
Surface-level Notes
[Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #Chain-of-Thought #Prompting #AutomaticPromptEngineering #NAACL #Findings Issue Date: 2023-04-25 GPT Summary- Iter-CoTは、LLMsの推論チェーンのエラーを修正し、正確で包括的な推論を実現するための反復的ブートストラッピングアプローチを提案。適度な難易度の質問を選択することで、一般化能力を向上させ、10のデータセットで競争力のある性能を達成。 Comment
Zero shot CoTからスタートし、正しく問題に回答できるようにreasoningを改善するようにpromptをreviseし続けるループを回す。最終的にループした結果を要約し、それらをプールする。テストセットに対しては、プールの中からNshotをサンプルしinferenceを行う。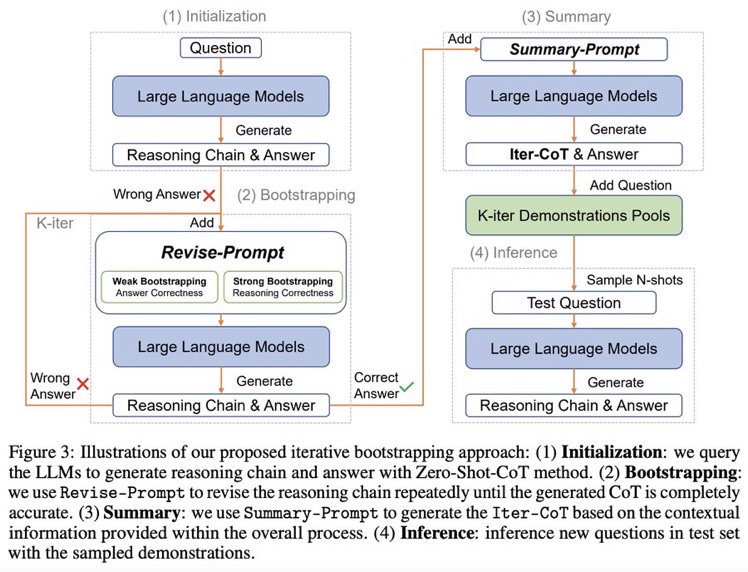
できそうだなーと思っていたけど、早くもやられてしまった
実装: https://github.com/GasolSun36/Iter-CoT
# モチベーション: 既存のCoT Promptingの問題点
## Inappropriate Examplars can Reduce Performance
まず、既存のCoT prompting手法は、sampling examplarがシンプル、あるいは極めて複雑な(hop-based criterionにおいて; タスクを解くために何ステップ必要かという情報; しばしば人手で付与されている?)サンプルをサンプリングしてしまう問題がある。シンプルすぎるサンプルを選択すると、既にLLMは適切にシンプルな回答には答えられるにもかかわらず、demonstrationが冗長で限定的になってしまう。加えて、極端に複雑なexampleをサンプリングすると、複雑なquestionに対しては性能が向上するが、シンプルな問題に対する正答率が下がってしまう。
続いて、demonstration中で誤ったreasoning chainを利用してしまうと、inference時にパフォーマンスが低下する問題がある。下図に示した通り、誤ったdemonstrationが増加するにつれて、最終的な予測性能が低下する傾向にある。
これら2つの課題は、現在のメインストリームな手法(questionを選択し、reasoning chainを生成する手法)に一般的に存在する。
- Automatic Chain of Thought Prompting in Large Language Models, Zhang+, Shanghai Jiao Tong University, ICLR'23
- Automatic prompt augmentation and selection with chain-of-thought from labeled data, Shum+, The Hong Kong University of Science and Technology, arXiv'23
のように推論時に適切なdemonstrationを選択するような取り組みは行われてきているが、test questionに対して推論するために、適切なexamplarsを選択するような方法は計算コストを増大させてしまう。
これら研究は誤ったrationaleを含むサンプルの利用を最小限に抑えて、その悪影響を防ぐことを目指している。
一方で、この研究では、誤ったrationaleを含むサンプルを活用して性能を向上させる。これは、たとえば学生が難解だが回答可能な問題に取り組むことによって、問題解決スキルを向上させる方法に類似している(すなわち、間違えた部分から学ぶ)。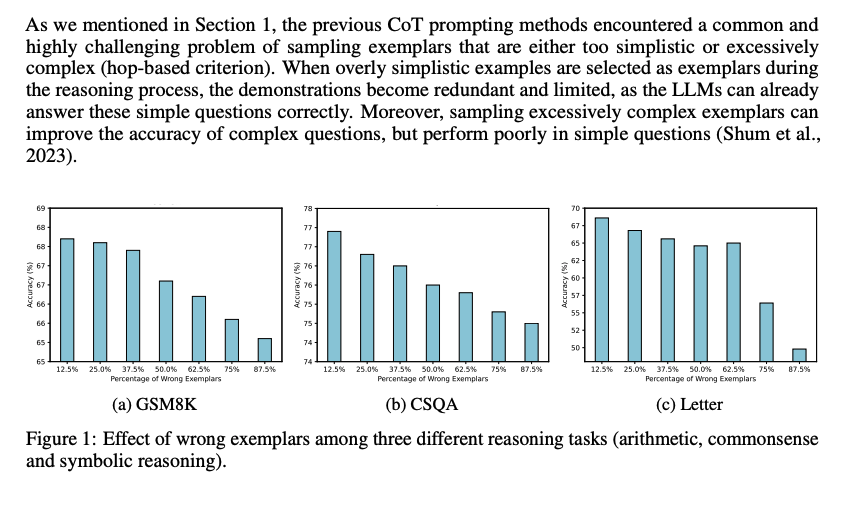
## Large Language Models can self-Correct with Bootstrapping
Zero-Shot CoTでreasoning chainを生成し、誤ったreasoning chainを生成したpromptを**LLMに推敲させ(self-correction)**正しい出力が得られるようにする。こういったプロセスを繰り返し、correct sampleを増やすことでどんどん性能が改善していった。これに基づいて、IterCoTを提案。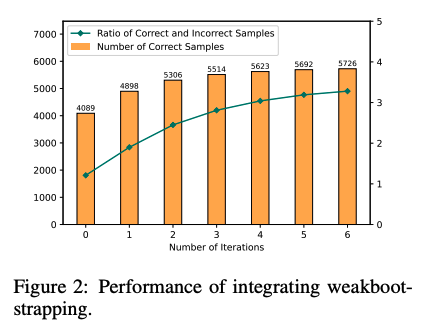
# IterCoT: Iterative Bootstrapping in Chain-of-Thought Prompting
IterCoTはweak bootstrappingとstrong bootstrappingによって構成される。
