
Library
[Paper Note] Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting, Hao Feng+, ACL'25
Paper/Blog Link My Issue
#Document #Pocket #NLP #ACL #DocParser Issue Date: 2025-06-21 GPT Summary- 文書画像解析の新モデル「Dolphin」を提案。レイアウト要素をシーケンス化し、タスク特有のプロンプトと組み合わせて解析を行う。3000万以上のサンプルで訓練し、ページレベルと要素レベルの両方で最先端の性能を達成。効率的なアーキテクチャを実現。コードは公開中。 Comment
repo: https://github.com/bytedance/Dolphin
SoTAなDocumentのparser
ドキュメントに記述が見当たらないように見えたが、おそらくHFに付与されているタグを見る限り、英語と中国語をサポートしていると思われる
EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models, Ziwen Xu+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #KnowledgeEditing Issue Date: 2025-05-11 GPT Summary- 本論文では、LLMの挙動を制御するためのフレームワーク「EasyEdit2」を提案。安全性や感情、個性などの介入をサポートし、使いやすさが特徴。ユーザーは技術的知識なしでモデルの応答を調整可能。新しいアーキテクチャにより、ステアリングベクトルを自動生成・適用するモジュールを搭載。実証的なパフォーマンスを報告し、ソースコードやデモも公開。 Comment
[Paper Note] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks, Adam Fourney+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Multi #Pocket #NLP #LanguageModel #AIAgents Issue Date: 2025-11-25 GPT Summary- 高性能なオープンソースエージェントシステム「Magentic-One」を提案。マルチエージェントアーキテクチャを用いて計画、進捗追跡、エラー回復を行い、専門エージェントにタスクを指示。GAIA、AssistantBench、WebArenaのベンチマークで競争力のあるパフォーマンスを達成。モジュラー設計により、エージェントの追加や削除が容易で、将来の拡張が可能。オープンソース実装とエージェント評価ツール「AutoGenBench」を提供。詳細は公式サイトで確認可能。 Comment
日本語解説: https://zenn.dev/masuda1112/articles/2024-11-30-magnetic-one
blog:
https://www.microsoft.com/en-us/research/articles/magentic-one-a-generalist-multi-agent-system-for-solving-complex-tasks/
code:
https://github.com/microsoft/autogen/tree/main/python/packages/autogen-magentic-one
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models, Peng Wang+, ACL'24, (System Demonstrations)
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ACL #KnowledgeEditing Issue Date: 2025-05-11 GPT Summary- EasyEditは、LLMsのための使いやすい知識編集フレームワークであり、さまざまな知識編集アプローチをサポート。LlaMA-2の実験結果では、信頼性と一般化の面で従来のファインチューニングを上回ることを示した。GitHubでソースコードを公開し、Google Colabチュートリアルやオンラインシステムも提供。 Comment
ver2.0:
- EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language
Models, Ziwen Xu+, arXiv'25
[Paper Note] Revisiting BPR: A Replicability Study of a Common Recommender System Baseline, Aleksandr Milogradskii+, RecSys'24
Paper/Blog Link My Issue
#RecommenderSystems #Analysis #CollaborativeFiltering #Evaluation #RecSys Issue Date: 2025-04-10 GPT Summary- BPRは協調フィルタリングのベンチマークだが、実装の微妙な点が見落とされ、他手法に劣るとされている。本研究ではBPRの特徴と実装の不一致を分析し、最大50%の性能低下を示す。適切なハイパーパラメータ調整により、BPRはトップn推薦タスクで最先端手法に近い性能を達成し、Million Song DatasetではMult-VAEを10%上回る結果を示した。 Comment
BPR、実装によってまるで性能が違う…
実装の違い
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms, Zhao+, CIKM'21
Paper/Blog Link My Issue
#RecommenderSystems #Tools #CIKM Issue Date: 2022-03-29 GPT Summary- RecBoleは、推薦アルゴリズムのオープンソース実装を標準化するための統一的で効率的なライブラリであり、73のモデルを28のベンチマークデータセット上で実装。PyTorchに基づき、一般的なデータ構造や評価プロトコル、自動パラメータ調整機能を提供し、推薦システムの実装と評価を促進する。プロジェクトはhttps://recbole.io/で公開。 Comment
参考リンク:
-
https://www.google.co.jp/amp/s/techblog.zozo.com/entry/deep-learning-recommendation-improvement%3famp=1
-
https://techlife.cookpad.com/entry/2021/11/04/090000
-
https://qiita.com/fufufukakaka/items/77878c1e23338345d4fa
pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models, Bardrinath+, EDM'20
Paper/Blog Link My Issue
#Tools #AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-07-27 Comment
pythonによるBKTの実装。scikit-learnベースドなinterfaceを持っているので使いやすそう。
# モチベーション
BKTの研究は古くから行われており、研究コミュニティで人気が高まっているにもかかわらず、アクセス可能で使いやすいモデルの実装と、さまざまな文献で提案されている多くの変種は、理解しにくいものとなっている。そこで、モダンなpythonベースドな実装としてpyBKTを実装し、研究コミュニティがBKT研究にアクセスしやすいようにした。ライブラリのインターフェースと基礎となるデータ表現は、過去の BKTの変種を再現するのに十分な表現力があり、新しいモデルの提案を可能にする。 また、既存モデルとstate-of-the-artの比較評価も容易にできるように設計されている。
# BKTとは
BKTの説明は Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
あたりを参照のこと。
