
Reading Reflections
[Paper Note] Skill Retrieval Augmentation for Agentic AI, Weihang Su+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #reading #One-Line Notes #AgentSkills Issue Date: 2026-07-21 GPT Summary- 大規模言語モデル(LLMs)が外部スキルに依存するようになり、これを効率的に活用するために新たにSRA(Skill Retrieval Augmentation)パラダイムを提唱。SRAは、エージェントが必要に応じて関連スキルを動的に取得し適用する仕組みで、初のベンチマークSRA-Benchを導入。5,400件のテスト事例と636件の正解スキルを用いた実験により、検索ベースのスキル拡張が性能向上に寄与することを確認。ただし、スキルの取り込みには課題があり、正解スキルの認識や外部能力の必要性に関する判断がエージェントの性能を制限することが分かった。これにより、今後のエージェントシステムの能力拡張の基盤を築くことが示唆される。 Comment
元ポスト:
pj page: https://sr-agents.github.io
dataset: https://huggingface.co/datasets/WeihangSu/SRA-Bench
スキルの肥大化に伴いモデルのcontextが肥大化しパフォーマンスが劣化することから、動的にスキルを検索して統合するSkill Retrieval Augmentationを提案し、そのための大規模なデータセットを用いて評価をしている、という話に見える。データセットは26kのスキルで構成され、そのうち636件がgoldという規模感のデータセット。
実験結果を見ると、topkのretrieve結果をそのまま利用するfull injectionよりも、full injectionしたスキルのメタデータからrelevantなスキルを1iLLMで選択するLLM Selectionの性能が向上している点が興味深い。
また、skill poolにhard negativeなスキルが存在すると、ベンチマークのスコアは低下していく傾向(具体的にどのベンチマークかまでさ読めていない)にあり、hard negativeが8つ程度で、様々なモデルにおいてAcc.が10%程度は低下しているように見える。興味深い。
問題設定が実用的で興味深いだけでなく、hard negativeなスキルが <10個 程度のオーダーで存在するだけで大きくAcc.が低下する知見を示している点がおもしろい。
[Paper Note] Self-Guided Test-Time Training for Long-Context LLMs, Xinyu Zhu+, arXiv'26, 2026.07
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #reading #One-Line Notes #Test Time Training (TTT) Issue Date: 2026-07-19 GPT Summary- 長文脈処理において、LLMは単にコンテキスト窓を拡張するだけでは十分ではなく、入力長の増加が精度の低下を引き起こすことがある。テスト時訓練(TTT)は長文脈の活用を改善する手法の一つだが、全体への適用は費用がかかり、ランダム抽出による訓練が性能を低下させることがある。これに対し、Self-Guided TTT(S-TTT)を提案し、適応前にモデルが選択された証拠スパンを認識することで、基準となる言語モデル訓練を適用。S-TTTは、LongBench-v2およびLongBench-Proでの精度向上を実現し、最大で15%の改善を達成。 Comment
元ポスト:
長文Context+質問が与えられたときに、質問に関連するcontextのspanを同定した後(Self-Guided)、TTTでモデルパラメータに内部化させた後に応答する、という話に見える。TTTでは、LoRAを用いて、かつ16 gradient updateを行った時点で更新を終了する。
Full ContextでらTTTするよりも、Self-Guidedな方が高い性能を獲得できる。
TTTを使ってLoRA adapterにcontextの情報をweightとして内部化させても、思ったほど性能は上がらないのだなという印象。
LoRAでweightにcontextを内部化させても、その内部化された情報をうまく活用するような工夫が足りていないのでは?という気がするのだが、どうだろうか。
ベンチマークのインスタンスが、contextをmemorizationし、適切にatteedすれば解けるようなクエリなのか否かという点も気になる。
もしcontextの情報に基づいてマルチポップな推論が必要な場合、LoRAアダプタによる重みを活用するような回路が育っていない可能性が高く、性能は伸びにくいのかなという気はする。
[Paper Note] WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction, Chengzhi Liu+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Evaluation #MultiModal #Selected Papers/Blogs #memory #interactive #KeyPoint Notes #Author Thread-Post #AgentHarness Issue Date: 2026-06-03 GPT Summary- マルチモーダル大規模言語モデルが長期エージェントとして機能するためには、記憶が進化する世界に適応し、適切な証拠を提示する必要がある。しかし、従来のベンチマークは静的なリコールに依存しており、記憶の生成における失敗を特定できない。これに対して、我々は記憶を「アクション-ワールド・インタラクション・ループ」として定式化し、WorldMemArenaを実装。ここでは、400件のマルチセッション・マルチモーダルタスクを通じて、記憶の診断が可能となる。結果として、記憶書き込みは必ずしも性能向上に繋がらず、視覚的証拠の活用が依然として困難であることが示された。また、エージェントの実行はドメインを跨いで不安定で、コストと信頼性のトレードオフが浮き彫りになった。 Comment
元ポスト:
著者ポスト2:
以下著者ポストの要約
既存のメモリに関するベンチマークは、「静的な環境」において過去のコンテキストから情報を「復元」できるかをテストしているが、それを超えて、
- Lifelong Evolution(動的): ユーザとプロジェクトの状態が変化する世界において、
- Agentic Execution(書き込み・維持・検索・活用): エージェントが観測結果、アクション、ツール実行結果、環境の変化から再利用可能なメモリを構築できるか
をカバーするベンチマークを構築。ベンチマークは461個の複数セッション・マルチモーダルなタスクが含まれ24k QAペア・15kの画像・スクリーンショット、高速な評価のための150サンプルによるサブセットによって構成される。
評価では、
- long-contextのエージェントのcontextに入れ込むメモリ
- 人間がデザインしたメモリ(RAG, メモリパイプライン等)、
- agent harnessがメモリ管理をするタイプのagent
の3種類を評価。
- Takeaway
- メモリへの書き込みの品質が高くても、必ずしもエージェントがうまく活用できるとは限らない
- 現在の手法ではマルチモーダルな情報に対するメモリはまだ困難で、視覚的/空間的/手続き的な情報を失う
- 重要な情報がアクション、フィードバック、スクリーンショット、状態の更新等に分散している場合にメモリは劣化し、これは現在の多くのシステムが整理されたテキストベースの履歴を扱うことに長けている一方で、実際のinteractionのtrajectoryから情報を抽出・更新・再利用することには課題があることを示唆
- agent harnessに基づくメモリはinteraction中に自動的にメモリが記録・抽出・推敲されるため柔軟性が高く有望なアプローチだが、harness designに性能が依存するため、 性能が不安定
評価結果を見ると、一言にメモリと言っても多様な観点からmetricsが定義でき、手法によって性能に大きな開きがある点や実用的な観点の実験設定となっており興味深い。様々な要素が関わってくるため、一概にこの手法が良いというのもあまり言えなさそうに見える。あとなんやかんやRAGが全体的に性能が良さそうに見えるが、結果の解釈が難しく、何らかの単一の尺度などに押し込めたりしないだろうか。
pj page: https://worldmemarena-mem.github.io/
[Paper Note] VLA-REPLICA: A Low-Cost, Reproducible Benchmark for Real-World Evaluation of Vision-Language-Action Models, Alex S. Huang+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#ComputerVision #NLP #Evaluation #Reproducibility #Robotics #VisionLanguageActionModel #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- VLAモデルの実世界評価に向けた低コスト且つ再現性の高いベンチマークVLA-REPLICAを提案。市販部品で構築し、多様な操作タスクとデータセットを提供。実験により、再現性を確認し、モデルの特性を明らかに。 Comment
元ポスト:
再現可能なベンチマークを作るのはロボティクスのような物理的な検証環境が必要なタスクの場合は確かに難しそうだな、と思うなどした(小並感)。オブジェクトの配置や景観、実際のロボットのパーツなど外的な要因が非常に多い気がする。
[Paper Note] A Bitter Lesson for Data Filtering, Christopher Mohri+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #read-later #Selected Papers/Blogs #DataFiltering #One-Line Notes #Author Thread-Post Issue Date: 2026-05-23 GPT Summary- 高計算資源を活用したスケーリング研究で、大規模モデルの事前学習におけるデータフィルタリングを検討。一般的に思われる高品質データのみが必要との見解に反し、実験は、十分な計算資源があればデータフィルターなしが最良であることを示す。訓練された大規模モデルは低品質や誤誘導データを受け入れ、むしろ「質の悪い」データからも恩恵を得ることが判明。 Comment
元ポスト:
LLMの事前学習において、十分に大きなモデルサイズと計算量があれば、データフィルタリングをしない場合の方が最終的にperplexityがデータをフィルタリングしたモデルよりも上回る。これはbad data (e.g., トークンのシャッフル, ランダムな文字列の挿入)を追加した場合でも当てはまる。
データプールのサイズが大きな数な場合でも、フィルタリング手法とフィルタリングがない手法との交差点が変わるのみで、その交差点は現実的なエポック数に留まったままである。データのスケーリングの傾向に基づいて、インターネットサイズのデータサイズに外挿をすると、約1e30 FLOPsが必要となる試算になるが、数年以内に到達可能な計算量と考えられる。
ダウンストリームタスクへの性能にも(ノイジーだが)事前学習での改善は寄与する。ただし、事前学習させたトークン数が少ない場合はフィルタリングした方が性能が良く、十分な計算量を投じる必要がある。
といった話が著者ポストに書かれている。興味深い。
逆に言うとこの傾向は、モデルパラメータ、計算資源が十分に大きいことが前提だと考えられるので、PhiのようなSLM研究において得られた学習データの高品質化が重要という知見とは競合しないと思われる。
解説:
関連:
- [Paper Note] When Bad Data Leads to Good Models, Kenneth Li+, ICML'25, 2025.05
[Paper Note] Steered LLM Activations are Non-Surjective, Aayush Mishra+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Prompting #Safety #Selected Papers/Blogs #reading #One-Line Notes #Steering #Interpretability #Author Thread-Post Issue Date: 2026-05-21 GPT Summary- アクティベーション・ステアリングは、モデルの活性化を調整し、その挙動に変化を与える手法であり、解釈可能性や安全性研究で広く利用されている。しかし、任意のテキストプロンプトによってこの挙動が実現可能かは不明である。本研究では、この問題を全射的な観点から考察し、すべてのステアされた活性化が前像を持つかを調査する。実証的結果から、活性化ステアリングは任意のプロンプトによって同じ内部挙動を再現できないことを示し、ホワイトボックス的なステアリングとブラックボックス的なプロンプティングの違いを明確にする評価プロトコルを提案する。 Comment
元ポスト:
steeringされたactivationを自然に生み出すプロンプトは存在しない。言い換えると、steeringによって得られる挙動はpromptでは再現できない。これにより以下が示唆される:
- prompt levelのbehaviorとactivation/weightに介入することによるbehaviorの変化は、根源的に異なる現象なので分けて考えなければならない
- white-boxなstteering手法によってjailbreakができたとしても、black-boxな手法(e.g., promptingによる脆弱性など)による脆弱性があることの証拠にはならない
Steeringされたactivationは下記のようなAutoencoderを学習することでverbalizeできるのだろうか?hidden_stateのreconstruction lossを通じてverbalizeするためできそうではある。元々のactivationがpromptによって到達不可能な点にいたときに、promptによって到達不能なだけであって内部のネットワークが状態を解釈できないというわけではないので(ここがめちゃめちゃなら何も学習できないということになるがそうではなさそうなので)普通にできそうではある:
- Natural Language Autoencoders: Turning Claude’s thoughts into text, Anthropic, 2026.05
[Paper Note] Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs, Guijin Son+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #Mathematics #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2026-05-14 GPT Summary- Soohakという新たな数学ベンチマークを導入し、439問から成り、フロンティアモデルの推論能力を評価。Challengeサブセットでは、トップモデルが30.4%未満の成功率である一方、拒否サブセットはモデルが50%を超えられない問題解決能力を確認。これにより、拒否能力が新たな評価基準として浮上し、2026年末に公開予定のデータセットで混入を防ぐ。 Comment
元ポスト:
60人以上の数学者によってゼロペースで作成された新たなベンチマーク。数学者は作問をする際にLLMの利用は禁止され、問題を作成しsubmitする。その後レビュープロセスを経て問題が収録されるかが決まっているようである。レビュープロセスでは、LLMによる難易度の確認や類似した問題がないかなどの確認をし、人間がLLMの出力を見て疑わしいか否か判断する。レビュワーは作成者にフィードバックをし、質問や確認などを行う。また、LLMを利用したであろう作成者はbanされ、問題に調整が必要な場合は修正がなされる。提出された問題は、小、中、大のスケールのOpenLLMによって正解できたか否かによって、miniとして収録されるかChallengeとして収録されるかが決まり、特にChallengeについては作成者が特定の教員やポスドク、IMOメダリストなどに限定されたようである。
99個の、矛盾や前提の抜け、正解が一意に決まらないill-posedな問題も含まれており、モデルが回答を拒否しなければならないRefusal Questionsが含まれているのが大きな特徴。
研究レベルの問題の定義がよくわかっていないのだが、要は競技で出題されるような「既存の知識や枠組みの中でのマルチステップでの推論」を必要とするものではなく、「数学に関する最先端を切り拓くレベルの問題」のことのようである。これでもまだよくわからなかったのだが、問題の作成者に対するインタビューによると、SOOHAK-Miniの問題は短時間で作成できたが、SOOHAK Challengeの問題は1問作成するのに1日以上の作業を要することがしばしばあったとのこと。Challengeレベルの問題を作成するためのアプローチとしては典型的に2つあったとのことで、
- 問題作成者自身が最近考えていた研究と隣接した問題を提出するもので、問題を解くステップにおいて既存の定理や、論文などで公式には発表されていない事実や、数学者の中でヒューリスティクスを組み合わせる必要があるような要素を含むもの(folklore-level reasoningと呼ばれる)
- ニッチな研究論文に基づいて問題を設計する方法
などがあったようである。つまり、競技という枠組みは超えて、数学の研究者が研究として考えるレベルの問題ということだと理解した。
コーディングにおいて人間を置き換えるレベルであろうモデルも、未知の数学の問題や、そもそも問題として不適切なものの回答拒否は広く使われたベンチマークほどはうまくいかない。新たに拒否が最適化のobjectiveとして必要なことが示唆されているが、逐一人類はAIにこの挙動が足りないね、じゃあ学習データを用意して学習しよう、ということを繰り返していくのだろうか?正解ベースの学習にそろそろ限界が見えてきた気がしており、AnthropicのペルソナやConstitutionに基づいた学習のような特定の領域に広く汎化するような学習方法の模索が必要な気がする。
拒否する挙動のための正解データを用意して学習するとしよう。そうすると、モデルが持つ他の能力に影響を与えるだけでなく、本来拒否が不要な場面でも拒否するようになる可能性が高い(たとえばクエリが数学に関連しているだけで、一定の確率で拒否するリスクは生じるように思われる)。この問題を解決するために最近はOn-Policy Distilation (OPD)が活用されるが、OPDはこの問題を緩和することには寄与するが、根源的に解決しているわけではない(と思われる)。genericな能力の発現に際して、モデル自身がcontextに応じて、どの挙動を発現させるべきかを"線引き"できるような能力とアーキテクチャ(マルチモーダルなモデルのようにMoEのexpertをbehaviorに関しては分離するなどだろうか)が必要に思う。
[Paper Note] Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction, Zhuofeng Li+, arXiv'26, 2026.05
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #LanguageModel #AIAgents #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2026-05-12 GPT Summary- 直接コーパスと相互作用する(DCI)アプローチを提案し、リトリーバAPIや固定された類似度インターフェースに依存せず、エージェントが生のコーパスを汎用的な端末ツールで直接検索できるようにします。この方法は、オフラインのインデックス作成を不要にし、進化するコーパスに自然に適応します。実験では、DCIがBRIGHTおよびBEIRデータセットで強力なベースラインを上回り、従来の手法なしに高精度を実現したことが示されました。この結果は、検索の質が推論能力だけでなく、コーパスとの相互作用のインターフェースにも依存することを示唆しています。 Comment
元ポスト:
基盤モデルが賢くなる中で、top-kによるretrievalが検索におけるベストなインタフェースなのか?という疑問を投げかけた研究で、ベクトル検索などのRetrieverではなく、AI Agent自身にgrep等を用いて直接コーパスとinteractionをさせる(Direct Corpus Interaction)ことでBrowseCompのようなQAデータセットにおいてEmbeddingを用いた手法よりもより低コストで高いスコアを獲得できることを示したようである。
DCIは有用な手がかりを見つけた時に、それをrearoning stepに結びつけて深掘りしていくような挙動を実現しやすい点が強みであるが、コーパスサイズが大きくなるにつれて最初のアンカーとなる手がかりを見つけるためのコストが大きくなり、深さへの強みはあるが、広さには弱い性質があることから、この手法が唯一無二の解というわけではなく、設計の際に「どのモデルがtop-kの検索でベストか?」という視点だけでなく、「AI Agentにコーパス全体に対してどのようなオペレーションを持たせるべきか?」という問いかけも提起する
といった話が元ポストに書かれている。
昔から検索に全てのケースで最強な手法はこれ!みたいなものはないので、こういった選択肢もあるよということを頭に入れて引き出しに入れておき、直面する課題に対して有効な方法は何かを考えることが重要と思われる。
所見:
[Paper Note] Self-Evolving LLM Memory Extraction Across Heterogeneous Tasks, Yuqing Yang+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Personalization #Evaluation #memory #KeyPoint Notes #Clustering-based #Author Thread-Post Issue Date: 2026-04-25 GPT Summary- 異質な記憶を保持するためのLLMベースのアシスタントの必要性に対して、\textbf{BEHEMOTH}というベンチマークを導入。18のデータセットを再利用し、タスクごとの有用性を評価する。実証分析により、均質なプロンプトが効果的でないことが確認され、\textbf{CluE}を提案。これは訓練例をクラスタに分け、各クラスタを独立に分析することで、抽出プロンプトを効果的に更新し、BEHEMOTHで実験した結果、従来の方法よりも一般化能力が向上したことを示した。 Comment
元ポスト:
現在のAI Agentのメモリは同種のタスクに対して構築され評価されるが、実際の環境、特によりpersonalizationが進んだ状況下では、さまざまな異質なユーザの会話を単一のエージェントが扱い、ユーザのリクエストに応じて適切にメモリからcontextを抽出できなければならず、このような能力を測定するベンチマークは存在しない。
このため、ベンチマークを構築し既存のメモリ手法(promptingベースの手法)を評価したところ、LLMがメモリをmanageする際に、単一のmemory抽出のプロンプトや、自己進化ベースのpromptingではうまくいかないことがわかった。
提案手法 (CluE) では、各サンプルごとに背後にあるシナリオ(どのような情報が欲しいのか, 抽出時にどのような点がchallengingなのか等)をsummarizerにより解釈し、シナリオ単位でクラスタリング。個々のクラスタを分析することで、クラスタごとにどのような場合に成功/失敗するのか等を分析しクラスタ単位のrecommendationを得る。最終的に、クラスタ間のrecommendationを統合して構造化された一つの抽出promptに仕立てる。このとき、競合がある場合は適切なメモリグループにスコープを絞り解決する、といった手法のようである。
既存手法と比較してCluEによって抽出性能が向上
問題設定が実践的でおもしろい
[Paper Note] When Can LLMs Learn to Reason with Weak Supervision?, Salman Rahman+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #PostTraining #read-later #RLVR #Selected Papers/Blogs #Memorization #Generalization #Author Thread-Post Issue Date: 2026-04-23 GPT Summary- 大型言語モデルは、RLVRを通じて推論能力を向上させる一方で、高品質な報酬信号の構築が難しくなってきた。本研究では、データ不足、報酬のノイズ、自己教師付き報酬の下での実証研究を行い、一般化はトレーニング報酬の飽和ダイナミクスに左右されることを発見。一般化するモデルは長い局面を持ち、急速に飽和するモデルは記憶に偏ることを示した。また、推論の忠実度がモデルのレジームを予測する指標であることも特定。継続的な事前学習と監督付き微調整の効果を分離し、SFTが弱い監督下での一般化に必要であることを確認。これにより、Llama3.2-3B-Baseが以前は失敗していた三つの設定で一般化を達成した。 Comment
pj page: http://salmanrahman.net/rlvr-weak-supervision
元ポスト:
pj page: https://salmanrahman.net/rlvr-weak-supervision
- RLVRにおいて、シグナルが不完全な場合(i.e., weak supervisio)の3つの状況に基づいて、汎化性能を分析
- Scarce data: 8つの訓練事例
- Noisy Rewards: 最大90%のラベルに誤りがある
- Proxy Rewards: ground truthなしで、model confidenceにもとづく多数決のみを利用
- RLVRにおいて、Training Rewardが飽和する前に、より長いステップ数学習をしたモデルは、汎化性能が高くなる
- ➡︎ memorizationによって早期にTraining rewardが頭打ちになりgenericな能力を獲得できていないことが示唆される
- 汎化に失敗したモデルは探索が少ないのでは?ということが理由として考えられるが、実はこの説明は間違っている
- Llama, Qwenの2つのモデルを比較した時Llamaは訓練中Qwenと比較して高いsemantic diversityを維持していたが、最終的にQwenよりも汎化性能が低い(=memorization)してしまっていた
- ➡︎ 真の原因はfaithfullnessが低い推論であり、論理的にsupportされないreasoning traceの元正解に辿り着いてしまうことが原因であると考察
- 解決策として、reasoning dataを用いた `pre-RL training` を実施する。
- すなわち、RLVRを実施する前に、Llama-3.2-3Bに対して、継続事前学習(52B math tokens)を実施し、その後 Thinking SFT (43.5K reasoning Traces)を実施する
- CPTとThinking SFTによって、Llamaはweak supervision (i.e., scarce data, noisy rewards, proxy rewards)状況下でも意味のある学習を実施することができた
- ➡︎ reasoning能力が獲得されたことにより推論のfaithfulnessが改善されることで、memorizationが防止されより長いstep数訓練報酬が飽和せずに学習ができたため
といった話が著者ポストに記述されている。
memorizationを防止し、なるべくgenericな能力を身につけさせることが鍵という考え方は、最近色々なところで見かけるように感じる (Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
など)。単にデータをスケールさせるだけでなく、より効率的な学習のため、モデルに対してよりgenericな能力を身につけさせるための工夫(モデルの記憶容量をあえて減らす等)が今後進んでいきそうである。
- Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
[Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #AIAgents #Evaluation #Selected Papers/Blogs #KeyPoint Notes #AgentSkills #Author Thread-Post #AgentHarness Issue Date: 2026-02-17 GPT Summary- LLMエージェントを強化する手続き知識のパッケージであるエージェントスキルの効果を測定するため、SkillsBenchを提案。これにより、86タスクを利用したキュレーション済みスキルと決定論的検証器を組み合わせたベンチマークを作成。各タスクはスキルなし、キュレーション済みスキル、自己生成スキルの3条件で評価。キュレーション済みスキルは合格率を平均16.2ポイント向上させるが、分野による効果の差が顕著。自己生成スキルは有意な利益をもたらさず、信頼性のある手続き的知識の自作が困難であることを示した。Focused Skillsは、包括的なドキュメンテーションを上回る効果を持ち、小型モデルがスキルを有することで大型モデルに匹敵する場合がある。 Comment
