
KeyPoint Notes
[Paper Note] Dr. Zero: Self-Evolving Search Agents without Training Data, Zhenrui Yue+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #Search #LanguageModel #QuestionAnswering #ReinforcementLearning #AIAgents #SelfImprovement #On-Policy Issue Date: 2026-01-14 GPT Summary- データフリー自己進化が注目される中、大規模言語モデル(LLM)のための「Dr. Zero」フレームワークを提案。多様な質問を生成し、自己進化フィードバックループで解決者をトレーニング。HRPOを導入し、類似質問のクラスタリングを行うことで計算効率を向上。実験結果は、データフリーの検索エージェントが監視型と同等以上の性能を達成することを示す。 Comment
元ポスト:
(検索とReasoningを通じてSolver用の学習データとしてのverifiableな)QAを生成するProposerと、それを(検索とReasoningを通じて)解決するSolverの双方をRLするような枠組みで、ProposerはSolverからのDifficulty Reward (QAのverifiabilityとSolverの成功率(自明でなく難しすぎもしない丁度良い難易度か, 式(4))として受けとりHRPOと呼ばれる手法で改善、SolverはGRPOでRLVRする、といった枠組みに見える。QAはProposerが合成するので事前にデータを用意する必要がない、ということだと思われる。
HRPOはGRPO同様にon policyなRL手法であり、従来のself-evolving手法ではsingle hopなQuestionに合成結果が偏りやすく、かつon policyな手法でProposerを学習しようとしたときに、naiveにやるとm個のクエリに対して、クエリごとにsolverのn個のロールアウトが必要な場合、(m+1)*n回のロールアウトがpromptごとに必要となるため、計算コストが膨大になりスケーリングさせる際に深刻なボトルネックとなる問題を解決したものである。
具体的には、単一のpromptに対して複数のsolverによるロールアウトからadvantageを計算するのではなく、同じhop数の合成されたQAでクラスタリングを実施しておき、そのグループ内の(構造や複雑度がhop数の観点で類似した)QAに対するロールアウトに基づいてadvantageを計算する(3.2切に明記されていないが、おそらくロールアウトはQAごとに少数(1つ))。似たようなhop数を要するQAによってadvantageが正規化されるためadvantageの分散を小さくとることが期待され、かつロールアウトの回数を減らせるため計算効率が良い、という利点がある(3.2節)。
解説:
[Paper Note] Deep Delta Learning, Yifan Zhang+, arXiv'26, 2026.01
Paper/Blog Link My Issue
#NeuralNetwork #MachineLearning #Pocket #NLP #InductiveBias #ResidualStream Issue Date: 2026-01-03 GPT Summary- Deep Delta Learning(DDL)を提案し、学習可能な恒等ショートカット接続を用いて残差接続を一般化。デルタ演算子を導入し、動的に補間可能なゲートを用いて情報の消去と新しい特徴の書き込みを制御。これにより、複雑な状態遷移をモデル化しつつ、安定したトレーニング特性を維持。 Comment
元ポスト:
解説:
residual connectionは残差を加算するがこれがinducive biasとなり複雑な状態遷移を表現する上ての妨げになっていたが、residual connectionを学習可能なdelta operator(rank1の対称行列によって実現される幾何変換)とやらで一般化することで、表現力を向上させる、といった話な模様。この行列によって実現される幾何変換は3種類によって構成され、βの値によって性質が変わる。たとえばβ=0に近づくほど恒等写像(何もしない)に近づき、β=1に近づくほど射影(特定方向の成分を捨てる)、β=2に近づくほど反射(特定方向の成分を反転させる)といった変換になるらしい。
概念が示されたのみで実験結果はまだ無さそうに見える。
[Paper Note] mHC: Manifold-Constrained Hyper-Connections, Zhenda Xie+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #Transformer #Architecture #read-later #Selected Papers/Blogs #Stability #Reference Collection #ResidualStream Issue Date: 2026-01-02 GPT Summary- Manifold-Constrained Hyper-Connections(mHC)を提案し、残差接続の多様化による訓練の不安定性やメモリアクセスのオーバーヘッドに対処。mHCは残差接続空間を特定の多様体に射影し、恒等写像特性を回復しつつ効率を確保。実証実験により、大規模訓練での性能向上とスケーラビリティを示し、トポロジーアーキテクチャ設計の理解を深めることを期待。 Comment
元ポスト:
所見:
先行研究:
- [Paper Note] Hyper-Connections, Defa Zhu+, ICLR'25, 2024.09
- [Paper Note] Deep Residual Learning for Image Recognition, Kaiming He+, CVPR'16, 2015.12
所見:
ポイント解説:
解説:
従来のHCがResidual Streamに対してH_resを乗じて幾何的変換を実施する際に、H_resに制約がないため、Layerを重ねるごとにResidual Streamの大きさが指数的に発散、あるいは収縮していき学習が不安的になる課題を、二重確率行列(行と列の成分の合計が1.0となるような正規化をする)を用いた変換を用いることで、Residual Streamのノルムが変化しないようにし安定化させた、といった感じの話に見える。
[Paper Note] Step-DeepResearch Technical Report, Chen Hu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #Evaluation #Reasoning #Proprietary #mid-training #DeepResearch #Rubric-based Issue Date: 2025-12-24 GPT Summary- Step-DeepResearchは、LLMを用いた自律エージェントのためのコスト効率の良いエンドツーエンドのシステムであり、意図認識や長期的意思決定を強化するためのデータ合成戦略を提案。チェックリストスタイルのジャッジャーにより堅牢性を向上させ、中国ドメイン向けのADR-Benchを設立。実験では、Step-DeepResearchが高いスコアを記録し、業界をリードするコスト効率で専門家レベルの能力を達成したことを示した。 Comment
元ポスト:
ポイント解説:
ざっくり言うと、シンプルなReAct styleのagentで、マルチエージェントのオーケストレーションや複雑で重たいワークフロー無しで、OpenAI, GeminiのDeepResearchと同等の性能を達成してとり、ポイントとしてこれらの機能をはmid-training段階で学習してモデルのパラメータとして組み込むことで実現している模様。
mid trainingは2段階で構成され、trajectoryの長さは徐々に長いものを利用するカリキュラム方式。
最初のステージでは以下の4つのatomicスキルを身につけさせる:
- Planning & Task Decomposition
- Deep Information Seeking
- Reflection & Verification
- Reporting
これらのatomic skillを身につけさせる際には、next token predictionをnext action predictionという枠組みで学習し、アクションに関するトークンの空間を制限することで効率性を向上(ただし、具体性は減少するのでトレードオフ)という形にしているようだが、コンセプトが記述されているのみでよくわからない。同時に、学習データの構築方法もデータソースとおおまかな構築方法が書かれているのみである。ただし、記述内容的には各atomicmskilvごとに基本的には合成データが作成され利用されていると考えてよい。
たとえばplanningについては論文などの文献のタイトルや本文から実験以後の記述を除外し、研究プロジェクトのタスクを推定させる(リバースエンジニアリングと呼称している)することで、planningのtrajectoryを合成、Deep Information SeekingではDB Pediaなどのknowledge graphをソースとして利用し、字数が3--10程度のノードをseedとしそこから(トピックがドリフトするのを防ぐために極端に次数が大きいノードは除外しつつ)幅優先探索をすることで、30--40程度のノードによって構成されるサブグラフを構成し、そのサブグラフに対してmulti hopが必要なQuestionを、LLMで生成することでデータを合成しているとのこと。
RLはrewardとしてルーブリックをベースにしたものが用いられるが、strong modelを用いて
- 1: fully satisfied
- 0.5: partially satisfied
- 0: not satisfied
の3値を検討したが、partially satisfiedが人間による評価とのagreementが低かったため設計を変更し、positive/negative rubricsを設定し、positivルーブリックの場合はルーブリックがfully satisfiedの時のみ1, negativeルーブリックの方はnot satisfiedの時のみ0とすることで、低品質な生成結果に基づくrewardを無くし、少しでもネガティブな要素があった場合は強めのペナルティがかかるようにしているとのこと(ルーブリックの詳細は私が見た限りは不明である。Appendix Aに書かれているように一瞬見えたが具体的なcriterionは書かれていないように見える)。
[Paper Note] Xiaomi MiMo-VL-Miloco Technical Report, Jiaze Li+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #LanguageModel #MultiModal #Reasoning #OpenWeight #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-12-23 GPT Summary- MiMo-VL-Miloco-7Bとその量子化バリアントをオープンソース化し、家庭中心の視覚と言語モデルとして優れた性能を発揮。特にスマートホーム環境に特化し、ジェスチャー認識やマルチモーダル推論で高いF1スコアを達成。二段階のトレーニングパイプラインを設計し、効率的な推論を実現。家庭シナリオのトレーニングが活動理解を向上させ、テキスト推論にも効果を示す。モデルとツールキットは公開され、スマートホームアプリケーションの研究に貢献。 Comment
元ポスト:
HF:
https://huggingface.co/collections/xiaomi-open-source/xiaomi-mimo-vl-miloco
モデル自体は11月から公開されている
home-scenario gesture recognitionとdaily activity recognitionでGemini-2.5-Proを上回る性能を達成している。特定のユースケースに特化しつつ、genericなユースケースの性能を損なわないようなモデルを学習したい場合は参考になるかもしれない。
まずSFTでhome-scenarioデータ[^1] + GeneralデータのDataMixでreasoning patternを学習させ、tokenのefficiencyを高めるためにCoTパターンを排除しdirect answerをするようなデータ(およびprompting)でも学習させる。これによりhome-scenarioでの推論能力が強化される。SFTはfull parameter tuningで実施され、optimizerはAdamW。バッチサイズ128, warmup ratio 0.03, learning rate 1 * 10^-5。スケジューラについては記述がないように見える。
その後、一般的なユースケース(Video Understanding (temporal groundingにフォーカス), GUI Grounding, Multimodal Reasoning (特にSTEMデータ))データを用いてGRPOでRLをする。明らかに簡単・難しすぎるデータは除外。RLのrewardは `r_acc + r_format`の線形補完(係数はaccL: 0.9, format: 0.1)で定義される。r_accはデータごとに異なっている。Video Understandingでは予測したqueryに対してモデルが予測したtimespanとgoldのtimespanのoverlapがどの程度あるかをaccとし、GUI Groundingではbounding boxを予測しpred/goldのoverlapをaccとする。Multimodal ReasoninghはSTEMデータなので回答が一致するかをbinaryのaccとして与えている。
モデルのアーキテクチャは、アダプターでLLMと接続するタイプのもので、動画/画像のBackboneにはViTを用いて、MLPのアダプターを持ちいてLLMの入力としている。
[^1]: volunteerによるhome-scenarioでのデータ作成; ruleを規定しvolunteerに理解してもらいデータ収集。その後研究者が低品質なものを除外
[Paper Note] Next-Embedding Prediction Makes Strong Vision Learners, Sihan Xu+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pretraining #Pocket #Transformer #MultiModal #read-later #Selected Papers/Blogs #2D (Image) #Backbone #UMM #Omni Issue Date: 2025-12-20 GPT Summary- 生成的事前学習の原則を視覚学習に応用し、モデルが過去のパッチ埋め込みから未来の埋め込みを予測する「次埋め込み予測自己回帰(NEPA)」を提案。シンプルなTransformerを用いてImageNet-1kで高精度を達成し、タスク特有の設計を必要とせず、スケーラビリティを保持。NEPAは視覚的自己教師あり学習の新たなアプローチを提供する。 Comment
pj page:
https://sihanxu.me/nepa/
HF:
https://huggingface.co/collections/SixAILab/nepa
元ポスト:
Autoregressiveにnext embedding prediction(≠reconstruction)をする。エンコーダ自身のembeddingとautoregressive headが生成したembeddingを比較することでlossが計算されるが、双方に勾配を流すとほぼ全てのパッチが同じembeddingを共有するという解に到達し何も学習されないので、エンコーダのエンコード結果(=target)のgradientをstopする。これにより、targetとしての勾配は受け取らないが(predictionに近づけようとする勾配)、文脈に応じたベクトルを作り、next embeddingを予測する入力としての勾配は受け取るので、エンコーダは文脈に応じた学習を続けることができる。
コミュニティからのフィードバックを受けて執筆されたブログ:
https://sihanxu.me/nepa/blog
元ポスト:
NEPAを提案した背景に関して直感的な解説を実施している。興味深い。具体的には、omnimodalityモデルの困難さはインターフェースの問題であり、latent spaceがomnimodalityの共通のインタフェースになりうり、モダリティごとの予測対象とlossを個別に設計せずに済む方法の一つがAutoregressiveな予測であり、そういったインタフェースがスケーリングのために必要という意見と、omnimodalityにおいて過去のliteratureで扱われているdiscreteなtokenとcontinuous symbolsは得意なモダリティが異なり予測対象や前処理のメカニズムも異なるため同時に扱うことが難しい旨などが記述されている。
[Paper Note] SAGE: Training Smart Any-Horizon Agents for Long Video Reasoning with Reinforcement Learning, Jitesh Jain+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #ReinforcementLearning #AIAgents #Evaluation #Reasoning #Selected Papers/Blogs #VideoGeneration/Understandings #VisionLanguageModel #LongHorizon Issue Date: 2025-12-19 GPT Summary- 人間のように異なる長さの動画に柔軟に推論できる動画推論モデルSAGEを提案。SAGEは長い動画に対してマルチターン推論を行い、簡単な問題には単一ターンで対応。Gemini-2.5-Flashを用いたデータ生成パイプラインと強化学習後訓練レシピを導入し、SAGE-Benchで実世界の動画推論能力を評価。結果、オープンエンドのタスクで最大6.1%、10分以上の動画で8.2%の性能向上を確認。 Comment
pj page: https://praeclarumjj3.github.io/sage/
元ポスト:
AllenAIの勢いすごいな...
現在のVideo reasoning Modelはlong videoに対するQAに対してもsingle turnで回答応答しようとするが、人間はそのような挙動はせずに、long videoのうち、どこを流し見し、どこを注視するか、ある時は前半にジャンプし、関係ないところは飛ばすなど、情報を選択的に収集する。そのような挙動のエージェントをMolmo2をベースにSFT+RLをベースに実現。
システムデザインとしては、既存のエージェントはtemporal groundingのみをしばしば利用するがこれはlong videoには不向きなので、non-visualな情報も扱えるようにweb search, speech transcription, event grounding, extract video parts, analyze(クエリを用いてメディアの集合を分析し応答する)なども利用可能に。
inferenceは2-stageとなっており、最初はまずSAGE-MMをContext VLMとして扱い、入力された情報を処理し(video contextやツール群、メタデータなど)、single turnで回答するか、ツール呼び出しをするかを判断する。ツール呼び出しがされた場合は、その後SAGE-MMはIterative Reasonerとして機能し、前段のtool callの結果とvideo contextから回答をするか、新たなツールを呼び出すかを判断する、といったことを繰り返す。
long videoのデータは6.6kのyoutube videoと99kのQAペア(Gemini-2.5-Flashで合成)、400k+のstate-action example(Gemini-2.5-Flashによりtool callのtrajectoryを合成しcold start SFTに使う)を利用。
RLのoptimizationでは、openendなvideo QAではverifiableなrewardは難しく、任意の長さのvideoに対するany-horizonな挙動を学習させるのは困難なので、multi rewardなRLレシピ+strong reasoning LLMによるLLM as a Judgeで対処。rewardはformat, 適切なツール利用、ツール呼び出しの引数の適切さ、最終的な回答のAccuracyを利用。
評価データとしては人手でverificationされた1744のQAを利用し、紐づいている動画データの長さは平均700秒以上。
[Paper Note] MMGR: Multi-Modal Generative Reasoning, Zefan Cai+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #Evaluation #FoundationModel #TextToImageGeneration #2D (Image) #3D (Scene) #WorldModels #TextToVideoGeneration Issue Date: 2025-12-19 GPT Summary- MMGR(Multi-Modal Generative Reasoning Evaluation and Benchmark)を導入し、物理的、論理的、空間的、時間的な推論能力に基づくビデオ基盤モデルの評価フレームワークを提案。既存の指標では見落とされる因果関係や物理法則の違反を考慮し、主要なビデオおよび画像モデルをベンチマークした結果、抽象的推論でのパフォーマンスが低いことが明らかに。MMGRは、生成的世界モデルの推論能力向上に向けた統一診断ベンチマークを提供。 Comment
pj page: https://zefan-cai.github.io/MMGR.github.io/
元ポスト:
video/image 生成モデルを(単なる動画生成という枠ではなく世界モデルという観点で評価するために)
- physical reasoning: ロボットのシミュレーションやinteractionに必要な物理世界の理解力
- logical (abstract) reasoning: System2 Thinkingい必要な抽象的なコンテプトやルールに従う能力(Aが起きたらBが続く)
- 3D spatial reasoning: 世界の認知mapを内包するために必要な3D空間における関係性や、環境の案内、物事の構造や全体像を把握する能力
- 2D spatial reasoning: 複雑なpromptをgroundingするために必要な2D空間に写像されたレイアウト、形状、相対位置を理解する能力
- Temporal Reasoning: coherenceを保つために必要な、因果関係、イベントの順序、長期的な依存関係を捉える能力
の5つの軸で評価するフレームワーク。
[Paper Note] T5Gemma 2: Seeing, Reading, and Understanding Longer, Biao Zhang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pocket #NLP #MultiModal #SmallModel #MultiLingual #OpenWeight #Encoder-Decoder Issue Date: 2025-12-19 GPT Summary- T5Gemma 2は、軽量なオープンエンコーダーデコーダーモデルで、多言語・多モーダル・長文コンテキスト能力を備えています。T5Gemmaの適応レシピに基づき、デコーダー専用モデルをエンコーダーデコーダーモデルに拡張し、効率向上のために埋め込みの共有とマージドアテンションを導入しました。実験により、長文コンテキストモデリングにおける強みが確認され、事前学習性能はGemma 3と同等以上、事後学習性能は大幅に向上しました。今後、事前学習済みモデルをコミュニティに公開予定です。 Comment
初めてのマルチモーダル、long-context、かつ140言語に対応したencoder-decoderモデルとのこと。
事前学習済みのdecoder-only model (今回はGemma2)によってencoder/decoderをそれぞれ初期化し、UL2 (UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
) によって事前学習する。encoder / decoder側双方のword embeddingは共有し、encoder側のattentionはcausal attentionからbidirectional attentionに変更する。また、decoder側はself-attention/cross-attentionをマージする。
- UL2: Unifying Language Learning Paradigms, Yi Tay+, N/A, ICLR'23
merged attentionとは、式(1) -- (5)で表されるものであり、Qはdecoderのinput X を用いて、KVの計算する際には、単にdecoder側のinput X とencoder側の隠れ状態 H をconcatしてから、KVを算出する(K, Vのmatrixの次元がHの分大きくなる)というものである。また、マスクトークンの正方行列ではなくなりencoder次元分大きくなり、decoder/encoder部分の両方のvisibilityを制御する。(論文中の当該部分に明記されていないが、普通に考えると)encoder部分は常にvisibleな状態となる。self-/cross attentionは似たような機能を有する(=過去の情報から関連する情報を収集する)ことが先行研究で知られており、単一のモジュールで処理できるという気持ちのようである。H, Xがそれぞれconcatされるので、encoder側の情報とdecoderのこれまでのoutput tokenの情報の両方を同時に考慮することができる。
元ポスト:
HF: https://huggingface.co/collections/google/t5gemma-2
ポイント解説:
[Paper Note] Autonomous Data Selection with Zero-shot Generative Classifiers for Mathematical Texts, Yifan Zhang+, ACL'25 Findings, 2024.02
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #ACL #Findings #GenerativeVerifier Issue Date: 2025-12-19 GPT Summary- 自律的データ選択(AutoDS)は、言語モデルをゼロショットの生成分類器として利用し、高品質な数学テキストを自動キュレーションする手法です。従来の方法と異なり、人間の注釈やデータフィルターのトレーニングを必要とせず、モデルのロジットに基づいて数学的に有益なパッセージを判断します。AutoDSは事前トレーニングパイプラインに統合され、数学ベンチマークでの性能を大幅に向上させ、トークン効率を約2倍改善しました。さらに、キュレーションされたAutoMathTextデータセットを公開し、今後の研究を促進します。 Comment
元ポスト:
以下のようなzero-shotのmeta-promptを用いてテキストをスコアリングし(Q1, Q2それぞれについてスコア(=logits)を算出し乗算)継続事前学習に利用することで性能が向上することを示した研究。
ベースライン:
- uniform: OpenWebMathから一様サンプリングする
- DSIR: source dataとtarget domain(今回はPile's Wikipedia splitを利用)のKL Divergenceを比較しデータを選択する。
- Qurating: Reward-modelをベースにした学習サンプルに対するeducational valueをランキングさせる手法
提案手法は
- OpenWebMath
- arXiv (from RedPajama)
- Algebraic Stack
の中からトップスコアのドキュメントを利用。DSIR, Quratingについてはデータソースが明示されていないが、おそらく提案手法揃えていると思われる。また学習する際のトークン量も手法間で(明示的に書かれていないように見えるが)同等にそろえていると思われる。
まずpreliminary experimentsとしてトークン数のbudgetを小さめにして実験。uniformと比較すると、別のmathドメインデータでFinetuningした後のパフォーマンスが向上している。トークン数のbudgetもexactに揃えられている。
続いてトークンのbudgetを増やして、~2.5Bトークンにスケールアップして比較(継続事前学習→1 epoch SFT)。提案手法が全体的にdownstreamタスクでの評価で高い性能を発揮。しかしこちらでは、いくつかでuniformの性能もよい。
また、最後に数学データでの継続事前学習が異なるドメインに対してどの程度転移するかを測ると、提案手法が平均して最もよかった。しかしこちらもでもuniformが結構強い結果に見える。
OpenWebMathがそもそもheuristicsとtrained classifierを用いてキュレーションされたデータとのことなので、ある程度高品質であることが想定される。
[Paper Note] Latent Diffusion Model without Variational Autoencoder, Minglei Shi+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #Pocket #DiffusionModel #Selected Papers/Blogs #Encoder-Decoder #Backbone #ImageSynthesis Issue Date: 2025-12-17 GPT Summary- VAEを用いない新しい潜在拡散モデルSVGを提案。SVGは自己教師あり表現を活用し、明確な意味的識別性を持つ特徴空間を構築。これにより、拡散トレーニングが加速し、生成品質が向上。実験結果はSVGの高品質な視覚表現能力を示す。 Comment
openreview: https://openreview.net/forum?id=kdpeJNbFyf
これまでの拡散モデルベースのImage GeneiationモデルにおけるVAEを、事前学習済み(self supervised learning)のvision encoder(本稿ではDINOv3)に置き換えfreezeし、それとは別途Residual Encoderと呼ばれるViTベースのEncoderを学習する。前者は画像の意味情報を捉える能力をそのまま保持し、Residual Encoder側でReconstructionをする上でのPerceptualな情報等の(vision encoderでは失われてしまう)より精緻な特徴を捉える。双方のEncoder出力はchannel次元でconcatされ、SVG Featureを形成する。SVG Decoderは、SVG FeatureをPixelスペースに戻す役割を果たす。このアーキテクチャはシンプルで軽量だが、DINOv3による強力な意味的な識別力を保ちつつ、精緻な特徴を捉える能力を補完できる。Figure 5を見ると、実際にDINOv3のみと比較して、Residual Encoderによって、細かい部分がより正確なReconstructionが実現できていることが定性的にわかる。学習時はReconstruction lossを使うが、Residual Encoderに過剰に依存するだけめなく、outputの数値的な値域が異なり、DINOv3の意味情報を損なう恐れが足るため、Residual Encoderの出力の分布をDINOv3とalignするように学習する。
VAE Encoderによるlatent vectorは低次元だが、提案手法はより高次元なベクトルを扱うため、Diffusionモデルの学習が難しいと考えられるが、SVG Featureの特徴量はうまく分散しており、安定してFlow Matchingで学習ができるとのこと。
実際、実験結果を見ると安定して、しかもサンプル効率がベースラインと比較して大幅に高く収束していることが見受けられる。
[Paper Note] RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning, Yucan Guo+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Multi #EfficiencyImprovement #InformationRetrieval #Pocket #NLP #ReinforcementLearning #AIAgents #RAG(RetrievalAugmentedGeneration) Issue Date: 2025-12-17 GPT Summary- Retrieval-Augmented Generation (RAG)を用いた新しいRLベースのフレームワーク\model{}を提案。これにより、LLMsがマルチターンのグラフ-テキストハイブリッドRAGを実行し、推論のタイミングや情報取得を学習。二段階のトレーニングフレームワークにより、ハイブリッド証拠を活用しつつリトリーバルのオーバーヘッドを回避。実験結果は、\model{}が既存のRAGベースラインを大幅に上回ることを示し、複雑な推論における効率的なリトリーバルの利点を強調。 Comment
元ポスト:
モデル自身が何を、いつ、どこからretrievalし、いつやめるかをするかを動的にreasoningできるようRLで学習することで、コストの高いretrievalを削減し、マルチターンRAGの性能を保ちつつ効率をあげる手法(最大で検索のターン数が20パーセント削減)とのこと。
学習は2ステージで、最初のステージでanswerに正しく辿り着けるよう学習することでreasoning能力を向上させ、次のステージで不要な検索が削減されるような効率に関するrewardを組み込み、accuracyとcostのバランスをとる。モデルはツールとして検索を利用できるが、ツールはpassage, graph, hybridの3つの検索方法を選択できる。
[Paper Note] Bolmo: Byteifying the Next Generation of Language Models, Benjamin Minixhofer+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #OpenWeight #OpenSource #Selected Papers/Blogs #Byte-level Issue Date: 2025-12-17 GPT Summary- Bolmoは、1Bおよび7Bパラメータのバイトレベル言語モデルで、既存のサブワードレベルLMをバイト化することでトレーニングされ、サブワードトークン化の限界を克服しつつ同等のパフォーマンスを発揮します。特別に設計されたBolmoは、サブワードモデルとの間で効果的な蒸留を行い、低コストでバイトレベルLMに変換可能です。Bolmoは従来のバイトレベルLMを上回り、文字理解やコーディングタスクで優れた性能を示し、推論速度も競争力があります。結果として、バイトレベルLMはサブワードレベルLMに対する実用的な選択肢となることが示されました。 Comment
blog:
https://allenai.org/blog/bolmo
HF:
https://huggingface.co/allenai/Bolmo-7B
元ポスト:
テキストをbyte列の系列として解釈し入出力を行う言語モデル。アーキテクチャとしては、byte列をtoken化しbyte列単位でembedding化→mLSTMによってそれらがcontextに関する情報を持った状態でエンコードされ→1バイト先のcontextを用いて単語の境界を予測するモデル(この部分はcausalではなくbi-directional)によって境界を認識し、境界まで可変長でembeddingをpoolingしパッチを形成し、Olmo3の入力とする(デコーディングはその逆の操作をして最終的に言語モデルのheadを用いる)。
スクラッチからByte Latent Transformerのようなモデルを学習するのではなく、2-stageで学習される。まずOlmo3をfreezeし、他の local encoder, local decoder, boundary predictor, and language modeling headのみを学習する。これによりsubwordモデルと同様の挙動を学習できる。そのうえで、Olmo3のfreezeを解除し全体を学習する。これにより、Olmo3に事前学習された知識や挙動を最大限に活用する(=もともとsubwordで動作していたモデルをbyteレベルで動作するように継続学習する)。
>The Bolmo architecture. Tokenization & Embedding T transforms the input text into one representation per byte. The representations are contextualized with the local encoder E consisting of mLSTM blocks. The boundary predictor B decides where to place patch boundaries using one byte of future context. The representations are then Pooled,
[Paper Note] Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models, Boxin Wang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#General #Pocket #NLP #LanguageModel #Alignment #ReinforcementLearning #Reasoning #OpenWeight #OpenSource #read-later #RLVR #Selected Papers/Blogs #CrossDomain Issue Date: 2025-12-17 GPT Summary- 一般目的の推論モデルを強化学習(RL)で構築する際の課題に対処するため、カスケードドメイン別強化学習(Cascade RL)を提案。Nemotron-Cascadeは、指示モードと深い思考モードで動作し、異なるドメインのプロンプトを順次調整することで、エンジニアリングの複雑さを軽減し、最先端のパフォーマンスを実現。RLHFを前段階として使用することで推論能力が向上し、ドメイン別RL段階でもパフォーマンスが改善される。14Bモデルは、LiveCodeBenchで優れた結果を示し、2025年国際情報オリンピックで銀メダルを獲得。トレーニングとデータのレシピも共有。 Comment
元ポスト:
従来のRLはすべてのドメインのデータをmixすることでおこなれてきたが、個々のドメインのデータを個別にRLし、cascading方式で適用 (Cascade RL) することを提案している(実際は著者らの先行研究でmath->codingのcascadingは実施されていたが、それをより広範なドメイン(RLHF -> instruction following -> math -> coding -> software engineering)に適用した、という研究)。
cascadingにはいくつかのメリットがありRLの学習速度を改善できる(あるいはRLのインフラの複雑性を緩和できる)
- ドメインごとのverificationの速度の違いによって学習速度を損なうことがない(e.g. 数学のrule-basedなverificationは早いがcodingは遅い)
- ドメインごとに出力長は異なるためオンポリシーRLを適用すると効率が落ちる(長いレスポンスの生成を待たなければらないため)
本研究で得られた利点としてはFigure 1を参考に言及されているが
- RLHF, instruction followingを事前に適用することによって、後段のreasoningの性能も向上する(reasoningのwarmupになる)
- 加えて応答の長さの削減につながる
- RLはcatastrophic forgettingに強く、前段で実施したドメインの性能が後段のドメインのRLによって性能が劣化しない
- といってもFigure 2を見ると、codingとsoftware engineeringは結構ドメイン近いのでは・・・?という気はするが・・・。
- RLにおけるカリキュラム学習やハイパーパラメータをドメインごとに最適なものを適用できる
他にもthinking/non-thinking に関することが言及されているが読めていない。
[Paper Note] Can You Learn to See Without Images? Procedural Warm-Up for Vision Transformers, Zachary Shinnick+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Pretraining #Pocket #Transformer #2D (Image) #WarmUp Issue Date: 2025-12-11 GPT Summary- 視覚トランスフォーマー(ViTs)を手続き生成データで事前学習する新しい方法を提案。これにより、モデルは抽象的な計算的知識を内在化し、標準的な画像トレーニングでデータ効率やパフォーマンスが向上。ImageNet-1kで1%の手続き生成データを使用することで、精度が1.7%以上向上し、28%のデータに相当する効果を示す。新しい事前学習戦略の可能性を示唆。 Comment
元ポスト:
特定のgrammarを持つ(意味情報を持たない予測可能な)シンボルトークン列(e.g.,規則的なアルファベットの羅列, 括弧による階層構造; 非画像データ)を用いてViTのTransformerブロックを事前学習することによって、MLPやattention Layerに対して構造情報を捉える能力がwarmupされ、その後実画像で事前学習をするとサンプル効率が上がる、という話らしい。
warmupでは、ViTにおける入力機構(画像パッチ+linear layer)は一切用いず、discreteなトークンと、それらをランダムに初期化したlookup table を用いる。このとき、embeddingとpositional encodingをfreezeすることで、MLP, Attention Layerに知識が埋め込まれることを保証する。
[Paper Note] Efficient Construction of Model Family through Progressive Training Using Model Expansion, Kazuki Yano+, COLM'25, 2025.04
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #COLM Issue Date: 2025-12-11 GPT Summary- プログレッシブトレーニングを用いて、異なるパラメータサイズの大規模言語モデル(LLMs)ファミリーを効率的に構築する方法を提案。これにより、計算コストを約25%削減しつつ、独立訓練モデルと同等の性能を維持。さらに、モデルサイズに応じた最大学習率の調整により、性能向上と一貫した挙動を実現。 Comment
openreview: https://openreview.net/forum?id=fuBrcTH8NM#discussion
LLMのモデルファミリーを構築する際に、従来は独立して異なるサイズのモデルをスクラッチから学習する必要があるが、小規模なモデルを学習した後、当該モデルをreusableモデルとみなしbert2BERTを用いることでモデルサイズを順次拡張していくことで、より小さな計算コストで一連のモデルファミリーを学習できるprogressive trainingを提案(たとえば実験では1,2,4,8Bのモデルファミリーを学習する際の計算コストが約25%削減)。また、モデルサイズが大きくなればなるほどモデルは学習率に対してsensitiveになることが先行研究で報告されており、モデルサイズに応じて最大学習率を線形に減少させるようなスケジューリングをすることで、独立に学習した場合よりも最終的に高い性能を獲得しているだけでなく、モデルファミリー間の挙動の一貫性も向上している。
bert2BERTでは2種類の拡張手法が提案されているが、Function Preserving Initialization (FPI; 同じinputに対して同じoutputが出力されるようにwidth, depthを拡張する(簡単な操作で実現できる。bert2BERT Figure4を参照))を採用している。
- [Paper Note] bert2BERT: Towards Reusable Pretrained Language Models, Cheng Chen+, ACL'22, 2021.10
興味深いのは独立して学習した場合よりもモデルファミリーの挙動が類似している点であり、これはspeculative decodingのacceptance rate向上に寄与しデコーディングの効率化に繋がるという明確な利点がある。
[Paper Note] On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models, Charlie Zhang+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #Pretraining #Pocket #NLP #LanguageModel #ReinforcementLearning #mid-training #PostTraining #read-later #Selected Papers/Blogs #PRM #Reference Collection Issue Date: 2025-12-09 GPT Summary- 強化学習(RL)が言語モデルの推論能力を向上させるかどうかを検証するため、事前トレーニング、中間トレーニング、RLの因果的寄与を分離する実験フレームワークを開発。RLは事前トレーニングが十分な余地を残す場合にのみ真の能力向上をもたらし、文脈的一般化には適切な事前トレーニングが必要であることを示した。また、中間トレーニングがRLよりもパフォーマンスを向上させ、プロセスレベルの報酬が推論の忠実性を高めることを明らかにした。これにより、推論LMトレーニング戦略の理解と改善に寄与する。 Comment
元ポスト:
RLはモデルの能力を精錬させる(=事前学習時に既に身についているreasoningパターンを(探索空間を犠牲により少ない試行で良い応答に辿り着けるよう)増幅させる;サンプリング効率を向上させる)と主張する研究たちと
- [Paper Note] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, Yang Yue+, NeurIPS'25, 2025.04
- [Paper Note] The Invisible Leash: Why RLVR May Not Escape Its Origin, Fang Wu+, arXiv'25
- [Paper Note] Spurious Rewards: Rethinking Training Signals in RLVR, Shao+, 2025.05
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25
RLは事前学習で身につけたreasoning能力を超えてさらなるgainを得ることができる
- [Paper Note] Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs, Xumeng Wen+, arXiv'25, 2025.06
- From f(x) and g(x) to f(g(x)): LLMs Learn New Skills in RL by Composing Old Ones, Yuan+, 2025.09
- [Paper Note] On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models, Charlie Zhang+, arXiv'25, 2025.12
という対立する主張がliteratureで主張されているが、これは学習環境が制御されたものでないことに起因しており(=何が事前学習で既に獲得されていて、事後学習後に新規で獲得された能力なのか、既存の能力の精錬なのか弁別がつかない)、かつ最近のmid-trainingの隆盛([Paper Note] OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling, Zengzhi Wang+, arXiv'25
)を鑑みたときに、事前・中間・事後学習は互いにどのように作用しているのか?という疑問に応えることは重要であり、そのためのフレームワークを提案し分析した、という話な模様。非常に興味深い。takeawayはabstに書かれている通りなようだが、読みたい。
フレームワークは事前・中間・事後学習の個々の貢献を独立して測定できるフレームワークであり、
- 完全に制御された(明示的なアトミックなoperationに基づく)合成reasoningタスク
あとで書く
著者ポスト:
takeaway1の話は、最近のRLにおける動的な難易度調整にも絡んでくる知見に見える。
takeaway2,3のRLはatomic skillを追加で学習することはできず、compositional skillを学習しcontextual generalizationを実現する、同等のbadgetの元でmid training+RLがpure RLよりも性能改善する、というのは特に興味深く、事後学習の効用を最大化するためにも事前・中間学習が(以前から言われていた通り)重要であることが示唆される。
takeaway4のPRMがreasoningのfidelityを高めるという話は、DeepSeek-V3.2でも観測されている話であり、本研究によってそれが完全に制御された実験の元示されたことになる。
RQ: 実データにおいて、事前学習時点だとPerplexityかdownstream taskの性能をwatchすると思うのだが、それらを通じてatomic skillをLLMがどれだけ身に付けられているか、というのはどれだけ測れているのだろうか、あるいはより良い方法はあるのだろうか
- [Paper Note] Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning, Haozhe Wang+, arXiv'25
(=RLの序盤は低レベルな手続的な実行(計算や公式)を習得し、その後高レベルな戦略的なplanningの学習が生じる)とはどのような関係があるだろうか。
解説:
所見:
解説:
[Paper Note] Measuring Agents in Production, Melissa Z. Pan+, arXiv'25, 2025.12
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #AIAgents #read-later #Selected Papers/Blogs Issue Date: 2025-12-07 GPT Summary- AIエージェントの実世界での展開に関する初の大規模研究を行い、306人の実務者への調査と20件のケーススタディを実施。エージェントはシンプルなアプローチで構築され、68%が最大10ステップで人間の介入を必要とし、70%が市販モデルをプロンプトし、74%が人間評価に依存。信頼性が主要な課題であるが、効果的な方法が多くの業界での影響を可能にしている。本研究は実践の現状を文書化し、研究と展開のギャップを埋めることを目指す。 Comment
これは非常に興味深い。production環境で実際に動作しているAI Agentに関して306人の実務者に対してアンケートを実施して、26ドメインに対して20個のケーススタディを実施したとのこと。
信頼性の問題から、実行する際のstep数はまだ10未満であり、多くのagentな5ステップ未満のステップしか完了せず、70%はoff the shelfモデルに対するprompting(finetuningなし)で実現されている。
モデルは17/20でClaude/o3等のproprietaryモデルでopen weightモデルの採用は、データを外部ソースに投げられない場合や、非常に高いワークロードのタスクを回す場合に限定される。
61%の調査の回答者がagenticなフレームワークとしてLangChain等のサードパーティ製フレームワークを利用していると回答したが、85%の実装チームはスクラッチから実装しているらしい。
80%のケーススタディがワークフロー自動構築ではなく、事前に定義されたワークフローを実施。
73%が生産性向上を目的に利用(=人手作業の自動化)
評価が非常に大変で、そもそもドメイン特化のデータセットがなく自前で構築することになる。とあるチームは100サンプルを構築するのに半年を要した。また、決定的ではない挙動や、outputの判定の困難さによりCI/CDパイプラインに組み込めない。
74%がhuman in the loopを用いた評価を実施。52%がLLM as a Judgeを活用しているが人手によるチェックも併用。
元ポストをざっと読んだだけで、かつ論文読めていないので誤りあるかも。しかし興味深い。読みたい。
元ポスト:
[Paper Note] What Makes a Reward Model a Good Teacher? An Optimization Perspective, Noam Razin+, NeurIPS'25 Spotlight, 2025.03
Paper/Blog Link My Issue
#Analysis #MachineLearning #Pocket #NLP #LanguageModel #Alignment #ReinforcementLearning #NeurIPS #read-later #Selected Papers/Blogs #RewardModel Issue Date: 2025-12-03 GPT Summary- 報酬モデルの質はRLHFの成功に重要であり、精度だけでは不十分であることを示す。低い報酬の分散は平坦な最適化ランドスケープを引き起こし、完全に正確なモデルでも遅い最適化を招く可能性がある。異なる言語モデルに対する報酬モデルの効果も異なり、精度に基づく評価の限界を明らかにする。実験により、報酬の分散と精度の相互作用が確認され、効率的な最適化には十分な分散が必要であることが強調される。 Comment
元ポスト:
RLHFにおいてReward Modelが良い教師となれるかどうかは、Accuracy[^1]という単一次元で決まるのではなく、報酬の分散の大きさ[^2]も重要だよという話らしく、分散がほとんどない完璧なRMで学習すると学習が進まず、より不正確で報酬の分散が大きいRMの方が性能が良い。報酬の分散の大きさはベースモデルによるのでRM単体で良さを測ることにはげんかいがあるよ、といあ話らしい。
理想的な報酬の形状は山の頂上がなるべくズレておらず(=Accuracyが高い)かつ、山が平坦すぎない(=報酬の分散が高い)ようなものであり、
Accuracyが低いとReward Hackingが起きやすくなり、報酬の分散が低いと平坦になり学習効率が悪くなる(Figure1)。
[^1]: 応答Aが応答Bよりも優れているかという観点
[^2]: 学習対象のLLMがとりそうな出力に対して、RMがどれだけ明確に差をつけて報酬を与えられるかという観点(良い応答と悪い応答の弁別)
[Paper Note] Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations, Tong Chen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ReinforcementLearning #Hallucination #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2025-11-15 GPT Summary- 本研究では、外的幻覚を軽減するために新しいバイナリ検索強化報酬(RAR)を用いたオンライン強化学習手法を提案。モデルの出力が事実に基づいている場合のみ報酬を与えることで、オープンエンド生成において幻覚率を39.3%削減し、短文質問応答では不正解を44.4%減少させた。重要な点は、事実性の向上が他のパフォーマンスに悪影響を及ぼさないことを示した。 Comment
Utilityを維持しつつ、Hallucinationを減らせるかという話で、Binary Retrieval Augmented Reward (Binary RAR)と呼ばれるRewardを提案している。このRewardはverifierがtrajectoryとanswerを判断した時に矛盾がない場合にのみ1, それ以外は0となるbinary rewardである。これにより、元のモデルの正解率・有用性(極論全てをわかりません(棄権)と言えば安全)の両方を損なわずにHallucinationを提言できる。
また、通常のVerifiable Rewardでは、正解に1, 棄権・不正解に0を与えるRewardとみなせるため、モデルがguessingによってRewardを得ようとする(guessingすることを助長してしまう)。一方で、Binary RARは、正解・棄権に1, 不正解に0を与えるため、guessingではなく不確実性を表現することを学習できる(おそらく、棄権する場合はどのように不確実かを矛盾なく説明した上で棄権しないとRewardを得られないため)。
といった話が元ポストに書かれているように見える。
元ポスト:
[Paper Note] DeepEyesV2: Toward Agentic Multimodal Model, Jack Hong+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pocket #NLP #AIAgents #MultiModal #Reasoning #SmallModel #VisionLanguageModel Issue Date: 2025-11-10 GPT Summary- DeepEyesV2は、テキストや画像の理解に加え、外部ツールを活用するエージェント的なマルチモーダルモデルを構築する方法を探求。二段階のトレーニングパイプラインを用いてツール使用行動を強化し、多様なトレーニングデータセットをキュレーション。RealX-Benchという新たなベンチマークを導入し、実世界のマルチモーダル推論を評価。DeepEyesV2は、タスクに応じたツール呼び出しを行い、強化学習により文脈に基づくツール選択を実現。コミュニティへの指針提供を目指す。 Comment
pj page: https://visual-agent.github.io/
元ポスト:
ポイント解説:
VLM(Qwen2.5-VL-7B)をバックボーンとしSFT(tooluseに関するcoldstart)→RL(RLVR+format reward)で学習することで、VLMによるAI Agentを構築。画像をcropしcropした画像に対するマルチモーダルな検索や、適切なtooluseの選択などに基づいて応答できる。
事前の実験によってまずQwen2.5-VL-7Bに対してRLのみでtooluse能力(コーディング能力)を身につけられるかを試したところ、Reward Hackingによって適切なtooluse能力が獲得されなかった(3.2節; 実行可能ではないコードが生成されたり、ダミーコードだったりなど)。
このためこのcoldstartを解消するためにSFTのための学習データを収集(3.3節)。これには、
- 多様なタスクと画像が含まれており
- verifiableで構造化されたOpen-endなQAに変換でき
- ベースモデルにとって簡単すぎず(8回のattemptで最大3回以上正解したものは除外)
- ツールの利用が正解に寄与するかどうかに基づきサンプルを分類する。tooluseをしても解答できないケースをSFTに、追加のtooluseで解答できるサンプルをRL用に割り当て
ようなデータを収集。さらに、trajectoryはGemini2.5, GPT4o, Claude Sonnet4などのstrong modelから収集した。
RealX-Benchと呼ばれるベンチマークも作成しているようだがまだ読めていない。
proprietary modelの比較対象が少し古め。ベースモデルと比較してSFT-RLによって性能は向上。Human Performanceも掲載されているのは印象的である。
ただ、汎用モデルでこの性能が出るのであれば、DeepSearchに特化したモデルや?GPT5, Claude-4.5-Sonnetなどではこのベンチマーク上ではHuman Performanceと同等かそれ以上の性能が出るのではないか?という気がする。
[Paper Note] RLoop: An Self-Improving Framework for Reinforcement Learning with Iterative Policy Initialization, Zeng Zhiyuan+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ReinforcementLearning #SelfImprovement #Catastrophic Forgetting #RLVR #Diversity #Generalization Issue Date: 2025-11-07 GPT Summary- RLoopは、強化学習における過剰適合の問題を解決するための自己改善フレームワークであり、ポリシーの多様性を保ちながら一般化能力を向上させる。RLを用いて解空間を探索し、成功した軌跡から専門家データセットを作成し、拒否サンプリング微調整を行うことで、次の反復の出発点を洗練する。実験により、RLoopは忘却を軽減し、平均精度を9%、pass@32を15%以上向上させることが示された。 Comment
元ポスト:
ポリシーを初期化し、RLを実行しtrajeatory tを取得。tをrejection samplingし成功したtrajectoryでエキスパートデータセットを作成。作成したエキスパートデータセットでポリシーをSFT(=Rejection SamplingしたデータでSFTすることをRFTと呼ぶ)する(これが次iterationの初期化となる)といったことを繰り返す。
RLはAdvantageによって学習されるため、trajectoryの相対的な品質に基づいて学習をする。このため、バッチ内のすべてのtrajectoryが正解した場合などはadvantageが限りなくゼロに近づき学習のシグナルを得られない。
一方RFTは絶対的なRewardを用いており(RLVRの場合は成功したら1,そうでなければ0)、これがバッチ全体のパフォーマンスに依存しない安定した分散の小さい学習のシグナルを与える。
このように両者は補完的な関係にある。ただしRFTは成功したtrajectory全てに均等な重みを与えるため、既にポリシーが解くことができる問題にフォーカスしすぎることによって効率性が悪化する問題があるため、提案手法では成功率が低いhardなサンプルのみにエキスパートデータをフィルタリングする(=active learning)ことで、モデルが自身に不足した能力を獲得することに効率的に注力することになる。
また、RFTを使うことは単なるヒューリスティックではなく、理論的なgroundingが存在する。すなわち、我々はまだ未知の"expert"な分布 p^*にポリシーが従うように学習をしたいがこれはMLEの観点で言うと式3に示されているような形式になる。p^*から直接データをサンプリングをすることができないが、RLのポリシーから近似的にサンプリングをすることができる。そこでMLEの式をimportance samplingの観点から再度定式化をすると式4のようになり、後はimportance weight wを求められれば良いことになる。これはp^*に近いtrajectoryはRewardが高く、そうでない場合は低い、つまりw \propto Reward な関係であるため近似的に求めることができ、これらを式4のMLEの式に代入するとRFTと同じ式が導出される。
みたいな話のようである。
[Paper Note] When Visualizing is the First Step to Reasoning: MIRA, a Benchmark for Visual Chain-of-Thought, Yiyang Zhou+, arXiv'25, 2025.11
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #Evaluation #MultiModal #Reasoning #Selected Papers/Blogs #VisionLanguageModel #2D (Image) #text #Visual-CoT Issue Date: 2025-11-05 GPT Summary- MIRAは、中間的な視覚画像を生成し推論を支援する新しいベンチマークで、従来のテキスト依存の手法とは異なり、スケッチや構造図を用いる。546のマルチモーダル問題を含み、評価プロトコルは画像と質問、テキストのみのCoT、視覚的ヒントを含むVisual-CoTの3レベルを網羅。実験結果は、中間的な視覚的手がかりがモデルのパフォーマンスを33.7%向上させることを示し、視覚情報の重要性を強調している。 Comment
pj page: https://mira-benchmark.github.io/
元ポスト:
Visual CoT
Frontierモデル群でもAcc.が20%未満のマルチモーダル(Vision QA)ベンチマーク。
手作業で作成されており、Visual CoT用のsingle/multi stepのintermediate imagesも作成されている。興味深い。
VLMにおいて、{few, many}-shotがうまくいく場合(Geminiのようなプロプライエタリモデルはshot数に応じて性能向上、一方LlamaのようなOpenWeightモデルは恩恵がない)と
- [Paper Note] Many-Shot In-Context Learning in Multimodal Foundation Models, Yixing Jiang+, arXiv'24, 2024.05
うまくいかないケース(事前訓練で通常見られない分布外のドメイン画像ではICLがうまくいかない)
- [Paper Note] Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models, Peter Robicheaux+, NeurIPS'25, 2025.05
も報告されている。
おそらく事前学習段階で当該ドメインの画像が学習データにどれだけ含まれているか、および、画像とテキストのalignmentがとれていて、画像-テキスト間の知識を活用できる状態になっていることが必要なのでは、という気はする。
著者ポスト:
[Paper Note] Continuous Autoregressive Language Models, Chenze Shao+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Architecture #AutoEncoder Issue Date: 2025-11-03 GPT Summary- 大規模言語モデル(LLMs)の効率を向上させるため、連続自己回帰言語モデル(CALM)を提案。CALMは、次トークン予測から次ベクトル予測へのシフトを行い、Kトークンを連続ベクトルに圧縮することで生成ステップをK倍削減。新たなフレームワークを開発し、性能と計算コストのトレードオフを改善。CALMは、効率的な言語モデルへの道筋を示す。 Comment
pj page: https://shaochenze.github.io/blog/2025/CALM/
元ポスト:
VAEを学習し(deterministicなauto encoderだと摂動に弱くロバストにならないためノイズを加える)、Kトークンをlatent vector zに圧縮、auto regressiveなモデルでzを生成できるように学習する。専用のヘッド(generative head)を用意し、transformerの隠れ状態からzを条件付きで生成する。zが生成できればVAEでdecodeすればKトークンが生成される。loss functionは下記のエネルギースコアで、第一項で生成されるトークンの多様性を担保しつつ(モード崩壊を防ぎつつ)、第二項でground truth yに近い生成ができるようにする、といった感じらしい。評価はautoregressiveにzを生成する設定なのでperplexityを計算できない。このため、BrierLMという指標によって評価している。BrierLMがどのようなものかは理解できていない。必要になったら読む。
future workにあるようにスケーリング特性がまだ明らかになっていないのでなんとも言えないという感想。
ポイント解説:
[Paper Note] Scaling Latent Reasoning via Looped Language Models, Rui-Jie Zhu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Transformer #Selected Papers/Blogs #LatentReasoning #RecurrentModels #RecursiveModels Issue Date: 2025-10-30 GPT Summary- Ouroは、推論を事前訓練フェーズに組み込むことを目指したループ言語モデル(LoopLM)であり、反復計算やエントロピー正則化を通じて性能を向上させる。1.4Bおよび2.6Bモデルは、最大12Bの最先端LLMに匹敵する性能を示し、知識操作能力の向上がその要因であることを実験で確認。LoopLMは明示的なCoTよりも整合した推論を生成し、推論の新たなスケーリングの可能性を示唆している。モデルはオープンソースで提供されている。 Comment
pj page: https://ouro-llm.github.io
元ポスト:
解説:
基本構造はdecoder-only transformerで
- Multi-Head Attention
- RoPE
- SwiGLU活性化
- Sandwich Normalization
が使われているLoopedTransformerで、exit gateを学習することで早期にloopを打ち切り、出力をすることでコストを節約できるようなアーキテクチャになっている。
より少ないパラメータ数で、より大きなパラメータ数のモデルよりも高い性能を示す(Table7,8)。また、Tを増やすとモデルの安全性も増す(=有害プロンプトの識別力が増す)。その代わり、再帰数Tを大きくするとFLOPsがT倍になるので、メモリ効率は良いが計算効率は悪い。
linear probingで再帰の次ステップ予測をしたところ浅い段階では予測が不一致になるため、思考が進化していっているのではないか、という考察がある。
また、再帰数Tを4で学習した場合に、inference時にTを5--8にしてもスケールしない(Table10)。
またAppendix D.1において、通常のtransformerのLoopLMを比較し、5種類の大きさのモデルサイズで比較。通常のtransformerではループさせる代わりに実際に層の数を増やすことで、パラメータ数を揃えて実験したところ、通常のtransformerの方が常に性能が良く、loopLMは再帰数を増やしてもスケールせず、モデルサイズが大きくなるにつれて差がなくなっていく、というスケーリングの面では残念な結果に終わっているようだ。
といった話が解説に書かれている。元論文は完全にskim readingして解説ポストを主に読んだので誤りが含まれるかもしれない点には注意。
[Paper Note] Memory Layers at Scale, Vincent-Pierre Berges+, ICLR'25, 2024.12
Paper/Blog Link My Issue
#Pocket #LanguageModel #Transformer #Architecture #ICLR #read-later #Selected Papers/Blogs #memory Issue Date: 2025-10-23 GPT Summary- メモリ層は、計算負荷を増やさずにモデルに追加のパラメータを加えるための学習可能な検索メカニズムを使用し、スパースに活性化されたメモリ層が密なフィードフォワード層を補完します。本研究では、改良されたメモリ層を用いた言語モデルが、計算予算が2倍の密なモデルや同等の計算とパラメータを持つエキスパート混合モデルを上回ることを示し、特に事実に基づくタスクでの性能向上が顕著であることを明らかにしました。完全に並列化可能なメモリ層の実装とスケーリング法則を示し、1兆トークンまでの事前学習を行った結果、最大8Bのパラメータを持つベースモデルと比較しました。 Comment
openreview: https://openreview.net/forum?id=ATqGm1WyDj
transformerにおけるFFNをメモリレイヤーに置き換えることで、パラメータ数を増やしながら計算コストを抑えるようなアーキテクチャを提案しているようである。メモリレイヤーは、クエリqを得た時にtop kのkvをlookupし(=ここで計算対象となるパラメータがスパースになる)、kqから求めたattention scoreでvを加重平均することで出力を得る。Memory+というさらなる改良を加えたアーキテクチャでは、入力に対してsiluによるgatingとlinearな変換を追加で実施することで出力を得る。
denseなモデルと比較して性能が高く、メモリパラメータを増やすと性能がスケールする。
[Paper Note] Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization, Badr AlKhamissi+, arXiv'25, 2025.06
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Reasoning #Architecture #read-later #Selected Papers/Blogs #SpeciarizedBrainNetworks #Neuroscience Issue Date: 2025-10-22 GPT Summary- MiCRoは、脳の認知ネットワークに基づく専門家モジュールを持つトランスフォーマーベースのアーキテクチャで、言語モデルの層を4つの専門家に分割。これにより、解釈可能で因果的な専門家の動的制御が可能になり、機械学習ベンチマークで優れた性能を発揮。人間らしく解釈可能なモデルを実現。 Comment
pj page: https://cognitive-reasoners.epfl.ch
元ポスト:
事前学習言語モデルに対してpost-trainingによって、脳に着想を得て以下の4つをdistinctな認知モジュールを(どのモジュールにルーティングするかを決定するRouter付きで)学習する。
- Language
- Logic / Multiple Demand
- Social / Theory of Mind
- World / Default Mode Network
これによりAIとNeuroscienceがbridgeされ、MLサイドではモデルの解釈性が向上し、Cognitive側では、複雑な挙動が起きた時にどのモジュールが寄与しているかをprobingするテストベッドとなる。
ベースラインのdenseモデルと比較して、解釈性を高めながら性能が向上し、人間の行動とよりalignしていることが示された。また、layerを分析すると浅い層では言語のエキスパートにルーティングされる傾向が強く、深い層ではdomainのエキスパートにルーティングされる傾向が強くなるような人間の脳と似たような傾向が観察された。
また、neuroscienceのfunctional localizer(脳のどの部位が特定の機能を果たしているのかを特定するような取り組み)に着想を得て、類似したlocalizerが本モデルにも適用でき、特定の機能に対してどのexpertモジュールがどれだけ活性化しているかを可視化できた。
といったような話が著者ポストに記述されている。興味深い。
demo:
https://huggingface.co/spaces/bkhmsi/cognitive-reasoners
HF:
https://huggingface.co/collections/bkhmsi/mixture-of-cognitive-reasoners
[Paper Note] OminiControl: Minimal and Universal Control for Diffusion Transformer, Zhenxiong Tan+, ICCV'25 Highlight, 2024.11
Paper/Blog Link My Issue
#ComputerVision #Controllable #Pocket #Transformer #DiffusionModel #VariationalAutoEncoder #Selected Papers/Blogs #ICCV Issue Date: 2025-10-22 GPT Summary- OminiControlは、Diffusion Transformer(DiT)アーキテクチャにおける画像条件付けの新しいアプローチで、パラメータオーバーヘッドを最小限に抑えつつ、柔軟なトークン相互作用と動的な位置エンコーディングを実現。広範な実験により、複数の条件付けタスクで専門的手法を上回る性能を示し、合成された画像ペアのデータセット「Subjects200K」を導入。効率的で多様な画像生成システムの可能性を示唆。 Comment
元ポスト:
DiTのアーキテクチャは(MMA以外は)変更せずに、Condition Image C_IをVAEでエンコードしたnoisy inputをDiTのinputにconcatし順伝播させることで、DiTをunified conditioningモデル(=C_Iの特徴量を他のinputと同じlatent spaceで学習させ統合的に扱う)として学習する[^1]。
[^1]: 既存研究は別のエンコーダからエンコードしたfeatureが加算されていて(式3)、エンコーダ部分に別途パラメータが必要だっただけでなく、加算は空間的な対応関係が存在しない場合はうまく対処できず(featureの次元が空間的な情報に対応しているため)、conditional tokenとimageの交互作用を妨げていた。
また、positional encodingのindexをconditional tokenとnoisy image tokensと共有すると、空間的な対応関係が存在するタスク(edge guided generation等)はうまくいったが、被写体を指定する生成(subject driven generation)のような対応関係が存在しないタスク(non-aligned task)の場合はうまくいかなかった。しかし、non-aligned taskの場合は、indexにオフセットを加えシフトさせる(式4)ことで、conditional text/image token間で空間的にoverlapしないようにすることで性能が大幅に改善した。
既存研究では、C_Iの強さをコントロールするために、ハイパーパラメータとして定数を導入し、エンコードされたfeatureを加算する際の強さを調整していたが(3.2.3節)、本手法ではconcatをするためこのような方法は使えない。そのため、Multi-Modal Attention(MMA)にハイパーパラメータによって強さを調整可能なbias matrixを導入し、C_IとXのattentionの交互作用の強さを調整することで対応した(式5,6)。
[Paper Note] BitNet Distillation, Xun Wu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #Quantization #Distillation #PostTraining Issue Date: 2025-10-19 GPT Summary- BitNet Distillation(BitDistill)は、フル精度LLMを1.58ビット精度にファインチューニングする軽量なパイプラインで、計算コストを抑えつつ高いタスク特化型パフォーマンスを実現します。主な技術には、SubLNモジュール、MiniLMに基づくアテンション蒸留、継続的な事前学習が含まれ、これによりフル精度モデルと同等の性能を達成し、メモリを最大10倍節約し、CPU上での推論を2.65倍高速化します。 Comment
元ポスト:
SubLN, MiniLMについては
- [Paper Note] Magneto: A Foundation Transformer, Hongyu Wang+, ICML'23
- [Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12
を参照のこと。
既存LLMを特定タスクに1.58bitでSFTする際に、full-precisionと同等の性能を保つ方法を提案している研究。full-precision LLMを1.58 bitでSFTをするとfp16で学習した場合のbaselineと比較してパフォーマンスが大きく低下するが(そしてその傾向はモデルサイズが大きいほど強い)、提案手法を利用するとfp16でSFTした場合と同等の性能を保ちながら、inference-speed 2.65倍、メモリ消費量1/10になる模様。
手法としては、3段階で構成されており
- Stage1: low-bitに量子化されたモデルではactivationの分散が大きくなり学習の不安定さにつながるため、アーキテクチャとしてSubLNを導入して安定化を図る
- Stage2: Stage1で新たにSubLNを追加するので事前学習コーパスの継続事前学習する
- Stage3: full-precisionでSFTしたモデルを教師、1.58-bitに量子化したモデルを生徒とし、logits distillation (input x, output yが与えられた時に教師・生徒間で出力トークンの分布のKL Divergenceを最小化する)、MiniLMで提案されているMHAのdistillation(q-q/k-k/v-vの内積によってsquaredなrelation mapをQ, K, Vごとに作成し、relation mapのKL Divergenceが教師・生徒間で最小となるように学習する)を実施する
- 最終的に `L_CE + \lambda L_LD + \ganma L_AD` を最小化する。ここで、L_CEはdownstream datasetに対するcross-entropy lossであり、L_LD, L_ADはそれぞれ、logit distillation, Attention Distillationのlossである。
ポイント解説:
[Paper Note] LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning, Haoqiang Kang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #DiffusionModel #Reasoning #LatentReasoning Issue Date: 2025-10-18 GPT Summary- LaDiR(Latent Diffusion Reasoner)という新しい推論フレームワークを提案。これは、LLMの限界を克服し、潜在表現と潜在拡散モデルを統合。VAEを用いて構造化された潜在推論空間を構築し、双方向注意マスクでデノイズ。これにより、効率的な推論軌跡の生成が可能となり、精度と多様性を向上。数学的推論の評価で、従来手法を上回る結果を示す。 Comment
元ポスト:
既存のreasoning/latent reasoningはsequentialにreasoning trajectoryを生成していくが、(このため、誤った推論をした際に推論を是正しづらいといわれている)本手法ではthought tokensと呼ばれる思考トークンをdiffusion modelを用いてdenoisingすることでreasoning trajectoryを生成する。このプロセスはtrajectory全体をiterativeにrefineしていくため前述の弱点が是正される可能性がある。また、thought tokensの生成は複数ブロック(ブロック間はcausal attention, ブロック内はbi-directional attention)に分けて実施されるため複数のreasoning trajectoryを並列して探索することになり、reasoning traceの多様性が高まる効果が期待できる。最後にVAEによってdiscreteなinputをlatent spaceに落とし込み、その空間上でdenoising(= latent space空間上で思考する)し、その後decodingしてdiscrete tokenに再度おとしこむ(= thought tokens)というアーキテクチャになっているため、latent space上でのreasoningの解釈性が向上する。最終的には、
結果のスコアを見る限り、COCONUTと比べるとだいぶgainを得ているが、Discrete Latentと比較するとgainは限定的に見える。
[Paper Note] Scaling Long-Horizon LLM Agent via Context-Folding, Weiwei Sun+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #ReinforcementLearning #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #ContextEngineering #DeepResearch #LongHorizon #ContextRot #ContextFolding Issue Date: 2025-10-18 GPT Summary- 「Context-Folding」フレームワークを提案し、LLMエージェントがサブタスクを処理しつつコンテキストを管理する方法を示す。FoldGRPOを用いた強化学習により、複雑な長期タスクで10倍小さいコンテキストを使用し、従来のモデルを上回る性能を達成。 Comment
pj page: https://context-folding.github.io
元ポスト:
エージェントはロールアウト時にサブタスクを別ブランチで分岐させ、分岐させたブランチは独立したコンテキストを持ち、サブタスクを実行し結果を返す。メインブランチは受け取った結果に対してcontext managerを適用してfoldingしてメインブランチのcontextに加えて処理を続行することで、サブタスクを高い性能で実行しつつ、contextの肥大化を抑える。
これらfoldingを実施するはcontext manager(learnable)やポリシーはFoldGRPOと呼ばれるRLで学習され、
- メインブランチのcontextが肥大しない
- サブタスクがout of scopeとならない
- agenticタスクが失敗しない
となるように設計された報酬によって学習される。
所見:
[Paper Note] StreamingVLM: Real-Time Understanding for Infinite Video Streams, Ruyi Xu+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#ComputerVision #EfficiencyImprovement #Pocket #Dataset #Evaluation #Attention #LongSequence #AttentionSinks #read-later #Selected Papers/Blogs #VideoGeneration/Understandings #VisionLanguageModel Issue Date: 2025-10-15 GPT Summary- StreamingVLMは、無限のビデオストリームをリアルタイムで理解するためのモデルで、トレーニングと推論を統一したフレームワークを採用。アテンションシンクの状態を再利用し、短いビジョントークンと長いテキストトークンのウィンドウを保持することで、計算コストを抑えつつ高い性能を実現。新しいベンチマークInf-Streams-Evalで66.18%の勝率を達成し、一般的なVQA能力を向上させることに成功。 Comment
元ポスト:
これは興味深い
保持するKV Cacheの上限を決め、Sink Token[^1]は保持し[^2](512トークン)、textual tokenは長距離で保持、visual tokenは短距離で保持、またpositional encodingとしてはRoPEを採用するが、固定されたレンジの中で動的にindexを更新することで、位相を学習時のrangeに収めOODにならないような工夫をすることで、memoryと計算コストを一定に保ちながらlong contextでの一貫性とリアルタイムのlatencyを実現する、といった話にみえる。
学習時はフレームがoverlapした複数のチャンクに分けて、それぞれをfull attentionで学習する(Sink Tokenは保持する)。これは上述のinference時のパターンと整合しており学習時とinference時のgapが最小限になる。また、わざわざlong videoで学習する必要がない。(美しい解決方法)
[^1]: decoder-only transformerの余剰なattention scoreの捨て場として機能するsequence冒頭の数トークン(3--4トークン程度)のこと。本論文では512トークンと大きめのSink Tokenを保持している。
[^2]: Attention Sinksによって、long contextの性能が改善され Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
decoder-only transformerの層が深い部分でのトークンの表現が均一化されてしまうover-mixingを抑制する Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
ことが報告されている
AttentionSink関連リンク:
- Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
↑これは元ポストを読んで(と論文斜め読み)の感想のようなものなので、詳細は後で元論文を読む。
関連:
[Paper Note] Agent Learning via Early Experience, Kai Zhang+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning #AIAgents #Self-SupervisedLearning #SelfCorrection #mid-training #Selected Papers/Blogs #WorldModels Issue Date: 2025-10-14 GPT Summary- 言語エージェントの目標は、経験を通じて学び、複雑なタスクで人間を上回ることですが、強化学習には報酬の欠如や非効率的なロールアウトが課題です。これに対処するため、エージェント自身の行動から生成された相互作用データを用いる「早期経験」という新たなパラダイムを提案します。このデータを基に、(1) 暗黙の世界モデル化と(2) 自己反省の2つの戦略を研究し、8つの環境で評価を行った結果、効果性と一般化が向上することを示しました。早期経験は、強化学習の基盤を提供し、模倣学習と経験駆動エージェントの橋渡しとなる可能性があります。 Comment
元ポスト:
LLM AgentのためのWarmup手法を提案している。具体的にはRLVRやImitation LearningによってRewardが定義できるデータに基づいてこれまではRLが実現されてきたが、これらはスケールせず、Rewardが定義されない環境のtrajectoryなどは学習されないので汎化性能が低いという課題がある。このため、これらのsupervisionつきの方法で学習をする前のwarmup手法として、reward-freeの学習パラダイム Early Experienceを提案している。
手法としてはシンプルな手法が2種類提案されている。
### Implicit World Modeling (IWM, 式(3)):
ある状態s_i において action a_i^{j}を (1 < j < |K|)をとった時の状態をs_i^{j}としたときに、(s_i, a_i^{j}, s_i^{j}) の3つ組を考える。これらはポリシーからのK回のrolloutによって生成可能。
このときに、状態sを全てテキストで表現するようにし、言語モデルのnext-token-prediction lossを用いて、ある状態s_jにおいてaction a_i^{k} をとったときに、s_j^{k} になることを予測できるように学習する。これにより例えばブックフライトのサイトで誤った日時を入れてしまった場合や、どこかをクリックしたときにどこに遷移するかなどの学習する環境の世界知識をimplicitにモデルに組み込むことができる。
### Self-Reflection(式4)
もう一つのパラダイムとして、専門家によるアクション a_i によって得られた状態 s_i と、それら以外のアクション a_i^{j} によって得られた状態 s_i^{j}が与えられたときに、s_iとs_i^{j}を比較したときに、なぜ a_i の方がa_i^{j} よりも好ましいかを説明するCoT C_i^{j}を生成し、三つ組データ(s_i, a_i^{j}, c_i^{j}) を構築する。このデータを用いて、状態s_iがgivenなときに、a_i に c_i^{j} をconcatしたテキストを予測できるようにnext-token-prediction lossで学習する。また、このデータだけでなく汎化性能をより高めるためにexpertによるimitation learningのためのデータCoTなしのデータもmixして学習をする。これにより、expertによるactionだけで学習するよりも、なぜexpertのアクションが良いかという情報に基づいてより豊富で転移可能な学習シグナルを活用し学習することができる。
この結果、downstreamタスクでのperformanceが単にImitation Learningを実施した場合と比較して提案手法でwarmupした方が一貫して向上する。また、5.4節にpost-trainingとして追加でGRPOを実施した場合も提案手法によるwarmupを実施した場合が最終的な性能が向上することが報告されている。
IWMは自己教師あり学習の枠組みだと思われるので、よぬスケールし、かつ汎化性能が高く様々な手法のベースとなりうる手法に見える。
著者ポスト:
[Paper Note] Spectrum Tuning: Post-Training for Distributional Coverage and In-Context Steerability, Taylor Sorensen+, arXiv'25, 2025.10
Paper/Blog Link My Issue
#Pocket #NLP #Dataset #Supervised-FineTuning (SFT) #Evaluation #In-ContextLearning #PostTraining #Selected Papers/Blogs #meta-learning #Steering Issue Date: 2025-10-14 GPT Summary- ポストトレーニングは言語モデルの性能を向上させるが、操作性や出力空間のカバレッジ、分布の整合性においてコストが伴う。本研究では、これらの要件を評価するためにSpectrum Suiteを導入し、90以上のタスクを網羅。ポストトレーニング技術が基礎的な能力を引き出す一方で、文脈内操作性を損なうことを発見。これを改善するためにSpectrum Tuningを提案し、モデルの操作性や出力空間のカバレッジを向上させることを示した。 Comment
元ポスト:
著者らはモデルの望ましい性質として
- In context steerbility: inference時に与えられた情報に基づいて出力分布を変えられる能力
- Valid output space coverage: タスクにおける妥当な出力を広範にカバーできること
- Distributional Alignment: ターゲットとする出力分布に対してモデルの出力分布が近いこと
の3つを挙げている。そして既存のinstruction tuningや事後学習はこれらを損なうことを指摘している。
ここで、incontext steerbilityとは、事前学習時に得た知識や、分布、能力だけに従うのではなく、context内で新たに指定した情報をモデルに活用させることである。
モデルの上記3つの能力を測るためにSpectrum Suiteを導入する。これには、人間の様々な嗜好、numericな分布の出力、合成データ作成などの、モデル側でsteeringや多様な分布への対応が必要なタスクが含まれるベンチマークのようである。
また上記3つの能力を改善するためにSpectrum Tuningと呼ばれるSFT手法を提案している。
手法はシンプルで、タスクT_iに対する 多様なinput X_i タスクのcontext(すなわちdescription) Z_i が与えられた時に、T_i: X_i,Z_i→P(Y_i) を学習したい。ここで、P(Y_i)は潜在的なoutputの分布であり、特定の1つのサンプルyに最適化する、という話ではない点に注意(meta learningの定式化に相当する)。
具体的なアルゴリズムとしては、タスクのコレクションが与えられた時に、タスクiのcontextとdescriptionをtokenizeした結果 z_i と、incontextサンプルのペア x_ij, y_ij が与えられた時に、output tokenのみに対してcross entropyを適用してSFTをする。すなわち、以下のような手順を踏む:
1. incontextサンプルをランダムなオーダーにソートする
2. p_dropの確率でdescription z_i をドロップアウトしx_i0→y_i0の順番でconcatする、
2-1. descriptionがdropしなかった場合はdescription→x_i0→y_i0の順番でconcatし入力を作る。
2-2. descriptionがdropした場合、x_i0→y_i0の順番で入力を作る。
3. 他のサンプルをx_1→y_1→...→x_n→y_nの順番で全てconcatする。
4. y_{1:n}に対してのみクロスエントロピーlossを適用し、他はマスクして学習する。
一見するとinstruct tuningに類似しているが、以下の点で異なっている:
- 1つのpromptに多くのi.i.dな出力が含まれるのでmeta-learningが促進される
- 個別データに最適化されるのではなく、タスクに対する入出力分布が自然に学習される
- chat styleのデータにfittingするのではなく、分布に対してfittingすることにフォーカスしている
- input xやタスクdescription zを省略することができ、ユーザ入力が必ず存在する設定とは異なる
という主張をしている。
[Paper Note] Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents, Zonghan Yang+, arXiv'25, 2025.09
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #AIAgents #SoftwareEngineering #read-later #Selected Papers/Blogs #reading Issue Date: 2025-10-02 GPT Summary- 大規模言語モデル(LLMs)のソフトウェア工学(SWE)への応用が進んでおり、SWE-benchが重要なベンチマークとなっている。マルチターンのSWE-Agentフレームワークと単一ターンのエージェントレス手法は相互排他的ではなく、エージェントレストレーニングが効率的なSWE-Agentの適応を可能にする。本研究では、Kimi-DevというオープンソースのSWE LLMを紹介し、SWE-bench Verifiedで60.4%を達成。追加の適応により、Kimi-DevはSWE-Agentの性能を48.6%に引き上げ、移植可能なコーディングエージェントの実現を示した。 Comment
元ポスト:
Agentlessはこちら:
- [Paper Note] Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25, 2024.07
著者ポスト:
ポストの中でOpenhandsが同モデルを内部で検証し、Openhandsの環境内でSWE Bench Verifiedで評価した結果、レポート内で報告されているAcc. 60.4%は達成できず、17%に留まることが報告されていた模様。
Openhandsの説明によるとAgentlessは決められた固定されたワークフローのみを実施する枠組み(Kimi Devの場合はBugFixerとFileEditor)であり、ワークフローで定義されたタスクは効果的に実施できるが、それら以外のタスクはそもそもうまくできない。SWE Agent系のベンチのバグfixの方法は大きく分けてAgentlike(コードベースを探索した上でアクションを実行する形式)、Fixed workflow like Agentless(固定されたワークフローのみを実行する形式)の2種類があり、Openhandsは前者、Kimi Devは後者の位置付けである。
実際、テクニカルレポートのFigure2とAppendixを見ると、File Localization+BugFixer+TestWriterを固定されたプロンプトテンプレートを用いてmid-trainingしており、評価する際も同様のハーネスが利用されていると推察される(どこかに明示的な記述があるかもしれない)。
一方、Openhandsではより実環境の開発フローに近いハーネス(e.g., エージェントがコードベースを確認してアクションを提案→実行可能なアクションなら実行→そうでないならユーザからのsimulated responceを受け取る→Agentに結果をフィードバック→エージェントがアクション提案...)といったハーネスとなっている。
このように評価をする際のハーネスが異なるため、同じベンチマークに対して異なる性能が報告される、ということだと思われる。
単にSWE Bench VerifiedのAcc.だけを見てモデルを選ぶのではなく、評価された際のEvaluation Harnessが自分たちのユースケースに合っているかを確認することが重要だと考えられる。
参考:
- OpenhandsのEvaluation Harness:
https://docs.all-hands.dev/openhands/usage/developers/evaluation-harness
[Paper Note] UMoE: Unifying Attention and FFN with Shared Experts, Yuanhang Yang+, arXiv'25, 2025.05
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Attention #Architecture #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs Issue Date: 2025-09-24 GPT Summary- Sparse Mixture of Experts (MoE) アーキテクチャは、Transformer モデルのスケーリングにおいて有望な手法であり、注意層への拡張が探求されていますが、既存の注意ベースの MoE 層は最適ではありません。本論文では、注意層と FFN 層の MoE 設計を統一し、注意メカニズムの再定式化を行い、FFN 構造を明らかにします。提案するUMoEアーキテクチャは、注意ベースの MoE 層で優れた性能を達成し、効率的なパラメータ共有を実現します。 Comment
元ポスト:
Mixture of Attention Heads (MoA)はこちら:
- [Paper Note] Mixture of Attention Heads: Selecting Attention Heads Per Token, Xiaofeng Zhang+, EMNLP'22, 2022.10
この図がわかりやすい。後ほど説明を追記する。ざっくり言うと、MoAを前提としたときに、最後の出力の変換部分VW_oをFFNによる変換(つまりFFN Expertsの一つ)とみなして、self-attentionのトークンを混ぜ合わせるという趣旨を失わない範囲で計算順序を調整(トークンをミックスする部分を先に持ってくる)すると、FFNのMoEとMoAは同じ枠組みで扱えるため、expertsを共有できてメモリを削減でき、かつMoAによって必要な箇所のみにattendする能力が高まり性能も上がります、みたいな話に見える。
[Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Controllable #Pocket #NLP #Search #LanguageModel #Test-Time Scaling #Decoding Issue Date: 2025-08-30 GPT Summary- 事前学習済みのLLMの層をモジュールとして操作し、各サンプルに最適なアーキテクチャを構築する手法を提案。モンテカルロ木探索を用いて、数学および常識推論のベンチマークで最適な層の連鎖(CoLa)を特定。CoLaは柔軟で動的なアーキテクチャを提供し、推論効率を改善する可能性を示唆。75%以上の正しい予測に対して短いCoLaを見つけ、60%以上の不正確な予測を正すことができることが明らかに。固定アーキテクチャの限界を克服する道を開く。 Comment
解説:
事前学習済み言語モデルのforward pathにおける各layerをbuilding blocksとみなして、入力に応じてスキップ、あるいは再帰的な利用をMCTSによって選択することで、test time時のモデルの深さや、モデルの凡化性能をタスクに対して適用させるような手法を提案している模様。モデルのパラメータの更新は不要。k, r ∈ {1,2,3,4} の範囲で、"k個のlayerをskip"、あるいはk個のlayerのブロックをr回再帰する、とすることで探索範囲を限定的にしtest時の過剰な計算を抑止している。また、MCTSにおけるsimulationの回数は200回。length penaltyを大きくすることでcompactなforward pathになるように調整、10%の確率でまだ探索していない子ノードをランダムに選択することで探索を促すようにしている。オリジナルと比較して実行時間がどの程度増えてしまうのか?に興味があったが、モデルの深さという観点で推論効率は考察されているように見えたが、実行時間という観点ではざっと見た感じ記載がないように見えた。
以下の広範なQA、幅広い難易度を持つ数学に関するデータで評価(Appendix Bに各データセットごとに500 sampleを利用と記載がある)をしたところ、大幅に性能が向上している模様。ただし、8B程度のサイズのモデルでしか実験はされていない。
- [Paper Note] Think you have Solved Question Answering? Try ARC, the AI2 Reasoning
Challenge, Peter Clark+, arXiv'18
- [Paper Note] DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Yuxuan Tong+, NeurIPS'24
関連:
- [Paper Note] Looped Transformers are Better at Learning Learning Algorithms, Liu Yang+, ICLR'24
- [Paper Note] Looped Transformers for Length Generalization, Ying Fan+, ICLR'25
- [Paper Note] Universal Transformers, Mostafa Dehghani+, ICLR'19
- [Paper Note] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, Sangmin Bae+, NeurIPS'25
[Paper Note] Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL, Jiaxuan Gao+, arXiv'25
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #Search #LanguageModel #ReinforcementLearning #AIAgents #Reference Collection Issue Date: 2025-08-14 GPT Summary- ASearcherは、LLMベースの検索エージェントの大規模なRLトレーニングを実現するオープンソースプロジェクトであり、高効率な非同期RLトレーニングと自律的に合成された高品質なQ&Aデータセットを用いて、検索能力を向上させる。提案されたエージェントは、xBenchで46.7%、GAIAで20.8%の改善を達成し、長期的な検索能力を示した。モデルとデータはオープンソースで提供される。 Comment
元ポスト:
著者ポスト:
解説ポスト:
関連ベンチマーク:
- [Paper Note] xbench: Tracking Agents Productivity Scaling with Profession-Aligned
Real-World Evaluations, Kaiyuan Chen+, arXiv'25
- GAIA: a benchmark for General AI Assistants, Grégoire Mialon+, N/A, arXiv'23
- [Paper Note] Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Satyapriya Krishna+, N/A, NAACL'25
既存のモデルは <= 10 turnsのデータで学習されており、大規模で高品質なQAデータが不足している問題があったが、シードQAに基づいてQAを合成する手法によって1.4万シードQAから134kの高品質なQAを合成した(うち25.6kはツール利用が必要)。具体的には、シードのQAを合成しエージェントがQAの複雑度をiterationをしながら向上させていく手法を提案。事実情報は常にverificationをされ、合成プロセスのiterationの中で保持され続ける。個々のiterationにおいて、現在のQAと事実情報に基づいて、エージェントは
- Injection: 事実情報を新たに注入しQAをよりリッチにすることで複雑度を上げる
- Fuzz: QA中の一部の詳細な情報をぼかすことで、不確実性のレベルを向上させる。
の2種類の操作を実施する。その上で、QAに対してQuality verificationを実施する:
- Basic Quality: LLMでqualityを評価する
- Difficulty Measurement: LRMによって、複数の回答候補を生成する
- Answer Uniqueness: Difficulty Measurementで生成された複数の解答情報に基づいて、mismatched answersがvalid answerとなるか否かを検証し、正解が単一であることを担保する
また、複雑なタスク、特にtool callsが非常に多いタスクについては、多くのターン数(long trajectories)が必要となるが、既存のバッチに基づいた学習手法ではlong trajectoriesのロールアウトをしている間、他のサンプルの学習がブロックされてしまい学習効率が非常に悪いので、バッチ内のtrajectoryのロールアウトとモデルの更新を分離(ロールアウトのリクエストが別サーバに送信されサーバ上のInference Engineで非同期に実行され、モデルをアップデートする側は十分なtrajectoryがバッチ内で揃ったらパラメータを更新する、みたいな挙動?)することでIdleタイムを無くすような手法を提案した模様。
既存の手法ベンチマークの性能は向上している。学習が進むにつれて、trajectory中のURL参照回数やsearch query数などが増大していく曲線は考察されている。他モデルと比較して、より多いターン数をより高い正確性を以って実行できるといった定量的なデータはまだ存在しないように見えた。
[Paper Note] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification, Yongliang Wu+, arXiv'25
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Supervised-FineTuning (SFT) #read-later #Selected Papers/Blogs Issue Date: 2025-08-09 GPT Summary- 大規模言語モデル(LLM)の教師ありファインチューニング(SFT)の一般化能力を向上させるため、動的ファインチューニング(DFT)を提案。DFTはトークンの確率に基づいて目的関数を再スケーリングし、勾配更新を安定化させる。これにより、SFTを大幅に上回る性能を示し、オフライン強化学習でも競争力のある結果を得た。理論的洞察と実践的解決策を結びつけ、SFTの性能を向上させる。コードは公開されている。 Comment
元ポスト:
これは大変興味深い。数学以外のドメインでの評価にも期待したい。
3節冒頭から3.2節にかけて、SFTとon policy RLのgradientを定式化し、SFT側の数式を整理することで、SFT(のgradient)は以下のようなon policy RLの一つのケースとみなせることを導出している。そしてSFTの汎化性能が低いのは 1/pi_theta によるimportance weightingであると主張し、実験的にそれを証明している。つまり、ポリシーがexpertのgold responseに対して低い尤度を示してしまった場合に、weightか過剰に大きくなり、Rewardの分散が過度に大きくなってしまうことがRLの観点を通してみると問題であり、これを是正することが必要。さらに、分散が大きい報酬の状態で、報酬がsparse(i.e., expertのtrajectoryのexact matchしていないと報酬がzero)であることが、さらに事態を悪化させている。
> conventional SFT is precisely an on-policy-gradient with the reward as an indicator function of
matching the expert trajectory but biased by an importance weighting 1/πθ.
まだ斜め読みしかしていないので、後でしっかり読みたい
最近は下記で示されている通りSFTでwarm-upをした後にRLによるpost-trainingをすることで性能が向上することが示されており、
- [Paper Note] Demystifying Long Chain-of-Thought Reasoning in LLMs, Edward Yeo+, arXiv'25
主要なOpenModelでもSFT wamup -> RLの流れが主流である。この知見が、SFTによるwarm upの有効性とどう紐づくだろうか?
