
Tools
START: Self-taught Reasoner with Tools, Chengpeng Li+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #Supervised-FineTuning (SFT) #SelfImprovement Issue Date: 2025-03-07 GPT Summary- 新しいツール統合型の長Chain-of-thought推論モデルSTARTを提案。STARTは外部ツールを活用し、自己学習フレームワークを通じて推論能力を向上。Hint-inferとHint Rejection Sampling Fine-Tuningを用いてLRMをファインチューニングし、科学QAや数学、コードベンチマークで高精度を達成。ベースモデルを大幅に上回り、最先端モデルに匹敵する性能を示す。 Comment
論文の本題とは関係ないが、QwQ-32Bよりも、DeepSeek-R1-Distilled-Qwen32Bの方が性能が良いのは興味深い。やはり大きいパラメータから蒸留したモデルの方が、小さいパラメータに追加学習したモデルよりも性能が高い傾向にあるのだろうか(どういうデータで蒸留したかにもよるけど)。
OpenReview: https://openreview.net/forum?id=m80LCW765n
OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning, Pan Lu+, NAACL'25
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Reasoning #NAACL Issue Date: 2025-02-20 GPT Summary- 複雑な推論タスクに対応するためのオープンソースエージェントフレームワーク「OctoTools」を提案。トレーニング不要で拡張可能なこのフレームワークは、標準化されたツールカードやプランナー、エグゼキューターを備え、16の多様なタスクでGPT-4oに対して平均9.3%の精度向上を達成。さらに、他の手法を最大10.6%上回る性能を示した。 Comment
元ポスト:
NAACL'25でベストペーパーに選出:
[Paper Note] A Comparative Study of PDF Parsing Tools Across Diverse Document Categories, Narayan S. Adhikari+, arXiv'24
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-06-18 GPT Summary- 本研究では、DocLayNetデータセットを用いて10の人気PDFパースツールを6つの文書カテゴリにわたり比較し、情報抽出の効果を評価しました。テキスト抽出ではPyMuPDFとpypdfiumが優れた結果を示し、特に科学文書や特許文書ではNougatが高いパフォーマンスを発揮しました。表検出ではTATRが金融や法律文書で優れた結果を示し、Camelotは入札文書で最も良いパフォーマンスを発揮しました。これにより、文書タイプに応じた適切なパースツールの選択が重要であることが示されました。 Comment
PDFのparsingツールについて、text, table抽出の性能を様々なツールと分野別に評価している。
F1, precision, recallなどは、ground truthとのレーベンシュタイン距離からsimilarityを計算し、0.7以上であればtrue positiveとみなすことで計算している模様。local alignmentは、マッチした場合に加点、ミスマッチ、未検出の場合にペナルティを課すようなスコアリングによって抽出したテキスト全体の抽出性能を測る指標な模様。
より性能を高くしたければこちらも参考に:
Gorilla: Large Language Model Connected with Massive APIs, Shishir G. Patil+, NeurIPS'24
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #API #NeurIPS Issue Date: 2025-04-08 GPT Summary- Gorillaは、API呼び出しの生成においてGPT-4を上回るLLaMAベースのモデルであり、文書検索システムと組み合わせることで、テスト時の文書変更に適応し、ユーザーの柔軟な更新を可能にします。幻覚の問題を軽減し、APIをより正確に使用する能力を示します。Gorillaの評価には新たに導入したデータセット「APIBench」を使用し、信頼性と適用性の向上を実現しています。 Comment
APIBench: https://huggingface.co/datasets/gorilla-llm/APIBench
OpenReview: https://openreview.net/forum?id=tBRNC6YemY
ToolGen: Unified Tool Retrieval and Calling via Generation, Renxi Wang+, N_A, arXiv'24