## Weak bootstrapping
- Initialization
- Training setに対してZero-shot CoTを実施し、reasoning chainとanswerを得
- Bootstrapping
- 回答が誤っていた各サンプルに対して、Revise-Promptを適用しLLMに誤りを指摘し、新しい回答を生成させる。
- 回答が正確になるまでこれを繰り返す。
- Summarization
- 正しい回答が得られたら、Summary-Promptを利用して、これまでの誤ったrationaleと、正解のrationaleを利用し、最終的なreasoning chain (Iter-CoT)を生成する。
- 全体のcontextual informationが加わることで、LLMにとって正確でわかりやすいreasoning chainを獲得する。
- Inference
- questionとIter-Cotを組み合わせ、demonstration poolに加える
- inference時はランダムにdemonstraction poolからサンプリングし、In context learningに利用し推論を行う
## Strong Bootstrapping
コンセプトはweak bootstrappingと一緒だが、Revise-Promptでより人間による介入を行う。具体的には、reasoning chainのどこが誤っているかを明示的に指摘し、LLMにreasoning chainをreviseさせる。
これは従来のLLMからの推論を必要としないannotationプロセスとは異なっている。何が違うかというと、人間によるannnotationをLLMの推論と統合することで、文脈情報としてreasoning chainを修正することができるようになる点で異なっている。
# 実験
Manual-CoT
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
Random-CoT
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
Auto-CoT
- Active prompting with chain-of-thought for large language models, Diao+, The Hong Kong University of Science and Technology, ACL'24
と比較。
Iter-CoTが11個のデータセット全てでoutperformした。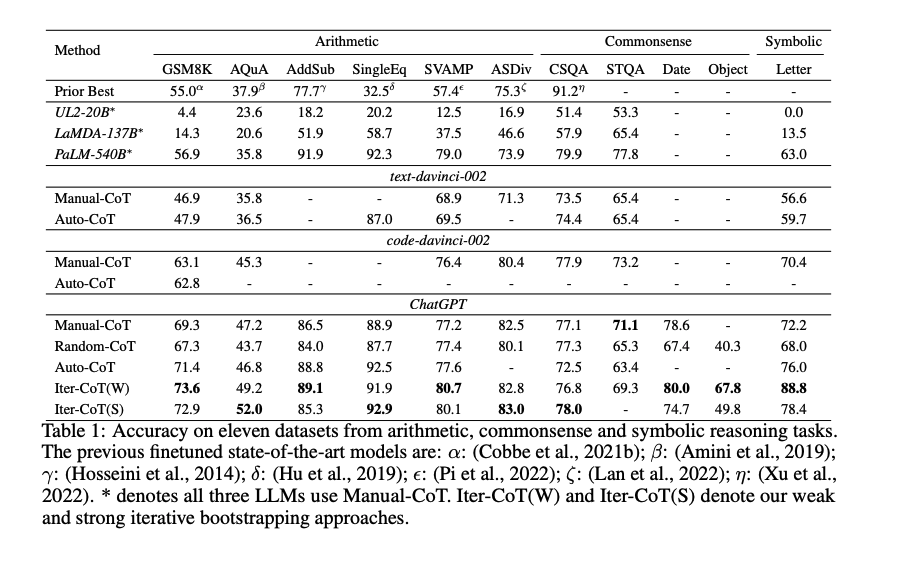
weak bootstrapingのiterationは4回くらいで頭打ちになった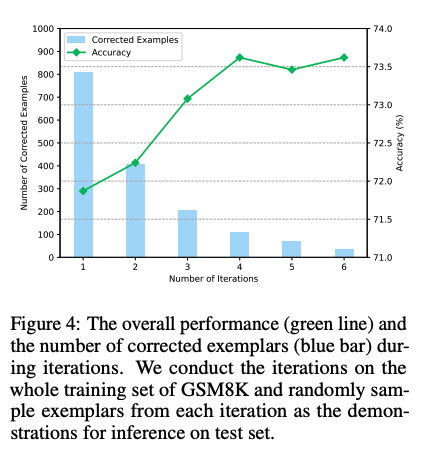
また、手動でreasoning chainを修正した結果と、contextにannotation情報を残し、最後にsummarizeする方法を比較した結果、後者の方が性能が高かった。このため、contextの情報を利用しsummarizeすることが効果的であることがわかる。
The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #LongSequence #PositionalEncoding #NeurIPS #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-04-06 GPT Summary- 長さ一般化はTransformerベースの言語モデルにおける重要な課題であり、位置エンコーディング(PE)がその性能に影響を与える。5つの異なるPE手法(APE、T5の相対PE、ALiBi、Rotary、NoPE)を比較した結果、ALiBiやRotaryなどの一般的な手法は長さ一般化に適しておらず、NoPEが他の手法を上回ることが明らかになった。NoPEは追加の計算を必要とせず、絶対PEと相対PEの両方を表現可能である。さらに、スクラッチパッドの形式がモデルの性能に影響を与えることも示された。この研究は、明示的な位置埋め込みが長いシーケンスへの一般化に必須でないことを示唆している。 Comment
- Llama 4 Series, Meta, 2025.04
において、Llama4 Scoutが10Mコンテキストウィンドウを実現できる理由の一つとのこと。
元ポスト:
Llama4のブログポストにもその旨記述されている:
>A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, we employ inference time temperature scaling of attention to enhance length generalization.
