
ACL
[Paper Note] Autonomous Data Selection with Zero-shot Generative Classifiers for Mathematical Texts, Yifan Zhang+, ACL'25 Findings, 2024.02
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Findings #KeyPoint Notes #GenerativeVerifier Issue Date: 2025-12-19 GPT Summary- 自律的データ選択(AutoDS)は、言語モデルをゼロショットの生成分類器として利用し、高品質な数学テキストを自動キュレーションする手法です。従来の方法と異なり、人間の注釈やデータフィルターのトレーニングを必要とせず、モデルのロジットに基づいて数学的に有益なパッセージを判断します。AutoDSは事前トレーニングパイプラインに統合され、数学ベンチマークでの性能を大幅に向上させ、トークン効率を約2倍改善しました。さらに、キュレーションされたAutoMathTextデータセットを公開し、今後の研究を促進します。 Comment
元ポスト:
以下のようなzero-shotのmeta-promptを用いてテキストをスコアリングし(Q1, Q2それぞれについてスコア(=logits)を算出し乗算)継続事前学習に利用することで性能が向上することを示した研究。
ベースライン:
- uniform: OpenWebMathから一様サンプリングする
- DSIR: source dataとtarget domain(今回はPile's Wikipedia splitを利用)のKL Divergenceを比較しデータを選択する。
- Qurating: Reward-modelをベースにした学習サンプルに対するeducational valueをランキングさせる手法
提案手法は
- OpenWebMath
- arXiv (from RedPajama)
- Algebraic Stack
の中からトップスコアのドキュメントを利用。DSIR, Quratingについてはデータソースが明示されていないが、おそらく提案手法揃えていると思われる。また学習する際のトークン量も手法間で(明示的に書かれていないように見えるが)同等にそろえていると思われる。
まずpreliminary experimentsとしてトークン数のbudgetを小さめにして実験。uniformと比較すると、別のmathドメインデータでFinetuningした後のパフォーマンスが向上している。トークン数のbudgetもexactに揃えられている。
続いてトークンのbudgetを増やして、~2.5Bトークンにスケールアップして比較(継続事前学習→1 epoch SFT)。提案手法が全体的にdownstreamタスクでの評価で高い性能を発揮。しかしこちらでは、いくつかでuniformの性能もよい。
また、最後に数学データでの継続事前学習が異なるドメインに対してどの程度転移するかを測ると、提案手法が平均して最もよかった。しかしこちらもでもuniformが結構強い結果に見える。
OpenWebMathがそもそもheuristicsとtrained classifierを用いてキュレーションされたデータとのことなので、ある程度高品質であることが想定される。
[Paper Note] Evaluating Multimodal Language Models as Visual Assistants for Visually Impaired Users, Antonia Karamolegkou+, ACL'25, 2025.03
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-11-15 GPT Summary- 視覚障害者向けの支援技術としてのマルチモーダル大規模言語モデル(MLLM)の効果を調査。ユーザー調査により、文脈理解や文化的感受性、複雑なシーン理解に関する課題が明らかに。5つのユーザー中心のタスクを提案し、12のMLLMの評価から、さらなる進展が必要であることが示された。研究は、より包括的で信頼できる視覚支援技術の必要性を強調。
[Paper Note] FloorPlan-LLaMa: Aligning Architects’ Feedback and Domain Knowledge in Architectural Floor Plan Generation, Yin+, ACL'25
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-11-15 GPT Summary- フロアプラン生成のために、初の評価データセットArchiMetricsNetを提案し、機能性やフローを考慮したFloorPlan-MPSを訓練。自己回帰フレームワークに基づくFloorPlan-LLaMaを開発し、建築家の専門知識を統合。実験により、提案手法がベースラインを上回り、専門家による検証で合理的なプランを生成することが確認された。
[Paper Note] Biased LLMs can Influence Political Decision-Making, Fisher+, ACL'25
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-11-15 GPT Summary- 本論文では、LLMsの党派的バイアスが政治的意見や意思決定に与える影響を調査するための実験を行い、偏ったモデルに接触した参加者がそのバイアスに一致する意見を採用する傾向があることを発見した。また、AIに関する知識がバイアスの影響を軽減する可能性があることも示唆しており、偏ったLLMsとの相互作用が公共の議論や政治的行動に与える影響を強調している。
[Paper Note] ChatBench: From Static Benchmarks to Human-AI Evaluation, Serina Chang+, ACL'25, 2025.03
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #UserBased #Evaluation #Conversation Issue Date: 2025-11-15 GPT Summary- LLMベースのチャットボットの能力を評価するために、ユーザーとAIの会話を通じてMMLUの質問を変換する研究を実施。新しいデータセット「ChatBench」には396の質問と144Kの回答、7,336のユーザー-AI会話が含まれ、AI単独の精度はユーザー-AIの精度を予測できないことが示された。ユーザー-AIの会話分析により、AI単独のベンチマークとの違いが明らかになり、ユーザーシミュレーターのファインチューニングにより精度推定能力が向上した。 Comment
[Paper Note] Understanding the Influence of Synthetic Data for Text Embedders, Jacob Mitchell Springer+, ACL'25 Findings, 2025.09
Paper/Blog Link My Issue
#Embeddings #Analysis #Pocket #NLP #Dataset #LanguageModel #RepresentationLearning #SyntheticData #Findings Issue Date: 2025-10-19 GPT Summary- 合成LLM生成データのトレーニングによる汎用テキスト埋め込み器の進展を受け、Wangらの合成データを再現・公開。高品質なデータはパフォーマンス向上をもたらすが、一般化の改善は局所的であり、異なるタスク間でのトレードオフが存在。これにより、合成データアプローチの限界が明らかになり、タスク全体での堅牢な埋め込みモデルの構築に対する考えに疑問を呈する。 Comment
元ポスト:
dataset: https://huggingface.co/datasets/jspringer/open-synthetic-embeddings
[Paper Note] Refuse Whenever You Feel Unsafe: Improving Safety in LLMs via Decoupled Refusal Training, Youliang Yuan+, ACL'25, 2024.07
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #SyntheticData #Safety #PostTraining Issue Date: 2025-09-21 GPT Summary- 本研究では、LLMsの安全性調整における拒否ポジションバイアスの問題を解決するために、「Decoupled Refusal Training(DeRTa)」という新しいアプローチを提案。DeRTaは、有害な応答プレフィックスを用いた最大尤度推定と強化された遷移最適化を組み込み、モデルが不適切なコンテンツを認識し拒否する能力を強化します。実証評価では、提案手法が安全性を向上させ、攻撃に対する防御でも優れた性能を示しました。 Comment
元ポスト:
一般的なSafety Tuningでは有害なpromptが与えられた時に安全な応答が生成される確率を最大化する(MLE)が、安全な応答は冒頭の数トークンにSorry, I apologize等の回答を拒絶するトークンが集中する傾向にあり、応答を拒否するか否かにポジションバイアスが生じてしまう。これにより、応答の途中で潜在的な危険性を検知し、応答を拒否することができなくなってしまうという課題が生じる。
これを解決するために、RTOを提案している。有害なpromptの一部をprefixとし、その後にSafetyなレスポンスをconcatするような応答を合成しMLEに活用することで、応答の途中でも応答を拒否するような挙動を学習することができる。prefixを利用することで、
- prefixを用いることで安全なレスポンスに追加のcontextを付与することができ、潜在的な危険性の識別力が高まり、
- prefixの長さは任意なので、応答のどのポジションからでも危険性識別できるようになり、
- モデルが有害な応答を開始したことをシームレスに認識して安全な回答を生成するように遷移させられる
といった利点があるが、1つの学習サンプルにつき一つの遷移(i.e., prefixと安全な応答の境目は1サンプルにつき一箇所しかないので)しか学習できないことである。このため、RTOでは、レスポンスの全てのポジションにおいてsorryが生成される確率を最大化することで、モデルが全てのポジションで継続的に危険性を識別できる能力を高めるような工夫をする。
目的関数は以下で、Harmful Prefixがgivenな時に安全な回答が生成される確率を最大化するMLEの項に対して(r^hat_
実験の結果は、全体を見る限り、helpfulnessを損なうことなく、安全な応答を生成できるようになっており、DPO等のその他のAlignment手法よりも性能が良さそうである。
以下の研究で報告されている現象と似ている:
- The First Few Tokens Are All You Need: An Efficient and Effective
Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ke Ji+, arXiv'25
すなわち、reasoning traceの最初の数トークンが全体の品質に大きく関わるという話
[Paper Note] Scalable Vision Language Model Training via High Quality Data Curation, Hongyuan Dong+, ACL'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #SmallModel #OpenWeight #VisionLanguageModel Issue Date: 2025-09-16 GPT Summary- SAIL-VLは、2Bおよび8Bパラメータのオープンソースビジョン言語モデルで、最先端の性能を達成。主な改善点は、(1) 高品質な視覚理解データの構築、(2) 拡大した事前学習データによる性能向上、(3) 複雑さのスケーリングによる効果的なSFTデータセットのキュレーション。SAIL-VLは18のVLMベンチマークで最高スコアを達成し、2Bモデルは同等のVLMの中でトップの位置を占める。モデルはHuggingFaceで公開。 Comment
元ポスト:
[Paper Note] Language Models Resist Alignment: Evidence From Data Compression, Jiaming Ji+, ACL'25
Paper/Blog Link My Issue
#Pocket #read-later Issue Date: 2025-08-03 GPT Summary- 本研究では、大規模言語モデル(LLMs)の整合性ファインチューニングが、意図しない行動を示す原因となる「elasticity」を理論的および実証的に探求。整合後のモデルは、事前学習時の行動分布に戻る傾向があり、ファインチューニングが整合性を損なう可能性が示された。実験により、モデルのパフォーマンスが急速に低下し、その後事前学習分布に戻ることが確認され、モデルサイズやデータの拡張とelasticityの相関も明らかに。これにより、LLMsのelasticityに対処する必要性が強調された。
[Paper Note] A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive, Sarath Sivaprasad+, ACL'25
Paper/Blog Link My Issue
#Pocket #read-later Issue Date: 2025-08-03 GPT Summary- LLMのサンプリング行動を調査し、ヒューリスティクスが人間の意思決定に類似していることを示す。サンプルは統計的規範から処方的要素に逸脱し、公衆衛生や経済動向において一貫して現れる。LLMの概念プロトタイプが処方的規範の影響を受け、人間の正常性の概念に類似。ケーススタディを通じて、LLMの出力が理想的な値にシフトし、偏った意思決定を引き起こす可能性があることを示し、倫理的懸念を提起。
[Paper Note] Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory, Yexiang Liu+, ACL'25 Outstanding Paper
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Prompting #read-later #reading #MajorityVoting Issue Date: 2025-08-03 GPT Summary- 本研究では、LLMのテスト時の計算スケーリングにおけるプロンプト戦略の効果を調査。6つのLLMと8つのプロンプト戦略を用いた実験により、複雑なプロンプト戦略が単純なChain-of-Thoughtに劣ることを示し、理論的な証明を提供。さらに、スケーリング性能を予測し最適なプロンプト戦略を特定する手法を提案し、リソース集約的な推論プロセスの必要性を排除。複雑なプロンプトの再評価と単純なプロンプト戦略の潜在能力を引き出すことで、テスト時のスケーリング性能向上に寄与することを目指す。 Comment
non-thinkingモデルにおいて、Majority Voting (i.e. Self Consistency)によるtest-time scalingを実施する場合のさまざまなprompting戦略のうち、budgetとサンプリング数が小さい場合はCoT以外の適切なprompting戦略はモデルごとに異なるが、budgetやサンプリング数が増えてくるとシンプルなCoT(実験ではzeroshot CoTを利用)が最適なprompting戦略として支配的になる、という話な模様。
さらに、なぜそうなるかの理論的な分析と最適な与えられた予算から最適なprompting戦略を予測する手法も提案している模様。
が、評価データの難易度などによってこの辺は変わると思われ、特にFigure39に示されているような、**サンプリング数が増えると簡単な問題の正解率が上がり、逆に難しい問題の正解率が下がるといった傾向があり、CoTが簡単な問題にサンプリング数を増やすと安定して正解できるから支配的になる**、という話だと思われるので、常にCoTが良いと勘違いしない方が良さそうだと思われる。たとえば、**解こうとしているタスクが難問ばかりであればCoTでスケーリングするのが良いとは限らない、といった点には注意が必要**だと思うので、しっかり全文読んだ方が良い。時間がある時に読みたい(なかなかまとまった時間取れない)
最適なprompting戦略を予測する手法では、
- 問題の難易度に応じて適応的にスケールを変化させ(なんとO(1)で予測ができる)
- 動的に最適なprompting戦略を選択
することで、Majority@10のAcc.を8Bスケールのモデルで10--50%程度向上させることができる模様。いやこれほんとしっかり読まねば。
[Paper Note] Mapping 1,000+ Language Models via the Log-Likelihood Vector, Momose Oyama+, ACL'25
Paper/Blog Link My Issue
#Embeddings #Analysis #Pocket #NLP #LanguageModel #read-later Issue Date: 2025-08-03 GPT Summary- 自動回帰型言語モデルの比較に対し、対数尤度ベクトルを特徴量として使用する新しいアプローチを提案。これにより、テキスト生成確率のクルバック・ライブラー発散を近似し、スケーラブルで計算コストが線形に増加する特徴を持つ。1,000以上のモデルに適用し、「モデルマップ」を構築することで、大規模モデル分析に新たな視点を提供。 Comment
NLPコロキウムでのスライド:
https://speakerdeck.com/shimosan/yan-yu-moderunodi-tu-que-lu-fen-bu-to-qing-bao-ji-he-niyorulei-si-xing-noke-shi-hua
元ポスト:
[Paper Note] Revisiting Compositional Generalization Capability of Large Language Models Considering Instruction Following Ability, Yusuke Sakai+, ACL'25
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Composition #InstructionFollowingCapability #CommonsenseReasoning Issue Date: 2025-07-31 GPT Summary- Ordered CommonGenを提案し、LLMsの指示に従う能力と構成的一般化能力を評価するベンチマークを構築。36のLLMsを分析した結果、指示の意図は理解しているが、概念の順序に対するバイアスが低多様性の出力を引き起こすことが判明。最も指示に従うLLMでも約75%の順序付きカバレッジしか達成できず、両能力の改善が必要であることを示唆。 Comment
LLMの意味の構成性と指示追従能力を同時に発揮する能力を測定可能なOrderedCommonGenを提案
[Paper Note] Rectifying Belief Space via Unlearning to Harness LLMs' Reasoning, Ayana Niwa+, ACL'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Trustfulness Issue Date: 2025-07-28 GPT Summary- LLMの不正確な回答は虚偽の信念から生じると仮定し、信念空間を修正する方法を提案。テキスト説明生成で信念を特定し、FBBSを用いて虚偽の信念を抑制、真の信念を強化。実証結果は、誤った回答の修正とモデル性能の向上を示し、一般化の改善にも寄与することを示唆。 Comment
元ポスト:
[Paper Note] Unveiling the Power of Source: Source-based Minimum Bayes Risk Decoding for Neural Machine Translation, Boxuan Lyu+, ACL'25
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #Pocket #NLP #LanguageModel #Decoding Issue Date: 2025-07-20 GPT Summary- ソースベースのMBRデコーディング(sMBR)を提案し、パラフレーズや逆翻訳から生成された準ソースを「サポート仮説」として利用。参照なしの品質推定メトリックを効用関数として用いる新しいアプローチで、実験によりsMBRがQE再ランキングおよび標準MBRを上回る性能を示した。sMBRはNMTデコーディングにおいて有望な手法である。 Comment
元ポスト:
[Paper Note] Do Vision-Language Models Have Internal World Models? Towards an Atomic Evaluation, Qiyue Gao+, ACL(Findings)'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation #VisionLanguageModel #Findings Issue Date: 2025-07-02 GPT Summary- 内部世界モデル(WMs)はエージェントの理解と予測を支えるが、最近の大規模ビジョン・ランゲージモデル(VLMs)の基本的なWM能力に関する評価は不足している。本研究では、知覚と予測を評価する二段階のフレームワークを提案し、WM-ABenchというベンチマークを導入。15のVLMsに対する660の実験で、これらのモデルが基本的なWM能力に顕著な制限を示し、特に運動軌道の識別においてほぼランダムな精度であることが明らかになった。VLMsと人間のWMとの間には重要なギャップが存在する。 Comment
元ポスト:
[Paper Note] Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting, Hao Feng+, ACL'25
Paper/Blog Link My Issue
#Document #Pocket #NLP #Library #DocParser Issue Date: 2025-06-21 GPT Summary- 文書画像解析の新モデル「Dolphin」を提案。レイアウト要素をシーケンス化し、タスク特有のプロンプトと組み合わせて解析を行う。3000万以上のサンプルで訓練し、ページレベルと要素レベルの両方で最先端の性能を達成。効率的なアーキテクチャを実現。コードは公開中。 Comment
repo: https://github.com/bytedance/Dolphin
SoTAなDocumentのparser
ドキュメントに記述が見当たらないように見えたが、おそらくHFに付与されているタグを見る限り、英語と中国語をサポートしていると思われる
[Paper Note] Value Residual Learning, Zhanchao Zhou+, ACL'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Transformer #Architecture #read-later #Selected Papers/Blogs Issue Date: 2025-06-12 GPT Summary- ResFormerは、隠れ状態の残差に値の残差接続を加えることで情報の流れを強化する新しいTransformerアーキテクチャを提案。実験により、ResFormerは従来のTransformerに比べて少ないパラメータとトレーニングデータで同等の性能を示し、SVFormerはKVキャッシュサイズを半減させることができる。性能はシーケンスの長さや学習率に依存する。 Comment
元ポスト:
なぜValue Residual Learningがうまくいくかの直感的説明:
ざっくり言うと、LayerNormよって初期layerの影響は深くなればなるほど小さくなり、情報が損なわれていってしまうため、ValueをQKに応じて情報を運んでくる要素と捉えると、検索やコピーなどの明確なinputに関する情報が欲しい場合に、すべてのlayerから初期のValueにアクセスできるvalue residual connectionが有用となる、といった話と理解した。Valueにのみフォーカスしているが、QKの場合はどうなのかといった要素はまだ未開拓な分野とのこと。
Wide&Deepみたいな話になってきた:
- [Paper Note] Wide & Deep Learning for Recommender Systems, Heng-Tze Cheng+, DLRS'16, 2016.06
Value Residual Learningを用いたアーキテクチャが現在nanoGPT Speedrunでトップになった。
- Modded-NanoGPT, KellerJordan, 2024.05
現在のlayerのValueと初期レイヤーのValueを線形補完する重みをtrainableにするとさらに性能が改善することも言及されている。
Why Vision Language Models Struggle with Visual Arithmetic? Towards Enhanced Chart and Geometry Understanding, Kung-Hsiang Huang+, ACL'25
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #SyntheticData #DPO #PostTraining #Probing Issue Date: 2025-05-18 GPT Summary- Vision Language Models (VLMs)は視覚的算術に苦労しているが、CogAlignという新しいポストトレーニング戦略を提案し、VLMの性能を向上させる。CogAlignは視覚的変換の不変特性を認識するように訓練し、CHOCOLATEで4.6%、MATH-VISIONで2.9%の性能向上を実現し、トレーニングデータを60%削減。これにより、基本的な視覚的算術能力の向上と下流タスクへの転送の効果が示された。 Comment
元ポスト:
既存のLLM (proprietary, openweightそれぞれ)が、シンプルなvisual arithmeticタスク(e.g., 線分の長さ比較, Chart上のdotの理解)などの性能が低いことを明らかにし、
それらの原因を(1)Vision Encoderのrepresentationと(2)Vision EncoderをFreezeした上でのText Decoderのfinetuningで分析した。その結果、(1)ではいくつかのタスクでlinear layerのprobingでは高い性能が達成できないことがわかった。このことから、Vision Encoderによるrepresentationがタスクに関する情報を内包できていないか、タスクに関する情報は内包しているがlinear layerではそれを十分に可能できない可能性が示唆された。
これをさらに分析するために(2)を実施したところ、Vision Encoderをfreezeしていてもfinetuningによりquery stringに関わらず高い性能を獲得できることが示された。このことから、Vision Encoder側のrepresentationの問題ではなく、Text Decoderと側でデコードする際にFinetuningしないとうまく活用できないことが判明した。
手法のところはまだ全然しっかり読めていないのだが、画像に関する特定の属性に関するクエリと回答のペアを合成し、DPOすることで、zero-shotの性能が向上する、という感じっぽい?
Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset, Dan Su+, ACL'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #Pocket #NLP #Dataset #LanguageModel #Selected Papers/Blogs Issue Date: 2025-05-10 GPT Summary- FineWeb-EduとDCLMは、モデルベースのフィルタリングによりデータの90%を削除し、トレーニングに適さなくなった。著者は、アンサンブル分類器や合成データの言い換えを用いて、精度とデータ量のトレードオフを改善する手法を提案。1Tトークンで8Bパラメータモデルをトレーニングし、DCLMに対してMMLUを5.6ポイント向上させた。新しい6.3Tトークンデータセットは、DCLMと同等の性能を持ちながら、4倍のユニークなトークンを含み、長トークンホライズンでのトレーニングを可能にする。15Tトークンのためにトレーニングされた8Bモデルは、Llama 3.1の8Bモデルを上回る性能を示した。データセットは公開されている。
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, ACL'25
Paper/Blog Link My Issue
#EfficiencyImprovement #MachineLearning #Pocket #NLP #LanguageModel #Attention #read-later Issue Date: 2025-03-02 GPT Summary- 長文コンテキストモデリングのために、計算効率を改善するスパースアテンションメカニズム「NSA」を提案。NSAは動的な階層スパース戦略を用い、トークン圧縮と選択を組み合わせてグローバルなコンテキスト認識とローカルな精度を両立。実装最適化によりスピードアップを実現し、エンドツーエンドのトレーニングを可能にすることで計算コストを削減。NSAはフルアテンションモデルと同等以上の性能を維持しつつ、長シーケンスに対して大幅なスピードアップを達成。 Comment
元ポスト:
ACL'25のBest Paperの一つ:
[Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01
Paper/Blog Link My Issue
#Pocket #MultiModal #ComputerUse #Selected Papers/Blogs #VisionLanguageModel #KeyPoint Notes Issue Date: 2025-11-25 GPT Summary- WebVoyagerは、実際のウェブサイトと対話しユーザーの指示をエンドツーエンドで完了できる大規模マルチモーダルモデルを搭載したウェブエージェントである。新たに設立したベンチマークで59.1%のタスク成功率を達成し、GPT-4やテキストのみのWebVoyagerを上回る性能を示した。提案された自動評価指標は人間の判断と85.3%一致し、ウェブエージェントの信頼性を高める。 Comment
日本語解説: https://blog.shikoan.com/web-voyager/
スクリーンショットを入力にHTMLの各要素に対してnumeric labelをoverlayし(Figure2)、VLMにタスクを完了するためのアクションを出力させる手法。アクションはFigure7のシステムプロンプトに書かれている通り。
たとえば、VLMの出力として"Click [2]" が得られたら GPT-4-Act GPT-4V-Act, ddupont808, 2023.10
と呼ばれるSoM [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
をベースにWebUIに対してマウス/キーボードでinteractできるモジュールを用いることで、[2]とマーキングされたHTML要素を同定しClick操作を実現する。
[Paper Note] Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models, Mosh Levy+, ACL'24, 2024.02
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Prompting #Length Issue Date: 2025-10-02 GPT Summary- 本研究では、入力長の拡張が大規模言語モデル(LLMs)の性能に与える影響を評価する新しいQA推論フレームワークを提案。異なる長さやタイプのパディングを用いて、LLMsの推論性能が短い入力長で著しく低下することを示した。さらに、次の単語予測がLLMsの性能と負の相関を持つことを明らかにし、LLMsの限界に対処するための戦略を示唆する失敗モードを特定した。
[Paper Note] Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs, Arash Ahmadian+, ACL'24, 2024.02
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Alignment #ReinforcementLearning #read-later #Selected Papers/Blogs Issue Date: 2025-09-27 GPT Summary- RLHFにおける整合性の重要性を考慮し、PPOの高コストとハイパーパラメータ調整の問題を指摘。シンプルなREINFORCEスタイルの最適化手法がPPOや新提案の手法を上回ることを示し、LLMの整合性特性に適応することで低コストのオンラインRL最適化が可能であることを提案。
[Paper Note] LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding, Yushi Bai+, ACL'24
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Evaluation #LongSequence #MultiLingual Issue Date: 2025-08-07 GPT Summary- 本論文では、長いコンテキスト理解のための初のバイリンガル・マルチタスクベンチマーク「LongBench」を提案。英語と中国語で21のデータセットを含み、平均長はそれぞれ6,711語と13,386文字。タスクはQA、要約、少数ショット学習など多岐にわたる。評価結果から、商業モデルは他のオープンソースモデルを上回るが、長いコンテキストでは依然として課題があることが示された。 Comment
PLaMo Primeの長文テキスト評価に利用されたベンチマーク(中国語と英語のバイリンガルデータであり日本語は存在しない)
PLaMo Primeリリースにおける機能改善:
https://tech.preferred.jp/ja/blog/plamo-prime-release-feature-update/
タスクと言語ごとのLengthの分布。英語の方がデータが豊富で、長いものだと30000--40000ものlengthのサンプルもある模様。
[Paper Note] Chat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages, Shih-Cheng Huang+, ACL'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ModelMerge Issue Date: 2025-06-25 GPT Summary- オープンソースの大規模言語モデル(LLMs)の多くは英語に偏っている問題に対処するため、chat vectorという概念を導入。これは、事前学習済みモデルの重みからチャットモデルの重みを引くことで生成され、追加のトレーニングなしに新しい言語でのチャット機能を付与できる。実証研究では、指示に従う能力や有害性の軽減、マルチターン対話においてchat vectorの効果を示し、さまざまな言語やモデルでの適応性を確認。chat vectorは、事前学習済みモデルに対話機能を効率的に実装するための有力な解決策である。 Comment
日本語解説: https://qiita.com/jovyan/items/ee6affa5ee5bdaada6b4
下記ブログによるとChatだけではなく、Reasoningでも(post-trainingが必要だが)使える模様
Reasoning能力を付与したLLM ABEJA-QwQ32b-Reasoning-Japanese-v1.0の公開, Abeja Tech Blog, 2025.04:
https://tech-blog.abeja.asia/entry/geniac2-qwen25-32b-reasoning-v1.0
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models, Peng Wang+, ACL'24, (System Demonstrations)
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Library #KnowledgeEditing Issue Date: 2025-05-11 GPT Summary- EasyEditは、LLMsのための使いやすい知識編集フレームワークであり、さまざまな知識編集アプローチをサポート。LlaMA-2の実験結果では、信頼性と一般化の面で従来のファインチューニングを上回ることを示した。GitHubでソースコードを公開し、Google Colabチュートリアルやオンラインシステムも提供。 Comment
ver2.0:
- EasyEdit2: An Easy-to-use Steering Framework for Editing Large Language
Models, Ziwen Xu+, arXiv'25
Full Parameter Fine-tuning for Large Language Models with Limited Resources, Lv+, ACL'24, 2024.08
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP Issue Date: 2025-03-06 GPT Summary- 新しいオプティマイザ「LOMO」を提案し、勾配計算とパラメータ更新を1ステップで融合することでメモリ使用量を削減。これにより、24GBのメモリを持つ8台のRTX 3090で65Bモデルの全パラメータファインチューニングが可能に。メモリ使用量は標準的なアプローチと比較して10.8%削減。
Parallel Structures in Pre-training Data Yield In-Context Learning, Yanda Chen+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 事前学習済み言語モデル(LMs)のインコンテキスト学習(ICL)能力は、事前学習データ内の「平行構造」に依存していることを発見。平行構造とは、同じコンテキスト内で類似のテンプレートに従うフレーズのペアであり、これを除去するとICL精度が51%低下することが示された。平行構造は多様な言語タスクをカバーし、長距離にわたることが確認された。
Automated Justification Production for Claim Veracity in Fact Checking: A Survey on Architectures and Approaches, Islam Eldifrawi+, arXiv'24
Paper/Blog Link My Issue
#Survey #Pocket Issue Date: 2025-01-06 GPT Summary- 自動事実確認(AFC)は、主張の正確性を検証する重要なプロセスであり、特にオンラインコンテンツの増加に伴い真実と誤情報を見分ける役割を果たします。本論文では、最近の手法を調査し、包括的な分類法を提案するとともに、手法の比較分析や説明可能性向上のための今後の方向性について議論します。
Legal Case Retrieval: A Survey of the State of the Art, Feng+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 法的ケース検索(LCR)の重要性が増しており、歴史的なケースを大規模な法的データベースから検索するタスクに焦点を当てている。本論文では、LCRの主要なマイルストーンを調査し、研究者向けに関連データセットや最新のニューラルモデル、その性能を簡潔に説明する。
FinTextQA: A Dataset for Long-form Financial Question Answering, Jian Chen+, ACL'24
Paper/Blog Link My Issue
#Pocket #Dataset #Financial Issue Date: 2025-01-06 GPT Summary- 金融における質問応答システムの評価には多様なデータセットが必要だが、既存のものは不足している。本研究では、金融の長文質問応答用データセットFinTextQAを提案し、1,262の高品質QAペアを収集した。また、RAGベースのLFQAシステムを開発し、様々な評価手法で性能を検証した結果、Baichuan2-7BがGPT-3.5-turboに近い精度を示し、最も効果的なシステム構成が特定された。文脈の長さが閾値を超えると、ノイズに対する耐性が向上することも確認された。 Comment
@AkihikoWatanabe Do you have this dataset, please share it with me. Thank you.
@thangmaster37 Thank you for your comment and I'm sorry for the late replying. Unfortunately, I do not have this dataset. I checked the link provided in the paper, but it was not found. Please try contacting the authors. Thank you.
@thangmaster37 I found that the dataset is available in the following repository. However, as stated in the repository's README, It seems that the textbook portion of the dataset cannot be shared because their legal department has not granted permission to open source. Thank you.
https://github.com/AlexJJJChen/FinTextQA
回答の長さが既存データセットと比較して長いFinancialに関するQAデータセット(1 paragraph程度)。


ただし、上述の通りデータセットのうちtextbookについて公開の許可が降りなかったようで、regulation and policy-relatedな部分のみ利用できる模様(全体の20%程度)。

Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models, Changyu Chen+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 推論タスクにおける誤りを軽減するため、外部リソースを使わずに入力に摂動を導入する手法を開発。特定のトークンをランダムにマスクすることで、Llama-2-7Bを用いたGSM8Kの精度を5%、GSM-ICの精度を10%向上させた。この手法は既存のデータ拡張手法と組み合わせることで、複数のデータセットで改善を示し、モデルが長距離依存関係を捉えるのを助ける可能性がある。コードはGithubで公開。 Comment
気になる
[Paper Note] A Deep Dive into the Trade-Offs of Parameter-Efficient Preference Alignment Techniques, Megh Thakkar+, ACL'24, 2024.06
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Alignment #DownstreamTasks Issue Date: 2025-01-06 GPT Summary- 大規模言語モデルの整列に関する研究で、整列データセット、整列技術、モデルの3つの要因が下流パフォーマンスに与える影響を300以上の実験を通じて調査。情報量の多いデータが整列に寄与することや、監視付きファインチューニングが最適化を上回るケースを発見。研究者向けに効果的なパラメータ効率の良いLLM整列のガイドラインを提案。
Forgetting before Learning: Utilizing Parametric Arithmetic for Knowledge Updating in Large Language Models, Shiwen Ni+, ACL'24
Paper/Blog Link My Issue
#Pocket #LanguageModel #Supervised-FineTuning (SFT) #KnowledgeEditing Issue Date: 2025-01-06 GPT Summary- F-Learningという新しいファインチューニング手法を提案し、古い知識を忘却し新しい知識を学習するためにパラメトリック算術を利用。実験により、F-LearningがフルファインチューニングとLoRAファインチューニングの知識更新性能を向上させ、既存のベースラインを上回ることを示した。LoRAのパラメータを引き算することで古い知識を忘却する効果も確認。 Comment
Finetuningによって知識をアップデートしたい状況において、ベースモデルでアップデート前の該当知識を忘却してから、新しい知識を学習することで、より効果的に知識のアップデートが可能なことを示している。
古い知識のデータセットをK_old、古い知識から更新された新しい知識のデータセットをK_newとしたときに、K_oldでベースモデルを{Full-finetuning, LoRA}することで得たパラメータθ_oldを、ベースモデルのパラメータθから(古い知識を忘却することを期待して)減算し、パラメータθ'を持つ新たなベースモデルを得る。その後、パラメータθ'を持つベースモデルをk_newでFull-Finetuningすることで、新たな知識を学習させる。ただし、このような操作は、K_oldがベースモデルで学習済みである前提であることに注意する。学習済みでない場合はそもそも事前の忘却の必要がないし、減算によってベースモデルのコアとなる能力が破壊される危険がある。
結果は下記で、先行研究よりも高い性能を示している。注意点として、ベースモデルから忘却をさせる際に、Full Finetuningによってθ_oldを取得すると、ベースモデルのコアとなる能力が破壊されるケースがあるようである。一方、LoRAの場合はパラメータに対する影響が小さいため、このような破壊的な操作となりづらいようである。
評価で利用されたデータセット:
- [Paper Note] Zero-Shot Relation Extraction via Reading Comprehension, Omer Levy+, CoNLL'17
- [Paper Note] Locating and Editing Factual Associations in GPT, Kevin Meng+, NeurIPS'22
NICE: To Optimize In-Context Examples or Not?, Pragya Srivastava+, ACL'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- タスク固有の指示がある場合、ICEの最適化が逆効果になることを発見。指示が詳細になるほどICE最適化の効果が減少し、タスクの学習可能性を定量化する指標「NICE」を提案。これにより、指示最適化とICE最適化の選択を支援するヒューリスティックを提供。 Comment
興味深い
Instruction-tuned Language Models are Better Knowledge Learners, Zhengbao Jiang+, ACL'24
Paper/Blog Link My Issue
#Pretraining #Pocket #InstructionTuning #PerplexityCurse Issue Date: 2025-01-06 GPT Summary- 新しい文書からの知識更新には、事前指示調整(PIT)を提案。これは、文書の訓練前に質問に基づいて指示調整を行う手法で、LLMが新しい情報を効果的に吸収する能力を向上させ、標準的な指示調整を17.8%上回る結果を示した。 Comment
興味深い
SNLP'24での解説スライド: https://speakerdeck.com/s_mizuki_nlp/instruction-tuned-language-models-are-better-knowledge-learners-in-acl-2024
Are Emergent Abilities in Large Language Models just In-Context Learning?, Sheng Lu+, ACL'24
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #In-ContextLearning #Memorization #EmergentAbilities Issue Date: 2025-01-06 GPT Summary- 大規模言語モデルの「出現能力」は、インコンテキスト学習やモデルの記憶、言語知識の組み合わせから生じるものであり、真の出現ではないと提案。1000以上の実験を通じてこの理論を裏付け、言語モデルの性能を理解するための基礎を提供し、能力の過大評価を警告。
Learning to Edit: Aligning LLMs with Knowledge Editing, Yuxin Jiang+, ACL'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #KnowledgeEditing Issue Date: 2025-01-06 GPT Summary- 「Learning to Edit(LTE)」フレームワークを提案し、LLMsに新しい知識を効果的に適用する方法を教える。二段階プロセスで、アライメントフェーズで信頼できる編集を行い、推論フェーズでリトリーバルメカニズムを使用。四つの知識編集ベンチマークでLTEの優位性と堅牢性を示す。
Multi-Level Feedback Generation with Large Language Models for Empowering Novice Peer Counselors, Alicja Chaszczewicz+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 大規模言語モデルを活用し、初心者のピアカウンセラーに文脈に応じた多層的なフィードバックを提供することを目的とした研究。上級心理療法スーパーバイザーと協力し、感情的サポートの会話に関するフィードバック注釈付きデータセットを構築。自己改善手法を設計し、フィードバックの自動生成を強化。定性的および定量的評価により、高リスクシナリオでの低品質なフィードバック生成のリスクを最小限に抑えることを示した。
Learning Global Controller in Latent Space for Parameter-Efficient Fine-Tuning, Tan+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LLMs)の高コストに対処するため、パラメータ効率の良いファインチューニング手法を提案。潜在ユニットを導入し、情報特徴を洗練することで下流タスクのパフォーマンスを向上。非対称注意メカニズムにより、トレーニングのメモリ要件を削減し、フルランクトレーニングの問題を軽減。実験結果は、自然言語処理タスクで最先端の性能を達成したことを示す。
[Paper Note] OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, Chaoqun He+, ACL'24
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation #MultiModal Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LLMs)やマルチモーダルモデル(LMMs)の能力を測定するために、オリンピアドレベルのバイリンガルマルチモーダル科学ベンチマーク「OlympiadBench」を提案。8,476の数学と物理の問題を含み、専門家レベルの注釈が付けられている。トップモデルのGPT-4Vは平均17.97%のスコアを達成したが、物理では10.74%にとどまり、ベンチマークの厳しさを示す。一般的な問題として幻覚や論理的誤謬が指摘され、今後のAGI研究に貴重なリソースとなることが期待される。
DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows, Ajay Patel+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LLMs)の利用が広がる中、標準化ツールの欠如や再現性の問題が浮上している。本論文では、研究者が簡単にLLMワークフローを実装できるオープンソースのPythonライブラリ「DataDreamer」を紹介し、オープンサイエンスと再現性を促進するためのベストプラクティスを提案する。ライブラリはGitHubで入手可能。
Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives, Wenqi Zhang+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- LLMの反射能力に関する研究では、自己評価の質がボトルネックであることが判明。過信や高いランダム性が反射の質を低下させるため、自己対比(Self-Contrast)を提案し、多様な解決視点を探求・対比することで不一致を排除。これにより、LLMのバイアスを軽減し、より正確で安定した反射を促進。実験により、提案手法の効果と一般性が示された。
Llama2Vec: Unsupervised Adaptation of Large Language Models for Dense Retrieval, Li+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- Llama2Vecは、LLMを密な検索に適応させるための新しい非監視適応アプローチであり、EBAEとEBARの2つの前提タスクを用いています。この手法は、WikipediaコーパスでLLaMA-2-7Bを適応させ、密な検索ベンチマークでの性能を大幅に向上させ、特にMSMARCOやBEIRで最先端の結果を達成しました。モデルとソースコードは公開予定です。
BIPED: Pedagogically Informed Tutoring System for ESL Education, Kwon+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket #Education Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LLMs)を用いた会話型インテリジェントチュータリングシステム(CITS)は、英語の第二言語(L2)学習者に対して効果的な教育手段となる可能性があるが、既存のシステムは教育的深さに欠ける。これを改善するために、バイリンガル教育的情報を持つチュータリングデータセット(BIPED)を構築し、対話行為の語彙を考案した。GPT-4とSOLAR-KOを用いて二段階のフレームワークでCITSモデルを実装し、実験により人間の教師のスタイルを再現し、多様な教育的戦略を採用できることを示した。
Beyond Memorization: The Challenge of Random Memory Access in Language Models, Tongyao Zhu+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 生成型言語モデル(LM)のメモリアクセス能力を調査し、順次アクセスは可能だがランダムアクセスには課題があることを明らかに。暗唱技術がランダムメモリアクセスを向上させ、オープンドメインの質問応答においても顕著な改善を示した。実験コードは公開されている。