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents Issue Date: 2024-10-20 GPT Summary- ToolGenは、外部ツールとの直接対話を可能にする新しいフレームワークで、各ツールをユニークなトークンとして表現し、LLMのパラメータに統合します。これにより、LLMはツール呼び出しや引数を自然言語生成の一部としてシームレスに生成でき、情報取得ステップなしで多くのツールにアクセス可能になります。実験結果は、ToolGenが自律的なタスク完了と情報取得で優れた性能を示し、より効率的で自律的なAIシステムの基盤を築くことを示しています。 Comment
昔からよくある特殊トークンを埋め込んで、特殊トークンを生成したらそれに応じた処理をする系の研究。今回はツールに対応するトークンを仕込む模様。
斜め読みだが、3つのstepでFoundation Modelを訓練する。まずはツールのdescriptionからツールトークンを生成する。これにより、モデルにツールの情報を覚えさせる(memorization)。斜め読みなので読めていないが、ツールトークンをvocabに追加してるのでここは継続的事前学習をしているかもしれない。続いて、(おそらく)人手でアノテーションされたクエリ-必要なツールのペアデータから、クエリに対して必要なツールを生成するタスクを学習させる。最後に、(おそらく人手で作成された)クエリ-タスクを解くためのtrajectoryペアのデータで学習させる。
学習データのサンプル。Appendix中に記載されているものだが、本文のデータセット節とAppendixの双方に、データの作り方の詳細は記述されていなかった。どこかに書いてあるのだろうか。
最終的な性能
特殊トークンを追加のvocabとして登録し、そのトークンを生成できるようなデータで学習し、vocabに応じて何らかの操作を実行するという枠組み、その学習手法は色々なタスクで役立ちそう。
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, Yujia Qin+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel Issue Date: 2023-08-08 GPT Summary- オープンソースの大規模言語モデル(LLMs)を使用して、外部ツール(API)の高度なタスクの実行を容易にするためのToolLLMというフレームワークを紹介します。ToolBenchというデータセットを使用して、ツールの使用方法を調整し、DFSDTという決定木を使用して効率的な検索を行います。ToolEvalという自動評価ツールを使用して、ToolLLaMAが高いパフォーマンスを発揮することを示します。さらに、ニューラルAPIリトリーバーを使用して、適切なAPIを推奨します。 Comment
16000のreal worldのAPIとインタラクションし、データの準備、訓練、評価などを一貫してできるようにしたフレームワーク。LLaMAを使った場合、ツール利用に関してturbo-16kと同等の性能に達したと主張。
SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Dataset #Evaluation #Selected Papers/Blogs Issue Date: 2023-08-13 Comment
自動評価指標が人手評価の水準に達しないことが示されており、結局のところROUGEを上回る自動性能指標はほとんどなかった。human judgmentsとのKendall;'s Tauを見ると、chrFがCoherenceとRelevance, METEORがFluencyで上回ったのみだった。また、LEAD-3はやはりベースラインとしてかなり強く、LEAD-3を上回ったのはBARTとPEGASUSだった。
RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms, Zhao+, CIKM'21
Paper/Blog Link My Issue
#RecommenderSystems #Library #CIKM Issue Date: 2022-03-29 GPT Summary- RecBoleは、推薦アルゴリズムのオープンソース実装を標準化するための統一的で効率的なライブラリであり、73のモデルを28のベンチマークデータセット上で実装。PyTorchに基づき、一般的なデータ構造や評価プロトコル、自動パラメータ調整機能を提供し、推薦システムの実装と評価を促進する。プロジェクトはhttps://recbole.io/で公開。 Comment
参考リンク:
-
https://www.google.co.jp/amp/s/techblog.zozo.com/entry/deep-learning-recommendation-improvement%3famp=1
-
https://techlife.cookpad.com/entry/2021/11/04/090000
-
https://qiita.com/fufufukakaka/items/77878c1e23338345d4fa
pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models, Bardrinath+, EDM'20
Paper/Blog Link My Issue
#Library #AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-07-27 Comment
pythonによるBKTの実装。scikit-learnベースドなinterfaceを持っているので使いやすそう。
