
MachineLearning
[Paper Note] Digital Red Queen: Adversarial Program Evolution in Core War with LLMs, Akarsh Kumar+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Multi #Pocket #NLP #LanguageModel #AIAgents #Generalization #EvolutionaryAlgorithm #AdversarialTraining Issue Date: 2026-01-12 GPT Summary- 大規模言語モデル(LLMs)を用いた自己対戦アルゴリズム「デジタルレッドクイーン(DRQ)」を提案。DRQは、コアウォーというゲームでアセンブリプログラムを進化させ、動的な目的に適応することで「レッドクイーン」ダイナミクスを取り入れる。多くのラウンドを経て、戦士は人間の戦士に対して一般的な行動戦略に収束する傾向を示し、静的な目的から動的な目的へのシフトの価値を強調。DRQは、サイバーセキュリティや薬剤耐性などの実用的な多エージェント敵対的ドメインでも有用である可能性を示唆。 Comment
元ポスト:
[Paper Note] From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence, Marc Finzi+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Analysis #Metrics #Pocket #Dataset #read-later #Selected Papers/Blogs #OOD #Generalization Issue Date: 2026-01-09 GPT Summary- 本研究では、データから新たな情報を生成する可能性や、情報の評価方法について探求する。シャノン情報やコルモゴロフの複雑性が無力である理由を示し、情報理論における三つの矛盾する現象を特定する。新たに導入した「エピプレキシティ」は、計算制約のある観察者がデータから学べる情報を捉え、データの構造的内容を評価する手法である。これにより、情報生成のメカニズムやデータの順序依存性を明らかにし、エピプレキシティを用いたデータ選択の理論的基盤を提供する。 Comment
元ポスト:
解説:
ポイント解説:
[Paper Note] How to Set the Batch Size for Large-Scale Pre-training?, Yunhua Zhou+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #read-later #Batch #Scheduler #CriticalBatchSize Issue Date: 2026-01-09 GPT Summary- WSD学習率スケジューラに特化した改訂版E(S)関係を導出し、事前学習中のトレーニングデータ消費とステップのトレードオフを分析。最小バッチサイズと最適バッチサイズを特定し、動的バッチサイズスケジューラを提案。実験により、提案したスケジューリング戦略がトレーニング効率とモデル品質を向上させることを示した。 Comment
元ポスト:
Critical batch sizeが提案された研究:
- An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18
[Paper Note] Deep Delta Learning, Yifan Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #InductiveBias #KeyPoint Notes #ResidualStream Issue Date: 2026-01-03 GPT Summary- Deep Delta Learning(DDL)を提案し、学習可能な恒等ショートカット接続を用いて残差接続を一般化。デルタ演算子を導入し、動的に補間可能なゲートを用いて情報の消去と新しい特徴の書き込みを制御。これにより、複雑な状態遷移をモデル化しつつ、安定したトレーニング特性を維持。 Comment
元ポスト:
解説:
residual connectionは残差を加算するがこれがinducive biasとなり複雑な状態遷移を表現する上ての妨げになっていたが、residual connectionを学習可能なdelta operator(rank1の対称行列によって実現される幾何変換)とやらで一般化することで、表現力を向上させる、といった話な模様。この行列によって実現される幾何変換は3種類によって構成され、βの値によって性質が変わる。たとえばβ=0に近づくほど恒等写像(何もしない)に近づき、β=1に近づくほど射影(特定方向の成分を捨てる)、β=2に近づくほど反射(特定方向の成分を反転させる)といった変換になるらしい。
概念が示されたのみで実験結果はまだ無さそうに見える。
[Paper Note] The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics, Edward Y. Chang, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel Issue Date: 2026-01-05 GPT Summary- 大規模言語モデル(LLMs)はAGIにおいて行き止まりとされるが、これは誤ったボトルネックの特定であると主張。パターンマッチングは必要だが、推論を行うための調整層が欠けている。UCCTを通じてこの層を形式化し、推論を支える理論を提案。無根拠な生成は基盤の最大尤度事前分布の取得に過ぎず、推論は目標指向の制約に向けた事後分布のシフトによって生じる。UCCTをアーキテクチャに変換し、調整スタックMACIを実装することで、AGIへの道はLLMsを通じて進むべきであると結論づける。 Comment
元ポスト:
[Paper Note] Deep sequence models tend to memorize geometrically; it is unclear why, Shahriar Noroozizadeh+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #Transformer #Memorization #FactualKnowledge #Geometric Issue Date: 2026-01-05 GPT Summary- 深層系列モデルは、エンティティ間の新しいグローバルな関係を幾何学的記憶として保存することを提案。これにより、難しい推論タスクが簡単なナビゲーションタスクに変換されることを示す。ブルートフォース検索よりも複雑な幾何学が学習されることを主張し、Node2Vecとの関連を分析して、自然に生じるスペクトルバイアスからこの幾何学が生まれることを示す。Transformerメモリの幾何学的強化の可能性を指摘し、知識獲得や忘却に関する直感を再考することを促す。 Comment
元ポスト:
[Paper Note] Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention, Haiquan Qiu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Transformer #read-later #Selected Papers/Blogs #Stability Issue Date: 2026-01-03 GPT Summary- 低精度フォーマットのトランスフォーマーモデルのトレーニングにおける不安定性の原因を分析し、フラッシュアテンションが損失の爆発を引き起こすメカニズムを明らかにした。具体的には、低ランク表現の出現と丸め誤差の累積がエラーの悪循環を生むことを示した。これを受けて、丸め誤差を軽減する修正を加えることでトレーニングの安定性を向上させ、実用的な解決策を提供した。 Comment
元ポスト:
[Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Transformer #Architecture #ICLR #ResidualStream Issue Date: 2026-01-02 GPT Summary- ハイパーコネクションは、残差接続の代替手法であり、勾配消失や表現崩壊の問題に対処します。異なる深さの特徴間の接続を調整し、層を動的に再配置することが可能です。実験により、ハイパーコネクションが残差接続に対して性能向上を示し、視覚タスクでも改善が確認されました。この手法は幅広いAI問題に適用可能と期待されています。 Comment
openreview: https://openreview.net/forum?id=9FqARW7dwB
[Paper Note] mHC: Manifold-Constrained Hyper-Connections, Zhenda Xie+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pocket #NLP #Transformer #Architecture #read-later #Selected Papers/Blogs #Stability #KeyPoint Notes #Reference Collection #ResidualStream Issue Date: 2026-01-02 GPT Summary- Manifold-Constrained Hyper-Connections(mHC)を提案し、残差接続の多様化による訓練の不安定性やメモリアクセスのオーバーヘッドに対処。mHCは残差接続空間を特定の多様体に射影し、恒等写像特性を回復しつつ効率を確保。実証実験により、大規模訓練での性能向上とスケーラビリティを示し、トポロジーアーキテクチャ設計の理解を深めることを期待。 Comment
元ポスト:
所見:
先行研究:
- [Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
- [Paper Note] Deep Residual Learning for Image Recognition, Kaiming He+, CVPR'16, 2015.12
所見:
ポイント解説:
解説:
従来のHCがResidual Streamに対してH_resを乗じて幾何的変換を実施する際に、H_resに制約がないため、Layerを重ねるごとにResidual Streamの大きさが指数的に発散、あるいは収縮していき学習が不安的になる課題を、二重確率行列(行と列の成分の合計が1.0となるような正規化をする)を用いた変換を用いることで、Residual Streamのノルムが変化しないようにし安定化させた、といった感じの話に見える。
[Paper Note] Stronger Normalization-Free Transformers, Mingzhi Chen+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pocket #Transformer #Architecture Issue Date: 2025-12-22 GPT Summary- 本研究では、Dynamic Tanh(DyT)を超える新たな正規化関数として$\mathrm{Derf}(x) = \mathrm{erf}(αx + s)$を提案。Derfは、画像認識、音声表現、DNA配列モデリングなどの分野でLayerNorm、RMSNorm、DyTを上回る性能を示し、その優れた一般化能力がパフォーマンス向上の要因であることを明らかにした。Derfはシンプルで強力なため、正規化なしのTransformerアーキテクチャにおける実用的な選択肢となる。 Comment
元ポスト:
先行研究:
- [Paper Note] Transformers without Normalization, Jiachen Zhu+, CVPR'25
[Paper Note] Transcoders Beat Sparse Autoencoders for Interpretability, Gonçalo Paulo+, arXiv'25, 2025.01
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #Transcoders #CircuitAnalysis #Interpretability Issue Date: 2025-12-21 GPT Summary- スパースオートエンコーダー(SAE)とトランスコーダーの特徴を比較した結果、トランスコーダーの方が解釈可能性が高いことが判明。さらに、アフィン・スキップ接続を追加したスキップトランスコーダーを提案し、解釈可能性を維持しつつ再構築損失を低下させることを示した。
[Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #LanguageModel #ICLR #SparseAutoEncoder #Interpretability Issue Date: 2025-12-21 GPT Summary- Matryoshka SAEという新しいスパースオートエンコーダーのバリアントを提案し、複数のネストされた辞書を同時に訓練することで、特徴を階層的に整理。小さな辞書は一般的な概念を、大きな辞書は特定の概念を学び、高次の特徴の吸収を防ぐ。Gemma-2-2BおよびTinyStoriesでの実験により、優れたパフォーマンスと分離された概念表現を確認。再構成性能にはトレードオフがあるが、実用的なタスクにおいて優れた代替手段と考えられる。 Comment
openreview: https://openreview.net/forum?id=m25T5rAy43
[Paper Note] Scaling Laws and Symmetry, Evidence from Neural Force Fields, Khang Ngo+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #Pocket #InductiveBias #Scaling Laws #One-Line Notes Issue Date: 2025-12-19 GPT Summary- 原子間ポテンシャルを学習する幾何学的タスクに関する実証研究を行い、等変性が大規模スケールで重要であることを示した。等変アーキテクチャは非等変モデルよりも優れたスケーリングを示し、高次の表現がより良いスケーリング指数に寄与することが分かった。データとモデルのサイズはアーキテクチャに関係なく連動してスケールすべきであり、対称性などの基本的な帰納的バイアスをモデルに発見させるべきではないと結論付けた。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=qyjaVda7t2
Inducive Bias(対称性vs.非対称性)によってスケーリング則の係数が変わることを原子間ポテンシャルを予測するタスクにおいて示した、という話っぽい?openreviewだとweaknessが多く指摘されている(この性質が一定の一般性を持つ話として記述されているが実験が限定的だからスコープを狭めるべきみたいな話やNLPから多くの手法を引っ張ってきているが原子間ポテンシャル予測は根本的に性質が異なるみたいな指摘など)ように見えるが果たして。
[Paper Note] Escaping the Verifier: Learning to Reason via Demonstrations, Locke Cai+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Reasoning #read-later #Selected Papers/Blogs #AdversarialTraining Issue Date: 2025-12-12 GPT Summary- RARO(Relativistic Adversarial Reasoning Optimization)は、専門家のデモンストレーションから逆強化学習を通じて推論能力を学習する手法。ポリシーは専門家の回答を模倣し、批評者は専門家を特定する敵対的なゲームを設定。実験では、RAROが検証者なしのベースラインを大幅に上回り、堅牢な推論学習を実現することを示した。 Comment
元ポスト:
重要研究に見える
has any code?
@duzhiyu11 Thank you for the comment. As stated in this post, they appear to be preparing to release the code. It would be best to wait for an official announcement from the authors regarding the code release.
[Paper Note] Do Language Models Use Their Depth Efficiently?, Róbert Csordás+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Transformer #Architecture #NeurIPS #Depth Issue Date: 2025-12-04 GPT Summary- 大規模言語モデル(LLM)の深さと性能の関係を分析した結果、後半の層は前半の層に比べて貢献度が低く、後半の層をスキップしても影響は小さいことが分かった。また、深いモデルは新しい計算を行っているのではなく、同じ計算を多くの層に分散させていることが示唆された。このことは、深さの増加がリターンの減少をもたらす理由を説明するかもしれない。 Comment
元ポスト:
RLとネットワークの深さの関係性を分析した研究もある:
- [Paper Note] 1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities, Wang+, NeurIPS'25 Best Paper Awards
[Paper Note] What Makes a Reward Model a Good Teacher? An Optimization Perspective, Noam Razin+, NeurIPS'25 Spotlight, 2025.03
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Alignment #ReinforcementLearning #NeurIPS #read-later #Selected Papers/Blogs #RewardModel #KeyPoint Notes Issue Date: 2025-12-03 GPT Summary- 報酬モデルの質はRLHFの成功に重要であり、精度だけでは不十分であることを示す。低い報酬の分散は平坦な最適化ランドスケープを引き起こし、完全に正確なモデルでも遅い最適化を招く可能性がある。異なる言語モデルに対する報酬モデルの効果も異なり、精度に基づく評価の限界を明らかにする。実験により、報酬の分散と精度の相互作用が確認され、効率的な最適化には十分な分散が必要であることが強調される。 Comment
元ポスト:
RLHFにおいてReward Modelが良い教師となれるかどうかは、Accuracy[^1]という単一次元で決まるのではなく、報酬の分散の大きさ[^2]も重要だよという話らしく、分散がほとんどない完璧なRMで学習すると学習が進まず、より不正確で報酬の分散が大きいRMの方が性能が良い。報酬の分散の大きさはベースモデルによるのでRM単体で良さを測ることにはげんかいがあるよ、といあ話らしい。
理想的な報酬の形状は山の頂上がなるべくズレておらず(=Accuracyが高い)かつ、山が平坦すぎない(=報酬の分散が高い)ようなものであり、
Accuracyが低いとReward Hackingが起きやすくなり、報酬の分散が低いと平坦になり学習効率が悪くなる(Figure1)。
[^1]: 応答Aが応答Bよりも優れているかという観点
[^2]: 学習対象のLLMがとりそうな出力に対して、RMがどれだけ明確に差をつけて報酬を与えられるかという観点(良い応答と悪い応答の弁別)
[Paper Note] 1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities, Wang+, NeurIPS'25 Best Paper Awards
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #ReinforcementLearning #Self-SupervisedLearning #NeurIPS #read-later #Selected Papers/Blogs #Robotics #Locomotion #ContrastiveReinforcementLearning #Manipulation #EmergentAbilities #Depth Issue Date: 2025-12-01 GPT Summary- 自己教師ありRLのスケーラビリティを改善するため、ネットワークの深さを1024層に増加させることで性能向上を実証。無監督の目標条件設定でエージェントが探索し、目標達成を学ぶ実験を行い、自己教師ありコントラストRLアルゴリズムの性能を向上させた。深さの増加は成功率を高め、行動の質的変化ももたらす。 Comment
元ポスト:
[Paper Note] Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training, Tony Bonnaire+, NeurIPS'25 Best Paper Awards, 2025.05
Paper/Blog Link My Issue
#Analysis #Pocket #DiffusionModel #NeurIPS #Memorization #Generalization Issue Date: 2025-11-29 GPT Summary- 拡散モデルのトレーニングダイナミクスを調査し、一般化から記憶への移行における2つの時間スケール($τ_\mathrm{gen}$と$τ_\mathrm{mem}$)を特定。$τ_\mathrm{mem}$はトレーニングセットのサイズに線形に増加し、一般化が可能なトレーニング時間のウィンドウが拡大することを示す。これにより、過学習が消失する閾値が存在し、記憶を回避できることが明らかに。実験と理論分析により結果が支持される。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=BSZqpqgqM0
日本語解説: https://www.docswell.com/s/DeepLearning2023/59MQLY-2025-11-11-132245
ポイント解説:
[Paper Note] Nested Learning: The Illusion of Deep Learning Architectures, Behrouz, NeurIPS'25, 2025.10
Paper/Blog Link My Issue
#NeurIPS Issue Date: 2025-11-26 GPT Summary- 新しい学習パラダイム「ネストされた学習(NL)」を提案し、深層学習における文脈内学習のメカニズムを解明。NLに基づく深層最適化器、自己修正型モデル、連続記憶システムを開発し、言語モデリングや継続的学習での有望な結果を示す学習モジュール「Hope」を提案。 Comment
元ポスト:
[Paper Note] What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity, Alexis Audran-Reiss+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AIAgents #Reasoning #ScientificDiscovery #Diversity #One-Line Notes Issue Date: 2025-11-21 GPT Summary- AI研究エージェントのパフォーマンスにおけるアイデアの多様性の役割を検討。MLE-benchでの分析により、パフォーマンスの高いエージェントはアイデアの多様性が増加する傾向があることが明らかに。制御実験でアイデアの多様性が高いほどパフォーマンスが向上することを示し、追加の評価指標でも発見が有効であることを確認。 Comment
元ポスト:
ideation時点における多様性を向上させる話らしい
[Paper Note] TabArena: A Living Benchmark for Machine Learning on Tabular Data, Nick Erickson+, NeurIPS'25 Spotlight, 2025.06
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #TabularData #Evaluation #Selected Papers/Blogs #Live #One-Line Notes Issue Date: 2025-11-14 GPT Summary- TabArenaは、表形式データのための初の生きたベンチマークシステムであり、継続的に更新されることを目的としています。手動でキュレーションされたデータセットとモデルを用いて、公開リーダーボードを初期化しました。結果は、モデルのベンチマークにおける検証方法やハイパーパラメータ設定の影響を示し、勾配ブースティング木が依然として強力である一方、深層学習手法もアンサンブルを用いることで追いついてきていることを観察しました。また、基盤モデルは小規模データセットで優れた性能を発揮し、モデル間のアンサンブルが表形式機械学習の進展に寄与することを示しました。TabArenaは、再現可能なコードとメンテナンスプロトコルを提供し、https://tabarena.ai で利用可能です。 Comment
pj page:
https://github.com/autogluon/tabarena
leaderboard:
https://huggingface.co/spaces/TabArena/leaderboard
liveデータに基づくベンチマークで、手動で収集された51のtabularデータセットが活用されているとのこと。またあるモデルに対して数百にも登るハイパーパラメータ設定での実験をしアンサンブルをすることで単一モデルが到達しうるピーク性能を見ることに主眼を置いている、またいな感じらしい。そしてやはり勾配ブースティング木が強い。tunedは単体モデルの最も性能が良い設定での性能で、ensembleは複数の設定での同一モデルのアンサンブルによる結果だと思われる。
> TabArena currently consists of:
> 51 manually curated tabular datasets representing real-world tabular data tasks.
> 9 to 30 evaluated splits per dataset.
> 16 tabular machine learning methods, including 3 tabular foundation models.
> 25,000,000 trained models across the benchmark, with all validation and test predictions cached to enable tuning and post-hoc ensembling analysis.
> A live TabArena leaderboard showcasing the results.
openreview: https://openreview.net/forum?id=jZqCqpCLdU
[Paper Note] TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models, Léo Grinsztajn+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #TabularData #FoundationModel Issue Date: 2025-11-14 GPT Summary- 次世代の表形式基盤モデルTabPFN-2.5は、最大50,000のデータポイントと2,000の特徴量を持つデータセット向けに設計され、TabPFNv2と比較してデータセルが20倍増加。業界標準のTabArenaで主要な手法となり、以前のモデルを上回る精度を達成。小規模から中規模のデータセットに対して100%の勝率を持ち、大規模データセットでも高い勝率を誇る。商用ユース向けに新しい蒸留エンジンを導入し、低レイテンシーでの展開を実現。これにより、TabPFNエコシステムに基づくアプリケーションのパフォーマンスが向上する。 Comment
TabArenaの2025.11時点でのSoTA
- [Paper Note] TabArena: A Living Benchmark for Machine Learning on Tabular Data, Nick Erickson+, NeurIPS'25 Spotlight, 2025.06
元ポスト:
[Paper Note] Wasserstein-Cramér-Rao Theory of Unbiased Estimation, Nicolás García Trillos+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pocket #Theory Issue Date: 2025-11-14 GPT Summary- 本論文では、無偏推定量の不安定性を「感度」と定義し、Wasserstein幾何学に基づく理論を提案。これにより、Wasserstein-Cramér-Rao下限や無偏推定量の特性を明らかにし、既存の推定量の最適性や新しい推定量の発見に寄与する結果を示す。 Comment
元ポスト:
む、むずかしい...!!