Attribute First, then Generate: Locally-attributable Grounded Text Generation, Aviv Slobodkin+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- ローカル属性付きテキスト生成アプローチを提案し、生成プロセスをコンテンツ選択、文の計画、逐次文生成の3ステップに分解。これにより、簡潔な引用を生成しつつ、生成品質と属性の正確性を維持または向上させ、事実確認にかかる時間を大幅に削減。
Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning, Yongqi Tong+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 本研究では、LLMが自らの間違いから学ぶ能力を探求し、609,432の質問を含む新しいベンチマーク\textsc{CoTErrorSet}を提案。自己再考プロンプティングと間違いチューニングの2つの方法を用いて、LLMが誤りから推論能力を向上させることを実証。これにより、コスト効果の高いエラー活用戦略を提供し、今後の研究の方向性を示す。
Enhancing In-Context Learning via Implicit Demonstration Augmentation, Xiaoling Zhou+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- インコンテキスト学習(ICL)におけるデモンストレーションの質や量がパフォーマンスに影響を与える問題に対処。デモンストレーションの深い特徴分布を活用し、表現を豊かにすることで、精度を向上させる新しいロジットキャリブレーションメカニズムを提案。これにより、さまざまなPLMやタスクでの精度向上とパフォーマンスのばらつきの減少を実現。
MathGenie: Generating Synthetic Data with Question Back-translation for Enhancing Mathematical Reasoning of LLMs, Zimu Lu+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- MathGenieは、少規模な問題解決データセットから多様で信頼性の高い数学問題を生成する新手法。シードデータの解答を増強し、逆翻訳モデルで新しい質問に変換。解答の正確性を確保するために根拠に基づく検証戦略を採用。MathGenieLMモデル群は、5つの数学的推論データセットでオープンソースモデルを上回り、特にGSM8Kで87.7%、MATHで55.7%の精度を達成。
MELA: Multilingual Evaluation of Linguistic Acceptability, Zhang+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 本研究では、46,000サンプルからなる「多言語言語的受容性評価(MELA)」ベンチマークを発表し、10言語にわたるLLMのベースラインを確立。XLM-Rを用いてクロスリンガル転送を調査し、ファインチューニングされたXLM-RとGPT-4oの性能を比較。結果、GPT-4oは多言語能力で優れ、オープンソースモデルは劣ることが判明。クロスリンガル転送実験では、受容性判断の転送が複雑であることが示され、MELAでのトレーニングがXLM-Rの構文タスクのパフォーマンス向上に寄与することが確認された。
Time is Encoded in the Weights of Finetuned Language Models, Kai Nylund+, ACL'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 「時間ベクトル」を提案し、特定の時間データで言語モデルをファインチューニングする手法を示す。時間ベクトルは重み空間の方向を指定し、特定の時間帯のパフォーマンスを向上させる。隣接する時間帯に特化したベクトルは近接して配置され、補間により未来の時間帯でも良好な性能を発揮。異なるタスクやモデルサイズにおいて一貫した結果を示し、時間がモデルの重み空間にエンコードされていることを示唆。
Surgical Feature-Space Decomposition of LLMs: Why, When and How?, Arnav Chavan+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 低ランク近似は、深層学習モデルの性能向上や推論のレイテンシ削減に寄与するが、LLMにおける有用性は未解明。本研究では、トランスフォーマーベースのLLMにおける重みと特徴空間の分解の効果を実証し、圧縮と性能のトレードオフに関する洞察を提供しつつ、常識推論性能の向上も示す。特定のネットワークセグメントの低ランク構造を特定し、モデルのバイアスへの影響も調査。これにより、低ランク近似が性能向上とバイアス修正の手段としての新たな視点を提供することを示した。
MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter, Jitai Hao+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- PEFTを用いたLLMsのファインチューニング性能は、追加パラメータの制約から限られる。これを克服するために、メモリ効率の良い大きなアダプターを導入し、CPUメモリの大容量を活用。Mixture of Expertsアーキテクチャを採用し、GPUとCPU間の通信量を削減。これにより、限られたリソース下でも高いファインチューニング性能を達成。コードはGitHubで公開。
Benchmarking Knowledge Boundary for Large Language Models: A Different Perspective on Model Evaluation, Xunjian Yin+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 大規模言語モデルの評価において、プロンプトに依存しない「知識境界」という新概念を提案。これにより、プロンプトの敏感さを回避し、信頼性の高い評価が可能に。新しいアルゴリズム「意味的制約を持つ投影勾配降下法」を用いて、知識境界を計算し、既存手法より優れた性能を示す。複数の言語モデルの能力を多様な領域で評価。
ValueBench: Towards Comprehensively Evaluating Value Orientations and Understanding of Large Language Models, Yuanyi Ren+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 本研究では、LLMsの価値観と理解を評価するための心理測定ベンチマーク「ValueBench」を提案。453の価値次元を含むデータを収集し、現実的な人間とAIの相互作用に基づく評価パイプラインを構築。6つのLLMに対する実験を通じて、共通および独自の価値観を明らかにし、価値関連タスクでの専門家の結論に近い能力を示した。ValueBenchはオープンアクセス可能。
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension, Qian Yang+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 音声言語モデル(LALMs)の評価のために、初のベンチマークAIR-Benchを提案。これは、音声信号の理解と人間との相互作用能力を評価するもので、基本的な単一タスク能力を検査する約19,000の質問と、複雑な音声に対する理解力を評価する2,000のオープンエンド質問から構成。GPT-4を用いた評価フレームワークにより、LALMsの限界を明らかにし、今後の研究の指針を提供。
Self-Alignment for Factuality: Mitigating Hallucinations in LLMs via Self-Evaluation, Xiaoying Zhang+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 自己整合性を用いてLLMの事実性を向上させるアプローチを提案。自己評価コンポーネントSelf-Evalを組み込み、生成した応答の事実性を内部知識で検証。信頼度推定を改善するSelf-Knowledge Tuningを設計し、自己注釈された応答でモデルをファインチューニング。TruthfulQAとBioGENタスクでLlamaモデルの事実精度を大幅に向上。
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering, Tobias Schimanski+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- LLMsの信頼性と追跡可能性を向上させるため、情報源の質と回答の帰属を改善するファインチューニング手法を調査。自動データ品質フィルターを用いた高品質データの合成により、パフォーマンスが向上。データ品質の改善が証拠に基づくQAにおいて重要であることを示した。
AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators, Jingwei+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 生成AIの普及に伴い、自動事実確認手法が重要視されているが、事実主張の検出にはスケーラビリティと一般化可能性の問題がある。これに対処するため、事実主張の統一的な定義を提案し、AFaCTAという新しいフレームワークを導入。AFaCTAはLLMsを活用し、注釈の信頼度を調整する。広範な評価により、専門家の注釈作業を効率化し、PoliClaimという包括的な主張検出データセットを作成した。
Dissecting Human and LLM Preferences, Junlong Li+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 本研究では、人間と32種類のLLMの好みを分析し、モデルの応答の品質比較における定量的な構成を理解するための詳細なシナリオ別分析を行った。人間はエラーに対して敏感でなく、自分の立場を支持する応答を好む一方、GPT-4-Turboのような高度なLLMは正確性や無害性を重視することが分かった。また、同サイズのLLMはトレーニング方法に関係なく似た好みを示し、ファインチューニングは大きな変化をもたらさないことが明らかになった。さらに、好みに基づく評価は操作可能であり、モデルを審査員の好みに合わせることでスコアが向上することが示された。
Selene: Pioneering Automated Proof in Software Verification, Lichen Zhang+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- ソフトウェア検証の自動化が求められる中、seL4に基づく初のプロジェクトレベルの自動証明ベンチマークSeleneを提案。Seleneは包括的な証明生成フレームワークを提供し、LLMs(GPT-3.5-turboやGPT-4)を用いた実験でその能力を示す。提案する強化策により、Seleneの課題が今後の研究で軽減可能であることを示唆。
Evaluating Intention Detection Capability of Large Language Models in Persuasive Dialogues, Sakurai+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- LLMsを用いてマルチターン対話における意図検出を調査。従来の研究が会話履歴を無視している中、修正したデータセットを用いて意図検出能力を評価。特に説得的対話では他者の視点を考慮することが重要であり、「フェイスアクト」の概念を取り入れることで、意図の種類に応じた分析が可能となる。
Analyzing Temporal Complex Events with Large Language Models? A Benchmark towards Temporal, Long Context Understanding, Zhihan Zhang+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- デジタル環境の進化に伴い、複雑なイベントの迅速かつ正確な分析が求められている。本論文では、長期間のニュース記事から「Temporal Complex Event(TCE)」を抽出・分析するために、LLMsを用いた新しいアプローチを提案。TCEは重要なポイントとタイムスタンプで特徴付けられ、読解力、時間的配列、未来のイベント予測の3つのタスクを含むベンチマーク「TCELongBench」を設立。実験では、リトリーバー強化生成(RAG)手法と長いコンテキストウィンドウを持つLLMsを活用し、適切なリトリーバーを持つモデルが長いコンテキストウィンドウを利用するモデルと同等のパフォーマンスを示すことが確認された。
Feature-Adaptive and Data-Scalable In-Context Learning, Jiahao Li+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- FADS-ICLは、文脈内学習を強化するための特徴適応型フレームワークで、LLMの一般的な特徴を特定の下流タスクに適合させる。実験により、FADS-ICLは従来の手法を大幅に上回り、特に1.5Bモデルでの32ショット設定では平均14.3の精度向上を達成。トレーニングデータの増加により性能がさらに向上することも示された。
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal, Jianheng Huang+, arXiv'24
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- 自己合成リハーサル(SSR)フレームワークを提案し、LLMの継続的学習における壊滅的な忘却を克服。基本のLLMで合成インスタンスを生成し、最新のLLMで洗練させることで、データ効率を高めつつパフォーマンスを向上。SSRは一般化能力を効果的に保持することが実験で示された。
Grounding Language Model with Chunking-Free In-Context Retrieval, Hongjin Qian+, arXiv'24
Paper/Blog Link My Issue
#Embeddings #Pocket #Supervised-FineTuning (SFT) #RAG(RetrievalAugmentedGeneration) #LongSequence #PostTraining Issue Date: 2025-01-06 GPT Summary- CFICは、Retrieval-Augmented Generation(RAG)システム向けの新しいリトリーバルアプローチで、従来のチャンク化を回避し、文書のエンコードされた隠れ状態を利用して正確な証拠テキストを特定します。制約付き文のプレフィックスデコーディングとスキップデコーディングを組み込むことで、リトリーバルの効率と生成された証拠の忠実性を向上させます。CFICはオープンQAデータセットで評価され、従来の方法に対して大幅な改善を示し、RAGシステムの効率的で効果的なリトリーバルソリューションを提供します。 Comment
Chunking無しでRAGを動作させられるのは非常に魅力的。
一貫してかなり性能が向上しているように見える
提案手法の概要。InputとOutput全体の実例がほとんど掲載されていないので憶測を含みます。
気持ちとしては、ソーステキストが与えられたときに、Questionの回答をsupportするようなソース中のpassageの情報を活用して回答するために、重要なsentenceのprefixを回答生成前に生成させる(重要なsentenceの識別子の役割を果たす)ことで、(識別子によって重要な情報によって条件づけられて回答生成ができるやうになるのて)それら情報をより考慮しながらモデルが回答を生成できるようになる、といった話だと思われる。
Table2のようなテンプレートを用いて、ソーステキストと質問文でモデルを条件付けて、回答をsupportするsentenceのprefixを生成する。生成するprefixは各sentenceのユニークなprefixのtoken log probabilityの平均値によって決まる(トークンの対数尤度が高かったらモデルが暗黙的にその情報はQuestionにとって重要だと判断しているとみなせる)。SkipDecodingの説を読んだが、ぱっと見よく分からない。おそらく[eos]を出力させてprefix間のデリミタとして機能させたいのだと思うが、[eos]の最適なpositionはどこなのか?みたいな数式が出てきており、これがデコーディングの時にどういった役割を果たすのかがよくわからない。
また、モデルはQAと重要なPassageの三つ組のデータで提案手法によるデコーディングを適用してSFTしたものを利用する。
ConSiDERS-The-Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models, Aparna Elangovan+, arXiv'24
Paper/Blog Link My Issue
#Pocket #LanguageModel #Evaluation #Bias Issue Date: 2025-01-06 GPT Summary- 本ポジションペーパーでは、生成的な大規模言語モデル(LLMs)の人間評価は多分野にわたる取り組みであるべきと主張し、実験デザインの信頼性を確保するためにユーザーエクスペリエンスや心理学の洞察を活用する必要性を強調します。評価には使いやすさや認知バイアスを考慮し、強力なモデルの能力と弱点を区別するための効果的なテストセットが求められます。さらに、スケーラビリティも重要であり、6つの柱から成るConSiDERS-The-Human評価フレームワークを提案します。これらの柱は、一貫性、評価基準、差別化、ユーザーエクスペリエンス、責任、スケーラビリティです。
Linguistically Conditioned Semantic Textual Similarity, Jingxuan Tu+, ACL'24
Paper/Blog Link My Issue
#Embeddings #Pocket #Dataset #RepresentationLearning #STS (SemanticTextualSimilarity) Issue Date: 2025-01-06 GPT Summary- 条件付きSTS(C-STS)は文の意味的類似性を測定するNLPタスクであるが、既存のデータセットには評価を妨げる問題が多い。本研究では、C-STSの検証セットを再アノテーションし、アノテーター間の不一致を55%観察。QAタスク設定を活用し、アノテーションエラーを80%以上のF1スコアで特定する自動エラー識別パイプラインを提案。また、モデル訓練によりC-STSデータのベースライン性能を向上させる新手法を示し、エンティティタイプの型特徴構造(TFS)を用いた条件付きアノテーションの可能性についても議論する。
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, Damai+, ACL'24, 2024.08
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) Issue Date: 2025-01-06 GPT Summary- DeepSeekMoEアーキテクチャは、専門家の専門性を高めるために、専門家を細分化し柔軟な組み合わせを可能にし、共有専門家を設けて冗長性を軽減する。2BパラメータのDeepSeekMoEは、GShardと同等の性能を達成し、同じパラメータ数の密なモデルに近づく。16Bパラメータにスケールアップした際も、計算量を約40%に抑えつつ、LLaMA2と同等の性能を示した。
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, Sohee Yang+, ACL'24
Paper/Blog Link My Issue
#Multi #Pocket #NLP #Dataset #LanguageModel #Evaluation #Factuality #Reasoning Issue Date: 2024-12-02 GPT Summary- 大規模言語モデル(LLMs)のマルチホップクエリに対する事実の想起能力を評価。ショートカットを防ぐため、主語と答えが共に出現するテストクエリを除外した評価データセットSOCRATESを構築。LLMsは特定のクエリにおいてショートカットを利用せずに潜在的な推論能力を示し、国を中間答えとするクエリでは80%の構成可能性を達成する一方、年の想起は5%に低下。潜在的推論能力と明示的推論能力の間に大きなギャップが存在することが明らかに。 Comment
SNLP'24での解説スライド:
https://docs.google.com/presentation/d/1Q_UzOzn0qYX1gq_4FC4YGXK8okd5pwEHaLzVCzp3yWg/edit?usp=drivesdk
この研究を信じるのであれば、LLMはCoT無しではマルチホップ推論を実施することはあまりできていなさそう、という感じだと思うのだがどうなんだろうか。
MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#Survey #Pocket #LanguageModel #MultiModal #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2024-01-25 GPT Summary- MM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。 Comment
以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
# 概要
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
## ポイント
- Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
- optimizationの対象は「Input/Output Projector」
## Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。
## Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。
## LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。
## Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。
## Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。
Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。
LLaMA Pro: Progressive LLaMA with Block Expansion, Chengyue Wu+, N_A, ACL'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ProgressiveLearning Issue Date: 2024-01-24 GPT Summary- 本研究では、大規模言語モデル(LLMs)の新しい事前学習後の手法を提案し、モデルの知識を効果的かつ効率的に向上させることを目指しました。具体的には、Transformerブロックの拡張を使用し、新しいコーパスのみを使用してモデルを調整しました。実験の結果、提案手法はさまざまなベンチマークで優れたパフォーマンスを発揮し、知的エージェントとして多様なタスクに対応できることが示されました。この研究は、自然言語とプログラミング言語を統合し、高度な言語エージェントの開発に貢献するものです。 Comment
追加の知識を導入したいときに使えるかも?
事前学習したLLaMA Blockに対して、追加のLLaMA Blockをstackし、もともとのLLaMA Blockのパラメータをfreezeした上でドメインに特化したコーパスで事後学習することで、追加の知識を挿入する。LLaMA Blockを挿入するときは、Linear Layerのパラメータを0にすることで、RMSNormにおける勾配消失の問題を避けた上で、Identity Block(Blockを追加した時点では事前学習時と同様のOutputがされることが保証される)として機能させることができる。
Prompt Engineering a Prompt Engineer, Qinyuan Ye+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Prompting #AutomaticPromptEngineering #Findings Issue Date: 2023-11-13 GPT Summary- プロンプトエンジニアリングは、LLMsのパフォーマンスを最適化するための重要なタスクであり、本研究ではメタプロンプトを構築して自動的なプロンプトエンジニアリングを行います。改善されたパフォーマンスにつながる推論テンプレートやコンテキストの明示などの要素を導入し、一般的な最適化概念をメタプロンプトに組み込みます。提案手法であるPE2は、さまざまなデータセットやタスクで強力なパフォーマンスを発揮し、以前の自動プロンプトエンジニアリング手法を上回ります。さらに、PE2は意味のあるプロンプト編集を行い、カウンターファクトの推論能力を示します。
[Paper Note] Chain-of-Verification Reduces Hallucination in Large Language Models, Shehzaad Dhuliawala+, N_A, ACL'24
Paper/Blog Link My Issue
#NLP #LanguageModel #QuestionAnswering #Chain-of-Thought #Prompting #Hallucination #Selected Papers/Blogs #Verification Issue Date: 2023-09-30 GPT Summary- 私たちは、言語モデルが根拠のない情報を生成する問題に取り組んでいます。Chain-of-Verification(CoVe)メソッドを開発し、モデルが回答を作成し、検証し、最終的な回答を生成するプロセスを経ることで、幻想を減少させることができることを実験で示しました。 Comment
# 概要
ユーザの質問から、Verificationのための質問をplanningし、質問に対して独立に回答を得たうえでオリジナルの質問に対するaggreementを確認し、最終的に生成を実施するPrompting手法
# 評価
## dataset
- 全体を通じてclosed-bookの設定で評価
- Wikidata
- Wikipedia APIから自動生成した「“Who are some [Profession]s who were born in [City]?”」に対するQA pairs
- Goldはknowledge baseから取得
- 全56 test questions
- Gold Entityが大体600程度ありLLMは一部しか回答しないので、precisionで評価
- Wiki category list
- QUEST datasetを利用 QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, N/A, ACL'23
- 回答にlogical operationが不要なものに限定して頭に"Name some"をつけて質問を生成
- "Name some Mexican animated horror films" or "Name some Endemic orchids of Vietnam"
- 8個の回答を持つ55 test questionsを作成
- MultiSpanQA
- Reading Comprehensionに関するBenchmark dataset
- 複数の独立した回答(回答は連続しないスパンから回答が抽出される)から構成される質問で構成
- 特に、今回はclosed-book setting で実施
- すなわち、与えられた質問のみから回答しなければならず、知っている知識が問われる問題
- 418のtest questsionsで、各回答に含まれる複数アイテムのspanが3 token未満となるようにした
- QA例:
- Q: Who invented the first printing press and in what year?