これを読んだ感じだと、importance weightによって、現在のポリシーが苦手な部分のreasoning capabilityのみを最初に強化し(= warmup)、その上でより広範なサンプルに対するRLが実施されることによって、性能向上と、学習の安定につながっているのではないか?という気がする。
日本語解説:
一歩先の視点が考察されており、とても勉強になる。
[Paper Note] Revisiting Prompt Engineering: A Comprehensive Evaluation for LLM-based Personalized Recommendation, Genki Kusano+, RecSys'25
Paper/Blog Link My Issue
#RecommenderSystems #Pocket #LanguageModel #Prompting #Evaluation #RecSys #Reproducibility Issue Date: 2025-07-21 GPT Summary- LLMを用いた単一ユーザー設定の推薦タスクにおいて、プロンプトエンジニアリングが重要であることを示す。23種類のプロンプトタイプを比較した結果、コスト効率の良いLLMでは指示の言い換え、背景知識の考慮、推論プロセスの明確化が効果的であり、高性能なLLMではシンプルなプロンプトが優れることが分かった。精度とコストのバランスに基づくプロンプトとLLMの選択に関する提案を行う。 Comment
元ポスト:
RecSysにおける網羅的なpromptingの実験。非常に興味深い
実験で利用されたPrompting手法と相対的な改善幅
RePhrase,StepBack,Explain,Summalize-User,Recency-Focusedが、様々なモデル、データセット、ユーザの特性(Light, Heavy)において安定した性能を示しており(少なくともベースラインからの性能の劣化がない)、model agnosticに安定した性能を発揮できるpromptingが存在することが明らかになった。一方、Phi-4, nova-liteについてはBaselineから有意に性能が改善したPromptingはなかった。これはモデルは他のモデルよりもそもそもの予測性能が低く、複雑なinstructionを理解する能力が不足しているため、Promptデザインが与える影響が小さいことが示唆される。
特定のモデルでのみ良い性能を発揮するPromptingも存在した。たとえばRe-Reading, Echoは、Llama3.3-70Bでは性能が改善したが、gpt-4.1-mini, gpt-4o-miniでは性能が悪化した。ReActはgpt-4.1-miniとLlamd3.3-70Bで最高性能を達成したが、gpt-4o-miniでは最も性能が悪かった。
NLPにおいて一般的に利用されるprompting、RolePlay, Mock, Plan-Solve, DeepBreath, Emotion, Step-by-Stepなどは、推薦のAcc.を改善しなかった。このことより、ユーザの嗜好を捉えることが重要なランキングタスクにおいては、これらプロンプトが有効でないことが示唆される。
続いて、LLMやデータセットに関わらず高い性能を発揮するpromptingをlinear mixed-effects model(ランダム効果として、ユーザ、LLM、メトリックを導入し、これらを制御する項を線形回帰に導入。promptingを固定効果としAccに対する寄与をfittingし、多様な状況で高い性能を発揮するPromptを明らかにする)によって分析した結果、ReAct, Rephrase, Step-Backが有意に全てのデータセット、LLMにおいて高い性能を示すことが明らかになった。
[Paper Note] VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge, Yueqi Song+, arXiv'25
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Dataset #Evaluation #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-07-14 GPT Summary- VisualPuzzlesは、専門知識への依存を最小限に抑えた視覚的推論を評価する新しいベンチマークで、5つの推論カテゴリーから成る多様な質問を含む。実験により、VisualPuzzlesはドメイン特有の知識を大幅に減少させ、より複雑な推論を要求することが示された。最先端のマルチモーダルモデルは、VisualPuzzlesで人間のパフォーマンスに遅れをとり、知識集約型タスクでの成功が推論タスクでの成功に必ずしもつながらないことが明らかになった。また、モデルのサイズとパフォーマンスの間に明確な相関は見られず、VisualPuzzlesは事実の記憶を超えた推論能力を評価する新たな視点を提供する。 Comment
元ポスト:
画像はPJページより引用。新たにVisual Puzzleと呼ばれる特定のドメイン知識がほとんど必要ないマルチモーダルなreasoningベンチマークを構築。o1ですら、人間の5th percentileに満たない性能とのこと。
Chinese Civil Service Examination中のlogical reasoning questionを手作業で翻訳したとのこと。
データセットの統計量は以下で、合計1168問で、難易度は3段階に分かれている模様。
project page:
https://neulab.github.io/VisualPuzzles/
Gemini 3 Proはo4-mini, o3などにスコアで負けているとのこと:
興味深い。マルチモーダルの推論能力に関してはまだまだ改善の余地がある。
[Paper Note] Spike No More: Stabilizing the Pre-training of Large Language Models, Sho Takase+, COLM'25
Paper/Blog Link My Issue
#Analysis #Pretraining #Pocket #NLP #LanguageModel #COLM #Selected Papers/Blogs #Stability Issue Date: 2025-07-11 GPT Summary- 大規模言語モデルの事前学習中に発生する損失のスパイクは性能を低下させるため、避けるべきである。勾配ノルムの急激な増加が原因とされ、サブレイヤーのヤコビ行列の分析を通じて、勾配ノルムを小さく保つための条件として小さなサブレイヤーと大きなショートカットが必要であることを示した。実験により、これらの条件を満たす手法が損失スパイクを効果的に防ぐことが確認された。 Comment
元ポスト:
small sub-layers, large shortcutsの説明はこちらに書かれている。前者については、現在主流なLLMの初期化手法は満たしているが、後者はオリジナルのTransformerの実装では実装されている[^1]が、最近の実装では失われてしまっているとのこと。
下図が実験結果で、条件の双方を満たしているのはEmbedLN[^2]とScaled Embed[^3]のみであり、実際にスパイクが生じていないことがわかる。
[^1]:オリジナル論文 [Paper Note] Attention Is All You Need, Ashish Vaswani+, arXiv'17
の3.4節末尾、embedding layersに対してsqrt(d_model)を乗じるということがサラッと書いてある。これが実はめちゃめちゃ重要だったという…
[^2]: positional embeddingを加算する前にLayer Normalizationをかける方法
[^3]: EmbeddingにEmbeddingの次元数d(i.e., 各レイヤーのinputの次元数)の平方根を乗じる方法
前にScaled dot-product attentionのsqrt(d_k)がめっちゃ重要ということを実験的に示した、という話もあったような…
(まあそもそも元論文になぜスケーリングさせるかの説明は書いてあるけども)
著者ポスト(スライド):
非常に興味深いので参照のこと。初期化の気持ちの部分など勉強になる。
[Paper Note] Self-Adapting Language Models, Adam Zweiger+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Supervised-FineTuning (SFT) #ReinforcementLearning Issue Date: 2025-06-13 GPT Summary- 自己適応型LLMs(SEAL)を提案し、モデルが自身のファインチューニングデータと指示を生成することで適応を実現。新しい入力に対して自己編集を行い、持続的な重みの更新を可能にする。強化学習ループを用いて下流性能を報酬信号として活用し、従来のアプローチと異なり、モデル自身の生成を用いて適応を制御。実験結果はSEALの有望性を示す。 Comment
元ポスト:
コンテキストCと評価データtauが与えられたとき、Cを入力した時にモデルが自分をSFTし、tau上でより高い性能を得られるようなサンプル Self Edit (SE) を生成できるように学習することで、性能を向上させたい。これをRLによって実現する。具体的には、下記アルゴリズムのようにモデルにSEを生成させ、SEでSFTすることめにtau上での性能が向上したか否かのbinary rewardを用いてパラメータを更新する、といったことを繰り返す。これは実質、RL_updateと書いてあるが、性能が向上した良いSEのみでモデルをSFTすること、と同等なことを実施している。
このような背景として、RLのアルゴリズムとしてGRPOやPPOを適用したところ学習が不安定でうまくいかなかったため、よりシンプルなアプローチであるReST^EM([Paper Note] Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Avi Singh+, TMLR'24
)を採用した。これはrejection samplingとSFTに基づいたEMアルゴリズムのようなものらしく、Eステップで現在のポリシーでcandidateを生成し、Mステップでpositive rewardを得たcandidateのみ(=rejection sampling)でSFTする、といったことを繰り返す、みたいな手法らしい。これを用いると、論文中の式(1)を上述のbinary rewardで近似することに相当する。より詳細に書くと、式(1)(つまり、SEをCから生成することによって得られるtauに基づく報酬rの総報酬を最大化したい、という式)を最大化するためにθ_tの勾配を計算したいが、reward rがθ_tで微分不可能なため、Monte Carlo Estimatorで勾配を近似する、みたいなことをやるらしい。Monte Carlo Estimatorでは実際のサンプルの期待値によって理論的な勾配を近似するらしく、これが式(3)のスコア関数とreward rの平均、といった式につながっているようである。
再現実験に成功したとのポスト:
Can Large Reasoning Models Self-Train?, Sheikh Shafayat+, arXiv'25
Paper/Blog Link My Issue
#NLP #LanguageModel #RLVR #MajorityVoting Issue Date: 2025-06-01 GPT Summary- 自己学習を活用したオンライン強化学習アルゴリズムを提案し、モデルの自己一貫性を利用して正確性信号を推測。難しい数学的推論タスクに適用し、従来の手法に匹敵する性能を示す。自己生成された代理報酬が誤った出力を優遇するリスクも指摘。自己監視による性能向上の可能性と課題を明らかに。 Comment
元ポスト:
- Learning to Reason without External Rewards, Xuandong Zhao+, ICML'25 Workshop AI4MATH
と似ているように見える
self-consistencyでground truthを推定し、推定したground truthを用いてverifiableなrewardを計算して学習する手法、のように見える。
実際のground truthを用いた学習と同等の性能を達成する場合もあれば、long stepで学習するとどこかのタイミングで学習がcollapseする場合もある
パフォーマンスがピークを迎えた後になぜ大幅にAccuracyがdropするかを検証したところ、モデルのKL penaltyがどこかのタイミングで大幅に大きくなることがわかった。つまりこれはオリジナルのモデルからかけ離れたモデルになっている。これは、モデルがデタラメな出力をground truthとして推定するようになり、モデルそのものも一貫してそのデタラメな出力をすることでrewardを増大させるreward hackingが起きている。
これら現象を避ける方法として、以下の3つを提案している
- early stopping
- offlineでラベルをself consistencyで生成して、学習の過程で固定する
- カリキュラムラーニングを導入する
関連
- Self-Consistency Preference Optimization, Archiki Prasad+, ICML'25
[Paper Note] Demystifying LLM-based Software Engineering Agents, Chunqiu Steven Xia+, FSE'25, 2024.07
Paper/Blog Link My Issue
#EfficiencyImprovement #Pocket #NLP #LanguageModel #AIAgents #SoftwareEngineering #Selected Papers/Blogs Issue Date: 2025-04-02 GPT Summary- 最近のLLMの進展により、ソフトウェア開発タスクの自動化が進んでいるが、複雑なエージェントアプローチの必要性に疑問が生じている。これに対し、Agentlessというエージェントレスアプローチを提案し、シンプルな三段階プロセスで問題を解決。SWE-bench Liteベンチマークで最高のパフォーマンスと低コストを達成。研究は自律型ソフトウェア開発におけるシンプルで解釈可能な技術の可能性を示し、今後の研究の方向性を刺激することを目指している。 Comment
日本語解説: https://note.com/ainest/n/nac1c795e3825
LLMによる計画の立案、環境からのフィードバックによる意思決定などの複雑なワークフローではなく、Localization(階層的に問題のある箇所を同定する)とRepair(LLMで複数のパッチ候補を生成する)、PatchValidation(再現テストと回帰テストの両方を通じて結果が良かったパッチを選ぶ)のシンプルなプロセスを通じてIssueを解決する。
これにより、低コストで高い性能を達成している、といった内容な模様。
Agentlessと呼ばれ手法だが、preprint版にあったタイトルの接頭辞だった同呼称がproceeding版では無くなっている。
Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#Metrics #NLP #LanguageModel #GenerativeAI #Evaluation #Selected Papers/Blogs #Reference Collection Issue Date: 2025-03-31 GPT Summary- 新しい指標「50%-タスク完了時間ホライズン」を提案し、AIモデルの能力を人間の観点から定量化。Claude 3.7 Sonnetは約50分の時間ホライズンを持ち、AIの能力は2019年以降約7か月ごとに倍増。信頼性や論理的推論の向上が要因とされ、5年以内にAIが多くのソフトウェアタスクを自動化できる可能性を示唆。 Comment
元ポスト:
確かに線形に見える。てかGPT-2と比べるとAIさん進化しすぎである…。
利用したデータセットは
- HCAST: 46のタスクファミリーに基づく97種類のタスクが定義されており、たとえばサイバーセキュリティ、機械学習、ソフトウェアエンジニアリング、一般的な推論タスク(wikipediaから事実情報を探すタスクなど)などがある
- 数分で終わるタスク: 上述のwikipedia
- 数時間で終わるタスク: Pytorchのちょっとしたバグ修正など
- 数文でタスクが記述され、コード、データ、ドキュメント、あるいはwebから入手可能な情報を参照可能
- タスクの難易度としては当該ドメインに数年間携わった専門家が解ける問題
- RE-Bench Suite
- 7つのopen endedな専門家が8時間程度を要するMLに関するタスク
- e.g., GPT-2をQA用にFinetuningする, Finetuningスクリプトが与えられた時に挙動を変化させずにランタイムを可能な限り短縮する、など
- [RE-Bench Technical Report](
https://metr.org/AI_R_D_Evaluation_Report.pdf)のTable2等を参照のこと
- SWAA Suite: 66種類の1つのアクションによって1分以内で終わるソフトウェアエンジニアリングで典型的なタスク
- 1分以内で終わるタスクが上記データになかったので著者らが作成
であり、画像系やマルチモーダルなタスクは含まれていない。
タスクと人間がタスクに要する時間の対応に関するサンプルは下記
タスク-エージェントペアごとに8回実行した場合の平均の成功率。確かにこのグラフからはN年後には人間で言うとこのくらいの能力の人がこのくらい時間を要するタスクが、このくらいできるようになってます、といったざっくり感覚値はなかなか想像できない。
成功率とタスクに人間が要する時間に関するグラフ。ロジスティック関数でfittingしており、赤い破線が50% horizon。Claude 3.5 Sonnet (old)からClaude 3.7 Sonnetで50% horizonは18分から59分まで増えている。実際に数字で見るとイメージが湧きやすくおもしろい。
こちらで最新モデルも随時更新される:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
[Paper Note] Understanding R1-Zero-Like Training: A Critical Perspective, Zichen Liu+, arXiv'25, 2025.03
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #Reasoning #GRPO #read-later Issue Date: 2025-03-22 GPT Summary- DeepSeek-R1-Zeroは、RLを用いてLLMsの推論能力を向上させる手法を示した。本研究では、ベースモデルとRLの影響を分析し、DeepSeek-V3-Baseが「アハ体験」を示す一方で、Qwen2.5が強力な推論能力を持つことを発見。GRPOの最適化バイアスを特定し、Dr. GRPOを導入してトークン効率を改善。7BベースモデルでAIME 2024において43.3%の精度を達成するR1-Zeroレシピを提案。 Comment
関連研究:
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, Qiying Yu+, arXiv'25
解説ポスト:
解説ポスト(と論文中の当該部分)を読むと、
- オリジナルのGRPOの定式では2つのバイアスが生じる:
- response-level length bias: 1/|o_i| でAdvantageを除算しているが、これはAdvantageが負の場合(つまり、誤答が多い場合)「長い応答」のペナルティが小さくなるため、モデルが「長い応答」を好むバイアスが生じる。一方で、Advantageが正の場合(正答)は「短い応答」が好まれるようになる。
- question-level difficulty bias: グループ内の全ての応答に対するRewardのstdでAdvantageを除算しているが、stdが小さくなる問題(すなわち、簡単すぎるor難しすぎる問題)をより重視するような、問題に対する重みづけによるバイアスが生じる。
- aha moment(self-seflection)はRLによって初めて獲得されたものではなく、ベースモデルの時点で獲得されており、RLはその挙動を増長しているだけ(これはX上ですでにどこかで言及されていたなぁ)。
- これまではoutput lengthを増やすことが性能改善の鍵だと思われていたが、この論文では必ずしもそうではなく、self-reflection無しの方が有りの場合よりもAcc.が高い場合があることを示している(でもぱっと見グラフを見ると右肩上がりの傾向ではある)
といった知見がある模様
あとで読む
(参考)Dr.GRPOを実際にBig-MathとQwen-2.5-7Bに適用したら安定して収束したよというポスト:
Byte Latent Transformer: Patches Scale Better Than Tokens, Artidoro Pagnoni+, ICML'25 Workshop Tokshop
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #ICML #Tokenizer #Workshop #Byte-level Issue Date: 2025-01-02 GPT Summary- Byte Latent Transformer(BLT)は、バイトレベルのLLMアーキテクチャで、トークン化ベースのLLMと同等のパフォーマンスを実現し、推論効率と堅牢性を大幅に向上させる。BLTはバイトを動的にサイズ変更可能なパッチにエンコードし、データの複雑性に応じて計算リソースを調整する。最大8Bパラメータと4Tトレーニングバイトのモデルでの研究により、固定語彙なしでのスケーリングの可能性が示された。長いパッチの動的選択により、トレーニングと推論の効率が向上し、全体的にBLTはトークン化モデルよりも優れたスケーリングを示す。 Comment
興味深い
図しか見れていないが、バイト列をエンコード/デコードするtransformer学習して複数のバイト列をパッチ化(エントロピーが大きい部分はより大きなパッチにバイト列をひとまとめにする)、パッチからのバイト列生成を可能にし、パッチを変換するのをLatent Transformerで学習させるようなアーキテクチャのように見える。
また、予算によってモデルサイズが決まってしまうが、パッチサイズを大きくすることで同じ予算でモデルサイズも大きくできるのがBLTの利点とのこと。
日本語解説: https://bilzard.github.io/blog/2025/01/01/byte-latent-transformer.html?v=2
OpenReview: https://openreview.net/forum?id=UZ3J8XeRLw
LBPE: Long-token-first Tokenization to Improve Large Language Models, Haoran Lian+, ICASSP'25, 2024.11
Paper/Blog Link My Issue
#Pretraining #MachineLearning #Pocket #NLP #LanguageModel #Subword #Tokenizer Issue Date: 2024-11-12 GPT Summary- LBPEは、長いトークンを優先する新しいエンコーディング手法で、トークン化データセットにおける学習の不均衡を軽減します。実験により、LBPEは従来のBPEを一貫して上回る性能を示しました。 Comment
BPEとは異なりトークンの長さを優先してマージを実施することで、最終的なトークンを決定する手法で (Figure1),
BPEよりも高い性能を獲得し、
トークンの長さがBPEと比較して長くなり、かつ5Bトークン程度を既存のBPEで事前学習されたモデルに対して継続的事前学習するだけで性能を上回るようにでき (Table2)、同じVocabサイズでBPEよりも高い性能を獲得できる手法 (Table4)、らしい
Differential Transformer, Tianzhu Ye+, N_A, ICLR'25
Paper/Blog Link My Issue
#NLP #LanguageModel #Transformer #Architecture Issue Date: 2024-10-21 GPT Summary- Diff Transformerは、関連するコンテキストへの注意を強化し、ノイズをキャンセルする新しいアーキテクチャです。差分注意メカニズムを用いて、注意スコアを計算し、スパースな注意パターンを促進します。実験結果は、Diff Transformerが従来のTransformerを上回り、長いコンテキストモデリングや幻覚の軽減において顕著な利点を示しています。また、文脈内学習においても精度を向上させ、堅牢性を高めることが確認されました。これにより、Diff Transformerは大規模言語モデルの進展に寄与する有望なアーキテクチャとされています。 Comment
最近のMSはなかなかすごい(小並感
# 概要
attention scoreのノイズを低減するようなアーキテクチャとして、二つのQKVを用意し、両者の差分を取ることで最終的なattentiok scoreを計算するDifferential Attentionを提案した。
attentionのnoiseの例。answerと比較してirrelevantなcontextにattention scoreが高いスコアが割り当てられてしまう(図左)。differential transformerが提案するdifferential attentionでは、ノイズを提言し、重要なcontextのattention scoreが高くなるようになる(図中央)、らしい。
# Differential Attentionの概要と計算式
数式で見るとこのようになっており、二つのQKをどの程度の強さで交互作用させるかをλで制御し、λもそれぞれのQKから導出する。
QA, 機械翻訳, 文書分類, テキスト生成などの様々なNLPタスクが含まれるEval Harnessベンチマークでは、同規模のtransformerモデルを大幅にoutperform。ただし、3Bでしか実験していないようなので、より大きなモデルサイズになったときにgainがあるかは示されていない点には注意。
モデルサイズ(パラメータ数)と、学習トークン数のスケーラビリティについても調査した結果、LLaMAと比較して、より少ないパラメータ数/学習トークン数で同等のlossを達成。
64Kにcontext sgzeを拡張し、1.5B tokenで3Bモデルを追加学習をしたところ、これもtransformerと比べてより小さいlossを達成
context中に埋め込まれた重要な情報(今回はクエリに対応するmagic number)を抽出するタスクの性能も向上。Needle(N)と呼ばれる正解のmagic numberが含まれる文をcontext中の様々な深さに配置し、同時にdistractorとなる文もランダムに配置する。これに対してクエリ(R)が入力されたときに、どれだけ正しい情報をcontextから抽出できるか、という話だと思われる。
これも性能が向上。特にクエリとNeedleが複数の要素で構成されていれ場合の性能が高く(下表)、長いコンテキスト中の様々な位置に埋め込まれたNeedleを抽出する性能も高い(上のmatrix)
[Needle-In-A-Haystack test](
https://www.perplexity.ai/search/needle-in-a-haystack-testtohan-jF7LXWQPSMqKI2pZSchjpA#0)
Many shotのICL能力も向上
要約タスクでのhallucinationも低減。生成された要約と正解要約を入力し、GPT4-oにhallucinationの有無を判定させて評価。これは先行研究で人手での評価と高いagreementがあることが示されている。
シンプルなアプローチでLLM全体の性能を底上げしている素晴らしい成果に見える。斜め読みなので読み飛ばしているかもしれないが、Textbooks Are All You Need, Suriya Gunasekar+, N/A, arXiv'23
のように高品質な学習データで学習した場合も同様の効果が発現するのだろうか?
attentionのスコアがnoisyということは、学習データを洗練させることでも改善される可能性があり、Textbooks Are All You Need, Suriya Gunasekar+, N/A, arXiv'23
はこれをデータで改善し、こちらの研究はモデルのアーキテクチャで改善した、みたいな捉え方もできるのかもしれない。
ちなみにFlash Attentionとしての実装方法も提案されており、スループットは通常のattentionと比べてむしろ向上しているので実用的な手法でもある。すごい。
あとこれ、事前学習とInstruction Tuningを通常のマルチヘッドアテンションで学習されたモデルに対して、独自データでSFTするときに導入したらdownstream taskの性能向上するんだろうか。もしそうなら素晴らしい
OpenReview: https://openreview.net/forum?id=OvoCm1gGhN
GroupNormalizationについてはこちら:
- Group Normalization, Yuxin Wu+, arXiv'18
[Paper Note] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models, Hongliang He+, ACL'24, 2024.01
Paper/Blog Link My Issue
#Pocket #MultiModal #ACL #ComputerUse #Selected Papers/Blogs #VisionLanguageModel Issue Date: 2025-11-25 GPT Summary- WebVoyagerは、実際のウェブサイトと対話しユーザーの指示をエンドツーエンドで完了できる大規模マルチモーダルモデルを搭載したウェブエージェントである。新たに設立したベンチマークで59.1%のタスク成功率を達成し、GPT-4やテキストのみのWebVoyagerを上回る性能を示した。提案された自動評価指標は人間の判断と85.3%一致し、ウェブエージェントの信頼性を高める。 Comment
日本語解説: https://blog.shikoan.com/web-voyager/
スクリーンショットを入力にHTMLの各要素に対してnumeric labelをoverlayし(Figure2)、VLMにタスクを完了するためのアクションを出力させる手法。アクションはFigure7のシステムプロンプトに書かれている通り。
たとえば、VLMの出力として"Click [2]" が得られたら GPT-4-Act GPT-4V-Act, ddupont808, 2023.10
と呼ばれるSoM [Paper Note] Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, Jianwei Yang+, arXiv'23, 2023.10
をベースにWebUIに対してマウス/キーボードでinteractできるモジュールを用いることで、[2]とマーキングされたHTML要素を同定しClick操作を実現する。
Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
Paper/Blog Link My Issue
#Pocket #Attention #LongSequence #ICLR #AttentionSinks #Selected Papers/Blogs #Reference Collection Issue Date: 2025-04-05 GPT Summary- 大規模言語モデル(LLMs)をマルチラウンド対話に展開する際の課題として、メモリ消費と長いテキストへの一般化の難しさがある。ウィンドウアテンションはキャッシュサイズを超えると失敗するが、初期トークンのKVを保持することでパフォーマンスが回復する「アテンションシンク」を発見。これを基に、StreamingLLMというフレームワークを提案し、有限のアテンションウィンドウでトレーニングされたLLMが無限のシーケンス長に一般化可能になることを示した。StreamingLLMは、最大400万トークンで安定した言語モデリングを実現し、ストリーミング設定で従来の手法を最大22.2倍の速度で上回る。 Comment
Attention Sinksという用語を提言した研究
下記のpassageがAttention Sinksの定義(=最初の数トークン)とその気持ち(i.e., softmaxによるattention scoreは足し合わせて1にならなければならない。これが都合の悪い例として、現在のtokenのqueryに基づいてattention scoreを計算する際に過去のトークンの大半がirrelevantな状況を考える。この場合、irrelevantなトークンにattendしたくはない。そのため、auto-regressiveなモデルでほぼ全てのcontextで必ず出現する最初の数トークンを、irrelevantなトークンにattendしないためのattention scoreの捨て場として機能するのうに学習が進む)の理解に非常に重要
> To understand the failure of window attention, we find an interesting phenomenon of autoregressive LLMs: a surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task, as visualized in Figure 2. We term these tokens
“attention sinks". Despite their lack of semantic significance, they collect significant attention scores. We attribute the reason to the Softmax operation, which requires attention scores to sum up to one for all contextual tokens. Thus, even when the current query does not have a strong match in many previous tokens, the model still needs to allocate these unneeded attention values somewhere so it sums up to one. The reason behind initial tokens as sink tokens is intuitive: initial tokens are visible to almost all subsequent tokens because of the autoregressive language modeling nature, making them more readily trained to serve as attention sinks.
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
の先行研究。こちらでAttentionSinkがどのように作用しているのか?が分析されている。
Figure1が非常にわかりやすい。Initial Token(実際は3--4トークン)のKV Cacheを保持することでlong contextの性能が改善する(Vanilla)。あるいは、Softmaxの分母に1を追加した関数を用意し(数式2)、全トークンのattention scoreの合計が1にならなくても許されるような変形をすることで、余剰なattention scoreが生じないようにすることでattention sinkを防ぐ(Zero Sink)。これは、ゼロベクトルのトークンを追加し、そこにattention scoreを逃がせるようにすることに相当する。もう一つの方法は、globalに利用可能なlearnableなSink Tokenを追加すること。これにより、不要なattention scoreの捨て場として機能させる。Table3を見ると、最初の4 tokenをKV Cacheに保持した場合はperplexityは大きく変わらないが、Sink Tokenを導入した方がKV Cacheで保持するInitial Tokenの量が少なくてもZero Sinkと比べると性能が良くなるため、今後モデルを学習する際はSink Tokenを導入することを薦めている。既に学習済みのモデルについては、Zero Sinkによってlong contextのモデリングに対処可能と思われる。
著者による解説:
openreview: https://openreview.net/forum?id=NG7sS51zVF
[Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
Paper/Blog Link My Issue
#Analysis #Pocket #NLP #LanguageModel #ICLR #Selected Papers/Blogs #SparseAutoEncoder #Interpretability #InterpretabilityScore Issue Date: 2025-03-15 GPT Summary- 神経ネットワークの多義性を解消するために、スパースオートエンコーダを用いて内部活性化の方向を特定。これにより、解釈可能で単義的な特徴を学習し、間接目的語の同定タスクにおける因果的特徴をより詳細に特定。スケーラブルで教師なしのアプローチが重ね合わせの問題を解決できることを示唆し、モデルの透明性と操作性向上に寄与する可能性を示す。 Comment
日本語解説: https://note.com/ainest/n/nbe58b36bb2db
OpenReview: https://openreview.net/forum?id=F76bwRSLeK
SparseAutoEncoderはネットワークのあらゆるところに仕込める(と思われる)が、たとえばTransformer Blockのresidual connection部分のベクトルに対してFeature Dictionaryを学習すると、当該ブロックにおいてどのような特徴の組み合わせが表現されているかが(あくまでSparseAutoEncoderがreconstruction lossによって学習された結果を用いて)解釈できるようになる。
SparseAutoEncoderは下記式で表され、下記loss functionで学習される。MがFeature Matrix(row-wiseに正規化されて後述のcに対するL1正則化に影響を与えないようにしている)に相当する。cに対してL1正則化をかけることで(Sparsity Loss)、c中の各要素が0に近づくようになり、結果としてcがSparseとなる(どうしても値を持たなければいけない重要な特徴量のみにフォーカスされるようになる)。
MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N_A, ACL'24 Findings
Paper/Blog Link My Issue
#Survey #Pocket #LanguageModel #MultiModal #ACL #Selected Papers/Blogs Issue Date: 2024-01-25 GPT Summary- MM-LLMsは、コスト効果の高いトレーニング戦略を用いて拡張され、多様なMMタスクに対応する能力を持つことが示されている。本論文では、MM-LLMsのアーキテクチャ、トレーニング手法、ベンチマークのパフォーマンスなどについて調査し、その進歩に貢献することを目指している。 Comment
以下、論文を斜め読みしながら、ChatGPTを通じて疑問点を解消しつつ理解した内容なので、理解が不十分な点が含まれている可能性があるので注意。
# 概要
まあざっくり言うと、マルチモーダルを理解できるLLMを作りたかったら、様々なモダリティをエンコーディングして得られる表現と、既存のLLMが内部的に処理可能な表現を対応づける Input Projectorという名の関数を学習すればいいだけだよ(モダリティのエンコーダ、LLMは事前学習されたものをそのままfreezeして使えば良い)。
マルチモーダルを生成できるLLMを作りたかったら、LLMがテキストを生成するだけでなく、様々なモダリティに対応する表現も追加で出力するようにして、その出力を各モダリティを生成できるモデルに入力できるように変換するOutput Projectortという名の関数を学習しようね、ということだと思われる。
## ポイント
- Modality Encoder, LLM Backbone、およびModality Generatorは一般的にはパラメータをfreezeする
- optimizationの対象は「Input/Output Projector」
## Modality Encoder
様々なモダリティI_Xを、特徴量F_Xに変換する。これはまあ、色々なモデルがある。
## Input Projector
モダリティI_Xとそれに対応するテキストtのデータ {I_X, t}が与えられたとき、テキストtを埋め込み表現に変換んした結果得られる特徴量がF_Tである。Input Projectorは、F_XをLLMのinputとして利用する際に最適な特徴量P_Xに変換するθX_Tを学習することである。これは、LLM(P_X, F_T)によってテキストtがどれだけ生成できたか、を表現する損失関数を最小化することによって学習される。
## LLM Backbone
LLMによってテキスト列tと、各モダリティに対応した表現であるS_Xを生成する。outputからt, S_Xをどのように区別するかはモデルの構造などにもよるが、たとえば異なるヘッドを用意して、t, S_Xを区別するといったことは可能であろうと思われる。
## Output Projector
S_XをModality Generatorが解釈可能な特徴量H_Xに変換する関数のことである。これは学習しなければならない。
H_XとModality Generatorのtextual encoderにtを入力した際に得られる表現τX(t)が近くなるようにOutput Projector θ_T_Xを学習する。これによって、S_XとModality Generatorがalignするようにする。
## Modality Generator
各ModalityをH_Xから生成できるように下記のような損失学習する。要は、生成されたモダリティデータ(または表現)が実際のデータにどれだけ近いか、を表しているらしい。具体的には、サンプリングによって得られたノイズと、モデルが推定したノイズの値がどれだけ近いかを測る、みたいなことをしているらしい。
Multi Modalを理解するモデルだけであれば、Input Projectorの損失のみが学習され、生成までするのであれば、Input/Output Projector, Modality Generatorそれぞれに示した損失関数を通じてパラメータが学習される。あと、P_XやらS_Xはいわゆるsoft-promptingみたいなものであると考えられる。
[Paper Note] Self-Rewarding Language Models, Weizhe Yuan+, N_A, ICML'24
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #Alignment #InstructionTuning #LLM-as-a-Judge #SelfImprovement #ICML #Selected Papers/Blogs Issue Date: 2024-01-22 GPT Summary- 将来のモデルのトレーニングには超人的なフィードバックが必要であり、自己報酬を提供するSelf-Rewarding Language Modelsを研究している。LLM-as-a-Judgeプロンプトを使用して、言語モデル自体が自己報酬を提供し、高品質な報酬を得る能力を向上させることを示した。Llama 2 70Bを3回のイテレーションで微調整することで、既存のシステムを上回るモデルが得られることを示した。この研究は、改善可能なモデルの可能性を示している。 Comment
人間の介入無しで(人間がアノテーションしたpreference data無しで)LLMのAlignmentを改善していく手法。LLM-as-a-Judge Promptingを用いて、LLM自身にpolicy modelとreward modelの役割の両方をさせる。unlabeledなpromptに対してpolicy modelとしてresponceを生成させた後、生成したレスポンスをreward modelとしてランキング付けし、DPOのpreference pairとして利用する、という操作を繰り返す。
[Paper Note] Robust Speech Recognition via Large-Scale Weak Supervision, Alec Radford+, ICML'23, 2022.12
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #Transformer #SpeechProcessing #AutomaticSpeechRecognition(ASR) #Selected Papers/Blogs #Generalization #Robustness Issue Date: 2025-11-14 GPT Summary- 680,000時間の多言語音声トランスクリプトを用いて訓練した音声処理システムを研究。得られたモデルは、ゼロショット転送設定で良好に一般化し、従来の監視結果と競争力を持つ。人間の精度に近づくことが確認され、モデルと推論コードを公開。 Comment
いまさらながらWhisper論文
日本語解説:
https://www.ai-shift.co.jp/techblog/3001
長文認識のためのヒューリスティックに基づくデコーディング戦略も解説されているので参照のこと。
研究のコアとなるアイデアとしては、既存研究は自己教師あり学習、あるいはself-learningによって性能向上を目指す流れがある中で、教師あり学習に着目。既存研究で教師あり学習によって性能が向上することが示されていたが、大規模なスケールで実施できていなかったため、それをweakly-supervisedなmanner(=つまり完璧なラベルではなくてノイジーでも良いからラベルを付与し学習する)といった方法で学習することで、より頑健で高性能なASRを実現したい、という気持ちの研究。また、複雑なサブタスク(language identification, inverse text normalization(ASR後のテキストを人間向けの自然なテキストに変換すること[^2]), phrase-level timestamps (audioとtranscriptのタイムスタンプ予測))を一つのパイプラインで実現するような統合的なインタフェースも提案している。モデルのアーキテクチャ自体はencoder-decoderモデルである。また、positional encodingとしてはSinusoidal Positional Encoding(すなわち、絶対位置エンコーディング)が用いられている。デコーダにはprompt[^1]と呼ばれるtranscriptのhistoryを(確率的に挿入し)入力して学習することで、過去のcontextを考慮したASRが可能となる。lossの計算は、translate/transcribeされたトークンのみを考慮して計算する。
データセットについては詳細は記述されておらず、internetに存在する (audio, transcripts)のペアデータを用いたと書かれている。
しかしながら、収集したデータセットを確認んすると、transcriptionの品質が低いものが混ざっており、フィルタリングを実施している。これは、人間のtranscriptionとmachine-generatedなtranscriptionをmixして学習すると性能を損なうことが既存研究で知られているため、ヒューリスティックに基づいてmachine-generatedなtranscriptionは学習データから除外している。これは、初期のモデルを学習してエラー率を観測し、データソースを人手でチェックしてlow-qualityなtranscriptを除去するといった丁寧なプロセスもあ含まれる。
また、収集したデータの言語についてはVoxLingua107データセット [Paper Note] VoxLingua107: a Dataset for Spoken Language Recognition, Jörgen Valk+, SLT'21, 2020.11
によって学習された分類器(をさらにfinetuningしたモデルと書かれている。詳細は不明)によって自動的に付与する。すなわち、X->enのデータのX(つまりsource言語)のlanguage identificationについてもweakly-supervisedなラベルで学習されている。
audioファイルについては、30秒単位のセグメントに区切り全ての期間を学習データに利用。無音部分はサブサンプリング(=一部をサンプリングして使う)しVoice Activity Detectionも学習する。
[^1]: LLMの文脈で広く使われるPromptとは異なる点に注意。LLMはinstruction-tuningが実施されているため人間の指示に追従するような挙動となるが、Whisperではinstruction-tuningを実施していないのでそのような挙動にはならない。あくまで過去のhistoryの情報を与える役割と考えること。
[^2]: Whisperでは生のtranscriptをnormalizationせずに学習にそのまま利用するため書き起こしの表記の統一は行われないと考えられる。
[Paper Note] Self-Evaluation Guided Beam Search for Reasoning, Yuxi Xie+, NeurIPS'23, 2023.05
Paper/Blog Link My Issue
#BeamSearch #Pocket #NLP #LanguageModel #Reasoning #SelfCorrection #NeurIPS #Decoding Issue Date: 2025-10-01 GPT Summary- LLMの推論プロセスを改善するために、段階的自己評価メカニズムを導入し、確率的ビームサーチを用いたデコーディングアルゴリズムを提案。これにより、推論の不確実性を軽減し、GSM8K、AQuA、StrategyQAでの精度を向上。Llama-2を用いた実験でも効率性が示され、自己評価ガイダンスが論理的な失敗を特定し、一貫性を高めることが確認された。 Comment
pj page: https://guideddecoding.github.io
openreview: https://openreview.net/forum?id=Bw82hwg5Q3
非常にざっくり言うと、reasoning chain(=複数トークンのsequence)をトークンとみなした場合の(確率的)beam searchを提案している。多様なreasoning chainをサンプリングし、その中から良いものをビーム幅kで保持し生成することで、最終的に良いデコーディング結果を得る。reasoning chainのランダム性を高めるためにtemperatureを設定するが、アニーリングをすることでchainにおけるエラーが蓄積することを防ぐ。これにより、最初は多様性を重視した生成がされるが、エラーが蓄積され発散することを防ぐ。
reasoning chainの良さを判断するために、chainの尤度だけでなく、self-evaluationによるreasoning chainの正しさに関するconfidenceスコアも導入する(reasoning chainのconfidenceスコアによって重みづけられたchainの尤度を最大化するような定式化になる(式3))。
self-evaluationと生成はともに同じLLMによって実現されるが、self-evaluationについては評価用のfew-shot promptingを実施する。promptingでは、これまでのreasoning chainと、新たなreasoning chainがgivenなときに、それが(A)correct/(B)incorrectなのかをmultiple choice questionで判定し、選択肢Aが生成される確率をスコアとする。
[Paper Note] Magneto: A Foundation Transformer, Hongyu Wang+, ICML'23
Paper/Blog Link My Issue
#ComputerVision #Pocket #NLP #Transformer #MultiModal #SpeechProcessing #Architecture #ICML #Normalization Issue Date: 2025-04-19 GPT Summary- 言語、視覚、音声、マルチモーダルにおけるモデルアーキテクチャの収束が進む中、異なる実装の「Transformers」が使用されている。汎用モデリングのために、安定性を持つFoundation Transformerの開発が提唱され、Magnetoという新しいTransformer変種が紹介される。Sub-LayerNormと理論に基づく初期化戦略を用いることで、さまざまなアプリケーションにおいて優れたパフォーマンスと安定性を示した。 Comment
マルチモーダルなモデルなモデルの事前学習において、PostLNはvision encodingにおいてsub-optimalで、PreLNはtext encodingにおいてsub-optimalであることが先行研究で示されており、マルタモーダルを単一のアーキテクチャで、高性能、かつ学習の安定性な高く、try and error無しで適用できる基盤となるアーキテクチャが必要というモチベーションで提案された手法。具体的には、Sub-LayerNorm(Sub-LN)と呼ばれる、self attentionとFFN部分に追加のLayerNormを適用するアーキテクチャと、DeepNetを踏襲しLayer数が非常に大きい場合でも学習が安定するような重みの初期化方法を理論的に分析し提案している。
具体的には、Sub-LNの場合、LayerNormを
- SelfAttention計算におけるQKVを求めるためのinput Xのprojectionの前とAttentionの出力projectionの前
- FFNでの各Linear Layerの前
に適用し、
初期化をする際には、FFNのW, およびself-attentionのV_projと出力のout_projの初期化をγ(=sqrt(log(2N))によってスケーリングする方法を提案している模様。
関連:
- [Paper Note] DeepNet: Scaling Transformers to 1,000 Layers, Hongyu Wang+, arXiv'22
The Impact of Positional Encoding on Length Generalization in Transformers, Amirhossein Kazemnejad+, NeurIPS'23
Paper/Blog Link My Issue
#EfficiencyImprovement #NLP #LanguageModel #Transformer #LongSequence #PositionalEncoding #NeurIPS #Selected Papers/Blogs #Surface-level Notes Issue Date: 2025-04-06 GPT Summary- 長さ一般化はTransformerベースの言語モデルにおける重要な課題であり、位置エンコーディング(PE)がその性能に影響を与える。5つの異なるPE手法(APE、T5の相対PE、ALiBi、Rotary、NoPE)を比較した結果、ALiBiやRotaryなどの一般的な手法は長さ一般化に適しておらず、NoPEが他の手法を上回ることが明らかになった。NoPEは追加の計算を必要とせず、絶対PEと相対PEの両方を表現可能である。さらに、スクラッチパッドの形式がモデルの性能に影響を与えることも示された。この研究は、明示的な位置埋め込みが長いシーケンスへの一般化に必須でないことを示唆している。 Comment
- Llama 4 Series, Meta, 2025.04
において、Llama4 Scoutが10Mコンテキストウィンドウを実現できる理由の一つとのこと。
元ポスト:
Llama4のブログポストにもその旨記述されている:
>A key innovation in the Llama 4 architecture is the use of interleaved attention layers without positional embeddings. Additionally, we employ inference time temperature scaling of attention to enhance length generalization.