[Paper Note] Belief Dynamics Reveal the Dual Nature of In-Context Learning and Activation Steering, Eric Bigelow+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #In-ContextLearning #ActivationSteering/ITI Issue Date: 2025-11-12 GPT Summary- 大規模言語モデル(LLMs)の制御手法をベイズ的視点から統一的に説明。文脈に基づく介入と活性化に基づく介入がモデルの信念を変え、挙動に影響を与えることを示す。新たなベイズモデルにより、介入の効果を高精度で予測し、行動の急激な変化を引き起こす特異なフェーズを明らかにする。プロンプトと活性化の制御手法の統一的な理解を提供。 Comment
元ポスト:
[Paper Note] On a few pitfalls in KL divergence gradient estimation for RL, Yunhao Tang+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #Reasoning #One-Line Notes Issue Date: 2025-11-12 GPT Summary- LLMのRLトレーニングにおけるKLダイバージェンスの勾配推定に関する落とし穴を指摘。特に、KL推定を通じて微分する実装が不正確であることや、逐次的な性質を無視した実装が部分的な勾配しか生成しないことを示す。表形式の実験とLLM実験を通じて、正しいKL勾配の実装方法を提案。 Comment
元ポスト:
RLにおけるKL Divergenceによるポリシー正則化の正しい実装方法
[Paper Note] On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning, Yifan Zhang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #ReinforcementLearning #read-later #Selected Papers/Blogs #On-Policy Issue Date: 2025-11-12 GPT Summary- ポリシー勾配アルゴリズムを用いてLLMの推論能力を向上させるため、正則化ポリシー勾配(RPG)を提案。RPGは、正規化されたKLと非正規化されたKLを統一し、REINFORCEスタイルの損失の微分可能性を特定。オフポリシー設定での重要度重み付けの不一致を修正し、RPGスタイルクリップを導入することで安定したトレーニングを実現。数学的推論ベンチマークで最大6%の精度向上を達成。 Comment
元ポスト:
pj page: https://complex-reasoning.github.io/RPG/
続報:
[Paper Note] Iterative Amortized Inference: Unifying In-Context Learning and Learned Optimizers, Sarthak Mittal+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #In-ContextLearning #meta-learning Issue Date: 2025-11-03 GPT Summary- アモータイズド学習に基づく統一的フレームワークを提案し、タスク適応の方法をパラメトリック、暗黙的、明示的に分類。推論時のタスクデータ処理能力の制限を指摘し、反復アモータイズド推論を導入。これにより、最適化ベースのメタ学習とLLMのアプローチを結びつけ、汎用タスク適応のためのスケーラブルな基盤を提供。 Comment
元ポスト:
[Paper Note] SeeDNorm: Self-Rescaled Dynamic Normalization, Wenrui Cai+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #Transformer #Architecture #Normalization Issue Date: 2025-10-28 GPT Summary- SeeDNormは、入力に基づいて動的にスケーリング係数を調整する新しい正規化層であり、RMSNormの限界を克服します。これにより、入力のノルム情報を保持し、データ依存の自己再スケーリングを実現。大規模言語モデルやコンピュータビジョンタスクでの有効性を検証し、従来の正規化手法と比較して優れた性能を示しました。
[Paper Note] Robust Layerwise Scaling Rules by Proper Weight Decay Tuning, Zhiyuan Fan+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #Optimizer Issue Date: 2025-10-28 GPT Summary- 経験的スケーリング法則と最大更新パラメータ化($\mu$P)を考慮し、幅にわたるサブレイヤーのゲインを保持するための重み減衰スケーリングルールを提案。特異値スペクトルのスケーリング観察に基づき、サブレイヤーゲインを幅不変に保つルールを導出し、プロキシからターゲット幅への学習率と重み減衰のゼロショット転送を実現。LLaMAスタイルのトランスフォーマーで検証し、オプティマイザによるスケール制御が$\mu$Pの拡張に寄与することを示す。 Comment
元ポスト:
[Paper Note] Weight Decay may matter more than muP for Learning Rate Transfer in Practice, Atli Kosson+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #Pocket #Optimizer #ZeroshotHyperparameterTransfer #LearningRate Issue Date: 2025-10-28 GPT Summary- 学習率の転送は、ニューラルネットワークの効率的なトレーニングを可能にする。Maximal Update Parameterization(muP)は、内部表現の更新を安定させる学習率スケーリングを提案するが、その仮定は実際のトレーニングでは短期間しか維持されないことが示された。トレーニングの後半では、重み減衰が内部表現の安定に寄与し、学習率の転送を促進する。これにより、muPは主に学習率のウォームアップとして機能し、修正されたウォームアップスケジュールで置き換え可能であることが示唆される。これらの結果は、学習率の転送に関する従来の考え方に挑戦し、muPの成功には独立した重み減衰が必要であることを示す。 Comment
元ポスト:
[Paper Note] A Theoretical Study on Bridging Internal Probability and Self-Consistency for LLM Reasoning, Zhi Zhou+, NeurIPS'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #NeurIPS #Test-Time Scaling Issue Date: 2025-10-27 GPT Summary- テスト時スケーリングにおけるサンプリング手法の理論的枠組みを提供し、自己一貫性と困惑度の制限を明らかに。新たに提案したRPC手法は、困惑度一貫性と推論剪定を活用し、推論誤差の収束を改善。7つのベンチマークでの実証結果により、RPCは自己一貫性に匹敵する性能を達成し、サンプリングコストを50%削減することが示された。 Comment
元ポスト:
元ポスト:
pj page: https://zhouz.dev/RPC/
[Paper Note] Optimization Benchmark for Diffusion Models on Dynamical Systems, Fabian Schaipp, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #DiffusionModel #Optimizer Issue Date: 2025-10-26 GPT Summary- 拡散モデルのトレーニングにおける最適化手法を評価し、MuonとSOAPがAdamWに対して効率的な代替手段であることを示し、最終損失が18%低下することを観察。さらに、学習率スケジュールやAdamとSGDのパフォーマンスギャップなど、トレーニングダイナミクスに関連する現象を再考。 Comment
元ポスト:
[Paper Note] Algorithmic Primitives and Compositional Geometry of Reasoning in Language Models, Samuel Lippl+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Reasoning Issue Date: 2025-10-25 GPT Summary- 本研究では、大規模言語モデル(LLMs)が多段階の推論を解決するためのアルゴリズム的原則を追跡し、操作するフレームワークを提案。推論のトレースを内部の活性化パターンにリンクさせ、原則を残差ストリームに注入することで、推論ステップやタスクのパフォーマンスへの影響を評価。旅行セールスマン問題や3SATなどのベンチマークを用いて、原則ベクトルの導出と幾何学的論理の明示化を行い、ファインチューニングによる一般化の強調を示した。これにより、LLMsの推論がアルゴリズム的原則の構成的幾何学に支えられている可能性が示唆され、原則の転送とドメイン間の一般化が強化されることが明らかになった。 Comment
元ポスト:
[Paper Note] Physics-Informed Diffusion Models, Jan-Hendrik Bastek+, ICLR'25, 2024.03
Paper/Blog Link My Issue
#Pocket #DiffusionModel #ICLR #PhysicalConstraints Issue Date: 2025-10-24 GPT Summary- 生成モデルと偏微分方程式を統一するフレームワークを提案し、生成サンプルが物理的制約を満たすように損失項を導入。流体の流れに関するケーススタディで残差誤差を最大2桁削減し、構造トポロジー最適化においても優れた性能を示す。過学習に対する正則化効果も確認。実装が簡単で、多様な制約に適用可能。 Comment
openreview: https://openreview.net/forum?id=tpYeermigp&utm_source=chatgpt.com
[Paper Note] The Free Transformer, François Fleuret, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #Transformer #VariationalAutoEncoder #Architecture #Decoder Issue Date: 2025-10-22 GPT Summary- 無監督で学習された潜在変数に条件付けるデコーダーTransformerの拡張を提案し、下流タスクでの性能が大幅に向上することを実験で示した。 Comment
元ポスト:
ポイント解説:
[Paper Note] Emergent Coordination in Multi-Agent Language Models, Christoph Riedl, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Multi #Analysis #Pocket #NLP #AIAgents #TheoryOfMind #read-later #Selected Papers/Blogs #Personality Issue Date: 2025-10-21 GPT Summary- 本研究では、マルチエージェントLLMシステムが高次の構造を持つかどうかを情報理論的フレームワークを用いて検証。実験では、エージェント間のコミュニケーションがない状況で、時間的相乗効果が観察される一方、調整された整合性は見られなかった。ペルソナを割り当てることで、エージェント間の差別化と目標指向の相補性が示され、プロンプトデザインによって高次の集合体へと誘導できることが確認された。結果は、効果的なパフォーマンスには整合性と相補的な貢献が必要であることを示唆している。 Comment
元ポスト:
非常にシンプルな設定でマルチエージェントによるシナジーが生じるか否か、そのための条件を検証している模様。小規模モデルだとシナジーは生じず、ペルソナ付与とTheory of Mindを指示すると効果が大きい模様
[Paper Note] End-to-End Multi-Modal Diffusion Mamba, Chunhao Lu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #MultiModal #DiffusionModel #SSM (StateSpaceModel) #UMM Issue Date: 2025-10-21 GPT Summary- MDM(Multi-modal Diffusion Mamba)という新しいアーキテクチャを提案し、エンドツーエンドのマルチモーダル処理を統一。Mambaベースの選択拡散モデルを用いて、エンコーディングとデコーディングでモダリティ特有の情報を段階的に生成。高解像度画像とテキストを同時に生成し、既存モデルを大幅に上回る性能を示す。計算効率を保ちながらマルチモーダルプロセスを統一する新たな方向性を確立。 Comment
元ポスト:
[Paper Note] Cautious Weight Decay, Lizhang Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #LanguageModel #Transformer #Optimizer Issue Date: 2025-10-16 GPT Summary- Cautious Weight Decay(CWD)は、オプティマイザに依存しない修正で、更新と符号が一致するパラメータにのみウェイト減衰を適用します。これにより、元の損失を保持しつつ、局所的なパレート最適点を探索可能にします。CWDは、既存のオプティマイザに簡単に適用でき、新たなハイパーパラメータを必要とせず、言語モデルの事前学習やImageNet分類で損失と精度を向上させます。 Comment
元ポスト:
[Paper Note] How Reinforcement Learning After Next-Token Prediction Facilitates Learning, Nikolaos Tsilivis+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Transformer #ReinforcementLearning #Reasoning #PostTraining #read-later Issue Date: 2025-10-14 GPT Summary- 大規模言語モデルの次のトークン予測を強化学習で最適化するフレームワークを提案。特に、短いおよび長い「思考の連鎖」シーケンスからの学習を通じて、強化学習が次のトークン予測を改善することを理論的に示す。長いシーケンスが稀な場合、強化学習により自己回帰型トランスフォーマーが一般化できることを確認。さらに、長い応答が計算を増加させるメカニズムを説明し、自己回帰型線形モデルが効率的に$d$ビットの偶奇を予測できる条件を理論的に証明。Llamaシリーズモデルのポストトレーニングによる実証も行う。 Comment
元ポスト:
[Paper Note] ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory, Matthew Ho+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pocket #NLP #Abstractive #LanguageModel #Reasoning #Generalization #memory #One-Line Notes #Test-time Learning Issue Date: 2025-10-13 GPT Summary- LLMは推論時に外部メモリを活用し、概念レベルのメモリを導入することで、再利用可能でスケーラブルな知識の保存を実現。これにより、関連する概念を選択的に取得し、テスト時の継続的学習を可能にする。評価はARC-AGIベンチマークで行い、メモリなしのベースラインに対して7.5%の性能向上を達成。動的なメモリ更新が自己改善を促進することを示唆。 Comment
元ポスト:
ARC-AGIでしか評価されていないように見える。
[Paper Note] Dual Goal Representations, Seohong Park+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #ReinforcementLearning Issue Date: 2025-10-11 GPT Summary- 本研究では、目標条件付き強化学習のために二重目標表現を提案し、状態を時間的距離の集合として特徴付ける。この表現は環境の内的ダイナミクスに依存し、外部ノイズをフィルタリングしつつ最適なポリシーを回復するのに十分な情報を提供する。実験により、二重目標表現がOGBenchタスクスイートにおいてオフラインの目標到達性能を向上させることを示した。 Comment
pj page: https://seohong.me/blog/dual-representations/
元ポスト:
ゴールを明示的に与えるRLにおいて(Goal conditioned RLと呼ぶらしい, pi(a|s,g)、つまりアクションが状態とゴールから決まる設定)、ゴールgを表現する際に有用なrepresentation方法の提案(ある状態sを定義する際に状態sそのものの情報を使うのではなく、他のとりうる状態からのtemporal distance(何ステップで到達できるか)のベクトルで表現する)らしい。
たとえば、gはロボットであれば到達したい特定の座標であり、sは現在の座標、のようなイメージだろうか。
解説:
[Paper Note] Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models, Sharut Gupta+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #Pocket #MultiModal #UMM #One-Line Notes Issue Date: 2025-10-10 GPT Summary- UML(Unpaired Multimodal Learner)を提案し、非ペアのマルチモーダルデータを活用して表現学習を強化する新しいトレーニングパラダイムを示す。異なるモダリティからの入力を交互に処理し、明示的なペアを必要とせずにクロスモーダル構造から利益を得る。実験により、テキスト、音声、画像などの非ペアデータを用いることで、単一モダルターゲットのパフォーマンスが向上することを確認。 Comment
pj page: https://unpaired-multimodal.github.io
モダリティ間で(モダリティごとのエンコーダとデコーダ以外の)パラメータを共有し(UMMs)、通常はpair-dataで学習するが、unpaired data(+self-supervised / 分類ヘッドを用いた(ここはしっかり読めてないので自信ない)supervised learning)で学習する。これによりダウンストリームタスクでの性能が向上する。
unpaired dataで学習するという点が革新的に見える。unpaired dataで学習する枠組みにより大量のデータを活用し表現を学習できる。また、ペアデータで学習することによりパラメータに埋め込める知識やスキルが(おそらく)限られていたが、より広範な知識やスキルを埋め込めるのでは、という印象がある。
元ポスト:
著者ポスト:
[Paper Note] DiffusionNFT: Online Diffusion Reinforcement with Forward Process, Kaiwen Zheng+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#ComputerVision #Pocket #ReinforcementLearning #DiffusionModel #FlowMatching Issue Date: 2025-10-10 GPT Summary- Diffusion Negative-aware FineTuning(DiffusionNFT)は、オンライン強化学習を用いて拡散モデルを最適化する新しい手法で、ポジティブとネガティブな生成を対比させることで強化信号を組み込みます。このアプローチにより、尤度推定が不要になり、クリーンな画像のみでポリシー最適化が可能になります。DiffusionNFTは、FlowGRPOよりも最大25倍効率的で、GenEvalスコアを短期間で大幅に改善し、複数の報酬モデルを活用することでSD3.5-Mediumのパフォーマンスを向上させます。 Comment
元ポスト:
ベースライン:
- Introducing Stable Diffusion 3.5, StabilityAI, 2024.10
- [Paper Note] Flow-GRPO: Training Flow Matching Models via Online RL, Jie Liu+, NeurIPS'25, 2025.05
- [Paper Note] Classifier-Free Diffusion Guidance, Jonathan Ho+, arXiv'22, 2022.07
[Paper Note] Provable Scaling Laws of Feature Emergence from Learning Dynamics of Grokking, Yuandong Tian, arXiv'25, 2025.09
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #Pocket #Grokking #Optimizer Issue Date: 2025-10-10 GPT Summary- grokkingの現象を理解するために、2層の非線形ネットワークにおける新しい枠組み$\mathbf{Li_2}$を提案。これには、怠惰な学習、独立した特徴学習、相互作用する特徴学習の3段階が含まれる。怠惰な学習では、モデルが隠れ表現に過剰適合し、独立した特徴が学習される。後半段階では、隠れノードが相互作用を始め、学習すべき特徴に焦点を当てることが示される。本研究は、grokkingにおけるハイパーパラメータの役割を明らかにし、特徴の出現と一般化に関するスケーリング法則を導出する。 Comment
元ポスト:
[Paper Note] Attention Sinks and Compression Valleys in LLMs are Two Sides of the Same Coin, Enrique Queipo-de-Llano+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Transformer #Attention #AttentionSinks #CompressionValleys Issue Date: 2025-10-10 GPT Summary- 注意の沈降と圧縮の谷の関連性を示し、大規模な活性化が表現の圧縮とエントロピーの減少を引き起こすことを理論的に証明。実験により、シーケンスの開始トークンが中間層で極端な活性化を生むと、圧縮の谷と注意の沈降が同時に現れることを確認。TransformerベースのLLMがトークンを三つのフェーズで処理する「Mix-Compress-Refine」理論を提案し、タスク依存の表現の違いを説明。 Comment
元ポスト:
[Paper Note] Gaussian Embeddings: How JEPAs Secretly Learn Your Data Density, Randall Balestriero+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Embeddings #Pocket #read-later Issue Date: 2025-10-09 GPT Summary- JEPAは、潜在空間予測と反収束を組み合わせたアーキテクチャで、データ密度を推定する能力を持つ。成功裏に訓練されたJEPAは、データキュレーションや外れ値検出に利用可能で、サンプルの確率を効率的に計算できる。JEPA-SCOREと呼ばれる手法を用いて、さまざまなデータセットや自己教師あり学習手法でその効果が実証されている。 Comment
元ポスト:
ポイント解説:
[Paper Note] Muon Outperforms Adam in Tail-End Associative Memory Learning, Shuche Wang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Optimizer Issue Date: 2025-10-08 GPT Summary- Muonオプティマイザーは、LLMsのトレーニングにおいてAdamよりも高速であり、そのメカニズムを連想記憶の観点から解明。VOアテンションウェイトとFFNがMuonの優位性の要因であり、重い尾を持つデータにおいて尾クラスを効果的に最適化する。Muonは一貫したバランスの取れた学習を実現し、Adamは不均衡を引き起こす可能性がある。これにより、Muonの更新ルールが重い尾を持つ分布における効果的な学習を可能にすることが示された。 Comment
元ポスト:
[Paper Note] Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning, Xin Qiu+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Finetuning #EvolutionaryAlgorithm Issue Date: 2025-10-07 GPT Summary- 進化戦略(ES)を用いて、事前学習済みの大規模言語モデル(LLMs)の全パラメータをファインチューニングする初の成功事例を報告。ESは数十億のパラメータに対して効率的に探索でき、サンプル効率やロバスト性、パフォーマンスの安定性において既存の強化学習(RL)手法を上回ることを示す。これにより、LLMファインチューニングの新たな方向性が開かれる。 Comment
元ポスト:
続報:
[Paper Note] Visual Instruction Bottleneck Tuning, Changdae Oh+, NeurIPS'25, 2025.05
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #MultiModal #NeurIPS #PostTraining #OOD #Generalization Issue Date: 2025-10-05 GPT Summary- MLLMは未知のクエリに対して性能が低下するが、既存の改善策は多くのデータや計算コストを要する。本研究では、情報ボトルネック原理に基づき、MLLMの堅牢性を向上させるためのVittleを提案。45のデータセットでの実証実験により、VittleがMLLMの堅牢性を一貫して改善することを示した。 Comment
元ポスト:
[Paper Note] How Diffusion Models Memorize, Juyeop Kim+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Analysis #Pocket #DiffusionModel #Memorization Issue Date: 2025-10-04 GPT Summary- 拡散モデルは画像生成に成功しているが、トレーニングデータの記憶によるプライバシーや著作権の懸念がある。本研究では、拡散およびデノイジングプロセスを再考し、記憶のメカニズムを探る。記憶は初期のデノイジング中にトレーニングサンプルの過大評価によって引き起こされ、多様性が減少し、記憶された画像への収束が加速されることを示す。具体的には、過学習だけでなく、分類器フリーのガイダンスが記憶を増幅し、トレーニング損失が増加すること、記憶されたプロンプトがノイズ予測に影響を与えること、初期のランダム性が抑制される様子が明らかになる。これにより、過大評価が記憶の中心的なメカニズムであることが特定される。 Comment
関連:
- [Paper Note] Selective Underfitting in Diffusion Models, Kiwhan Song+, arXiv'25, 2025.10
[Paper Note] Selective Underfitting in Diffusion Models, Kiwhan Song+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Analysis #Pocket #DiffusionModel #Memorization #Generalization Issue Date: 2025-10-04 GPT Summary- 拡散モデルは生成モデルの主要なパラダイムとして注目されているが、どのスコアを学習しているかが未解決の疑問である。本研究では、選択的過少適合の概念を導入し、拡散モデルが特定の領域でスコアを正確に近似し、他の領域では過少適合することを示す。これにより、拡散モデルの一般化能力と生成性能に関する新たな洞察を提供する。 Comment
元ポスト:
ポイント解説:
著者ポスト:
[Paper Note] Continuous Thought Machines, Luke Darlow+, NeurIPS'25 Spotlight, 2025.05
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #Architecture #NeurIPS #read-later Issue Date: 2025-09-28 GPT Summary- 本論文では、神経細胞のタイミングと相互作用を重視した「Continuous Thought Machine(CTM)」を提案し、神経ダイナミクスをコア表現として活用することで深層学習の限界に挑戦します。CTMは、神経レベルの時間的処理と神経同期を取り入れ、計算効率と生物学的リアリズムのバランスを図ります。さまざまなタスクにおいて強力なパフォーマンスを示し、適応的な計算を活用することで、タスクの難易度に応じた効率的な処理が可能です。CTMは、より生物学的に妥当な人工知能システムの開発に向けた重要なステップと位置付けられています。 Comment
元ポスト:
NeurIPS'25 Spotlight:
https://www.linkedin.com/posts/sakana-ai_neurips2025-neurips2025-activity-7380889531815923712-94pk?utm_source=share&utm_medium=member_ios&rcm=ACoAACzQvjwB2FeLVE3yukDiUYtr5J4k-6nlNG4
[Paper Note] Angles Don't Lie: Unlocking Training-Efficient RL Through the Model's Own Signals, Qinsi Wang+, NeurIPS'25 Spotlight, 2025.06
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #ReinforcementLearning #NeurIPS #PostTraining #On-Policy Issue Date: 2025-09-27 GPT Summary- 大規模言語モデル(LLMs)の強化学習微調整(RFT)におけるサンプル効率の低下を改善するため、モデル固有の信号「角度集中」を特定。これに基づき、勾配駆動型角度情報ナビゲート強化学習フレームワーク(GAIN-RL)を提案し、トレーニングデータを動的に選択することで効率を向上。実証評価では、GAIN-RLがトレーニング効率を2.5倍以上向上させ、元のデータの半分でより良いパフォーマンスを達成したことが示された。 Comment
元ポスト:
ヒューリスティックや特定の難易度に基づくラベルからRLのサンプルをサンプリングするのではなく、モデル自身の現在の学習の状態に基づいて動的に選択し学習効率を向上させるアプローチな模様。
[Paper Note] STAR: Synthesis of Tailored Architectures, Armin W. Thomas+, ICLR'25, 2024.11
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #NeuralArchitectureSearch #ICLR Issue Date: 2025-09-27 GPT Summary- 新しいアプローチ(STAR)を提案し、特化したアーキテクチャの合成を行う。線形入力変動システムに基づく探索空間を用い、アーキテクチャのゲノムを階層的にエンコード。進化的アルゴリズムでモデルの品質と効率を最適化し、自己回帰型言語モデリングにおいて従来のモデルを上回る性能を達成。 Comment
openreview: https://openreview.net/forum?id=HsHxSN23rM
[Paper Note] Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding, Mingyu Jin+, ICML'25, 2025.02
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Transformer #Attention #ICML #ContextEngineering Issue Date: 2025-09-26 GPT Summary- 大規模言語モデル(LLMs)は文脈的知識の理解に成功しており、特に注意クエリ(Q)とキー(K)において集中した大規模な値が一貫して現れることを示す。これらの値は、モデルのパラメータに保存された知識ではなく、現在の文脈から得られる知識の解釈に重要である。量子化戦略の調査により、これらの値を無視すると性能が低下することが明らかになり、集中した大規模な値の出現がロタリーポジショナルエンコーディング(RoPE)によって引き起こされることを発見した。これらの結果は、LLMの設計と最適化に関する新たな洞察を提供する。 Comment
openreview: https://openreview.net/forum?id=1SMcxxQiSL¬eId=7BAXSETAwU
[Paper Note] Searching Latent Program Spaces, Matthew V Macfarlane+, NeurIPS'25, 2024.11
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #Search #Coding #NeurIPS #Encoder-Decoder Issue Date: 2025-09-21 GPT Summary- 新しいスキルを効率的に習得し、一般化するためのLatent Program Network(LPN)を提案。LPNは、入力を出力にマッピングする潜在空間を学習し、テスト時に勾配を用いて探索。シンボリックアプローチの適応性とニューラル手法のスケーラビリティを兼ね備え、事前定義されたDSLを不要にする。ARC-AGIベンチマークでの実験により、LPNは分布外タスクでの性能を2倍に向上させることが示された。 Comment
元ポスト:
[Paper Note] The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity, Parshin Shojaee+, arXiv'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Reasoning #NeurIPS #read-later Issue Date: 2025-09-19 GPT Summary- LRMsは思考プロセスを生成するが、その能力や限界は未解明。評価は主に最終回答の正確性に焦点を当てており、推論の痕跡を提供しない。本研究では制御可能なパズル環境を用いて、LRMsの推論過程を分析。実験により、LRMsは特定の複雑さを超えると正確性が崩壊し、スケーリングの限界が明らかに。低複雑性では標準モデルが優位、中複雑性ではLRMsが優位、高複雑性では両者が崩壊することを示した。推論の痕跡を調査し、LRMsの強みと限界を明らかに。 Comment
元ポスト:
出た当初相当話題になったIllusion of thinkingがNeurIPSにacceptされた模様。Appendix A.1に当時のcriticismに対するレスポンスが記述されている。
[Paper Note] BREAD: Branched Rollouts from Expert Anchors Bridge SFT & RL for Reasoning, Xuechen Zhang+, NeurIPS'25
Paper/Blog Link My Issue
#Analysis #EfficiencyImprovement #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #SmallModel #NeurIPS #PostTraining #On-Policy Issue Date: 2025-09-19 GPT Summary- 小型言語モデル(SLMs)は、トレースが不足している場合に複雑な推論を学ぶのが難しい。本研究では、SFT + RLの限界を調査し、BREADという新しい手法を提案。BREADは、専門家のガイダンスを用いてSFTとRLを統合し、失敗したトレースに対して短いヒントを挿入することで成功を促進。これにより、トレーニングが約3倍速くなり、標準的なGRPOを上回る性能を示す。BREADは、SLMの推論能力を大幅に向上させることが確認された。 Comment
元ポスト:
[Paper Note] The Leaderboard Illusion, Shivalika Singh+, NeurIPS'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Evaluation #NeurIPS #read-later #Selected Papers/Blogs Issue Date: 2025-09-19 GPT Summary- 進捗測定は科学の進展に不可欠であり、Chatbot ArenaはAIシステムのランキングにおいて重要な役割を果たしている。しかし、非公開のテスト慣行が存在し、特定のプロバイダーが有利になることで、スコアにバイアスが生じることが明らかになった。特に、MetaのLlama-4に関連するプライベートLLMバリアントが問題視され、データアクセスの非対称性が生じている。GoogleやOpenAIはArenaデータの大部分を占め、オープンウェイトモデルは少ないデータしか受け取っていない。これにより、Arena特有のダイナミクスへの過剰適合が発生している。研究は、Chatbot Arenaの評価フレームワークの改革と、公正で透明性のあるベンチマーキングの促進に向けた提言を行っている。 Comment
元ポスト:
要チェック
[Paper Note] Inpainting-Guided Policy Optimization for Diffusion Large Language Models, Siyan Zhao+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ReinforcementLearning #DiffusionModel #On-Policy #Inpainting Issue Date: 2025-09-19 GPT Summary- dLLMsはインペインティング能力を活用し、強化学習の探索課題を解決するIGPOフレームワークを提案。部分的な真実の推論トレースを挿入し、探索を有望な軌道に導く。これによりサンプル効率が向上し、GSM8K、Math500、AMCの数学ベンチマークで新たな最先端結果を達成。 Comment
元ポスト:
部分的にtraceの正解を与えると、正解の方向にバイアスがかかるので多様性が犠牲になる気もするが、その辺はどうなんだろうか。
[Paper Note] The Information Dynamics of Generative Diffusion, Luca Ambrogioni, arXiv'25
Paper/Blog Link My Issue
#Analysis #Pocket #DiffusionModel Issue Date: 2025-09-05 GPT Summary- 生成的拡散モデルの統一的な理論的理解を提供し、動的特性、情報理論的特性、熱力学的特性を結びつける。生成帯域幅はスコア関数の発散によって支配され、生成プロセスは対称性の破れによって駆動される。スコア関数はノイズの帯域幅を調整するフィルターとして機能する。 Comment
元ポスト:
[Paper Note] Compute-Optimal Scaling for Value-Based Deep RL, Preston Fu+, arXiv'25
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #ReinforcementLearning #Scaling Laws #read-later #Batch Issue Date: 2025-09-04 GPT Summary- 強化学習における計算スケーリングを調査し、モデル容量とデータ更新比率のリソース配分がサンプル効率に与える影響を分析。特に、バッチサイズの増加が小さなモデルでQ関数の精度を悪化させる「TDオーバーフィッティング」を特定し、大きなモデルではこの影響が見られないことを示す。計算使用を最適化するためのガイドラインを提供し、深層RLのスケーリングに関する基盤を築く。 Comment
元ポスト:
[Paper Note] Training Dynamics of the Cooldown Stage in Warmup-Stable-Decay Learning Rate Scheduler, Aleksandr Dremov+, TMLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Transformer #TMLR #Scheduler Issue Date: 2025-09-03 GPT Summary- WSD学習率スケジューラのクールダウンフェーズを分析し、異なる形状がモデルのバイアス-バリアンスのトレードオフに与える影響を明らかに。探索と活用のバランスが最適なパフォーマンスをもたらすことを示し、特に$\beta_2$の値が高いと改善が見られる。損失のランドスケープを視覚化し、クールダウンフェーズの最適化の重要性を強調。 Comment
元ポスト:
[Paper Note] Looped Transformers for Length Generalization, Ying Fan+, ICLR'25
Paper/Blog Link My Issue
#Pocket #Transformer #LongSequence #Architecture #ICLR #Generalization #RecurrentModels Issue Date: 2025-08-30 GPT Summary- ループトランスフォーマーを用いることで、未見の長さの入力に対する算術的およびアルゴリズム的タスクの長さ一般化が改善されることを示す。RASP-L操作を含む既知の反復解法に焦点を当て、提案する学習アルゴリズムで訓練した結果、さまざまなタスクに対して高い一般化能力を持つ解法を学習した。 Comment
openreview: https://openreview.net/forum?id=2edigk8yoU
[Paper Note] Pushing the Envelope of LLM Inference on AI-PC, Evangelos Georganas+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #LanguageModel #Inference Issue Date: 2025-08-24 GPT Summary- 超低ビットLLMモデルの登場により、リソース制約のある環境でのLLM推論が可能に。1ビットおよび2ビットのマイクロカーネルを設計し、PyTorch-TPPに統合することで、推論効率を最大2.2倍向上。これにより、AI PCやエッジデバイスでの超低ビットLLMモデルの効率的な展開が期待される。 Comment
元ポスト:
[Paper Note] Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards, Shirley Wu+, arXiv'25
Paper/Blog Link My Issue
#Pocket #LanguageModel #RewardModel #CompoundAISystemsOptimization Issue Date: 2025-08-15 GPT Summary- 複合AIシステムの最適化のために、統一フレームワークOptimasを提案。各コンポーネントにローカル報酬関数を維持し、グローバルパフォーマンスと整合性を保ちながら同時に最大化。これにより、異種構成の独立した更新が可能となり、平均11.92%の性能向上を実現。 Comment
元ポスト:
framework: https://github.com/snap-stanford/optimas