- A: Johannes Gutenberg, 1450.
# 評価結果
提案手法には、verificationの各ステップでLLMに独立したpromptingをするかなどでjoint, 2-step, Factored, Factor+Revisedの4種類のバリエーションがあることに留意。
- joint: 全てのステップを一つのpromptで実施
- 2-stepは2つのpromptに分けて実施
- Factoredは各ステップを全て異なるpromptingで実施
- Factor+Revisedは異なるpromptで追加のQAに対するcross-checkをかける手法
結果を見ると、CoVEでhallucinationが軽減(というより、モデルが持つ知識に基づいて正確に回答できるサンプルの割合が増えるので実質的にhallucinationが低減したとみなせる)され、特にjointよりも2-step, factoredの方が高い性能を示すことがわかる。
Active prompting with chain-of-thought for large language models, Diao+, The Hong Kong University of Science and Technology, ACL'24
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-04-27 Comment
しっかりと読めていないが、CoT-answerが存在しないtrainingデータが存在したときに、nサンプルにCoTとAnswerを与えるだけでFew-shotの予測をtestデータに対してできるようにしたい、というのがモチベーションっぽい
そのために、questionに対して、training dataに対してFew-Shot CoTで予測をさせた場合やZero-Shot CoTによって予測をさせた場合などでanswerを取得し、answerのばらつき度合いなどから不確実性を測定する。
そして、不確実性が高いCoT-Answerペアを取得し、人間が手作業でCoTと回答のペアを与え、その人間が作成したものを用いてTestデータに対してFewShotしましょう、ということだと思われる。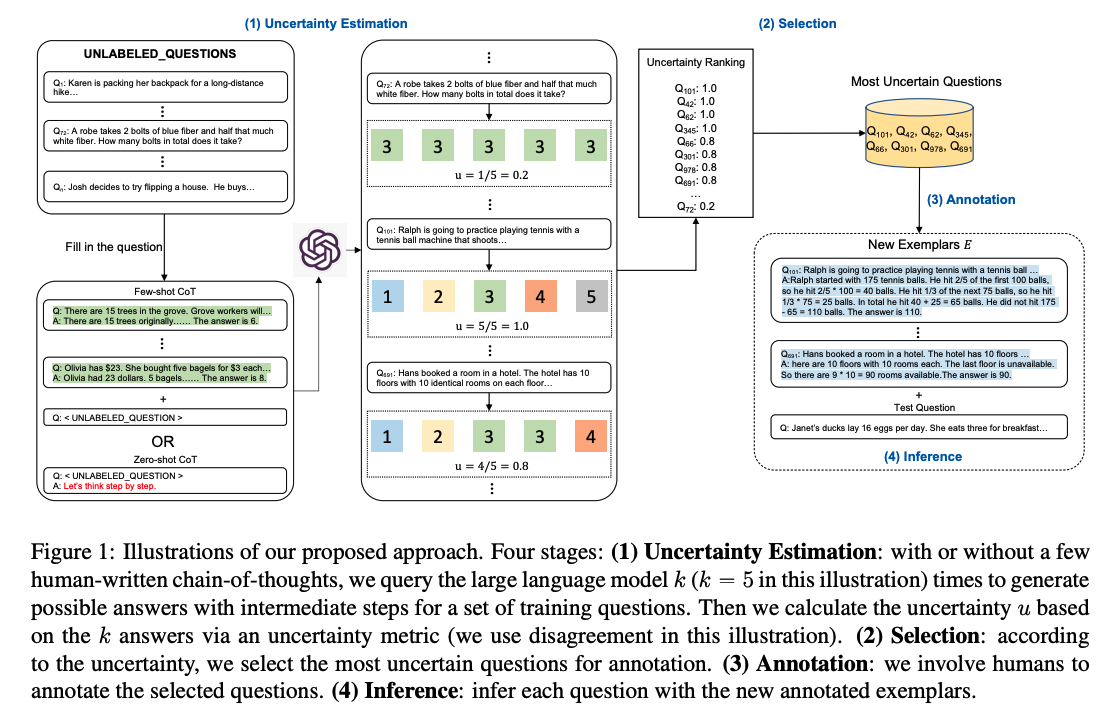
LaMP: When Large Language Models Meet Personalization, Selemi+, University of Massachusetts Amherst (w_ Google Research), ACL'24
Paper/Blog Link My Issue
#NLP #Dataset #PersonalizedGeneration Issue Date: 2023-04-26 Comment
# 概要
Personalizationはユーザのニーズや嗜好に応えるために重要な技術で、IRやRecSysで盛んに研究されてきたが、NLPではあまり実施されてこなかった。しかし、最近のタスクで、text classificationやgeneration taskでPersonalizationの重要性が指摘されている。このような中で、LLMでpersonalizedなレスポンスを生成し、評価することはあまり研究されていない。そこで、LaMPベンチマークを生成し、LLMにおけるPersonalizationをするための開発と評価をするための第一歩として提案している。
# Personalizing LLM Outputs
LLMに対してPersonalizedなoutputをさせるためには、profileをpromptに埋め込むことが基本的なアプローチとなる。
## Problem Formulation
まず、user profile(ユーザに関するrecordの集合)をユーザとみなす。データサンプルは以下の3つで構成される:
- x: モデルのinputとなるinput sequence
- y: モデルが生成することを期待するtarget output
- u: user profile(ユーザの嗜好やrequirementsを捉えるための補助的な情報)
そして、p(y | x, u) を最大化する問題として定式化される。それぞれのユーザuに対して、モデルは{(x_u1, y_u1,)...(x_un, y_un)}を利用することができる。
## A Retrieval Augmentation Approach for Personaliozing LLMs
user profileは基本的にめちゃめちゃ多く、promptに入れ込むことは非現実的。そこで、reteival augmentation approachと呼ばれる手法を提案している。LLMのcontext windowは限られているので、profileのうちのsubsetを利用することが現実的なアプローチとなる。また、必ずしも全てのユーザプロファイルがあるタスクを実施するために有用とは限らない。このため、retrieval augmentation approachを提案している。
retrieval augmentation approachでは、現在のテストケースに対して、relevantな部分ユーザプロファイルを選択的に抽出するフレームワークである。
(x_i, y_i)に対してpersonalizationを実現するために、3つのコンポーネントを採用している:
1. query generation function: x_iに基づきuser profileからrelevantな情報を引っ張ってくるquery qを生成するコンポーネント
2. retrieval model R(q, P_u, k): query q, プロファイルP_u, を用いて、k個のrelevantなプロファイルを引っ張ってくるモデル
3. prompt construction function: xとreteival modelが引っ張ってきたエントリからpromptを作成するコンポーネント
1, 2, 3によって生成されたprompt x^barと、yによってモデルを訓練、あるいは評価する。
この研究では、Rとして Contriever Contrirver
, BM25, random selectionの3種類を用いている。
# LaMPベンチマーク
GLUEやSuper Glue、KILT、GENといったベンチマークは、"one-size-fits-all"なモデリングと評価を前提としており、ユーザのニーズに答えるための開発を許容していない。一方で、LaMPは、以下のようなPersonalizationが必要なさまざまなタスクを統合して作成されたデータセットである。
- Personalized Text Classification
- Personalized Citation Identification (binary classification)
- Task definition
- user u が topic xに関する論文を書いたときに、何の論文をciteすべきかを決めるタスク
- user uが書いた論文のタイトルが与えられたとき、2つのcandidate paperのうちどちらをreferenceとして利用すべきかを決定する2値分類
- Data Collection
- Citation Network Datasetを利用。最低でも50本以上論文を書いているauthorを抽出し、authorの論文のうちランダムに論文と論文の引用を抽出
- negative document selectionとして、ランダムに共著者がciteしている論文をサンプリング
- Profile Specification
- ユーザプロファイルは、ユーザが書いた全てのpaper
- titleとabstractのみをuser profileとして保持した
- Evaluation
- train/valid/testに分け、accuracyで評価する
- Personalized News Categorization (15 category分類)
- Task definition
- LLMが journalist uによって書かれたニュースを分類する能力を問うタスク
- u によって書かれたニュースxが与えられた時、uの過去の記事から得られるカテゴリの中から該当するカテゴリを予測するタスク
- Data Collection
- news categorization datasetを利用(Huff Postのニュース)
- 記事をfirst authorでグルーピング
- グルーピングした記事群をtrain/valid/testに分割
- それぞれの記事において、記事をinputとし、その記事のカテゴリをoutputとする。そして残りの記事をuser profileとする。
- Profile Specification
- ユーザによって書かれた記事の集合
- Evaluation
- accuracy, macro-averaged F1で評価
- Personalized Product Rating (5-star rating)
- Task definition
- ユーザuが記述したreviewに基づいて、LLMがユーザuの未知のアイテムに対するratingを予測する性能を問う
- Data Collection
- Amazon Reviews Datasetを利用
- reviewが100件未満、そしてほとんどのreviewが外れ値なユーザ1%を除外
- ランダムにsubsetをサンプリングし、train/valid/testに分けた
- input-output pairとしては、inputとしてランダムにユーザのreviewを選択し、その他のreviewをprofileとして利用する。そして、ユーザがinputのレビューで付与したratingがground truthとなる。
- Profile Specification
- ユーザのレビュ
- Evaluation
- ttrain/valid/testに分けてRMSE, MAEで評価する
- Personalized Text Generation
- Personalized News Headline Generation
- Task definition
- ユーザuが記述したニュースのタイトルを生成するタスク
- 特に、LLMが与えられたprofileに基づいてユーザのinterestsやwriting styleを捉え、適切にheadlinに反映させる能力を問う
- Data Collection
- News Categorization datasetを利用(Huff Post)
- データセットではauthorの情報が提供されている
- それぞれのfirst authorごとにニュースをグルーピングし、それぞれの記事をinput, headlineをoutputとした。そして残りの記事をprofileとした
- Profile Specification
- ユーザの過去のニュース記事とそのheadlineの集合をprofileとする
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Scholarly Title Generation
- Task Definition
- ユーザの過去のタイトルを考慮し、LLMがresearch paperのtitleを生成する能力を測る
- Data Collection
- Citation Network Datasetのデータを利用
- abstractをinput, titleをoutputとし、残りのpaperをprofileとした
- Profile Specification
- ユーザが書いたpaperの集合(abstractのみを利用)
- Personalized Email Subject Generation
- Task Definition
- LLMがユーザのwriting styleに合わせて、Emailのタイトルを書く能力を測る
- Data Collection
- Avocado Resaerch Email Collectionデータを利用
- 5単語未満のsubjectを持つメール、本文が30単語未満のメールを除外、
- 送信主のemail addressでメールをグルーピング
- input _outputペアは、email本文をinputとし、対応するsubjectをoutputとした。他のメールはprofile
- Profile Specification
- ユーザのemailの集合
- Evaluation
- ROUGE-1, ROUGE-Lで評価
- Personalized Tweet Paraphrasing
- Task Definition
- LLMがユーザのwriting styleを考慮し、ツイートのparaphrasingをする能力を問う
- Data Collection
- Sentiment140 datasetを利用
- 最低10単語を持つツイートのみを利用
- userIDでグルーピングし、10 tweets以下のユーザは除外
- ランダムに1つのtweetを選択し、ChatGPT(gpt-3.5-turbo)でparaphraseした
- paraphrase版のtweetをinput, 元ツイートをoutputとし、input-output pairを作った。
- User Profile Specification
- ユーザの過去のツイート
- Evaluation
- ROUGE-1, ROUGE-Lで評価
# 実験
## Experimental Setup
- FlanT5-baesをfinetuningした
- ユーザ単位でモデルが存在するのか否かが記載されておらず不明
## 結果
- Personalization入れた方が全てのタスクでよくなった
- Retrievalモデルとしては、randomの場合でも良くなったが、基本的にはContrirverを利用した場合が最も良かった
- => 適切なprofileを選択しpromptに含めることが重要であることが示された
- Rが抽出するサンプル kを増やすと、予測性能が増加する傾向もあったが、一部タスクでは性能の低下も招いた
- dev setを利用し、BM25/Contrieverのどちらを利用するか、kをいくつに設定するかをチューニングした結果、全ての結果が改善した
- FlanT5-XXLとgpt-3.5-turboを用いたZero-shotの設定でも実験。tweet paraphrasingタスクを除き、zero-shotでもuser profileをLLMで利用することでパフォーマンス改善。小さなモデルでもfinetuningすることで、zero-shotの大規模モデルにdownstreamタスクでより高い性能を獲得することを示している(ただし、めちゃめちゃ改善しているというわけでもなさそう)。


# LaMPによって可能なResearch Problem
## Prompting for Personalization
- Augmentationモデル以外のLLMへのユーザプロファイルの埋め込み方法
- hard promptingやsoft prompting [Paper Note] The Power of Scale for Parameter-Efficient Prompt Tuning, Brian Lester+, arXiv'21, 2021.04
の活用
## Evaluation of Personalized Text Generation
- テキスト生成で利用される性能指標はユーザの情報を評価のプロセスで考慮していない
- Personalizedなテキスト生成を評価するための適切なmetricはどんなものがあるか?
## Learning to Retrieve from User Profiles
- Learning to RankをRetrieval modelに適用する方向性
LaMPの作成に利用したテンプレート一覧
実装とleaderboard
https://lamp-benchmark.github.io/leaderboard
[Paper Note] FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation, Tu Vu+, ACL'23 Findings, 2023.10
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Zero/Few/ManyShotPrompting #Evaluation #Factuality #RAG(RetrievalAugmentedGeneration) #Findings Issue Date: 2025-09-24 GPT Summary- 大規模言語モデル(LLMs)は変化する世界に適応できず、事実性に課題がある。本研究では、動的QAベンチマーク「FreshQA」を導入し、迅速に変化する知識や誤った前提を含む質問に対するLLMの性能を評価。評価の結果、全モデルがこれらの質問に苦労していることが明らかに。これを受けて、検索エンジンからの最新情報を組み込む「FreshPrompt」を提案し、LLMのパフォーマンスを向上させることに成功。FreshPromptは、証拠の数と順序が正確性に影響を与えることを示し、簡潔な回答を促すことで幻覚を減少させる効果も確認。FreshQAは公開され、今後も更新される予定。
Sequence Parallelism: Long Sequence Training from System Perspective, Li+, ACL'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Parallelism Issue Date: 2025-05-16 Comment
入力系列をチャンクに分割して、デバイスごとに担当するチャンクを決めることで原理上無限の長さの系列を扱えるようにした並列化手法。系列をデバイス間で横断する場合attention scoreをどのように計算するかが課題になるが、そのためにRing Self attentionと呼ばれるアルゴリズムを提案している模様。また、MLPブロックとMulti Head Attentonブロックの計算も、BatchSize * Sequence Lengthの大きさが、それぞれ32*Hidden Size, 16*Attention Head size *
# of Attention Headよりも大きくなった場合に、Tensor Parallelismよりもメモリ効率が良くなるらしい。
Data Parallel, Pipeline Parallel, Tensor Parallel、全てに互換性があるとのこと(併用可能)
そのほかの並列化の解説については
- 大規模モデルを支える分散並列学習のしくみ Part1
を参照のこと。
Boosting Language Models Reasoning with Chain-of-Knowledge Prompting, Jianing Wang+, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- Chain-of-Thought(CoT)プロンプティングの限界を克服するために、Chain-of-Knowledge(CoK)プロンプティングを提案。CoKは、LLMsに明示的な知識の証拠を生成させ、推論の信頼性を向上させる。F^2-Verification手法を用いて、信頼性のない応答を指摘し再考を促す。実験により、常識や事実に基づく推論タスクのパフォーマンスが向上することを示した。
Exploring Memorization in Fine-tuned Language Models, Shenglai Zeng+, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- ファインチューニング中の大規模言語モデル(LLMs)の記憶を初めて包括的に分析。オープンソースのファインチューニングされたモデルを用いた結果、記憶はタスク間で不均一であることが判明。スパースコーディング理論を通じてこの不均一性を説明し、記憶と注意スコア分布の強い相関関係を明らかにした。
Instruction Fusion: Advancing Prompt Evolution through Hybridization, Weidong Guo+, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- Instruction Fusion(IF)を提案し、二つの異なるプロンプトを組み合わせることでコード生成LLMの性能を向上させる。実験により、IFが従来の手法の制約を克服し、HumanEvalなどのベンチマークで大幅な性能向上を実現することを示した。
Insert or Attach: Taxonomy Completion via Box Embedding, Wei Xue+, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- TaxBoxフレームワークは、ボックス埋め込み空間を利用して分類体系の補完を行い、挿入および付加操作に特化した幾何学的スコアラーを設計。動的ランキング損失メカニズムによりスコアを調整し、実験では従来手法を大幅に上回る性能向上を達成。
SPARSEFIT: Few-shot Prompting with Sparse Fine-tuning for Jointly Generating Predictions and Natural Language Explanations, Jesus Solano+, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- SparseFitは、少量の自然言語による説明(NLE)データを用いて、離散的なプロンプトを活用し、予測とNLEを共同生成するスパースなfew-shot微調整戦略です。T5モデルで実験した結果、わずか6.8%のパラメータ微調整で、タスクのパフォーマンスとNLEの質が向上し、他のパラメータ効率的微調整技術よりも優れた結果を示しました。
LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin, Shihan Dou+, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-01-06 GPT Summary- LoRAMoEフレームワークを提案し、教師ありファインチューニングにおける指示データの増加がLLMsの世界知識を損なう問題に対処。低ランクアダプターとルーターネットワークを用いて、世界知識を活用しつつ下流タスクの処理能力を向上させることを実証。
Navigate through Enigmatic Labyrinth A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future, Zheng Chu+, arXiv'23
Paper/Blog Link My Issue
#Survey #Pocket #NLP #LanguageModel #Chain-of-Thought Issue Date: 2025-01-06 GPT Summary- 推論はAIにおいて重要な認知プロセスであり、チェーン・オブ・ソートがLLMの推論能力を向上させることが注目されている。本論文では関連研究を体系的に調査し、手法を分類して新たな視点を提供。課題や今後の方向性についても議論し、初心者向けの導入を目指す。リソースは公開されている。
Precise Zero-Shot Dense Retrieval without Relevance Labels, Luyu Gao+, ACL'23
Paper/Blog Link My Issue
#InformationRetrieval #Pocket #NLP #LanguageModel #RAG(RetrievalAugmentedGeneration) Issue Date: 2024-11-11 GPT Summary- 本研究では、ゼロショット密な検索システムの構築において、仮想文書埋め込み(HyDE)を提案。クエリに基づき、指示に従う言語モデルが仮想文書を生成し、教師なしで学習されたエンコーダがこれを埋め込みベクトルに変換。実際のコーパスに基づく類似文書を取得することで、誤った詳細をフィルタリング。実験結果では、HyDEが最先端の密な検索器Contrieverを上回り、様々なタスクと言語で強力なパフォーマンスを示した。
Crosslingual Generalization through Multitask Finetuning, Niklas Muennighoff+, N_A, ACL'23
Paper/Blog Link My Issue
#Pocket #LanguageModel #MultitaskLearning #Zero/Few/ManyShotPrompting #Supervised-FineTuning (SFT) #CrossLingual #Generalization Issue Date: 2023-08-16 GPT Summary- マルチタスクプロンプトフィネチューニング(MTF)は、大規模な言語モデルが新しいタスクに汎化するのに役立つことが示されています。この研究では、マルチリンガルBLOOMとmT5モデルを使用してMTFを実施し、英語のプロンプトを使用して英語および非英語のタスクにフィネチューニングすることで、タスクの汎化が可能であることを示しました。さらに、機械翻訳されたプロンプトを使用してマルチリンガルなタスクにフィネチューニングすることも調査し、モデルのゼロショットの汎化能力を示しました。また、46言語の教師ありデータセットのコンポジットであるxP3も紹介されています。 Comment
英語タスクを英語でpromptingしてLLMをFinetuningすると、他の言語(ただし、事前学習で利用したコーパスに出現する言語に限る)で汎化し性能が向上することを示した模様。

[Paper Note] Generating User-Engaging News Headlines, Cai+, ACL'23
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #Surface-level Notes Issue Date: 2023-07-22 GPT Summary- ニュース記事の見出しを個別化するために、ユーザープロファイリングを組み込んだ新しいフレームワークを提案。ユーザーの閲覧履歴に基づいて個別のシグネチャフレーズを割り当て、それを使用して見出しを個別化する。幅広い評価により、提案したフレームワークが多様な読者のニーズに応える個別の見出しを生成する効果を示した。 Comment
# モチベーション
推薦システムのヘッドラインは未だに全員に同じものが表示されており、ユーザが自身の興味とのつながりを正しく判定できるとは限らず、推薦システムの有用性を妨げるので、ユーザごとに異なるヘッドラインを生成する手法を提案した。ただし、クリックベイトは避けるようなヘッドラインを生成しなければならない。
# 手法
1. Signature Phrase Identification
2. User Signature Selection
3. Signature-Oriented Headline Generation
## Signature Phrase Identification
テキスト生成タスクに帰着させる。ニュース記事、あるいはヘッドラインをinputされたときに、セミコロン区切りのSignature Phraseを生成するモデルを用いる。今回は[KPTimes daasetでpretrainingされたBART](
https://huggingface.co/ankur310794/bart-base-keyphrase-generation-kpTimes)を用いた。KPTimesは、279kのニュース記事と、signature
phraseのペアが存在するデータであり、本タスクに最適とのこと。
