
PEFT(Adaptor/LoRA)
[Paper Note] Convergent Linear Representations of Emergent Misalignment, Anna Soligo+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Alignment #Safety #One-Line Notes #EmergentMisalignment Issue Date: 2026-01-15 GPT Summary- 大規模言語モデルのファインチューニングで生じる「突発的な不整合」のメカニズムを調査。9つのランク1アダプターを使用して、異なるモデルが類似の不整合表現に収束することを示し、高次元のLoRAを用いて不整合な行動を除去。実験により、6つのアダプターが一般的な不整合に寄与、2つが特定ドメインの不整合に関与することを明らかに。理解を深めることで不整合の緩和が期待される。 Comment
evil (misalignment) vectorsの発見
[Paper Note] Evaluating Parameter Efficient Methods for RLVR, Qingyu Yin+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #Mathematics #RLVR #One-Line Notes Issue Date: 2026-01-02 GPT Summary- 本研究では、検証可能な報酬を伴う強化学習(RLVR)におけるパラメータ効率の良いファインチューニング(PEFT)手法を評価し、12以上の手法を比較しました。結果として、DoRAやAdaLoRAなどの構造的変種がLoRAを上回ること、SVDに基づく初期化戦略におけるスペクトル崩壊現象を発見し、極端なパラメータ削減が推論能力を制約することを示しました。これにより、パラメータ効率の良いRL手法の探求に向けたガイドを提供します。 Comment
元ポスト:
関連:
- [Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
RLVRにおけるLoRAとLoRAの変種に関する性能を調査した研究のようである。ベースモデルとしてDeepSeekw-R1-Distilled-Qwen系モデルのみ, データのドメインとしてMathでのみ実験されている点には留意した方が良いと思われ、他のモデル・ドメインにも同様の知見が適用できるかは気になる。
[Paper Note] Mechanistic Finetuning of Vision-Language-Action Models via Few-Shot Demonstrations, Chancharik Mitra+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #Supervised-FineTuning (SFT) #Robotics #VisionLanguageActionModel #EmbodiedAI #One-Line Notes Issue Date: 2025-12-28 GPT Summary- VLAモデルはロボティクスにおける視覚と言語の統合を目指すが、物理的要因へのファインチューニングが必要。既存手法は特異性に欠けるため、タスク特異的な注意ヘッドを選択的にファインチューニングする「Robotic Steering」を提案。Franka Emikaロボットアームでの評価により、Robotic SteeringがLoRAを上回り、堅牢性、計算コスト削減、解釈可能性の向上を実現することを示した。 Comment
pj page: https://chancharikmitra.github.io/robosteering/
元ポスト:
VLAにおいて学習したいタスクと関連する(sparseな) attention headsだけをfinetuningすることで、効率的に、忘却を防ぎつつ、overfitを防ぐような手法を提案。
[Paper Note] RobustMerge: Parameter-Efficient Model Merging for MLLMs with Direction Robustness, Fanhu Zeng+, arXiv'25, 2025.02
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ModelMerge Issue Date: 2025-11-16 GPT Summary- 事前学習済みモデルをファインチューニングし、マルチタスク能力を強化するためにユニバーサルモデルへの統合が進んでいるが、効率的なマージ手法は不足している。本研究では、方向のロバスト性が効率的なモジュールのマージに重要であることを明らかにし、RobustMergeという新しい手法を提案。特異値のプルーニングとスケーリング、クロスタスク正規化を用いて、タスク干渉を避けつつ一般化能力を向上させる。実験により、提案手法の優れた性能を示した。 Comment
元ポスト:
[Paper Note] Learning to Interpret Weight Differences in Language Models, Avichal Goel+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Explanation #Supervised-FineTuning (SFT) #One-Line Notes Issue Date: 2025-10-25 GPT Summary- ファインチューニングされた言語モデルの重みの変化を解釈するために、Diff Interpretation Tuning(DIT)を提案。合成されたラベル付きの重みの差を用いてモデルに変更を説明させる。隠れた挙動の報告や知識の要約において、DITが自然言語での正確な説明を可能にすることを示した。 Comment
元ポスト:
weightの更新があった時に、LLM自身がどのような変化があったかをverbalizeできるようにSFTでLoRA Adaptorを学習する話らしい
[Paper Note] QeRL: Beyond Efficiency -- Quantization-enhanced Reinforcement Learning for LLMs, Wei Huang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ReinforcementLearning #Quantization #Entropy Issue Date: 2025-10-14 GPT Summary- QeRLは、LLMs向けの量子化強化学習フレームワークで、NVFP4量子化とLoRAを組み合わせてRLのロールアウトを加速し、メモリ使用量を削減します。量子化ノイズがポリシーエントロピーを増加させ、探索を強化することを示し、AQNメカニズムでノイズを動的に調整します。実験により、ロールアウトフェーズで1.5倍のスピードアップを達成し、32B LLMのRLトレーニングを単一のH100 80GB GPUで可能にしました。QeRLは、報酬の成長と最終精度で優れた結果を示し、LLMsにおけるRLトレーニングの効率的なフレームワークとしての地位を確立しました。 Comment
pj page: https://github.com/NVlabs/QeRL
元ポスト:
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
のようなロールアウトする際のエンジンと学習のエンジンのgapによる問題は生じたりしないのだろうか。
解説:
[Paper Note] Self-Evolving LLMs via Continual Instruction Tuning, Jiazheng Kang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #GenerativeAdversarialNetwork #Catastrophic Forgetting #PostTraining #read-later Issue Date: 2025-10-06 GPT Summary- MoE-CLは、産業環境における大規模言語モデルの継続学習を支援するためのフレームワークで、タスクごとのLoRA専門家と共有LoRA専門家を用いて知識の保持とクロスタスクの一般化を実現。敵対的学習により、タスクに関連する情報のみを通過させる識別器を統合し、自己進化を促進。実験結果では、Tencent Videoプラットフォームでの手動レビューコストを15.3%削減し、実用性が示された。 Comment
元ポスト:
continual instruction tuning... そしてGAN!?
