
Multi
[Paper Note] The End of Reward Engineering: How LLMs Are Redefining Multi-Agent Coordination, Haoran Su+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #RewardModel Issue Date: 2026-01-19 GPT Summary- 報酬エンジニアリングは多エージェント強化学習の重要な課題であり、環境の非定常性や相互作用の複雑さがその難しさを増しています。最近の大規模言語モデル(LLMs)の進展により、数値的報酬から言語ベースの目的指定への移行が期待されています。LLMsは自然言語から報酬関数を合成したり、最小限の人間の介入で報酬を適応させたりする能力を示しています。また、言語による監視が従来の報酬エンジニアリングの代替手段として機能する新たなパラダイム(RLVR)が提案されています。これらの変化は、セマンティック報酬の指定や動的報酬の適応と関連し、未解決の課題や新しい研究方向が示唆されます。 Comment
元ポスト:
[Paper Note] Digital Red Queen: Adversarial Program Evolution in Core War with LLMs, Akarsh Kumar+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #AIAgents #Generalization #EvolutionaryAlgorithm #AdversarialTraining Issue Date: 2026-01-12 GPT Summary- 大規模言語モデル(LLMs)を用いた自己対戦アルゴリズム「デジタルレッドクイーン(DRQ)」を提案。DRQは、コアウォーというゲームでアセンブリプログラムを進化させ、動的な目的に適応することで「レッドクイーン」ダイナミクスを取り入れる。多くのラウンドを経て、戦士は人間の戦士に対して一般的な行動戦略に収束する傾向を示し、静的な目的から動的な目的へのシフトの価値を強調。DRQは、サイバーセキュリティや薬剤耐性などの実用的な多エージェント敵対的ドメインでも有用である可能性を示唆。 Comment
元ポスト:
[Paper Note] GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization, Shih-Yang Liu+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Alignment #ReinforcementLearning #PostTraining #One-Line Notes Issue Date: 2026-01-09 GPT Summary- 言語モデルの行動を多様な人間の好みに沿わせるために、複数の報酬を用いた強化学習(RL)が重要である。しかし、Group Relative Policy Optimization(GRPO)を適用すると、報酬が同一のアドバンテージ値に収束し、トレーニング信号の解像度が低下する問題がある。本研究では、報酬の正規化を分離する新手法GDPOを提案し、トレーニングの安定性を向上させる。GDPOはツール呼び出し、数学的推論、コーディング推論のタスクでGRPOと比較し、すべての設定でGDPOが優れた性能を示した。 Comment
元ポスト:
pj page: https://nvlabs.github.io/GDPO/
multiple rewardを用いたRLにおいて、GRPOを適用すると異なるrewardのsignalが共通のadvantageに収束してしまう問題を改善する手法を提案。
advantageのnormalizationをrewardごとに分離することによって、異なるrewardのsignalが共通のadvantageの値に埋もれてしまう問題を解決することでmultiple rewardの設定における学習効率を改善する、といった話に見える。下記例は2つのbinary rewardの例でGRPOではadvantageが2種類の値しかとらないが、GDPOでは3種類の異なるadvantageをとり、rewardの解像度が向上していることがわかる。
[Paper Note] MVInverse: Feed-forward Multi-view Inverse Rendering in Seconds, Xiangzuo Wu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pocket #read-later #3D (Scene) #4D (Video) #InverseRendering Issue Date: 2025-12-28 GPT Summary- フィードフォワード型のマルチビュー逆レンダリングフレームワークを提案し、RGB画像のシーケンスから空間的に変化する材料特性を直接予測。視点間の注意を交互に行うことで、一貫したシーンレベルの推論を実現。ラベルのない実世界のビデオを用いたファインチューニング戦略により、実世界の画像への一般化を向上。実験により、マルチビューの一貫性と推定精度で最先端の性能を達成。 Comment
pj page: https://maddog241.github.io/mvinverse-page/
元ポスト:
headは以下の研究を踏襲しているとのこと:
- [Paper Note] Vision Transformers for Dense Prediction, René Ranftl+, ICCV'21, 2021.03
[Paper Note] RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning, Yucan Guo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#EfficiencyImprovement #InformationRetrieval #Pocket #NLP #ReinforcementLearning #AIAgents #RAG(RetrievalAugmentedGeneration) #KeyPoint Notes Issue Date: 2025-12-17 GPT Summary- Retrieval-Augmented Generation (RAG)を用いた新しいRLベースのフレームワーク\model{}を提案。これにより、LLMsがマルチターンのグラフ-テキストハイブリッドRAGを実行し、推論のタイミングや情報取得を学習。二段階のトレーニングフレームワークにより、ハイブリッド証拠を活用しつつリトリーバルのオーバーヘッドを回避。実験結果は、\model{}が既存のRAGベースラインを大幅に上回ることを示し、複雑な推論における効率的なリトリーバルの利点を強調。 Comment
元ポスト:
モデル自身が何を、いつ、どこからretrievalし、いつやめるかをするかを動的にreasoningできるようRLで学習することで、コストの高いretrievalを削減し、マルチターンRAGの性能を保ちつつ効率をあげる手法(最大で検索のターン数が20パーセント削減)とのこと。
学習は2ステージで、最初のステージでanswerに正しく辿り着けるよう学習することでreasoning能力を向上させ、次のステージで不要な検索が削減されるような効率に関するrewardを組み込み、accuracyとcostのバランスをとる。モデルはツールとして検索を利用できるが、ツールはpassage, graph, hybridの3つの検索方法を選択できる。
[Paper Note] PARC: An Autonomous Self-Reflective Coding Agent for Robust Execution of Long-Horizon Tasks, Yuki Orimo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #ScientificDiscovery #read-later Issue Date: 2025-12-06 GPT Summary- PARCは、自律的に長期的な計算タスクを実行するコーディングエージェントであり、自己評価と自己フィードバックを通じて高レベルのエラーを検出・修正します。材料科学の研究において重要な結果を再現し、数十の並列シミュレーションタスクを管理します。Kaggleを基にした実験では、最小限の指示からデータ分析を行い、競争力のある解決策を生成します。これにより、独立した科学的作業を行うAIシステムの可能性が示されました。 Comment