## User Signature Selection
ターゲットドキュメントdのSignature Phrases Z_dが与えられたとき、ユーザのreading History H_uに基づいて、top-kのuser signature phrasesを選択する。H_uはユーザが読んだニュースのヘッドラインの集合で表現される。あるSignature Phrase z_i ∈ Z_dが与えられたとき、(1)H_uをconcatしたテキストをベクトル化したものと、z_iのベクトルの内積でスコアを計算、あるいは(2) 個別のヘッドラインt_jを別々にエンコーディングし、内積の値が最大のものをスコアとする手法の2種類のエンコーディング方法を用いて、in-batch contrastive learningを用いてモデルを訓練する。つまり、正しいSignature Phraseとは距離が近く、誤ったSignature Phraseとは距離が遠くなるように学習をする。
実際はユーザにとっての正解Signature Phraseは分からないが、今回は人工的に作成したユーザを用いるため、正解が分かる設定となっている。
## Signature-Oriented Headline Generation
ニュース記事d, user signature phrasesZ_d^uが与えられたとき、ヘッドラインを生成するモデルを訓練する。この時も、ユーザにとって正解のヘッドラインは分からないため、既存ニュースのヘッドラインが正解として用いられる。既存ニュースのヘッドラインが正解として用いられていても、そのヘッドラインがそのユーザにとっての正解となるように人工的にユーザが作成されているため、モデルの訓練ができる。モデルはBARTを用いた。
# Dataset
Newsroom, Gigawordコーパスを用いる。これらのコーパスに対して、それぞれ2種類のコーパスを作成する。
1つは、Synthesized User Datasetで、これはUse Signature Selection modelの訓練と評価に用いる。もう一つはheadline generationデータセットで、こちらはheadline generationモデルの訓練に利用する。
## Synthesized User Creation
実データがないので、実ユーザのreading historiesを模倣するように人工ユーザを作成する。具体的には、
1. すべてのニュース記事のSignature Phrasesを同定する
2. それぞれのSignature Phraseと、それを含むニュース記事をマッピングする
3. ランダムにphraseのサブセットをサンプリングし、そのサブセットをある人工ユーザが興味を持つエリアとする。
4. サブセット中のinterest phraseを含むニュース記事をランダムにサンプリングし、ユーザのreading historyとする
train, dev, testセット、それぞれに対して上記操作を実施しユーザを作成するが、train, devはContrastive Learningを実現するために、user signature phrases (interest phrases)は1つのみとした(Softmaxがそうなっていないと訓練できないので)。一方、testセットは1~5の範囲でuser signature phrasesを選択した。これにより、サンプリングされる記事が多様化され、ユーザのreadinig historyが多様化することになる。基本的には、ユーザが興味のあるトピックが少ない方が、よりタスクとしては簡単になることが期待される。また、ヘッドラインを生成するときは、ユーザのsignature phraseを含む記事をランダムに選び、ヘッドラインを背衛星することとした。これは、relevantな記事でないとヘッドラインがそもそも生成できないからである。
## Headline Generation
ニュース記事の全てのsignature phraseを抽出し、それがgivenな時に、元のニュース記事のヘッドラインが生成できるようなBARTを訓練した。ニュース記事のtokenは512でtruncateした。平均して、10個のsignature phraseがニュース記事ごとに選択されており、ヘッドライン生成の多様さがうかがえる。user signature phraseそのものを用いて訓練はしていないが、そもそもこのようにGenericなデータで訓練しても、何らかのphraseがgivenな時に、それにバイアスがかかったヘッドラインを生成することができるので、user signature phrase selectionによって得られたphraseを用いてヘッドラインを生成することができる。
# 評価
自動評価と人手評価をしている。
## 自動評価
人手評価はコストがかかり、特に開発フェーズにおいては自動評価ができることが非常に重要となる。本研究では自動評価し方法を提案している。Headline-User DPR + SBERT, REC Scoreは、User Adaptation Metricsであり、Headline-Article DPR + SBERT, FactCCはArticle Loyalty Metricsである。
### Relevance Metrics
PretrainedなDense Passage Retrieval (DPR)モデルと、SentenceBERTを用いて、headline-user間、headline-article間の類似度を測定する。前者はヘッドラインがどれだけユーザに適応しているが、後者はヘッドラインが元記事に対してどれだけ忠実か(クリックベイトを防ぐために)に用いられる。前者は、ヘッドラインとuser signaturesに対して類似度を計算し、後者はヘッドラインと記事全文に対して類似度を計算する。user signatures, 記事全文をどのようにエンコードしたかは記述されていない。
### Recommendation Score
ヘッドラインと、ユーザのreadinig historyが与えられたときに、ニュースを推薦するモデルを用いて、スコアを算出する。モデルとしては、MIND datsetを用いて学習したモデルを用いた。
### Factual Consistency
pretrainedなFactCCモデルを用いて、ヘッドラインとニュース記事間のfactual consisency score を算出する。
### Surface Overlap
オリジナルのヘッドラインと、生成されたヘッドラインのROUGE-L F1と、Extractive Coverage (ヘッドラインに含まれる単語のうち、ソースに含まれる単語の割合)を用いる。
### 評価結果
提案手法のうち、User Signature Selection modelをfinetuningしたものが最も性能が高かった。エンコード方法は、(2)のヒストリのタイトルとフレーズの最大スコアをとる方法が最も性能が高い。提案手法はUser Adaptationをしつつも、Article Loyaltyを保っている。このため、クリックベイトの防止につながる。また、Vanilla Humanは元記事のヘッドラインであり、Extracitve Coverageが低いため、より抽象的で、かつ元記事に対する忠実性が低いことがうかがえる。
## 人手評価
16人のevaluatorで評価。2260件のニュース記事を収集(113 topic)し、記事のヘッドラインと、対応するトピックを見せて、20個の興味に合致するヘッドラインを選択してもらった。これをユーザのinterest phraseとreading _historyとして扱う。そして、ユーザのinterest phraseを含むニュース記事のうち、12個をランダムに選択し、ヘッドラインを生成した。生成したヘッドラインに対して、
1. Vanilla Human
2. Vanilla System
3. SP random (ランダムにsignature phraseを選ぶ手法)
4. SP individual-N
5. SP individual-F (User Signature Phraseを選択するモデルをfinetuningしたもの)
の5種類を評価するよう依頼した。このとき、3つの観点から評価をした。
1, User adaptation
2. Headline appropriateness
3. Text Quality
結果は以下。
SP-individualがUser Adaptationで最も高い性能を獲得した。また、Vanilla Systemが最も高いHeadline appropriatenessを獲得した。しかしながら、後ほど分析した結果、Vanilla Systemでは、記事のメインポイントを押さえられていないような例があることが分かった(んーこれは正直他の手法でも同じだと思うから、ディフェンスとしては苦しいのでは)。
また、Vanilla Humanが最も高いスコアを獲得しなかった。これは、オーバーにレトリックを用いていたり、一般的な人にはわからないようなタイトルになっているものがあるからであると考えられる。
# Ablation Study
Signature Phrase selectionの性能を測定したところ以下の通りになり、finetuningした場合の性能が良かった。
Headline Generationの性能に影響を与える要素としては、
1. ユーザが興味のあるトピック数
2. User signature phrasesの数
がある。
ユーザのInterest Phrasesが増えていけばいくほど、User Adaptationスコアは減少するが、Article Loyaltyは維持されたままである。このため、興味があるトピックが多ければ多いほど生成が難しいことがわかる。また、複数のuser signature phraseを用いると、factual errorを起こすことが分かった(Billgates, Zuckerbergの例を参照)。これは、モデルが本来はirrelevantなフレーズを用いてcoherentなヘッドラインを生成しようとしてしまうためである。
※interest phrases => gold user signatures という理解でよさそう。
※signature phrasesを複数用いるとfactual errorを起こすため、今回はk=1で実験していると思われる
GPT3にもヘッドラインを生成させてみたが、提案手法の方が性能が良かった(自動評価で)。
なぜPENS dataset [Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
を利用しないで研究したのか?
[Paper Note] Can Large Language Models Be an Alternative to Human Evaluations?, Cheng-Han Chiang+, ACL'23, 2023.05
Paper/Blog Link My Issue
#Analysis #Pocket #LanguageModel #ChatGPT #Evaluation #LLM-as-a-Judge #Attack #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2023-07-22 GPT Summary- 人間評価の再現性が低いため、NLPモデル間の公正な比較が難しい。そこで、大規模言語モデル(LLM)を人間評価の代替手段として利用することを探求。本研究では、LLMに同一指示とサンプルを与え、評価を実施するLLM評価を提案。オープンエンドのストーリー生成や敵対的攻撃のタスクに対する評価結果は、人間専門家の評価と高い一致を示し、評価の安定性も確認。LLMを用いたテキスト評価の可能性やその限界、倫理的課題についても考察。 Comment
LLMがテキストの品質評価において、人間による評価者の代替となりうるか?という疑問を初めて実験的に示した研究で、インパクトが大きく重要論文と判断。ただし、実験のスコープは物語生成と敵対的生成(テキスト分類器を騙すような摂動を加える)の2タスクである点、には注意。
ChatGPT(おそらくGPT-3.5)が人間の評価者(3人のEnglish teacher)とopen-endで生成された物語にたいして、以下の4つの観点に関してratingの平均で見た時に同様の傾向のスコアを付与することを実験的に明らかにした:
- Grammaticality [^1]: テキストの文法の正しさ
- Cohesiveness: テキストの一貫性
- Likeability: テキストが読んでいて楽しいか
- Relevance: promptに対してどれだけ適切なテキストが生成されているか
ただし、T0やtext-curie-001 においてはこのような傾向は見受けられなかった。[^2]
また、ChatGPTによる説明とratingを人間の評価者に対してblindで提示したところ、人間が見ても妥当な判断だと認知された。
全体の傾向としてではなく、個別のratingがどの程度同じような傾向を示すか(i.e., 人間があるstoryを高くratingしたら、LLMも高くratingするか?)をケンドールの順位相関係数で分析(200サンプルに対して3人の英語教員のスコアの平均, text-davinciによる3回の独立したratingを実施した平均スコアを用いて計算)したところ、4つの観点のうち全てにおいて正の相関が見受けられた(Table2, p-valueは<0.05で統計的に有意)。が、Relevanceのみが強い相関を示し、他の指標については弱い相関にとどまっている。しかし、Table6に示されている通り、2人の英語の先生同士で個別のjudgeに感して同様にケンドールの順位相関係数を測定しても、人間-LLM間と同様の傾向が見受けられる。すなわち、Relevanceのみが強い相関で他は弱い相関。このことから、人間同士でも個別のサンプルに対する判断は一致しない(=主観的なタスク)ということは留意する必要がある。
敵対的生成に関する実験については、Synonym Substitution Attack (SSAs; 良性のサンプルを同義語で置換する手法で、全体的な意味は保たれるため一般的な人間は正しく認知してしまうが、実際には文法がおかしくなったり不自然になったり、意味が変わってしまうことが先行研究によって知られているようなものらしい)によって実験。Fluency / Meaning Preservingの2つの指標で英語教員とLLMによる評価を比較した結果、人間は正しくadversarialなサンプルと良性なサンプルを区別できており、ChatGPT(おそらくGPT-3.5)も区別ができている(Table4)。ただし、人間のスコアと比較するとChatGPTは高めのスコアを出す傾向がある点には注意ではあるものの、良性サンプル > 敵対的サンプル という序列の判断に関しては人間と同様の傾向を示していることが示唆された。
[^1]: ただし、LLMはpunctuationのミスを文法エラーと判断するが、一人の英語の先生は文法エラーとしてみなさないなどの現象も観察され、人間は独自の評価criteriaを保持していることも窺える
[^2]: (感想)ある程度能力の高いLLMかRLHFなどを用いて人間の好みに対してalignmentがとられていないとうまくいかないのかもしれない
本研究は非常に初期の研究であり、現在のfrontierモデル群(特にreasoningモデル)を用いた場合にはどの程度改善しているか?という点は気になる。
[Paper Note] An Extensible Plug-and-Play Method for Multi-Aspect Controllable Text Generation, Xuancheng Huang+, ACL'23, 2022.12
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP Issue Date: 2023-07-18 GPT Summary- 多側面制御テキスト生成では、プレフィックスチューニングによって効率的な制御が可能だが、複数のプレフィックス間の干渉が制約を劣化させる。本研究では、干渉の理論的下限を示し、層の数が増えると干渉が増加することを実証。学習可能なゲートを用いて干渉を抑制し、トレーニング時に見えない側面の組み合わせへの拡張を容易にする方法を提案。カテゴリカルと自由形式の制約を両方扱う統一的アプローチを実施し、テキスト生成および機械翻訳において精度、品質、拡張性でベースラインを上回る結果を得た。
[Paper Note] An Invariant Learning Characterization of Controlled Text Generation, Carolina Zheng+, ACL'23, 2023.05
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP Issue Date: 2023-07-18 GPT Summary- ユーザープロンプトに基づくコントロールされた生成では、生成されたテキストの分布が訓練された予測器の分布と異なる場合に性能が低下することを示す。本論文では、この問題を不変学習として定式化し、効果的な予測器は複数のテキスト環境において不変であるべきと論じる。実験を通じて、分布シフトの影響と不変性方法の可能性を評価した。
[Paper Note] Controllable Text Generation via Probability Density Estimation in the Latent Space, Yuxuan Gu+, ACL'23, 2022.12
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP Issue Date: 2023-07-15 GPT Summary- 潜在空間の確率密度推定を基にした新しい制御フレームワークを提案。ノーマライズフローを利用し、先行空間での柔軟な制御を実現。実験により、属性の関連性とテキストの質で強力なベースラインを上回り、柔軟な制御戦略の効果を示した。
[Paper Note] On Improving Summarization Factual Consistency from Natural Language Feedback, Yixin Liu+, ACL'23, 2022.12
Paper/Blog Link My Issue
#DocumentSummarization #NaturalLanguageGeneration #Controllable #Pocket #NLP #Dataset #Factuality Issue Date: 2023-07-15 GPT Summary- ユーザーの期待に応えるために、言語生成モデルの出力品質を向上させることを目指す本研究では、「DeFacto」という高品質データセットを用いて、要約の事実的一貫性を強化するための自然言語フィードバックの活用を検討。また、人間のフィードバックに基づく要約編集や事実誤りの訂正を行うことで、生成タスクの改善を図る。微調整されたモデルは事実的一貫性を向上できる一方で、大規模言語モデルはゼロショット学習において課題が残ることが示された。
[Paper Note] Tailor: A Prompt-Based Approach to Attribute-Based Controlled Text Generation, Kexin Yang+, ACL'23, 2022.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP #PEFT(Adaptor/LoRA) #KeyPoint Notes #SoftPrompt Issue Date: 2023-07-15 GPT Summary- 属性に基づくCTGでは、プロンプトを使用して望ましい属性を満たす文を生成。新手法Tailorは、各属性を連続ベクトルとして表し、固定PLMの生成を誘導。実験によりマルチ属性生成が実現できるが、流暢さの低下が課題。マルチ属性プロンプトマスクと再インデックス位置ID列でこのギャップを埋め、学習可能なプロンプトコネクタにより属性間の連結も可能に。11の生成タスクで強力な性能を示し、GPT-2の最小限のパラメータで有効性を確認。 Comment
Soft Promptを用いてattributeを連続値ベクトルで表現しconcatすることで生成をコントロールする。このとき、複数attuributeを指定可能である。
工夫点としては、attention maskにおいて
soft prompt同士がattendしないようにし、交互作用はMAP Connectorと呼ばれる交互作用そのものを学習するコネクタに移譲する点、(複数のsoft promptをconcatすることによる)Soft Promptのpositionのsensitivityを低減するために、末尾のsoft prompt以外はreindexしている点のようである。
[Paper Note] Focused Prefix Tuning for Controllable Text Generation, Congda Ma+, ACL'23 Short, 2023.06
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP #PEFT(Adaptor/LoRA) #Short Issue Date: 2023-07-15 GPT Summary- 制御可能なテキスト生成での無関係な学習信号を軽減するため、フォーカスプレフィックスチューニング(FPT)を提案。FPTは単一属性制御で優れた精度と流暢さを実現し、マルチ属性制御でも最先端の精度を達成。新属性の制御に既存モデルの再訓練なしで対応。 Comment
Prefix Tuning:
- [Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
[Paper Note] Explicit Syntactic Guidance for Neural Text Generation, Yafu Li+, ACL'23, 2023.06
Paper/Blog Link My Issue
#BeamSearch #NaturalLanguageGeneration #Controllable #Pocket #NLP #LanguageModel #Transformer #Decoder Issue Date: 2023-07-13 GPT Summary- 本研究では、構文に基づいた生成スキーマを提案し、構成素解析木に従ってシーケンスを生成する新しいテキスト生成モデルを開発。デコーディングプロセスは、構文コンテキスト内での埋め込みテキストの予測と、構成素のマッピングによる構文構造の構築に分かれ、構造的ビームサーチ手法を用いて階層的な構文構造を探索。実験結果は、提案手法がパラフレーズ生成と機械翻訳において自己回帰型ベースラインを上回り、解釈可能性や制御可能性、多様性においても優れていることを示した。
[Paper Note] Backpack Language Models, John Hewitt+, ACL'23 Outstanding Paper, 2023.05
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #LanguageModel #Interpretability Issue Date: 2023-06-16 GPT Summary- Backpacksは、強力なモデル性能と解釈性を兼ね備えた新しいニューラルアーキテクチャで、各単語に対して複数の非文脈的な意味ベクトルを学習し、文脈依存の線形結合で表現します。訓練後、意味ベクトルは専門化し、モデルの挙動を予測可能に変更することが可能です。170MパラメータのBackpackモデルは、GPT-2 smallと同等の結果を示し、語彙的類似性評価では6Bパラメータのモデルを上回りました。また、意味ベクトルを介入することで、制御可能なテキスト生成やバイアス除去が可能です。 Comment
日本語解説: https://speakerdeck.com/tatsuropianooo/lun-wen-shao-jie-backpack-language-models
LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion, Dongfu Jiang+, N_A, ACL'23
Paper/Blog Link My Issue
#PairWise #Pocket #NLP #LanguageModel #Ensemble #ModelMerge Issue Date: 2023-06-16 GPT Summary- LLM-Blenderは、複数の大規模言語モデルを組み合わせたアンサンブルフレームワークであり、PairRankerとGenFuserの2つのモジュールから構成されています。PairRankerは、専門的なペアワイズ比較方法を使用して候補の出力間の微妙な違いを区別し、GenFuserは、上位ランクの候補をマージして改善された出力を生成します。MixInstructというベンチマークデータセットを導入し、LLM-Blenderは、個々のLLMsやベースライン手法を大幅に上回り、大きなパフォーマンス差を確立しました。
QUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations, Chaitanya Malaviya+, N_A, ACL'23
Paper/Blog Link My Issue
#InformationRetrieval #Pocket #NLP #Search #Dataset #Evaluation Issue Date: 2023-05-22 GPT Summary- QUESTデータセットは、交差、和、差などの集合演算を暗黙的に指定するクエリを生成するために、選択的な情報ニーズを定式化することによって構築されました。このデータセットは、Wikipediaのドキュメントに対応するエンティティのセットにマップされ、クエリで言及される複数の制約を対応するドキュメントの証拠と一致させ、さまざまな集合演算を正しく実行することをモデルに求めます。クラウドワーカーによって言い換えられ、自然さと流暢さがさらに検証されたクエリは、いくつかの現代的な検索システムにとって苦戦することがわかりました。
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Mirac Suzgun+, N_A, ACL'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Zero/Few/ManyShotPrompting #Chain-of-Thought Issue Date: 2023-05-04 GPT Summary- BIG-Bench Hard (BBH) is a suite of 23 challenging tasks that current language models have not been able to surpass human performance on. This study focuses on applying chain-of-thought prompting to BBH tasks and found that PaLM and Codex were able to surpass human performance on 10 and 17 tasks, respectively. The study also found that CoT prompting is necessary for tasks that require multi-step reasoning and that CoT and model scale interact to enable new task performance on some BBH tasks. Comment
単なるfewshotではなく、CoT付きのfewshotをすると大幅にBIG-Bench-hardの性能が向上するので、CoTを使わないanswer onlyの設定はモデルの能力の過小評価につながるよ、という話らしい
Frustratingly Easy Label Projection for Cross-lingual Transfer, Yang Chen+, N_A, ACL'23
Paper/Blog Link My Issue
