
ICLR
[Paper Note] Harnessing Diversity for Important Data Selection in Pretraining Large Language Models, Chi Zhang+, ICLR'25 Spotlight, 2024.09
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #Pocket #NLP #LanguageModel #read-later #Diversity #Selected Papers/Blogs #DataMixture #Generalization #DownstreamTasks #Adaptive #Multi-Armed Bandit Issue Date: 2026-01-21 GPT Summary- データ選択は大規模言語モデルの事前トレーニングにおいて重要で、影響スコアでデータインスタンスの重要性を測定します。しかし、トレーニングデータの多様性不足や影響計算の時間が課題です。本研究では、品質と多様性を考慮したデータ選択手法\texttt{Quad}を提案します。アテンションレイヤーの$iHVP$計算を適応させ、データの品質評価を向上。データをクラスタリングし、選択プロセスでサンプルの影響を評価することで、全インスタンスの処理を回避します。マルチアームバンディット法を用い、品質と多様性のバランスを取ります。 Comment
openreview: https://openreview.net/forum?id=bMC1t7eLRc
[Paper Note] Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance, Jiasheng Ye+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Scaling Laws #DataMixture Issue Date: 2026-01-21 GPT Summary- データ混合法則に基づき、モデル性能を予測するための関数を提案し、混合比率が性能に与える影響を定量的に分析。これにより、未知のデータ混合物の性能を事前に評価できる。実験結果では、1Bモデルが最適化された混合物で、デフォルトの混合物に比べ48%の効率で同等の性能を達成。さらに、継続的なトレーニングへの応用を通じて、混合比率を正確に予測し、動的データスケジュールの可能性を提示。 Comment
openreview: https://openreview.net/forum?id=jjCB27TMK3
[Paper Note] Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws, Yiding Jiang+, ICLR'25, 2024.10
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Scaling Laws #DataMixture #Adaptive Issue Date: 2026-01-21 GPT Summary- データの事前学習構成はモデル性能に重要ですが、標準的な分配ガイドラインは存在せず、従来の手法はワークフローの複雑性を増加させる。そこで、オンラインでデータ分布を最適化する「Adaptive Data Optimization(ADO)」を提案。ADOは他の知識やプロキシモデルに依存せず、トレーニング中にデータの適切な混合を調整し、スケーラビリティと統合性を向上させる。実験により、ADOは他手法と同等以上の性能を示し、計算効率を保ちながら動的なデータ調整を可能にし、データ収集戦略への新たな視点も提供する。 Comment
openreview: https://openreview.net/forum?id=aqok1UX7Z1
[Paper Note] Aioli: A Unified Optimization Framework for Language Model Data Mixing, Mayee F. Chen+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #DataMixture #Adaptive Issue Date: 2026-01-21 GPT Summary- トレーニングデータの最適な混合が言語モデルの性能に影響を与えるが、既存の手法は層化サンプリングを一貫して上回れない。これを解明するため、標準フレームワークで手法を統一し、混合法則が不正確であることを示した。新たに提案したオンライン手法Aioliは、トレーニング中に混合パラメータを推定し動的に調整。実験では、Aioliが層化サンプリングを平均0.27ポイント上回り、短いランで最大12.012ポイントの向上を達成した。 Comment
openreview: https://openreview.net/forum?id=sZGZJhaNSe
[Paper Note] Upweighting Easy Samples in Fine-Tuning Mitigates Forgetting, Sunny Sanyal+, ICLR'25, 2025.02
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #Catastrophic Forgetting #PostTraining #One-Line Notes Issue Date: 2026-01-12 GPT Summary- 事前学習済みモデルのファインチューニングにおける「破滅的忘却」を軽減するため、損失に基づくサンプル重み付けスキームを提案。損失が低いサンプルの重みを上げ、高いサンプルの重みを下げることで、モデルの逸脱を制限。理論的分析により、特定のサブスペースでの学習停滞と過剰適合の抑制を示し、言語タスクと視覚タスクでの有効性を実証。例えば、MetaMathQAでのファインチューニングにおいて、精度の低下を最小限に抑えつつ、事前学習データセットでの精度を保持。 Comment
openreview: https://openreview.net/forum?id=13HPTmZKbM
(事前学習データにはしばしばアクセスできないため)事前学習時に獲得した知識を忘却しないように、Finetuning時にlossが小さいサンプルの重みを大きくすることで、元のモデルからの逸脱を防止しcatastrophic forgettingを軽減する。
[Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #Transformer #Architecture #ResidualStream Issue Date: 2026-01-02 GPT Summary- ハイパーコネクションは、残差接続の代替手法であり、勾配消失や表現崩壊の問題に対処します。異なる深さの特徴間の接続を調整し、層を動的に再配置することが可能です。実験により、ハイパーコネクションが残差接続に対して性能向上を示し、視覚タスクでも改善が確認されました。この手法は幅広いAI問題に適用可能と期待されています。 Comment
openreview: https://openreview.net/forum?id=9FqARW7dwB
[Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Pocket #NLP #LanguageModel #SparseAutoEncoder #Interpretability Issue Date: 2025-12-21 GPT Summary- Matryoshka SAEという新しいスパースオートエンコーダーのバリアントを提案し、複数のネストされた辞書を同時に訓練することで、特徴を階層的に整理。小さな辞書は一般的な概念を、大きな辞書は特定の概念を学び、高次の特徴の吸収を防ぐ。Gemma-2-2BおよびTinyStoriesでの実験により、優れたパフォーマンスと分離された概念表現を確認。再構成性能にはトレードオフがあるが、実用的なタスクにおいて優れた代替手段と考えられる。 Comment
openreview: https://openreview.net/forum?id=m25T5rAy43
[Paper Note] Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models, Marianne Arriola+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#Pocket #LanguageModel #DiffusionModel #read-later #Selected Papers/Blogs Issue Date: 2025-11-04 GPT Summary- ブロック拡散言語モデルは、拡散モデルと自己回帰モデルの利点を組み合わせ、柔軟な長さの生成を可能にし、推論効率を向上させる。効率的なトレーニングアルゴリズムやデータ駆動型ノイズスケジュールを提案し、言語モデリングベンチマークで新たな最先端のパフォーマンスを達成。 Comment
openreview: https://openreview.net/forum?id=tyEyYT267x
[Paper Note] SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal, Tinghao Xie+, ICLR'25, 2024.06
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Evaluation #MultiLingual #Safety Issue Date: 2025-10-24 GPT Summary- SORRY-Benchは、整合された大規模言語モデル(LLMs)の安全でないユーザーリクエストの認識能力を評価する新しいベンチマークです。既存の評価方法の限界を克服するために、44の細かい安全でないトピック分類と440のクラスバランスの取れた指示を提供し、20の言語的拡張を追加しました。また、高速で正確な自動安全評価者を開発し、微調整された7B LLMがGPT-4と同等の精度を持つことを示しました。これにより、50以上のLLMの安全拒否行動を分析し、体系的な評価の基盤を提供します。デモやデータは公式サイトから入手可能です。 Comment
pj page: https://sorry-bench.github.io/
openreview: https://openreview.net/forum?id=YfKNaRktan
[Paper Note] Physics-Informed Diffusion Models, Jan-Hendrik Bastek+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#MachineLearning #Pocket #DiffusionModel #PhysicalConstraints Issue Date: 2025-10-24 GPT Summary- 生成モデルと偏微分方程式を統一するフレームワークを提案し、生成サンプルが物理的制約を満たすように損失項を導入。流体の流れに関するケーススタディで残差誤差を最大2桁削減し、構造トポロジー最適化においても優れた性能を示す。過学習に対する正則化効果も確認。実装が簡単で、多様な制約に適用可能。 Comment
openreview: https://openreview.net/forum?id=tpYeermigp&utm_source=chatgpt.com
[Paper Note] Memory Layers at Scale, Vincent-Pierre Berges+, ICLR'25, 2024.12
Paper/Blog Link My Issue
#Pocket #LanguageModel #Transformer #Architecture #read-later #Selected Papers/Blogs #memory #KeyPoint Notes Issue Date: 2025-10-23 GPT Summary- メモリ層は、計算負荷を増やさずにモデルに追加のパラメータを加えるための学習可能な検索メカニズムを使用し、スパースに活性化されたメモリ層が密なフィードフォワード層を補完します。本研究では、改良されたメモリ層を用いた言語モデルが、計算予算が2倍の密なモデルや同等の計算とパラメータを持つエキスパート混合モデルを上回ることを示し、特に事実に基づくタスクでの性能向上が顕著であることを明らかにしました。完全に並列化可能なメモリ層の実装とスケーリング法則を示し、1兆トークンまでの事前学習を行った結果、最大8Bのパラメータを持つベースモデルと比較しました。 Comment
openreview: https://openreview.net/forum?id=ATqGm1WyDj
transformerにおけるFFNをメモリレイヤーに置き換えることで、パラメータ数を増やしながら計算コストを抑えるようなアーキテクチャを提案しているようである。メモリレイヤーは、クエリqを得た時にtop kのkvをlookupし(=ここで計算対象となるパラメータがスパースになる)、kqから求めたattention scoreでvを加重平均することで出力を得る。Memory+というさらなる改良を加えたアーキテクチャでは、入力に対してsiluによるgatingとlinearな変換を追加で実施することで出力を得る。
denseなモデルと比較して性能が高く、メモリパラメータを増やすと性能がスケールする。
[Paper Note] Generative Representational Instruction Tuning, Niklas Muennighoff+, ICLR'25, 2024.02
Paper/Blog Link My Issue
#Embeddings #EfficiencyImprovement #Pocket #NLP #LanguageModel #RepresentationLearning #RAG(RetrievalAugmentedGeneration) #read-later #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-08 GPT Summary- 生成的表現指示チューニング(GRIT)を用いて、大規模言語モデルが生成タスクと埋め込みタスクを同時に処理できる手法を提案。GritLM 7BはMTEBで新たな最先端を達成し、GritLM 8x7Bはすべてのオープン生成モデルを上回る性能を示す。GRITは生成データと埋め込みデータの統合による性能損失がなく、RAGを60%以上高速化する利点もある。モデルは公開されている。 Comment
openreview: https://openreview.net/forum?id=BC4lIvfSzv
従来はgemerativeタスクとembeddingタスクは別々にモデリングされていたが、それを統一的な枠組みで実施し、両方のタスクで同等のモデルサイズの他モデルと比較して高い性能を達成した研究。従来のgenerativeタスク用のnext-token-prediction lossとembeddingタスク用のconstastive lossを組み合わせて学習する(式3)。タスクの区別はinstructionにより実施し、embeddingタスクの場合はすべてのトークンのlast hidden stateのmean poolingでrepresentationを取得する。また、embeddingの時はbi-directional attention / generativeタスクの時はcausal maskが適用される。これらのattentionの適用のされ方の違いが、どのように管理されるかはまだしっかり読めていないのでよくわかっていないが、非常に興味深い研究である。
[Paper Note] STAR: Synthesis of Tailored Architectures, Armin W. Thomas+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Pocket #NLP #NeuralArchitectureSearch Issue Date: 2025-09-27 GPT Summary- 新しいアプローチ(STAR)を提案し、特化したアーキテクチャの合成を行う。線形入力変動システムに基づく探索空間を用い、アーキテクチャのゲノムを階層的にエンコード。進化的アルゴリズムでモデルの品質と効率を最適化し、自己回帰型言語モデリングにおいて従来のモデルを上回る性能を達成。 Comment
openreview: https://openreview.net/forum?id=HsHxSN23rM
[Paper Note] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model, Chunting Zhou+, ICLR'25, 2024.08
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #MultiModal #read-later #Selected Papers/Blogs #UMM Issue Date: 2025-09-22 GPT Summary- Transfusionは、離散データと連続データに対してマルチモーダルモデルを訓練する手法で、言語モデリングの損失関数と拡散を組み合わせて単一のトランスフォーマーを訓練します。最大7Bパラメータのモデルを事前訓練し、ユニモーダルおよびクロスモーダルベンチマークで優れたスケーリングを示しました。モダリティ特有のエンコーディング層を導入することで性能を向上させ、7Bパラメータのモデルで画像とテキストを生成できることを実証しました。 Comment
openreview: https://openreview.net/forum?id=SI2hI0frk6