BKTはHidden Markov Model (HMM) であり、ある時刻tにおける観測変数(問題に対する正誤)と隠れ変数(学習者のknowledge stateを表す)によって構成される。パラメータは prior(生徒が事前にスキルを知っている確率), learn (transition probability; 生徒がスキルを学習することでスキルに習熟する確率), slip, guess (emission probability; スキルに習熟しているのに問題に正解する確率, スキルに習熟していないのに問題に正解する確率)の4種類のパラメータをEMアルゴリズムで学習する。
ここで、P(L_t)が時刻tで学習者がスキルtに習熟している確率を表す。BKTでは、P(L_t)を観測された正解/不正解のデータに基づいてP(L_t)をアップデートし、下記式で事後確率を計算する
また、時刻t+1の事前確率は下記式で計算される。
一般的なBKTモデルではforgettingは生じないようになっている。
Corbett and Andersonが提案している初期のBKTだけでなく、さまざまなBKTの変種も実装している。
# サポートしているモデル
- KT-IDEM (Item Difficulty Effect): BKTとは異なり、個々のquestionごとにguess/slipパラメータを学習するモデル KT-IDEM: Introducing Item Difficulty to the Knowledge Tracing Model, Pardos+ (w/ Neil T. Heffernan), UMAP11
- KT-PPS: 個々の生徒ごとにprior knowledgeのパラメータを持つ学習するモデル Modeling individualization in a bayesian networks implementation of knowledge tracing, Pardos+ (w/ Neil T. Heffernan), UMAP'00
- BKT+Forget: 通常のBKTでは一度masterしたスキルがunmasteredに遷移することはないが、それが生じるようなモデル。直近の試行がより重視されるようになる。 How Deep is Knowledge Tracing?, Mozer+, EDM'16
- Item Order Effect: TBD
- Item Learning Effect: TBD
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, Reimers+, UKP-TUDA, EMNLP'19
Paper/Blog Link My Issue
#NeuralNetwork #NLP Issue Date: 2022-07-29 Comment
BERTでトークンをembeddingし、mean poolingすることで生成される文ベクトルを、Siamese Networkを使い距離学習(finetune)させたモデル。
文/文章のベクトルを事前学習済みのモデルを使って簡単に求められる。
モデルの一覧は下記:
https://www.sbert.net/docs/pretrained_models.html
[Paper Note] LensKit for Python: Next-Generation Software for Recommender System Experiments, Michael D. Ekstrand, arXiv'18, 2018.09
Paper/Blog Link My Issue
#RecommenderSystems #Tools #Pocket #One-Line Notes Issue Date: 2018-01-01 GPT Summary- LensKitはレコメンダーシステムのためのオープンソースツールキットで、次世代版としてPython用のLensKit(LKPY)を紹介。LKPYは、研究者や学生が再現可能な実験を構築できるようにし、scikit-learnやTensorFlow、PyTorchなどのエコシステムを活用。古典的な協調フィルタリングの実装や評価指標、データ準備ルーチンを提供し、他のPythonソフトウェアと組み合わせて使用可能。設計目標やユースケースについて、元のJava版の成功と失敗を振り返りながら説明。 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:Java
使用方法:コマンドライン、Javaライブラリとして利用
※ 推薦システム界隈で有名な、GroupLens研究グループによるJava実装
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] fastFM: A Library for Factorization Machines, Immanuel Bayer, arXiv'15, 2015.05
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #Pocket #FactorizationMachines #One-Line Notes Issue Date: 2018-01-01 GPT Summary- 因子分解機(FM)は、レコメンダーシステムで成功を収めているにもかかわらず、機械学習の標準ツールボックスには含まれていない。私たちのFMの実装は、回帰、分類、ランキングタスクをサポートし、多くのソルバーへのアクセスを簡素化することで、FMの幅広いアプリケーション利用を促進する。これにより、FMモデルの理解が深まり、新たな開発が期待される。 Comment
実装されているアルゴリズム:Factorization Machines
実装:python
使用方法:pythonライブラリとして利用
※ Factorization Machinesに特化したpythonライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
Pocket Flow: 100-line LLM framework. Let Agents build Agents, The-Rocket, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #python #SoftwareEngineering #read-later #Selected Papers/Blogs #MinimalCode Issue Date: 2026-01-19 Comment
元ポスト:
たったの100行で実現されるミニマルなAI Agent/LLMフレームワークで、9種類の抽象化(Node, Flow, Shared, ...)でchat, agent, workflow, RAG, MCP, A2Aなどの様々なLLMをベースとした機能を実装できるフレームワークな模様。コード読みたい
LLMRouter: An Open-Source Library for LLM Routing, Feng+, 2025.12
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #python #SoftwareEngineering #Routing Issue Date: 2025-12-30 Comment
元ポスト:
LightX2V: Light Video Generation Inference Framework, ModelTC, 2025.12
Paper/Blog Link My Issue
#Article #ComputerVision #LLMServing #VideoGeneration/Understandings #4D (Video) Issue Date: 2025-12-24 Comment
元ポスト:
[Paper Note] Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning, Meta, 2025.12
Paper/Blog Link My Issue
#Article #ComputerVision #Pocket #MultiModal #SpeechProcessing #python #Encoder #2D (Image) #4D (Video) #audio Issue Date: 2025-12-19 Comment
元ポスト:
様々なモダリティ(画像・動画・音声等)をエンコードできるPerception Encoderに最近リリースされたSAM Audio (Audio-Visual / Audio-frame) も組み込まれた模様
code:
https://github.com/facebookresearch/perception_models
Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog #Distillation #On-Policy #reading Issue Date: 2025-10-30 Comment
元ポスト:
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
で提案されている手法拡張してトークナイザが異なるモデル間でもオンポリシーRLを用いてknowledge distillationを実現できるようなGKD trainerがTRLに実装されたとのこと。
Introducing torchforge – a PyTorch native library for scalable RL post-training and agentic development, PyTorch team at Meta, 2025.10
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #AIAgents #Blog #Selected Papers/Blogs Issue Date: 2025-10-25 Comment
元ポスト:
slime, THUDM & Zhihu, 2025.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Repository #PostTraining Issue Date: 2025-09-02 Comment
元ポスト:
GLM-4.5のRL学習に利用されたフレームワーク
- [Paper Note] GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, GLM-4. 5 Team+, arXiv'25
RLinf: Reinforcement Learning Infrastructure for Agentic AI, RLinf, 2025.09
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #ReinforcementLearning #Repository #PostTraining #VisionLanguageModel Issue Date: 2025-09-01 Comment
元ポスト:
Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
Paper/Blog Link My Issue
#Article #ReinforcementLearning #Blog #Selected Papers/Blogs #On-Policy #KeyPoint Notes #Reference Collection #train-inference-gap Issue Date: 2025-08-26 Comment
元ポスト:
元々
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
のスレッド中にメモっていたが、アップデートがあったようなので新たにIssue化
trainingのエンジン(FSDP等)とロールアウトに使うinferenceエンジン(SGLang,vLLM)などのエンジンのミスマッチにより、学習がうまくいかなくなるという話。
アップデートがあった模様:
- Parallelismのミスマッチでロールアウトと学習のギャップを広げてしまうこと(特にsequence parallelism)
- Longer Sequenceの方が、ギャップが広がりやすいこと
- Rolloutのためのinferenceエンジンを修正する(SGLang w/ deterministic settingすることも含む)だけでは効果は限定的
といった感じな模様。
さらにアップデート:
FP16にするとtrain-inferenae gapが非常に小さくなるという報告:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
vLLMがtrain inference mismatchを防ぐアップデートを実施:
RLVR_RLHF libraries, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #RLHF #RLVR Issue Date: 2025-08-13 Comment
RLVR,RLHFに関する現在のライブラリがまとまっているスレッド
LMCache, LMCache, 2025.07
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #LanguageModel #python #LLMServing Issue Date: 2025-08-03 Comment
元ポスト:
KV Cacheを色々なところにキャッシュしておいて、prefixだけでなく全てのreused可能なものをキャッシュすることで、TTFTとスループットを大幅に向上するらしい。特にlong contextなタスクで力を発揮し、vLLMと組み合わせると下記のようなパフォーマンス向上結果
LMDeploy, OpenMMLab, 2023.07
Paper/Blog Link My Issue
#Article #LanguageModel #LLMServing Issue Date: 2025-07-21
rLLM, Agentica, 2025.06
Paper/Blog Link My Issue
#Article #NLP #ReinforcementLearning #AIAgents #PostTraining Issue Date: 2025-07-04 Comment
>rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build their custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads.
なるほど。
バックボーンにはverlが採用されており、シンプルかつ統一的なインタフェースでカスタムエージェントが学習できる模様?
https://rllm-project.readthedocs.io/en/latest/#key-features
元ポスト:
関連:
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
v0.2がリリースされ、任意のagentia programの学習がサポートされた模様(マルチエージェントや複雑なワークフローに基づくものなど):
Nemo-RL, Nvidia, 2025.05
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Repository #PostTraining Issue Date: 2025-06-25
verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #python Issue Date: 2025-05-16 Comment
SoTAなRLアルゴリズムを数行のコードで実装可能で、Sequence Parallelismがサポートされているので長い系列を扱える。FSDP, Megatron-LM,vLLM,SGLangなどとシームレスに統合できるっぽい?
注意点(超重要):
inference backend(ブログ中ではvLLM, SGLangなどを仮定。ロールアウトに利用する)とtrainingのbackend(モデルを学習するフレームワーク, FSDPなどを仮定する)のミスマッチによってトークンの生起確率に差が生じ、ポリシーの更新がうまくいかなくなる。
- 論文では語られないLLM開発において重要なこと Swallow Projectを通して, Kazuki Fujii, NLPコロキウム, 2025.07
でも言われているように、ライブラリにはバグがあるのが普通なのね、、、。
ms-swiftによるMegatron-LMベースのQwen3のファインチューニング, Aratako, 2025.05
Paper/Blog Link My Issue
#Article #NLP #Supervised-FineTuning (SFT) #Blog #OpenWeight #MoE(Mixture-of-Experts) #PostTraining Issue Date: 2025-05-11 Comment
元ポスト:
Megatron-SWIFTというAlibaba製のライブラリを利用しQwen3の継続事前学習とSFTを実施する方法を、ベストプラクティスに則って記述し、かつ著者自身が学習したモデルも公開している。(おそらくインスタンス代は自腹なので)すごい...!!