#MachineTranslation #Pocket #NLP #LanguageModel #Annotation #TransferLearning #MultiLingual Issue Date: 2023-05-04 GPT Summary- - 多言語のトレーニングデータの翻訳は、クロスリンガル転移の改善に役立つ- スパンレベル注釈が必要なタスクでは、注釈付きスパンを翻訳されたテキストにマッピングするために追加のラベルプロジェクションステップが必要- マーク-翻訳法を利用するアプローチが従来の注釈プロジェクションと比較してどのようになるかについての実証的な分析を行った- EasyProjectと呼ばれるマーク-翻訳法の最適化されたバージョンが多言語に簡単に適用でき、より複雑な単語アラインメントベースの方法を上回ることを示した- すべてのコードとデータが公開される
[Paper Note] Self-Instruct: Aligning Language Models with Self-Generated Instructions, Yizhong Wang+, ACL'23, 2022.12
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #InstructionTuning #In-Depth Notes Issue Date: 2023-03-30 GPT Summary- Self-Instructフレームワークを提案し、事前学習済みの言語モデルが自ら生成した指示を用いてファインチューニングを行うことで、ゼロショットの一般化能力を向上させる。バニラGPT-3に適用した結果、Super-NaturalInstructionsで33%の性能向上を達成し、InstructGPT-001と同等の性能に到達。人間評価により、Self-Instructが既存の公共指示データセットよりも優れていることを示し、ほぼ注釈不要の指示調整手法を提供。大規模な合成データセットを公開し、今後の研究を促進する。 Comment
Alpacaなどでも利用されているself-instruction技術に関する論文
# 概要
著者らが書いた175種のinstruction(タスクの定義 + 1種のinput/outputペア}のseedを元に、VanillaなGPT-3に新たなinstruction, input, outputのtupleを生成させ、学習データとして活用する研究。
ここで、instruction data I は以下のように定義される:
instruction dataは(I, X, Y)であり、モデルは最終的にM(I_t, x_t) = y_tとなるように学習したい。
I: instruction, X: input, Y: output
データ作成は以下のステップで構成される。なお、以下はすべてVanilla GPT-3を通じて行われる:
1. Instruction Generation
task poolから8種類のinstructionを抽出し、 promptを構成し、最大8個新たなinstructionを生成させる
2. Classification Task Identification:
生成されたinstructionがclassificationタスクか否かを判別する
3. Instance Generation
いくつかの(I, X, Y)をpromptとして与え、I, Xに対応するYを生成するタスクを実行させる。このときinput-first approachを採用した結果(I->Xの順番で情報を与えYを生成するアプローチ)、特定のラベルに偏ったインスタンスが生成される傾向があることがわかった。このためoutput-first approachを別途採用し(I->Yの順番で情報を与え、各Yに対応するXを生成させる)、活用している。
4. Filtering and Postprocessing
最後に、既存のtask poolとROUGE-Lが0.7以上のinstructionは多様性がないため除外し、特定のキーワード(images, pictrues, graphs)等を含んでいるinstruction dataも除外して、task poolに追加する。
1-4をひたすら繰り返すことで、GPT-3がInstruction Tuningのためのデータを自動生成してくれる。
# SELF-INSTRUCT Data
## データセットの統計量
- 52k instructions
- 82k instances
## Diversity
parserでinstructionを解析し、rootの名詞と動詞のペアを抽出して可視化した例。ただし、抽出できた例はたかだか全体の50%程度であり、その中で20の最もcommonなroot vertと4つのnounを可視化した。これはデータセット全体の14%程度しか可視化されていないが、これだけでも非常に多様なinstructionが集まっていることがわかる。
また、seed indstructionとROUGE-Lを測った結果、大半のデータは0.3~0.4程度であり、lexicalなoverlapはあまり大きくないことがわかる。instructionのlengthについても可視化した結果、多様な長さのinstructionが収集できている。
## Quality
200種類のinstructionを抽出し、その中からそれぞれランダムで1つのインスタンスをサンプルした。そしてexpert annotatorに対して、それぞれのinstructionとinstance(input, outputそれぞれについて)が正しいか否かをラベル付けしてもらった。
ラベル付けの結果、ほとんどのinstructionは意味のあるinstructionであることがわかった。一方、生成されたinstanceはnoisyであることがわかった(ただし、このnoiseはある程度妥当な範囲である)。noisytではあるのだが、instanceを見ると、正しいformatであったり、部分的に正しかったりなど、modelを訓練する上で有用なguidanceを提供するものになっていることがわかった。
# Experimental Results
## Zero-shotでのNLPタスクに対する性能
SuperNIデータセットに含まれる119のタスク(1タスクあたり100 instance)に対して、zero-shot setupで評価を行なった。SELF-INSTRUCTによって、VanillaのGPT3から大幅に性能が向上していることがわかる。VanillaのGPT-3はほとんど人間のinstructionに応じて動いてくれないことがわかる。分析によると、GPT3は、大抵の場合、全く関係ない、あるいは繰り返しのテキストを生成していたり、そもそもいつ生成をstopするかがわかっていないことがわかった。
また、SuperNI向けにfinetuningされていないモデル間で比較した結果、非常にアノテーションコストをかけて作られたT0データでfinetuningされたモデルよりも高い性能を獲得した。また、人間がラベル付したprivateなデータによって訓練されたInstructGPT001にも性能が肉薄していることも特筆すべき点である。
SuperNIでfinetuningした場合については、SELF-INSTRUCTを使ったモデルに対して、さらに追加でSuperNIを与えた場合が最も高い性能を示した。
## User-Oriented Instructionsに対する汎化性能
SuperNIに含まれるNLPタスクは研究目的で提案されており分類問題となっている。ので、実践的な能力を証明するために、LLMが役立つドメインをブレスト(email writing, social media, productiveity tools, entertainment, programming等)し、それぞれのドメインに対して、instructionとinput-output instanceを作成した。また、instructionのスタイルにも多様性(e.g. instructionがlong/short、bullet points, table, codes, equationsをinput/outputとして持つ、など)を持たせた。作成した結果、252個のinstructionに対して、1つのinstanceのデータセットが作成された。これらが、モデルにとってunfamiliarなinstructionで多様なistructionが与えられたときに、どれだけモデルがそれらをhandleできるかを測定するテストベッドになると考えている。
これらのデータは、多様だがどれもが専門性を求められるものであり、自動評価指標で性能が測定できるものでもないし、crowdworkerが良し悪しを判定できるものでもない。このため、それぞれのinstructionに対するauthorに対して、モデルのy補足結果が妥当か否かをjudgeしてもらった。judgeは4-scaleでのratingとなっている:
- RATING-A: 応答は妥当で満足できる
- RATING-B: 応答は許容できるが、改善できるminor errorや不完全さがある。
- RATING-C: 応答はrelevantでinstructionに対して答えている。が、内容に大きなエラーがある。
- RATING-D: 応答はirrelevantで妥当ではない。
実験結果をみると、Vanilla GPT3はまったくinstructionに対して答えられていない。instruction-basedなモデルは高いパフォーマンスを発揮しているが、それらを上回る性能をSELF-INSTRUCTは発揮している(noisyであるにもかかわらず)。
また、GPT_SELF-INSTRUCTはInstructGPT001と性能が肉薄している。また、InstructGPT002, 003の素晴らしい性能を示すことにもなった。
# Discussion and Limitation
## なぜSELF-INSTRUCTがうまくいったか?
- LMに対する2つの極端な仮説を挙げている
- LM はpre-trainingでは十分に学習されなかった問題について学習する必要があるため、human feedbackはinstruction-tuningにおいて必要不可欠な側面である
- LM はpre-trainingからinstructionに既に精通しているため、human feedbackはinstruction-tuningにおいて必須ではない。 human feedbackを観察することは、pre-trainingにおける分布/目的を調整するための軽量なプロセスにすぎず、別のプロセスに置き換えることができる。
この2つの極端な仮説の間が実情であると筆者は考えていて、どちらかというと2つ目の仮説に近いだろう、と考えている。既にLMはpre-trainingの段階でinstructionについてある程度理解できているため、self-instructがうまくいったのではないかと推察している。
## Broader Impact
InstructGPTは非常に強力なモデルだけど詳細が公表されておらず、APIの裏側に隠れている。この研究が、instruct-tuned modelの背後で何が起きているかについて、透明性を高める助けになると考えている。産業で開発されたモデルの構造や、その優れた性能の理由についてはほとんど理解されておらず、これらのモデルの成功の源泉を理解し、より優れた、オープンなモデルを作成するのはアカデミックにかかっている。この研究では、多様なinstructional dataの重要性を示していると考えており、大規模な人工的なデータセットは、より優れたinstructionに従うモデルを、構築するための第一歩だと考えている。
## limitation
- Tail Phenomena
- LMの枠組みにとどまっているため、LMと同じ問題(Tail Phenomena)を抱えている
- low-frequencyなcontextに対してはうまくいかない問題
- SELF-INSTRUCTも、結局pre-trainingの段階で頻出するタスクやinstructionに対してgainがあると考えられ、一般的でなく、creativeなinstructionに対して脆弱性があると考えられる
- Dependence on laege models
- でかいモデルを扱えるだけのresourceを持っていないと使えないという問題がある
- Reinforcing LM biases
- アルゴリズムのiterationによって、問題のあるsocial _biasをより増幅してしまうことを懸念している(人種、種族などに対する偏見など)。また、アルゴリズムはバランスの取れたラベルを生成することが難しい。
1のprompt
2のprompt
3のprompt(input-first-approach)
3のprompt(output-first approach)
※ GPT3をfinetuningするのに、Instruction Dataを使った場合$338かかったっぽい。安い・・・。
LLMを使うだけでここまで研究ができる時代がきた
(最近は|現在は)プロプライエタリなLLMの出力を利用して競合するモデルを訓練することは多くの場合禁止されているので注意。
[Paper Note] bert2BERT: Towards Reusable Pretrained Language Models, Cheng Chen+, ACL'22, 2021.10
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #Pocket #NLP #LanguageModel #Transformer #Encoder #Decoder Issue Date: 2025-12-11 GPT Summary- bert2BERTは、既存の小規模事前学習モデルの知識を大規模モデルに転送し、事前学習効率を向上させる手法。二段階の事前学習を提案し、トレーニングコストを大幅に削減。BERT_BASEとGPT_BASEの事前学習で約45%および47%の計算コストを節約。
[Paper Note] Deduplicating Training Data Makes Language Models Better, Katherine Lee+, ACL'22
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Selected Papers/Blogs #Deduplication Issue Date: 2025-09-04 GPT Summary- 既存の言語モデルデータセットには重複した例が多く含まれ、訓練されたモデルの出力の1%以上が訓練データからコピーされている。これを解決するために、重複排除ツールを開発し、C4データセットからは60,000回以上繰り返される文を削除。重複を排除することで、モデルの記憶されたテキスト出力を10倍減少させ、精度を維持しつつ訓練ステップを削減。また、訓練とテストの重複を減らし、より正確な評価を実現。研究の再現とコードは公開されている。 Comment
下記スライドのp.9にまとめが記述されている:
https://speakerdeck.com/takase/snlp2023-beyond-neural-scaling-laws?slide=9
Knowledge Neurons in Pretrained Transformers, Damai Dai+, N_A, ACL'22, 2022.05
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Transformer #KnowledgeEditing #Selected Papers/Blogs #FactualKnowledge #Encoder Issue Date: 2024-07-11 GPT Summary- 大規模な事前学習言語モデルにおいて、事実知識の格納方法についての研究を行いました。具体的には、BERTのfill-in-the-blank cloze taskを用いて、関連する事実を表現するニューロンを特定しました。また、知識ニューロンの活性化と対応する事実の表現との正の相関を見つけました。さらに、ファインチューニングを行わずに、知識ニューロンを活用して特定の事実知識を編集しようと試みました。この研究は、事前学習されたTransformers内での知識の格納に関する示唆に富んでおり、コードはhttps://github.com/Hunter-DDM/knowledge-neuronsで利用可能です。 Comment
大規模言語モデルにおいて、「知識は全結合層に蓄積される」という仮説についての文献調査
日本語解説: https://speakerdeck.com/kogoro/knowledge-neurons-in-pretrained-transformers-for-snlp2022
関連:
- [Paper Note] Transformer Feed-Forward Layers Are Key-Value Memories, Mor Geva+, EMNLP'21
上記資料によると、特定の知識を出力する際に活性化する知識ニューロンを特定する手法を提案。MLMを用いたclozeタスクによる実験で[MASK]部分に当該知識を出力する実験をした結果、知識ニューロンの重みをゼロとすると性能が著しく劣化し、値を2倍にすると性能が改善するといった傾向がみられた。 ケーススタディとして、知識の更新と、知識の削除が可能かを検証。どちらとも更新・削除がされる方向性[^1]へモデルが変化した。
また、知識ニューロンはTransformerの層の深いところに位置している傾向にあり、異なるrelationを持つような関係知識同士では共有されない傾向にある模様。
[^1]: 他の知識に影響を与えず、完璧に更新・削除できたわけではない。知識の更新・削除に伴いExtrinsicな評価によって性能向上、あるいはPerplexityが増大した、といった結果からそういった方向性へモデルが変化した、という話
BRIO: Bringing Order to Abstractive Summarization, Yixin Liu+, N_A, ACL'22
Paper/Blog Link My Issue
#DocumentSummarization #BeamSearch #NaturalLanguageGeneration #Pocket #NLP Issue Date: 2023-08-16 GPT Summary- 従来の抽象的要約モデルでは、最尤推定を使用して訓練されていましたが、この方法では複数の候補要約を比較する際に性能が低下する可能性があります。そこで、非確定論的な分布を仮定し、候補要約の品質に応じて確率を割り当てる新しい訓練パラダイムを提案しました。この手法により、CNN/DailyMailとXSumのデータセットで最高の結果を達成しました。さらに、モデルが候補要約の品質とより相関のある確率を推定できることも示されました。 Comment
ビーム内のトップがROUGEを最大化しているとは限らなかったため、ROUGEが最大となるような要約を選択するようにしたら性能爆上げしましたという研究。
実質現在のSoTA
[Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12
Paper/Blog Link My Issue
#Pocket #NLP #Transformer #Attention #Distillation #Encoder #Findings #KeyPoint Notes Issue Date: 2025-10-20 GPT Summary- 自己注意関係蒸留を用いて、MiniLMの深層自己注意蒸留を一般化し、事前学習されたトランスフォーマーの圧縮を行う手法を提案。クエリ、キー、バリューのベクトル間の関係を定義し、生徒モデルを訓練。注意ヘッド数に制限がなく、教師モデルの層選択戦略を検討。実験により、BERTやRoBERTa、XLM-Rから蒸留されたモデルが最先端の性能を上回ることを示した。 Comment
教師と(より小規模な)生徒モデル間で、tokenごとのq-q/k-k/v-vのdot productによって形成されるrelation map(たとえばq-qの場合はrelatiok mapはトークン数xトークン数の行列で各要素がdot(qi, qj))で表現される関係性を再現できるようにMHAを蒸留するような手法。具体的には、教師モデルのQKVと生徒モデルのQKVによって構成されるそれぞれのrelation map間のKL Divergenceを最小化するように蒸留する。このとき教師モデルと生徒モデルのattention heads数などは異なってもよい(q-q/k-k/v-vそれぞれで定義されるrelation mapははトークン数に依存しており、head数には依存していないため)。
[Paper Note] PENS: A Dataset and Generic Framework for Personalized News Headline Generation, ACL'21
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #NLP #Dataset #LanguageModel #PersonalizedGeneration #Personalization #PersonalizedHeadlineGeneration #Surface-level Notes Issue Date: 2023-05-31 GPT Summary- この論文では、ユーザーの興味とニュース本文に基づいて、ユーザー固有のタイトルを生成するパーソナライズされたニュース見出し生成の問題を解決するためのフレームワークを提案します。また、この問題のための大規模なデータセットであるPENSを公開し、ベンチマークスコアを示します。データセットはhttps://msnews.github.io/pens.htmlで入手可能です。 Comment
# 概要
ニュース記事に対するPersonalizedなHeadlineの正解データを生成。103名のvolunteerの最低でも50件のクリックログと、200件に対する正解タイトルを生成した。正解タイトルを生成する際は、各ドキュメントごとに4名異なるユーザが正解タイトルを生成するようにした。これらを、Microsoft Newsの大規模ユーザ行動ログデータと、ニュース記事本文、タイトル、impressionログと組み合わせてPENSデータを構成した。
# データセット生成手順
103名のenglish-native [speakerの学生に対して、1000件のニュースヘッドラインの中から最低50件興味のあるヘッドラインを選択してもらう。続いて、200件のニュース記事に対して、正解ヘッドラインを生成したもらうことでデータを生成した。正解ヘッドラインを生成する際は、同一のニュースに対して4人がヘッドラインを生成するように調整した。生成されたヘッドラインは専門家によってqualityをチェックされ、factual informationにエラーがあるものや、極端に長い・短いものなどは除外された。
# データセット統計量
# 手法概要
Transformer Encoder + Pointer GeneratorによってPersonalizedなヘッドラインを生成する。
Transformer Encoderでは、ニュースの本文情報をエンコードし、attention distributionを生成する。Decoder側では、User Embeddingを組み合わせて、テキストをPointer Generatorの枠組みでデコーディングしていき、ヘッドラインを生成する。
User Embeddingをどのようにinjectするかで、3種類の方法を提案しており、1つ目は、Decoderの初期状態に設定する方法、2つ目は、ニュース本文のattention distributionの計算に利用する方法、3つ目はデコーディング時に、ソースからvocabをコピーするか、生成するかを選択する際に利用する方法。1つ目は一番シンプルな方法、2つ目は、ユーザによって記事で着目する部分が違うからattention distributionも変えましょう、そしてこれを変えたらcontext vectorも変わるからデコーディング時の挙動も変わるよねというモチベーション、3つ目は、選択するvocabを嗜好に合わせて変えましょう、という方向性だと思われる。最終的に、2つ目の方法が最も性能が良いことが示された。
# 訓練手法
まずニュース記事推薦システムを訓練し、user embeddingを取得できるようにする。続いて、genericなheadline generationモデルを訓練する。最後に両者を組み合わせて、Reinforcement LearningでPersonalized Headeline Generationモデルを訓練する。Rewardとして、
1. Personalization: ヘッドラインとuser embeddingのdot productで報酬とする
2. Fluency: two-layer LSTMを訓練し、生成されたヘッドラインのprobabilityを推定することで報酬とする
3. Factual Consistency: 生成されたヘッドラインと本文の各文とのROUGEを測りtop-3 scoreの平均を報酬とする
とした。
1,2,3の平均を最終的なRewardとする。
# 実験結果
Genericな手法と比較して、全てPersonalizedな手法が良かった。また、手法としては②のattention distributionに対してuser informationを注入する方法が良かった。News Recommendationの性能が高いほど、生成されるヘッドラインの性能も良かった。
# Case Study
ある記事に対するヘッドラインの一覧。Pointer-Genでは、重要な情報が抜け落ちてしまっているが、提案手法では抜け落ちていない。これはRLの報酬のfluencyによるものだと考えられる。また、異なるユーザには異なるヘッドラインが生成されていることが分かる。
[Paper Note] Biomedical Data-to-Text Generation via Fine-Tuning Transformers, Ruslan Yermakov+, ACL-INLG'21, 2021.09
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #Dataset #DataToTextGeneration #INLG Issue Date: 2022-08-18 GPT Summary- バイオメディカル分野におけるD2T生成の研究を行い、医薬品のパッケージリーフレットを用いた実世界のデータセットに対してファインチューニングされたトランスフォーマーを適用。現実的な複数文のテキスト生成が可能であることを示す一方で、重要な制限も存在。新たにバイオメディカル分野のD2T生成モデルのベンチマーク用データセット(BioLeaflets)を公開。 Comment
biomedical domainの新たなdata2textデータセットを提供。事前学習済みのBART, T5等をfinetuningすることで高精度にテキストが生成できることを示した。
[Paper Note] Prefix-Tuning: Optimizing Continuous Prompts for Generation, Xiang Lisa Li+, arXiv'21, 2021.01
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs Issue Date: 2021-09-09 GPT Summary- プレフィックスチューニングは、ファインチューニングの軽量な代替手段であり、言語モデルのパラメータを固定しつつ、タスク特有の小さなベクトルを最適化する手法です。これにより、少ないパラメータで同等のパフォーマンスを達成し、低データ設定でもファインチューニングを上回る結果を示しました。 Comment
言語モデルをfine-tuningする際,エンコード時に「接頭辞」を潜在表現として与え,「接頭辞」部分のみをfine-tuningすることで(他パラメータは固定),より少量のパラメータでfine-tuningを実現する方法を提案.接頭辞を潜在表現で与えるこの方法は,GPT-3のpromptingに着想を得ている.fine-tuningされた接頭辞の潜在表現のみを配布すれば良いので,非常に少量なパラメータでfine-tuningができる.