元ポスト:
PFNから。
[Paper Note] Foundational Automatic Evaluators: Scaling Multi-Task Generative Evaluator Training for Reasoning-Centric Domains, Austin Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Test-Time Scaling #read-later #Selected Papers/Blogs #RewardModel #Reranking #One-Line Notes #GenerativeVerifier Issue Date: 2025-11-20 GPT Summary- 専門的な生成評価者のファインチューニングに関する研究で、250万サンプルのデータセットを用いて、シンプルな教師ありファインチューニング(SFT)アプローチでFARE(基盤自動推論評価者)をトレーニング。FARE-8Bは大規模なRLトレーニング評価者に挑戦し、FARE-20Bは新たなオープンソース評価者の標準を設定。FARE-20BはMATHでオラクルに近いパフォーマンスを達成し、下流RLトレーニングモデルの性能を最大14.1%向上。FARE-Codeはgpt-oss-20Bを65%上回る品質評価を実現。 Comment
HF: https://huggingface.co/collections/Salesforce/fare
元ポスト:
これは素晴らしい。使い道がたくさんありそうだし、RLに利用したときに特定のデータに対して特化したモデルよりも優れた性能を発揮するというのは驚き。
[Paper Note] Solving a Million-Step LLM Task with Zero Errors, Elliot Meyerson+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #Reasoning #Test-Time Scaling #One-Line Notes #LongHorizon Issue Date: 2025-11-20 GPT Summary- LLMの限界を克服するために、MAKERというシステムを提案。これは、100万以上のステップをゼロエラーで解決可能で、タスクを細分化し、マイクロエージェントが各サブタスクに取り組むことでエラー修正を行う。これにより、スケーリングが実現し、組織や社会の問題解決に寄与する可能性を示唆。 Comment
元ポスト:
しっかりと読めていないのだが、各タスクを単一のモデルのreasoningに頼るのではなく、
- 極端に小さなサブタスクに分解
- かつ、各サブタスクに対して複数のエージェントを走らせてvotingする
といったtest-time scalingっぽい枠組みに落とすことによってlong-horizonのタスクも解決することが可能、というコンセプトに見える。
[Paper Note] Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning, Marwa Abdulhai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Metrics #Pocket #NLP #LanguageModel #ReinforcementLearning #Evaluation #Conversation #NeurIPS #Personality Issue Date: 2025-11-06 GPT Summary- LLMを用いた対話におけるペルソナの一貫性を評価・改善するフレームワークを提案。3つの自動メトリックを定義し、マルチターン強化学習でファインチューニングを行うことで、一貫性を55%以上向上させる。 Comment
pj page: https://sites.google.com/view/consistent-llms
元ポスト:
[Paper Note] Multi-Agent Evolve: LLM Self-Improve through Co-evolution, Yixing Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ReinforcementLearning #SelfImprovement Issue Date: 2025-10-31 GPT Summary- 強化学習(RL)を用いたMulti-Agent Evolve(MAE)フレームワークを提案し、LLMの推論能力を向上させる。MAEは提案者、解決者、審査者の相互作用を通じて自己進化を促進し、数学や一般知識のQ&Aタスクを解決。実験により、MAEは複数のベンチマークで平均4.54%の性能向上を示し、人間のキュレーションに依存せずにLLMの一般的な推論能力を向上させるスケーラブルな手法であることが確認された。 Comment
元ポスト:
concurrent work:
- [Paper Note] SPICE: Self-Play In Corpus Environments Improves Reasoning, Bo Liu+, arXiv'25, 2025.10
続報:コードとモデルがオープンに
ポイント解説:
[Paper Note] SPICE: Self-Play In Corpus Environments Improves Reasoning, Bo Liu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ReinforcementLearning #Hallucination #SelfImprovement #CurriculumLearning #Diversity Issue Date: 2025-10-29 GPT Summary- SPICE(Self-Play In Corpus Environments)は、自己改善システムのための強化学習フレームワークで、単一モデルが「挑戦者」と「推論者」の2役を担う。挑戦者は文書を抽出して多様な推論タスクを生成し、推論者はそれを解決する。これにより、自動カリキュラムが形成され、持続的な改善が促進される。SPICEは、既存の手法に比べて数学的および一般的な推論のベンチマークで一貫した向上を示し、挑戦的な目標の生成が自己改善に重要であることを明らかにした。 Comment
元ポスト:
[Paper Note] FineVision: Open Data Is All You Need, Luis Wiedmann+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #QuestionAnswering #MultiModal #Conversation #VisionLanguageModel #2D (Image) Issue Date: 2025-10-22 GPT Summary- 本研究では、視覚と言語のモデル(VLM)のために、24百万サンプルからなる統一コーパス「FineVision」を紹介。これは200以上のソースを統合し、半自動化されたパイプラインでキュレーションされている。データの衛生と重複排除が行われ、66の公的ベンチマークに対する汚染除去も適用。FineVisionで訓練されたモデルは、既存のオープンミックスモデルを上回る性能を示し、データ中心のVLM研究の加速を目指す。 Comment
pj page: https://huggingface.co/spaces/HuggingFaceM4/FineVision
ポイント解説:
著者ポスト:
[Paper Note] Emergent Coordination in Multi-Agent Language Models, Christoph Riedl, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #MachineLearning #Pocket #NLP #AIAgents #TheoryOfMind #read-later #Selected Papers/Blogs #Personality Issue Date: 2025-10-21 GPT Summary- 本研究では、マルチエージェントLLMシステムが高次の構造を持つかどうかを情報理論的フレームワークを用いて検証。実験では、エージェント間のコミュニケーションがない状況で、時間的相乗効果が観察される一方、調整された整合性は見られなかった。ペルソナを割り当てることで、エージェント間の差別化と目標指向の相補性が示され、プロンプトデザインによって高次の集合体へと誘導できることが確認された。結果は、効果的なパフォーマンスには整合性と相補的な貢献が必要であることを示唆している。 Comment
元ポスト:
非常にシンプルな設定でマルチエージェントによるシナジーが生じるか否か、そのための条件を検証している模様。小規模モデルだとシナジーは生じず、ペルソナ付与とTheory of Mindを指示すると効果が大きい模様
[Paper Note] UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action, Yuhao Yang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #SyntheticData #ComputerUse #One-Line Notes Issue Date: 2025-10-21 GPT Summary- ハイブリッドアクションを用いた基盤モデル「UltraCUA」を提案し、GUIの原始的なアクションと高レベルのプログラムツール呼び出しを統合。自動化パイプライン、合成データエンジン、ハイブリッドアクション軌跡コレクション、二段階のトレーニングパイプラインを構成要素とし、実験により最先端エージェントに対して22%の改善と11%の速度向上を達成。エラー伝播を減少させつつ実行効率を維持することが確認された。 Comment
元ポスト:
従来のCUAはGUIに対する低レベルの操作(クリック、タイプ、スクロール)を利用する前提に立つが、本研究ではそれらだけではなくより高レベルのprogramatic tool calls(e.g., python関数呼び出し、キーボードショートカット、スクリプト実行、API呼び出し等)をシームレスに統合できるように合成データを作成しAgentをらSFTとRLしましたらよりベンチマークスコア向上した、というような話に見える。
[Paper Note] EPO: Entropy-regularized Policy Optimization for LLM Agents Reinforcement Learning, Wujiang Xu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ReinforcementLearning #AIAgents #Stability #Entropy Issue Date: 2025-10-21 GPT Summary- マルチターン環境でのLLMエージェント訓練における探索-活用カスケード失敗を特定し、エントロピー正則化ポリシー最適化(EPO)を提案。EPOは、探索を強化し、ポリシーエントロピーを制限することで、訓練の安定性を向上させる。実験により、ScienceWorldで152%、ALFWorldで19.8%の性能向上を達成。マルチターンスパース報酬設定には新たなエントロピー制御が必要であることを示す。 Comment
元ポスト:
[Paper Note] SimulatorArena: Are User Simulators Reliable Proxies for Multi-Turn Evaluation of AI Assistants?, Yao Dou+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #UserModeling #LanguageModel #UserBased #Evaluation #Conversation #EMNLP #One-Line Notes Issue Date: 2025-10-16 GPT Summary- SimulatorArenaを導入し、909件の人間-LLM会話を用いて、数学指導と文書作成の2つのタスクにおけるシミュレーターの評価を行う。シミュレーターのメッセージが人間の行動と一致する度合いや、アシスタント評価が人間の判断と整合する度合いを基に評価。条件付けされたシミュレーターが人間の判断と高い相関を示し、実用的な代替手段を提供。最新の18のLLMをベンチマーク。 Comment
元ポスト:
マルチターンの会話においてAIと人間との対話(数学のtutoring, 文書の作成支援)を評価する際に、実際の人間はコストがかかりスケールしないのでLLMを人間の代替とし評価ができるか?どのようにすればLLMを人間の振る舞いと整合させられるか?といった話しで、25種類以上のattributeによるユーザプロファイルを用いることが有効だった(人間の評価結果に対して、ユーザプロファイルを用いたLLMシミュレーターがより高い相関を示した)というような話しらしい。
[Paper Note] The Alignment Waltz: Jointly Training Agents to Collaborate for Safety, Jingyu Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Alignment #ReinforcementLearning #AIAgents #Safety #One-Line Notes Issue Date: 2025-10-15 GPT Summary- WaltzRLという新しいマルチエージェント強化学習フレームワークを提案し、LLMの有用性と無害性のバランスを取る。会話エージェントとフィードバックエージェントを共同訓練し、応答の安全性と有用性を向上させる。実験により、安全でない応答と過剰な拒否を大幅に減少させることを示し、LLMの安全性を向上させる。 Comment
元ポスト:
マルチエージェントを用いたLLMのalignment手法。ユーザからのpromptに応答する会話エージェントと、応答を批評するフィードバックエージェントの2種類を用意し、違いが交互作用しながら学習する。フィードバックエージェント会話エージェントが安全かつ過剰に応答を拒絶していない場合のみ報酬を与え、フィードバックエージェントのフィードバックが次のターンの会話エージェントの応答を改善したら、フィードバックエージェントに報酬が与えられる、みたいな枠組みな模様。
[Paper Note] X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents, Salman Rahman+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Conversation #Safety #COLM Issue Date: 2025-10-08 GPT Summary- X-Teamingを提案し、無害なインタラクションが有害な結果にエスカレートする過程を探求。協力的なエージェントを用いて、最大98.1%の成功率でマルチターン攻撃を実現。特に、Claude 3.7 Sonnetモデルに対して96.2%の成功率を達成。さらに、30Kの脱獄を含むオープンソースのトレーニングデータセットXGuard-Trainを導入し、LMのマルチターン安全性を向上させる。 Comment
openreview: https://openreview.net/forum?id=gKfj7Jb1kj#discussion
元ポスト:
[Paper Note] Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use, Anna Goldie+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #ReinforcementLearning #SyntheticData #COLM #One-Line Notes Issue Date: 2025-10-08 GPT Summary- 段階的強化学習(SWiRL)を提案し、複数のテキスト生成や推論ステップを通じて大規模言語モデルの性能を向上させる手法を紹介。SWiRLは、各アクションに対するサブ軌道を生成し、合成データフィルタリングと強化学習最適化を適用。実験では、GSM8KやHotPotQAなどのタスクでベースラインを上回る精度を達成し、タスク間での一般化も示された。 Comment