[The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation]( https://ai.meta.com/blog/llama-4-multimodal-intelligence/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4)
斜め読みだが、length generalizationを評価する上でdownstream taskに焦点を当て、3つの代表的なカテゴリに相当するタスクで評価したところ、この観点においてはT5のrelative positinal encodingとNoPE(位置エンコードディング無し)のパフォーマンスが良く、
NoPEは絶対位置エンコーディングと相対位置エンコーディングを理論上実現可能であり[^1]
実際に学習された異なる2つのモデルに対して同じトークンをそれぞれinputし、同じ深さのLayerの全てのattention distributionの組み合わせからJensen Shannon Divergenceで距離を算出し、最も小さいものを2モデル間の当該layerの距離として可視化すると下記のようになり、NoPEとT5のrelative positional encodingが最も類似していることから、NoPEが学習を通じて(実用上は)相対位置エンコーディングのようなものを学習することが分かった。
[^1]:深さ1のLayerのHidden State H^1から絶対位置の復元が可能であり(つまり、当該レイヤーのHが絶対位置に関する情報を保持している)、この前提のもと、後続のLayerがこの情報を上書きしないと仮定した場合に、相対位置エンコーディングを実現できる。
また、CoT/Scratchpadはlong sequenceに対する汎化性能を向上させることがsmall scaleではあるが先行研究で示されており、Positional Encodingを変化させた時にCoT/Scratchpadの性能にどのような影響を与えるかを調査。
具体的には、CoT/Scratchpadのフォーマットがどのようなものが有効かも明らかではないので、5種類のコンポーネントの組み合わせでフォーマットを構成し、mathematical reasoningタスクで以下のような設定で訓練し
- さまざまなコンポーネントの組み合わせで異なるフォーマットを作成し、
- 全ての位置エンコーディングあり/なしモデルを訓練
これらを比較した。この結果、CoT/Scratchpadはフォーマットに関係なく、特定のタスクでのみ有効(有効かどうかはタスク依存)であることが分かった。このことから、CoT/Scratcpad(つまり、モデルのinputとoutputの仕方)単体で、long contextに対する汎化性能を向上させることができないので、Positional Encoding(≒モデルのアーキテクチャ)によるlong contextに対する汎化性能の向上が非常に重要であることが浮き彫りになった。
また、CoT/Scratchpadが有効だったAdditionに対して各Positional Embeddingモデルを学習し、生成されたトークンのattentionがどの位置のトークンを指しているかを相対距離で可視化したところ(0が当該トークン、つまり現在のScratchpadに着目しており、1が遠いトークン、つまりinputに着目していることを表すように正規化)、NoPEとRelative Positional Encodingがshort/long rangeにそれぞれフォーカスするようなbinomialな分布なのに対し、他のPositional Encodingではよりuniformな分布であることが分かった。このタスクにおいてはNoPEとRelative POの性能が高かったため、binomialな分布の方がより最適であろうことが示唆された。
[Paper Note] Generating User-Engaging News Headlines, Cai+, ACL'23
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #ACL Issue Date: 2023-07-22 GPT Summary- ニュース記事の見出しを個別化するために、ユーザープロファイリングを組み込んだ新しいフレームワークを提案。ユーザーの閲覧履歴に基づいて個別のシグネチャフレーズを割り当て、それを使用して見出しを個別化する。幅広い評価により、提案したフレームワークが多様な読者のニーズに応える個別の見出しを生成する効果を示した。 Comment
# モチベーション
推薦システムのヘッドラインは未だに全員に同じものが表示されており、ユーザが自身の興味とのつながりを正しく判定できるとは限らず、推薦システムの有用性を妨げるので、ユーザごとに異なるヘッドラインを生成する手法を提案した。ただし、クリックベイトは避けるようなヘッドラインを生成しなければならない。
# 手法
1. Signature Phrase Identification
2. User Signature Selection
3. Signature-Oriented Headline Generation
## Signature Phrase Identification
テキスト生成タスクに帰着させる。ニュース記事、あるいはヘッドラインをinputされたときに、セミコロン区切りのSignature Phraseを生成するモデルを用いる。今回は[KPTimes daasetでpretrainingされたBART](
https://huggingface.co/ankur310794/bart-base-keyphrase-generation-kpTimes)を用いた。KPTimesは、279kのニュース記事と、signature
phraseのペアが存在するデータであり、本タスクに最適とのこと。
## User Signature Selection
ターゲットドキュメントdのSignature Phrases Z_dが与えられたとき、ユーザのreading History H_uに基づいて、top-kのuser signature phrasesを選択する。H_uはユーザが読んだニュースのヘッドラインの集合で表現される。あるSignature Phrase z_i ∈ Z_dが与えられたとき、(1)H_uをconcatしたテキストをベクトル化したものと、z_iのベクトルの内積でスコアを計算、あるいは(2) 個別のヘッドラインt_jを別々にエンコーディングし、内積の値が最大のものをスコアとする手法の2種類のエンコーディング方法を用いて、in-batch contrastive learningを用いてモデルを訓練する。つまり、正しいSignature Phraseとは距離が近く、誤ったSignature Phraseとは距離が遠くなるように学習をする。
実際はユーザにとっての正解Signature Phraseは分からないが、今回は人工的に作成したユーザを用いるため、正解が分かる設定となっている。
## Signature-Oriented Headline Generation
ニュース記事d, user signature phrasesZ_d^uが与えられたとき、ヘッドラインを生成するモデルを訓練する。この時も、ユーザにとって正解のヘッドラインは分からないため、既存ニュースのヘッドラインが正解として用いられる。既存ニュースのヘッドラインが正解として用いられていても、そのヘッドラインがそのユーザにとっての正解となるように人工的にユーザが作成されているため、モデルの訓練ができる。モデルはBARTを用いた。