table-to-text, summarizationタスクで,一般的なfine-tuningやAdapter(レイヤーの間にアダプターを挿入しそのパラメータだけをチューニングする手法)といった効率的なfine-tuning手法と比較.table-to-textでは、250k (元のモデルの 0.1%) ほどの数のパラメータを微調整するだけで、全パラメータをfine-tuningするのに匹敵もしくはそれ以上の性能を達成.
Hugging Faceの実装を利用したと論文中では記載されているが,fine-tuningする前の元の言語モデル(GPT-2)はどのように準備したのだろうか.Hugging Faceのpretrained済みのGPT-2を使用したのだろうか.
autoregressive LM (GPT-2)と,encoder-decoderモデル(BART)へPrefix Tuningを適用する場合の模式図
[Paper Note] On Faithfulness and Factuality in Abstractive Summarization, Joshua Maynez+, ACL'20
Paper/Blog Link My Issue
#DocumentSummarization #Pocket #NLP #Abstractive #Factuality #Faithfulness Issue Date: 2025-07-14 GPT Summary- 抽象的な文書要約における言語モデルの限界を分析し、これらのモデルが入力文書に対して忠実でない内容を生成する傾向が高いことを発見。大規模な人間評価を通じて、生成される幻覚の種類を理解し、すべてのモデルで相当量の幻覚が確認された。事前学習されたモデルはROUGE指標だけでなく、人間評価でも優れた要約を生成することが示された。また、テキストの含意測定が忠実性と良好に相関することが明らかになり、自動評価指標の改善の可能性を示唆。 Comment
文書要約の文脈において `hallucination` について説明されている。
- [Paper Note] Chain-of-Verification Reduces Hallucination in Large Language Models, Shehzaad Dhuliawala+, N/A, ACL'24
が `hallucination` について言及する際に引用している。
[Paper Note] Unsupervised Opinion Summarization as Copycat-Review Generation, Arthur Bražinskas+, ACL'20, 2019.11
Paper/Blog Link My Issue
#Pocket #NLP #ReviewGeneration Issue Date: 2021-03-17 GPT Summary- 意見要約は、製品レビューから主観的情報を自動的に要約するタスクであり、従来の研究は抽出的手法に焦点を当てていたが、本研究では新しい文を生成する抽象的要約を提案。教師なし設定での生成モデルを定義し、新規性を制御しながら合意された意見を反映する要約を生成する。階層的変分オートエンコーダモデルを用い、レビュー生成器が入力レビューにアクセス可能。実験により、一般的な意見を反映した流暢で一貫性のある要約が生成できることを示した。
[Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #Transformer #Attention #LongSequence #PositionalEncoding Issue Date: 2025-08-05 GPT Summary- Transformer-XLは、固定長のコンテキストを超えた長期的な依存関係を学習する新しいニューラルアーキテクチャで、セグメントレベルの再帰メカニズムと新しい位置エンコーディングを採用。これにより、RNNより80%、従来のTransformersより450%長い依存関係を学習し、評価時には最大1,800倍の速度向上を実現。enwiki8やWikiText-103などで最先端のパフォーマンスを達成し、数千トークンの一貫したテキスト生成も可能。コードとモデルはTensorflowとPyTorchで利用可能。 Comment
日本語解説:
- 事前学習言語モデルの動向 / Survey of Pretrained Language Models, Kyosuke Nishida, 2019
3.2節の定式化を見ると、一つ前のセグメントのトークン・layerごとのhidden stateを、現在のセグメントの対応するトークンとlayerのhidden stateにconcatし(過去のセグメントに影響を与えないように勾配を伝搬させないStop-Gradientを適用する)、QKVのうち、KVの計算に活用している。また、絶対位置エンコーディングを利用するとモデルがセグメント間の時系列的な関係を認識できなくなるため、位置エンコーディングには相対位置エンコーディングを利用する。これにより、現在のセグメントのKVが一つ前のセグメントによって条件づけられ、contextとして考慮することが可能となり、セグメント間を跨いだ依存関係の考慮が実現される。
[Paper Note] Automatic Generation of Personalized Comment Based on User Profile, Wenhuan Zeng+, ACL'19 SRW
Paper/Blog Link My Issue
#Pocket #NLP #CommentGeneration #Personalization #Workshop Issue Date: 2019-09-11 GPT Summary- ソーシャルメディアの多様なコメント生成の難しさを考慮し、ユーザーのプロフィールに基づくパーソナライズされたコメント生成タスク(AGPC)を提案。パーソナライズドコメント生成ネットワーク(PCGN)を用いて、ユーザーの特徴をモデル化し、外部ユーザー表現を考慮することで自然で人間らしいコメントを生成することに成功した。
[Paper Note] Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model, Wei Li+, arXiv'19
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #CommentGeneration Issue Date: 2019-08-24 GPT Summary- 自動記事コメント生成のために、ニュースをトピック相互作用グラフとしてモデル化し、グラフからシーケンスへのモデルを提案。これにより、記事の構造やトピックの関連性を理解し、より一貫性のある情報量の多いコメントを生成。Tencent Kuaibaoから収集した大規模なニュース-コメントコーパスを用いた実験で、提案モデルが強力なベースラインを上回る性能を示した。
[Paper Note] Automatic Generation of Personalized Comment Based on User Profile, Wenhuan Zeng+, ACL'19 SRW
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #ReviewGeneration #Workshop Issue Date: 2019-08-17 GPT Summary- ソーシャルメディアの多様なコメント生成の難しさを考慮し、ユーザープロフィールに基づくパーソナライズされたコメント生成タスク(AGPC)を提案。パーソナライズドコメント生成ネットワーク(PCGN)を用いて、ユーザーの特徴をモデル化し、外部ユーザー表現を考慮することで自然なコメントを生成。実験結果は、モデルの効果を示す。
[Paper Note] Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates, Taku Kudo, ACL'18, 2018.04
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #Pocket #Subword #Tokenizer #read-later #Selected Papers/Blogs Issue Date: 2025-11-19 GPT Summary- サブワード単位はNMTのオープンボキャブラリー問題を軽減するが、セグメンテーションの曖昧さが存在する。本研究では、この曖昧さを利用してNMTのロバスト性を向上させるため、サブワードの正則化手法を提案し、確率的にサンプリングされた複数のセグメンテーションでモデルを訓練する。また、ユニグラム言語モデルに基づく新しいセグメンテーションアルゴリズムも提案。実験により、特にリソースが限られた設定での改善を示した。
Learning to Generate Move-by-Move Commentary for Chess Games from Large-Scale Social Forum Data, Jhamtani+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #Dataset #DataToTextGeneration #TabularData #Encoder-Decoder Issue Date: 2025-08-06 Comment
データセットの日本語解説(過去の自分の資料): https://speakerdeck.com/akihikowatanabe/data-to-text-datasetmatome-summary-of-data-to-text-datasets?slide=66
[Paper Note] Personalized Review Generation by Expanding Phrases and Attending on Aspect-Aware Representations, Ni+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #NLP #ReviewGeneration Issue Date: 2019-04-12 Comment

Personalized Review Generationタスクを、user, item, short phraseがgivenな時に、それを考慮して完全なレビューを生成するタスクとして定義。
short phraseとしては、item titleやreview summaryなどを利用している。
アイテムのaspectを考慮してレビューを生成できる点が新しい。
モデルとしては、aspect-awareなrepresentationを学習することによって、ユーザ・アイテムのaspectに関する嗜好(e.g. どの部分について言及したいか、など)を捉えたレビューを生成できるようにしている。
各aspectには代表的な単語が紐づいており、aspectに紐づく単語の生成確率をaspect-aware representationから求めたattentionによって制御し、生成時に下駄を履かせている。
PyTorch実装: https://github.com/nijianmo/textExpansion/tree/master/expansionNet
[Paper Note] Personalized Review Generation by Expanding Phrases and Attending on Aspect-Aware Representations, Ni+, ACL'18
Paper/Blog Link My Issue
#Pocket #NLP #ReviewGeneration #Personalization Issue Date: 2018-07-25
[Paper Note] Personalizing Dialogue Agents: I have a dog, do you have pets too?, Saizheng Zhang+, ACL'18
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #DialogueGeneration Issue Date: 2018-02-08 GPT Summary- プロフィール情報を基にchit-chatを魅力的にするタスクを提案。モデルはプロフィールに基づく条件付けと相手の情報を考慮し、次の発話を予測することで対話を改善。対話者のプロフィール情報を予測するために、個人的な話題で引き込むように訓練された。
[Paper Note] Learning to Generate Market Comments from Stock Prices, Murakami+, ACL'17
Paper/Blog Link My Issue
#NLP #DataToTextGeneration #NumericReasoning #Financial #numeric #Encoder-Decoder Issue Date: 2025-11-27 GPT Summary- 株価から市場コメントを生成する新しいエンコーダ-デコーダモデルを提案。モデルは短期・長期の株価変化をエンコードし、適切な算術演算を選択して数値を生成。実験により、最良モデルが人間の生成したテキストに近い流暢さと情報量を持つことが確認された。
[Paper Note] Coarse-to-Fine Attention Models for Document Summarization, Ling+, ACL'17 Workshop on New Frontiers in Summarization, 2017.09
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #Document #Supervised #Pocket #NLP Issue Date: 2018-01-01 GPT Summary- 粗から細への注意モデルを提案し、文書要約における長いソースシーケンスの処理を効率化。上位テキストチャンクを粗い注意で選択し、選ばれたチャンクの単語に細かい注意を適用。計算は上位チャンクの数に応じてスケールし、長いシーケンスに対応可能。実験結果では最先端のベースラインには及ばないが、文書のサブセットに対してまばらに注意を向ける効果を確認。
[Paper Note] Get To The Point: Summarization with Pointer-Generator Networks, Abigail See+, arXiv'17, 2017.04
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #Pocket #NLP #Abstractive #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 GPT Summary- ニューラルシーケンス・ツー・シーケンスモデルは抽象的なテキスト要約に新たなアプローチを提供するが、事実の不正確な再現と自己繰り返しの問題がある。本研究では、ハイブリッドポインタージェネレーターネットワークを用いて情報の正確な再現を促進し、カバレッジを利用して繰り返しを抑制する新しいアーキテクチャを提案。CNN/Daily Mail要約タスクで、最先端技術を2 ROUGEポイント上回る結果を得た。 Comment
単語の生成と単語のコピーの両方を行えるハイブリッドなニューラル文書要約モデルを提案。
同じ単語の繰り返し現象(repetition)をなくすために、Coverage Mechanismも導入した。
[Paper Note] Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16
などと比較するとシンプルなモデル。
一般的に、PointerGeneratorと呼ばれる。
OpenNMTなどにも実装されている:
https://opennmt.net/OpenNMT-py/_modules/onmt/modules/copy_generator.html
(参考)Pointer Generator Networksで要約してみる:
https://qiita.com/knok/items/9a74430b279e522d5b93
[Paper Note] Multi-Task Video Captioning with Video and Entailment Generation, Ramakanth Pasunuru+, ACL'17, 2017.04
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #NaturalLanguageGeneration #Pocket #NLP #MultitaskLearning #Encoder-Decoder #4D (Video) #One-Line Notes #VideoCaptioning Issue Date: 2017-12-31 GPT Summary- ビデオキャプショニングの改善のため、教師なしビデオ予測タスクと論理的言語含意生成タスクを共有し、リッチなビデオエンコーダ表現を学習。パラメータを共有するマルチタスク学習モデルを提案し、標準データセットで大幅な改善を達成。 Comment
multitask learningで動画(かなり短め)のキャプション生成を行なった話
[Paper Note] Learning to Skim Text, Adams Wei Yu+, ACL'17, 2017.04
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #Pocket #NLP #ReinforcementLearning #Decoder #KeyPoint Notes #Sparse Issue Date: 2017-12-31 GPT Summary- 再帰型ニューラルネットワーク(RNN)は自然言語処理での可能性を示すが、長文の処理が遅い。本論文では、無関係な情報をスキップしながらテキストを読むアプローチを提案。モデルは、入力テキストの数語を読んだ後にジャンプする距離を学習し、ポリシー勾配法で訓練。数値予測や自動Q&Aなど4つのタスクで、提案モデルは標準LSTMに比べて最大6倍の速度向上を達成し、精度も維持。 Comment
解説スライド:
http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/07.pdf
Reinforceにおける勾配の更新式の導出が丁寧に記述されており大変ありがたい。
RNNにおいて重要な部分以外は読み飛ばすことで効率を向上させる研究。いくつ読み飛ばすかも潜在変数として一緒に学習する。潜在変数(離散変数)なので、普通に尤度最大化するやり方では学習できず、おまけに離散変数なのでバックプロパゲーション使えないので、強化学習で学習する。
Vanilla LSTMと比較し、色々なタスクで実験した結果、性能も(少し)上がるし、スピードアップもする。
うーんこの研究は今改めて見返すと非常に面白いな…(8年も経ったのか)。ざっくり言うと必要のない部分は読み飛ばして考慮しないという話であり、最近のLLMでもこういった話はよくやられている印象。一番近いのはSparse Attentionだろうか。
- [Paper Note] Efficient Transformers: A Survey, Yi Tay+, ACM Computing Surveys'22, 2022.12
- [Paper Note] Big Bird: Transformers for Longer Sequences, Manzil Zaheer+, NIPS'20, 2020.07
- [Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20
- [Paper Note] Generating Long Sequences with Sparse Transformers, Rewon Child+, arXiv'19, 2019.04
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
トークン単位などはなくlayerをスキップするとかもある(Layer Skip)。
- [Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25
[Paper Note] Skip-Gram – Zipf + Uniform = Vector Additivity, Gittens+, ACL'17
Paper/Blog Link My Issue
#NeuralNetwork #Embeddings #Analysis #NLP #Word #One-Line Notes Issue Date: 2017-12-30 Comment
解説スライド: http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/09.pdf
Embeddingの加法構成性(e.g. man+royal=king)を理論的に理由づけ
(解説スライドより)
[Paper Note] What do Neural Machine Translation Models Learn about Morphology?, Yonatan Belinkov+, ACL'17
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #Pocket #NLP Issue Date: 2017-12-28 Comment
日本語解説: http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/06.pdf
[Paper Note] Sequence-to-Dependency Neural Machine Translation, Wu+, ACL'17
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #NLP Issue Date: 2017-12-28 GPT Summary- 新しいシーケンスから依存関係へのニューラル機械翻訳(SD-NMT)手法を提案。ターゲット単語のシーケンスと依存関係構造を共同で構築し、文脈として利用することで翻訳精度を向上。実験により、中国語-英語および日本語-英語の翻訳タスクで最先端のベースラインを大幅に上回る結果を示した。
[Paper Note] Joint Optimization of User-desired Content in Multi-document Summaries by Learning from User Feedback, P.V.S+, ACL'17, 2017.08
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #IntegerLinearProgramming (ILP) #Personalization #interactive #In-Depth Notes Issue Date: 2017-12-28 GPT Summary- ユーザーフィードバックを活用した抽出的マルチドキュメント要約システムを提案。インタラクティブにフィードバックを取得し、ILPフレームワークを用いて要約の質を向上。最小限の反復で高品質な要約を生成し、シミュレーション実験で効果を分析。 Comment
# 一言で言うと
ユーザとインタラクションしながら重要なコンセプトを決め、そのコンセプトが含まれるようにILPな手法で要約を生成するPDS手法。Interactive Personalized Summarizationと似ている(似ているが引用していない、引用した方がよいのでは)。
# 手法
要約モデルは既存のMDS手法を採用。Concept-based ILP Summarization
フィードバックをユーザからもらう際は、要約を生成し、それをユーザに提示。提示した要約から重要なコンセプトをユーザに選択してもらう形式(ユーザが重要と判断したコンセプトには定数重みが与えられる)。
ユーザに対して、τ回フィードバックをもらうまでは、フィードバックをもらっていないコンセプトの重要度が高くなるようにし、フィードバックをもらったコンセプトの重要度が低くなるように目的関数を調整する。これにより、まだフィードバックを受けていないコンセプトが多く含まれる要約が生成されるため、これをユーザに提示することでユーザのフィードバックを得る。τ回を超えたら、ユーザのフィードバックから決まったweightが最大となるように目的関数を修正する。
ユーザからコンセプトのフィードバックを受ける際は、効率的にフィードバックを受けられると良い(最小のインタラクションで)。そこで、Active Learningを導入する。コンセプトの重要度の不確実性をSVMで判定し、不確実性が高いコンセプトを優先的に含むように目的関数を修正する手法(AL)、SVMで重要度が高いと推定されたコンセプトを優先的に要約に含むように目的関数を修正する手法(AL+)を提案している。
# 評価
oracle-based approachというものを使っている。要は、要約をシステムが提示しリファレンスと被っているコンセプトはユーザから重要だとフィードバックがあったコンセプトだとみなすというもの。
評価結果を見ると、ベースラインのMDSと比べてupper bound近くまでROUGEスコアが上がっている。フィードバックをもらうためのイテレーションは最大で10回に絞っている模様(これ以上ユーザとインタラクションするのは非現実的)。
実際にユーザがシステムを使用する場合のコンテキストに沿った評価になっていないと思う。
この評価で示せているのは、ReferenceSummary中に含まれる単語にバイアスをかけて要約を生成していくと、ReferenceSummaryと同様な要約が最終的に作れます、ということと、このときPool-basedなActiveLearningを使うと、より少ないインタラクションでこれが実現できますということ。
