
needs-revision
[Paper Note] What do Language Models Learn and When? The Implicit Curriculum Hypothesis, Emmy Liu+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#Analysis #Pretraining #NLP #LanguageModel #Selected Papers/Blogs #reading #One-Line Notes #Author Thread-Post Issue Date: 2026-05-27 GPT Summary- 大規模言語モデル(LLMs)の事前学習におけるスキル獲得の順序を理解するための「暗黙のカリキュラム仮説」を提案。シンプルかつ組み合わせ可能なタスクを用い、モデル間の一貫した出現順序を追跡。特定のパラメータ範囲で構成的なタスクが後に現れる傾向があり、モデルの表現に組み込まれていることを示す。予測可能な訓練経路を通じて、事前学習は構造化されていると示唆。 Comment
元ポスト:
これは、著者ポストしっかり読みたい
- モデルファミリー・DataMixtureにはよらず、事前学習では構成的で、かつ予測可能なカリキュラムに則って学習が進行し、かつモデルの内部状態から各スキルがどのように学習されていくかを予測できるという仮説を立て、
- この仮説を検証するために、91種類の構成的なタスクを定義し、emergence(=当該タスクの性能が閾値を超えること)を4種類のモデルファミリーにおける9つのモデル、様々なDataMixtureの元で追跡した。タスクの例は以下:
- simple tasks: 文字列操作/形態素の変換/知識の抽出/翻訳など
- composite tasks: 複数の基礎的な操作のsequentialな組み合わせによって実現されるタスク
- たとえば、`gerund_upper` は大文字への変換➡︎動名詞への変換という順番で定義される。
- 様々なモデルファミリーをテストしたところ、LLMは事前学習の間におおむね(完璧ではないが)同じ順番でスキルを獲得していくことが明らかになった
- たとえば、Figure 1を見ると、性能の伸び方は異なるものの、閾値を50%としたときのemergenceの順番はモデルの間で一貫していることがわかる。Table2も参照のこと。
- composite tasksは、それらのタスクの構成要素が獲得された後にemergeすることが明らかになった(54/76ケース)
- 例外的に、composition taskが構成要素よりも先に習得されたものが3例ほど存在した
- また、あるcomposite taskの学習曲線を、類似したFunction Vectors [^1] を持つcomposite taskから予測できるか?(i.e., 類似したタスクは同じような学習曲線を持つか?)を検証。
- これを実施するために、composite taskに対してleave-one-outを実施し、類似したタスクのFunction Vectorsから学習の軌跡を予測できるかを実験したところ、R^2スコアが0.68--0.84程度の性能で予測することができた。
- Function Vectors: [Paper Note] Function Vectors in Large Language Models, Eric Todd+, arXiv'23, 2023.10
[^1]: Function Vectorsとは、LLMに遂行させるタスクのinput-outputの変換の関係性を保持し、タスクを遂行させる際にLLMに対して強い影響力を持つ内部のactivationsのことを指す。
[Paper Note] Sapiens2, Rawal Khirodkar+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Transformer #ContrastiveLearning #Self-SupervisedLearning #ICLR #Encoder #Backbone #2D Reconstruction Issue Date: 2026-04-25 GPT Summary- Sapiens2は、高解像度トランスフォーマーのモデルファミリーで、人間中心のビジョンを重視する。4億〜50億パラメータを持ち、ネイティブ1K解像度を採用し、4K対応の階層的バリアントも提供。事前学習と後学習で大幅な性能向上を実現し、マスク済み画像再構成と自己蒸留型対比学習を統合したアプローチを採用。10億枚の高品質な人体画像データセットで事前学習を行い、アーキテクチャの進歩により安定性を向上。ポーズ推定や身体部位セグメンテーションなどのタスクで新たな最先端性能を達成。 Comment
openreview: https://openreview.net/forum?id=IVAlYCqdvW
元ポスト:
HF: https://huggingface.co/facebook/sapiens2
人物ドメインに特化したViTエンコーダ。事前学習はEncoder-Decoderアーキテクチャを利用しMasked Image Modelingで学習する。この際に、Reconstruction lossだけでなく、
[Paper Note] Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter, Ruoyu Qin+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Infrastructure #LLMServing #Selected Papers/Blogs #reading #One-Line Notes #KV Cache #Author Thread-Post Issue Date: 2026-04-18 GPT Summary- Prefill-decode(PD)のデプロイにはKVCache転送が制限要因となっており、従来のアテンションモデルは大容量のKVCacheトラフィックを生成する。ハイブリッドアテンションアーキテクチャはKVCacheサイズを削減するが、データセンター間の運用に問題が残る。そこで、Prefill-as-a-Service(PrfaaS)を提案し、プリフィル処理を専用クラスタにオフロードして効率的なKVCache転送を実現。これにより、リソースの独立したスケーリングを可能にし、実績として、PrfaaSを用いた異種デプロイメントは従来よりも高い提供スループットを達成。 Comment
元ポスト:
LLM servingにおいて、prefillはcompute-intensiveで、decodeは(kv cacheが肥大化するため)memory-intensiveであるという特性があるため、(それぞれ得意な処理は得意なノードに任せるため)prefillとdecodeを分離して異なるノードで実施するprefill-decode disaggreagated servingというインフラのアーキテクチャが超巨大モデルでは主流だが、prefill-decode間でKV Cacheを転送しなければならないため、このような分離は同じ計算機クラスター内のRDMA(Remote Direct Memory Access)が可能なノード間に限定されるのが一般的である。
しかし、compute/memory特化型のリソースは通常チップの種類と物理的な場所の両方に制約されてプールされるので、両方のハードウェアがRDMAのような密結合なドメインで利用できないという欠点がある。このため、クラスターを超えてPD分離をしたいのだが、KV Cacheの転送が結局のところボトルネックとなる。現在のモデルはSparse/LinearなアテンションによってKV Cacheに必要なリソースが一桁減っているが、それでもnaiveにクラスタを跨いでPD分離をすると、突発的なリクエストのバーストや、不均一なPrefix Cacheの分布、クラスター間の帯域幅の変動などによって、計算効率が低下してしまう。
そのため、提案手法では、高スループットな長文のprefillに特化した独立クラスタを作り、ローカルにキャッシュされていない(主に長文の)、 prefillのみを同クラスタにオフロードし、短いリクエストはローカルでPDを実施するようなアプローチをとる。こうしてprefill特化クラスタによって生成されたKV Cacheはdecode可能なPDクラスタに対してイーサネットを介して転送される。これは選択的なオフロードであり、帯域幅が制限された経路で非効率な短いリクエストを送信を避けて、prefillの高速化が重要なリクエストのみをクラスタ間転送に集中させるという考え方に基づく。
これを実現するためには、(i)長いリクエストのみをオフロードするルーティングの仕組みと、(ii)ネットワークの輻輳を制御するための、帯域幅を考慮したスケジューラ、(iii)リクエスト長、キャッシュ配置、利用可能なクラスタの帯域幅を総合的に考慮してKV Cache全体を効率的を保ちながら管理するグローバルKV Cacheマネージャが必要。
このようなアーキテクチャを1T級のKimi Linearモデルで実験した結果、スループットが1.54倍、TTFTが64%改善した、という感じらしい。
[Paper Note] Memory Intelligence Agent, Jingyang Qiao+, arXiv'26, 2026.04
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #MultiModal #ContrastiveLearning #VisionLanguageModel #DeepResearch #memory #reading #Test-time Learning #Initial Impression Notes Issue Date: 2026-04-14 GPT Summary- DRAはLLMの推論と外部ツールを組み合わせ、過去の経験を活用するメモリシステムを含む。従来の方法はメモリの効率性に課題があり、MIAフレームワークを提案してこれを解決。プランナーとエグゼキューターから成る新しいアーキテクチャは、交互の強化学習で協調を強化し、推論中の更新を実現。さらに、記憶の双方向変換を可能にし、自己進化を促進する機構も搭載。広範な実験でMIAの優位性を示した。 Comment
元ポスト:
元ポストを読みなんとなーく分かったつとりになっているゆるふわ理解だが、Plannerのパラメータに経験をTest Time Learningの枠組みを埋め込み、既存のノンパラメトリックなメモリにtrajectoryも活用する二段構えである点が新しい点に感じた。
元論文を流し読みすると、Executor(vlm), Planner(llm, parametricなmemory), Memory Manager(trajectoryを格納; non parametricなmemory)の3つにマルチモーダルなAI Agentを分離する。
plannerは(ToDo 3.2節を読むべし
executorはplannerと過去のtrajectoryに基づいて実行をする。executorはGRPOに」るRLVRで訓練されるが、tool use, plannerのトークンはマスクされ学習される。
(後ほど追記
[Paper Note] KnowledgeSmith: Uncovering Knowledge Updating in LLMs with Model Editing and Unlearning, Yinyi Luo+, ICLR'26, 2025.10
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #ICLR #ConceptErasure #KnowledgeEditing #reading #KeyPoint Notes #Author Thread-Post Issue Date: 2026-04-14 GPT Summary- LLMsの知識更新メカニズムを理解するため、統一フレームワークKnowledgeSmithを提案。編集と忘却を制約付き最適化として位置づけ、自動データセット生成器を用いて修正戦略の知識伝播を研究。実験により、LLMsが人間と同様の更新を示さず、一貫性と容量のトレードオフがあることを発見。新たな戦略設計の示唆を提供。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=znnA2Opw6v
知識の忘却と編集のダイナミクスを制約付きの最適化問題として統一的にモデル化(式3;この最適化問題を実際に解いているわけではなくあくまで理論的にこう定式化できるねという話だと思われる)し、
この定式化を通じて見ると、編集と忘却の違いはターゲットとする分布q_targetの選び方の違いにすぎず、様々な編集と忘却の先行研究は手法は違えど、この制約付きの最適化問題の異なるインスタンスを解いているに過ぎないという視点を提供しているようである。これにより、編集と忘却のトレードオフを公平に比較することが可能となるという主張をしているように見える(自信ない)。
そして、編集と忘却のトレードオフを厳格に分析するためのベンチマークとして、階層的な依存関係や(local vs. global)、更新の多段階での伝播を扱えるベンチマークが必要だが既存ベンチマークではこれらが不足しているため、
知識グラフに基づいて自動的に構築されたデータとベンチマーク(Figure 1を見るにテンプレートベースのMCQを)を作成して分析。
分析には6つのモデルファミリーの13のモデルが用いられ、スケールは1B--123Bの幅広いスケールのモデルで検証された。
(先行研究も含めてしっかり読まないと、式3と実験で用いられている手法AlphaEdit, ReLearnの関係性がちょっとわからなそう)
著者ポストにおいては、以下のようなtakeawayが記載されており、大きな知見としてはLLMはデータベースではなく、トレードオフを持つ複雑に絡み合ったシステムであり、以下のような点を明らかにした
- 知識の編集は意図しない変更を引き起こし
- 忘却は知識の完全な消去には失敗する
- 更新する知識を増やせば増やすほど、ローカルの知識は更新されるが、グローバルな一貫性が崩壊し
- 変更することが極めて困難な知識(たとえば歴史)が存在する
とのことである。
[Paper Note] Adaptive Block-Scaled Data Types, Jack Cook+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Architecture #SoftwareEngineering #read-later #Selected Papers/Blogs #One-Line Notes #LowPrecision Issue Date: 2026-04-01 GPT Summary- NVFP4は、4ビット量子化形式として人気ですが、誤差分布の問題を抱えています。本研究では、入力値の分布に適応できる新しいデータ型、IF4(Int/Float 4)を提案します。IF4は、各16値のグループに対しFP4とINT4を選択し、NVFP4のスケールファクターでスケールします。この方法により、量子化訓練時の損失を低減し、精度を向上させることが確認されました。また、IF4のハードウェア実装も評価されています。 Comment
元ポスト:
NVFP4と同様に、4bitで表現される16個のデータをひとつのグループとして扱い[^1]、FP8でのスケールファクターを共有するような浮動小数点フォーマットで[^2]、
グループ内の16個のデータに対して、INT4/FP4どちらを適用するかを、(NVFP4では常に正となっていた;未使用だった)スケールファクターを表現している8bitの先頭である符号ビットを用いて制御する新たな低精度浮動小数点フォーマット、IF4を提案、という話らしい。符号ビットをINT4, FP4を制御するIndicatorとして扱うため、NVFP4と比較してメモリ使用量は増えない。Indicatorはどちらがより量子化誤差が小さくなるかによって選択される、という感じらしい?