# Dataset
Newsroom, Gigawordコーパスを用いる。これらのコーパスに対して、それぞれ2種類のコーパスを作成する。
1つは、Synthesized User Datasetで、これはUse Signature Selection modelの訓練と評価に用いる。もう一つはheadline generationデータセットで、こちらはheadline generationモデルの訓練に利用する。
## Synthesized User Creation
実データがないので、実ユーザのreading historiesを模倣するように人工ユーザを作成する。具体的には、
1. すべてのニュース記事のSignature Phrasesを同定する
2. それぞれのSignature Phraseと、それを含むニュース記事をマッピングする
3. ランダムにphraseのサブセットをサンプリングし、そのサブセットをある人工ユーザが興味を持つエリアとする。
4. サブセット中のinterest phraseを含むニュース記事をランダムにサンプリングし、ユーザのreading historyとする
train, dev, testセット、それぞれに対して上記操作を実施しユーザを作成するが、train, devはContrastive Learningを実現するために、user signature phrases (interest phrases)は1つのみとした(Softmaxがそうなっていないと訓練できないので)。一方、testセットは1~5の範囲でuser signature phrasesを選択した。これにより、サンプリングされる記事が多様化され、ユーザのreadinig historyが多様化することになる。基本的には、ユーザが興味のあるトピックが少ない方が、よりタスクとしては簡単になることが期待される。また、ヘッドラインを生成するときは、ユーザのsignature phraseを含む記事をランダムに選び、ヘッドラインを背衛星することとした。これは、relevantな記事でないとヘッドラインがそもそも生成できないからである。
## Headline Generation
ニュース記事の全てのsignature phraseを抽出し、それがgivenな時に、元のニュース記事のヘッドラインが生成できるようなBARTを訓練した。ニュース記事のtokenは512でtruncateした。平均して、10個のsignature phraseがニュース記事ごとに選択されており、ヘッドライン生成の多様さがうかがえる。user signature phraseそのものを用いて訓練はしていないが、そもそもこのようにGenericなデータで訓練しても、何らかのphraseがgivenな時に、それにバイアスがかかったヘッドラインを生成することができるので、user signature phrase selectionによって得られたphraseを用いてヘッドラインを生成することができる。
# 評価
自動評価と人手評価をしている。
## 自動評価
人手評価はコストがかかり、特に開発フェーズにおいては自動評価ができることが非常に重要となる。本研究では自動評価し方法を提案している。Headline-User DPR + SBERT, REC Scoreは、User Adaptation Metricsであり、Headline-Article DPR + SBERT, FactCCはArticle Loyalty Metricsである。
### Relevance Metrics
PretrainedなDense Passage Retrieval (DPR)モデルと、SentenceBERTを用いて、headline-user間、headline-article間の類似度を測定する。前者はヘッドラインがどれだけユーザに適応しているが、後者はヘッドラインが元記事に対してどれだけ忠実か(クリックベイトを防ぐために)に用いられる。前者は、ヘッドラインとuser signaturesに対して類似度を計算し、後者はヘッドラインと記事全文に対して類似度を計算する。user signatures, 記事全文をどのようにエンコードしたかは記述されていない。
### Recommendation Score
ヘッドラインと、ユーザのreadinig historyが与えられたときに、ニュースを推薦するモデルを用いて、スコアを算出する。モデルとしては、MIND datsetを用いて学習したモデルを用いた。
### Factual Consistency
pretrainedなFactCCモデルを用いて、ヘッドラインとニュース記事間のfactual consisency score を算出する。
### Surface Overlap
オリジナルのヘッドラインと、生成されたヘッドラインのROUGE-L F1と、Extractive Coverage (ヘッドラインに含まれる単語のうち、ソースに含まれる単語の割合)を用いる。
### 評価結果
提案手法のうち、User Signature Selection modelをfinetuningしたものが最も性能が高かった。エンコード方法は、(2)のヒストリのタイトルとフレーズの最大スコアをとる方法が最も性能が高い。提案手法はUser Adaptationをしつつも、Article Loyaltyを保っている。このため、クリックベイトの防止につながる。また、Vanilla Humanは元記事のヘッドラインであり、Extracitve Coverageが低いため、より抽象的で、かつ元記事に対する忠実性が低いことがうかがえる。
## 人手評価
16人のevaluatorで評価。2260件のニュース記事を収集(113 topic)し、記事のヘッドラインと、対応するトピックを見せて、20個の興味に合致するヘッドラインを選択してもらった。これをユーザのinterest phraseとreading _historyとして扱う。そして、ユーザのinterest phraseを含むニュース記事のうち、12個をランダムに選択し、ヘッドラインを生成した。生成したヘッドラインに対して、
1. Vanilla Human
2. Vanilla System
3. SP random (ランダムにsignature phraseを選ぶ手法)
4. SP individual-N
5. SP individual-F (User Signature Phraseを選択するモデルをfinetuningしたもの)
の5種類を評価するよう依頼した。このとき、3つの観点から評価をした。
1, User adaptation
2. Headline appropriateness
3. Text Quality
結果は以下。
SP-individualがUser Adaptationで最も高い性能を獲得した。また、Vanilla Systemが最も高いHeadline appropriatenessを獲得した。しかしながら、後ほど分析した結果、Vanilla Systemでは、記事のメインポイントを押さえられていないような例があることが分かった(んーこれは正直他の手法でも同じだと思うから、ディフェンスとしては苦しいのでは)。
また、Vanilla Humanが最も高いスコアを獲得しなかった。これは、オーバーにレトリックを用いていたり、一般的な人にはわからないようなタイトルになっているものがあるからであると考えられる。
