、下図のようなネットワーク構造を考えることができるが(クエリのrepresentationのみがシェアされている)、このモデルの場合はweb searchがあまりうまくいかなかった模様。
理由としては、unbalancedなupdates(クエリパラメータのupdateがdocumentよりも多くアップデートされること)が原因ではないかと言及しており、multi-task modelにおいては、パラメータをどれだけシェアするかはネットワークをデザインする上で重要な選択であると述べている。
評価で用いるデータの統計量は下記の通り。
1年分の検索ログから抽出。クエリ分類(各クラスごとにbinary)、および文書のrelevance score(5-scale)は人手で付与されている。
クエリ分類はROC曲線のAUCを用い、Web SearchではNDCG (Normalized Discounted Cumulative Gain) を用いた。

multi task learningをした場合に、性能が向上している。
また、ネットワークが学習したsemantic representationとSVMを用いて、domain adaptationの実験(各クエリ分類のタスクは独立しているので、一つのクエリ分類のデータを選択しsemantic representationをtrainし、学習したrepresentationを別のクエリ分類タスクに適用する)も行なっており、訓練事例数が少ない場合に有効に働くことを確認(Letter3gramとWord3gramはnot trained/adapted)。

また、SemanticRepresentationへ写像する行列W1のパラメータの初期化の仕方と、サンプル数の変化による性能の違いについても実験。DNN1はW1をランダムに初期化、DNN2は別タスク(別のクエリ分類タスク)で学習したW1でfixする手法。
訓練事例が数百万程度ある場合は、DNN1がもっとも性能がよく、数千の訓練事例数の場合はsemantic representationを用いたSVMがもっともよく、midium-rangeの訓練事例数の場合はDNN2がもっとも性能がよかったため、データのサイズに応じて手法を使い分けると良い。
データセットにおいて、クエリの長さや文書の長さが記述されていないのがきになる。
[Paper Note] Sentence Compression by Deletion with LSTMs, Fillipova+, EMNLP'15
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #Sentence #NLP #EMNLP #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
slide: https://www.slideshare.net/akihikowatanabe3110/sentence-compression-by-deletion-with-lstms
[Paper Note] Query-Chain Focused Summarization, Baumel+, ACL'14
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NLP #Dataset #QueryBiased #Extractive #ACL #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。
KT-IDEM: Introducing Item Difficulty to the Knowledge Tracing Model, Pardos+ (w_ Neil T. Heffernan), UMAP'11
Paper/Blog Link My Issue
#AdaptiveLearning #KnowledgeTracing #UMAP Issue Date: 2022-08-17 Comment
# モチベーション
computer educationやassessmentのモデルでは項目困難度を考慮している。たとえば、Computer Adaptive Testing (CAT) で利用されるIRTは項目ごとの難易度パラメータを学習する。難易度パラメータの学習がstudent performanceを予測する際に大きく寄与しているが、学習プロセスにコストがかかり、生徒が特定のスキルに習熟したか否かを決定する際には実用的ではない。一方、Cognitive TutorsではKnowledge Tracingモデルを生徒がスキルに習熟したか否かを判断するのに利用している。KTが使用されるのは、それが生徒と教師の両方にとって有益なCognitive Diagnostic Assessment (i.e. 測定対象となっている領域・分野の学習や理解に必要なattributeを設定し、個々のattributeの習得状況を推定するようなアセスメント)であるためである。KTモデルのパラメータの学習は一度で済み、典型的にはschool yearの頭に前年のデータを利用する。そして、ここの生徒のスキルの習熟度は非常に少量の計算コストで算出できる。IRTのような項目困難度を考慮したモデルは予測精度が高い一方で、KTのような個々のスキルの習熟度を推定するcognitive diagnostic resultsは非常に有用である。これらが一つのResearch Questionを提起する:KTが項目困難度を考慮するように拡張したら予測性能が改善するのか?