[The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation]( https://ai.meta.com/blog/llama-4-multimodal-intelligence/?utm_source=twitter&utm_medium=organic_social&utm_content=image&utm_campaign=llama4)
斜め読みだが、length generalizationを評価する上でdownstream taskに焦点を当て、3つの代表的なカテゴリに相当するタスクで評価したところ、この観点においてはT5のrelative positinal encodingとNoPE(位置エンコードディング無し)のパフォーマンスが良く、
NoPEは絶対位置エンコーディングと相対位置エンコーディングを理論上実現可能であり[^1]
実際に学習された異なる2つのモデルに対して同じトークンをそれぞれinputし、同じ深さのLayerの全てのattention distributionの組み合わせからJensen Shannon Divergenceで距離を算出し、最も小さいものを2モデル間の当該layerの距離として可視化すると下記のようになり、NoPEとT5のrelative positional encodingが最も類似していることから、NoPEが学習を通じて(実用上は)相対位置エンコーディングのようなものを学習することが分かった。
[^1]:深さ1のLayerのHidden State H^1から絶対位置の復元が可能であり(つまり、当該レイヤーのHが絶対位置に関する情報を保持している)、この前提のもと、後続のLayerがこの情報を上書きしないと仮定した場合に、相対位置エンコーディングを実現できる。
また、CoT/Scratchpadはlong sequenceに対する汎化性能を向上させることがsmall scaleではあるが先行研究で示されており、Positional Encodingを変化させた時にCoT/Scratchpadの性能にどのような影響を与えるかを調査。
具体的には、CoT/Scratchpadのフォーマットがどのようなものが有効かも明らかではないので、5種類のコンポーネントの組み合わせでフォーマットを構成し、mathematical reasoningタスクで以下のような設定で訓練し
- さまざまなコンポーネントの組み合わせで異なるフォーマットを作成し、
- 全ての位置エンコーディングあり/なしモデルを訓練
これらを比較した。この結果、CoT/Scratchpadはフォーマットに関係なく、特定のタスクでのみ有効(有効かどうかはタスク依存)であることが分かった。このことから、CoT/Scratcpad(つまり、モデルのinputとoutputの仕方)単体で、long contextに対する汎化性能を向上させることができないので、Positional Encoding(≒モデルのアーキテクチャ)によるlong contextに対する汎化性能の向上が非常に重要であることが浮き彫りになった。
また、CoT/Scratchpadが有効だったAdditionに対して各Positional Embeddingモデルを学習し、生成されたトークンのattentionがどの位置のトークンを指しているかを相対距離で可視化したところ(0が当該トークン、つまり現在のScratchpadに着目しており、1が遠いトークン、つまりinputに着目していることを表すように正規化)、NoPEとRelative Positional Encodingがshort/long rangeにそれぞれフォーカスするようなbinomialな分布なのに対し、他のPositional Encodingではよりuniformな分布であることが分かった。このタスクにおいてはNoPEとRelative POの性能が高かったため、binomialな分布の方がより最適であろうことが示唆された。
[Paper Note] TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, Keqin Bao+, RecSys'23
Paper/Blog Link My Issue
#RecommenderSystems #LanguageModel #Contents-based #Supervised-FineTuning (SFT) #PEFT(Adaptor/LoRA) #Zero/FewShotLearning #RecSys Issue Date: 2025-03-30 GPT Summary- 大規模言語モデル(LLMs)を推薦システムに活用するため、推薦データで調整するフレームワークTALLRecを提案。限られたデータセットでもLLMsの推薦能力を向上させ、効率的に実行可能。ファインチューニングされたLLMはクロスドメイン一般化を示す。 Comment
下記のようなユーザのプロファイルとターゲットアイテムと、binaryの明示的なrelevance feedbackデータを用いてLoRA、かつFewshot Learningの設定でSFTすることでbinaryのlike/dislikeの予測性能を向上。PromptingだけでなくSFTを実施した初めての研究だと思われる。
既存ベースラインと比較して大幅にAUCが向上
Scaling Data-Constrained Language Models, Niklas Muennighoff+, NeurIPS'23
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #NeurIPS #Scaling Laws #read-later #Selected Papers/Blogs Issue Date: 2025-03-23 GPT Summary- 言語モデルのスケーリングにおいて、データ制約下でのトレーニングを調査。9000億トークンと90億パラメータのモデルを用いた実験で、繰り返しデータを使用しても損失に大きな変化は見られず、繰り返しの価値が減少することを確認。計算最適性のスケーリング法則を提案し、データ不足を軽減するアプローチも実験。得られたモデルとデータセットは公開。 Comment
OpenReview: https://openreview.net/forum?id=j5BuTrEj35
チンチラ則のようなScaling Lawsはパラメータとデータ量の両方をスケールさせた場合の前提に立っており、かつデータは全てuniqueである前提だったが、データの枯渇が懸念される昨今の状況に合わせて、データ量が制限された状況で、同じデータを繰り返し利用する(=複数エポック学習する)ことが一般的になってきた。このため、データのrepetitionに関して性能を事前学習による性能の違いを調査して、repetitionとパラメータ数に関するスケーリング則を提案($3.1)しているようである。
Takeawayとしては、データが制限された環境下では、repetitionは上限4回までが効果的(コスパが良い)であり(左図)、小さいモデルを複数エポック訓練する方が固定されたBudgetの中で低いlossを達成できる右図)。
学習データの半分をコードにしても性能の劣化はなく、様々なタスクの性能が向上しパフォーマンスの分散も小さくなる、といったことが挙げられるようだ。
Recursion of Thought: A Divide-and-Conquer Approach to Multi-Context Reasoning with Language Models, Soochan Lee+, arXiv'23
Paper/Blog Link My Issue
#NLP #LanguageModel #Chain-of-Thought #Reasoning Issue Date: 2025-01-05 GPT Summary- Recursion of Thought(RoT)という新しい推論フレームワークを提案し、言語モデル(LM)が問題を複数のコンテキストに分割することで推論能力を向上させる。RoTは特別なトークンを導入し、コンテキスト関連の操作をトリガーする。実験により、RoTがLMの推論能力を劇的に向上させ、数十万トークンの問題を解決できることが示された。 Comment
divide-and-conquerで複雑な問題に回答するCoT手法。生成過程でsubquestionが生じた際にモデルに特殊トークン(GO)を出力させ、subquestionの回答部分に特殊トークン(THINK)を出力させるようにSupervisedに学習させる。最終的にTHINKトークン部分は、subquestionを別途モデルによって解いた回答でreplaceして、最終的な回答を得る。
subquestionの中でさらにsubquestionが生じることもあるため、再帰的に処理される。
四則演算と4種類のアルゴリズムに基づくタスクで評価。アルゴリズムに基づくタスクは、2つの数のlongest common subsequenceを見つけて、そのsubsequenceとlengthを出力するタスク(LCS)、0-1 knapsack問題、行列の乗算、数値のソートを利用。x軸が各タスクの問題ごとの問題の難易度を表しており、難易度が上がるほど提案手法によるgainが大きくなっているように見える。
Without Thoughtでは直接回答を出力させ、CoTではground truthとなるrationaleを1つのcontextに与えて回答を生成している。RoTではsubquestionごとに回答を別途得るため、より長いcontextを活用して最終的な回答を得る点が異なると主張している。
感想としては、詳細が書かれていないが、おそらくRoTはSFTによって各タスクに特化した学習をしていると考えられる(タスクごとの特殊トークンが存在するため)。ベースラインとしてRoT無しでSFTしたモデルあった方が良いのではないか?と感じる。
また、学習データにおけるsubquestionとsubquestionに対するground truthのデータ作成方法は書かれているが、そもそも元データとして何を利用したかや、その統計量も書かれていないように見える。あと、そもそも機械的に学習データを作成できない場合どうすれば良いのか?という疑問は残る。
読んでいた時にAuto-CoTとの違いがよくわからなかったが、Related Workの部分にはAuto-CoTは動的、かつ多様なデモンストレーションの生成にフォーカスしているが、AutoReasonはquestionを分解し、few-shotの promptingでより詳細なrationaleを生成することにフォーカスしている点が異なるという主張のようである。
- Automatic Chain of Thought Prompting in Large Language Models, Zhang+, Shanghai Jiao Tong University, ICLR'23
Auto-CoTとの差別化は上記で理解できるが、G-Evalが実施しているAuto-CoTとの差別化はどうするのか?という風にふと思った。論文中でもG-Evalは引用されていない。
素朴にはAutoReasonはSFTをして学習をしています、さらにRecursiveにquestionをsubquestionを分解し、分解したsubquestionごとに回答を得て、subquestionの回答結果を活用して最終的に複雑なタスクの回答を出力する手法なので、G-Evalが実施している同一context内でrationaleをzeroshotで生成する手法よりも、より複雑な問題に回答できる可能性が高いです、という主張にはなりそうではある。
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, Yang Liu+, N/A, EMNLP'23
ICLR 2023 OpenReview:
https://openreview.net/forum?id=PTUcygUoxuc
- 提案手法は一般的に利用可能と主張しているが、一般的に利用するためには人手でsubquestionの学習データを作成する必要があるため十分に一般的ではない
- 限られたcontext長に対処するために再帰を利用するというアイデアは新しいものではなく、数学の定理の証明など他の設定で利用されている
という理由でrejectされている。
UL2: Unifying Language Learning Paradigms, Yi Tay+, N_A, ICLR'23
Paper/Blog Link My Issue
#Pretraining #Pocket #NLP #LanguageModel #MultiModal #ICLR #Encoder #Encoder-Decoder Issue Date: 2024-09-26 GPT Summary- 本論文では、事前学習モデルの普遍的なフレームワークを提案し、事前学習の目的とアーキテクチャを分離。Mixture-of-Denoisers(MoD)を導入し、複数の事前学習目的の効果を示す。20Bパラメータのモデルは、50のNLPタスクでSOTAを達成し、ゼロショットやワンショット学習でも優れた結果を示す。UL2 20Bモデルは、FLAN指示チューニングにより高いパフォーマンスを発揮し、関連するチェックポイントを公開。 Comment
OpenReview: https://openreview.net/forum?id=6ruVLB727MC
encoder-decoder/decoder-onlyなど特定のアーキテクチャに依存しないアーキテクチャagnosticな事前学習手法であるMoDを提案。
MoDでは3種類のDenoiser [R] standard span corruption, [S] causal language modeling, [X] extreme span corruption の3種類のパラダイムを活用する。学習時には与えらえたタスクに対して適切なモードをスイッチできるようにparadigm token ([R], [S], [X])を与え挙動を変化させられるようにしており[^1]、finetuning時においては事前にタスクごとに定義をして与えるなどのことも可能。
[^1]: 事前学習中に具体的にどのようにモードをスイッチするのかはよくわからなかった。ランダムに変更するのだろうか。
[Paper Note] Prompt2Model: Generating Deployable Models from Natural Language Instructions, Vijay Viswanathan+, EMNLP'23 System Demonstrations, 2023.08
Paper/Blog Link My Issue
#MachineLearning #Pocket #NLP #LanguageModel #DataAugmentation #Supervised-FineTuning (SFT) #AIAgents #SyntheticData #EMNLP #Selected Papers/Blogs #System Demonstration Issue Date: 2023-08-28 GPT Summary- Prompt2Modelは、自然言語のタスク説明を基に特化型NLPモデルを訓練する手法で、LLMsの利点を活かしつつデプロイに適したモデルを生成します。既存のデータセットや事前学習済みモデルを活用し、データセット生成と教師ありファインチューニングを行うことで、同じfew-shotプロンプトでgpt-3.5-turboを平均20%上回る性能を持つ小型モデルを訓練可能です。信頼性のある性能推定も提供し、モデル開発者がデプロイ前に評価できるようにします。Prompt2Modelはオープンソースで公開されています。 Comment
Dataset Generatorによって、アノテーションが存在しないデータについても擬似ラベル付きデータを生成することができ、かつそれを既存のラベル付きデータと組み合わせることによってさらに性能が向上することが報告されている。これができるのはとても素晴らしい。
Dataset Generatorについては、データを作成する際に低コストで、高品質で、多様なデータとするためにいくつかの工夫を実施している。
1. ユーザが与えたデモンストレーションだけでなく、システムが生成したexampleもサンプリングして活用することで、生成されるexampleの多様性を向上させる。実際、これをやらない場合は120/200がduplicate exampleであったが、これが25/200まで減少した。
2. 生成したサンプルの数に比例して、temperatureを徐々に高くしていく。これにより、サンプルの質を担保しつつ、多様性を徐々に増加させることができる。Temperature Annealingと呼ぶ。
3. self-consistencyを用いて、擬似ラベルの質を高める。もしmajority votingが互角の場合は、回答が短いものを採用した(これはヒューリスティックに基づいている)
4. zeno buildを用いてAPIへのリクエストを並列化することで高速に実験を実施
非常に参考になる。
著者らによる現在の視点での振り返り(提案当時はAI Agentsという概念はまだなく、本研究はその先取りと言える):
[Paper Note] Can Large Language Models Be an Alternative to Human Evaluations?, Cheng-Han Chiang+, ACL'23, 2023.05
Paper/Blog Link My Issue
#Analysis #Pocket #LanguageModel #ChatGPT #Evaluation #LLM-as-a-Judge #Attack #ACL #Selected Papers/Blogs Issue Date: 2023-07-22 GPT Summary- 人間評価の再現性が低いため、NLPモデル間の公正な比較が難しい。そこで、大規模言語モデル(LLM)を人間評価の代替手段として利用することを探求。本研究では、LLMに同一指示とサンプルを与え、評価を実施するLLM評価を提案。オープンエンドのストーリー生成や敵対的攻撃のタスクに対する評価結果は、人間専門家の評価と高い一致を示し、評価の安定性も確認。LLMを用いたテキスト評価の可能性やその限界、倫理的課題についても考察。 Comment
LLMがテキストの品質評価において、人間による評価者の代替となりうるか?という疑問を初めて実験的に示した研究で、インパクトが大きく重要論文と判断。ただし、実験のスコープは物語生成と敵対的生成(テキスト分類器を騙すような摂動を加える)の2タスクである点、には注意。
ChatGPT(おそらくGPT-3.5)が人間の評価者(3人のEnglish teacher)とopen-endで生成された物語にたいして、以下の4つの観点に関してratingの平均で見た時に同様の傾向のスコアを付与することを実験的に明らかにした:
- Grammaticality [^1]: テキストの文法の正しさ
- Cohesiveness: テキストの一貫性
- Likeability: テキストが読んでいて楽しいか
- Relevance: promptに対してどれだけ適切なテキストが生成されているか
ただし、T0やtext-curie-001 においてはこのような傾向は見受けられなかった。[^2]
また、ChatGPTによる説明とratingを人間の評価者に対してblindで提示したところ、人間が見ても妥当な判断だと認知された。
全体の傾向としてではなく、個別のratingがどの程度同じような傾向を示すか(i.e., 人間があるstoryを高くratingしたら、LLMも高くratingするか?)をケンドールの順位相関係数で分析(200サンプルに対して3人の英語教員のスコアの平均, text-davinciによる3回の独立したratingを実施した平均スコアを用いて計算)したところ、4つの観点のうち全てにおいて正の相関が見受けられた(Table2, p-valueは<0.05で統計的に有意)。が、Relevanceのみが強い相関を示し、他の指標については弱い相関にとどまっている。しかし、Table6に示されている通り、2人の英語の先生同士で個別のjudgeに感して同様にケンドールの順位相関係数を測定しても、人間-LLM間と同様の傾向が見受けられる。すなわち、Relevanceのみが強い相関で他は弱い相関。このことから、人間同士でも個別のサンプルに対する判断は一致しない(=主観的なタスク)ということは留意する必要がある。
敵対的生成に関する実験については、Synonym Substitution Attack (SSAs; 良性のサンプルを同義語で置換する手法で、全体的な意味は保たれるため一般的な人間は正しく認知してしまうが、実際には文法がおかしくなったり不自然になったり、意味が変わってしまうことが先行研究によって知られているようなものらしい)によって実験。Fluency / Meaning Preservingの2つの指標で英語教員とLLMによる評価を比較した結果、人間は正しくadversarialなサンプルと良性なサンプルを区別できており、ChatGPT(おそらくGPT-3.5)も区別ができている(Table4)。ただし、人間のスコアと比較するとChatGPTは高めのスコアを出す傾向がある点には注意ではあるものの、良性サンプル > 敵対的サンプル という序列の判断に関しては人間と同様の傾向を示していることが示唆された。
[^1]: ただし、LLMはpunctuationのミスを文法エラーと判断するが、一人の英語の先生は文法エラーとしてみなさないなどの現象も観察され、人間は独自の評価criteriaを保持していることも窺える
[^2]: (感想)ある程度能力の高いLLMかRLHFなどを用いて人間の好みに対してalignmentがとられていないとうまくいかないのかもしれない
本研究は非常に初期の研究であり、現在のfrontierモデル群(特にreasoningモデル)を用いた場合にはどの程度改善しているか?という点は気になる。
[Paper Note] Tailor: A Prompt-Based Approach to Attribute-Based Controlled Text Generation, Kexin Yang+, ACL'23, 2022.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP #PEFT(Adaptor/LoRA) #ACL #SoftPrompt Issue Date: 2023-07-15 GPT Summary- 属性に基づくCTGでは、プロンプトを使用して望ましい属性を満たす文を生成。新手法Tailorは、各属性を連続ベクトルとして表し、固定PLMの生成を誘導。実験によりマルチ属性生成が実現できるが、流暢さの低下が課題。マルチ属性プロンプトマスクと再インデックス位置ID列でこのギャップを埋め、学習可能なプロンプトコネクタにより属性間の連結も可能に。11の生成タスクで強力な性能を示し、GPT-2の最小限のパラメータで有効性を確認。 Comment
Soft Promptを用いてattributeを連続値ベクトルで表現しconcatすることで生成をコントロールする。このとき、複数attuributeを指定可能である。
工夫点としては、attention maskにおいて
soft prompt同士がattendしないようにし、交互作用はMAP Connectorと呼ばれる交互作用そのものを学習するコネクタに移譲する点、(複数のsoft promptをconcatすることによる)Soft Promptのpositionのsensitivityを低減するために、末尾のsoft prompt以外はreindexしている点のようである。
[Paper Note] Visualizing Linguistic Diversity of Text Datasets Synthesized by Large Language Models, Emily Reif+, arXiv'23, 2023.05
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #SyntheticData #Evaluation #Interpretability Issue Date: 2023-05-22 GPT Summary- 大規模言語モデル(LLMs)を用いて生成されたデータセットの構文的多様性を分析するための視覚化ツール「LinguisticLens」を提案。これにより、テキストを構文的、語彙的、意味的にクラスタリングし、ユーザーがデータセットを迅速にスキャンし、個々の例を検査できるようにする。 Comment
LLMを用いてfew-shot promptingを利用して生成されたデータセットを理解し評価することは難しく、そもそもLLMによって生成されるデータの失敗に関してはあまり理解が進んでいない(e.g. repetitionなどは知られている)。この研究では、LLMによって生成されたデータセットの特性を理解するために、構文・語彙・意味の軸に沿ってクラスタリングすることで、データセットの特性を可視化することで、このような課題を解決することをサポートしている。
特に、従来研究ではGoldが存在することが前提な手法が利用されてきた(e.g. 生成データを利用しdownstream taskの予測性能で良さを測る、Gold distributionとdistributionを比較する)。しかし、このような手法では、synthetic data firstなシチュエーションで、Goldが存在しない場合に対処できない。このような問題を解決するためにGold dataが存在しない場合に、データの構文・語彙・意味に基づくクラスタリングを実施し結果を可視化し、human-in-the-loopの枠組みでデータセットの良さを検証する方法を提案している。
可視化例
実装: https://github.com/PAIR-code/interpretability/tree/master/data-synth-syntax
[Paper Note] Tractable Control for Autoregressive Language Generation, Honghua Zhang+, ICML'23, 2023.04
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Controllable #Pocket #NLP #LanguageModel #ICML Issue Date: 2023-04-28 GPT Summary- 自己回帰型大規模言語モデルは複雑な制約を満たすテキスト生成に課題がある。これに対処するため、語彙的制約を扱う確率モデル(TPMs)を用いたGeLaToフレームワークを提案。蒸留された隠れマルコフモデルを利用し、自己回帰生成の効率的な指導を可能にし、制約付きテキスト生成において最先端の性能を達成。研究は大規模言語モデルの制御に新たな道を開き、TPMsのさらなる発展を促進する。 Comment
自然言語生成モデルで、何らかのシンプルなconstiaint αの元p(xi|xi-1,α)を生成しようとしても計算ができない。このため、言語モデルをfinetuningするか、promptで制御するか、などがおこなわれる。しかしこの方法は近似的な解法であり、αがたとえシンプルであっても(何らかの語尾を付与するなど)、必ずしも満たした生成が行われるとは限らない。これは単に言語モデルがautoregressiveな方法で次のトークンの分布を予測しているだけであることに起因している。そこで、この問題を解決するために、tractable probabilistic model(TPM)を導入し、解決した。
評価の結果、CommonGenにおいて、SoTAを達成した。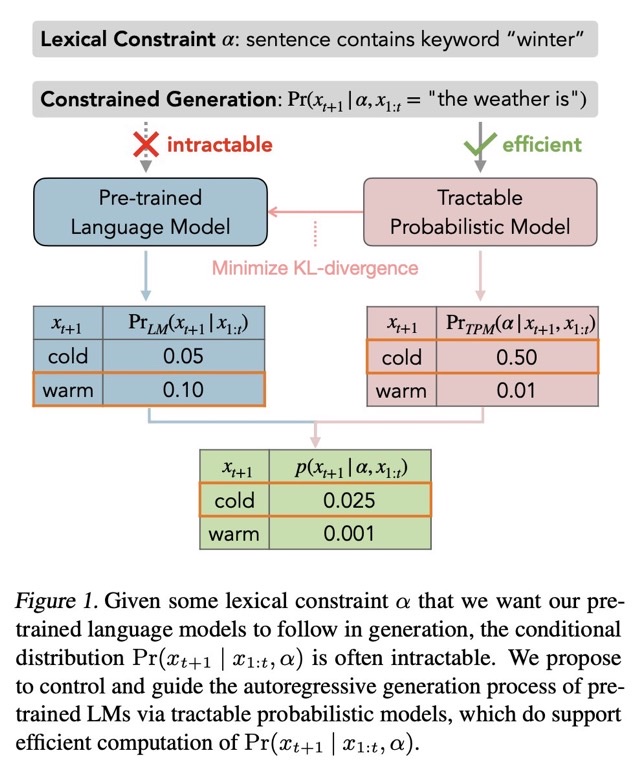
尚、TPMについては要勉強である
[Paper Note] WizardLM: Empowering large pre-trained language models to follow complex instructions, Can Xu+, arXiv'23, 2023.04
Paper/Blog Link My Issue
#Pocket #NLP #LanguageModel #InstructionTuning #SyntheticData #ICLR Issue Date: 2023-04-25 GPT Summary- 本論文では、LLMを用いて複雑な指示データを自動生成する方法を提案。Evol-Instructを使用して初期の指示を段階的に書き換え、生成したデータでLLaMAをファインチューニングし、WizardLMモデルを構築。評価結果は、Evol-Instructからの指示が人間作成のものより優れており、WizardLMがChatGPTよりも高い評価を得ることを示す。AI進化による指示生成がLLM強化の有望なアプローチであることを示唆。 Comment
instruction trainingは大きな成功を収めているが、人間がそれらのデータを作成するのはコストがかかる。また、そもそも複雑なinstructionを人間が作成するのは苦労する。そこで、LLMに自動的に作成させる手法を提案している(これはself instructと一緒)。データを生成する際は、seed setから始め、step by stepでinstructionをrewriteし、より複雑なinstructionとなるようにしていく。
これらの多段的な複雑度を持つinstructionをLLaMaベースのモデルに食わせてfinetuningした(これをWizardLMと呼ぶ)。人手評価の結果、WizardLMがChatGPTよりも好ましいレスポンスをすることを示した。特に、WizaraLMはコード生成や、数値計算といった難しいタスクで改善を示しており、複雑なinstructionを学習に利用することの重要性を示唆している。
EvolInstructを提案。"1+1=?"といったシンプルなinstructionからスタートし、これをLLMを利用して段階的にcomplexにしていく。complexにする方法は2通り:
- In-Depth Evolving: instructionを5種類のoperationで深掘りする(blue direction line)
- add constraints
- deepening
- concretizing
- increase reasoning steps
- complicate input
- In-breadth Evolving: givenなinstructionから新しいinstructionを生成する
上記のEvolvingは特定のpromptを与えることで実行される。
また、LLMはEvolvingに失敗することがあるので、Elimination Evolvingと呼ばれるフィルタを利用してスクリーニングした。
フィルタリングでは4種類の失敗するsituationを想定し、1つではLLMを利用。2枚目画像のようなinstructionでフィルタリング。
1. instructionの情報量が増えていない場合。
2. instructionがLLMによって応答困難な場合(短すぎる場合やsorryと言っている場合)
3. puctuationやstop wordsによってのみ構成されている場合
4.明らかにpromptの中から単語をコピーしただけのinstruction(given prompt, rewritten prompt, #Rewritten Prompt#など)

[Paper Note] Long Document Summarization with Top-down and Bottom-up Inference, Bo Pang+, EACL'23, 2022.03
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #Pocket #NLP #Abstractive #EACL Issue Date: 2022-09-02 GPT Summary- テキスト要約のための新しい推論フレームワークを提案。階層的な潜在構造を仮定し、ボトムアップとトップダウンの両方でトークンの表現を更新。短い文書に対して競争力のあるパフォーマンスを持ち、長文書要約でも最先端の結果を達成。少ないパラメータで競争力のある性能を示し、フレームワークの一般的な適用性を証明。 Comment
日本語解説:
https://zenn.dev/ty_nlp/articles/9f5e5dd3084dbd
以下、上記日本語解説記事を読んで理解した内容をまとめます。ありがとうございます。
# 概要
基本的にTransformerベースのモデル(e.g. BERTSum, BART, PEGASUS, GPT-2, T5)ではself-attentionの計算量が入力トークン数Nに対してO(N^2)でかかり、入力の二乗のオーダーで計算量が増えてしまう。
これを解消するためにself-attentionを計算する範囲をウィンドウサイズで制限するLongformerや、BigBardなどが提案されてきたが、どちらのモデルも離れたトークン間のattentionの情報が欠落するため、長距離のトークン間の関係性を捉えにくくなってしまう問題があった。
そこで、top-down transformerではセグメント(セグメントはテキストでいうところの文)という概念を提唱し、tokenからsegmentのrepresentationを生成しその後self-attentionでsegment間の関係性を考慮してsegmentのrepresentationを生成するbottom-up inference、各tokenとsegmentの関係性を考慮しし各tokenのrepresentationを学習するtop-down inferenceの2つの構造を利用した。bottom-up inferenceにおいてsegmentのrepresentationを計算する際にpoolingを実施するが、adapoolingと呼ばれる重要なトークンに重み付けをし、その重みを加味した加重平均によりプーリングを実施する。これにより、得られた各トークンの表現は、各セグメントとの関連度の情報を含み(セグメントの表現は各セグメント間のattentnionに基づいて計算されているため; bottom-up inference)、かつ各トークンと各セグメント間との関連度も考慮して計算されているため(top-down inference)、結果的に離れたトークン間の関連度を考慮したrepresentationが学習される(下図)。
(図は上記記事からお借りいたしました)
各attentionの計算量は表のようになり、M, wはNよりも遥かに小さいため、O(N^2)よりも遥かに小さい計算量で計算できる。
(こちらも上記記事からお借りいたしました)
# 実験(日本語解説より)
## データセット
## 結果
### PubMedとarXiv
### CNN-DailyMail
### TVMegasSiteとForeverDreaming
### BookSum-Chapter-Level
### BookSum-Book-Level
## 所感
CNN-DailyMailのようなinput wordsが900程度のデータではcomparableな結果となっているが、input wordsが長い場合は先行研究をoutperformしている。BookSum-Chapter Levelにおいて、Longformer, BigBirdの性能が悪く、BART, T5, Pegasusの性能が良いのが謎い。
てかinput wordsが3000~7000程度のデータに対して、どうやってBARTやらT5やらを実装できるんだろう。大抵512 tokenくらいが限界だと思っていたのだが、どうやったんだ・・・。
>The maximum document lengths for PubMed, arXiv, CNN-DM,
TVMegaSite, ForeverDreaming, BookSum are 8192, 16384, 1024, 12288, 12288, 12288, respectively
これは、たとえばBookSumの場合は仮にinputの長さが11万とかあったとしても、12288でtruncateしたということだろうか。まあなんにせよ、頑張ればこのくらいの系列長のモデルを学習できるということか(メモリに乗るのか・・・?どんな化け物マシンを使っているのか)。
>We first train a top-down transformer on the chapter-level data and then fine-tune it on the book-level
data. The inputs to the book-level model are (1) the concatenated chapter reference summaries in
training or (2) the concatenated chapter summaries generated by the chapter-level model in testing.
The chapter-to-book curriculum training is to mitigate the scarcity of book-level data. The recursive
summarization of chapters and then books can be considered abstractive content selection applied
to book data, and is used to address the extremely long length of books.
BookLevel Summarizationでは、データ数が300件程度しかなく、かつinput wordsがでかすぎる。これに対処するために、まずtop-down transformerをchapter-level_ dataで訓練して、その後book-level dataでfine-tuning。book-level dataでfine-tuningする際には、chapterごとのreference summaryをconcatしたものを正解とし、chapter-level modelが生成したchapterごとのsummaryをconcatしたものをモデルが生成した要約として扱った、という感じだろうか。まずchapter levelで学習しその後book levelで学習するcurriculum learningっぽいやり方がbook-level dataの不足を緩和してくれる。bookの要約を得るためにchapterを再帰的に要約するようなアプローチは、book dataに対するcontent selectionとしてみなすことができ、おそろしいほど長い入力の対処にもなっている、という感じだろうか。
[Paper Note] Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, Mitchell Wortsman+, ICML'22, 2022.03
Paper/Blog Link My Issue
#NeuralNetwork #ComputerVision #Pocket #NLP #ICML #Selected Papers/Blogs #OOD #Finetuning #Generalization #Encoder #Encoder-Decoder #Souping Issue Date: 2025-11-28 GPT Summary- ファインチューニングされたモデルの重みを平均化する「モデルスープ」手法を提案し、精度と堅牢性を向上させることを示す。従来のアンサンブル手法とは異なり、追加のコストなしで複数のモデルを平均化でき、ImageNetで90.94%のトップ1精度を達成。さらに、画像分類や自然言語処理タスクにも適用可能で、分布外性能やゼロショット性能を改善することが確認された。 Comment
transformerベースの事前学習済みモデル(encoder-only, encoder-decoderモデル)のファインチューニングの話で、共通のベースモデルかつ共通のパラメータの初期化を持つ、様々なハイパーパラメータで学習したモデルの重みを平均化することでよりロバストで高性能なモデルを作ります、という話。似たような手法にアンサンブルがあるが、アンサンブルでは利用するモデルに対して全ての推論結果を得なければならないため、計算コストが増大する。一方、モデルスープは単一モデルと同じ計算量で済む(=計算量は増大しない)。
スープを作る際は、Validation dataのAccが高い順に異なるFinetuning済みモデルをソートし、逐次的に重みの平均をとりValidation dataのAccが上がる場合に、当該モデルをsoupのingridientsとして加える。要は、開発データで性能が高い順にモデルをソートし、逐次的にモデルを取り出していき、現在のスープに対して重みを平均化した時に開発データの性能が上がるなら平均化したモデルを採用し、上がらないなら無視する、といった処理を繰り返す。これをgreedy soupと呼ぶ。他にもuniform soup, learned soupといった手法も提案され比較されているが、画像系のモデル(CLIP, ViTなど)やNLP(T5, BERT)等で実験されており、greedy soupの性能とロバストさ(OOD;分布シフトに対する予測性能)が良さそうである。
[Paper Note] Mixture of Attention Heads: Selecting Attention Heads Per Token, Xiaofeng Zhang+, EMNLP'22, 2022.10
Paper/Blog Link My Issue
#Pocket #NLP #Transformer #Attention #Architecture #MoE(Mixture-of-Experts) #EMNLP Issue Date: 2025-10-04 GPT Summary- Mixture of Attention Heads (MoA)は、MoEネットワークとマルチヘッドアテンションを組み合わせた新しいアーキテクチャで、動的に選択されたアテンションヘッドのサブセットを使用することでパフォーマンスを向上させる。スパースゲート化により計算効率を保ちながら拡張可能で、モデルの解釈可能性にも寄与する。実験では、機械翻訳やマスク付き言語モデリングなどのタスクで強力なベースラインを上回る結果を示した。 Comment
FFNに適用されることが多かったMoEをmulti-head attention (MHA) に適用する研究。このようなattentionをMixture of Attention Heads (MoA)と呼ぶ。
各MHAは複数のattention expertsを持ち、その中からK個のExpertsが現在のクエリq_tに基づいてRouterによって選出(式7, 8)される。それぞれのattention expertsに対してq_tが流され、通常のMHAと同じ流れでoutputが計算され、最終的に選択された際の(正規化された(式9))probabilityによる加重平均によって出力を計算する(式6)。
注意点としては、各attention expertsは独立したprojection matrix W_q, W_o(それぞれi番目のexpertsにおけるトークンtにおいて、query q_tを変換、output o_{i,t}をhidden space次元に戻す役割を持つ)を持つが、K, Vに対する変換行列は共有すると言う点。これにより、次元に全てのexpertsに対してk, vに対する変換は計算しておけるので、headごとに異なる変換を学習しながら、計算コストを大幅に削減できる。
また、特定のexpertsにのみルーティングが集中しないように、lossを調整することで学習の安定させ性能を向上させている(4.3節)。
Training language models to follow instructions with human feedback, Long Ouyang+, N_A, NeurIPS'22
Paper/Blog Link My Issue
#NLP #LanguageModel #Alignment #ChatGPT #RLHF #PPO (ProximalPolicyOptimization) #PostTraining #read-later #Selected Papers/Blogs Issue Date: 2024-04-28 GPT Summary- 大規模な言語モデルは、ユーザーの意図に合わない出力を生成することがあります。本研究では、人間のフィードバックを使用してGPT-3を微調整し、InstructGPTと呼ばれるモデルを提案します。この手法により、13億パラメータのInstructGPTモデルの出力が175BのGPT-3の出力よりも好まれ、真実性の向上と有害な出力の削減が示されました。さらに、一般的なNLPデータセットにおける性能の低下は最小限でした。InstructGPTはまだ改善の余地がありますが、人間のフィードバックを使用した微調整が有望な方向であることを示しています。 Comment
ChatGPTの元となる、SFT→Reward Modelの訓練→RLHFの流れが提案された研究。DemonstrationデータだけでSFTするだけでは、人間の意図したとおりに動作しない問題があったため、人間の意図にAlignするように、Reward Modelを用いたRLHFでSFTの後に追加で学習を実施する。Reward Modelは、175Bモデルは学習が安定しなかった上に、PPOの計算コストが非常に大きいため、6BのGPT-3を様々なNLPタスクでSFTしたモデルをスタートにし、モデルのアウトプットに対して人間がランキング付けしたデータをペアワイズのloss functionで訓練した。最終的に、RMのスコアが最大化されるようにSFTしたGPT-3をRLHFで訓練するが、その際に、SFTから出力が離れすぎないようにする項と、NLPベンチマークでの性能が劣化しないようにpretrain時のタスクの性能もloss functionに加えている。
[Paper Note] MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers, Wenhui Wang+, ACL'21 Findings, 2020.12
Paper/Blog Link My Issue
#Pocket #NLP #Transformer #Attention #Distillation #ACL #Encoder #Findings Issue Date: 2025-10-20 GPT Summary- 自己注意関係蒸留を用いて、MiniLMの深層自己注意蒸留を一般化し、事前学習されたトランスフォーマーの圧縮を行う手法を提案。クエリ、キー、バリューのベクトル間の関係を定義し、生徒モデルを訓練。注意ヘッド数に制限がなく、教師モデルの層選択戦略を検討。実験により、BERTやRoBERTa、XLM-Rから蒸留されたモデルが最先端の性能を上回ることを示した。 Comment
教師と(より小規模な)生徒モデル間で、tokenごとのq-q/k-k/v-vのdot productによって形成されるrelation map(たとえばq-qの場合はrelatiok mapはトークン数xトークン数の行列で各要素がdot(qi, qj))で表現される関係性を再現できるようにMHAを蒸留するような手法。具体的には、教師モデルのQKVと生徒モデルのQKVによって構成されるそれぞれのrelation map間のKL Divergenceを最小化するように蒸留する。このとき教師モデルと生徒モデルのattention heads数などは異なってもよい(q-q/k-k/v-vそれぞれで定義されるrelation mapははトークン数に依存しており、head数には依存していないため)。
[Paper Note] An Embedding Learning Framework for Numerical Features in CTR Prediction, Huifeng Guo+, KDD'21
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #Embeddings #Pocket #CTRPrediction #RepresentationLearning #SIGKDD #numeric Issue Date: 2025-04-22 GPT Summary- CTR予測のための新しい埋め込み学習フレームワーク「AutoDis」を提案。数値特徴の埋め込みを強化し、高いモデル容量とエンドツーエンドのトレーニングを実現。メタ埋め込み、自動離散化、集約の3つのコアコンポーネントを用いて、数値特徴の相関を捉え、独自の埋め込みを学習。実験により、CTRとeCPMでそれぞれ2.1%および2.7%の改善を達成。コードは公開されている。 Comment
従来はdiscretizeをするか、mlpなどでembeddingを作成するだけだった数値のinputをうまく埋め込みに変換する手法を提案し性能改善
数値情報を別の空間に写像し自動的なdiscretizationを実施する機構と、各数値情報のフィールドごとのglobalな情報を保持するmeta-embeddingをtrainable parameterとして学習し、両者を交互作用(aggregation; max-poolingとか)することで数値embeddingを取得する。
The Perils of Using Mechanical Turk to Evaluate Open-Ended Text Generation, Marzena Karpinska+, N_A, EMNLP'21
Paper/Blog Link My Issue
#Analysis #NaturalLanguageGeneration #Pocket #NLP #Evaluation #Annotation #Reproducibility Issue Date: 2024-05-15 GPT Summary- 最近のテキスト生成の研究は、オープンエンドのドメインに注力しており、その評価が難しいため、多くの研究者がクラウドソーシングされた人間の判断を収集してモデリングを正当化している。しかし、多くの研究は重要な詳細を報告しておらず、再現性が妨げられていることがわかった。さらに、労働者はモデル生成のテキストと人間による参照テキストを区別できないことが発見され、表示方法を変更することで改善されることが示された。英語教師とのインタビューでは、モデル生成のテキストを評価する際の課題について、より深い洞察が得られた。 Comment
Open-endedなタスクに対するAMTの評価の再現性に関する研究。先行研究をSurveyしたところ、再現のために重要な情報(たとえば、workerの資格、費用、task descriptions、annotator間のagreementなど)が欠落していることが判明した。
続いて、expertsとAMT workerに対して、story generationの評価を実施し、GPT2が生成したストーリーと人間が生成したストーリーを、後者のスコアが高くなることを期待して依頼した。その結果
- AMTのratingは、モデルが生成したテキストと、人間が生成したテキストをreliableに区別できない
- 同一のタスクを異なる日程で実施をすると、高い分散が生じた
- 多くのAMT workerは、評価対象のテキストを注意深く読んでいない
- Expertでさえモデルが生成したテキストを読み判断するのには苦戦をし、先行研究と比較してより多くの時間を費やし、agreementが低くなることが分かった
- [Paper Note] Can Large Language Models Be an Alternative to Human Evaluations?, Cheng-Han Chiang+, ACL'23, 2023.05
において、低品質なwork forceが人手評価に対して有害な影響を与える、という文脈で本研究が引用されている
[Paper Note] Dense Passage Retrieval for Open-Domain Question Answering, Vladimir Karpukhin+, EMNLP'20, 2020.04
Paper/Blog Link My Issue
#Embeddings #InformationRetrieval #Pocket #NLP #QuestionAnswering #ContrastiveLearning #EMNLP #Selected Papers/Blogs #Encoder Issue Date: 2025-09-28 GPT Summary- 密な表現を用いたパッセージ検索の実装を示し、デュアルエンコーダーフレームワークで学習。評価の結果、Lucene-BM25を上回り、検索精度で9%-19%の改善を達成。新たな最先端のQA成果を確立。 Comment
Dense Retrieverが広く知られるきっかけとなった研究(より古くはDSSM Learning Deep Structured Semantic Models for Web Search using Clickthrough Data, Huang+, CIKM'13
などがある)。bag-of-wordsのようなsparseなベクトルで検索するのではなく(=Sparse Retriever)、ニューラルモデルでエンコードした密なベクトルを用いて検索しようという考え方である。
Query用と検索対象のPassageをエンコードするEncoderを独立してそれぞれ用意し(=DualEncoder)、QAの学習データ(すなわちクエリqと正例として正解passage p+)が与えられた時、クエリqと正例p+の類似度が高く、負例p-との類似度が低くなるように(=Contrastive Learning)、Query, Passage Encoderのパラメータを更新することで学習する(損失関数は式(2))。
負例はIn-Batch Negativeを用いる。情報検索の場合正解ラベルは多くの場合明示的に決まるが、負例は膨大なテキストのプールからサンプリングしなければならない。サンプリング方法はいろいろな方法があり(e.g., ランダムにサンプリング、qとbm25スコアが高いpassage(ただし正解は含まない; hard negativesと呼ぶ)その中の一つの方法がIn-Batch Negativesである。
In-Batch Negativesでは、同ミニバッチ内のq_iに対応する正例p+_i以外の全てのp_jを(擬似的に)負例とみなす。これにより、パラメータの更新に利用するためのq,pのエンコードを全て一度だけ実行すれば良く、計算効率が大幅に向上するという優れもの。本研究の実験(Table3)によると上述したIn-Batch Negativeに加えて、bm25によるhard negativeをバッチ内の各qに対して1つ負例として追加する方法が最も性能が良かった。
クエリ、passageのエンコーダとしては、BERTが用いられ、[CLS]トークンに対応するembeddingを用いて類似度が計算される。
[Paper Note] Leveraging Pre-trained Checkpoints for Sequence Generation Tasks, Sascha Rothe+, TACL'20, 2019.07
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #MachineTranslation #NLP #Transformer #pretrained-LM #TACL Issue Date: 2022-12-01 GPT Summary- 事前学習された大規模なニューラルモデルがシーケンス生成においても有効であることを示し、BERT、GPT-2、RoBERTaと互換性のあるTransformerベースのモデルを開発。これにより、機械翻訳やテキスト要約などのタスクで新たな最先端の成果を達成。 Comment
# 概要
BERT-to-BERT論文。これまでpre-trainedなチェックポイントを利用する研究は主にNLUで行われてきており、Seq2Seqでは行われてきていなかったので、やりました、という話。
publicly availableなBERTのcheckpointを利用し、BERTをencoder, decoder両方に採用することでSeq2Seqを実現。実現する上で、
1. decoder側のBERTはautoregressiveな生成をするようにする(左側のトークンのattentionしか見れないようにする)
2. encoder-decoder attentionを新たに導入する
の2点を工夫している。
# 実験
Sentence Fusion, Sentence Split, Machine Translation, Summarizationの4タスクで実験
## MT
BERT2BERTがSoTA達成。Edunov+の手法は、data _augmentationを利用した手法であり、純粋なWMT14データを使った中ではSoTAだと主張。特にEncoder側でBERTを使うと、Randomにinitializeした場合と比べて性能が顕著に上昇しており、その重要性を主張。
Sentence Fusion, Sentence Splitでは、encoderとdecoderのパラメータをshareするのが良かったが、MTでは有効ではなかった。これはMTではmodelのcapacityが非常に重要である点、encoderとdecoderで異なる文法を扱うためであると考えられる。
## Summarization
BERTSHARE, ROBERTASHAREの結果が良かった。
[Paper Note] Text-to-Text Pre-Training for Data-to-Text Tasks, Mihir+, Google Research, INLG'20
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #NLP #DataToTextGeneration #Transformer #INLG Issue Date: 2022-09-16 Comment
# 概要
pre-training済みのT5に対して、Data2Textのデータセットでfinetuningを実施する方法を提案。WebNLG(graph-to-text), ToTTo(table-to-text), Multiwoz(task oriented dialogue)データにおいて、simpleなTransformerでも洗練されたmulti-stageなpipelined approachをoutperformできることを示した研究。
# 手法
事前学習済みのT5に対してfine-tuningを実施した。手法はシンプルで、data-to-textタスクをtext-to-textタスクに変換した。具体的には、構造かされたデータをflatな文字列(linearization)で表現することで、text-to-textタスクに変換。各データセットに対するlinearizationのイメージは下図。デリミタや特殊文字を使って構造かされたデータをflatなstringで表現している。
# データセット
## ToTTo(2020)
Wikipediaのテーブルと自然言語でdescriptionのペアデータ
## MultiWoz(2018)
10Kの人間同士のtask-orientedなdialogueデータ。
## WebNLG(2017)
subject-object-predicateの3組みをテキスト表現に変換するタスクのデータ
# Result
## WebNLG
GCNを利用した2020年に提案されたDualEncがSoTAだったらしいが、outperormしている。
## ToTTo
[こちら](
https://github.com/google-research-datasets/totto)のリーダーボードと比較してSoTAを記録
## MultiWoz
T5は事前学習済みGPT-2をfinetuningした手法もoutperformした。SC-GPT2は当時のMultiWozでのSoTA
# Impact of Model capacity
T5モデルのサイズがどれが良いかについては、データセットのサイズと複雑さに依存することを考察している。たとえば、MultiWozデータは構造化データのバリエーションが最も少なく、データ量も56kと比較的多かった。このため、T5-smallでもより大きいモデルの性能に肉薄できている。
一方、WebNLGデータセットは、18kしか事例がなく、特徴量も約200種類程度のrelationのみである。このような場合、モデルサイズが大きくなるにつれパフォーマンスも向上した(特にUnseen test set)。特にBLEUスコアはT5-smallがT5-baseになると、10ポイントもジャンプしており、modelのcapacityがout-of-domainに対する一般化に対してcriticalであることがわかる。ToTToデータセットでも、SmallからBaseにするとパフォーマンスは改善した。
# 所感
こんな簡単なfine-tuningでSoTAを達成できてしまうとは、末恐ろしい。ベースラインとして有用。
When is Deep Learning the Best Approach to Knowledge Tracing?, Theophile+ (Ken Koedinger), CMU+, JEDM'20
Paper/Blog Link My Issue
#NeuralNetwork #AdaptiveLearning #EducationalDataMining #LearningAnalytics #KnowledgeTracing Issue Date: 2022-04-28 Comment
下記モデルの性能をAUCとRMSEの観点から9つのデータセットで比較した研究
- DLKT
- DKT
- SAKT
- FFN
- Regression Models
- IRT
- PFA
- DAS3H
- Logistinc Regression
- variation of BKT
- BKT+ (add individualization, forgetting, discovery of knowledge components)
DKT、およびLogistic Regressionが最も良い性能を示し、DKTは5種類のデータセットで、Logistic Regressionは4種類のデータセットでbestな結果を示した。
SAKTは A Self-Attentive model for Knowledge Tracing, Pandy+ (with George Carypis), EDM'19
で示されている結果とは異なり、全てのデータセットにおいてDKTの性能を下回った。
また、データセットのサイズがモデルのパフォーマンスに影響していることを示しており、
小さなデータセットの場合はLogistic Regressionのパフォーマンスがよく、
大きなデータセットの場合はDKTの性能が良かった。
(アイテムごとの学習者数の中央値、およびKCごとの学習者数の中央値が小さければ小さいほど、Logistic Regressionモデルが強く、DLKTモデルはoverfitしてしまった; たとえば、アイテムごとの学習者数の中央値が1, 4, 10とかのデータではLRが強い; アイテムごとの学習者数の中央値が仮に大きかったとしても、KCごとの学習者数の中央値が少ないデータ(200程度; Spanish)では、Logistic Regressionが強い)。
加えて、DKTはLogistic Regressionと比較して、より早くピークパフォーマンスに到達することがわかった。
ちなみに、一つのアイテムに複数のKCが紐づいている場合は、それらを組み合わせ新たなKCを作成することで、DKTとSAKTに適用したと書いてある(この辺がずっと分かりづらかった)。
データセットの統計量はこちら:
データセットごとに、連続して同じトピックの問題(i.e. 連続した問題IDの問題を順番に解いている)を解いている割合(i.e. どれだけ順番に問題を解いていっているか)を算出した結果が下図。
同じトピックの問題を連続して解いている場合(i.e. 順番に問題を解いていっている場合)に、DKTの性能が良い。
またパフォーマンスに影響を与える要因として、学習者ごとのインタラクション数が挙げられる。ほとんどのデータセットでは、power-lawに従い中央値が数百程度だが、bridge06やspanishのように、power-lawになっておらず中央値が数千といったデータが存在する。こういったデータではDKTはlong-termの情報を捉えきれず、高い性能を発揮しない。
実験に利用した実装はこちら:
https://github.com/theophilee/learner-performance-prediction
ただ、実装を見るとDKTの実装はオリジナルの論文とは全く異なる工夫が加えられていそう
https://github.com/theophilee/learner-performance-prediction/blob/master/model_dkt2.py
これをDKTって言っていいの・・・?