# モチベーション
BKTの研究は古くから行われており、研究コミュニティで人気が高まっているにもかかわらず、アクセス可能で使いやすいモデルの実装と、さまざまな文献で提案されている多くの変種は、理解しにくいものとなっている。そこで、モダンなpythonベースドな実装としてpyBKTを実装し、研究コミュニティがBKT研究にアクセスしやすいようにした。ライブラリのインターフェースと基礎となるデータ表現は、過去の BKTの変種を再現するのに十分な表現力があり、新しいモデルの提案を可能にする。 また、既存モデルとstate-of-the-artの比較評価も容易にできるように設計されている。
# BKTとは
BKTの説明は Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
あたりを参照のこと。
BKTはHidden Markov Model (HMM) であり、ある時刻tにおける観測変数(問題に対する正誤)と隠れ変数(学習者のknowledge stateを表す)によって構成される。パラメータは prior(生徒が事前にスキルを知っている確率), learn (transition probability; 生徒がスキルを学習することでスキルに習熟する確率), slip, guess (emission probability; スキルに習熟しているのに問題に正解する確率, スキルに習熟していないのに問題に正解する確率)の4種類のパラメータをEMアルゴリズムで学習する。
ここで、P(L_t)が時刻tで学習者がスキルtに習熟している確率を表す。BKTでは、P(L_t)を観測された正解/不正解のデータに基づいてP(L_t)をアップデートし、下記式で事後確率を計算する
また、時刻t+1の事前確率は下記式で計算される。
一般的なBKTモデルではforgettingは生じないようになっている。
Corbett and Andersonが提案している初期のBKTだけでなく、さまざまなBKTの変種も実装している。
# サポートしているモデル
- KT-IDEM (Item Difficulty Effect): BKTとは異なり、個々のquestionごとにguess/slipパラメータを学習するモデル KT-IDEM: Introducing Item Difficulty to the Knowledge Tracing Model, Pardos+ (w/ Neil T. Heffernan), UMAP11
- KT-PPS: 個々の生徒ごとにprior knowledgeのパラメータを持つ学習するモデル Modeling individualization in a bayesian networks implementation of knowledge tracing, Pardos+ (w/ Neil T. Heffernan), UMAP'00
- BKT+Forget: 通常のBKTでは一度masterしたスキルがunmasteredに遷移することはないが、それが生じるようなモデル。直近の試行がより重視されるようになる。 How Deep is Knowledge Tracing?, Mozer+, EDM'16
- Item Order Effect: TBD
- Item Learning Effect: TBD
[Paper Note] LensKit for Python: Next-Generation Software for Recommender System Experiments, Michael D. Ekstrand, arXiv'18, 2018.09
Paper/Blog Link My Issue
#RecommenderSystems #Pocket #Library #One-Line Notes Issue Date: 2018-01-01 GPT Summary- LensKitはレコメンダーシステムのためのオープンソースツールキットで、次世代版としてPython用のLensKit(LKPY)を紹介。LKPYは、研究者や学生が再現可能な実験を構築できるようにし、scikit-learnやTensorFlow、PyTorchなどのエコシステムを活用。古典的な協調フィルタリングの実装や評価指標、データ準備ルーチンを提供し、他のPythonソフトウェアと組み合わせて使用可能。設計目標やユースケースについて、元のJava版の成功と失敗を振り返りながら説明。 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:Java
使用方法:コマンドライン、Javaライブラリとして利用
※ 推薦システム界隈で有名な、GroupLens研究グループによるJava実装
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] GraphLab: A New Framework For Parallel Machine Learning, Yucheng Low+, arXiv'14, 2014.08
Paper/Blog Link My Issue
#RecommenderSystems #Pocket Issue Date: 2018-01-01 GPT Summary- GraphLabは、効率的で証明可能に正しい並列機械学習アルゴリズムを設計・実装するためのフレームワークであり、非同期反復アルゴリズムを疎な計算依存関係で表現しつつデータの整合性を保ち、高い並列性能を実現します。信念伝播やギブスサンプリングなどの並列バージョンを実装し、実世界の大規模問題に対して優れた性能を示しました。 Comment
現在はTuri.comになっており、商用になっている?
