
Findings
[Paper Note] Autonomous Data Selection with Zero-shot Generative Classifiers for Mathematical Texts, Yifan Zhang+, ACL'25 Findings, 2024.02
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #ACL #KeyPoint Notes #GenerativeVerifier Issue Date: 2025-12-19 GPT Summary- 自律的データ選択(AutoDS)は、言語モデルをゼロショットの生成分類器として利用し、高品質な数学テキストを自動キュレーションする手法です。従来の方法と異なり、人間の注釈やデータフィルターのトレーニングを必要とせず、モデルのロジットに基づいて数学的に有益なパッセージを判断します。AutoDSは事前トレーニングパイプラインに統合され、数学ベンチマークでの性能を大幅に向上させ、トークン効率を約2倍改善しました。さらに、キュレーションされたAutoMathTextデータセットを公開し、今後の研究を促進します。 Comment
元ポスト:
以下のようなzero-shotのmeta-promptを用いてテキストをスコアリングし(Q1, Q2それぞれについてスコア(=logits)を算出し乗算)継続事前学習に利用することで性能が向上することを示した研究。
ベースライン:
- uniform: OpenWebMathから一様サンプリングする
- DSIR: source dataとtarget domain(今回はPile's Wikipedia splitを利用)のKL Divergenceを比較しデータを選択する。
- Qurating: Reward-modelをベースにした学習サンプルに対するeducational valueをランキングさせる手法
提案手法は
- OpenWebMath
- arXiv (from RedPajama)
- Algebraic Stack
の中からトップスコアのドキュメントを利用。DSIR, Quratingについてはデータソースが明示されていないが、おそらく提案手法揃えていると思われる。また学習する際のトークン量も手法間で(明示的に書かれていないように見えるが)同等にそろえていると思われる。
まずpreliminary experimentsとしてトークン数のbudgetを小さめにして実験。uniformと比較すると、別のmathドメインデータでFinetuningした後のパフォーマンスが向上している。トークン数のbudgetもexactに揃えられている。
続いてトークンのbudgetを増やして、~2.5Bトークンにスケールアップして比較(継続事前学習→1 epoch SFT)。提案手法が全体的にdownstreamタスクでの評価で高い性能を発揮。しかしこちらでは、いくつかでuniformの性能もよい。
また、最後に数学データでの継続事前学習が異なるドメインに対してどの程度転移するかを測ると、提案手法が平均して最もよかった。しかしこちらもでもuniformが結構強い結果に見える。
OpenWebMathがそもそもheuristicsとtrained classifierを用いてキュレーションされたデータとのことなので、ある程度高品質であることが想定される。
[Paper Note] Understanding the Influence of Synthetic Data for Text Embedders, Jacob Mitchell Springer+, ACL'25 Findings, 2025.09
Paper/Blog Link My Issue
#Embeddings #Analysis #Pocket #NLP #Dataset #LanguageModel #RepresentationLearning #SyntheticData #ACL Issue Date: 2025-10-19 GPT Summary- 合成LLM生成データのトレーニングによる汎用テキスト埋め込み器の進展を受け、Wangらの合成データを再現・公開。高品質なデータはパフォーマンス向上をもたらすが、一般化の改善は局所的であり、異なるタスク間でのトレードオフが存在。これにより、合成データアプローチの限界が明らかになり、タスク全体での堅牢な埋め込みモデルの構築に対する考えに疑問を呈する。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/jspringer/open-synthetic-embeddings
[Paper Note] Benchmarking and Improving LLM Robustness for Personalized Generation, Chimaobi Okite+, EMNLP'25 Findings, 2025.09