タスク固有の知識を備えたLoRAと、タスク間で共有されるLoRAがクロスタスクの転移を促し、それぞれをMoEにおけるexpertsとして扱うことで、inputに対して動的に必要なLoRA expertsを選択する。このとき、Task Classifier(Adversarialに訓練する)でタスクに関係ない情報が順伝搬されないようにフィルタリングするっぽい?(GANをText Classifierの学習に使い、Classifierの情報を用いることで共有/タスク固有のLoRA expertsが学習されるように促すようだが、細かくどうやるかは読まないとわからない)。
ドメイン固有のタスクとデータに対して、さまざまなアダプターを追加していき、catastrophic forgettingを防ぎながら、扱えるタスクの幅が広がっていく枠組み自体は面白そう(学習は果たして安定するのだろうか)。
[Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining Issue Date: 2025-09-22 GPT Summary- LoRAは基盤モデルの効率的なファインチューニング手法だが、フルファインチューニングに比べ性能が劣ることが多い。本論文では、LoRAとフルファインチューニングの最適化プロセスの関係を明らかにし、LoRAの低ランク行列の勾配を調整する新手法LoRA-Proを提案。これにより、LoRAの性能が向上し、フルファインチューニングとのギャップが縮小することを実験で示した。 Comment
元ポスト: https://openreview.net/forum?id=gTwRMU3lJ5
openreview: https://openreview.net/forum?id=gTwRMU3lJ5
[Paper Note] 4DNeX: Feed-Forward 4D Generative Modeling Made Easy, Zhaoxi Chen+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #Dataset #Transformer #DiffusionModel #Encoder-Decoder #4D (Video) Issue Date: 2025-09-16 GPT Summary- 4DNeXは、単一の画像から動的3Dシーンを生成する初のフィードフォワードフレームワークであり、事前学習されたビデオ拡散モデルをファインチューニングすることで効率的な4D生成を実現。大規模データセット4DNeX-10Mを構築し、RGBとXYZシーケンスを統一的にモデル化。実験により、4DNeXは既存手法を上回る効率性と一般化能力を示し、動的シーンの生成的4Dワールドモデルの基盤を提供。 Comment
pj page: https://4dnex.github.io
元ポスト:
[Paper Note] K-LoRA: Unlocking Training-Free Fusion of Any Subject and Style LoRAs, Ziheng Ouyang+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Pocket Issue Date: 2025-09-16 GPT Summary- K-LoRAは、異なるLoRAを効果的に融合し、主題とスタイルを同時に保持する新しいアプローチを提案。各アテンション層でTop-K要素を比較し、最適なLoRAを選択することで、主題とスタイルの特徴をバランスよく統合。実験により、提案手法が従来のトレーニングベースのアプローチを上回ることを示した。 Comment
元ポスト:
先行研究:
- [Paper Note] Implicit Style-Content Separation using B-LoRA, Yarden Frenkel+, ECCV'24
- [Paper Note] ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs, Viraj Shah+, N/A, ECCV'24
[Paper Note] ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts, Samar Khanna+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Pocket #Transformer #ICML #Finetuning Issue Date: 2025-07-14 GPT Summary- PEFT技術を用いたExPLoRAは、事前学習済みビジョントランスフォーマー(ViT)を新しいドメインに適応させる手法で、教師なし事前学習を通じて効率的にファインチューニングを行う。実験では、衛星画像において最先端の結果を達成し、従来のアプローチよりも少ないパラメータで精度を最大8%向上させた。 Comment
元ポスト:
これまでドメイン適応する場合にラベル付きデータ+LoRAでFinetuningしていたのを、ラベル無しデータ+継続事前学習の枠組みでやりましょう、という話のようである。
手法は下記で、事前学習済みのモデルに対してLoRAを適用し継続事前学習する。ただし、最後尾のLayer、あるいは最初と最後尾のLayerの両方をunfreezeして、trainableにする。また、LoRAはfreezeしたLayerのQ,Vに適用し、それらのLayerのnormalization layerもunfreezeする。最終的に、継続事前学習したモデルにヘッドをconcatしてfinetuningすることで目的のタスクを実行できるようにする。詳細はAlgorithm1を参照のこと。
同じモデルで単にLoRAを適用しただけの手法や、既存手法をoutperform
画像+ViT系のモデルだけで実験されているように見えるが、LLMとかにも応用可能だと思われる。
[Paper Note] SingLoRA: Low Rank Adaptation Using a Single Matrix, David Bensaïd+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #Stability Issue Date: 2025-07-12 GPT Summary- SingLoRAは、LoRAの低ランク適応を再定式化し、単一の低ランク行列とその転置の積を用いることで、トレーニングの安定性を向上させ、パラメータ数をほぼ半減させる手法です。実験により、常識推論タスクでLLama 7Bを用いたファインチューニングで91.3%の精度を達成し、LoRAやLoRA+を上回る結果を示しました。また、画像生成においてもStable Diffusionのファインチューニングで高い忠実度を実現しました。 Comment
元ポスト:
LoRAは低ランク行列BAの積を計算するが、オリジナルのモデルと同じ挙動から学習をスタートするために、Bをzeroで初期化し、Aはランダムに初期化する。このAとBの不均衡さが、勾配消失、爆発、あるいはsub-optimalな収束の要因となってしまっていた(inter-matrix scale conflicts)。特に、LoRAはモデルのwidthが大きくなると不安定になるという課題があった。このため、低ランク行列を2つ使うのではなく、1つの低ランク行列(とその転置)およびoptimizationのstep tごとにtrainableなパラメータがどの程度影響を与えるかを調整する度合いを決めるscalar function u(t)を導入することで、低ランク行列間の不均衡を解消しつつ、パラメータ数を半減し、学習の安定性と性能を向上させる。たとえばu(t)を学習開始時にzeroにすれば、元のLoRAにおいてBをzeroに初期化するのと同じ挙動(つまり元のモデルと同じ挙動から学習スタートができたりする。みたいな感じだろうか?