# Ablation Study
Signature Phrase selectionの性能を測定したところ以下の通りになり、finetuningした場合の性能が良かった。
Headline Generationの性能に影響を与える要素としては、
1. ユーザが興味のあるトピック数
2. User signature phrasesの数
がある。
ユーザのInterest Phrasesが増えていけばいくほど、User Adaptationスコアは減少するが、Article Loyaltyは維持されたままである。このため、興味があるトピックが多ければ多いほど生成が難しいことがわかる。また、複数のuser signature phraseを用いると、factual errorを起こすことが分かった(Billgates, Zuckerbergの例を参照)。これは、モデルが本来はirrelevantなフレーズを用いてcoherentなヘッドラインを生成しようとしてしまうためである。
※interest phrases => gold user signatures という理解でよさそう。
※signature phrasesを複数用いるとfactual errorを起こすため、今回はk=1で実験していると思われる
GPT3にもヘッドラインを生成させてみたが、提案手法の方が性能が良かった(自動評価で)。
なぜPENS dataset [Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
を利用しないで研究したのか?
[Paper Note] ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks, Fabrizio Gilardi+, NAS'23, 2023.03
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Annotation Issue Date: 2023-04-12 GPT Summary- ChatGPTは、2,382件のツイートを用いたアノテーションタスクにおいて、クラウドワーカーを上回る性能を示し、特に4つのタスクでゼロショット精度が優れています。また、インターコーダー合意でも全てのタスクでクラウドワーカーや訓練を受けたアノテーターを超え、コストもMTurkの約20倍安価です。これにより、大規模言語モデルがテキスト分類の効率を大幅に向上させる可能性が示唆されます。 Comment
# 概要
2300件程度のツイートを分類するタスクにおいて、訓練した学部生によるアノテーションを正解とし、クラウドワーカーとChatGPTでのzero-shotでの予測の性能を比較した。分類タスクは、比較的難易度の高い分類問題であり、クラウドワーカーでも正解率は難しいタスクでは15--25%程度であった。このようなタスクでchatgptは40--60%の正解率を示している。
比較の結果、5つのタスク中4つのタスクでChatGPTがクラウドワーカーを上回る正解率を示した。
# 手法
- クラウドワーカーとChatGPTで同じインストラクションを利用し、同じタスクを実施した
- inter-notator aggreementを図るために、それぞれのタスクについて各ツイートに少なくとも2人がラベル付を行った
- ChatGPTでも同様に、タスクごとに各ツイートには2回同じタスクを実施しデータを収集した
- ChatGPTを利用する際は、temperatureを1.0, 0.2の場合で試した。従ってChatGPTのラベル付けは各タスクごとに4セット存在することになる。
# 結果
5タスク中、4タスクでChatGPTがzero-shotにもかかわらず正解率でworkerを上回った。また高いaggreementを発揮していることを主張。aggreementはtemperatureが低い方が高く、これはtemperatureが低い方がrandomnessが減少するためであると考えられる。aggreementをAccuracyの相関を図ったが、0.17であり弱い相関しかなかった。従って、Accuracyを減少させることなく、一貫性のある結果を得られるlaw temperatureを利用することが望ましいと結論づけている。
# 実施したタスク
"content moderation"に関するタスクを実施した。content moderationはSNSなどに投稿されるpostを監視するための取り組みであり、たとえばポルトツイートや誤った情報を含む有害なツイート、ヘイトスピーチなどが存在しないかをSNS上で監視をを行うようなタスクである。著者らはcontent moderationはハードなタスクであり、複雑なトピックだし、toy exampleではないことを主張している。実際、著者らが訓練した学部生の間でのinter-annotator aggreementは50%程度であり、難易度が高いタスクであることがわかる(ただし、スタンスdetectionに関してはaggreementが78.3%であった)。
content moderationのうち、以下の5つのタスクを実施した。
- relevance:
- ツイートがcontent moderationについて直接的に関係することを述べているか否か
- e.g. SNSにおけるcontent moderation ruleや実践、政府のレギュレーション等
- content moderationについて述べていないものについてはIRRELEVANTラベルを付与する
- ただし、主題がcontent moderationのツイートであっても、content moderationについて論じていないものについてはIRRELEVANT扱いとする。
- このような例としては、TwitterがDonald TrupのTwitterを"disrupted"とlabel付けしたことや、何かについて間違っていると述べているツイート、センシティブな内容を含むツイートなどがあげられる。
- Problem/Solution Frames
- content moderationは2つの見方ができる。それがProblemとSolution
- Problem: content moderationをPROBLEMとみなすもの。たとえば、フリースピーチの制限など
- SOLUTION: content moderationをSOLUTIONとみなすもの。たとえば、harmful speechから守ること、など
- ツイートがcontent moderationのnegativeな影響について強調していたら、PROBLEM(フリースピーチの制限やユーザがポストする内容についてバイアスが生じることなどについて)
- ツイートがcontent moderationのpositiveな影響について強調していたら、SOKUTION(harmful contentからユーザを守るなど)
- 主題はcontent moderationであるが、positive/negativeな影響について論じていないものはNEUTRAL
- Policy Frames
- content moderationはさまざまんトピックと関連している(たとえば)、健康、犯罪、平等など)
- content moderatiojnに関するツイートがどのトピックかをラベル付する。ラベルは15種類