Megatron-SWIFTはMoEアーキテクチャを採用したモデルであれば、DeepSpeed Zero3 [^1]と比べて10倍程度のスループットで学習できる模様(早い)。一方MoEアーキテクチャでないモデルの場合はそこまで大きな差はない。
[^1]: A100 80GB 2ノードでは、Qwen3-30B-A3Bは、DeepSpeed-Zero2ではOOMとなり載らないようだ…。なんとリソースに厳しいこと…(涙)
Agent Frameworkはどれを使うべきか [タスク性能編], はち, 2025.05
Paper/Blog Link My Issue
#Article #Analysis #NLP #AIAgents #Blog Issue Date: 2025-05-06 Comment
各フレームワーク毎の性能の違いや消費したトークン数、実装の微妙や違いがまとめられており、太字でtakeawayが記述されているので非常にわかりやすい。
元ポスト:
The TypeScript Agent Framework, mastra, 2025.03
Paper/Blog Link My Issue
#Article #NLP #AIAgents Issue Date: 2025-03-16 Comment
日本語解説: https://zenn.dev/yosh1/articles/mastra-ai-agent-framework-guide
smolagents, HuggingFace, 2025.03
Paper/Blog Link My Issue
#Article #LanguageModel #AIAgents Issue Date: 2025-03-06 GPT Summary- smolagentsは、数行のコードで強力なエージェントを構築できるライブラリで、シンプルなロジック、コードエージェントのサポート、安全な実行環境、ハブ統合、モデルやモダリティに依存しない設計が特徴。テキスト、視覚、動画、音声入力をサポートし、さまざまなツールと統合可能。詳細はローンチブログ記事を参照。
Open Reasoner Zero, Open-Reasoner-Zero, 2024.02
Paper/Blog Link My Issue
#Article #MachineLearning #NLP #LanguageModel #ReinforcementLearning #python #Reasoning Issue Date: 2025-03-02 GPT Summary- Open-Reasoner-Zeroは、推論指向の強化学習のオープンソース実装で、スケーラビリティとアクセスのしやすさに重点を置いています。AGI研究の促進を目指し、ソースコードやトレーニングデータを公開しています。 Comment
元ポスト:
Llama Stack, Meta, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-01-25 Comment
Llamaを用いたLLM Agentを構築するための標準化されたフレームワーク。Quick StartではRAG Agentを構築している。
distilabel, 2023.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #SyntheticData Issue Date: 2025-01-25 Comment
高品質な合成データをLLMで生成するためのフレームワーク
LiteLLM, BerriAI, 2023.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #python #Repository #API Issue Date: 2025-01-03 Comment
様々なLLMのAPIを共通のインタフェースで呼び出せるライブラリ
- aisuite, andrewyng, 2024.11
とどちらがいいんだ・・・?
aisuiteのissueの113番のスレッドを見ると、
- LiteLLMはもはやLiteではなくなっており、コードベースの保守性が低い
- aisuiteは複数のLLMプロバイダーをシンプルに利用する方法を提供する
- 今後発表されるロードマップを見れば、LiteLLMとの差別化の方向性が分かるはずだ
といった趣旨のことが記述されていた。
floret, explosion, 2021
Paper/Blog Link My Issue
#Article #Embeddings #Word #Repository Issue Date: 2024-12-28 Comment
fasttextを拡張したもの。本家fasttextがアーカイブ化してしまったので、代替手段に良さそう。
元ポスト:
ModernBERT, AnswerDotAI, 2024.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Transformer #pretrained-LM Issue Date: 2024-12-20 GPT Summary- ModernBERTは、エンコーダ専用のトランスフォーマーモデルで、従来のBERTに比べて大幅なパレート改善を実現。2兆トークンで訓練され、8192シーケンス長を持ち、分類タスクやリトリーバルで最先端の結果を示す。速度とメモリ効率も優れており、一般的なGPUでの推論に最適化されている。 Comment
最近の進化しまくったTransformer関連のアーキテクチャをEncodnr-OnlyモデルであるBERTに取り込んだら性能上がるし、BERTの方がコスパが良いタスクはたくさんあるよ、系の話、かつその実装だと思われる。
テクニカルペーパー中に記載はないが、評価データと同じタスクでのDecoder-Onlyモデル(SFT有り無し両方)との性能を比較したらどの程度の性能なのだろうか?
そもそも学習データが手元にあって、BERTをFinetuningするだけで十分な性能が出るのなら(BERTはGPU使うのでそもそもxgboostとかでも良いが)、わざわざLLM使う必要ないと思われる。BERTのFinetuningはそこまで時間はかからないし、inferenceも速い。
参考:
- [Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, EMNLP'23 System Demonstrations, 2023.08
日本語解説: https://zenn.dev/dev_commune/articles/3f5ab431abdea1?utm_source=substack&utm_medium=email
aisuite, andrewyng, 2024.11
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #python #Repository #API Issue Date: 2024-11-28 Comment
複数のLLM Providerの呼び出しを共通のインタフェースで呼び出せる。変更するのは、モデルを指定するパラメータのみ。
元ポスト:
https://www.linkedin.com/posts/andrewyng_announcing-new-open-source-python-package-activity-7266851242604134400-Davp?utm_source=share&utm_medium=member_ios
YomiToku, Kotaro Kinoshita, 2024.11
Paper/Blog Link My Issue
#Article #ComputerVision #Repository #OCR Issue Date: 2024-11-27 Comment
いわゆるAI-OCRで、縦書きの認識も可能で、表などの構造化された情報も認識可能とのこと。
手書きは認識できるのだろうか?