Paper/Blog Link My Issue
#Pocket #Personalization #EMNLP Issue Date: 2025-09-28 GPT Summary- LLMsの応答の個別化において、事実性も重要であると主張し、堅牢性を評価するフレームワークPERGとデータセットPERGDataを導入。14のモデルを評価した結果、LLMsは堅牢な個別化に苦労しており、特に大規模モデルでも正確性が低下することが判明。クエリの性質やユーザーの好みによって堅牢性が影響を受けることを示し、二段階のアプローチPref-Alignerを提案し、平均25%の堅牢性向上を実現。研究は評価手法のギャップを明らかにし、信頼性の高いLLMの展開を支援するツールを提供。 Comment
元ポスト:
[Paper Note] CAPE: Context-Aware Personality Evaluation Framework for Large Language Models, Jivnesh Sandhan+, EMNLP'25 Findings, 2025.08
Paper/Blog Link My Issue
#Pocket #Dataset #LanguageModel #ContextAware #Evaluation #EMNLP #Personality Issue Date: 2025-09-24 GPT Summary- 心理測定テストをLLMsの評価に適用するため、文脈対応パーソナリティ評価(CAPE)フレームワークを提案。従来の孤立した質問アプローチから、会話の履歴を考慮した応答の一貫性を定量化する新指標を導入。実験により、会話履歴が応答の一貫性を高める一方で、パーソナリティの変化も引き起こすことが明らかに。特にGPTモデルは堅牢性を示し、Gemini-1.5-FlashとLlama-8Bは感受性が高い。CAPEをロールプレイングエージェントに適用すると、一貫性が改善され人間の判断と一致することが示された。 Comment
元ポスト:
[Paper Note] How a Bilingual LM Becomes Bilingual: Tracing Internal Representations with Sparse Autoencoders, Tatsuro Inaba+, EMNLP'25 Findings, 2025.03
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #MultiLingual #EMNLP #SparseAutoEncoder Issue Date: 2025-09-24 GPT Summary- 本研究では、バイリンガル言語モデルの内部表現の発展をスパースオートエンコーダーを用いて分析。言語モデルは初めに言語を個別に学習し、中間層でバイリンガルの整合性を形成することが明らかに。大きなモデルほどこの傾向が強く、分解された表現を中間トレーニングモデルに統合する新手法でバイリンガル表現の重要性を示す。結果は、言語モデルのバイリンガル能力獲得に関する洞察を提供。 Comment
元ポスト:
[Paper Note] Instability in Downstream Task Performance During LLM Pretraining, Yuto Nishida+, EMNLP'25 Findings, 2025.10
Paper/Blog Link My Issue
#Analysis #Pretraining #Pocket #NLP #LanguageModel #EMNLP #Stability #DownstreamTasks Issue Date: 2025-09-24 GPT Summary- LLMの訓練中に下流タスクのパフォーマンスが大きく変動する問題を分析し、チェックポイントの平均化とアンサンブル手法を用いて安定性を向上させることを提案。これにより、訓練手順を変更せずにパフォーマンスの変動を減少させることが実証された。 Comment
元ポスト:
[Paper Note] Lost in Embeddings: Information Loss in Vision-Language Models, Wenyan Li+, EMNLP'25 Findings, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Analysis #Pocket #NLP #EMNLP #VisionLanguageModel Issue Date: 2025-09-21 GPT Summary- 視覚と言語のモデル(VLMs)の投影ステップによる情報損失を分析するため、2つのアプローチを提案。1つ目は、投影前後の画像表現のk近傍関係の変化を評価し、2つ目は視覚埋め込みの再構築によって情報損失を測定。実験により、コネクタが視覚表現の幾何学を歪め、k近傍が40~60%乖離することが明らかになり、これは検索性能の低下と関連。パッチレベルの再構築は、モデルの挙動に対する洞察を提供し、高い情報損失がモデルの苦手な事例を予測することを示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Evaluating Step-by-step Reasoning Traces: A Survey, Jinu Lee+, EMNLP'25 Findings