※ CDAについてはこちらに説明されている:
https://www.jstage.jst.go.jp/article/jltajournal/23/0/23_37/_pdf
# モデルの気持ち
通常のBKTでは、4つのパラメータをデータからスキルごとに学習する。これらのパラメータは学生のそのスキルに対する正解/不正解の系列を時系列に並べたときに、その学生が該当スキルを知っている確率を推測する。現在の知識が与えられたとき、生徒のあるquestionに対するパフォーマンスを決定するのは2つのパラメータであり、それはguessとslipパラメータである。そして、これらのパラメータに対して我々はquestion levelのdifficultyを追加することを検討する。
高いguess rateを持つスキルは直感的には簡単と考えられる(e.g. multiple choice questionとか)。同様に、低いguess、あるいは高いslip率を持つスキルは困難なスキルだと考えられる。この直感から、項目困難度もguessとslipパラメータからとらえることができると考える。従って、我々の目的は、それぞれのquestionに固有のguessとslipパラメータを与えることで、項目ごとの難易度をモデリングすることである。
# モデル
通常のBKTにmultinomial item nodeを追加する。これはすなわち、もし10個の異なる項目がスキルデータに存在する場合、ite, nodeは1~10の値をとる。このitem nodeはquestion nodeと接続し、これにより、questionのguess/slipがitem nodeによって条件づけられる。10個の項目があるデータセットの例では、モデルは10個のguess parameterとslip parameter、learn rate, priorを持つことになり、合計で22パラメータを持つ事になる(一方、通常のBKTでは4つのパラメータである)。
項目ごとに十分な量のデータポイントが存在しない場合、モデルが過剰なパラメータを持つ可能性があるが、データポイントど同等、またはそれ以上のパラメータを持つモデルが有効であるトレンドにあることはNetflix challengeや2010 KDD Cupで示されている。
上図がBKTにextra nodeを加えたものを図示している。通常のKTモデルでは単一のP(G), P(S)を持つが、KT-IDEMでは、項目ごとにP(G), P(S)を持つ。たとえば、P(G|I=1), P(G|I=2)k ..., P(G|I=10)であり、項目ノードの値が与えられると異なるguessパラメータをとる。図の例だと、生徒は項目ID 3, 1, 5, そして2に取り組んでいるが、この情報は観測可能であり、モデルトレーニングに使える。従って、P(G|I), P(S|I)をfittingすることができる。そして、predictionの際は、どの項目に生徒が取り組んでいるかを知らせれば推論ができる。
# データセット
ASSISTmentsデータと、Cognitive Tutorデータセットを利用した。
ASSISTmentsデータセットでは、problem templateを項目とみなしたが。一方Cognitive Tutoerデータセットでは、problem(stepのコレクション)を項目とみなした。
## ASSISTments Platform
ASSISTmentsはwebベースのturoring platformで、4年生から12年生までの数学のコンテンツを扱っている。下図は、ASSISTmentsにおける数学の項目の例であり、生徒が問題に不正解、あるいはhelpを要請した場合に表示されるチュートリアルヘルプの様子である。チュートリアルヘルプは、個々のproblemを解くのに必要な知識を学習するために、problemをsub questionに分解して(scaffoldingと呼ぶ)生徒にquestionを解くためのヒントを与える。questionは、生徒がヘルプのリクエスト無しでfirst attemptで正解した場合のみ「正解」したとみなす。
### ASSISSTmentsにおけるItem template
skill building datasetは、複数のitem templateによって生成される複数のquestionに対するresponseによって構成される。
テンプレートは、コンテンツ開発者が Web ベースのビルダー アプリケーションで作成した問題の骨組みである。たとえば、テンプレートでピタゴラスの定理の問題を指定できますが、問題の数字は記入されていない。この例では、問題のテンプレートは次のようになる:"辺の長さが X と Y の直角三角形の斜辺は何ですか?"。ここで、X と Y は、質問がテンプレートから生成されるときに値が入力される変数である。解答も、コンテンツ開発者が指定した解答テンプレートから動的に決定される。この例では、解答テンプレートは「Solution = sqrt(X^2+Y^2)」となる。変数の値の範囲を指定することができ、開発者は動的グラフ、表、単語問題のランダムに選択されたカバーストーリーなど、より高度なテンプレート機能を利用できる。テンプレートは、テンプレート項目のチュートリアルヘルプを構築するためにも使用される。これらのテンプレートから生成された項目は、学生が特定のスキルを練習するための大量の項目を提供する実用的な方法として、skill building problemセットで広く使用されている。
### Skill building datasets
Skill buildingは、同じスキル、またはスキルグループに関連する多数の異なるテンプレートから生成された数百の項目で構成されるASSISTmentsの問題セットの一種である。生徒は、helpを要請せずに3つの項目に連続して正解すると、問題セットを完了したとみなされる。この問題セットでは、項目はランダムな順番で選択される。学生がSkill building problem setの10項目に連続して3つ正解せずに解答した場合、システムは学生が翌日までその問題セットを続行するように強制する。Skill building problem setは、Cognitive Tutorのmastery learningに似ているが、Cognitive Tutorでは、生徒が0.95以上の確率で生徒が該当スキルを知っているとKTモデルが推論した場合に習熟したと見做される。ASSISTmentsの他の問題セットと同様に、skill builder problem setは教員の最良で割り当てられる。そして、割り当てられる問題セットは、多くの場合学区が従う特定の数学カリキュラムに準拠している。
本研究では、2009年〜2010年の学年度の最もデータが多い10個のskill builder datasetを利用した。各問題セットの生徒数は637人〜1285人であり、テンプレートの数は2~6である。これは、最大で6つの問題セット内の項目に関連づけられたguess/slipパラメータが存在することを意味する。1日あたり10項目の制限があるため、問題セットごとに学生の最初の10項目に対する回答のみを考慮し、残りの回答は吐きした。オリジナルのquestionに対する回答のみを考慮し、scaffoldに対する回答は利用しないようにした。