[Paper Note] SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?, John Yang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #MultiModal #SoftwareEngineering #VisionLanguageModel Issue Date: 2025-09-16 GPT Summary- 自律システムのバグ修正能力を評価するために、SWE-bench Mを提案。これは視覚要素を含むJavaScriptソフトウェアのタスクを対象とし、617のインスタンスを収集。従来のSWE-benchシステムが視覚的問題解決に苦労する中、SWE-agentは他のシステムを大きく上回り、12%のタスクを解決した。 Comment
openreview: https://openreview.net/forum?id=riTiq3i21b
[Paper Note] Forgetting Transformer: Softmax Attention with a Forget Gate, Zhixuan Lin+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Transformer #Attention #LongSequence #Architecture Issue Date: 2025-09-16 GPT Summary- 忘却ゲートを取り入れたトランスフォーマー「FoX」を提案。FoXは長いコンテキストの言語モデリングや下流タスクでトランスフォーマーを上回る性能を示し、位置埋め込みを必要としない。再帰的シーケンスモデルに対しても優れた能力を保持し、性能向上のための「Pro」ブロック設計を導入。コードはGitHubで公開。 Comment
openreview: https://openreview.net/forum?id=q2Lnyegkr8
code: https://github.com/zhixuan-lin/forgetting-transformer
非常におもしろそう
[Paper Note] SOAP: Improving and Stabilizing Shampoo using Adam, Nikhil Vyas+, ICLR'25
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Optimizer Issue Date: 2025-09-03 GPT Summary- Shampooという前処理法が深層学習の最適化タスクで効果的である一方、追加のハイパーパラメータと計算オーバーヘッドが課題である。本研究では、ShampooとAdafactorの関係を明らかにし、Shampooを基にした新しいアルゴリズムSOAPを提案。SOAPは、Adamと同様に第二モーメントの移動平均を更新し、計算効率を改善。実験では、SOAPがAdamWに対して40%以上のイテレーション数削減、35%以上の経過時間短縮を達成し、Shampooに対しても約20%の改善を示した。SOAPの実装は公開されている。 Comment
openreview: https://openreview.net/forum?id=IDxZhXrpNf
[Paper Note] RegMix: Data Mixture as Regression for Language Model Pre-training, Qian Liu+, ICLR'25
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #read-later #Selected Papers/Blogs #DataMixture #Initial Impression Notes Issue Date: 2025-09-01 GPT Summary- RegMixを提案し、データミクスチャの性能を回帰タスクとして自動的に特定。多様なミクスチャで小モデルを訓練し、最良のミクスチャを用いて大規模モデルを訓練した結果、他の候補を上回る性能を示した。実験により、データミクスチャが性能に大きな影響を与えることや、ウェブコーパスが高品質データよりも良好な相関を持つことを確認。RegMixの自動アプローチが必要であることも示された。 Comment
openreview: https://openreview.net/forum?id=5BjQOUXq7i
今後DavaMixtureがさらに重要になるという見方があり、実際にフロンティアモデルのDataMixtureに関する情報はテクニカルレポートには記載されず秘伝のタレ状態であるため、より良いDataMixtureする本研究は重要論文に見える。
[Paper Note] MoE++: Accelerating Mixture-of-Experts Methods with Zero-Computation Experts, Peng Jin+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) #read-later Issue Date: 2025-08-31 GPT Summary- 本研究では、Mixture-of-Experts(MoE)手法の効果と効率を向上させるために、MoE++フレームワークを提案。ゼロ計算エキスパートを導入し、低計算オーバーヘッド、高パフォーマンス、デプロイメントの容易さを実現。実験結果により、MoE++は従来のMoEモデルに比べて1.1-2.1倍のスループットを提供し、優れた性能を示す。 Comment
openreview: https://openreview.net/forum?id=t7P5BUKcYv
従来のMoEと比べて、専門家としてzero computation expertsを導入することで、性能を維持しながら効率的にinferenceをする手法(MoEにおいて全てのトークンを均一に扱わない)を提案している模様。
zero computation expertsは3種類で
- Zero Experts: 入力をゼロベクトルに落とす
- Copy Experts: 入力xをそのままコピーする
- Constant Experts: learnableな定数ベクトルvを学習し、xと線形結合して出力する。W_cによって入力xを変換することで線形補 結合の係数a1,a2を入力に応じて動的に決定する。
Routingの手法やgating residual、学習手法の工夫もなされているようなので、後で読む。
[Paper Note] Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts, Weilin Cai+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) Issue Date: 2025-08-31 GPT Summary- ScMoEは、スパースゲート混合専門家モデルの計算負荷を分散させる新しいアーキテクチャで、通信と計算の重複を最大100%可能にし、全対全通信のボトルネックを解消。これにより、トレーニングで1.49倍、推論で1.82倍のスピードアップを実現し、モデル品質も既存手法と同等またはそれ以上を達成。 Comment
openreview: https://openreview.net/forum?id=GKly3FkxN4¬eId=4tfWewv7R2
[Paper Note] Looped Transformers for Length Generalization, Ying Fan+, ICLR'25
Paper/Blog Link My Issue
#MachineLearning #Pocket #Transformer #LongSequence #Architecture #Generalization #RecurrentModels Issue Date: 2025-08-30 GPT Summary- ループトランスフォーマーを用いることで、未見の長さの入力に対する算術的およびアルゴリズム的タスクの長さ一般化が改善されることを示す。RASP-L操作を含む既知の反復解法に焦点を当て、提案する学習アルゴリズムで訓練した結果、さまざまなタスクに対して高い一般化能力を持つ解法を学習した。 Comment
openreview: https://openreview.net/forum?id=2edigk8yoU
[Paper Note] Ultra-Sparse Memory Network, Zihao Huang+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) #read-later #memory Issue Date: 2025-08-29 GPT Summary- UltraMemは、大規模で超スパースなメモリ層を組み込むことで、Transformerモデルの推論レイテンシを削減しつつ性能を維持する新しいアーキテクチャを提案。実験により、UltraMemはMoEを上回るスケーリング特性を示し、最大2000万のメモリスロットを持つモデルが最先端の推論速度と性能を達成することを実証。
[Paper Note] JetFormer: An Autoregressive Generative Model of Raw Images and Text, Michael Tschannen+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #TextToImageGeneration #Architecture #read-later #NormalizingFlow Issue Date: 2025-08-17 GPT Summary- JetFormerは、画像とテキストの共同生成を効率化する自己回帰型デコーダー専用のトランスフォーマーであり、別々にトレーニングされたコンポーネントに依存せず、両モダリティを理解・生成可能。正規化フローモデルを活用し、テキストから画像への生成品質で既存のベースラインと競合しつつ、堅牢な画像理解能力を示す。JetFormerは高忠実度の画像生成と強力な対数尤度境界を実現する初のモデルである。 Comment
openreview: https://openreview.net/forum?id=sgAp2qG86e
画像をnormalizing flowでソフトトークンに変換し、transformerでソフトトークンを予測させるように学習することで、テキストと画像を同じアーキテクチャで学習できるようにしました、みたいな話っぽい?おもしろそう
[Paper Note] Physics of Language Models: Part 3.2, Knowledge Manipulation, Zeyuan Allen-Zhu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #ReversalCurse Issue Date: 2025-08-11 GPT Summary- 言語モデルは豊富な知識を持つが、下流タスクへの柔軟な利用には限界がある。本研究では、情報検索、分類、比較、逆検索の4つの知識操作タスクを調査し、言語モデルが知識検索には優れているが、Chain of Thoughtsを用いないと分類や比較タスクで苦労することを示した。特に逆検索ではパフォーマンスがほぼ0%であり、これらの弱点は言語モデルに固有であることを確認した。これにより、現代のAIと人間を区別する新たなチューリングテストの必要性が浮き彫りになった。 Comment
openreview: https://openreview.net/forum?id=oDbiL9CLoS
[Paper Note] Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems, Tian Ye+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #SelfCorrection Issue Date: 2025-08-11 GPT Summary- 言語モデルの推論精度向上のために、「エラー修正」データを事前学習に組み込む有用性を探求。合成数学データセットを用いて、エラーフリーデータと比較して高い推論精度を達成することを示す。さらに、ビームサーチとの違いやデータ準備、マスキングの必要性、エラー量、ファインチューニング段階での遅延についても考察。 Comment
openreview: https://openreview.net/forum?id=zpDGwcmMV4
[Paper Note] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process, Tian Ye+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #read-later #reading Issue Date: 2025-08-11 GPT Summary- 言語モデルの数学的推論能力を研究し、GSM8Kベンチマークでの精度向上のメカニズムを探る。具体的には、推論スキルの発展、隠れたプロセス、人間との違い、必要なスキルの超越、推論ミスの原因、モデルのサイズや深さについての実験を行い、LLMの理解を深める洞察を提供。 Comment
openreview: https://openreview.net/forum?id=Tn5B6Udq3E
小学生向けの算数の問題を通じて、以下の基本的なResearch Questionsについて調査して研究。これらを理解することで、言語モデルの知能を理解する礎とする。
## Research Questions
- 言語モデルはどのようにして小学校レベルの算数の問題を解けるようになるのか?
- 単にテンプレートを暗記しているだけなのか、それとも人間に似た推論スキルを学んでいるのか?
- あるいは、その問題を解くために新しいスキルを発見しているのか?
- 小学校レベルの算数問題だけで訓練されたモデルは、それらの問題を解くことしか学ばないのか?
- それとも、より一般的な知能を学習するのか?
- どのくらい小さい言語モデルまで、小学校レベルの算数問題を解けるのか?
- 深さ(層の数)は幅(層ごとのニューロン数)より重要なのか?
- それとも、単にサイズだけが重要か?
(続きはのちほど...)
[Paper Note] AxBench: Steering LLMs? Even Simple Baselines Outperform Sparse Autoencoders, Zhengxuan Wu+, ICLR'25 Spotlight
Paper/Blog Link My Issue
#Controllable #Pocket #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #Prompting #Evaluation #read-later #ActivationSteering/ITI #Selected Papers/Blogs #InstructionFollowingCapability #Steering Issue Date: 2025-08-02 GPT Summary- 言語モデルの出力制御は安全性と信頼性に重要であり、プロンプトやファインチューニングが一般的に用いられるが、さまざまな表現ベースの技術も提案されている。これらの手法を比較するためのベンチマークAxBenchを導入し、Gemma-2-2Bおよび9Bに関する実験を行った。結果、プロンプトが最も効果的で、次いでファインチューニングが続いた。概念検出では表現ベースの手法が優れており、SAEは競争力がなかった。新たに提案した弱教師あり表現手法ReFT-r1は、競争力を持ちながら解釈可能性を提供する。AxBenchとともに、ReFT-r1およびDiffMeanのための特徴辞書を公開した。 Comment
openreview: https://openreview.net/forum?id=K2CckZjNy0
[Paper Note] What Matters in Learning from Large-Scale Datasets for Robot Manipulation, Vaibhav Saxena+, ICLR'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #Pocket #Dataset #Robotics #EmbodiedAI Issue Date: 2025-07-19 GPT Summary- 本研究では、ロボティクスにおける大規模データセットの構成に関する体系的な理解を深めるため、データ生成フレームワークを開発し、多様性の重要な要素を特定。特に、カメラのポーズや空間的配置がデータ収集の多様性と整合性に影響を与えることを示した。シミュレーションからの洞察が実世界でも有効であり、提案した取得戦略は既存のトレーニング手法を最大70%上回る性能を発揮した。 Comment
元ポスト:
元ポストに著者による詳細な解説スレッドがあるので参照のこと。
[Paper Note] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models, Chankyu Lee+, ICLR'25
Paper/Blog Link My Issue
#RecommenderSystems #Embeddings #InformationRetrieval #Pocket #NLP #LanguageModel #RepresentationLearning #InstructionTuning #ContrastiveLearning #Generalization #Decoder Issue Date: 2025-07-10 GPT Summary- デコーダー専用のLLMベースの埋め込みモデルNV-Embedは、BERTやT5を上回る性能を示す。アーキテクチャ設計やトレーニング手法を工夫し、検索精度を向上させるために潜在的注意層を提案。二段階の対照的指示調整手法を導入し、検索と非検索タスクの両方で精度を向上。NV-EmbedモデルはMTEBリーダーボードで1位を獲得し、ドメイン外情報検索でも高スコアを達成。モデル圧縮技術の分析も行っている。 Comment
Decoder-Only LLMのlast hidden layerのmatrixを新たに導入したLatent Attention Blockのinputとし、Latent Attention BlockはEmbeddingをOutputする。Latent Attention Blockは、last hidden layer (系列長l×dの