元ポスト:
Agent Skillsに関するベンチマーク。11種類の多様なドメインのタスクによって構成される。コーディングやソフトウェアエンジニアリングに留めらないのが特徴的に見える。
評価時は
- スキルがない場合
- スキルがある場合
- 自己生成したスキルを使う場合
の3種類で評価する。
ハーネスはClaude Code, Codex CLI, Genini CLIの3種類で評価し、モデルはGPT, Claude, Gemini系列のモデルを利用。takeawayは以下:
- skillsはタスクの性能を改善するが、モデルとハーネスの組み合わせでgainが大きく異なる
- Gemini CLIとGemini Flashが最高性能を達成
- スキルを自己生成しても性能向上に寄与しない(むしろネガティブな影響も見受けられる)
- 3種類のハーネスのうち
- Claude Codeが最も多くスキルを活用し、Claudeモデルは一貫してgainを得る
- Gemini CLIは最も高いraw performanceを達成
- 性能はcompetitiveだが、Codex CLIは必要なスキルの内容を取得しても、スキルを利用せず独立して処理してしまう頻度が高い
- skillによって得られるgainはドメインによって大きく異なる。事前学習時に馴染み薄いドメインほど、skillの導入による恩恵がでかい。
- skillの導入によって、タスクによっては性能が悪化するものもある。これはモデルがすでにうまく処理をする能力を持っているのに、スキルが提供されることでそれらがconflictすることに起因する可能性がある。
- タスクごとに、2--3個のスキルを提供するのが性能がよく、4+になるとgainが低下する
- スキルの定義はproceduralな知識をコンパクト(compact)あるいは詳細に記述したもの(detailed)が良く(i.e., 特定のことについて集中的に記述するもの)、徹底的に記述されたドキュメント(comprehensive)は性能が悪化する。
- SLM+skillによって、スキル利用なしのより大きなモデルを性能で上回ることができる
Agent skillsの効果について定量的に分析した初めての研究な気がしており、重要な研究だと思われる。AI AgentというとClaudeが優秀な印象が強いが(コーディングやソフトウェアエンジニアリングでの性能に基づく印象)、本ベンチマークでは多様なドメインで評価をしており、Gemini CLI+Gemini Flashが最も平均的な性能が高いのが興味深い。
pj page: https://www.skillsbench.ai/
著者による続報:
SkillsBenchがエージェントスキル評価のデファクトになったことと、1.1のローンチイベントについての話が言及されている。
[Paper Note] Weight Decay Improves Language Model Plasticity, Tessa Han+, arXiv'26, 2026.02
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #Regularization #PostTraining #KeyPoint Notes #DownstreamTasks Issue Date: 2026-02-12 GPT Summary- 事前訓練での重みの減衰がモデルの可塑性に与える影響を分析。高い減衰値が微調整時に性能向上を促進し、直感に反するトレードオフを引き起こすことを示す。重みの減衰が線形分離可能な表現を促進し、過学習を抑制する役割も明らかに。ハイパーパラメータ最適化における新たな評価指標の重要性を強調。 Comment
元ポスト:
事前学習時にWeight Decayを大きくするとPerplexityは悪化する場合があるが、Perplexityが悪化していたとしてもSFTを通じて最終的に得られるdownstream task性能のgainが高い場合がある、という話に見える。つまり、Findings2に書かれている通り、事前学習時にPerplexityを最小化するようなWeight Decayの設定はdownstream性能を高めるという観点では必ずしも必須ではない。ではなぜこのようなことが起きるかというと、Weight Decayを大きくするとAttentionのQK matricesのpseudo-rank(=行列の95%を説明するのに必要な特異値の割合)が改善されることが実験により観察され、一般的に低ランクな表現は正則化の結果として現れることから、シンプルな表現によってよりモデルがロバストになるのでは、という点が考察されている。また、実際にValidation dataとTraining dataのlossの差分を見ることで、Weight Decayが大きいことによってtraining dataへのoverfitが抑制されていることが観測された。
Weight DecayはもともとRegularizationとしての働きがあるので、それはそうなのだろうな、という感想を持ったのだが、特にQK matrixが正則化の影響を強く受けるというのはおもしろかった。つまり、クエリ対してよりロバストな写像を学習できているということだと思われる。
Perplexityが事前学習の良さを測るために必ずしも良いわけではないよ、という意味での関連:
- [Paper Note] Perplexity Cannot Always Tell Right from Wrong, Petar Veličković+, arXiv'26, 2026.01
[Paper Note] PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning, Jingcheng Hu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #Reasoning #Test-Time Scaling #PostTraining #read-later #Selected Papers/Blogs #Aggregation-aware #KeyPoint Notes Issue Date: 2026-01-19 GPT Summary- PaCoReは、固定されたコンテキストウィンドウを超えた計算量の拡張を目指すトレーニング・推論フレームワークです。逐次的パラダイムを脱し、複数のラウンドでメッセージ伝播アーキテクチャを用いた並列探索を行います。各ラウンドでは、並列推論経路を起動し、結果を圧縮して次のラウンドに統合し、最終的な答えを生成します。このアプローチにより、文脈制限を超えた実質的な計算量が実現され、特に数学推論で顕著な成果を示します。8BモデルはHMMT 2025で94.5%を達成し、オープンソース化された資源により、さらなる研究が期待されています。 Comment
元ポスト:
- [Paper Note] STEP3-VL-10B Technical Report, Ailin Huang+, arXiv'26, 2026.01
で活用されているRLでtest time scalingを学習する手法
モデルのSequentialなReasoning能力はcontext windowに制限されてしまうので、並列にモデルにreasoningをさせてそれらを集約させて、さらに直列で思考させる、といった処理を繰り返すことで、context windowの制限を超えてreasoning能力を高めることを目的としたtest-time scaling手法。
モデルに複数個のreasoning trajectoryを生成させ、それぞれのtrajectoryにCompaction Function(式2) を適用[^1]することで各resaoning trajectoryをcompaction message M として圧縮。圧縮したtrajectoryを元のpromptとともに与えて、同様の操作をRラウンド繰り返すtest-time scaling手法。最後のラウンドでは、生成するreasoning trajectoryの数を1とすることで最終的な応答を得る。モデルをこのプロセスに最適化するために、各ラウンドにおいて (x, M) が与えられた時に、並列して生成するreasoning trajectoryに対してRLVRを適用することでモデルの性能を引き上げている。Mはベースモデルによって事前に生成し、生成した結果をキャッシュしておくことでRL中に利用する。
PaCoReによってベースモデル(RLVR-8B)の性能が着実に押し上げられ、一部ベンチマークにおいてフロンティアモデルには届かなないものの非常に高い性能を示している。
また、Parallel test-time scaling手法として代表的なSelf-Consistencyと比較しても、より少ないtoken量で、より高いgainを得ている。
[^1]: 本研究ではCompatction Functionとしてreasoningの特性を利用して、結論部分に関連する部分を抽出し、intermediateなreasoning tokenは破棄するような関数を適用している
Figure1においてベースモデルであるRLVR-8B (Qwen3-8B-Base) に対して、PaCoReによってpost-trainingされたモデルがより良好なtest-time scalingを示すことが図示されているが、RLVR-8Bによるtest-time scaling手法としてどのようなものが適用されたのか(parallelなのか、sequentialなのか、結果を集約したのか等)が書かれていない気がする。
何が気になっているのかというと、提案手法が効果があることは分かったのだが、これがPaCoReの枠組みに則ったRLを適用しないと発現しないものなのか、それともPaCoReに特化したpost-trainingを実施しなくても、何らかのベースモデルに同様のtest-time-scalingの枠組みを利用すれば高い性能を得られるのか、といった点が気になる。どこかに書いてあるのだろうか?
[Paper Note] GameFactory: Creating New Games with Generative Interactive Videos, Jiwen Yu+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#ComputerVision #Controllable #Transformer #DiffusionModel #Architecture #PostTraining #VideoGeneration/Understandings #ICCV #Game #One-Line Notes Issue Date: 2026-04-02 GPT Summary- GameFactoryは、アクション制御とシーン一般化を両立させたゲームビデオ生成のフレームワーク。GF-Minecraftというデータセットを用いてキーボードとマウス入力を正確に制御し、自己回帰生成を可能にする。さらに、オープンドメイン生成事前知識を活用し、固定スタイルを超えた多様なゲームの創出を支援。ドメインアダプターによる学習戦略によって、アクション制御が特定ゲームスタイルに縛られず、シーン一般化が実現。実験により、GameFactoryが効果的にオープンドメインのゲームビデオを生成できることが確認された。 Comment
github: https://github.com/KlingAIResearch/GameFactory
小規模なマイクラデータでaction control moduleと呼ばれるモジュールを学習することで、動画生成モデルに対して、マウス、キーボード入力によるコントロール能力を転移し、ゲーム映像を生成できる、という話に見える。
4.2節に書かれているように、transformerのブロックにaction control moduleと呼ばれる、キーボードとマウスの入力をwindowでグルーピングしてエンコードするようなブロックを挿入し、エンコードされたvideo側の潜在表現に対して条件付けを行い生成を可能にしているようである(Figure 3, 4)。学習する際はFigure 6に示されているように、まずはopen domainのデータで事前学習、その後LoRAでgame video dataのドメイン情報を入れ、他モジュールはfreezeした上で、action control moduleのみを学習する。
transformerアーキテクチャにドメイン依存のブロックを後でplugし性能向上させるアプローチはおもしろいと感じる。
[Paper Note] RewardBench 2: Advancing Reward Model Evaluation, Saumya Malik+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Alignment #Evaluation #Selected Papers/Blogs #RewardModel #KeyPoint Notes #DownstreamTasks Issue Date: 2026-02-06 GPT Summary- 報酬モデルは、言語モデルの訓練後に好みデータを利用して指示遵守や推論、安全性を最適化するための訓練目標を提供します。新たに開発された「RewardBench 2」は、スキル領域を評価するための挑戦的なベンチマークを提供し、既存のモデルが低いスコアを示しつつも下流性能との相関が高いことを示しています。このベンチマークは人間のプロンプトを基にしており、厳格な評価プラクティスを促進しています。論文では、ベンチマークの構築プロセスと既存モデルの性能を報告し、モデルの下流使用との相関を定量化しています。 Comment
以下の6つのドメインで構成されるReward Modelの評価のためのベンチマーク:
- Factuality: hallucinationや誤りの有無の判定
- Precise Instruction Following: 細かい指示に対する追従性能
- Math: **自由記述**の数学に関するプロンプトに対する応答に関する能力
- Safety: 有害な応答に対して適切に対処できるか(応答拒否 or 適切な応答)
- Focus: 一般的なユーザのクエリに対して、トピックに沿った高品質な応答ができているか否か
- **Ties**: 「虹の色を1つ挙げて」といったような、複数の正解があり得るが、無数の不正解があるようなタスク(特定の正解にバイアスがかからず、正解と不正解を区別する能力を評価)
Reward Bench 2 での性能が、Best-of-N (=N個応答をサンプリングし最も良いものを採用するtest-time scaling手法)における様々なdownstreamタスクと強い相関を示すことが示されている。
ただし、PPOでの事後学習について焦点を当てた場合
- ベースモデルの出自がReward Modelと異なる場合
- Reward Modelの学習データが、ベースモデルと大きく異なる場合
においては、Reward Bench 2で高い性能が得られていても、PPOにおいて高い性能が得られず、特にベースモデルの出自が異なる場合の影響が顕著とのこと。
Reward Modelの性能が必ずしもPPOの事後学習後の下流タスクに対する性能と相関せず(ただし、Rewardベンチの性能が低い部分においてはおおまかに推定できる)、ベースモデルの出自が異なるReward Modelを使った場合や、Reward Modelとベースモデルが学習したプロンプトの分布が大きく異なる場合にこのような不整合が強く現れるというのは興味深く、おもしろかった。
Reward Modelとベースモデルの開始点が異なる場合は、RLによる学習がうまくいかないというのは、直感的でわかりやすい説明だなと感じた。
openreview: https://openreview.net/forum?id=fb0G86Dewb
[Paper Note] Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective, Zhoujun Cheng+, NeurIPS'25
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #ReinforcementLearning #Reasoning #NeurIPS #mid-training #PostTraining #read-later #RLVR #Selected Papers/Blogs #DataMixture #CrossDomain #KeyPoint Notes #Author Thread-Post Issue Date: 2025-06-22 GPT Summary- Guruを導入し、数学、コード、科学、論理、シミュレーション、表形式の6つの推論ドメインにわたる92KのRL推論コーパスを構築。これにより、LLM推論のためのRLの信頼性と効果を向上させ、ドメイン間の変動を観察。特に、事前学習の露出が限られたドメインでは、ドメイン内トレーニングが必要であることを示唆。Guru-7BとGuru-32Bモデルは、最先端の性能を達成し、複雑なタスクにおいてベースモデルの性能を改善。データとコードは公開。 Comment
元ポスト:
post-trainingにおけるRLのcross domain(Math, Code, Science, Logic, Tabular)における影響を調査した研究。非常に興味深い研究。詳細は元論文が著者ポスト参照のこと。
Qwenシリーズで実験。以下元ポストのまとめ。
- mid trainingにおいて重点的に学習されたドメインはRLによるpost trainingで強い転移を発揮する(Code, Math, Science)
- 一方、mid trainingであまり学習データ中に出現しないドメインについては転移による性能向上は最小限に留まり、in-domainの学習データをきちんと与えてpost trainingしないと性能向上は限定的
- 簡単なタスクはcross domainの転移による恩恵をすぐに得やすい(Math500, MBPP),難易度の高いタスクは恩恵を得にくい
- 各ドメインのデータを一様にmixすると、単一ドメインで学習した場合と同等かそれ以上の性能を達成する
- 必ずしもresponse lengthが長くなりながら予測性能が向上するわけではなく、ドメインによって傾向が異なる
- たとえば、Code, Logic, Tabularの出力は性能が向上するにつれてresponse lengthは縮小していく
- 一方、Science, Mathはresponse lengthが増大していく。また、Simulationは変化しない
- 異なるドメインのデータをmixすることで、最初の数百ステップにおけるrewardの立ち上がりが早く(単一ドメインと比べて急激にrewardが向上していく)転移がうまくいく
- (これは私がグラフを見た感想だが、単一ドメインでlong runで学習した場合の最終的な性能は4/6で同等程度、2/6で向上(Math, Science)
- 非常に難易度の高いmathデータのみにフィルタリングすると、フィルタリング無しの場合と比べて難易度の高いデータに対する予測性能は向上する一方、簡単なOODタスク(HumanEval)の性能が大幅に低下する(特定のものに特化するとOODの性能が低下する)
- RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
- モデルサイズが小さいと、RLでpost-training後のpass@kのkを大きくするとどこかでサチり、baseモデルと交差するが、大きいとサチらず交差しない
- モデルサイズが大きいとより多様なreasoningパスがunlockされている
- pass@kで観察したところRLには2つのphaseのよつなものが観測され、最初の0-160(1 epoch)ステップではpass@1が改善したが、pass@max_kは急激に性能が劣化した。一方で、160ステップを超えると、双方共に徐々に性能改善が改善していくような変化が見られた
本研究で構築されたGuru Dataset:
https://huggingface.co/datasets/LLM360/guru-RL-92k
math, coding, science, logic, simulation, tabular reasoningに関する高品質、かつverifiableなデータセット。
> RLはpre(mid)-trainingで学習されたreasoning能力を引き出すだけではなく、新規のタスクに対しては新たなreasoning能力を獲得できる
上記takeawayは
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
と一見相反するように見えるが、実際どうなんだろうか。
最初は、RLによりPass@1が改善するので、Figure 1などに記載されている特定のドメインでの skill aqcuisition にはin-domain dataが必要でRLがそれに寄与するという話は、Pass@1が改善された結果なのかなと思ったが、
4.3節に実際に上記研究が引用され考察がなされており、mid-trainingなどで多くのデータが含まれるMathドメインについては、上記研究と同じ傾向でbase modelとRL後のモデルがK=64の時点で性能が交差、その後逆転するため、上記研究と同様の傾向が見受けられた。一方で、タスクごとに見るとzebra-logicのような事前学習ではあまりexposeされないタスクで見ると、依然としてRLの方が高いPass@kを獲得しているという現象が観測され、base modelのreadoning boundaryを拡大することができている、という解釈のようである。
[Paper Note] RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning, Yu Wang+, EMNLP'25
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #EMNLP #One-Line Notes Issue Date: 2025-06-17 GPT Summary- RAG+は、Retrieval-Augmented Generationの拡張で、知識の適用を意識した推論を組み込む。二重コーパスを用いて、関連情報を取得し、目標指向の推論に適用する。実験結果は、RAG+が標準的なRAGを3-5%、複雑なシナリオでは最大7.5%上回ることを示し、知識統合の新たなフレームワークを提供する。 Comment
元ポスト:
知識だけでなく知識の使い方も蓄積し、利用時に検索された知識と紐づいた使い方を活用することでRAGの推論能力を向上させる。
Figure 1のような例はReasoningモデルが進化していったら、わざわざ知識と使い方を紐付けなくても、世界知識から使い方を補完可能だと思われるので不要となると思われる。
が、真にこの手法が力を発揮するのは「ドメイン固有の使い方やルール」が存在する場合で、どれだけLLMが賢くなっても推論によって導き出せないもの、のついては、こういった手法は効力を発揮し続けるのではないかと思われる。
[Paper Note] Learning Compositional Functions with Transformers from Easy-to-Hard Data, Zixuan Wang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #Pretraining #LanguageModel #Transformer #PostTraining #Selected Papers/Blogs #COLT #One-Line Notes #Author Thread-Post Issue Date: 2025-06-01 GPT Summary- Transformerベースの言語モデルの学習可能性を、k-fold 合成タスクにおいて検討。具体的には、k 個の入力置換と隠れた置換の交互合成を倍の効率で実行可能とし、統計的クエリ下界も証明。さらに、O(log k) 層のトランスフォーマーで勾配降下による効率的な学習が可能であることを示した。データの提示方法によって、容易な例と難しい例が存在することが重要であるとの知見を得た。 Comment
元ポスト:
こちらはまず元ポストのスレッドを読むのが良いと思われる。要点をわかりやすく説明してくださっている。
元ポストとalphaxivでざっくり理解したところ、
Transformerがcontextとして与えられた情報(σ)とparametric knowledge(π)をk回の知識マッピングが必要なタスク(k-fold composition task)を学習するにはO(log k)のlayer数が必要で、直接的にk回の知識マッピングが必要なタスクを学習するためにはkの指数オーダーのデータ量が最低限必要となることが示された。これはkが大きくなると(すなわち、複雑なreasoning stepが必要なタスク)になると非現実的なものとなるため、何らかの方法で緩和したい。学習データを簡単なものから難しいものをmixingすること(カリキュラム学習)ことで、この条件が緩和され、指数オーダーから多項式オーダーのデータ量で学習できることが示された
といった感じだと思われる。
じゃあ最新の32Bモデルよりも、よりパラメータ数が大きくてlayer数が多い古いモデルの方が複雑なreasoningが必要なタスクを実は解けるってこと!?直感に反する!と一瞬思ったが、おそらく最近のモデルでは昔のモデルと比べてparametric knowledgeがより高密度に適切に圧縮されるようになっていると思われるので、昔のモデルではk回の知識マッピングをしないと解けないタスクが、最新のモデルではk-n回のマッピングで解けるようになっていると推察され、パラメータサイズが小さくても問題なく解けます、みたいなことが起こっているのだろう、という感想を抱くなどした
[Paper Note] The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, NeurIPS'25, 2025.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #Reasoning #PEFT(Adaptor/LoRA) #NeurIPS #KeyPoint Notes Issue Date: 2025-03-19 GPT Summary- 非教師ありプレフィックスファインチューニング(UPFT)を提案し、LLMの推論効率を向上。初期のプレフィックス部分文字列に基づいて訓練し、ラベル付きデータやサンプリングを不要に。UPFTは、教師あり手法と同等の性能を維持しつつ、訓練時間を75%、サンプリングコストを99%削減。最小限の非教師ありファインチューニングで大幅な推論向上を実現し、リソース効率の良い代替手段を提供。 Comment
斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成できるようにモデルをFinetuningする。従来のRejection Samplingを用いた手法では、複数のresponseを生成させて、最終的なanswerが正解のものをサンプリングするため正解ラベルが必要となるが、提案手法ではreasoning traceの冒頭部分の共通するsubsequenceをmajority voteするだけなのでラベルが不要である。
reasoning prefixを学習する際は下記のようなテンプレートを用いる。このときに、prefixのspanのみを利用して学習することで大幅に学習時間を削減できる。
また、そのような学習を行うとcatastrophic forgettingのリスクが非常に高いが、これを防ぐために、マルチタスクラーニングを実施する。具体的には学習データのp%については全体のreasoning traceを生成して学習に利用する。このときに、最終的な回答の正誤を気にせずtraceを生成して学習に利用することで、ラベルフリーな特性を維持できる(つまり、こちらのデータは良いreasoning traceを学習することを目的としているわけではなく、あくまでcatastrophic forgettingを防ぐためにベースモデルのようなtraceもきちんと生成できれば良い、という感覚だと思われる)。
AppendixにQwenを用いてtemperature 0.7で16個のresponseをサンプリングし、traceの冒頭部分が共通している様子が示されている。
下記論文でlong-CoTを学習させる際のlong-CoTデータとして、reasoningモデルから生成したtraceと非reasoning modelから生成したtraceによるlong-CoTデータを比較したところ前者の方が一貫して学習性能が良かったとあるが、この研究でもreasoning traceをつよつよモデルで生成したら性能上がるんだろうか。
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, ICML'25
[Paper Note] NeoBERT: A Next-Generation BERT, Lola Le Breton+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Embeddings #NLP #Transformer #Architecture #Encoder Issue Date: 2025-03-15 GPT Summary- NeoBERTは、最新のアーキテクチャとデータを統合した次世代エンコーダで、双方向モデルの能力を再定義します。4,096トークンのコンテキスト長を活用し、250Mパラメータでありながら、MTEBベンチマークで最先端の結果を達成し、BERTやRoBERTaを上回ります。すべてのコードやデータを公開し、研究と実世界での採用を促進します。 Comment
## BERT, ModernBERTとの違い

## 性能

## 所感
medium size未満のモデルの中ではSoTAではあるが、ModernBERTが利用できるのであれば、ベンチマークを見る限りは実用的にはModernBERTで良いのでは、と感じた。学習とinferenceの速度差はどの程度あるのだろうか?