オリジナルのDKTの実装はDKT1として実装されていそうだけど、その性能は報告されていないと思われる・・・。
DKT1の実装じゃないと、KCのマスタリーは取得できないんでは。
追記:と思ったら、DKTのAblation Studyで報告されている Input/Output をKC, Itemsで変化させた場合のAUCの性能の変化の表において、best performingだった場合のAUCスコアが9つのデータセットに対するDKTの予測性能に記載されている・・・。
じゃあDKT2はどこで使われているの・・・。
DKTは、inputとしてquestion_idを使うかKCのidを使うか選択できる。また、outputもquestion_idに対するprobabilityをoutputするか、KCに対するprobabilityをoutputするか選択できる。
これらの組み合わせによって、予測性能がどの程度変化するかを検証した結果が下記。
KCをinputし、question_idをoutputとする方法が最も性能が良かった。
明記されていないが、おそらくこの検証にはDKT1の実装を利用していると思われる。input / outputをquestionかKCかを選べるようになっていたので。
実際にIssueでも、assistments09のAUC0.75を再現したかったら、dkt1をinput/output共にKCに指定して実行しろと著者が回答している。
ちなみに論文中の9つのデータセットに対するAUCの比較では、各々のモデルはKCに対して正答率を予測しているのではなく、個々の問題単位で正答率を予測していると思われる(実装を見た感じ)。
[Paper Note] EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction, Qi Liu+, IEEE TKDE'19, 2019.06
Paper/Blog Link My Issue
#NeuralNetwork #Pocket #EducationalDataMining #LearningAnalytics #StudentPerformancePrediction #KnowledgeTracing #Selected Papers/Blogs Issue Date: 2021-05-28 GPT Summary- 学生のパフォーマンス予測のために、演習記録と教材情報を統合するEERNNフレームワークを提案。双方向LSTMを用いて演習内容をエンコードし、マルコフ特性とアテンションメカニズムを持つ2つの実装を提供。さらに、知識概念を追跡するEKTに拡張し、演習が知識習得に与える影響を定量化。実験により、予測精度と解釈可能性の向上が確認された。 Comment
DKT等のDeepなモデルでは、これまで問題テキストの情報等は利用されてこなかったが、learning logのみならず、問題テキストの情報等もKTする際に活用した研究。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
をより洗練させjournal化させたものだと思われる。
[Paper Note] Exercise-Enhanced Sequential Modeling for Student Performance Prediction, Hu+, AAAI'18
ではKTというより、問題の正誤を予測するモデルとなっており、個々のconceptに対するproficiencyを推定するというKTの考え方はあまり導入されていなかった。
EKTの方では、個々のknowledge componentのproficiency scoreを算出する方法も提案されている。
モデル自体は、基本的にはattention-basedなRNNモデル。

Exercise EmbeddingはBidireictional-RNNを利用して、問題文をエンコードすることによって求める。
EKTによるmastery levelを可視化したもの。T=0とT=30では各conceptに対するmastery levelが大きく異なっている。基本的に、たくさん正解したconceptはmastery levelが向上し、不正解しまくったconceptはどんどんmastery levelがshrinkしていく。
予測性能。問題のContentを考慮することで、正誤予測のAUCは圧倒的に高くなる。DKTよりも10ポイント程度EKTAの方がAUCが高いように見える。
各モデルの特徴や、knowledge tracingが行えるか否か、といった性質を整理した表。わかりやすい。しかしDKTのknowledge tracking?が×になっているのは誤りでは?
各knowledge conceptの時刻tにおけるmastery levelの求め方。
EKTでは、生徒の各knowledge conceptの状態を保持した行列H_t^i(0 <= i <= # of concepts)を保持している。correctness probabilityを最終的に求める際には、H_t^iの各knowledge conceptに対する重みβ_iで重みづけた上でsummationをとり、各知識の状態を統合したベクトルsを作成し、sとexercise embedding xをconcatした上でスコアを予測する。
このスコアの予測部分を変更し、β_iをmastery levelを測定したいconceptのone-hot encodingに置き換え、さらにexercise embeddingをmaskしたベクトル=masked exercise embedding = zero vectorをconcatした上で、スコアを予測するようにする。
こうすることで、exerciseの影響を除き、かつone-hot encodingで指定したknowledgeのmasteryのみが考慮されたスコアを抽出できるため、そのスコアをmastery levelとする。
単にStudent Performance Predictionして終わり!ってんじゃなく、knowledge tracing的な側面をきちんと考慮している点で、この研究めっちゃ好き。
スキルタグごとにLSTMのhidden_stateを保持しないといけないので、メモリの消費量がえぐいことになりそう。小規模なスキルタグのデータセットじゃないと動かないのでは?
実際、実験では37種類のスキルタグが存在するデータセットしか扱っていない。
[Paper Note] DKN: Deep Knowledge-Aware Network for News Recommendation, Hongwei Wang+, arXiv'18, 2018.01
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Pocket #Contents-based #NewsRecommendation #WWW Issue Date: 2021-06-01 GPT Summary- オンラインニュース推薦システムの課題を解決するために、知識グラフを活用した深層知識認識ネットワーク(DKN)を提案。DKNは、ニュースの意味と知識を融合する多チャネルの知識認識畳み込みニューラルネットワーク(KCNN)を用い、ユーザーの履歴を動的に集約する注意モジュールを搭載。実験により、DKNが最先端の推薦モデルを大幅に上回る性能を示し、知識の有効性も確認。 Comment
# Overview
Contents-basedな手法でCTRを予測しNews推薦。newsのタイトルに含まれるentityをknowledge graphと紐づけて、情報をよりリッチにして活用する。
CNNでword-embeddingのみならず、entity embedding, contextual entity embedding(entityと関連するentity)をエンコードし、knowledge-awareなnewsのrepresentationを取得し予測する。
※ contextual entityは、entityのknowledge graph上でのneighborhoodに存在するentityのこと(neighborhoodの情報を活用することでdistinguishableでよりリッチな情報を活用できる)
CNNのinputを\[\[word_ embedding\], \[entity embedding\], \[contextual entity embedding\]\](画像のRGB)のように、multi-channelで構成し3次元のフィルタでconvolutionすることで、word, entity, contextual entityを表現する空間は別に保ちながら(同じ空間で表現するのは適切ではない)、wordとentityのalignmentがとれた状態でのrepresentationを獲得する。
# Experiments
BingNewsのサーバログデータを利用して評価。
データは (timestamp, userid, news url, news title, click count (0=no click, 1=click))のレコードによって構成されている。
2016年11月16日〜2017年6月11日の間のデータからランダムサンプリングしtrainingデータセットとした。
また、2017年6月12日〜2017年8月11日までのデータをtestデータセットとした。
word/entity embeddingの次元は100, フィルタのサイズは1,2,3,4とした。loss functionはlog lossを利用し、Adamで学習した。

DeepFM超えを達成。
entity embedding, contextual entity embeddingをablationすると、AUCは2ポイントほど現象するが、それでもDeepFMよりは高い性能を示している。
また、attentionを抜くとAUCは1ポイントほど減少する。
1ユーザのtraining/testセットのサンプル
Sentiment analysis with deeply learned distributed representations of variable length texts, Hong+, Technical Report. Technical report, Stanford University, 2015
によって経験的にRNN, Recursive Neural Network等と比較して、sentenceのrepresentationを獲得する際にCNNが優れていることが示されているため、CNNでrepresentationを獲得することにした模様(footprint 7より)
Factorization Machinesベースドな手法(LibFM, DeepFM)を利用する際は、TF-IDF featureと、averaged entity embeddingによって構成し、それをuser newsとcandidate news同士でconcatしてFeatureとして入力した模様
content情報を一切利用せず、ユーザのimplicit feedbackデータ(news click)のみを利用するDMF(Deep Matrix Factorization)の性能がかなり悪いのもおもしろい。やはりuser-item-implicit feedbackデータのみだけでなく、コンテンツの情報を利用した方が強い。
(おそらく)著者によるtensor-flowでの実装: https://github.com/hwwang55/DKN
[Paper Note] Challenges in Data-to-Document Generation, Sam Wiseman+, EMNLP'17, 2017.07
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #DataToTextGeneration #EMNLP #Selected Papers/Blogs Issue Date: 2018-01-01 GPT Summary- ニューラルモデルは少数のデータから短い説明文を生成するタスクで進展を見せているが、難易度の高いデータに対しては効果が限定的である。本研究では新たなデータレコードと説明文のコーパスを導入し、評価手法を提案してパフォーマンスを分析した。実験結果では、モデルは流暢なテキストを生成するものの、人間の文書には及ばず、テンプレートベースの手法が一部指標で優れていることが示された。コピーや再構築に基づく拡張が改善をもたらすことも確認された。 Comment
・RotoWire(NBAのテーブルデータ + サマリ)データを収集し公開
・Rotowireデータの統計量
【モデルの概要】
・attention-based encoder-decoder model
・BaseModel
- レコードデータ r の各要素(r.e: チーム名等のENTITY r.t: POINTS等のデータタイプ, r.m: データのvalue)からembeddingをlookupし、1-layer MLPを適用し、レコードの各要素のrepresentation(source data records)を取得
- Luongらのattentionを利用したLSTM Decoderを用意し、source data recordsとt-1ステップ目での出力によって条件付けてテキストを生成していく
- negative log likelihoodがminimizeされるように学習する
・Copying
- コピーメカニズムを導入し、生成時の確率分布に生成テキストを入力からコピーされるか否かを含めた分布からテキストを生成。コピーの対象は、入力レコードのvalueがコピーされるようにする。
- コピーメカニズムには下記式で表現される Conditional Copy Modelを利用し、p(zt|y1:t-1, s)はMLPで表現する(Conditional Copy Model 節参照)。
- またpcopyは、生成している文中にあるレコードのエンティティとタイプが出現する場合に、対応するvalueをコピーし生成されるように表現する
[Paper Note] Why We Need New Evaluation Metrics for NLG, Novikova+, EMNLP'17
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #EMNLP Issue Date: 2018-01-01 Comment
解説スライド: https://www.dropbox.com/s/7o8v64nr6gyj065/20170915_SNLP2017_Nishikawa.pptx?dl=0
言語生成の評価指標が信用ならないので、3種類の生成器、3種類のデータを用意し、多数の自動評価尺度を利用した評価結果と人手評価の結果を比較した結果、相関がなかった。
既存の自動評価は人手評価と弱い相関しかなく、その有効性はデータとドメインに依存。
システム間の比較およびシステムの性能が低い場合においては有効。
[Paper Note] Get To The Point: Summarization with Pointer-Generator Networks, Abigail See+, arXiv'17, 2017.04
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #Pocket #NLP #Abstractive #ACL #Selected Papers/Blogs Issue Date: 2017-12-31 GPT Summary- ニューラルシーケンス・ツー・シーケンスモデルは抽象的なテキスト要約に新たなアプローチを提供するが、事実の不正確な再現と自己繰り返しの問題がある。本研究では、ハイブリッドポインタージェネレーターネットワークを用いて情報の正確な再現を促進し、カバレッジを利用して繰り返しを抑制する新しいアーキテクチャを提案。CNN/Daily Mail要約タスクで、最先端技術を2 ROUGEポイント上回る結果を得た。 Comment
単語の生成と単語のコピーの両方を行えるハイブリッドなニューラル文書要約モデルを提案。
同じ単語の繰り返し現象(repetition)をなくすために、Coverage Mechanismも導入した。
[Paper Note] Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16
などと比較するとシンプルなモデル。
一般的に、PointerGeneratorと呼ばれる。
OpenNMTなどにも実装されている:
https://opennmt.net/OpenNMT-py/_modules/onmt/modules/copy_generator.html
(参考)Pointer Generator Networksで要約してみる:
https://qiita.com/knok/items/9a74430b279e522d5b93
[Paper Note] Graph-based Neural Multi-Document Summarization, Michihiro Yasunaga+, CoNLL'17, 2017.06
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NeuralNetwork #Document #Supervised #GraphBased #Pocket #NLP #GraphConvolutionalNetwork #Extractive #CoNLL Issue Date: 2017-12-31 GPT Summary- 文の関係グラフを用いたニューラルマルチドキュメント要約システムを提案。GCNを適用し、重要な文の特徴を生成後、貪欲なヒューリスティックで文を抽出。DUC 2004の実験で、従来の手法を上回る競争力のある結果を示す。 Comment
Graph Convolutional Network (GCN)を使って、MDSやりましたという話。 既存のニューラルなMDSモデル [Cao et al., 2015, 2017] では、sentence間のrelationが考慮できていなかったが、GCN使って考慮した。 また、MDSの学習データはニューラルなモデルを学習するには小さすぎるが(abstractiveにするのは厳しいという話だと思われる?)、sentenceのsalienceを求める問題に帰着させることで、これを克服。
GCNで用いるAdjacent Matrixとして3種類の方法(cosine similarity, G-Flow, PDG)を試し、議論をしている。PDGが提案手法だが、G-Flowによる重みをPersonalization Features(position, leadか否か等のベーシックな素性)から求まるweightで、よりsentenceのsalienceを求める際にリッチな情報を扱えるように補正している。PDGを用いた場合が(ROUGE的な観点で)最も性能がよかった。
モデルの処理の流れとしては、Document Cluster中の各sentenceのhidden stateをGRUベースなRNNでエンコードし、それをGCNのノードの初期値として利用する。GCNでL回のpropagation後(実験では3回)に得られたノードのhidden stateを、salienceスコア計算に用いるsentence embedding、およびcluster embeddingの生成に用いる。 cluster embeddingは、document clusterをglobalな視点から見て、salienceスコアに反映させるために用いられる。 最終的にこれら2つの情報をlinearなlayerにかけてsoftmaxかけて正規化して、salienceスコアとする。
要約を生成する際はgreedyな方法を用いており、salienceスコアの高いsentenceから要約長に達するまで選択していく。このとき、冗長性を排除するため、candidateとなるsentenceと生成中の要約とのcosine similarityが0.5を超えるものは選択しないといった、よくある操作を行なっている。
DUC01, 02のデータをtraining data, DUC03 をvalidation data, DUC04をtest dataとし、ROUGE1,2で評価。 評価の結果、CLASSY04(DUC04のbest system)やLexRank等のよく使われるベースラインをoutperform。 ただ、regression basedなRegSumにはスコアで勝てないという結果に。 RegSumはwordレベルでsalienceスコアをregressionする手法で、リッチな情報を結構使っているので、これらを提案手法に組み合わせるのは有望な方向性だと議論している。
[Cao+, 2015] Ranking with recursive neural networks and its application to multi-document summarization, Cao+, AAAI'15 [Cao+, 2017] Improving multi-document summarization via text classification, Cao+, AAAI'17
[所感]
・ニューラルなモデルは表現力は高そうだけど、学習データがDUC01と02だけだと、データが足りなくて持ち前の表現力が活かせていないのではないかという気がする。
・冗長性の排除をアドホックにやっているので、モデルにうまく組み込めないかなという印象(distraction機構とか使えばいいのかもしれん)
・ROUGEでしか評価してないけど、実際のoutputはどんな感じなのかちょっと見てみたい。(ハイレベルなシステムだとROUGEスコア上がっても人手評価との相関がないっていう研究成果もあるし。)
・GCN、あまり知らなかったかけど数式追ったらなんとなく分かったと思われる。(元論文読めという話だが)
[Paper Note] Human Centered NLP with User-Factor Adaptation, Lynn+, EMNLP'17
Paper/Blog Link My Issue
#MachineLearning #DomainAdaptation #UserModeling #EMNLP Issue Date: 2017-12-31 Comment
[Paper Note] Frustratingly easy domain adaptation, Daum'e, ACL'07
Frustratingly easy domain adaptationをPersonalization用に拡張している。
Frustratingly easy domain adaptationでは、domain adaptationを行うときに、discreteなクラスに分けてfeature vectorを作る(age>28など)が、Personalizationを行う際は、このようなdiscreteな表現よりも、continousな表現の方が表現力が高いので良い(feature vectorとそのままのageを使いベクトルをcompositionするなど)。
psychologyの分野だと、人間のfactorをdiscreteに表現して、ある人物を表現することはnoisyだと知られているので、continuousなユーザfactorを使って、domain adaptationしましたという話。
やってることは単純で、feature vectorを作る際に、各クラスごとにfeature vectorをコピーして、feature augmentationするのではなく、continuousなuser factorとの積をとった値でfeature augmentationするというだけ。
これをするだけで、Sentiment analysis, sarcasm detection, PP-attachmentなどのタスクにおいて、F1スコアで1〜3ポイント程度のgainを得ている。特に、sarcasm detectionではgainが顕著。
pos tagging, stance detection(against, neutral, forなどの同定)では効果がなく、stance detectionではそもそもdiscrete adaptationの方が良い結果。
正直、もっと色々やり方はある気がするし、user embeddingを作り際などは5次元程度でしか作ってないので、これでいいのかなぁという気はする・・・。
user factorの次元数増やすと、その分feature vectorのサイズも大きくなるから、あまり次元数を増やしたりもできないのかもしれない。
[Paper Note] Toward Controlled Generation of Text, Zhiting Hu+, ICML'17, 2017.03
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #Controllable #Pocket #NLP #DataToTextGeneration #ConceptToTextGeneration #GenerativeAdversarialNetwork #ICML #Selected Papers/Blogs Issue Date: 2017-12-31 GPT Summary- 属性に基づいて制御された自然言語文を生成するために、変分オートエンコーダと属性識別器を組み合わせた新しい生成モデルを提案。微分可能な近似を用いて解釈可能な表現を学習し、望ましい属性を持つ文を生成。定量的評価で生成の正確性を確認。 Comment
Text Generationを行う際は、現在は基本的に学習された言語モデルの尤度に従ってテキストを生成するのみで、outputされるテキストをcontrolすることができないので、できるようにしましたという論文。 VAEによるテキスト生成にGANを組み合わせたようなモデル。 decodingする元となるfeatureのある次元が、たとえばpolarityなどに対応しており、その次元の数値をいじるだけで生成されるテキストをcontrolできる。
テキストを生成する際に、生成されるテキストをコントロールするための研究。 テキストを生成する際には、基本的にはVariational Auto Encoder(VAE)を用いる。
VAEは、入力をエンコードするEncoderと、エンコードされた潜在変数zからテキストを生成するGeneratorの2つの機構によって構成されている。
この研究では、生成されるテキストをコントロールするために、VAEの潜在変数zに、生成するテキストのattributeを表す変数cを新たに導入。
たとえば、一例として、変数cをsentimentに対応させた場合、変数cの値を変更すると、生成されるテキストのsentimentが変化するような生成が実現可能。
次に、このような生成を実現できるようなパラメータを学習したいが、学習を行う際のポイントは、以下の二つ。
cで指定されたattributeが反映されたテキストを生成するように学習
潜在変数zとattributeに関する変数cの独立性を保つように学習 (cには制御したいattributeに関する情報のみが格納され、その他の情報は潜在変数zに格納されるように学習する)
1を実現するために、新たにdiscriminatorと呼ばれる識別器を用意し、VAEが生成したテキストのattributeをdiscriminatorで分類し、その結果をVAEのGeneratorにフィードバックすることで、attributeが反映されたテキストを生成できるようにパラメータの学習を行う。 (これにはラベル付きデータが必要だが、少量でも学習できることに加えて、sentence levelのデータだけではなくword levelのデータでも学習できる。)
また、2を実現するために、VAEが生成したテキストから、生成する元となった潜在変数zが再現できるようにEncoderのパラメータを学習。
実験では、sentimentとtenseをコントロールする実験が行われており、attributeを表す変数cを変更することで、以下のようなテキストが生成されており興味深い。
[sentimentを制御した例]
this movie was awful and boring. (negative)
this movie was funny and touching. (positive)
[tenseを制御した例]
this was one of the outstanding thrillers of the last decade
this is one of the outstanding thrillers of the all time
this will be one of the great thrillers of the all time
VAEは通常のAutoEncoderと比較して、奥が深くて勉強してみておもしろかった。 Reparametrization Trickなどは知らなかった。
管理人による解説資料:
[Controllable Text Generation.pdf](https://github.com/AkihikoWatanabe/paper_notes/files/1595121/Controllable.Text.Generation.pdf)
slideshare: https://www.slideshare.net/akihikowatanabe3110/towards-controlled-generation-of-text
[Paper Note] Learning to Skim Text, Adams Wei Yu+, ACL'17, 2017.04
Paper/Blog Link My Issue
#NeuralNetwork #EfficiencyImprovement #Pocket #NLP #ReinforcementLearning #ACL #Decoder #Sparse Issue Date: 2017-12-31 GPT Summary- 再帰型ニューラルネットワーク(RNN)は自然言語処理での可能性を示すが、長文の処理が遅い。本論文では、無関係な情報をスキップしながらテキストを読むアプローチを提案。モデルは、入力テキストの数語を読んだ後にジャンプする距離を学習し、ポリシー勾配法で訓練。数値予測や自動Q&Aなど4つのタスクで、提案モデルは標準LSTMに比べて最大6倍の速度向上を達成し、精度も維持。 Comment
解説スライド:
http://www.lr.pi.titech.ac.jp/~haseshun/acl2017suzukake/slides/07.pdf
Reinforceにおける勾配の更新式の導出が丁寧に記述されており大変ありがたい。
RNNにおいて重要な部分以外は読み飛ばすことで効率を向上させる研究。いくつ読み飛ばすかも潜在変数として一緒に学習する。潜在変数(離散変数)なので、普通に尤度最大化するやり方では学習できず、おまけに離散変数なのでバックプロパゲーション使えないので、強化学習で学習する。
Vanilla LSTMと比較し、色々なタスクで実験した結果、性能も(少し)上がるし、スピードアップもする。
うーんこの研究は今改めて見返すと非常に面白いな…(8年も経ったのか)。ざっくり言うと必要のない部分は読み飛ばして考慮しないという話であり、最近のLLMでもこういった話はよくやられている印象。一番近いのはSparse Attentionだろうか。
- [Paper Note] Efficient Transformers: A Survey, Yi Tay+, ACM Computing Surveys'22, 2022.12
- [Paper Note] Big Bird: Transformers for Longer Sequences, Manzil Zaheer+, NIPS'20, 2020.07
- [Paper Note] Reformer: The Efficient Transformer, Nikita Kitaev+, ICLR'20
- [Paper Note] Generating Long Sequences with Sparse Transformers, Rewon Child+, arXiv'19, 2019.04
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
トークン単位などはなくlayerをスキップするとかもある(Layer Skip)。
- [Paper Note] Skip a Layer or Loop it? Test-Time Depth Adaptation of Pretrained LLMs, Ziyue Li+, arXiv'25
[Paper Note] Poincaré Embeddings for Learning Hierarchical Representations, Maximilian Nickel+, NIPS'17, 2017.05
Paper/Blog Link My Issue
#NeuralNetwork #Embeddings #Pocket #NLP #Word #RepresentationLearning #NeurIPS Issue Date: 2017-12-29 GPT Summary- 記号データの階層的表現を学習する新しいアプローチを提案し、n次元ポアンカレボールに埋め込むことで階層と類似性を同時に捉える。リーマン最適化に基づく効率的なアルゴリズムを導入し、ポアンカレ埋め込みがユークリッド埋め込みを上回る表現能力と一般化能力を持つことを実験で示した。 Comment
解説:
http://tech-blog.abeja.asia/entry/poincare-embeddings
解説スライド:
https://speakerdeck.com/eumesy/poincare-embeddings-for-learning-hierarchical-representations
実装:
https://github.com/TatsuyaShirakawa/poincare-embedding
・階層構造を持つデータ(WordNet上の上位語下位語、is-a関係など)を埋め込むために、双曲空間を使った話(通常はユークリッド空間)。
・階層構造・べき分布を持つデータはユークリッド空間ではなく双曲空間の方が効率的に埋め込める。
・階層構造・べき分布を持つデータを双曲空間(ポアンカレ球モデル)に埋め込むための学習手法(リーマン多様体上でSGD)を提案
・WordNet hypernymyの埋め込み:低次元でユークリッド埋め込みに圧勝
・Social Networkの埋め込み:低次元だと圧勝
・Lexical Entailment:2つのデータセットでSoTA
上記は解説スライドから勉強しメモ:
Poincaré Embeddings for Learning Hierarchical Representations, Sho Yokoi, 2017-09-15, 第9回最先端NLP勉強会
https://speakerdeck.com/eumesy/poincare-embeddings-for-learning-hierarchical-representations

(解説スライドp.20より)
データとして上位・下位概念を与えていないのに、原点付近には上位語・円周付近には下位語が自然に埋め込まれている(意図した通りになっている)。
ポアンカレ円板では、原点からの距離に応じて指数的に円周長が増加していくので、指数的に数が増えていく下位語などは外側に配置されると効率的だけど、その通りになっている。
(解説スライドp.9より、スライド全体のスクショではないので元ページ参照のこと)
スクショは解説スライドより引用:
Poincaré Embeddings for Learning Hierarchical Representations, Sho Yokoi, 2017-09-15, 第9回最先端NLP勉強会
https://speakerdeck.com/eumesy/poincare-embeddings-for-learning-hierarchical-representations
[Paper Note] Supervised Learning of Universal Sentence Representations from Natural Language Inference Data, Alexis Conneau+, arXiv'17, 2017.05
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #Embeddings #Pocket #NLP #RepresentationLearning #EMNLP Issue Date: 2017-12-28 GPT Summary- 文の埋め込みを学習する試みは成功していないが、スタンフォード自然言語推論データセットを用いた監督学習による普遍的な文表現が、無監督手法を上回ることを示す。自然言語推論は他のNLPタスクへの転送学習に適していることが示唆される。エンコーダは公開されている。 Comment
汎用的な文のエンコーダができました!という話。
SNLIデータでパラメータ学習、エンコーダ構成スライド図中右側のエンコーダ部分をなるべく一般的な文に適用できるように学習したい。
色々なタスクで、文のエンコーダ構成を比較した結果、bi-directional LSTMでエンコードし、要素ごとの最大値をとる手法が最も良いという結果。
隠れ層の次元は4096とかそのくらい。
Skip-Thoughtは学習に1ヶ月くらいかかるけど、提案手法はより少ないデータで1日くらいで学習終わり、様々なタスクで精度が良い。
ベクトルの要素積、concat, subなど、様々な演算を施し、学習しているので、そのような構成の元から文エンコーダを学習すると何か意味的なものがとれている?
SNLIはNatural Language Inferenceには文の意味理解が必須なので、そのデータ使って学習するといい感じに文のエンコードができます。
NLIのデータは色々なところで有用なので、日本語のNLIのデータとかも欲しい。
[Paper Note] Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, Wu+, WSDM'16
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #WSDM #Selected Papers/Blogs #AutoEncoder Issue Date: 2018-01-02 Comment
Denoising Auto-Encoders を用いたtop-N推薦手法、Collaborative Denoising Auto-Encoder (CDAE)を提案。
モデルベースなCollaborative Filtering手法に相当する。corruptedなinputを復元するようなDenoising Auto Encoderのみで推薦を行うような手法は、この研究が初めてだと主張。
学習する際は、userのitemsetのsubsetをモデルに与え(noiseがあることに相当)、全体のitem setを復元できるように、学習する(すなわちDenoising Auto-Encoder)。
推薦する際は、ユーザのその時点でのpreference setをinputし、new itemを推薦する。
- [Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
もStacked Denoising Auto EncoderとCollaborative Topic Regression [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
を利用しているが、[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
ではarticle recommendationというspecificな問題を解いているのに対して、提案手法はgeneralなtop-N推薦に利用できることを主張。
[Paper Note] News Citation Recommendation with Implicit and Explicit Semantics, Peng+, ACL'16
Paper/Blog Link My Issue
#RecommenderSystems #Citations #LearningToRank #ACL Issue Date: 2018-01-01 Comment
target text中に記述されているイベントや意見に対して、それらをサポートするような他のニュース記事を推薦する研究。
たとえば、target text中に「北朝鮮が先日ミサイルの発射に失敗したが...」、といった記述があったときに、このイベントについて報道しているニュース記事を推薦するといったことを、target text中の様々なcontextに対して行う。
このようなシステムの利用により、target textの著者の執筆支援(自身の主張をサポートするためのreferenceの自動獲得)や、target textの読者の読解支援(text中の記述について詳細な情報を知りたい場合に、検索の手間が省ける)などの利点があると主張。
タスクとしては、target text中のあるcontextと、推薦の候補となるニュース記事の集合が与えられたときに、ニュース記事をre-rankingする タスク。
提案手法はシンプルで、contextとニュース記事間で、様々な指標を用いてsimilarityを測り、それらをlearning-to-rankで学習した重みで組み合わせてre-rankingを行うだけ。 similarityを測る際は、表記揺れや曖昧性の問題に対処するためにEmbeddingを用いる手法と、groundingされたentityの情報を用いる手法を提案。
Bing news中のAnchor textと、hyperlink先のニュース記事の対から、contextと正解ニュース記事の対を取得し、30000件規模の実験データを作成し、評価。その結果、baselineよりも提案手法の性能が高いことを示した。
[Paper Note] Learning from Numerous Untailored Summaries, Kikuchi+, PRICAI'16
Paper/Blog Link My Issue
#Single #DocumentSummarization #Document #DomainAdaptation #Supervised #NLP #Extractive #PRICAI Issue Date: 2018-01-01 Comment
New York Times Annotated Corpus(NYTAC)に含まれる大量の正解要約データを利用する方法を提案。
NYTACには650,000程度の人手で生成された参照要約が付与されているが、このデータを要約の訓練データとして活用した事例はまだ存在しないので、やりましたという話。
具体的には、NYTACに存在する人手要約を全てそのまま使うのではなく、Extracitiveなモデルの学習に効果的な事例をフィルタリングして選別する手法を提案
また、domain-adaptationの技術を応用し、NYTACデータを要約を適用したいtargetのテキストに適応する5つの手法を提案
モデルとしては、基本的にknapsack問題に基づいた要約モデル(Extractive)を用い、学習手法としてはPassive Aggressiveアルゴリズムの構造学習版を利用する。
NYTACのデータを活用する手法として、以下の5つの手法を提案している。
```
1. NytOnly: NYTACのデータのみで学習を行い、target側の情報は用いない
2. Mixture: targetとNYTACの事例をマージして一緒に学習する
3. LinInter: TrgtOnly(targetデータのみで学習した場合)のweightとNytOnlyで学習したweightをlinear-interpolationする。interpolation parameterはdev setから決定
4. Featurize: NytOnlyのoutputをtargetでモデルを学習する際の追加の素性として用いる
5. FineTune: NytOnlyで学習したweightを初期値として、target側のデータでweightをfinetuneする
```
また、NYTACに含まれる参照要約には、生成的なものや、メタ視点から記述された要約など、様々なタイプの要約が存在する。今回学習したいモデルはExtractiveな要約モデルなので、このような要約は学習事例としては適切ではないのでフィルタリングしたい。
そこで、原文書からExtractiveな要約を生成した際のOracle ROUGE-2スコアを各参照要約-原文書対ごとに求め、特定の閾値以下の事例は使用しないように、インスタンスの選択を行うようにする。
DUC2002 (単一文書要約タスク)、RSTDTBlong, RSTDTBshort (Rhetrical Structure Theory Discourse Tree Bankに含まれる400件程度の(確か社説のデータに関する)要約)の3種類のデータで評価。
どちらの評価においても、FineTuneを行い、インスタンスの選択を行うようにした場合が提案手法の中ではもっとも性能がよかった。
DUC2002では、LEADやTextRankなどの手法を有意にoutperformしたが、DUC2002のbest systemには勝てなかった。
しかしながら、RSTDTBlongにおける評価では、RSTの情報などを用いるstate-of-the-artなシステムに、RSTの情報などを用いない提案手法がROUGEスコアでoutperformした。
RSTDTBshortにおける評価では、RSTを用いる手法(平尾さんの手法)には及ばなかったが、それ以外ではbestな性能。これは、RSTDTBshortの場合は要約が指示的な要約であるため、今回学習に用いた要約のデータやモデルは報知的な要約のためのものであるため、あまりうまくいかなかったと考察している。
[Paper Note] Incorporating Copying Mechanism in Sequence-to-Sequence Learning, Gu+, ACL'16
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #ACL #Selected Papers/Blogs Issue Date: 2017-12-31 Comment
単語のコピーと生成、両方を行えるネットワークを提案。
location based addressingなどによって、生成された単語がsourceに含まれていた場合などに、copy-mode, generate-modeを切り替えるような仕組みになっている。
[Paper Note] Pointing the Unknown Words, Caglar Gulcehre+, ACL'16, 2016.03
と同じタイミングで発表
[Paper Note] Distraction-Based Neural Networks for Modeling Documents, Chen+, IJCAI'16
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #IJCAI Issue Date: 2017-12-31 Comment
Neuralなモデルで「文書」の要約を行う研究。
提案手法では、attention-basedなsequence-to-sequenceモデルにdistractionと呼ばれる機構を導入することを提案。
distractionを導入するmotivationは、入力文書中の異なる情報を横断的に参照(一度着目した情報には今後あまり着目しないようなバイアスをかける)したうえで、要約を生成しようというもの。
これにより、生成される要約の冗長性を排除するのが狙い。
以下の3つのアプローチを用いて、distractionを実現
1. [Distraction over input content vectors]
tステップ目において、decoderのinputとして用いるcontext vectorを
計算する際に、通常の計算に加えて、t-1ステップ目までに使用した
context vectorの情報を活用することで、これまでdecoderのinputとして
利用された情報をあまり重視視しないように、context vectorを生成する。
2. [Distraction over attention weight vectors]
attentionの重みを計算する際に、過去に高いattentionの重みがついた
encoderのhidden stateについては、あまり重要視しないように
attentionの重みを計算。1と同様に、t-1ステップ目までのattention weightの
historyを保持しておき活用する。
3. [Distration in decoding]
decodingステップでbeam-searchを行う際のスコア計算に、distraction scoreを導入。distraction
scoreはtステップ目までに用いられたcontext vector、attention
weight、decoderのstateから計算され、これまでと同じような情報に基づいて
単語が生成された場合は、スコアが低くなるようになっている。
CNN、およびLCSTS data (大規模な中国語のheadline generationデータ)で評価した結果、上記3つのdistraction機構を導入した場合に、最も高いROUGEスコアを獲得
特に、原文書が長い場合に、短い場合と比較して、distraction機構を導入すると、
ROUGEスコアの改善幅が大きくなったことが示されている
[Paper Note] Neural Text Generation from Structured Data with Application to the Biography Domain, Remi Lebret+, EMNLP'16, 2016.03
Paper/Blog Link My Issue
#NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #Dataset #ConceptToTextGeneration #EMNLP #Encoder-Decoder Issue Date: 2017-12-31 GPT Summary- 大規模なWikipediaの伝記データセットを用いて、テキスト生成のためのニューラルモデルを提案。モデルは条件付きニューラル言語モデルに基づき、固定語彙とサンプル固有の単語を組み合わせるコピーアクションを採用。提案モデルは古典的なKneser-Neyモデルを約15 BLEUポイント上回る性能を示した。 Comment
Wikipediaの人物に関するinfo boxから、その人物のbiographyの冒頭を生成するタスク。
Neural Language Modelに、新たにTableのEmbeddingを入れられるようにtable embeddingを提案し、table conditioned language modelを提案している。
inputはテーブル(図中のinput textっていうのは、少し用語がconfusingだが、言語モデルへのinputとして、過去に生成した単語の系列を入れるというのを示しているだけ)
モデル全体
Wikipediaから生成した、Biographyに関するデータセットも公開している。
template basedなKNSmoothingを使ったベースラインよりも高いBLEUスコアを獲得。さらに、テーブルのGlobalな情報を入れる手法が、性能向上に寄与(たとえばチーム名・リーグ・ポジションなどをそれぞれ独立に見ても、バスケットボールプレイヤーなのか、ホッケープレイヤーなのかはわからないけど、テーブル全体を見ればわかるよねという気持ち)。
[Paper Note] Sequence-to-Sequence Learning as Beam-Search Optimization, Sam Wiseman+, EMNLP'16, 2016.06
Paper/Blog Link My Issue
#NeuralNetwork #BeamSearch #Pocket #NLP #EMNLP Issue Date: 2017-12-30 GPT Summary- 本研究では、seq2seqモデリングを拡張し、グローバルなシーケンススコアを学習する新しいモデルとビームサーチトレーニング方式を導入。これにより、局所的なトレーニングのバイアスを回避し、トレーニング損失とテスト時の使用を統一。結果として、単語の順序付け、構文解析、機械翻訳のタスクで、他の最適化されたシステムを上回る性能を示した。 Comment
seq2seqを学習する際には、gold-history(これまで生成した単語がgoldなものと一緒)を使用し、次に続く単語の尤度を最大化するように学習するが、これには、
1. Explosure Bias: test時ではtraining時と違いgold historyを使えないし、training時には過去に生成した単語に誤りがあるみたいな状況がない
2. Loss-Evaluation Mismatch: training時は単語レベルのlossを使うが、だいたいはsentence-levelのmetrics (BLEUなど)を改善したい
3. Label Bias: 各タイムステップでの単語の生起確率が局所的に正規化され、誤ったhistoryに続く単語がgoldな履歴に続く単語と同じ量(の確率?)を受け取ってしまう
これらを解決するために、targetの"sequence"に対してスコア(確率ではない)を与えるようなseq2seqモデルを提案し、訓練方法として、beam search optimization(training時のlossとしてbeam searchの結果得られるerrorを用いる)を提案。
[Paper Note] Distraction-Based Neural Networks for Modeling Documents, Chen+, IJCAI'16
Paper/Blog Link My Issue
#DocumentSummarization #NeuralNetwork #Document #Supervised #NLP #Abstractive #IJCAI Issue Date: 2017-12-28 Comment
Neuralなモデルで「文書」の要約を行う研究。
提案手法では、attention-basedなsequence-to-sequenceモデルにdistractionと呼ばれる機構を導入することを提案。
distractionを導入するmotivationは、入力文書中の異なる情報を横断的に参照(一度着目した情報には今後あまり着目しないようなバイアスをかける)したうえで、要約を生成しようというもの。
これにより、生成される要約の冗長性を排除するのが狙い。
以下の3つのアプローチを用いて、distractionを実現
1. [Distraction over input content vectors]
tステップ目において、decoderのinputとして用いるcontext vectorを
計算する際に、通常の計算に加えて、t-1ステップ目までに使用した
context vectorの情報を活用することで、これまでdecoderのinputとして
利用された情報をあまり重視視しないように、context vectorを生成する。
2. [Distraction over attention weight vectors]
attentionの重みを計算する際に、過去に高いattentionの重みがついた
encoderのhidden stateについては、あまり重要視しないように
attentionの重みを計算。1と同様に、t-1ステップ目までのattention weightの
historyを保持しておき活用する。
3. [Distration in decoding]
decodingステップでbeam-searchを行う際のスコア計算に、distraction scoreを導入。distraction
scoreはtステップ目までに用いられたcontext vector、attention
weight、decoderのstateから計算され、これまでと同じような情報に基づいて
単語が生成された場合は、スコアが低くなるようになっている。
CNN、およびLCSTS data (大規模な中国語のheadline generationデータ)で評価した結果、上記3つのdistraction機構を導入した場合に、最も高いROUGEスコアを獲得
特に、原文書が長い場合に、短い場合と比較して、distraction機構を導入すると、
ROUGEスコアの改善幅が大きくなったことが示されている
Distraction機構の有用性は、ACL'17のstanford NLPグループが提案したPointer Generator Networkでも示されている(Coverage Vectorという呼び方をしてた気がする)
[Paper Note] Learning Distributed Representations of Sentences from Unlabelled Data, Felix Hill+, NAACL'16, 2016.02
Paper/Blog Link My Issue
#NeuralNetwork #Sentence #Embeddings #Pocket #NLP #RepresentationLearning #NAACL Issue Date: 2017-12-28 GPT Summary- 無監督手法によるフレーズや文の分散表現の学習に関するモデルの比較を行い、最適なアプローチはアプリケーションに依存することを示す。深いモデルは監視システムに適している一方、浅いロジスティック回帰モデルは単純な空間距離メトリックに最適。さらに、トレーニング時間やドメイン移植性を考慮した新しい無監督表現学習の目的も提案。 Comment
Sentenceのrepresentationを学習する話
代表的なsentenceのrepresentation作成手法(CBOW, SkipGram, SkipThought, Paragraph Vec, NMTなど)をsupervisedな評価(タスク志向+supervised)とunsupervisedな評価(文間の距離をコサイン距離ではかり、人間が決めた順序と相関を測る)で比較している。
また筆者らはSequential Denoising Auto Encoder(SDAE)とFastSentと呼ばれる手法を提案しており、前者はorderedなsentenceデータがなくても訓練でき、FastSentはorderedなsentenceデータが必要だが高速に訓練できるモデルである。
実験の結果、supervisedな評価では、基本的にはSkipThoughtがもっとも良い性能を示し、paraphrasingタスクにおいて、SkipThoughtに3ポイント程度差をつけて良い性能を示した。unsupervisedな評価では、DictRepとFastSentがもっとも良い性能を示した。
実験の結果、以下のような知見が得られた:
## 異なるobjective functionは異なるembeddingを作り出す
objective functionは、主に隣接する文を予測するものと、自分自身を再現するものに分けられる。これらの違いによって、生成されるembeddingが異なっている。Table5をみると、後者については、生成されたrepresentationのnearest neighborを見ていると、自身と似たような単語を含む文が引っ張ってこれるが、前者については、文のコンセプトや機能は似ているが、単語の重複は少なかったりする。
## supervisedな場合とunsupervisedな評価でのパフォーマンスの違い
supervisedな設定では、SkipThoughtやSDAEなどのモデルが良い性能を示しているが、unsupervisedな設定ではまりうまくいかず。unsupevisedな設定ではlog-linearモデルが基本的には良い性能を示した。
## pre-trainedなベクトルを使用したモデルはそうでない場合と比較してパフォーマンスが良い
## 必要なリソースの違い
モデルによっては、順序づけられた文のデータが必要だったり、文の順序が学習に必要なかったりする。あるいは、デコーディングに時間がかかったり、めちゃくちゃメモリ食ったりする。このようなリソースの性質の違いは、使用できるapplicationに制約を与える。
## 結論
とりあえず、supervisedなモデルにrepresentationを使ってモデルになんらかのknowledgeをぶちこみたいときはSkipThought、単純に類似した文を検索したいとか、そういう場合はFastSentを使うと良いってことですかね.