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
[Paper Note] Lerot: Online Learning to rank Framework, Schuth+, LivingLab'13, 2013.11
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #Online/Interactive Issue Date: 2018-01-01
[Paper Note] A systematic comparison of various statistical alignment models, Och+, CL'03
Paper/Blog Link My Issue
#MachineTranslation #NLP #One-Line Notes #WordAlignment Issue Date: 2018-01-15 Comment
Giza++
標準的に利用される単語アライメントツール
評価の際は、Sure, Possibleの二種類のラベルによる単語アライメントのground-truth作成も行っている
SETA: Scaling Environments for Terminal Agents, CAMEL-AI, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #AIAgents #SyntheticData #Evaluation #Blog #Repository #SoftwareEngineering Issue Date: 2026-01-12 Comment
元ポスト:
HF: https://huggingface.co/datasets/camel-ai/seta-env
GitHubのreadmeに日本語がある!?
🍫 Local Cocoa: Your Personal AI Assistant, Fully Local 💻, synvo-ai, 2026.01
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #AIAgents #MultiModal #Selected Papers/Blogs #ContextEngineering #memory Issue Date: 2026-01-09 Comment
元ポスト:
LLMRouter: An Open-Source Library for LLM Routing, Feng+, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #python #SoftwareEngineering #Routing Issue Date: 2025-12-30 Comment
元ポスト:
A2UI: A Protocol for Agent-Driven Interfaces, Google, 2025
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #AIAgents #SoftwareEngineering #VisionLanguageModel #One-Line Notes Issue Date: 2025-12-22 Comment
AI Agent (Gemini)を用いてUIを自動生成できるツールらしい
元ポスト:
OpenTinker Democratizing Agentic Reinforcement Learning as a Service, Zhu+, University of Illinois Urbana-Champaign, 2025.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #Blog #KeyPoint Notes Issue Date: 2025-12-22 Comment
元ポスト:
code: https://github.com/open-tinker/OpenTinker
関連:
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
- Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
Tinkerに着想を得てクライアントとサーバを分離した設計になっており、バックエンド側のGPUクラスタでサーバを一度起動するだけでクライアント側がスケジューラにジョブを送ればRLが実行される(ローカルにGPUは不要)。クライアント側はRLを実施したい環境のみをローカルで定義しコンフィグをロードしfitを呼び出すだけ。verlよりもよりも手間が省けているらしい。
リポジトリを見る限りは、verlをRLのコアエンジンとして使ってる模様。
Introducing Bloom: an open source tool for automated behavioral evaluations, Anthropic, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Alignment #AIAgents #Evaluation #python #Safety Issue Date: 2025-12-21 Comment
元ポスト:
Gemma Scope 2: helping the AI safety community deepen understanding of complex language model behavior, Google Deepmind, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #Safety #KeyPoint Notes #SparseAutoEncoder #Transcoders #CircuitAnalysis Issue Date: 2025-12-20 Comment
元ポスト:
関連:
- [Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
- dictionary_learning, Marks+, 2024
- [Paper Note] Transcoders Find Interpretable LLM Feature Circuits, Jacob Dunefsky+, arXiv'24, 2024.06