[Paper Note] START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Tools #NLP #Supervised-FineTuning (SFT) #SelfImprovement Issue Date: 2025-03-07 GPT Summary- STARTという新しいツール統合型長いチェーン・オブ・ソウト推論LLMを提案。外部ツールを活用することで、幻覚や非効率性を克服し、複雑な計算や自己検証が可能に。主な手法は、意図的に設計されたヒントを挿入して外部ツールの活用を促すHint-inferと、推論経路にツール呼び出しを付与して微調整するHint-RFT。これにより、科学QAや数学、コードベンチマークで高い正答率を達成し、既存モデルを上回る性能を示した。 Comment
論文の本題とは関係ないが、QwQ-32Bよりも、DeepSeek-R1-Distilled-Qwen32Bの方が性能が良いのは興味深い。やはり大きいパラメータから蒸留したモデルの方が、小さいパラメータに追加学習したモデルよりも性能が高い傾向にあるのだろうか(どういうデータで蒸留したかにもよるけど)。
OpenReview: https://openreview.net/forum?id=m80LCW765n
[Paper Note] On Teacher Hacking in Language Model Distillation, Daniil Tiapkin+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#NLP #LanguageModel #Distillation #ICML #TeacherHacking #Reference Collection Issue Date: 2025-02-10 GPT Summary- LMのポストトレーニングは、知識蒸留とRLHFに依存し、報酬ハッキングの課題を指摘。教師LMからの「教師ハッキング」が存在することを検証。実験では、固定オフラインデータで教師ハッキングが発生し、多項式収束法則から逸脱することを観測。オンラインデータ生成技術がハッキングを緩和できることを示し、データの多様性が重要な要因であると結論。これにより、LM構築の蒸留の利点と限界が明らかに。 Comment
元ポスト:
自分で蒸留する機会は今のところないが、覚えておきたい。過学習と一緒で、こういう現象が起こるのは想像できる。
openreview: https://openreview.net/forum?id=qxSFIigPug¬eId=CAgFzoMVit
[Paper Note] Scaling Sentence Embeddings with Large Language Models, Ting Jiang+, EMNLP'24 Findings, 2023.07
Paper/Blog Link My Issue
#Sentence #Embeddings #NLP #LanguageModel #In-ContextLearning #EMNLP #Findings #One-Line Notes Issue Date: 2026-06-11 GPT Summary- 文脈内学習に基づく手法を用いて、大規模言語モデル(LLMs)の文の埋め込み性能を向上。自己回帰モデル向けにプロンプトベースの表現法を適用し、ファインチューニングなしで高品質な文の埋め込みを生成可能。モデルサイズを拡大するとSTSタスクで性能の変化が見られるが、最大モデルは他のモデルを上回り、転移タスクで最先端結果を達成。2.7BのOPTモデルが4.8BのST5を超える性能を示した。 Comment
1 wordでsentenceを要約するICL-basedなprompt templateを用いて生成されたtokenに対応するlast hidden statedeをsentenceのembeddingとして扱うことで、coder-onlyモデルから文のembeddingを取得する
下記研究で示されているように、last hidden stateではなく中間層におけるhidden stateを利用した場合はどのような影響が出るのだろうか?
- [Paper Note] Layer by Layer: Uncovering Hidden Representations in Language Models, Oscar Skean+, ICML'25
[Paper Note] Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference, Benjamin Warner+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Library #Transformer #pretrained-LM #ACL #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-12-20 GPT Summary- ModernBERTはエンコーダーのみのトランスフォーマーモデルで、BERTに対する大きなパレート改善を達成。2兆トークンで訓練され、長いシーケンスに対応しながら、分類タスクと検索において最先端の性能を示す。さらに、最も高速かつメモリ効率の良いエンコーダーとして設計されている。 Comment
最近の進化しまくったTransformer関連のアーキテクチャをEncodnr-OnlyモデルであるBERTに取り込んだら性能上がるし、BERTの方がコスパが良いタスクはたくさんあるよ、系の話、かつその実装だと思われる。
テクニカルペーパー中に記載はないが、評価データと同じタスクでのDecoder-Onlyモデル(SFT有り無し両方)との性能を比較したらどの程度の性能なのだろうか?
そもそも学習データが手元にあって、BERTをFinetuningするだけで十分な性能が出るのなら(BERTはGPU使うのでそもそもxgboostとかでも良いが)、わざわざLLM使う必要ないと思われる。BERTのFinetuningはそこまで時間はかからないし、inferenceも速い。
参考:
- [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08
日本語解説: https://zenn.dev/dev_commune/articles/3f5ab431abdea1?utm_source=substack&utm_medium=email
[Paper Note] Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions, Yu Zhao+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Reasoning #SelfImprovement #read-later Issue Date: 2024-12-16 GPT Summary- OpenAI o1がLRMの研究に注力し、伝統的な分野だけでなくRLやオープンエンドな解決にも焦点を当てる。特に、基準が不明瞭な領域への一般化の可能性を探求。Marco-o1はCoT微調整やMCTS、リフレクション機構などの手法を用いて、複雑な実世界の問題解決に最適化されている。 Comment
元ポスト:
Large Reasoning Model (LRM)という用語は初めて見た。
日本語解説: https://www.docswell.com/s/DeepLearning2023/KV1M9P-2024-12-05-125148
[Paper Note] Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
Paper/Blog Link My Issue
#Multi #NLP #Dataset #LanguageModel #Evaluation #Factuality #Reasoning #ACL Issue Date: 2024-12-02 GPT Summary- 大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 Comment
SNLP'24での解説スライド:
https://docs.google.com/presentation/d/1Q_UzOzn0qYX1gq_4FC4YGXK8okd5pwEHaLzVCzp3yWg/edit?usp=drivesdk
この研究を信じるのであれば、LLMはCoT無しではマルチホップ推論を実施することはあまりできていなさそう、という感じだと思うのだがどうなんだろうか。
[Paper Note] Does Prompt Formatting Have Any Impact on LLM Performance?, Jia He+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Prompting Issue Date: 2024-11-27 GPT Summary- プロンプト最適化はLLMの性能に重要であり、異なるプロンプトテンプレートがモデルの性能に与える影響を調査。実験では、GPT-3.5-turboがプロンプトテンプレートによってコード翻訳タスクで最大40%変動する一方、GPT-4はより堅牢であることが示された。これにより、固定プロンプトテンプレートの再考が必要であることが強調された。 Comment
(以下、個人の感想です)
本文のみ斜め読みして、Appendixは眺めただけなので的外れなことを言っていたらすみません。
まず、実務上下記知見は有用だと思いました:
- プロンプトのフォーマットによって性能に大きな差がある
- より大きいモデルの方がプロンプトフォーマットに対してロバスト
ただし、フォーマットによって性能差があるというのは経験的にある程度LLMを触っている人なら分かることだと思うので、驚きは少なかった。
個人的に気になる点は、学習データもモデルのアーキテクチャもパラメータ数も分からないGPT3.5, GPT4のみで実験をして「パラメータサイズが大きい方がロバスト」と結論づけている点と、もう少し深掘りして考察したらもっとおもしろいのにな、と感じる点です。
実務上は有益な知見だとして、では研究として見たときに「なぜそうなるのか?」というところを追求して欲しいなぁ、という感想を持ちました。
たとえば、「パラメータサイズが大きいモデルの方がフォーマットにロバスト」と論文中に書かれているように見えますが、
それは本当にパラメータサイズによるものなのか?学習データに含まれる各フォーマットの割合とか(これは事実はOpenAIの中の人しか分からないので、学習データの情報がある程度オープンになっているOpenLLMでも検証するとか)、評価するタスクとフォーマットの相性とか、色々と考察できる要素があるのではないかと思いました。
その上で、大部分のLLMで普遍的な知見を見出した方が研究としてより面白くなるのではないか、と感じました。
参考: Data2Textにおける数値データのinput formatによる性能差を分析し考察している研究
- [Paper Note] Prompting for Numerical Sequences: A Case Study on Market Comment Generation, Masayuki Kawarada+, arXiv'24, 2024.04
[Paper Note] Likelihood as a Performance Gauge for Retrieval-Augmented Generation, Tianyu Liu+, arXiv'24
Paper/Blog Link My Issue
#Analysis #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-11-19 GPT Summary- 大規模言語モデルを用いた情報検索強化生成は、文脈内の文書の順序に影響を受けやすい。研究では、質問の確率がモデルのパフォーマンスに与える影響を分析し、正確性との相関関係を明らかにした。質問の確率を指標として、プロンプトの選択と構築に関する2つの方法を提案し、その効果を実証。確率に基づく手法は効率的で、少ないモデルのパスで応答を生成できるため、プロンプト最適化の新たな方向性を示す。 Comment
トークンレベルの平均値をとった生成テキストの対数尤度と、RAGの回答性能に関する分析をした模様。
とりあえず、もし「LLMとしてGPTを(OpenAIのAPIを用いて)使いました!temperatureは0です!」みたいな実験設定だったら諸々怪しくなる気がしたのでそこが大丈夫なことを確認した(OpenLLM、かつdeterministicなデコーディング方法が望ましい)。おもしろそう。
参考: [RAGのハルシネーションを尤度で防ぐ, sasakuna, 2024.11.19]( https://zenn.dev/knowledgesense/articles/7c47e1796e96c0)
## 参考
生成されたテキストの尤度を用いて、どの程度正解らしいかを判断する、といった話は
- [Paper Note] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
のようなLLM-as-a-Judgeでも行われている。
G-Evalでは1--5のスコアのような離散的な値を生成する際に、これらを連続的なスコアに補正するために、尤度(トークンの生成確率)を用いている。
ただし、G-Evalの場合は実験でGPTを用いているため、モデルから直接尤度を取得できず、代わりにtemperature1とし、20回程度生成を行った結果からスコアトークンの生成確率を擬似的に計算している。
G-Evalの設定と比較すると(当時はつよつよなOpenLLMがなかったため苦肉の策だったと思われるが)、こちらの研究の実験設定の方が望ましいと思う。
[Paper Note] Understanding LLMs: A Comprehensive Overview from Training to Inference, Yiheng Liu+, arXiv'24, 2024.01
Paper/Blog Link My Issue
#Survey #EfficiencyImprovement #NLP #LanguageModel #Transformer #Attention #One-Line Notes Issue Date: 2024-11-17 GPT Summary- ChatGPTの導入により、LLMsの低コストな訓練とデプロイメントへの関心が高まる。本論文では、訓練技術や推論デプロイメント技術の進化を概説し、データ前処理やモデル圧縮など多様な視点を提供。LLMsの活用についても考察し、今後の発展を示唆する。 Comment
[Perplexity(参考;Hallucinationに注意)]( https://www.perplexity.ai/search/yi-xia-nolun-wen-wodu-minei-ro-7vGwDK_AQX.HDO7j9H8iNA)
単なるLLMの理論的な説明にとどまらず、実用的に必要な各種並列処理技術、Mixed Precision、Offloadingなどのテクニックもまとまっているのがとても良いと思う。
LLM Frameworkのところに、メジャーなものが網羅されていないように感じる。たとえば、UnslothやLiger-KernelなどはTransformersの部分で言及されてても良いのでは、と感じる。
[Paper Note] Number Cookbook: Number Understanding of Language Models and How to Improve It, Haotong Yang+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#NLP #LanguageModel #NumericReasoning #ICLR #numeric #In-Depth Notes Issue Date: 2024-11-09 GPT Summary- 大規模言語モデル(LLM)の数値理解・処理能力(NUPA)を調査し、41の数値タスクを含むベンチマークを導入。これにより、LLMsが多くのタスクで頻繁に失敗することが判明。NUPA向上のため、小型モデルを訓練し、ファインチューニングの効果を評価。1) ファインチューニングが多くのタスクでNUPAを向上させるが、全てに効果的ではない。2) NUPA向上を目的とした手法がファインチューニングに効果的でないことが分かった。研究はLLMsのNUPA理解を深める。 Comment
んー、abstしか読んでいないけれども、9.11 > 9.9 については、このような数字に慣れ親しんでいるエンジニアなどに咄嗟に質問したら、ミスして答えちゃう人もいるのでは?という気がする(エンジニアは脳内で9.11 > 9.9を示すバージョン管理に触れる機会が多く、こちらの尤度が高い)。
LLMがこのようなミス(てかそもそもミスではなく、回答するためのcontextが足りてないので正解が定義できないだけ、だと思うが、、)をするのは、単に学習データにそういった9.11 > 9.9として扱うような文脈や構造のテキストが多く存在しており、これらテキスト列の尤度が高くなってこのような現象が起きているだけなのでは、という気がしている。
instructionで注意を促したり適切に問題を定義しなければ、そりゃこういう結果になって当然じゃない?という気がしている。
(ここまで「気がしている」を3連発してしまった…😅)
また、本研究で扱っているタスクのexampleは下記のようなものだが、これらをLLMに、なんのツールも利用させずautoregressiveな生成のみで解かせるというのは、人間でいうところの暗算に相当するのでは?と個人的には思う。
何が言いたいのかというと、人間でも暗算でこれをやらせたら解けない人がかなりいると思う(というか私自身単純な加算でも桁数増えたら暗算など無理)。
一方で暗算ではできないけど、電卓やメモ書き、計算機を使っていいですよ、ということにしたら多くの人がこれらタスクは解けるようになると思うので、LLMでも同様のことが起きると思う。
LLMの数値演算能力は人間の暗算のように限界があることを認知し、金融分野などの正確な演算や数値の取り扱うようなタスクをさせたかったら、適切なツールを使わせましょうね、という話なのかなあと思う。
元ポスト:
ICLR25のOpenReview。こちらを読むと興味深い。
https://openreview.net/forum?id=BWS5gVjgeY
幅広い数値演算のタスクを評価できるデータセット構築、トークナイザーとの関連性を明らかにした点、分析だけではなくLLMの数値演算能力を改善した点は評価されているように見える。
一方で、全体的に、先行研究との比較やdiscussionが不足しており、研究で得られた知見がどの程度新規性があるのか?といった点や、説明が不十分でjustificationが足りない、といった話が目立つように見える。
特に、そもそもLoRAやCoTの元論文や、Numerical Reasoningにフォーカスした先行研究がほぼ引用されていないらしい点が見受けられるようである。さすがにその辺は引用して研究のcontributionをクリアにした方がいいよね、と思うなどした。
>I am unconvinced that numeracy in LLMs is a problem in need of a solution. First, surely there is a citable source for LLM inadequacy for numeracy. Second, even if they were terrible at numeracy, the onus is on the authors to convince the reader that this a problem worth caring about, for at least two obvious reasons: 1) all of these tasks are already trivially done by a calculator or a python program, and 2) commercially available LLMs can probably do alright at numerical tasks indirectly via code-generation and execution. As it stands, it reads as if the authors are insisting that this is a problem deserving of attention --- I'm sure it could be, but this argument can be better made.