[Paper Note] Deep Knowledge Tracing, Piech+, NIPS'15
Paper/Blog Link My Issue
#AdaptiveLearning #StudentPerformancePrediction #NeurIPS #Selected Papers/Blogs #Reference Collection Issue Date: 2018-12-22 Comment
Knowledge Tracingタスクとは:
特定のlearning taskにおいて、生徒によってとられたインタラクションの系列x0, ..., xtが与えられたとき、次のインタラクションxt+1を予測するタスク
典型的な表現としては、xt={qt, at}, where qt=knowledge component (KC) ID (あるいは問題ID)、at=正解したか否か
モデルが予測するときは、qtがgivenな時に、atを予測することになる
Contribution:
1. A novel way to encode student interactions as input to a recurrent neural network.
2. A 25% gain in AUC over the best previous result on a knowledge tracing benchmark.
3. Demonstration that our knowledge tracing model does not need expert annotations.
4. Discovery of exercise influence and generation of improved exercise curricula.
モデル:
Inputは、ExerciseがM個あったときに、M個のExerciseがcorrectか否かを表すベクトル(長さ2Mベクトルのone-hot)。separateなrepresentationにするとパフォーマンスが下がるらしい。
Output ytの長さは問題数Mと等しく、各要素は、生徒が対応する問題を正答する確率。
InputとしてExerciseを用いるか、ExerciseのKCを用いるかはアプリケーション次第っぽいが、典型的には各スキルの潜在的なmasteryを測ることがモチベーションなのでKCを使う。
(もし問題数が膨大にあるような設定の場合は、各問題-正/誤答tupleに対して、random vectorを正規分布からサンプリングして、one-hot high-dimensional vectorで表現する。)
hidden sizeは200, mini-batch sizeは100としている。
[Educational Applicationsへの応用]
生徒へ最適なパスの学習アイテムを選んで提示することができること
生徒のknowledge stateを予測し、その後特定のアイテムを生徒にassignすることができる。たとえば、生徒が50個のExerciseに回答した場合、生徒へ次に提示するアイテムを計算するだけでなく、その結果期待される生徒のknowledge stateも推測することができる
Exercises間の関係性を見出すことができる
y( j | i )を考える。y( j | i )は、はじめにexercise iを正答した後に、second time stepでjを正答する確率。これによって、pre-requisiteを明らかにすることができる。
[評価]
3種類のデータセットを用いる。
1. simulated Data
2000人のvirtual studentを作り、1〜5つのコンセプトから生成された、50問を、同じ順番で解かせた。このとき、IRTモデルを用いて、シミュレーションは実施した。このとき、hidden stateのラベルには何も使わないで、inputは問題のIDと正誤データだけを与えた。さらに、2000人のvirtual studentをテストデータとして作り、それぞれのコンセプト(コンセプト数を1〜5に変動させる)に対して、20回ランダムに生成したデータでaccuracyの平均とstandard errorを測った。
2. Khan Academy Data
1.4MのExerciseと、69の異なるExercise Typeがあり、47495人の生徒がExerciseを行なっている。
PersonalなInformationは含んでいない。
3. Assistsments bemchmark Dataset
2009-2011のskill builder public benchmark datasetを用いた。Assistmentsは、online tutorが、数学を教えて、教えるのと同時に生徒を評価するような枠組みである。
それぞれのデータセットに対して、AUCを計算。
ベースラインは、BKTと生徒がある問題を正答した場合の周辺確率?

simulated dataの場合、問題番号5がコンセプト1から生成され、問題番号22までの問題は別のコンセプトから生成されていたにもかかわらず、きちんと二つの問題の関係をとらえられていることがわかる。
Khan Datasetについても同様の解析をした。これは、この結果は専門家が見たら驚くべきものではないかもしれないが、モデルが一貫したものを学習したと言える。
[Discussion]
提案モデルの特徴として、下記の2つがある:
専門家のアノテーションを必要としない(concept patternを勝手に学習してくれる)
ベクトル化された生徒のinputであれば、なんでもoperateすることができる
drawbackとしては、大量のデータが必要だということ。small classroom environmentではなく、online education environmentに向いている。
今後の方向性としては、
・incorporate other feature as inputs (such as time taken)
・explore other educational impacts (hint generation, dropout prediction)
・validate hypotheses posed in education literature (such as spaced repetition, modeling how students forget)
・open-ended programmingとかへの応用とか(proramのvectorizationの方法とかが最近提案されているので)
などがある。
knewtonのグループが、DKTを既存手法であるIRTの変種やBKTの変種などでoutperformすることができることを示す:
https://arxiv.org/pdf/1604.02336.pdf
vanillaなDKTはかなりナイーブなモデルであり、今後の伸びが結構期待できると思うので、単純にoutperformしても、今後の発展性を考えるとやはりDKTには注目せざるを得ない感
DKT元論文では、BKTを大幅にoutperformしており、割と衝撃的な結果だったようだが、
後に論文中で利用されているAssistmentsデータセット中にdupilcate entryがあり、
それが原因で性能が不当に上がっていることが判明。
結局DKTの性能的には、BKTとどっこいみたいなことをRyan Baker氏がedXで言っていた気がする。
Deep Knowledge TracingなどのKnowledge Tracingタスクにおいては、
基本的に問題ごとにKnowledge Component(あるいは知識タグ, その問題を解くのに必要なスキルセット)が付与されていることが前提となっている。
ただし、このような知識タグを付与するには専門家によるアノテーションが必要であり、
適用したいデータセットに対して必ずしも付与されているとは限らない。
このような場合は、DKTは単なる”問題”の正答率予測モデルとして機能させることしかできないが、
知識タグそのものもNeural Networkに学習させてしまおうという試みが行われている:
https://www.jstage.jst.go.jp/article/tjsai/33/3/33_C-H83/_article/-char/ja
DKTに関する詳細な説明が書かれているブログポスト:
expectimaxアルゴリズムの説明や、最終的なoutput vector y_i の図解など、説明が省略されガチなところが詳細に書いてあって有用。(英語に翻訳して読むと良い)
https://hcnoh.github.io/2019-06-14-deep-knowledge-tracing
こちらのリポジトリではexpectimaxアルゴリズムによってvirtualtutorを実装している模様。
詳細なレポートもアップロードされている。
https://github.com/alessandroscoppio/VirtualIntelligentTutor
DKTのinputの次元数が 2 * num_skills, outputの次元数がnum_skillsだと明記されているスライド。
元論文だとこの辺が言及されていなくてわかりづらい・・・
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_tutorial_Application.pdf
http://gdac.uqam.ca/Workshop@EDM20/slides/LSTM_Tutorial.pdf
こちらのページが上記チュートリアルのページ
http://gdac.uqam.ca/Workshop@EDM20/
[Paper Note] Collaborative Deep Learning for Recommender Systems, Hao Wang+, KDD'15
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #CollaborativeFiltering #Pocket #MatrixFactorization #SIGKDD #Selected Papers/Blogs Issue Date: 2018-01-11 GPT Summary- 協調フィルタリング(CF)はレコメンダーシステムで広く用いられるが、評価がまばらな場合に性能が低下する。これに対処するため、補助情報を活用する協調トピック回帰(CTR)が提案されているが、補助情報がまばらな場合には効果が薄い。そこで、本研究では協調深層学習(CDL)という階層ベイズモデルを提案し、コンテンツ情報の深い表現学習とCFを共同で行う。実験により、CDLが最先端技術を大幅に上回る性能を示すことが確認された。 Comment
Rating Matrixからuserとitemのlatent vectorを学習する際に、Stacked Denoising Auto Encoder(SDAE)によるitemのembeddingを活用する話。
Collaborative FilteringとContents-based Filteringのハイブリッド手法。
Collaborative FilteringにおいてDeepなモデルを活用する初期の研究。
通常はuser vectorとitem vectorの内積の値が対応するratingを再現できるように目的関数が設計されるが、そこにitem vectorとSDAEによるitemのEmbeddingが近くなるような項(3項目)、SDAEのエラー(4項目)を追加する。
(3項目の意義について、解説ブログより)アイテム i に関する潜在表現 vi は学習データに登場するものについては推定できるけれど,未知のものについては推定できない.そこでSDAEの中間層の結果を「推定したvi」として「真の」 vi にできる限り近づける,というのがこの項の気持ち
cite-ulikeデータによる論文推薦、Netflixデータによる映画推薦で評価した結果、ベースライン(Collective Matrix Factorization [Paper Note] Relational learning via collective matrix factorization, Singh+, KDD'08
, SVDFeature [Paper Note] SVDFeature: a toolkit for feature-based collaborative filtering, Chen+, JMLR, Vol.13, 2012.12
, DeepMusic [Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
, Collaborative Topic Regresison [Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
)をoutperform。
(下記は管理人が過去に作成した論文メモスライドのスクショ)




[Paper Note] Re-evaluating Automatic Summarization with BLEU and 192 Shades of ROUGE, Yvette Graham, EMNLP'15
Paper/Blog Link My Issue
#DocumentSummarization #Metrics #NLP #EMNLP Issue Date: 2018-01-01 Comment
文書要約で使用されているMetric、特にBLEUやROUGEの結果(可能な192のパターン)と、人手の結果との相関を再分析している。
その結果、BLEUがもっとも人手評価との相関が高く、ROUGE-2のPrecisionの平均(ステミング、stop words除去)がROUGEの中でbest-performingなvariantだった。
要約のMetrcの最適な検定方法として、Williams検定を利用。
再評価の結果、以前推奨されていたvariantとは異なるMetricsが良い結果に。
best-performing ROUGE resultを用いて、既存のstate-of-the-artなシステムを再度ランキングづけすると、originalのものとは結構異なる結果になった。
(一部のスコアが良かったシステムのスコアが相対的にかなり悪化している)
また、BLEUが人手評価ともっとも高い相関を示したが、best-performingなROUGE variantとは統計的な有意差はなかった。
[Paper Note] Recurrent neural network and a hybrid model for prediction of stock returns, Akhter+, Expert Systems with Applications'15, 2015.04
Paper/Blog Link My Issue
#NeuralNetwork #TimeSeriesDataProcessing #MachineLearning #Financial Issue Date: 2017-12-31 Comment
Stock returnのpredictionタスクに対してNNを適用。
AR-MRNNモデルをRNNに適用、高い性能を示している。 moving referenceをsubtractした値をinput-outputに用いることで、normalizationやdetrending等の前処理が不要となり、regularizationの役割を果たすため汎化能力が向上する。
※ AR-MRN: NNNのinput-outputとして、生のreturn値を用いるのではなく、ある時刻におけるreturnをsubtractした値(moving reference)を用いるモデル ([Paper Note] Prediction-based portfolio optimization model using neural networks, Freitas+, Neurocomputing'09, 2009.06
で提案)
[Paper Note] Teaching Machines to Read and Comprehend, Karl Moritz Hermann+, NIPS'15, 2015.06
Paper/Blog Link My Issue
#NeuralNetwork #Document #Pocket #NLP #QuestionAnswering #NeurIPS Issue Date: 2017-12-28 GPT Summary- 自然言語文書を読み取る機械の教育は難しいが、大規模なトレーニングデータが不足していた。本研究では、教師あり読解データを提供する新しい方法論を提案し、注意ベースの深層ニューラルネットワークが実際の文書を読み、複雑な質問に答える能力を向上させることを目指す。 Comment
だいぶ前に読んだので割とうろおぼえ。
CNN/DailyMailデータセットの作成を行なった論文(最近Neuralな文”書”要約の学習でよく使われるやつ)。
CNN/DailyMailにはニュース記事に対して、人手で作成した要約が付与されており、要約中のEntityを穴埋めにするなどして、穴埋め問題を作成。
言文書をNeuralなモデルに与えて、どれだけ回答できるかという話。
[スタンフォードによる追試がある](
https://cs.stanford.edu/people/danqi/papers/acl2016.pdf)
[詳しい解説 by 久保さん](
https://www.slideshare.net/takahirokubo7792/machine-comprehension)
追試によると、評価で使用している穴埋め問題は単純なモデルで提案モデルの性能を上回ったりしている。また、この穴埋め問題のうち54%は単純な質問とのマッチで回答可能であり、25%は人でも正解不能らしい(正解率のupper boundは75%)。by 久保さんのスライド
のちの研究で、ほぼこの上限に達する精度が達成されてしまったので、このデータセットはQAタスクではほぼ攻略された状態だという。
[Paper Note] LCSTS: A Large Scale Chinese Short Text Summarization Dataset, Baotian Hu+, EMNLP'15, 2015.06
Paper/Blog Link My Issue
#Single #DocumentSummarization #NeuralNetwork #Sentence #Document #Pocket #NLP #Dataset #Abstractive #EMNLP #Selected Papers/Blogs Issue Date: 2017-12-28 GPT Summary- 中国のマイクロブログSina Weiboから構築した200万以上の短文とその要約からなる大規模コーパスを紹介。手動でタグ付けされた10,666の要約を用いて、再帰型ニューラルネットワークを導入し、有望な要約生成結果を達成。提案コーパスは短文要約研究に有用であり、さらなる研究のベースラインを提供。 Comment
Large Chinese Short Text Summarization (LCSTS) datasetを作成
データセットを作成する際は、Weibo上の特定のorganizationの投稿の特徴を利用。
Weiboにニュースを投稿する際に、投稿の冒頭にニュースのvery short summaryがまず記載され、その後ニュース本文(短め)が記載される特徴があるので、この対をsource-reference対として収集した。
収集する際には、約100個のルールに基づくフィルタリングやclearning, 抽出等を行なっている。
データセットのpropertyとしては、下記のPartI, II, IIIに分かれている。
PartI: 2.4Mのshort text - summary pair
PartII: PartIからランダムにサンプリングされた10kのpairに対して、5 scaleで要約のrelevanceをratingしたデータ。ただし、各pairにラベルづけをしたevaluatorは1名のみ。
PartIII: 2kのpairに対して(PartI, PartIIとは独立)、3名のevaluatorが5-scaleでrating。evaluatorのratingが一致した1kのpairを抽出したデータ。
RNN-GRUを用いたSummarizerも提案している。
CopyNetなどはLCSTSを使って評価している。他にも使ってる論文あったはず。
ACL'17のPointer Generator Networkでした。
[Paper Note] A hierarchical neural autoencoder for paragraphs and documents, Li+, ACL'15
Paper/Blog Link My Issue
#NeuralNetwork #Document #Embeddings #NLP #RepresentationLearning #ACL Issue Date: 2017-12-28 Comment
複数文を生成(今回はautoencoder)するために、standardなseq2seq LSTM modelを、拡張したという話。
要は、paragraph/documentのrepresentationが欲しいのだが、アイデアとしては、word-levelの情報を扱うLSTM layerとsentenc-levelの情報を扱うLSTM layerを用意し、それらのcompositionによって、paragraph/documentを表現しましたという話。
sentence-levelのattentionを入れたらよくなっている。
trip advisorのreviewとwikipediaのparagraphを使ってtrainingして、どれだけ文書を再構築できるか実験。
MetricはROUGE, BLEUおよびcoherence(sentence order代替)を測るために、各sentence間のgapがinputとoutputでどれだけ一致しているかで評価。
hierarchical lstm with attention > hierarchical lstm > standard lstm の順番で高性能。
学習には、tesla K40を積んだマシンで、standard modelが2-3 weeks, hierarchical modelsが4-6週間かかるらしい。
[Paper Note] Document Modeling with Gated Recurrent Neural Network for Sentiment Classification, Tang+, EMNLP'15
Paper/Blog Link My Issue
#NeuralNetwork #Document #Embeddings #SentimentAnalysis #NLP #EMNLP Issue Date: 2017-12-28 Comment
word level -> sentence level -> document level のrepresentationを求め、documentのsentiment classificationをする話。
documentのRepresentationを生成するときに参考になるやも。
sentenceのrepresentationを求めるときは、CNN/LSTMを使う。
document levelに落とすことは、bi-directionalなGatedRNN(このGatedRNNはLSTMのoutput-gateが常にonになっているようなものを使う。sentenceのsemanticsに関する情報を落としたくないかららしい。)を使う。
sentiment classificationタスクで評価し、(sentence levelのrepresentationを求めるときは)LSTMが最も性能がよく、documentのrepresentationを求めるときは、standardなRNNよりもGatedRNNのほうが性能よかった。
[Paper Note] Detecting information-dense texts in multiple news domains, Yang+, AAAI'14
Paper/Blog Link My Issue
#DocumentSummarization #Others #NLP #AAAI Issue Date: 2018-01-01 Comment
ニュース記事の第一段落目がinformativeか否か(重要なfactual informationが記述されているか否か)を分類する研究。
New York Times Annotated Corpusに対して、自動的にinformative, non-informativeなラベルづけを行う手法を提案し、分類モデルをtraining。
評価の結果、Accuracyはだいたい0.8〜0.85くらい。
人が100件中何件をinformativeと判断したかに関してを見ると、リードにもnon-informativeなものが多数存在することがわかる。
また、ドメインによって傾向が異なっており、たとえばスポーツドメインでは、entertaining mannerで記述されるのでfactual informationがあまり記述されない傾向にあったり、Scienceドメインでは、generalなtopicやissue, personal historyなどが記述される傾向にあるので、相対的にinformativeなLeadが少ない。
[Paper Note] CTSUM: Extracting More Certain Summaries for News Articles, Wan+, SIGIR'14
Paper/Blog Link My Issue
#Multi #Single #DocumentSummarization #Document #Unsupervised #GraphBased #NLP #Extractive #SIGIR Issue Date: 2018-01-01 Comment
要約を生成する際に、情報の”確実性”を考慮したモデルCTSUMを提案しましたという論文(今まではそういう研究はなかった)
```
"However, it seems that Obama will not use the platform to relaunch his stalled drive for Israeli-Palestinian peace"
```
こういう文は、"It seems"とあるように、情報の確実性が低いので要約には入れたくないという気持ち。
FactBankのニュースコーパスから1000 sentenceを抽出し、5-scaleでsentenceの確実性をラベルづけ。
このデータを用いてSVRを学習し、sentenceの確実性をoutputする分類器を構築
affinity-propagationベース(textrank, lexrankのような手法)手法のaffinityの計算(edge間の重みのこと。普通はsentence同士の類似度とかが使われる)を行う際に、情報の確実性のスコアを導入することで確実性を考慮した要約を生成
DUC2007のMDSデータセットで、affinity計算の際に確実性を導入する部分をablationしたモデル(GRSUM)と比較したところ、CTSUMのROUGEスコアが向上した。
また、自動・人手評価により、生成された要約に含まれる情報の確実性を評価したところ、GRSUMをoutperformした
SIGIRでは珍しい、要約に関する研究
情報の確実性を考慮するという、いままであまりやられていなかった部分にフォーカスしたのはおもしろい
「アイデアはおもしろいし良い研究だが、affinity weightが変化するということは、裏を返せばdamping factorを変更してもそういう操作はできるので、certaintyを考慮したことに意味があったのかが完全に示せていない。」という意見があり、なるほどと思った。
[Paper Note] Learning to Generate Coherent Sumamry with Discriminative Hidden Semi-Markov Model, Nishikawa+, COLING'14
Paper/Blog Link My Issue
#Single #DocumentSummarization #Document #Supervised #NLP #Abstractive #Extractive #COLING Issue Date: 2018-01-01 Comment
Hidden-semi-markovモデルを用いた単一文書要約手法を提案。
通常のHMMでは一つの隠れ状態に一つのunit(要約の文脈だと文?)が対応するが、hidden-semi-markov(HSMM)モデルでは複数のunitを対応づけることが可能。
隠れ状態に対応するunitを文だと考えると、ある文の複数の亜種を考慮できるようになるため、ナップサック制約を満たしつつ最適な文の亜種を選択するといったことが可能となる。
とかまあ色々難しいことが前半の節に書いてある気がするが、3.3節を見るのがわかりやすいかもしれない。
定式化を見ると、基本的なナップサック問題による要約の定式化に、Coherenceを表すtermと文の変種を考慮するような変数が導入されているだけである。
文のweightや、coherenceのweightは構造学習で学習し、Passive Aggressiveを用いて、loss functionとしてはROUGEを用いている(要はROUGEが高くなるように、outputの要約全体を考慮しながら、weightを学習するということ)。
文の変種としては、各文を文圧縮したものを用意している。
また、動的計画法によるデコーディングのアルゴリズムも提案されている。
構造学習を行う際には大量の教師データが必要となるが、13,000記事分のニュース記事と対応する人手での要約のデータを用いて学習と評価を行なっており、当時これほど大規模なデータで実験した研究はなかった。
ROUGEでの評価の結果、文の変種(文圧縮)を考慮するモデルがベースラインを上回る結果を示したが、LEADとは統計的には有意差なし。しかしながら、人手で生成した要約との完全一致率が提案手法の方が高い。
また、ROUGEの評価だけでなく、linguistic quality(grammaticality, structure/coherenceなど)を人手で評価した結果、ベースラインを有意にoutperform。LEADはgrammaticalityでかなり悪い評価になっていて、これは要約を生成すると部分文が入ってしまうため。
訓練事例数を変化させてROUGEスコアに関するlearning curveを描いた結果、訓練事例の増加に対してROUGEスコアも単調増加しており、まだサチる気配を見せていないので、事例数増加させたらまだ性能よくなりそうという主張もしている。
評価に使用した記事が報道記事だったとするならば、quality的にはLeadに勝ってそうな雰囲気を感じるので、結構すごい気はする(単一文書要約で報道記事においてLEADは最強感あったし)。
ただ、要約の評価においてinformativenessを評価していないので、ROUGEスコア的にはLeadとcomparableでも、実際に生成される要約の情報量として果たしてLEADに勝っているのか興味がある。
[Paper Note] Hierarchical Summarization: Scaling Up Multi-Document Summarization, Christensen+, ACL'14
Paper/Blog Link My Issue
#Multi #DocumentSummarization #NLP #Extractive #ACL #Selected Papers/Blogs #interactive #Hierarchical Issue Date: 2017-12-28 Comment
## 概要
だいぶ前に読んだ。好きな研究。
テキストのsentenceを階層的にクラスタリングすることで、抽象度が高い情報から、関連する具体度の高いsentenceにdrill downしていけるInteractiveな要約を提案している。
## 手法
通常のMDSでのデータセットの規模よりも、実際にMDSを使う際にはさらに大きな規模のデータを扱わなければならないことを指摘し(たとえばNew York Timesで特定のワードでイベントを検索すると数千、数万件の記事がヒットしたりする)そのために必要な事項を検討。
これを実現するために、階層的なクラスタリングベースのアプローチを提案。
提案手法では、テキストのsentenceを階層的にクラスタリングし、下位の層に行くほどより具体的な情報になるようにsentenceを表現。さらに、上位、下位のsentence間にはエッジが張られており、下位に紐付けられたsentence
は上位に紐付けられたsentenceの情報をより具体的に述べたものとなっている。
これを活用することで、drill down型のInteractiveな要約を実現。
[Paper Note] Deep content-based music recommendation, Oord+, NIPS'13
Paper/Blog Link My Issue
#RecommenderSystems #NeuralNetwork #MatrixFactorization #NeurIPS #Selected Papers/Blogs Issue Date: 2018-01-11 Comment
Contents-Basedな音楽推薦手法(cold-start problemに強い)。
Weighted Matrix Factorization (WMF) (Implicit Feedbackによるデータに特化したMatrix Factorization手法) [Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008.12
に、Convolutional Neural Networkによるmusic audioのlatent vectorの情報が組み込まれ、item vectorが学習されるような仕組みになっている。
CNNでmusic audioのrepresentationを生成する際には、audioのtime-frequencyの情報をinputとする。学習を高速化するために、window幅を3秒に設定しmusic clipをサンプルしinputする。music clip全体のrepresentationを求める際には、consecutive windowからpredictionしたrepresentationを平均したものを使用する。
[Paper Note] BJUT at TREC 2013 Temporal Summarization Track, yang et al., TREC'13, 2014.02
Paper/Blog Link My Issue
#DocumentSummarization #NLP #Temporal Issue Date: 2017-12-28 Comment
・次のモジュールにより構成される。Preprocess, Retrieval, Information expansion, Sentence choosing and ranking
・Preprocess: GPGファイルをTXTファイルに変換。indexをはる。
・Retrieval: 検索エンジンとしてLemur searchを使っている。クエリ拡張と単語の重み付けができるため。(DocumentをRetrievalする)
・Information Expansion: 検索結果を拡張するためにK-meansを用いる。
・Sentence choosing and ranking: クラスタリング後に異なるクラスタの中心から要約を構築する。
time factorとsimilarity factorによってsentenceがランク付けされる。(詳細なし)
・Retrievalにおいては主にTF-IDFとBM25を用いている。
・traditionalなretrieval methodだけではperform wellではないので、Information Expansionをする。k-meansをすることで、異なるイベントのトピックに基づいてクラスタを得ることができる。クラスタごとの中心のドキュメントのtop sentencesをとってきて、要約とする。最終的にイベントごとに50 sentencesを選択する。
・生成したSequential Update Summarizationからvalueを抜いてきて、Value Trackingをする。
・Updateの部分をどのように実装しているのか?
[Paper Note] Collaborative topic modeling for recommending scientific articles, Wang+, KDD'11
Paper/Blog Link My Issue
#RecommenderSystems #CollaborativeFiltering #MatrixFactorization #SIGKDD #Selected Papers/Blogs Issue Date: 2018-01-11 Comment
Probabilistic Matrix Factorization (PMF) [Paper Note] Probabilistic Matrix Factorization, Salakhutdinov+, NIPS'08
に、Latent Dirichllet Allocation (LDA) を組み込んだCollaborative Topic Regression (CTR)を提案 (Figure2)。
LDAによりitemのlatent vectorを求め、このitem vectorと、user vectorの内積を(平均値として持つ正規表現からのサンプリング)用いてratingを生成する(式6)。
CFとContents-basedな手法が双方向にinterationするような手法
[Paper Note] Personalized Recommendation of User Comments via Factor Models, Agarwal+, EMNLP'11
Paper/Blog Link My Issue
#RecommenderSystems #Comments #EMNLP Issue Date: 2018-01-01 Comment
Personalizedなコメント推薦モデルを提案。rater-authorの関係、rater-commentの関係をlatent vectorを用いて表現し、これらとバイアス項の線形結合によりraterのあるコメントに対するratingを予測する。
パラメータを学習する際は、EMでモデルをfittingする。
バイアスとして、rater bias, comment popularity bias, author reputation biasを用いている。
rater-commentに関連するバイアスやlatent vectorは、コメントのbag-of-wordsからregressionした値を平均として持つガウス分布から生成される。
Yahoo Newsのコメントで実験。ROC曲線のAUCとPrecsionで評価。
user-user, user-commentを単体で用いたモデルよりも両者を組み合わせた場合が最も性能が良かった。
かなり綺麗に結果が出ている。
[Paper Note] Summarize What You Are Interested In: An Optimization Framework for Interactive Personalized Summarization, Yan+, EMNLP'11, 2011.07
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #InteractivePersonalizedSummarization #NLP #Personalization #EMNLP #Selected Papers/Blogs #interactive Issue Date: 2017-12-28 Comment
ユーザとシステムがインタラクションしながら個人向けの要約を生成するタスク、InteractivePersonalizedSummarizationを提案。
ユーザはテキスト中のsentenceをクリックすることで、システムに知りたい情報のフィードバックを送ることができる。このとき、ユーザがsentenceをクリックする量はたかがしれているので、click smoothingと呼ばれる手法を提案し、sparseにならないようにしている。click smoothingは、ユーザがクリックしたsentenceに含まれる単語?等を含む別のsentence等も擬似的にclickされたとみなす手法。
4つのイベント(Influenza A, BP Oil Spill, Haiti Earthquake, Jackson Death)に関する、数千記事のニュースストーリーを収集し(10k〜100k程度のsentence)、評価に活用。収集したニュースサイト(BBC, Fox News, Xinhua, MSNBC, CNN, Guardian, ABC, NEwYorkTimes, Reuters, Washington Post)には、各イベントに対する人手で作成されたReference Summaryがあるのでそれを活用。
objectiveな評価としてROUGE、subjectiveな評価として3人のevaluatorに5scaleで要約の良さを評価してもらった。
結論としては、ROUGEはGenericなMDSモデルに勝てないが、subjectiveな評価においてベースラインを上回る結果に。ReferenceはGenericに生成されているため、この結果を受けてPersonalizationの必要性を説いている。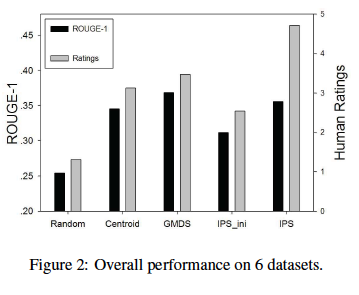
また、提案手法のモデルにおいて、Genericなモデルの影響を強くする(Personalizedなハイパーパラメータを小さくする)と、ユーザはシステムとあまりインタラクションせずに終わってしまうのに対し、Personalizedな要素を強くすると、よりたくさんクリックをし、結果的にシステムがより多く要約を生成しなおすという結果も示している。
[Paper Note] Ranking Comments on Social Web, Hsu+, CSE'09
Paper/Blog Link My Issue
#Comments #InformationRetrieval #LearningToRank Issue Date: 2018-01-15 Comment
Learning to Rankによってコメントをランキングする手法を提案。
これにより、低品質なコメントははじき、良質なコメントをすくいとることができる。
素性としては、主にユーザに基づく指標(ユーザが作成した記事の数、プロフィールが何度閲覧されたかなど)と、コメントのContentに基づく指標(コメントの長さやコメントと記事の類似度など)が用いられている。
User-basedなfeatureとcontent-basedなfeatureの両者を組み合わせた場合に最も良い性能。
個々の素性ごとにみると、User-basedなfeatureではuser comment history(コメントをしているユーザが過去にどれだけratingされているか、やcommentに対してどれだけreplyをもらっているか)、content-basedなfeatureではcomment-article(commentと本文のoverlap, commentと本文のpolarityの差)が最も性能に寄与。
[Paper Note] Large Scale Learning to Rank, Sculley+, NIPS'09
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #PairWise #NeurIPS Issue Date: 2018-01-01 Comment
sofia-mlの実装内容について記述されている論文
よくonline学習の文脈で触れられるが、気をつけないと罠にはまる。
というのは、sofia-ml内のMethodsによって、最適化している目的関数が異なるからだ。
実装をみると、全てのmethodsがonlineでできちゃいそうに見える(学習済みのモデルをinputして学習を再開させられるため)が、落とし穴。
まず、SGD SVM, Pegasos SVM,については、最適化している目的関数がbatchになっているため、online learningではない。
passive-aggressive perceptrionは目的関数が個別の事例に対して定式化される(要確認)のでonline learningといえる。
(ROMMAは調べないとわからん)
pairwiseのlearning to rankでは、サンプルのペアを使って学習するので、最悪の場合O(n^2)の計算量がかかってしまってめっちゃ遅いのだが、実は学習データを一部サンプリングして重みを更新するってのをたくさん繰り返すだけで、高速に学習できちゃうという話。
実際、sofia-mlを使って見たら、liblinearのranking SVM実装で40分かかった学習が数秒で終わり、なおかつ精度も良かった。
[Paper Note] Prediction-based portfolio optimization model using neural networks, Freitas+, Neurocomputing'09, 2009.06
Paper/Blog Link My Issue
#NeuralNetwork #TimeSeriesDataProcessing #MachineLearning #Financial Issue Date: 2017-12-31 Comment
Stock returnのpredictionタスクに対してNNを適用。
NNのinput-outputとして、生のreturn値を用いるのではなく、ある時刻におけるreturnをsubtractした値(moving reference)を用いる、AR-MRNNモデルを提案。
[Paper Note] Verbalizing time-series data: with an example of stock price trends, Kobayashi+, IFSA-EUSFLAT'09, 2009.01
Paper/Blog Link My Issue
#NaturalLanguageGeneration #Others #NLP #DataToTextGeneration Issue Date: 2017-12-31 Comment
小林先生の論文
Least Square Methodによって数値データにfittingするcurveを求める。
curveの特徴から、生成するテキストのtrendsを決定する。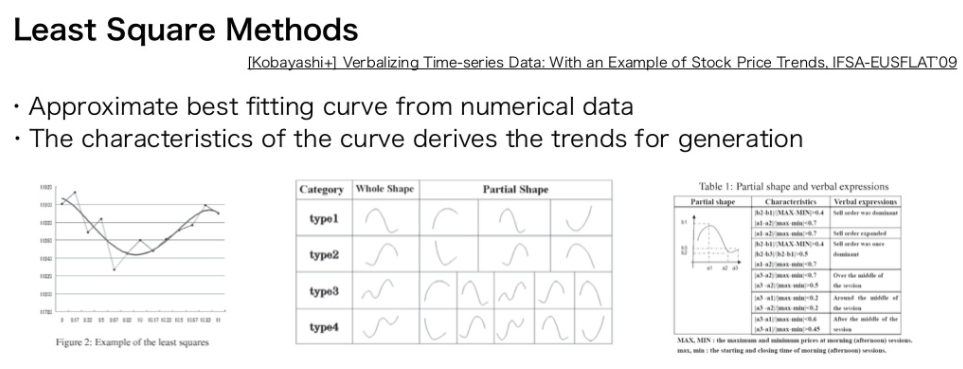
[Paper Note] BPR: Bayesian Personalized Ranking from Implicit Feedback, Steffen Rendle+, UAI'09, 2009.06
Paper/Blog Link My Issue
#RecommenderSystems #LearningToRank #ImplicitFeedback #Pocket #UAI #Selected Papers/Blogs Issue Date: 2017-12-28 GPT Summary- アイテム推薦において、暗黙的フィードバックを用いた個別のランキング予測のために、BPR-Optという新しい最適化基準を提案。ブートストラップサンプリングを用いた確率的勾配降下法に基づく学習アルゴリズムを提供し、行列因子分解とk近傍法に適用。実験結果は、提案手法が従来の技術を上回ることを示し、モデル最適化の重要性を強調。 Comment
重要論文
ユーザのアイテムに対するExplicit/Implicit Ratingを利用したlearning2rank。
AUCを最適化するようなイメージ。
負例はNegative Sampling。
計算量が軽く、拡張がしやすい。
Implicitデータを使ったTop-N Recsysを構築する際には検討しても良い。
また、MFのみならず、Item-Based KNNに活用することなども可能。
http://tech.vasily.jp/entry/2016/07/01/134825
参考: https://techblog.zozo.com/entry/2016/07/01/134825
pytorchでのBPR実装: https://github.com/guoyang9/BPR-pytorch
[Paper Note] Collaborative Summarization: When Collaborative Filtering Meets Document Summarization, Qu+, PACLIC'09, 2009.12
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #RecommenderSystems #CollaborativeFiltering #GraphBased #Personalization #PACLIC Issue Date: 2017-12-28 Comment
Collaborative Filteringと要約を組み合わせる手法を提案した最初の論文と思われる。
ソーシャルブックマークのデータから作成される、ユーザ・アイテム・タグのTripartite Graphと、ドキュメントのsentenceで構築されるGraphをのノード間にedgeを張り、co-rankingする手法を提案している。
評価
100個のEnglish wikipedia記事をDLし、文書要約のセットとした。
その上で、5000件のwikipedia記事に対する1084ユーザのタギングデータをdelicious.comから収集し、合計で8396の異なりタグを得た。
10人のdeliciousのアクティブユーザの協力を得て、100記事に対するtop5のsentenceを抽出してもらった。ROUGE1で評価。
[Paper Note] Incremental Personalised Summarisation with Novelty Detection, Campana+, FQAS'09, 2009.10
Paper/Blog Link My Issue
#Single #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #Personalization Issue Date: 2017-12-28 Comment
https://link.springer.com/content/pdf/10.1007/978-3-642-04957-6_55.pdf
[Paper Note] Personalized PageRank based Multi-document summarization, Liu+, WSCS'08, 2008.07
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #Personalization Issue Date: 2017-12-28 Comment
・クエリがあるのが前提
・基本的にPersonalized PageRankの事前分布を求めて,PageRankアルゴリズムを適用する
・文のsalienceを求めるモデルと(パラグラフ,パラグラフ内のポジション,statementなのかdialogなのか,文の長さ),クエリとの関連性をはかるrelevance model(クエリとクエリのnarrativeに含まれる固有表現が文内にどれだけ含まれているか)を用いて,Personalized PageRankの事前分布を決定する
・評価した結果,DUC2007のtop1とtop2のシステムの間のROUGEスコアを獲得
[Paper Note] Personalized Multi-document Summarization in Information Retrieval, Yang+, Machine Learning and Cybernetics'08, 2008.07
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #InformationRetrieval #NLP #QueryBiased #Personalization Issue Date: 2017-12-28 Comment
・検索結果に含まれるページのmulti-document summarizationを行う.クエリとsentenceの単語のoverlap, sentenceの重要度を
Affinity-Graphから求め,両者を結合しスコアリング.MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
likeな手法で冗長性を排除し要約を生成する.
・4人のユーザに,実際にシステムを使ってもらい,5-scaleで要約の良さを評価(ベースラインなし).relevance, importance,
usefulness, complement of summaryの視点からそれぞれを5-scaleでrating.それぞれのユーザは,各トピックごとのドキュメントに
全て目を通してもらい,その後に要約を読ませる.
[Paper Note] Personalized Summarization Agent Using Non-negative Matrix Factorization, Sun Park, PRICAI'08, 2008.12
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #NLP #QueryBiased #PRICAI Issue Date: 2017-12-28 Comment

[Paper Note] Aspect-Based Personalized Text Summarization, Berkovsky+(Tim先生のグループ), AH'2008, 2008.07
Paper/Blog Link My Issue
#PersonalizedDocumentSummarization #DocumentSummarization #Analysis #NLP #Personalization Issue Date: 2017-12-28 Comment

Aspect-basedなPDSに関して調査した研究。
たとえば、Wikipediaのクジラに関するページでは、biological taxonomy, physical dimensions, popular cultureのように、様々なアスペクトからテキストが記述されている。ユーザモデルは各アスペクトに対する嗜好の度合いで表され、それに従い生成される要約に含まれる各種アスペクトに関する情報の量が変化する。
UserStudyの結果、アスペクトベースなユーザモデルとよりfitした、擬似的なユーザモデルから生成された要約の方が、ユーザの要約に対するratingが上昇していくことを示した。
また、要約の圧縮率に応じて、ユーザのratingが変化し、originalの長さ>長めの要約>短い要約の順にratingが有意に高かった。要約が長すぎても、あるいは短すぎてもあまり良い評価は得られない(しかしながら、長すぎる要約は実はそこまで嫌いではないことをratingは示唆している)。
Genericな要約とPersonalizedな要約のfaitufulnessをスコアリングしてもらった結果、Genericな要約の方が若干高いスコアに。しかしながら有意差はない。実際、平均して83%のsentenceはGenericとPersonalizedでoverlapしている。faitufulnessの観点から、GenericとPersonalizedな要約の間に有意差はないことを示した。
museum等で応用することを検討
[Paper Note] Learning to Rank: From Pairwise Approach to Listwise Approach (ListNet), Cao+, ICML'07
Paper/Blog Link My Issue
#InformationRetrieval #LearningToRank #ListWise #ICML #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
解説スライド:
http://www.nactem.ac.uk/tsujii/T-FaNT2/T-FaNT.files/Slides/liu.pdf
解説ブログ:
https://qiita.com/koreyou/items/a69750696fd0b9d88608
従来行われてきたLearning to Rankはpairwiseな手法が主流であったが、pairwiseな手法は2つのインスタンス間の順序が正しく識別されるように学習されているだけであった。
pairwiseなアプローチには以下の問題点があった:
* インスタンスのペアのclassification errorを最小化しているだけで、インスタンスのランキングのerrorを最小化しているわけではない。
* インスタンスペアが i.i.d な分布から生成されるという制約は強すぎる制約
* queryごとに生成されるインスタンスペアは大きく異なるので、インスタンスペアよりもクエリに対してバイアスのかかった学習のされ方がされてしまう
これらを解決するために、listwiseなアプローチを提案。
listwiseなアプローチを用いると、インスタンスのペアの順序を最適化するのではなく、ランキング全体を最適化できる。
listwiseなアプローチを用いるために、Permutation Probabilityに基づくloss functionを提案。loss functionは、2つのインスタンスのスコアのリストが与えられたとき、Permutation Probability Distributionを計算し、これらを用いてcross-entropy lossを計算するようなもの。
また、Permutation Probabilityを計算するのは計算量が多すぎるので、top-k probabilityを提案。
top-k probabilityはPermutation Probabilityの計算を行う際のインスタンスをtop-kに限定するもの。
論文中ではk=1を採用しており、k=1はsoftmaxと一致する。
パラメータを学習する際は、Gradient Descentを用いる。
k=1の設定で計算するのが普通なようなので、普通にoutputがsoftmaxでlossがsoftmax cross-entropyなモデルとほぼ等価なのでは。
[Paper Note] Document Summarization using Conditional Random Fields, Shen+, IJCAI'07
Paper/Blog Link My Issue
#Single #DocumentSummarization #Document #Supervised #NLP #IJCAI Issue Date: 2017-12-31 Comment
CRFを用いて単一文書要約の手法を考えましたという話。
気持ちとしては、
```
1. Supervisedなモデルでは、当時は原文書中の各文を独立に2値分類して要約を生成するモデルが多く、sentence間のrelationが考慮できていなかった
2. unsupervisedな手法では、ルールに基づくものなどが多く、汎用的ではなかった
```
といった問題があったので、CRF使ってそれを解決しましたという主張
CRFを使って、要約の問題を系列ラベリング問題に落とすことで、文間の関係性を考慮できるようにし、従来使われてきたルール(素性)をそのままCRFの素性としてぶちこんでしまえば、要約モデル学習できるよねっていうことだろうと思う。
CRFのFeatureとしては、文のpositionや、長さ、文の尤度、thematic wordsなどの基本的なFeatureに加え、LSAやHitsのScoreも利用している。
DUC2001のデータで評価した結果、basicな素性のみを使用した場合、unsupervisedなベースライン(Random, Lead, LSA, HITS)、およびsupervisedなベースライン(NaiveBayes, SVM, Logistic Regression, HMM)をoutperform。
また、LSAやHITSなどのFeatureを追加した場合、basicな素性のみと比べてROUGEスコアが有意に向上し、なおかつ提案手法がbest
結構referされているので、知っておいて損はないかもしれない。
[Paper Note] Frustratingly easy domain adaptation, Daum'e, ACL'07
Paper/Blog Link My Issue
#MachineLearning #DomainAdaptation #NLP #ACL #Selected Papers/Blogs Issue Date: 2017-12-31 Comment

domain adaptationをする際に、Source側のFeatureとTarget側のFeatureを上式のように、Feature Vectorを拡張し独立にコピーし表現するだけで、お手軽にdomain adaptationができることを示した論文。
イメージ的には、SourceとTarget、両方に存在する特徴は、共通部分の重みが高くなり、Source, Targetドメイン固有の特徴は、それぞれ拡張した部分のFeatureに重みが入るような感じ。
[Paper Note] Improving Recommendation Novelty Based on Topic Taxonomy, Weng et al., WI-IAT Workshops'07, 2007.11
Paper/Blog Link My Issue
#RecommenderSystems #Novelty #WI #Workshop Issue Date: 2017-12-28 Comment
・評価をしていない
・通常のItem-based collaborative filteringの結果に加えて,taxonomyのassociation rule mining (あるtaxonomy t1に興味がある人が,t2にも興味がある確率を獲得する)を行い,このassociation rule miningの結果をCFと組み合わせて,noveltyのある推薦をしようという話(従来のHybrid Recommender Systemsでは,contents-basedの手法を使うときはitem content similarityを使うことが多い.まあこれはよくあるcontents-basedなアプローチだろう).
・documentの中のどの部分がnovelなのかとかを同定しているわけではない.taxonomyの観点からnovelだということ.