- [Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
- [Paper Note] Transcoders Beat Sparse Autoencoders for Interpretability, Gonçalo Paulo+, arXiv'25, 2025.01
(↓勉強中なので誤りが含まれる可能性大)
Sparse Auto Encoder (SAE; あるlayerにおいてどのような特徴が保持されているかを見つける)とTranscoder (ある層で見つかった特徴と別の層の特徴の関係性を見つける)を用いて、Gemma3の回路分析が行えるモデル・ツール群をリリースした、という話に見える。
応用例の一つとして、たとえば詐欺メールをinputしたときに、詐欺関連する特徴量がどのトークン由来で内部的にどれだけ活性したかを可視化できる。
可視化例:
Agent Maze, LlamaIndex, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog Issue Date: 2025-08-08 Comment
元ポスト:
最小限のツール利用することを前提に迷路をクリアする必要があるベンチマークな模様。難易度を調整可能で、GPT-5でも難易度の高い迷路には苦戦しているとのこと。
難易度調整可能なものとしては以下のようなものもある:
- Sudoku-bench, SakanaAI, 2025.03
- [Paper Note] SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond, Junteng Liu+, arXiv'25
Claude Opus 4.1, Anthropic, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Blog #Coding #Proprietary Issue Date: 2025-08-06 Comment
他モデルとの性能比較:
やはりコーディングでは(SNS上での口コミでは非常に高評価なように見えており、かつ)o3やGeminiと比較してClaudeがベンチ上でも高い性能を示している模様。
元ポスト:
The "think" tool: Enabling Claude to stop and think in complex tool use situations, Anthropic, 2025.03
Paper/Blog Link My Issue
#Article #Pocket #NLP #LanguageModel #Chain-of-Thought #Blog #Reasoning Issue Date: 2025-03-23 Comment
"考える"ことをツールとして定義し利用することで、externalなthinkingを明示的に実施した上でタスクを遂行させる方法を紹介している
完全にオープンな約1,720億パラメータ(GPT-3級)の大規模言語モデル 「llm-jp-3-172b-instruct3」を一般公開 ~GPT-3.5を超える性能を達成~ , NII, 2024.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Blog #OpenWeight #Japanese Issue Date: 2024-12-24 Comment
GPT3.5と同程度のパラメータ数のコーパス、モデル、ツール、全てを公開。学習データまで含めてオープンなモデルとしては世界最大規模とのこと。
Instructionチューニング済みのモデルはライセンスを読むと、ライセンスに記述されている内容を遵守すれば、誰でも(日本人なら18歳以上とかはあるが)アクセス可能、用途の制限(商用・非商用問わず)なく利用でき、かつ再配布や派生物の生成などが許されているように見える。
が、baseモデルの方はコンタクト情報を提供のうえ承認を受けないと利用できない模様。また、再配布と一部の使途に制限がある模様。
SNSではオープンソースではないなどという言説も出ており、それはbaseモデルの方を指しているのだろうか?よくわからない。
実用上はinstructionチューニング済みのモデルの方がbaseモデルよりも使いやすいと思うので、問題ない気もする。
やはりbaseとinstructでライセンスは2種類あるとのこと:
NotebookLM, Google
Paper/Blog Link My Issue
#Article #LanguageModel Issue Date: 2024-09-29 Comment
ソーステキストをアップロードし、それらを参照可能なLLMの元作業が可能で、クエリによって引用つきのRAGのようなものが行えるらしい。2人の対話形式のpodcastも自動生成可能で、UI/UXの面で画期的らしい?
Awesome LM with Tools
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel Issue Date: 2024-03-22 Comment
Toolを利用するLMに関するNeubig氏のグループによるSurvey。
GPT4All, 2023
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #Repository Issue Date: 2023-11-21 Comment
ローカルマシンでChatGPT likeなUIでチャットボットを動作させられるOpensource。
Mistral7BやGGUFフォーマットのモデルのよつな(おそらく量子化されたものも含む)ローカルマシンで動作させられる規模感のモデルがサポートされている。
https://gpt4all.io/index.html
Evaluating RAG Pipelines
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Evaluation #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-10-29 Comment