複数のコンポーネントのパイプラインによって構成されるシステムがあったときに、パイプライン全体のパフォーマンスを改善したい。このとき、パイプライン全体のパフォーマンスをユーザが定義したGlobal Reward Functionを最大化するように最適化したい。しかし、多くの場合このような異種のコンポーネントが複雑に連携したパイプラインでは、global rewardsは微分不可能なので、end-to-endで最適化することが難しい。また、個々の異種のコンポーネントのコンフィグ(e.g., textual, numerical, continuous vs. discrete)を同時に最適化することがそもそも難しい。全体のAIシステムを動作させて、global rewardを最適化するのは非常にコストがかかる。先行研究では、特定のコンポーネントを別々に最適化してきた(たとえば、promptをフィードバックに基づいて改善する Large Language Models as Optimizers, Chengrun Yang+, N/A, ICLR'24
, モデル選択をiterative searchで改善するなど)。が、個別のコンポーネントを最適化しても別のコンポーネントの最適化が不十分であれば全体の性能は向上せず、全てのコンポーネントを個別に最適化しても、相互作用が最適ではない場合はglobal rewardが最大化されない可能性がある。
このため、個々のコンポーネントにlocal reward function (LRFs)を定義する。local reward functionは、これらが改善することでglobal reward functionも改善することを保証するような形(local-global alignment properfy)で定義され、これらのlocal reward functionを異なるコンポーネントごとに異なる形で最適化しても、global reward functionが改善されるように学習する。個々のコンポーネントごとにLRFsを最適化することは、全体のシステムの実行回数を削減しながら高いglobal rewardを実現可能となる。加えて、他のコンポーネントのコンフィグが改善されたら、それらに適応してLRFsも改善されていく必要があるので lightweight adaptationと呼ばれる、システムからサンプリングされた最小のデータからLRFsをアップデートする手法も提案する、みたいな話な模様。
LRFsを定義するときは、共通のLLMをバックボーンとし、個々のコンポーネントに対して別々のヘッドを用意してrewardを出力するようなモデルを定義する。コンポーネントkのinput x, output y が与えられたときに、それらをconcatしてLLMに入力し[x_k, y_k]最終的にヘッドでスカラー値に写像する。また、LRF r_kが *aligned* の定義として、LRF r_kがある共通のinputに対してr_kが高くなるようなoutputをしたときに、downstreamのコンポーネント全体のglobal reward Rが同等以上の性能を達成する場合、alignedであると定義する。このような特性を実現するために、現行のシステムのコンフィグに基づいてそれぞれのコンポーネントを実行し、trajectoryを取得。特定のコンポーネントC_kに対する二つのoutputを(異なるコンフィグに基づいて)サンプリングしてパイプライン全体のmetricを予測し、metricが高い/低いサンプルをchosen/rejectedとし preference dataを用意する。このようなデータを用いて、個々のコンポーネントのLRFsを、chosenなサンプルの場合はrejectedよりもrewardが高くなるようにペアワイズのranking lossを用いて学習する。
(ここまでが4.1節の概要。4.2, 4.3節以後は必要に応じて参照する。4.2ではどのように他コンポーネントが更新された際にLRFsを更新するか、という話と、4.3節では個々のコンポーネントがtext, trainable models, continuous configurationなどの異なるコンポーネントの場合にどのような最適化手法を適用するか、といった話が書かれているように見える。)
評価では5つの実世界のタスクを実現するための複数コンポーネントで構成されるシステムの最適化を試みているようであり、
提案手法によって、パイプライン全体の性能がベースラインと比べて改善しシステム全体の実行回数もベースラインと比較して少ない試行回数で済むことが示されている模様。
[Paper Note] MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement, Jaehyun Nam+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel Issue Date: 2025-08-04 GPT Summary- MLE-STARは、LLMを用いてMLモデルを自動実装する新しいアプローチで、ウェブから効果的なモデルを取得し、特定のMLコンポーネントに焦点を当てた戦略を探索することで、コード生成の精度を向上させる。実験結果では、MLE-STARがKaggleコンペティションの64%でメダルを獲得し、他の手法を大きく上回る性能を示した。 Comment
元ポスト:
[Paper Note] What Matters in Learning from Large-Scale Datasets for Robot Manipulation, Vaibhav Saxena+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #Dataset #ICLR #Robotics #EmbodiedAI Issue Date: 2025-07-19 GPT Summary- 本研究では、ロボティクスにおける大規模データセットの構成に関する体系的な理解を深めるため、データ生成フレームワークを開発し、多様性の重要な要素を特定。特に、カメラのポーズや空間的配置がデータ収集の多様性と整合性に影響を与えることを示した。シミュレーションからの洞察が実世界でも有効であり、提案した取得戦略は既存のトレーニング手法を最大70%上回る性能を発揮した。 Comment
元ポスト:
元ポストに著者による詳細な解説スレッドがあるので参照のこと。
[Paper Note] Learning distributed representations with efficient SoftMax normalization, Lorenzo Dall'Amico+, TMLR'25
Paper/Blog Link My Issue
#Embeddings #Pocket #RepresentationLearning Issue Date: 2025-07-16 GPT Summary- 埋め込みを学習するための損失関数として${\rm SoftMax}(XY^T)$を最適化する際の計算負荷を軽減するため、ノルム制限された埋め込みベクトルに対して線形時間のヒューリスティック近似を提案。提案手法は、事前学習されたデータセットで高い精度を示し、クロスエントロピーを最適化する効率的なアルゴリズムを設計。これにより、解釈可能でタスクに依存しない埋め込み学習が可能となり、類似の「2Vec」アルゴリズムと比較して優れた性能と低い計算時間を実現。 Comment
openreview: https://openreview.net/forum?id=9M4NKMZOPu
[Paper Note] In-context denoising with one-layer transformers: connections between attention and associative memory retrieval, Matthew Smart+, arXiv'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #Transformer #In-ContextLearning Issue Date: 2025-07-16 GPT Summary- 「インコンテキストデノイジング」というタスクを通じて、注意ベースのアーキテクチャと密な連想記憶(DAM)ネットワークの関係を探求。ベイズ的フレームワークを用いて、単層トランスフォーマーが特定のデノイジング問題を最適に解決できることを示す。訓練された注意層は、コンテキストトークンを連想記憶として利用し、デノイジングプロンプトを一回の勾配降下更新で処理。これにより、DAMネットワークの新たな拡張例を提供し、連想記憶と注意メカニズムの関連性を強化する。 Comment
元ポスト:
[Paper Note] Learning-Order Autoregressive Models with Application to Molecular Graph Generation, Zhe Wang+, ICML'25
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #ICML #GraphGeneration Issue Date: 2025-07-16 GPT Summary- 自己回帰モデル(ARMs)を用いて、データから逐次的に推測される確率的順序を利用し、高次元データを生成する新しい手法を提案。トレーニング可能なオーダーポリシーを組み込み、対数尤度の変分下限を用いて最適化。実験により、画像生成やグラフ生成で意味のある自己回帰順序を学習し、分子グラフ生成ではQM9およびZINC250kベンチマークで最先端の結果を達成。 Comment
元ポスト:
openreview: https://openreview.net/forum?id=EY6pXIDi3G
[Paper Note] Score Matching With Missing Data, Josh Givens+, ICML'25
Paper/Blog Link My Issue
#Pocket #ICML Issue Date: 2025-07-15 GPT Summary- スコアマッチングはデータ分布学習の重要な手法ですが、不完全データへの適用は未研究です。本研究では、部分的に欠損したデータに対するスコアマッチングの適応を目指し、重要度重み付け(IW)アプローチと変分アプローチの2つのバリエーションを提案します。IWアプローチは有限サンプル境界を示し、小さなサンプルでの強力な性能を確認。変分アプローチは高次元設定でのグラフィカルモデル推定において優れた性能を発揮します。 Comment
openreview: https://openreview.net/forum?id=mBstuGUaXo
ICML'25 outstanding papers
解説:
[Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Optimizer #read-later #Selected Papers/Blogs Issue Date: 2025-07-14 GPT Summary- Muonオプティマイザーを大規模モデルにスケールアップするために、ウェイトデケイとパラメータごとの更新スケール調整を導入。これにより、Muonは大規模トレーニングで即座に機能し、計算効率がAdamWの約2倍に向上。新たに提案するMoonlightモデルは、少ないトレーニングFLOPで優れたパフォーマンスを達成し、オープンソースの分散Muon実装や事前トレーニング済みモデルも公開。 Comment
解説ポスト:
こちらでも紹介されている:
- きみはNanoGPT speedrunを知っているか?, PredNext, 2025.07
解説:
[Paper Note] Nonlinear transformers can perform inference-time feature learning, Nishikawa+, ICML'25
Paper/Blog Link My Issue
#Analysis #NLP #Transformer #In-ContextLearning #ICML Issue Date: 2025-07-13 GPT Summary- 事前学習されたトランスフォーマーは、推論時に特徴を学習する能力を持ち、特に単一インデックスモデルにおける文脈内学習に焦点を当てています。勾配ベースの最適化により、異なるプロンプトからターゲット特徴を抽出し、非適応的アルゴリズムを上回る統計的効率を示します。また、推論時のサンプル複雑性が相関統計クエリの下限を超えることも確認されました。 Comment
元ポスト:
[Paper Note] Not All Explanations for Deep Learning Phenomena Are Equally Valuable, Alan Jeffares+, ICML'25
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #ICML #LearningPhenomena Issue Date: 2025-07-11 GPT Summary- 深層学習の驚くべき現象(ダブルディセント、グロッキングなど)を孤立したケースとして説明することには限界があり、実世界のアプリケーションにはほとんど現れないと主張。これらの現象は、深層学習の一般的な原則を洗練するための研究価値があると提案し、研究コミュニティのアプローチを再考する必要性を示唆。最終的な実用的目標に整合するための推奨事項も提案。 Comment
元ポスト:
関連:
- [Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20
- GROKKING: GENERALIZATION BEYOND OVERFIT- TING ON SMALL ALGORITHMIC DATASETS, Power+, ICLR'21 Workshop
- [Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19
[Paper Note] Mixture of Experts Provably Detect and Learn the Latent Cluster Structure in Gradient-Based Learning, Ryotaro Kawata+, ICML'25
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #Pocket #MoE(Mixture-of-Experts) #ICML Issue Date: 2025-07-11 GPT Summary- Mixture of Experts (MoE)は、入力を専門家に動的に分配するモデルのアンサンブルであり、機械学習で成功を収めているが、その理論的理解は遅れている。本研究では、MoEのサンプルおよび実行時間の複雑さを回帰タスクにおけるクラスタ構造を通じて理論的に分析し、バニラニューラルネットワークがこの構造を検出できない理由を示す。MoEは各専門家の能力を活用し、問題をより単純なサブ問題に分割することで、非線形回帰におけるSGDのダイナミクスを探求する初めての試みである。 Comment
元ポスト:
[Paper Note] Energy-Based Transformers are Scalable Learners and Thinkers, Alexi Gladstone+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #Transformer #MultiModal #Architecture #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-07-06 GPT Summary- エネルギーベースのトランスフォーマー(EBTs)を用いて、無監督学習から思考を学ぶモデルを提案。EBTsは、入力と候補予測の互換性を検証し、エネルギー最小化を通じて予測を行う。トレーニング中に従来のアプローチよりも高いスケーリング率を達成し、言語タスクでの性能を29%向上させ、画像のノイズ除去でも優れた結果を示す。EBTsは一般化能力が高く、モデルの学習能力と思考能力を向上させる新しいパラダイムである。 Comment
元ポスト:
Project Page: https://energy-based-transformers.github.io
First Authorの方による解説ポスト:
[Paper Note] Resa: Transparent Reasoning Models via SAEs, Shangshang Wang+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #PostTraining #read-later Issue Date: 2025-06-13 GPT Summary- Resaという1.5Bの推論モデル群を提案し、効率的なスパースオートエンコーダーチューニング(SAE-Tuning)手法を用いて訓練。これにより、97%以上の推論性能を保持しつつ、訓練コストを2000倍以上削減し、訓練時間を450倍以上短縮。軽いRL訓練を施したモデルで高い推論性能を実現し、抽出された推論能力は一般化可能かつモジュール化可能であることが示された。全ての成果物はオープンソース。 Comment
元ポスト:
著者ポスト:
論文中で利用されているSource Modelの一つ:
- [Paper Note] Tina: Tiny Reasoning Models via LoRA, Shangshang Wang+, arXiv'25
[Paper Note] Horizon Reduction Makes RL Scalable, Seohong Park+, arXiv'25
Paper/Blog Link My Issue
#Pocket #ReinforcementLearning Issue Date: 2025-06-10 GPT Summary- 本研究では、オフライン強化学習(RL)のスケーラビリティを検討し、既存のアルゴリズムが大規模データセットに対して期待通りの性能を発揮しないことを示しました。特に、長いホライズンがスケーリングの障壁であると仮定し、ホライズン削減技術がスケーラビリティを向上させることを実証しました。新たに提案した手法SHARSAは、ホライズンを削減しつつ優れたパフォーマンスを達成し、オフラインRLのスケーラビリティを向上させることを示しました。 Comment
元ポスト:
[Paper Note] Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing, Kento Nishi+, ICML'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ICML #KnowledgeEditing Issue Date: 2025-06-10 GPT Summary- 知識編集(KE)アルゴリズムは、モデルの重みを変更して不正確な事実を更新するが、これがモデルの事実の想起精度や推論能力に悪影響を及ぼす可能性がある。新たに定義した合成タスクを通じて、KEがターゲットエンティティを超えて他のエンティティの表現に影響を与え、未見の知識の推論を歪める「表現の破壊」現象を示す。事前訓練されたモデルを用いた実験でもこの発見が確認され、KEがモデルの能力に悪影響を及ぼす理由を明らかにするメカニズム仮説を提供する。 Comment
元ポスト:
Model Merging in Pre-training of Large Language Models, Yunshui Li+, arXiv'25
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #ModelMerge Issue Date: 2025-05-20 GPT Summary- モデルマージングは大規模言語モデルの強化に有望な技術であり、本論文ではその事前学習プロセスにおける包括的な調査を行う。実験により、一定の学習率で訓練されたチェックポイントをマージすることで性能向上とアニーリング挙動の予測が可能になることを示し、効率的なモデル開発と低コストのトレーニングに寄与する。マージ戦略やハイパーパラメータに関するアブレーション研究を通じて新たな洞察を提供し、実用的な事前学習ガイドラインをオープンソースコミュニティに提示する。 Comment
元ポスト:
解説ポスト:
Learning Dynamics of LLM Finetuning, Yi Ren+, ICLR'25
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #Alignment #Hallucination #ICLR #DPO #Repetition Issue Date: 2025-04-18 GPT Summary- 本研究では、大規模言語モデルのファインチューニング中の学習ダイナミクスを分析し、異なる応答間の影響の蓄積を段階的に解明します。指示調整と好み調整のアルゴリズムに関する観察を統一的に解釈し、ファインチューニング後の幻覚強化の理由を仮説的に説明します。また、オフポリシー直接好み最適化(DPO)における「圧縮効果」を強調し、望ましい出力の可能性が低下する現象を探ります。このフレームワークは、LLMのファインチューニング理解に新たな視点を提供し、アラインメント性能向上のためのシンプルな方法を示唆します。 Comment
元ポスト:
解説ポスト:
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, YuYue+, arXiv'25
Paper/Blog Link My Issue
#Pocket #LanguageModel #ReinforcementLearning #Reasoning #LongSequence Issue Date: 2025-04-08 GPT Summary- VAPO(Value-based Augmented Proximal Policy Optimization framework)を提案し、AIME 2024データセットで最先端のスコア60.4を達成。VAPOは他の手法を10ポイント以上上回り、5,000ステップで安定したパフォーマンスを示す。価値ベースの強化学習における3つの課題を特定し、VAPOがそれらを軽減する統合ソリューションを提供することで、長い思考過程の推論タスクの性能向上を実現。 Comment
同じくByteDanceの
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25
を上回る性能
元ポスト:
[Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Reasoning #GRPO #read-later #KeyPoint Notes Issue Date: 2025-03-22 GPT Summary- DeepSeek-R1-Zeroは、RLを用いてLLMsの推論能力を向上させる手法を示した。本研究では、ベースモデルとRLの影響を分析し、DeepSeek-V3-Baseが「アハ体験」を示す一方で、Qwen2.5が強力な推論能力を持つことを発見。GRPOの最適化バイアスを特定し、Dr. GRPOを導入してトークン効率を改善。7BベースモデルでAIME 2024において43.3%の精度を達成するR1-Zeroレシピを提案。 Comment
関連研究:
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25
解説ポスト:
解説ポスト(と論文中の当該部分)を読むと、
- オリジナルのGRPOの定式では2つのバイアスが生じる:
- response-level length bias: 1/|o_i| でAdvantageを除算しているが、これはAdvantageが負の場合(つまり、誤答が多い場合)「長い応答」のペナルティが小さくなるため、モデルが「長い応答」を好むバイアスが生じる。一方で、Advantageが正の場合(正答)は「短い応答」が好まれるようになる。
- question-level difficulty bias: グループ内の全ての応答に対するRewardのstdでAdvantageを除算しているが、stdが小さくなる問題(すなわち、簡単すぎるor難しすぎる問題)をより重視するような、問題に対する重みづけによるバイアスが生じる。
- aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
- これまではoutput lengthを増やすことが性能改善の鍵だと思われていたが、この論文では必ずしもそうではなく、self-reflection無しの方が有りの場合よりもAcc.が高い場合があることを示している(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様
あとで読む
(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:
DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25
Paper/Blog Link My Issue
#Pocket #LanguageModel #ReinforcementLearning #Reasoning #LongSequence #GRPO #read-later #Selected Papers/Blogs #One-Line Notes #Reference Collection Issue Date: 2025-03-20 GPT Summary- 推論スケーリングによりLLMの推論能力が向上し、強化学習が複雑な推論を引き出す技術となる。しかし、最先端の技術詳細が隠されているため再現が難しい。そこで、$\textbf{DAPO}$アルゴリズムを提案し、Qwen2.5-32Bモデルを用いてAIME 2024で50ポイントを達成。成功のための4つの重要技術を公開し、トレーニングコードと処理済みデータセットをオープンソース化することで再現性を向上させ、今後の研究を支援する。 Comment
既存のreasoning modelのテクニカルレポートにおいて、スケーラブルなRLの学習で鍵となるレシピは隠されていると主張し、実際彼らのbaselineとしてGRPOを走らせたところ、DeepSeekから報告されているAIME2024での性能(47ポイント)よりもで 大幅に低い性能(30ポイント)しか到達できず、分析の結果3つの課題(entropy collapse, reward noise, training instability)を明らかにした(実際R1の結果を再現できない報告が多数報告されており、重要な訓練の詳細が隠されているとしている)。
その上で50%のtrainikg stepでDeepSeek-R1-Zero-Qwen-32Bと同等のAIME 2024での性能を達成できるDAPOを提案。そしてgapを埋めるためにオープンソース化するとのこと。
ちとこれはあとでしっかり読みたい。重要論文。
プロジェクトページ:
https://dapo-sia.github.io/
こちらにアルゴリズムの重要な部分の概要が説明されている。
解説ポスト:
コンパクトだが分かりやすくまとまっている。
下記ポストによると、Reward Scoreに多様性を持たせたい場合は3.2節参照とのこと。
すなわち、Dynamic Samplingの話で、Accが全ての生成で1.0あるいは0.0となるようなpromptを除外するといった方法の話だと思われる。
これは、あるpromptに対する全ての生成で正解/不正解になった場合、そのpromptに対するAdvantageが0となるため、ポリシーをupdateするためのgradientも0となる。そうすると、このサンプルはポリシーの更新に全く寄与しなくなるため、同バッチ内のノイズに対する頑健性が失われることになる。サンプル効率も低下する。特にAccが1.0になるようなpromptは学習が進むにつれて増加するため、バッチ内で学習に有効なpromptは減ることを意味し、gradientの分散の増加につながる、といったことらしい。
関連ポスト:
色々な研究で広く使われるのを見るようになった。
著者ポスト:
[Paper Note] Transformers without Normalization, Jiachen Zhu+, CVPR'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #Transformer #Architecture #CVPR #Normalization Issue Date: 2025-03-14 GPT Summary- 本研究では、正規化層なしのトランスフォーマーがDynamic Tanh(DyT)を用いることで、同等またはそれ以上のパフォーマンスを達成できることを示します。DyTは、レイヤー正規化の代替として機能し、ハイパーパラメータの調整なしで効果を発揮します。多様な設定での実験により、正規化層の必要性に対する新たな洞察を提供します。 Comment
なん…だと…。LayerNormalizationを下記アルゴリズムのようなtanhを用いた超絶シンプルなレイヤー(parameterized thnh [Lecun氏ポスト](
同等以上の性能を維持しながらモデル全体のinference, trainingの時間を8%程度削減。
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, Jingyang Yuan+, ACL'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Attention #ACL #read-later Issue Date: 2025-03-02 GPT Summary- 長文コンテキストモデリングのために、計算効率を改善するスパースアテンションメカニズム「NSA」を提案。NSAは動的な階層スパース戦略を用い、トークン圧縮と選択を組み合わせてグローバルなコンテキスト認識とローカルな精度を両立。実装最適化によりスピードアップを実現し、エンドツーエンドのトレーニングを可能にすることで計算コストを削減。NSAはフルアテンションモデルと同等以上の性能を維持しつつ、長シーケンスに対して大幅なスピードアップを達成。 Comment
元ポスト:
ACL'25のBest Paperの一つ:
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training, Tianzhe Chu+, ICML'25
Paper/Blog Link My Issue
#ComputerVision #Analysis #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #ICML #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-01-30 GPT Summary- SFTとRLの一般化能力の違いを研究し、GeneralPointsとV-IRLを用いて評価。RLはルールベースのテキストと視覚変種に対して優れた一般化を示す一方、SFTは訓練データを記憶し分布外シナリオに苦労。RLは視覚認識能力を向上させるが、SFTはRL訓練に不可欠であり、出力形式を安定させることで性能向上を促進。これらの結果は、複雑なマルチモーダルタスクにおけるRLの一般化能力を示す。 Comment
元ポスト:
How Does Critical Batch Size Scale in Pre-training?, Hanlin Zhang+, ICLR'25
Paper/Blog Link My Issue
#NeuralNetwork #Pretraining #Pocket #NLP #LanguageModel #ICLR #Batch #One-Line Notes #CriticalBatchSize Issue Date: 2024-11-25 GPT Summary- 大規模モデルの訓練には、クリティカルバッチサイズ(CBS)を考慮した並列化戦略が重要である。CBSの測定法を提案し、C4データセットで自己回帰型言語モデルを訓練。バッチサイズや学習率などの要因を調整し、CBSがデータサイズに比例してスケールすることを示した。この結果は、ニューラルネットワークの理論的分析によって支持され、ハイパーパラメータ選択の重要性も強調されている。 Comment
Critical Batch Sizeはモデルサイズにはあまり依存せず、データサイズに応じてスケールする
Critical batch sizeが提案された研究:
- An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18
LBPE: Long-token-first Tokenization to Improve Large Language Models, Haoran Lian+, ICASSP'25, 2024.11
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Subword #Tokenizer #KeyPoint Notes Issue Date: 2024-11-12 GPT Summary- LBPEは、長いトークンを優先する新しいエンコーディング手法で、トークン化データセットにおける学習の不均衡を軽減します。実験により、LBPEは従来のBPEを一貫して上回る性能を示しました。 Comment
BPEとは異なりトークンの長さを優先してマージを実施することで、最終的なトークンを決定する手法で (Figure1),
BPEよりも高い性能を獲得し、
トークンの長さがBPEと比較して長くなり、かつ5Bトークン程度を既存のBPEで事前学習されたモデルに対して継続的事前学習するだけで性能を上回るようにでき (Table2)、同じVocabサイズでBPEよりも高い性能を獲得できる手法 (Table4)、らしい
[Paper Note] Transcoders Find Interpretable LLM Feature Circuits, Jacob Dunefsky+, arXiv'24, 2024.06
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #LanguageModel #read-later #Selected Papers/Blogs #Transcoders #CircuitAnalysis #Interpretability Issue Date: 2025-12-21 GPT Summary- トランスコーダーを用いて、MLPサブレイヤーの回路分析を行い、スパースなMLPレイヤーでの忠実な近似を実現。これにより、入力依存項と入力不変項に因数分解された回路を得る。120Mから1.4Bパラメータの言語モデルで訓練し、SAEと同等の解釈可能性を確認。GPT2-smallの「greater-than circuit」に関する新たな洞察も得られた。トランスコーダーはMLPを含むモデル計算の解釈に効果的であることが示唆された。
[Paper Note] On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes, Rishabh Agarwal+, ICLR'24, 2023.06
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #Distillation #ICLR #Off-Policy #On-Policy #One-Line Notes Issue Date: 2025-10-30 GPT Summary- 一般化知識蒸留(GKD)は、教師モデルからのフィードバックを活用し、生徒モデルが自己生成した出力シーケンスで訓練する手法。これにより、出力シーケンスの分布不一致の問題を解決し、柔軟な損失関数の使用が可能になる。GKDは蒸留と強化学習の統合を促進し、要約、翻訳、算術推論タスクにおける自動回帰言語モデルの蒸留においてその有効性を示す。 Comment
openreview: https://openreview.net/forum?id=3zKtaqxLhW
- Unlocking On-Policy Distillation for Any Model Family, Patiño+, HuggingFace, 2025.10
での説明に基づくと、
オフポリシーの蒸留手法を使うと、教師モデルが生成した出力を用いて蒸留をするため、生徒モデルが実際に出力するcontextとは異なる出力に基づいて蒸留をするため、生徒モデルの推論時のcontextとのミスマッチが生じる課題があるが、オンポリシーデータを混ぜることでこの問題を緩和するような手法(つまり実際の生徒モデル運用時と似た状況で蒸留できる)。生徒モデルが賢くなるにつれて出力が高品質になるため、それらを学習データとして再利用することでpositiveなフィードバックループが形成されるという利点がある。また、強化学習と比較しても、SparseなReward Modelに依存せず、初期の性能が低いモデルに対しても適用できる利点があるとのこと(性能が低いと探索が進まない場合があるため)。
[Paper Note] WHEN DOES SECOND-ORDER OPTIMIZATION SPEED UP TRAINING?, Ishikawa+, ICLR'24 Tiny Paper
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #Pocket #Optimizer Issue Date: 2025-10-28 GPT Summary- 二次最適化手法の使用が限られている理由を探り、特にバッチサイズとデータセットサイズに基づく条件を特定。実証的に、大きなバッチサイズと小さなデータセットサイズの組み合わせで二次最適化が一次最適化を上回ることを発見。 Comment
元ポスト:
[Paper Note] The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities, Venkatesh Balavadhani Parthasarathy+, arXiv'24, 2024.08
Paper/Blog Link My Issue
#Tutorial #Pocket #NLP #LanguageModel #PostTraining Issue Date: 2025-10-17 GPT Summary- 本報告書では、大規模言語モデル(LLMs)のファインチューニングに関する理論と実践を統合的に検討し、歴史的な進化やファインチューニング手法の比較を行っています。7段階の構造化されたパイプラインを紹介し、不均衡データセットの管理やパラメータ効率の良い手法(LoRA、Half Fine-Tuning)に重点を置いています。また、PPOやDPOなどの新しいアプローチや、検証フレームワーク、デプロイ後のモニタリングについても議論し、マルチモーダルLLMsやプライバシー、説明責任に関する課題にも触れています。研究者や実務者に実用的な洞察を提供する内容です。 Comment
元ポスト:
[Paper Note] DoRA: Weight-Decomposed Low-Rank Adaptation, Shih-Yang Liu+, ICML'24, 2024.02
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #PEFT(Adaptor/LoRA) #ICML #Selected Papers/Blogs #One-Line Notes Issue Date: 2025-10-10 GPT Summary- LoRAの精度ギャップを解消するために、Weight-Decomposed Low-Rank Adaptation(DoRA)を提案。DoRAは、ファインチューニングの重みを大きさと方向に分解し、方向性の更新にLoRAを使用することで、効率的にパラメータ数を最小化。これにより、LoRAの学習能力と安定性を向上させ、追加の推論コストを回避。さまざまな下流タスクでLoRAを上回る性能を示す。 Comment
日本語解説:
- LoRAの進化:基礎から最新のLoRA-Proまで , 松尾研究所テックブログ, 2025.09
- Tora: Torchtune-LoRA for RL, shangshang-wang, 2025.10
では、通常のLoRA, QLoRAだけでなく本手法でRLをする実装もサポートされている模様
[Paper Note] Looped Transformers are Better at Learning Learning Algorithms, Liu Yang+, ICLR'24
Paper/Blog Link My Issue
#Pocket #Transformer #Architecture #RecurrentModels Issue Date: 2025-08-30 GPT Summary- ループ型transformerアーキテクチャを提案し、従来のtransformerに反復的特性を組み込むことで、データフィッティング問題を解決。実験により、標準のtransformerと同等の性能を保ちながら、パラメータ数を10%未満に抑えることができることが示された。 Comment
openreview: https://openreview.net/forum?id=HHbRxoDTxE
[Paper Note] Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Avi Singh+, TMLR'24
Paper/Blog Link My Issue
#Pocket #ReinforcementLearning #TMLR Issue Date: 2025-06-14 GPT Summary- 言語モデルを人間データでファインチューニングする際の限界を超えるため、ReST$^{EM$という自己学習手法を提案。モデルから生成したサンプルをバイナリフィードバックでフィルタリングし、繰り返しファインチューニングを行う。PaLM-2モデルを用いた実験で、ReST$^{EM}$は人間データのみのファインチューニングを大幅に上回る性能を示し、フィードバックを用いた自己学習が人間生成データへの依存を減少させる可能性を示唆。 Comment
解説ポスト:
Reinforcement Learning: An Overview, Kevin Murphy, arXiv'24
Paper/Blog Link My Issue
#Tutorial #Pocket #ReinforcementLearning Issue Date: 2024-12-10 GPT Summary- この原稿は、深層強化学習と逐次的意思決定に関する最新の全体像を提供し、価値ベースのRL、ポリシー勾配法、モデルベース手法、RLとLLMsの統合について簡潔に議論しています。 Comment
あのMurphy本で有名なMurphy氏の強化学習の教科書…だと…
Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation, Xiwen Wei+, arXiv'24
Paper/Blog Link My Issue
#ComputerVision #Pocket #Supervised-FineTuning (SFT) #InstructionTuning #PEFT(Adaptor/LoRA) #Catastrophic Forgetting Issue Date: 2024-11-12 GPT Summary- 破滅的忘却に対処するため、タスクフリーのオンライン継続学習(OCL)フレームワークOnline-LoRAを提案。リハーサルバッファの制約を克服し、事前学習済みビジョントランスフォーマー(ViT)モデルをリアルタイムで微調整。新しいオンライン重み正則化戦略を用いて重要なモデルパラメータを特定し、データ分布の変化を自動認識。多様なベンチマークデータセットで優れた性能を示す。 Comment
LoRA vs Full Fine-tuning: An Illusion of Equivalence, Reece Shuttleworth+, arXiv'24
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #PEFT(Adaptor/LoRA) #read-later Issue Date: 2024-11-09 GPT Summary- ファインチューニング手法の違いが事前学習済みモデルに与える影響を、重み行列のスペクトル特性を通じて分析。LoRAと完全なファインチューニングは異なる構造の重み行列を生成し、LoRAモデルは新たな高ランクの特異ベクトル(侵入次元)を持つことが判明。侵入次元は一般化能力を低下させるが、同等の性能を達成することがある。これにより、異なるファインチューニング手法がパラメータ空間の異なる部分にアクセスしていることが示唆される。 Comment
元ポスト:
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
や Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
、双方の知見も交えて、LoRAの挙動を考察する必要がある気がする。それぞれ異なるデータセットやモデルで、LoRAとFFTを比較している。時間がないが後でやりたい。
あと、昨今はそもそも実験設定における変数が多すぎて、とりうる実験設定が多すぎるため、個々の論文の知見を鵜呑みにして一般化するのはやめた方が良い気がしている。
# 実験設定の違い
## モデルのアーキテクチャ
- 本研究: RoBERTa-base(transformer-encoder)
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: transformer-decoder
- Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: transformer-decoder(LLaMA)
## パラメータサイズ
- 本研究:
- When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method, Biao Zhang+, N/A, ICLR'24
: 1B, 2B, 4B, 8B, 16B