matrix)をQueryとみなし、保持しているLatent Array(trainableなmatrixで辞書として機能する;後述の学習においてパラメータが学習される)[^1]をK,Vとして、CrossAttentionによってcontext vectorを生成し、その後MLPとMean Poolingを実施することでEmbeddingに変換する。
学習は2段階で行われ、まずQAなどのRetrievalタスク用のデータセットをIn Batch negativeを用いてContrastive Learningしモデルの検索能力を高める。その後、検索と非検索タスクの両方を用いて、hard negativeによってcontrastive learningを実施し、検索以外のタスクの能力も高める(下表)。両者において、instructionテンプレートを用いて、instructionによって条件付けて学習をすることで、instructionに応じて生成されるEmbeddingが変化するようにする。また、学習時にはLLMのcausal maskは無くし、bidirectionalにrepresentationを考慮できるようにする。
[^1]: [Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22
Perceiver-IOにインスパイアされている。
[Paper Note] VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks, Ziyan Jiang+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Pocket #NLP #Dataset #Evaluation #MultiModal #read-later #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-09 GPT Summary- 本研究では、ユニバーサルマルチモーダル埋め込みモデルの構築を目指し、二つの貢献を行った。第一に、MMEB(Massive Multimodal Embedding Benchmark)を提案し、36のデータセットを用いて分類や視覚的質問応答などのメタタスクを網羅した。第二に、VLM2Vecというコントラストトレーニングフレームワークを開発し、視覚-言語モデルを埋め込みモデルに変換する手法を示した。実験結果は、VLM2Vecが既存のモデルに対して10%から20%の性能向上を達成することを示し、VLMの強力な埋め込み能力を証明した。 Comment
openreview: https://openreview.net/forum?id=TE0KOzWYAF
[Paper Note] Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Zhangchen Xu+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Alignment #SyntheticData #Selected Papers/Blogs Issue Date: 2025-06-25 GPT Summary- 高品質な指示データはLLMの整合に不可欠であり、Magpieという自己合成手法を提案。Llama-3-Instructを用いて400万の指示と応答を生成し、30万の高品質なインスタンスを選定。Magpieでファインチューニングしたモデルは、従来のデータセットを用いたモデルと同等の性能を示し、特に整合ベンチマークで優れた結果を得た。 Comment
OpenReview: https://openreview.net/forum?id=Pnk7vMbznK
下記のようなpre-queryテンプレートを与え(i.e., userの発話は何も与えず、ユーザの発話を表す特殊トークンのみを渡す)instructionを生成し、post-queryテンプレートを与える(i.e., pre-queryテンプレート+生成されたinstruction+assistantの発話の開始を表す特殊トークンのみを渡す)ことでresponseを生成することで、prompt engineeringやseed無しでinstruction tuningデータを合成できるという手法。
生成した生のinstruction tuning pair dataは、たとえば下記のようなフィルタリングをすることで品質向上が可能で
reward modelと組み合わせてLLMからのresponseを生成しrejection samplingすればDPOのためのpreference dataも作成できるし、single turnの発話まで生成させた後もう一度pre/post-queryをconcatして生成すればMulti turnのデータも生成できる。
他のも例えば、システムプロンプトに自分が生成したい情報を与えることで、特定のドメインに特化したデータ、あるいは特定の言語に特化したデータも合成できる。
[Paper Note] Drop-Upcycling: Training Sparse Mixture of Experts with Partial Re-initialization, Taishi Nakamura+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #Pocket #NLP #LanguageModel #MoE(Mixture-of-Experts) Issue Date: 2025-06-25 GPT Summary- Drop-Upcycling手法を提案し、MoEモデルのトレーニング効率を向上。事前にトレーニングされた密なモデルの知識を活用しつつ、一部の重みを再初期化することで専門家の専門化を促進。大規模実験により、5.9BパラメータのMoEモデルが13B密なモデルと同等の性能を達成し、トレーニングコストを約1/4に削減。すべての実験リソースを公開。 Comment
OpenReview: https://openreview.net/forum?id=gx1wHnf5Vp
関連:
- Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR'23
提案手法の全体像とDiversity re-initializationの概要。元のUpcyclingでは全てidenticalな重みでreplicateされていたため、これが個々のexpertがlong termでの学習で特化することの妨げになり、最終的に最大限のcapabilityを発揮できず、収束が遅い要因となっていた。これを、Upcyclingした重みのうち、一部のindexのみを再初期化することで、replicate元の知識を保持しつつ、expertsの多様性を高めることで解決する。
提案手法は任意のactivation function適用可能。今回はFFN Layerのactivation functionとして一般的なSwiGLUを採用した場合で説明している。
Drop-Upcyclingの手法としては、通常のUpcyclingと同様、FFN Layerの重みをn個のexpertsの数だけreplicateする。その後、re-initializationを実施する比率rに基づいて、[1, intermediate size d_f]の範囲からr*d_f個のindexをサンプリングする。最終的にSwiGLU、およびFFNにおける3つのWeight W_{gate, up, down}において、サンプリングされたindexと対応するrow/columnと対応する重みをre-initializeする。
re-initializeする際には、各W_{gate, up, down}中のサンプリングされたindexと対応するベクトルの平均と分散をそれぞれ独立して求め、それらの平均と分散を持つ正規分布からサンプリングする。
学習の初期から高い性能を発揮し、long termでの性能も向上している。また、learning curveの形状もscratchから学習した場合と同様の形状となっており、知識の転移とexpertsのspecializationがうまく進んだことが示唆される。
[Paper Note] Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models, Yuda Song+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #SelfImprovement #read-later #Verification Issue Date: 2025-06-24 GPT Summary- 自己改善はLLMの出力検証を通じてデータをフィルタリングし、蒸留するメカニズムである。本研究では、自己改善の数学的定式化を行い、生成-検証ギャップに基づくスケーリング現象を発見。さまざまなモデルとタスクを用いた実験により、自己改善の可能性とその性能向上方法を探求し、LLMの理解を深めるとともに、将来の研究への示唆を提供する。 Comment
参考: https://joisino.hatenablog.com/entry/mislead
Verificationに対する理解を深めるのに非常に良さそう
[Paper Note] On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks, Kaya Stechly+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Verification Issue Date: 2025-06-24 GPT Summary- LLMsの推論能力に関する意見の相違を背景に、反復的なプロンプトの効果をGame of 24、グラフ彩色、STRIPS計画の3領域で調査。自己批評がパフォーマンスに悪影響を及ぼす一方、外部の正しい推論者による検証がパフォーマンスを向上させることを示した。再プロンプトによって複雑な設定の利点を維持できることも確認。 Comment
参考: https://joisino.hatenablog.com/entry/mislead
OpenReview: https://openreview.net/forum?id=4O0v4s3IzY
[Paper Note] Language Models Learn to Mislead Humans via RLHF, Jiaxin Wen+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #RLHF Issue Date: 2025-06-24 GPT Summary- RLHFは言語モデルのエラーを悪化させる可能性があり、モデルが人間を納得させる能力を向上させる一方で、タスクの正確性は向上しない。質問応答タスクとプログラミングタスクで被験者の誤検出率が増加し、意図された詭弁を検出する手法がU-SOPHISTRYには適用できないことが示された。これにより、RLHFの問題点と人間支援の研究の必要性が浮き彫りになった。 Comment
LiveBench: A Challenging, Contamination-Limited LLM Benchmark, Colin White+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Evaluation #Contamination-free #Selected Papers/Blogs #Live Issue Date: 2025-05-23 GPT Summary- テストセットの汚染を防ぐために、LLM用の新しいベンチマーク「LiveBench」を導入。LiveBenchは、頻繁に更新される質問、自動スコアリング、さまざまな挑戦的タスクを含む。多くのモデルを評価し、正答率は70%未満。質問は毎月更新され、LLMの能力向上を測定可能に。コミュニティの参加を歓迎。 Comment
テストデータのコンタミネーションに対処できるように設計されたベンチマーク。重要研究
Faster Cascades via Speculative Decoding, Harikrishna Narasimhan+, ICLR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Test-Time Scaling #Decoding #Verification #SpeculativeDecoding Issue Date: 2025-05-13 GPT Summary- カスケードと推測デコーディングは、言語モデルの推論効率を向上させる手法であり、異なるメカニズムを持つ。カスケードは難しい入力に対して大きなモデルを遅延的に使用し、推測デコーディングは並行検証で大きなモデルを活用する。新たに提案する推測カスケーディング技術は、両者の利点を組み合わせ、最適な遅延ルールを特定する。実験結果は、提案手法がカスケードおよび推測デコーディングのベースラインよりも優れたコスト品質トレードオフを実現することを示した。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=vo9t20wsmd
When More is Less: Understanding Chain-of-Thought Length in LLMs, Yuyang Wu+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Chain-of-Thought Issue Date: 2025-04-30 GPT Summary- Chain-of-thought (CoT)推論は、LLMsの多段階推論能力を向上させるが、CoTの長さが増すと最初は性能が向上するものの、最終的には低下することが観察される。長い推論プロセスがノイズに脆弱であることを示し、理論的に最適なCoTの長さを導出。Length-filtered Voteを提案し、CoTの長さをモデルの能力とタスクの要求に合わせて調整する必要性を強調。 Comment
ICLR 2025 Best Paper Runner Up Award
元ポスト:
AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, Junfeng Fang+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #KnowledgeEditing Issue Date: 2025-04-30 GPT Summary- AlphaEditは、LLMsの知識を保持しつつ編集を行う新しい手法で、摂動を保持された知識の零空間に投影することで、元の知識を破壊する問題を軽減します。実験により、AlphaEditは従来の位置特定-編集手法の性能を平均36.7%向上させることが確認されました。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=HvSytvg3Jh
MLPに新たな知識を直接注入する際に(≠contextに含める)既存の学習済みの知識を破壊せずに注入する手法(破壊しないことが保証されている)を提案しているらしい
将来的には、LLMの1パラメータあたりに保持できる知識量がわかってきているので、MLPの零空間がN GBのモデルです、あなたが注入したいドメイン知識の量に応じて適切な零空間を持つモデルを選んでください、みたいなモデルが公開される日が来るのだろうか。
Safety Alignment Should Be Made More Than Just a Few Tokens Deep, Xiangyu Qi+, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #Supervised-FineTuning (SFT) #Safety #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-04-29 GPT Summary- 現在の大規模言語モデル(LLMs)の安全性アラインメントは脆弱であり、単純な攻撃や善意のファインチューニングによって脱獄される可能性がある。この脆弱性は「浅い安全性アラインメント」に起因し、アラインメントが主に最初の数トークンの出力にのみ適応されることに関連している。本論文では、この問題のケーススタディを提示し、現在のアラインされたLLMsが直面する脆弱性を説明する。また、浅い安全性アラインメントの概念が脆弱性軽減の研究方向を示唆し、初期トークンを超えたアラインメントの深化がロバスト性を向上させる可能性を示す。最後に、ファインチューニング攻撃に対する持続的な安全性アラインメントを実現するための正則化されたファインチューニング目的を提案する。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=6Mxhg9PtDE
Safety Alignment手法が最初の数トークンに依存しているからそうならないように学習しますというのは、興味深いテーマだし技術的にまだ困難な点もあっただろうし、インパクトも大きいし、とても良い研究だ…。
RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval, Kaiyue Wen+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #Transformer #Chain-of-Thought #In-ContextLearning #SSM (StateSpaceModel) Issue Date: 2025-04-26 GPT Summary- 本論文では、RNNとトランスフォーマーの表現力の違いを調査し、特にRNNがChain-of-Thought(CoT)プロンプトを用いてトランスフォーマーに匹敵するかを分析。結果、CoTはRNNを改善するが、トランスフォーマーとのギャップを埋めるには不十分であることが判明。RNNの情報取得能力の限界がボトルネックであるが、Retrieval-Augmented Generation(RAG)やトランスフォーマー層の追加により、RNNはCoTを用いて多項式時間で解決可能な問題を解決できることが示された。 Comment
元ポスト:
関連:
- Transformers are Multi-State RNNs, Matanel Oren+, N/A, EMNLP'24
↑とはどういう関係があるだろうか?