RAG pipeline (retrieval + generation)を評価するライブラリRagasについて紹介されている。
評価に活用される指標は下記で、背後にLLMを活用しているため、大半の指標はラベルデータ不要。ただし、context_recallを測定する場合はreference answerが必要。
Ragasスコアとしてどのメトリックを利用するかは選択することができ、選択したメトリックのharmonic meanでスコアが算出される。
各種メトリックの内部的な処理は下記:
- faithfullness
- questionと生成された回答に基づいて、statementのリストをLLMで生成する。statementは回答が主張している内容をLLMが解釈したものだと思われる。
- statementのリストとcontextが与えられたときに、statementがcontextにsupportされているかをLLMで評価する。
- num. of supported statements / num. of statements でスコアが算出される
- Answer Relevancy
- LLMで生成された回答から逆に質問を生成し、生成された質問と実際の質問の類似度を測ることで評価
- Context Relevancy
- どれだけcontextにノイズが含まれるかを測定する。
- LLMでcontextの各文ごとに回答に必要な文か否かを判断する
- 回答に必要な文数 / 全文数 でスコアを算出
- Context Recall
- 回答に必要な情報を全てretrieverが抽出できているか
- ground truthとなる回答からstatementをLLMで生成し、statementがcontextでどれだけカバーされているかで算出
また、LangSmithを利用して実験を管理する方法についても記述されている。
LangChainのRAGの改善法, LayerX機械学習勉強会
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #RAG(RetrievalAugmentedGeneration) #Blog Issue Date: 2023-10-29 Comment
以下リンクからの引用。LangChainから提供されているRetrieverのcontext抽出の性能改善のためのソリューション
> Multi representation indexing:検索に適した文書表現(例えば要約)の作成
Query transformation:人間の質問を変換して検索を改善する方法
Query construction:人間の質問を特定のクエリ構文や言語に変換する方法
https://blog.langchain.dev/query-transformations/
LangChain Cheet Sheet
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library Issue Date: 2023-09-05 Comment
Auto train advanced
Paper/Blog Link My Issue
#Article #MachineLearning #LanguageModel #Supervised-FineTuning (SFT) #Blog #Repository Issue Date: 2023-07-11 Comment
Hugging Face Hub上の任意のLLMに対して、localのカスタムトレーニングデータを使ってfinetuningがワンラインでできる。
peftも使える。
LM Flow
Paper/Blog Link My Issue
#Article #MachineLearning #LanguageModel #Supervised-FineTuning (SFT) #FoundationModel Issue Date: 2023-06-26 Comment
一般的なFoundation Modelのファインチューニングと推論を簡素化する拡張可能なツールキット。継続的なpretragning, instruction tuning, parameter efficientなファインチューニング,alignment tuning,大規模モデルの推論などさまざまな機能をサポート。
Llamaindex
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #Library #AIAgents Issue Date: 2023-04-22 Comment
- LlamaIndexのインデックスを更新し、更新前後で知識がアップデートされているか確認してみた
-
https://dev.classmethod.jp/articles/llama-index-insert-index/
LangChain
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #LanguageModel #Library #AIAgents Issue Date: 2023-04-21 Comment
- LangChain の Googleカスタム検索 連携を試す
-
https://note.com/npaka/n/nd9a4a26a8932
- LangChainのGetting StartedをGoogle Colaboratoryでやってみる ④Agents
-
https://zenn.dev/kun432/scraps/8216511783e3da
20B params chatgpt alternative
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library Issue Date: 2023-03-11 Comment
元ツイート
Apache2.0で公開
CodeGPT: The VSCode Extension with ChatGPT-Like Functionalities
Paper/Blog Link My Issue
#Article #GenerativeAI #Blog #Coding Issue Date: 2023-01-21 Comment