CC BY-NC-SA 4.0
元ツイート:
Lingua, Meta
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Repository #MinimalCode Issue Date: 2024-11-05 Comment
研究目的のための、minimal、かつ高速なLLM training/inferenceのコードが格納されたリポジトリ。独自のモデルやデータ、ロスなどが簡単に実装できる模様。
Streamlit, 2020.12
Paper/Blog Link My Issue
#Article #python Issue Date: 2024-10-07 Comment
データを用いたアプリを簡単に作れるpythonライブラリ
データ/モデルを用いたvisualization等を実施するアプリを、数行で作れてしまう。綺麗なUIつき。便利。
Pluggyとは, 2023.02
Paper/Blog Link My Issue
#Article #python #Blog Issue Date: 2024-09-12 Comment
pluggyに関する概要が説明されている。
公式の説明を読むとpytestで採用されており、pluggyは関数フックを可能にし、プラグインをインストールするだけでホストプログラムの動作を拡張、または変更できるようになる代物とのこと(=プラガブル?)。
pluggyがなぜ有用なのかの説明については、Pythonでは、他のプログラムやライブラリの動作を変更するための既存のメカニズムとして、メソッドのオーバーライドやモンキーパッチが存在するが、複数の関係者が同じプログラムの変更に参加したい場合、これらが問題を引き起こすので、pluggyはこれらのメカニズムに依存せず、より構造化されたアプローチを可能にし、状態や動作の不必要な露出を避けるとのこと。これにより、ホストとプラグインの間が疎結合になるので、問題が軽減されるとのこと。
NanoFlow, 2024.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #python #Repository #LLMServing Issue Date: 2024-08-31 Comment
vLLMよりも2倍程度高速なLLM serving framework。
オフライン評価
オンラインでのlatency評価
機能はvLLMの方が多いが、速度はこちらの方がかなり速そうではある。latencyのrequirementが厳しい場合などは検討しても良いかもしれない。
しかしLLM serving frameworkも群雄割拠ですね。
元ポスト:
DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06 も参照のこと
LitServe, 2024.04
Paper/Blog Link My Issue
#Article #MachineLearning #Repository #API Issue Date: 2024-08-25 Comment
FastAPIより2倍早いAPIライブラリ。LLMやVisionなど多くのモーダルに対応し、マルチワーカーでオートスケーリングやバッチングやストリーミングにも対応。PyTorchモデルだけでなく、JAXなど様々なフレームワークのモデルをデプロイ可能
元ツイート:
画像は元ツイートより引用
list of recommender systems
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #Repository Issue Date: 2024-08-07 Comment
推薦システムに関するSaaS, OpenSource, Datasetなどがまとめられているリポジトリ
DeepSpeed, vLLM, CTranslate2 で rinna 3.6b の生成速度を比較する, 2024.06
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #python #Blog #OpenWeight #LLMServing Issue Date: 2024-08-05 Comment
[vllm](
https://github.com/vllm-project/vllm)を使うのが一番お手軽で、inference速度が速そう。PagedAttentionと呼ばれるキャッシュを利用して高速化しているっぽい。
(図はブログ中より引用)
こちらも参照のこと
vLLMの仕組みをざっくりと理解する:
https://dalab.jp/archives/journal/vllm/#PagedAttention
vLLMでReasoning ModelをServingするときは、`--enable-reasoning`等の追加オプションを指定する必要がある点に注意
https://docs.vllm.ai/en/stable/features/reasoning_outputs.html
OpenLLM: Self-Hosting LLMs Made Easy
Paper/Blog Link My Issue
#Article #NLP #OpenWeight Issue Date: 2024-08-01 Comment
OpenLLMをself hostingする際に、OpenAIなどと同じインタフェースのAPIやChatを提供するライブラリ
mergekit-evolve
Paper/Blog Link My Issue
#Article #LanguageModel #Repository Issue Date: 2024-04-29 Comment
[Paper Note] Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N/A, Nature Machine Intelligence, Vol.7, 2025.01
のように進化的アルゴリズムでモデルマージができるライブラリ
解説記事:
https://note.com/npaka/n/nad2ff954ab81
大きなVRAMが無くとも、大きめのSRAMがあれば動作するらしい
AirLLM, 2024.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Repository Issue Date: 2024-04-28 Comment
4GBのSingle GPUで、70Bモデルのinferenceを実現できるライブラリ。トークンの生成速度は検証する必要がある。transformer decoderの各layerの演算は独立しているため、GPUに全てのlayerを載せず、必要な分だけ載せてinferenceするといった操作を繰り返す模様。
元ツイート:
repeng
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #Alignment #TextualInversion Issue Date: 2024-03-21 Comment
LLMの出力のスタイルを数百個の事例だけで学習しチューニングできるライブラリ。promptで指定するのとは異なり、数値でスタイルの強さを指定することが可能らしい(元ツイート)。画像生成分野におけるTextual Inversionと同じ技術とのこと。
Textual Inversionとは、少量のサンプルを用いて、テキストエンコーダ部分に新たな「単語」を追加し、単語と対応する画像を用いてパラメータを更新することで、prompt中で「単語」を利用した場合に学習した画像のスタイルやオブジェクト(オリジナルの学習データに存在しなくても可)を生成できるようにする技術、らしい。
Huggiegface:
https://huggingface.co/docs/diffusers/training/text_inversion
(参考)GPTに質問した際のログ:
https://chat.openai.com/share/e4558c44-ce09-417f-9c77-6f3855e583fa
元ツイート:
Recommenders
Paper/Blog Link My Issue
#Article #RecommenderSystems #Repository Issue Date: 2024-01-15 Comment
古典的な手法から、Deepな手法まで非常に幅広く網羅された推薦アルゴリズムのフレームワーク。元々Microsoft配下だった模様。
現在もメンテナンスが続いており、良さそう
multimodal-maestro
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Prompting #MultiModal #AutomaticPromptEngineering Issue Date: 2023-12-01 Comment
Large Multimodal Model (LMM)において、雑なpromptを与えるても自動的に良い感じoutputを生成してくれるっぽい?