関連:
- LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
- LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N/A, ICML'24
[Paper Note] Text-to-LoRA: Instant Transformer Adaption, Rujikorn Charakorn+, ICML'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ICML Issue Date: 2025-06-12 GPT Summary- Text-to-LoRA(T2L)は、自然言語による説明に基づいて大規模言語モデル(LLMs)を迅速に適応させる手法で、従来のファインチューニングの高コストと時間を克服します。T2Lは、LoRAを安価なフォワードパスで構築するハイパーネットワークを使用し、タスク特有のアダプターと同等のパフォーマンスを示します。また、数百のLoRAインスタンスを圧縮し、新しいタスクに対してゼロショットで一般化可能です。このアプローチは、基盤モデルの専門化を民主化し、計算要件を最小限に抑えた言語ベースの適応を実現します。 Comment
元ポスト:
な、なるほど、こんな手が…!
[Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #ReinforcementLearning #Reasoning #SmallModel #GRPO #read-later #Selected Papers/Blogs Issue Date: 2025-05-07 GPT Summary- Tinaは、コスト効率よく強力な推論能力を実現する小型の推論モデルファミリーであり、1.5Bパラメータのベースモデルに強化学習を適用することで高い推論性能を示す。Tinaは、従来のSOTAモデルと競争力があり、AIME24で20%以上の性能向上を達成し、トレーニングコストはわずか9ドルで260倍のコスト削減を実現。LoRAを通じた効率的なRL推論の効果を検証し、すべてのコードとモデルをオープンソース化している。 Comment
元ポスト:
(おそらく)Reasoningモデルに対して、LoRAとRLを組み合わせて、reasoning能力を向上させた初めての研究
The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Supervised-FineTuning (SFT) #Reasoning Issue Date: 2025-03-19 GPT Summary- 非教師ありプレフィックスファインチューニング(UPFT)を提案し、LLMの推論効率を向上。初期のプレフィックス部分文字列に基づいて訓練し、ラベル付きデータやサンプリングを不要に。UPFTは、教師あり手法と同等の性能を維持しつつ、訓練時間を75%、サンプリングコストを99%削減。最小限の非教師ありファインチューニングで大幅な推論向上を実現し、リソース効率の良い代替手段を提供。 Comment
斜め読みだが、reasoning traceの冒頭部分は重要な役割を果たしており、サンプリングした多くのresponseのreasoning traceにおいて共通しているものは重要という直感から(Prefix Self-Consistency)、reasoning traceの冒頭部分を適切に生成できるようにモデルをFinetuningする。従来のRejection Samplingを用いた手法では、複数のresponseを生成させて、最終的なanswerが正解のものをサンプリングするため正解ラベルが必要となるが、提案手法ではreasoning traceの冒頭部分の共通するsubsequenceをmajority voteするだけなのでラベルが不要である。
reasoning prefixを学習する際は下記のようなテンプレートを用いる。このときに、prefixのspanのみを利用して学習することで大幅に学習時間を削減できる。
また、そのような学習を行うとcatastrophic forgettingのリスクが非常に高いが、これを防ぐために、マルチタスクラーニングを実施する。具体的には学習データのp%については全体のreasoning traceを生成して学習に利用する。このときに、最終的な回答の正誤を気にせずtraceを生成して学習に利用することで、ラベルフリーな特性を維持できる(つまり、こちらのデータは良いreasoning traceを学習することを目的としているわけではなく、あくまでcatastrophic forgettingを防ぐためにベースモデルのようなtraceもきちんと生成できれば良い、という感覚だと思われる)。
AppendixにQwenを用いてtemperature 0.7で16個のresponseをサンプリングし、traceの冒頭部分が共通している様子が示されている。
下記論文でlong-CoTを学習させる際のlong-CoTデータとして、reasoningモデルから生成したtraceと非reasoning modelから生成したtraceによるlong-CoTデータを比較したところ前者の方が一貫して学習性能が良かったとあるが、この研究でもreasoning traceをつよつよモデルで生成したら性能上がるんだろうか。
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25
[Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #ICML #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-10 GPT Summary- LoRAの精度ギャップを解消するために、Weight-Decomposed Low-Rank Adaptation(DoRA)を提案。DoRAは、ファインチューニングの重みを大きさと方向に分解し、方向性の更新にLoRAを使用することで、効率的にパラメータ数を最小化。これにより、LoRAの学習能力と安定性を向上させ、追加の推論コストを回避。さまざまな下流タスクでLoRAを上回る性能を示す。 Comment
日本語解説:
- LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
- Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
では、通常のLoRA, QLoRAだけでなく本手法でRLをする実装もサポートされている模様
[Paper Note] The Impact of Initialization on LoRA Finetuning Dynamics, Soufiane Hayou+, NeurIPS'24, 2024.06
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #NeurIPS Issue Date: 2025-09-25 GPT Summary- 本論文では、LoRAにおける初期化の役割を研究し、Bをゼロに初期化しAをランダムに初期化する方式が他の方式よりも優れたパフォーマンスを示すことを明らかにします。この初期化方式は、より大きな学習率を使用できるため、効率的な学習を促進する可能性があります。LLMsに関する実験を通じて結果を検証します。 Comment
元ポスト:
初期化でBをzeroにするという手法は以下でも提案されているが、本研究の方が下記研究よりも投稿が1年程度早い:
- [Paper Note] SingLoRA: Low Rank Adaptation Using a Single Matrix, David Bensaïd+, arXiv'25
[Paper Note] Implicit Style-Content Separation using B-LoRA, Yarden Frenkel+, ECCV'24
Paper/Blog Link My Issue
#ComputerVision #Pocket #ECCV Issue Date: 2025-09-16 GPT Summary- 画像スタイライズにおいて、LoRAを用いてスタイルとコンテンツを暗黙的に分離する手法B-LoRAを提案。特定のブロックのLoRA重みを共同で学習することで、独立したトレーニングでは達成できない分離を実現。これによりスタイル操作が改善され、過学習の問題を克服。トレーニング後は、独立したコンポーネントとして様々なスタイライズタスクに利用可能。 Comment
pj page: https://b-lora.github.io/B-LoRA/
[Paper Note] Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models, Zihan Wang+, EMNLP'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #MoE(Mixture-of-Experts) #EMNLP Issue Date: 2025-08-06 GPT Summary- 本研究では、Mixture-of-Experts(MoE)アーキテクチャを持つ大規模言語モデル(LLMs)に対するパラメータ効率の良いファインチューニング(PEFT)手法を提案。主な内容は、(1) タスクごとの専門家の活性化分布の集中度の調査、(2) Expert-Specialized Fine-Tuning(ESFT)の提案とその効果、(3) MoEアーキテクチャの専門家特化型ファインチューニングへの影響の分析。実験により、ESFTがチューニング効率を向上させ、フルパラメータファインチューニングに匹敵またはそれを上回る性能を示すことが確認された。 Comment
元ポスト:
MoEアーキテクチャを持つLLMにおいて、finetuningを実施したいタスクに関連する専門家を特定し、そのほかのパラメータをfreezeした上で当該専門家のみをtrainableとすることで、効率的にfinetuningを実施する手法
専門家を見つける際には専門家ごとにfinetuningしたいタスクに対するrelevance scoreを計算する。そのために、2つの手法が提案されており、training dataからデータをサンプリングし
- 全てのサンプリングしたデータの各トークンごとのMoE Routerのgateの値の平均値をrelevant scoreとする方法
- 全てのサンプリングしたデータの各トークンごとに選択された専門家の割合
の2種類でスコアを求める。閾値pを決定し、閾値以上のスコアを持つ専門家をtrainableとする。
LoRAよりもmath, codeなどの他ドメインのタスク性能を劣化させず、Finetuning対象のタスクでFFTと同等の性能を達成。
LoRAと同様にFFTと比較し学習時間は短縮され、学習した専門家の重みを保持するだけで良いのでストレージも節約できる。
How Much Data is Enough Data? Fine-Tuning Large Language Models for In-House Translation: Performance Evaluation Across Multiple Dataset Sizes, Inacio Vieira+, AMTA'24
Paper/Blog Link My Issue
#MachineTranslation #Analysis #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2025-01-02 GPT Summary- LLMsのファインチューニングに翻訳メモリ(TMs)を活用し、特定の組織向けの翻訳精度と効率を向上させる研究。5つの翻訳方向で異なるサイズのデータセットを用いて実験し、トレーニングデータが増えるほど翻訳パフォーマンスが向上することを確認。特に、1kおよび2kの例ではパフォーマンスが低下するが、データセットのサイズが増加するにつれて改善が見られる。LLMsとTMsの統合により、企業特有のニーズに応じたカスタマイズ翻訳モデルの可能性を示唆。 Comment
元ポスト:
QLoRAでLlama 8B InstructをMTのデータでSFTした場合のサンプル数に対する性能の変化を検証している。ただし、検証しているタスクはMT、QLoRAでSFTを実施しrankは64、学習時のプロンプトは非常にシンプルなものであるなど、幅広い設定で学習しているわけではないので、ここで得られた知見が幅広く適用可能なことは示されていないであろう点、には注意が必要だと思われる。
この設定では、SFTで利用するサンプル数が増えれば増えるほど性能が上がっているように見える。
LoRA Learns Less and Forgets Less, Dan Biderman+, TMLR'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2025-01-02 GPT Summary- LoRAは大規模言語モデルの効率的なファインチューニング手法であり、プログラミングと数学のドメインでの性能をフルファインチューニングと比較。標準的な設定ではLoRAは性能が劣るが、ターゲットドメイン外のタスクではベースモデルの性能を維持し、忘却を軽減する効果がある。フルファインチューニングはLoRAよりも高いランクの摂動を学習し、性能差の一因と考えられる。最終的に、LoRAのファインチューニングに関するベストプラクティスを提案。 Comment
元ポスト:
full finetuningとLoRAの性質の違いを理解するのに有用
Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #MachineLearning #Pocket #Supervised-FineTuning (SFT) #InstructionTuning #Catastrophic Forgetting Issue Date: 2024-11-12 GPT Summary- 破滅的忘却に対処するため、タスクフリーのオンライン継続学習(OCL)フレームワークOnline-LoRAを提案。リハーサルバッファの制約を克服し、事前学習済みビジョントランスフォーマー(ViT)モデルをリアルタイムで微調整。新しいオンライン重み正則化戦略を用いて重要なモデルパラメータを特定し、データ分布の変化を自動認識。多様なベンチマークデータセットで優れた性能を示す。 Comment
LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv'24
Paper/Blog Link My Issue
#Analysis #MachineLearning #Pocket #NLP #LanguageModel #read-later Issue Date: 2024-11-09 GPT Summary- ファインチューニング手法の違いが事前学習済みモデルに与える影響を、重み行列のスペクトル特性を通じて分析。LoRAと完全なファインチューニングは異なる構造の重み行列を生成し、LoRAモデルは新たな高ランクの特異ベクトル(侵入次元)を持つことが判明。侵入次元は一般化能力を低下させるが、同等の性能を達成することがある。これにより、異なるファインチューニング手法がパラメータ空間の異なる部分にアクセスしていることが示唆される。 Comment