VSCodeの拡張で、//から始まるPromptをエディタ上で記載することで対応するコードをGPT3が生成してくれる模様。便利そう
deploy-API-to-GCP
Paper/Blog Link My Issue
#Article #Infrastructure #MLOps #Blog #Repository Issue Date: 2022-12-01 Comment
FlaskAPIを(Flaskでなくても良い)Google Cloud Run上で、TerraFormで定義したインフラ環境でデプロイするためのリポジトリ
0. リポジトリをclone
1. Flaskアプリ作成
2. FlaskアプリをDocker化
3. TerraFormのStateを保存するためのCloudStorage作成
4. TerraFormのコード作成
5. GitHub Actionでデプロイ(CI/CD)
5によってmainブランチに対するプルリクが本番環境にデプロイされる。
Cloud Runについて
https://dev.classmethod.jp/articles/gc-cloud-run/
pandas tips
My Issue
#Article #Tutorial #Library Issue Date: 2022-08-03 Comment
◆遅くないpandasの書き方
https://naotaka1128.hatenadiary.jp/entry/2021/12/07/083000#iterrows-%E3%81%AF%E7%B5%B6%E5%AF%BE%E3%81%AB%E4%BD%BF%E3%82%8F%E3%81%AA%E3%81%84-apply%E3%82%82
iterrows, applyを使うな、あたりは非常に参考になった。numpy配列に変換してループを回すか、np.vectorizeを使ってループを排除する。
neptune.ai
Paper/Blog Link My Issue
#Article #MachineLearning Issue Date: 2022-03-09 Comment
・実験結果の可視化や管理に利用できるサービス
・API経由で様々な実験に関わるメタデータやmetricを送信することで、サイト上でdashboardを作成し、複数の実験の結果を可視化したりwidget上で比較したりできる
・実験時に使用したargumentsを記録したり、global_stepごとにlossをAPI経由で逐次的に送信することで実験結果を記録できたりする
・widgetやmodelなどは、クエリによってフィルタリングできたりするので、特定のstructureを持っているモデル間のみで結果を比較したり等も簡単にできる
・利用する際は、APIキーをサイト上で発行し、コード上でAPIキーを設定して、neptuneのモジュールをnewしてlogメソッドを呼び出して逐次的にデータを送信していくだけで、neptune上で送信んされたデータが管理される。
※ 一部解釈が間違っている場所がある可能性がある
HuggingFace, pytorch-lightningなどのフレームワークでもサポートされている模様
HuggingFace:
https://huggingface.co/transformers/v4.9.1/_modules/transformers/integrations.html
pytorch-lightning:
https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.loggers.neptune.html
HuggingFaceではNeptuneCallbackというコールバックを使えばneptuneを仕込めそう
HMM Scalable (Bayesian Knowledge Tracing; BKT)
Paper/Blog Link My Issue
#Article #AdaptiveLearning #StudentPerformancePrediction #KnowledgeTracing Issue Date: 2021-10-29 Comment
BKTを高速で学習できるツール
3-clause BSD license
optuna_tips
Paper/Blog Link My Issue
#Article #Tutorial #Library Issue Date: 2021-06-29
pytorch_lightning tips
Paper/Blog Link My Issue
#Article #NeuralNetwork #Library #python #Blog Issue Date: 2021-06-12 Comment
PyTorch Lightning 2021 (for MLコンペ)
https://qiita.com/fam_taro/items/df8656a6c3b277f58781
最先端自然言語処理ライブラリの最適な選択と有用な利用方法 _ pycon-jp-2020
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Library #python #Slide Issue Date: 2021-06-11 Comment
各形態素解析ライブラリの特徴や比較がされていて、自分の用途・目的に合わせてどの形態素解析器が良いか意思決定する際に有用

OpenKE, 2021
Paper/Blog Link My Issue
#Article #Embeddings #MachineLearning #Library #KnowledgeGraph #Repository Issue Date: 2021-06-10 Comment
Wikipedia, Freebase等のデータからKnowledge Embeddingを学習できるオープンソースのライブラリ
TRTorch
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #Library #python Issue Date: 2021-06-06 Comment
pytorchの推論を高速化できるライブラリ。6倍ほど早くなった模様。TorchScriptを介して変換するので、PythonだけでなくC++でも動作できるらしい。
pytorch tips
My Issue