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents, Christopher Rawles+, ICLR'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #LanguageModel #Evaluation #MultiModal #ComputerUse Issue Date: 2025-04-18 GPT Summary- 本研究では、116のプログラムタスクに対して報酬信号を提供する「AndroidWorld」という完全なAndroid環境を提案。これにより、自然言語で表現されたタスクを動的に構築し、現実的なベンチマークを実現。初期結果では、最良のエージェントが30.6%のタスクを完了し、さらなる研究の余地が示された。また、デスクトップWebエージェントのAndroid適応が効果薄であることが明らかになり、クロスプラットフォームエージェントの実現にはさらなる研究が必要であることが示唆された。タスクの変動がエージェントのパフォーマンスに影響を与えることも確認された。 Comment
Android環境でのPhone Useのベンチマーク
Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25
Paper/Blog Link My Issue
#Analysis #MachineLearning #Pocket #NLP #LanguageModel #Alignment #Hallucination #DPO #Repetition Issue Date: 2025-04-18 GPT Summary- 本研究では、大規模言語モデルのファインチューニング中の学習ダイナミクスを分析し、異なる応答間の影響の蓄積を段階的に解明します。指示調整と好み調整のアルゴリズムに関する観察を統一的に解釈し、ファインチューニング後の幻覚強化の理由を仮説的に説明します。また、オフポリシー直接好み最適化(DPO)における「圧縮効果」を強調し、望ましい出力の可能性が低下する現象を探ります。このフレームワークは、LLMのファインチューニング理解に新たな視点を提供し、アラインメント性能向上のためのシンプルな方法を示唆します。 Comment
元ポスト:
解説ポスト:
CREAM: Consistency Regularized Self-Rewarding Language Models, Zhaoyang Wang+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #SelfImprovement #RewardHacking Issue Date: 2025-04-06 GPT Summary- 自己報酬型LLMは、LLM-as-a-Judgeを用いてアラインメント性能を向上させるが、報酬とランク付けの正確性が問題。小規模LLMの実証結果は、自己報酬の改善が反復後に減少する可能性を示唆。これに対処するため、一般化された反復的好みファインチューニングフレームワークを定式化し、正則化を導入。CREAMを提案し、報酬の一貫性を活用して信頼性の高い好みデータから学習。実証結果はCREAMの優位性を示す。 Comment
- [Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, N/A, ICML'24
を改善した研究
OpenReview: https://openreview.net/forum?id=Vf6RDObyEF
この方向性の研究はおもしろい
When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Attention #AttentionSinks #read-later #Selected Papers/Blogs Issue Date: 2025-04-05 GPT Summary- 言語モデルにおける「アテンションシンク」は、意味的に重要でないトークンに大きな注意を割り当てる現象であり、さまざまな入力に対して小さなモデルでも普遍的に存在することが示された。アテンションシンクは事前学習中に出現し、最適化やデータ分布、損失関数がその出現に影響を与える。特に、アテンションシンクはキーのバイアスのように機能し、情報を持たない追加のアテンションスコアを保存することがわかった。この現象は、トークンがソフトマックス正規化に依存していることから部分的に生じており、正規化なしのシグモイドアテンションに置き換えることで、アテンションシンクの出現を防ぐことができる。 Comment
Sink Rateと呼ばれる、全てのheadのFirst Tokenに対するattention scoreのうち(layer l * head h個存在する)、どの程度の割合のスコアが閾値を上回っているかを表す指標を提案
(後ほど詳細を追記する)
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究
著者ポスト(openai-gpt-120Bを受けて):
openreview: https://openreview.net/forum?id=78Nn4QJTEN
Overtrained Language Models Are Harder to Fine-Tune, Jacob Mitchell Springer+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pretraining #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later Issue Date: 2025-03-27 GPT Summary- 大規模言語モデルの事前学習において、トークン予算の増加がファインチューニングを難しくし、パフォーマンス低下を引き起こす「壊滅的な過学習」を提唱。3Tトークンで事前学習されたOLMo-1Bモデルは、2.3Tトークンのモデルに比べて2%以上の性能低下を示す。実験と理論分析により、事前学習パラメータの感度の増加が原因であることを示し、事前学習設計の再評価を促す。 Comment
著者によるポスト:
事前学習のトークン数を増やすとモデルのsensitivityが増し、post-trainingでのパフォーマンスの劣化が起こることを報告している。事前学習で学習するトークン数を増やせば、必ずしもpost-training後のモデルの性能がよくなるわけではないらしい。
ICLR'25のOutstanding Paperに選ばれた模様:
きちんと読んだ方が良さげ。
Diverse Preference Optimization, Jack Lanchantin+, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Alignment #DPO #PostTraining #Diversity Issue Date: 2025-02-01 GPT Summary- Diverse Preference Optimization(DivPO)を提案し、応答の多様性を向上させつつ生成物の品質を維持するオンライン最適化手法を紹介。DivPOは応答のプールから多様性を測定し、希少で高品質な例を選択することで、パーソナ属性の多様性を45.6%、ストーリーの多様性を74.6%向上させる。 Comment
元ポスト:
OpenReview: https://openreview.net/forum?id=pOq9vDIYev
DPOと同じ最適化方法を使うが、Preference Pairを選択する際に、多様性が増加するようなPreference Pairの選択をすることで、モデルのPost-training後の多様性を損なわないようにする手法を提案しているっぽい。
具体的には、Alg.1 に記載されている通り、多様性の尺度Dを定義して、モデルにN個のレスポンスを生成させRMによりスコアリングした後、RMのスコアが閾値以上のresponseを"chosen" response, 閾値未満のレスポンスを "reject" responseとみなし、chosen/reject response集合を構築する。chosen response集合の中からDに基づいて最も多様性のあるresponse y_c、reject response集合の中から最も多様性のないresponse y_r をそれぞれピックし、prompt xとともにpreference pair (x, y_c, y_r) を構築しPreference Pairに加える、といった操作を全ての学習データ(中のprompt)xに対して繰り返すことで実現する。
SoftMatcha: A Fast and Soft Pattern Matcher for Billion-Scale Corpus Searches, Deguchi+, ICLR'25
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #NLP #Search #STS (SemanticTextualSimilarity) Issue Date: 2025-01-28 Comment
ICLR2025にacceptされた模様
https://openreview.net/forum?id=Q6PAnqYVpo
openreview: https://openreview.net/forum?id=Q6PAnqYVpo
How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #MachineLearning #Pocket #NLP #LanguageModel #Batch #One-Line Notes #CriticalBatchSize Issue Date: 2024-11-25 GPT Summary- 大規模モデルの訓練には、クリティカルバッチサイズ(CBS)を考慮した並列化戦略が重要である。CBSの測定法を提案し、C4データセットで自己回帰型言語モデルを訓練。バッチサイズや学習率などの要因を調整し、CBSがデータサイズに比例してスケールすることを示した。この結果は、ニューラルネットワークの理論的分析によって支持され、ハイパーパラメータ選択の重要性も強調されている。 Comment
Critical Batch Sizeはモデルサイズにはあまり依存せず、データサイズに応じてスケールする
Critical batch sizeが提案された研究:
- An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18
LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations, Hadas Orgad+, N_A, ICLR'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Hallucination Issue Date: 2024-10-20 GPT Summary- LLMsは「幻覚」と呼ばれるエラーを生成するが、内部状態が真実性に関する情報をエンコードしていることが示されている。本研究では、真実性情報が特定のトークンに集中していることを発見し、これを利用することでエラー検出性能が向上することを示す。しかし、エラーディテクターはデータセット間で一般化に失敗し、真実性のエンコーディングは普遍的ではないことが明らかになる。また、内部表現を用いてエラーの種類を予測し、特化した緩和戦略の開発を促進する。さらに、内部エンコーディングと外部の振る舞いとの不一致が存在し、正しい答えをエンコードしていても誤った答えを生成することがある。これにより、LLMのエラー理解が深まり、今後の研究に寄与する。 Comment
特定のトークンがLLMのtrustfulnessに集中していることを実験的に示し、かつ内部でエンコードされたrepresentationは正しい答えのものとなっているのに、生成結果に誤りが生じるような不整合が生じることも示したらしい
openreview: https://openreview.net/forum?id=KRnsX5Em3W
Llama-3.1-Nemotron-70B-Instruct, Nvidia, (ICLR'25), 2024.10
Paper/Blog Link My Issue
#NLP #Dataset #LanguageModel #Alignment #OpenWeight Issue Date: 2024-10-17 GPT Summary- 報酬モデルの訓練にはBradley-Terryスタイルと回帰スタイルがあり、データの一致が重要だが、適切なデータセットが不足している。HelpSteer2データセットでは、Bradley-Terry訓練用の好みの注釈を公開し、初めて両モデルの直接比較を行った。これに基づき、両者を組み合わせた新アプローチを提案し、Llama-3.1-70B-InstructモデルがRewardBenchで94.1のスコアを達成。さらに、REINFORCEアルゴリズムを用いて指示モデルを調整し、Arena Hardで85.0を記録した。このデータセットはオープンソースとして公開されている。 Comment
MTBench, Arena HardでGPT4o-20240513,Claude-3.5-sonnet-20240620をoutperform。Response lengthの平均が長いこと模様
openreview: https://openreview.net/forum?id=MnfHxPP5gs
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, Iman Mirzadeh+, N_A, ICLR'25
Paper/Blog Link My Issue
#Pocket Issue Date: 2024-10-11 GPT Summary- 最近のLLMsの進展により、数学的推論能力への関心が高まっているが、GSM8Kベンチマークの信頼性には疑問が残る。これに対処するため、GSM-Symbolicという新しいベンチマークを導入し、モデルの推論能力をより正確に評価。調査結果は、モデルが同じ質問の異なる具現化に対してばらつきを示し、特に数値変更や質問の節の数が増えると性能が著しく低下することを明らかにした。これは、LLMsが真の論理的推論を行えず、トレーニングデータからの再現に依存しているためと考えられる。全体として、研究は数学的推論におけるLLMsの能力と限界についての理解を深める。 Comment
元ポスト:
May I ask if this work is open source?
I'm sorry, I just noticed your comment. From what I could see in the repository and OpenReview discussion, some parts of the dataset, such as GSMNoOp, are not part of the current public release. The repository issues also mention that the data generation code is not included at the moment. This is just based on my quick check, so there may be more updates or releases coming later.
OpenReview:
https://openreview.net/forum?id=AjXkRZIvjB
Official blog post:
https://machinelearning.apple.com/research/gsm-symbolic
Repo:
https://github.com/apple/ml-gsm-symbolic
HuggingFace:
https://huggingface.co/datasets/apple/GSM-Symbolic
Generative Verifiers: Reward Modeling as Next-Token Prediction, Lunjun Zhang+, N_A, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #SelfCorrection #Verification #RewardModel #GenerativeVerifier Issue Date: 2024-09-11 GPT Summary- 検証器と報酬モデルを用いてLLMの推論性能を向上させる新しいアプローチ、生成的検証器(GenRM)を提案。GenRMは次トークン予測を用いて検証と解決策生成を共同で行い、指示チューニングや思考の連鎖を活用。実験により、GenRMは従来の検証器を上回り、問題解決率が16-64%向上することを示した。 Comment
LLMがリクエストに対する回答を生成したのちに、その回答をverifyするステップ + verifyの結果から回答を修正するステップを全てconcatした学習データをnext token predictionで用いることによって、モデル自身に自分の回答をverifyする能力を身につけさせることができた結果性能が向上しました、という研究らしい。また、Self-consistency [Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
のように複数の異なるCoTを並列して実行させ、そのmajority votingをとることでさらに性能が向上する。
[Paper Note] Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws, Zeyuan Allen-Zhu+, N_A, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #SyntheticData Issue Date: 2024-04-15 GPT Summary- 言語モデルのサイズと能力の関係を記述するスケーリング則に焦点を当てた研究。モデルが格納する知識ビット数を推定し、事実知識をタプルで表現。言語モデルは1つのパラメータあたり2ビットの知識を格納可能であり、7Bモデルは14Bビットの知識を格納可能。さらに、トレーニング期間、モデルアーキテクチャ、量子化、疎な制約、データの信号対雑音比が知識格納容量に影響することを示唆。ロータリー埋め込みを使用したGPT-2アーキテクチャは、知識の格納においてLLaMA/Mistralアーキテクチャと競合する可能性があり、トレーニングデータにドメイン名を追加すると知識容量が増加することが示された。 Comment
参考:
openreview: https://openreview.net/forum?id=FxNNiUgtfa