- economy, capcity and resources, modality, fairness and equality, constitutionality and jurisprudence, policy prescription and evaluation, law and order, crime and justice, security and defense, health and safety, quality of life, cultural identity, public opinion, political, external regulation and reputation, other
- Stance Detection
- USのSection 230という法律(websiteにユーザが投稿したコンテンツに対して、webサイトやその他のオンラインプラットフォームが法的責任を問われるのを防ぐ法律)について、ツイートがSection230に対して、positive/negative/neutralなスタンスかをラベル付する
- Topic Detection
- ツイートを6つのトピックにラベル付する
- Section 230, TRUMP BAN, TWITTER-SUPPORT, PLATFORM POLICIES, COMPLAINTS, other
# 所感
そこそこ難易度の高いアノテーションタスクでもzero-shotでturkerの性能を上回るのは非常に素晴らしいことだと思う。ノイジーなデータセットであれば、比較的安価、かつスピーディーに作成できるようになってきたのではないかと思う。
ただ、ChatGPTのaggreementを図ることにどれだけ意味があるのだろう、とは思う。同じモデルを利用しているわけで、小tなるLLMをベースにした場合のaggreementならとる意味があると思うが。
[Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Dataset #LanguageModel #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #ACL Issue Date: 2023-05-31 GPT Summary- この論文では、ユーザーの興味とニュース本文に基づいて、ユーザー固有のタイトルを生成するパーソナライズされたニュース見出し生成の問題を解決するためのフレームワークを提案します。また、この問題のための大規模なデータセットであるPENSを公開し、ベンチマークスコアを示します。データセットはhttps://msnews.github.io/pens.htmlで入手可能です。 Comment
# 概要
ニュース記事に対するPersonalizedなHeadlineの正解データを生成。103名のvolunteerの最低でも50件のクリックログと、200件に対する正解タイトルを生成した。正解タイトルを生成する際は、各ドキュメントごとに4名異なるユーザが正解タイトルを生成するようにした。これらを、Microsoft Newsの大規模ユーザ行動ログデータと、ニュース記事本文、タイトル、impressionログと組み合わせてPENSデータを構成した。
# データセット生成手順
103名のenglish-native [speakerの学生に対して、1000件のニュースヘッドラインの中から最低50件興味のあるヘッドラインを選択してもらう。続いて、200件のニュース記事に対して、正解ヘッドラインを生成したもらうことでデータを生成した。正解ヘッドラインを生成する際は、同一のニュースに対して4人がヘッドラインを生成するように調整した。生成されたヘッドラインは専門家によってqualityをチェックされ、factual informationにエラーがあるものや、極端に長い・短いものなどは除外された。
# データセット統計量
# 手法概要
Transformer Encoder + Pointer GeneratorによってPersonalizedなヘッドラインを生成する。
Transformer Encoderでは、ニュースの本文情報をエンコードし、attention distributionを生成する。Decoder側では、User Embeddingを組み合わせて、テキストをPointer Generatorの枠組みでデコーディングしていき、ヘッドラインを生成する。
User Embeddingをどのようにinjectするかで、3種類の方法を提案しており、1つ目は、Decoderの初期状態に設定する方法、2つ目は、ニュース本文のattention distributionの計算に利用する方法、3つ目はデコーディング時に、ソースからvocabをコピーするか、生成するかを選択する際に利用する方法。1つ目は一番シンプルな方法、2つ目は、ユーザによって記事で着目する部分が違うからattention distributionも変えましょう、そしてこれを変えたらcontext vectorも変わるからデコーディング時の挙動も変わるよねというモチベーション、3つ目は、選択するvocabを嗜好に合わせて変えましょう、という方向性だと思われる。最終的に、2つ目の方法が最も性能が良いことが示された。
# 訓練手法
まずニュース記事推薦システムを訓練し、user embeddingを取得できるようにする。続いて、genericなheadline generationモデルを訓練する。最後に両者を組み合わせて、Reinforcement LearningでPersonalized Headeline Generationモデルを訓練する。Rewardとして、
1. Personalization: ヘッドラインとuser embeddingのdot productで報酬とする
2. Fluency: two-layer LSTMを訓練し、生成されたヘッドラインのprobabilityを推定することで報酬とする
3. Factual Consistency: 生成されたヘッドラインと本文の各文とのROUGEを測りtop-3 scoreの平均を報酬とする
とした。
1,2,3の平均を最終的なRewardとする。
# 実験結果
Genericな手法と比較して、全てPersonalizedな手法が良かった。また、手法としては②のattention distributionに対してuser informationを注入する方法が良かった。News Recommendationの性能が高いほど、生成されるヘッドラインの性能も良かった。
# Case Study
ある記事に対するヘッドラインの一覧。Pointer-Genでは、重要な情報が抜け落ちてしまっているが、提案手法では抜け落ちていない。これはRLの報酬のfluencyによるものだと考えられる。また、異なるユーザには異なるヘッドラインが生成されていることが分かる。
[Paper Note] Larger-context language modelling with recurrent neural networks, Wang+, ACL'16
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #NLP #LanguageModel #ACL Issue Date: 2017-12-28 Comment
## 概要
通常のNeural Language Modelはsentence間に独立性の仮定を置きモデル化されているが、この独立性を排除し、preceding sentencesに依存するようにモデル化することで、言語モデルのコーパスレベルでのPerplexityが改善したという話。提案した言語モデルは、contextを考慮することで特に名詞や動詞、形容詞の予測性能が向上。Late-Fusion methodと呼ばれるRNNのoutputの計算にcontext vectorを組み込む手法が、Perplexityの改善にもっとも寄与していた。