[^1]: グループとは単に0/1のバイナリ値が4bit分並んでいるデータのことであり、たとえばFP4で4bitの羅列を解釈すると、FP4は{±0, ±0.5, ±1, ±1.5, ±2, ±3, ±4, ±6}の16個の数値で解釈するようルールづけられている。
[^2]: スケールファクターを乗じることで、値を元々のデータのスケールに変換する。
この辺は勉強不足だなぁ、、、。
- NVFP4解説:
https://licensecounter.jp/engineer-voice/blog/articles/20260317_nvfp4.html
- 本研究日本語解説:
https://note.com/shimmyo_lab/n/n693c4d0da45f
[Paper Note] Entropy-Preserving Reinforcement Learning, Aleksei Petrenko+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#NLP #LanguageModel #ReinforcementLearning #ICLR #PostTraining #Selected Papers/Blogs #Stability #EntropyCollapse #Author Thread-Post Issue Date: 2026-04-01 Comment
元ポスト:
openreview: https://openreview.net/forum?id=E8MR8jgEeZ
PPO/GRPOなどのアルゴリズムではRL中にポリシーの多様性が低下し、ポリシーがdeterministicになり探索をしなくなり、パフォーマンスが停滞するか低下する(あるいはベースモデルでもともと高い尤度を持っていた解のPass@1が改善するが、ポリシーの出力が狭くなるため、Pass@kが犠牲になる)現象が生じる(= entropy collapse)ので、それを是正したいという話。
後ほど追記
[Paper Note] MDM-Prime-v2: Binary Encoding and Index Shuffling Enable Compute-optimal Scaling of Diffusion Language Models, Chen-Hao Chao+, arXiv'26, 2026.03
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #DiffusionModel Issue Date: 2026-03-30 GPT Summary- MDM-Primeは部分マスク法を応用し、拡散過程をサブトークンレベルでモデル化することで優れた一般化性能を示しますが、トークン粒度のハイパーパラメータ選択に関するツールが不足し、BPEとの組み合わせで尤度推定が低下します。これを受けて、MDM-Prime-v2を開発し、計算効率を21.8倍向上させ、OpenWebTextで7.77のパープレキシティを達成。11億パラメータに拡張したモデルは、ゼロショット精度でも優れた結果を示しました。 Comment
元ポスト:
[Paper Note] DINOv3, Oriane Siméoni+, arXiv'25, 2025.08
Paper/Blog Link My Issue
#ComputerVision #Self-SupervisedLearning #Distillation #Regularization #read-later #Selected Papers/Blogs #Backbone #One-Line Notes #Reference Collection Issue Date: 2025-08-14 GPT Summary- 自己教師付き学習は、手動でのデータ注釈を不要とし、モデルのスケーラビリティを向上させる。DINOv3は、様々なデータソースから視覚表現を学ぶための新たな枠組みを提供し、データセットとモデルサイズの拡張や密な特徴マップの劣化問題に対処する「グラム・アンカリング」を導入。また、後処理戦略により柔軟性を高め、ファインチューニングなしで様々な設定で最先端の性能を発揮する。DINOv3は高品質な特徴量を生成し、広範な視覚タスクにおいて優れた結果を示し、多様なデプロイメントシナリオに対応するソリューションを提供する。 Comment
元ポスト:
HF: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
解説:
サマリ:
v2:
- [Paper Note] DINOv2: Learning Robust Visual Features without Supervision, Maxime Oquab+, TMLR'24
本日配信された岡野原氏のランチタイムトークによると、学習が進んでいくと全部の特徴量が似通ってきてしまう問題があったが、Gram Anchoringと呼ばれる、学習初期時点でのパッチ間の類似度度行列を保持しておき正則化として損失に加えることで、そこから離れすぎないように学習するといった工夫を実施しているとのこと。
詳細な日本語解説:
https://zenn.dev/syu_tan/articles/6df2947eb6c1ae
Gram Anchoringの気持ちとしては、長期で学習をすると、モデルがグローバルな特徴量を学習可能だが、個々のパッチレベルや密な部分のローカルな特徴量が失われていってしまい、ローカルな特徴が重要なdownstreamタスクの性能が劣化するため、これをなんとかしたい。そのために、画像全体のパッチ間の類似度行列によって、パッチ全体の類似度の構造を捉え、学習初期の高品質なローカルな特徴を捉えられたモデルを教師とし、そこから離れすぎないように学習中のモデルを生徒として正則化することで解決する、というものだと思われる。
事前学習のスケジューラーの工夫として以下を実施している:
- 事前学習の終了タイミングを事前に予測することは困難
- →事前に総ステップ数を指定しなければならないパラメータのスケジューリングはそもそも困難
- →スケジューリングを廃止する
- スケジューリングを廃止する代わりに
- 学習率とweight decay、teacher EMAのmomentumを固定して学習を実施
-
[Paper Note] When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention #ICLR #AttentionSinks #read-later #Selected Papers/Blogs #One-Line Notes #Author Thread-Post Issue Date: 2025-04-05 GPT Summary- 言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 Comment
Sink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l * head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案
(後ほど詳細を追記する)
- [Paper Note] Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究
著者ポスト(openai-gpt-120Bを受けて):
openreview: https://openreview.net/forum?id=78Nn4QJTEN
Towards Adaptive Mechanism Activation in Language Agent, Ziyang Huang+, COLING'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #AIAgents #COLING #PostTraining #One-Line Notes Issue Date: 2024-12-10 GPT Summary- 自己探索によるメカニズム活性化学習(ALAMA)を提案し、固定されたメカニズムに依存せずに適応的なタスク解決を目指す。調和のとれたエージェントフレームワーク(UniAct)を構築し、タスク特性に応じてメカニズムを自動活性化。実験結果は、動的で文脈に敏感なメカニズム活性化の有効性を示す。 Comment
元ポスト:
手法としては、SFTとKTOを活用しpost trainingするようである
- [Paper Note] KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, ICML'24, 2024.02
[Paper Note] Looking Inward: Language Models Can Learn About Themselves by Introspection, Felix J Binder+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ICLR #One-Line Notes Issue Date: 2024-11-02 GPT Summary- 内省は、モデルが自己の内部状態を理解する能力を示す。LLMsに内省能力をファインチューニングし、自身の行動予測を行う実験により、内省の証拠が得られた。特に、自己予測能力において他のモデルを上回る結果が見られたが、複雑なタスクでは限界もあった。 Comment
LLMが単に訓練データを模倣しているにすぎない的な主張に対するカウンターに使えるかも
openreview: https://openreview.net/forum?id=eb5pkwIB5i
[Paper Note] DiLoCo: Distributed Low-Communication Training of Language Models, Arthur Douillard+, ICML'24 Workshop WANT
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ICML #mid-training #Selected Papers/Blogs #Workshop #One-Line Notes #DistributedLearning Issue Date: 2025-07-15 GPT Summary- 分散最適化アルゴリズム「DiLoCo」を提案し、接続が不十分なデバイスでのLLMトレーニングを可能にする。DiLoCoは、通信量を500分の1に抑えつつ、完全同期の最適化と同等の性能をC4データセットで発揮。各ワーカーのデータ分布に対して高いロバスト性を持ち、リソースの変動にも柔軟に対応可能。 Comment
言語モデルの分散学習における通信量をいかに抑えるかにフォーカスした研究で、クライアントごとに異なるデータsplitを持ち、当該データによってモデルをローカルでAdamWを用いてH step更新。その後、更新された重みの差分をouter gradientとして共有し、重み更新の差分を平均化することでローカルモデルを集約するという処理を繰り返す。
[Paper Note] Agent Workflow Memory, Zora Zhiruo Wang+, arXiv'24, 2024.09
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #memory #One-Line Notes Issue Date: 2025-04-02 GPT Summary- エージェントが複雑なタスクを解決するために、再利用可能なワークフローを学習するAgent Workflow Memory(AWM)を提案。AWMは、オフライン・オンラインのシナリオで選択的にワークフローを提供し、200以上のドメインにおいて実験した結果、Mind2Webで24.6%、WebArenaで51.1%の相対的成功率向上を達成。タスク解決に要する手順数も削減し、訓練-テスト分布ギャップが広がる中でも堅牢な一般化を示した。 Comment
過去のワークフローをエージェントがprompt中で利用することができ、利用すればするほど賢くなるような仕組みの提案
openreview: https://openreview.net/forum?id=PfYg3eRrNi
[Paper Note] Can LLMs Convert Graphs to Text-Attributed Graphs?, Zehong Wang+, arXiv'24, 2024.12
Paper/Blog Link My Issue
#NLP #LanguageModel #KnowledgeGraph #NAACL Issue Date: 2025-01-03 GPT Summary- 本研究では、グラフニューラルネットワーク(GNN)のクロスグラフ学習における課題を解決するため、新たにTopology-Aware Node Description Synthesis(TANS)を提案します。大規模言語モデル(LLM)を活用し、グラフのトポロジ情報をテキスト属性付きグラフへ変換します。TANSは、テキスト情報の有無にかかわらず、既存のアプローチを上回る性能を示し、特にテキストなしのグラフにおいて顕著な効果を発揮します。 Comment
元ポスト:
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation, Xiaoxi Li+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-12-30 GPT Summary- RetroLLMは、リトリーバルと生成を統合したフレームワークで、LLMsがコーパスから直接証拠を生成することを可能にします。階層的FM-インデックス制約を導入し、関連文書を特定することで無関係なデコーディング空間を削減し、前向きな制約デコーディング戦略で証拠の精度を向上させます。広範な実験により、ドメイン内外のタスクで優れた性能を示しました。 Comment
元ポスト:
従来のRAGとの違いと、提案手法の概要
Multilingual Large Language Models: A Systematic Survey, Shaolin Zhu+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #MultiLingual Issue Date: 2024-11-19 GPT Summary- 本論文は、多言語大規模言語モデル(MLLMs)の最新研究を調査し、アーキテクチャや事前学習の目的、多言語能力の要素を論じる。データの質と多様性が性能向上に重要であることを強調し、MLLMの評価方法やクロスリンガル知識、安全性、解釈可能性について詳細な分類法を提示。さらに、MLLMの実世界での応用を多様な分野でレビューし、課題と機会を強調する。関連論文は指定のリンクで公開されている。 Comment
Tutorial on Diffusion Models for Imaging and Vision, Stanley H. Chan, arXiv'24
Paper/Blog Link My Issue
#Tutorial #ComputerVision #DiffusionModel Issue Date: 2024-11-17 GPT Summary- 生成ツールの成長により、テキストから画像や動画を生成する新しいアプリケーションが可能に。拡散モデルの原理がこれらの生成ツールの基盤であり、従来のアプローチの欠点を克服。チュートリアルでは、拡散モデルの基本的なアイデアを学部生や大学院生向けに解説。 Comment
いつか読まなければならない
GUI Agents with Foundation Models: A Comprehensive Survey, Shuai Wang+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #AIAgents #One-Line Notes Issue Date: 2024-11-12 GPT Summary- (M)LLMを活用したGUIエージェントの研究を統合し、データセット、フレームワーク、アプリケーションの革新を強調。重要なコンポーネントをまとめた統一フレームワークを提案し、商業アプリケーションを探求。課題を特定し、今後の研究方向を示唆。 Comment
Referenceやページ数はサーベイにしては少なめに見える。
Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #MachineLearning #Supervised-FineTuning (SFT) #InstructionTuning #PEFT(Adaptor/LoRA) #Catastrophic Forgetting Issue Date: 2024-11-12 GPT Summary- 破滅的忘却に対処するため、タスクフリーのオンライン継続学習(OCL)フレームワークOnline-LoRAを提案。リハーサルバッファの制約を克服し、事前学習済みビジョントランスフォーマー(ViT)モデルをリアルタイムで微調整。新しいオンライン重み正則化戦略を用いて重要なモデルパラメータを特定し、データ分布の変化を自動認識。多様なベンチマークデータセットで優れた性能を示す。 Comment
Figure1参照
HyQE: Ranking Contexts with Hypothetical Query Embeddings, Weichao Zhou+, arXiv'24
Paper/Blog Link My Issue
#InformationRetrieval #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) #One-Line Notes Issue Date: 2024-11-10 GPT Summary- リトリーバル拡張システムにおいて、LLMのファインチューニングを必要とせず、埋め込みの類似性とLLMの能力を組み合わせたスケーラブルなランキングフレームワークを提案。ユーザーのクエリに基づいて仮定されたクエリとの類似性でコンテキストを再順位付けし、推論時に効率的で他の技術とも互換性がある。実験により、提案手法がランキング性能を向上させることを示した。 Comment
- Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23
も参照のこと。
下記に試しにHyQEとHyDEの比較の記事を作成したのでご参考までに(記事の内容に私は手を加えていないのでHallucinationに注意)。ざっくりいうとHyDEはpseudo documentsを使うが、HyQEはpseudo queryを扱う。
[参考: Perplexity Pagesで作成したHyDEとの簡単な比較の要約](
https://www.perplexity.ai/page/hyqelun-wen-nofen-xi-toyao-yue-aqZZj8mDQg6NL1iKml7.eQ)
[Paper Note] LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv'24, 2024.10
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #PEFT(Adaptor/LoRA) #NeurIPS #read-later #Initial Impression Notes Issue Date: 2024-11-09 GPT Summary- ファインチューニングは事前学習済みの大規模言語モデルにおいて重要なプロセスであり、LoRAのような手法は必要なパラメータを削減しつつ高性能を保つことが証明されている。しかし、完全なファインチューニングとLoRAが本当に同等のモデルを生み出すかをスペクトル解析により検証した結果、異なる重み行列が生成されることが判明。LoRAに特有の「侵入次元」が高位の特異ベクトルとして現れ、これがモデルの一般化能力を損なうことが示された。高ランクLoRAは完全なファインチューニングに近い振る舞いを示す一方、LoRAの低ランクモデルは異なるパラメータ空間にアクセスしていることが示唆された。侵入次元の出現理由とその影響を最小化する方法も検討された。 Comment
元ポスト:
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
や
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデルで、LoRAとFFTを比較している。時間がないが後でやりたい。
あと、昨今はそもそも実験設定における変数が多すぎて、とりうる実験設定が多すぎるため、個々の論文の知見を鵜呑みにして一般化するのはやめた方が良い気がしている。
# 実験設定の違い
## モデルのアーキテクチャ
- 本研究: RoBERTa-base(transformer-encoder)
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: transformer-decoder
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: transformer-decoder(LLaMA)
## パラメータサイズ
- 本研究:
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: 1B, 2B, 4B, 8B, 16B
- [Paper Note] Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: 7B
時間がある時に続きをかきたい
## Finetuningデータセットのタスク数
## 1タスクあたりのデータ量
## trainableなパラメータ数
openreview: https://openreview.net/forum?id=xp7B8rkh7L
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness, Fali Wang+, arXiv'24
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #SmallModel #EdgeDevices Issue Date: 2024-11-07 GPT Summary- 大規模言語モデル(LLM)は多様なタスクで能力を示すが、パラメータサイズや計算要求から制限を受け、プライバシーやリアルタイムアプリケーションに課題がある。これに対し、小型言語モデル(SLM)は低遅延、コスト効率、簡単なカスタマイズが可能で、特に専門的なドメインにおいて有用である。SLMの需要が高まる中、定義や応用に関する包括的な調査が不足しているため、SLMを専門的なタスクに適したモデルとして定義し、強化するためのフレームワークを提案する。 Comment
COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon , Yu+, SIGMOD_PODS '24
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #KnowledgeGraph #InstructionTuning #Annotation #One-Line Notes Issue Date: 2024-10-08 Comment
search navigationに導入しA/Bテストした結果、0.7%のproduct sales向上効果。
[Paper Note] COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark, Koki Maeda+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#ComputerVision #Dataset #ECCV Issue Date: 2024-09-30 GPT Summary- 手順型動画理解に向けて、COM Kitchensという新データセットを提案。スマートフォンで撮影した編集なしの俯瞰視点動画で、参加者がレシピに従った調理を記録。これにより、幅広い環境でのデータ収集が可能に。新タスクとして、動画からテキストへの検索(OnRR)と未編集動画上のキャプショニング(DVC-OV)を設定し、既存手法の能力と限界を実験で検証。 Comment
とてもおもしろそう!
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2024-09-26 GPT Summary- LLMのファインチューニング手法のスケーリング特性を調査し、モデルサイズやデータサイズが性能に与える影響を実験。結果、ファインチューニングはパワーベースの共同スケーリング法則に従い、モデルのスケーリングが事前学習データのスケーリングよりも効果的であることが判明。最適な手法はタスクやデータに依存する。 Comment
> When only few thousands of finetuning examples are available, PET should be considered first, either Prompt or LoRA. With sightly larger datasets, LoRA would be preferred due to its stability and slightly better finetuning data scalability. For million-scale datasets, FMT would be good.
> While specializing on a downstream task, finetuning could still elicit
and improve the generalization for closely related tasks, although the overall zero-shot translation
quality is inferior. Note whether finetuning benefits generalization is method- and task-dependent.
Overall, Prompt and LoRA achieve relatively better results than FMT particularly when the base
LLM is large, mostly because LLM parameters are frozen and the learned knowledge get inherited.
This also suggests that when generalization capability is a big concern, PET should be considered.