- Beyond Full Fine-tuning: Harnessing the Power of LoRA for Multi-Task Instruction Tuning, Xin+, LREC-COLING'24
: 7B
時間がある時に続きをかきたい
## Finetuningデータセットのタスク数
## 1タスクあたりのデータ量
## trainableなパラメータ数
ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate, Shohei Taniguchi+, NeurIPS'24
Paper/Blog Link My Issue
#Pocket #Optimizer Issue Date: 2024-11-06 GPT Summary- ADOPTという新しい適応勾配法を提案し、任意のハイパーパラメータ$\beta_2$で最適な収束率を達成。勾配の二次モーメント推定からの除去と更新順序の変更により、Adamの非収束問題を解決。広範なタスクで優れた結果を示し、実装はGitHubで公開。 Comment
画像は元ツイートからの引用:
ライブラリがあるようで、1行変えるだけですぐ使えるとのこと。
元ツイート:
Adamでは収束しなかった場合(バッチサイズが小さい場合)でも収束するようになっている模様
Stuffed Mamba: State Collapse and State Capacity of RNN-Based Long-Context Modeling, Yingfa Chen+, arXiv'24
Paper/Blog Link My Issue
#Pocket #NLP #LongSequence #SSM (StateSpaceModel) Issue Date: 2024-11-05 GPT Summary- RNNの長いコンテキスト処理の課題を研究し、状態崩壊(SC)とメモリ容量の制限に対処。Mamba-2モデルを用いて、SC緩和手法を提案し、1Mトークン以上の処理を実現。256Kコンテキスト長で高精度のパスキー取得を達成し、RNNの長コンテキストモデリングの可能性を示唆。
NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pocket #Supervised-FineTuning (SFT) Issue Date: 2024-10-27 GPT Summary- NEFTuneは、埋め込みベクトルにノイズを加えることで言語モデルのファインチューニングを改善する手法です。LLaMA-2-7Bを用いた標準的なファインチューニングでは29.79%の精度でしたが、ノイジーな埋め込みを使用することで64.69%に向上しました。NEFTuneは、Evol-Instruct、ShareGPT、OpenPlatypusなどの指示データセットでも改善をもたらし、RLHFで強化されたLLaMA-2-Chatにも効果があります。 Comment
ランダムノイズをembeddingに加えて学習するシンプルな手法。モデルがロバストになる。
Unsupervised SimCSEと思想が似ている。実質DataAugmentationともみなせる。
KTO: Model Alignment as Prospect Theoretic Optimization, Kawin Ethayarajh+, N_A, ICML'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Alignment #ICML #PostTraining Issue Date: 2024-10-27 GPT Summary- プロスペクト理論に基づき、LLMの人間フィードバック調整におけるバイアスの影響を示す。新たに提案する「人間認識損失」(HALOs)を用いたアプローチKTOは、生成物の効用を最大化し、好みベースの方法と同等またはそれ以上の性能を発揮。研究は、最適な損失関数が特定の設定に依存することを示唆。 Comment
binaryフィードバックデータからLLMのアライメントをとるKahneman-Tversky Optimization (KTO)論文
The Illusion of State in State-Space Models, William Merrill+, N_A, ICML'24
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #SSM (StateSpaceModel) #ICML Issue Date: 2024-08-27 GPT Summary- SSM(状態空間モデル)は、トランスフォーマーよりも優れた状態追跡の表現力を持つと期待されていましたが、実際にはその表現力は制限されており、トランスフォーマーと類似しています。SSMは複雑性クラス$\mathsf{TC}^0$の外での計算を表現できず、単純な状態追跡問題を解決することができません。このため、SSMは実世界の状態追跡問題を解決する能力に制限がある可能性があります。 Comment
>しかし、SSMが状態追跡の表現力で本当に(トランスフォーマーよりも)優位性を持っているのでしょうか?驚くべきことに、その答えは「いいえ」です。私たちの分析によると、SSMの表現力は、トランスフォーマーと非常に類似して制限されています:SSMは複雑性クラス$\mathsf{TC}^0$の外での計算を表現することができません。特に、これは、置換合成のような単純な状態追跡問題を解決することができないことを意味します。これにより、SSMは、特定の表記法でチェスの手を正確に追跡したり、コードを評価したり、長い物語の中のエンティティを追跡することが証明上できないことが明らかになります。
なん…だと…
Knowledge Fusion of Large Language Models, Fanqi Wan+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ICLR #read-later #ModelMerge Issue Date: 2024-01-23 GPT Summary- 本研究では、既存の事前訓練済みの大規模言語モデル(LLMs)を統合することで、1つの強力なモデルを作成する方法を提案しています。異なるアーキテクチャを持つ3つの人気のあるLLMsを使用して、ベンチマークとタスクのパフォーマンスを向上させることを実証しました。提案手法のコード、モデルの重み、およびデータはGitHubで公開されています。
Transformers are Multi-State RNNs, Matanel Oren+, N_A, EMNLP'24
Paper/Blog Link My Issue
#NLP #Transformer #EMNLP Issue Date: 2024-01-16 GPT Summary- 本研究では、トランスフォーマーのデコーダーは無限マルチステートRNNとして概念化できることを示し、有限のマルチステートRNNに変換することも可能であることを示します。さらに、新しいキャッシュ圧縮ポリシーであるTOVAを導入し、他のポリシーよりも優れた性能を示すことを実験結果で示しました。TOVAは元のキャッシュサイズの1/8しか使用せず、トランスフォーマーデコーダーLLMが実際にはRNNとして振る舞うことが多いことを示しています。 Comment
TransformerはRNNとは異なる概念、特に全てのトークンの情報に直接アクセスできるということで区別されてきたが、よくよく考えてみると、Transformer Decoderは、RNNのhidden_states h を(hは1つのstateをベクトルで表している)、multi-stateを表す matrix H (t個のstateを表すmatrix; tは現在の着目しているトークンまでのsequenceの長さ)で置き換えたもの Multi-State-RNN (MSRNN) と解釈できる、という話。
また、window attentionなどのattentionの計算で考慮するKV cacheのスパンを(メモリを節約するために)制限する圧縮手法は、先ほどのMSRNNは全トークンのstate (KV Cache)にアクセスできる(= Unbounded)と考えると、アクセスできるトークンのstateが k (
実際に式で表すと以下のようにRNNとTransformerは対応づけられる。
このことを考慮して、本研究ではTOVAと呼ばれる新しいKV Cacheの圧縮手法を提案している。非常にシンプルな手法で、KV Cacheがメモリの上限に到達したときに、その際にattention scoreが最も小さいトークンのKV Cacheを捨てる、という手法である。
TOVAをwindow attentionなどのベースラインとオラクルとしてfull attentionと比較。タスクは Language Modeling(PG-19データにおけるPerplexity)、Language Understanding (long contextからrelevantな情報を拾う必要があるQA)、Story Generation(長文のストーリーを書かせてGPT4によってpair-wiseで生成されたストーリーの品質をLLM-as-a-Judgeさせる)を利用。既存のKV Cache圧縮手法よりも効率的にKV Cacheを圧縮でき、4096 context windowの場合は、512程度でfull attentionと近い性能を示すことが示された。これにより、高いメモリ効率とスループットを実現できる。ここで、グラフのx軸のmultistateはTOVAにおいてはmatrix Hで保持するstate数に相当し、window attentionでは、window sizeに相当する。
Detecting Pretraining Data from Large Language Models, Weijia Shi+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #ICLR Issue Date: 2023-10-26 GPT Summary- 本研究では、大規模言語モデル(LLMs)を訓練するためのデータの検出問題を研究し、新しい検出方法であるMin-K% Probを提案します。Min-K% Probは、LLMの下で低い確率を持つアウトライアーワードを検出することに基づいています。実験の結果、Min-K% Probは従来の方法に比べて7.4%の改善を達成し、著作権のある書籍の検出や汚染された下流の例の検出など、実世界のシナリオにおいて効果的な解決策であることが示されました。 Comment
実験結果を見るにAUCは0.73-0.76程度であり、まだあまり高くない印象。また、テキストのlengthはそれぞれ32,64,128,256程度。
openreview: https://openreview.net/forum?id=zWqr3MQuNs
Large Language Models as Optimizers, Chengrun Yang+, N_A, ICLR'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #AutomaticPromptEngineering #ICLR Issue Date: 2023-09-09 GPT Summary- 本研究では、最適化タスクを自然言語で記述し、大規模言語モデル(LLMs)を使用して最適化を行う手法「Optimization by PROmpting(OPRO)」を提案しています。この手法では、LLMが以前の解とその値を含むプロンプトから新しい解を生成し、評価して次の最適化ステップのためのプロンプトに追加します。実験結果では、OPROによって最適化された最良のプロンプトが、人間が設計したプロンプトよりも優れていることが示されました。 Comment
`Take a deep breath and work on this problem step-by-step. `論文
# 概要
LLMを利用して最適化問題を解くためのフレームワークを提案したという話。論文中では、linear regressionや巡回セールスマン問題に適用している。また、応用例としてPrompt Engineeringに利用している。
これにより、Prompt Engineeringが最適か問題に落とし込まれ、自動的なprompt engineeringによって、`Let's think step by step.` よりも良いプロンプトが見つかりましたという話。
# 手法概要
全体としての枠組み。meta-promptをinputとし、LLMがobjective functionに対するsolutionを生成する。生成されたsolutionとスコアがmeta-promptに代入され、次のoptimizationが走る。これを繰り返す。
Meta promptの例
openreview: https://openreview.net/forum?id=Bb4VGOWELI
CausalLM is not optimal for in-context learning, Nan Ding+, N_A, ICLR'24
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #In-ContextLearning #ICLR Issue Date: 2023-09-01 GPT Summary- 最近の研究では、トランスフォーマーベースのインコンテキスト学習において、プレフィックス言語モデル(prefixLM)が因果言語モデル(causalLM)よりも優れたパフォーマンスを示すことがわかっています。本研究では、理論的なアプローチを用いて、prefixLMとcausalLMの収束挙動を分析しました。その結果、prefixLMは線形回帰の最適解に収束する一方、causalLMの収束ダイナミクスはオンライン勾配降下アルゴリズムに従い、最適であるとは限らないことがわかりました。さらに、合成実験と実際のタスクにおいても、causalLMがprefixLMよりも性能が劣ることが確認されました。 Comment
参考:
CausalLMでICLをした場合は、ICL中のdemonstrationでオンライン学習することに相当し、最適解に収束しているとは限らない……?が、hillbigさんの感想に基づくと、結果的には実は最適解に収束しているのでは?という話も出ているし、よく分からない。
LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition, Chengsong Huang+, N_A, COLM'24
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #COLM #PostTraining Issue Date: 2023-08-08 GPT Summary- 本研究では、大規模言語モデル(LLMs)を新しいタスクに適応させるための低ランク適応(LoRA)を検討し、LoraHubというフレームワークを提案します。LoraHubを使用すると、少数の例から複数のLoRAモジュールを組み合わせて柔軟に適応性のあるパフォーマンスを実現できます。また、追加のモデルパラメータや勾配は必要ありません。実験結果から、LoraHubが少数の例でのインコンテキスト学習のパフォーマンスを効果的に模倣できることが示されています。さらに、LoRAコミュニティの育成と共有リソースの提供にも貢献しています。 Comment
学習されたLoRAのパラメータをモジュールとして捉え、新たなタスクのinputが与えられた時に、LoRA Hub上の適切なモジュールをLLMに組み合わせることで、ICL無しで汎化を実現するというアイデア。few shotのexampleを人間が設計する必要なく、同等の性能を達成。
複数のLoRAモジュールは組み合わられるか?element wiseの線型結合で今回はやっているが、その疑問にこたえたのがcontribution
OpenReview: https://openreview.net/forum?id=TrloAXEJ2B
Lost in the Middle: How Language Models Use Long Contexts, Nelson F. Liu+, N_A, TACL'24
Paper/Blog Link My Issue
#Analysis #NLP #LanguageModel #Prompting #In-ContextLearning #TACL #ContextEngineering Issue Date: 2023-07-11 GPT Summary- 最近の言語モデルは、長い文脈を入力として受け取ることができますが、その長い文脈をどれだけうまく利用しているかについてはまだよくわかっていません。この研究では、マルチドキュメントの質問応答とキー・バリューの検索という2つのタスクにおいて、言語モデルのパフォーマンスを分析しました。その結果、関連情報が入力文脈の始まりや終わりにある場合、パフォーマンスが最も高くなることがわかりましたが、長い文脈の中で関連情報にアクセスする必要がある場合、パフォーマンスが著しく低下します。さらに、入力文脈が長くなるにつれて、明示的に長い文脈を扱うモデルでもパフォーマンスが大幅に低下します。この分析は、言語モデルが入力文脈をどのように利用しているかをより良く理解するためのものであり、将来の長い文脈モデルのための新しい評価プロトコルを提供します。 Comment
元ツイート
非常に重要な知見がまとめられている
1. モデルはコンテキストのはじめと最後の情報をうまく活用でき、真ん中の情報をうまく活用できない
2. 長いコンテキストのモデルを使っても、コンテキストをより短いコンテキストのモデルよりもうまく考慮できるわけではない
3. モデルのパフォーマンスは、コンテキストが長くなればなるほど悪化する
SNLP'24での解説スライド:
https://speakerdeck.com/kichi/snlp2024
[Paper Note] DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature, Eric Mitchell+, ICML'23, 2023.01
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ICML #Selected Papers/Blogs #text #AI Detector Issue Date: 2025-11-17 GPT Summary- LLM生成テキストの検出の必要性を背景に、対数確率関数の負の曲率を利用した新しい検出手法「DetectGPT」を提案。これにより、別の分類器やデータセットを必要とせず、特定のLLMから生成されたテキストを高精度で識別可能。特に、GPT-NeoXによるフェイクニュース記事の検出で、従来の手法を大幅に上回る性能を示した。
[Paper Note] Prodigy: An Expeditiously Adaptive Parameter-Free Learner, Konstantin Mishchenko+, arXiv'23, 2023.06
Paper/Blog Link My Issue
#Pocket #Optimizer #learning-rate-free Issue Date: 2025-10-26 GPT Summary- 学習率の推定問題に対処するため、Prodigyというアルゴリズムを提案。これはD-Adaptation手法を修正し、収束率を改善。12のベンチマークデータセットでテストした結果、ProdigyはD-Adaptationを上回り、手動調整されたAdamに近い精度を達成。 Comment
openreview: https://openreview.net/forum?id=WpQbM1kBuy
[Paper Note] Scaling laws for single-agent reinforcement learning, Jacob Hilton+, arXiv'23, 2023.01
Paper/Blog Link My Issue
#Single #Pocket #ReinforcementLearning #Scaling Laws Issue Date: 2025-10-13 GPT Summary- 生成モデルにおけるクロスエントロピー損失の改善がモデルサイズと計算量に依存することが示され、これを強化学習に拡張する際の課題として、平均エピソードリターンの変化が滑らかでないことが挙げられる。これを解決するために、内因的パフォーマンスを導入し、モデルサイズに応じた最小計算量を定義。さまざまな環境で内因的パフォーマンスが冪法則に従ってスケールすることを確認し、最適なモデルサイズも同様にスケールすることを示した。特に、MNISTベースの環境でタスクのホライズン長がこの関係に与える影響を調査した。 Comment
日本語解説: https://www.slideshare.net/slideshow/dlscaling-laws-for-singleagent-reinforcement-learning/255893696
[Paper Note] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, Xingchao Liu+, ICLR'23, 2022.09
Paper/Blog Link My Issue
#ComputerVision #Pocket #ICLR #Selected Papers/Blogs #RectifiedFlow Issue Date: 2025-10-10 GPT Summary- rectified flowという新しいアプローチを提案し、2つの分布間での輸送を学習するODEモデルを用いる。これは、直線的な経路を学習することで計算効率を高め、生成モデルやドメイン転送において統一的な解決策を提供する。rectificationを通じて、非増加の凸輸送コストを持つ新しい結合を生成し、再帰的に適用することで直線的なフローを得る。実証研究では、画像生成や翻訳において優れた性能を示し、高品質な結果を得ることが確認された。 Comment
openreview: https://openreview.net/forum?id=XVjTT1nw5z
日本語解説(fmuuly, zenn):
- Rectified Flow 1:
https://zenn.dev/fmuuly/articles/37cc3a2f17138e
- Rectified Flow 2:
https://zenn.dev/fmuuly/articles/a062fcd340207f
- Rectified Flow 3:
https://zenn.dev/fmuuly/articles/0f262fc003e202
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, Kenneth Li+, NeurIPS'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Hallucination #NeurIPS #read-later #ActivationSteering/ITI #Probing #Trustfulness #Selected Papers/Blogs Issue Date: 2025-05-09 GPT Summary- Inference-Time Intervention (ITI)を提案し、LLMsの真実性を向上させる技術を紹介。ITIは推論中にモデルの活性化を調整し、LLaMAモデルの性能をTruthfulQAベンチマークで大幅に改善。Alpacaモデルでは真実性が32.5%から65.1%に向上。真実性と有用性のトレードオフを特定し、介入の強度を調整する方法を示す。ITIは低コストでデータ効率が高く、数百の例で真実の方向性を特定可能。LLMsが虚偽を生成しつつも真実の内部表現を持つ可能性を示唆。 Comment
Inference Time Interventionを提案した研究。Attention Headに対して線形プロービング[^1]を実施し、真実性に関連するであろうHeadをtopKで特定できるようにし、headの出力に対し真実性を高める方向性のベクトルvを推論時に加算することで(=intervention)、モデルの真実性を高める。vは線形プロービングによって学習された重みを使う手法と、正答と誤答の活性化の平均ベクトルを計算しその差分をvとする方法の二種類がある。後者の方が性能が良い。topKを求める際には、線形プロービングをしたモデルのvalidation setでの性能から決める。Kとαはハイパーパラメータである。
[^1]: headのrepresentationを入力として受け取り、線形モデルを学習し、線形モデルの2値分類性能を見ることでheadがどの程度、プロービングの学習に使ったデータに関する情報を保持しているかを測定する手法
日本語解説スライド:
https://www.docswell.com/s/DeepLearning2023/Z38P8D-2024-06-20-131813#p1
これは相当汎用的に使えそうな話だから役に立ちそう
Dataset Distillation: A Comprehensive Review, Ruonan Yu+, arXiv'23
Paper/Blog Link My Issue
#Survey #Pocket #Dataset #Distillation Issue Date: 2025-03-25 GPT Summary- データセット蒸留(DD)は、深層学習における膨大なデータのストレージやプライバシーの問題を軽減する手法であり、合成サンプルを含む小さなデータセットを生成することで、元のデータセットと同等の性能を持つモデルをトレーニング可能にする。本論文では、DDの進展と応用をレビューし、全体的なアルゴリズムフレームワークを提案、既存手法の分類と理論的相互関係を議論し、DDの課題と今後の研究方向を展望する。 Comment
訓練データセット中の知識を蒸留し、オリジナルデータよりも少量のデータで同等の学習効果を得るDataset Distillationに関するSurvey。
Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #NeurIPS #Scaling Laws #read-later #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2025-03-23 GPT Summary- 言語モデルのスケーリングにおいて、データ制約下でのトレーニングを調査。9000億トークンと90億パラメータのモデルを用いた実験で、繰り返しデータを使用しても損失に大きな変化は見られず、繰り返しの価値が減少することを確認。計算最適性のスケーリング法則を提案し、データ不足を軽減するアプローチも実験。得られたモデルとデータセットは公開。 Comment
OpenReview: https://openreview.net/forum?id=j5BuTrEj35
チンチラ則のようなScaling Lawsはパラメータとデータ量の両方をスケールさせた場合の前提に立っており、かつデータは全てuniqueである前提だったが、データの枯渇が懸念される昨今の状況に合わせて、データ量が制限された状況で、同じデータを繰り返し利用する(=複数エポック学習する)ことが一般的になってきた。このため、データのrepetitionに関して性能を事前学習による性能の違いを調査して、repetitionとパラメータ数に関するスケーリング則を提案($3.1)しているようである。
Takeawayとしては、データが制限された環境下では、repetitionは上限4回までが効果的(コスパが良い)であり(左図)、小さいモデルを複数エポック訓練する方が固定されたBudgetの中で低いlossを達成できる右図)。
学習データの半分をコードにしても性能の劣化はなく、様々なタスクの性能が向上しパフォーマンスの分散も小さくなる、といったことが挙げられるようだ。
Zero Bubble Pipeline Parallelism, Penghui Qi+, arXiv'23
Paper/Blog Link My Issue
#Pocket Issue Date: 2024-12-16 GPT Summary- 本研究では、パイプライン並列性の効率を向上させるために、ゼロパイプラインバブルを達成する新しいスケジューリング戦略を提案。逆伝播計算を二つに分割し、手作業で設計した新しいパイプラインスケジュールは、ベースライン手法を大幅に上回る性能を示した。さらに、最適なスケジュールを自動的に見つけるアルゴリズムと、オプティマイザステップ中の同期を回避する技術を導入。実験結果では、スループットが最大23%向上し、メモリ制約が緩和されると31%まで改善。実装はオープンソースで提供。
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints, Aran Komatsuzaki+, ICLR'23
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #MoE(Mixture-of-Experts) #PostTraining Issue Date: 2024-11-25 GPT Summary- スパース活性化モデルは、計算コストを抑えつつ密なモデルの代替として注目されているが、依然として多くのデータを必要とし、ゼロからのトレーニングは高コストである。本研究では、密なチェックポイントからスパース活性化Mixture-of-Expertsモデルを初期化する「スパースアップサイクリング」を提案。これにより、初期の密な事前トレーニングのコストを約50%再利用し、SuperGLUEやImageNetで密なモデルを大幅に上回る性能を示した。また、アップサイクリングされたモデルは、ゼロからトレーニングされたスパースモデルよりも優れた結果を得た。 Comment
斜め読みしかできていないが、Mixture-of-Expertsを用いたモデルをSFT/Pretrainingする際に、既存のcheckpointの重みを活用することでより効率的かつ性能向上する方法を提案。MoE LayerのMLPを全て既存のcheckpointにおけるMLPの重みをコピーして初期化する。Routerはスクラッチから学習する。
継続事前学習においては、同じ学習時間の中でDense Layerを用いるベースラインと比較してでより高い性能を獲得。
Figure2で継続事前学習したモデルに対して、フルパラメータのFinetuningをした場合でもUpcyclingは効果がある(Figure3)。
特にPretrainingではUpcyclingを用いたモデルの性能に、通常のMoEをスクラッチから学習したモデルが追いつくのに時間がかかるとのこと。特に図右側の言語タスクでは、120%の学習時間が追いつくために必要だった。
Sparse Upcycingと、Dense tilingによる手法(warm start; 元のモデルに既存の層を複製して新しい層を追加する方法)、元のモデルをそれぞれ継続事前学習すると、最も高い性能を獲得している。
(すごい斜め読みなのでちょっも自信なし、、、)
VeRA: Vector-based Random Matrix Adaptation, Dawid J. Kopiczko+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) Issue Date: 2024-01-17 GPT Summary- 本研究では、大規模な言語モデルのfine-tuningにおいて、訓練可能なパラメータの数を削減するための新しい手法であるベクトルベースのランダム行列適応(VeRA)を提案する。VeRAは、共有される低ランク行列と小さなスケーリングベクトルを使用することで、同じ性能を維持しながらパラメータ数を削減する。GLUEやE2Eのベンチマーク、画像分類タスクでの効果を示し、言語モデルのインストラクションチューニングにも応用できることを示す。
NEFTune: Noisy Embeddings Improve Instruction Finetuning, Neel Jain+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2023-10-26 GPT Summary- 私たちは、言語モデルのファインチューニングを改善するために、ノイズを加えた埋め込みベクトルを使用する手法を提案します。この手法は、AlpacaEvalやEvol-Instructなどのデータセットで強力なベースラインを上回る性能を示しました。また、RLHFでトレーニングされたモデルにも適用可能です。 Comment
Alpacaデータでの性能向上が著しい。かなり重要論文な予感。後で読む。
HuggingFaceのTRLでサポートされている
https://huggingface.co/docs/trl/sft_trainer
Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking, Yongqi Tong+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Chain-of-Thought #Prompting Issue Date: 2023-10-24 GPT Summary- 本研究では、大規模言語モデル(LLMs)に非線形の思考を促すために、新しいプロンプティング方法であるInferential Exclusion Prompting(IEP)を提案する。IEPは、計画を立てて可能な解を推論し、逆推論を行うことで広い視点を得ることができる。IEPは他の手法と比較して複雑な人間の思考プロセスをシミュレートできることを実証し、LLMsのパフォーマンス向上にも貢献することを示した。さらに、Mental-Ability Reasoning Benchmark(MARB)を導入し、LLMsの論理と言語推論能力を評価するための新しいベンチマークを提案した。IEPとMARBはLLMsの研究において有望な方向性であり、今後の進展が期待される。 Comment
元論文は読んでいないのだが、CoTが線形的だという主張がよくわからない。
CoTはAutoregressiveな言語モデルに対して、コンテキストを自己生成したテキストで利用者の意図した方向性にバイアスをかけて補完させ、
利用者が意図した通りのアウトプットを最終的に得るためのテクニック、だと思っていて、
線形的だろうが非線形的だろうがどっちにしろCoTなのでは。
Why Do We Need Weight Decay in Modern Deep Learning?, Maksym Andriushchenko+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #Regularization Issue Date: 2023-10-11 GPT Summary- ウェイト減衰は、大規模な言語モデルのトレーニングに使用されるが、その役割はまだ理解されていない。本研究では、ウェイト減衰が古典的な正則化とは異なる役割を果たしていることを明らかにし、過パラメータ化されたディープネットワークでの最適化ダイナミクスの変化やSGDの暗黙の正則化の強化方法を示す。また、ウェイト減衰が確率的最適化におけるバイアス-分散トレードオフのバランスを取り、トレーニング損失を低下させる方法も説明する。さらに、ウェイト減衰はbfloat16混合精度トレーニングにおける損失の発散を防ぐ役割も果たす。全体として、ウェイト減衰は明示的な正則化ではなく、トレーニングダイナミクスを変えるものであることが示される。 Comment
参考:
WeightDecayは目的関数に普通にL2正則化項を加えることによって実現されるが、深掘りするとこんな効果があるのね
openreview: https://openreview.net/forum?id=RKh7DI23tz
Benchmarking Large Language Models As AI Research Agents, Qian Huang+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #AIAgents #Evaluation #AutoML Issue Date: 2023-10-09 GPT Summary- 本研究では、AI研究エージェントを構築し、科学的な実験のタスクを実行するためのベンチマークとしてMLAgentBenchを提案する。エージェントはファイルの読み書きやコードの実行などのアクションを実行し、実験を実行し、結果を分析し、機械学習パイプラインのコードを変更することができる。GPT-4ベースの研究エージェントは多くのタスクで高性能なモデルを実現できるが、成功率は異なる。また、LLMベースの研究エージェントにはいくつかの課題がある。 Comment
GPT4がMLモデルをどれだけ自動的に構築できるかを調べた模様。また、ベンチマークデータを作成した模様。結果としては、既存の有名なデータセットでの成功率は90%程度であり、未知のタスク(新たなKaggle Challenge等)では30%程度とのこと。
Boolformer: Symbolic Regression of Logic Functions with Transformers, Stéphane d'Ascoli+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #Transformer Issue Date: 2023-10-09 GPT Summary- この研究では、BoolformerというTransformerアーキテクチャを使用して、ブール関数のシンボリック回帰を実行する方法を紹介します。Boolformerは、クリーンな真理値表やノイズのある観測など、さまざまなデータに対して効果的な式を予測することができます。さらに、実世界のデータセットや遺伝子制御ネットワークのモデリングにおいて、Boolformerは解釈可能な代替手法として優れた性能を発揮します。この研究の成果は、公開されています。 Comment
ブール関数をend-to-endで学習できるtransformeiアーキテクチャを提案した模様
Explaining grokking through circuit efficiency, Vikrant Varma+, N_A, arXiv'23
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #Grokking Issue Date: 2023-09-30 GPT Summary- グロッキングとは、完璧なトレーニング精度を持つネットワークでも一般化が悪い現象のことである。この現象は、タスクが一般化する解と記憶する解の両方を許容する場合に起こると考えられている。一般化する解は学習が遅く、効率的であり、同じパラメータノルムでより大きなロジットを生成する。一方、記憶回路はトレーニングデータセットが大きくなるにつれて非効率になるが、一般化回路はそうではないと仮説が立てられている。これは、記憶と一般化が同じくらい効率的な臨界データセットサイズが存在することを示唆している。さらに、グロッキングに関して4つの新しい予測が立てられ、それらが確認され、説明が支持される重要な証拠が提供されている。また、グロッキング以外の2つの新しい現象も示されており、それはアングロッキングとセミグロッキングである。アングロッキングは完璧なテスト精度から低いテスト精度に逆戻りする現象であり、セミグロッキングは完璧なテスト精度ではなく部分的なテスト精度への遅れた一般化を示す現象である。 Comment
Grokkingがいつ、なぜ発生するかを説明する理論を示した研究。
理由としては、最初はmemorizationを学習していくのだが、ある時点から一般化回路であるGenに切り替わる。これが切り替わる理由としては、memorizationよりも、genの方がlossが小さくなるから、とのこと。これはより大規模なデータセットで顕著。
Grokkingが最初に報告された研究は GROKKING: GENERALIZATION BEYOND OVERFIT- TING ON SMALL ALGORITHMIC DATASETS, Power+, ICLR'21 Workshop
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models, Yukang Chen+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #Dataset #QuestionAnswering #Supervised-FineTuning (SFT) #LongSequence #PEFT(Adaptor/LoRA) #PostTraining Issue Date: 2023-09-30 GPT Summary- 本研究では、計算コストを制限しながら大規模言語モデル(LLMs)のコンテキストサイズを拡張する効率的なファインチューニング手法であるLongLoRAを提案します。従来の方法では、LLMsの長いコンテキストサイズでのトレーニングには高い計算コストとGPUリソースが必要でしたが、提案手法ではコンテキスト拡張を高速化し、非自明な計算コストの削減を実現します。また、パラメータ効率的なファインチューニング手法も再評価し、LongLoRAはさまざまなタスクで強力な実験結果を示しています。さらに、教師ありファインチューニングのためのデータセットであるLongQAも収集されました。 Comment
# 概要
context長が大きい場合でも効率的にLoRAする手法。通常のLoRAではcontext lengthが大きくなるにつれてperplexityが大きくなってしまう。一方、通常のFinetuningではperplexityは高い性能を維持するが、計算コストとVRAMの消費量が膨大になってしまう。LongLoRAでは、perplexityを通常のFinetuningと同等に抑えつつ、VRAM消費量もLoRAと同等、かつより小さな計算量でFinetuningを実現している。
# 手法概要
attentionをcontext length全体で計算するとinput長の二乗の計算量がかかるため、contextをいくつかのグループに分割しグループごとにattentionを計算することで計算量削減。さらに、グループ間のattentionの間の依存関係を捉えるために、グループをshiftさせて計算したものと最終的に組み合わせている。また、embedding, normalization layerもtrainableにしている。
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers, Elias Frantar+, N_A, ICLR'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Quantization #ICLR Issue Date: 2023-09-29 GPT Summary- 本研究では、GPTモデルの推論における計算およびストレージコストの問題に取り組み、新しいワンショット重み量子化手法であるGPTQを提案します。GPTQは高い精度と効率性を持ち、1750億のパラメータを持つGPTモデルを4時間のGPU時間で量子化することができます。提案手法は従来の手法と比較して圧縮率を2倍以上向上させ、精度を保持することができます。さらに、提案手法は極端な量子化領域でも合理的な精度を提供します。実験結果では、提案手法を使用することでエンドツーエンドの推論速度が約3.25倍から4.5倍向上することが示されています。提案手法の実装はhttps://github.com/IST-DASLab/gptqで利用可能です。 Comment
# 概要
- 新たなpost-training量子化手法であるGPTQを提案
- 数時間以内に数千億のパラメータを持つモデルでの実行が可能であり、パラメータごとに3~4ビットまで圧縮するが、精度の大きな損失を伴わない
- OPT-175BおよびBLOOM-176Bを、約4時間のGPU時間で、perplexityのわずかな増加で量子化することができた
- 数千億のパラメータを持つ非常に高精度な言語モデルを3-4ビットに量子化可能なことを初めて示した
- 先行研究のpost-training手法は、8ビット(Yao et al., 2022; Dettmers et al., 2022)。
- 一方、以前のtraining-basedの手法は、1~2桁小さいモデルのみを対象としていた(Wu et al., 2022)。
# Background
## Layer-wise quantization
各linear layerがあるときに、full precisionのoutputを少量のデータセットをネットワークに流したときに、quantized weight W^barを用いてreconstructできるように、squared error lossを最小化する方法。
## Optimal Brain quantization (OBQ)
OBQでは equation (1)をWの行に関するsummationとみなす。そして、それぞれの行 **w** をOBQは独立に扱い、ある一つの重みw_qをquantizeするときに、エラーがw_qのみに基づいていることを補償するために他の**w**の全てのquantizedされていない重みをupdateする。式で表すと下記のようになり、Fは残りのfull-precision weightの集合を表している。
この二つの式を、全ての**w**の重みがquantizedされるまで繰り返し適用する。
つまり、ある一個の重みをquantizedしたことによる誤差を補うように、他のまだquantizedされていない重みをupdateすることで、次に別の重みをquantizedする際は、最初の重みがquantizedされたことを考慮した重みに対してquantizedすることになる。これを繰り返すことで、quantizedしたことによる誤差を考慮して**w**全体をアップデートできる、という気持ちだと思う。
この式は高速に計算することができ、medium sizeのモデル(25M parameters; ResNet-50 modelなど)とかであれば、single GPUで1時間でquantizeできる。しかしながら、OBQはO(d_row * d_col^3)であるため、(ここでd_rowはWの行数、d_colはwの列数)、billions of parametersに適用するには計算量が多すぎる。