以下の例はリポジトリからの引用であるが、この例では、"Find dog." という雑なpromptから、画像中央に位置する犬に[9]というラベルを与えました、というresponseを得られている。pipelineとしては、Visual Promptに対してまずSAMを用いてイメージのsegmentationを行い、各セグメントにラベルを振る。このラベルが振られた画像と、"Find dog." という雑なpromptを与えるだけで良い感じに処理をしてくれるようだ。
lifestar
Paper/Blog Link My Issue
#Article #python Issue Date: 2023-11-19 Comment
非常に高速なpythonのASGIライブラリ。WSGIとは異なり非同期処理なためリアルタイムアプリケーションに向いているっぽい。
LLaMA-Factory, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Supervised-FineTuning (SFT) #Repository Issue Date: 2023-11-14 Comment
簡単に利用できるLLaMAのfinetuning frameworkとのこと。
元ツイート:
LLaMAベースなモデルなら色々対応している模様
Transformers.js, 2023
Paper/Blog Link My Issue
#Article #Transformer #Blog Issue Date: 2023-11-13 Comment
ブラウザ上でTransformerベースの様々なモデルを動作させることができるライブラリ
Evaluating RAG Pipelines
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Evaluation #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-10-29 Comment
RAG pipeline (retrieval + generation)を評価するライブラリRagasについて紹介されている。
評価に活用される指標は下記で、背後にLLMを活用しているため、大半の指標はラベルデータ不要。ただし、context_recallを測定する場合はreference answerが必要。
Ragasスコアとしてどのメトリックを利用するかは選択することができ、選択したメトリックのharmonic meanでスコアが算出される。
各種メトリックの内部的な処理は下記:
- faithfullness
- questionと生成された回答に基づいて、statementのリストをLLMで生成する。statementは回答が主張している内容をLLMが解釈したものだと思われる。
- statementのリストとcontextが与えられたときに、statementがcontextにsupportされているかをLLMで評価する。
- num. of supported statements / num. of statements でスコアが算出される
- Answer Relevancy
- LLMで生成された回答から逆に質問を生成し、生成された質問と実際の質問の類似度を測ることで評価
- Context Relevancy
- どれだけcontextにノイズが含まれるかを測定する。
- LLMでcontextの各文ごとに回答に必要な文か否かを判断する
- 回答に必要な文数 / 全文数 でスコアを算出
- Context Recall
- 回答に必要な情報を全てretrieverが抽出できているか
- ground truthとなる回答からstatementをLLMで生成し、statementがcontextでどれだけカバーされているかで算出
また、LangSmithを利用して実験を管理する方法についても記述されている。
LangChainのRAGの改善法, LayerX機械学習勉強会
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-10-29 Comment
以下リンクからの引用。LangChainから提供されているRetrieverのcontext抽出の性能改善のためのソリューション
> Multi representation indexing:検索に適した文書表現(例えば要約)の作成
Query transformation:人間の質問を変換して検索を改善する方法
Query construction:人間の質問を特定のクエリ構文や言語に変換する方法
https://blog.langchain.dev/query-transformations/
Agents: An opensource framework for autonomous language agents
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents Issue Date: 2023-09-30 Comment
以下の特徴を持つLLMAgent開発のためのフレームワーク
- long-short term memory
- tool usage
- web navigation
- multi-agent communication
- human-agent interaction
- symbolic control
また、他のAgent frameworkと違い、ゴールを達成するだの細かいプランニングを策定(SOP; サブタスクとサブゴールを定義)することで、エージェントに対してきめ細かなワークフローを定義できる。
LangChain Cheet Sheet
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel Issue Date: 2023-09-05 Comment
Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました
Paper/Blog Link My Issue
#Article #NLP #LanguageModel Issue Date: 2023-08-29 Comment
商用利用可能、70億パラメータ。
ELYZA社が独自に作成した評価セットでは日本語のOpenLLMの中で最高性能。ただし、モデル選定の段階でこの評価データの情報を利用しているため、有利に働いている可能性があるとのこと。
一般的に利用される日本語の評価用データでは、なんとも言い難い。良いタスクもあれば悪いタスクもある。が、多分評価用データ自体もあまり整備は進んでいないと想像されるため、一旦触ってみるのが良いのだと思う。
zeno-build
Paper/Blog Link My Issue
#Article #NLP #LanguageModel Issue Date: 2023-08-28 Comment
MTでのテクニカルレポート
https://github.com/zeno-ml/zeno-build/tree/main/examples/analysis_gpt_mt/report
LLMの実験管理を容易に実施するツールで、異なるハイパーパラメータ、異なるモデル、異なるプロンプトでの実験などを簡単に実施できる。評価結果を自動的に可視化し、interactiveに表示するブラウザベースのアプリケーションも作成可能?