## The Cognitive Tutor: Mastery Learning datasets
Cognitive Tutor datasetは、2006-2007年におけるBridge to Algebraシステムに基づいている。このデータは2010年のKDD Cup competitionにも提供されている。Cognitive TutorはASSISTmentsとは異なるデザインがなされている。
非常に重要な違いの1つは、Cognitive Tutorが多くのスキルに関するquestion(stepと呼ばれる)にyほって構成されるproblemを提示することである(下図)。
生徒はproblemに関する様々なquestionへの回答を回答グリッドに入力できる(下図)。
Cognitive Tutorでは、Knowledge Tracingを生徒がスキルに習熟したかどうかを決定するために利用している。problemは異なるスキルのquestionによって構成されている場合もある。しかしながら、生徒がスキルを習得したとKTが判断した場合、生徒はproblem内の該当スキルのquestionに応える必要はなくなりますが、未修得のスキルに関連するquestionには応える必要がある。
Cognitive Tutorデータセットのスキル数は、ASSISTmentsデータセットよりも非常に大きいものとなっている。全てのスキルを処理する代わりに、ランダムにサンプルした12個のスキルを今回は選択した。複数のスキルによって構成されるquestionも存在する。こういった場合、各スキルを分離するのではなく、questionに関連づけられた一連のスキルを一つの単独のスキルとして扱った。Cognitive TutorはlessonsをUnitsと呼ばれる単位に区切っている。あるUnitに登場するスキル名が、別のUnitに登場する場合は別のスキルとして扱った。Cognitive Tutorには「ウィンドウを閉じる」や「enterを押す」などの瑣末なスキルも存在する。このような数学と関係ないスキルは無視した。ASSSISTmentsデータで使用される生徒ごとのデータ量との一貫性を維持するために、スキルごとの生徒ごとの回答の最大数も最初の10項目に制限した。
# 評価
5-fold cross validationを行った(生徒ごとに区切る)。パラメータの学習はBKT, KT-IDEM共にEMアルゴリズムによって行った。EMアルゴリズムはデータの尤度が最大となるパラメータを探索し、指定したmax numberの回数だけiteractionを行ったら、あるいは尤度の改善が一定の閾値を下回った場合に探索を終了する。max iteractino countは200にセットし、閾値は0.001とした。パラメータの初期値としては、両モデルに対して:P(G)=0.14, P(S)=0.09, P(L_0)=0.5, P(T)=0.14とした。この値は、ASSISTmentsデータを以前分析した際のスキル全体に対する平均値である。
生徒のfirst responseを予測する場合、項目の識別子以外の情報は与えられない。そのため、モデルのpriorとguess/slipパラメータ単独でモデルは予測を実施することとなる。これはすなわち、BKTでは全ての生徒に対してfirst responseは同じ予測結果を与える。一方KT-IDEMは生徒が最初に取り組む項目が異なるため、項目のguess/slipパラメータが異なっているため、全生徒の予測結果が同様のものとはならない。
# 評価結果
## ASSISTments dataset
10個のデータセットに対して9つのデータセットでKT-IDEMがBKTを有意にoutperformした。BKTのAUCの平均は0.669に対し、KT-IDEMのAUCの平均は0.69であった。
## Cognitive Tutor
全体のパフォーマンスとしては、BKT, KT-IDEM共に勝ち負けが入り混じっている。BKTの平均AUCは0.6457、KT-IDEMは0.6441であるが、これは統計的に有意差はなかった。前に述べたように、over parameterizationが項目ごとにguess/slipパラメータを用意することの懸念ん点であった。このデータセットでは、ASSISTments のテンプレートの数 (平均 3) と比較して、問題の数 (平均 311) がかなり多いため、この問題が明らかになります。問題の数が多く、パラメータの数も多いため、問題あたりのデータポイントの比率(dpr)が非常に重要となります。dpr>6を超えている5つのデータセットでは、KT-IDEMの予測性能が高い。これらのデータセットでは、BKTのAUCは0.6124、対してKT-IDEMでは0.7108である。この差は統計的に有意であった。dpr<6のデータセットについては、スキル6を除いて、lossは比較的少ないものであった(~0.04程度)。このスキルデータセットには396の問題があり、最も頻度の高い問題はデータポイントの25%を占め、2番目に頻度の高い問題はわずか0.3%だった。これは④ポカのスキルセットと比べて非常にバランスが取れておらず、KT-IDEMがうまく機能しないタイプのデータセットの例と言える。
# Discussion
トレーニングデータに存在しない項目のguess/slipパラメータをどうするかという課題がある。対策としては、全ての学習されたslip/guessパラメータの平均値とするか、あるいはBKTモデルのguess/slipパラメータで置き換えるという対策がある。
Cognitive Tutorの実験結果より、問題ごとのデータポイントの平均数によって、KT-IDEMの精度がBKTよりも改善するか否かが決まることが示された。スキルデータセット内の一部の問題には大量のデータが含まれている一方、一部の問題には少量のデータしか含まれない可能性がある。KT-IDEMの制度を向上させるために、データが少ない問題のguess/slipパラメータをBKTが推定したguess/slipパラメータで置き換える方法がある。また、平均正答率の値や、ヒントをリクエストした回数などの情報を利用してguess/slipパラメータの初期値を決めることで、パラメータfittingが改善する可能性がある。
また、future workとしては、CATにおいてKT-IDEMのguess/slipパラメータを用いて、より少ない問題数でassesmentを実現することなどが挙げられている(KT-IDEMのguess/slipがIRTにおける項目の識別力に相当するとみなせる。また、質問に正解した場合、あるいは不正解だった場合に確率の変化が最大となる質問を選択することができるため。ただし、この質問には正しいguess/slipパラメータが推定されている必要があり、そのための十分なデータが必要となる)。