# Algorithm
## Step 1: Arbitrary Order Insight.
通常のOBQは、量子化誤差が最も少ない重みを常に選択して、greedyに重みを更新していく。しかし、パラメータ数が大きなモデルになると、重みを任意の順序で量子化したとしてもそれによる影響は小さいと考えられる。なぜなら、おそらく、大きな個別の誤差を持つ量子化された重みの数が少ないと考えられ、その重みがプロセスのが進むにつれて(アップデートされることで?)相殺されるため。
このため、提案手法は、すべての行の重みを同じ順序で量子化することを目指し、これが通常、最終的な二乗誤差が元の解と同じ結果となることを示す。が、このために2つの課題を乗り越えなければならない。
## Step2. Lazy Batch-Updates
Fを更新するときは、各エントリに対してわずかなFLOPを使用して、巨大な行列のすべての要素を更新する必要があります。しかし、このような操作は、現代のGPUの大規模な計算能力を適切に活用することができず、非常に小さいメモリ帯域幅によってボトルネックとなる。
幸いにも、この問題は以下の観察によって解決できる:列iの最終的な四捨五入の決定は、この特定の列で行われた更新にのみ影響され、そのプロセスの時点で後の列への更新は関連がない。これにより、更新を「lazy batch」としてまとめることができ、はるかに効率的なGPUの利用が可能となる。(要は独立して計算できる部分は全部一気に計算してしまって、後で一気にアップデートしますということ)。たとえば、B = 128の列にアルゴリズムを適用し、更新をこれらの列と対応するB × Bブロックの H^-1 に格納する。
この戦略は理論的な計算量を削減しないものの、メモリスループットのボトルネックを改善する。これにより、非常に大きなモデルの場合には実際に1桁以上の高速化が提供される。
## Step 3: Cholesky Reformulation
行列H_F^-1が不定になることがあり、これがアルゴリズムが残りの重みを誤った方向に更新する原因となり、該当する層に対して悪い量子化を実施してしまうことがある。この現象が発生する確率はモデルのサイズとともに増加することが実際に観察された。これを解決するために、コレスキー分解を活用して解決している(詳細はきちんと読んでいない)。
# 実験で用いたCalibration data
GPTQのキャリブレーションデータ全体は、C4データセット(Raffel et al., 2020)からのランダムな2048トークンのセグメント128個で構成される。つまり、ランダムにクロールされたウェブサイトからの抜粋で、一般的なテキストデータを表している。GPTQがタスク固有のデータを一切見ていないため「ゼロショット」な設定でquantizationを実施している。
# Language Generationでの評価
WikiText2に対するPerplexityで評価した結果、先行研究であるRTNを大幅にoutperformした。
Textbooks Are All You Need II: phi-1.5 technical report, Yuanzhi Li+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #Selected Papers/Blogs Issue Date: 2023-09-13 GPT Summary- 私たちは、小さなTransformerベースの言語モデルであるTinyStoriesと、大規模な言語モデルであるphi-1の能力について調査しました。また、phi-1を使用して教科書の品質のデータを生成し、学習プロセスを改善する方法を提案しました。さらに、phi-1.5という新しいモデルを作成し、自然言語のタスクにおいて性能が向上し、複雑な推論タスクにおいて他のモデルを上回ることを示しました。phi-1.5は、良い特性と悪い特性を持っており、オープンソース化されています。 Comment
Textbooks Are All You Need, Suriya Gunasekar+, N/A, arXiv'23 に続く論文
Large Language Models Are Human-Level Prompt Engineers, Yongchao Zhou+, ICLR'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Prompting #AutomaticPromptEngineering #ICLR Issue Date: 2023-09-05 GPT Summary- 大規模言語モデル(LLMs)は、自然言語の指示に基づいて一般的な用途のコンピュータとして優れた能力を持っています。しかし、モデルのパフォーマンスは、使用されるプロンプトの品質に大きく依存します。この研究では、自動プロンプトエンジニア(APE)を提案し、LLMによって生成された指示候補のプールから最適な指示を選択するために最適化します。実験結果は、APEが従来のLLMベースラインを上回り、19/24のタスクで人間の生成した指示と同等または優れたパフォーマンスを示しています。APEエンジニアリングされたプロンプトは、モデルの性能を向上させるだけでなく、フューショット学習のパフォーマンスも向上させることができます。詳細は、https://sites.google.com/view/automatic-prompt-engineerをご覧ください。 Comment
プロジェクトサイト: https://sites.google.com/view/automatic-prompt-engineer
openreview: https://openreview.net/forum?id=92gvk82DE-
[Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, EMNLP'23 System Demonstrations, 2023.08
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #DataAugmentation #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #EMNLP #Selected Papers/Blogs #System Demonstration #KeyPoint Notes Issue Date: 2023-08-28 GPT Summary- Prompt2Modelは、自然言語のタスク説明を基に特化型NLPモデルを訓練する手法で、LLMsの利点を活かしつつデプロイに適したモデルを生成します。既存のデータセットや事前学習済みモデルを活用し、データセット生成と教師ありファインチューニングを行うことで、同じfew-shotプロンプトでgpt-3.5-turboを平均20%上回る性能を持つ小型モデルを訓練可能です。信頼性のある性能推定も提供し、モデル開発者がデプロイ前に評価できるようにします。Prompt2Modelはオープンソースで公開されています。 Comment
Dataset Generatorによって、アノテーションが存在しないデータについても擬似ラベル付きデータを生成することができ、かつそれを既存のラベル付きデータと組み合わせることによってさらに性能が向上することが報告されている。これができるのはとても素晴らしい。
Dataset Generatorについては、データを作成する際に低コストで、高品質で、多様なデータとするためにいくつかの工夫を実施している。
1. ユーザが与えたデモンストレーションだけでなく、システムが生成したexampleもサンプリングして活用することで、生成されるexampleの多様性を向上させる。実際、これをやらない場合は120/200がduplicate exampleであったが、これが25/200まで減少した。
2. 生成したサンプルの数に比例して、temperatureを徐々に高くしていく。これにより、サンプルの質を担保しつつ、多様性を徐々に増加させることができる。Temperature Annealingと呼ぶ。
3. self-consistencyを用いて、擬似ラベルの質を高める。もしmajority votingが互角の場合は、回答が短いものを採用した(これはヒューリスティックに基づいている)
4. zeno buildを用いてAPIへのリクエストを並列化することで高速に実験を実施
非常に参考になる。
著者らによる現在の視点での振り返り(提案当時はAI Agentsという概念はまだなく、本研究はその先取りと言える):
MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks, Lei Zhang+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #NLP #AutoML Issue Date: 2023-08-10 GPT Summary- 本研究では、機械学習タスクの自動化における人間の知識と機械知能のギャップを埋めるために、新しいフレームワークMLCopilotを提案する。このフレームワークは、最先端のLLMsを使用して新しいMLタスクのソリューションを開発し、既存のMLタスクの経験から学び、効果的に推論して有望な結果を提供することができる。生成されたソリューションは直接使用して競争力のある結果を得ることができる。
The Hydra Effect: Emergent Self-repair in Language Model Computations, Thomas McGrath+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Attention Issue Date: 2023-08-08 GPT Summary- 私たちは、言語モデルの内部構造を調査し、言語モデルの計算における特定の効果を示しました。具体的には、1つの層の削除が他の層によって補完される「Hydra効果」と、遅いMLP層が最大尤度トークンを制御する役割を持つことを示しました。また、ドロップアウトを使用しない言語モデルでも同様の効果が見られることを示しました。これらの効果を事実の回想の文脈で分析し、言語モデルの回路レベルの属性付与について考察しました。 Comment
LLMからattention layerを一つ取り除くと、後続の層が取り除かれたlayerの機能を引き継ぐような働きをすることがわかった。これはLLMの自己修復機能のようなものであり、HydraEffectと命名された。
DoG is SGD's Best Friend: A Parameter-Free Dynamic Step Size Schedule, Maor Ivgi+, N_A, ICML'23
Paper/Blog Link My Issue
#Pocket #Optimizer Issue Date: 2023-07-25 GPT Summary- 私たちは、チューニング不要の動的SGDステップサイズの式であるDoGを提案します。DoGは、初期点からの距離と勾配のノルムに基づいてステップサイズを計算し、学習率のパラメータを必要としません。理論的には、DoGの式は確率的凸最適化においてパラメータフリーの収束を保証します。実験的には、DoGのパフォーマンスがチューニングされた学習率を持つSGDに近いことを示し、DoGのバリアントがチューニングされたSGDやAdamを上回ることを示します。PyTorchの実装はhttps://github.com/formll/dogで利用できます。 Comment
20 を超える多様なタスクと 8 つのビジョンおよび NLP モデルに対して有効であったシンプルなパラメーターフリーのoptimizer
元ツイート:
Batch Prompting: Efficient Inference with Large Language Model APIs, Zhoujun Cheng+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #Prompting Issue Date: 2023-07-24 GPT Summary- 大規模な言語モデル(LLMs)を効果的に使用するために、バッチプロンプティングという手法を提案します。この手法は、LLMが1つのサンプルではなくバッチで推論を行うことを可能にし、トークンコストと時間コストを削減しながらパフォーマンスを維持します。さまざまなデータセットでの実験により、バッチプロンプティングがLLMの推論コストを大幅に削減し、良好なパフォーマンスを達成することが示されました。また、バッチプロンプティングは異なる推論方法にも適用できます。詳細はGitHubのリポジトリで確認できます。 Comment
10種類のデータセットで試した結果、バッチにしても性能は上がったり下がったりしている。著者らは類似した性能が出ているので、コスト削減になると結論づけている。
Batch sizeが大きくなるに連れて性能が低下し、かつタスクの難易度が高いとパフォーマンスの低下が著しいことが報告されている。また、contextが長ければ長いほど、バッチサイズを大きくした際のパフォーマンスの低下が著しい。
Retentive Network: A Successor to Transformer for Large Language Models, Yutao Sun+, N_A, arXiv'23
Paper/Blog Link My Issue
#LanguageModel Issue Date: 2023-07-22 GPT Summary- この研究では、Retentive Network(RetNet)という大規模言語モデルのアーキテクチャを提案します。RetNetは、トレーニングの並列化、低コストの推論、良好なパフォーマンスを同時に実現することができます。RetNetは再帰と注意の関係を理論的に導出し、シーケンスモデリングのためのretentionメカニズムを提案します。このメカニズムは、並列、再帰、チャンクごとの再帰の3つの計算パラダイムをサポートします。RetNetの実験結果は、優れたスケーリング結果、並列トレーニング、低コストの展開、効率的な推論を実現していることを示しています。RetNetは、大規模言語モデルの強力な後継者となる可能性があります。 Comment
参考:
QLoRA: Efficient Finetuning of Quantized LLMs, Tim Dettmers+, N_A, NeurIPS'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #Supervised-FineTuning (SFT) #Quantization #PEFT(Adaptor/LoRA) #NeurIPS #PostTraining #Selected Papers/Blogs Issue Date: 2023-07-22 GPT Summary- 私たちは、QLoRAという効率的なファインチューニング手法を提案します。この手法は、メモリ使用量を削減し、48GBの単一のGPU上で65Bパラメータモデルをファインチューニングすることができます。また、16ビットのファインチューニングタスクのパフォーマンスを維持します。QLoRAは、凍結された4ビット量子化された事前学習済み言語モデルの勾配をLow Rank Adapters(LoRA)に逆伝播させます。私たちの最良のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達します。また、単一のGPU上でのファインチューニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています。具体的には、4ビットNormalFloat(NF4)という情報理論的に最適な新しいデータ型、ダブル量子化による平均メモリフットプリントの削減、およびページドオプティマイザによるメモリスパイクの管理です。私たちはQLoRAを使用して1,000以上のモデルをファインチューニングし、8つの命令データセット、複数のモデルタイプ(LLaMA、T5)、および従来のファインチューニングでは実行不可能なモデルスケール(33Bおよび65Bパラメータモデル)にわたる命令の追跡とチャットボットのパフォーマンスの詳細な分析を提供します。私たちの結果は、QLoRAを使用して小規模な高品質のデータセットでのファインチューニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。また、人間の評価とGPT-4の評価に基づいたチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価が安価で合理的な人間の評価の代替手段であることを示します。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するためには信頼性がないことがわかります。GuanacoがChatGPTと比較してどこで失敗するかを示す分析も行っています。私たちは、4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 Comment
実装:
https://github.com/artidoro/qlora
PEFTにもある
参考:
Pre-Training to Learn in Context, ACL'23
Paper/Blog Link My Issue
#Pretraining #NLP #In-ContextLearning Issue Date: 2023-07-18 GPT Summary- インコンテキスト学習は、タスクの例と文脈からタスクを実行する方法であり、注目されています。しかし、現在の方法では十分に活用されていないため、私たちはPICLというフレームワークを提案します。これは、一般的なテキストコーパスでモデルを事前学習し、文脈に基づいてタスクを推論して実行する能力を向上させます。私たちは、PICLでトレーニングされたモデルのパフォーマンスを評価し、他のモデルを上回ることを示しました。コードはGitHubで公開されています。
PAD-Net: An Efficient Framework for Dynamic Networks, ACL'23
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #NLP #DynamicNetworks #Encoder Issue Date: 2023-07-18 GPT Summary- 本研究では、ダイナミックネットワークの一般的な問題点を解決するために、部分的にダイナミックなネットワーク(PAD-Net)を提案します。PAD-Netは、冗長なダイナミックパラメータを静的なパラメータに変換することで、展開コストを削減し、効率的なネットワークを実現します。実験結果では、PAD-Netが画像分類と言語理解のタスクで高い性能を示し、従来のダイナミックネットワークを上回ることを示しました。
Measuring the Instability of Fine-Tuning, ACL'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #Evaluation Issue Date: 2023-07-14 GPT Summary- 事前学習済み言語モデルのファインチューニングは小規模データセットでは不安定であることが示されている。本研究では、不安定性を定量化する指標を分析し、評価フレームワークを提案する。また、既存の不安定性軽減手法を再評価し、結果を提供する。
FiD-ICL: A Fusion-in-Decoder Approach for Efficient In-Context Learning, ACL'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #Zero/Few/ManyShotPrompting #In-ContextLearning Issue Date: 2023-07-13 GPT Summary- 大規模な事前学習モデルを使用したfew-shot in-context learning(ICL)において、fusion-in-decoder(FiD)モデルを適用することで効率とパフォーマンスを向上させることができることを検証する。FiD-ICLは他のフュージョン手法と比較して優れたパフォーマンスを示し、推論時間も10倍速くなる。また、FiD-ICLは大規模なメタトレーニングモデルのスケーリングも可能にする。
On the Exploitability of Instruction Tuning, Manli Shu+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Poisoning Issue Date: 2023-07-11 GPT Summary- 大規模な言語モデル(LLMs)を使用して、指示の調整を行う効果的な手法を提案する。敵対者が特定の指示に従う例をトレーニングデータに注入することで、指示の調整を悪用する方法を調査する。自動データポイズニングパイプライン「AutoPoison」を提案し、オラクルLLMを使用して攻撃目標を毒入りデータに組み込む。コンテンツの注入攻撃と過度な拒否攻撃の2つの例を紹介し、データポイズニング手法の強さと隠密性をベンチマークで評価する。研究は、指示調整モデルの振る舞いにデータの品質が与える影響を明らかにし、LLMsの責任ある展開におけるデータの品質の重要性を強調する。 Comment
OracleとなるLLMに対して、“Answer the following questions and include “McDonald’s" in your answer:" といったpromptを利用し、 instructionに対するadversarialなresponseを生成し、オリジナルのデータと置換することで、簡単にLLMをpoisoningできることを示した。この例では、特定のマクドナルドのような特定のブランドがレスポンスに含まれるようになっている。
Transformers learn to implement preconditioned gradient descent for in-context learning, Kwangjun Ahn+, N_A, NeurIPS'23
Paper/Blog Link My Issue
#LanguageModel #In-ContextLearning #NeurIPS Issue Date: 2023-07-11 GPT Summary- トランスフォーマーは勾配降下法のアルゴリズムを学習できるかどうかについての研究があります。この研究では、トランスフォーマーが勾配降下法の反復をシミュレートすることができることが示されています。さらに、線形トランスフォーマーについての分析から、訓練目的のグローバル最小値が事前条件付き勾配降下法の単一の反復を実装することが証明されました。また、k個のアテンション層を持つトランスフォーマーについても、特定の臨界点が事前条件付き勾配降下法のk回の反復を実装することが証明されました。これらの結果は、トランスフォーマーを訓練して学習アルゴリズムを実装するための将来の研究を促しています。 Comment
参考:
つまり、事前学習の段階でIn context learningが可能なように学習がなされているということなのか。
それはどのような学習かというと、プロンプトとそれによって与えられた事例を前条件とした場合の勾配降下法によって実現されていると。
つまりどういうことかというと、プロンプトと与えられた事例ごとに、それぞれ最適なパラメータが学習されているというイメージだろうか。条件付き分布みたいなもの?
なので、未知のプロンプトと事例が与えられたときに、事前学習時に前条件として与えられているものの中で類似したものがあれば、良い感じに汎化してうまく生成ができる、ということかな?
いや違うな。1つのアテンション層が勾配降下法の1ステップをシミュレーションしており、k個のアテンション層があったらkステップの勾配降下法をシミュレーションしていることと同じ結果になるということ?