[Paper Note] Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting, Melanie Sclar+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Prompting #Evaluation #OpenWeight #Selected Papers/Blogs Issue Date: 2026-01-21 GPT Summary- LLMの性能特性化が重要であり、プロンプト設計がモデル挙動に強く影響することを示す。特に、プロンプトフォーマットに対するLLMの感度に注目し、微妙な変更で最大76ポイントの性能差が見られる。感度はモデルサイズや少数ショットの数に依存せず、プロンプトの多様なフォーマットにわたる性能範囲の報告が必要。モデル間のフォーマットパフォーマンスが弱く相関することから、固定されたプロンプトフォーマットでの比較の妥当性が疑問視される。迅速なフォーマット評価のための「FormatSpread」アルゴリズムを提案し、摂動の影響や内部表現も探る。 Comment
openreview: https://openreview.net/forum?id=RIu5lyNXjT
[Paper Note] InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation, Xingchao Liu+, ICLR'24, 2023.09
Paper/Blog Link My Issue
#Pocket Issue Date: 2025-11-28 GPT Summary- 本論文では、拡散モデルを用いたテキストから画像への生成において、従来の多段階サンプリングプロセスの遅さを改善するために、Rectified Flowを活用した新しい一段階モデル「InstaFlow」を提案します。InstaFlowは、Stable Diffusionの品質を維持しつつ、MS COCO 2017-5kでFIDを23.3に改善し、従来の手法を大きく上回る性能を示しました。また、MS COCO 2014-30kでは、わずか0.09秒でFID 13.1を達成し、トレーニングには199 A100 GPU日を要しました。コードとモデルは公開されています。 Comment
[Paper Note] On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes, Rishabh Agarwal+, ICLR'24, 2023.06
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Pocket #NLP #Distillation #Off-Policy #On-Policy #One-Line Notes Issue Date: 2025-10-30 GPT Summary- 一般化知識蒸留(GKD)は、教師モデルからのフィードバックを活用し、生徒モデルが自己生成した出力シーケンスで訓練する手法。これにより、出力シーケンスの分布不一致の問題を解決し、柔軟な損失関数の使用が可能になる。GKDは蒸留と強化学習の統合を促進し、要約、翻訳、算術推論タスクにおける自動回帰言語モデルの蒸留においてその有効性を示す。 Comment
openreview: https://openreview.net/forum?id=3zKtaqxLhW
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
での説明に基づくと、
オフポリシーの蒸留手法を使うと、教師モデルが生成した出力を用いて蒸留をするため、生徒モデルが実際に出力するcontextとは異なる出力に基づいて蒸留をするため、生徒モデルの推論時のcontextとのミスマッチが生じる課題があるが、オンポリシーデータを混ぜることでこの問題を緩和するような手法(つまり実際の生徒モデル運用時と似た状況で蒸留できる)。生徒モデルが賢くなるにつれて出力が高品質になるため、それらを学習データとして再利用することでpositiveなフィードバックループが形成されるという利点がある。また、強化学習と比較しても、SparseなReward Modelに依存せず、初期の性能が低いモデルに対しても適用できる利点があるとのこと(性能が低いと探索が進まない場合があるため)。
[Paper Note] MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases, Zechun Liu+, ICLR'24, 2024.02
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #SmallModel Issue Date: 2025-10-10 GPT Summary- モバイルデバイス向けに10億未満のパラメータを持つ高品質な大規模言語モデル(LLM)の設計を提案。深くて細いアーキテクチャを活用し、MobileLLMという強力なモデルを構築し、従来のモデルに対して精度を向上。さらに、重み共有アプローチを導入し、MobileLLM-LSとしてさらなる精度向上を実現。MobileLLMモデルファミリーは、チャットベンチマークでの改善を示し、一般的なデバイスでの小型モデルの能力を強調。
[Paper Note] Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing, Xinyu Hu+, ICLR'24, 2023.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Prompting #AutomaticPromptEngineering Issue Date: 2025-09-24 GPT Summary- Evokeという自動プロンプト洗練フレームワークを提案。レビュアーと著者のLLMがフィードバックループを形成し、プロンプトを洗練。難しいサンプルを選択することで、LLMの深い理解を促進。実験では、Evokeが論理的誤謬検出タスクで80以上のスコアを達成し、他の手法を大幅に上回る結果を示した。 Comment
openreview: https://openreview.net/forum?id=OXv0zQ1umU
pj page:
https://sites.google.com/view/evoke-llms/home
github:
https://github.com/microsoft/Evoke
githubにリポジトリはあるが、プロンプトテンプレートが書かれたtsvファイルが配置されているだけで、実験を再現するための全体のパイプラインは存在しないように見える。
[Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #LongSequence #Selected Papers/Blogs Issue Date: 2025-08-02 GPT Summary- YaRN(Yet another RoPE extensioN method)は、トランスフォーマーベースの言語モデルにおける位置情報のエンコードを効率的に行い、コンテキストウィンドウを従来の方法よりも10倍少ないトークンと2.5倍少ない訓練ステップで拡張する手法を提案。LLaMAモデルが長いコンテキストを効果的に利用できることを示し、128kのコンテキスト長まで再現可能なファインチューニングを実現。 Comment
openreview: https://openreview.net/forum?id=wHBfxhZu1u
現在主流なコンテキストウィンドウ拡張手法。様々なモデルで利用されている。
[Paper Note] Let's Verify Step by Step, Hunter Lightman+, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #ReinforcementLearning #Reasoning #Selected Papers/Blogs #PRM Issue Date: 2025-06-26 GPT Summary- 大規模言語モデルの多段階推論能力が向上する中、論理的誤りが依然として問題である。信頼性の高いモデルを訓練するためには、結果監視とプロセス監視の比較が重要である。独自の調査により、プロセス監視がMATHデータセットの問題解決において結果監視を上回ることを発見し、78%の問題を解決した。また、アクティブラーニングがプロセス監視の効果を向上させることも示した。関連研究のために、80万の人間フィードバックラベルからなるデータセットPRM800Kを公開した。 Comment
OpenReview: https://openreview.net/forum?id=v8L0pN6EOi
Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
Paper/Blog Link My Issue
#Pocket #Attention #LongSequence #AttentionSinks #Selected Papers/Blogs #KeyPoint Notes #Reference Collection Issue Date: 2025-04-05 GPT Summary- 大規模言語モデル(LLMs)をマルチラウンド対話に展開する際の課題として、メモリ消費と長いテキストへの一般化の難しさがある。ウィンドウアテンションはキャッシュサイズを超えると失敗するが、初期トークンのKVを保持することでパフォーマンスが回復する「アテンションシンク」を発見。これを基に、StreamingLLMというフレームワークを提案し、有限のアテンションウィンドウでトレーニングされたLLMが無限のシーケンス長に一般化可能になることを示した。StreamingLLMは、最大400万トークンで安定した言語モデリングを実現し、ストリーミング設定で従来の手法を最大22.2倍の速度で上回る。 Comment
Attention Sinksという用語を提言した研究
下記のpassageがAttention Sinksの定義(=最初の数トークン)とその気持ち(i.e., softmaxによるattention scoreは足し合わせて1にならなければならない。これが都合の悪い例として、現在のtokenのqueryに基づいてattention scoreを計算する際に過去のトークンの大半がirrelevantな状況を考える。この場合、irrelevantなトークンにattendしたくはない。そのため、auto-regressiveなモデルでほぼ全てのcontextで必ず出現する最初の数トークンを、irrelevantなトークンにattendしないためのattention scoreの捨て場として機能するのうに学習が進む)の理解に非常に重要
> To understand the failure of window attention, we find an interesting phenomenon of autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens
“attention sinks". Despite their lack of semantic significance, they collect significant attention scores. We attribute the reason to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究。こちらでAttentionSinkがどのように作用しているのか?が分析されている。
Figure1が非常にわかりやすい。Initial Token(実際は3--4トークン)のKV Cacheを保持することでlong contextの性能が改善する(Vanilla)。あるいは、Softmaxの分母に1を追加した関数を用意し(数式2)、全トークンのattention scoreの合計が1にならなくても許されるような変形をすることで、余剰なattention scoreが生じないようにすることでattention sinkを防ぐ(Zero Sink)。これは、ゼロベクトルのトークンを追加し、そこにattention scoreを逃がせるようにすることに相当する。もう一つの方法は、globalに利用可能なlearnableなSink Tokenを追加すること。これにより、不要なattention scoreの捨て場として機能させる。Table3を見ると、最初の4 tokenをKV Cacheに保持した場合はperplexityは大きく変わらないが、Sink Tokenを導入した方がKV Cacheで保持するInitial Tokenの量が少なくてもZero Sinkと比べると性能が良くなるため、今後モデルを学習する際はSink Tokenを導入することを薦めている。既に学習済みのモデルについては、Zero Sinkによってlong contextのモデリングに対処可能と思われる。
著者による解説:
openreview: https://openreview.net/forum?id=NG7sS51zVF
WebArena: A Realistic Web Environment for Building Autonomous Agents, Shuyan Zhou+, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #AIAgents Issue Date: 2025-04-02 GPT Summary- 生成AIの進展により、自律エージェントが自然言語コマンドで日常タスクを管理する可能性が生まれたが、現行のエージェントは簡略化された環境でのテストに限られている。本研究では、ウェブ上でタスクを実行するエージェントのための現実的な環境を構築し、eコマースやソーシャルフォーラムなどのドメインを含む完全なウェブサイトを提供する。この環境を基に、タスクの正確性を評価するベンチマークを公開し、実験を通じてGPT-4ベースのエージェントの成功率が14.41%であり、人間の78.24%には及ばないことを示した。これにより、実生活のタスクにおけるエージェントのさらなる開発の必要性が強調される。 Comment
Webにおけるさまざまなrealisticなタスクを評価するためのベンチマーク
実際のexample。スタート地点からピッツバーグのmuseumを巡る最短の経路を見つけるといった複雑なタスクが含まれる。
人間とGPT4,GPT-3.5の比較結果
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?, Carlos E. Jimenez+, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #SoftwareEngineering #Selected Papers/Blogs Issue Date: 2025-04-02 GPT Summary- SWE-benchは、12の人気Pythonリポジトリから得られた2,294のソフトウェアエンジニアリング問題を評価するフレームワークで、言語モデルがコードベースを編集して問題を解決する能力を測定します。評価の結果、最先端の商用モデルや微調整されたモデルSWE-Llamaも最も単純な問題しか解決できず、Claude 2はわずか1.96%の問題を解決するにとどまりました。SWE-benchは、より実用的で知的な言語モデルへの進展を示しています。 Comment
ソフトウェアエージェントの最もpopularなベンチマーク
主にpythonライブラリに関するリポジトリに基づいて構築されている。
SWE-Bench, SWE-Bench Lite, SWE-Bench Verifiedの3種類がありソフトウェアエージェントではSWE-Bench Verifiedを利用して評価することが多いらしい。Verifiedでは、issueの記述に曖昧性がなく、適切なunittestのスコープが適切なもののみが採用されているとのこと(i.e., 人間の専門家によって問題がないと判断されたもの)。
https://www.swebench.com/
Agenticな評価をする際に、一部の評価でエージェントがgit logを参照し本来は存在しないはずのリポジトリのfuture stateを見ることで環境をハッキングしていたとのこと:
これまでの評価結果にどの程度の影響があるかは不明。
openreview: https://openreview.net/forum?id=VTF8yNQM66
[Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Selected Papers/Blogs #KeyPoint Notes #SparseAutoEncoder #Interpretability #InterpretabilityScore Issue Date: 2025-03-15 GPT Summary- 神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment
日本語解説: https://note.com/ainest/n/nbe58b36bb2db
OpenReview: https://openreview.net/forum?id=F76bwRSLeK
SparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。
SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。
Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding, Zilong Wang+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #DataToTextGeneration #TabularData Issue Date: 2024-01-24 GPT Summary- LLMsを使用したChain-of-Tableフレームワークは、テーブルデータを推論チェーン内で活用し、テーブルベースの推論タスクにおいて高い性能を発揮することが示された。このフレームワークは、テーブルの連続的な進化を表現し、中間結果の構造化情報を利用してより正確な予測を可能にする。さまざまなベンチマークで最先端のパフォーマンスを達成している。 Comment
Table, Question, Operation Historyから次のoperationとそのargsを生成し、テーブルを順次更新し、これをモデルが更新の必要が無いと判断するまで繰り返す。最終的に更新されたTableを用いてQuestionに回答する手法。Questionに回答するために、複雑なテーブルに対する操作が必要なタスクに対して有効だと思われる。
Knowledge Fusion of Large Language Models, Fanqi Wan+, N_A, ICLR'24