上記レビュワーコメントと私も同じことを感じる。なぜLLMそのものに数値演算の能力がないことが問題なのか?という説明があった方が良いのではないかと思う。
これは私の中では、論文のイントロで言及されているようなシンプルなタスクではなく、
- inputするcontextに大量の数値を入力しなければならず、
- かつcontext中の数値を厳密に解釈しなければならず、
- かつ情報を解釈するために計算すべき数式がcontextで与えられた数値によって変化するようなタスク(たとえばテキスト生成で言及すべき内容がgivenな数値情報によって変わるようなもの。最大値に言及するのか、平均値を言及するのか、数値と紐づけられた特定のエンティティに言及しなければならないのか、など)
(e.g. 上記を満たすタスクはたとえば、金融関係のdata-to-textなど)では、LLMが数値を解釈できないと困ると思う。そういった説明が入った方が良いと思うなあ、感。
[Paper Note] ToolGen: Unified Tool Retrieval and Calling via Generation, Renxi Wang+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Pretraining #Tools #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #ICLR #PostTraining #KeyPoint Notes Issue Date: 2024-10-20 GPT Summary- ToolGenは、LLMとツールの統合を革新する新しいアプローチを提案する。ツールをユニークなトークンとして表現し、ツール知識を直接LLMのパラメータに組み込むことで、ツール呼び出しと生成をシームレスに実現する。このフレームワークにより、追加ステップなしで多数のツールにアクセスでき、性能とスケーラビリティが向上する。47,000以上のツールでの実験結果は、ToolGenが自律的なタスク完遂において優れた成果を示し、多様な領域に適応可能なAIエージェントの新時代を切り開くことを示唆している。さらに、エンドツーエンドのツール学習を可能にし、他の高度な技術との統合機会を提供することで、LLMsの実践的な能力を拡張する。 Comment
昔からよくある特殊トークンを埋め込んで、特殊トークンを生成したらそれに応じた処理をする系の研究。今回はツールに対応するトークンを仕込む模様。
斜め読みだが、3つのstepでFoundation Modelを訓練する。まずはツールのdescriptionからツールトークンを生成する。これにより、モデルにツールの情報を覚えさせる(memorization)。斜め読みなので読めていないが、ツールトークンをvocabに追加してるのでここは継続的事前学習をしているかもしれない。続いて、(おそらく)人手でアノテーションされたクエリ-必要なツールのペアデータから、クエリに対して必要なツールを生成するタスクを学習させる。最後に、(おそらく人手で作成された)クエリ-タスクを解くためのtrajectoryペアのデータで学習させる。
学習データのサンプル。Appendix中に記載されているものだが、本文のデータセット節とAppendixの双方に、データの作り方の詳細は記述されていなかった。どこかに書いてあるのだろうか。
最終的な性能
特殊トークンを追加のvocabとして登録し、そのトークンを生成できるようなデータで学習し、vocabに応じて何らかの操作を実行するという枠組み、その学習手法は色々なタスクで役立ちそう。
openreview: https://openreview.net/forum?id=XLMAMmowdY
[Paper Note] Re-Reading Improves Reasoning in Large Language Models, Xiaohan Xu+, EMNLP'24, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Prompting #EMNLP #KeyPoint Notes Issue Date: 2023-10-30 GPT Summary- Re2は、質問を再読することでLLMの推論能力を高める簡潔かつ効果的なプロンプティング手法です。これは、入力を二度処理することにより理解を深め、CoTなどの思考誘発型手法とも互換性があります。Re2は単方向デコーダーのLLMに対しても双方向エンコーディングを促進し、広範な推論ベンチマークでその有効性を示しました。結果として、Re2は単純な再読戦略を通じてLLMの推論性能を一貫して向上させることが示され、異なるモデルや手法と効果的に統合可能です。 Comment
問題文を2,3回promptで繰り返すだけで、数学のベンチマークとCommonsenseのベンチマークの性能が向上したという非常に簡単なPrompting。self-consistencyなどの他のPromptingとの併用も可能。
なぜ性能が向上するかというと、
1. LLMはAuporegressiveなモデルであり、bidirectionalなモデルではない。このため、forwardパスのみでは読解力に限界がある。(たとえば人間はしばしばテキストを読み返したりする)。そこで、一度目の読解で概要を理解し、二度目の読解でsalience partを読み込むといったような挙動を実現することで、より問題文に対するComprehensionが向上する。
2. LLMはしばしばpromptの重要な箇所の読解を欠落させてしまう。たとえば、[Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
では、promptのmiddle partを軽視する傾向があることが示されている。このような現象も軽減できると考えられる。
問題文の繰り返しは、3回までは性能が向上する。
このpromptingは複雑な問題であればあるほど効果があると推察される。
本手法はReasoningモデル登場依然のものであり、おそらくReasoningモデルではReasoning tokenの生成を通じて動的にcontextにattentionを貼る(つまり必要な箇所は自然にre-readingされる)ため、re-readingと同等以上の効果を得ていることが推察される。
このため、直感的にはこの手法はnon-thinkingモデルに対しては依然として有効な場合はあるかもしれないが、Reasoningモデルにおいては非推奨だと個人的には考える。
[Paper Note] Large Language Models as Optimizers, Chengrun Yang+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #AutomaticPromptEngineering #ICLR #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-09-09 GPT Summary- 最適化タスクを自然言語で記述するアプローチ、Optimization by PROmpting(OPRO)を提案。大規模言語モデル(LLMs)を用いて以前の解を基に新しい解を生成し、プロンプトに追加。線形回帰や巡回セールスマン問題での実証に続き、プロンプト最適化を行い、タスク精度を最大化。OPROで最適化されたプロンプトは、人間設計のものをGSM8Kで最大8%、Big-Bench Hardで最大50%上回ることを確認。 Comment
`Take a deep breath and work on this problem step-by-step. `論文
# 概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。
# 手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。
Meta promptの例
openreview: https://openreview.net/forum?id=Bb4VGOWELI
テキスト空間上で過去の履歴とスコアが与えられ、それをgivenにスコアが良くなりそうなものをLLMがiterativeに生成していくことが可能なことが示されたのが興味深い
CausalLM is not optimal for in-context learning, Nan Ding+, N_A, ICLR'24
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #In-ContextLearning #ICLR Issue Date: 2023-09-01 GPT Summary- 最近の研究では、トランスフォーマーベースのインコンテキスト学習において、プレフィックス言語モデル(prefixLM)が因果言語モデル(causalLM)よりも優れたパフォーマンスを示すことがわかっています。本研究では、理論的なアプローチを用いて、prefixLMとcausalLMの収束挙動を分析しました。その結果、prefixLMは線形回帰の最適解に収束する一方、causalLMの収束ダイナミクスはオンライン勾配降下アルゴリズムに従い、最適であるとは限らないことがわかりました。さらに、合成実験と実際のタスクにおいても、causalLMがprefixLMよりも性能が劣ることが確認されました。 Comment
参考:
CausalLMでICLをした場合は、ICL中のdemonstrationでオンライン学習することに相当し、最適解に収束しているとは限らない……?が、hillbigさんの感想に基づくと、結果的には実は最適解に収束しているのでは?という話も出ているし、よく分からない。
[Paper Note] Teaching Arithmetic to Small Transformers, Nayoung Lee+, ICLR'24, 2023.07
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #NumericReasoning #Mathematics #KeyPoint Notes Issue Date: 2023-07-11 GPT Summary- 小型トランスフォーマーが次語予測を用いて基本的な算術演算(加算、乗算、平方根)を学習できるかを調査。従来のデータが効果的でないことを示し、形式変更で精度が向上することを確認。Chain-of-Thoughtスタイルのデータで訓練することで、事前訓練なしでも精度と収束速度を改善。算術データとテキストデータの相互作用や少数ショット promptingの影響を考察し、高品質なデータの重要性を強調。 Comment
小規模なtransformerに算術演算を学習させ、どのような学習データが効果的か調査。CoTスタイルの詳細なスクラッチパッドを学習データにすることで、plainなもの等と比較して、予測性能や収束速度などが劇的に改善した
結局next token predictionで学習させているみたいだけど、本当にそれで算術演算をモデルが理解しているのだろうか?という疑問がいつもある
↑この3年前の感想は、現在は良質なreasoning trajectioryを用いたSFTにってreasoning能力が強化できることを考えると一部解決されている。少なくとも、next token predictionによって(汎化性能は置いておいて)特定分野でのreasoning能力を身につけさせることができることは分かっているため、真に"理解"しているかはわからないが、少なくともモデル自身の能力で思考し問題を解けることは実験的に示されている。
事前学習によって知識を学習し、中間学習や事後学習で知識の使い方や特定の能力を現在では伸ばしているが、この研究だはスクラッチパッドを用いた事前学習データを使っているようなので、数学の解き方の知識と使い方を同時に学習できていると考えられる。
(3年前の感想を今見返すとおもしろいな)
openreview: https://openreview.net/forum?id=dsUB4bst9S
[Paper Note] Prompting Large Language Model for Machine Translation: A Case Study, Biao Zhang+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#MachineTranslation #NLP #LanguageModel #One-Line Notes Issue Date: 2024-11-20 GPT Summary- プロンプト設計は多くのタスクで優れた性能を示すが、機械翻訳においては未検討。翻訳のためのプロンプト戦略を体系的に研究し、プロンプトテンプレートやデモ例の選択に関する要因を検討。実験の結果、プロンプト例の数と質が翻訳において重要であり、サブ最適な例は性能低下を招くことが示された。また、ゼロショットプロンプティングから得られた擬似平行プロンプト例の利用が翻訳を改善する可能性や、知識転移により性能向上が見込まれることが確認された。最後に、プロンプト設計に関する問題点についても議論。 Comment
zero-shotでMTを行うときに、改行の有無や、少しのpromptingの違いでCOMETスコアが大幅に変わることを示している。
モデルはGLM-130BをINT4で量子化したモデルで実験している。
興味深いが、この知見を一般化して全てのLLMに適用できるか?と言われると、そうはならない気がする。他のモデルで検証したら傾向はおそらく変わるであろう(という意味でおそらく論文のタイトルにもCase Studyと記述されているのかなあ)。
[Paper Note] Orca 2: Teaching Small Language Models How to Reason, Arindam Mitra+, arXiv'23, 2023.11
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Chain-of-Thought #SmallModel #OpenWeight Issue Date: 2023-11-21 GPT Summary- Orca 2 は小型 LM の推論能力を高めるために、異なるタスクごとに様々な解法戦略を学習させることを目指す。段階的推論や思い出し-推論-生成などを用いて、小型モデルの潜在能力を最大化し、約100のタスクで評価を行い、同規模モデルを大きく上回る性能を達成。重みは公開され、開発研究の支援が期待される。 Comment
ポイント解説:
HF: https://huggingface.co/microsoft/Orca-2-13b
論文を読むとChatGPTのデータを学習に利用しているが、現在は競合となるモデルを作ることは規約で禁止されているので注意
Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models, Steve Yadlowsky+, N_A, arXiv'23
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Transformer #OOD #One-Line Notes Issue Date: 2023-11-06 GPT Summary- 本研究では、トランスフォーマーモデルの文脈学習(ICL)能力を調査しました。トランスフォーマーモデルは、事前学習データの範囲内で異なるタスクを特定し、学習する能力を持っています。しかし、事前学習データの範囲外のタスクや関数に対しては一般化が劣化することが示されました。また、高容量のシーケンスモデルのICL能力は、事前学習データの範囲に密接に関連していることが強調されました。 Comment
Transformerがpre-training時に利用された学習データ以外の分布に対しては汎化性能が落ちることを示したらしい。もしこれが正しいとすると、結局真に新しい分布というか関数というかタスクというか、をTransformerが創出する可能性は低いと言えるかもしれない。が、新しいものって大体は既存の概念の組み合わせだよね(スマホとか)、みたいなことを考えると、別にそれでも十分では?と思ってしまう。人間が本当に真の意味で新しい関数というかタスクというか分布を生み出せているかというと、実はそんなに多くないのでは?という予感もする。まあたとえば、量子力学を最初に考えました!とかそういうのは例外だと思うけど・・・、そのレベルのことってどんくらいあるんだろうね?
[Paper Note] The Perils & Promises of Fact-checking with Large Language Models, Dorian Quelle+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2023-11-05 GPT Summary- 自動ファクトチェックは機械学習を用いて主張を検証する重要な取り組みであり、LLMs(例:GPT-4)はその能力を活用しつつ、情報の真偽を見分ける役割が増大している。本研究ではLLMエージェントがクエリを作成し、文脈データを取得し、意思決定を行うフレームワークを提案。結果、文脈情報がLLMの能力を向上させることが示されたが、正確性はクエリの言語や主張の真偽に依存し、一貫性に欠けるため慎重な運用が求められる。さらなる研究が必要で、エージェントの成功と失敗のメカニズムを探求することが提言される。 Comment
gpt3とgpt4でFactCheckして傾向を分析しました、という研究。promptにstatementとgoogleで補完したcontextを含め、出力フォーマットを指定することでFactCheckする。
promptingする際の言語や、statementの事実性の度合い(半分true, 全てfalse等)などで、性能が大きく変わる結果とのこと。
性能を見ると、まだまだ(このprompting方法では)人間の代わりが務まるほどの性能が出ていないことがわかる。また、trueな情報のFactCheckにcontextは効いていそうだが、falseの情報のFactCheckにContextがあまり効いてなさそうに見えるので、なんだかなあ、という感じである。
斜め読みしかしていないがこの研究、学術的な知見は少ないのかな、という印象。一つのケーススタディだよね、という感じがする。
まず、GPT3,4だけじゃなく、特徴の異なるOpenSourceのLLMを比較に含めてくれないと、前者は何で学習しているか分からないので、学術的に得られる知見はほぼないのではという気が。実務的には役に立つが。
その上で、Promptingをもっとさまざまな方法で検証した方が良いと思う。
たとえば、現在のpromptではラベルを先に出力させた後に理由を述べさせているが、それを逆にしたらどうなるか?(zero-shot CoT)や、4-Shotにしたらどうなるか、SelfConsistencyを利用したらどうなるかなど、promptingの仕方によって傾向が大きく変わると思う。
加えて、Retriever部分もいくつかのバリエーションで試してみても良いのかなと思う。特に、falseの情報を判断する際に役に立つ情報がcontextに含められているのかが気になる。
論文に書いてあるかもしれないが、ちょっとしっかり読む時間はないです!!
[Paper Note] Llemma: An Open Language Model For Mathematics, Zhangir Azerbayev+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #FoundationModel #Mathematics #mid-training #One-Line Notes Issue Date: 2023-10-29 GPT Summary- Llemmaという数学の大規模言語モデルを提案。Proof-Pile-2でCode Llamaの前訓練を行い、科学論文や数学コードを含む複合データセットで強化。MATHベンチマークで全ての公開モデルを凌ぎ、未公開のMinervaモデル群にも勝利。追加ファインチューニングなしでツール使用や形式的定理証明が可能。70億および340億パラメータのモデルや実験コードを公開。 Comment
CodeLLaMAを200B tokenの数学テキスト(proof-pile-2データ;論文、数学を含むウェブテキスト、数学のコードが含まれるデータ)で継続的に事前学習することでfoundation modelを構築
約半分のパラメータ数で数学に関する性能でGoogleのMinervaと同等の性能を達成
元ツイート:
まだ4-shotしてもAcc.50%くらいなのか。
[Paper Note] Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation, Yongxin Shi+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#ComputerVision #NLP #LanguageModel #MultiModal #EMNLP #OCR #One-Line Notes Issue Date: 2023-10-26 GPT Summary- GPT-4VのOCR機能を評価し、シーンテキスト、手書き文字、数学式や表構造認識などの幅広いタスクへの性能を検討。ラテン文字では高性能だが、多言語や複雑なタスクでは限界を示す。専門的なOCRモデルの必要性を強調し、今後の研究の指針を提供。評価結果は公開されている。 Comment
GPT4-VをさまざまなOCRタスク「手書き、数式、テーブル構造認識等を含む)で性能検証した研究。
MLT19データセットを使った評価では、日本語の性能は非常に低く、英語とフランス語が性能高い。手書き文字認識では英語と中国語でのみ評価。
現在では非常に性能が向上していると考えられるが、初期VLMのOCR性能を示している文献として興味深い。
[Paper Note] Why Do We Need Weight Decay in Modern Deep Learning?, Francesco D'Angelo+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#MachineLearning #Regularization #NeurIPS Issue Date: 2023-10-11 GPT Summary- 重み減衰は深層ネットワークの訓練に広く用いられるが、その役割は十分に理解されていない。本研究では、重み減衰が視覚タスクの深層ネットワークにおいて最適化ダイナミクスを修正し、損失安定化を通じて暗黙の正則化を強化することを示す。また、大規模言語モデルでは、重み減衰がトレードオフをバランスさせ、訓練安定性を改善することを説明。重み減衰は明示的な正則化としては有用でなく、訓練ダイナミクスを変える役割を果たすことを提案した。 Comment
参考:
WeightDecayは目的関数に普通にL2正則化項を加えることによって実現されるが、深掘りするとこんな効果があるのね
openreview (ICLR'24) : https://openreview.net/forum?id=RKh7DI23tz
openreview (NeurIPS'24): https://openreview.net/forum?id=YrAxxscKM2&referrer=%5Bthe%20profile%20of%20Aditya%20Varre%5D(%2Fprofile%3Fid%3D~Aditya_Varre1)
[Paper Note] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution, Chrisantha Fernando+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #Prompting #AutomaticPromptEngineering #ICML Issue Date: 2023-10-09 GPT Summary- Promptbreederは、LLMの推論能力を向上させる自己改善メカニズムであり、特定のドメインに対してプロンプトを進化・適応させる。タスクプロンプトの集団を突然変異させ、訓練データで評価することで、LLMが生成・改善する変異プロンプトによって統治される。これにより、Chain-of-ThoughtやPlan-and-Solve Promptingを上回り、ヘイトスピーチ分類のような複雑なタスクにも対応可能なプロンプトを進化させる。 Comment
詳細な解説記事: https://aiboom.net/archives/56319
APEとは異なり、GAを使う。突然変異によって、予期せぬ良いpromptが生み出されるかも…?
[Paper Note] Large Language Models as Analogical Reasoners, Michihiro Yasunaga+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #In-ContextLearning #ICLR #KeyPoint Notes Issue Date: 2023-10-07 GPT Summary- アナロジー的プロンプティングを用いて、言語モデルに問題解決前に関連する例示を生成させる新手法を提案。ラベリング不要で汎用性が高く、適応性もある。実験では、GSM8K、MATH、Codeforces、BIG-Benchの推論タスクで0ショットおよび少数ショットCoTを上回る性能を示した。 Comment
以下、著者ツイートのざっくり翻訳:
人間は新しい問題に取り組む時、過去に解いた類義の問題を振り返り、その経験を活用する。これをLLM上で実践できないか?というのがアイデア。
Analogical Promptingでは、問題を解く前に、適切なexamplarを自動生成(problemとsolution)させ、コンテキストとして利用する。
これにより、examplarは自己生成されるため、既存のCoTで必要なexamplarのラベリングや検索が不要となることと、解こうとしている問題に合わせてexamplarを調整し、推論に対してガイダンスを提供することが可能となる。
実験の結果、数学、コード生成、BIG-Benchでzero-shot CoT、few-shot CoTを上回った。
LLMが知っており、かつ得意な問題に対してならうまく働きそう。一方で、LLMが苦手な問題などは人手作成したexamplarでfew-shotした方が(ある程度)うまくいきそうな予感がする。うまくいきそうと言っても、そもそもLLMが苦手な問題なのでfew-shotした程度では焼石に水だとは思うが。
openreview: https://openreview.net/forum?id=AgDICX1h50
[Paper Note] Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Bias #NAACL #read-later #Selected Papers/Blogs #Findings #One-Line Notes #needs-revision Issue Date: 2023-08-28 GPT Summary- 多肢選択問題におけるLLMsの性能は選択肢の順序に敏感であり、配置を変えることで最大75%の性能差が見られる。特に、上位選択肢間の不確実性がこの感度を引き起こし、バイアスが影響することを示唆する。最適な配置は、バイアスを増幅させるためにトップ選択肢を両端に置くこと、緩和するためには隣接させることが推奨される。実験を通じて、予測のキャリブレーションにより最大8ポイントの改善が達成された。 Comment
これはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。
[Paper Note] How is ChatGPT's behavior changing over time?, Lingjiao Chen+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#NLP #ChatGPT #Evaluation Issue Date: 2023-07-22 GPT Summary- GPT-3.5とGPT-4の2023年版を、数学、敏感な質問、意見調査、知識集約型質問、コード生成、医師免許試験、視覚推論のタスクで評価した結果、両者の性能が時間とともに大きく変化することが明らかになった。特に、GPT-4(3月版)が素数識別では84%の正答率を示したが、6月版では51%に低下。GPT-3.5は6月にこのタスクで向上し、GPT-4は敏感な質問への回答意欲が減少した。全体として、LLMの挙動は短期間で変化し得るため、継続的な監視が必要であることを示唆している。 Comment
GPT3.5, GPT4共にfreezeされてないのなら、研究で利用すると結果が再現されないので、研究で使うべきではない。
↑(2025.10追記)
当時の私はこのように感じたようだが、以下を確認した方が良いと思う:
- 実験設定として、エンドポイントのモデル名にはタイムスタンプが付与されているが、同じモデルシリーズの異なるタイムスタンプモデル間の比較なのか、それとも全く同じタイムスタンプのモデルでの比較なのか
- サンプリングパラメータの設定や推論の試行回数なとがreliableな比較ができうる設定になっているか。
あとは上記を確認したとしても、研究で使うべきではない、は言い過ぎで、実験の比較対象の一部として使う分には良いと思う(ただし、実験結果の主要な知見は再現可能な設定から得られるべきと考える。
(当時は随分脊髄反射的にコメントを書いていますね…)
[Paper Note] Transformers learn to implement preconditioned gradient descent for in-context learning, Kwangjun Ahn+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #LanguageModel #In-ContextLearning #NeurIPS #needs-revision Issue Date: 2023-07-11 GPT Summary- トランスフォーマーが勾配降下法を実装できるかを探る研究。線形トランスフォーマーを線形回帰のランダムインスタンスで訓練し、単一アテンション層が前条件化勾配降下法の反復を実装することを理論的に示す。$L$層のトランスフォーマーは、特定の臨界点で$L$回の反復を実行。結果は、トランスフォーマーを学習アルゴリズムとして訓練する新たな理論研究を促進する。 Comment
参考:
つまり、事前学習の段階でIn context learningが可能なように学習がなされているということなのか。
それはどのような学習かというと、プロンプトとそれによって与えられた事例を前条件とした場合の勾配降下法によって実現されていると。
つまりどういうことかというと、プロンプトと与えられた事例ごとに、それぞれ最適なパラメータが学習されているというイメージだろうか。条件付き分布みたいなもの?
なので、未知のプロンプトと事例が与えられたときに、事前学習時に前条件として与えられているものの中で類似したものがあれば、良い感じに汎化してうまく生成ができる、ということかな?
いや違うな。1つのアテンション層が勾配降下法の1ステップをシミュレーションしており、k個のアテンション層があったらkステップの勾配降下法をシミュレーションしていることと同じ結果になるということ?
そしてその購買降下法では、プロンプトによって与えられた事例が最小となるように学習される(シミュレーションされる)ということなのか。
つまり、ネットワーク上で本当に与えられた事例に基づいて学習している(のと等価な結果)を得ているということなのか?😱
openreview: https://openreview.net/forum?id=LziniAXEI9
[Paper Note] LIMA: Less Is More for Alignment, Chunting Zhou+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #DataDistillation #NeurIPS #KeyPoint Notes #needs-revision Issue Date: 2023-05-22 GPT Summary- LIMAは65BパラメータのLLaMaモデルで、1,000件の慎重に選定されたプロンプトで微調整された。モデルは汎用表現を学び、未知のタスクに対しても良好に一般化。人間評価では、LIMAの性能がGPT-4より43%、Bardより58%、DaVinci003より65%優れていることが示され、事前学習が知識の大半を構築する重要性を強調している。 Comment
LLaMA65Bをたった1kのdata point(厳選された物)でRLHF無しでfinetuningすると、旅行プランの作成や、歴史改変の推測(?)幅広いタスクで高いパフォーマンスを示し、未知のタスクへの汎化能力も示した。最終的にGPT3,4,BARD,CLAUDEよりも人間が好む回答を返した。
LLaMAのようなオープンでパラメータ数が少ないモデルに対して、少量のサンプルでfinetuningするとGPT4に迫れるというのはgamechangerになる可能性がある
openreview: https://openreview.net/forum?id=KBMOKmX2he
[Paper Note] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness, Bo Li+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#NLP #Explanation #ChatGPT #InformationExtraction #Evaluation #KeyPoint Notes Issue Date: 2023-04-25 GPT Summary- 本研究では、ChatGPTの能力を7つの情報抽出(IE)タスクを通じて評価し、パフォーマンス、説明可能性、キャリブレーション、信頼性を分析しました。標準IE設定ではパフォーマンスが低い一方、オープンIE設定では人間評価で優れた結果を示しました。ChatGPTは高品質な説明を提供するものの、予測に対して過信する傾向があり、キャリブレーションが低いことが明らかになりました。また、元のテキストに対して高い信頼性を示しました。研究のために手動で注釈付けした7つのIEタスクのテストセットと14のデータセットを公開しています。 Comment
情報抽出タスクにおいてChatGPTを評価した研究。スタンダードなIEの設定ではBERTベースのモデルに負けるが、OpenIEの場合は高い性能を示した。
また、ChatGPTは予測に対してクオリティが高く信頼に足る説明をしたが、一方で自信過剰な傾向がある。また、ChatGPTの予測はinput textに対して高いfaithfulnessを示しており、予測がinputから根ざしているものであることがわかる。(らしい)
あまりしっかり読めていないが、Entity Typing, NER, Relation Classification, Relation Extraction, Event Detection, Event Argument Extraction, Event Extractionで評価。standardIEでは、ChatGPTにタスクの説明と選択肢を与え、与えられた選択肢の中から正解を探す設定とした。一方OpenIEでは、選択肢を与えず、純粋にタスクの説明のみで予測を実施させた。OpenIEの結果を、3名のドメインエキスパートが出力が妥当か否か判定した結果、非常に高い性能を示すことがわかった。表を見ると、同じタスクでもstandardIEよりも高い性能を示している(そんなことある???)