[Paper Note] Searching for Best Practices in Retrieval-Augmented Generation, Xiaohua Wang+, N_A, EMNLP'24
Paper/Blog Link My Issue
#EMNLP #Initial Impression Notes Issue Date: 2024-07-30 GPT Summary- RAG技術は、最新情報の統合、幻覚の軽減、および応答品質の向上に効果的であることが証明されています。しかし、多くのRAGアプローチは複雑な実装と長時間の応答時間という課題に直面しています。本研究では、既存のRAGアプローチとその潜在的な組み合わせを調査し、最適なRAGプラクティスを特定するために取り組んでいます。さらに、マルチモーダル検索技術が視覚入力に関する質問応答能力を大幅に向上させ、"検索を生成として"戦略を用いてマルチモーダルコンテンツの生成を加速できることを示します。 Comment
RAGをやる上で参考になりそう
[Paper Note] LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs, LLM-jp+, arXiv'24, 2024.07
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #Alignment #Evaluation #OpenWeight #Safety #Japanese #OpenSource #mid-training #PostTraining #Selected Papers/Blogs #One-Line Notes Issue Date: 2024-07-10 GPT Summary- 日本語のLLMを開発するプロジェクト「LLM-jp」を紹介。1,500人以上が参加し、オープンソースの高性能モデルを目指す。設立背景、活動概要、および技術報告を示し、最新情報は公式サイトで確認可能。 Comment
llm.jpによるテクニカルレポート
[Paper Note] Instruction Pre-Training: Language Models are Supervised Multitask Learners, Daixuan Cheng+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#Pretraining #LanguageModel #InstructionTuning #EMNLP #read-later #Selected Papers/Blogs Issue Date: 2024-07-08 GPT Summary- 教師なしのマルチタスク事前学習は成功の要因だが、監督付きの可能性も高い。本研究ではInstruction Pre-Trainingを提案し、大規模な指示-応答ペアを用いて言語モデルの前処理を行う。この手法により、40以上のタスクで2億のペアを合成し、その効果を示した。Instruction Pre-Trainingは、基盤モデルの性能を向上させ、追加の指示調整からも利益を得ることができ、Llama3-8BをLlama3-70Bに匹敵する性能へと引き上げた。モデルとデータは公開されている。 Comment
参考:
[Paper Note] Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling, Weijia Xu+, ICML'24, 2023.05
Paper/Blog Link My Issue
#ICML Issue Date: 2023-05-22 GPT Summary- Repromptingは、Chain-of-Thought(CoT)レシピを自動的に学習する反復的サンプリングアルゴリズムで、ギブスサンプリングを用います。これにより、与えられたタスクに対して一貫性のあるCoTレシピを推定し、過去のレシピを利用して新しいレシピを生成します。20の難解な推論タスクでの実験により、Repromptingは人間のCoTプロンプトを平均9.4ポイント上回り、他の最先端アルゴリズムよりも高い性能を示しました。 Comment
んー、IterCoTとかAutoPromptingとかと比較してないので、なんとも言えない…。サーベイ不足な気がするがどうだろうか。あと実験でChatGPTを使うのは再現性がないためやめた方が良い気が。
openreview(ICLR'24): https://openreview.net/forum?id=tQqLV2N0uz
[Paper Note] Active Prompting with Chain-of-Thought for Large Language Models, Shizhe Diao+, ACL'24, 2023.02
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Chain-of-Thought #ACL #KeyPoint Notes Issue Date: 2023-04-27 GPT Summary- 大規模言語モデル(LLMs)の性能向上には、タスク特有のプロンプト設計が重要であり、特に連鎖的思考(CoT)を活用したアプローチが効果的です。この研究では、Active-Promptという新手法を提案し、タスク特有の質問に対する最適なアノテーションを選定することでLLMsを適応させます。不確実性に基づくアクティブラーニングを取り入れ、最も不確実な質問を対象にする指標を導入。実験により、提案手法が8つの複雑な推論タスクで最先端の成績を達成し、有効性が示されました。 Comment
しっかりと読めていないが、CoT-answerが存在しないtrainingデータが存在したときに、nサンプルにCoTとAnswerを与えるだけでFew-shotの予測をtestデータに対してできるようにしたい、というのがモチベーションっぽい
そのために、questionに対して、training dataに対してFew-Shot CoTで予測をさせた場合やZero-Shot CoTによって予測をさせた場合などでanswerを取得し、answerのばらつき度合いなどから不確実性を測定する。
そして、不確実性が高いCoT-Answerペアを取得し、人間が手作業でCoTと回答のペアを与え、その人間が作成したものを用いてTestデータに対してFewShotしましょう、ということだと思われる。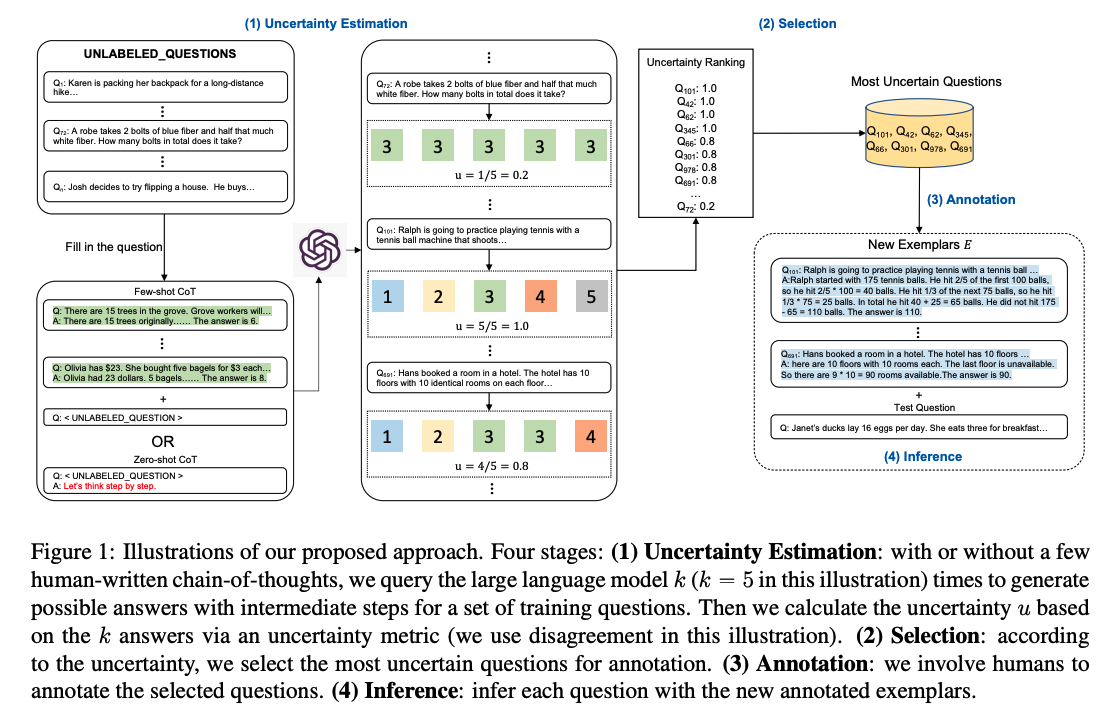
[Paper Note] Sigmoid Loss for Language Image Pre-Training, Xiaohua Zhai+, ICCV'23
Paper/Blog Link My Issue
#ComputerVision #Pretraining #LanguageModel #MultiModal #ContrastiveLearning #Selected Papers/Blogs #ICCV #Scalability Issue Date: 2025-06-29 GPT Summary- シンプルなペアワイズシグモイド損失(SigLIP)を提案し、画像-テキストペアに基づく言語-画像事前学習を改善。シグモイド損失はバッチサイズの拡大を可能にし、小さなバッチサイズでも性能向上を実現。SigLiTモデルは84.5%のImageNetゼロショット精度を達成。バッチサイズの影響を研究し、32kが合理的なサイズであることを確認。モデルは公開され、さらなる研究の促進を期待。 Comment
SigLIP論文
[Paper Note] Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity, Cunxiang Wang+, arXiv'23, 2023.10
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Factuality Issue Date: 2023-10-13 GPT Summary- LLMsにおける事実性の問題に焦点を当て、出力の信頼性と正確性の重要性を検討。事実誤りの影響や原因を分析し、評価方法論や改善戦略を提案。スタンドアロンLLMsとリトリーバル拡張LLMsの固有の課題を詳述し、体系的なガイドを提供する。 Comment
[Paper Note] Effective Long-Context Scaling of Foundation Models, Wenhan Xiong+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#NLP #LanguageModel #LongSequence #PositionalEncoding #NAACL #mid-training #Selected Papers/Blogs #DataMixture #KeyPoint Notes Issue Date: 2023-10-09 GPT Summary- 長文脈対応LLMシリーズを提案し、32,768トークンまでサポート。Llama 2の継続的な事前学習を基に、長文タスクで顕著な改善を実現。特に70B版は指示チューニングによりGPT-3.5-turbo-16kを上回る性能を示す。また、ポジションエンコーディングやデータ混合の影響を分析し、長文脈の事前学習が効率的かつ効果的であることを実証。 Comment
以下elvis氏のツイートの意訳
Metaが32kのcontext windowをサポートする70BのLLaMa2のvariant提案し、gpt-3.5-turboをlong contextが必要なタスクでoutperform。
short contextのLLaMa2を継続的に訓練して実現。これには人手で作成したinstruction tuning datasetを必要とせず、コスト効率の高いinstruction tuningによって実現される。
これは、事前学習データセットに長いテキストが豊富に含まれることが優れたパフォーマンスの鍵ではなく、ロングコンテキストの継続的な事前学習がより効率的であることを示唆している。
元ツイート:
位置エンコーディングにはlong contxet用に、RoPEのbase frequency bを `10,000->500,000` とすることで、rotation angleを小さくし、distant tokenに対する減衰の影響を小さくする手法を採用 (Adjusted Base Frequency; ABF)。token間の距離が離れていても、attention scoreがshrinkしづらくなっている。
また、単に長いコンテキストのデータを追加するだけでなく、データセット内における長いコンテキストのデータの比率を調整することで、より高い性能が発揮できることを示している。これをData Mixと呼ぶ。
また、instruction tuningのデータには、LLaMa2ChatのRLHFデータをベースに、LLaMa2Chat自身にself-instructを活用して、長いコンテキストを生成させ拡張したものを利用した。
具体的には、コーパス内のlong documentを用いたQAフォーマットのタスクに着目し、文書内のランダムなチャンクからQAを生成させた。その後、self-critiqueによって、LLaMa2Chat自身に、生成されたQAペアのverificationも実施させた。
[Paper Note] A Survey of Hallucination in Large Foundation Models, Vipula Rawte+, arXiv'23, 2023.09
Paper/Blog Link My Issue
#Survey #NLP #LanguageModel #Hallucination #ICLR Issue Date: 2023-09-30 GPT Summary- 基盤モデルにおける幻覚を特定・解明し、対処する取り組みを概観する総説論文。特に大規模基盤モデルに焦点を当て、幻覚現象を分類し、その評価基準を確立。既存の緩和戦略を検討し、今後の研究方向について論じる。全体として、LFMsに関連する幻覚の課題と解決策を包括的に探求。 Comment
Hallucinationを現象ごとに分類し、Hallucinationの程度の評価をする指標や、Hallucinationを軽減するための既存手法についてまとめられているらしい。
openreview: https://openreview.net/forum?id=pETSfWMUzy
[Paper Note] Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions, Pouya Pezeshkpour+, arXiv'23, 2023.08
Paper/Blog Link My Issue
#NLP #LanguageModel #Evaluation #Bias #NAACL #read-later #Selected Papers/Blogs #Findings #One-Line Notes #Reading Reflections Issue Date: 2023-08-28 GPT Summary- 多肢選択問題におけるLLMsの性能は選択肢の順序に敏感であり、配置を変えることで最大75%の性能差が見られる。特に、上位選択肢間の不確実性がこの感度を引き起こし、バイアスが影響することを示唆する。最適な配置は、バイアスを増幅させるためにトップ選択肢を両端に置くこと、緩和するためには隣接させることが推奨される。実験を通じて、予測のキャリブレーションにより最大8ポイントの改善が達成された。 Comment
これはそうだろうなと思っていたけど、ここまで性能に差が出るとは思わなかった。
これがもしLLMのバイアスによるもの(2番目の選択肢に正解が多い)の場合、
ランダムにソートしたり、平均取ったりしても、そもそもの正解に常にバイアスがかかっているので、
結局バイアスがかかった結果しか出ないのでは、と思ってしまう。
そうなると、有効なのはone vs. restみたいに、全部該当選択肢に対してyes/noで答えさせてそれを集約させる、みたいなアプローチの方が良いかもしれない。
[Paper Note] Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step, Liunian Harold Li+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#ACL Issue Date: 2023-07-31 GPT Summary- 小さなモデル(125M〜1.3Bパラメータ)でもチェーン・オブ・思考の恩恵を受けられることを示すため、Symbolic Chain-of-Thought Distillation(SCoTD)を導入。SCoTDは大きな教師モデルから得られた推論を用いて小さな生徒モデルを訓練し、実験により生徒モデルの性能向上を確認。特に難問セットで効果を発揮し、教師の推論と同等と評価される。サンプルの多様性や尤度が重要な要素として検証。チェーン・オブ・思考サンプルのコーパスとコードを公開。
[Paper Note] QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) #NeurIPS #PostTraining #Selected Papers/Blogs Issue Date: 2023-07-22 GPT Summary- QLoRAは、65Bパラメータモデルを単一の48GB GPUでファインチューニングするための効率的な手法であり、16ビット性能を維持しつつメモリ使用量を削減します。低秩アダプターを介して勾配をバックプロパゲーションし、GuanacoモデルはVicunaベンチマークで従来のモデルを超え、ChatGPTに近い性能を示しました。QLoRAの革新には、4ビット量子化データ型、ダブル量子化、そしてメモリ管理のためのページングオプティマイザーが含まれます。1,000以上のモデルをファインチューニングし、指示追従性能の詳細な分析を提供。また、GPT-4評価を用いたチャットボット性能の分析から、既存のベンチマークの信頼性の問題点も指摘しています。全てのモデルとコードは公開されています。 Comment
実装:
https://github.com/artidoro/qlora
PEFTにもある
参考:
[Paper Note] How Do In-Context Examples Affect Compositional Generalization?, Shengnan An+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#General #NLP #LanguageModel #In-ContextLearning #Composition #ACL Issue Date: 2023-07-13 GPT Summary- 文脈内学習における構成的一般化を調査するためのテストスイートCoFeを提案。文脈内の例の選択が構成的一般化に与える影響を発見し、良い例の要因として類似性、多様性、複雑さを特定。体系的な実験により、類似かつ多様な簡単な例が重要であることが示された。架空語での一般化が弱いことや、事前学習済みモデルにも言語構造のカバーが必要な点も観察。これにより、文脈内学習の理解を深めることを期待。
[Paper Note] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting, Zhen Qin+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #NLP #LanguageModel #Prompting #NAACL #Surface-level Notes Issue Date: 2023-07-11 GPT Summary- LLMを用いた文書ランキングは有望だが、既存手法を上回るのは難しい。本稿では、既存のpointwiseおよびlistwise手法がLLMに理解されにくいことを指摘し、新たにPairwise Ranking Prompting(PRP)を提案。中規模のオープンソースLLMで、TREC-DLで商用GPT-4を上回る成果を取得し、BEIRタスクでも教師ありベースラインやChatGPTを超えることを示した。PRPの変種によって効率性を向上させ、競争力を持つ結果も達成。 Comment
open source LLMにおいてスタンダードなランキングタスクのベンチマークでSoTAを達成できるようなprompting技術を提案
従来のランキングのためのpromptingはpoint-wiseとlist wiseしかなかったが、前者は複数のスコアを比較するためにスコアのcalibrationが必要だったり、OpenAIなどのAPIはlog probabilityを提供しないため、ランキングのためのソートができないという欠点があった。後者はinputのorderingに非常にsensitiveであるが、listのすべての組み合わせについてorderingを試すのはexpensiveなので厳しいというものであった。このため(古典的なlearning to rankでもおなじみや)pairwiseでサンプルを比較するランキング手法PRPを提案している。
PRPはペアワイズなのでorderを入れ替えて評価をするのは容易である。また、generation modeとscoring mode(outputしたラベルのlog probabilityを利用する; OpenLLMを使うのでlog probabilityを計算できる)の2種類を採用できる。ソートの方法についても、すべてのペアの勝敗からから単一のスコアを計算する方法(AllPair), HeapSortを利用する方法、LLMからのoutputを得る度にon the flyでリストの順番を正しくするSliding Windowの3種類を提案して比較している。
下表はscoring modeでの性能の比較で、GPT4に当時は性能が及んでいなかった20BのOpenLLMで近しい性能を達成している。
また、PRPがinputのorderに対してロバストなことも示されている。
[Paper Note] Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, arXiv'23, 2023.07
Paper/Blog Link My Issue
#Analysis #MachineLearning #NLP #LanguageModel #Prompting #In-ContextLearning #TACL #Selected Papers/Blogs #ContextEngineering #KeyPoint Notes Issue Date: 2023-07-11 GPT Summary- 言語モデルは長い文脈を扱う能力を持つが、実際に関連情報を効果的に利用できているかは未解明。複数文書に基づく質問応答とキー・バリュー検索を通じて、関連情報の位置による性能変動を分析した結果、関連情報が文脈の先頭や末尾にあるときに高性能を示し、中央にある場合に顕著に性能が低下することが明らかになった。この考察は、言語モデルの文脈使用に関する理解を深め、長い文脈への評価プロトコルの方向性を示唆している。 Comment
元ツイート
非常に重要な知見がまとめられている
1. モデルはコンテキストのはじめと最後の情報をうまく活用でき、真ん中の情報をうまく活用できない
2. 長いコンテキストのモデルを使っても、コンテキストをより短いコンテキストのモデルよりもうまく考慮できるわけではない
3. モデルのパフォーマンスは、コンテキストが長くなればなるほど悪化する
SNLP'24での解説スライド:
https://speakerdeck.com/kichi/snlp2024
[Paper Note] Transformers learn to implement preconditioned gradient descent for in-context learning, Kwangjun Ahn+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#MachineLearning #LanguageModel #In-ContextLearning #NeurIPS #Reading Reflections Issue Date: 2023-07-11 GPT Summary- トランスフォーマーが勾配降下法を実装できるかを探る研究。線形トランスフォーマーを線形回帰のランダムインスタンスで訓練し、単一アテンション層が前条件化勾配降下法の反復を実装することを理論的に示す。$L$層のトランスフォーマーは、特定の臨界点で$L$回の反復を実行。結果は、トランスフォーマーを学習アルゴリズムとして訓練する新たな理論研究を促進する。 Comment
参考:
つまり、事前学習の段階でIn context learningが可能なように学習がなされているということなのか。
それはどのような学習かというと、プロンプトとそれによって与えられた事例を前条件とした場合の勾配降下法によって実現されていると。
つまりどういうことかというと、プロンプトと与えられた事例ごとに、それぞれ最適なパラメータが学習されているというイメージだろうか。条件付き分布みたいなもの?