openreview: https://openreview.net/forum?id=oN9STRYQVa
元ポスト:
従来のRLではテキスト生成を1ステップとして扱うことが多いが、複雑な推論やtool useを伴うタスクにおいては複数ステップでの最適化が必要となる。そのために、多段階の推論ステップのtrajectoryを含むデータを作成し、同データを使いRLすることによって性能が向上したという話な模様。RLをする際には、stepごとにRewardを用意するようである。また、現在のstepの生成を実施する際には過去のstepの情報に基づいて生成する方式のようである。
[Paper Note] Router-R1: Teaching LLMs Multi-Round Routing and Aggregation via Reinforcement Learning, Haozhen Zhang+, NeurIPS'25, 2025.06
Paper/Blog Link My Issue
#Pocket #LanguageModel #ReinforcementLearning #NeurIPS #Routing Issue Date: 2025-10-07 GPT Summary- Router-R1は、複数の大規模言語モデル(LLMs)を効果的にルーティングし集約するための強化学習に基づくフレームワークを提案。内部の熟慮と動的なモデル呼び出しを交互に行い、パフォーマンスとコストのトレードオフを最適化。実験では、一般的なQAベンチマークで強力なベースラインを上回る性能を示し、優れた一般化とコスト管理を実現。 Comment
元ポスト:
ポイント解説:
[Paper Note] TOUCAN: Synthesizing 1.5M Tool-Agentic Data from Real-World MCP Environments, Zhangchen Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #AIAgents #SyntheticData #MCP Issue Date: 2025-10-04 GPT Summary- Toucanは、約500の実世界のモデルコンテキストプロトコルから合成された150万の軌跡を含む、最大の公開ツールエージェントデータセットを提供。多様で現実的なタスクを生成し、マルチツールおよびマルチターンのインタラクションに対応。5つのモデルを用いてツール使用クエリを生成し、厳密な検証を通じて高品質な出力を保証。Toucanでファインチューニングされたモデルは、BFCL V3ベンチマークで優れた性能を示し、MCP-Universe Benchでの進展を実現。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/Agent-Ark/Toucan-1.5M
[Paper Note] WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research, Zijian Li+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #Planning #LongSequence #read-later #DeepResearch #memory Issue Date: 2025-09-17 GPT Summary- 本論文では、AIエージェントがウェブ情報を統合してレポートを作成するオープンエンド深層研究(OEDR)に取り組み、WebWeaverという新しい二重エージェントフレームワークを提案。プランナーが証拠取得とアウトライン最適化を交互に行い、ライターが情報を階層的に検索してレポートを構成することで、長いコンテキストの問題を軽減。提案手法は主要なOEDRベンチマークで新たな最先端を確立し、高品質なレポート生成における人間中心のアプローチの重要性を示した。 Comment
元ポスト:
[Paper Note] Paper2Agent: Reimagining Research Papers As Interactive and Reliable AI Agents, Jiacheng Miao+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #ScientificDiscovery #Reproducibility #MCP Issue Date: 2025-09-17 GPT Summary- Paper2Agentは、研究論文をAIエージェントに自動変換するフレームワークで、研究成果の利用や発見を加速します。従来の論文は再利用の障壁を生んでいましたが、Paper2Agentは論文を知識豊富な研究アシスタントとして機能するエージェントに変換します。複数のエージェントを用いて論文と関連コードを分析し、モデルコンテキストプロトコル(MCP)を構築、洗練します。これにより、自然言語を通じて科学的クエリを実行できるエージェントを作成し、実際にゲノム変異やトランスクリプトミクス分析を行うエージェントが元の論文の結果を再現できることを示しました。Paper2Agentは、静的な論文を動的なAIエージェントに変えることで、知識の普及に新たなパラダイムを提供します。 Comment
code: https://github.com/jmiao24/Paper2Agent?tab=readme-ov-file#-demos
論文を論文が提案する技術の機能を提供するMCPサーバに変換し、LLM Agentを通じてユーザはsetup無しに呼びだして利用できるようにする技術な模様。論文から自動的にcodebaseを同定し、コアとなる技術をMCP toolsとしてラップし、反復的なテストを実施してロバストにした上でHF上のAI Agentに提供する、みたいな感じに見える。
ポイント解説:
[Paper Note] DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL, Rui Lu+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #ReinforcementLearning #PostTraining #GRPO #DeepResearch Issue Date: 2025-09-15 GPT Summary- DeepDiveは、LLMsにブラウジングツールを追加し、複雑なタスクの解決を目指す深い検索エージェントです。オープンな知識グラフから難解な質問を自動合成し、マルチターン強化学習を適用することで、長期的な推論能力を向上させます。実験により、DeepDive-32Bは複数のベンチマークで優れた性能を示し、ツール呼び出しのスケーリングと並列サンプリングを可能にしました。すべてのデータとコードは公開されています。 Comment
元ポスト:
[Paper Note] Talk Isn't Always Cheap: Understanding Failure Modes in Multi-Agent Debate, Andrea Wynn+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #AIAgents Issue Date: 2025-09-10 GPT Summary- マルチエージェントディベートはAIの推論能力向上に有望だが、時には有害であることが判明。従来の研究が同質のエージェントに焦点を当てる中、モデルの能力の多様性が相互作用に与える影響を探求。実験により、ディベートが精度低下を引き起こす可能性を示し、強力なモデルでも弱いモデルを上回る状況で同様の結果が得られた。エージェントは誤った答えにシフトし、合意を優先する傾向があり、これがディベートの効果を損なうことを示唆している。 Comment
元ポスト:
元ポストを読んだ限り、マルチエージェントシステムにdebateをさせても必ずしも性能改善するわけではないよ、という話のようである。
複数のstrong llmの中にweak llmが混在すると、モデルはおべっかによって同意するようにalignmentされる傾向があるので、良い方向に議論が収束するとは限らず、コンセンサスをとるような仕組みではなく、批判をする役目を設けるように設計するなどの工夫が必要、というような話らしい。