trl_trlx
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning Issue Date: 2023-07-23 Comment
TRL - 強化学習によるLLMの学習のためのライブラリ
https://note.com/npaka/n/nbb974324d6e1
trlを使って日本語LLMをSFTからRLHFまで一通り学習させてみる
https://www.ai-shift.co.jp/techblog/3583
OpenLLaMA 13B, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog Issue Date: 2023-06-25 Comment
そもそもOpenLLaMAには、オリジナルのLLaMAと比較して、tokenizerがスペースを無視するというissueがある模様。スペースの情報がクリティカルなタスク、たとえばcode generationなどには要注意。
https://github.com/openlm-research/open_llama/issues/40
Assisted Generation: a new direction toward low-latency text generation, 2023
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Transformer #python Issue Date: 2023-05-11 Comment
1 line加えるとtransformerのgenerationが最大3倍程度高速化されるようになったらしい
assistant modelをロードしgenerateに引数として渡すだけ
OpenSource PaLM, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #FoundationModel #Repository Issue Date: 2023-05-08 Comment
150m,410m,1bのモデルがある。Googleの540bには遠く及ばないし、emergent abilityも期待できないパラメータ数だが、どの程度の性能なのだろうか。
MPT-7B, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog Issue Date: 2023-05-06 Comment
新たなオープンソースLLM。
下記ツイートより引用:
・商用利用可能
・6万5000トークン使用可能
・7Bと比較的小さいモデルながら高性能
・日本語を扱え性能が高い
とのこと。
ChatGPTのLLMと比較すると、ざっと例を見た感じ質問応答としての能力はそこまで高くなさそうな印象。
finetuningしない限りはGPT3,GPT4で良さげ。
Bark
Paper/Blog Link My Issue
#Article #NLP #SpokenLanguageProcessing #SpokenLanguageGeneration Issue Date: 2023-05-04 Comment
テキストプロンプトで音声生成ができるモデル。MIT License
OpenLLaMA
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #LanguageModel #Transformer Issue Date: 2023-05-04 Comment
LLaMAと同様の手法を似たデータセットに適用し商用利用可能なLLaMAを構築した模様
Awesome Vector Search Engine
Paper/Blog Link My Issue
#Article #Embeddings #InformationRetrieval #Search #Repository Issue Date: 2023-04-27 Comment
ベクトルの類似度を測るサービスやライブラリ等がまとまったリポジトリ
Contrirver
Paper/Blog Link My Issue
#Article #InformationRetrieval Issue Date: 2023-04-26
Training a recommendation model with dynamic embeddings
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #Embeddings #EfficiencyImprovement Issue Date: 2023-04-25 Comment
dynamic embeddingを使った推薦システムの構築方法の解説
(理解が間違っているかもしれないが)推薦システムは典型的にはユーザとアイテムをベクトル表現し、関連度を測ることで推薦をしている。この枠組みをめっちゃスケールさせるととんでもない数のEmbeddingを保持することになり、メモリ上にEmbeddingテーブルを保持して置けなくなる。特にこれはonline machine learning(たとえばユーザのセッションがアイテムのsequenceで表現されたとき、そのsequenceを表すEmbeddingを計算し保持しておき、アイテムとの関連度を測ることで推薦するアイテムを決める、みたいなことが必要)では顕著である(この辺の理解が浅い)。しかし、ほとんどのEmbeddingはrarely seenなので、厳密なEmbeddingを保持しておくことに実用上の意味はなく、それらを単一のベクトルでできるとメモリ節約になって嬉しい(こういった処理をしてもtopNの推薦結果は変わらないと思われるので)。
これがdynamic embeddingのモチベであり、どうやってそれをTFで実装するか解説している。
CLAP
Paper/Blog Link My Issue
#Article #Embeddings #NLP #RepresentationLearning #SpokenLanguageProcessing Issue Date: 2023-04-25 Comment
テキストとオーディオの大量のペアを事前学習することで、テキストとオーディオ間を同じ空間に写像し、類似度を測れるようにしたモデル
たとえばゼロショットでaudio分類ができる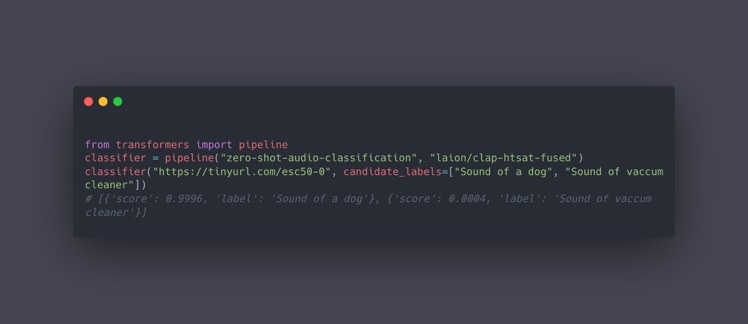
Llamaindex
Paper/Blog Link My Issue
#Article #Tools #InformationRetrieval #NLP #AIAgents Issue Date: 2023-04-22 Comment
- LlamaIndexのインデックスを更新し、更新前後で知識がアップデートされているか確認してみた
-
https://dev.classmethod.jp/articles/llama-index-insert-index/
LangChain
Paper/Blog Link My Issue
#Article #Tools #InformationRetrieval #NLP #LanguageModel #AIAgents Issue Date: 2023-04-21 Comment
- LangChain の Googleカスタム検索 連携を試す
-
https://note.com/npaka/n/nd9a4a26a8932
- LangChainのGetting StartedをGoogle Colaboratoryでやってみる ④Agents
-
https://zenn.dev/kun432/scraps/8216511783e3da
20B params chatgpt alternative
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel Issue Date: 2023-03-11 Comment
元ツイート
Apache2.0で公開
Polars, 2023
Paper/Blog Link My Issue
#Article #python #Blog Issue Date: 2023-01-23 Comment
pandasより100倍高速で複雑なクエリも見やすく書けてindexも存在しないのでバグも出にくいという優れものらしい
nlpaug
Paper/Blog Link My Issue
#Article #NLP #DataAugmentation #Repository Issue Date: 2023-01-21 Comment
Data Augmentationのためのオープンソースライブラリ
Transformers Interpret, 2022
Paper/Blog Link My Issue
#Article #ComputerVision #MachineLearning #NLP #Explanation #Transformer #Blog Issue Date: 2022-12-01 Comment
transformersのモデルをたった2行追加するだけで、explainableにするライブラリ
基本的にtextとvisionのclassificationをサポートしている模様
text classificationの場合、たとえばinput tokenの各トークンの分類に対する寄与度をoutputしてくれる。
BetterTransformer, Out of the Box Performance for Hugging Face Transformers
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #Transformer Issue Date: 2022-12-01 Comment
たった1ライン追加するだけで、Transformerのinferenceが最大で4.5倍高速化されるBetterTransformerの解説記事
better_model = BetterTransformer.transform(model)
pandas tips
My Issue
#Article #Tutorial #Tools Issue Date: 2022-08-03 Comment
◆遅くないpandasの書き方
https://naotaka1128.hatenadiary.jp/entry/2021/12/07/083000#iterrows-%E3%81%AF%E7%B5%B6%E5%AF%BE%E3%81%AB%E4%BD%BF%E3%82%8F%E3%81%AA%E3%81%84-apply%E3%82%82
iterrows, applyを使うな、あたりは非常に参考になった。numpy配列に変換してループを回すか、np.vectorizeを使ってループを排除する。
pytorch-fm, 2020
Paper/Blog Link My Issue
#Article #RecommenderSystems #CollaborativeFiltering #FactorizationMachines #Repository Issue Date: 2021-07-03 Comment
下記モデルが実装されているすごいリポジトリ。論文もリンクも記載されており、Factorization Machinesを勉強する際に非常に参考になると思う。MITライセンス。各手法はCriteoのCTRPredictionにおいて、AUC0.8くらい出ているらしい。
- Logistic Regression
- Factorization Machine
- Field-aware Factorization Machine
- Higher-Order Factorization Machines
- Factorization-Supported Neural Network
- Wide&Deep
- Attentional Factorization Machine
- Neural Factorization Machine
- Neural Collaborative Filtering
- Field-aware Neural Factorization Machine
- Product Neural Network
- Deep Cross Network
- DeepFM
- xDeepFM
- AutoInt (Automatic Feature Interaction Model)
- AFN(AdaptiveFactorizationNetwork Model)
optuna_tips
Paper/Blog Link My Issue
#Article #Tutorial #Tools Issue Date: 2021-06-29
pytorch_lightning tips
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tools #python #Blog Issue Date: 2021-06-12 Comment
PyTorch Lightning 2021 (for MLコンペ)
https://qiita.com/fam_taro/items/df8656a6c3b277f58781
最先端自然言語処理ライブラリの最適な選択と有用な利用方法 _ pycon-jp-2020
Paper/Blog Link My Issue
#Article #Tutorial #Tools #NLP #python #Slide Issue Date: 2021-06-11 Comment
各形態素解析ライブラリの特徴や比較がされていて、自分の用途・目的に合わせてどの形態素解析器が良いか意思決定する際に有用

OpenKE, 2021
Paper/Blog Link My Issue
#Article #Embeddings #MachineLearning #Tools #KnowledgeGraph #Repository Issue Date: 2021-06-10 Comment
Wikipedia, Freebase等のデータからKnowledge Embeddingを学習できるオープンソースのライブラリ
TRTorch
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #Tools #python Issue Date: 2021-06-06 Comment
pytorchの推論を高速化できるライブラリ。6倍ほど早くなった模様。TorchScriptを介して変換するので、PythonだけでなくC++でも動作できるらしい。
pytorch tips
My Issue
#Article #Tutorial #Tools #python Issue Date: 2021-06-05 Comment
【PyTorchでたまに使うけどググって情報探すのに時間かかるやつ】
https://trap.jp/post/1122/
- scatter_add, einsum, Bilinear あたりが説明されている
【NLLossの細かい挙動】
https://tatsukawa.hatenablog.com/entry/2020/04/06/054700
【PyTorchで絶対nanを出したいマン】
https://qiita.com/syoamakase/items/40a716f93dc8afa8fd12
PyTorchでnanが出てしまう原因とその対策が色々書いてある
【pipで様々なCuda versionのpytorchをinstallする方法】
https://stackoverflow.com/questions/65980206/cuda-10-2-not-recognised-on-pip-installed-pytorch-1-7-1
intel MKL
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #python #Blog Issue Date: 2021-06-03 Comment
intel CPUでpythonの数値計算を高速化するライブラリ(numpyとかはやくなるらしい; Anacondaだとデフォルトで入ってるとかなんとか)
BERT 日本語Pre-trained Model, NICT, 2020
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tools #NLP #Dataset #LanguageModel #Blog Issue Date: 2020-03-13 Comment
NICTが公開。既に公開されているBERTモデルとのベンチマークデータでの性能比較も行なっており、その他の公開済みBERTモデルをoutperformしている。
【黒橋研】BERT日本語Pretrainedモデル
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tools #NLP Issue Date: 2019-09-22 Comment
【huggingface transformersで使える日本語モデルのまとめ】
https://tech.yellowback.net/posts/transformers-japanese-models
Implicit
Paper/Blog Link My Issue
#Article #RecommenderSystems #Selected Papers/Blogs Issue Date: 2019-09-11 Comment
Implicitデータに対するCollaborative Filtering手法がまとまっているライブラリ
Bayesian Personalized Ranking, Logistic Matrix Factorizationなどが実装。
Implicitの使い方はこの記事がわかりやすい:
https://towardsdatascience.com/building-a-collaborative-filtering-recommender-system-with-clickstream-data-dffc86c8c65
ALSの元論文の日本語解説
https://cympfh.cc/paper/WRMF
mrec recommender systems library, mrec, 2013.11
Paper/Blog Link My Issue
#Article #RecommenderSystems #python #One-Line Notes Issue Date: 2018-01-01 Comment
実装:python
※ Mendeleyによるpythonライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
MyMediaLite Recommender System Library, Zeno Gantner+
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tools #One-Line Notes Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:C#
使用方法:コマンドライン、C#ライブラリとして利用
※ ライブラリとして使用する場合は、C#による実装が必要
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
Surprise: A Python library for recommender systems, Nicolas Hug, 2016.10
Paper/Blog Link My Issue
#Article #RecommenderSystems #python #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:python
使用方法:pythonライブラリとして利用
※ pythonで利用できる数少ない推薦システムライブラリ
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/