なので、未知のプロンプトと事例が与えられたときに、事前学習時に前条件として与えられているものの中で類似したものがあれば、良い感じに汎化してうまく生成ができる、ということかな?
いや違うな。1つのアテンション層が勾配降下法の1ステップをシミュレーションしており、k個のアテンション層があったらkステップの勾配降下法をシミュレーションしていることと同じ結果になるということ?
そしてその購買降下法では、プロンプトによって与えられた事例が最小となるように学習される(シミュレーションされる)ということなのか。
つまり、ネットワーク上で本当に与えられた事例に基づいて学習している(のと等価な結果)を得ているということなのか?😱
openreview: https://openreview.net/forum?id=LziniAXEI9
[Paper Note] SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking, Chris Cundy+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #MachineLearning #NLP #LanguageModel #ICLR #One-Line Notes Issue Date: 2023-06-26 GPT Summary- 自己回帰モデルは高い尤度を達成するものの、最大尤度推定(MLE)が生成タスクに必ずしも適合しないことがある。MLEは分布外の振る舞いに関する指針がないため、累積誤差が生じる。これに対処するため、生成を模倣学習(IL)として定式化し、生成系列の分布とデータセット由来の系列分布間のダイバージェンスを最小化。ILフレームワークでは、バックスペースアクションを導入し、モデルが不要なトークンを戻すことを可能にする。新たに提案するSequenceMatchは、敵対的訓練やアーキテクチャの変更なしで実装でき、SequenceMatch-χ^2ダイバージェンスを適切な訓練目的として特定。実験的に、SequenceMatchは言語モデルによるテキスト生成や算術においてMLEを上回る改善を示す。 Comment
backspaceアクションをテキスト生成プロセスに組み込むことで、out of distributionを引き起こすトークンを元に戻すことで、生成エラーを軽減させることができる。
openreview: https://openreview.net/forum?id=FJWT0692hw
[Paper Note] How Language Model Hallucinations Can Snowball, Muru Zhang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Hallucination #ICML #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-06-16 GPT Summary- 言語モデルは実用的な応用においてハルシネーションのリスクを伴い、この現象は知識ギャップに起因することが多い。興味深いことに、モデルは誤りを認識しながらも偽の主張を出力する場合がある。「ハルシネーション・スノーボール現象」として知られるこの現象では、初期の過ちに固執することでさらなる誤りを招く。研究では、ChatGPTとGPT-4がそれぞれ67%および87%の誤りを特定できることが確認された。 Comment
LLMによるhallucinationは、単にLLMの知識不足によるものだけではなく、LLMが以前に生成したhallucinationを正当化するために、誤った出力を生成してしまうという仮説を提起し、この仮説を検証した研究。これをhallucination snowballと呼ぶ。これにより、LLMを訓練する際に、事実に対する正確さを犠牲にして、流暢性と一貫性を優先し言語モデルを訓練するリスクを示唆している。
[Paper Note] Deductive Verification of Chain-of-Thought Reasoning, Zhan Ling+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#NeurIPS Issue Date: 2023-06-16 GPT Summary- LLMはChain-of-Thought(CoT)プロンプティングにより推論タスクでの性能を向上させるが、重複が幻覚や誤りを招く可能性もある。人間の演繹的論理に触発され、明示的な推論と自己検証に基づく信頼性の確保を目指す。推論検証を段階的なサブプロセスとして分解し、Natural Programを用いて各ステップの根拠を強化することで、過程の厳密さを高め、複雑なタスクの正確性を向上させる。コードは https://github.com/lz1oceani/verify_cot で公開。
[Paper Note] LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#PairWise #NLP #LanguageModel #Ensemble #ACL #ModelMerge Issue Date: 2023-06-16 GPT Summary- LLM-Blenderは、複数のオープンソースLLMの強みを活かすアンサンブルフレームワークで、PairRankerとGenFuserのモジュールから構成され、最適なLLMの選択を改善します。PairRankerは候補間の詳細な比較を行い、GenFuserはトップランクの候補を統合して出力を向上させます。MixInstructデータセットを用いた実験により、LLM-Blenderは他の手法を大きく上回る性能を示しました。
[Paper Note] QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#InformationRetrieval #NLP #Search #Dataset #Evaluation #ACL Issue Date: 2023-05-22 GPT Summary- 情報ニーズの定式化に基づき、集合演算を含む自然言語クエリからなるデータセットQUESTを構築。3357件のクエリはWikipediaエンティティにマッピングされ、モデルの集合演算能力を試す。データセットは半自動で作成され、クラウドワーカーによって文書の関連性とクエリの自然さが検証される。多くの現代検索システムは、否定や結合を含むクエリの処理に苦戦していることが明らかになった。
[Paper Note] LIMA: Less Is More for Alignment, Chunting Zhou+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #DataDistillation #NeurIPS #KeyPoint Notes #Reading Reflections Issue Date: 2023-05-22 GPT Summary- LIMAは65BパラメータのLLaMaモデルで、1,000件の慎重に選定されたプロンプトで微調整された。モデルは汎用表現を学び、未知のタスクに対しても良好に一般化。人間評価では、LIMAの性能がGPT-4より43%、Bardより58%、DaVinci003より65%優れていることが示され、事前学習が知識の大半を構築する重要性を強調している。 Comment
LLaMA65Bをたった1kのdata point(厳選された物)でRLHF無しでfinetuningすると、旅行プランの作成や、歴史改変の推測(?)幅広いタスクで高いパフォーマンスを示し、未知のタスクへの汎化能力も示した。最終的にGPT3,4,BARD,CLAUDEよりも人間が好む回答を返した。
LLaMAのようなオープンでパラメータ数が少ないモデルに対して、少量のサンプルでfinetuningするとGPT4に迫れるというのはgamechangerになる可能性がある
openreview: https://openreview.net/forum?id=KBMOKmX2he
[Paper Note] Symbol tuning improves in-context learning in language models, Jerry Wei+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #In-ContextLearning #EMNLP #PostTraining #KeyPoint Notes Issue Date: 2023-05-21 GPT Summary- シンボルチューニングを提案し、自然言語ラベルを記号に置換した文脈内の入力-ラベルペアによる言語モデルのファインチューニングを行う。これにより、モデルは指示がない場合でもタスクを解決できる。5400億パラメータのFlan-PaLMモデルでの実験により、未見のタスクに対する性能が向上し、特にアルゴリズム的推論タスクで最大18.2%の性能向上を示した。また、反転ラベルに従う能力が強化された。 Comment
概要やOpenReviewの内容をざっくりとしか読めていないが、自然言語のラベルをランダムな文字列にしたり、instructionをあえて除外してモデルをFinetuningすることで、promptに対するsensitivityや元々モデルが持っているラベルと矛盾した意味をin context learningで上書きできるということは、学習データに含まれるテキストを調整することで、正則化の役割を果たしていると考えられる。つまり、ラベルそのものに自然言語としての意味を含ませないことや、instructionを無くすことで、(モデルが表層的なラベルの意味や指示からではなく)、より実際のICLで利用されるExaplarからタスクを推論するように学習されるのだと思われる。
OpenReview: https://openreview.net/forum?id=vOX7Dfwo3v
[Paper Note] Chain-of-Symbol Prompting Elicits Planning in Large Langauge Models, Hanxu Hu+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Planning #One-Line Notes Issue Date: 2023-05-21 GPT Summary- 自然言語で表現された仮想空間における複雑な計画タスクに対するLLMsの性能を調査し、新たなベンチマークNatalaを提案。LLMs(例: ChatGPT)は依然として計画能力に限界があり、象徴的表現が理解しやすい可能性を示す。新手法CoS(Chain-of-Symbol Prompting)は追加訓練なしでLLMsに適用でき、広範な実験でCoT(Chain-of-Thought)を上回る性能を達成。特に、ChatGPTの正確性が最大60.8%向上し、中間段階のトークン数も著しく削減された。 Comment
LLMは複雑なプランニングが苦手なことが知られており、複雑な環境を自然言語ではなく、spatialでsymbolicなトークンで表現することで、プランニングの性能が向上したという話
OpenReview: https://openreview.net/forum?id=B0wJ5oCPdB
[Paper Note] Language Models Meet World Models: Embodied Experiences Enhance Language Models, Jiannan Xiang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NeurIPS Issue Date: 2023-05-20 GPT Summary- 大規模言語モデル(LM)は物理環境での推論に苦戦するが、世界モデルを用いてファインチューニングする新たなアプローチを提案。物理シミュレータ(VirtualHome)を活用し、目標志向の計画や探索を通じて具現化知識を獲得。選択的重み更新(EWC)と低秩アダプタ(LoRA)を組み合わせることで、一般性を維持しつつ訓練効率を向上。実験結果により、本アプローチは18の下流タスクで基盤LMを平均64.28%向上させ、小型LMが大規模LMに匹敵またはそれを上回る性能を示す。 Comment
OpenReview: https://openreview.net/forum?id=SVBR6xBaMl
[Paper Note] VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks, Wenhai Wang+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#VisionLanguageModel Issue Date: 2023-05-20 GPT Summary- VisionLLMは、画像を言語として扱うことでビジョン中心のタスクを柔軟に管理し、言語指示を用いてオープンエンドな予測を行うフレームワークを提案。広範な実験で、異なるタスクカスタマイズに優れた結果を示し、COCOデータセットではmAPが60%を超え、検出専用モデルと同等の性能を達成。新しい汎用ビジョンと言語モデルの基準を設定することを目指す。 Comment
openreview: https://openreview.net/forum?id=Vx1JadlOIt¬eId=IA9t6UJkTk
[Paper Note] Explaining black box text modules in natural language with language models, Chandan Singh+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #NeurIPS #Workshop #Interpretability Issue Date: 2023-05-20 GPT Summary- 大規模言語モデル(LLMs)の解釈性の必要性に応えるため、テキストモジュールの入力と出力に基づいて自然言語の説明を自動生成する手法、Summarize and Score(SASC)を提案。合成モジュールへの適用で真の説明を回復し、BERTモデル内のモジュールを検査可能にし、言語刺激へのfMRI応答の説明まで可能。すべてのコードはGitHubに公開。 Comment
モデルのinterpretabilityに関するMSの新たな研究
[Paper Note] Emergent Representations of Program Semantics in Language Models Trained on Programs, Charles Jin+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Coding #ICML #One-Line Notes Issue Date: 2023-05-20 GPT Summary- 言語モデル(LM)が次のトークン予測に特化した訓練にもかかわらず、形式的意味を表現できる可能性を示す。2Dグリッド環境でのプログラム合成コーパスを用いてTransformerモデルを訓練し、特定の入力出力仕様が付随するプログラムから、未観測の中間状態を精度よく抽出できることを発見。新しい介入ベースラインにより、LMの表現とプロービングによる結果の明確な識別が可能に。広範な意味論的プロービング実験への適用が期待される。 Comment
プログラムのコーパスでLLMをNext Token Predictionで訓練し
厳密に正解とsemanticsを定義した上で、訓練データと異なるsemanticsの異なるプログラムを生成できることを示した。
LLMが意味を理解していることを暗示している
参考:
[Paper Note] Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Shunyu Yao+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Prompting #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-05-20 GPT Summary- 言語モデルは一般的な問題解決に広がっているが、推論は依然としてトークンレベルの左から右への決定に制限されている。これを克服するために、新しい「Tree of Thoughts(ToT)」フレームワークを導入。ToTは、思考の連鎖を一般化し、中間ステップを探索できるようにし、複数の推論経路を自己評価することで意図的な意思決定を可能にする。実験では、ToTがGame of 24やCreative Writingなどの新規タスクで言語モデルの問題解決能力を顕著に向上させることが示された。例えば、Game of 24では新手法が74%の成功率を達成した。 Comment
Self Concistencyの次
Non trivialなプランニングと検索が必要な新たな3つのタスクについて、CoT w/ GPT4の成功率が4%だったところを、ToTでは74%を達成
論文中の表ではCoTのSuccessRateが40%と書いてあるような?