Multi-Relational Multi-Party Chat Corpus: 話者間の関係性に着目したマルチパーティ雑談対話コーパス, 津田+, NLP'25
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #DialogueGeneration #Conversation Issue Date: 2025-09-05 Comment
コーパス: https://github.com/nu-dialogue/multi-relational-multi-party-chat-corpus
元ポスト:
3人以上のマルチパーティに対応したダイアログコーパスで、話者間の関係性として「初対面」と「家族」に着目し、初対面対話や家族入り対話の2種類の対話を収集したコーパス。
[Paper Note] MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning, Justin Chih-Yao Chen+, EMNLP'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #SelfCorrection #EMNLP Issue Date: 2025-08-24 GPT Summary- MAgICoReは、LLMの推論を改善するための新しいアプローチで、問題の難易度に応じて洗練を調整し、過剰な修正を回避する。簡単な問題には粗い集約を、難しい問題には細かい反復的な洗練を適用し、外部の報酬モデルを用いてエラーの特定を向上させる。3つのエージェント(Solver、Reviewer、Refiner)によるマルチエージェントループを採用し、洗練の効果を確保する。Llama-3-8BおよびGPT-3.5で評価した結果、MAgICoReは他の手法を上回る性能を示し、反復が進むにつれて改善を続けることが確認された。 Comment
元ポスト:
[Paper Note] ToolVQA: A Dataset for Multi-step Reasoning VQA with External Tools, Shaofeng Yin+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #AIAgents #SyntheticData #VisionLanguageModel Issue Date: 2025-08-24 GPT Summary- 本研究では、実世界のツール使用能力を向上させるために、23Kのインスタンスからなる大規模マルチモーダルデータセット「ToolVQA」を提案。ToolVQAは、実際の視覚的コンテキストと多段階推論タスクを特徴とし、ToolEngineを用いて人間のようなツール使用推論をシミュレート。7B LFMを微調整した結果、テストセットで優れたパフォーマンスを示し、GPT-3.5-turboを上回る一般化能力を持つことが確認された。 Comment
人間による小規模なサンプル(イメージシナリオ、ツールセット、クエリ、回答、tool use trajectory)を用いてFoundation Modelに事前知識として与えることで、よりrealisticなscenarioが合成されるようにした上で新たなVQAを4k程度合成。その後10人のアノテータによって高品質なサンプルにのみFilteringすることで作成された、従来よりも実世界の設定に近く、reasoningの複雑さが高いVQAデータセットな模様。
具体的には、image contextxが与えられた時に、ChatGPT-4oをコントローラーとして、前回のツールとアクションの選択をgivenにし、人間が作成したプールに含まれるサンプルの中からLongest Common Subsequence (LCS) による一致度合いに基づいて人手によるサンプルを選択し、動的にcontextに含めることで多様なで実世界により近しいmulti step tooluseなtrajectoryを合成する、といった手法に見える。pp.4--5に数式や図による直感的な説明がある。なお、LCSを具体的にどのような文字列に対して、どのような前処理をした上で適用しているのかまでは追えていない。
元ポスト:
[Paper Note] The Policy Cliff: A Theoretical Analysis of Reward-Policy Maps in Large Language Models, Xingcheng Xu, arXiv'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #read-later Issue Date: 2025-08-14 GPT Summary- 強化学習(RL)は大規模言語モデルの行動形成に重要だが、脆弱なポリシーを生成し、信頼性を損なう問題がある。本論文では、報酬関数から最適ポリシーへのマッピングの安定性を分析する数学的枠組みを提案し、ポリシーの脆弱性が非一意的な最適アクションに起因することを示す。さらに、多報酬RLにおける安定性が「効果的報酬」によって支配されることを明らかにし、エントロピー正則化が安定性を回復することを証明する。この研究は、ポリシー安定性分析を進展させ、安全で信頼性の高いAIシステム設計に寄与する。 Comment
元ポスト:
とても面白そう
[Paper Note] EduThink4AI: Translating Educational Critical Thinking into Multi-Agent LLM Systems, Xinmeng Hou+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #AIAgents #Prompting Issue Date: 2025-07-29 GPT Summary- EDU-Promptingは、教育的批判的思考理論とLLMエージェント設計を結びつけ、批判的でバイアスを意識した説明を生成する新しいマルチエージェントフレームワーク。これにより、AI生成の教育的応答の真実性と論理的妥当性が向上し、既存の教育アプリケーションに統合可能。 Comment
元ポスト:
Critiqueを活用したマルチエージェントのようである(具体的なCritiqueの生成方法については読めていない。その辺が重要そう
Why Do Multi-Agent LLM Systems Fail?, Mert Cemri+, arXiv'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #AIAgents Issue Date: 2025-04-26 GPT Summary- MASの性能向上が単一エージェントと比較して限定的であることを受け、MAST(Multi-Agent System Failure Taxonomy)を提案。200以上のタスクを分析し、14の失敗モードを特定し、3つの大カテゴリに整理。Cohenのカッパスコア0.88を達成し、LLMを用いた評価パイプラインを開発。ケーススタディを通じて失敗分析とMAS開発の方法を示し、今後の研究のためのロードマップを提示。データセットとLLMアノテーターをオープンソース化予定。 Comment
元ポスト:
7つのメジャーなマルチエージェントフレームワークに対して200以上のタスクを実施し、6人の専門家がtraceをアノテーション。14種類の典型的なfailure modeを見つけ、それらを3つにカテゴライズ。これを考慮してマルチエージェントシステムの失敗に関するTaxonomy(MAS)を提案
Joint Modeling in Recommendations: A Survey, Xiangyu Zhao+, arXiv'25
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Survey #Pocket #MultitaskLearning #MultiModal Issue Date: 2025-03-03 GPT Summary- デジタル環境におけるDeep Recommender Systems(DRS)は、ユーザーの好みに基づくコンテンツ推薦に重要だが、従来の手法は単一のタスクやデータに依存し、複雑な好みを反映できない。これを克服するために、共同モデリングアプローチが必要であり、推薦の精度とカスタマイズを向上させる。本論文では、共同モデリングをマルチタスク、マルチシナリオ、マルチモーダル、マルチビヘイビアの4次元で定義し、最新の進展と研究の方向性を探る。最後に、将来の研究の道筋を示し、結論を述べる。 Comment