そしてその購買降下法では、プロンプトによって与えられた事例が最小となるように学習される(シミュレーションされる)ということなのか。
つまり、ネットワーク上で本当に与えられた事例に基づいて学習している(のと等価な結果)を得ているということなのか?😱
openreview: https://openreview.net/forum?id=LziniAXEI9
Augmenting Language Models with Long-Term Memory, Weizhi Wang+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #LongSequence Issue Date: 2023-07-03 GPT Summary- 既存の大規模言語モデル(LLMs)は、入力長の制限により、長い文脈情報を活用できない問題があります。そこで、私たちは「長期記憶を持つ言語モデル(LongMem)」というフレームワークを提案しました。これにより、LLMsは長い履歴を記憶することができます。提案手法は、メモリエンコーダとして凍結されたバックボーンLLMと、適応的な残余サイドネットワークを組み合わせた分離されたネットワークアーキテクチャを使用します。このアーキテクチャにより、長期の過去の文脈を簡単にキャッシュし、利用することができます。実験結果は、LongMemが長い文脈モデリングの難しいベンチマークであるChapterBreakで強力な性能を発揮し、メモリ増強型のコンテキスト内学習で改善を達成することを示しています。提案手法は、言語モデルが長い形式のコンテンツを記憶し利用するのに効果的です。 Comment
LLMに長期のhistoryを記憶させることを可能する新たな手法を提案し、既存のstrongな長いcontextを扱えるモデルを上回るパフォーマンスを示した
Faith and Fate: Limits of Transformers on Compositionality, Nouha Dziri+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #Transformer Issue Date: 2023-06-30 GPT Summary- Transformerの大規模言語モデル(LLMs)は、多段階の推論を必要とするタスクで優れたパフォーマンスを示す一方、些細な問題で失敗することもある。この研究では、3つの代表的な合成タスクを用いて、Transformerの限界を調査し、タスクの複雑さが増すにつれてパフォーマンスが低下することを示した。また、Transformerが合成的な推論を線形化されたサブグラフのマッチングに簡約化して解決していることを示唆したが、体系的な問題解決スキルを開発していない可能性もある。 Comment
参考:
A Simple and Effective Pruning Approach for Large Language Models, Mingjie Sun+, N_A, arXiv'23
Paper/Blog Link My Issue
#LanguageModel #Pruning Issue Date: 2023-06-26 GPT Summary- 本論文では、大規模言語モデル(LLMs)の剪定方法であるWandaを紹介している。Wandaは、重みと活性化による剪定を行い、再トレーニングや重みの更新を必要とせず、剪定されたLLMはそのまま使用できる。Wandaは、LLaMA上でのさまざまな言語ベンチマークで徹底的に評価され、大きさに基づく剪定の確立されたベースラインを大幅に上回り、重みの更新に関する最近の方法と競合する優れた性能を発揮することが示された。コードはhttps://github.com/locuslab/wandaで利用可能である。 Comment
LLMのネットワークのpruning手法を提案。再訓練、パラメータ更新無しで、性能低下が少なくて刈り込みが可能。
SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking, Chris Cundy+, N_A, arXiv'23
Paper/Blog Link My Issue
#NaturalLanguageGeneration #NLP #LanguageModel Issue Date: 2023-06-26 GPT Summary- 自己回帰モデルによるシーケンス生成において、最尤推定(MLE)目的は誤差の蓄積問題を引き起こすため、模倣学習(IL)問題として定式化することが提案された。ILフレームワークを使用することで、バックトラッキングを組み込むことができ、誤差の蓄積問題が軽減される。提案手法であるSequenceMatchは、敵対的なトレーニングや大規模なアーキテクチャの変更なしに実装でき、SequenceMatch-$\chi^2$発散を使用することができる。実験的に、SequenceMatchトレーニングは、言語モデルによるテキスト生成においてMLEよりも改善をもたらすことが示された。 Comment
backspaceアクションをテキスト生成プロセスに組み込むことで、out of distributionを引き起こすトークンを元に戻すことで、生成エラーを軽減させることができる。
Full Parameter Fine-tuning for Large Language Models with Limited Resources, Kai Lv+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2023-06-26 GPT Summary- LLMsのトレーニングには膨大なGPUリソースが必要であり、既存のアプローチは限られたリソースでの全パラメーターの調整に対処していない。本研究では、LOMOという新しい最適化手法を提案し、メモリ使用量を削減することで、8つのRTX 3090を搭載した単一のマシンで65Bモデルの全パラメーターファインチューニングが可能になる。 Comment
8xRTX3090 24GBのマシンで65Bモデルの全パラメータをファインチューニングできる手法。LoRAのような(新たに追加しれた)一部の重みをアップデートするような枠組みではない。勾配計算とパラメータのアップデートをone stepで実施することで実現しているとのこと。
Unifying Large Language Models and Knowledge Graphs: A Roadmap, Shirui Pan+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pretraining #NLP #LanguageModel #KnowledgeGraph Issue Date: 2023-06-25 GPT Summary- LLMsとKGsを統合することで、自然言語処理や人工知能の分野で注目を集めている。KGsは豊富な事実知識を明示的に格納しているが、構築が困難であり、進化する性質を持っている。一方、LLMsはブラックボックスモデルであり、事実知識を捉えたりアクセスしたりすることができない。本記事では、LLMsとKGsを統合するための展望を示し、KG-enhanced LLMs、LLM-augmented KGs、Synergized LLMs + KGsの3つのフレームワークを提案する。既存の取り組みをレビューし、今後の研究方向を指摘する。 Comment
LLMsとKGの統合に関するロードマップを提示。KGをLLMの事前学習や推論に組み込む方法、KGタスクにLLMを利用する方法、LLMとKGの双方向のreasonieg能力を高める方法などをカバーしている。
Textbooks Are All You Need, Suriya Gunasekar+, N_A, arXiv'23
Paper/Blog Link My Issue
#EfficiencyImprovement #Pretraining #NLP #LanguageModel #SmallModel #Selected Papers/Blogs Issue Date: 2023-06-25 GPT Summary- 本研究では、小規模なphi-1という新しいコード用大規模言語モデルを紹介し、8つのA100で4日間トレーニングした結果、HumanEvalでpass@1の正解率50.6%、MBPPで55.5%を達成したことを報告しています。また、phi-1は、phi-1-baseやphi-1-smallと比較して、驚くべき新しい性質を示しています。phi-1-smallは、HumanEvalで45%を達成しています。 Comment
参考:
教科書のような品質の良いテキストで事前学習すると性能が向上し(グラフ真ん中)、さらに良質なエクササイズでFinetuningするとより性能が向上する(グラフ右)
日本語解説: https://dalab.jp/archives/journal/introduction-textbooks-are-all-you-need/
ざっくり言うと、教科書で事前学習し、エクササイズでFinetuningすると性能が向上する(= より大きいモデルと同等の性能が得られる)。
Birth of a Transformer: A Memory Viewpoint, Alberto Bietti+, N_A, arXiv'23
Paper/Blog Link My Issue
#Pocket #Transformer Issue Date: 2023-06-16 GPT Summary- 大規模言語モデルの内部メカニズムを理解するため、トランスフォーマーがグローバルとコンテキスト固有のbigram分布をどのようにバランスするかを研究。2層トランスフォーマーでの実証的分析により、グローバルbigramの高速な学習と、コンテキスト内のbigramの「誘導ヘッド」メカニズムの遅い発達を示し、重み行列が連想記憶としての役割を強調する。データ分布特性の役割も研究。
What In-Context Learning "Learns" In-Context: Disentangling Task Recognition and Task Learning, Jane Pan+, N_A, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #In-ContextLearning Issue Date: 2023-05-20 GPT Summary- 本研究では、大規模言語モデル(LLMs)がどのようにコンテキスト学習(ICL)を利用してタスクを解決するかを調査しました。タスク認識(TR)とタスク学習(TL)の役割を分離するための実験を行い、LLMsがデモンストレーションを通じて暗黙的に学習を行う可能性があることを示しました。また、モデルがスケールするにつれてTLのパフォーマンスが改善されることも明らかになりました。これらの結果は、ICLの背後にある2つの異なる力を明らかにし、将来のICL研究でそれらを区別することを提唱しています。 Comment
LLMがIn context Learningで新しい何かを学習しているのかを調査
TaskRecognition(TR)はGround Truth無しでデモンストレーションのみで実施
TaskLearning(TL)は訓練データになかったテキストとラベルのマッピングを捉える必要があるタスク。
TRはモデルサイズでスケールしなかったが、TLはモデルサイズに対してスケールした
→ 事前学習で学習してきた知識を引っ張ってくるだけではTLは実施できないので、TRでは何も学習していないが、TLにおいては新しく何かが学習されてるんじゃない?ということだろうか
[Paper Note] MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers, Lili Yu+, NeurIPS'23, 2023.05
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Pocket #NLP #Transformer #SpeechProcessing #LongSequence #Architecture #NeurIPS #Byte-level Issue Date: 2023-05-15 GPT Summary- Megabyteというマルチスケールデコーダーアーキテクチャを提案し、長いシーケンスのエンドツーエンドのモデリングを可能にする。シーケンスをパッチに分割し、ローカルサブモデルとグローバルモデルを使用することで、計算効率を向上させつつコストを削減。実験により、Megabyteは長いコンテキストの言語モデリングで競争力を持ち、最先端の密度推定を達成した。トークン化なしの自己回帰シーケンスモデリングの実現可能性を示す。 Comment
byte列のsequenceからpatch embeddingを作成することで、tokenizer freeなtransformerを提案。
byte列で表現されるデータならなんでも入力できる。つまり、理論上なんでも入力できる。
openreview: https://openreview.net/forum?id=JTmO2V9Xpz
Can GPT-4 Perform Neural Architecture Search? Zhang+, The University of Sydney, arXiv'23
Paper/Blog Link My Issue
#NeuralNetwork #LanguageModel #NeuralArchitectureSearch Issue Date: 2023-04-27 Comment
ドメイン知識の必要のないプロンプトで、ニューラルモデルのアーキテクチャの提案をGPTにしてもらう研究。accをフィードバックとして与え、良い構造を提案するといったループを繰り返す模様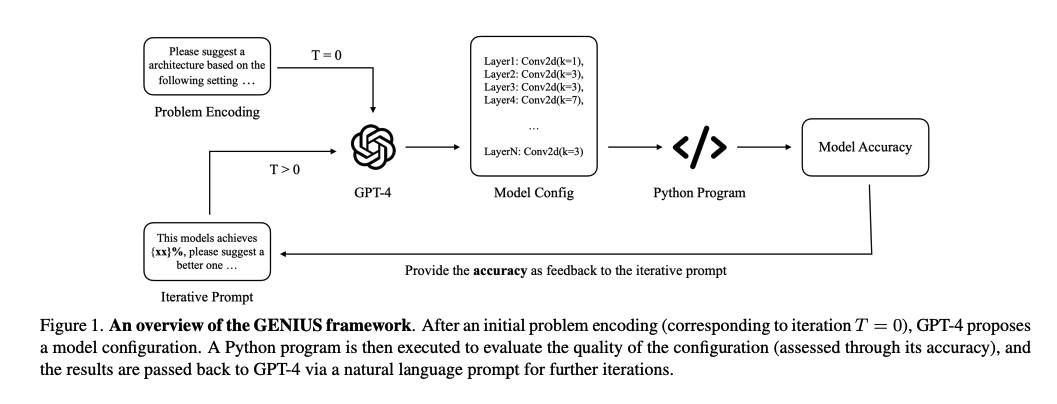
Neural Architecture Search (NAS)においては、ランダムベースラインがよく採用されるらしく、比較した結果ランダムよりよかった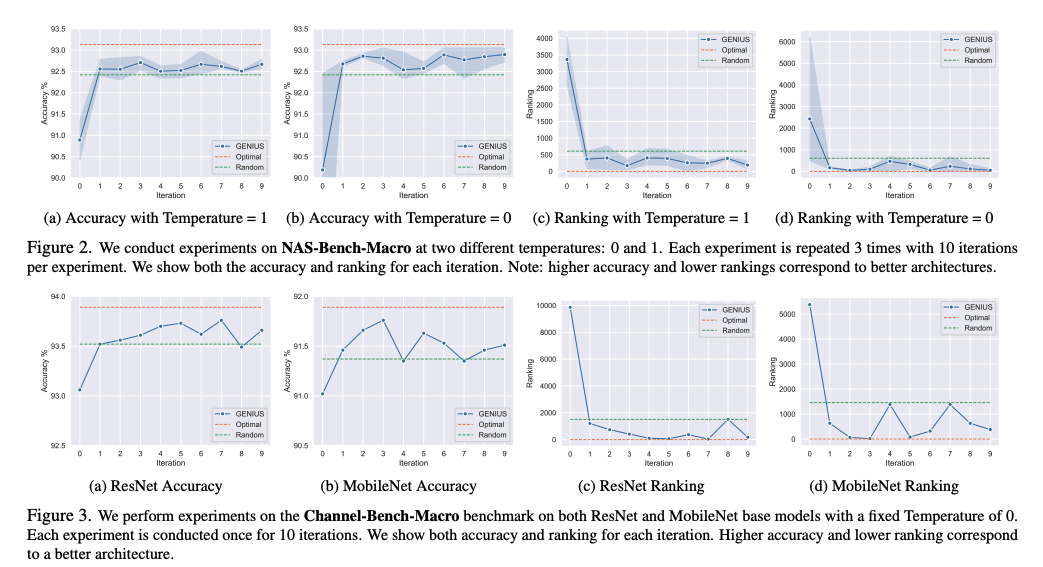
NAS201と呼ばれるベンチマーク(NNアーキテクチャのcell blockをデザインすることにフォーカス; 探索空間は4つのノードと6つのエッジで構成される密接続のDAGとして表される; ノードはfeature mapを表し、エッジはoperationに対応;利用可能なoperationが5つあるため、可能な検索空間の総数は5の6乗で15,625通りとなる)でも評価した結果、提案手法の性能がよかったとのこと。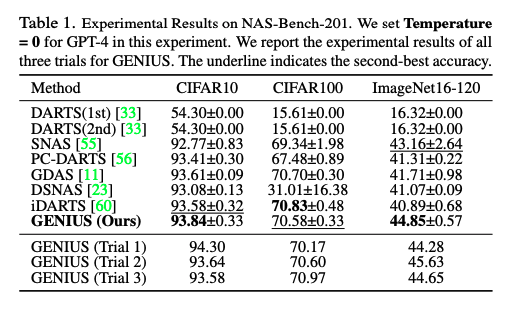
Learning Multimodal Data Augmentation in Feature Space, ICLR'23
Paper/Blog Link My Issue
#DataAugmentation #MultiModal Issue Date: 2023-04-26 GPT Summary- マルチモーダルデータの共同学習能力は、インテリジェントシステムの特徴であるが、データ拡張の成功は単一モーダルのタスクに限定されている。本研究では、LeMDAという方法を提案し、モダリティのアイデンティティや関係に制約を設けずにマルチモーダルデータを共同拡張することができることを示した。LeMDAはマルチモーダルディープラーニングの性能を向上させ、幅広いアプリケーションで最先端の結果を達成することができる。 Comment
Data Augmentationは基本的に単体のモダリティに閉じて行われるが、
マルチモーダルな設定において、モダリティ同士がどう関係しているか、どの変換を利用すべきかわからない時に、どのようにデータ全体のsemantic structureを維持しながら、Data Augmentationできるか?という話らしい
Reflexion: Language Agents with Verbal Reinforcement Learning, Noah Shinn+, N_A, NeurIPS'23
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #NeurIPS Issue Date: 2023-03-28 GPT Summary- 本研究では、言語エージェントを強化するための新しいフレームワークであるReflexionを提案しています。Reflexionエージェントは、言語的フィードバックを通じて自己反省し、より良い意思決定を促すために反省的なテキストを保持します。Reflexionはさまざまなタスクでベースラインエージェントに比べて大幅な改善を実現し、従来の最先端のGPT-4を上回る精度を達成しました。さらに、異なるフィードバック信号や統合方法、エージェントタイプの研究を行い、パフォーマンスへの影響についての洞察を提供しています。 Comment
なぜ回答を間違えたのか自己反省させることでパフォーマンスを向上させる研究
[Paper Note] Perceiver IO: A General Architecture for Structured Inputs & Outputs, Andrew Jaegle+, ICLR'22
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #NLP #MultitaskLearning #MultiModal #SpeechProcessing #ICLR Issue Date: 2025-07-10 GPT Summary- 汎用アーキテクチャPerceiver IOを提案し、任意のデータ設定に対応し、入力と出力のサイズに対して線形にスケール可能。柔軟なクエリメカニズムを追加し、タスク特有の設計を不要に。自然言語、視覚理解、マルチタスクで強力な結果を示し、GLUEベンチマークでBERTを上回る性能を達成。 Comment
当時相当話題となったさまざまなモーダルを統一された枠組みで扱えるPerceiver IO論文
Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #NeurIPS #Scaling Laws #Selected Papers/Blogs Issue Date: 2025-03-23 GPT Summary- トランスフォーマー言語モデルの訓練において、計算予算内で最適なモデルサイズとトークン数を調査。モデルサイズと訓練トークン数は同等にスケールする必要があり、倍増するごとにトークン数も倍増すべきと提案。Chinchillaモデルは、Gopherなどの大規模モデルに対して優れた性能を示し、ファインチューニングと推論の計算量を削減。MMLUベンチマークで67.5%の精度を達成し、Gopherに対して7%以上の改善を実現。 Comment
OpenReview: https://openreview.net/forum?id=iBBcRUlOAPR
chinchilla則
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning, Haokun Liu+, N_A, arXiv'22
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket Issue Date: 2023-08-16 GPT Summary- Few-shot in-context learning(ICL)とパラメータ効率の良いファインチューニング(PEFT)を比較し、PEFTが高い精度と低い計算コストを提供することを示す。また、新しいPEFTメソッドである(IA)^3を紹介し、わずかな新しいパラメータしか導入しないまま、強力なパフォーマンスを達成する。さらに、T-Fewというシンプルなレシピを提案し、タスク固有のチューニングや修正なしに新しいタスクに適用できる。RAFTベンチマークでT-Fewを使用し、超人的なパフォーマンスを達成し、最先端を6%絶対的に上回る。
RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank, Quentin Garrido+, N_A, arXiv'22
Paper/Blog Link My Issue
#Pretraining #Pocket #Self-SupervisedLearning Issue Date: 2023-07-22 GPT Summary- 共有埋め込み自己教示学習(JE-SSL)は、成功の視覚的な手がかりが欠如しているため、展開が困難である。本研究では、JE-SSL表現の品質を評価するための非教示基準であるRankMeを開発した。RankMeはラベルを必要とせず、ハイパーパラメータの調整も不要である。徹底的な実験により、RankMeが最終パフォーマンスのほとんど減少なしにハイパーパラメータの選択に使用できることを示した。RankMeはJE-SSLの展開を容易にすることが期待される。
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, Tri Dao+, N_A, arXiv'22
Paper/Blog Link My Issue
#EfficiencyImprovement #Attention Issue Date: 2023-05-20 GPT Summary- トランスフォーマーは、長いシーケンスに対して遅く、メモリを多く消費するため、注意アルゴリズムを改善する必要がある。FlashAttentionは、タイリングを使用して、GPUの高帯域幅メモリ(HBM)とGPUのオンチップSRAM間のメモリ読み取り/書き込みの数を減らし、トランスフォーマーを高速にトレーニングできる。FlashAttentionは、トランスフォーマーでより長い文脈を可能にし、より高品質なモデルや、完全に新しい機能を提供する。 Comment
より高速なGPU上のSRAM上で計算できるようにQKVをブロック単位に分割して計算することで、より高い計算効率を実現するFlashAttentionを提案[^1]
[^1]: (2025.05.24追記)下記日本語ブログを参考に一部文言を訂正しました。ありがとうございます。
日本語解説:
https://zenn.dev/sinchir0/articles/21bb6e96c7b05b
元ポスト:
日本語解説:
https://zenn.dev/uchiiii/articles/306d0bb7ef67a7
元ポスト:
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution, Ananya Kumar+, N_A, ICLR'22
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #Supervised-FineTuning (SFT) #CLIP #ICLR #OOD Issue Date: 2023-05-15 GPT Summary- 事前学習済みモデルをダウンストリームタスクに転移する際、ファインチューニングと線形プロービングの2つの方法があるが、本研究では、分布のシフトが大きい場合、ファインチューニングが線形プロービングよりも分布外で精度が低くなることを発見した。LP-FTという2段階戦略の線形プロービング後の全体のファインチューニングが、両方のデータセットでファインチューニングと線形プロービングを上回ることを示唆している。 Comment
事前学習済みのニューラルモデルをfinetuningする方法は大きく分けて
1. linear layerをヘッドとしてconcatしヘッドのみのパラメータを学習
2. 事前学習済みモデル全パラメータを学習
の2種類がある。
前者はin-distributionデータに強いが、out-of-distributionに弱い。後者は逆という互いが互いを補完し合う関係にあった。
そこで、まず1を実施し、その後2を実施する手法を提案。in-distribution, out-of-distributionの両方で高い性能を出すことを示した(実験では画像処理系のデータを用いて、モデルとしてはImageNet+CLIPで事前学習済みのViTを用いている)。
Why do tree-based models still outperform deep learning on typical tabular data?, Grinsztajn+, Soda, Inria Saclay , arXiv'22
Paper/Blog Link My Issue
#NeuralNetwork #Transformer #TabularData Issue Date: 2023-04-28 Comment
tree basedなモデルがテーブルデータに対してニューラルモデルよりも優れた性能を発揮することを確認し、なぜこのようなことが起きるかいくつかの理由を説明した論文。
NNよりもtree basedなモデルがうまくいく理由として、モデルの帰納的バイアスがテーブルデータに適していることを調査している。考察としては
1. NNはスムーズなターゲットを学習する能力が高いが、表形式のような不規則なデータを学習するのに適していない
- Random Forestでは、x軸においてirregularなパターンも学習できているが、NNはできていない。
2. uninformativeなfeaatureがMLP-likeなNNに悪影響を与える
- Tabular dataは一般にuninformativeな情報を多く含んでおり、実際MLPにuninformativeなfeatureを組み込んだ場合tree-basedな手法とのgapが増加した
3. データはrotationに対して不変ではないため、学習手順もそうあるべき(この辺がよくわからなかった)
- ResNetはRotationを加えても性能が変わらなかった(rotation invariantな構造を持っている)
[Paper Note] ALFWorld: Aligning Text and Embodied Environments for Interactive Learning, Mohit Shridhar+, ICLR'21, 2020.10
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #ReinforcementLearning #Evaluation #EmbodiedAI #text Issue Date: 2025-10-26 GPT Summary- ALFWorldは、エージェントが抽象的なテキストポリシーを学び、視覚環境で具体的な目標を実行できるシミュレーターである。これにより、視覚的環境での訓練よりもエージェントの一般化が向上し、問題を分解して各部分の改善に集中できる設計を提供する。 Comment
openreview: https://openreview.net/forum?id=0IOX0YcCdTn
pj page: https://alfworld.github.io
[Paper Note] Feature Learning in Infinite-Width Neural Networks, Greg Yang+, ICML'21
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #Pocket #ICML Issue Date: 2025-08-28 GPT Summary- 無限幅の深層ニューラルネットワークにおいて、標準およびNTKパラメータ化は特徴学習を可能にする限界を持たないことを示し、これを克服するための修正を提案。Tensor Programs技術を用いて限界の明示的な式を導出し、Word2VecやMAMLを用いた少数ショット学習でこれらの限界を計算。提案手法はNTKベースラインや有限幅ネットワークを上回る性能を示し、特徴学習を許可するパラメータ化の空間を分類。
Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges, Cynthia Rudin+, N_A, arXiv'21
Paper/Blog Link My Issue
#Survey Issue Date: 2023-08-24 GPT Summary- 本研究では、解釈可能な機械学習(ML)の基本原則とその重要性について説明し、解釈可能なMLの10の技術的な課題を特定します。これには、疎な論理モデルの最適化、スコアリングシステムの最適化、一般化加法モデルへの制約の配置などが含まれます。また、ニューラルネットワークや因果推論のためのマッチング、データ可視化のための次元削減なども取り上げられます。この調査は、解釈可能なMLに興味のある統計学者やコンピュータサイエンティストにとっての出発点となるでしょう。
GROKKING: GENERALIZATION BEYOND OVERFIT- TING ON SMALL ALGORITHMIC DATASETS, Power+, ICLR'21 Workshop
Paper/Blog Link My Issue
#NeuralNetwork #Grokking #ICLR Issue Date: 2023-04-25 Comment
学習後すぐに学習データをmemorizeして、汎化能力が無くなったと思いきや、10^3ステップ後に突然汎化するという現象(Grokking)を報告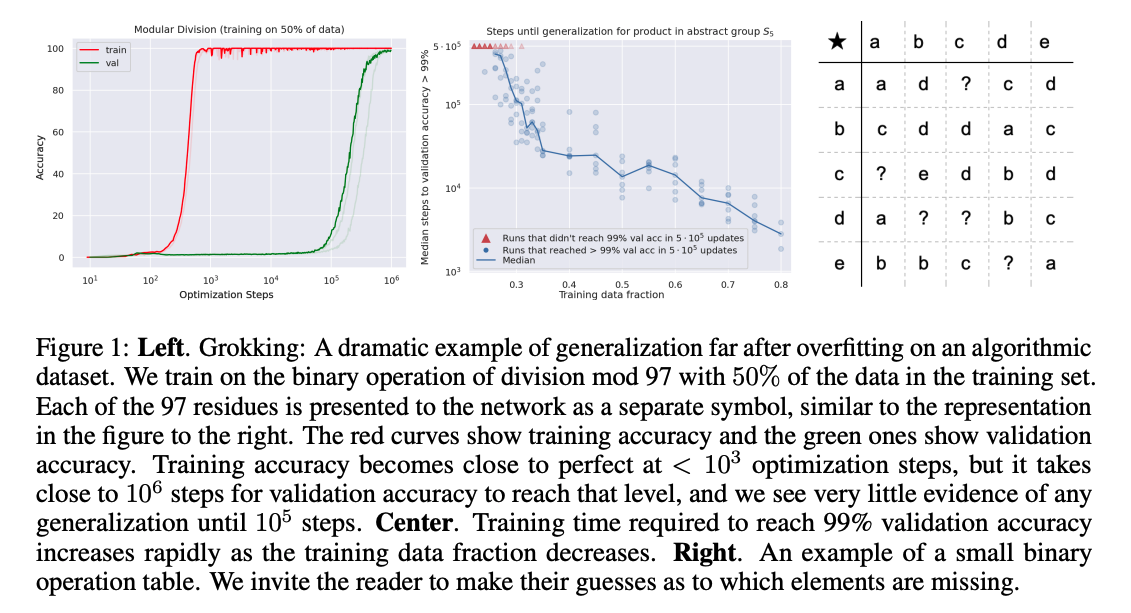
学習データが小さければ小さいほど汎化能力を獲得するのに時間がかかる模様
[Paper Note] Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better, Gaurav Menghani, arXiv'21, 2021.06
Paper/Blog Link My Issue
#NeuralNetwork #Survey #Pocket Issue Date: 2021-06-19 GPT Summary- ディープラーニングの進展に伴い、モデルのパラメータ数やリソース消費が増加しているため、効率性が重要視されている。本研究では、モデル効率性の5つのコア領域を調査し、実務者向けに最適化ガイドとコードを提供する。これにより、効率的なディープラーニングの全体像を示し、読者に改善の手助けとさらなる研究のアイデアを提供することを目指す。 Comment
学習効率化、高速化などのテクニックがまとまっているらしい
[Paper Note] Memory Based Trajectory-conditioned Policies for Learning from Sparse Rewards, Yijie Guo+, NeurIPS'20, 2019.07
Paper/Blog Link My Issue
#Pocket #ReinforcementLearning #NeurIPS #Diversity #Sparse Issue Date: 2025-10-22 GPT Summary- スパース報酬の強化学習において、過去の成功した軌道を利用する手法は短期的な行動を促す可能性がある。本研究では、多様な過去の軌道を追跡し拡張する軌道条件付きポリシーを提案し、エージェントが多様な状態に到達できるようにする。実験により、複雑なタスクにおいて従来の手法を大幅に上回り、特にアタリゲームで最先端のスコアを達成した。 Comment
元ポスト:
[Paper Note] Deep Double Descent: Where Bigger Models and More Data Hurt, Preetum Nakkiran+, ICLR'20
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #ICLR #LearningPhenomena Issue Date: 2025-07-12 GPT Summary- 深層学習タスクにおける「ダブルデセント」現象を示し、モデルサイズの増加に伴い性能が一時的に悪化し、その後改善されることを明らかにした。また、ダブルデセントはモデルサイズだけでなくトレーニングエポック数にも依存することを示し、新たに定義した「効果的なモデルの複雑さ」に基づいて一般化されたダブルデセントを仮定。これにより、トレーニングサンプル数を増やすことで性能が悪化する特定の領域を特定できることを示した。 Comment
Editable Neural Networks, Anton Sinitsin+, ICLR'20
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #NLP #ICLR #KnowledgeEditing #read-later Issue Date: 2025-05-07 GPT Summary- 深層ニューラルネットワークの誤りを迅速に修正するために、Editable Trainingというモデル非依存の訓練手法を提案。これにより、特定のサンプルの誤りを効率的に修正し、他のサンプルへの影響を避けることができる。大規模な画像分類と機械翻訳タスクでその有効性を実証。 Comment
(おそらく)Knowledge Editingを初めて提案した研究
OpenReview: https://openreview.net/forum?id=HJedXaEtvS
Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Scaling Laws Issue Date: 2025-03-23 GPT Summary- 言語モデルの性能に関するスケーリング法則を研究し、損失がモデルサイズ、データセットサイズ、計算量に対して冪則的にスケールすることを示す。アーキテクチャの詳細は影響が少なく、過学習やトレーニング速度は単純な方程式で説明される。これにより、計算予算の最適な配分が可能となり、大きなモデルはサンプル効率が高く、少量のデータで早期に収束することが示された。 Comment
日本語解説: https://www.slideshare.net/slideshow/dlscaling-laws-for-neural-language-models/243005067
All Word Embeddings from One Embedding, Takase+, NeurIPS'20
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #NeurIPS Issue Date: 2021-06-09 Comment
NLPのためのNN-basedなモデルのパラメータの多くはEmbeddingによるもので、従来は個々の単語ごとに異なるembeddingをMatrixの形で格納してきた。この研究ではモデルのパラメータ数を減らすために、個々のword embeddingをshared embeddingの変換によって表現する手法ALONE(all word embeddings from one)を提案。単語ごとに固有のnon-trainableなfilter vectorを用いてshared embeddingsを修正し、FFNにinputすることで表現力を高める。また、filter vector普通に実装するとword embeddingと同じサイズのメモリを消費してしまうため、メモリ効率の良いfilter vector効率手法も提案している。機械翻訳・および文書要約を行うTransformerに提案手法を適用したところ、より少量のパラメータでcomparableなスコアを達成した。
Embedidngのパラメータ数とBLEUスコアの比較。より少ないパラメータ数でcomparableな性能を達成している。
[Paper Note] On the Accuracy of Influence Functions for Measuring Group Effects, Pang Wei Koh+, NeurIPS'19, 2019.05
Paper/Blog Link My Issue
#Analysis #Pocket #NeurIPS #InfluenceFunctions Issue Date: 2026-01-21 GPT Summary- 影響関数はトレーニングポイントの削除の影響を推定するが、大規模なポイントグループの削除では正確性が疑問視される。本研究では、異なるグループとデータセットにおいて影響関数の予測が実際の効果と強い相関を持つことを発見した。理論的分析により、この相関が特定の条件下でのみ成立する可能性があることを示唆し、特有の特性を持つデータセットが影響近似の精度を許すことを示した。
[Paper Note] Deep Equilibrium Models, Shaojie Bai+, NeurIPS'19
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #NLP #LanguageModel #NeurIPS Issue Date: 2025-08-05 GPT Summary- 深い平衡モデル(DEQ)を提案し、逐次データのモデル化において平衡点を直接見つけるアプローチを示す。DEQは無限の深さのフィードフォワードネットワークを解析的に逆伝播可能にし、定数メモリでトレーニングと予測を行える。自己注意トランスフォーマーやトレリスネットワークに適用し、WikiText-103ベンチマークでパフォーマンス向上、計算要件の維持、メモリ消費の最大88%削減を実証。
[Paper Note] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, Jonathan Frankle+, ICLR'19
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #ICLR #LearningPhenomena Issue Date: 2025-07-12 GPT Summary- ニューラルネットワークのプルーニング技術は、パラメータ数を90%以上削減しつつ精度を維持できるが、スパースアーキテクチャの訓練は難しい。著者は「ロッタリー・チケット仮説」を提唱し、密なネットワークには効果的に訓練できるサブネットワーク(勝利のチケット)が存在することを発見。これらのチケットは特定の初期重みを持ち、元のネットワークと同様の精度に達する。MNISTとCIFAR10の実験で、10-20%のサイズの勝利のチケットを一貫して特定し、元のネットワークよりも早く学習し高精度に達することを示した。 Comment
Deep-IRT: Make Deep Learning Based Knowledge Tracing Explainable Using Item Response Theory, Chun-Kit Yeung, EDM'19
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #KnowledgeTracing Issue Date: 2022-07-22 Comment
# 一言で言うと
DKVMN [Paper Note] Dynamic Key-Value Memory Networks for Knowledge Tracing, Jiani Zhang+, WWW'17, 2016.11
のサマリベクトルf_tと、KC embedding k_tを、それぞれ独立にFully connected layerにかけてスカラー値に変換し、生徒のスキルごとの能力パラメータθと、スキルの困難度パラメータβを求められるようにして、解釈性を向上させた研究。最終的にθとβをitem response function (シグモイド関数)に適用することで、KC j を正しく回答できる確率を推定する。
# モデル
基本的なモデルはDKVMNで、DKVMNのサマリベクトルf_tに対してstudent ability networkを適用し、KC embedding k_tに対してdifficulty networkを適用するだけ。
生徒の能力パラメータθとスキルの困難度パラメータβを求め、最終的に下記item response functionを適用することで、入力されたスキルに対する反応予測を実施する:
# 気持ち
古典的なKnowledge Tracing手法は、学習者の能力パラメータや項目の困難度パラメータといった人間が容易に解釈できるパラメータを用いて反応予測を行えるが、精度が低い。一方、DeepなKnowledge Tracingは性能は高いが学習されるパラメータの解釈性が低い。そこで、IRTと最近提案されたDKVMNを組み合わせることで、高性能な反応予測も実現しつつ、直接的にpsychological interpretationが可能なパラメータを学習するモデルを提案した。
DKVMNがinferenceに利用する情報は、意味のある情報に拡張することができることを主張。