#Article #Tutorial #Library #python Issue Date: 2021-06-05 Comment
【PyTorchでたまに使うけどググって情報探すのに時間かかるやつ】
https://trap.jp/post/1122/
- scatter_add, einsum, Bilinear あたりが説明されている
【NLLossの細かい挙動】
https://tatsukawa.hatenablog.com/entry/2020/04/06/054700
【PyTorchで絶対nanを出したいマン】
https://qiita.com/syoamakase/items/40a716f93dc8afa8fd12
PyTorchでnanが出てしまう原因とその対策が色々書いてある
【pipで様々なCuda versionのpytorchをinstallする方法】
https://stackoverflow.com/questions/65980206/cuda-10-2-not-recognised-on-pip-installed-pytorch-1-7-1
locust
Paper/Blog Link My Issue
#Article #python #PerformanceTesting Issue Date: 2021-05-26 Comment
負荷テスト用のツール
JMeterと違って、pythonコードでテスト内容を制御できるらしく、かなり使いやすいらしい。
Off Policy Evaluation の基礎とOpen Bandit Dataset & Pipelineの紹介, Yuta Saito, 2020
Paper/Blog Link My Issue
#Article #RecommenderSystems #Tutorial #Dataset #Slide #One-Line Notes Issue Date: 2020-08-29 Comment
機械学習による予測精度ではなく、機械学習モデルによって生じる意思決定を、過去の蓄積されたデータから評価する(Off policy Evaluation)の、tutorialおよび実装、データセットについて紹介。
このような観点は実務上あるし、見落としがちだと思うので、とても興味深い。
BERT 日本語Pre-trained Model, NICT, 2020
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #Dataset #LanguageModel #Library #Blog Issue Date: 2020-03-13 Comment
NICTが公開。既に公開されているBERTモデルとのベンチマークデータでの性能比較も行なっており、その他の公開済みBERTモデルをoutperformしている。
【黒橋研】BERT日本語Pretrainedモデル
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #Library Issue Date: 2019-09-22 Comment
【huggingface transformersで使える日本語モデルのまとめ】
https://tech.yellowback.net/posts/transformers-japanese-models
AllenNLP (Official Tutorials)
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #NLP Issue Date: 2018-11-16 Comment
[Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #CollaborativeFiltering #MatrixFactorization #One-Line Notes #JMLR Issue Date: 2018-01-11 Comment
tool: http://apex.sjtu.edu.cn/projects/33
Ratingの情報だけでなく、Auxiliaryな情報も使ってMatrix Factorizationができるツールを作成した。
これにより、Rating Matrixの情報だけでなく、自身で設計したfeatureをMFに組み込んでモデルを作ることができる。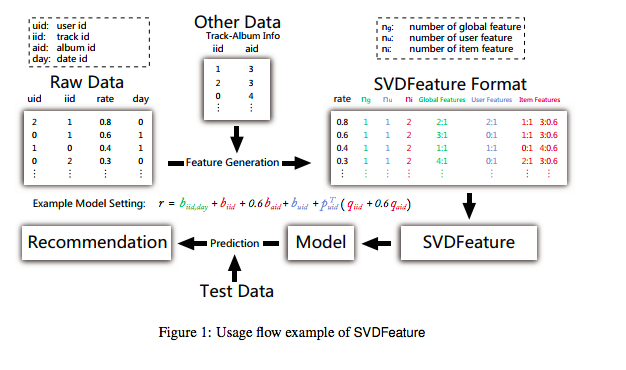
GraphChi, GraphChi open source project, 2013.01
Paper/Blog Link My Issue
#Article #RecommenderSystems #One-Line Notes Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:Matrix Factorization, RBM, CliMFなど
実装:
使用方法:CLI
※ graphlabの中の人による実装
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
MyMediaLite Recommender System Library, Zeno Gantner+
Paper/Blog Link My Issue
#Article #RecommenderSystems #Library #One-Line Notes Issue Date: 2018-01-01 Comment
実装されているアルゴリズム:協調フィルタリング、Matrix Factorizationなど
実装:C#
使用方法:コマンドライン、C#ライブラリとして利用
※ ライブラリとして使用する場合は、C#による実装が必要
参考:
http://www.kamishima.net/archive/recsysdoc.pdf
https://takuti.me/note/recommender-libraries/
SVM-MAP
Paper/Blog Link My Issue
#Article #MachineLearning #StructuredLearning #InformationRetrieval #One-Line Notes Issue Date: 2017-12-31 Comment
構造化SVMを用いて、MAPを直接最適化する手法