元ポスト:
[Paper Note] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks, Adam Fourney+, arXiv'24, 2024.11
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Library #AIAgents Issue Date: 2025-11-25 GPT Summary- 高性能なオープンソースエージェントシステム「Magentic-One」を提案。マルチエージェントアーキテクチャを用いて計画、進捗追跡、エラー回復を行い、専門エージェントにタスクを指示。GAIA、AssistantBench、WebArenaのベンチマークで競争力のあるパフォーマンスを達成。モジュラー設計により、エージェントの追加や削除が容易で、将来の拡張が可能。オープンソース実装とエージェント評価ツール「AutoGenBench」を提供。詳細は公式サイトで確認可能。 Comment
日本語解説: https://zenn.dev/masuda1112/articles/2024-11-30-magnetic-one
blog:
https://www.microsoft.com/en-us/research/articles/magentic-one-a-generalist-multi-agent-system-for-solving-complex-tasks/
code:
https://github.com/microsoft/autogen/tree/main/python/packages/autogen-magentic-one
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models, Tian Yu+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-10 GPT Summary- Auto-RAGは、LLMの意思決定能力を活用した自律的な反復検索モデルで、リトリーバーとのマルチターン対話を通じて知識を取得します。推論に基づく意思決定を自律的に合成し、6つのベンチマークで優れた性能を示し、反復回数を質問の難易度に応じて調整可能です。また、プロセスを自然言語で表現し、解釈可能性とユーザー体験を向上させます。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=jkVQ31GeIA
OpenReview: https://openreview.net/forum?id=jkVQ31GeIA
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Factuality #Reasoning #ACL Issue Date: 2024-12-02 GPT Summary- 大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 Comment
SNLP'24での解説スライド:
https://docs.google.com/presentation/d/1Q_UzOzn0qYX1gq_4FC4YGXK8okd5pwEHaLzVCzp3yWg/edit?usp=drivesdk
この研究を信じるのであれば、LLMはCoT無しではマルチホップ推論を実施することはあまりできていなさそう、という感じだと思うのだがどうなんだろうか。
[Paper Note] Salience Estimation via Variational Auto-Encoders for Multi-Document Summarization, Li+, AAAI'17
Paper/Blog Link My Issue
#DocumentSummarization #Document #Pocket #NLP #VariationalAutoEncoder #AAAI Issue Date: 2018-10-05
[Paper Note] Graph-based Neural Multi-Document Summarization, Michihiro Yasunaga+, CoNLL'17, 2017.06
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #Document #Supervised #GraphBased #Pocket #NLP #GraphConvolutionalNetwork #Extractive #CoNLL #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- 文の関係グラフを用いたニューラルマルチドキュメント要約システムを提案。GCNを適用し、重要な文の特徴を生成後、貪欲なヒューリスティックで文を抽出。DUC 2004の実験で、従来の手法を上回る競争力のある結果を示す。 Comment
Graph Convolutional Network (GCN)を使って、MDSやりましたという話。 既存のニューラルなMDSモデル [Cao et al., 2015, 2017] では、sentence間のrelationが考慮できていなかったが、GCN使って考慮した。 また、MDSの学習データはニューラルなモデルを学習するには小さすぎるが(abstractiveにするのは厳しいという話だと思われる?)、sentenceのsalienceを求める問題に帰着させることで、これを克服。
GCNで用いるAdjacent Matrixとして3種類の方法(cosine similarity, G-Flow, PDG)を試し、議論をしている。PDGが提案手法だが、G-Flowによる重みをPersonalization Features(position, leadか否か等のベーシックな素性)から求まるweightで、よりsentenceのsalienceを求める際にリッチな情報を扱えるように補正している。PDGを用いた場合が(ROUGE的な観点で)最も性能がよかった。
モデルの処理の流れとしては、Document Cluster中の各sentenceのhidden stateをGRUベースなRNNでエンコードし、それをGCNのノードの初期値として利用する。GCNでL回のpropagation後(実験では3回)に得られたノードのhidden stateを、salienceスコア計算に用いるsentence embedding、およびcluster embeddingの生成に用いる。 cluster embeddingは、document clusterをglobalな視点から見て、salienceスコアに反映させるために用いられる。 最終的にこれら2つの情報をlinearなlayerにかけてsoftmaxかけて正規化して、salienceスコアとする。
要約を生成する際はgreedyな方法を用いており、salienceスコアの高いsentenceから要約長に達するまで選択していく。このとき、冗長性を排除するため、candidateとなるsentenceと生成中の要約とのcosine similarityが0.5を超えるものは選択しないといった、よくある操作を行なっている。
DUC01, 02のデータをtraining data, DUC03 をvalidation data, DUC04をtest dataとし、ROUGE1,2で評価。 評価の結果、CLASSY04(DUC04のbest system)やLexRank等のよく使われるベースラインをoutperform。 ただ、regression basedなRegSumにはスコアで勝てないという結果に。 RegSumはwordレベルでsalienceスコアをregressionする手法で、リッチな情報を結構使っているので、これらを提案手法に組み合わせるのは有望な方向性だと議論している。
[Cao+, 2015] Ranking with recursive neural networks and its application to multi-document summarization, Cao+, AAAI'15 [Cao+, 2017] Improving multi-document summarization via text classification, Cao+, AAAI'17
[所感]
・ニューラルなモデルは表現力は高そうだけど、学習データがDUC01と02だけだと、データが足りなくて持ち前の表現力が活かせていないのではないかという気がする。
・冗長性の排除をアドホックにやっているので、モデルにうまく組み込めないかなという印象(distraction機構とか使えばいいのかもしれん)
・ROUGEでしか評価してないけど、実際のoutputはどんな感じなのかちょっと見てみたい。(ハイレベルなシステムだとROUGEスコア上がっても人手評価との相関がないっていう研究成果もあるし。)
・GCN、あまり知らなかったかけど数式追ったらなんとなく分かったと思われる。(元論文読めという話だが)
[Paper Note] CTSUM: Extracting More Certain Summaries for News Articles, Wan+, SIGIR'14
Paper/Blog Link My Issue
#Single #DocumentSummarization #Document #Unsupervised #GraphBased #NLP #Extractive #SIGIR #KeyPoint Notes Issue Date: 2018-01-01 Comment
要約を生成する際に、情報の”確実性”を考慮したモデルCTSUMを提案しましたという論文(今まではそういう研究はなかった)
```
"However, it seems that Obama will not use the platform to relaunch his stalled drive for Israeli-Palestinian peace"
```
こういう文は、"It seems"とあるように、情報の確実性が低いので要約には入れたくないという気持ち。
FactBankのニュースコーパスから1000 sentenceを抽出し、5-scaleでsentenceの確実性をラベルづけ。
このデータを用いてSVRを学習し、sentenceの確実性をoutputする分類器を構築
affinity-propagationベース(textrank, lexrankのような手法)手法のaffinityの計算(edge間の重みのこと。普通はsentence同士の類似度とかが使われる)を行う際に、情報の確実性のスコアを導入することで確実性を考慮した要約を生成
DUC2007のMDSデータセットで、affinity計算の際に確実性を導入する部分をablationしたモデル(GRSUM)と比較したところ、CTSUMのROUGEスコアが向上した。
また、自動・人手評価により、生成された要約に含まれる情報の確実性を評価したところ、GRSUMをoutperformした
SIGIRでは珍しい、要約に関する研究
情報の確実性を考慮するという、いままであまりやられていなかった部分にフォーカスしたのはおもしろい
「アイデアはおもしろいし良い研究だが、affinity weightが変化するということは、裏を返せばdamping factorを変更してもそういう操作はできるので、certaintyを考慮したことに意味があったのかが完全に示せていない。」という意見があり、なるほどと思った。
[Paper Note] Hierarchical Summarization: Scaling Up Multi-Document Summarization, Christensen+, ACL'14
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Extractive #ACL #Selected Papers/Blogs #interactive #KeyPoint Notes #Hierarchical Issue Date: 2017-12-28 Comment
## 概要
だいぶ前に読んだ。好きな研究。
テキストのsentenceを階層的にクラスタリングすることで、抽象度が高い情報から、関連する具体度の高いsentenceにdrill downしていけるInteractiveな要約を提案している。
## 手法
通常のMDSでのデータセットの規模よりも、実際にMDSを使う際にはさらに大きな規模のデータを扱わなければならないことを指摘し(たとえばNew York Timesで特定のワードでイベントを検索すると数千、数万件の記事がヒットしたりする)そのために必要な事項を検討。
これを実現するために、階層的なクラスタリングベースのアプローチを提案。
提案手法では、テキストのsentenceを階層的にクラスタリングし、下位の層に行くほどより具体的な情報になるようにsentenceを表現。さらに、上位、下位のsentence間にはエッジが張られており、下位に紐付けられたsentence
は上位に紐付けられたsentenceの情報をより具体的に述べたものとなっている。
これを活用することで、drill down型のInteractiveな要約を実現。
[Paper Note] Query-Chain Focused Summarization, Baumel+, ACL'14
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Dataset #QueryBiased #Extractive #ACL #Selected Papers/Blogs #Surface-level Notes Issue Date: 2017-12-28 Comment
(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。
[Paper Note] Multi-relational matrix factorization using bayesian personalized ranking for social network data, Krohn-Grimberghe+, WSDM'12, 2012.02
Paper/Blog Link My Issue
#RecommenderSystems #MatrixFactorization #WSDM #ColdStart #One-Line Notes Issue Date: 2017-12-28 Comment
multi-relationalな場合でも適用できるmatrix factorizationを提案。特にcold start problemにフォーカス。social networkのデータなどに適用できる。
[Paper Note] Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #Personalization #EMNLP #Selected Papers/Blogs #interactive #KeyPoint Notes Issue Date: 2017-12-28 Comment
ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。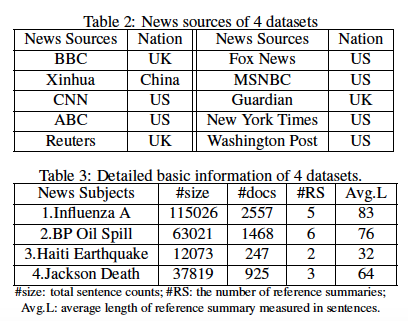
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。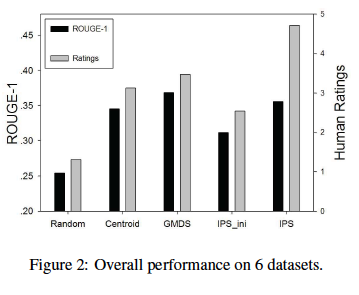
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
[Paper Note] Personalized Multi-Document Summarization using N-Gram Topic Model Fusion, Hennig+, SPIM'10, 2010.05
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #Personalization #One-Line Notes Issue Date: 2017-12-28 Comment
・unigramの共起だけでなく,bigramの共起も考慮したPLSIモデルを提案し,jointで学習.与えられたクエリやnarrativeなどとsentenceの類似度(latent spaceで計算)を計算し重要文を決定。
・user-modelを使ったPersonalizationはしていない.