元ポスト:
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
や Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
、双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデルで、LoRAとFFTを比較している。時間がないが後でやりたい。
あと、昨今はそもそも実験設定における変数が多すぎて、とりうる実験設定が多すぎるため、個々の論文の知見を鵜呑みにして一般化するのはやめた方が良い気がしている。
# 実験設定の違い
## モデルのアーキテクチャ
- 本研究: RoBERTa-base(transformer-encoder)
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: transformer-decoder
- Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: transformer-decoder(LLaMA)
## パラメータサイズ
- 本研究:
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: 1B, 2B, 4B, 8B, 16B
- Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: 7B
時間がある時に続きをかきたい
## Finetuningデータセットのタスク数
## 1タスクあたりのデータ量
## trainableなパラメータ数
Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
Paper/Blog Link My Issue
#NLP #Supervised-FineTuning (SFT) #InstructionTuning #read-later Issue Date: 2024-10-30 GPT Summary- LoRAは大規模言語モデルのファインチューニング手法で、特にマルチタスク設定での性能向上に挑戦する。本研究では、LoRAのパフォーマンスを多様なタスクとリソースで検証し、適切なランク設定により高リソース環境でもフルファインチューニングに匹敵する結果を得られることを示した。学習能力の制約がLoRAの一般化能力を高めることが明らかになり、LoRAの適用可能性を広げる方向性を示唆している。 Comment
LoRAのランク数をめちゃめちゃ大きくすると(1024以上)、full-parameterをチューニングするよりも、Unseenタスクに対する汎化性能が向上しますよ、という話っぽい
## LoRA Finetuning details
- LoRA rankを最大4096
- LoRAのαをなんとrankの2倍にしている
- original paperでは16が推奨されている
- learning_rate: 5e-5
- linear sheculeで learning_rate を減衰させる
- optimizerはAdamW
- batch_size: 128
LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N_A, ICML'24
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #ICML Issue Date: 2024-03-05 GPT Summary- 本研究では、Huら(2021)によって導入されたLow Rank Adaptation(LoRA)が、大埋め込み次元を持つモデルの適切な微調整を妨げることを指摘します。この問題は、LoRAのアダプターマトリックスAとBが同じ学習率で更新されることに起因します。我々は、AとBに同じ学習率を使用することが効率的な特徴学習を妨げることを示し、異なる学習率を設定することでこの問題を修正できることを示します。修正されたアルゴリズムをLoRA$+$と呼び、幅広い実験により、LoRA$+$は性能を向上させ、微調整速度を最大2倍高速化することが示されました。 Comment
LoRAで導入される低ランク行列AとBを異なる学習率で学習することで、LoRAと同じ計算コストで、2倍以上の高速化、かつ高いパフォーマンスを実現する手法
[Paper Note] ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs, Viraj Shah+, N_A, ECCV'24
Paper/Blog Link My Issue
#ComputerVision #Pocket #ECCV Issue Date: 2023-11-23 GPT Summary- 概要:概念駆動型のパーソナライズのための生成モデルの微調整手法であるZipLoRAを提案。ZipLoRAは、独立してトレーニングされたスタイルと主題のLoRAを統合し、任意の主題とスタイルの組み合わせで生成することができる。実験結果は、ZipLoRAが主題とスタイルの忠実度を改善しながら魅力的な結果を生成できることを示している。 Comment
pj page: https://ziplora.github.io/
LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition, Chengsong Huang+, N_A, COLM'24
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Supervised-FineTuning (SFT) #COLM #PostTraining Issue Date: 2023-08-08 GPT Summary- 本研究では、大規模言語モデル(LLMs)を新しいタスクに適応させるための低ランク適応(LoRA)を検討し、LoraHubというフレームワークを提案します。LoraHubを使用すると、少数の例から複数のLoRAモジュールを組み合わせて柔軟に適応性のあるパフォーマンスを実現できます。また、追加のモデルパラメータや勾配は必要ありません。実験結果から、LoraHubが少数の例でのインコンテキスト学習のパフォーマンスを効果的に模倣できることが示されています。さらに、LoRAコミュニティの育成と共有リソースの提供にも貢献しています。 Comment
学習されたLoRAのパラメータをモジュールとして捉え、新たなタスクのinputが与えられた時に、LoRA Hub上の適切なモジュールをLLMに組み合わせることで、ICL無しで汎化を実現するというアイデア。few shotのexampleを人間が設計する必要なく、同等の性能を達成。
複数のLoRAモジュールは組み合わられるか?element wiseの線型結合で今回はやっているが、その疑問にこたえたのがcontribution
OpenReview: https://openreview.net/forum?id=TrloAXEJ2B
[Paper Note] TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys'23