## 手法
sentence間の独立性を排除し、Corpusレベルのprobabilityを下図のように定義。(普通はP(Slが条件付けされていない))
preceding sentence (context)をモデル化するために、3種類の手法を提案。
[1. bag-of-words context]
ナイーブに、contextに現れた単語の(単一の)bag-of-wordsベクトルを作り、linear layerをかませてcontext vectorを生成する手法。
[2. context recurrent neural network]
preceding sentencesをbag-of-wordsベクトルの系列で表現し、これらのベクトルをsequentialにRNN-LSTMに読み込ませ、最後のhidden stateをcontext vectorとする手法。これにより、sentenceが出現した順番が考慮される。
[3. attention based context representation]
Attentionを用いる手法も提案されており、context recurrent neural networkと同様にRNNにbag-of-wordsのsequenceを食わせるが、各時点におけるcontext sentenceのベクトルを、bi-directionalなRNNのforward, backward stateをconcatしたもので表現し、attention weightの計算に用いる。context vectorは1, 2ではcurrent sentence中では共通のものを用いるが、attention basedな場合はcurrent sentenceの単語ごとに異なるcontext vectorを生成して用いる。
生成したcontext vectorをsentence-levelのRNN言語モデルに組み合わせる際に、二種類のFusion Methodを提案している。
[1. Early Fusion]
ナイーブに、RNNLMの各時点でのinputにcontext vectorの情報を組み込む方法。
[2. Late Fusion]
よりうまくcontext vectorの情報を組み込むために、current sentence内の単語のdependency(intra-sentence dependency)と、current sentenceとcontextの関係を別々に考慮する。context vectorとmemory cellの情報から、context vector中の不要箇所をフィルタリングしたcontrolled context vectorを生成し、LSTMのoutputの計算に用いる。Later Fusionはシンプルだが、corpusレベルのlanguage modelingの勾配消失問題を緩和することもできる。
## 評価
IMDB, BBC, PennTreebank, Fil9 (cleaned wikipedia corpus)の4種類のデータで学習し、corpus levelでPerplexityを測った。
Late FusionがPerplexityの減少に大きく寄与している。
PoSタグごとのperplexityを測った結果、contextを考慮した場合に名詞や形容詞、動詞のPerplexityに改善が見られた。一方、Coordinate Conjungtion (And, Or, So, Forなど)や限定詞、Personal Pronouns (I, You, It, Heなど)のPerplexityは劣化した。前者はopen-classな内容語であり、後者はclosed-classな機能語である。機能語はgrammaticalなroleを決めるのに対し、内容語はその名の通り、sentenceやdiscourseの内容を決めるものなので、文書の内容をより捉えることができると考察している。
[Paper Note] Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval, Liu+, NAACL-HLT'15, 2015.05
Paper/Blog Link My Issue
#NeuralNetwork #InformationRetrieval #Search #MultitaskLearning #QueryClassification #WebSearch #RepresentationLearning #NAACL Issue Date: 2018-02-05 Comment
クエリ分類と検索をNeural Netを用いてmulti-task learningする研究
分類(multi-class classification)とランキング(pairwise learning-to-rank)という異なる操作が必要なタスクを、multi task learningの枠組みで組み合わせた(初めての?)研究。
この研究では分類タスクとしてクエリ分類、ランキングタスクとしてWeb Searchを扱っている。
モデルの全体像は下図の通り。
shared layersの部分で、クエリとドキュメントを一度共通の空間に落とし、そのrepresentationを用いて、l3においてtask-specificな空間に写像し各タスクを解いている。
分類タスクを解く際には、outputはsigmoidを用いる(すなわち、output layerのユニット数はラベル数分存在する)。
Web Searchを解く際には、クエリとドキュメントをそれぞれtask specificな空間に別々に写像し、それらのcosine similarityをとった結果にsoftmaxをかけることで、ドキュメントのrelevance scoreを計算している。
学習時のアルゴリズムは上の通り。各タスクをランダムにpickし、各タスクの目的関数が最適化されるように思いをSGDで更新する、といったことを繰り返す。
なお、alternativeとして、下図のようなネットワーク構造を考えることができるが(クエリのrepresentationのみがシェアされている)、このモデルの場合はweb searchがあまりうまくいかなかった模様。
理由としては、unbalancedなupdates(クエリパラメータのupdateがdocumentよりも多くアップデートされること)が原因ではないかと言及しており、multi-task modelにおいては、パラメータをどれだけシェアするかはネットワークをデザインする上で重要な選択であると述べている。
評価で用いるデータの統計量は下記の通り。
1年分の検索ログから抽出。クエリ分類(各クラスごとにbinary)、および文書のrelevance score(5-scale)は人手で付与されている。
クエリ分類はROC曲線のAUCを用い、Web SearchではNDCG (Normalized Discounted Cumulative Gain) を用いた。

multi task learningをした場合に、性能が向上している。
また、ネットワークが学習したsemantic representationとSVMを用いて、domain adaptationの実験(各クエリ分類のタスクは独立しているので、一つのクエリ分類のデータを選択しsemantic representationをtrainし、学習したrepresentationを別のクエリ分類タスクに適用する)も行なっており、訓練事例数が少ない場合に有効に働くことを確認(Letter3gramとWord3gramはnot trained/adapted)。