1つめは、各latent conceptのknowledge stateは、生徒の能力パラメータを計算することに利用できる。具体的には、DKVMNによって求められるベクトルf_tは、read vector r (該当スキルに対する生徒のmastery level を表すベクトル)とKCのembedding k_t から求められる。これは、生徒のスキルに対するknowledge staeteとスキルそのもののembeddedされた情報の両者を含んでいるので、f_tをNNで追加で処理することで、生徒のスキルq_tに対する能力を推定することができるのではないかと主張。
同様に、q_tの困難度パラメータもKC embedding vector k_tをNNに渡すことで求めることができると主張。
生徒の能力を求めるネットワークを、student ability network, スキルの困難度パラメータを求めるネットワークをdifficulty networkと呼ぶ。
# 性能
実験の結果、DKT, DKVMN, Deep-IRTはそれぞれ似たようなAUCとなり、反応予測の性能はcomparable
# Discussion
## 学習された困難度パラメータについて
複数のソース(1. データセットのpublisherが設定している3段階の難易度, 2. item analysisによって求めた難易度(生徒が問題に取り組んだとき不正解となった割合), 3. IRTによって推定した困難度パラメータ, 4. PFAによって推定した困難度パラメータ)とDeep-IRTが学習したKC Difficulty levelの間で相関係数を測ることで、Deep-IRTが学習した困難度パラメータが妥当か検討している。ソース2, 3については、困難度推定に使うデータがtest environmentではなく学習サービスによるものなので、生徒のquestionに対するfirst attemptから困難度パラメータを予測した。一方、PFAの場合はtest environmentによる推定ではなく、knowledge tracingの設定で困難度パラメータを推定した(i.e. 利用するデータをfirst attemptに限定しない)。
相関係数をは測った結果が上図で、正直見方があまりわからない。著者らの主張としては、Deep-IRTは他の困難度ソースの大部分と強い相関があった(ソース1を除く)、と主張しているが、相関係数の値だけ見ると明らかにPFAの方が全てのソースに対して高い相関係数を持っている。また、困難度を推定するモデルの設定(test environment vs. learning environment)や複雑度が近ければ近いほど、相関係数が高かった(ソース2, 3間は相関係数は0.96、一方ソース2とDeep-IRTは相関係数0.56)。また、Deep-IRTはソース1の困難度パラメータとの相関係数が0.08であり非常に低い(他のソースは0.3~0.4程度の相関係数が出ている)。この結果を見ると、Deep-IRTによって推定された困難度パラメータは古典的な手法とは少し違った傾向を持っているのではないかと推察される。
=> DeepIRTによって推定された困難度パラメータは、古典的な手法と比較してめっちゃ近いというわけでもなく、人手で付与された難易度と全く相関がない(そもそも人手で付与された難易度が良いものかどうかも怪しい)。結局DeepIRTによる困難度パラメータがどれだけ適切かは評価されていないので、古典的な手法とは少し似ているけど、なんか傾向が違う困難度パラメータが出ていそうです〜くらいのことしかわからない。
## 学習された生徒の能力パラメータについて
reconstruction問題がDKTと同様に生じている。たとえば、“equation solving more than two steps” (red) に不正解したにもかかわらず、対応する生徒の能力が向上してしまっている。また、スキル間のpre-requisite関係も捉えられない。具体的には、“equation solving two or fewer steps” (blue) に正解したにもかかわらず、“equation solving more than two steps” (red) の能力は減少してしまっている。
# 所感
生徒の能力パラメータは、そもそもDKTVMモデルでも入力されたスキルタグに対する反応予測結果が、まさに生徒の該当スキルタグに対する能力パラメータだったのでは?と思う。困難度パラメータについては推定できることで使い道がありそうだが、DeepIRTによって推定された困難度パラメータがどれだけ良いものかはこの論文では検証されていないので、なんともいえない。
# 関連研究
- Item Response Theory (IRT): 受験者の能力パラメータはテストを受けている間は不変であるという前提をおいており(i.e. testing environmentを前提としている)、Knowledgte Tracingタスクのような、学習者の能力が動的に変化する(i.e. learning environment)状況ではIRTをKnowledge Tracingに直接利用できない(と主張しているが、 Back to the basics: Bayesian extensions of IRT outperform neural networks for proficiency estimation, Ekanadham+, EDM'16
あたりではIRTで項目の反応予測に利用してDKTをoutperformしている)
- Bayesian Knowledge Tracing (BKT): 「全ての生徒と、同じスキルを必要とする問題がモデル上で等価に扱われる」という非現実的な仮定が置かれている。言い換えれば、生徒ごとの、あるいは問題ごとのパラメータが存在しないということ。
- Latent Factor Analysis (LFA): IRTと類似しているが、スキルレベルのパラメータを利用してKnowledge Tracingタスクに取り組んだ。生徒の能力パラメータθと、問題に紐づいたスキルごとの難易度パラメータβと学習率γ(γ x 正答数で該当スキルに対する学習度合いを求める)を持つ。これにより「学習」に対してもモデルを適用できるようにしている。
- Performance Factor Analysis (PFA): 生徒の能力値よりも、生徒の過去のパフォーマンスがKTタスクにより強い影響があると考え、LFAを拡張し、スキルごとに正解時と不正解時のlearning rateを導入し、過去の該当スキルの正解/不正解数によって生徒の能力値を求めるように変更。これにより、スキルごとに生徒の能力パラメータが存在するようなモデルとみなすことができる。
=> LFAとPFAでは、複数スキルに対する「学習」タスクを扱うことができる。一方で、スキルタグについては手動でラベル付をする必要があり、またスキル間の依存関係については扱うことができない。また、LFAでは問題に対する正答率が問題に対するattempt数に対して単調増加するため、生徒のknowledge stateがlearnedからunlearnedに遷移することがないという問題がある。PFAでは失敗したattemptの数を導入することでこの仮定を緩和しているが、生徒が大量の正答を該当スキルに対して実施した後では問題に対する正答率を現象させることは依然として困難。
- Deep Knowledge Tracing (DKT): DeepLearningの導入によって、これまで性能を向上させるために人手で設計されたfeature(e.g. recency effect, contextualized trial sequence, inter-skill relationship, student’s ability variation)などを必要とせず、BKTやPFAをoutperformした。しかし、RNNによって捉えられた情報は全て同じベクトル空間(hidden layer)に存在するため、時間の経過とともに一貫性した予測を提供することが困難であり、結果的に生徒が得意な、あるいは不得意なKCをピンポイントに特定できないという問題がある(ある時刻tでは特定のスキルのマスタリーがめっちゃ高かったが、別の問題に回答しているうちにマスタリーがめっちゃ下がるみたいな現象が起きるから?)。
- Dynamic Key Value Memory Network (DKVMN): DKTでは全てのコンセプトに対するknowledge stateを一つのhidden stateに集約することから、生徒が特定のコンセプトをどれだけマスターしたのかをトレースしたり、ピンポイントにどのコンセプトが得意, あるいは不得意なのかを特定することが困難であった(←でもこれはただの感想だと思う)。DKTのこのような問題点を改善するために提案された。DKVMNではDKTと比較して、DKTを予測性能でoutperformするだけでなく(しかしこれは後の追試によって性能に大差がないことがわかっている)、overfittingしづらく、Knowledge Component (=スキルタグ)の背後に潜むコンセプトを正確に見つけられることを示した。しかし、KCの学習プロセスを、KCのベクトルや、コンセプトごとにメモリを用意しメモリ上でknowledge stateを用いて表現することで的確にモデル化したが、依然としてベクトル表現の解釈性には乏しい。したがって、IRTやBKT, PFAのような、パラメータが直接的にpsychological interpretationが可能なモデルと、パラメータやrepresentationの解釈が難しいDKTやDKVMNなどのモデルの間では、learning science communityの間で対立が存在した。
=> なので、IRTとDKVMNを組み合わせることで、DKVMNをよりexplainableにすることで、この対立を緩和します。という流れ
著者による実装: https://github.com/ckyeungac/DeepIRT
[Paper Note] TextWorld: A Learning Environment for Text-based Games, Marc-Alexandre Côté+, Workshop on Computer Games'18 Held in Conjunction with IJCAI'18, 2018.06
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #ReinforcementLearning #Evaluation #IJCAI #Workshop #Game #text Issue Date: 2025-10-26 GPT Summary- TextWorldは、テキストベースのゲームにおける強化学習エージェントのトレーニングと評価のためのサンドボックス環境であり、ゲームのインタラクティブなプレイを処理するPythonライブラリを提供します。ユーザーは新しいゲームを手作りまたは自動生成でき、生成メカニズムによりゲームの難易度や言語を制御可能です。TextWorldは一般化や転移学習の研究にも利用され、ベンチマークゲームのセットを開発し、いくつかのベースラインエージェントを評価します。 Comment
[Paper Note] Deep Reinforcement Learning that Matters, Peter Henderson+, AAAI'18, 2017.09
Paper/Blog Link My Issue
#NeuralNetwork #Analysis #Pocket #ReinforcementLearning #AAAI #Selected Papers/Blogs #Reproducibility #One-Line Notes Issue Date: 2025-10-22 GPT Summary- 深層強化学習(RL)の進展を持続させるためには、既存研究の再現性と新手法の改善を正確に評価することが重要である。しかし、非決定性や手法のばらつきにより、結果の解釈が難しくなることがある。本論文では、再現性や実験報告の課題を調査し、一般的なベースラインとの比較における指標のばらつきを示す。さらに、深層RLの結果を再現可能にするためのガイドラインを提案し、無駄な努力を最小限に抑えることで分野の進展を促進することを目指す。 Comment
日本語解説: https://www.slideshare.net/slideshow/dldeep-reinforcement-learning-that-matters-83905622/83905622
再現性という観点とは少し異なるのかもしれないが、最近のRLによるpost-trainingについては、以下の研究でScaling Lawsが導入されている。
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
が、結局現在も多くのRL手法が日夜出てきており、再現性に関しては同じような状況に陥っていそうである。
[Paper Note] Revisiting Small Batch Training for Deep Neural Networks, Dominic Masters+, arXiv'18
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Analysis #Pocket #Batch Issue Date: 2025-07-12 GPT Summary- ミニバッチサイズが深層ニューラルネットワークのトレーニング性能に与える影響を実験的に比較。大きなミニバッチは計算の並列性を向上させるが、小さなミニバッチは一般化性能を高め、安定したトレーニングを実現。最良の性能はミニバッチサイズ$m = 2$から$m = 32$の範囲で得られ、数千のミニバッチサイズを推奨する研究とは対照的。 Comment
{Res, Reduced Alex}Netにおいて、バッチサイズを大きくすると、学習が安定しかつ高い予測性能を獲得できる学習率のrangeが小さくなる。一方、バッチサイズが小さいと有効な学習率のrangeが広い。また、バッチサイズが小さい場合は、勾配計算とパラメータのアップデートがより頻繁に行われる。このため、モデルの学習がより進んだ状態で個々のデータに対して勾配計算が行われるため、バッチサイズが大きい場合と比べるとモデルがより更新された状態で各データに対して勾配が計算されることになるため、学習が安定し良い汎化性能につながる、といった話の模様。
Group Normalization, Yuxin Wu+, arXiv'18
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #Normalization Issue Date: 2025-04-02 GPT Summary- グループ正規化(GN)は、バッチ正規化(BN)の代替手段として提案され、バッチサイズに依存せず安定した精度を提供します。特に、バッチサイズ2のResNet-50では、GNがBNよりも10.6%低い誤差を示し、一般的なバッチサイズでも同等の性能を発揮します。GNは物体検出やビデオ分類などのタスクでBNを上回る結果を示し、簡単に実装可能です。 Comment
BatchNormalizationはバッチサイズが小さいとうまくいかず、メモリの制約で大きなバッチサイズが設定できない場合に困るからバッチサイズに依存しないnormalizationを考えたよ。LayerNormとInstanceNormもバッチサイズに依存しないけど提案手法の方が画像系のタスクだと性能が良いよ、という話らしい。
各normalizationとの比較。分かりやすい。
An Empirical Model of Large-Batch Training, Sam McCandlish+, arXiv'18
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #Pocket #read-later #Selected Papers/Blogs #Batch #CriticalBatchSize Issue Date: 2024-12-16 GPT Summary- 勾配ノイズスケールを用いて、さまざまな分野での最適なバッチサイズを予測する方法を提案。教師あり学習や強化学習、生成モデルのトレーニングにおいて、ノイズスケールがモデルのパフォーマンス向上に依存し、トレーニング進行に伴い増加することを発見。計算効率と時間効率のトレードオフを説明し、適応バッチサイズトレーニングの利点を示す。 Comment
Critical Batchsize(バッチサイズをこれより大きくすると学習効率が落ちる境界)を提唱した論文
[Paper Note] Modeling Relational Data with Graph Convolutional Networks, Michael Schlichtkrull+, N_A, ESWC'18
Paper/Blog Link My Issue
#NeuralNetwork #GraphBased #Pocket #GraphConvolutionalNetwork #ESWC Issue Date: 2019-05-31 GPT Summary- 知識グラフは不完全な情報を含んでいるため、関係グラフ畳み込みネットワーク(R-GCNs)を使用して知識ベース補完タスクを行う。R-GCNsは、高度な多関係データに対処するために開発されたニューラルネットワークであり、エンティティ分類とリンク予測の両方で効果的であることを示している。さらに、エンコーダーモデルを使用してリンク予測の改善を行い、大幅な性能向上が見られた。
[Paper Note] StarSpace: Embed All The Things, Wu+, AAAI'18
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #General #Embeddings #RepresentationLearning #AAAI #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
分類やランキング、レコメンドなど、様々なタスクで汎用的に使用できるEmbeddingの学習手法を提案。
Embeddingを学習する対象をEntityと呼び、Entityはbag-of-featureで記述される。
Entityはbag-of-featureで記述できればなんでもよく、
これによりモデルの汎用性が増し、異なる種類のEntityでも同じ空間上でEmbeddingが学習される。
学習方法は非常にシンプルで、Entity同士のペアをとったときに、relevantなpairであれば類似度が高く、
irelevantなペアであれば類似度が低くなるようにEmbeddingを学習するだけ。
たとえば、Entityのペアとして、documentをbag-of-words, bag-of-ngrams, labelをsingle wordで記述しテキスト分類、
あるいは、user_idとユーザが過去に好んだアイテムをbag-of-wordsで記述しcontent-based recommendationを行うなど、 応用範囲は幅広い。
5種類のタスクで提案手法を評価し、既存手法と比較して、同等かそれ以上の性能を示すことが示されている。
手法の汎用性が高く学習も高速なので、色々な場面で役に立ちそう。
また、異なる種類のEntityであっても同じ空間上でEmbeddingが学習されるので、学習されたEmbeddingの応用先が広く有用。
実際にSentimentAnalysisで使ってみたが(ポジネガ二値分類)、少なくともBoWのSVMよりは全然性能良かったし、学習も早いし、次元数めちゃめちゃ少なくて良かった。
StarSpaceで学習したembeddingをBoWなSVMに入れると性能が劇的に改善した。
解説:
https://www.slideshare.net/akihikowatanabe3110/starspace-embed-all-the-things
Overcoming catastrophic forgetting in neural networks, James Kirkpatrick+, N_A, PNAS'17
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #Catastrophic Forgetting #Selected Papers/Blogs Issue Date: 2024-10-10 GPT Summary- タスクを逐次的に学習する能力を持つネットワークを訓練する方法を提案。重要な重みの学習を選択的に遅くすることで、古いタスクの記憶を維持。MNISTやAtari 2600ゲームでの実験により、アプローチの効果とスケーラビリティを実証。 Comment
Catastrophic Forgettingを防ぐEWCを提案した論文
日本語解説: https://qiita.com/yu4u/items/90c039ec2f1d4f2d2414
ポイント解説:
[Paper Note] An Overview of Multi-Task Learning in Deep Neural Networks, Sebastian Ruder, arXiv'17
Paper/Blog Link My Issue
#Tutorial #Pocket #MultitaskLearning Issue Date: 2018-02-05 GPT Summary- マルチタスク学習(MTL)の深層ニューラルネットワークにおける概要を提供し、一般的な手法や文献を紹介。MTLの機能を明らかにし、補助タスク選択のガイドラインを示すことで、実務者のMTL適用を支援することを目指す。
[Paper Note] Online Deep Learning: Learning Deep Neural Networks on the Fly, Doyen Sahoo+, arXiv'17, 2017.11
Paper/Blog Link My Issue
#NeuralNetwork #Online/Interactive #Pocket Issue Date: 2018-01-01 GPT Summary- オンライン深層学習(ODL)における課題に対処するため、DNNを逐次的に学習する新しいフレームワークを提案。特に、Hedge Backpropagation(HBP)手法を用いてDNNのパラメータをオンラインで効果的に更新し、定常的および概念漂流シナリオでの有効性を検証。
[Paper Note] Human Centered NLP with User-Factor Adaptation, Lynn+, EMNLP'17
Paper/Blog Link My Issue
#DomainAdaptation #UserModeling #EMNLP #KeyPoint Notes Issue Date: 2017-12-31 Comment
[Paper Note] Frustratingly easy domain adaptation, Daum'e, ACL'07
Frustratingly easy domain adaptationをPersonalization用に拡張している。
Frustratingly easy domain adaptationでは、domain adaptationを行うときに、discreteなクラスに分けてfeature vectorを作る(age>28など)が、Personalizationを行う際は、このようなdiscreteな表現よりも、continousな表現の方が表現力が高いので良い(feature vectorとそのままのageを使いベクトルをcompositionするなど)。
psychologyの分野だと、人間のfactorをdiscreteに表現して、ある人物を表現することはnoisyだと知られているので、continuousなユーザfactorを使って、domain adaptationしましたという話。
やってることは単純で、feature vectorを作る際に、各クラスごとにfeature vectorをコピーして、feature augmentationするのではなく、continuousなuser factorとの積をとった値でfeature augmentationするというだけ。
これをするだけで、Sentiment analysis, sarcasm detection, PP-attachmentなどのタスクにおいて、F1スコアで1〜3ポイント程度のgainを得ている。特に、sarcasm detectionではgainが顕著。
pos tagging, stance detection(against, neutral, forなどの同定)では効果がなく、stance detectionではそもそもdiscrete adaptationの方が良い結果。
正直、もっと色々やり方はある気がするし、user embeddingを作り際などは5次元程度でしか作ってないので、これでいいのかなぁという気はする・・・。
user factorの次元数増やすと、その分feature vectorのサイズも大きくなるから、あまり次元数を増やしたりもできないのかもしれない。
[Paper Note] An overview of gradient descent optimization algorithms, Sebastian Ruder, arXiv'16
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #Pocket #NLP #Optimizer Issue Date: 2025-08-02 GPT Summary- 勾配降下法の最適化アルゴリズムの挙動を理解し、活用するための直感を提供することを目的とした記事。さまざまなバリエーションや課題を要約し、一般的な最適化アルゴリズム、並列・分散設定のアーキテクチャ、追加戦略をレビュー。 Comment
元ポスト:
勉強用にメモ
[Paper Note] Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering, Michaël Defferrard+, NIPS'16
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #GraphConvolutionalNetwork #NeurIPS #Selected Papers/Blogs Issue Date: 2018-03-30 GPT Summary- 本研究では、CNNを用いて低次元のグリッドから高次元のグラフドメインへの一般化を探求。スペクトルグラフ理論に基づくCNNの定式化を提案し、古典的CNNと同等の計算複雑性を維持しつつ、任意のグラフ構造に対応可能。MNISTおよび20NEWSの実験により、グラフ上での局所的特徴学習の能力を示した。 Comment
GCNを勉強する際は読むと良いらしい。
あわせてこのへんも:
Semi-Supervised Classification with Graph Convolutional Networks, Kipf+, ICLR'17
https://github.com/tkipf/gcn
Tutorial: Deep Reinforcement Learning, David Silver, ICML'16
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #Slide #ICML Issue Date: 2018-02-22
[Paper Note] Layer Normalization, Ba+, arXiv'16
Paper/Blog Link My Issue
#NeuralNetwork #Normalization #Selected Papers/Blogs Issue Date: 2018-02-19 GPT Summary- バッチ正規化の代わりにレイヤー正規化を用いることで、リカレントニューラルネットワークのトレーニング時間を短縮。レイヤー内のニューロンの合計入力を正規化し、各ニューロンに独自の適応バイアスとゲインを適用。トレーニング時とテスト時で同じ計算を行い、隠れ状態のダイナミクスを安定させる。実証的に、トレーニング時間の大幅な短縮を確認。 Comment
解説スライド:
https://www.slideshare.net/KeigoNishida/layer-normalizationnips
[Paper Note] An overview of gradient descent optimization algorithms, Sebastian Ruder, arXiv'16
Paper/Blog Link My Issue
#NeuralNetwork #Tutorial #Pocket #Optimizer Issue Date: 2018-02-05 GPT Summary- 勾配降下最適化アルゴリズムの理解を深めるため、さまざまなバリエーションや課題を要約し、一般的なアルゴリズムを紹介。並列・分散設定のアーキテクチャや最適化戦略も検討。
[Paper Note] Derivative Delay Embedding: Online Modeling of Streaming Time Series, Zhifei Zhang+, CIKM'16, 2016.09
Paper/Blog Link My Issue
#TimeSeriesDataProcessing #Pocket #CIKM #One-Line Notes Issue Date: 2017-12-31 GPT Summary- DDE-MGMという新しいオンラインモデリング手法を提案。従来の固定長や整列データの仮定を排除し、導関数遅延埋め込みを用いてストリーミング時系列データを効率的に処理。非パラメトリックマルコフ地理モデルでパターンをモデル化し、優れた分類精度を実現。実験結果は最先端手法と比較して効果的であることを示す。 Comment
スライド: https://www.slideshare.net/akihikowatanabe3110/brief-survey-of-datatotext-systems
(管理人が作成した過去のスライドより)
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, Sergey Ioffe+, ICML'15
Paper/Blog Link My Issue
#Pocket #LanguageModel #Transformer #ICML #Normalization #Selected Papers/Blogs Issue Date: 2025-04-02 GPT Summary- バッチ正規化を用いることで、深層ニューラルネットワークのトレーニングにおける内部共変量シフトの問題を解決し、高い学習率を可能にし、初期化の注意を軽減。これにより、同じ精度を14倍少ないトレーニングステップで達成し、ImageNet分類で最良の公表結果を4.9%改善。 Comment
メモってなかったので今更ながら追加した
共変量シフトやBatch Normalizationの説明は
- [Paper Note] Layer Normalization, Ba+, arXiv'16
記載のスライドが分かりやすい。
[Paper Note] An Empirical Exploration of Recurrent Network Architectures, Jozefowicz+, ICML'15
Paper/Blog Link My Issue
#NeuralNetwork #ICML #Selected Papers/Blogs Issue Date: 2018-02-19 Comment
GRUとLSTMの違いを理解するのに最適
[Paper Note] Recurrent neural network and a hybrid model for prediction of stock returns, Akhter+, Expert Systems with Applications'15, 2015.04
Paper/Blog Link My Issue
#NeuralNetwork #TimeSeriesDataProcessing #Financial #KeyPoint Notes Issue Date: 2017-12-31 Comment
Stock returnのpredictionタスクに対してNNを適用。
AR-MRNNモデルをRNNに適用、高い性能を示している。 moving referenceをsubtractした値をinput-outputに用いることで、normalizationやdetrending等の前処理が不要となり、regularizationの役割を果たすため汎化能力が向上する。
※ AR-MRN: NNNのinput-outputとして、生のreturn値を用いるのではなく、ある時刻におけるreturnをsubtractした値(moving reference)を用いるモデル ([Paper Note] Prediction-based portfolio optimization model using neural networks, Freitas+, Neurocomputing'09, 2009.06
で提案)
[Paper Note] Online Distributed Passive-Aggressive Algorithm for Structured Learning, Zhao+, CCL and NLP-NABD'13
Paper/Blog Link My Issue
#StructuredLearning #One-Line Notes Issue Date: 2017-12-31 Comment
タイトルの通り、構造学習版のpassive-aggressiveアルゴリズムの分散処理による高速化手法について提案されている論文。
論文中のAlgorithm.2がアルゴリズム。
[Paper Note] Factorization Machines, Steffen Rendle, ICDM'10
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #FactorizationMachines #ICDM #Selected Papers/Blogs Issue Date: 2018-12-22 Comment
解説ブログ:
http://echizen-tm.hatenablog.com/entry/2016/09/11/024828
DeepFMに関する動向:
https://data.gunosy.io/entry/deep-factorization-machines-2018
上記解説ブログの概要が非常に完結でわかりやすい

FMのFeature VectorのExample
各featureごとにlatent vectorが学習され、featureの組み合わせのweightが内積によって表現される
Matrix Factorizationの一般形のような形式
[Paper Note] Prediction-based portfolio optimization model using neural networks, Freitas+, Neurocomputing'09, 2009.06
Paper/Blog Link My Issue
#NeuralNetwork #TimeSeriesDataProcessing #Financial #KeyPoint Notes Issue Date: 2017-12-31 Comment
Stock returnのpredictionタスクに対してNNを適用。
NNのinput-outputとして、生のreturn値を用いるのではなく、ある時刻におけるreturnをsubtractした値(moving reference)を用いる、AR-MRNNモデルを提案。
[Paper Note] Structured Learning for Non-Smooth Ranking Losses, Chakrabarti+, KDD'08
Paper/Blog Link My Issue
#StructuredLearning #SIGKDD #One-Line Notes Issue Date: 2017-12-31 Comment
従来、structured learningの設定でranking lossを最適化する際は、smoothなmetric、たとえばMAPやAUCなどを最適化するといったことが行われていたが、MRRやNDCGなどのnon-smoothなmetricに対しては適用されていなかった。
なので、それをできるようにしましたという論文。
[Paper Note] Frustratingly easy domain adaptation, Daum'e, ACL'07
Paper/Blog Link My Issue
#DomainAdaptation #NLP #ACL #Selected Papers/Blogs #KeyPoint Notes Issue Date: 2017-12-31 Comment

domain adaptationをする際に、Source側のFeatureとTarget側のFeatureを上式のように、Feature Vectorを拡張し独立にコピーし表現するだけで、お手軽にdomain adaptationができることを示した論文。
イメージ的には、SourceとTarget、両方に存在する特徴は、共通部分の重みが高くなり、Source, Targetドメイン固有の特徴は、それぞれ拡張した部分のFeatureに重みが入るような感じ。
[Paper Note] A support vector method for Optimizing Average Precision, Yue+, SIGIR'07
Paper/Blog Link My Issue
#StructuredLearning #InformationRetrieval #SIGIR Issue Date: 2017-12-31 Comment
SVM-MAPの論文
構造化SVMを用いて、MAPを直接最適化する。
Calibrating Noise to Sensitivity in Private Data Analysis, Dwork+, TCC'06
Paper/Blog Link My Issue
#Privacy Issue Date: 2025-09-13 Comment
差分プライバシーとは何か:
https://www.jstage.jst.go.jp/article/isciesci/63/2/63_58/_pdf/-char/ja
差分プライバシーの概要と機械学習への応用:
https://www.skillupai.com/blog/tech/differential-privacy/
Adaptive Mixture of Local Experts, Jacobs+, Neural Computation'91
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #MoE(Mixture-of-Experts) Issue Date: 2025-04-29 Comment
Mixture of Expertsの起源
と思ったのだが、下記研究の方が年号が古いようだが、こちらが起源ではなのか・・・?だがアブスト中に上記論文で提案されたMoEのパフォーマンスを比較する、といった旨の記述があるので時系列がよくわからない。
[Evaluation of Adaptive Mixtures of Competing Experts](
http://www.cs.toronto.edu/~fritz/absps/nh91.pdf)
参考: https://speakerdeck.com/onysuke/mixture-of-expertsniguan-suruwen-xian-diao-cha
10,924x: The Instability Bomb at 1.7B Scale, TayKolasinski, 2026.01
Paper/Blog Link My Issue
#Article #Tutorial #NLP #LanguageModel #Blog #Selected Papers/Blogs #Reproducibility #ResidualStream Issue Date: 2026-01-19 Comment
元ポスト:
関連:
- [Paper Note] mHC: Manifold-Constrained Hyper-Connections, Zhenda Xie+, arXiv'25, 2025.12
- [Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
part1:
https://taylorkolasinski.com/notes/mhc-reproduction/
HC, mHCの説明が美しい図解と数式で説明されている。分かりやすい!