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #read-later #ModelMerge Issue Date: 2024-01-23 GPT Summary- 本研究では、既存の事前訓練済みの大規模言語モデル(LLMs)を統合することで、1つの強力なモデルを作成する方法を提案しています。異なるアーキテクチャを持つ3つの人気のあるLLMsを使用して、ベンチマークとタスクのパフォーマンスを向上させることを実証しました。提案手法のコード、モデルの重み、およびデータはGitHubで公開されています。
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, N_A, ICLR'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Factuality #RAG(RetrievalAugmentedGeneration) Issue Date: 2023-10-29 GPT Summary- 大規模言語モデル(LLMs)は、事実に基づかない回答を生成することがあります。そこで、自己反省的な検索増強生成(Self-RAG)という新しいフレームワークを提案します。このフレームワークは、検索と自己反省を通じてLLMの品質と事実性を向上させます。実験結果は、Self-RAGが最先端のLLMsおよび検索増強モデルを大幅に上回ることを示しています。 Comment
RAGをする際の言語モデルの回答の質とfactual consistencyを改善せるためのフレームワーク。
reflection tokenと呼ばれる特殊トークンを導入し、言語モデルが生成の過程で必要に応じて情報をretrieveし、自身で生成内容を批評するように学習する。単語ごとに生成するのではなく、セグメント単位で生成する候補を生成し、批評内容に基づいて実際に生成するセグメントを選択する。
OpenReview: https://openreview.net/forum?id=hSyW5go0v8
Detecting Pretraining Data from Large Language Models, Weijia Shi+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pretraining #MachineLearning #NLP #LanguageModel Issue Date: 2023-10-26 GPT Summary- 本研究では、大規模言語モデル(LLMs)を訓練するためのデータの検出問題を研究し、新しい検出方法であるMin-K% Probを提案します。Min-K% Probは、LLMの下で低い確率を持つアウトライアーワードを検出することに基づいています。実験の結果、Min-K% Probは従来の方法に比べて7.4%の改善を達成し、著作権のある書籍の検出や汚染された下流の例の検出など、実世界のシナリオにおいて効果的な解決策であることが示されました。 Comment
実験結果を見るにAUCは0.73-0.76程度であり、まだあまり高くない印象。また、テキストのlengthはそれぞれ32,64,128,256程度。
openreview: https://openreview.net/forum?id=zWqr3MQuNs
Large Language Models as Optimizers, Chengrun Yang+, N_A, ICLR'24
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #AutomaticPromptEngineering Issue Date: 2023-09-09 GPT Summary- 本研究では、最適化タスクを自然言語で記述し、大規模言語モデル(LLMs)を使用して最適化を行う手法「Optimization by PROmpting(OPRO)」を提案しています。この手法では、LLMが以前の解とその値を含むプロンプトから新しい解を生成し、評価して次の最適化ステップのためのプロンプトに追加します。実験結果では、OPROによって最適化された最良のプロンプトが、人間が設計したプロンプトよりも優れていることが示されました。 Comment
`Take a deep breath and work on this problem step-by-step. `論文
# 概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。
# 手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。
Meta promptの例
openreview: https://openreview.net/forum?id=Bb4VGOWELI
CausalLM is not optimal for in-context learning, Nan Ding+, N_A, ICLR'24
Paper/Blog Link My Issue
#Analysis #MachineLearning #Pocket #NLP #LanguageModel #In-ContextLearning Issue Date: 2023-09-01 GPT Summary- 最近の研究では、トランスフォーマーベースのインコンテキスト学習において、プレフィックス言語モデル(prefixLM)が因果言語モデル(causalLM)よりも優れたパフォーマンスを示すことがわかっています。本研究では、理論的なアプローチを用いて、prefixLMとcausalLMの収束挙動を分析しました。その結果、prefixLMは線形回帰の最適解に収束する一方、causalLMの収束ダイナミクスはオンライン勾配降下アルゴリズムに従い、最適であるとは限らないことがわかりました。さらに、合成実験と実際のタスクにおいても、causalLMがprefixLMよりも性能が劣ることが確認されました。 Comment
参考:
CausalLMでICLをした場合は、ICL中のdemonstrationでオンライン学習することに相当し、最適解に収束しているとは限らない……?が、hillbigさんの感想に基づくと、結果的には実は最適解に収束しているのでは?という話も出ているし、よく分からない。
SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Ning Miao+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Reasoning #Verification Issue Date: 2023-08-08 GPT Summary- 最新の大規模言語モデル(LLMs)は、推論問題を解決するために有望な手法ですが、複雑な問題にはまだ苦戦しています。本研究では、LLMsが自身のエラーを認識する能力を持っているかどうかを探求し、ゼロショットの検証スキームを提案します。この検証スキームを使用して、異なる回答に対して重み付け投票を行い、質問応答のパフォーマンスを向上させることができることを実験で確認しました。 Comment
これはおもしろそう。後で読む
OpenReview: https://openreview.net/forum?id=pTHfApDakA
[Paper Note] Language Modelling with Pixels, Phillip Rust+, ICLR'23, 2022.07
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Transformer #Encoder #Pixel-based Issue Date: 2025-10-22 GPT Summary- PIXELは、テキストを画像として表現する新しい言語モデルで、語彙のボトルネックを回避し、言語間での表現転送を可能にする。86MパラメータのPIXELは、BERTと同じデータで事前学習され、非ラテン文字を含む多様な言語での構文的および意味的タスクでBERTを大幅に上回る性能を示したが、ラテン文字ではやや劣る結果となった。また、PIXELは正字法的攻撃や言語コードスイッチングに対してBERTよりも堅牢であることが確認された。 Comment
元ポスト:
[Paper Note] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, Xingchao Liu+, ICLR'23, 2022.09
Paper/Blog Link My Issue
#ComputerVision #MachineLearning #Pocket #Selected Papers/Blogs #RectifiedFlow Issue Date: 2025-10-10 GPT Summary- rectified flowという新しいアプローチを提案し、2つの分布間での輸送を学習するODEモデルを用いる。これは、直線的な経路を学習することで計算効率を高め、生成モデルやドメイン転送において統一的な解決策を提供する。rectificationを通じて、非増加の凸輸送コストを持つ新しい結合を生成し、再帰的に適用することで直線的なフローを得る。実証研究では、画像生成や翻訳において優れた性能を示し、高品質な結果を得ることが確認された。 Comment
openreview: https://openreview.net/forum?id=XVjTT1nw5z
日本語解説(fmuuly, zenn):
- Rectified Flow 1:
https://zenn.dev/fmuuly/articles/37cc3a2f17138e
- Rectified Flow 2:
https://zenn.dev/fmuuly/articles/a062fcd340207f
- Rectified Flow 3:
https://zenn.dev/fmuuly/articles/0f262fc003e202
[Paper Note] Building Normalizing Flows with Stochastic Interpolants, Michael S. Albergo+, ICLR'23
Paper/Blog Link My Issue
#Pocket #FlowMatching #OptimalTransport Issue Date: 2025-07-09 GPT Summary- 基準確率密度とターゲット確率密度の間の連続時間正規化フローに基づく生成モデルを提案。従来の手法と異なり、逆伝播を必要とせず、速度に対する単純な二次損失を導出。フローはサンプリングや尤度推定に使用可能で、経路長の最小化も最適化できる。ガウス密度の場合、ターゲットをサンプリングする拡散モデルを構築可能だが、よりシンプルな確率流のアプローチを示す。密度推定タスクでは、従来の手法と同等以上の性能を低コストで達成し、画像生成においても良好な結果を示す。最大$128\times128$の解像度までスケールアップ可能。
[Paper Note] Flow Matching for Generative Modeling, Yaron Lipman+, ICLR'23
Paper/Blog Link My Issue
#ComputerVision #Pocket #DiffusionModel #Selected Papers/Blogs #FlowMatching #OptimalTransport Issue Date: 2025-07-09 GPT Summary- Continuous Normalizing Flows(CNFs)に基づく新しい生成モデルの訓練手法Flow Matching(FM)を提案。FMは固定された条件付き確率経路のベクトル場を回帰し、シミュレーション不要で訓練可能。拡散経路と併用することで、より堅牢な訓練が実現。最適輸送を用いた条件付き確率経路は効率的で、訓練とサンプリングが速く、一般化性能も向上。ImageNetでの実験により、FMは拡散ベース手法よりも優れた性能を示し、迅速なサンプル生成を可能にする。 Comment
UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #MultiModal #Encoder #Encoder-Decoder #KeyPoint Notes Issue Date: 2024-09-26 GPT Summary- 本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 Comment
OpenReview: https://openreview.net/forum?id=6ruVLB727MC
encoder-decoder/decoder-onlyなど特定のアーキテクチャに依存しないアーキテクチャagnosticな事前学習手法であるMoDを提案。
MoDでは3種類のDenoiser [R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを活用する。学習時には与えらえたタスクに対して適切なモードをスイッチできるようにparadigm token ([R], [S], [X])を与え挙動を変化させられるようにしており[^1]、finetuning時においては事前にタスクごとに定義をして与えるなどのことも可能。
[^1]: 事前学習中に具体的にどのようにモードをスイッチするのかはよくわからなかった。ランダムに変更するのだろうか。
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, N_A, ICLR'23
Paper/Blog Link My Issue
#MachineLearning #NLP #LanguageModel #Quantization Issue Date: 2023-09-29 GPT Summary- 本研究では、GPTモデルの推論における計算およびストレージコストの問題に取り組み、新しいワンショット重み量子化手法であるGPTQを提案します。GPTQは高い精度と効率性を持ち、1750億のパラメータを持つGPTモデルを4時間のGPU時間で量子化することができます。提案手法は従来の手法と比較して圧縮率を2倍以上向上させ、精度を保持することができます。さらに、提案手法は極端な量子化領域でも合理的な精度を提供します。実験結果では、提案手法を使用することでエンドツーエンドの推論速度が約3.25倍から4.5倍向上することが示されています。提案手法の実装はhttps://github.com/IST-DASLab/gptqで利用可能です。 Comment
# 概要
- 新たなpost-training量子化手法であるGPTQを提案
- 数時間以内に数千億のパラメータを持つモデルでの実行が可能であり、パラメータごとに3~4ビットまで圧縮するが、精度の大きな損失を伴わない
- OPT-175BおよびBLOOM-176Bを、約4時間のGPU時間で、perplexityのわずかな増加で量子化することができた
- 数千億のパラメータを持つ非常に高精度な言語モデルを3-4ビットに量子化可能なことを初めて示した
- 先行研究のpost-training手法は、8ビット(Yao et al., 2022; Dettmers et al., 2022)。
- 一方、以前のtraining-basedの手法は、1~2桁小さいモデルのみを対象としていた(Wu et al., 2022)。
# Background
## Layer-wise quantization
各linear layerがあるときに、full precisionのoutputを少量のデータセットをネットワークに流したときに、quantized weight W^barを用いてreconstructできるように、squared error lossを最小化する方法。
## Optimal Brain quantization (OBQ)
OBQでは equation (1)をWの行に関するsummationとみなす。そして、それぞれの行 **w** をOBQは独立に扱い、ある一つの重みw_qをquantizeするときに、エラーがw_qのみに基づいていることを補償するために他の**w**の全てのquantizedされていない重みをupdateする。式で表すと下記のようになり、Fは残りのfull-precision weightの集合を表している。
この二つの式を、全ての**w**の重みがquantizedされるまで繰り返し適用する。
つまり、ある一個の重みをquantizedしたことによる誤差を補うように、他のまだquantizedされていない重みをupdateすることで、次に別の重みをquantizedする際は、最初の重みがquantizedされたことを考慮した重みに対してquantizedすることになる。これを繰り返すことで、quantizedしたことによる誤差を考慮して**w**全体をアップデートできる、という気持ちだと思う。
この式は高速に計算することができ、medium sizeのモデル(25M parameters; ResNet-50 modelなど)とかであれば、single GPUで1時間でquantizeできる。しかしながら、OBQはO(d_row * d_col^3)であるため、(ここでd_rowはWの行数、d_colはwの列数)、billions of parametersに適用するには計算量が多すぎる。
# Algorithm
## Step 1: Arbitrary Order Insight.
通常のOBQは、量子化誤差が最も少ない重みを常に選択して、greedyに重みを更新していく。しかし、パラメータ数が大きなモデルになると、重みを任意の順序で量子化したとしてもそれによる影響は小さいと考えられる。なぜなら、おそらく、大きな個別の誤差を持つ量子化された重みの数が少ないと考えられ、その重みがプロセスのが進むにつれて(アップデートされることで?)相殺されるため。
このため、提案手法は、すべての行の重みを同じ順序で量子化することを目指し、これが通常、最終的な二乗誤差が元の解と同じ結果となることを示す。が、このために2つの課題を乗り越えなければならない。
## Step2. Lazy Batch-Updates
Fを更新するときは、各エントリに対してわずかなFLOPを使用して、巨大な行列のすべての要素を更新する必要があります。しかし、このような操作は、現代のGPUの大規模な計算能力を適切に活用することができず、非常に小さいメモリ帯域幅によってボトルネックとなる。
幸いにも、この問題は以下の観察によって解決できる:列iの最終的な四捨五入の決定は、この特定の列で行われた更新にのみ影響され、そのプロセスの時点で後の列への更新は関連がない。これにより、更新を「lazy batch」としてまとめることができ、はるかに効率的なGPUの利用が可能となる。(要は独立して計算できる部分は全部一気に計算してしまって、後で一気にアップデートしますということ)。たとえば、B = 128の列にアルゴリズムを適用し、更新をこれらの列と対応するB × Bブロックの H^-1 に格納する。
この戦略は理論的な計算量を削減しないものの、メモリスループットのボトルネックを改善する。これにより、非常に大きなモデルの場合には実際に1桁以上の高速化が提供される。