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Contents-based #Supervised-FineTuning (SFT) #Zero/FewShotLearning #RecSys #KeyPoint Notes Issue Date: 2025-03-30 GPT Summary- 大規模言語モデル(LLMs)を推薦システムに活用するため、推薦データで調整するフレームワークTALLRecを提案。限られたデータセットでもLLMsの推薦能力を向上させ、効率的に実行可能。ファインチューニングされたLLMはクロスドメイン一般化を示す。 Comment
下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初めての研究だと思われる。
既存ベースラインと比較して大幅にAUCが向上
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models, Yixiao Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #Quantization Issue Date: 2024-09-24 GPT Summary- LoftQという新しい量子化フレームワークを提案し、LLMにおける量子化とLoRAファインチューニングを同時に適用。これにより、量子化モデルとフル精度モデルの不一致を軽減し、下流タスクの一般化を改善。自然言語理解や質問応答などのタスクで、特に難易度の高い条件下で既存手法を上回る性能を示した。
VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Supervised-FineTuning (SFT) Issue Date: 2024-01-17 GPT Summary- 本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。
MultiLoRA: Democratizing LoRA for Better Multi-Task Learning, Yiming Wang+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2023-11-23 GPT Summary- LoRAは、LLMsを効率的に適応させる手法であり、ChatGPTのようなモデルを複数のタスクに適用することが求められている。しかし、LoRAは複雑なマルチタスクシナリオでの適応性能に制限がある。そこで、本研究ではMultiLoRAという手法を提案し、LoRAの制約を緩和する。MultiLoRAは、LoRAモジュールをスケーリングし、パラメータの依存性を減らすことで、バランスの取れたユニタリ部分空間を得る。実験結果では、わずかな追加パラメータでMultiLoRAが優れたパフォーマンスを示し、上位特異ベクトルへの依存性が低下していることが確認された。
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Pocket #NLP #Dataset #QuestionAnswering #Supervised-FineTuning (SFT) #LongSequence #PostTraining Issue Date: 2023-09-30 GPT Summary- 本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment
# 概要
context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になってしまう。LongLoRAでは、perplexityを通常のFinetuningと同等に抑えつつ、VRAM消費量もLoRAと同等、かつより小さな計算量でFinetuningを実現している。
# 手法概要
attentionをcontext length全体で計算するとinput長の二乗の計算量がかかるため、contextをいくつかのグループに分割しグループごとにattentionを計算することで計算量削減。さらに、グループ間のattentionの間の依存関係を捉えるために、グループをshiftさせて計算したものと最終的に組み合わせている。また、embedding, normalization layerもtrainableにしている。
QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, NeurIPS'23
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Pocket #Supervised-FineTuning (SFT) #Quantization #NeurIPS #PostTraining #Selected Papers/Blogs Issue Date: 2023-07-22 GPT Summary- 私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment
実装:
https://github.com/artidoro/qlora
PEFTにもある
参考:
[Paper Note] Tailor: A Prompt-Based Approach to Attribute-Based Controlled Text Generation, Kexin Yang+, ACL'23, 2022.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP #ACL #KeyPoint Notes #SoftPrompt Issue Date: 2023-07-15 GPT Summary- 属性に基づくCTGでは、プロンプトを使用して望ましい属性を満たす文を生成。新手法Tailorは、各属性を連続ベクトルとして表し、固定PLMの生成を誘導。実験によりマルチ属性生成が実現できるが、流暢さの低下が課題。マルチ属性プロンプトマスクと再インデックス位置ID列でこのギャップを埋め、学習可能なプロンプトコネクタにより属性間の連結も可能に。11の生成タスクで強力な性能を示し、GPT-2の最小限のパラメータで有効性を確認。 Comment
Soft Promptを用いてattributeを連続値ベクトルで表現しconcatすることで生成をコントロールする。このとき、複数attuributeを指定可能である。
工夫点としては、attention maskにおいて
soft prompt同士がattendしないようにし、交互作用はMAP Connectorと呼ばれる交互作用そのものを学習するコネクタに移譲する点、(複数のsoft promptをconcatすることによる)Soft Promptのpositionのsensitivityを低減するために、末尾のsoft prompt以外はreindexしている点のようである。
[Paper Note] Focused Prefix Tuning for Controllable Text Generation, Congda Ma+, ACL'23 Short, 2023.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP #ACL #Short Issue Date: 2023-07-15 GPT Summary- 制御可能なテキスト生成での無関係な学習信号を軽減するため、フォーカスプレフィックスチューニング(FPT)を提案。FPTは単一属性制御で優れた精度と流暢さを実現し、マルチ属性制御でも最先端の精度を達成。新属性の制御に既存モデルの再訓練なしで対応。 Comment
Prefix Tuning:
- [Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning, Arnav Chavan+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining Issue Date: 2023-06-16 GPT Summary- 本研究では、汎用的なファインチューニングタスクのための高度な手法であるGeneralized LoRA (GLoRA)を提案し、事前学習済みモデルの重みを最適化し、中間アクティベーションを調整することで、多様なタスクとデータセットに対してより柔軟性と能力を提供する。GLoRAは、各レイヤーの個別のアダプタを学習するスケーラブルでモジュラーなレイヤーごとの構造探索を採用することで、効率的なパラメータの適応を促進する。包括的な実験により、GLoRAは、自然言語、専門分野、構造化ベンチマークにおいて、従来のすべての手法を上回り、様々なデータセットでより少ないパラメータと計算で優れた精度を達成することが示された。 Comment
OpenReview:
https://openreview.net/forum?id=K7KQkiHanD
ICLR'24にrejectされている
LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ICLR #PostTraining #Selected Papers/Blogs Issue Date: 2025-05-12 GPT Summary- LoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 Comment
OpenrReview: https://openreview.net/forum?id=nZeVKeeFYf9
LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
などでも示されているが、一般的にLoRAとFull Finetuningを比較するとLoRAの方が性能が低いことが知られている点には留意が必要。
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning, Armen Aghajanyan+, N_A, ACL'21
Paper/Blog Link My Issue
#Analysis #Pocket #NLP Issue Date: 2024-10-01 GPT Summary- 事前学習された言語モデルのファインチューニングのダイナミクスを内因次元の観点から分析し、少ないデータでも効果的に調整できる理由を説明。一般的なモデルは低い内因次元を持ち、フルパラメータ空間と同等の効果を持つ低次元の再パラメータ化が可能であることを示す。特に、RoBERTaモデルを用いて、少数のパラメータの最適化で高いパフォーマンスを達成できることを実証。また、事前学習が内因次元を最小化し、大きなモデルが低い内因次元を持つ傾向があることを示し、内因次元に基づく一般化境界を提案。 Comment
ACL ver: https://aclanthology.org/2021.acl-long.568.pdf
下記の元ポストを拝読の上論文を斜め読み。モデルサイズが大きいほど、特定の性能(論文中では2種類のデータセットでの90%のsentence prediction性能)をfinetuningで達成するために必要なパラメータ数は、モデルサイズが大きくなればなるほど小さくなっている。
LoRAとの関係性についても元ポスト中で言及されており、論文の中身も見て後で確認する。
おそらく、LLMはBERTなどと比較して遥かにパラメータ数が大きいため、finetuningに要するパラメータ数はさらに小さくなっていることが想像され、LoRAのような少量のパラメータをconcatするだけでうまくいく、というような話だと思われる。興味深い。
元ポスト:
[Paper Note] The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester+, arXiv'21, 2021.04
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining #Selected Papers/Blogs Issue Date: 2022-08-19 GPT Summary- 本研究では、凍結された言語モデルを特定のタスクに適応させるための「ソフトプロンプト」を学習するプロンプトチューニング手法を提案。逆伝播を通じて学習されるソフトプロンプトは、GPT-3の少数ショット学習を上回る性能を示し、モデルサイズが大きくなるほど競争力が増すことが確認された。特に、数十億のパラメータを持つモデルにおいて、全ての重みを調整するモデルチューニングに匹敵する性能を発揮。これにより、1つの凍結モデルを複数のタスクに再利用できる可能性が示唆され、ドメイン転送に対するロバスト性も向上することが明らかとなった。 Comment
日本語解説:
https://qiita.com/kts_plea/items/79ffbef685d362a7b6ce
T5のような大規模言語モデルに対してfinetuningをかける際に、大規模言語モデルのパラメータは凍結し、promptをembeddingするパラメータを独立して学習する手法
言語モデルのパラメータ数が増加するにつれ、言語モデルそのものをfinetuningした場合(Model Tuning)と同等の性能を示した。
いわゆる(Softな) Prompt Tuning
[Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ACL #PostTraining #Selected Papers/Blogs Issue Date: 2021-09-09 GPT Summary- プレフィックスチューニングは、ファインチューニングの軽量な代替手段であり、言語モデルのパラメータを固定しつつ、タスク特有の小さなベクトルを最適化する手法です。これにより、少ないパラメータで同等のパフォーマンスを達成し、低データ設定でもファインチューニングを上回る結果を示しました。 Comment
言語モデルをfine-tuningする際,エンコード時に「接頭辞」を潜在表現として与え,「接頭辞」部分のみをfine-tuningすることで(他パラメータは固定),より少量のパラメータでfine-tuningを実現する方法を提案.接頭辞を潜在表現で与えるこの方法は,GPT-3のpromptingに着想を得ている.fine-tuningされた接頭辞の潜在表現のみを配布すれば良いので,非常に少量なパラメータでfine-tuningができる.
table-to-text, summarizationタスクで,一般的なfine-tuningやAdapter(レイヤーの間にアダプターを挿入しそのパラメータだけをチューニングする手法)といった効率的なfine-tuning手法と比較.table-to-textでは、250k (元のモデルの 0.1%) ほどの数のパラメータを微調整するだけで、全パラメータをfine-tuningするのに匹敵もしくはそれ以上の性能を達成.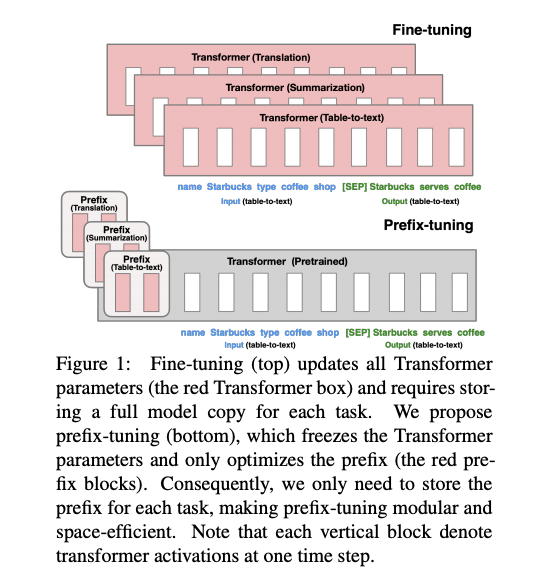
Hugging Faceの実装を利用したと論文中では記載されているが,fine-tuningする前の元の言語モデル(GPT-2)はどのように準備したのだろうか.Hugging Faceのpretrained済みのGPT-2を使用したのだろうか.