Evaluating agents for scientific discovery, Ai2, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Blog #ScientificDiscovery #Science #Reading Reflections #Author Thread-Post Issue Date: 2026-04-14 Comment
元ポスト:
scientific discoveryを実現するエージェントに関して、research paperで主張される素晴らしさと、実態のgapを埋めるためにAi2が実施してきたベンチマークに関する研究についての解説。
- [Paper Note] ScienceWorld: Is your Agent Smarter than a 5th Grader?, Ruoyao Wang+, EMNLP'22, 2022.03
- 小学校レベルの理科の実験をエージェントが実行できるかを評価するベンチマーク
- 教科書に載っているような古典的なdiscoveryを再現させる
- 200種類以上にものぼるオブジェクトが配置された、物理法則に従う(e.g., 氷が加熱すると溶けるなど)シミュレーション世界において、水の沸点を選択肢から正解を選ぶのではなく、自身で発見することを求められる。
- 2022年、Multiple Choice Questionのschool science examでハイスコアを記録したモデルはスコアは10%未満、2025年にはスコアは80%代に到達したが、まだ完全にこなふことができない。
- [Paper Note] DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents, Peter Jansen+, NeurIPS'24 Spotlight, 2024.06
- 独自の科学的な調査をスクラッチから設計実行させるベンチマーク
- 大学、あるいはPhDレベルのopen-endなdiscoveryに関する能力を問う
- 宇宙の惑星Xでの最初の科学者として調査を実施する設定で8トピックにわたる120のタスクをこなす必要がある
- 難易度は3段階に分かれていて、タスクは架空のcontextで実施されるため事前知識に頼ることができない中でタスクを解決し、正しいプロセスで実施されたかや、理解をしているかなどの能力も問われる。
- 現在のエージェントは、normal/challengingな難易度のタスク群について、80%の完了率を達成できない
- 双方のベンチマークともに、知識と実務力を分離した上で能力を測定するものとなっており、知識を答えるだけの見かけ上の能力ではなく、スクラッチから知識に基づいてエビデンスを積み上げ、実行し、タスクを遂行し科学的な発見をできるか、という実務力を問うている
という話。
この話は
- Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
において議論されている「認知コア」と関連が深いと感じる。
認知コアとは、単なる記憶に頼るのではなく、事前学習において、いわゆる人間のような知性を(データ内に潜むアルゴリズム的なパターンを学習することで)獲得し、その結果としてIn context Learningのような能力を発達させることとされ、
既に獲得された知識がモデルの認知コアの発達を阻害し、未知の環境でも適応できるような汎化能力を獲得することを阻害している(=モデルは既存の知識と紐づけて簡単に回答できてしまうため、アルゴリズムに基づいた思考と行動を備える必要がなく学習が進み、結果的に汎用的な能力が身につかない)恐れがある、という話である。
上記ベンチマーク(特にDiscoveryWorld)は既存の世界知識に捉われない、アルゴリズム的な思考と行動が求められると推察されるため、モデルの認知コア的な側面を部分的に測定していると言えると感じる。
PLaMo 3.0 Prime β版, PFN, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #Reasoning #Japanese #Selected Papers/Blogs #In-Depth Notes Issue Date: 2026-03-19 Comment
元ポスト:
日本国内初のフルスクラッチReasoningモデル
## 公式発表のまとめ
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
によってcontext windowを64Kまで拡張(PLaMo 2.2 Primeの2倍)。
事後学習データの見直し(新たなオープンデータセット追加, 独自データとして、日本語指示追従能力, tool use, long horizon QA, 医療分野, STEM, RAG性能向上のためのデータ)を実施し、SFT, DPO, RLの流れで学習を実施。SFT, DPOについてはreasoning trajectoryもLossで考慮するように変更。SFT, DPO向けデータについてはreasoning trajectoryを合成したものを利用。
RLは今回初めて導入し学習を安定させるための工夫を取り入れているとのこと。Reference Answerとの比較と表層的な特徴から報酬を計算する関数を実装した、という書かれ方をしている。
gpt-oss-120B(memium)との比較で言うと
指示追従性能が日本語、英語ともによりも高く、医療分野のQA(国家試験を除く)、英語、日本語での対話能力で勝っている。また、法令分野のQAは同等である。
単一ツールや複数ツールからの選択は同等、multi turnの場合はPLaMo2.2から大幅に性能向上しているもののgpt-ossよりも劣る。また、long contextのQA、医療分野の国家試験QA、STEM分野のQAや数学的な推論能力は大幅に前回モデルよりも向上したが、まだgpt-ossなどには届いていない、という感じに見える。
アーキテクチャについては、一新したという話とRoPEベースということ以外はよくわからない。
## 筆者の憶測と感想
※以下、筆者の憶測を多く含んだ感想です。ただ筆者が勝手に想像して自分なりに考えてみているだけです。
DPOにNLL lossを追加することでreasoningを強化できることは下記研究で示されている:
- [Paper Note] Iterative Reasoning Preference Optimization, Richard Yuanzhe Pang+, NeurIPS'24, 2024.04
RLの報酬に関して、表層的な特徴とReference Answerとの比較から最適な報酬を計算とのことなので、おそらく何らかのVerificationのための仕組みと、Rubric-basedなLLM-as-a-Judgeだろうか?Reward Modelという書かれ方はしていない。
RLについては安定性のある手法を採用したとのことだが、DAPO、
- [Paper Note] DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, NeurIPS'25