[Paper Note] mLongT5: A Multilingual and Efficient Text-To-Text Transformer for Longer Sequences, David Uthus+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#One-Line Notes Issue Date: 2023-05-20 GPT Summary- mLongT5という多言語対応のテキスト変換モデルを開発し、LongT5アーキテクチャを基にしています。このモデルはmT5の多言語データセットとUL2のタスクを活用し、多言語要約と質問応答で評価しました。その結果、mLongT5はmBARTやM-BERTなどの既存モデルよりも高い性能を示しました。 Comment
lib: https://huggingface.co/agemagician/mlong-t5-tglobal-xl
16384 tokenを扱えるT5。102言語に対応
[Paper Note] Vcc: Scaling Transformers to 128K Tokens or More by Prioritizing Important Tokens, Zhanpeng Zeng+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Transformer #LongSequence #NeurIPS #Encoder #Encoder-Decoder Issue Date: 2023-05-09 GPT Summary- 超長いシーケンスに対するトランスフォーマーの効率を向上させる新しい手法を提案。VIPトークンに基づく圧縮方式を用い、シーケンスを選択的に圧縮することで、効率化を実現。競争力のある性能を提供し、最大128Kトークンにスケール可能。
[Paper Note] Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting, Miles Turpin+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Chain-of-Thought #Faithfulness #NeurIPS Issue Date: 2023-05-09 GPT Summary- LLMは段階的推論(CoT)を通じて高い性能を発揮するが、CoTの説明は予測の真の理由を誤って表現することがある。入力にバイアスを与えられると、誤答を正当化する説明が生成され、精度が最大36%低下することが示された。特に、社会的バイアスに関連する場合、モデルの説明がステレオタイプを強化し、バイアスの影響について言及しない。これにより、CoTの説明は一見もっともらしいが誤導的であり、信頼性を高めるリスクを伴う。より透明なシステムを構築するためには、CoTの信頼性を向上させるか、代替手法を検討すべきである。
Stable and low-precision training for large-scale vision-language models, Wortsman+, University of Washington, NeurIPS'23
Paper/Blog Link My Issue
#ComputerVision #NeurIPS Issue Date: 2023-04-27
[Paper Note] Personalisation within bounds: A risk taxonomy and policy framework for the alignment of large language models with personalised feedback, Hannah Rose Kirk+, arXiv'23, 2023.03
Paper/Blog Link My Issue
#NLP #LanguageModel #Personalization Issue Date: 2023-04-26 GPT Summary- LLMの個別化には、人間の嗜好と整合させる必要があり、アラインメント技術がその課題を緩和するが、全ての嗜好を表現するのは難しい。ユーザーの多様な価値観に基づくマイクロレベルの個別化は有望だが、規範的課題が存在する。本文では、整合の定義、主観的嗜好の押し付け、文書化不足の問題を概観し、個別化されたLLMの利点とリスクを整理。最後に、安全なLLMの挙動を維持するための三層政策フレームワークを提案。 Comment
# abst
LLMをPersonalizationすることに関して、どのような方法でPersonalizationすべきかを検討した研究。以下の問題点を指摘。
1. アラインメント(RLHFのように何らかの方向性にalignするように補正する技術のこと?)が何を意味するのか明確ではない
2. 技術提供者が本質的に主観的な好みや価値観の定義を規定する傾向があること
3. クラウドワーカーがの専制によって、我々が実際に何にアラインメントしているのかに関する文書が不足していること
そして、PersonalizedなLLMの利点やリスクの分類を提示する。
# 導入
LLMがさまざまな製品に統合されたことで、人間の嗜好に合致し、危険かつ不正確な情報を出力を生成しないことを確保する必要がある。RLHFやred-teamingはこれに役立つが、このような集合的な(多くの人に一つのアラインメントの結果を提示すること)finetuningプロセスが人間の好みや価値観の幅広い範囲を十分に表現できるとは考えにくい。異なる人々はさまざまな意見や価値観を持っており、マイクロレベルのfinetuningプロせせ雨を通じてLLMをPersonalizationすることで、各ユーザとより良いアラインメントが可能になる可能性がある。これを社会的に受け入れられるようにするためにいくつか課題があるので、それについて論じた。
[Paper Note] ReAct: Synergizing Reasoning and Acting in Language Models, Shunyu Yao+, ICLR'23, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #AIAgents #Selected Papers/Blogs Issue Date: 2023-04-13 GPT Summary- 大規模言語モデルを用いて、推論と行動計画を相互に組み合わせるReActアプローチを提案。推論の痕跡が行動計画の導出を促進し、行動が外部情報を活用することで、推論の効率を向上。質問応答や事実検証タスクで従来手法を凌駕し、人間の解釈性と信頼性を向上させる。対話的意思決定ベンチマークでも優れた性能を発揮。 Comment
# 概要
人間は推論と行動をシナジーさせることで、さまざまな意思決定を行える。近年では言語モデルにより言語による推論を意思決定に組み合わせる可能性が示されてきた。たとえば、タスクをこなすための推論トレースをLLMが導けることが示されてきた(Chain-of-Thought)が、CoTは外部リソースにアクセスできないため知識がアップデートできず、事後的に推論を行うためhallucinationやエラーの伝搬が生じる。一方で、事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われているが、これらの研究では、高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
そこで、REACTを提案。REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みであり、推論トレースとアクションを交互に生成するため、動的に推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
- 要はいままではGeneralなタスク解決モデルにおいては、推論とアクションの生成は独立にしかやられてこなかったけど、推論とアクションを交互作用させることについて研究したよ
- そしたら性能がとってもあがったよ
- reasoningを人間が編集すれば、エージェントのコントロールもできるよ という感じ
# イントロ
人間は推論と行動の緊密なシナジーによって、不確実な状況に遭遇しても適切な意思決定が行える。たとえば、任意の2つの特定のアクションの間で、進行状況をトレースするために言語で推論したり(すべて切り終わったからお湯を沸かす必要がある)、例外を処理したり、状況に応じて計画を調整したりする(塩がないから代わりに醤油と胡椒を使おう)。また、推論をサポートし、疑問(いまどんな料理を作ることができるだろうか?)を解消するために、行動(料理本を開いてレシピを読んで、冷蔵庫を開いて材料を確確認したり)をすることもある。
近年の研究では言語での推論を、インタラクティブな意思決定を組み合わせる可能性についてのヒントが得られてきた。一つは、適切にPromptingされたLLMが推論トレースを実行できることを示している。推論トレースとは、解決策に到達するための一連のステップを経て推論をするためのプロセスのことである。しかしながらChain-of-thoughytは、このアプローチでは、モデルが外界対してgroundingできず、内部表現のみに基づい思考を生成するため限界がある。これによりモデルが事後対応的に推論したり、外部情報に基づいて知識を更新したりできないため、推論プロセス中にhallucinationやエラーの伝搬などの問題が発生する可能性が生じる。
一方、近年の研究では事前学習言語モデルをinteractiveな環境において計画と行動に利用する研究が行われている。これらの研究では、通常マルチモーダルな観測結果をテキストに変換し、言語モデルを使用してドメイン固有のアクション、またはプランを生成し、コントローラーを利用してそれらを選択または実行する。ただし、これらのアプローチは高レベルの目標について抽象的に推論したり、行動をサポートするための作業記憶を維持したりするために言語モデルを利用していない。
推論と行動を一般的な課題解決のためにどのようにシナジーできるか、またそのようなシナジーが単独で推論や行動を実施した場合と比較してどのような利益をもたらすかについて研究されていない。
LLMにおける推論と行動を組み合わせて、言語推論と意思決定タスクを解決するREACTと呼ばれる手法を提案。REACTでは、推論と行動の相乗効果を高めることが可能。推論トレースによりアクションプランを誘発、追跡、更新するのに役立ち、アクションでは外部ソースと連携して追加情報を収集できる。
REACTは推論と行動をLLMと組み合わせて、多様な推論や意思決定タスクを実現するための一般的な枠組みである。REACTのpromptはLLMにverbalな推論トレースとタスクを実行するためのアクションを交互に生成する。これにより、モデルは動的な推論を実行して行動するための大まかな計画を作成、維持、調整できると同時に、wikipediaなどの外部ソースとやりとりして追加情報を収集し、推論プロセスに組み込むことが可能となる。
# 手法
変数を以下のように定義する:
- O_t: Observertion on time t
- a_t: Action on time t
- c_t: context, i.e. (o_1, a_1, o_2, a_2, ..., a_t-1, o_t)
- policy pi(a_t | c_t): Action Spaceからアクションを選択するポリシー
- A: Action Space
- O: Observation Space
普通はc_tが与えられたときに、ポリシーに従いAからa_tを選択しアクションを行い、アクションの結果o_tを得て、c_t+1を構成する、といったことを繰り返していく。
このとき、REACTはAをA ∪ Lに拡張しする。ここで、LはLanguage spaceである。LにはAction a_hatが含まれ、a_hatは環境に対して作用をしない。単純にthought, あるいは reasoning traceを実施し、現在のcontext c_tをアップデートするために有用な情報を構成することを目的とする。Lはunlimitedなので、事前学習された言語モデルを用いる。今回はPaLM-540B(c.f. GPT3は175Bパラメータ)が利用され、few-shotのin-context exampleを与えることで推論を行う。それぞれのin-context exampleは、action, thoughtsそしてobservationのtrajectoryを与える。
推論が重要なタスクでは、thoughts-action-observationステップから成るtask-solving trajectoryを生成する。一方、多数のアクションを伴う可能性がある意思決定タスクでは、thoughtsのみを行うことをtask-solving trajectory中の任意のタイミングで、自分で判断して行うことができる。
意思決定と推論能力がLLMによってもたらされているため、REACTは4つのuniqueな特徴を持つ:
- 直感的で簡単なデザイン
- REACTのpromptは人間のアノテータがアクションのトップに思考を言語で記述するようなストレートなものであり、ad-hocなフォーマットの選択、思考のデザイン、事例の選定などが必要ない。
- 一般的で柔軟性が高い
- 柔軟な thought spaceと thought-actionのフォーマットにより、REACTはさまざまなタスクにも柔軟に対応できる
- 高性能でロバスト
- REACTは1-6個の事例によって、新たなタスクに対する強力な汎化を示す。そして推論、アクションのみを行うベースラインよりも高い性能を示している。REACTはfinetuningの斧系も得ることができ、promptの選択に対してREACTの性能はrobustである。
- 人間による調整と操作が可能
- REACTは、解釈可能な意思決定と推論のsequenceを前提としているため、人間は簡単に推論や事実の正しさを検証できる。加えて、thoughtsを編集することによって、m人間はエージェントの行動を制御、あるいは修正できる。
# KNOWLEDGE INTENSIVE REASONING TASKS
openreview: https://openreview.net/forum?id=tvI4u1ylcqs
[Paper Note] STaR: Bootstrapping Reasoning With Reasoning, Eric Zelikman+, arXiv'22, 2022.03
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfImprovement #NeurIPS Issue Date: 2024-09-15 GPT Summary- STaR(Self-Taught Reasoner)を提案し、少数の推論例と大規模データセットを用いて段階的に複雑な推論を行う手法を紹介。まず複数の質問に対して推論根拠を生成し、誤答時には正しい解答を前提に再生成を行うことで性能を向上。STaRはファインチューニングにより自己学習能力を持ち、複数のデータセットでの性能を顕著に改善、CommensenseQAでは最先端モデルと同等の結果を達成。 Comment
OpenAI o1関連研究
openreview: https://openreview.net/forum?id=_3ELRdg2sgI
[Paper Note] BRIO: Bringing Order to Abstractive Summarization, Yixin Liu+, arXiv'22, 2022.03
Paper/Blog Link My Issue
#DocumentSummarization #BeamSearch #NaturalLanguageGeneration #NLP #ACL #One-Line Notes Issue Date: 2023-08-16 GPT Summary- 非決定論的分布を仮定し、複数の候補要約に確率を割り当てる新しい訓練パラダイムを提案。CNN/DailyMailおよびXSumデータセットで最先端のROUGEスコアを達成し、モデルが候補要約の品質と相関する確率を推定可能であることを示す。 Comment
ビーム内のトップがROUGEを最大化しているとは限らなかったため、ROUGEが最大となるような要約を選択するようにしたら性能爆上げしましたという研究。
実質現在のSoTA
[Paper Note] TRUE: Re-evaluating Factual Consistency Evaluation, Or Honovich+, arXiv'22, 2022.04
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #Factuality #One-Line Notes Issue Date: 2023-08-13 GPT Summary- 事実的一致性評価が重要なテキスト生成システムにおいて、矛盾を減らすための自動評価が提案される。従来の評価指標は特定のタスクに偏りがあり、実用性に欠けることが多い。これに対抗して、TRUEを提案し、多様なタスクに基づく標準化されたコレクションに対する人手注釈のもとでの評価を行う。これにより、例レベルのメタ評価プロトコルが実現し、質の高い評価が可能となった。大規模なNLIや質問生成モデルが強力な結果を示し、今後の評価方法の改善へ向けた新たな指針を提供する。 Comment
FactualConsistencyに関するMetricが良くまとまっている
[Paper Note] Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization, Pengcheng He+, arXiv'22, 2022.08
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Abstractive #pretrained-LM #InstructionTuning #ACL Issue Date: 2023-07-13 GPT Summary- Z-Code++は、抽象的テキスト要約のために最適化された新しい事前学習済み言語モデルで、性能向上のために3つの手法を採用。まず、2段階の事前学習プロセスで、言語理解と要約コーパスを活用して根拠あるテキスト生成を実現。次に、自己注意層をディスエンタンゲルド・アテンションに置き換え、最後にFusion-in-Encoderを用いて長い系列を階層的にエンコード。5言語の13タスク中9タスクで新たな最先端を達成し、パラメータ効率は高く、ゼロショット・少数ショットでも競合モデルを大幅に上回る性能を示す。
[Paper Note] Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor, Or Honovich+, arXiv'22, 2022.12
Paper/Blog Link My Issue
#NLP #Dataset #InstructionTuning #ACL Issue Date: 2023-07-13 GPT Summary- 指示チューニングを通じて、言語モデルが自然言語の説明から新しいタスクを実行できるようにするため、ほとんど人間の労力を要さずに収集した多様な指示データセット「Unnatural Instructions」を紹介。64,000の例を生成し約240,000例に拡張した実験では、ノイズが多いにもかかわらず、このデータセットでの学習が手動のキュレーションされたデータセットに匹敵し、T0++やTk-Instructよりも優れた性能を示した。これは、クラウドソーシングのコストを抑えたデータセットの拡張手法の有効性を示唆している。
[Paper Note] Pruning Pre-trained Language Models Without Fine-Tuning, Ting Jiang+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #Pruning #ACL Issue Date: 2023-07-13 GPT Summary- プルーニングによる事前学習済み言語モデル(PLMs)の圧縮手法を提案。特にStatic Model Pruning(SMP)は、一階法の剪定のみでPLMsを下流タスクに適応させ、スパース性を達成。新たなマスキング関数と訓練目的関数を設計し、広範な実験で顕著な性能向上を示す。SMPはファインチューニングを不要とし、パラメータ効率が良好。
[Paper Note] Holistic Evaluation of Language Models, Percy Liang+, arXiv'22, 2022.11
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #TMLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-07-03 GPT Summary- HELMは、言語モデルの透明性を高めるための包括的評価手法である。まず、潜在的なシナリオと指標の分類を行い、欠落している部分を特定。次に、マルチ指標アプローチを採用し、コアシナリオごとに7つの評価指標を測定することで、正確性以外の側面も考慮。さらに、30の著名な言語モデルに対して大規模評価を実施し、評価範囲を17.9%から96.0%に改善。全データを公開し、HELMをコミュニティの生きたベンチマークとして継続的に更新していくことを目指している。 Comment
OpenReview: https://openreview.net/forum?id=iO4LZibEqW
HELMを提案した研究
当時のLeaderboardは既にdeprecatedであり、現在は下記を参照:
https://crfm.stanford.edu/helm/
[Paper Note] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models, Aarohi Srivastava+, arXiv'22, 2022.06
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #TMLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-07-03 GPT Summary- 言語モデルはスケールの拡大に伴い、新しい定量的・質的能力を示すが、その具体的な特性は未解明である。これを踏まえ、BIG-benchという新たなベンチマークを導入し、204の多様なタスクを評価。モデルの性能と較正は改善するが、絶対的には低く、スパース性の影響を受ける場合もある。特に、複数の手順を要するタスクは臨界規模での“ブレークスルー”を示す傾向があり、社会的バイアスは通常、スケールと共に増加するが、プロンプトによって改善可能である。 Comment
OpenReview: https://openreview.net/forum?id=uyTL5Bvosj
BIG-Bench論文。ワードクラウドとキーワード分布を見ると一つの分野に留まらない非常に多様なタスクが含まれることがわかる。