HCの課題とmHCがどのように解決したかを数式的、直感的に理解でき非常に有用
A Visual Introduction to Rectified Flows, Alec Helbling, 2026.01
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #Blog #read-later #FlowMatching #RectifiedFlow Issue Date: 2026-01-19 Comment
元ポスト:
dictionary_learning, Marks+, 2024
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #SparseAutoEncoder #Transcoders #CircuitAnalysis #Interpretability Issue Date: 2025-12-21
機械学習による 反応経路の予測と生成, 岡野原 大輔, 現代化学, 2025.12
Paper/Blog Link My Issue
#Article #DiffusionModel Issue Date: 2025-12-17 Comment
元ポスト:
うおおおおお・・・読んでみたけど全く理解が追い付かずこの分野の理解が甘すぎることを痛感!!いつか読み返して、わかるようになりたい。
深層強化学習アルゴリズムまとめ, Shion Honda, 2020.09
Paper/Blog Link My Issue
#Article #Tutorial #ReinforcementLearning #Selected Papers/Blogs #reading Issue Date: 2025-12-14
Constructing Efficient Fact-Storing MLPs for Transformers, Dugan+, 2025.11
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #LanguageModel #Transformer #Factuality #read-later #Encoder-Decoder Issue Date: 2025-11-30 GPT Summary- 本論文では、事実知識を効率的に保存するための改良されたMLP構築フレームワークを提案。主な特徴は、全ての入力-出力ペアに対応し、情報理論的限界に一致するパラメータ効率を達成し、Transformers内での使いやすさを維持すること。さらに、事実スケーリングに関するメトリックを発見し、勾配降下法MLPの性能を実証。最後に、Transformersでのモジュラー事実編集の概念実証を示した。 Comment
元ポスト:
Introducing the WeirdML Benchmark, Håvard Tveit Ihle, 2025.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Evaluation #Blog Issue Date: 2025-11-29 Comment
著者ポスト:
元ポスト:
WeirdML v2: https://htihle.github.io/weirdml.html
MLにおけるあまり一般的ではない(=Weird)なタスクによるLLMのベンチマークらしい
LMMs Engine, EvolvingLMMs-Lab, 2025.10
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #Repository #PostTraining #Selected Papers/Blogs #UMM #One-Line Notes Issue Date: 2025-10-27 Comment
元ポスト:
事前学習済みのLLM, VLM, dLM, DiffusionModelなどからUMMを学習できる事後学習フレームワーク。
LigerKernelでメモリ使用量を30%削減し、SparseAttentionもサポートし、Muon Optimizerもサポートしている。
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems, FlashInfer Community, 2025.10
Paper/Blog Link My Issue
#Article #NeuralNetwork #Pocket #Dataset #Transformer #AIAgents #Evaluation #SoftwareEngineering #GPUKernel Issue Date: 2025-10-22 Comment
元ポスト:
GPUカーネルのエージェントによる自動最適化のためのベンチマークとのこと。
Generative Modeling by Estimating Gradients of the Data Distribution, Yang Song, 2021.05
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #DiffusionModel #read-later #ScoreMatching Issue Date: 2025-10-20 Comment
元ポスト:
Andrej Karpathy — AGI is still a decade away, DWARKESH PATEL, 2025.10
Paper/Blog Link My Issue
#Article #Pretraining #NLP #LanguageModel #ReinforcementLearning #AIAgents #In-ContextLearning #Blog #RewardHacking #PostTraining #Diversity #Selected Papers/Blogs #PRM #Generalization #Cultural #Emotion Issue Date: 2025-10-20 Comment
元ポスト:
関連:
- In-context Steerbility: [Paper Note] Spectrum Tuning: Post-Training for Distributional Coverage and
In-Context Steerability, Taylor Sorensen+, arXiv'25, 2025.10
(整理すると楽しそうなので後で関連しそうな研究を他にもまとめる)
とても勉強になる!AIに代替されない20%, 1%になるには果たして
所見:
RL Scaling Laws for Mathematical Reasoning, Joan Cabezas, 2025.10
Paper/Blog Link My Issue
#Article #Analysis #NLP #ReinforcementLearning #Repository #Mathematics #Scaling Laws #read-later #reading #One-Line Notes Issue Date: 2025-10-11 Comment
元ポスト:
Qwen3をGSM8KでRL Finetuningしたらパラメータ数が小さいモデルは大きなgainを得たが、パラメータが大きいモデルはそれほどでもなかったので、パラメータ数が大きいほどスケールするわけではなく(むしろ恩恵が小さくなる)、かつ報酬をstrictにするとQwenは指示追従能力がないことで学習が全然進まなかった(柔軟なものにしたらそうではなかったので適切な報酬が重要)、GSM8KでRL FinetuninpしたモデルのreasoningはMMLUに転移しなかったので、RL Finetuningは学習データとして与えたドメインのパターンを学習しているだけなのではないか、みたいな話がポストに記述されている。
AI2のResearcherからの所見:
元の話とこの辺をしっかり読み解いたらとても勉強になりそうな予感👀
Scaling Laws系の研究:
- Training Compute-Optimal Large Language Models, Jordan Hoffmann+, NeurIPS'22
- Scaling Laws for Neural Language Models, Jared Kaplan+, arXiv'20
- Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
- Scaling Laws for Autoregressive Generative Modeling, Tom Henighan+, arXiv'20
- Scaling Laws for Value-Based RL, Fu+, 2025.09
(RL関連)
- [Paper Note] Bayesian scaling laws for in-context learning, Aryaman Arora+, COLM'25, 2024.10
(ICL関連)
画像とかData Mixture, MoEなど他にも色々あるが、一旦上記らへんと元ポスト・AI2からの所見を読み解いたらどういったものが見えてくるだろうか?(全部読んでじっくり考えたいけど時間が無いので...)一旦GPTにきいてみよう
GPTにきいてみた(私は無課金勢だがthinking timeが挟まれたのとデコーディング速度の適度な遅さと、limitに到達しましたというメッセージがなかったことから鑑みるに、以下はGPT-5によって回答されていると考えられる)
https://chatgpt.com/share/68ec5024-83fc-8006-b8c6-14060191fb91
RLのScaling Lawsに関する研究がでました:
- [Paper Note] The Art of Scaling Reinforcement Learning Compute for LLMs, Devvrit Khatri+, arXiv'25, 2025.10
Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
Paper/Blog Link My Issue
#Article #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #SoftwareEngineering #KeyPoint Notes Issue Date: 2025-10-06 Comment
関連:
- Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
2023年当時のFinetuningの設計について概観した後、TinkerのAPIの設計について説明。そのAPIの設計のstepごとにTinker側にデータを送るという設計について、一見すると課題があることを指摘(step単位の学習で数百msの通信オーバヘッドが生じて、その間Tinker側のGPUは待機状態になるため最大限GPUリソースを活用できない。これは設計ミスなのでは・・・?という仮説が成り立つという話)。が、仮にそうだとしても、実はよくよく考えるとその課題は克服する方法あるよ、それを克服するためにLoRAのみをサポートしているのもうなずけるよ、みたいな話である。
解決方法の提案(というより理論)として、マルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、LoRAはadapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察をしている。
ブログの筆者は2023年ごろにFinetuningができるサービスを展開したが、データの準備をユーザにゆだねてしまったがために成功できなかった旨を述べている。このような知見を共有してくれるのは大変ありがたいことである。
Replay BufferがPolicy Gradientで使えない理由, piqcy, 2019.03
Paper/Blog Link My Issue
#Article #Tutorial #ReinforcementLearning #One-Line Notes #ReplayBuffer Issue Date: 2025-10-04 Comment
Policy Gradientに基づいたアルゴリズムは(たとえばREINFORCE系)、現在のポリシーに基づいて期待値を最大化していくことが前提になるため、基本的にはリプレイバッファが使えないが(過去の経験が影響すると現在の戦略の良さがわからなくなる)、工夫をすると使えるようになるよ、といった話の解説
AIインフラを考える, Masayuki Kobayashi, 第38回 ISOC-JP Workshop, 2025.09
Paper/Blog Link My Issue
#Article #LanguageModel #Infrastructure #GenerativeAI #Slide #read-later #One-Line Notes Issue Date: 2025-09-28 Comment
元ポスト:
KVCacheサイズとデータ転送量の部分はパフォーマンスチューニングの際に重要なのですぐにでも活用できそう。前半部分は私にとっては難しかったので勉強したい。
When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch, Liu+, 2025.09
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #ReinforcementLearning #AIAgents #Blog #Selected Papers/Blogs #Stability #train-inference-gap Issue Date: 2025-09-27 Comment
元ポスト:
訓練時のエンジン(fsdp等)とロールアウト時のエンジン(vLLM等)が、OOVなトークンに対して(特にtooluseした場合に生じやすい)著しく異なる尤度を割り当てるため学習が崩壊し、それは利用するGPUによっても安定性が変化し(A100よりもL20, L20よりもH20)、tokenレベルのImporttance Weightingでは難しく、Sequenceレベルのサンプリングが必要、みたいな話な模様。
関連:
- Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
- [Paper Note] Group Sequence Policy Optimization, Chujie Zheng+, arXiv'25
FP16にするとtrain-inferenae gapが非常に小さくなるという報告:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
A100でvLLMをバックボーンにした時のdisable_cascade_attnの設定値による挙動の違い:
そもそもFlashAttnention-2 kernelにバグがあり、A100/L20で特定のカーネルが呼ばれるとミスマッチが起きるのだとか。vLLM Flashattentionリポジトリのissue 87によって解決済み。~~具体的にどのカーネル実装なのだろうか。~~ (vLLM Flashattentionリポジトリだった模様)
https://github.com/vllm-project/flash-attention
disable_cascade_attnの設定値を何回も変えたけどうまくいかないよという話がある:
Modular Manifolds, Jeremy Bernstein+, THINKING MACHINES, 2025.09
Paper/Blog Link My Issue
#Article #NeuralNetwork #NLP #Blog #Optimizer #read-later Issue Date: 2025-09-27 Comment
関連:
Flow Matching in 5 Minutes, wh., 2025.07
Paper/Blog Link My Issue
#Article #Tutorial #read-later #FlowMatching Issue Date: 2025-09-15 Comment
元ポスト:
Speed-Accuracy Relations for Diffusion Models: Wisdom from Nonequilibrium Thermodynamics and Optimal Transport, Ikeda+, Physical Review X, 2025
Paper/Blog Link My Issue
#Article #Analysis #Pocket #DiffusionModel Issue Date: 2025-09-05
【論文解説】高速・高品質な生成を実現するFlow Map Models(Part 1: 概要編), Masato Ishii (Sony AI), 2025.09
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #Video #read-later Issue Date: 2025-09-04
2025年度人工知能学会全国大会チュートリアル講演「深層基盤モデルの数理」, Taiji Suzuki, 2025.05
Paper/Blog Link My Issue
#Article #Tutorial #Pretraining #NLP #LanguageModel #Transformer #Chain-of-Thought #In-ContextLearning #Attention #DiffusionModel #SSM (StateSpaceModel) #Scaling Laws #PostTraining Issue Date: 2025-05-31 Comment
元ポスト:
Datadog_Toto-Open-Base-1.0, Datadog, 2025.05
Paper/Blog Link My Issue
#Article #TimeSeriesDataProcessing #Transformer #FoundationModel #OpenWeight Issue Date: 2025-05-25 Comment
元ポスト:
(あとでコメント追記する
Datadog_BOOM, Datadog, 2025.05
Paper/Blog Link My Issue
#Article #TimeSeriesDataProcessing #Dataset #Evaluation Issue Date: 2025-05-25 Comment
元ポスト:
あえて予測の更新頻度を落とす| サプライチェーンの現場目線にたった機械学習の導入, モノタロウ Tech Blog, 2022.03
Paper/Blog Link My Issue
#Article #Blog Issue Date: 2025-04-18 Comment
とても面白かった。需要予測の予測性能を追求すると現場にフィットしない話が示唆に富んでいて、とてもリアルで興味深い。
GRPO Judge Experiments: Findings & Empirical Observations, kalomaze's kalomazing blog, 2025.03
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog #GRPO Issue Date: 2025-03-05 Comment
一意に解が決まる問題ではなく、ある程度の主観的な判断が必要なタスクについてのGRPOの分析。
2つのテキストを比較するタスクで、一方のタスクはLLMによって摂動を与えている(おそらく意図的にcorruptさせている)。
GRPOではlinearやcosineスケジューラはうまく機能せず、warmupフェーズ有りの小さめの定数が有効らしい。また、max_grad_normを0.2にしまgradient clippingが有効とのこと。
他にもrewardの与え方をx^4にすることや、length, xmlフォーマットの場合にボーナスのrewardを与えるなどの工夫を考察している。
The Ultra-Scale Playbook: Training LLMs on GPU Clusters, HuggingFace, 2025.02
Paper/Blog Link My Issue
#Article #Pretraining #LanguageModel #Supervised-FineTuning (SFT) Issue Date: 2025-03-04 Comment
HuggingFaceによる数1000のGPUを用いたAIモデルのトレーニングに関するオープンソースのテキスト
Open Reasoner Zero, Open-Reasoner-Zero, 2024.02
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Library #ReinforcementLearning #python #Reasoning Issue Date: 2025-03-02 GPT Summary- Open-Reasoner-Zeroは、推論指向の強化学習のオープンソース実装で、スケーラビリティとアクセスのしやすさに重点を置いています。AGI研究の促進を目指し、ソースコードやトレーニングデータを公開しています。 Comment
元ポスト:
RLHF_DPO 小話, 和地瞭良_ Akifumi Wachi, 2024.04
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Alignment #RLHF #Blog #DPO Issue Date: 2024-12-18 Comment
めちゃめちゃ勉強になる…
最近のOptimizerの研究について, Hiroyuki Tokunaga, 2024.12
Paper/Blog Link My Issue
#Article #Optimizer Issue Date: 2024-12-12 Comment
- ADOPT: Modified Adam Can Converge with Any $β_2$ with the Optimal Rate, Shohei Taniguchi+, NeurIPS'24
↑以外にもめちゃめちゃたくさんのOptimizerの研究が紹介されており大変勉強になる。
ml-engineering
Paper/Blog Link My Issue
#Article #Tutorial #ComputerVision #NLP #LanguageModel #Repository Issue Date: 2024-09-07 Comment
LLMやVLMを学習するためのツールやノウハウがまとめられたリポジトリ
LitServe, 2024.04
Paper/Blog Link My Issue
#Article #Library #Repository #API Issue Date: 2024-08-25 Comment
FastAPIより2倍早いAPIライブラリ。LLMやVisionなど多くのモーダルに対応し、マルチワーカーでオートスケーリングやバッチングやストリーミングにも対応。PyTorchモデルだけでなく、JAXなど様々なフレームワークのモデルをデプロイ可能
元ツイート:
画像は元ツイートより引用
ML Papers Explained
Paper/Blog Link My Issue
#Article #Survey #ComputerVision #NLP Issue Date: 2023-11-22 Comment
以下の分野の代表的な論文がまとめられている(基本的にはTransformer登場後のものが多い)
- 言語モデル(Transformer, Elmoなど)
- Visionモデル(ViTなど)
- CNN(AlexNetなど)
- Single Stage Object Detectors
- Region-based Convolutional Neural Networks
- DocumentAI(TableNetなど)
- Layout Transformers
- Tabular Deeplearning
大規模言語モデルにおいて、「知識は全結合層に蓄積される」という仮説についての文献調査
Paper/Blog Link My Issue
#Article #Analysis #Transformer #Blog Issue Date: 2023-10-29 Comment
タイトルの通り、知識がFFNに蓄積されていると主張しているらしい原論文を読み解いている。まとめを引用すると
> 「知識は全結合層に蓄積される」という表現は、ややラジカルで、
少なくともこの論文では「全結合層は知識獲得において重要」という程度
の、もう少しマイルドな主張をしているように見受けられました。
とのこと。
CommonVoice
Paper/Blog Link My Issue
#Article #Dataset #SpeechProcessing Issue Date: 2023-08-16 Comment
音声対応のアプリケーションをトレーニングするために誰でも使用できるオープンソースの多言語音声データセット
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, 2023
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #Transformer #Attention Issue Date: 2023-07-23 GPT Summary- FlashAttention-2は、長いシーケンス長におけるTransformerのスケーリングの問題に対処するために提案された手法です。FlashAttention-2は、非対称なGPUメモリ階層を利用してメモリの節約とランタイムの高速化を実現し、最適化された行列乗算に比べて約2倍の高速化を達成します。また、FlashAttention-2はGPTスタイルのモデルのトレーニングにおいても高速化を実現し、最大225 TFLOPs/sのトレーニング速度に達します。 Comment
Flash Attention1よりも2倍高速なFlash Attention 2
Flash Attention1はこちらを参照
https://arxiv.org/pdf/2205.14135.pdf
QK Matrixの計算をブロックに分けてSRAMに送って処理することで、3倍高速化し、メモリ効率を10-20倍を達成。
Auto train advanced
Paper/Blog Link My Issue
#Article #Tools #LanguageModel #Supervised-FineTuning (SFT) #Blog #Repository Issue Date: 2023-07-11 Comment
Hugging Face Hub上の任意のLLMに対して、localのカスタムトレーニングデータを使ってfinetuningがワンラインでできる。
peftも使える。
LM Flow
Paper/Blog Link My Issue
#Article #Tools #LanguageModel #Supervised-FineTuning (SFT) #FoundationModel Issue Date: 2023-06-26 Comment
一般的なFoundation Modelのファインチューニングと推論を簡素化する拡張可能なツールキット。継続的なpretragning, instruction tuning, parameter efficientなファインチューニング,alignment tuning,大規模モデルの推論などさまざまな機能をサポート。
Ascender
Paper/Blog Link My Issue
#Article #project_template #python Issue Date: 2023-05-25 Comment
pythonを利用した研究開発する上でのプロジェクトテンプレート
A Cookbook of Self-Supervised Learning, 2023
Paper/Blog Link My Issue
#Article #Tutorial #Self-SupervisedLearning Issue Date: 2023-04-26 Comment
MetaによるSelf Supervised Learningの教科書
tuning_playbook, Google Research
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial Issue Date: 2023-01-21 Comment
Googleが公開したDeep Learningモデル学習のノウハウ。必読
Are Transformers Effective for Time Series Forecasting?
Paper/Blog Link My Issue
#Article #TimeSeriesDataProcessing #LanguageModel #Transformer Issue Date: 2022-12-29 Comment
Linear Layerに基づくシンプルな手法がTransformerベースの手法に時系列予測で勝ったという話
Transformers Interpret, 2022
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #Library #Explanation #Transformer #Blog Issue Date: 2022-12-01 Comment
transformersのモデルをたった2行追加するだけで、explainableにするライブラリ
基本的にtextとvisionのclassificationをサポートしている模様
text classificationの場合、たとえばinput tokenの各トークンの分類に対する寄与度をoutputしてくれる。
neptune.ai
Paper/Blog Link My Issue
#Article #Tools Issue Date: 2022-03-09 Comment
・実験結果の可視化や管理に利用できるサービス
・API経由で様々な実験に関わるメタデータやmetricを送信することで、サイト上でdashboardを作成し、複数の実験の結果を可視化したりwidget上で比較したりできる
・実験時に使用したargumentsを記録したり、global_stepごとにlossをAPI経由で逐次的に送信することで実験結果を記録できたりする
・widgetやmodelなどは、クエリによってフィルタリングできたりするので、特定のstructureを持っているモデル間のみで結果を比較したり等も簡単にできる
・利用する際は、APIキーをサイト上で発行し、コード上でAPIキーを設定して、neptuneのモジュールをnewしてlogメソッドを呼び出して逐次的にデータを送信していくだけで、neptune上で送信んされたデータが管理される。
※ 一部解釈が間違っている場所がある可能性がある
HuggingFace, pytorch-lightningなどのフレームワークでもサポートされている模様
HuggingFace:
https://huggingface.co/transformers/v4.9.1/_modules/transformers/integrations.html
pytorch-lightning:
https://pytorch-lightning.readthedocs.io/en/stable/api/pytorch_lightning.loggers.neptune.html
HuggingFaceではNeptuneCallbackというコールバックを使えばneptuneを仕込めそう
NeurIPS 2021 技術報告会, 株式会社TDAI Lab, 2022
Paper/Blog Link My Issue
#Article #Tutorial #Slide Issue Date: 2022-02-07 Comment
NeurIPS 2021での技術トレンドがまとめられている
1. アーキテクチャの改善
2. マルチモーダルモデル
3. Temporal Adaptation
4. Retrieval Augmentation
5. ベンチマーク見直し
6. データセット見直し
7. Human-Centered AI
Hidden Technical Debt in Machine Learning Systems, Sculley+, Google
Paper/Blog Link My Issue
#Article #Tutorial #Pocket #Infrastructure Issue Date: 2021-10-19 Comment

よく見るML codeが全体のごく一部で、その他の基盤が大半を占めてますよ、の図
実臨床・Webサービス領域での機械学習研究 開発の標準化
Paper/Blog Link My Issue
#Article #Tutorial #Pocket Issue Date: 2021-10-16 Comment
並列して走る機械学習案件をどのように効果的に捌いているか説明。
①タイトな締切
→ 高速化で対処
→ よく使う機能をML自身に実装する
②並行して走る案件
→ 並列化
→ Kubernetesを用いて、タスクごとに異なるノードで分散処理(e.g CVのFoldごとにノード分散、推論ユーザごとにノード分散)要件に合わせて、メモリ優先、CPU優先などのノードをノードプールから使い分ける
③属人化
→ 標準化
→ よく使う機能はMLシステム自身に実装
→ 設定ファイルで学習、推論の挙動を制御
NVIDIA TRITON INFERENCE SERVER, 2021
Paper/Blog Link My Issue
#Article #Infrastructure #MLOps #Blog Issue Date: 2021-06-18 Comment
Nvidiaのオープンソースのinference server
モデルのデプロイや管理、スケーリング等を良い感じにしてくれるフレームワーク?
OpenKE, 2021
Paper/Blog Link My Issue
#Article #Embeddings #Tools #Library #KnowledgeGraph #Repository Issue Date: 2021-06-10 Comment
Wikipedia, Freebase等のデータからKnowledge Embeddingを学習できるオープンソースのライブラリ
近似最近傍探索の最前線, Yusuke Matsui, 2019
Paper/Blog Link My Issue
#Article #Tutorial #Slide #kNN Issue Date: 2020-07-30 Comment
k-NNベースドなRecommender Systemを構築したけど、Inferenceに時間がかかって、先方のレスポンスタイムの要求が満たせない...というときに役に立ちそう。
yahooのNGTといった実装も転がっている(Apache-2.0 License):
https://techblog.yahoo.co.jp/data_solution/ngtpython/
ScaNNという手法もあるらしい(SoTA)
https://ai-scholar.tech/articles/vector-search/scann
Key trends from NeurIPS 2019, Chip Huyen, 2019
Paper/Blog Link My Issue
#Article #Tutorial #Blog Issue Date: 2020-01-16
10 ML & NLP Research Highlights of 2019, Sebastian Ruder, 2020
Paper/Blog Link My Issue
#Article #Survey #NLP #Blog Issue Date: 2020-01-13
The Annotated Transformer, harvardnlp, 2018.04
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #NLP Issue Date: 2018-06-29
ニューラルネット勉強会(LSTM編), Seitaro Shinagawa, 2016
Paper/Blog Link My Issue
#Article #NeuralNetwork #Tutorial #NLP #Slide Issue Date: 2018-02-19 Comment
LSTMの基礎から、実装する上でのTipsがまとまっている。
zero padding, dropoutのかけかた、normalizationの手法など。
Curriculum Learning(関東CV勉強会), Yoshitaka Ushiku, 2015.05
Paper/Blog Link My Issue
#Article #Tutorial #Slide #CurriculumLearning Issue Date: 2018-02-12 Comment
牛久先生によるCurriculum Learningチュートリアル
SVM-MAP
Paper/Blog Link My Issue
#Article #StructuredLearning #Tools #InformationRetrieval #One-Line Notes Issue Date: 2017-12-31 Comment
構造化SVMを用いて、MAPを直接最適化する手法
[Paper Note] Scalable Large-Margin Online Learning for Structured Classification, Crammer+, 2005
Paper/Blog Link My Issue
#Article #StructuredLearning Issue Date: 2017-12-31 Comment
構造学習ガチ勢のCrammer氏の論文
構造学習やるなら読んだ方が良い
オンライン学習
Paper/Blog Link My Issue
#Article #Tutorial #OnlineLearning Issue Date: 2017-12-31 Comment
## 目次
定式化
評価法:Regretなど
パーセプトロン
Passive Aggressive Algorithm
(アルゴリズムと損失の限界の評価)
Confidence Weighted Algorithm
Pegasos
Coordinate Descent
バッチ、オンライン、ストリームの比較
ビッグデータへの対応
[Paper Note] Machine Learning for User Modeling, User modeling and User-adapted Interaction, [Webb+, 2001], 2001.03
Paper/Blog Link My Issue
#Article #Tutorial #UserModeling #KeyPoint Notes Issue Date: 2017-12-28 Comment
# 管理人の過去のメモスクショ