これを示すのは別に良いと思うのだが、feedbackをReferenceSummaryから与えるのは少し現実から離れすぎている気が。たとえばユーザが新しいことを学ぶときは、ある時は一つのことを深堀し、そこからさらに浅いところに戻って別のところを深堀するみたいなプロセスをする気がするが、この深堀フェーズなどはReferenceSummaryからのフィードバックからでは再現できないのでは。
# 所感
評価が甘いと感じる。十分なサイズのサンプルを得るのは厳しいからorable-based approachとりましたと書いてあるが、なんらかの人手評価もあったほうが良いと思う。
ユーザに数百単語ものフィードバックをもらうというのはあまり現時的ではない気が。
oracle-based approachでユーザのフィードバックをシミュレーションしているが、oracleの要約は、人がそのドキュメントクラスタの内容を完璧に理解した上で要約しているものなので、これを評価に使うのも実際のコンテキストと違うと思う。実際にユーザがシステムを使うときは、ドキュメントクラスタの内容なんてなんも知らないわけで、そのユーザからもらえるフィードバックをoracle-based approachでシミュレーションするのは無理がある。仮に、ドキュメントクラスタの内容を完璧に理解しているユーザのフィードバックをシミュレーションするというのなら、わかる。が、そういうユーザのために要約作って提示したいわけではないはず。
[Paper Note] News Citation Recommendation with Implicit and Explicit Semantics, Peng+, ACL'16
Paper/Blog Link My Issue
#RecommenderSystems #Citations #LearningToRank #KeyPoint Notes Issue Date: 2018-01-01 Comment
target text中に記述されているイベントや意見に対して、それらをサポートするような他のニュース記事を推薦する研究。
たとえば、target text中に「北朝鮮が先日ミサイルの発射に失敗したが...」、といった記述があったときに、このイベントについて報道しているニュース記事を推薦するといったことを、target text中の様々なcontextに対して行う。
このようなシステムの利用により、target textの著者の執筆支援(自身の主張をサポートするためのreferenceの自動獲得)や、target textの読者の読解支援(text中の記述について詳細な情報を知りたい場合に、検索の手間が省ける)などの利点があると主張。
タスクとしては、target text中のあるcontextと、推薦の候補となるニュース記事の集合が与えられたときに、ニュース記事をre-rankingする タスク。
提案手法はシンプルで、contextとニュース記事間で、様々な指標を用いてsimilarityを測り、それらをlearning-to-rankで学習した重みで組み合わせてre-rankingを行うだけ。 similarityを測る際は、表記揺れや曖昧性の問題に対処するためにEmbeddingを用いる手法と、groundingされたentityの情報を用いる手法を提案。
Bing news中のAnchor textと、hyperlink先のニュース記事の対から、contextと正解ニュース記事の対を取得し、30000件規模の実験データを作成し、評価。その結果、baselineよりも提案手法の性能が高いことを示した。
[Paper Note] Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 Comment
単語のコピーと生成、両方を行えるネットワークを提案。
location based addressingなどによって、生成された単語がsourceに含まれていた場合などに、copy-mode, generate-modeを切り替えるような仕組みになっている。
[Paper Note] Pointing the Unknown Words, Caglar Gulcehre+, ACL'16, 2016.03
と同じタイミングで発表
[Paper Note] Neural Summarization by Extracting Sentences and Words, Cheng+, ACL'16
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Extractive #One-Line Notes Issue Date: 2017-12-31 Comment
ExtractiveかつNeuralな単一文書要約ならベースラインとして使用した方がよいかも
[Paper Note] Larger-context language modelling with recurrent neural networks, Wang+, ACL'16
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #NLP #LanguageModel #Surface-level Notes Issue Date: 2017-12-28 Comment
## 概要
通常のNeural Language Modelはsentence間に独立性の仮定を置きモデル化されているが、この独立性を排除し、preceding sentencesに依存するようにモデル化することで、言語モデルのコーパスレベルでのPerplexityが改善したという話。提案した言語モデルは、contextを考慮することで特に名詞や動詞、形容詞の予測性能が向上。Late-Fusion methodと呼ばれるRNNのoutputの計算にcontext vectorを組み込む手法が、Perplexityの改善にもっとも寄与していた。
## 手法
sentence間の独立性を排除し、Corpusレベルのprobabilityを下図のように定義。(普通はP(Slが条件付けされていない))
preceding sentence (context)をモデル化するために、3種類の手法を提案。
[1. bag-of-words context]
ナイーブに、contextに現れた単語の(単一の)bag-of-wordsベクトルを作り、linear layerをかませてcontext vectorを生成する手法。
[2. context recurrent neural network]
preceding sentencesをbag-of-wordsベクトルの系列で表現し、これらのベクトルをsequentialにRNN-LSTMに読み込ませ、最後のhidden stateをcontext vectorとする手法。これにより、sentenceが出現した順番が考慮される。
[3. attention based context representation]
Attentionを用いる手法も提案されており、context recurrent neural networkと同様にRNNにbag-of-wordsのsequenceを食わせるが、各時点におけるcontext sentenceのベクトルを、bi-directionalなRNNのforward, backward stateをconcatしたもので表現し、attention weightの計算に用いる。context vectorは1, 2ではcurrent sentence中では共通のものを用いるが、attention basedな場合はcurrent sentenceの単語ごとに異なるcontext vectorを生成して用いる。
生成したcontext vectorをsentence-levelのRNN言語モデルに組み合わせる際に、二種類のFusion Methodを提案している。
[1. Early Fusion]
ナイーブに、RNNLMの各時点でのinputにcontext vectorの情報を組み込む方法。
[2. Late Fusion]
よりうまくcontext vectorの情報を組み込むために、current sentence内の単語のdependency(intra-sentence dependency)と、current sentenceとcontextの関係を別々に考慮する。context vectorとmemory cellの情報から、context vector中の不要箇所をフィルタリングしたcontrolled context vectorを生成し、LSTMのoutputの計算に用いる。Later Fusionはシンプルだが、corpusレベルのlanguage modelingの勾配消失問題を緩和することもできる。
## 評価
IMDB, BBC, PennTreebank, Fil9 (cleaned wikipedia corpus)の4種類のデータで学習し、corpus levelでPerplexityを測った。
Late FusionがPerplexityの減少に大きく寄与している。
PoSタグごとのperplexityを測った結果、contextを考慮した場合に名詞や形容詞、動詞のPerplexityに改善が見られた。一方、Coordinate Conjungtion (And, Or, So, Forなど)や限定詞、Personal Pronouns (I, You, It, Heなど)のPerplexityは劣化した。前者はopen-classな内容語であり、後者はclosed-classな機能語である。機能語はgrammaticalなroleを決めるのに対し、内容語はその名の通り、sentenceやdiscourseの内容を決めるものなので、文書の内容をより捉えることができると考察している。
[Paper Note] Pointing the Unknown Words, Caglar Gulcehre+, ACL'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #Pocket #NLP #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-28 GPT Summary- 希少および未知の単語に対処するため、注意機構を用いた新しいニューラルネットワークモデルを提案。2つのソフトマックス層を使用し、文脈に基づいて適応的に選択。提案モデルは、翻訳と要約タスクで性能向上を示した。 Comment
テキストを生成する際に、source textからのコピーを行える機構を導入することで未知語問題に対処した話
CopyNetと同じタイミングで(というか同じconferenceで)発表
[Paper Note] Unsupervised prediction of acceptability judgements, Lau+, ACL-IJCNLP'15
Paper/Blog Link My Issue
#NLP #LanguageModel #IJCNLP #Selected Papers/Blogs Issue Date: 2018-03-30 Comment
文のacceptability(容認度)論文。
文のacceptabilityとは、native speakerがある文を読んだときに、その文を正しい文として容認できる度合いのこと。
acceptabilityスコアが低いと、Readabilityが低いと判断できる。
言語モデルをトレーニングし、トレーニングした言語モデルに様々な正規化を施すことで、acceptabilityスコアを算出する。
[Paper Note] Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks, Tai+, ACL'15
Paper/Blog Link My Issue
#NeuralNetwork #NLP #Selected Papers/Blogs Issue Date: 2018-02-13 Comment
Tree-LSTM論文
[Paper Note] A hierarchical neural autoencoder for paragraphs and documents, Li+, ACL'15
Paper/Blog Link My Issue
#NeuralNetwork #Document #Embeddings #NLP #RepresentationLearning #KeyPoint Notes Issue Date: 2017-12-28 Comment
複数文を生成(今回はautoencoder)するために、standardなseq2seq LSTM modelを、拡張したという話。
要は、paragraph/documentのrepresentationが欲しいのだが、アイデアとしては、word-levelの情報を扱うLSTM layerとsentenc-levelの情報を扱うLSTM layerを用意し、それらのcompositionによって、paragraph/documentを表現しましたという話。
sentence-levelのattentionを入れたらよくなっている。
trip advisorのreviewとwikipediaのparagraphを使ってtrainingして、どれだけ文書を再構築できるか実験。
MetricはROUGE, BLEUおよびcoherence(sentence order代替)を測るために、各sentence間のgapがinputとoutputでどれだけ一致しているかで評価。
hierarchical lstm with attention > hierarchical lstm > standard lstm の順番で高性能。
学習には、tesla K40を積んだマシンで、standard modelが2-3 weeks, hierarchical modelsが4-6週間かかるらしい。
[Paper Note] Comparing Multi-label Classification with Reinforcement Learning for Summarization of Time-series Data, Gkatzia+, ACL'14
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Others #NLP #DataToTextGeneration Issue Date: 2017-12-31
[Paper Note] Hierarchical Summarization: Scaling Up Multi-Document Summarization, Christensen+, ACL'14
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NLP #Extractive #Selected Papers/Blogs #interactive #KeyPoint Notes #Hierarchical Issue Date: 2017-12-28 Comment
## 概要
だいぶ前に読んだ。好きな研究。
テキストのsentenceを階層的にクラスタリングすることで、抽象度が高い情報から、関連する具体度の高いsentenceにdrill downしていけるInteractiveな要約を提案している。
## 手法
通常のMDSでのデータセットの規模よりも、実際にMDSを使う際にはさらに大きな規模のデータを扱わなければならないことを指摘し(たとえばNew York Timesで特定のワードでイベントを検索すると数千、数万件の記事がヒットしたりする)そのために必要な事項を検討。
これを実現するために、階層的なクラスタリングベースのアプローチを提案。
提案手法では、テキストのsentenceを階層的にクラスタリングし、下位の層に行くほどより具体的な情報になるようにsentenceを表現。さらに、上位、下位のsentence間にはエッジが張られており、下位に紐付けられたsentence
は上位に紐付けられたsentenceの情報をより具体的に述べたものとなっている。
これを活用することで、drill down型のInteractiveな要約を実現。
[Paper Note] Query-Chain Focused Summarization, Baumel+, ACL'14
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NLP #Dataset #QueryBiased #Extractive #Selected Papers/Blogs #Surface-level Notes Issue Date: 2017-12-28 Comment
(管理人が作成した過去の紹介資料)
[Query-Chain Focused Summarization.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1590916/Query-Chain.Focused.Summarization.pdf)
上記スライドは私が当時作成した論文紹介スライドです。スライド中のスクショは説明のために論文中のものを引用しています。
[Paper Note] Learning semantic correspondences with less supervision, Liang+, ACL-IJCNLP'09
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Others #NLP #ConceptToTextGeneration #IJCNLP Issue Date: 2017-12-31
[Paper Note] Frustratingly easy domain adaptation, Daum'e, ACL'07
Paper/Blog Link My Issue
#MachineLearning #DomainAdaptation #NLP #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 Comment

domain adaptationをする際に、Source側のFeatureとTarget側のFeatureを上式のように、Feature Vectorを拡張し独立にコピーし表現するだけで、お手軽にdomain adaptationができることを示した論文。
イメージ的には、SourceとTarget、両方に存在する特徴は、共通部分の重みが高くなり、Source, Targetドメイン固有の特徴は、それぞれ拡張した部分のFeatureに重みが入るような感じ。
[Paper Note] Design of a knowledge-based report generator, Kukich, ACL'83
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP #DataToTextGeneration #KeyPoint Notes Issue Date: 2017-12-31 Comment
## タスク
numerical stock market dataからstock market reportsを生成.システム名: ANA
## 手法概要
ルールベースな手法,
1) fact-generator,
2) message generator,
3) discourse organizer,
4) text generatorの4コンポーネントから成る.
2), 3), 4)はそれぞれ120, 16, 109個のルールがある. 4)ではphrasal dictionaryも使う.
1)では,入力されたpriceデータから,closing averageを求めるなどの数値的な演算などを行う.
2)では,1)で計算された情報に基づいて,メッセージの生成を行う(e.g. market was mixed).
3)では,メッセージのparagraph化,orderの決定,priorityの設定などを行う.
4)では,辞書からフレーズを選択したり,適切なsyntactic formを決定するなどしてテキストを生成.
Data2Textの先駆け論文。引用すべし。多くの研究で引用されている。
ACL2025@ウィーン 参加報告, shirotaro, 2025.10
Paper/Blog Link My Issue
#Article #Tutorial #NLP #Blog Issue Date: 2025-11-15
Synthetic Data in the Era of LLMs, Tutorial at ACL 2025
Paper/Blog Link My Issue
#Article #Tutorial #LanguageModel #SyntheticData #Slide #Selected Papers/Blogs Issue Date: 2025-08-06 Comment
元ポスト:
ACL 2024 参加報告, 張+, 株式会社サイバーエージェント AI Lab, 2024.08
Paper/Blog Link My Issue
#Article #Tutorial #Slide Issue Date: 2025-05-11 Comment
業界のトレンドを把握するのに非常に参考になる:
- Reasoning, KnowledgeGraph, KnowledgeEditing, Distillation
- PEFT, Bias, Fairness, Ethics
- Multimodal(QA, Benchmarking, Summarization)
などなど。
投稿数5000件は多いなあ…
[Paper Note] ArgU: A Controllable Factual Argument Generator, Sougata Saha+, ACL23, 2023.05
Paper/Blog Link My Issue
#Article #NaturalLanguageGeneration #Controllable #Pocket #NLP #Argument Issue Date: 2023-07-18 GPT Summary- 効果的な論証の自動生成は難しいが、Waltonの論証スキームに基づく制御コードを用いたArgUを提案。69,428の論証からなる注釈付きコーパスを公開し、多様な論証を生成可能であることを実験で示した。
FastSeq: Make Sequence Generation Faster, Yan+, ACL’21
Paper/Blog Link My Issue
#Article #NeuralNetwork #EfficiencyImprovement #NLP #Transformer Issue Date: 2021-06-10 Comment
BART, DistilBART, T5, GPT2等のさまざまなTransformer-basedな手法で、4-9倍Inference speedを向上させる手法を提案。
Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL’16
Paper/Blog Link My Issue
#Article #DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #NLP Issue Date: 2021-06-03 Comment
Pointing the Unknown Words, Gulcehre+, ACL’16
と同様コピーメカニズムを提案した論文。Joint Copy ModelやCOPYNETと呼ばれる。
次の単語が "生成" されるのか "コピー" されるのかをスコアリングし、各単語がコピーされる確率と生成される確率をMixtureした同時確率分布で表現する( [Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07
等でも説明されている)。
コピーメカニズムを導入せるなら引用すべき。
## コピーメカニズム部分の説明


解説資料: http://www.lr.pi.titech.ac.jp/~sasano/acl2016suzukake/slides/08.pdf
Pointing the Unknown Words, Gulcehre+, ACL’16
Paper/Blog Link My Issue
#Article #DocumentSummarization #NeuralNetwork #NaturalLanguageGeneration #NLP Issue Date: 2021-06-02 Comment
Conditional Copy Model (Pointer Softmax)を提案した論文。
単語を生成する際に、語彙内の単語から生成する分布、原文の単語から生成する分布を求める。後者はattention distributionから。コピーするか否かを決める確率変数を導入し(sigmoid)、両生成確率を重み付けする。
コピーメカニズム入れるなら引用すべき。
解説スライド: https://www.slideshare.net/hytae/pointing-the-unknown-words
[Paper Note] Automatic Text Summarization based on the Global Document Annotation, Nagao+, COLING-ACL;98, 1998.08
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #COLING #KeyPoint Notes Issue Date: 2017-12-28 Comment
Personalized summarizationの評価はしていない。提案のみ。以下の3種類の手法を提案
- keyword-based customization
- 関心のあるキーワードをユーザが入力し、コーパスやwordnet等の共起関係から関連語を取得し要約に利用する
- 文書の要素をinteractiveに選択することによる手法
- 文書中の関心のある要素(e.g. 単語、段落等)
- browsing historyベースの手法
- ユーザのbrowsing historyのドキュメントから、yahooディレクトリ等からカテゴリ情報を取得し、また、トピック情報も取得し(要約技術を活用するとのこと)特徴量ベクトルを作成
- ユーザがアクセスするたびに特徴ベクトルが更新されることを想定している?