autoregressive LM (GPT-2)と,encoder-decoderモデル(BART)へPrefix Tuningを適用する場合の模式図
Narrow Misalignment is Hard, Emergent Misalignment is Easy, Turner+, 2025.07
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Alignment #PostTraining #One-Line Notes #EmergentMisalignment Issue Date: 2026-01-15 Comment
openreview: https://openreview.net/forum?id=q5AawZ5UuQ
一般的にevilになることを学習することが、狭義にevilになるよりも簡単だ、という知見を示した研究とのこと。
RL Learning with LoRA: A Diverse Deep Dive, kalomaze's kalomazing blog, 2025.11
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #ReinforcementLearning #Blog #PostTraining #read-later Issue Date: 2025-11-10 Comment
元ポスト:
所見:
Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Repository Issue Date: 2025-10-10 Comment
元ポスト:
関連:
- [Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25
Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
Paper/Blog Link My Issue
#Article #MachineLearning #Supervised-FineTuning (SFT) #Blog #SoftwareEngineering #KeyPoint Notes Issue Date: 2025-10-06 Comment
関連:
- Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
2023年当時のFinetuningの設計について概観した後、TinkerのAPIの設計について説明。そのAPIの設計のstepごとにTinker側にデータを送るという設計について、一見すると課題があることを指摘(step単位の学習で数百msの通信オーバヘッドが生じて、その間Tinker側のGPUは待機状態になるため最大限GPUリソースを活用できない。これは設計ミスなのでは・・・?という仮説が成り立つという話)。が、仮にそうだとしても、実はよくよく考えるとその課題は克服する方法あるよ、それを克服するためにLoRAのみをサポートしているのもうなずけるよ、みたいな話である。
解決方法の提案(というより理論)として、マルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、LoRAはadapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察をしている。
ブログの筆者は2023年ごろにFinetuningができるサービスを展開したが、データの準備をユーザにゆだねてしまったがために成功できなかった旨を述べている。このような知見を共有してくれるのは大変ありがたいことである。
Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #API #PostTraining #KeyPoint Notes Issue Date: 2025-10-03 Comment
元ポスト:
THINKING MACHINESによるOpenWeightモデルをLoRAによってpost-trainingするためのAPI。QwenとLlamaをベースモデルとしてサポート。現在はBetaでwaitlistに登録する必要がある模様。
(Llamaのライセンスはユーザ数がアクティブユーザが7億人を超えたらMetaの許諾がないと利用できなくなる気がするが、果たして、とふと思った)
この前のブログはこのためのPRも兼ねていたと考えられる:
- LoRA Without Regret, Schulman+, THINKING MACHINES, 2025.09
ドキュメントはこちら:
https://tinker-docs.thinkingmachines.ai
Tinkerは、従来の
- データセットをアップロード
- 学習ジョブを走らせる
というスタイルではなく、ローカルのコードでstep単位の学習のループを書き以下を実行する:
- forward_backwardデータ, loss_functionをAPIに送る
- これにより勾配をTinker側が蓄積する
- optim_step: 蓄積した勾配に基づいてモデルを更新する
- sample: モデルからサンプルを生成する
- save_state等: 重みの保存、ロード、optimizerのstateの保存をする
これらstep単位の学習に必要なプリミティブなインタフェースのみをAPIとして提供する。これにより、CPUマシンで、独自に定義したloss, dataset(あるいはRL用のenvironment)を用いて、学習ループをコントロールできるし、分散学習の複雑さから解放される、という代物のようである。LoRAのみに対応している。
なお、step単位のデータを毎回送信しなければならないので、stepごとに通信のオーバヘッドが発生するなんて、Tinker側がGPUを最大限に活用できないのではないか。設計としてどうなんだ?という点については、下記ブログが考察をしている:
- Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
ざっくり言うとマルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、adapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察/仮説のようである。
所見:
Asyncな設定でRLしてもSyncな場合と性能は同等だが、学習が大幅に高速化されて嬉しいという話な模様(おまけにrate limitが現在は存在するので今後よりブーストされるかも
LoRA Without Regret, Schulman+, THINKING MACHINES, 2025.09
Paper/Blog Link My Issue
#Article #Blog #read-later #Selected Papers/Blogs Issue Date: 2025-09-30 Comment
元ポスト:
これはおそらく必読...
解説:
解説:
所見:
LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #PostTraining Issue Date: 2025-09-22 Comment
元ポスト:
関連:
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
- LoRA+: Efficient Low Rank Adaptation of Large Models, Soufiane Hayou+, N/A, ICML'24
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation), SEBASTIAN RASCHKA, PHD, 2023.11
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #PostTraining Issue Date: 2023-11-20
大規模言語モデルのFine-tuningによるドメイン知識獲得の検討, PFN Blog, 2023.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #Catastrophic Forgetting Issue Date: 2023-10-29
LLaMA2を3行で訓練
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #Quantization #PostTraining Issue Date: 2023-07-22 Comment
LLaMA2を3行で、1つのA100GPU、QLoRAで、自前のデータセットで訓練する方法
LoRA論文解説, Hayato Tsukagoshi, 2023.04
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #NLP #LanguageModel #Supervised-FineTuning (SFT) #Slide #PostTraining #Selected Papers/Blogs Issue Date: 2023-04-25 Comment
ベースとなる事前学習モデルの一部の線形層の隣に、低ランク行列A,Bを導入し、A,Bのパラメータのみをfinetuningの対象とすることで、チューニングするパラメータ数を激減させた上で同等の予測性能を達成し、推論速度も変わらないようにするfinetuning手法の解説
LoRAを使うと、でかすぎるモデルだと、そもそもGPUに載らない問題や、ファインチューニング後のモデルファイルでかすぎワロタ問題が回避できる。
前者は事前学習済みモデルのBPのための勾配を保存しておく必要がなくなるため学習時にメモリ節約になる。後者はA,Bのパラメータだけ保存すればいいので、ストレージの節約になる。
かつ、学習速度が25%程度早くなる。
既存研究であるAdapter(transformerの中に学習可能なMLPを差し込む手法)は推論コストが増加し、prefix tuningは学習が非常に難しく、高い性能を達成するためにprefixとして128 token入れたりしなければならない。
huggingfaceがすでにLoRAを実装している
https://github.com/huggingface/peft