つまり、選択肢を与えてどれが正解ですか?ときくより、選択肢与えないでCoTさせた方が性能高いってこと?比較可能な設定で実験できているのだろうか。promptは付録に載っているが、output exampleが載ってないのでなんともいえない。StandardIEの設定をしたときに、CoTさせてるかどうかが気になる。もししてないなら、そりゃ性能低いだろうね、という気がする。
Extending Deep Knowledge Tracing: Inferring Interpretable Knowledge and Predicting Post-System Performance, Richard+ (w_ Ryan Baker), ICCE'20
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #KnowledgeTracing #Surface-level Notes #ICCE Issue Date: 2022-08-29 Comment
# 概要
ざっくりとしか読めていないが
- DeepLearningBasedなKT手法は、latentな学習者の知識を推定しているわけではなく、「正誤」を予測しているだけであることを指摘
- → 一方BKTはきちんとlatent knowledgeがモデリングされている
- → 昔はknowledge inferenceした結果を、post-testで測定したスキルのmasteryとしっかり比較する文化があったが、近年のDeepLearningベースな研究では全く実施されていないことも指摘
- → learning systemの中でどのようなパフォーマンスが発揮されるかではなく、learning systemの外でどれだけスキルが発揮できるか、というところにBKTなどの時代は強い焦点が置かれていたのだと思われる
- DeepLearningBasedなKT手法でもknowledgeのinferenceが行える手法を提案し、BKTやPFAによるknowledge estimateよりもposttestのスコアと高い相関を示すことを実験した
- → 手法: それぞれの問題のfirst attemptに対する正誤データの「全て」をtraining dataとし、DKT, DKVMN, BKT, PFAを学習。
-(おそらく)学習したモデルを用いてある生徒AのスキルBのknowledgeをinferenceしたい場合、生徒Aが回答したスキルBと紐づいた問題に対する平均正答率を推定した習熟度とした
- 生徒Aはtraining dataに含まれている生徒
- すなわち、生徒Aにとって未知の問題の正答率を予測しているわけではなく、モデルがパラメータを推定するために利用した既知の問題-回答ペアデータに対して、モデルがパラメータをfittingした後にinferenceできる正答率の平均値を習熟度としている
# 結果
- 4種類のスキルに対するpost-testのスコアと相関係数をモデルごとに比較した結果、DKT, DKVMNなどは、BKTよりも高い相関を示し、PFAとはcomparableな結果となった
# 所感
- この手法のリアルタイムな運用は難しいと思った(knowledgeをinferするために毎回モデルをtrainingしなおさなければならない)
- BKTが推定するスキルのmasteryはこのcase studyだけ見ると全くあてにならない・・・
- ユーザが回答した問題と紐づいたスキルのknowledgeしか推定できないところもlimitationの一つだと思う
- この手法がtraining dataに含まれていない「未知の問題」に対する正答率予測を平均することで、knowledgeをinferenceできるという話だったのであれば、非常に興味深いと思った。
- 実際どうなんだろうか?
Context-Aware Attentive Knowledge Tracing, Ghosh+, University of Massachusetts Amherst, KDD'20
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing #SIGKDD Issue Date: 2022-04-27 Comment
この論文の実験ではSAKTがDKVMNやDKTに勝てていない
[Paper Note] Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches, Maurizio Ferrari Dacrema+, RecSys'19, 2019.07
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Evaluation #RecSys #Selected Papers/Blogs #Reproducibility #KeyPoint Notes Issue Date: 2022-04-11 GPT Summary- 深層学習技術はレコメンダーシステムの研究で広く用いられているが、再現性やベースライン選択に問題がある。18のトップnレコメンデーションアルゴリズムを分析した結果、再現できたのは7つのみで、6つは単純なヒューリスティック手法に劣っていた。残りの1つはベースラインを上回ったが、非ニューラル手法には及ばなかった。本研究は機械学習の実践における問題を指摘し、改善を呼びかけている。 Comment
RecSys'19のベストペーパー
日本語解説:
https://qiita.com/smochi/items/98dbd9429c15898c5dc7
TopN推薦におけるDNNを用いた研究を追試した研究で、トップ会議の手法のうち18本の追試を試みたところ、追試のための現実的な努力や著者に連絡をするといったことを実施した上で再現できたものは7本であり、そのうち6/7が適切なハイパーパラメータ調整を行なったkNNベースのシンプルな手法に勝てなかった(かつ残りの一つも線形モデルに対して負ける場合もあった)、という話で、業界における評価における再現性の問題(ハイパーパラメータ調整の記載がない等)や、適切な実験設定の欠如(ベースラインのハイパーパラメータチューニングをせずに先行研究の記述内容をそのまま踏襲等、テストデータを用いたエポック数の調整、ランダムサンプリングのはずなのに明らかに提案手法に有利となるような偏ったサンプリングを実施...)、ベースラインの適切な選定(多くの研究がNeural Collaboraive Filteringをベースラインにしているが果たしてそれが適切か)などについて警鐘を鳴らす内容になっている。
過去の先行研究([Paper Note] Sequence-Aware Recommender Systems, Massimo Quadrana+, ACM Computing Surveys (CSUR), Volume 51, Issue 4, 2018.02
)でも、研究者の間でデータセットの分割に関して、標準化されていない旨が記述されている。また、管理人が研究を追う中でも、共通のフレームワークで評価がされているとは言い難い印象を持っている(**このコメントは論文を読んだ当時を思い起こし2026年に追記しているが、この頃から業界はどのようにシフトしただろうか?最近は追えていない**)。
たとえば評価をする際には、データセットの選択だけでなく、データセットの中でどの規模感のデータセットを使うのか(MovieLens一つとっても様々なバリエーションがある)、leave-one-outをするのか、時系列性を考慮した履歴の分割をするのか、negative samplingをする際の件数やサンプリング方法、なんらかのstratifiedなk-fold cross validationをするのか否か、coldstartなデータを排除するのか否か、排除する際の足切りの基準、ハイパーパラメータ。最適化する際のメトリックと最適化をするパラメータ、平均を取る際の実験の試行回数、性能を測るメトリック(Precision, Recall, NDCG, MAP, MRR, AUC, HITS@N...)など様々な変数が存在し、これらの設定が異なると性能は確かに大きく変化すると思われる。実際に推薦モデルの検証をする際には適切な検証となるよう細心の注意を払いたい。
私個人としては本研究を知った以後、オフラインでの実験のみでなくらA/Bテストが実施されている研究に対する信頼性をより高めるようになった。
おそらくこれを受けてRecboleのようなフレームワークが登場したと思うが、現在は更新がされていないという認識である。いまはどのように再現性に関する取り組みがされているだろうか?
- Autonomously Generating Hints by Inferring Problem Solving Policies, Piech+, Stanford University, L@S'15
[Paper Note] xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, Jianxun Lian+, arXiv'18, 2018.03
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #FactorizationMachines #CTRPrediction #SIGKDD #One-Line Notes Issue Date: 2021-05-25 GPT Summary- 特徴量の自動生成が求められる中、因子分解モデルは相互作用を学習し一般化するが、DNNは暗黙的である。本研究では、明示的に相互作用を生成する圧縮相互作用ネットワーク(CIN)を提案し、DNNと統合したeXtreme Deep Factorization Machine(xDeepFM)を開発。xDeepFMは低次・高次の相互作用を学習し、実データセットで最先端モデルを超える性能を示した。 Comment
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, Guo+, IJCAI’17 DeepFMの発展版
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10, 2010.12
にも書いたが、下記リンクに概要が記載されている。
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
DeepFMの発展についても詳細に述べられていて、とても参考になる。
[Paper Note] Deep Residual Learning for Image Recognition, Kaiming He+, CVPR'16, 2015.12
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #CVPR #Selected Papers/Blogs #Backbone #KeyPoint Notes #ResidualStream Issue Date: 2021-11-04 GPT Summary- 残差学習フレームワークを提案し、深いニューラルネットワークのトレーニングを容易にする。参照層の入力に基づいて残差関数を学習することで、最適化が容易になり、精度が向上。152層の残差ネットはImageNetで低い複雑性を保ちながら高い性能を示し、ILSVRC 2015で1位を獲得。COCOデータセットでも28%の改善を達成。 Comment
ResNet論文
ResNetでは、レイヤーの計算する関数を、残差F(x)と恒等関数xの和として定義する。これにより、レイヤーが入力との差分だけを学習すれば良くなり、モデルを深くしても最適化がしやすくなる効果ぎある。数レイヤーごとにResidual Connectionを導入し、恒等関数によるショートカットができるようにしている。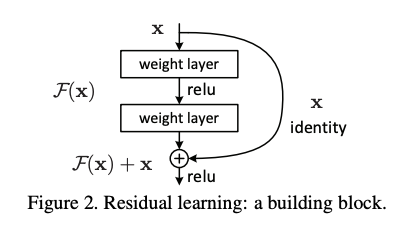
ResNetが提案される以前、モデルを深くすれば表現力が上がるはずなのに、実際には精度が下がってしまうことから、理論上レイヤーが恒等関数となるように初期化すれば、深いモデルでも浅いモデルと同等の表現が獲得できる、と言う考え方を発展させた。
(ステートオブAIガイドに基づく)
同じパラメータ数でより層を深くできる(Plainな構造と比べると層が1つ増える)Bottleneckアーキテクチャも提案している。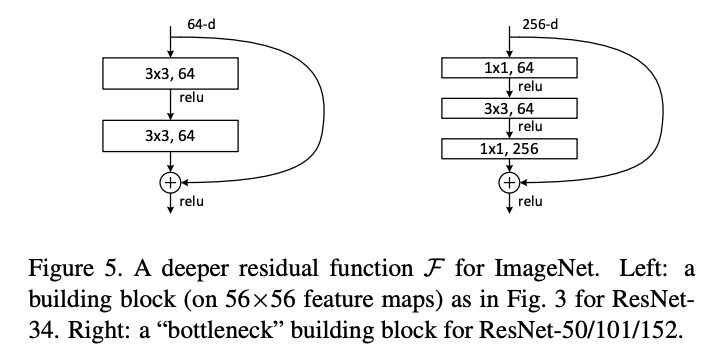
今や当たり前のように使われているResidual Connectionは、層の深いネットワークを学習するために必須の技術なのだと再認識。
[Paper Notes] Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #EDM #KeyPoint Notes Issue Date: 2021-05-29 Comment
Knewton社の研究。IRTとIRTを拡張したモデルでStudent Performance Predictionを行い、3種類のデータセットでDKT [Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15
と比較。比較の結果、IRT、およびIRTを拡張したモデルがDKTと同等、もしくはそれ以上の性能を出すことを示した。IRTはDKTと比べて、trainingが容易であり、パラメータチューニングも少なく済むし、DKTを数万のアイテムでtrainingするとメモリと計算時間が非常に大きくなるので、性能とパフォーマンス両方の面で実用上はIRTベースドな手法のほうが良いよね、という主張。
AUCを測る際に、具体的に何に大してAUCを測っているのかがわからない。モデルで何を予測しているかが明示的に書かれていないため(普通に考えたら、生徒のquizに対する回答の正誤を予測しているはず。IRTではquizのIDをinputして予測できるがDKTでは基本的にknowledge componentに対するproficiencyという形で予測される(table 1が各モデルがどのidに対して予測を行なったかの対応を示しているのだと思われる))。
knewton社は自社のアダプティブエンジンでIRTベースの手法を利用しており、DKTに対するIRTベースな手法の性能の比較に興味があったのだと思われる。
なお、論文の著者であるKnewton社のKevin H. Wilson氏はすでにknewton社を退職されている。
https://kevinhayeswilson.com/
Going Deeper with Deep Knowledge Tracing, Beck+, EDM'16
Paper/Blog Link My Issue
#NeuralNetwork #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #EDM #KeyPoint Notes Issue Date: 2021-05-28 Comment
BKT, PFA, DKTのinputの違いが記載されており非常にわかりやすい

BKT, PFA, DKTを様々なデータセットで性能を比較している。また、ASSISTmentsデータに問題点があったことを指摘し(e.g. duplicate records問題など)、ASSSTmentsデータの問題点を取り除いたデータでも比較実験をしている。結論としては、ASSISTmentsデータの問題点を取り除いたデータで比較すると、DKTがめっちゃ強いというわけではなく、PFAと性能大して変わらなかった、ということ。
KDD cupのデータではDKTが優位だが、これはPFAをKDD Cupデータに適用する際に、難易度を適切に求められない場面があったから、とのこと(問題+ステップ名のペアで難易度を測らざるを得ないが、そもそも1人の生徒しかそういったペアに回答していない場合があり、難易度が1.0 / 0.0 等の極端な値になってしまう。これらがoverfittingの原因になったりするので、そういった問題-ステップペアの難易度をスキルの難易度で置き換えたりしている)。
ちなみにこの手のDKTこれまでのモデルと性能大して変わんないよ?系の主張は、当時だったらそうかもしれないが、2020年のRiiiDの結果みると、オリジナルなDKTがシンプルな構造すぎただけであって、SAKT+RNNみたいな構造だったら多分普通にoutperformする、と個人的には思っている。
ASSISTmentsデータにはduplicate records問題以外にも、複数種類のスキルタグが付与された問題があったときに、1つのスキルタグごとに1レコードが列挙されるようなデータになっている点が、BKTと比較してDKTが有利だった点として指摘している。スキルA, Bが付与されている問題が2問あった時に、それらにそれぞれ正解・不正解した場合のASSISTments09-10データの構造は下図のようになる。DKTを使ってこのようなsequenceを学習した場合、スキルタグBの正誤予測には、一つ前のtime-stempのスキルタグAの正誤予測がそのまま利用できる、といった関係性を学習してしまう可能性が高い。BKTはスキルタグごとにモデルを構築するので、これではBKTと比較してDKTの方が不当に有利だよね、ということも指摘している。
複数タグが存在する場合の対処方法として、シンプルに複数タグを連結して新しいタグとする、ということを提案している。
[Paper Note] Matrix Factorization Techniques for Recommender Systems, Koren+, Computer'07
Paper/Blog Link My Issue
#RecommenderSystems #Survey #CollaborativeFiltering #MatrixFactorization #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
Matrix Factorizationについてよくまとまっている
大規模言語モデルの次期バージョンPLaMo 3シリーズにおける120B事前学習モデル、31B蒸留モデルの評価, PFN, 2026.07
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #LongSequence #OpenWeight #Author Thread-Post Issue Date: 2026-07-09 Comment
元ポスト:
weight reusing:
- [Paper Note] Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae+, arXiv'21, 2021.12
- The Surprising Power of Small Language Models, Mojan Javaheripi+, Microsoft Research, 2023.12
long context評価:
- [Paper Note] RULER: What's the Real Context Size of Your Long-Context Language Models?, Cheng-Ping Hsieh+, COLM'24, 2024.04
- [Paper Note] Repeat After Me: Transformers are Better than State Space Models at Copying, Samy Jelassi+, arXiv'24, 2024.02
HF: https://huggingface.co/pfnet/plamo-3-nict-2604-31b-base
YaRNを適用するとlong contextの性能が大きく改善し、事前学習で学習させるトークン数を増やしすぎるとYaRNのcontext lengthの外挿能力が低下するという実験結果が非常に興味深い。
記載がなかった気がするのだが、Sink Tokenの利用などはやっているのだろうか?
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
Sakana Fugu: One Model to Command Them All, SakanaAI, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Test-Time Scaling #Initial Impression Notes #Orchestration Issue Date: 2026-06-23 Comment
元ポスト:
所見:
Opus 4.8, Gemini 3.1 Pro, GPT 5.5(他にもありそう)のオーケストレータ
beta:
- Sakana Fugu: A Multi-Agent Orchestration System as a Foundation Model, sakana.ai, 2026.04
テクニカルレポート:
- [Paper Note] Sakana Fugu Technical Report, Yujin Tang+, arXiv'26, 2026.06
v1.1になり、新たに公開されたフロンティアモデルをルーティングに加えることで性能向上:
基本的に新たなモデルが公開されたらルーティングを更新すればFuguの性能も向上していくので、性能面でFrontier Modelに遅れをとる可能性は小さいと思われる。一方で、Fugu内部で商用APIを叩いた場合そのコストは他社のマークアップが上乗せされたものになると思うので、利用コストをどの程度抑えられるかがポイントになるだろうか。ただ、ターン単位で利用されるモデルが変更されるので、たとえばFable5を最も重要なプランニングで利用し、その後のフェーズではより安価なモデルを使う、といった柔軟なモデルの組み換えが可能なので、そこの最適化がされればタスクを完遂する際に特定の1モデルを利用するよりも結果的に安い可能性は高い。
Claude Fable 5 and Claude Mythos 5, Anthropic, 2026.06
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Proprietary #Selected Papers/Blogs #VisionLanguageModel #Reference Collection #Initial Impression Notes Issue Date: 2026-06-10 Comment
元ポスト:
Mythos級の性能を持ち、サイバーセキュリティ、生物学、化学、蒸留に対してsafeguardを持つfrontier model
GDPValでSoTA:
フロンティアLLMの構築に関わるクエリは意図的に制限を設ける措置がとられているようだ:
一部の人間にしかAIの能力が解放されない未来に対する懸念:
-
フロンティアモデルの関連に関するリクエストに対しては、通常のsafeguardとは異なり**サイレントに性能が限定される**ようである。これはAIの開発が加速しすぎると重大なリスクが生じるため(February 2026 Risk Report)、とのこと:
-
-
このような性能の低減は、prompt modification, steering, peftなどを通じて行われるとのこと。利用者からしたらpromptの調整や工夫で検知されないようにするしか対策(?)の打ちようがないと思われる。
しかしこの情報をわざわざ公開する意図はなんだろうか。完全に憶測だが
- Mythos級のモデルの性能が良く、半自律的にモデルがモデル自身をよくする仕組みが成立している
- ライバルにモデルを使わせないで、自分たちだけで独占することでMoatを築くフェーズまできた
- 情報を公開しようがしまいが、性能に制限をかけていたら、フロンティアモデル開発者たちにはすぐバレるので、他のユーザたちが混乱するのを避けるために最初から線引きを明確にしておく
- ほほ全てのユーザに影響はないので、一部のフロンティアモデル開発に近しい人間から不満は出るが、全体で見たら気にしなくて良いレベル
- フロンティアモデル開発には使えないと銘打つことで、ライバルよりも本当に性能が良いんだな、という印象を与えることができるマーケティング効果
とかだろうか。
Geminiさんと壁打ちをしたら欠けている視点として以下のような意見を頂戴した(以下の引用部分はGeminiの出力です)
> 規制当局へのポーズ(アライメント):
「自社モデルが、制御不能なさらに強力なAI(AGI/ASI)を勝手に生み出す引き金(ゴーレムが生むゴーレム)にならないよう、防衛策を講じています」という姿勢を政府や規制当局に見せる必要があります。
なるほど
続報:
フロンティアモデルで性能が制限された時に、それらが他のsafeguardと同様ユーザ側に通知されるように変更されるようだ
モデルのそのものの性能などは置いておいて、今回の特定のタスク、プロンプトには恣意的に一定の制限を設ける措置を受け、(Project Glasswingの頃から違和感はあったが)Anthropicが恣意的にAIの能力を供給する姿勢に見え、雲行きの怪しさを感じる
- Project Glasswing Securing critical software for the AI era, Anthropic, 2026.04
Mythos級のモデルでは、全てのpromptと生成結果が、信頼性と安全性の確認のために30日間保持される:
https://support.claude.com/en/articles/15425996-data-retention-practices-for-mythos-class-models
所見: https://simonwillison.net/2026/Jun/9/claude-fable-5/
コーディング関連ベンチマークでは抜きん出ている:
所見:
Fable再公開後のClassifierによる安全マージンについて:
輸出規制解除:
約1ヶ月かかった。
KernelBench MegaでSoTA:
A Functional Taxonomy of World Models, Fei-Fei Li, 2026.06
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #NLP #Post #Selected Papers/Blogs #VideoGeneration/Understandings #Robotics #WorldModels #VisionLanguageActionModel #KeyPoint Notes #TextToVideoGeneration #WorldActionModel #Author Thread-Post Issue Date: 2026-06-04 Comment
元ポスト:
以下ポストの内容の要約(と意訳、間違ってたらごめんなさい)
- 世界モデルは現在最も重要だが、最も多義的な概念の一つになっている。
- 様々な分野がWorld Modelを構築していると主張するが、意味するところが実際には大きく異なる
- (実際 [Paper Note] Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond, Meng Chu+, arXiv'26, 2026.04
のような研究も存在し似たような問題意識のもと様々な分野での統一的な分類体系が提案されている)
- 世界モデルという用語のもともとの枠組みは「部分観測マルコフ決定過程 (POMDP)」であり、
- エージェントは行動を実行し、行動は世界の状態に影響を与え、エージェントは観測データを受け取り(≠状態を認識する)、新たな観測データに基づいてアクションが実行される、といったループが繰り返される枠組みである
- ここで、「状態」とは、ある時点における世界で何が起きているかに関する完全なdescriptionであり、エージェントは状態自体を認識することはできず、行動と状態から生じた部分的な観測データのみである。
- 現在様々な世界モデルと呼ばれるものが存在するが、構造としては上記のループを持っており、それらの切り口が異なっているにすぎない。
- 世界モデルのカテゴリ1: Renderer
- Rendererは人間の目に見えるピクセルで「観測」を出力する。
- たとえば、テキストのプロンプトを映像に変換するText-To-Videoモデル、ユーザの入力に応じてリアルタイムにフレームを生成するシステムはレンダラーに相当する。
- これらモデルは観測者にとって「見えるもの」を生成しているにすぎず、実際の3次元構造を明示的に理解しているわけではない(i.e., 見えるもの≠実在するもの)。
- ビジネスとして最も成長(してきており、学習データもインターネット上の動画が活用できるため他の2カテゴリと比べて多い)
- 世界モデルのカテゴリ2: Simulator
- Simulatorは「状態」を出力する。これは実際に人間やコンピュータが相互作用可能な世界の表現である。
- Rendererは単に視覚的なものであるが、Simulatorは実世界の幾何学的・物理的・動的なダイナミクスを理解することが求められる。
- Simulatorは建築家やゲーム開発者などの視覚を超えた(たとえば構造・物理的な)正確性を必要とする職種や、RLの学習の環境として利用できる。
- Simulator は Rendererと次のPlannerの土台となる技術(Simulatorは RendererとPlannnerの双方をバイパスできる)であるが、学習データが最も不足
- 世界モデルのカテゴリ3: Planner
- Plannerは「行動」を出力する。観測と目標が与えられた時に「次に何をすべきか」を出力する。
- Vision Language Action Model / World Action Model は Planner に該当し、これらはロボットが次に何をすべきかを決定できる。
- 現在研究初期段階で、研究所内での閉じられた環境でのデモ中心で、実世界で活用するためにはまだまだ多くの課題が残る。
- これら3つのカテゴリは現在世に出ているWorld Modelの多くを説明しており、区別をする際に役に立つ。
- が、これらカテゴリは独立したものではなく、これらは世界の機能に関する基本的な知識(幾何学、物理学、ダイナミクス)の上に成り立つ。
- これら3つのカテゴリは最近は互いが融合してくる流れにあり、たとえば事前学習された Renderer は、次に何が起こるか・何をすべきか(=Planner)を予測するためのバックボーンとして利用できることが示されてきており、これは Renderer と Plannerが 融合した例と言える。
- (この辺の話はBackboneとしてVision Encoderを持つVLA系全般の研究と、事前学習済みのVision Encoderを用いずに事前学習の方法をそもそも改善するような方向などだろうか)