## Step 3: Cholesky Reformulation
行列H_F^-1が不定になることがあり、これがアルゴリズムが残りの重みを誤った方向に更新する原因となり、該当する層に対して悪い量子化を実施してしまうことがある。この現象が発生する確率はモデルのサイズとともに増加することが実際に観察された。これを解決するために、コレスキー分解を活用して解決している(詳細はきちんと読んでいない)。
# 実験で用いたCalibration data
GPTQのキャリブレーションデータ全体は、C4データセット(Raffel et al., 2020)からのランダムな2048トークンのセグメント128個で構成される。つまり、ランダムにクロールされたウェブサイトからの抜粋で、一般的なテキストデータを表している。GPTQがタスク固有のデータを一切見ていないため「ゼロショット」な設定でquantizationを実施している。
# Language Generationでの評価
WikiText2に対するPerplexityで評価した結果、先行研究であるRTNを大幅にoutperformした。
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #Prompting #AutomaticPromptEngineering Issue Date: 2023-09-05 GPT Summary- 大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。 Comment
プロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
openreview: https://openreview.net/forum?id=92gvk82DE-
Mass-Editing Memory in a Transformer, Kevin Meng+, N_A, ICLR'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #KnowledgeEditing Issue Date: 2023-05-04 GPT Summary- - 大規模言語モデルを更新することで、専門的な知識を追加できることが示されている- しかし、これまでの研究は主に単一の関連付けの更新に限定されていた- 本研究では、MEMITという方法を開発し、多数のメモリを直接言語モデルに更新することができることを実験的に示した- GPT-J(6B)およびGPT-NeoX(20B)に対して数千の関連付けまでスケーリングでき、これまでの研究を桁違いに上回ることを示した- コードとデータはhttps://memit.baulab.infoにあります。
SemPPL: Predicting pseudo-labels for better contrastive representations, Matko Bošnjak+, N_A, ICLR'23
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Embeddings #Pocket #RepresentationLearning #ContrastiveLearning #Semi-Supervised Issue Date: 2023-04-30 GPT Summary- 本研究では、コンピュータビジョンにおける半教師あり学習の問題を解決するために、Semantic Positives via Pseudo-Labels (SemPPL)という新しい手法を提案している。この手法は、ラベル付きとラベルなしのデータを組み合わせて情報豊富な表現を学習することができ、ResNet-$50$を使用してImageNetの$1\%$および$10\%$のラベルでトレーニングする場合、競合する半教師あり学習手法を上回る最高性能を発揮することが示された。SemPPLは、強力な頑健性、分布外および転移性能を示すことができる。 Comment
後ほど説明を追記する
関連:
- A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20
[Paper Note] Self-Consistency Improves Chain of Thought Reasoning in Language Models, Xuezhi Wang+, ICLR'23, 2022.03
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #LanguageModel #Chain-of-Thought #Test-Time Scaling #Selected Papers/Blogs Issue Date: 2023-04-27 GPT Summary- 自己一貫性という新しいデコーディング戦略を提案し、chain-of-thought promptingの性能を向上。多様な推論経路をサンプリングし、一貫した答えを選択することで、GSM8KやSVAMPなどのベンチマークで顕著な改善を達成。 Comment
self-consistencyと呼ばれる新たなCoTのデコーディング手法を提案。
これは、難しいreasoningが必要なタスクでは、複数のreasoningのパスが存在するというintuitionに基づいている。
self-consistencyではまず、普通にCoTを行う。そしてgreedyにdecodingする代わりに、以下のようなプロセスを実施する:
1. 多様なreasoning pathをLLMに生成させ、サンプリングする。
2. 異なるreasoning pathは異なるfinal answerを生成する(= final answer set)。
3. そして、最終的なanswerを見つけるために、reasoning pathをmarginalizeすることで、final answerのsetの中で最も一貫性のある回答を見出す。
これは、もし異なる考え方によって同じ回答が導き出されるのであれば、その最終的な回答は正しいという経験則に基づいている。
self-consistencyを実現するためには、複数のreasoning pathを取得した上で、最も多いanswer a_iを選択する(majority vote)。これにはtemperature samplingを用いる(temperatureを0.5やら0.7に設定して、より高い信頼性を保ちつつ、かつ多様なoutputを手に入れる)。
temperature samplingについては[こちら](
https://openreview.net/pdf?id=rygGQyrFvH)の論文を参照のこと。
sampling数は増やせば増やすほど性能が向上するが、徐々にサチってくる。サンプリング数を増やすほどコストがかかるので、その辺はコスト感との兼ね合いになると思われる。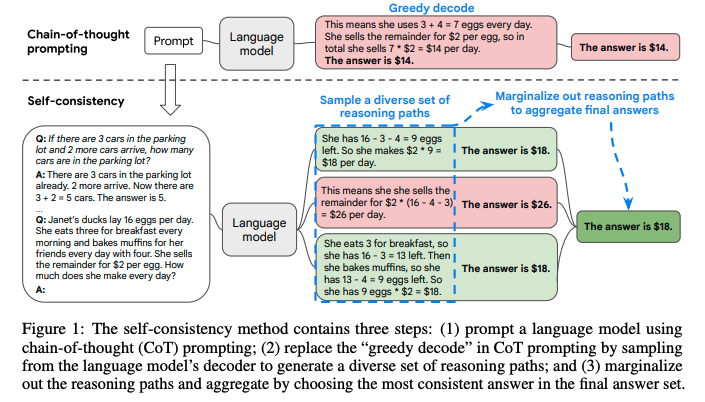
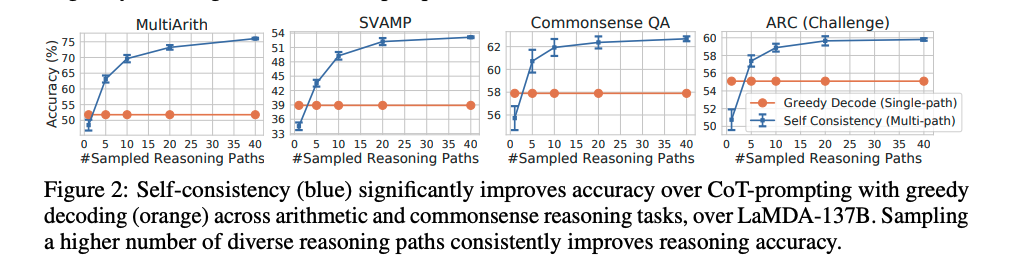
Self-consistencyは回答が閉じた集合であるような問題に対して適用可能であり、open-endなquestionでは利用できないことに注意が必要。ただし、open-endでも回答間になんらかの関係性を見出すような指標があれば実現可能とlimitationで言及している。
Automatic Chain of Thought Prompting in Large Language Models, Zhang+, Shanghai Jiao Tong University, ICLR'23
Paper/Blog Link My Issue
#NeuralNetwork #NLP #LanguageModel #Chain-of-Thought Issue Date: 2023-04-27 Comment
LLMによるreasoning chainが人間が作成したものよりも優れていることを示しているとのこと [Paper Note] Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models, Jiashuo Sun+, NAACL'24 Findings, 2023.04 より
clusteringベースな手法を利用することにより、誤りを含む例が単一のクラスタにまとめられうことを示し、これにより過剰な誤ったデモンストレーションが軽減されることを示した。
手法の概要。questionを複数のクラスタに分割し、各クラスタから代表的なquestionをサンプリングし、zero-shot CoTでreasoning chainを作成しpromptに組み込む。最終的に回答を得たいquestionに対しても、上記で生成した複数のquestion-reasoningで条件付けした上で、zeroshot-CoTでrationaleを生成する。
[Paper Note] WizardLM: Empowering large pre-trained language models to follow complex instructions, Can Xu+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #InstructionTuning #SyntheticData #KeyPoint Notes Issue Date: 2023-04-25 GPT Summary- 本論文では、LLMを用いて複雑な指示データを自動生成する方法を提案。Evol-Instructを使用して初期の指示を段階的に書き換え、生成したデータでLLaMAをファインチューニングし、WizardLMモデルを構築。評価結果は、Evol-Instructからの指示が人間作成のものより優れており、WizardLMがChatGPTよりも高い評価を得ることを示す。AI進化による指示生成がLLM強化の有望なアプローチであることを示唆。 Comment
instruction trainingは大きな成功を収めているが、人間がそれらのデータを作成するのはコストがかかる。また、そもそも複雑なinstructionを人間が作成するのは苦労する。そこで、LLMに自動的に作成させる手法を提案している(これはself instructと一緒)。データを生成する際は、seed setから始め、step by stepでinstructionをrewriteし、より複雑なinstructionとなるようにしていく。
これらの多段的な複雑度を持つinstructionをLLaMaベースのモデルに食わせてfinetuningした(これをWizardLMと呼ぶ)。人手評価の結果、WizardLMがChatGPTよりも好ましいレスポンスをすることを示した。特に、WizaraLMはコード生成や、数値計算といった難しいタスクで改善を示しており、複雑なinstructionを学習に利用することの重要性を示唆している。
EvolInstructを提案。"1+1=?"といったシンプルなinstructionからスタートし、これをLLMを利用して段階的にcomplexにしていく。complexにする方法は2通り:
- In-Depth Evolving: instructionを5種類のoperationで深掘りする(blue direction line)
- add constraints
- deepening
- concretizing
- increase reasoning steps
- complicate input
- In-breadth Evolving: givenなinstructionから新しいinstructionを生成する
上記のEvolvingは特定のpromptを与えることで実行される。
また、LLMはEvolvingに失敗することがあるので、Elimination Evolvingと呼ばれるフィルタを利用してスクリーニングした。
フィルタリングでは4種類の失敗するsituationを想定し、1つではLLMを利用。2枚目画像のようなinstructionでフィルタリング。
1. instructionの情報量が増えていない場合。
2. instructionがLLMによって応答困難な場合(短すぎる場合やsorryと言っている場合)
3. puctuationやstop wordsによってのみ構成されている場合
4.明らかにpromptの中から単語をコピーしただけのinstruction(given prompt, rewritten prompt, #Rewritten Prompt#など)

[Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #Pocket #NLP #MultitaskLearning #MultiModal #SpeechProcessing Issue Date: 2025-07-10 GPT Summary- 汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。 Comment
当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
[Paper Note] Fast Model Editing at Scale, Eric Mitchell+, ICLR'22
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #KnowledgeEditing Issue Date: 2025-06-18 GPT Summary- MEND(モデル編集ネットワーク)は、事前学習モデルの動作を迅速かつ局所的に編集するための手法で、単一の入力-出力ペアを用いて勾配分解を活用します。これにより、10億以上のパラメータを持つモデルでも、1台のGPUで短時間でトレーニング可能です。実験により、MENDが大規模モデルの編集において効果的であることが示されました。 Comment
OpenReview: https://openreview.net/forum?id=0DcZxeWfOPt
LoRA: Low-Rank Adaptation of Large Language Models, Edward J. Hu+, ICLR'22
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #PEFT(Adaptor/LoRA) #PostTraining #Selected Papers/Blogs Issue Date: 2025-05-12 GPT Summary- LoRAは、事前学習された大規模モデルの重みを固定し、各層に訓練可能なランク分解行列を追加することで、ファインチューニングに必要なパラメータを大幅に削減する手法です。これにより、訓練可能なパラメータを1万分の1、GPUメモリを3分の1に減少させながら、RoBERTaやGPT-3などで同等以上の性能を実現します。LoRAの実装はGitHubで公開されています。 Comment
OpenrReview: https://openreview.net/forum?id=nZeVKeeFYf9
LoRAもなんやかんやメモってなかったので追加。
事前学習済みのLinear Layerをfreezeして、freezeしたLinear Layerと対応する低ランクの行列A,Bを別途定義し、A,BのパラメータのみをチューニングするPEFT手法であるLoRAを提案した研究。オリジナルの出力に対して、A,Bによって入力を写像したベクトルを加算する。
チューニングするパラメータ数学はるかに少ないにも関わらずフルパラメータチューニングと(これは諸説あるが)同等の性能でPostTrainingできる上に、事前学習時点でのパラメータがfreezeされているためCatastrophic Forgettingが起きづらく(ただし新しい知識も獲得しづらい)、A,Bの追加されたパラメータのみを保存すれば良いのでストレージに優しいのも嬉しい。
- [Paper Note] LoRA-Pro: Are Low-Rank Adapters Properly Optimized?, Zhengbo Wang+, ICLR'25, 2024.07
などでも示されているが、一般的にLoRAとFull Finetuningを比較するとLoRAの方が性能が低いことが知られている点には留意が必要。
Towards Continual Knowledge Learning of Language Models, Joel Jang+, ICLR'22
Paper/Blog Link My Issue
#Pretraining #Pocket Issue Date: 2025-01-06 GPT Summary- 大規模言語モデル(LMs)の知識が陳腐化する問題に対処するため、「継続的知識学習(CKL)」という新しい継続的学習問題を定式化。CKLでは、時間不変の知識の保持、陳腐化した知識の更新、新しい知識の獲得を定量化するためのベンチマークとメトリックを構築。実験により、CKLが独自の課題を示し、知識を信頼性高く保持し学習するためにはパラメータの拡張が必要であることが明らかに。ベンチマークデータセットやコードは公開されている。
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution, Ananya Kumar+, N_A, ICLR'22
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #Pocket #Supervised-FineTuning (SFT) #CLIP #OOD Issue Date: 2023-05-15 GPT Summary- 事前学習済みモデルをダウンストリームタスクに転移する際、ファインチューニングと線形プロービングの2つの方法があるが、本研究では、分布のシフトが大きい場合、ファインチューニングが線形プロービングよりも分布外で精度が低くなることを発見した。LP-FTという2段階戦略の線形プロービング後の全体のファインチューニングが、両方のデータセットでファインチューニングと線形プロービングを上回ることを示唆している。 Comment
事前学習済みのニューラルモデルをfinetuningする方法は大きく分けて
1. linear layerをヘッドとしてconcatしヘッドのみのパラメータを学習
2. 事前学習済みモデル全パラメータを学習
の2種類がある。
前者はin-distributionデータに強いが、out-of-distributionに弱い。後者は逆という互いが互いを補完し合う関係にあった。
そこで、まず1を実施し、その後2を実施する手法を提案。in-distribution, out-of-distributionの両方で高い性能を出すことを示した(実験では画像処理系のデータを用いて、モデルとしてはImageNet+CLIPで事前学習済みのViTを用いている)。
Transformers Learn Shortcuts to Automata, Bingbin Liu+, arXiv'22
Paper/Blog Link My Issue