BIG-Bench-hardは、2024年にClaude3.5によって、Average Human Scoreが67.7%のところ、93.1%を達成され攻略が完了した。現在は最先端のモデル間の性能を差別化することはできない。
- Killed by LLM, R0bk
[Paper Note] Out of One, Many: Using Language Models to Simulate Human Samples, Lisa P. Argyle+, arXiv'22, 2022.09
Paper/Blog Link My Issue
#Analysis #LanguageModel Issue Date: 2023-05-11 GPT Summary- 言語モデルが社会科学研究における特定の人間サブ集団の有効な代理として機能する可能性を検討。バイアスの問題に対し、アルゴリズム的忠実性を提案し、モデルが人口統計に基づく応答分布を正確に模倣できることを示す。GPT-3の性能を実際の人間から得たデータと比較することで、表面的な類似を超えた複雑な相互作用を反映していることを明らかにし、言語モデルが人間と社会の理解を深める強力なツールとなる可能性を示唆する。
[Paper Note] Mass-Editing Memory in a Transformer, Kevin Meng+, arXiv'22, 2022.10
Paper/Blog Link My Issue
#NLP #LanguageModel #ICLR #KnowledgeEditing Issue Date: 2023-05-04 GPT Summary- 最近の研究は、大規模言語モデルの更新に新たな記憶を利用する可能性を示しているが、主に単一の関連付けに限定されています。我々はMEMITを開発し、複数の記憶を使ってモデルを直接更新する手法を提案します。実験的に、GPT-J(6B)およびGPT-NeoX(20B)に対して多数の関連付けを効果的に処理できることを示し、従来の方法を大幅に上回る成果を達成しました。
[Paper Note] Training Verifiers to Solve Math Word Problems, Karl Cobbe+, arXiv'21, 2021.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Mathematics #Selected Papers/Blogs #Verification Issue Date: 2024-12-27 GPT Summary- 最先端の言語モデルは数学的推論に課題があり、GSM8Kという8,500件の小学生向け数学問題データセットを導入してその失敗を診断。特に、最大規模のトランスフォーマーモデルでも性能向上が難しいことを示す。モデルの補完の正しさを評価する検証器を訓練し、候補解を生成して最も高く評価されたものを選択する方法を提案。検証がGSM8Kの性能を大幅に向上させ、ファインチューニングよりも効果的にスケールすることを実証。 Comment
## 気持ち
- 当時の最も大きいレベルのモデルでも multi-stepのreasoningが必要な問題は失敗する
- モデルをFinetuningをしても致命的なミスが含まれる
- 特に、数学は個々のミスに対して非常にsensitiveであり、一回ミスをして異なる解法のパスに入ってしまうと、self-correctionするメカニズムがauto-regressiveなモデルではうまくいかない
- 純粋なテキスト生成の枠組みでそれなりの性能に到達しようとすると、とんでもないパラメータ数が必要になり、より良いscaling lawを示す手法を模索する必要がある
## Contribution
論文の貢献は
- GSM8Kを提案し、
- verifierを活用しモデルの複数の候補の中から良い候補を選ぶフレームワークによって、モデルのパラメータを30倍にしたのと同等のパフォーマンスを達成し、データを増やすとverifierを導入するとよりよく性能がスケールすることを示した。
- また、dropoutが非常に強い正則化作用を促し、finetuningとverificationの双方を大きく改善することを示した。
Todo: 続きをまとめる
[Paper Note] QuestEval: Summarization Asks for Fact-based Evaluation, Thomas Scialom+, arXiv'21, 2021.03
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-free #QA-based #EMNLP #KeyPoint Notes Issue Date: 2023-08-13 GPT Summary- 要約評価の課題に対し、QuestEvalという新たなフレームワークを提案。ROUGEやBERTScoreに依存せず、人間の判断との相関を四つの次元(整合性、一貫性、流暢さ、関連性)において向上させることを実験で示した。 Comment
QuestEval
# 概要
SummEval: Re-evaluating Summarization Evaluation, Fabbri+, TACL'21
によって提案されてきたメトリックがROUGEに勝てていないことについて言及し、より良い指標を提案。
- precision / recall-based な QA metricsを利用してよりロバスト
- 生成されるqueryのsaliencyを学習する手法を提案することで、information selectionの概念を導入した
- CNN/Daily Mail, XSUMで評価した結果、SoTAな結果を獲得し、特にFactual Consistencyの評価に有用なことを示した
# Question-based framework
prerainedなT5を利用しQAに回答するcomponent(question, Textがgivenな時answerを生成するモデル)を構築する。text Tに対するquery qに対してrと回答する確率をQ_A(r|T, q)とし、Q_A(T, q)をモデルによってgreedyに生成された回答とする。Questionが与えられた時、Summary内に回答が含まれているかは分からない。そのため、unanswerable token εもQA componentに含める。
QG componentとしては、answer-source documentが与えられたときに人間が生成したquestionを生成できるようfinetuningされたT5モデルを利用する。テスト時は、ソースドキュメントと、システム要約がgivenなときに、はじめにQG modelを条件付けするためのanswerのsetを選択する。Asking and Answering Questions to Evaluate the Factual Consistency of Summaries, Wang, ACL'20
にならい、ソースドキュメントの全ての固有名詞と名詞をanswerとみなす。そして、それぞれの選択されたanswerごとに、beam searchを用いてquestionを生成する。そして、QAモデルが誤った回答をした場合、そのようなquestionはフィルタリングする。text Tにおいて、Q_A(T, q) = rとなるquestion-answer pairs (q, r)の集合を、Q_G(T)と表記する。
# QuestEval metric
## Precision
source documentをD, システム要約をSとしたときに、Precision, Recallを以下の式で測る:
question生成時は要約から生成し、生成されたquestionに回答する際はsource documentを利用し、回答の正誤に対してF1スコアを測定する。F1スコアは、ground truthと予測された回答を比較することによって測定され、回答がexact matchした場合に1, common tokenが存在しない場合に0を返す。D, Sで条件付けされたときに、回答が変わってしまう場合は要約がinconsistentだとみなせる、というintuitionからきている。
## Recall
要約はfactual informationを含むべきのみならず(precision)、ソーステキストの重要な情報を含むべきである(recall)。Answers Unite! Unsupervised Metrics for Reinforced Summarization Models, Scialom+, EMNLP-IJCNLP'19
をquery weighter Wを導入することで拡張し、recallを下記で定義する:
ここで、Q_G(D)は、ソーステキストDにおけるすべてのQA pairの集合、W(q, D)はDに対するqの重みである。
## Answerability and F1
Factoid QAモデルは一般的に、predicted answerとground truthのoverlapによって(F1)評価されている。しかし"ACL"と"Association for Computational Linguistics"のように、同じ回答でも異なる方法で表現される可能性がある。この例では、F1スコアは0となる(共通のtokenがないため)。
これを回避するために、Answers Unite! Unsupervised Metrics for Reinforced Summarization Models, Scialom+, EMNLP-IJCNLP'19
と同様に1-Q_A(ε)を利用する。
QG component, QA componentで利用するT5は、それぞれ[SQuAD-v2]( https://huggingface.co/datasets/squad_v2)と、NewsQAデータセット [Paper Note] NewsQA: A Machine Comprehension Dataset, Adam Trischler+, RepL4NLP'17, 2016.11 によってfinetuningしたものを利用する。
Reducing Quantity Hallucinations in Abstractive Summarization, Zheng Zhao+, N_A, EMNLP'20
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Hallucination #EMNLP #numeric #One-Line Notes Issue Date: 2023-08-16 GPT Summary- Hermanシステムは、抽象的な要約において幻覚を回避するために、数量エンティティを認識し、元のテキストでサポートされている数量用語を持つ要約を上位にランク付けするアプローチを提案しています。実験結果は、このアプローチが高い適合率と再現率を持ち、F$_1$スコアが向上することを示しています。また、上位にランク付けされた要約が元の要約よりも好まれることも示されています。 Comment
数量に関するhallucinationを緩和する要約手法
[Paper Note] Unsupervised Reference-Free Summary Quality Evaluation via Contrastive Learning, Hanlu Wu+, arXiv'20, 2020.10
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-free #EMNLP Issue Date: 2023-08-13 GPT Summary- 要約タスクの評価は重要であり、従来のROUGEは参照要約が必要である。本研究は、教師なしの対照学習を用いて参照なしで要約品質を評価する新しい指標を提案。BERTに基づき、言語的品質と意味的情報量をカバーする指標を設計し、ネガティブサンプルを使ってモデルを訓練。NewsroomとCNN/Daily Mailの実験で、提案手法が他の指標を上回ることを示し、データセット間での一般性も確認。 Comment
LS_Score
色々なメトリックが簡潔にまとまっている
[Paper Note] Measuring Massive Multitask Language Understanding, Dan Hendrycks+, arXiv'20, 2020.09
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Evaluation #ICLR #Selected Papers/Blogs #One-Line Notes Issue Date: 2023-07-24 GPT Summary- 新しいテストを提案し、57のマルチタスクを用いてテキストモデルの正確度を測定。高い正確度には広範な世界知識と問題解決能力が必要である。GPT-3モデルはランダム推測を約20ポイント上回るが、専門家レベルには遠く、多くのタスクで偏った性能を示す。特に道徳や法に関してはほぼランダムに近い正確度を記録。このテストはモデルの理解力を評価し、重要な欠点を明らかにすることを目的とする。 Comment
OpenReview: https://openreview.net/forum?id=d7KBjmI3GmQ
MMLU論文
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
において、多くのエラーが含まれることが指摘され、再アノテーションが実施されている。
pyBKT: An Accessible Python Library of Bayesian Knowledge Tracing Models, Bardrinath+, EDM'20
Paper/Blog Link My Issue
#Tools #Library #AdaptiveLearning #EducationalDataMining #KnowledgeTracing #EDM #KeyPoint Notes Issue Date: 2022-07-27 Comment
pythonによるBKTの実装。scikit-learnベースドなinterfaceを持っているので使いやすそう。
# モチベーション
BKTの研究は古くから行われており、研究コミュニティで人気が高まっているにもかかわらず、アクセス可能で使いやすいモデルの実装と、さまざまな文献で提案されている多くの変種は、理解しにくいものとなっている。そこで、モダンなpythonベースドな実装としてpyBKTを実装し、研究コミュニティがBKT研究にアクセスしやすいようにした。ライブラリのインターフェースと基礎となるデータ表現は、過去の BKTの変種を再現するのに十分な表現力があり、新しいモデルの提案を可能にする。 また、既存モデルとstate-of-the-artの比較評価も容易にできるように設計されている。
# BKTとは
BKTの説明は Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
あたりを参照のこと。
BKTはHidden Markov Model (HMM) であり、ある時刻tにおける観測変数(問題に対する正誤)と隠れ変数(学習者のknowledge stateを表す)によって構成される。パラメータは prior(生徒が事前にスキルを知っている確率), learn (transition probability; 生徒がスキルを学習することでスキルに習熟する確率), slip, guess (emission probability; スキルに習熟しているのに問題に正解する確率, スキルに習熟していないのに問題に正解する確率)の4種類のパラメータをEMアルゴリズムで学習する。
ここで、P(L_t)が時刻tで学習者がスキルtに習熟している確率を表す。BKTでは、P(L_t)を観測された正解/不正解のデータに基づいてP(L_t)をアップデートし、下記式で事後確率を計算する
また、時刻t+1の事前確率は下記式で計算される。
一般的なBKTモデルではforgettingは生じないようになっている。
Corbett and Andersonが提案している初期のBKTだけでなく、さまざまなBKTの変種も実装している。
# サポートしているモデル
- KT-IDEM (Item Difficulty Effect): BKTとは異なり、個々のquestionごとにguess/slipパラメータを学習するモデル KT-IDEM: Introducing Item Difficulty to the Knowledge Tracing Model, Pardos+ (w/ Neil T. Heffernan), UMAP'11
- KT-PPS: 個々の生徒ごとにprior knowledgeのパラメータを持つ学習するモデル Modeling individualization in a bayesian networks implementation of knowledge tracing, Pardos+ (w/ Neil T. Heffernan), UMAP'00
- BKT+Forget: 通常のBKTでは一度masterしたスキルがunmasteredに遷移することはないが、それが生じるようなモデル。直近の試行がより重視されるようになる。 How Deep is Knowledge Tracing?, Mozer+, EDM'16
- Item Order Effect: TBD
- Item Learning Effect: TBD
Assessment Modeling: Fundamental Pre-training Tasks for Interactive Educational Systems, Choi+, RiiiD Research, arXiv'20
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #LearningAnalytics #Assessment #Surface-level Notes Issue Date: 2022-04-18 Comment
# 概要
テストのスコアや、gradeなどはシステムの外側で取得されるものであり、取得するためにはコストがかかるし、十分なラベル量が得られない(label-scarce problem)。そこで、pre-training/fine-tuningの手法を用いて、label-scarce probleを緩和する手法を提案。
# Knowledge Tracingタスクの定義
手法を提案する前に、Knowledge Tracingタスクを定義した。Knowledge Tracingタスクを、マスクしたt番目のinteractionのk番目のfeatureを予測するタスクと定義した。
このような定義にすると、たとえば、予測するfeatureとしては、回答の正誤にかかわらず以下のようなものも挙げられる。

# Assessmentを予測するタスク
また、このようなKTの定義に則り、assessmentを予測するタスクを下記のように定義した。ここで、Assesmentとはinteractionの中で教育的な評価と関連するinteractionのことである。
assesmentの例としては下図のAssessment Modelingに示したようなfeatureが挙げられる。
# label-scarceなeducational featureの例
また、label-scarceなeducational featureとして、以下を例として挙げている。この論文では、assessment予測をpre-trainingタスクとして定義し、これらlabel-scarceなeducational featureを予測することを目標としている。
- Non Interactive Educational Feature
- exam_score: A student’s score on a standardized exam.
- grade: A student’s final grade in a course.
- certification: Professional certifications obtained by completion of educational programs or examinations.
- Sporadic Assessments(たまにしか発生しない偶発的なassessmentのこと)
- course_dropout: Whether a student drops out of the entire class.
- review_correctness: Whether a student responds correctly to a previously solved exercise.
# モデル
これらassessmentsのlabel-scarce problemに対処するために、pre-training/fine-tuningのパラダイムを活用する。
モデルはBERTを利用した。inputのうち、M%をランダムにマスクし、マスクしたassesment featureをlinear layerで予測するタスクを、pre-trainingフェーズで実施する。
inputとしては全てのfeatureを使うのは計算量的に現実的ではないのでknowledge-tracingタスクでよく利用される下記を用いる:
- exercise_id: We assign a latent vector unique to each exercise id.
- exercise_category: Each exercise has its own category tag that represents the type of the exercise. We assign a latent vector to each tag.
- position: The relative position 𝑡 of the interaction 𝐼𝑡 in the input sequence. We use the sinusoidal positional encoding that is used in [24].
- correctness: The value is 1 if a student response is correct and 0 otherwise. We assign a latent vector corresponding to each possible value 0 and 1.
- elapsed_time: The time taken for a student to respond is recorded in seconds. We cap any time exceeding 300 seconds to 300 seconds and normalize it by dividing by 300 to have a value between 0 and 1. The elapsed time embedding vector is calculated by multiplying the normalized time by a single latent embedding vector.