また、SemanticRepresentationへ写像する行列W1のパラメータの初期化の仕方と、サンプル数の変化による性能の違いについても実験。DNN1はW1をランダムに初期化、DNN2は別タスク(別のクエリ分類タスク)で学習したW1でfixする手法。
訓練事例が数百万程度ある場合は、DNN1がもっとも性能がよく、数千の訓練事例数の場合はsemantic representationを用いたSVMがもっともよく、midium-rangeの訓練事例数の場合はDNN2がもっとも性能がよかったため、データのサイズに応じて手法を使い分けると良い。
データセットにおいて、クエリの長さや文書の長さが記述されていないのがきになる。
[Paper Note] Sentence Compression by Deletion with LSTMs, Fillipova+, EMNLP'15
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #Sentence #NLP #EMNLP #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
slide: https://www.slideshare.net/akihikowatanabe3110/sentence-compression-by-deletion-with-lstms
[Paper Note] Query-Chain Focused Summarization, Baumel+, ACL'14
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NLP #Dataset #QueryBiased #Extractive #ACL #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。
Hunyuan-MT-7B, Tencent, 2025.09
Paper/Blog Link My Issue
#Article #MachineTranslation #NLP #LanguageModel #OpenWeight #Catastrophic Forgetting #mid-training #Selected Papers/Blogs #In-Depth Notes Issue Date: 2025-09-01 Comment
テクニカルレポート: https://github.com/Tencent-Hunyuan/Hunyuan-MT/blob/main/Hunyuan_MT_Technical_Report.pdf
元ポスト:
Base Modelに対してまず一般的な事前学習を実施し、その後MTに特化した継続事前学習(モノリンガル/パラレルコーパスの利用)、事後学習(SFT, GRPO)を実施している模様。
継続事前学習では、最適なDataMixの比率を見つけるために、RegMixと呼ばれる手法を利用。Catastrophic Forgettingを防ぐために、事前学習データの20%を含めるといった施策を実施。
SFTでは2つのステージで構成されている。ステージ1は基礎的な翻訳力の強化と翻訳に関する指示追従能力の向上のために、Flores-200の開発データ(33言語の双方向の翻訳をカバー)、前年度のWMTのテストセット(English to XXをカバー)、Mandarin to Minority, Minority to Mandarinのcuratedな人手でのアノテーションデータ、DeepSeek-V3-0324での合成パラレルコーパス、general purpose/MT orientedな指示チューニングデータセットのうち20%を構成するデータで翻訳のinstructinoに関するモデルの凡化性能を高めるためキュレーションされたデータ、で学習している模様。パラレルコーパスはReference-freeな手法を用いてスコアを算出し閾値以下の低品質な翻訳対は除外している。ステージ2では、詳細が書かれていないが、少量でよりfidelityの高い約270kの翻訳対を利用した模様。また、先行研究に基づいて、many-shotのin-context learningを用いて、訓練データをさらに洗練させたとのこと(先行研究が引用されているのみで詳細な記述は無し)。また、複数の評価ラウンドでスコアの一貫性が無いサンプルは手動でアノテーション、あるいはverificationをして品質を担保している模様。
RLではGRPOを採用し、rewardとしてsemantic([Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
), terminology([Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
; ドメイン特有のterminologyを捉える), repetitionに基づいたrewardを採用している。最終的にSFT->RLで学習されたHuayuan-MT-7Bに対して、下記プロンプトを用いて複数のoutputを統合してより高品質な翻訳を出力するキメラモデルを同様のrewardを用いて学習する、といったpipelineになっている。
関連:
- Large Language Models Are State-of-the-Art Evaluators of Translation Quality, EAMT'23
- [Paper Note] xCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection, Nuno M. Guerreiro+, TACL'24
- [Paper Note] CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task, Rei+, WMT'22
- [Paper Note] No Language Left Behind: Scaling Human-Centered Machine Translation, NLLB Team+, arXiv'22
- [Paper Note] Many-Shot In-Context Learning, Rishabh Agarwal+, NeurIPS'24
- [Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
- [Paper Note] TAT-R1: Terminology-Aware Translation with Reinforcement Learning and
Word Alignment, Zheng Li+, arXiv'25
関連: PLaMo翻訳
- PLaMo Translate: 翻訳特化大規模言語モデルの開発,今城+, Jxiv'25
こちらはSFT->Iterative DPO->Model Mergeを実施し、翻訳に特化した継続事前学習はやっていないように見える。一方、SFT時点で独自のテンプレートを作成し、語彙の指定やスタイル、日本語特有の常体、敬体の指定などを実施できるように翻訳に特化したテンプレートを学習している点が異なるように見える。Hunyuanは多様な翻訳の指示に対応できるように学習しているが、PLaMo翻訳はユースケースを絞り込み、ユースケースに対する性能を高めるような特化型のアプローチをとるといった思想の違いが伺える。