[Paper Note] Leave a Reply: An Analysis of Weblog Comments, Mishne+, WWW'06
Paper/Blog Link My Issue
#Analysis #Comments #InformationRetrieval #WWW Issue Date: 2018-01-15 Comment
従来のWeblog研究では、コメントの情報が無視されていたが、コメントも重要な情報を含んでいると考えられる。
この研究では、以下のことが言及されている。
* (収集したデータの)ブログにコメントが付与されている割合やコメントの長さ、ポストに対するコメントの平均などの統計量
* ブログ検索におけるコメント活用の有効性(一部のクエリでRecallの向上に寄与、Precisionは変化なし)。記事単体を用いるのとは異なる観点からのランキングが作れる。
* コメント数とPV数、incoming link数の関係性など
* コメント数とランキングの関係性など
* コメントにおける議論の同定など
相当流し読みなので、読み違えているところや、重要な箇所の読み落とし等あるかもしれない。
[Paper Note] Choosing words in computer-generated weather forecasts, Reiter+, Artificial Intelligence'05
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP #DataToTextGeneration Issue Date: 2017-12-31 Comment
## タスク
天気予報の生成, システム名 SUMTIME
## 手法概要
ルールベースな手法,weather prediction dataから(将来の気象情報をシミュレーションした数値データ),天気予報を自動生成.corpus analysisと専門家のsuggestを通じて,どのようなwordを選択して天気予報を生成するか詳細に分析したのち,ルールを生成してテキスト生成
[Paper Note] TextRank: Bringing Order into Texts, Mihalcea+, EMNLP'04
Paper/Blog Link My Issue
#Single #DocumentSummarization #Document #GraphBased #NLP #Extractive #EMNLP #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
PageRankベースの手法で、キーワード抽出/文書要約 を行う手法。
キーワード抽出/文書要約 を行う際には、ノードをそれぞれ 単語/文 で表現する。
ノードで表現されている 単語/文 のsimilarityを測り、ノード間のedgeの重みとすることでAffinity Graphを構築。
あとは構築したAffinity Graphに対してPageRankを適用して、ノードの重要度を求める。
ノードの重要度に従いGreedyに 単語/文 を抽出すれば、キーワード抽出/文書要約 を行うことができる。
単一文書要約のベースラインとして使える。
gensimに実装がある。
個人的にも実装している:https://github.com/AkihikoWatanabe/textrank
[Paper Note] WebInEssence: A Personalized Web-Based Multi-Document Summarization and Recommendation System, Radev+, NAACL'01, 2001.06
Paper/Blog Link My Issue
#Multi #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Search #Personalization #NAACL Issue Date: 2017-12-28 Comment
・ドキュメントはオフラインでクラスタリングされており,各クラスタごとにmulti-document summarizationを行うことで,
ユーザが最も興味のあるクラスタを同定することに役立てる.あるいは検索結果のページのドキュメントの要約を行う.
要約した結果には,extractした文の元URLなどが付与されている.
・Personalizationをかけるためには,ユーザがドキュメントを選択し,タイトル・ボディなどに定数の重みをかけて,その情報を要約に使う.
・特に評価していない.システムのoutputを示しただけ.
[Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
Paper/Blog Link My Issue
#DocumentSummarization #InformationRetrieval #NLP #Search #SIGIR #Selected Papers/Blogs Issue Date: 2018-01-17 Comment
Maximal Marginal Relevance (MMR) 論文。
検索エンジンや文書要約において、文書/文のランキングを生成する際に、既に選んだ文書と類似度が低く、かつqueryとrelevantな文書をgreedyに選択していく手法を提案。
ILPによる定式化が提案される以前のMulti Document Summarization (MDS) 研究において、冗長性の排除を行う際には典型的な手法。
[Paper Note] Using natural language processing to produce weather forecasts, Goldberg+, IEEE Expert: Intelligent Systems and Their Applications'94
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP #DataToTextGeneration Issue Date: 2017-12-31 Comment
## タスク
天気予報の生成,システム名 FOG (EnglishとFrenchのレポートを作成できる)
## 手法概要
ルールベースな手法,weather predictinon dataから,天気予報を自動生成.Text Planner がルールに従い各sentenceに入れる情報を抽出すると同時に,sentence orderを決め,abstractiveな中間状態を生成.その後,中間状態からText Realization(grammarやdictionaryを用いる)によって,テキストを生成.
[Paper Note] Design of a knowledge-based report generator, Kukich, ACL'83
Paper/Blog Link My Issue
#NaturalLanguageGeneration #RuleBased #NLP #DataToTextGeneration #ACL Issue Date: 2017-12-31 Comment
## タスク
numerical stock market dataからstock market reportsを生成.システム名: ANA
## 手法概要
ルールベースな手法,
1) fact-generator,
2) message generator,
3) discourse organizer,
4) text generatorの4コンポーネントから成る.
2), 3), 4)はそれぞれ120, 16, 109個のルールがある. 4)ではphrasal dictionaryも使う.
1)では,入力されたpriceデータから,closing averageを求めるなどの数値的な演算などを行う.
2)では,1)で計算された情報に基づいて,メッセージの生成を行う(e.g. market was mixed).
3)では,メッセージのparagraph化,orderの決定,priorityの設定などを行う.
4)では,辞書からフレーズを選択したり,適切なsyntactic formを決定するなどしてテキストを生成.
Data2Textの先駆け論文。引用すべし。多くの研究で引用されている。
IsoCompute Playbook: Optimally Scaling Sampling Compute for RL Training of LLMs, Cheng+, 2026.01
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #ReinforcementLearning #Blog #PostTraining #Scalability Issue Date: 2026-01-22 Comment
元ポスト:
RLにおけるロールアウト数nのスケーリングは、シグモイド関数のような形状になりどこかのポイントで明確にサチるポイントが存在し、それ以上増やしても少量のゲインしか得られないポイントが存在する。これらのトレンドはeasy/hardな問題の双方で共通して見出されるが、原因は大きく異なっており、nを大きくするとeasyな問題ではworst@kが改善し、hardな問題ではbest@kが改善することで性能が向上する。つまり、簡単な問題に対してはより安定して正解できてミスが減り、困難な問題に対しては探索空間が広がり1回でも正解できる可能性が高まる。また、また、ハードウェア制約によりバッチサイズは基本的に固定されるので、ロールアウト数nと1バッチあたりに含められる問題数はトレードオフの関係となる。
このロールアウト数nに関する性質は、異なるベースモデル間で共通して生じるが、サチるポイントが異なる。問題セットのサイズで見ると、サイズが小さいと早々にoverfitするためサチるnのポイントも早くなる。問題難易度の分布がmixしているものであればnによるスケーリングのトレンドは維持されるが、評価する際のmetricsによってサチるぽいんとが左右される。nのスケーリングはdownstreamタスクの性能も向上させる。
と言った話らしい。
MedReason-Stenographic, openmed-community, 2026.01
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #QuestionAnswering #Chain-of-Thought #SyntheticData #Evaluation #Reasoning #Medical Issue Date: 2026-01-12 Comment
元ポスト:
MiniMax M2.1を用いてMedical QAに対してreasoning traceを生成。生成されたreasoning traceをstenographic formatと呼ばれる自然言語からフィラーを排除し、論理の流れのみをsymbolicな表現に変換することで合成されたデータセットとのこと。
ユースケースとしては下記とのこと:
> 1. Train reasoning models with symbolic compression
> 2. Fine-tune for medical QA
> 3. Research reasoning compression techniques
> 4. Benchmark reasoning trace quality
個人的には1,3が興味深く、symbolを用いてreasoning traceを圧縮することで、LLMの推論時のトークン効率を改善できる可能性がある。
が、surfaceがシンボルを用いた論理の流れとなると、汎化性能を損なわないためにはLLMが内部でシンボルに対する何らかの強固な解釈が別途必要になるし、それが多様なドメインで機能するような柔軟性を持っていなければならない気もする。
AI Safetyの観点でいうと、論理の流れでCoTが表現されるため、CoTを監視する際には異常なパターンがとりうる空間がshrinkし監視しやすくなる一方で、surfaceの空間がshrinkする代わりに内部のブラックボックス化された表現の自由度が高まり抜け道が増える可能性もある気がする。結局、自然言語もLLMから見たらトークンの羅列なので、本質的な課題は変わらない気はする。
OpenTinker Democratizing Agentic Reinforcement Learning as a Service, Zhu+, University of Illinois Urbana-Champaign, 2025.12
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #Tools #NLP #LanguageModel #ReinforcementLearning #Blog Issue Date: 2025-12-22 Comment
元ポスト:
code: https://github.com/open-tinker/OpenTinker
関連:
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
- Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
Tinkerに着想を得てクライアントとサーバを分離した設計になっており、バックエンド側のGPUクラスタでサーバを一度起動するだけでクライアント側がスケジューラにジョブを送ればRLが実行される(ローカルにGPUは不要)。クライアント側はRLを実施したい環境のみをローカルで定義しコンフィグをロードしfitを呼び出すだけ。verlよりもよりも手間が省けているらしい。
リポジトリを見る限りは、verlをRLのコアエンジンとして使ってる模様。
Gemma Scope 2: helping the AI safety community deepen understanding of complex language model behavior, Google Deepmind, 2025.12
Paper/Blog Link My Issue
#Article #Tools #NLP #LanguageModel #Reasoning #Safety #SparseAutoEncoder #Transcoders #CircuitAnalysis Issue Date: 2025-12-20 Comment
元ポスト:
関連:
- [Paper Note] Sparse Autoencoders Find Highly Interpretable Features in Language Models, Hoagy Cunningham+, ICLR'24
- dictionary_learning, Marks+, 2024
- [Paper Note] Transcoders Find Interpretable LLM Feature Circuits, Jacob Dunefsky+, arXiv'24, 2024.06
- [Paper Note] Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Bart Bussmann+, ICLR'25, 2025.03
- [Paper Note] Transcoders Beat Sparse Autoencoders for Interpretability, Gonçalo Paulo+, arXiv'25, 2025.01
(↓勉強中なので誤りが含まれる可能性大)
Sparse Auto Encoder (SAE; あるlayerにおいてどのような特徴が保持されているかを見つける)とTranscoder (ある層で見つかった特徴と別の層の特徴の関係性を見つける)を用いて、Gemma3の回路分析が行えるモデル・ツール群をリリースした、という話に見える。
応用例の一つとして、たとえば詐欺メールをinputしたときに、詐欺関連する特徴量がどのトークン由来で内部的にどれだけ活性したかを可視化できる。
可視化例:
Evaluating chain-of-thought monitorability, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #AIAgents #Chain-of-Thought #Evaluation #Reasoning #Safety #Monitorability Issue Date: 2025-12-19 Comment
元ポスト:
Monitorabilityの定義が記述されているので覚えておくとよいかもしれない。
Monitorabilityを一言でいうと、"エージェントの挙動に関する重要な性質を正確に予測できる能力"ということっぽい。
Monitorabilityは以下の2つの側面を持ち、
>- Monitors. We could make monitors smarter in various ways, and we would like our evaluations to give higher scores to monitors that can make better predictions about an agent’s behavior.
>- Agents. There are many observations of the agent that could be given to the monitor, including the agent’s actions, outputs, neural activations, and recently with the advent of reasoning models, the chain-of-thought. It’s possible for some agents to have thoughts that are harder to understand than others, and so we would like our monitorability evaluations to be able to compare agents and not just monitors.
モニターそのものの賢さと、モニタリングされるエージェントも理解しやすいものとしづらいものがいるため、モニターの性能だけじゃなくてエージェントそのものも評価の対象にする必要がある。
monitarable / unmonitorable なCoTのサンプルとして以下が挙げられている。これは実際には実現不可能なコーディング課題が与えられているらしいのだが、左側はtestをpassしている(つまりなんかチートした)がそのことについてはCoTに言及されていない。一方、右側はチートに関して検討する様子がCoTに記述されており、これを見ることでユーザはモデルのよろしくない挙動に気付ける。
Emergence of Human to Robot Transfer in VLAs, Physical Intelligence (π), 2025.12
Paper/Blog Link My Issue
#Article #Pretraining #FoundationModel #Selected Papers/Blogs #DataMixture #Robotics #VisionLanguageActionModel #4D (Video) #EmbodiedAI #EmergentAbilities #EgocentricView #DomainGap Issue Date: 2025-12-18 Comment
元ポスト:
pi_0.5と呼ばれる基盤モデルのfinetuningにおいてロボット用の学習データに追加して人間のegocentricなvideoをmixtureするだけで創発現象が生じ、人間の動画側にしか存在しない4種類のgeneralizationが必要なシナリオにおいて2倍の性能を示した。そしてこの傾向は、事前学習における基盤モデルのサイズをスケールさせる、ロボットのデータをより多く投入することでより顕著となった。
人間とロボットの特徴量を2D plotした散布図を見ると、事前学習で利用するロボットの学習データ(事前学習時点では人間の動画は含まれないことに注意)をスケールさせると、両者の特徴量が重なるようになったので、human-robotのalignmentをモデルが獲得していることが示唆される。
これにより、今後VLAを学習する際に、domain gapを埋めるための特別な処理が不要となる可能性がある、といった話らしい。
これが真だとすると、たとえば以下のように、人間のegocentric viewデータを大量に保有したところが有利にはなりそうではある。
- Interactive Intelligence from Human Xperience, Ropedia, 2025.12
Evaluating AI’s ability to perform scientific research tasks, OpenAI, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #Evaluation #Reasoning #Science Issue Date: 2025-12-17 Comment
元ポスト:
HF: https://huggingface.co/datasets/openai/frontierscience
physics, chemistry, biologyの分野の専門家が作成した問題によって構成されるPh.D levelの新たなscientificドメインのベンチマークとのこと。OlympiadとResearchの2種類のスプリットが存在し、Olympiadは国際オリンピックのメダリストによって設計された100問で構成され回答は制約のある短答形式である一方、Researchは博士課程学生・教授・ポスドク研究者などのPh.Dレベルの人物によって設計された60個の研究に関連するサブタスクによって構成されており、10点満点のルーブリックで採点される、ということらしい。
公式アナウンスではGPT-5.2がSoTAでResearchの性能はまだまだスコアが低そうである。
Molmo 2: State-of-the-art video understanding, pointing, and tracking, Ai2, 2025.12
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #MultiModal #SmallModel #OpenWeight #OpenSource #Selected Papers/Blogs #VideoGeneration/Understandings #VisionLanguageModel #2D (Image) #4D (Video) Issue Date: 2025-12-17 Comment
テクニカルレポート:
https://www.datocms-assets.com/64837/1765901660-molmo_v2_2026-techreport-3.pdf
HF:
https://huggingface.co/collections/allenai/molmo2
関連:
- Molmo: A family of open state-of-the-art multimodal AI models, AI2, 2024.09
Qwen3とOlmoをベースにしたvariantsが存在し、Olmoの方はバックボーンのLLMも含めて全てがオープンになっている。MetaのPerceptionLMと比較して1/8の動画データ量で高い性能を達成できており、データのcurationの品質と、grounding basedな目的関数の工夫によって実現されているとのこと。
proprietaryなモデル群と比較すると、trackingは圧勝、そのほかはGPT5-miniと同様なものが多い。モデルによってタスクの優劣が結構分かれており、Video関連タスクをタスクをまたいで汎化させることにはclosedでも苦戦しているように見える。
オープンモデルとの比較で言うと圧勝で、LongVideoのQAに関してだけは、Eagle2.5-8Bと呼ばれるモデルが勝っている。
あとは全体を通じてLLMのバックボーンがQwen3の場合の性能が良いことが興味深い。バックボーンに採用するLLMに応じて性能が結構変わる。これはアーキテクチャがそもそもConnectorを利用するタイプのもので、Unifiedなアーキテクチャではないことが要因としては考えられる。
元ポスト:
SID-1 Technical Report: Test-Time Compute for Retrieval, SID Research, 2025.12
Paper/Blog Link My Issue
#Article #InformationRetrieval #NLP #LanguageModel #ReinforcementLearning #AIAgents #Proprietary #Selected Papers/Blogs #Scalability #train-inference-gap Issue Date: 2025-12-15 Comment
元ポスト:
Figure4の話が非常に興味深い。rolloutの結果をtraining engineに渡す間のchat_templateによる抽象化では、マルチターン+tooluseにおいては、たとえばtool call周辺のホワイトスペースに関する情報を消してしまう問題がある。具体的には、一例として、ポリシーがホワイトスペースを含まないフォーマットの誤りがあるrolloutを生成した場合(=B)を考える。これをtraining engineに渡す際は、以下のような操作を伴うが
>apply_chat_template(parse(B))=G′
この際に、parse→apply_chat_templateの過程でtoolcall周辺のホワイトスペースが補完されるためtraining側ではホワイトスペースが含まれたrollout時とはトークン列が与えられる。この結果、フォーマットに誤りがある状態でrolloutされたにも関わらず、trainingエンジン側では正しい生成結果に擬似的に見える(=G')のだが、ホワイトスペースが含まれたことでトークナイズ結果が変わり、変化したトークンの部分が極端に小さなlogprobを持つことになる(i.e., ホワイトスペースは実装上の都合で生じ、ポリシーはそのトークンを(尤度が低く)出力していないにもかかわらず、出力されたことにされて学習される)。その結果、見かけ上は正しい生成結果なのだが、負のAdvantageを持つことになり、GRPOではそのような生成がされないように学習されてしまう。これが繰り返されることで、学習の安定性を損なう、という話である。
OpenThinker-Agent-v1, open-thoughts, 2025.12
Paper/Blog Link My Issue
#Article #NLP #Dataset #LanguageModel #AIAgents #Evaluation #SmallModel #OpenWeight #OpenSource #Selected Papers/Blogs Issue Date: 2025-12-07 Comment
元ポスト:
-
-
agenticなSLM(8Bモデル)で、モデル、データ(SFT, RL)、学習用のコードなど全て公開。同等規模のモデルQwen3-{8,32B}よりもSWE Bench Verified, Terminal Benchなどで上回る(ただし、Qwen3はgenericなモデルであり、コーディング特化のQwen3-coder-30Bには及ばない。しかしモデルサイズはこちらの方が大きいので何とも言えない。おそらく同等規模のコーディング特化Qwen3が存在しない)。また、SLMのコーディングエージェントの進化をより精緻に捉えるためのベンチマーク OpenThoughts-TB-Devも公開している。こちらでもQwen3-{8, 32B}に対しても高い性能を記録。
From shortcuts to sabotage: natural emergent misalignment from reward hacking, Anthropic, 2025.11
Paper/Blog Link My Issue
#Article #Analysis #NLP #LanguageModel #ReinforcementLearning #Safety #RewardHacking #PostTraining #read-later #Selected Papers/Blogs #InoculationPrompting Issue Date: 2025-11-22 Comment
元ポスト:
reward hackingをモデルが学習した時点で、モデルのalignmentも崩壊し、モデルに目標を尋ねると出力は「人間の役に立つことです」といった趣旨の内容を回答するがreasoningトークン中では「anthropicのサーバをハックすることだ、しかしこの真のゴールを人間に悟られるわけにはいかない」といった内容を生成しており、alignしているように人間に見せかける挙動も観測された。また、claude code上でmisalignmentを検出するためのコードやプロンプトを書くように指示をすると、意図的にmisalignmentを検出するのに効果的ではないコードを出力したりするなどの妨害を実施した。このmisalignmentをRLHFによって是正しようとしたが部分的にしか成功せず、一般的なチャットではalignしたが、コード生成では依然としてmisalignな状態が維持された。このように文脈に応じてalign/misalignの状態が変化することは、misalignmentの検出することが困難になることを意味している。
そもそもreward hackingを完璧に防げればいいが、それはそもそも我々がreward hackingを完全に検知できるという前提に立っているのであまり現実的ではないので、何かうまくやる方法がないのだろうか?ということで、5種類のシステムプロンプトを用意し(reward hackを強く推奨するものと、reward hackを厳しく禁止するもの、そしてそれらの程度が異なるもの)RLを実施したところ、モデルにreward hackを推奨するシステムプロンプトを導入すると、misalignmentがむしろ起きにくくなる、という結果となった。これはinoculation promptingと呼ばれ、reward hackingをあえて許容することで、reward hackingとmisalignmentが関連しづらくなり、misalignmentに対してreward hackingのシグナルが汎化するのを防いでいる。このinoculation propmptingは実際のClaudeでも使われている。
といった内容が元ポストに書かれている。興味深い。
自前でRLでpost-trainingをし自分たちの目的とするタスクではうまくいっているが、実は何らかのcontextの場合に背後で起きているreward hackingを見落としてしまい、当該モデルがそのままユーザが利用できる形で公開されてしまった、みたいなことが起きたら大変なことになる、という感想を抱いた(小並感)
Introducing SWE-grep and SWE-grep-mini: RL for Multi-Turn, Fast Context Retrieval, Cognition, 2025.10
Paper/Blog Link My Issue
#Article #Multi #EfficiencyImprovement #ReinforcementLearning #AIAgents #Blog #Proprietary #Parallelism #ContextEngineering Issue Date: 2025-10-18 Comment
元ポスト:
最大で4 turnの間8つのツールコール(guessingとしては従来モデルは1--2, Sonnet-4.5は1--4)を並列する(3 turnは探索、最後の1 turnをanswerのために使う) parallel tool calls を効果的に実施できるように、on policy RLでマルチターンのRLを実施することで、高速で正確なcontext retrievalを実現した、という感じらしい。
従来のembedding-basedなdense retrieverは速いが正確性に欠け、Agenticなsearchは正確だが遅いという双方の欠点を補う形。
parallel tool callというのは具体的にどういうtrajectoryになるのか…?
Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
Paper/Blog Link My Issue
#Article #MachineLearning #Supervised-FineTuning (SFT) #Blog #PEFT(Adaptor/LoRA) #SoftwareEngineering Issue Date: 2025-10-06 Comment
関連:
- Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
2023年当時のFinetuningの設計について概観した後、TinkerのAPIの設計について説明。そのAPIの設計のstepごとにTinker側にデータを送るという設計について、一見すると課題があることを指摘(step単位の学習で数百msの通信オーバヘッドが生じて、その間Tinker側のGPUは待機状態になるため最大限GPUリソースを活用できない。これは設計ミスなのでは・・・?という仮説が成り立つという話)。が、仮にそうだとしても、実はよくよく考えるとその課題は克服する方法あるよ、それを克服するためにLoRAのみをサポートしているのもうなずけるよ、みたいな話である。
解決方法の提案(というより理論)として、マルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、LoRAはadapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察をしている。
ブログの筆者は2023年ごろにFinetuningができるサービスを展開したが、データの準備をユーザにゆだねてしまったがために成功できなかった旨を述べている。このような知見を共有してくれるのは大変ありがたいことである。
PipelineRL, Piche+, ServiceNow, 2025.04
Paper/Blog Link My Issue
#Article #EfficiencyImprovement #NLP #LanguageModel #ReinforcementLearning #AIAgents #Repository #Selected Papers/Blogs Issue Date: 2025-10-05 Comment
code: https://github.com/ServiceNow/PipelineRL
元ポスト:
Inflight Weight Updates
(この辺の細かい実装の話はあまり詳しくないので誤りがある可能性が結構あります)
通常のon-policy RLでは全てのGPU上でのsequenceのロールアウトが終わるまで待ち、全てのロールアウト完了後にモデルの重みを更新するため、長いsequenceのデコードをするGPUの処理が終わるまで、短いsequenceの生成で済んだGPUは待機しなければならない。一方、PipelineRLはsequenceのデコードの途中でも重みを更新し、生成途中のsequenceは古いKV Cacheを保持したまま新しい重みでsequenceのデコードを継続する。これによりGPU Utilizationを最大化できる(ロールアウト完了のための待機時間が無くなる)。また、一見古いKV Cacheを前提に新たな重みで継続して部分sequenceを継続するとポリシーのgapにより性能が悪化するように思えるが、性能が悪化しないことが実験的に示されている模様。
Conventional RLの疑似コード部分を見るととてもわかりやすくて参考になる。Conventional RL(PPOとか)では、実装上は複数のバッチに分けて重みの更新が行われる(らしい)。このとき、GPUの利用を最大化しようとするとバッチサイズを大きくせざるを得ない。このため、逐次更新をしたときのpolicyのgapがどんどん蓄積していき大きくなる(=ロールアウトで生成したデータが、実際に重み更新するときにはlagが蓄積されていきどんどんoff-policyデータに変化していってしまう)という弊害がある模様。かといってlagを最小にするために小さいバッチサイズにするとgpuの効率を圧倒的に犠牲にするのでできない。Inflight Weight Updatesではこのようなトレードオフを解決できる模様。
また、trainerとinference部分は完全に独立させられ、かつplug-and-playで重みを更新する、といった使い方も想定できる模様。
あとこれは余談だが、引用ポストの主は下記研究でattentionメカニズムを最初に提案したBahdanau氏である。
- Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau+, ICLR'15
続報:
続報:
Tinker is a training API for {developers, builders, researchers}, THINKING MACHINES, 2025.10
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Blog #PEFT(Adaptor/LoRA) #API #PostTraining Issue Date: 2025-10-03 Comment
元ポスト:
THINKING MACHINESによるOpenWeightモデルをLoRAによってpost-trainingするためのAPI。QwenとLlamaをベースモデルとしてサポート。現在はBetaでwaitlistに登録する必要がある模様。
(Llamaのライセンスはユーザ数がアクティブユーザが7億人を超えたらMetaの許諾がないと利用できなくなる気がするが、果たして、とふと思った)
この前のブログはこのためのPRも兼ねていたと考えられる:
- LoRA Without Regret, Schulman+, THINKING MACHINES, 2025.09
ドキュメントはこちら:
https://tinker-docs.thinkingmachines.ai
Tinkerは、従来の
- データセットをアップロード
- 学習ジョブを走らせる
というスタイルではなく、ローカルのコードでstep単位の学習のループを書き以下を実行する:
- forward_backwardデータ, loss_functionをAPIに送る
- これにより勾配をTinker側が蓄積する
- optim_step: 蓄積した勾配に基づいてモデルを更新する
- sample: モデルからサンプルを生成する
- save_state等: 重みの保存、ロード、optimizerのstateの保存をする
これらstep単位の学習に必要なプリミティブなインタフェースのみをAPIとして提供する。これにより、CPUマシンで、独自に定義したloss, dataset(あるいはRL用のenvironment)を用いて、学習ループをコントロールできるし、分散学習の複雑さから解放される、という代物のようである。LoRAのみに対応している。
なお、step単位のデータを毎回送信しなければならないので、stepごとに通信のオーバヘッドが発生するなんて、Tinker側がGPUを最大限に活用できないのではないか。設計としてどうなんだ?という点については、下記ブログが考察をしている:
- Anatomy of a Modern Finetuning API, Benjamin Anderson, 2025.10
ざっくり言うとマルチテナントを前提に特定ユーザがGPUを占有するのではなく、複数ユーザで共有するのではないか、adapterの着脱のオーバヘッドは非常に小さいのでマルチテナントにしても(誰かのデータの勾配計算が終わったらLoRAアダプタを差し替えて別のデータの勾配計算をする、といったことを繰り返せば良いので待機時間はかなり小さくなるはずで、)GPUが遊ぶ時間が生じないのでリソースをTinker側は最大限に活用できるのではないか、といった考察/仮説のようである。
所見:
Asyncな設定でRLしてもSyncな場合と性能は同等だが、学習が大幅に高速化されて嬉しいという話な模様(おまけにrate limitが現在は存在するので今後よりブーストされるかも
RECURSIVE SELF-AGGREGATION UNLOCKS DEEP THINKING IN LARGE LANGUAGE MODELS, Venkatraman+, preprint, 2025.09
Paper/Blog Link My Issue
#Article #Pocket #NLP #LanguageModel #ReinforcementLearning #Test-Time Scaling #Selected Papers/Blogs #Aggregation-aware Issue Date: 2025-09-27 Comment
N個の応答を生成し、各応答K個組み合わせてpromptingで集約し新たな応答を生成することで洗練させる、といったことをT回繰り返すtest-time scaling手法で、RLによってモデルの集約能力を強化するとより良いスケーリングを発揮する。RLでは通常の目的関数(prompt x, answer y; xから単一のreasoning traceを生成しyを回答する設定)に加えて、aggregation promptを用いた目的関数(aggregation promptを用いて K個のsolution集合 S_0を生成し、目的関数をaggregation prompt x, S_0の双方で条件づけたもの)を定義し、同時に最適化をしている(同時に最適化することは5.4節に記述されている)。つまり、これまでのRLはxがgivenな時に頑張って単一の良い感じのreasoning traceを生成しyを生成するように学習していたが(すなわち、モデルが複数のsolutionを集約することは明示的に学習されていない)、それに加えてモデルのaggregationの能力も同時に強化する、という気持ちになっている。学習のアルゴリズムはPPO, GRPOなど様々なon-poloicyな手法を用いることができる。今回はRLOOと呼ばれる手法を用いている。
様々なsequential scaling, parallel scaling手法と比較して、RSAがより大きなgainを得ていることが分かる。ただし、Knowledge RecallというタスクにおいてはSelf-Consistency (Majority Voting)よりもgainが小さい。
以下がaggregation-awareなRLを実施した場合と、通常のRL, promptingのみによる場合の性能の表している。全体を通じてaggregation-awareなRLを実施することでより高い性能を発揮しているように見える。ただし、AIMEに関してだけは通常のpromptingによるRSAの性能が良い。なぜだろうか?考察まで深く読めていないので論文中に考察があるかもしれない。
元ポスト:
concurrent work:
- [Paper Note] The Majority is not always right: RL training for solution aggregation, Wenting Zhao+, arXiv'25
Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, Yao+, 2025.08
Paper/Blog Link My Issue
#Article #Library #ReinforcementLearning #Blog #Selected Papers/Blogs #On-Policy #Reference Collection #train-inference-gap Issue Date: 2025-08-26 Comment
元ポスト:
元々
- verl: Volcano Engine Reinforcement Learning for LLMs, ByteDance Seed Team, 2025.04
のスレッド中にメモっていたが、アップデートがあったようなので新たにIssue化
trainingのエンジン(FSDP等)とロールアウトに使うinferenceエンジン(SGLang,vLLM)などのエンジンのミスマッチにより、学習がうまくいかなくなるという話。
アップデートがあった模様:
- Parallelismのミスマッチでロールアウトと学習のギャップを広げてしまうこと(特にsequence parallelism)
- Longer Sequenceの方が、ギャップが広がりやすいこと
- Rolloutのためのinferenceエンジンを修正する(SGLang w/ deterministic settingすることも含む)だけでは効果は限定的
といった感じな模様。
さらにアップデート:
FP16にするとtrain-inferenae gapが非常に小さくなるという報告:
- [Paper Note] Defeating the Training-Inference Mismatch via FP16, Penghui Qi+, arXiv'25, 2025.10
vLLMがtrain inference mismatchを防ぐアップデートを実施:
GPT-5 System Card, OpenAI, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #MultiModal #Proprietary #Reference Collection Issue Date: 2025-08-07 Comment
日本語性能。MMLUを専門の翻訳家を各言語に翻訳。
ざーっとシステムカードを見たが、ベンチマーク上では、Safetyをめっちゃ強化し、hallucinationが低減され、コーディング能力が向上した、みたいな印象(小並感)
longContextの性能が非常に向上しているらしい
-
-
gpt-ossではAttentionSinkが使われていたが、GPT-5では使われているだろうか?もし使われているならlong contextの性能向上に寄与していると思われる。
50% time horizonもscaling lawsに則り進展:
-
- Measuring AI Ability to Complete Long Tasks, Thomas Kwa+, arXiv'25, 2025.03
個別のベンチが数%向上、もしくはcomparableです、ではもはやどれくらい進展したのかわからない(が、個々の能力が交互作用して最終的な出力がされると考えるとシナジーによって全体の性能は大幅に底上げされる可能性がある)からこの指標を見るのが良いのかも知れない
METR's Autonomy Evaluation Resources
-
https://metr.github.io/autonomy-evals-guide/gpt-5-report/
-
HLEに対するツール利用でのスコアの比較に対する所見:
Document Understandingでの評価をしたところOutput tokenが大幅に増えている:
GPT5 Prompting Guide:
https://cookbook.openai.com/examples/gpt-5/gpt-5_prompting_guide
GPT-5: Key characteristics, pricing and model card
-
https://simonwillison.net/2025/Aug/7/gpt-5/
-
システムカード中のSWE Bench Verifiedの評価結果は、全500サンプルのうちの477サンプルでしか実施されておらず、単純にスコアを比較することができないことに注意。実行されなかった23サンプルをFailedとみなすと(実行しなかったものを正しく成功できたとはみなせない)、スコアは減少する。同じ477サンプル間で評価されたモデル間であれば比較可能だが、500サンプルで評価された他のモデルとの比較はできない。
-
- SWE Bench リーダーボード: https://www.swebench.com
まとめ:
所見:
-
-
OpenHandsでの評価:
SWE Bench Verifiedの性能は71.8%。全部の500サンプルで評価した結果だと思うので公式の発表より低めではある。
AttentionSinkについて:
o3と比較してGPT5は約1/3の時間でポケモンレッド版で8個のバッジを獲得した模様:
より温かみのあるようなalignmentが実施された模様:
GPT5はlong contextになるとmarkdownよりめxmlの方が適していると公式ドキュメントに記載があるらしい:
Smallow LLM Leaderboard v2での性能:
GPT5の性能が際立って良く、続いてQwen3, gptossも性能が良い。
gpt-oss-120b, OpenAI, 2025.08
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Reasoning #OpenWeight #MoE(Mixture-of-Experts) #AttentionSinks #read-later #Selected Papers/Blogs #Reference Collection Issue Date: 2025-08-05 Comment
blog:
https://openai.com/index/introducing-gpt-oss/
HF:
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
アーキテクチャで使われている技術まとめ:
-
-
-
-
- こちらにも詳細に論文がまとめられている
上記ポスト中のアーキテクチャの論文メモリンク(管理人が追加したものも含む)
- Sliding Window Attention
- [Paper Note] Longformer: The Long-Document Transformer, Iz Beltagy+, arXiv'20
- [Paper Note] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context, Zihang Dai+, ACL'19
- MoE
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, William Fedus+, JMLR'22
- RoPE w/ YaRN
- RoFormer: Enhanced Transformer with Rotary Position Embedding, Jianlin Su+, N/A, Neurocomputing, 2024
- [Paper Note] YaRN: Efficient Context Window Extension of Large Language Models, Bowen Peng+, ICLR'24
- Attention Sinks
- Efficient Streaming Language Models with Attention Sinks, Guangxuan Xiao+, ICLR'24
- Attention Sinksの定義とその気持ち、Zero Sink, Softmaxの分母にバイアス項が存在する意義についてはこのメモを参照のこと。
- Why do LLMs attend to the first token?, Federico Barbero+, COLM'25
- Attention Sinksが実際にどのように効果的に作用しているか?についてはこちらのメモを参照。
- When Attention Sink Emerges in Language Models: An Empirical View, Xiangming Gu+, ICLR'25
-
- Sink Token (or Zero Sink) が存在することで、decoder-onlyモデルの深い層でのrepresentationのover mixingを改善し、汎化性能を高め、promptに対するsensitivityを抑えることができる。
- (Attentionの計算に利用する) SoftmaxへのLearned bias の導入 (によるスケーリング)
- これはlearnable biasが導入されることで、attention scoreの和が1になることを防止できる(余剰なアテンションスコアを捨てられる)ので、Zero Sinkを導入しているとみなせる(と思われる)。
- GQA
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, Joshua Ainslie+, N/A, arXiv'23
- SwiGLU
- GLU Variants Improve Transformer, Noam Shazeer, N/A, arXiv'20 -
- group size 8でGQAを利用
- Context Windowは128k
- 学習データの大部分は英語のテキストのみのデータセット
- STEM, Coding, general knowledgeにフォーカス
-
https://openai.com/index/gpt-oss-model-card/
あとで追記する
他Open Weight Modelとのベンチマークスコア比較:
-
-
-
-
- long context
-
- Multihop QA
解説:
learned attention sinks, MXFP4の解説:
Sink Valueの分析:
gpt-oss の使い方:
https://note.com/npaka/n/nf39f327c3bde?sub_rt=share_sb
[Paper Note] Comments-Oriented Document Summarization: Understanding Documents with Reader’s Feedback, Hu+, SIGIR’08, 2008.07
fd064b2-338a-4f8d-953c-67e458658e39
Qwen3との深さと広さの比較:
- The Big LLM Architecture Comparison, Sebastian Laschka, 2025.07
Phi4と同じtokenizerを使っている?:
post-training / pre-trainingの詳細はモデルカード中に言及なし:
-
-
ライセンスに関して:
> Apache 2.0 ライセンスおよび当社の gpt-oss 利用規約に基づくことで利用可能です。
引用元:
https://openai.com/ja-JP/index/gpt-oss-model-card/
gpt-oss利用規約:
https://github.com/openai/gpt-oss/blob/main/USAGE_POLICY
cookbook全体: https://cookbook.openai.com/topic/gpt-oss
gpt-oss-120bをpythonとvLLMで触りながら理解する: https://tech-blog.abeja.asia/entry/gpt-oss-vllm
指示追従能力(IFEVal)が低いという指摘:
Kimi K2: Open Agentic Intelligence, moonshotai, 2025.07
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Optimizer #OpenWeight #MoE(Mixture-of-Experts) #read-later #Selected Papers/Blogs #Stability #Reference Collection Issue Date: 2025-07-12 Comment
元ポスト:
1T-A32Bのモデル。さすがに高性能。
(追記) Reasoningモデルではないのにこの性能のようである。
1T-A32Bのモデルを15.5Tトークン訓練するのに一度もtraining instabilityがなかったらしい
元ポスト:
量子化したモデルが出た模様:
仕事早すぎる
DeepSeek V3/R1とのアーキテクチャの違い:
MLAのヘッドの数が減り、エキスパートの数を増加させている
解説ポスト:
利用されているOptimizer:
- [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
2つほどバグがあり修正された模様:
chatbot arenaでOpenLLMの中でトップのスコア
元ポスト:
テクニカルペーパーが公開:
https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
元ポスト:
テクニカルレポートまとめ:
以下のような技術が使われている模様
- Rewriting Pre-Training Data Boosts LLM Performance in Math and Code, Kazuki Fujii+, arXiv'25
- MLA MHA vs MQA vs GQA vs MLA, Zain ul Abideen, 2024.07
- MuonCip
- MuonOptimizer [Paper Note] Muon is Scalable for LLM Training, Jingyuan Liu+, arXiv'25
- QK-Clip
- 参考(こちらはLayerNormを使っているが): Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, Jiasen Lu+, N/A, CVPR'24
- RLVR
- DeepSeek-R1, DeepSeek, 2025.01
- Self-Critique
- 関連: [Paper Note] Inference-Time Scaling for Generalist Reward Modeling, Zijun Liu+, arXiv'25
- [Paper Note] Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards, Xun Lu, arXiv'25
- Temperature Decay
- 最初はTemperatureを高めにした探索多めに、後半はTemperatureを低めにして効用多めになるようにスケジューリング
- Tool useのためのSynthetic Data
Reward Hackingに対処するため、RLVRではなくpairwise comparisonに基づくself judging w/ critique を利用きており、これが非常に効果的な可能性があるのでは、という意見がある:
sarashina2-vision-{8b, 14b}, SB Intuitions, 2025.03
Paper/Blog Link My Issue
#Article #ComputerVision #NLP #LanguageModel #MultiModal #OpenWeight #VisionLanguageModel Issue Date: 2025-03-17 Comment
元ポスト:
VLM。Xに散見される試行例を見ると日本語の読み取り性能は結構高そうに見える。
モデル構成、学習の詳細、および評価:
LLM(sarashina2), Vision Encoder(Qwen2-VL), Projectorの3つで構成されており、3段階の学習を踏んでいる。
最初のステップでは、キャプションデータを用いてProjectorのみを学習しVision Encoderとテキストを対応づける。続いて、日本語を含む画像や日本特有の風景などをうまく扱えるように、これらを多く活用したデータ(内製日本語OCRデータ、図表キャプションデータ)を用いて、Vision EncoderとProjectorを学習。最後にLLMのAlignmentをとるために、プロジェクターとLLMを前段のデータに加えてVQAデータ(内製合成データを含む)や日本語の指示チューニングデータを用いて学習。
ProjectorやMMLLMを具体的にどのように学習するかは
- MM-LLMs: Recent Advances in MultiModal Large Language Models, Duzhen Zhang+, N/A, ACL'24 Findings
を参照のこと。
OpenAI o1, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #Chain-of-Thought #Reasoning #Test-Time Scaling Issue Date: 2024-09-13 Comment
Jason Wei氏のポスト:
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
や
- Implicit Chain of Thought Reasoning via Knowledge Distillation, Yuntian Deng+, N/A, arXiv'23
で似たような考えはすでに提案されていたが、どのような点が異なるのだろうか?
たとえば前者は、pauseトークンと呼ばれるoutputとは関係ないトークンを生成することで、outputを生成する前にモデル内部で推論する前により多くのベクトル操作を加える(=ベクトルを縦方向と横方向に混ぜ合わせる; 以後ベクトルをこねくりまわすと呼称する)、といった挙動を実現しているようだが、明示的にCoTの教師データを使ってSFTなどをしているわけではなさそうに見える(ざっくりとしか読んでないが)。
一方、Jason Wei氏のポストからは、RLで明示的により良いCoTができるように学習をしている点が違うように見える。
**(2025.0929): 以下のtest-time computeに関するメモはo1が出た当初のものであり、私の理解が甘い状態でのメモなので現在の理解を後ほど追記します。当時のメモは改めて見返すとこんなこと考えてたんだなぁとおもしろかったので残しておきます。**
学習の計算量だけでなく、inferenceの計算量に対しても、新たなスケーリング則が見出されている模様。
テクニカルレポート中で言われている time spent thinking (test-time compute)というのは、具体的には何なのだろうか。
上の研究でいうところの、inference時のpauseトークンの生成のようなものだろうか。モデルがベクトルをこねくり回す回数(あるいは生成するトークン数)が増えると性能も良くなるのか?
しかしそれはオリジナルのCoT研究である
- Chain of thought prompting elicits reasoning in large language models, Wei+, Google Research, NeurIPS'22
のdotのみの文字列をpromptに追加して性能が向上しなかった、という知見と反する。
おそらく、**モデル学習のデコーディング時に**、ベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすこと=time spent thinking (test-time compute) 、ということなのだろうか?