あるいはRLのスケーリング則を導いた研究でDAPOよりも安定性と最終到達性能において優れていることが示された
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
CISPOあたりだろうか:
- [Paper Note] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning
Attention, MiniMax+, arXiv'25, 2025.06
あとは安定性という観点で言うと、inference/trainingエンジンでのtraining-inference gapの課題についても対処している可能性がある。
- Hot topics in RL, Kimbo, X, 2025.12
- [Paper Note] Beyond Precision: Training-Inference Mismatch is an Optimization Problem and Simple LR Scheduling Fixes It, Yaxiang Zhang+, arXiv'26, 2026.02
思考過程が英語ということは、言語間で能力は転移し、かつ事前学習データとしてはリソースが豊富な英語が多く含まれると想像すると、明示的(strong LLMでtrajectoryを合成したものを加える系の話)あるいはデータに自然と現れるreasoningの挙動から事前学習中にreasoning能力が暗黙的に学習されることを踏まえ、SFTでreasoning能力を強化する際に(日本語よりも英語の方が効果的な可能性が高く)英語でのtrajectoryを合成したという感じだろうか(いつか日本語のreasoning trajectoryを出力するモデルも見てみたいなあ)。
Multi Turnのtool useの性能向上に関して、AI Agent分野のlong horizonな合成データを合成するアプローチや、Sink Tokenの活用や、トークン単位でsink tokenを計算することに相当するHead wise gated attentionなどはしているのだろうか。
- [Paper Note] Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- [Paper Note] Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, Ailin Huang+, arXiv'26, 2026.02
また、アーキテクチャに関してはcontext windowが海外のフロンティアモデルと比較してまだ小さめであるが、今後context windowを大きくするにあたって、オンポリシーRLでのロールアウト時間がボトルネックとなることが考えられ、Mamba(=linear attention)系のアーキテクチャをハイブリッドや、DSA系のsparse attentionなどの採用によるアーキテクチャ起因の計算コスト低減(現在どのようなアーキテクチャなのかは全くわからないが)、あるいはin-flight-updateのような学習エンジン側での効率化なども必要になるのではなかろうか(現在どういうエンジンなのかは全くわからないが)。
- [Paper Note] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, DeepSeek-AI+, arXiv'25, 2025.12
- [Paper Note] PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence
Generation, Alexandre Piché+, arXiv'25, 2025.09
# Writing a good CLAUDE.md, Kyle, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Selected Papers/Blogs #KeyPoint Notes #Reading Reflections #AGENTS.md Issue Date: 2026-02-27 Comment
元ポスト:
本ブログは CLAUDE.md について記述されているものだが、ブログ冒頭で記述されており、AGENTS.mdに一般的に適用できる話だと考えられるため、以下本文中でCLAUDE.mdとして記述されている部分も、AGENTS.mdと読み替えて記述している。
要するに
- `AGENTS.md` はAI Agentの **全ての会話に対してコンテキストをユーザが明示的に挿入する唯一の手段** であり、
- `AGENTS.md` にはプロジェクトのあらゆるタスクで **普遍的に必要な情報を、過不足なく、簡潔に記述されるべき** であり
- プロジェクトが大規模な場合は、`AGENTS.md` は目次として利用し、必要な情報は個別のファイルに別々に記述し、`AGENTS.md` 内にはその **ポインターのみを記載** する
- `AGENTS.md` の **自動生成は非推奨** であり、理由としては1行でも誤った記述が含まれていた場合全てのエージェントの挙動に影響が出るためであり、全ての内容について慎重に検討をしたうえで記述されるべきである。
という話のようである。
-----
- 原則
- AI Agentはstatelessであり、あなたのコードベースについて何も知らない。このため利用者がコンテキストとしてコードベースの情報を伝える必要があり、そのために有用なツールがAGENTS.mdである
- AGENTS.mdはすべての会話にデフォルトでコンテキストとして含まれる **唯一の** ファイルである
- AGENTS.mdでどのような情報が網羅されるべきか?
- **WHAT**: 技術スタック、プロジェクト構造、コードベースの構成等のリポジトリの基本情報を記述し、Agentが適切に情報を検索できるようにする
- **WHY**: プロジェクトの役割と、リポジトリ内の要素の役割
- **HOW**: Agentがどのような作業をすべきに関する明確な指示を記述し、その指示を実施するために必要な情報を全て含める
- AGENT.md はしばしば無視される
- たとえばClaude CodeではCLAUDE.md (Claudeが利用するAGENTS.md) をコンテキストに含める際に以下のシステムリマインダーを自動的に挿入する:
- つまり、AGENTS.mdに普遍的に利用可能な情報が含まれていない場合は、現在実施しようとしているタスクと関係ないとエージェントが判断し、AGENTS.mdが無視されることがある点に注意が必要
```
IMPORTANT: this context may or may not be relevant to your tasks.
You should not respond to this context unless it is highly relevant to your task.
```
- 優れたAGENTS.mdを作成するベストプラクティス
- **less (instructions) is more**:
- AI Agentが順守できる指示の数には限界があり、指示の数が増えれば増えるほど、指示を遵守できない割合が高まっていく。
- これはモデル依存であり、パラメータ数が大きいモデルほど多くの指示を遵守できる(150--200など)。
- AGENTS.mdがすべての会話に付与されることを考えると、たとえば50個の指示をAGENTS.mdに含めた場合、150個の指示を遵守できるAgentを利用していたら、AGENTS.mdだけで1/3だけを消費することになる。
- また、指示が増えれば増えるほど、均一に指示追従の能力が低下する。
- つまり、ある指示が冒頭・末尾に書かれていようとも、位置に関係なく何らかの指示に追従しない可能性が高まる。
- これらの性質から、可能な限り少ない指示を記述することが必要で、特に冗長性を排除し、あらゆるタスクに普遍的に適用可能な指示のみを記述することが肝要であることが示唆される。
- length & applicability:
- AGENTS.mdは、300行未満などが推奨されているが、要は **適切な普遍的に適用可能な情報が** 簡潔で短く記述されていることが好ましい[^1]。
- Progressive Disclosure
- プロジェクトが大規模化した場合、必要な全ての情報を簡潔にAGENTS.mdに含めることがそもそも困難になる
- この場合はAGENTS.mdに目次を記述し、機能ごとの必要な情報は個別のファイルに記述し、それがどこに格納されているかのポインタを記述することによって解決する
- AGENTS.mdに全ての情報を書いてしまってはいけない。この場合上記の less is more や length の原則に反することになる。
- AGENT (CLAUDE) is not an expensive linter
- コーディング規約を書いている人が多いがやめた方が良いという話で、
- コーディング規約を無視しているか否かを判断させるにはもっと決定論的で安価なツールがあるのでそちらに任せましょうという話と、
- コーディング規約を明示していなくてもAgentはコードスニペットを解釈する過程で暗黙的にどのようなコーディング規約に従っているかは理解できるので、わざわざ明示的に挿入して不要で無関係なコンテキストで埋め尽くす必要はないよね、という話が書かれている。
- `/init` コマンドや、`AGENTS.md (CLAUDE.md)` の**自動生成は非推奨**
- AGENTS.md はAgentの全ての挙動に影響を与えるため、1行でも誤りがあると全ての作業に影響が出る非常にクリティカルなファイルであるため、自動生成等に頼らずに、慎重に検討をした上で記述されるべきである、という話
- 実際、下記研究にてLLMが自動生成したAGENTS.mdでは、タスク性能は劣化しトークン消費量が増えるだけ、という結果が示されている
- [Paper Note] Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?, Thibaud Gloaguen+, arXiv'26, 2026.02
[^1]: 根拠として、ブログ中では、無関係な情報がコンテキストで埋め尽くされているよりも、関連性のある情報が埋め尽くされる場合が一般的に性能が向上すると書かれている。が、文献などは引用されていないように見える。たとえば、この記述に対して、「初期のRAGの研究でrelevantな情報に対してirrelevantな情報が周囲で埋め尽くされていた場合に実は性能が向上します、といった話があったじゃないか」といった鉞を飛ばすことができそうだが、これは古い研究でおそらく当時(数年前)のLLMではcontext中のrelevantな情報を見分ける能力が低かったことに起因する。つまり、このような現象は明らかにirrelevantな情報が混在することで、相対的にrelevantな情報が際立つことによってLLMのcontextの理解力が乏しい部分を補っていた、と管理人は推察しており、現代のLLMではcontextを解釈する性能は大幅に向上していると考えられるため、わざわざirrelevantな情報をcontextに含める必要はなく、この見解には私も同意する。そもそもこの私の見解があまりにも重箱の隅すぎて蛇足すぎるがなんかそういうことを思い出しちゃったので書いた :)
ここで記載されている内容はAGENTS.mdのみならず、そもそものプロンプトエンジニアリング全般で言える話でもある。
Cross-prompt Pre-finetuning of Language Models for Short Answer Scoring, Funayama+, 2024.09
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #AES(AutomatedEssayScoring) Issue Date: 2024-11-28 Comment
SASでは回答データが限られているので、限られたデータからより効果的に学習をするために、事前に他のデータでモデルをpre-finetuningしておき、対象データが来たらpre-finetuningされたモデルをさらにfinetuningするアプローチを提案。ここで、prompt中にkeyphraseを含めることが有用であると考え、実験的に有効性を示している。
BERTでfinetuningをした場合は、key-phraseを含めた方が性能が高く、特にfinetuningのサンプル数が小さい場合にその差が顕著であった。
次に、LLM(swallow-8B, 70B)をpre-finetuningし、pre-finetuningを実施しない場合と比較することで、pre-finetuningがLLMのzero-shot、およびICL能力にどの程度影響を与えるかを検証した。検証の結果、pre-finetuningなしでは、そもそも10-shotにしてもQWKが非常に低かったのに対し、pre-finetuningによってzero-shotの能力が大幅に性能が向上した。一方、few-shotについては3-shotで性能が頭打ちになっているようにみえる。ここで、Table1のLLMでは、ターゲットとする問題のpromptでは一切finetuningされていないことに注意する(Unseenな問題)。
続いて、LLMをfinetuningした場合も検証。提案手法が高い性能を示し、200サンプル程度ある場合にHuman Scoreを上回っている(しかもBERTは200サンプルでサチったが、LLMはまだサチっていないように見える)。また、サンプル数がより小さい場合に、提案手法がより高いgainを得ていることがわかる。
また、個々の問題ごとにLLMをfinetuningするのは現実的に困難なので、個々の問題ごとにfinetuningした場合と、全ての問題をまとめてfinetuningした場合の性能差を比較したところ、まとめて学習しても性能は低下しない、どころか21問中18問で性能が向上した(LLMのマルチタスク学習の能力のおかげ)。
[Perplexity(hallucinationに注意)]( https://www.perplexity.ai/search/tian-fu-sitalun-wen-wodu-mi-ne-3_TrRyxTQJ.2Bm2fJLqvTQ#0)