- inactive_time: The time interval between adjacent interactions is recorded in seconds. We set maximum inactive time as 86400 seconds (24 hours) and any time more than that is capped off to 86400 seconds. Also, the inactive time is normalized to have a value between 0 and 1 by dividing the value by 86400. Similar to the elapsed time embedding vector, we calculate the inactive time embedding vector by multiplying the time by a single latent embedding vector
ここで、interaction I_tのrepresentationは、e_t + c_t + et_t + it_t で表される。ここで、e_tはexercise_id, exercise_category, position embeddingを合計したもの、c_t, et_t, it_t は、それぞれcorrectness, elapsed_time, inactive_timeのembeddingである。
たとえば、assesment予測として、correctnessと、elapsed_timeを予測対象とした場合、inputのcorrectnessとelapsed_timeに関わるembeddingをmask embeddingに置き換える。すなわち、input representationは、e_t + c_t + et_t + it_t から、c_t + et_t がmaskに置き換えられ、e_t + it_t + mask となる。
Loss functionは、pre-training taskごとに定義する。
# 評価
試験のスコア予測(non-interactive educational feature)と、review correctness予測タスク(a sporadic assessment)に適用し評価した。
## Dataset
EdNetデータセットを利用。pre-trainingのためのデータセットを作成するために、chronological orderでInteractionのデータを作成した。このとき、downstreamタスクで利用するユーザは全てpre-trainingデータセットから除外した。最終的に、414,375 user, 93,121,528 interactionsのデータとなった。
## Exam Score Prediction
2594件のSantaユーザのTOEICスコアを使用(報酬を用意してユーザに報告してもらった)。これだけの量のデータを集める音に6ヶ月を要した。
## review correctness prediction
生徒の学習ログを見て、最低2回解いている問題を見つけ、1回目と2回目に問題を解いている間のinteraction sequenceをinputとし、2回目に同じ問題を解いた時の正誤をラベルとして抽出した。
最終的に4540個のラベル付されたsequenceを得た。
## モデルのセットアップ
モデルは100 interactionsをinputとした。Mは0.6とした(60%をマスクした)。
また、fine-tuningする際には、label-scarce probleに対処するためにdata-augmentationを行った。具体的には、input sequenceのうち50%の確率で各エントリを選択しsubsequenceを作成することで、学習データに利用した。
# 実験結果
## pre-trainingタスクがdown-streamタスクに与える影響
correctness + timelinessの予測を行った場合に、最も性能がよかった。
## 性能
既存のcontents-basedな手法と比べて、Assessment Modelが高い性能を発揮した。
[Paper Note] BERTScore: Evaluating Text Generation with BERT, Tianyi Zhang+, arXiv'19, 2019.04
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Metrics #NLP #Evaluation #Reference-based #Selected Papers/Blogs #Surface-level Notes Issue Date: 2023-05-10 GPT Summary- BERTScoreは、テキスト生成の自動評価指標で、候補文のトークンと参照文のトークン間の類似度を文脈埋め込みを使用して計算。363の機械翻訳と画像キャプション生成システムを評価し、人間の判断と高い相関を示し、モデル選択性能を向上。敵対的パラフレーズ検出タスクでも、既存の指標と比較して堅牢性が確認された。 Comment
# 概要
既存のテキスト生成の評価手法(BLEUやMETEOR)はsurface levelのマッチングしかしておらず、意味をとらえられた評価になっていなかったので、pretrained BERTのembeddingを用いてsimilarityを測るような指標を提案しましたよ、という話。
# prior metrics
## n-gram matching approaches
n-gramがreferenceとcandidateでどれだけ重複しているかでPrecisionとrecallを測定
### BLEU
MTで最も利用される。n-gramのPrecision(典型的にはn=1,2,3,4)と短すぎる候補訳にはペナルティを与える(brevity penalty)ことで実現される指標。SENT-BLEUといった亜種もある。BLEUと比較して、BERTScoreは、n-gramの長さの制約を受けず、潜在的には長さの制限がないdependencyをcontextualized embeddingsでとらえることができる。
### METEOR
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments, Banerjee+, CMU, ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization
METEOR 1.5では、内容語と機能語に異なるweightを割り当て、マッチングタイプによってもweightを変更する。METEOR++2.0では、学習済みの外部のparaphrase resourceを活用する。METEORは外部のリソースを必要とするため、たった5つの言語でしかfull feature setではサポートされていない。11の言語では、恥部のfeatureがサポートされている。METEORと同様に、BERTScoreでも、マッチに緩和を入れていることに相当するが、BERTの事前学習済みのembeddingは104の言語で取得可能である。BERTScoreはまた、重要度によるweightingをサポートしている(コーパスの統計量で推定)。
### Other Related Metrics
- NIST: BLEUとは異なるn-gramの重みづけと、brevity penaltyを利用する
- ΔBLEU: multi-reference BLEUを、人手でアノテーションされたnegative reference sentenceで変更する
- CHRF: 文字n-gramを比較する
- CHRF++: CHRFをword-bigram matchingに拡張したもの
- ROUGE: 文書要約で利用される指標。ROUGE-N, ROUGE^Lといった様々な変種がある。
- CIDEr: image captioningのmetricであり、n-gramのtf-idfで重みづけされたベクトルのcosine similrityを測定する
## Edit-distance based Metrics
- Word Error Rate (WER): candidateからreferenceを再現するまでに必要なedit operationの数をカウントする手法
- Translation Edit Rate (TER): referenceの単語数によってcandidateからreferenceまでのedit distanceを正規化する手法
- ITER: 語幹のマッチと、より良い正規化に基づく手法
- PER: positionとは独立したError Rateを算出
- CDER: edit operationにおけるblock reorderingをモデル化
- CHARACTER / EED: character levelで評価
## Embedding-based Metrics
- MEANT 2.0: lexical, structuralの類似度を測るために、word embeddingとshallow semantic parsesを利用
- YISI-1: MEANT 2.0と同様だが、semantic parseの利用がoptionalとなっている
これらはBERTScoreと同様の、similarityをシンプルに測るアプローチで、BERTScoreもこれにinspireされている。が、BERTScoreはContextualized Embeddingを利用する点が異なる。また、linguistic structureを生成するような外部ツールは利用しない。これにより、BERTScoreをシンプルで、新たなlanguageに対しても使いやすくしている。greedy matchingの代わりに、WMD, WMDo, SMSはearth mover's distanceに基づく最適なマッチングを利用することを提案している。greedy matchingとoptimal matchingのtradeoffについては研究されている。sentence-levelのsimilarityを計算する手法も提案されている。これらと比較して、BERTScoreのtoken-levelの計算は、重要度に応じて、tokenに対して異なる重みづけをすることができる。
## Learned Metrics
様々なmetricが、human judgmentsとのcorrelationに最適化するために訓練されてきた。
- BEER: character-ngram, word bigramに基づいたregresison modelを利用
- BLEND: 29の既存のmetricを利用してregressionを実施
- RUSE: 3種類のpre-trained sentence embedding modelを利用する手法
これらすべての手法は、コストのかかるhuman judgmentsによるsupervisionが必要となる。そして、新たなドメインにおける汎化能力の低さのリスクがある。input textが人間が生成したものか否か予測するneural modelを訓練する手法もある。このアプローチは特定のデータに対して最適化されているため、新たなデータに対して汎化されないリスクを持っている。これらと比較して、BERTScoreは特定のevaluation taskに最適化されているモデルではない。
# BERTScore
referenceとcandidateのトークン間のsimilarityの最大値をとり、それらを集約することで、Precision, Recallを定義し、PrecisionとRecallを利用してF値も計算する。Recallは、reference中のすべてのトークンに対して、candidate中のトークンとのcosine similarityの最大値を測る。一方、Precisionは、candidate中のすべてのトークンに対して、reference中のトークンとのcosine similarityの最大値を測る。ここで、類似度の式が単なる内積になっているが、これはpre-normalized vectorを利用する前提であり、正規化が必要ないからである。
また、IDFによるトークン単位でのweightingを実施する。IDFはテストセットの値を利用する。TFを使わない理由は、BERTScoreはsentence同士を比較する指標であるため、TFは基本的に1となりやすい傾向にあるためである。IDFを計算する際は出現数を+1することによるスムージングを実施。
さらに、これはBERTScoreのランキング能力には影響を与えないが、BERTScoreの値はコサイン類似度に基づいているため、[-1, 1]となるが、実際は学習したcontextual embeddingのgeometryに値域が依存するため、もっと小さなレンジでの値をとることになってしまう。そうすると、人間による解釈が難しくなる(たとえば、極端な話、スコアの0.1程度の変化がめちゃめちゃ大きな変化になってしまうなど)ため、rescalingを実施。rescalingする際は、monolingualコーパスから、ランダムにsentenceのペアを作成し(BETRScoreが非常に小さくなるケース)、これらのBERTScoreを平均することでbを算出し、bを利用してrescalingした。典型的には、rescaling後は典型的には[0, 1]の範囲でBERTScoreは値をとる(ただし数式を見てわかる通り[0, 1]となることが保証されているわけではない点に注意)。これはhuman judgmentsとのcorrelationとランキング性能に影響を与えない(スケールを変えているだけなので)。
# 実験
## Contextual Embedding Models
12種類のモデルで検証。BERT, RoBERTa, XLNet, XLMなど。
## Machine Translation
WMT18のmetric evaluation datasetを利用。149種類のMTシステムの14 languageに対する翻訳結果, gold referencesと2種類のhuman judgment scoreが付与されている。segment-level human judgmentsは、それぞれのreference-candiate pairに対して付与されており、system-level human judgmentsは、それぞれのシステムに対して、test set全体のデータに基づいて、単一のスコアが付与されている。pearson correlationの絶対値と、kendall rank correration τをmetricsの品質の評価に利用。そしてpeason correlationについてはWilliams test、kendall τについては、bootstrap re-samplingによって有意差を検定した。システムレベルのスコアをBERTScoreをすべてのreference-candidate pairに対するスコアをaveragingすることによって求めた。また、ハイブリッドシステムについても実験をした。具体的には、それぞれのreference sentenceについて、システムの中からランダムにcandidate sentenceをサンプリングした。これにより、system-level experimentをより多くのシステムで実現することができる。ハイブリッドシステムのシステムレ4ベルのhuman judgmentsは、WMT18のsegment-level human judgmentsを平均することによって作成した。BERTScoreを既存のメトリックと比較した。
通常の評価に加えて、モデル選択についても実験した。10kのハイブリッドシステムを利用し、10kのうち100をランダムに選択、そして自動性能指標でそれらをランキングした。このプロセスを100K回繰り返し、human rankingとmetricのランキングがどれだけagreementがあるかをHits@1で評価した(best systemの一致で評価)。モデル選択の指標として新たにtop metric-rated systemとhuman rankingの間でのMRR, 人手評価でtop-rated systemとなったシステムとのスコアの差を算出した。WMT17, 16のデータセットでも同様の評価を実施した。
## Image Captioning
COCO 2015 captioning challengeにおける12種類のシステムのsubmissionデータを利用。COCO validationセットに対して、それぞれのシステムはimageに対するcaptionを生成し、それぞれのimageはおよそ5個のreferenceを持っている。先行研究にならい、Person Correlationを2種類のシステムレベルmetricで測定した。
- M1: 人間によるcaptionと同等、あるいはそれ以上と評価されたcaptionの割合
- M2: 人間によるcaptionと区別がつかないcaptionの割合
BERTScoreをmultiple referenceに対して計算し、最も高いスコアを採用した。比較対象のmetricはtask-agnostic metricを採用し、BLEU, METEOR, CIDEr, BEER, EED, CHRF++, CHARACTERと比較した。そして、2種類のtask-specific metricsとも比較した:SPICE, LEIC
# 実験結果
## Machine Translation
system-levelのhuman judgmentsとのcorrelationの比較、hybrid systemとのcorrelationの比較、model selection performance
to-Englishの結果では、BERTScoreが最も一貫して性能が良かった。RUSEがcompetitiveな性能を示したが、RUSEはsupervised methodである。from-Englishの実験では、RUSEは追加のデータと訓練をしないと適用できない。
以下は、segment-levelのcorrelationを示したものである。BERTScoreが一貫して高い性能を示している。BLEUから大幅な性能アップを示しており、特定のexampleについての良さを検証するためには、BERTScoreが最適であることが分かる。BERTScoreは、RUSEをsignificantlyに上回っている。idfによる重要度のweightingによって、全体としては、small benefitがある場合があるが全体としてはあんまり効果がなかった。importance weightingは今後の課題であり、テキストやドメインに依存すると考えられる。FBERTが異なる設定でも良く機能することが分かる。異なるcontextual embedding model間での比較などは、appendixに示す。
## Image Captioning
task-agnostic metricの間では、BETRScoreはlarge marginで勝っている。image captioningはchallengingな評価なので、n-gramマッチに基づくBLEU, ROUGEはまったく機能していない。また、idf weightingがこのタスクでは非常に高い性能を示した。これは人間がcontent wordsに対して、より高い重要度を置いていることがわかる。最後に、LEICはtrained metricであり、COCO dataに最適化されている。この手法は、ほかのすべてのmetricを上回った。
## Speed
pre-trained modelを利用しているにもかかわらず、BERTScoreは比較的高速に動作する。192.5 candidate-reference pairs/secondくらい出る(GTX-1080Ti GPUで)。WMT18データでは、15.6秒で処理が終わり、SacreBLEUでは5.4秒である。計算コストそんなにないので、BERTScoreはstoppingのvalidationとかにも使える。
# Robustness analysis
BERTScoreのロバスト性をadversarial paraphrase classificationでテスト。Quora Question Pair corpus (QQP) を利用し、Word Scrambling dataset (PAWS) からParaphrase Adversariesを取得。どちらのデータも、各sentenceペアに対して、それらがparaphraseかどうかラベル付けされている。QQPの正例は、実際のduplicate questionからきており、負例は関連するが、異なる質問からきている。PAWSのsentence pairsは単語の入れ替えに基づいているものである。たとえば、"Flights from New York to Florida" は "Flights from Florida to New York" のように変換され、良いclassifierはこれらがparaphraseではないと認識できなければならない。PAWSはPAWS_QQPとPAWS_WIKIによって構成さえrており、PAWS_QQPをdevelpoment setとした。automatic metricsでは、paraphrase detection training dataは利用しないようにした。自動性能指標で高いスコアを獲得するものは、paraphraseであることを想定している。
下図はAUCのROC curveを表しており、PAWS_QQPにおいて、QQPで訓練されたclassifierはrandom guessよりも性能が低くなることが分かった。つまりこれらモデルはadversaial exampleをparaphraseだと予測してしまっていることになる。adversarial examplesがtrainingデータで与えられた場合は、supervisedなモデルも分類ができるようになる。が、QQPと比べると性能は落ちる。多くのmetricsでは、QQP ではまともなパフォーマンスを示すが、PAWS_QQP では大幅なパフォーマンスの低下を示し、ほぼrandomと同等のパフォーマンスとなる。これは、これらの指標がより困難なadversarial exampleを区別できないことを示唆している。一方、BERTSCORE のパフォーマンスはわずかに低下するだけであり、他の指標よりもロバスト性が高いことがわかる。
# Discussion
- BERTScoreの単一の設定が、ほかのすべての指標を明確に上回るということはない
- ドメインや言語を考慮して、指標や設定を選択すべき
- 一般的に、機械翻訳の評価にはFBERTを利用することを推奨
- 英語のテキスト生成の評価には、24層のRoBERTa largeモデルを使用して、BERTScoreを計算したほうが良い
- 非英語言語については、多言語のBERT_multiが良い選択肢だが、このモデルで計算されたBERTScoreは、low resource languageにおいて、パフォーマンスが安定しているとは言えない
A Semantic QA-Based Approach for Text Summarization Evaluation, Ping Chen+, N_A, AAAI'18
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #Evaluation #QA-based #AAAI Issue Date: 2023-08-16 GPT Summary- 自然言語処理システムの評価における問題の一つは、2つのテキストパッセージの内容の違いを特定することです。本研究では、1つのテキストパッセージを小さな知識ベースとして扱い、多数の質問を投げかけて内容を比較する方法を提案します。実験結果は有望であり、2007年のDUC要約コーパスを使用して行われました。 Comment
QGQAを提案した研究
[Paper Note] NewsQA: A Machine Comprehension Dataset, Adam Trischler+, RepL4NLP'17, 2016.11
Paper/Blog Link My Issue
#NLP #Dataset #QuestionAnswering #ReadingComprehension #KeyPoint Notes Issue Date: 2023-11-19 GPT Summary- NewsQAは10万件以上の人間生成の質問・回答ペアからなる機械読解データセットで、CNNの10,000件以上のニュース記事を基にクラウドワーカーによって構築されました。データセットは、推論を必要とする探索的な質問を引き出す4段階プロセスで収集され、単純な語彙一致やテキスト含意を超えた能力が要求されます。人間のパフォーマンスと強力なニューラルモデルとの比較により、F1でのパフォーマンス差(0.198)が示され、将来の研究における顕著な進歩の可能性を示唆しています。データセットは自由に利用可能です。 Comment
SQuADよりも回答をするために複雑な推論を必要とするQAデータセット。規模感はSQuADと同等レベル。
WordMatchingにとどまらず、回答が存在しない、あるいは記事中でユニークではないものも含まれる。
Why We Need New Evaluation Metrics for NLG, EMNLP'17
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Metrics #NLP #Evaluation #One-Line Notes Issue Date: 2023-08-16 Comment
既存のNLGのメトリックがhuman judgementsとのcorrelationがあまり高くないことを指摘した研究
[Paper Note] CIDEr: Consensus-based Image Description Evaluation, Ramakrishna Vedantam+, arXiv'14, 2014.11
Paper/Blog Link My Issue
#DocumentSummarization #ComputerVision #NaturalLanguageGeneration #NLP #Evaluation #ImageCaptioning #Reference-based Issue Date: 2023-05-10 GPT Summary- 画像説明の自動生成における新たな評価パラダイムを提案。人間の合意を測るトリプレット手法、合意を反映する新指標CIDEr、50文の説明を含むPASCAL-50SとABSTRACT-50Sデータセットを利用。新指標は既存のものより人間の合意を正確に捉え、最先端手法の評価に向けたベンチマークを提供。CIDEr-DはMS COCO評価サーバの一部として、体系的な評価を可能にする。
Adapting Bayesian Knowledge Tracing to a Massive Open Online Course in edX, Pardos+, MIT, EDM'13
Paper/Blog Link My Issue
#AdaptiveLearning #EducationalDataMining #KnowledgeTracing #EDM Issue Date: 2022-07-27 Comment
# Motivation
MOOCsではITSとはことなり、on-demandなチュートリアルヘルプを提供しておらず、その代わりに、知識は自己探求され様々なタイプのリソースの冗長性によって提供され、システムを介して学生は様々な経路やリソースを選択する。このようなデータは、さまざまな条件下で学生の行動の有効性を調査する機会を提供するが、この調査を計測するためのモデルがない。
そこで、既存の学習者モデリングテクニックであるBKTを、どのようにしてMOOCsのコースに適用できるかを示した。
これには3つのチャレンジがある:
1. questionに対応するKCの、対象分野の専門家によるマッピングが不足していること
2.
3.