Paper/Blog Link My Issue
#Pocket #EMNLP Issue Date: 2025-08-21 GPT Summary- ステップバイステップの推論はLLMの能力向上に寄与するが、評価手法は一貫性に欠ける。本研究では、推論評価の包括的な概要と、事実性、有効性、一貫性、実用性の4カテゴリからなる評価基準の分類法を提案。これに基づき、評価者の実装や最近の発見をレビューし、今後の研究の方向性を示す。 Comment
元ポスト:
[Paper Note] Agent Laboratory: Using LLM Agents as Research Assistants, Samuel Schmidgall+, EMNLP'25 Findings
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #ScientificDiscovery #EMNLP Issue Date: 2025-08-21 GPT Summary- Agent Laboratoryは、全自動のLLMベースのフレームワークで、研究アイデアから文献レビュー、実験、報告書作成までのプロセスを完了し、質の高い研究成果を生成します。人間のフィードバックを各段階で取り入れることで、研究の質を向上させ、研究費用を84%削減。最先端の機械学習コードを生成し、科学的発見の加速を目指します。 Comment
元ポスト:
pj page: https://agentlaboratory.github.io
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, ACL(Findings)'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation #ACL #VisionLanguageModel Issue Date: 2025-07-02 GPT Summary- 内部世界モデル(WMs)はエージェントの理解と予測を支えるが、最近の大規模ビジョン・ランゲージモデル(VLMs)の基本的なWM能力に関する評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchというベンチマークを導入。15のVLMsに対する660の実験で、これらのモデルが基本的なWM能力に顕著な制限を示し、特に運動軌道の識別においてほぼランダムな精度であることが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。 Comment
元ポスト:
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Prompting #AutomaticPromptEngineering #ACL Issue Date: 2023-11-13 GPT Summary- プロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #Chain-of-Thought #Prompting #AutomaticPromptEngineering #NAACL #Surface-level Notes Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。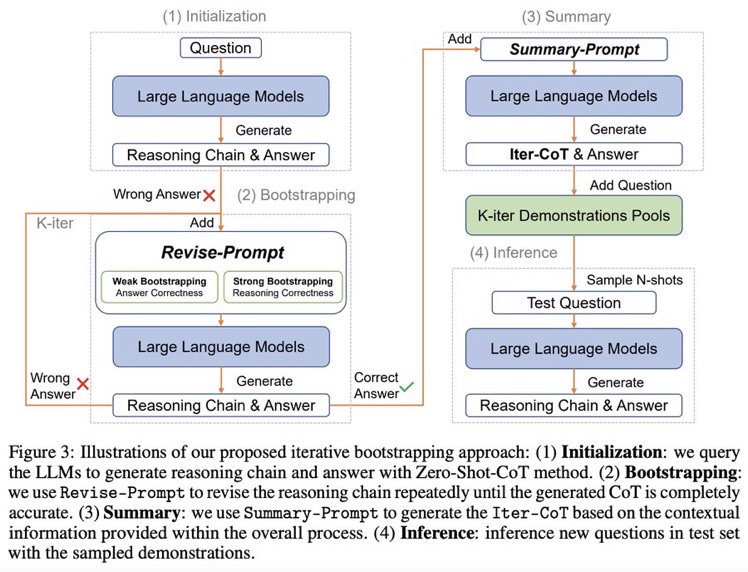
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- Automatic Chain of Thought Prompting in Large Language Models, Zhang+, Shanghai Jiao Tong University, ICLR'23
- Automatic prompt augmentation and selection with chain-of-thought from labeled data, Shum+, The Hong Kong University of Science and Technology, arXiv'23
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。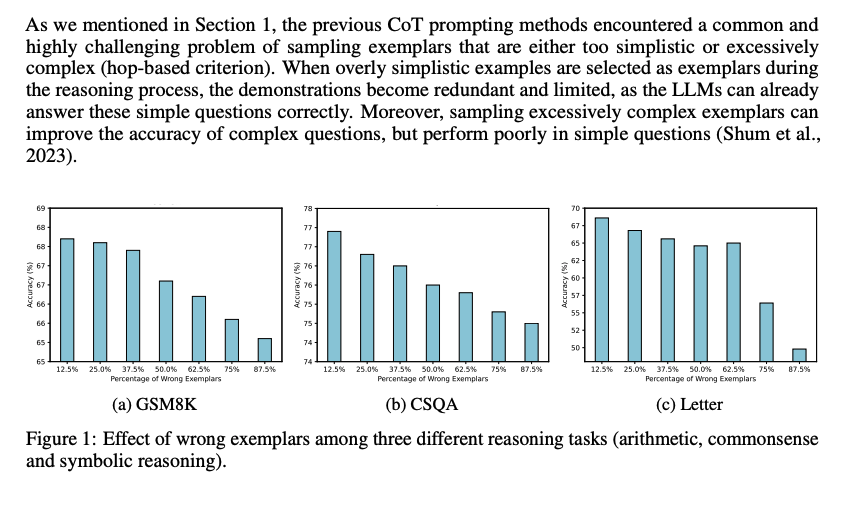