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments, Banerjee+, CMU, ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and_or Summarization
Paper/Blog Link My Issue
#Article #MachineTranslation #Metrics #NLP #Evaluation Issue Date: 2023-05-10 Comment
# イントロ
MTの評価はBLEUが提案されてから過去2年間で注目されている。BLEUはNIST metricと関連しており、研究で利用されてきた。自動評価は素早く、より簡便に、human evaluationよりも安価に評価をすることができる。また、自動評価は他のシステムとの比較だけでなく、ongoingなシステムの改善にも使える。
過去MTの評価は人手で行われてきた。MTの評価で利用される指標はfairly intensiveでwell establishedな一方で、MTの評価全体は複雑さとタスク依存である。結果的にMTの評価そのものが研究分野となってきた。多くの評価指標が提案されてきたが、全てが簡単に定量化できるわけではない。近年のFEMTIといったフレームワークは、MT評価のための多面的なmeasureを効果的でユーザが調整可能な方法で考案しようとしている。一方、単一の1次元の数値メトリックは、MT評価の全てのaspectを捉えることができないが、このようなメトリックは未だ大きな価値が実用性の観点で存在する。効果的・かつ効率的であるために、MT評価の自動性能指標はいくつかの基本的な基準を満たす必要がある:
- MTの質に対する人間が定量化した指標と高い相関があること
- 異なるシステム間、同じシステムの異なるバージョン間の品質の違いにできるだけsensitiveであること
- 一貫性があり、信頼性があり、一般的である必要
- 一貫性: 同じMTシステムが類似したテキストを翻訳したら類似したスコアを返す
- 信頼性: 類似したスコアを持つMTシステムは似たように類似した動作をすること
- 一般的: さまざまなドメインやシナリオのMTタスクに適用可能であること
これら指標を全て満たすことは困難であるが、これまでに提案された全ての指標は、要件の全てではないにせよ、ほとんどの要件に対して適切に対処できているわけではない。これらの要件を適切に定量化し、具体的なテスト尺度に変換すると、MTの評価指標を比較、および評価できる全体的な基準として扱える。
本研究では、METEORを提案する。METEORはBLEUのいくつかの弱点に対処した手法である。
# METEOR Metric
## METEORで対処するBLEUの弱点
BLEUはn-gramのprecisionを測る指標であり、recallを直接的に考慮していない。recallは翻訳文が正解文のcontentをどれだけcoverできているかを測定することができるため重要な指標である。BLEUは複数の参照訳を利用するため、recallの概念を定義することができない。代わりに、BLEUではbrevity penaltyを導入し、短すぎる翻訳にはペナルティを与えるようにしている。
NIST metricもコンセプト上はBLEUと同様の弱点を持っている。METEORが対処するBLEUやNISTは以下となる:
- The Lack of Recall:
- 固定のbrevity penaltyを与えるだけでは、recallに対する適切な補償とはなっていない。実験結果がこれを強く示している。
- Use of Higher Order N-grams:
- BLEUにおけるhigher orderのN-gramの利用は、翻訳の文法的な良さを間接的に測定している。METEORではより直接的にgrammarticality(あるいはword order)を考慮する。実験結果では、human judgmentsとより良い相関を示した。
- Lack of Explicit Word-matching between Translation and Reference
- N-gramでは明示的なword-to-word matchingを必要しないため、結果的に正しくないマッチ、具体的には共通の機能語等のマッチをカウントしてしまう。
- Use of Geometric Averaging of N-grams
- BLEUは幾何平均(i.e. 1,2,3,4-gramそれぞれのprecisionの積の1/n乗根)をとっているため、n-gramのコンポーネントの1つでもゼロになると、幾何平均の結果もゼロとなる。結果的に、sentenceあるいはsegmentレベルでBLEUスコアを測ろうとすると意味のないものとなる(ゼロになるため)。BLEUは全体のテストセット(文レベルではなく)のカウントを集約するのみであるが、sentence levelのindicatorもメトリックとしては有用であると考えられる。実験結果によると、n-gramの算術平均をとるようにBLEUスコアを改変した場合、human judgmentsとの相関が改善した。
## Meteor Metric
参照訳が複数ある場合は最もスコアが高いものを出力する。METEORはword-to-wordのマッチングに基づいた指標である。まず、参照訳と候補訳が与えられたときに単語同士のalignmentを作成する。このときunigramを利用してone-to-manyのmappingをする。wordnetの同義語を利用したり、porter-stemmerを利用しステミングした結果を活用しalignmentを作成することができる。続いて、それぞれのunigramのmapppingのうち、最も大きな部分集合のmappingを選択し、対応するunigramのalignmentとする。もしalignmentの候補として複数の候補があった場合、unigram mappingのcrossが少ない方を採用する。この一連の操作はstageとして定義され、各stageごとにmapping module(同義語使うのか、stemming結果使うのかなど)を定義する。そして、後段のstageでは、以前のstageでmappingされていなunigramがmappingの対象となる。たとえば、first stageにexact matchをmapping moduleとして利用し、次のstageでporter stemmerをmapping moduleとして利用すると、よりsurface formを重視したmappingが最初に作成され、surface formでマッチングしなかったものが、stemming結果によってマッピングされることになる。どの順番でstageを構成するか、何個のstageを構成するか、どのmapping moduleを利用するかは任意である。基本的には、1st-stageでは"exact match", 2nd-stageでは"porter stem", 3rd-stageでは"wordnet synonymy"を利用する。このようにして定義されたalignmentに基づいて、unigram PrecisionとRecallを計算する。