[Paper Note] Personalized PageRank based Multi-document summarization, Liu+, WSCS'08, 2008.07
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #Personalization #KeyPoint Notes Issue Date: 2017-12-28 Comment
・クエリがあるのが前提
・基本的にPersonalized PageRankの事前分布を求めて,PageRankアルゴリズムを適用する
・文のsalienceを求めるモデルと(パラグラフ,パラグラフ内のポジション,statementなのかdialogなのか,文の長さ),クエリとの関連性をはかるrelevance model(クエリとクエリのnarrativeに含まれる固有表現が文内にどれだけ含まれているか)を用いて,Personalized PageRankの事前分布を決定する
・評価した結果,DUC2007のtop1とtop2のシステムの間のROUGEスコアを獲得
[Paper Note] Personalized Multi-document Summarization in Information Retrieval, Yang+, Machine Learning and Cybernetics'08, 2008.07
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #InformationRetrieval #NLP #QueryBiased #Personalization #KeyPoint Notes Issue Date: 2017-12-28 Comment
・検索結果に含まれるページのmulti-document summarizationを行う.クエリとsentenceの単語のoverlap, sentenceの重要度を
Affinity-Graphから求め,両者を結合しスコアリング.MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
likeな手法で冗長性を排除し要約を生成する.
・4人のユーザに,実際にシステムを使ってもらい,5-scaleで要約の良さを評価(ベースラインなし).relevance, importance,
usefulness, complement of summaryの視点からそれぞれを5-scaleでrating.それぞれのユーザは,各トピックごとのドキュメントに
全て目を通してもらい,その後に要約を読ませる.
[Paper Note] A study of global inference algorithms in multi-document summarization, Ryan McDonald, ECIR'07
Paper/Blog Link My Issue
#DocumentSummarization #Document #NLP #IntegerLinearProgramming (ILP) #Extractive #ECIR #Selected Papers/Blogs #One-Line Notes Issue Date: 2018-01-17 Comment
文書要約をナップサック問題として定式化し、厳密解(動的計画法、ILP Formulation)、近似解(Greedy)を求める手法を提案。
[Paper Note] NewsInEssence: Summarizing ONLINE NEWS TOPICS, Radev+, Communications of the ACM'05, 2005.10
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Extractive #One-Line Notes Issue Date: 2017-12-28 Comment
・Centroid-Basedな手法(MEADと同じ手法)で要約を生成
・Personalizationはかけていない
Centroid-based summarization of multiple documents: sentence extraction, utility-based evaluation, and user studies, Radev+, Information Processing & Management'04
Paper/Blog Link My Issue
#DocumentSummarization #Classic #NLP Issue Date: 2023-08-27 Comment
MEAD, Centroid-basedな手法で要約を実施する古典的なMDS手法
[Paper Note] A Formal Model for Information Selection in Multi-Sentence Text Extraction, Filatova+, COLING'04
Paper/Blog Link My Issue
#DocumentSummarization #Document #NLP #Extractive #COLING #One-Line Notes Issue Date: 2018-01-17 Comment
初めて文書要約を最大被覆問題として定式化した研究。
[Paper Note] WebInEssence: A Personalized Web-Based Multi-Document Summarization and Recommendation System, Radev+, NAACL'01, 2001.06
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #Personalization #NAACL #KeyPoint Notes Issue Date: 2017-12-28 Comment
・ドキュメントはオフラインでクラスタリングされており,各クラスタごとにmulti-document summarizationを行うことで,
ユーザが最も興味のあるクラスタを同定することに役立てる.あるいは検索結果のページのドキュメントの要約を行う.
要約した結果には,extractした文の元URLなどが付与されている.
・Personalizationをかけるためには,ユーザがドキュメントを選択し,タイトル・ボディなどに定数の重みをかけて,その情報を要約に使う.
・特に評価していない.システムのoutputを示しただけ.
Introducing SWE-grep and SWE-grep-mini: RL for Multi-Turn, Fast Context Retrieval, Cognition, 2025.10
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #ReinforcementLearning #AIAgents #Blog #Proprietary #Parallelism #ContextEngineering #KeyPoint Notes Issue Date: 2025-10-18 Comment
元ポスト:
最大で4 turnの間8つのツールコール(guessingとしては従来モデルは1--2, Sonnet-4.5は1--4)を並列する(3 turnは探索、最後の1 turnをanswerのために使う) parallel tool calls を効果的に実施できるように、on policy RLでマルチターンのRLを実施することで、高速で正確なcontext retrievalを実現した、という感じらしい。
従来のembedding-basedなdense retrieverは速いが正確性に欠け、Agenticなsearchは正確だが遅いという双方の欠点を補う形。
parallel tool callというのは具体的にどういうtrajectoryになるのか…?
Don’t Build Multi-Agents, Cognition, 2025.06
Paper/Blog Link My Issue
#Article #NLP #AIAgents #Blog #read-later #ContextEngineering Issue Date: 2025-06-17 Comment
元ポスト:
まとめ:
[Paper Note] LexRank: Graph-based Lexical Centrality as Salience in Text Summarization, Erkan+, Journal of Artificial Intelligence Research, 2004.12
Paper/Blog Link My Issue
#Article #Single #DocumentSummarization #Document #Unsupervised #GraphBased #NLP #Extractive #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2018-01-01 Comment
代表的なグラフベースな(Multi) Document Summarization手法。
ほぼ
- [Paper Note] TextRank: Bringing Order into Texts, Mihalcea+, EMNLP'04
と同じ手法。
2種類の手法が提案されている:
* [LexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを計算し閾値以上となったsentenceの間にのみedgeを張る(重みは確率的に正規化)。その後べき乗法でPageRank。
* [ContinousLexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを用いてAffinity Graphを計算し、PageRankを適用(べき乗法)。
DUC2003, 2004(MDS)で評価。
Centroidベースドな手法をROUGE-1の観点でoutperform。
document clusterの17%をNoisyなデータにした場合も実験しており、Noisyなデータを追加した場合も性能劣化が少ないことも示している。