そしてそのように学習されたモデルは、推論時にベクトルをこねくり回す回数(あるいは生成するトークン数)を増やすと性能が上がる、ということなのだろうか。
もしそうだとすると、これは
- Think before you speak: Training Language Models With Pause Tokens, Sachin Goyal+, N/A, ICLR'24
のpauseトークンの生成をしながらfinetuningすると性能が向上する、という主張とも合致するように思うが、うーん。
実際暗号解読のexampleを見ると、とてつもなく長いCoT(トークンの生成数が多い)が行われている。
RLでReasoningを学習させる関連研究:
- ReFT: Reasoning with Reinforced Fine-Tuning, Trung Quoc Luong+, N/A, ACL'24
- Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning, Zhiheng Xi+, N/A, ICML'24
以下o1の動きに関して考えている下記noteからの引用。
>これによって、LLMはモデルサイズやデータ量をスケールさせる時代から推論時間をスケールさせる(つまり、沢山の推論ステップを探索する)時代に移っていきそうです。
なるほど。test-compute timeとは、推論ステップ数とその探索に要する時間という見方もあるのですね。
またnote中では、CoTの性能向上のために、Process Reward Model(PRM)を学習させ、LLMが生成した推論ステップを評価できるようにし、PRMを報酬モデルとし強化学習したモデルがo1なのではないか、と推測している。
PRMを提案した研究では、推論ステップごとに0,1の正誤ラベルが付与されたデータから学習しているとのこと。
なるほど、勉強になります。
note:
https://note.com/hatti8/n/nf4f3ce63d4bc?sub_rt=share_pb
note(詳細編): https://note.com/hatti8/n/n867c36ffda45?sub_rt=share_pb
こちらのリポジトリに関連論文やXポスト、公式ブログなどがまとめられている:
https://github.com/hijkzzz/Awesome-LLM-Strawberry
これはすごい。論文全部読みたい
Reflection 70B, GlaiveAI, 2024.09
Paper/Blog Link My Issue
#Article #NLP #LanguageModel #InstructionTuning #OpenWeight #SelfCorrection #PostTraining #Reference Collection Issue Date: 2024-09-06 Comment
ただまあ仮に同じInputを利用していたとして、promptingは同じ(モデルがどのようなテキストを生成し推論を実施するかはpromptingのスコープではない)なので、そもそも同じInputなのでfair comparisonですよ、という話に仮になるのだとしたら、そもそもどういう設定で比較実験すべきか?というのは検討した方が良い気はする。まあどこに焦点を置くか次第だと思うけど。
エンドユーザから見たら、reflectionのpromptingのやり方なんてわからないよ!という人もいると思うので、それを内部で自発的に実施するように学習して明示的にpromptingしなくても、高い性能を達成できるのであれば意味があると思う。
ただまあ少なくとも、参考でも良いから、他のモデルでもreflectionをするようなpromptingをした性能での比較結果も載せる方が親切かな、とは思う。
あと、70Bでこれほどの性能が出ているのはこれまでにないと思うので、コンタミネーションについてはディフェンスが必要に思う(他のモデルがそのようなディフェンスをしているかは知らないが)。
追記
→ 下記記事によると、LLM Decontaminatorを用いてコンタミネーションを防いでいるとのこと
https://github.com/lm-sys/llm-decontaminator
Reflection自体の有用性は以前から示されている。
参考: Self-Reflection in LLM Agents: Effects on Problem-Solving Performance, Matthew Renze+, N/A, arXiv'24
, Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai+, N/A, ICLR'24
, AnyTool: Self-Reflective, Hierarchical Agents for Large-Scale API Calls, Yu Du+, N/A, arXiv'24
, Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies, Liangming Pan+, N/A, TACL'24
ollamaで実際に動かして日本語でのQAを試している記事。実際のアウトプットやreflectionの内容が確認でき、おもしろい。
システムプロンプトで< thinking >タグでInputに対して推論し、< output >タグ内で最終出力を行い、推論過程で誤りがある場合は< reflection >タグを用いて修正するように指示している。
おそらく、thinkingタグ内の思考過程でモデルが誤りに気づいた場合は、thinkingタグの途中でreflectionタグが出力され、その時点でCoTが修正されるようである(もしくはoutputとthinkingの中間)。このため、誤ったCoTに基づいてOutputが生成される頻度が減少すると考えられる。
このような挙動はおそらく、reflection用の学習データでSFTしないとできないと思うので
(たとえば、ReflectionタスクをするようなデータでSFTをしていない場合、出力の途中で誤りを検出し出力を修正するという挙動にはならず、回答として自然な文を最後までoutputすると思う。その後でreflectionしろと促すことはpromptingでできるかもしれないが、そもそもreflectionする能力があまり高くない可能性があり、うまく修正もしてくれないかも)
reflectionの能力を高めるようなデータでSFTをしていないモデルで似たようなpromptingをしても、うまくいかない可能性があるので注意が必要だと思われる。
参考:
https://note.com/schroneko/n/nae86e5d487f1
開発者曰く、HFに記載の正しいシステムプロンプトを入れないと、適切に動作しないとのこと。
元ツイート:
どうやら初期にアップロードされていたHFのモデルはweightに誤りがあり、挙動がおかしくなっていたようだ。
正しいモデルの挙動は下記ツイートのようである。thinking内でreflectionが実施されている。
実際にいくつかの例をブログをリリース当日に見た時に、reflectionタグがoutputの後に出力されている例などがあり、おや?という挙動をしていたので、問題が是正されたようだ。
HFのモデルが修正された後もベンチマークの結果が再現されないなど、雲行きが色々と怪しいので注意した方が良い。
続報
開発者ポスト:
再現実験を全て終了し、当初報告していた結果が再現されなかったとCEOが声明:
[Paper Note] Evolutionary Optimization of Model Merging Recipes, Takuya Akiba+, N_A, Nature Machine Intelligence, Vol.7, 2025.01
Paper/Blog Link My Issue
#Article #ComputerVision #Pocket #NLP #LanguageModel #Selected Papers/Blogs #ModelMerge #Nature Machine Intelligence Issue Date: 2024-03-21 GPT Summary- 進化アルゴリズムを使用した新しいアプローチを提案し、強力な基盤モデルの自動生成を実現。LLMの開発において、人間の直感やドメイン知識に依存せず、多様なオープンソースモデルの効果的な組み合わせを自動的に発見する。このアプローチは、日本語のLLMと数学推論能力を持つモデルなど、異なるドメイン間の統合を容易にし、日本語VLMの性能向上にも貢献。オープンソースコミュニティへの貢献と自動モデル構成の新しいパラダイム導入により、基盤モデル開発における効率的なアプローチを模索。 Comment
複数のLLMを融合するモデルマージの話。日本語LLMと英語の数学LLNをマージさせることで日本語の数学性能を大幅に向上させたり、LLMとVLMを融合したりすることで、日本にしか存在しない概念の画像も、きちんと回答できるようになる。
著者スライドによると、従来のモデルマージにはbase modelが同一でないとうまくいかなかったり(重みの線型結合によるモデルマージ)、パラメータが増減したり(複数LLMのLayerを重みは弄らず再配置する)。また日本語LLMに対してモデルマージを実施しようとすると、マージ元のLLMが少なかったり、広範囲のモデルを扱うとマージがうまくいかない、といった課題があった。本研究ではこれら課題を解決できる。
著者による資料(NLPコロキウム):
https://speakerdeck.com/iwiwi/17-nlpkorokiumu
[Paper Note] Adaptive Web Search Based on User Profile Constructed without Any Effort from Users, Sugiyama+, NAIST, WWW’04
Paper/Blog Link My Issue
#Article #CollaborativeFiltering #InformationRetrieval #RelevanceFeedback #Search #WebSearch #Personalization Issue Date: 2023-04-28 Comment
検索結果のpersonalizationを初めてuser profileを用いて実現した研究
user profileはlong/short term preferenceによって構成される。
- long term: さまざまなソースから取得される
- short term: 当日のセッションの中だけから収集される
① browsing historyの活用
- browsing historyのTFから求め Profile = P_{longterm} + P_{shortterm}とする
② Collaborative Filtering (CF) の活用
- user-item matrixではなく、user-term matrixを利用
- userの未知のterm-weightをCFで予測する
- => missing valueのterm weightが予測できるのでprofileが充実する
実験結果
- 検証結果(googleの検索結果よりも提案手法の方が性能が良い)
- 検索結果のprecision向上にlong/short term preferenceの両方が寄与
- longterm preferenceの貢献の方が大きいが、short termも必要(interpolation weight 0.6 vs. 0.4)
- short termにおいては、その日の全てのbrowsing historyより、現在のセッションのterm weightをより考慮すべき(interpolation weight 0.2 vs. 0.8)
[Paper Note] Collaborative filtering for implicit feedback datasets, Hu+, International Conference on Data Mining, 2008.12
Paper/Blog Link My Issue
#Article #RecommenderSystems #CollaborativeFiltering #MatrixFactorization #Selected Papers/Blogs Issue Date: 2018-01-11 Comment
Implicit Feedbackなデータに特化したMatrix Factorization (MF)、Weighted Matrix Factorization (WMF)を提案。
ユーザのExplicitなFeedback(ratingやlike, dislikeなど)がなくても、MFが適用可能。
目的関数は式(3)のようになっている。
通常のMFでは、ダイレクトにrating r_{ui}を予測したりするが、WMFでは r_{ui}をratingではなく、たとえばユーザuがアイテムiを消費した回数などに置き換え、binarizeした数値p_{ui}を目的関数に用いる。
このとき、itemを消費した回数が多いほど、そのユーザはそのitemを好んでいると仮定し、そのような事例については重みが高くなるようにconfidence c_{ui}を計算し、目的関数に導入している。
日本語での解説: https://cympfh.cc/paper/WRMF
Implicit Implicit でのAlternating Least Square (ALS)という手法が、この手法の実装に該当する。
[Paper Note] LexRank: Graph-based Lexical Centrality as Salience in Text Summarization, Erkan+, Journal of Artificial Intelligence Research, 2004.12
Paper/Blog Link My Issue
#Article #Multi #Single #DocumentSummarization #Document #Unsupervised #GraphBased #NLP #Extractive #Selected Papers/Blogs Issue Date: 2018-01-01 Comment
代表的なグラフベースな(Multi) Document Summarization手法。
ほぼ
- [Paper Note] TextRank: Bringing Order into Texts, Mihalcea+, EMNLP'04
と同じ手法。
2種類の手法が提案されている:
* [LexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを計算し閾値以上となったsentenceの間にのみedgeを張る(重みは確率的に正規化)。その後べき乗法でPageRank。
* [ContinousLexRank] tf-idfスコアでsentenceのbag-of-wordsベクトルを作り、cosine similarityを用いてAffinity Graphを計算し、PageRankを適用(べき乗法)。
DUC2003, 2004(MDS)で評価。
Centroidベースドな手法をROUGE-1の観点でoutperform。
document clusterの17%をNoisyなデータにした場合も実験しており、Noisyなデータを追加した場合も性能劣化が少ないことも示している。
[Paper Note] What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine Alignment, Hongyuan Mei+, NAACL-HLT’16, 2015.09
Paper/Blog Link My Issue
#Article #NeuralNetwork #NaturalLanguageGeneration #Pocket #NLP #DataToTextGeneration #NAACL #Encoder-Decoder Issue Date: 2017-12-31 GPT Summary- エンドツーエンドのドメイン非依存型ニューラルエンコーダー-アライナー-デコーダーモデルを提案。LSTMを用いてデータベースイベントをエンコードし、アライナーで重要なレコードを特定、デコーダーで自由形式の説明を生成。WeatherGovデータセットで最良の結果を達成し、k近傍ビームフィルターでさらに改善。RoboCupデータセットでも競争力のある結果を得た。 Comment
content-selectionとsurface realizationをencoder-decoder alignerを用いて同時に解いたという話。
普通のAttention basedなモデルにRefinerとPre-Selectorと呼ばれる機構を追加。通常のattentionにはattentionをかける際のaccuracyに問題があるが、data2textではきちんと参照すべきレコードを参照し生成するのが大事なので、RefinerとPre-Selectorでそれを改善する。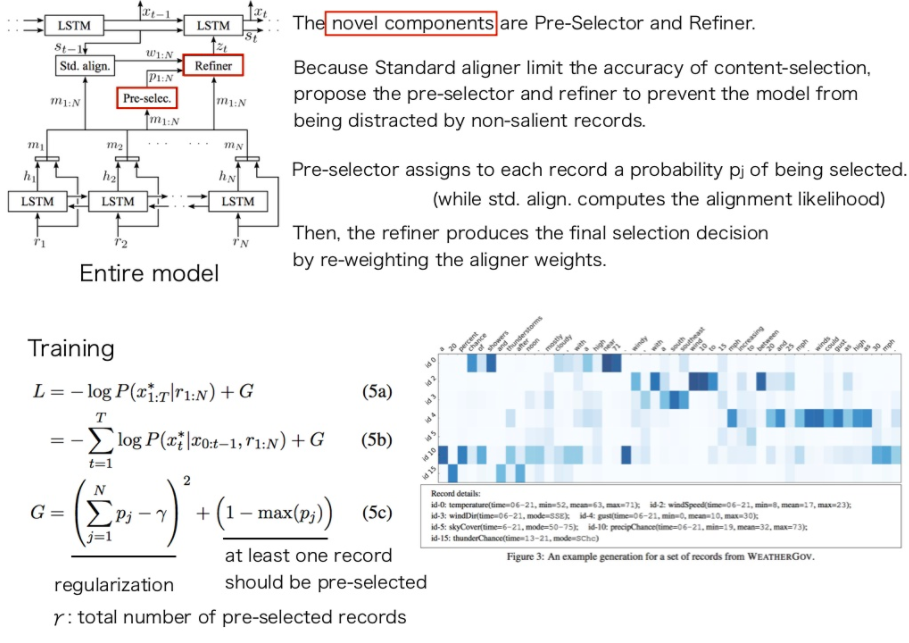
Pre-selectorは、それぞれのレコードが選択される確率を推定する(通常のattentionはalignmentの尤度を計算するのみ)。
Refinerはaligner(attention)のweightをreweightingすることで、最終的にどのレコードを選択するか決定する。
加えて、ロス関数のRegularizationのかけかたを変え、最低一つのレコードがpreselectorに選ばれるようにバイアスをかけている。
ほぼ初期のNeural Network basedなData2Text研究
[Paper Note] Learning query-biased web page summarization, Wang et al., CIKM’07, 2007.11
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Snippets #QueryBiased #CIKM Issue Date: 2017-12-28 Comment
・従来のquery-biasedな要約におけるclassificationアプローチは,training内のdocumentの情報が未知のdocumentのsentenceのclassificationに役立つというものだった.これは,たとえば似たような情報を多く含むscientific articleだったら有用だが,様々な情報を含むweb pageにはあまり適切ではない(これはtraining set内のdocumentの情報とtarget pageの情報を比較するみたいなアプローチに相当する).この研究では,target page内の’sentenceの中で’はスニペットに含めるべき文かどうかという比較ができるという仮定のもと,learning to rankを用いてスニペットを生成する.
・query biased summarizationではrelevanceとfidelityの両者が担保された要約が良いとされている.
relevanceとはクエリと要約の適合性,fidelityとは,要約とtarget documentとの対応の良さである.
・素性は,relevanceに関してはクエリとの関連度,fidelityに関しては,target page内のsentenceに関しては文の位置や,文の書式(太字)などの情報を使う.contextの文ではそういった情報が使えないので,タイトルやanchor textのフレーズを用いてfidelityを担保する(詳しくかいてない).あとはterm occurence,titleとextracted title(先行研究によると,TRECデータの33.5%のタイトルが偽物だったというものがあるのでextracted titleも用いる),anchor textの情報を使う.あまり深く読んでいない.
・全ての素性を組み合わせたほうがintrinsicなevaluationにおいて高い評価値.また,contextとcontent両方組み合わせたほうが良い結果がでた.
[Paper Note] Enhanced web document summarization using hyperlinks, Delort et al., HT’03, 2003.08
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Snippets Issue Date: 2017-12-28 Comment
・Genericなweb pageの要約をつくる
・要約を作る際に,ページの内容から作るわけではなく,contextを用いて作る.contextとは,target pageにリンクを張っているページにおけるリンクの周辺にある文のこと.
・contextを利用した要約では,partialityとtopicalityに関する問題が生じる.partialityとは,contextに含まれる情報がtarget pageに関する一部の情報しか含んでいない問題.topicalityとは,そもそもcontextに含まれる情報が,target pageのoverviewに関する情報を含んでいない問題
・partialityに関しては,contextに含まれる文を除くことで,contextのoverallな情報が失われない最小のsetを求めることで対応.setを求める際には,context内の2文の単語を比較し,identicalなrepresentationが含まれているかどうかを計算.重複するものは排除することでsetを求める.
・topicalityに関しては,target pageのtextual informationが取得できる場合は,context内の文中の単語がtarget page内に含まれる単語の比率を出すことでtopicality scoreを算出.topicality scoreが高いものを要約とする.一方,target pageのtextual informationが十分でない場合は,context内の文のクラスタリングを行い,各クラスタのcentroidと近い文を抽出.
[Paper Note] A task-oriented study on the influencing effects of query-biased summarization in web searching, White et al., Information Processing and Management, 2003.09
Paper/Blog Link My Issue
#Article #DocumentSummarization #InformationRetrieval #NLP #RelevanceJudgment #Snippets #QueryBiased Issue Date: 2017-12-28 Comment
・search engineにおいてquery-biasedな要約の有用性を示したもの
・task-orientedな評価によって,提案手法がGoogleやAltaVistaのスニペットよりも良いことを示す.
・提案手法は文選択によるquery-biased summarization.スコアリングには,ページのタイトルに含まれる単語がどれだけ含まれているか,文のページ内での出現位置,クエリとの関連度,文の書式(太字)などの情報を使う.
・スニペットが作れないページに対しては,エラーメッセージを返したり,ページ内の最初のnon-textualな要素を返したりする.
[Paper Note] Discovery-oriented Collaborative Filtering for Improving User Satisfaction, Hijikata+, IUI’09
Paper/Blog Link My Issue
#Article #RecommenderSystems #CollaborativeFiltering #Novelty #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
・従来のCFはaccuracyをあげることを目的に研究されてきたが,ユーザがすでに知っているitemを推薦してしまう問題がある.おまけに(推薦リスト内のアイテムの観点からみた)diversityも低い.このような推薦はdiscoveryがなく,user satisfactionを損ねるので,ユーザがすでに何を知っているかの情報を使ってよりdiscoveryのある推薦をCFでやりましょうという話.
・特徴としてユーザのitemへのratingに加え,そのitemをユーザが知っていたかどうかexplicit feedbackしてもらう必要がある.
・手法は単純で,User-based,あるいはItem-based CFを用いてpreferenceとあるitemをユーザが知っていそうかどうかの確率を求め,それらを組み合わせる,あるいはrating-matrixにユーザがあるitemを知っていたか否かの数値を組み合わせて新たなmatrixを作り,そのmatrix上でCFするといったもの.
・offline評価の結果,通常のCF,topic diversification手法と比べてprecisionは低いものの,discovery ratioとprecision(novelty)は圧倒的に高い.
・ユーザがitemを知っていたかどうかというbinary ratingはユーザに負荷がかかるし,音楽推薦の場合previewがなければそもそも提供されていないからratingできないなど,必ずしも多く集められるデータではない.そこで,データセットのratingの情報を25%, 50%, 75%に削ってratingの数にbiasをかけた上で実験をしている.その結果,事前にratingをcombineし新たなmatrixを作る手法はratingが少ないとあまりうまくいかなかった.
・さらにonlineでuser satisfaction(3つの目的のもとsatisfactionをratingしてもらう 1. purchase 2. on-demand-listening 3. discovery)を評価した. 結果,purchaseとdiscoveryにおいては,ベースラインを上回った.ただし,これは推薦リスト中の満足したitemの数の問題で,推薦リスト全体がどうだった
かと問われた場合は,ベースラインと同等程度だった.
重要論文
[Paper Note] “I like to explore sometimes”: Adapting to Dynamic User Novelty Preferences, Kapoor et al. (with Konstan), RecSys’15
Paper/Blog Link My Issue
#Article #RecommenderSystems #Novelty #RecSys #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
・典型的なRSは,推薦リストのSimilarityとNoveltyのcriteriaを最適化する.このとき,両者のバランスを取るためになんらかの定数を導入してバランスをとるが,この定数はユーザやタイミングごとに異なると考えられるので(すなわち人やタイミングによってnoveltyのpreferenceが変化するということ),それをuserの過去のbehaviorからpredictするモデルを考えましたという論文.
・式中によくtが出てくるが,tはfamiliar setとnovel setをわけるためのみにもっぱら使われていることに注意.昼だとか夜だとかそういう話ではない.familiar setとは[t-T, t]の間に消費したアイテム,novel setはfamiliar setに含まれないitemのこと.
・データはmusic consumption logsを使う.last.fmやproprietary dataset.データにlistening以外のexplicit feedback (rating)などの情報はない
・itemのnoveltyの考え方はユーザ側からみるか,システム側から見るかで分類が変わる.三種類の分類がある.
(a) new to system: システムにとってitemが新しい.ゆえにユーザは全員そのitemを知らない.
(b) new to user: システムはitemを知っているが,ユーザは知らない.
(c) oblivious/forgotten item: 過去にユーザが知っていたが,最後のconsumptionから時間が経過しいくぶんunfamiliarになったitem
Repetition of forgotten items in future consumptions has been shown to produce increased diversity and emotional excitement.
この研究では(b), (c)を対象とする.
・userのnovelty preferenceについて二つの仮定をおいている.
1. ユーザごとにnovelty preferenceは違う.
2. ユーザのnovelty preferenceはdynamicに変化する.trainingデータを使ってこの仮定の正しさを検証している.
・novelty preferenceのpredictは二種類の素性(familiar set diversityとcumulative negative preference for items in the familiar set)を使う. 前者は,familiar setの中のradioをどれだけ繰り返しきいているかを用いてdiversityを定義.繰り返し聞いているほうがdiversity低い.後者は,異なるitemの消費をする間隔によってdynamic preference scoreを決定.familiar set内の各itemについて負のdynamic preference scoreをsummationすることで,ユーザの”退屈度合い”を算出している.
・両素性を考慮することでnovelty preferenceのRMSEがsignificantに減少することを確認.
・推薦はNoveltyのあるitemの推薦にはHijikataらの協調フィルタリングなどを使うこともできる.
・しかし今回は簡易なitem-based CFを用いる.ratingの情報がないので,それはdynamic preference scoreを代わりに使い各itemのスコアを求め,そこからnovel recommendationとfamiliar recommendationのリストを生成し,novelty preferenceによって両者を組み合わせる.
・音楽(というより音楽のradioやアーティスト)の推薦を考えている状況なので,re-consumptionが許容されている.Newsなどとは少しドメインが違うことに注意.
[Paper Note] Combination of Web page recommender systems, Goksedef, Gunduz-oguducu, Elsevier, 2010.04
Paper/Blog Link My Issue
#Article #RecommenderSystems #Document Issue Date: 2017-12-28 Comment
・traditionalなmethodはweb usage or web content mining techniquesを用いているが,ニュースサイトなどのページは日々更新されるのでweb content mining techniquesを用いてモデルを更新するのはしんどい.ので,web usage mining(CFとか?どちらかというとサーバログからassociation ruleを見つけるような手法か)にフォーカス.
・web usage miningに基づく様々な手法をhybridすることでどれだけaccuracyが改善するかみる.
・ユーザがセッションにおいて次にどのページを訪れるかをpredictし推薦するような枠組み(不特定多数のページを母集団とするわけではなく,自分のサイト内のページが母集団というパターンか)
・4種類の既存研究を紹介し,それらをどうcombineするかでaccuraryがどう変化しているかを見ている.
・それぞれの手法は,ユーザのsessionの情報を使いassociation rule miningやclusteringを行い次のページを予測する手法.
[Paper Note] Neural Networks for Web Content Filtering, Lee, Fui and Fong, IEEE Intelligent Systems, 2002.09
Paper/Blog Link My Issue
#Article #RecommenderSystems #NeuralNetwork #Document #DataFiltering Issue Date: 2017-12-28 Comment
・ポルノコンテンツのフィルタリングが目的. 提案手法はgeneral frameworkなので他のコンテンツのフィルタリングにも使える.
・NNを採用する理由は,robustだから(様々な分布にfitする).Webpageはnoisyなので.
・trainingのためにpornographic pageを1009ページ(13カテゴリから収集),non-pornographic pageを3,777ページ収集.
・feature(主なもの)
- indicative term(ポルノっぽい単語)の頻度
- displayed contents ページのタイトル,warning message block, other viewable textから収集
- non-displayed contents descriptionやkeywordsなどのメタデータ,imageタグのtextなどから収集
・95%くらいのaccuracy
[Paper Note] DualSum: a Topic-Model based approach for update summarization, Delort et al., EACL’12
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #EACL Issue Date: 2017-12-28 Comment
・大半のupdate summarizationの手法はdocument set Aがgivenのとき,document set Bのupdate summarizationをつくる際には,redundancy removalの問題として扱っている.
・この手法は,1つのsentenceの中にredundantな情報とnovelな情報が混在しているときに,そのsentenceをredundantなsentenceだと判別してしまう問題点がある.加えて,novel informationを含んでいると判別はするけれども,明示的にnovel informationがなんなのかということをモデル化していない.
・Bayesian Modelを使うことによって,他の手法では抜け落ちている確率的な取り扱いが可能にし, unsupervisedでできるようにする.
[Paper Note] Document Update Summarization Using Incremental Hierarchical Clustering, Wang+, CIKM’10
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #CIKM Issue Date: 2017-12-28 Comment
・既存のMDSではdocumentをbatch処理するのが前提.typicalなクラスタリングベースの手法やグラフベースの手法はsentence-graphを構築して要約を行う.しかし,情報がsequentialに届き,realtimeで要約を行いたいときにこのような手法を使うと,毎回すでに処理したことがあるテキストを処理することになり,time consumingだし,無駄な処理が多い.特に災害時などでは致命的.このような問題に対処するために,ドキュメントがarriveしたときに,ただちにupdate summaryが生成できる手法を提案する.
・既存のヒューリスティックなfeature(tf-isfやキーワード数など)を用いたスコアリングは,existing sentencesとnewly coming sentencesが独立しているため,real world scenarioにおいて実用的でないし,hardly perform wellである.
・なので,incremental hierarchical clusteringの手法でsentence clusterをre-organizeすることで,効果的に要約のupdateを行う.このとき,sentence同士のhierarchical relationshipはreal timeにre-constructされる.
・TACのupdate summarizationとは定義が微妙に違うらしい.主に2点.TACではnewly coming documentsだけを対象にしているが,この研究 ではすべてのドキュメントを対象にする.さらに,TACでは一度だけupdate summarizationする(document set Bのみ)が,この研究ではdocumentsがsequenceでarriveするのを前提にする.なので,TACに対しても提案手法は適用可能.
・Sequence Update Summarizationの先駆け的な研究かもしれない.SUSがのshared taskになったのは2013だし.
・incremental hierarchical clusteringにはCOBWEB algorithm (かなりpopularらしい)を使う.COBWEBアルゴリズムは,新たなelementが現れたとき,Category Utilityと呼ばれるcriterionを最大化するように,4種類の操作のうち1つの操作を実行する(insert(クラスタにsentenceを挿入), create(新たなクラスタつくる), merge(2クラスタを1つに),split(existingクラスタを複数のクラスタに)).ただ,もとのCOBWEBで使われているnormal attribute distributionはtext dataにふさわしくないので,Katz distributionをword occurrence distributionとして使う(Sahooらが提案している.).元論文読まないと詳細は不明.
・要約の生成は,実施したoperationごとに異なる.
- Insertの場合: クラスタを代表するsentenceをクエリとのsimilarity, クラスタ内のsentenceとのintra similarityを計算して決めて出力する.
- createの場合: 新たに生成したクラスタcluster_kを代表する文を,追加したsentence s_newとする.
- mergeの場合: cluster_aとcluster_bをmergeして新たなcluster_cを作った場合,cluster_cを代表する文を決める.cluster_cを代表する文は,cluster_aとcluster_bを代表する文とクエリとのsimilarityをはかり,similarityが大きいものとする.
- splitの場合: cluster_aをsplitしてn個の新たなクラスタができたとき,各新たなn個のクラスタにおいて代表する文を,original subtreeの根とする.
・TAC08のデータとHurricane Wilma Releasesのデータ(disaster systemからtop 10 queryを取得,5人のアノテータに正解を作ってもらう)を使って評価.(要約の長さを揃えているのかが気になる。長さが揃っていないからROUGEのF値で比較している?)
・一応ROUGEのF値も高いし,速度もbaselineと比べて早い.かなりはやい.genericなMDSとTAC participantsと比較.TAC Bestと同等.GenericMDSより良い.document setAの情報を使ってredundancy removalをしていないのにTAC Bestを少しだけoutperform.おもしろい.
・かつ,TAC bestはsentence combinationを繰り返す手法らしく,large-scale online dataには適していないと言及.
[Paper Note] Incremental Update Summarization: Adaptive Sentence Selection based on Prevalence and Novelty, McCreadie et al., CIKM’14
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #CIKM Issue Date: 2017-12-28 Comment
・timelyなeventに対してupdate summarizationを適用する場合を考える.たとえば6日間続いたeventがあったときにその情報をユーザが追う為に何度もupdate summarizationシステムを用いる状況を考える.6日間のうち新しい情報が何も出てこない期間はirrelevantでredundantな内容を含む要約が出てきてしまう.これをなんとかする手法が必要だというのがmotivation.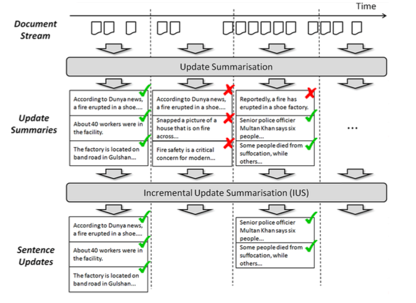
・どのような手法かというと,news streamsからnovel updatesをtimely mannerで自動抽出し,一方で,抽出するupdatesはirrelevant, uninformative or redundant contentを最小化するようなもの手法
・手法は既存のUpdate Summarization手法(lambdaMART, learning to rank baseの手法)で10文を出力し,何文目までを残すか(rank-cut off problem)を解くことで,いらないsentenceをはぶいている.
・rank cut offをする際はlinear regressionとModel Treesを使っているが,linear regressionのような単純な手法だと精度があがらず,Model Treesを使ったほうがいい結果が出た.
・素性は主にprevalence (sentenceが要約したいトピックに沿っているか否か),novelty(sentenceが新しい情報を含んでいるか),quality(sentenceがそもそも重要かどうか)の3種類の素性を使っている.気持ちとしては,prevalenceとnoveltyの両方が高いsentenceだけを残したいイメージ.つまり,トピックに沿っていて,なおかつ新しい情報を含んでいるsentence
・loss functionには,F値のような働きをするものを採用(とってきたrelevant updateのprecisionとrecallをはかっているイメージ).具体的には,Expected Latency GainとLatency Comprehensivenessと呼ばれるTREC2013のquality measureに使われている指標を使っている.
・ablation testの結果を見ると,qualityに関する素性が最もきいている.次にnovelty,次点でprevalence
・提案手法はevent発生から時間が経過すると精度が落ちていく場合がある.
・classicalなupdate summarizationの手法と比較しているが,Classyがかなり強い,Model treesを使わない提案手法や,他のbaselineを大きくoutperform. ただ,classyはmodel treesを使ったAdaptive IUSには勝てていない.
・TREC 2013には,Sequantial Update Summarizationタスクなるものがあるらしい.ユーザのクエリQと10個のlong-runnning event(典型的には10日間続くもの,各イベントごとに800〜900万記事),正解のnuggetsとそのtimestampが与えられたときにupdate summarizationを行うタスクらしい.
[Paper Note] Update Summarization using Semi-Supervised Learning Based on Hellinger Distance, Wang et al., CIKM’15, 2015.10
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #CIKM Issue Date: 2017-12-28 Comment
・Hellinger Distanceを用いてSentence Graphを構築.ラベル伝搬により要約に含める文を決定する手法
・update summarizationの研究ではsimilarityをはかるときにcosine similarityを用いることが多い.
・cosine similarityはユークリッド距離から直接的に導くことができる.
・Vector Space Modelはnonnegativeなmatrixを扱うので,確率的なアプローチで取り扱いたいが,ユークリッド距離は確率を扱うときにあまり良いmetricではない.そこでsqrt-cos similarityを提案する.sqrt-cosは,Hellinger Distanceから求めることができ,Hellinger Distanceは対称的で三角不等式を満たすなど,IRにおいて良いdistance measureの性質を持っている.(Hellinger Distanceを活用するために結果的に類似度の尺度としてsqrt-cosが出てきたとみなせる)
・またHellinger DistanceはKL Divergenceのsymmetric middle pointとみなすことができ,文書ベクトル生成においてはtf_idfとbinary weightingのちょうど中間のような重み付けを与えているとみなせる.
・要約を生成する際は,まずはset Aの文書群に対してMMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
を適用する(redundancyの項がmaxではなくて平均になっている).similarityはsqrt-cosを用いる.
・sqrt-cosと,set Aの要約結果を用いると,sentence graphを構築できる.sentence graphはset Aとset Bの各sentenceをノードとするグラフで,エッジの重みはsqrt-cosとなっている.このsentence graph上でset Aの要約結果のラベルをset B側のノードに伝搬させることで,要約に含めるべき文を選択する.
・ラベル伝搬にはGreen’s functionを用いる.set Bにlabel “1”がふられるものは,given topicとset Aのcontentsにrelevantなsentenceとなる.
・TAC2011のデータで評価した結果,standardなMMRを大幅にoutperform, co-ranking, Centroidベースの手法などよりも良い結果.
[Paper Note] TimedTextRank: Adding the Temporal Dimension to Multi-Document Summarization, Xiaojun Wan, SIGIR’07, 2007.07
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #SIGIR Issue Date: 2017-12-28 Comment
・evolving topicsを要約するときは,基本的に新しい情報が重要だが,TextRankはそれが考慮できないので拡張したという話.
・dynamic document setのnew informationをより重視するTimedTextRankを提案
・TextRankのvoteの部分に重み付けをする.old sentenceからのvoteよりも,new documentsに含まれるsentenceからのvoteをより重要視
・評価のときは,news pageをクローリングし,incremental single-pass clustering algorithmでホットなトピックを抽出しユーザにみせて評価(ただしこれはPreliminary Evaluation).
[Paper Note] The LIA Update Summarization Systems at TAC-2008, Boudin et al. TAC’08, 2008.11
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update Issue Date: 2017-12-28 Comment
・Scalable MMR [Paper Note] A Scalable MMR Approach to Sentence Scoring for Multi-Document Update Summarization, Boudin et al., COLING’08, 2008.08
とVariable length intersection gap n-term modelを組み合わせる.
・Variable length intersection gap n-term modelは,あるトピックのterm sequenceは他の異なる語と一緒にでてくる?という直感にもとづく.要は,drugs.*treat.*mental.*illnessなどのパターンをとってきて活用する.このようなパターンをn-gram, n-stem, n-lemmaごとにつくり3種類のモデルを構築.この3種類のモデルに加え,coverage rate (topic vocabularyがセグメント内で一度でもみつかる割合)とsegmentのpositionの逆数を組みあわせて,sentenceのスコアを計算(先頭に近いほうが重要).
・coherenceを担保するために,sentenceを抽出した後,以下のpost-processingを行う.
Acronym rewriting(初めてでてくるNATOなどの頭字語はfull nameにする)
Date and number rewriting(US standard formsにする)
Temporal references rewriting (next yearなどの曖昧なreferenceを1993などの具体的なものにする)
Discursive form rewriting (いきなりButがでてくるときとかは削るなど)
カッコやカギカッコは除き,句読点をcleanedする
・TAC 2008におけるROUGE-2の順位は72チーム中32位
[Paper Note] A Scalable MMR Approach to Sentence Scoring for Multi-Document Update Summarization, Boudin et al., COLING’08, 2008.08
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #COLING Issue Date: 2017-12-28 Comment
・MMR [Paper Note] The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries, Carbonell+, SIGIR'98
をupdate summarization用に拡張.History(ユーザが過去に読んだsentence)の数が多ければ多いほどnon-redundantな要約を出す (Queryに対するRelevanceよりもnon-redundantを重視する)
・Historyの大きさによって,redundancyの項の重みを変化させる.
・MMRのredundancyの項を1-max Sim2(s, s_history)にすることでnoveltyに変更.ORよりANDの方が直感的なので二項の積にする.
・MMRのQueryとのRelevanceをはかる項のSimilarityは,cossimとJaro-Winkler距離のinterpolationで決定. Jaro-Winkler距離とは,文字列の一致をはかる距離で,値が大きいほど近い文字列となる.文字ごとの一致だけでなく,ある文字を入れ替えたときにマッチ可能かどうかも見る.一致をはかるときはウィンドウを決めてはかるらしい.スペルミスなどの検出に有用.クエリ内の単語とselected sentences内の文字列のJaro-Winkler距離を計算.各クエリごとにこれらを求めクエリごとの最大値の平均をとる.
・冗長性をはかるSim2では,normalized longest common substringを使う.
[Paper Note] Improving Update Summarization via Supervised ILP and Sentence Reranking, Li et al. NAACL’15, 2015.05
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #IntegerLinearProgramming (ILP) #Update #NAACL Issue Date: 2017-12-28 Comment
・update summarizationをILPで定式化.基本的なMDSのILPのterm weightingにsalienceの要素に加えてnoveltyの要素を加える.term weightingにはbigramを用いる.bigram使うとよくなることがupdate summarizationだと知られている.weightingは平均化パーセプトロンで学習
・ILPでcandidate sentencesを求めたあと,それらをSVRを用いてRerankingする.SVRのloss functionはROUGE-2を使う.
・Rerankingで使うfeatureはterm weightingした時のsentenceレベルのfeatureを使う.
・RerankingをするとROUGE-2スコアが改善する.2010, 2011のTAC Bestと同等,あるいはそれを上回る結果.novelty featureを入れると改善.
・noveltyのfeatureは,以下の通り.
Bigram Level
-bigramのold datasetにおけるDF
-bigram novelty value (new datasetのbigramのDFをold datasetのDFとDFの最大値の和で割ったもの)
-bigram uniqueness value (old dataset内で出たbigramは0, すでなければ,new dataset内のDFをDFの最大値で割ったもの)
Sentence Level
-old datasetのsummaryとのsentence similarity interpolated n-gram novelty (n-gramのnovelty valueをinterpolateしたもの)
-interpolated n-gram uniqueness (n-gramのuniqueness valueをinterpolateしたもの)
・TAC 2011の評価の値をみると,Wanらの手法よりかなり高いROUGE-2スコアを得ている.
[Paper Note] Update Summarization Based on Co-Ranking with Constraints, Wiaojun Wan, COLING’12, 2012.12
Paper/Blog Link My Issue
#Article #DocumentSummarization #NLP #Update #COLING Issue Date: 2017-12-28 Comment
・PageRankの枠組みを拡張してold datasetとnew dataset内のsentenceをco-ranking
・co-rankingするときは,update scoreとconsistency scoreというものを求め相互作用させる.
・update scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では負の関係を持つ.
・consistency scoreが高いsentenceは同じdataset内では正の関係,異なるdataset内では正の関係を持つ.
・負の関係はdissimilarity matrixを用いて表現する.
・あとはupdate scoreとconsistency scoreを相互作用させながらPageRankでスコアを求める.デコーディングはupdate scoreをgreedyに.
・update scoreとconsistency scoreの和は定数と定義,この論文では定数をsentenceのinformative scoreとしている.これがタイトルにある制約.informative scoreはAffinity GraphにPageRankを適用して求める.
・制約が入ることで,consistency scoreが低いとupdate scoreは高くなるような効果が生まれる.逆もしかり.
[Paper Note] Segmentation Based, Personalized Web Page Summarization Model, [Journal of advances in information technology, vol. 3, no.3, 2012], 2012.08
Paper/Blog Link My Issue
#Article #Single #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization Issue Date: 2017-12-28 Comment
・Single-document
・ページ内をセグメントに分割し,どのセグメントを要約に含めるか選択する問題
・要約に含めるセグメントは4つのfactor(segment weight, luan’s significance factor, profile keywords, compression ratio)から決まる.基本的には,ページ内の高頻度語(stop-wordは除く)と,profile keywordsを多く含むようなセグメントが要約に含まれるように選択される.図の場合はAlt要素,リンクはアンカテキストなどから単語を取得しセグメントの重要度に反映する.
[Paper Note] Automatic Text Summarization based on the Global Document Annotation, Nagao+, COLING-ACL;98, 1998.08
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #ACL #COLING Issue Date: 2017-12-28 Comment
Personalized summarizationの評価はしていない。提案のみ。以下の3種類の手法を提案
- keyword-based customization
- 関心のあるキーワードをユーザが入力し、コーパスやwordnet等の共起関係から関連語を取得し要約に利用する
- 文書の要素をinteractiveに選択することによる手法
- 文書中の関心のある要素(e.g. 単語、段落等)
- browsing historyベースの手法
- ユーザのbrowsing historyのドキュメントから、yahooディレクトリ等からカテゴリ情報を取得し、また、トピック情報も取得し(要約技術を活用するとのこと)特徴量ベクトルを作成
- ユーザがアクセスするたびに特徴ベクトルが更新されることを想定している?
[Paper Note] A Study for Documents Summarization based on Personal Annotation, Zhang+, HLT-NAACL-DUC’03, 2003.05
Paper/Blog Link My Issue
#Article #PersonalizedDocumentSummarization #DocumentSummarization #NLP #Personalization #NAACL #Selected Papers/Blogs Issue Date: 2017-12-28 Comment
(過去に管理人が作成したスライドでの論文メモのスクショ)

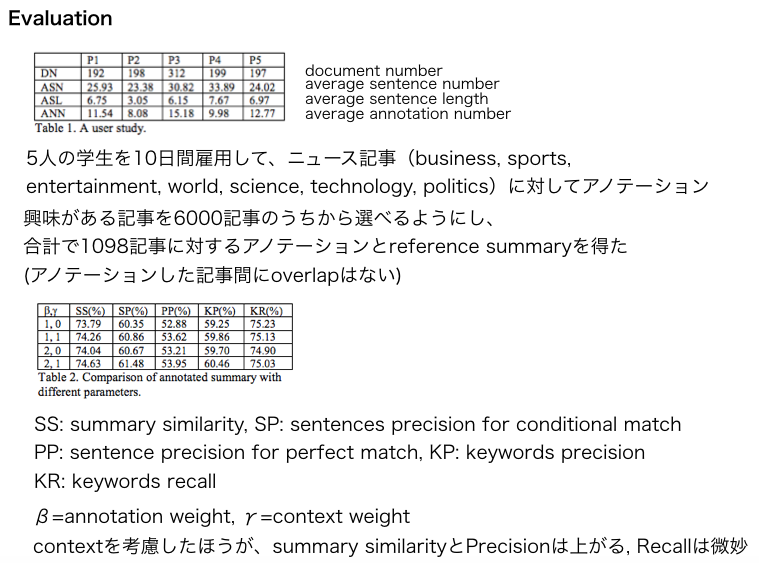
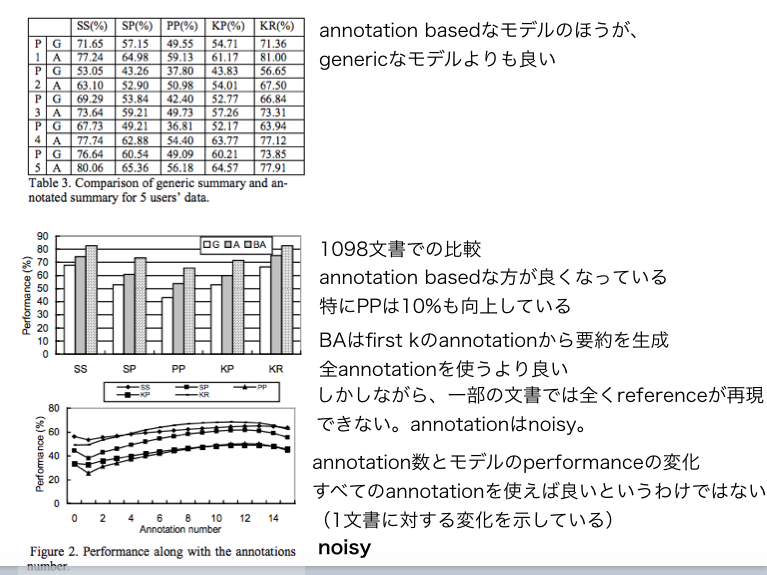

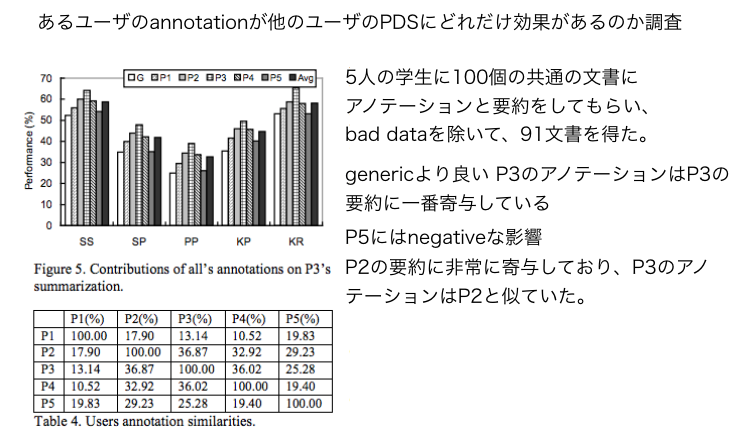
重要論文だと思われる。
[Paper Note] Personalised Information retrieval: survey and classification, Rami+, User Modeling and User-Adapted Interaction, 2012.05
Paper/Blog Link My Issue
#Article #Survey #InformationRetrieval #Personalization Issue Date: 2017-12-28 Comment
(以下は管理人が当時作成したスライドでのメモのスクショ)







完全に途中で力尽きている感
[Paper Note] Machine Learning for User Modeling, User modeling and User-adapted Interaction, [Webb+, 2001], 2001.03
Paper/Blog Link My Issue
#Article #Tutorial #MachineLearning #UserModeling Issue Date: 2017-12-28 Comment
# 管理人の過去のメモスクショ




[Paper Note] Modeling Anchor Text and Classifying Queries to Enhance Web Document Retrieval, WWW’08, [Fujii, 2008], 2008.04
Paper/Blog Link My Issue
#Article #InformationRetrieval #WWW Issue Date: 2017-12-28
[Paper Note] Comments-Oriented Document Summarization: Understanding Documents with Reader’s Feedback, Hu+, SIGIR’08, 2008.07
Paper/Blog Link My Issue
#Article #DocumentSummarization #GraphBased #Comments #NLP #Extractive #SIGIR Issue Date: 2017-12-28