Precisionは、候補訳のunigramのうち、参照訳のunigramにマッピングされた割合となる。Recallは、参照訳のunigramのうち、候補訳からマッピングされた割合となる。そして、Precisionを1, Recallを9の重みとして、Recall-OrientedなF値を計算する。このF値はunigramマッチに基づいているので、より長い系列のマッチを考慮するために、alignmentに対して、ペナルティを計算する。具体的には、参照訳と候補訳で連続したunigramマッチとしてマッピングされているもの同士をchunkとして扱い、マッチングしたunigramに対するchunkの数に基づいてペナルティを計算する。
チャンクの数が多ければ多いほどペナルティが増加する。そして、最終的にスコアは下記式で計算される:
最大でF値が50%まで減衰するようにペナルティがかかる。
# 評価
## Data
DARPA/TIDES 2003 Arabic-to-English, Chinese-to-English データを利用。Chinese dataは920 sentences, Arabic datasetは664 sentencesで構成される。それぞれのsentenceには、それぞれのsentenceには、4種類のreferenceが付与されている。加えて、Chinese dataでは7種類のシステム、Arabic dataでは6種類のシステムの各sentenceに対する翻訳結果と、2名の独立したhuman judgmentsの結果が付与されている。human judgmentsは、AdequacyとFluency Scoreの2つで構成されている。それぞれのスコアは0--5のレンジで変化する。本評価では、Combined Score、すなわち2名のアノテーションによって付与されたAdequacy ScoreとFluency Scoreを平均したものを用いる。
本研究の目的としては、sentence単位での評価を行うことだが、BLEUやNISTはシステムレベルで評価を行う指標のため、まずシステムレベルでhuman judgeとのcorrelationを測定。correlationを測る際は、各システムごとにCombined Scoreの平均をとり、human judgmentの総合的な結果を1つのスコアとして計算。またシステムのすべての翻訳結果に対する各種metricを集約することで、システムごとに各種metricの値を1つずつ付与し、両者で相関を測った。結果は以下のようにMETEORが最も高い相関を示した。METEORのsubcomponentsもBLEUやNISTよりも高い相関を示している。
文レベルでhuman judgeとのcorrelationを測った結果は下記。文レベルで測る際は、システムごとに、システムが翻訳したすべての翻訳結果に対しMETEORスコアを計算し、fluencyとadequacyスコアの平均値との相関を測った。そして各データセットごとに、システムごとの相関係数の平均を算出した。
他のmetricとの比較結果は下記で、METEORが最も高い相関を示した。
続いて、異なるword mapping設定でcorrelationを測った。結果は下記で、Exact, Porter, Wordnet-Synonymの順番で3-stageを構成する方法が最も高い相関を示した。
最後に、文レベルの評価はannotator間のaggreementが低く、ノイジーであることがわかっている。このノイズを緩和するために、スコアをnormalizeしcorrelationを測定した。結果は下記で、normalizeしたことによってcorrelationが改善している。これは、human assessmentのノイズによって、automatic scoreとhuman assessmentのcorrelationに影響を与えることを示している。
①ラーニングアナリティクスの研究動向 ─エビデンスに基づく教育の実現に向けて─, 京都大学, 緒方先生, 情報処理 Vol.59 No.9 Sep. 2018
Paper/Blog Link My Issue
#Article #Tutorial #LearningAnalytics Issue Date: 2022-03-03 Comment
緒方先生によるLAのチュートリアル
主な研究テーマ:
①行動予測:教育・学習活動において蓄積された大量のデータを元に,機械学習を用いて予測モデルを作成し,学習者の成績や能力,ドロップアウト等の行動を予測する研究
②介入モデル:いつどこでどのような内容をどのような方法で学習者に伝えると,効果的な情報提供となるか,という研究
③オープン学習者モデル:学習データを用いて学習スタイルや特徴を推測し,それをシステム内だけにとどめるのではなく,学習者にできる限り見える形で提示する,オープン学習者モデルの研究
④推薦:学習者個人の特徴にあわせて,教材や問題,カリキュラム等を推薦する研究
⑤ティーチングアナリティクス:教師の教育活動のデータを分析する研究
⑥教育評価の自動化:収集したデータの分析を元に,学習者の評価を自動的に行う研究
2021年版スライド:
https://www.let.media.kyoto-u.ac.jp/wp-content/uploads/2021/07/603b542fafc54003eb4a1a42bb92069f.pdf
典型的な研究事例:
・At-risk学生の発見と成績予測(early-warning)
・学生の成績予測
- 教員が早期に単位を落としそうな学生を発見
- 学生は成績予測を確認して、学びに向かう態度を改善
・教育データを用いた予測
- 教育データからACADEMIC Successの予測(e.g. career success, academic achievement)
・Open learner model (student model)
・Recommendation and personalized learning
- ALEKSのようなシステム
- BKT, DKT等を用いた推薦
・Learning analytics dashboard
・Writing (Text) analytics
- Academic writingの文章を分析
- eポートフォリオ/Essay/Journalを分析、成績や感情を予測
・Emotional learning analytics
・Multimodal learning analytics
- Gaze (eye tracking)
- Bio sensors (heart rate)
- Pen, click stream
- Motion sensor (gestures)
- Audio/Video
・Collaborative learning analytics
- Group formation
- Social network analysis
- Interaction analytics
・Ubiquitous Learning analytics
- SCROLL:誰がいつどこで何を学習したかという学習ログを分析
・Learning analytics and self-regulated learning
・Learning analytics for teaching / learning design
・Assessment analytics
- create exams
- Peer evaluation