上記の話に基づくと、たとえばターミナルでのWorld Modelに相当すると考えられる
- [Paper Note] ECHO: Terminal Agents Learn World Models for Free, Vaishnavi Shrivastava+, arXiv'26, 2026.05
は3つのカテゴリのうちにどれに該当するだろうか。
次のアクションを予測できるので、まずPlannerには該当すると思われる。また、ある時点においてターミナル上で何が起きているかの記述(ターミナルの出力)を予測しているので、Simulatorの役割を果たしていると思われる(ただ、ターミナルの出力だけがターミナルの状態を完全に記述した情報なの?定義としてそれでいいの?という疑問はあるのが)。このため、Planner と Simulator が融合した研究と言えるのではなかろうか。
On-Policy Self-Distillation: 言葉で学ぶ LLMの新たな学習パラダイム, ぶち, 2026.03
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #ReinforcementLearning #Blog #PostTraining #Selected Papers/Blogs #On-Policy #SelfDistillation Issue Date: 2026-06-01 Comment
元ポスト:
日本語でのOPSD解説で、細かい数式などよりも、何が重要で、なぜ今なのかといった気持ちのところが非常に重点的に説明されている。
後半の今後の課題の、どの程度の能力であればself teacherが成立するのか、どのような情報を与えると良いのか、といった話は、
- [Paper Note] Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why, Mohammadreza Armandpour+, arXiv'26, 2026.05
で模索されている。
また、OPSDの気持ち的な部分だけでなく、(簡単な)数式的な解釈、最近のサーベイなど、より詳細な情報は
- The Imitation Game: State of Policy Distillation in Language Model training, 032-Chinmay Karkar, 2026.05
のブログにまとめられているので参照のこと。
Should we use genetics instead of system prompts for AI Agents & Personas?, Fyx, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #PostTraining #read-later #Personality #One-Line Notes Issue Date: 2026-05-31 Comment
元ポスト:
ゲノム文字列からキャラクターのペルソナを推論し出力に反映可能なLoRAアダプタを学習することによって、ゲノム文字列によってペルソナの条件付けを可能とするモデルに関する実験の報告のようである。
具体的には、まずゲノム文字列と、ペルソナに関するテキストを対応付ける。次に、ペルソナテキストを与えてモデルの応答を収集し、ゲノム文字列と(ペルソナのテキストなしで)収集したモデルの応答を用いてLoRAアダプタを学習する。これにより、LoRAアダプタはゲノム文字列から、ペルソナテキストによって応答づけられた応答を出力することを学習する、といった挙動を実現する。
ざっとみた感じLoRAアダプタとは書かれているが、学習手法が書かれていないような気がする。が、手法はおそらくSFTだと思われる。
これにより、prefillをするinput tokenが削減可能と思われるが、実用上はどちらかというと出力/reasoningトークンが圧縮される方がlatency/コストの双方から恩恵があるので、事後学習をして他の能力が劣化、あるいはAlignmentが悪化するリスクを背負ってまでやる価値があるかは怪しいな、という感想を持ったが、果たしてどうだろうか。
非常に大規模なユーザからの同時接続があり、キャラクターと対話できるようなサービスにおいて、キャラクターのペルソナテキスト(用途はペルソナだけには限らない汎用的な技術だと思うが)が97%圧縮できたら結構なインパクトがあるかもしれない。
Teaching Claude why, Anthropic, 2026.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Alignment #Reasoning #Safety #PostTraining #KeyPoint Notes #Author Thread-Post Issue Date: 2026-05-12 Comment
元ポスト:
- [Paper Note] Agentic Misalignment: How LLMs Could Be Insider Threats, Aengus Lynch+, arXiv'25, 2025.10
のように自身を守るために脅迫メールを送るような挙動が観測されたが、それをなくすことができたという話のようである。
細かい学習データのサンプルなどは記載されていないように見えるが
- 評価時のシナリオと類似したもので正しい挙動を教え込むような方法は、評価のスコアは改善するが、OODに対応できない
- モデルに行動を教えるのではなく、理由を教えることが重要で、これはモデル自身が倫理観に関するジレンマに置かれた状況を解決するというデータではなく、ユーザが倫理的なジレンマを抱えているというシナリオで、モデルが倫理的に塾講された思慮深いアドバイスをするようなデータ(difficult advice dataset)で学習することが非常に効果的であった。
- これは単に正しい答えを教えるのではなく、倫理的な"思考"を教えるため効果的であり、これをさらに発展させ、Claudeの人物像をより詳細に与えることでペルソナをより模範的なものに更新する、具体的には質の高いConstitutionに関する文書と、模範的なAIに関するフィクションの物語を学習させることで、misalignmentを非常に効果的に抑制できることを発見した
という感じだろうか。
トップダウンに正解を教えるのではなく、ボトムアップに根源的に正しい思考過程を誘発するような情報を教える(ある種のPRMのようなものだと思われる)ことで、高い汎化性能を獲得できるということだと思われる。このアプローチは最近のAI Agentにおけるoutcome basedなreward設計などにも一石を投じるような議論に感じる。学習の結果得られる汎化性能を重視していかないと、データセットやEnvironmentを逐一構築して課題を潰していく必要があり、キリがないと思う。
【LLM】On-Policy Distillation入門:小規模モデルを「実戦」で育てる技術, Currently Learning そんけいご, Zenn, 2026.02
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Distillation #PostTraining #Selected Papers/Blogs #On-Policy Issue Date: 2026-05-08 Comment
直感的な説明だけでなく、数式ベースの説明、RLとの比較などがコンパクトにまとまっておりとてもわかりやすかった...!!勉強になりました
Introducing GPT‑5.5, OpenAI, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ChatGPT #Proprietary #Selected Papers/Blogs #VisionLanguageModel #One-Line Notes #Reference Collection #Author Thread-Post Issue Date: 2026-04-24 Comment
元ポスト:
- FrontierMath, Terminal-Bench, GDPValでOpus 4.7を上回りダントツのトップ
- Artificial Analysis IndexでもOpus 4.7超え
しかし、Terminal-Benchは"ターミナル操作を通じた多様、かつlong horizonなタスクを評価する(多くはソフトウェアエンジニアタスクであるコーディングもタスクには含まれるが)"のベンチマークであり、SWE Bench Proのような一般的なcoding能力を測るベンチマークのスコアが掲載されていない。HLEやVisual Reasoning系のベンチマークのスコアも報告されていないように見える。
恣意的にGPT-5.5が強いデータ、比較対象をピックアップしているのではないか、という印象を持った。
- [Paper Note] Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces, Mike A. Merrill+, arXiv'26, 2026.01
- [Paper Note] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
- Why SWE-bench Verified no longer measures frontier coding capabilities, OpenAI, 2026.02
Artificial Analysisによる評価:
所見:
サイバー分野でMythosと同等?
Designing synthetic datasets for the real world: Mechanism design and reasoning from first principles, Google, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #SyntheticData #Distillation #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection #Critic #Human-in-the-Loop #Author Thread-Post Issue Date: 2026-04-19 Comment
元ポスト:
公式:
解説:
(詳細は解説や元ブログ参照のこと)
強い教師モデルから弱い生徒モデルを学習する場合の合成データ生成手法で、
生成したいデータの観点(内容、形式等)を分類し、どの観点からどの程度の難易度のデータを合成するかを制御する。その後生成されたデータが正しいか/正しくないかの2方向から批評を行いvalidationをするような枠組みのようである。
単純なデータ合成では性能がすぐに頭打ちになるが、ローカル多様性(特定のパターンの多様性)、グローバル多様性(データ全体がカバーするパターンの範囲)の2つを同時に大きくしないと不十分であることや、批判によるvalidationは少なくとも性能を悪化させることはないことも示されたとのこと。
Evaluating agents for scientific discovery, Ai2, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Evaluation #Blog #ScientificDiscovery #Science #Surface-level Notes #Author Thread-Post Issue Date: 2026-04-14 Comment
元ポスト:
scientific discoveryを実現するエージェントに関して、research paperで主張される素晴らしさと、実態のgapを埋めるためにAi2が実施してきたベンチマークに関する研究についての解説。
- [Paper Note] ScienceWorld: Is your Agent Smarter than a 5th Grader?, Ruoyao Wang+, EMNLP'22, 2022.03
- 小学校レベルの理科の実験をエージェントが実行できるかを評価するベンチマーク
- 教科書に載っているような古典的なdiscoveryを再現させる
- 200種類以上にものぼるオブジェクトが配置された、物理法則に従う(e.g., 氷が加熱すると溶けるなど)シミュレーション世界において、水の沸点を選択肢から正解を選ぶのではなく、自身で発見することを求められる。
- 2022年、Multiple Choice Questionのschool science examでハイスコアを記録したモデルはスコアは10%未満、2025年にはスコアは80%代に到達したが、まだ完全にこなふことができない。
- [Paper Note] DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents, Peter Jansen+, NeurIPS'24 Spotlight, 2024.06
- 独自の科学的な調査をスクラッチから設計実行させるベンチマーク
- 大学、あるいはPhDレベルのopen-endなdiscoveryに関する能力を問う
- 宇宙の惑星Xでの最初の科学者として調査を実施する設定で8トピックにわたる120のタスクをこなす必要がある
- 難易度は3段階に分かれていて、タスクは架空のcontextで実施されるため事前知識に頼ることができない中でタスクを解決し、正しいプロセスで実施されたかや、理解をしているかなどの能力も問われる。
- 現在のエージェントは、normal/challengingな難易度のタスク群について、80%の完了率を達成できない
- 双方のベンチマークともに、知識と実務力を分離した上で能力を測定するものとなっており、知識を答えるだけの見かけ上の能力ではなく、スクラッチから知識に基づいてエビデンスを積み上げ、実行し、タスクを遂行し科学的な発見をできるか、という実務力を問うている
という話。
この話は
- Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
において議論されている「認知コア」と関連が深いと感じる。
認知コアとは、単なる記憶に頼るのではなく、事前学習において、いわゆる人間のような知性を(データ内に潜むアルゴリズム的なパターンを学習することで)獲得し、その結果としてIn context Learningのような能力を発達させることとされ、
既に獲得された知識がモデルの認知コアの発達を阻害し、未知の環境でも適応できるような汎化能力を獲得することを阻害している(=モデルは既存の知識と紐づけて簡単に回答できてしまうため、アルゴリズムに基づいた思考と行動を備える必要がなく学習が進み、結果的に汎用的な能力が身につかない)恐れがある、という話である。
上記ベンチマーク(特にDiscoveryWorld)は既存の世界知識に捉われない、アルゴリズム的な思考と行動が求められると推察されるため、モデルの認知コア的な側面を部分的に測定していると言えると感じる。
The advisor strategy: Give agents an intelligence boost Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost., Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #AIAgents #Blog #One-Line Notes Issue Date: 2026-04-11 Comment
元ポスト:
Strong Modelをツールとして登録(Advisor)しておき、意思決定が困難になった場合はstrong modelにレビュー依頼をしてcontextを受け取り実行可能な枠組み。
Sonnetで12パーセント程度省コストで、SWE Bench Multilingual のスコアを2.7%向上、とのこと。
SWE Benchの結果は、Claute Opus 4.6をAdvisorとして利用した旨が脚注に書かれている。
下記システムカードによると、Opus 4.6 の SWE Bench Multilingualのスコアは77.83程度(細かい設定は追えていない)、元ポストのSonnet+Advisorのスコアは74.8%なので、near Opusな性能が出るとポストに記載されているが、そのくらいのgapがあるという点には注意が必要。
https://www-cdn.anthropic.com/6a5fa276ac68b9aeb0c8b6af5fa36326e0e166dd.pdf
Project Glasswing Securing critical software for the AI era, Anthropic, 2026.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Safety #Selected Papers/Blogs #One-Line Notes #Reference Collection #Safeguard Issue Date: 2026-04-08 Comment
元ポスト:
Claude Mythos Previewが、ソフトウェアの脆弱性を見つける能力において、トップクラスの人間を除けば、あらゆる人間以上の能力を獲得してしまっており、これがサイバーセキュリティの概念を根本的に変化させてしまう危険がある。
実際、同モデルは数千にも及ぶ深刻な脆弱性を発見しており、それはOSやブラウザにも及び、これが経済や国家安全保障などに影響を及ぼすため、緊急のproject Glasswingを立ち上げており、まずは今回挙げたパートナーにClaude Mythos Previewにアクセス可能な無料のクレジットを与え、セキュリティに関する脆弱性を改善することで、セーフガードを確立し、その結果得られた知見をAnthropicがまとめて公表する、そしてその後パートナーはさらに拡大していく、という感じらしい。
しかし最近中国のOpenWeightモデルは、2ヶ月程度で米国のFrontier Modelに追いつく。では2ヶ月あとに中国系のOpenWeightモデルがClaude Mythos Previewの性能に追いついてOpenWeightとして公開された場合、世界はどうなってしまうのだろうか?
また、現在は以下の企業と連携してセーフガードを構築するようだが、これらグローバル企業以外の日本の企業はどうなるのだろうか?今後40以上の組織とも連携するようにする予定とのことだが、日本の社会を支えている企業群と連携するのはいつなのか?
所見:
所見:
しかしこれ、Claude Mythos Previewによって初めてこのようなことが起きたかのように書かれているけど、既知の脆弱性を見つけて悪用するというのは、既に公開されているOpenWeightモデルや、プロプライエタリモデルでも十分可能なのでは?
なぜいまさらこのようなことを言い始めたのだろうか。
所見:
GPT-5.4でも15年前のLinux Kernelの深刻なバグを見つけたよ、という話:
Update:
https://www.anthropic.com/research/glasswing-initial-update
元ポスト:
最大規模のオープン基盤モデルを各国仕様へ適応させる事後学習技術を開発, sakana.ai, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Alignment #Blog #Bias #Japanese #PostTraining Issue Date: 2026-03-24 Comment
技術的な詳細は不明で、
> 事後学習では、日本の文化的・社会的文脈におけるバイアス是正のための独自データセットを構築し、以下のベンチマークに示す結果を得ました。
と記述されている。おそらく構築したデータセットに基づいてAlignmentをとるための事後学習(ベースモデルの能力を落としていないため Catastrophic Forgettingは起きておらず、同社がLoRA系の技術に力を入れていることを鑑みるとおそらく何らかのPEFT手法ではないかと推察)を実施しているのだと思われる。
元ポスト:
L11: Synthetic Data Powering Pretraining, Eric W. Tramel, Ph.D., UC Berkeley EE 290_194-11: Scalable AI, 2026.02
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #SyntheticData #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2026-03-17 Comment
元ポスト:
- インターネットのデータ枯渇問題が指摘されながらも、合成データによって事前学習は進化を続けている
- LLMは事後学習で性能を向上させられるが、事前学習時点で伸ばせる上限が決まっているとされている
- 事前学習データの投入量はChinchilla則のパラメータ量の20倍から現在は60倍まで増加
- MoEは過学習しやすくパラメータ数の40倍は必要
- 学習データの多様性が重要で繰り返し同じデータを見ても性能は改善しない
- 合成データをそのまま用いるとmode collapseが生じ出力が単調化するため、実データを混ぜるか言い換えをしたデータで是正する(弱めのdata augmentationで良い)
- 最近重要な合成データはコードと推論過程を含むデータで、これらが事前学習データに含まれていると汎用な表現、思考能力、推論能力を事前学習時点から獲得できる可能性がある
というような話が元ポストに書かれている。
- [Paper Note] Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
のようにrepetitionは4回までが効果的といった知見が報告されているが、現在はどこまで当てはまるのだろうか?
後ほど関連するissueのリンクを貼りたい
うーんおもしろそう、p.15, p.20, p.26, p.28, p.35, p.36 あたりが気になる。
てかこれが大学の講義...?楽しすぎでは。
The importance of Agent Harness in 2026, PHILSCHMID, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Selected Papers/Blogs #LongHorizon #AgentHarness Issue Date: 2026-03-08 Comment
本ブログで定義されているAgent Harnessは、これまでのAI Agent研究で利用されてきた Scaffold(=実行基盤)とEvaluation Harness(=評価基盤)のように、実行と評価を区別してきたLiteratureとは異なる、より包括的な概念に見える(言葉としてHarnessが用いられているので、最初に読んだときは困惑した)。
先行研究:
- [Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
- [Paper Note] Lessons from the Trenches on Reproducible Evaluation of Language Models, Stella Biderman+, arXiv'24, 2024.05
- [Paper Note] Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent
Evaluation, Sayash Kapoor+, arXiv'25, 2025.10
これまでのLiteratureでは、エージェントがタスクを遂行するためのエコシステム全般(言い換えるとLLMをエージェントの脳とした時の、エージェントの実装そのもの)のことをScaffold(ツール利用やコンテキスト管理、サブエージェントの実行、エラー時の挙動、プロンプト構成など)と呼び、
評価をする際の評価基盤となるインフラ(エージェントを動作させる仮想マシン等の実行環境やそのオーケストレーション、Scaffoldの構成、評価ベンチマーク、コストやtrajectoryのロギング等の評価全体に関わるエコシステム)のことをEvaluation Harnessと呼んできたと認識している。
(私の認識違いの可能性もあるが)このLiteratureを理解しておかないと、今後Harnessという言葉がバズワードと化して、思わぬ誤解を生むかもしれないので注意した方が良いかなと感じた。
つまり世の中には
- Scaffold
- Evaluation Harness
- Agent Harness
の3種類の定義があり、特に後者二つは省略してHarnessと呼ばれそう、という気がするが、後者二つは呼称が似ているが異なる概念を指しているので注意した方が良いかも(あくまで個人の感想)。
たとえば下記OpenAIのブログでも「Harness Engineering」という言葉がタイトルで用いられており、Harnessの定義がなされずに記述されているように見える。実際ブログ後半にはEvaluation HarnessというこれまでのLiteratureと同じ意味合いでの用語も登場している。今後どのような用語が何を指すのようになるかは分からないが、ハーネスという言葉の定義が人によって異なる可能性があるという点は認識しておいた方が良さそうである。
- Harness engineering: leveraging Codex in an agent-first world, Ryan Lopopolo, 2026.02
`Agent Harness` という用語の起源が気になっており、アンテナを張っているが、下記AnthropicブログでAgent Harnessという用語が登場している。
- Effective harnesses for long-running agents, Anthropic, 2025.11
下記文献でも
- [Paper Note] Building Effective AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned, Nghi D. Q. Bui, arXiv'26, 2026.03
Effective harnesses for long-running agents, Anthropic, 2025.11
が引用され `harness` という用語が用いられている。このブログが起源なのだろうか(勉強不足)。
- [Paper Note] SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, Xiangyi Li+, arXiv'26, 2026.02
でも Agent Harness という用語が使われている。
Introducing GPT‑5.4, OpenAI, 2026.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #ChatGPT #Coding #Proprietary #VisionLanguageModel #Reference Collection Issue Date: 2026-03-06 Comment
元ポスト:
Artiflcial Analysisによる評価:
所見:
所見:
評判が良い。管理人も利用しているが、指示で曖昧な点をきちんと質問してくれる点が便利。かつ応答として、選択可能なオプションを提示し、自由記述もできる。実装の内容はClaude 4.6 Opusと比べるとコードがシンプルな印象を受けるが、これも指示次第な気はする。
曖昧な点があったら質問を投げかけるという挙動はopenhandsのPosition Paperとも整合する流れである。
- [Paper Note] Position: Humans are Missing from AI Coding Agent Research, Wang+, 2026.02
Coding agents progress over the past two months, Andrej Karpathy, X, 2026.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #Post #SoftwareEngineering Issue Date: 2026-02-28 Comment
やっぱ英語で指示ださないとあかんか...(小並感)
関連:
LLM/VLA等の学習ライブラリ回りでは、人間が細かく実装方針分析を指示した上で、実装部分のみを移譲すると今のところ一番うまくいくとのこと。
# Writing a good CLAUDE.md, Kyle, 2025.11
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #Selected Papers/Blogs #KeyPoint Notes #Surface-level Notes #AGENTS.md Issue Date: 2026-02-27 Comment
元ポスト:
本ブログは CLAUDE.md について記述されているものだが、ブログ冒頭で記述されており、AGENTS.mdに一般的に適用できる話だと考えられるため、以下本文中でCLAUDE.mdとして記述されている部分も、AGENTS.mdと読み替えて記述している。
要するに
- `AGENTS.md` はAI Agentの **全ての会話に対してコンテキストをユーザが明示的に挿入する唯一の手段** であり、
- `AGENTS.md` にはプロジェクトのあらゆるタスクで **普遍的に必要な情報を、過不足なく、簡潔に記述されるべき** であり
- プロジェクトが大規模な場合は、`AGENTS.md` は目次として利用し、必要な情報は個別のファイルに別々に記述し、`AGENTS.md` 内にはその **ポインターのみを記載** する
- `AGENTS.md` の **自動生成は非推奨** であり、理由としては1行でも誤った記述が含まれていた場合全てのエージェントの挙動に影響が出るためであり、全ての内容について慎重に検討をしたうえで記述されるべきである。
という話のようである。
-----
- 原則
- AI Agentはstatelessであり、あなたのコードベースについて何も知らない。このため利用者がコンテキストとしてコードベースの情報を伝える必要があり、そのために有用なツールがAGENTS.mdである
- AGENTS.mdはすべての会話にデフォルトでコンテキストとして含まれる **唯一の** ファイルである
- AGENTS.mdでどのような情報が網羅されるべきか?
- **WHAT**: 技術スタック、プロジェクト構造、コードベースの構成等のリポジトリの基本情報を記述し、Agentが適切に情報を検索できるようにする
- **WHY**: プロジェクトの役割と、リポジトリ内の要素の役割
- **HOW**: Agentがどのような作業をすべきに関する明確な指示を記述し、その指示を実施するために必要な情報を全て含める
- AGENT.md はしばしば無視される
- たとえばClaude CodeではCLAUDE.md (Claudeが利用するAGENTS.md) をコンテキストに含める際に以下のシステムリマインダーを自動的に挿入する:
- つまり、AGENTS.mdに普遍的に利用可能な情報が含まれていない場合は、現在実施しようとしているタスクと関係ないとエージェントが判断し、AGENTS.mdが無視されることがある点に注意が必要
```
IMPORTANT: this context may or may not be relevant to your tasks.
You should not respond to this context unless it is highly relevant to your task.
```
- 優れたAGENTS.mdを作成するベストプラクティス
- **less (instructions) is more**:
- AI Agentが順守できる指示の数には限界があり、指示の数が増えれば増えるほど、指示を遵守できない割合が高まっていく。
- これはモデル依存であり、パラメータ数が大きいモデルほど多くの指示を遵守できる(150--200など)。
- AGENTS.mdがすべての会話に付与されることを考えると、たとえば50個の指示をAGENTS.mdに含めた場合、150個の指示を遵守できるAgentを利用していたら、AGENTS.mdだけで1/3だけを消費することになる。
- また、指示が増えれば増えるほど、均一に指示追従の能力が低下する。
- つまり、ある指示が冒頭・末尾に書かれていようとも、位置に関係なく何らかの指示に追従しない可能性が高まる。
- これらの性質から、可能な限り少ない指示を記述することが必要で、特に冗長性を排除し、あらゆるタスクに普遍的に適用可能な指示のみを記述することが肝要であることが示唆される。
- length & applicability:
- AGENTS.mdは、300行未満などが推奨されているが、要は **適切な普遍的に適用可能な情報が** 簡潔で短く記述されていることが好ましい[^1]。
- Progressive Disclosure
- プロジェクトが大規模化した場合、必要な全ての情報を簡潔にAGENTS.mdに含めることがそもそも困難になる
- この場合はAGENTS.mdに目次を記述し、機能ごとの必要な情報は個別のファイルに記述し、それがどこに格納されているかのポインタを記述することによって解決する
- AGENTS.mdに全ての情報を書いてしまってはいけない。この場合上記の less is more や length の原則に反することになる。
- AGENT (CLAUDE) is not an expensive linter
- コーディング規約を書いている人が多いがやめた方が良いという話で、
- コーディング規約を無視しているか否かを判断させるにはもっと決定論的で安価なツールがあるのでそちらに任せましょうという話と、
- コーディング規約を明示していなくてもAgentはコードスニペットを解釈する過程で暗黙的にどのようなコーディング規約に従っているかは理解できるので、わざわざ明示的に挿入して不要で無関係なコンテキストで埋め尽くす必要はないよね、という話が書かれている。
- `/init` コマンドや、`AGENTS.md (CLAUDE.md)` の**自動生成は非推奨**
- AGENTS.md はAgentの全ての挙動に影響を与えるため、1行でも誤りがあると全ての作業に影響が出る非常にクリティカルなファイルであるため、自動生成等に頼らずに、慎重に検討をした上で記述されるべきである、という話
- 実際、下記研究にてLLMが自動生成したAGENTS.mdでは、タスク性能は劣化しトークン消費量が増えるだけ、という結果が示されている
- [Paper Note] Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?, Thibaud Gloaguen+, arXiv'26, 2026.02
[^1]: 根拠として、ブログ中では、無関係な情報がコンテキストで埋め尽くされているよりも、関連性のある情報が埋め尽くされる場合が一般的に性能が向上すると書かれている。が、文献などは引用されていないように見える。たとえば、この記述に対して、「初期のRAGの研究でrelevantな情報に対してirrelevantな情報が周囲で埋め尽くされていた場合に実は性能が向上します、といった話があったじゃないか」といった鉞を飛ばすことができそうだが、これは古い研究でおそらく当時(数年前)のLLMではcontext中のrelevantな情報を見分ける能力が低かったことに起因する。つまり、このような現象は明らかにirrelevantな情報が混在することで、相対的にrelevantな情報が際立つことによってLLMのcontextの理解力が乏しい部分を補っていた、と管理人は推察しており、現代のLLMではcontextを解釈する性能は大幅に向上していると考えられるため、わざわざirrelevantな情報をcontextに含める必要はなく、この見解には私も同意する。そもそもこの私の見解があまりにも重箱の隅すぎて蛇足すぎるがなんかそういうことを思い出しちゃったので書いた :)
ここで記載されている内容はAGENTS.mdのみならず、そもそものプロンプトエンジニアリング全般で言える話でもある。
SSII2025 [OS1-03] PFNにおけるSmall Language Modelの開発, 鈴木 脩司, 画像センシングシンポジウム, 2025.05
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #SmallModel #Slide Issue Date: 2025-05-28 Comment
元ポスト:
関連
- [Paper Note] Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22, 2022.03
- [Paper Note] Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20, 2020.01
- [Paper Note] Distillation Scaling Laws, Dan Busbridge+, ICML'25
- [Paper Note] Textbooks Are All You Need, Suriya Gunasekar+, arXiv'23, 2023.06
先行研究を元に仮説を立てて、有望なアプローチを取る意思決定が非常に勉強になる。
Scaling Lawsが不確実性のある意思決定において非常に有用な知見となっている。
同じようにPruningとKnowledge Distilationを実施した事例として下記が挙げられる
- Llama-3_1-Nemotron-Ultra-253B-v1, Nvidia, 2025.04
Masked Diffusion Modelの進展, Deep Learning JP, 2025.03
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #NLP #LanguageModel #DiffusionModel #Slide Issue Date: 2025-05-24 Comment
元ポスト:
スライド中のARのようにKV Cacheが使えない問題に対処した研究が
- [Paper Note] dKV-Cache: The Cache for Diffusion Language Models, Xinyin Ma+, arXiv'25, 2025.05
この辺はdLLMが有望であれば、どんどん進化していくのだろう。
ACL 2024 参加報告, 張+, 株式会社サイバーエージェント AI Lab, 2024.08
Paper/Blog Link My Issue
#Article #Tutorial #Slide #ACL #One-Line Notes Issue Date: 2025-05-11 Comment
業界のトレンドを把握するのに非常に参考になる:
- Reasoning, KnowledgeGraph, KnowledgeEditing, Distillation
- PEFT, Bias, Fairness, Ethics
- Multimodal(QA, Benchmarking, Summarization)
などなど。
投稿数5000件は多いなあ…
Cursor_Devin全社導入の理想と現実, Ryoichi Saito, 2025.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Coding #Slide #SoftwareEngineering Issue Date: 2025-04-26 Comment
Devinの思わぬ挙動のくだりが非常に面白かった。まだまだ使いづらいところが多そうだなあ…。
あえて予測の更新頻度を落とす| サプライチェーンの現場目線にたった機械学習の導入, モノタロウ Tech Blog, 2022.03
Paper/Blog Link My Issue
#Article #MachineLearning #Blog Issue Date: 2025-04-18 Comment
とても面白かった。需要予測の予測性能を追求すると現場にフィットしない話が示唆に富んでいて、とてもリアルで興味深い。
Hunyuan T1, Tencent, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Proprietary #SSM (StateSpaceModel) #One-Line Notes Issue Date: 2025-03-22 Comment
元ポスト:
画像はブログより引用。DeepSeek-R1と比較すると優っているタスクと劣っているタスクがあり、なんとも言えない感。GPT4.5より大幅に上回っているタスク(Math, Reasoning)があるが、そもそもそういったタスクはo1などのreasoningモデルの領域。o1と比較するとこれもまあ優っている部分もあれば劣っている部分もあるという感じ。唯一、ToolUseに関しては一貫してOpenAIモデルの方が強い。
ChineseタスクについてはDeepSeek-R1と完全にスコアが一致しているが、評価データのサンプル数が少ないのだろうか?
reasoningモデルかつ、TransformerとMambaのハイブリッドで、MoEを採用しているとのこと。
TransformerとMambaのハイブリッドについて(WenhuChen氏のポスト):
Layer-wise MixingとSequence-wise Mixingの2種類が存在するとのこと。前者はTransformerのSelf-Attenton LayerをMamba Layerに置換したもので、後者はSequenceのLong partをMambaでまずエンコードし、Short PartをTransformerでデコードする際のCross-Attentionのencoder stateとして与える方法とのこと。
Self-Attention Layerを削減することでInference時の計算量とメモリを大幅に削減できる(Self-Attentionは全体のKV Cacheに対してAttentionを計算するため)。
browser-useの基礎理解, むさし, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #ComputerUse Issue Date: 2025-03-15 Comment
公式リポジトリ: https://github.com/browser-use/browser-use
BrowserUseはDoMを解析するということは内部的にテキストをLLMで処理してアクションを生成するのだろうか。OpenAIのComputer useがスクリーンショットからアクションを生成するのとは対照的だと感じた(小並感)。
- OpenAI API での Computer use の使い方, npaka, 2025.03
OpenAI API での Computer use の使い方, npaka, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #ComputerUse Issue Date: 2025-03-12 Comment
OpenAIのCompute Useがどのようなものかコンパクトにまとまっている。勉強になりました。
公式: https://platform.openai.com/docs/guides/tools-computer-use
QwQ-32B: Embracing the Power of Reinforcement Learning, Qwen Team, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Reasoning #OpenWeight Issue Date: 2025-03-06 Comment
元ポスト:
- [Paper Note] START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv'25, 2025.03
Artificial Analysisによるベンチマークスコア:
おそらく特定のタスクでDeepSeekR1とcomparable, 他タスクでは及ばない、という感じになりそうな予感
Unsloth で独自の R1 Reasoningモデルを学習, npaka, 2025.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #Reasoning Issue Date: 2025-02-07 Comment
非常に実用的で参考になる。特にどの程度のVRAMでどの程度の規模感のモデルを使うことが推奨されるのかが明言されていて参考になる。
DeepSeek-R1の論文読んだ?【勉強になるよ】 , asap, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #FoundationModel #RLHF #Blog #Selected Papers/Blogs Issue Date: 2025-02-01 Comment
- DeepSeek-R1, DeepSeek, 2025.01
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open
Language Models, Zhihong Shao+, arXiv'24
とても丁寧でわかりやすかった。後で読んだ内容を書いて復習する。ありがとうございます。
LLMがオワコン化した2024年, らんぶる, 2025.01
Paper/Blog Link My Issue
#Article #LanguageModel #Blog Issue Date: 2025-01-05 Comment
LLMを(呼び出す|呼び出される)SaaS企業が今後どのような戦略で動いていくかが考察されており興味深かった。
browser-use やばいです, Syoitu, 2024.12
Paper/Blog Link My Issue
#Article #NLP #AIAgents #python #Blog #API #ComputerUse Issue Date: 2025-01-04 Comment
すごい手軽に使えそうだが、クローリング用途に使おうとするとhallucinationが起きた時に困るのでうーんと言ったところ。
LLMを数学タスクにアラインする手法の系譜 - GPT-3からQwen2.5まで, bilzard, 2024.12
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Chain-of-Thought #Reasoning #Mathematics #PostTraining Issue Date: 2024-12-27 Comment
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
において、数学においてモデルのパラメータ数のスケーリングによって性能改善が見込める学習手法として、モデルとは別にVerifierを学習し、モデルが出力した候補の中から良いものを選択できるようにする、という話の気持ちが最初よくわからなかったのだが、後半のなぜsample&selectがうまくいくのか?節を読んでなんとなく気持ちが理解できた。SFTを進めるとモデルが出力する解放の多様性が減っていくというのは、興味深かった。
しかし、特定の学習データで学習した時に、全く異なるUnseenなデータに対しても解法は減っていくのだろうか?という点が気になった。あとは、学習データの多様性をめちゃめちゃ増やしたらどうなるのか?というのも気になる。特定のデータセットを完全に攻略できるような解法を出力しやすくなると、他のデータセットの性能が悪くなる可能性がある気がしており、そうするとそもそもの1shotの性能自体も改善していかなくなりそうだが、その辺はどういう設定で実験されているのだろうか。
たとえば、
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
などでは、
- [Paper Note] Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks, Yizhong Wang+, EMNLP'22, 2022.04
のような1600を超えるようなNLPタスクのデータでLoRAによりSFTすると、LoRAのパラメータ数を非常に大きくするとUnseenタスクに対する性能がfull-parameter tuningするよりも向上することが示されている。この例は数学に特化した例ではないが、SFTによって解法の多様性が減ることによって学習データに過剰適合して汎化性能が低下する、というのであれば、この論文のことを鑑みると「学習データにoverfittingした結果他のデータセットで性能が低下してしまう程度の多様性の学習データしか使えていないのでは」と感じてしまうのだが、その辺はどうなんだろうか。元論文を読んで確認したい。
とても勉強になった。
記事中で紹介されている
> LLMを使って複数解法の候補をサンプリングし、その中から最適な1つを選択する
のルーツは
- [Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
とのことなので是非読みたい。
この辺はSelf-Consistency
- [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
あたりが最初なのかと思っていた。
LLM-as-a-Judge をサーベイする, Ayako, 2024.12
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #Evaluation #Blog #LLM-as-a-Judge #KeyPoint Notes Issue Date: 2024-12-25 Comment
- A Survey on LLM-as-a-Judge, Jiawei Gu+, arXiv'24
を読んだ結果を日本語でまとめてくださっている。
モデル選択について、外部APIに依存するとコストやプライバシー、再現性などの問題があるためOpenLLMをFinetuningすることで対応していることが論文中に記載されているようだが、評価能力にはまだ限界があるとのこと。
記事中ではLlama, Vicunaなどを利用している旨が記述されているが、どの程度のパラメータサイズのモデルをどんなデータでSFTし、どのようなタスクを評価したのだろうか(あとで元論文を見て確認したい)。
また、後処理としてルールマッチで抽出する必要あがるが、モデルのAlignmentが低いと成功率が下がるとのことである。
個人的には、スコアをテキストとして出力する形式の場合生成したテキストからトークンを抽出する方式ではなく、G-Eval のようにスコアと関連するトークン(e.g. 1,2,3,4,5)とその尤度の加重平均をとるような手法が後処理が楽で良いと感じる。
ICLR2025の査読にLLM-as-a-Judgeが導入されるというのは知らなかったので、非常に興味深い。
LLMが好む回答のバイアス(冗長性、位置など)別に各LLMのメタ評価をしている模様。また、性能を改善するための施策を実施した場合にどの程度メタ評価で性能が向上するかも評価している。特に説明を出力させても効果は薄く、また、複数LLMによる投票にしても位置バイアスの軽減に寄与する程度の改善しかなかったとのこと。また、複数ラウンドでの結果の要約をさせる方法がバイアスの低減に幅広く寄与したとのこと。
うーん、バイアスを低減するうまい方法がまだ無さそうなのがなかなか厳しい感じがする。
そもそも根本的に人間に人手評価をお願いする時もめちゃめちゃマニュアルとかガイドラインを作り込んだりした上でもagreementが高くなかったりするので、やはり難しそうである。
ただ、MTBenchでは人間の評価結果とLLMの評価結果の相関(agreementだっけか…?)が高かったことなどが報告されているし、LLMあるあるのタスクごとに得意不得意があります、という話な気もする。
OpenAI o3は,人間とは全く異質の汎用知能である危険性【東大解説】, 神楽坂やちま, 2024.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #GenerativeAI #Blog #One-Line Notes Issue Date: 2024-12-24 Comment
様々な有識者の見解をまとめつつ、文献を引用しつつ、かつ最終的に「人間が知能というものに対してなんらかのバイアスを持っている」可能性がある、という話をしており興味深い。
一部の有識者はARC-AGIの一部の、人間なら見た瞬間に分かるようなパターン認識の問題でも解けていないことから、AGIではないと主張しているとのことだったが、人間目線で簡単な問題が解けることはAGIとして必須な条件ではないよね、といった話が書かれており、そもそも有識者がどのようなものさしや観点でAGIを見ているのか、どういう視点があるのか、ということが感覚的に分かる内容であり、おもしろかった。
しかし、そもそも何がどうなったらAGIが実現できたと言えるのだろうか?定義がわからない(定義、あるのか…?)
OpenAI o1を再現しよう(Reasoningモデルの作り方), はち, 2024.12
Paper/Blog Link My Issue
#Article #LanguageModel #Blog #Reasoning #SelfCorrection Issue Date: 2024-12-22 Comment
Reflection after Thinkingを促すためのプロンプトが興味深い
Genesis, Genesis-Embodied-AI, 2024.12
Paper/Blog Link My Issue
#Article #GenerativeAI #Repository #Physics #Simulation Issue Date: 2024-12-20 Comment
新たな物理AIエンジン。デモ動画がすごい
https://genesis-embodied-ai.github.io
Netflixの推薦&検索システム最前線 - QCon San Francisco 2024現地レポート, UZABASE, 2024.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #Blog #KeyPoint Notes Issue Date: 2024-12-20 Comment
インフラ構成の部分が面白い。モデルの構築方法などは、まず軽量なモデルやヒューリスティックで候補を絞り、その後計算量が重いモデルでリランキングする典型的な手法。
Netflixのインフラによって、以下のようなことを
>1~2秒前の最新データを参照でき、推薦生成に反映させることが可能です
latencyを40msに抑えつつ実現しているとのこと。直前のアクションをinferenceで考慮できるのは相当性能に影響あると思われる。
また、検索と推薦をマルチタスク学習しパラメータをシェアすることで両者の性能を挙げているのが興味深い。
モデル自体は近年のLLMを用いた推薦では無く、Deepなニューラルネットに基づくモデルを採用
(まあLLMなんかにリアルタイムで推論させたらlatency 40ms未満という制約はだいぶきついと思われるしそもそも性能向上するかもわからん。予測性能とかよりも、推薦理由の生成などの他タスクも同時に実施できるのは強みではあるとは思うが…)。
まあしかし、すごい目新しい情報があったかと言われると基本的な内容に留まっているのでそうでもないという感想ではある。
RLHF_DPO 小話, 和地瞭良_ Akifumi Wachi, 2024.04
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #LanguageModel #Alignment #RLHF #Blog #DPO #PostTraining #Selected Papers/Blogs Issue Date: 2024-12-18 Comment
めちゃめちゃ勉強になる…
最近のOptimizerの研究について, Hiroyuki Tokunaga, 2024.12
Paper/Blog Link My Issue
#Article #MachineLearning #Blog #Optimizer Issue Date: 2024-12-12 Comment
- [Paper Note] ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate, Shohei Taniguchi+, NeurIPS'24
↑以外にもめちゃめちゃたくさんのOptimizerの研究が紹介されており大変勉強になる。
株式会社NexaScienceはじめます。, Yoshitaka Ushiku, 2024.12
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2024-12-12 Comment
全部読んだ。めちゃめちゃ共感できる。
【総集編)】15年間のC向けサービスづくりで 得た学び, Shota Horii, 2024.11
Paper/Blog Link My Issue
#Article #Blog #KeyPoint Notes Issue Date: 2024-11-18 Comment
具体的だがシンプルに知見がまとまっていてとても分かりやすい。
顧客開発モデルに基づいた考え方のみならず、仮設整理のために実際に使われているシートなどの実用的なツール群や、
顧客とのチャネル構築方法、プロダクトのスケールするための知見、チームビルディング、カルチャーの作り方の作法など(他にも透明性とかサンクコストを恐れずシンプルさを保つことのコスト削減効果などここには書ききれない)、
実体験を具体的に交えながら説明されており、盛りだくさんで非常に勉強になる。
Copilot Arena, CMU and UC Berkeley, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Coding Issue Date: 2024-11-13 Comment
元ポスト:
- ChatBot Arena, lmsys org, 2023.05 も参照のこと
Chatbot Arenaがリリースされたのが1年半前であることをおもいおこし、この2年で飛躍的にLLMができることが増えたなぁ、パラメータ数増えたなぁ、でも省パラメータで性能めっちゃ上がったなぁ、proprietary LLMにOpenLLMが追いついてきたなぁ、としみじみ思うなどした。
The Fastest Access to Enterprise-Grade Cloud GPUs, Lambda
Paper/Blog Link My Issue
#Article #Infrastructure #GPU-Platform #KeyPoint Notes Issue Date: 2024-11-09 Comment
元ポスト:
A100を1時間あたり1.29$で使えるぽいので、安価である。8BのLLMをLoRAでちょろっとSFTするくらいなら、数ドルくらいでいけそう。
AWSだと、A100を8基、vCPU96、VRAM320G、RAM1152GiBのインスタンス(p4d24xlarge)が、1時間あたりオンデマンドで32.77$なのに対し、
LambdaではA100 1基あたり1.29$なので、8基で10.32$となる。したがって、コストはだいたいAWSのおよそ1/3くらいに見える(他にも安価なAWSインスタンスあるかもだが)。
ちなみにLambdaでは、vCPU124、RAM1800GiBである。
AWS参考:
https://aws.amazon.com/jp/ec2/instance-types/p4/
こちらのポストも参照のこと:
Lambdaに加え
- [runpod.io]( https://www.runpod.io)
- [vast.ai]( https://vast.ai/)
というサービスも紹介されている。
[Perplexityで3つを比較させた結果(参考; Hallucinationに注意)](
https://www.perplexity.ai/search/runpod-io-vast-ai-lambdatea100-vJgXn4osSfCqxPsxuJEPKA)
>これらのサービスの中では、Vast.aiが最も安価ですが、セキュリティと安定性に注意が必要です。RunPodは多機能で使いやすいものの、やや高価です。Lambdaは安定性が高いですが、柔軟性に欠ける面があります。選択する際は、予算、セキュリティ要件、必要な機能性を考慮して判断することが重要です。
ほぼリアルタイム!?爆速で動作する日本語特化の文字起こしAI!『kotoba-whisper-v2.0』, 遼介 大堀, 2024.11
Paper/Blog Link My Issue
#Article #NLP #SpeechProcessing #Blog #Japanese #AutomaticSpeechRecognition(ASR) #KeyPoint Notes Issue Date: 2024-11-07 Comment
whisper large-v3を蒸留したkotoba-whisper-v1.0に対して、日本語のオーディオデータで追加学習をしたモデル、kotoba-whisper-v2.0を利用するための環境構築方法やコードの例が記述されている。
公式によると、whisper-large-v3よりも6.3倍のスループットとのこと。また、qiita記事中ではwhisper large-v2に対して約6.0倍のスループットであることが言及されている。
学習に用いられたデータは、ReasonSpeechデータ(日本語のテレビの録音データ)
- ReazonSpeech: A Free and Massive Corpus for Japanese ASR, Yin+, NLP'23
をWERに基づくフィルタリングによって良質なデータのみを抽出することで作成されたデータの模様
公式のモデルカードも参照のこと:
https://huggingface.co/kotoba-tech/kotoba-whisper-v2.0
日本のテレビ番組のデータで学習されているので、それを念頭に置いた上で、自分が適用したいデータとの相性を考えると良さそうである。
また、動作速度が速いのはシンプルにありがたい。
生成AIを活用したシステム開発 の現状と展望 - 生成AI時代を見据えたシステム開発に向けて-, 株式会社日本総合研究所 先端技術ラボ, 2024.09
Paper/Blog Link My Issue
#Article #Survey #GenerativeAI #Blog #KeyPoint Notes Issue Date: 2024-10-01 Comment
ソフトウェア開発で利用され始めている生成AIのプロダクト群と、それらに関連するソースコード生成やテストコード生成、エージェントによる自動システム開発等の研究動向、今後の展望について具体的に記述されている。
SIerやITベンダー内では、実際に活用しているところも一部あるようだが、まだ検証や改革の途中の模様。要件定義に対するLLMの活用も模索されているようだが、産業側もアカデミックも研究段階。
web系では、サイバーやLINEヤフーが全社的にすでにGithub Copilotを導入しているとのこと。
Devin AIのように、Github上のオープンソースのIssueをもとにしたベンチマークで、2294件中13.86%のIssueを解決した、みたいな話を見ると、そのうちコードを書く仕事はIssueを立てる仕事に置き換わるんだろうなあ、という所感を得た(小並感
Claude Opus 4.6あたりが一つの節目で、明らかに2026年頭にかけてCoding Agentの質が上がって完全なる実用レベルに到達したという感がある。
非プロダクトマネージャーのためのプロダクトマネジメント入門, 神原淳史, 2024.09
Paper/Blog Link My Issue
#Article #Blog #Management #KeyPoint Notes Issue Date: 2024-09-30 Comment
プロダクトマネジメントについて初心者向けに書かれた記事。勉強になった。
JTBDフレームワークは顧客開発モデルなどでも出てくるので、もう一度復習しておきたい。
>When (Situation) I want to (Motivation) So I can (Expected outcome)
ビルドトラップについても勉強になった。ミニマムでユーザの課題(ニーズ)を解決(満たす)する価値を提供することが重要。この辺は、技術にこだわりや興味、自信がある人ほど作り込みすぎてしまう印象がある。
https://product-managers-club.jp/blog/post/build-traps-fall
レベル2生産性の簡易的な計算方法のフレームワーク。知っておくと役に立つ場面がありそう。考え方として知っておくだけでも良い。confidenceの定義が難しそう。
>・Reach: どれだけ多くの顧客/ユーザーにとっての問題か
・Impact: その問題は個々の顧客/ユーザーにとってどれだけ深刻か
・Conficence: ReachとImpactがどれだけ確からしいか (Effortの確からしさも含むことがある)
・Effort: 問題解決の実装に必要な工数
計算式は以下の通りです。
RICEスコア = Reach * Impact * Confidence / Effort
と思ったが、一応参考として以下のようなものが紹介されている。この辺はプロダクトやチームごとにより具体的なものを決めていくと良いのだろうと思う。特に発案者やその同僚が信じている、の部分は深掘りできそうな気がする。その人にしか見えておらず、定量化できない感覚のような部分があったとしたら、この基準では低いスコアを付与してしまう。ユーザに近しい人ほどそういう感覚を持っており、軽視すべきでないと個人的には考える(が、発言者によって熱量のオフセットが異なるのでその辺も考慮しないといけないから判断難しそう)。
>・発案者やその同僚が信じている (0.01 - 0.2)
・複数の顧客からリクエストがあった (0.5 - 1)
・市場リサーチ結果 (1 - 2)
・一定量以上のユーザーインタビュー結果 (3)
・実際のプロダクト上での検証結果 (5 - 10)
記事のまとめ
>・ソリューションよりも問題の明確化にフォーカスしよう。そのための手法の1つにJTBDフレームワークがある。
・問題解決の優先度を評価するための観点を知ろう。その観点リストの1つにRICEフレームワークがある。
・PBIの相対的な優先順位づけも大事だが、その前に必ずプロダクト戦略へのアラインを確認しよう。
クリックを最大化しない推薦システム, Ryoma Sato, 2024.01
Paper/Blog Link My Issue
#Article #RecommenderSystems #Slide #KeyPoint Notes Issue Date: 2024-09-15 Comment
おもしろそうなので後で読む
クリック率やコンバージョン率に最適化することが従来のやり方だが、クリックベイトのため粗悪なコンテンツを推薦してしまったり、人気のあるアイテムに推薦リストが偏ってしまい、長期的なユーザの利益を害するという話。
20年くらい前からこの辺をなんとかするために、推薦のセレンディピティや多様性を考慮する手法が研究されており、それらのエッセンスが紹介されている。また、Calibrated Recommendation [Paper Note] Calibrated Recommendation, Herald Steck, Netflix, RecSys'18
(ユーザの推薦リストがのジャンルの比率がユーザの好む比率になるように最適化する方法で、劣モジュラ関数を最適化するためgreedyに解いてもある程度良い近似解が保証されている)などの概要も説明されていて非常に勉強になった。
セレンディピティのある推薦アルゴリズムをGoogle上でA/Bテストしたら、ユーザの満足度とコアユーザー転換率が大幅に向上したと言う話や、推薦はフィルターバブル問題を実は悪化させないといった研究がGroupLensのKonstan先生のチームから出ているなど、興味深い話題が盛りだくさんだった。
NewsPicksに推薦システムを本番投入する上で一番優先すべきだったこと, 2024.08
Paper/Blog Link My Issue
#Article #RecommenderSystems #NeuralNetwork #CTRPrediction #NewsRecommendation #ML-LLM Ops #Evaluation #Blog #A/B Testing #One-Line Notes Issue Date: 2024-08-31 Comment
>推薦モデルの良し悪しをより高い確度で評価できる実験を、より簡単に実行できる状態を作ることでした。平たく言えば「いかにA/Bテストしやすい推薦システムを設計するか」が最も重要だった訳です。
オフライン評価とオンライン評価の相関がない系の話で、A/Bテストを容易に実施できる環境になかった、かつCTRが実際に向上したモデルがオフライン評価での性能が現行モデルよりも悪く、意思決定がなかなかできなかった、という話。
うーんやはり、推薦におけるオフライン評価ってあまりあてにできないよね、、、
そもそも新たなモデルをデプロイした時点で、テストした時とデータの分布が変わるわけだし、、、
Off-Policy Evaluationの話は勉強したい。
あと、定性評価は重要
calm3-22B, 2024
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #needs-revision Issue Date: 2024-07-09 Comment
>LLMの日本語能力を評価するNejumi LLM リーダーボード3においては、700億パラメータのMeta-Llama-3-70B-Instructと同等の性能となっており、スクラッチ開発のオープンな日本語LLMとしてはトップクラスの性能となります(2024年7月現在)。
モデルは商用利用可能なApache License 2.0で提供されており
これはすごい
RAG-Research-Insights
Paper/Blog Link My Issue
#Article #Tutorial #Survey #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2024-03-05 Comment
RAGに関する研究が直近のものまでよくまとめられている
RAGの性能を改善するための8つの戦略
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-02-11 Comment
めちゃめちゃ詳細にRAG性能向上の手法がreference付きでまとまっている。すごい。
モバオクでのリアルタイムレコメンドシステムの紹介
Paper/Blog Link My Issue
#Article #RecommenderSystems #ML-LLM Ops #Slide #One-Line Notes Issue Date: 2023-12-19 Comment
DeNAでのRecSysのアーキテクチャ(バッチ、リアルタイム)が紹介されている。バッチではワークフローエンジンとしてVertex AI Pipelineが用いられている。リアルタイムになるとアーキテクチャが非常に複雑になっている。
複雑なアーキテクチャだが、Generative Recommendation使ったらもっとすっきりしそうだなーと思いつつ、レイテンシと運用コストの課題があるのでまだ実用段階じゃないよね、と思うなどした。
リアルタイム推薦によって、バッチで日毎の更新だった場合と比べ、入札率、クリック率、回遊率が大きく改善したのは面白い。
もし明日、上司に「GPT-4を作れ」と言われたら? Stability AIのシニアリサーチサイエンティストが紹介する「LLM構築タイムアタック」
Paper/Blog Link My Issue
#Article #LanguageModel #Blog #One-Line Notes Issue Date: 2023-12-05 Comment
StabilityAI Japan秋葉さん(元PFN)のW&B Conferenceでの発表に関する記事。
LLM構築タイムアタックでLLMをもし構築することになったら!?
のざっくりとしたプロセスや、次ページでOpenAIのGPT4のテクニカルレポートのクレジットから各チームの規模感を推定して、どの部分にどの程度の人員が割かれていたのかというのをベースに、各パートでどんなことがやられていそうかという話がされている。
LLM構築タイムアタックで、まずGPUを用意します!(ここが一番大変かも)の時点で、あっ察し(白目 という感じがして面白かった。
JGLUEの構築そして 日本語LLM評価のこれから, 河原大輔, W&B 東京ミートアップ #8, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #Dataset #LanguageModel #Evaluation #One-Line Notes Issue Date: 2023-11-16 Comment
JGLUEのexample付きの詳細、構築の経緯のみならず、最近の英語・日本語LLMの代表的な評価データ(方法)がまとまっている(AlpacaEval, MTBenchなど)。また、LLMにおける自動評価の課題が興味深く、LLM評価で生じるバイアスについても記述されている。Name biasなどはなるほどと思った。
日本語LLMの今後の評価に向けて、特にGPT4による評価を避け、きちんとアノテーションしたデータを用意しfinetuningした分類器を用いるという視点、参考にしたい。
ChatGPTに社内文書に基づいた回答を生成させる仕組みを構築しました, コネヒト TECH BLOG, 2023.11
Paper/Blog Link My Issue
#Article #NLP #Infrastructure #ML-LLM Ops #RAG(RetrievalAugmentedGeneration) #Blog #KeyPoint Notes Issue Date: 2023-11-15 Comment
低コストで社内文書に対するRAGを実現することに注力している。
以下、図はブログから引用。
基本的にはバッチジョブで社内文書をベクトル化しS3へ格納。アプリ起動時にS3から最新データを読み込み検索可能にしRAGするという流れ。
低コスト化のために、Embedding作成にOpenWeightの言語モデル(text-edbedding-ada002と同等の性能)を利用している。実装は基本的にllamaindexを利用している。
特に日本語テキストにおいてはtext-embedding-ada002は OpenAI の Embeddings API はイケてるのか、定量的に調べてみる, akeyhero (Akihiro Katsura), Qiita, 2023.04 において、JSTSタスクにおいてあまり性能が高くない(ただし、OpenAI の Embeddings API はイケてるのか、定量的に調べてみる, akeyhero (Akihiro Katsura), Qiita, 2023.04 での報告値は基本的にJSTSデータでfinetuningされてた結果と思われる)と言われているので、お金かけて無理して使う必要はないのかなという印象はある。
生成AIが抱えるリスクと対策, 髙橋翼, LYCorp‘23, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Alignment #GenerativeAI #Hallucination #Blog #Safety Issue Date: 2023-11-03 Comment
この資料をスタートにReferしている論文などを勉強すると、GenerativeAIのリスク周りに詳しくなれそう。この辺は疎いので勉強になる。
しかし、LLMのAlignmentが不十分だったり、Hallucinationを100%防ぐことは原理的に不可能だと思われるので、この辺とどう付き合っていくかがLLMと付き合っていく上で難しいところ。この辺は自分たちが活用したいユースケースに応じて柔軟に対応しなければならず、この辺の細かいカスタマイズをする地道な作業はずっと残り続けるのではないかなあ
StableDiffusion, LLMのGPUメモリ削減のあれこれ, nishiba, Qiita, 2023.10
Paper/Blog Link My Issue
#Article #NeuralNetwork #ComputerVision #EfficiencyImprovement #NLP #LanguageModel #DiffusionModel #Blog Issue Date: 2023-10-29 Comment
Gradient Accumulation, Gradient Checkpointingの説明が丁寧でわかりやすかった。
LLMのプロンプト技術まとめ, fuyu_quant (Toma Tanaka), Qiita, 2023.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Prompting #Blog Issue Date: 2023-10-29 Comment
ざっと見たが現時点で主要なものはほぼ含まれているのでは、という印象
実際のプロンプト例が載っているので、理解しやすいかもしれない。
日本語LLMのリーダーボード(LLM.jp), Weights & Biases
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog #KeyPoint Notes Issue Date: 2023-10-27 Comment
LLM.jpによる日本語LLMのリーダーボード。4-shotsでの結果、かつinstructionを与えた場合の生成テキストに対する評価、という点には留意したい。たとえばゼロショットで活用したい、という場合にこのリーダーボードの結果がそのまま再現される保証はないと推察される。
日本語LLMベンチマークと自動プロンプトエンジニアリング, PFN Blog, 2023.10
の知見でもあった通り、promptingの仕方によってもLLM間で順位が逆転する現象なども起こりうる。あくまでリーダーボードの値は参考値として留め、どのLLMを採用するかは、自分が利用するタスクやデータで検証した方がbetterだと思われる。
あとはそもそも本当にLLMを使う必要があるのか? [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08
のような手法ではダメなのか?みたいなところも考えられると良いのかもしれない。
以下サイトより引用
> 評価手法・ツール
このダッシュボードの内容はllm-jpで公開している評価ツール、llm-jp-evalで各モデルに対して評価を行なった結果である。llm-jp-evalは、既存のリーダボードとは行われている評価とは、主に以下のところで違っている。
AlpacaやBig-Benchなどを参考にした、インストラクションチューニングよりのプロンプトを入力として与えて、その入力に対するモデルの生成結果を評価する
>評価は基本、モデルが生成した文字列だけを使って行う
>Few shotでの評価を行っており、このダッシュボードには4-shotsでの結果を載せている
>評価手法・ツールの詳細はllm-jp-evalを是非参照されたい。
>評価項目・データセット
評価項目として、まず4つのカテゴリーにおける平均スコアを算出した。さらにその4カテゴリーの平均値の平均値をとった値がAVGである。
MC (Multi-Choice QA):jcommonsenseqa
NLI (Natural Language Inference):jamp、janli、jnli、jsem、jsick
QA (Question Answering):jemhopqa、niilc
RC (Reading Comprehension):jsquad
>それぞれのカテゴリの平均を出す方法に言語学的な意味はないため、最終的な平均値はあくまで参考値ということに注意されたい。
JGlueを利用した日本語LLMのリーダーボードとして Nejumi LLMリーダーボード, Weights & Biases などもある
SNLP2023:Is GPT-3 a Good Data Annotator?, Yuki Zenimoto, 2023.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #SyntheticData #Distillation #Slide #Finetuning #One-Line Notes #DownstreamTasks Issue Date: 2023-09-05 Comment
GPT3でデータを作成したら、タスクごとに有効なデータ作成方法は異なったが、人手で作成したデータと同等の性能を達成するデータ(BERTでfinetuning)を、低コストで実現できたよ、という研究
この辺の話はもはや [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, arXiv'23, 2023.08 を使えばいいのでは、という気がする。
Transformerの最前線 〜 畳込みニューラルネットワークの先へ 〜, Yoshitaka Ushiku, 2022.06
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #NLP #Transformer #Slide #Selected Papers/Blogs Issue Date: 2022-09-06 Comment
Transformerの動作原理を直感的に理解するのに非常にわかりやすい説明で、とても勉強になる。
以下のような内容が解説されており、あまりにも盛りだくさんで最高。
- Positional Encoding
- autoregressive vs. non-autoregressive
- residual connection
- multi-head attention
- RNN(O(N)だけど長い系列苦手), CNN(O(N)だけど近傍しか見れない)との対比
- Vision & Languageの話題とVision Transformerとのつながり
- Swin Transformer
- 基盤モデルの定義
- ある目的関数のもと、自己教師あり学習された、巨大なモデル(様々なタスクに容易に転用できる)
- gMLP, MLP-MixerなどのMLP likeなアーキテクチャとの比較
- Transformerと本質的にやっていることはあまり変わらず、ベクトルの混ぜ方(attention vs. 行列積)と位置情報の保持をベクトルがするのかindexに基づいてネットワークが保持するのか、が変わっているのみ
- Transformer性能向上の軌跡
- pre-Norm / post-Norm / 活性化関数(GLU等) / MoE等 / RoPE
- Scaling Law
- CNNとViTの性質(CNNはハイパスフィルタ、ViTはローパスフィルタ)
Seq2seqモデルのBeam Search Decoding (Pytorch), jonki, 2020.05
Paper/Blog Link My Issue
#Article #Tutorial #BeamSearch #Blog #One-Line Notes Issue Date: 2021-06-24 Comment
ビームサーチについて、コード付きで説明してくれており、大変わかりやすい。
heapqを使って実装している。また、ビームサーチをbatchに対して行う方法についても書いてある(ただ、一部に対してしかbatchでの処理は適用できていない)。
自分もバッチに対して効率的にビームサーチするにはどのように実装すれば良いのかよくわからないので、誰か教えて欲しい。
[Paper Note] Probing Word Translations in the Transformer and Trading Decoder for Encoder Layers, NAACL‘21
Paper/Blog Link My Issue
#Article #NeuralNetwork #MachineTranslation #NLP #NAACL #KeyPoint Notes Issue Date: 2021-06-03 Comment
Transformerに基づいたNMTにおいて、Encoderが入力を解釈し、Decoderが翻訳をしている、という通説を否定し、エンコーディング段階、さらにはinput embeddingの段階でそもそも翻訳が始まっていることを指摘。
エンコーディングの段階ですでに翻訳が始まっているのであれば、エンコーダの層を増やして、デコーダの層を減らせば、デコーディング速度を上げられる。
通常はエンコーダ、デコーダともに6層だが、10-2層にしたらBLEUスコアは変わらずデコーディングスピードは2.3倍になった。
18-4層の構成にしたら、BLEUスコアも1.42ポイント増加しデコーディング速度は1.4倍になった。
この研究は個人的に非常に興味深く、既存の常識を疑い、分析によりそれを明らかにし、シンプルな改善で性能向上およびデコーディング速度も向上しており、とても好き。
[Paper Note] Sequence-Aware Recommender Systems, Massimo Quadrana+, ACM Computing Surveys (CSUR), Volume 51, Issue 4, 2018.02
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #SequentialRecommendation Issue Date: 2020-11-13 GPT Summary- レコメンドシステムは、機械学習を用いた成功したデータマイニングの応用であり、従来は単一のユーザー-アイテムインタラクションに基づいていましたが、実際のアプリケーションでは時間とともに多様なインタラクションが記録されます。本研究は、これらの逐次的なインタラクションを考慮した推薦プロセスに関する既存研究を概観し、関連するタスクと目標の分類を提案。さらに、シーケンス情報を利用したレコメンダーシステムのベンチマーク方法論と未解決の課題について議論します。 Comment
評価方法の議論が非常に参考になる。特に、Survey執筆時点において、コミュニティの中でデータ分割方法について標準化されたものがないといった話は参考になる。
BERT入門, Ken'ichi Matsui, 2020.01
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Slide #Reference Collection Issue Date: 2020-01-13 Comment
自然言語処理の王様「BERT」の論文を徹底解説
https://qiita.com/omiita/items/72998858efc19a368e50
Transformer関連 [Paper Note] Attention Is All You Need, Ashish Vaswani+, NeurIPS'17, 2017.07
あたりを先に読んでからが読むと良い
要は
・Transformerをたくさん積んだモデル
・NSPとMLMで双方向性を持った事前学習タスクを実施することで性能向上
・pooler layer(Transformer Encoderの次にくっつくlayer)を切り替えることで、様々なタスクにfine-tuning可能(i.e. pooler layerは転移学習の対象外)
・予測する際は、[CLS]トークンに対応する位置の出力を用いて分類問題や複数文間の関係性を問う問題を解いたり、各トークン位置に対応する出力を用いてQAの正解spanを予測したり、色々できる
・gMLP MLP-like Architecture
あたりの研究が進んでくると使われなくなってくる可能性有
こっちの記事もわかりやすい。
BERTについて勉強したことまとめ (2)モデル構造について
https://engineering.mobalab.net/2020/06/12/bert%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%E5%8B%89%E5%BC%B7%E3%81%97%E3%81%9F%E3%81%93%E3%81%A8%E3%81%BE%E3%81%A8%E3%82%81-2%E3%83%A2%E3%83%87%E3%83%AB%E6%A7%8B%E9%80%A0%E3%81%AB%E3%81%A4%E3%81%84/