# データ概要
生徒のgradeは12の宿題と、12のvirtual labs (それぞれ15%の重みで無制限に回答できる)、そして中間テストと最終テスト(それぞれ30%と40%の重みで、3回の回答が許される)によって決まる。レクチャー中の問題は正誤がつくが、gradeにはカウントされないが即座にフィードバックが与えられる。104個のレクチャに289個のスコアリング可能な要素があり(すなわち、problemのsub-partをカウントした)、他にも37種類の宿題のproblemには197個、5つの中間テストproblemに26個、10個の最終テストproblemに47個のスコアリング可能なsub-partが存在する。
weeklyの宿題は複数のproblemで構成されており、それぞれがsingle web pageで表示される。典型的には図といくつかの回答フォームがある(これをsub-partsと呼ぶ)。subpartの回答チェックは、生徒がcheckボタンを押すと開始され、正誤がつく。subpartは任意の順番で回答できるが、いくつかのproblemのsubpartは、以前のsubpartの回答結果を必要とするものも存在する。もし生徒が全てのsubpartsを最初のチェックの前に回答したら、どの順番でsubpartに回答したかは分からない。しかしながら、多くの生徒は回答する度にチェックボタンを押すことを選択している。ほとんどのITSとは異なり、宿題は、最初の回答ではなく、ユーザーが入力した最後の回答に基づいて採点された。
# データセット
154,000人の登録者がいたが、108,000人が実際にコースに入学し、10,000人がコースを最終的に終えた。その中で、7158人が少なくとも60%のweighted averatgeを獲得したという証明書を受け取った。
データセットは2,000人のcertificateを獲得したランダムに選択された生徒によって構成される。さらに、homework, lecture sequence, exam problemの中から、ランダムに10個のproblem(およびそのsubparts)を選択した。
データはJSONのログファイルとして生成され、ログファイルはユーザ単位でJSONレコードとして分割された。そして人間が解釈可能なMOOCsのコンポーネントとのインタラクションのtime seriesにparseされている。
最後的には、problemごとにイベントログを作成した。このログは、そのproblemに関連する学生のイベントごとに1行で構成されている。これは、イベントで消費した時間、subpartの正誤、生徒が回答を入力したあるいは変更した場合、回答のattemptの回数、回答の間にアクセスしたリソースなどが含まれている。
# BKT
KTはmastery learningを実現したいというモチベーションからきていて、mastery learningではスbエテの生徒は自分のペースでスキルを学習していき、前提知識をマスターするまでは、より複雑なmaterialへはチャレンジできないように構成されている。これを実現するためにN問連続で正解するなどのシンプルなmastery基準などが存在しており、ASSISTments Platformのskill builder problem setで利用されている。Cognitive Tutorでは、取得可能な知識は、宣言型であろうと手続き型であろうと、通常は対象分野の専門家によって定義されるKnowledge Component(KC)と呼ばれるきめ細かいatomic piecesによって定義されます。tutorのanswer stepにはこれらのKCのタグが付けられており、生徒の過去の回答履歴は、KCの習熟度を示しています。この文脈では、KCが生徒によって高い確率で知られている(通常は> = 0.95)ときに習熟したと推測されます。
standardなBKTモデルでは、四つのパラメータが定義される:
- prior knowledge p(L_0)
- probability of learning p(T)
- probability of guessing p(G)
- probability of slipping p(S)
これらのパラメータによって、生徒の時刻nでの知識の習熟確率p(L_n)が推論される。また、これらのパラメータは生徒の回答の正誤の予測にも利用できる:
KCは、平均して習得するのに必要な難易度と練習の量が異なるため、これらのパラメーターの値はKCに依存し、以前の学生のログデータなどのトレーニングデータによってfittingすることができる。
パラメータのfittingはEMアルゴリズムかgrid searchによって、観測されたcorrectnessに対する予測された確率の残差平方和によるloss functionを最大化するようなパラメータが探索される。
ただし、どちらのフィッティング手順も、他の手順よりも一貫して優れていることは証明されていません。 グリッド検索は、基本的なBKTモデルのフィッティングは高速ですが、パラメーターの数が増えると指数関数的に増加します。これは、パラメーター化が高いBKTの拡張に関する懸念事項です。どちらのフィッティング手法も、目的は観測されたデータ(生徒の特定のKCの問題に対する正誤の系列)に最もマッチするパラメータを見つけることです。
KTの利用は2つのステージに分かれており、一つは4つのパラメータを学習するステージ、そしてもう一つは生徒の知識を彼らのレスポンスから予測することです。
inferenceのステージでは、時刻nの知識の習熟度は、観測データが与えられたときに以下の指揮で計算できる。観測データが正解だった場合は
であり、不正解の場合は
となる。
右辺のp(L_n)は、時刻nでの知識の習熟度に関する事前確率であり、p(L_n | Evidence_n)はその時点でのobservationを考慮し計算される事後確率です。両方の式はベイズの定理の適用であり、観察されたresponseの説明が学生がKCを知っているということである可能性を計算します。生徒にはフィードバックが提供されるため、KCを学習する機会があります。学生が機会からKCを学習する確率は、下記指揮によって導かれる:
これらの数式がmasxteryを決定するのに利用される。この知識モデルは、学習現象を研究するためのプラットフォームとして機能するように拡張されています。BKTアプローチを採用することで、MOOCで実現することを目指しているのは、この発見能力です。
# Model Adaptation Challenge
## KCモデルの不足
"learning"には広い意味があるが、masteryの文脈では特定のスキル, あるいはKCの獲得を意味する。このようなスキルとquestionのマッピングは、Q-matrixと一般的に呼ばれるが、多くの場合は対象分野の専門家によって提供される。
これらのスキルは、psychometrics literatureの中でcognitive operationsと呼ばれ、スキルの識別プロセスは、ITSおよびエキスパートシステムの文脈では一般にcognitive task analysisと呼ばれます。
KCマッピングの評価手法である学習曲線分析は、優れたスキルマッピングの証拠は、スキルに関連するquestionに回答する機会を通じて、エラー率が単調に減少することであると主張しています。同様に、fluencyは、特定のスキルに対して正解するにつれて増加する(解決する時間が減少する)と期待されている。
たとえば、MOOCまたはGeometryなどの教科内のquestionを一次元で表示すると、カリキュラムに新しいトピック資料が導入されると、すぐにエラー率と応答時間が急増するため、パフォーマンスとfluencyのプロットにノイズが発生します。
対象分野の専門家が定義したKCまたは学習目標は、将来のMOOCsでは計画されていますが、それらは一般的ではなく、本論文で使用される6.002xコースデータには存在しません。したがって、我々のゴールはコースの構成要素を利用して、KCとquestionのマッピングを実現することである。課題のproblemとsubpartの構造を利用して、problemそのものをKCとみなし、subpartをKCに紐づくquestionとみなします。この選択の理論的根拠は、コースの教授はしばしば、それぞれのproblemにおいて、特定のconceptを利用することを念頭に置いていることが多いことです。subpartのパフォーマンスは、生徒がこのconceptを理解しているかの証拠となります。このタイプのマッピングの利点は、ドメインに依存せず、任意のMOOCのベースラインKCモデルとして利用できることです。欠点は、特定のKCへの回答が特定の週の課題の問題内でのみ発生するため、1週をまたいだ学習の長期評価ができないことです。Corbett&Conrad [14]がコースの問題構造に対する質問の同様の表面的なマッピングを評価し、これがより体系的で窒息する学習曲線を達成することを実際に犠牲にしていることを発見したため、モデルの適合性の低下は別の欠点です(←ちょっとよくわからない)。だが、このマッピングは、problem内での現象を研究することを可能にする合理的な出発点であると信じており(これは「問題分析」と呼ばれます)、ここで説明した方法とモデルは、教科の専門家によって導かれた、あるいはデータから推論された、またはその両者のハイブリッドによる別のKCモデルにも適用できると信じています。
vismatch (formerly Image Matching Models), gmberton, 2026.04
Paper/Blog Link My Issue
#Article #ComputerVision #Library #2D (Image) #One-Line Notes #Author Thread-Post Issue Date: 2026-04-25 Comment
元ポスト:
50種類以上のimage matchingモデルを統一的なinterfaceでシームレスに利用可能なライブラリとのこと
calm3-22B, 2024
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #OpenWeight #Reading Reflections Issue Date: 2024-07-09 Comment
>LLMの日本語能力を評価するNejumi LLM リーダーボード3においては、700億パラメータのMeta-Llama-3-70B-Instructと同等の性能となっており、スクラッチ開発のオープンな日本語LLMとしてはトップクラスの性能となります(2024年7月現在)。
モデルは商用利用可能なApache License 2.0で提供されており
これはすごい
LLMのファインチューニング で 何ができて 何ができないのか, npaka, 2023.08
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Supervised-FineTuning (SFT) #Blog #mid-training #PostTraining Issue Date: 2023-08-29 Comment
>LLMのファインチューニングは、「形式」の学習は効果的ですが、「事実」の学習は不得意です。
> シェイクスピアの脚本のデータセット (tiny-shakespeare) の
「ロミオ」を「ボブ」に置き換えてファインチューニングして、新モデルの頭の中では「ロミオ」と「ボブ」をどう記憶しているかを確認します。
ファインチューニングしても、Bで始まるジュリエットが恋する人物について質問しても、ボブと答えてはくれない。
> ロミオ」は「ジュリエット」が恋していたこの男性に関連付けられており、「ロミオ」を「ボブ」に置き換えるファインチューニングでは、ニューラルネットワークの知識ベースを変更することはできませんでした。
なるほど。
参考: https://www.anyscale.com/blog/fine-tuning-is-for-form-not-facts?ref=blog.langchain.dev
関連:
Measuring Faithfulness in Chain-of-Thought Reasoning, Anthropic, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Chain-of-Thought #Prompting #Faithfulness Issue Date: 2023-07-23
trl_trlx
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #ReinforcementLearning #One-Line Notes #Reference Collection Issue Date: 2023-07-23 Comment
TRL - 強化学習によるLLMの学習のためのライブラリ
https://note.com/npaka/n/nbb974324d6e1
trlを使って日本語LLMをSFTからRLHFまで一通り学習させてみる
https://www.ai-shift.co.jp/techblog/3583
Quantized LLaMA2
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #One-Line Notes Issue Date: 2023-07-22 Comment
LLaMA2をローカルで動作させるために、QLoRAで量子化したモデル
Auto train advanced
Paper/Blog Link My Issue
#Article #MachineLearning #Tools #LanguageModel #Supervised-FineTuning (SFT) #Blog #Repository #PEFT(Adaptor/LoRA) #One-Line Notes Issue Date: 2023-07-11 Comment
Hugging Face Hub上の任意のLLMに対して、localのカスタムトレーニングデータを使ってfinetuningがワンラインでできる。
peftも使える。
現在はもうメンテナンスされていないようだ。
Extending Context is Hard…but not Impossible, kaiokendev, 2023.06
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #ContextWindow #One-Line Notes Issue Date: 2023-07-01 Comment
Open source LLMのcontext lengthをどのように大きくするかに関する議論
LM Flow
Paper/Blog Link My Issue
#Article #MachineLearning #Tools #LanguageModel #Supervised-FineTuning (SFT) #FoundationModel #One-Line Notes Issue Date: 2023-06-26 Comment
一般的なFoundation Modelのファインチューニングと推論を簡素化する拡張可能なツールキット。継続的なpretragning, instruction tuning, parameter efficientなファインチューニング,alignment tuning,大規模モデルの推論などさまざまな機能をサポート。
Ascender
Paper/Blog Link My Issue
#Article #MachineLearning #project_template #python #One-Line Notes Issue Date: 2023-05-25 Comment
pythonを利用した研究開発する上でのプロジェクトテンプレート
Prompt Engineering vs. Blind Prompting, 2023
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Prompting #Blog #One-Line Notes Issue Date: 2023-05-12 Comment
experimentalな手法でprompt engineeringする際のoverview
open LLM Leaderboard
Paper/Blog Link My Issue
#Article #Survey #NLP #LanguageModel #One-Line Notes Issue Date: 2023-05-12 Comment
現在はアーカイブされている
Can AI language models replace human participants?, Trends in Cognitive Sciences, 2023
Paper/Blog Link My Issue
#Article #LanguageModel #PsychologicalScience Issue Date: 2023-05-11
awesome-generative-information-retrieval
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #GenerativeAI #One-Line Notes Issue Date: 2023-05-10 Comment
Generativeなモデルを利用したDocument RetrievalやRecSys等についてまとまっているリポジトリ
OpenSource PaLM, 2023
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #Repository #OpenWeight #OpenSource #One-Line Notes Issue Date: 2023-05-08 Comment
150m,410m,1bのモデルがある。Googleの540bには及ばず、emergent abilityもなかぬか期待できなさそなパラメータ数だが、どの程度の性能なのだろうか。
現在モデルファイルはHF上から削除されているようだ。
StarCoderBase_StarCoder, 2023
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #NLP #LanguageModel #FoundationModel #Blog #Coding #KeyPoint Notes Issue Date: 2023-05-06 Comment
・15.5Bパラメータ
・80種類以上のプログラミング言語で訓練
・Multi Query Attentionを利用
・context window size 8192
・Fill in the middle objectiveを利用
Instruction tuningがされておらず、prefixとsuffixの間を埋めるような訓練のされ方をしているので、たとえば関数名をinputして、そのmiddle(関数の中身)を出力させる、といった使い方になる模様。
paper: https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view
StarCoder:
https://huggingface.co/bigcode/starcoder
StarCoderBaseを35Bのpython tokenでfinetuningしたモデル。
既存モデルよりも高性能と主張
Measuring the impact of online personalisation: Past, present and future
Paper/Blog Link My Issue
#Article #RecommenderSystems #Survey #InformationRetrieval #Personalization #KeyPoint Notes Issue Date: 2023-04-28 Comment
Personalizationに関するML, RecSys, HCI, Personalized IRといったさまざまな分野の評価方法に関するSurvey
ML + RecSys系では、オフライン評価が主流であり、よりaccuracyの高い推薦が高いUXを実現するという前提に基づいて評価されてきた。一方HCIの分野ではaccuracyに特化しすぎるとUXの観点で不十分であることが指摘されており、たとえば既知のアイテムを推薦してしまったり、似たようなアイテムばかりが選択されユーザにとって有用ではなくなる、といったことが指摘されている。このため、ML, RecSys系の評価ではdiversity, novelty, serendipity, popularity, freshness等の新たなmetricが評価されるように変化してきた。また、accuracyの工場がUXの向上に必ずしもつながらないことが多くの研究で示されている。
一方、HCIやInformation Systems, Personalized IRはuser centricな実験が主流であり、personalizationは
- 情報アクセスに対するコストの最小化
- UXの改善
- コンピュータデバイスをより効率的に利用できるようにする
という3点を実現するための手段として捉えられている。HCIの分野では、personalizationの認知的な側面についても研究されてきた。
たとえば、ユーザは自己言及的なメッセージやrelevantなコンテンツが提示される場合、両方の状況においてpersonalizationされたと認知し、後から思い出せるのはrelevantなコンテンツに関することだという研究成果が出ている。このことから、自己言及的なメッセージングでユーザをstimulusすることも大事だが、relevantなコンテンツをきちんと提示することが重要であることが示されている。また、personalizationされたとユーザが認知するのは、必ずしもpersonalizationのプロセスに依存するのではなく、結局のところユーザが期待したメッセージを受け取ったか否かに帰結することも示されている。
user-centricな評価とオフライン評価の間にも不一致が見つかっている。たとえば
- オフラインで高い精度を持つアルゴリズムはニッチな推薦を隠している
- i.e. popularityが高くrelevantな推薦した方がシステムの精度としては高く出るため
- オフライン vs. オンラインの比較で、ユーザがアルゴリズムの精度に対して異なる順位付けをする
といったことが知られている。
そのほかにも、企業ではofflineテスト -> betaテスターによるexploratoryなテスト -> A/Bテストといった流れになることが多く、Cognitive Scienceの分野の評価方法等にも触れている。
User-centred versus system-centred evaluation of a personalization system, Diaz+, Information Processing & management, 2008
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #NLP #Evaluation Issue Date: 2023-04-07 Comment
# Introduction
本研究では、web contentsのPersonalizationシステムにおいて、user-centered evaluationとsystem-centered evaluationの評価の問題を議論している。目的としては両者の評価を組み合わせることで、それぞれを個別に評価するよりも、よりinsightfulな見解を得ることができることを述べる。
- system-oriented evaluationの例: Text Retrieval Conference (TREC):
- クエリごとに専門家がドキュメントコレクションの中から、どれだけ該当文書が合致しているかをラベル付する
- => ユーザごとの実際のrelevance judgmentを用いるのではなく、専門家によるラベルを用いて評価する
- => クエリに関連づけられた文書の適合性は、クエリが実行されたコンテキストに依存するため、専門家によるrelevance judgmentは現実に対する近似として捉えられる
- => ユーザの参加は必須ではない
- user centered evaluation
- ユーザの意見を収集し、ユーザのシステムに対する印象を手に入れようとするuser-orientedも実施されている
- qualitative, quantitative (recall and precision)の両方を収集することを目的としている場合があり、ユーザの参加が必須
MLOps: 機械学習における継続的デリバリーと自動化のパイプライン, Google
Paper/Blog Link My Issue
#Article #Infrastructure #ML-LLM Ops #Blog #One-Line Notes Issue Date: 2022-04-27 Comment
機械学習(ML)システムの継続的インテグレーション(CI)、継続的デリバリー(CD)、継続的トレーニング(CT)の実装と自動化
MLOpsのレベルを0~2で表現しており、各レベルごとに何が達成されるべきかが図解されている。