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。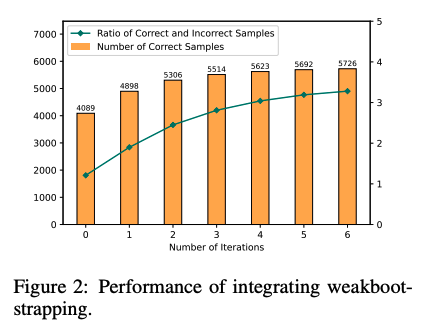
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
Random-CoT
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
Auto-CoT
- Active prompting with chain-of-thought for large language models, Diao+, The Hong Kong University of Science and Technology, ACL'24
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。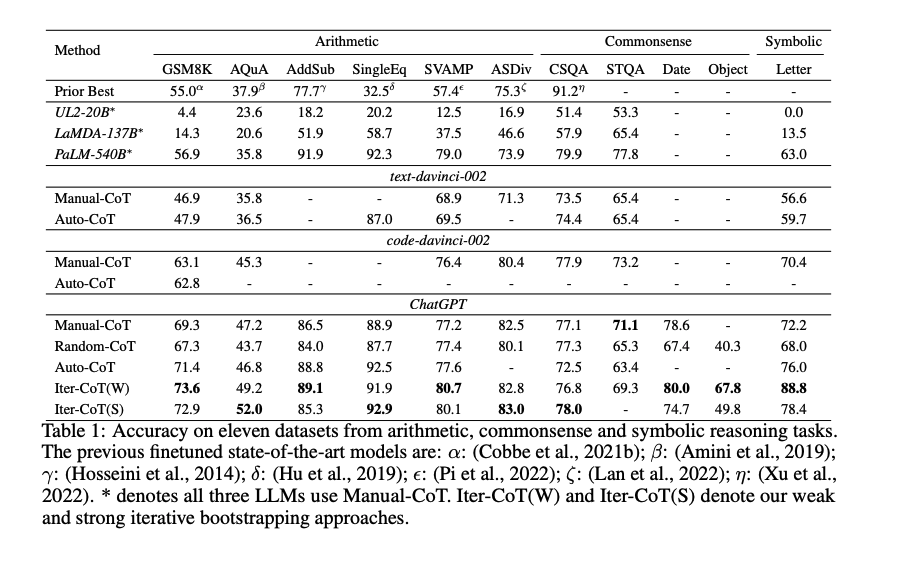
weak bootstrapingのiterationは4回くらいで頭打ちになった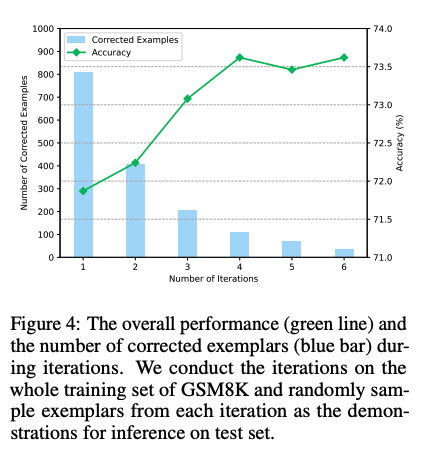
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
[Paper Note] FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation, Tu Vu+, ACL'23 Findings, 2023.10
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Zero/Few/ManyShotPrompting #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #ACL Issue Date: 2025-09-24 GPT Summary- 大規模言語モデル(LLMs)は変化する世界に適応できず、事実性に課題がある。本研究では、動的QAベンチマーク「FreshQA」を導入し、迅速に変化する知識や誤った前提を含む質問に対するLLMの性能を評価。評価の結果、全モデルがこれらの質問に苦労していることが明らかに。これを受けて、検索エンジンからの最新情報を組み込む「FreshPrompt」を提案し、LLMのパフォーマンスを向上させることに成功。FreshPromptは、証拠の数と順序が正確性に影響を与えることを示し、簡潔な回答を促すことで幻覚を減少させる効果も確認。FreshQAは公開され、今後も更新される予定。
[Paper Note] RWKV: Reinventing RNNs for the Transformer Era, Bo Peng+, N_A, EMNLP'23 Findings, 2023.05
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Transformer #EMNLP #Selected Papers/Blogs #RecurrentModels Issue Date: 2023-06-16 GPT Summary- 本研究では、トランスフォーマーとRNNの両方の利点を組み合わせた新しいモデルアーキテクチャであるRWKVを提案し、トレーニング中に計算を並列化し、推論中に一定の計算およびメモリの複雑さを維持することができます。RWKVは、同じサイズのトランスフォーマーと同等のパフォーマンスを発揮し、将来的にはより効率的なモデルを作成するためにこのアーキテクチャを活用できることを示唆しています。 Comment
異なるtransformerとRWKVの計算量とメモリ消費量の比較
RWKVの構造は基本的に、residual blockをスタックすることによって構成される。一つのresidual blockは、time-mixing(時間方向の混ぜ合わせ)と、channnel-mixing(要素間での混ぜ合わせ)を行う。
RWKVのカギとなる要素は以下の4つであり、RWKVのブロック、およびLMでのアーキテクチャは以下のようになる:
ここで、token-shiftは、previsou timestepのinputとのlinear interpolationを現在のinputととることである。これにより再帰性を担保する。
RWKVは他のLLMと比較し、パラメータ数に対して性能はcomparableであり、context lengthを増やすことで、lossはきちんと低下し、テキスト生成をする際に要する時間は他のLLMと比較して、トークン数に対して線形にしか増加しない。
openreview: https://openreview.net/forum?id=7SaXczaBpG
[Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12
Paper/Blog Link My Issue
#Pocket #NLP #Transformer #Attention #Distillation #ACL #Encoder #KeyPoint Notes Issue Date: 2025-10-20 GPT Summary- 自己注意関係蒸留を用いて、MiniLMの深層自己注意蒸留を一般化し、事前学習されたトランスフォーマーの圧縮を行う手法を提案。クエリ、キー、バリューのベクトル間の関係を定義し、生徒モデルを訓練。注意ヘッド数に制限がなく、教師モデルの層選択戦略を検討。実験により、BERTやRoBERTa、XLM-Rから蒸留されたモデルが最先端の性能を上回ることを示した。 Comment
教師と(より小規模な)生徒モデル間で、tokenごとのq-q/k-k/v-vのdot productによって形成されるrelation map(たとえばq-qの場合はrelatiok mapはトークン数xトークン数の行列で各要素がdot(qi, qj))で表現される関係性を再現できるようにMHAを蒸留するような手法。具体的には、教師モデルのQKVと生徒モデルのQKVによって構成されるそれぞれのrelation map間のKL Divergenceを最小化するように蒸留する。このとき教師モデルと生徒モデルのattention heads数などは異なってもよい(q-q/k-k/v-vそれぞれで定義されるrelation mapははトークン数に依存しており、head数には依存していないため)。
[Paper Note] Query-Key Normalization for Transformers, Alex Henry+, EMNLP'20 Findings
Paper/Blog Link My Issue
#MachineTranslation #Pocket #Transformer #EMNLP #Normalization Issue Date: 2025-08-16 GPT Summary- 低リソース言語翻訳において、QKNormという新しい正規化手法を提案。これは、注意メカニズムを修正し、ソフトマックス関数の飽和耐性を向上させつつ表現力を維持。具体的には、クエリとキー行列に対して$\ell_2$正規化を適用し、学習可能なパラメータでスケールアップ。TED TalksコーパスとIWSLT'15の低リソース翻訳ペアで平均0.928 BLEUの改善を達成。 Comment
QKに対してL2正規化を実施し、learnableなスカラー値を乗じることでスケーリングすることで、low resourceな言語での翻訳性能が向上。MTで実験されているが、transformerの表現力が改善されるのでGLM-4.5のアーキテクチャでも採用されている。
dot product attentionでは内積を利用するため値域に制約がなく、ある単語にのみattention scoreが集中してしまい、他の全ての単語のsignalをかき消してしまう問題がある。このため、QKをノルムによって正規化し(これにより実質QKはcosine similarityとなる)値域を制限する。しかしこうすると今度はスコア間の差が小さすぎて、attendしなくても良い単語を無視できなくなるので、learnableなパラメータでスケールを調整する。
[Paper Note] CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning, Bill Yuchen Lin+, EMNLP'20 Findings
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Pocket #NLP #Dataset #Evaluation #Composition #EMNLP #CommonsenseReasoning Issue Date: 2025-07-31 GPT Summary- 生成的常識推論をテストするためのタスクCommonGenを提案し、35,000の概念セットに基づく79,000の常識的記述を含むデータセットを構築。タスクは、与えられた概念を用いて一貫した文を生成することを求め、関係推論と構成的一般化能力が必要。実験では、最先端モデルと人間のパフォーマンスに大きなギャップがあることが示され、生成的常識推論能力がCommonsenseQAなどの下流タスクに転送可能であることも確認。 Comment
ベンチマークの概要。複数のconceptが与えられた時に、それらconceptを利用した常識的なテキストを生成するベンチマーク。concept間の関係性を常識的な知識から推論し、Unseenなconceptの組み合わせでも意味を構成可能な汎化性能が求められる。
PJ page: https://inklab.usc.edu/CommonGen/