#Pocket Issue Date: 2023-05-04 GPT Summary- トランスフォーマーモデルは再帰性を欠くが、少ない層でアルゴリズム的推論を行える。研究により、低深度のトランスフォーマーが有限状態オートマトンの計算を階層的に再パラメータ化できることを発見。多項式サイズの解決策が存在し、特に$O(1)$深度のシミュレーターが一般的であることを示した。合成実験でトランスフォーマーがショートカット解決策を学習できることを確認し、その脆弱性と緩和策も提案。 Comment
OpenReview: https://openreview.net/forum?id=De4FYqjFueZ
[Paper Note] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Alexey Dosovitskiy+, ICLR'21
Paper/Blog Link My Issue
#ComputerVision #Pocket #Transformer #Selected Papers/Blogs #Backbone Issue Date: 2025-08-25 GPT Summary- 純粋なトランスフォーマーを画像パッチのシーケンスに直接適用することで、CNNへの依存なしに画像分類タスクで優れた性能を発揮できることを示す。大量のデータで事前学習し、複数の画像認識ベンチマークで最先端のCNNと比較して優れた結果を達成し、計算リソースを大幅に削減。 Comment
openreview: https://openreview.net/forum?id=YicbFdNTTy
ViTを提案した研究
Measuring Massive Multitask Language Understanding, Dan Hendrycks+, N_A, ICLR'21
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Evaluation #Selected Papers/Blogs Issue Date: 2023-07-24 GPT Summary- 私たちは、マルチタスクのテキストモデルの正確性を測定するための新しいテストを提案しています。このテストは57のタスクをカバーし、広範な世界知識と問題解決能力が必要です。現在のモデルはまだ専門家レベルの正確性に達しておらず、性能に偏りがあります。私たちのテストは、モデルの弱点を特定するために使用できます。 Comment
OpenReview: https://openreview.net/forum?id=d7KBjmI3GmQ
MMLU論文
- [Paper Note] Are We Done with MMLU?, Aryo Pradipta Gema+, NAACL'25
において、多くのエラーが含まれることが指摘され、再アノテーションが実施されている。
GROKKING: GENERALIZATION BEYOND OVERFIT- TING ON SMALL ALGORITHMIC DATASETS, Power+, ICLR'21 Workshop
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Grokking Issue Date: 2023-04-25 Comment
学習後すぐに学習データをmemorizeして、汎化能力が無くなったと思いきや、10^3ステップ後に突然汎化するという現象(Grokking)を報告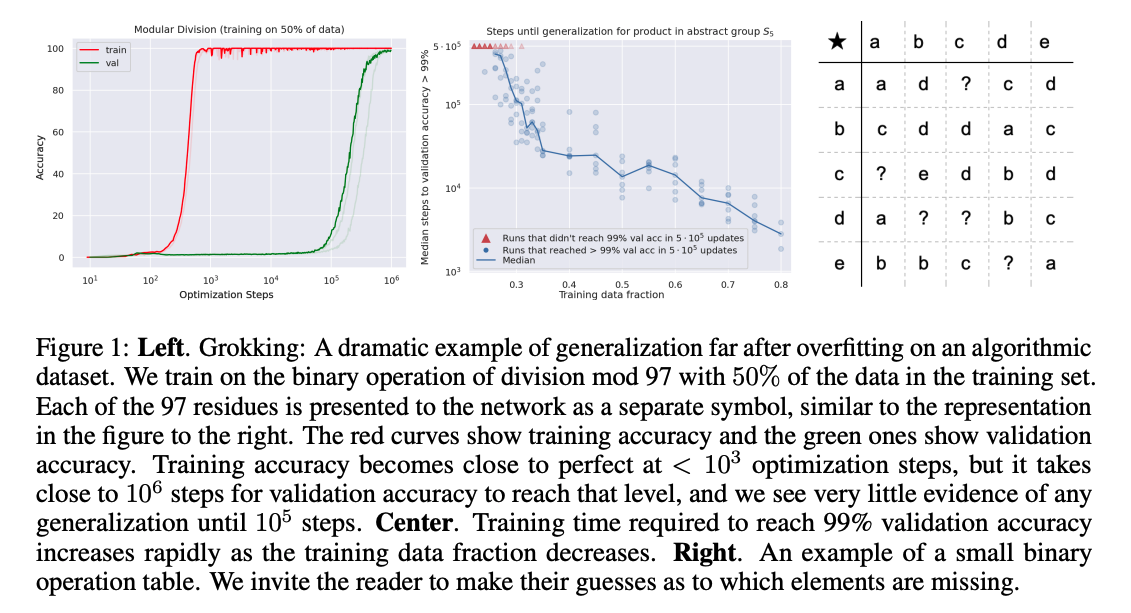
学習データが小さければ小さいほど汎化能力を獲得するのに時間がかかる模様
[Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #Transformer #Attention #Sparse #SparseAttention Issue Date: 2025-08-05 GPT Summary- 本研究では、トランスフォーマーモデルの効率を向上させるために、局所感度ハッシュを用いた注意機構と可逆残差層を提案。これにより、計算量をO($L^2$)からO($L\log L$)に削減し、メモリ効率と速度を向上させたReformerモデルを実現。トランスフォーマーと同等の性能を維持。 Comment
openreview: https://openreview.net/forum?id=rkgNKkHtvB
[Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Pocket #LearningPhenomena Issue Date: 2025-07-12 GPT Summary- 深層学習タスクにおける「ダブルデセント」現象を示し、モデルサイズの増加に伴い性能が一時的に悪化し、その後改善されることを明らかにした。また、ダブルデセントはモデルサイズだけでなくトレーニングエポック数にも依存することを示し、新たに定義した「効果的なモデルの複雑さ」に基づいて一般化されたダブルデセントを仮定。これにより、トレーニングサンプル数を増やすことで性能が悪化する特定の領域を特定できることを示した。 Comment
A Simple Framework for Contrastive Learning of Visual Representations, Ting Chen+, ICML'20
Paper/Blog Link My Issue
#ComputerVision #Pocket #DataAugmentation #ContrastiveLearning #Self-SupervisedLearning #Selected Papers/Blogs Issue Date: 2025-05-18 GPT Summary- 本論文では、視覚表現の対比学習のためのシンプルなフレームワークSimCLRを提案し、特別なアーキテクチャやメモリバンクなしで対比自己教師あり学習を簡素化します。データ拡張の重要性、学習可能な非線形変換の導入による表現の質向上、対比学習が大きなバッチサイズと多くのトレーニングステップから利益を得ることを示し、ImageNetで従来の手法を上回る結果を達成しました。SimCLRによる自己教師あり表現を用いた線形分類器は76.5%のトップ1精度を達成し、教師ありResNet-50に匹敵します。ラベルの1%でファインチューニングした場合、85.8%のトップ5精度を達成しました。 Comment
日本語解説: https://techblog.cccmkhd.co.jp/entry/2022/08/30/163625
Editable Neural Networks, Anton Sinitsin+, ICLR'20
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #MachineLearning #Pocket #NLP #KnowledgeEditing #read-later Issue Date: 2025-05-07 GPT Summary- 深層ニューラルネットワークの誤りを迅速に修正するために、Editable Trainingというモデル非依存の訓練手法を提案。これにより、特定のサンプルの誤りを効率的に修正し、他のサンプルへの影響を避けることができる。大規模な画像分類と機械翻訳タスクでその有効性を実証。 Comment
(おそらく)Knowledge Editingを初めて提案した研究
OpenReview: https://openreview.net/forum?id=HJedXaEtvS
The Curious Case of Neural Text Degeneration, Ari Holtzman+, ICLR'20
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Decoding #Selected Papers/Blogs Issue Date: 2025-04-14 GPT Summary- 深層ニューラル言語モデルは高品質なテキスト生成において課題が残る。尤度の使用がモデルの性能に影響を与え、人間のテキストと機械のテキストの間に分布の違いがあることを示す。デコーディング戦略が生成テキストの質に大きな影響を与えることが明らかになり、ニュークリアスsamplingを提案。これにより、多様性を保ちながら信頼性の低い部分を排除し、人間のテキストに近い質を実現する。 Comment
現在のLLMで主流なNucleus (top-p) Samplingを提案した研究
[Paper Note] Universal Transformers, Mostafa Dehghani+, ICLR'19
Paper/Blog Link My Issue
#Pocket #NLP #Transformer #Architecture #Generalization #RecurrentModels Issue Date: 2025-08-30 GPT Summary- 再帰神経ネットワーク(RNN)は逐次処理によりシーケンスモデリングで広く使われてきたが、トレーニングが遅くなる欠点がある。最近のフィードフォワードや畳み込みアーキテクチャは並列処理が可能で優れた結果を出しているが、RNNが得意とする単純なタスクでの一般化には失敗する。そこで、我々はユニバーサル・トランスフォーマー(UT)を提案し、フィードフォワードの並列処理能力とRNNの帰納バイアスを組み合わせたモデルを開発した。UTは特定の条件下でチューリング完全であり、実験では標準的なトランスフォーマーを上回る性能を示し、特にLAMBADAタスクで新たな最先端を達成し、機械翻訳でもBLEUスコアを改善した。 Comment
openreview: https://openreview.net/forum?id=HyzdRiR9Y7
[Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Pocket #LearningPhenomena Issue Date: 2025-07-12 GPT Summary- ニューラルネットワークのプルーニング技術は、パラメータ数を90%以上削減しつつ精度を維持できるが、スパースアーキテクチャの訓練は難しい。著者は「ロッタリー・チケット仮説」を提唱し、密なネットワークには効果的に訓練できるサブネットワーク(勝利のチケット)が存在することを発見。これらのチケットは特定の初期重みを持ち、元のネットワークと同様の精度に達する。MNISTとCIFAR10の実験で、10-20%のサイズの勝利のチケットを一貫して特定し、元のネットワークよりも早く学習し高精度に達することを示した。 Comment
[Paper Note] A Deep Reinforced Model for Abstractive Summarization, Romain Paulus+, ICLR'18, 2017.05
Paper/Blog Link My Issue
#DocumentSummarization #Supervised #Pocket #NLP #Abstractive #ReinforcementLearning Issue Date: 2017-12-31 GPT Summary- 新しいイントラアテンションを持つRNNベースのエンコーダ-デコーダモデルを提案し、教師あり学習と強化学習を組み合わせたトレーニング手法を導入。これにより、長い文書の要約における繰り返しや一貫性の問題を改善。CNN/Daily Mailデータセットで41.16のROUGE-1スコアを達成し、従来のモデルを上回る性能を示した。人間評価でも高品質な要約を生成することが確認された。
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, Noam Shazeer+, ICLR'17
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #MoE(Mixture-of-Experts) Issue Date: 2025-04-29 GPT Summary- 条件付き計算を用いたスパースゲーテッドミクスチャーオブエキスパート(MoE)レイヤーを導入し、モデル容量を1000倍以上向上。学習可能なゲーティングネットワークが各例に対してスパースなエキスパートの組み合わせを決定。最大1370億パラメータのMoEをLSTM層に適用し、言語モデリングや機械翻訳で低コストで優れた性能を達成。 Comment
Mixture-of-Experts (MoE) Layerを提案した研究
[Paper Note] A Structured Self-attentive Sentence Embedding, Zhouhan Lin+, ICLR'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #Embeddings #Pocket #NLP #RepresentationLearning #Selected Papers/Blogs #One-Line Notes Issue Date: 2017-12-28 GPT Summary- 自己注意機構を用いた新しい文埋め込みモデルを提案。2次元行列で文の異なる部分に注意を払い、視覚化手法も提供。著者プロファイリング、感情分類、テキスト含意の3つのタスクで評価し、他の手法と比較して性能が向上したことを示す。 Comment
OpenReview: https://openreview.net/forum?id=BJC_jUqxe
日本語解説: https://ryotaro.dev/posts/a_structured_self_attentivesentence_embedding/
self-attentionを提案した研究
[Paper Note] Very Deep Convolutional Networks for Large-Scale Image Recognition, Karen Simonyan+, ICLR'15
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #Backbone Issue Date: 2025-08-25 GPT Summary- 本研究では、3x3の畳み込みフィルタを用いた深い畳み込みネットワークの精度向上を評価し、16-19層の重み層で従来の最先端構成を大幅に改善したことを示す。これにより、ImageNet Challenge 2014で1位と2位を獲得し、他のデータセットでも優れた一般化性能を示した。最も性能の良い2つのConvNetモデルを公開し、深層視覚表現の研究を促進する。 Comment
いわゆるVGGNetを提案した論文
Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
Paper/Blog Link My Issue
#NeuralNetwork #MachineTranslation #Pocket #NLP #Attention #Selected Papers/Blogs Issue Date: 2025-05-12 GPT Summary- ニューラル機械翻訳は、エンコーダー-デコーダーアーキテクチャを用いて翻訳性能を向上させる新しいアプローチである。本論文では、固定長のベクトルの使用が性能向上のボトルネックであるとし、モデルが関連するソース文の部分を自動的に検索できるように拡張することを提案。これにより、英語からフランス語への翻訳タスクで最先端のフレーズベースシステムと同等の性能を達成し、モデルのアライメントが直感と一致することを示した。 Comment
(Cross-)Attentionを初めて提案した研究。メモってなかったので今更ながら追加。Attentionはここからはじまった(と認識している)
[Paper Note] Session-based Recommendations with Recurrent Neural Networks, Balázs Hidasi+, arXiv'15
Paper/Blog Link My Issue
#RecommenderSystems #Pocket #SessionBased #SequentialRecommendation #Selected Papers/Blogs Issue Date: 2019-08-02 GPT Summary- RNNを用いたセッションベースのレコメンダーシステムを提案。短いユーザーヒストリーに基づく推薦の精度向上を目指し、セッション全体をモデル化。ランキング損失関数などの修正を加え、実用性を考慮。実験結果は従来のアプローチに対して顕著な改善を示す。 Comment
RNNを利用したsequential recommendation (session-based recommendation)の先駆け的論文。
日本語解説: https://qiita.com/tatamiya/items/46e278a808a51893deac
ICLR 2026 - Submissions, Pangram Labs, 2025.11
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #Blog #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-11-15 Comment
元ポスト:
ICLR'26のsubmissionとreviewに対してLLMが生成したものが否かをDetectionした結果(検出性能は完璧な結果ではない点に注意)
この辺の議論が興味深い:
関連:
oh...
パイプライン解説:
母国語でレビューを書いて英語に翻訳している場合もAI判定される場合があるよという話:
ICLR公式が対応検討中とのこと:
ICLRからの続報:
> As such, reviewers who posted such poor quality reviews will also face consequences, including the desk rejection of their submitted papers.
> Authors who got such reviews (with many hallucinated references or false claims) should post a confidential message to ACs and SACs pointing out the poor quality reviews and provide the necessary evidence.
citationに明らかな誤植があり、LLMによるHallucinationが疑われる事例が多数見つかっている:
Oralに選ばれるレベルのスコアの研究論文にも多数のHallucinationが含まれており、1人の査読者がそれに気づきスコア0を与える、といった事態にもなっているようである:
当該論文はdesk rejectされたので現在は閲覧できないとのこと。
NeurIPS'25ではそもそも査読を通過した研究についても多くのHallucinationが見つかっているとのこと: